
Innovativeness, Work Flexibility, and Place Characteristics: A Spatial Econometric and Machine Learning Approach

 , , and
, , and 
Abstract
:1. Introduction
2. Literature Review
3. Theoretical Background

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
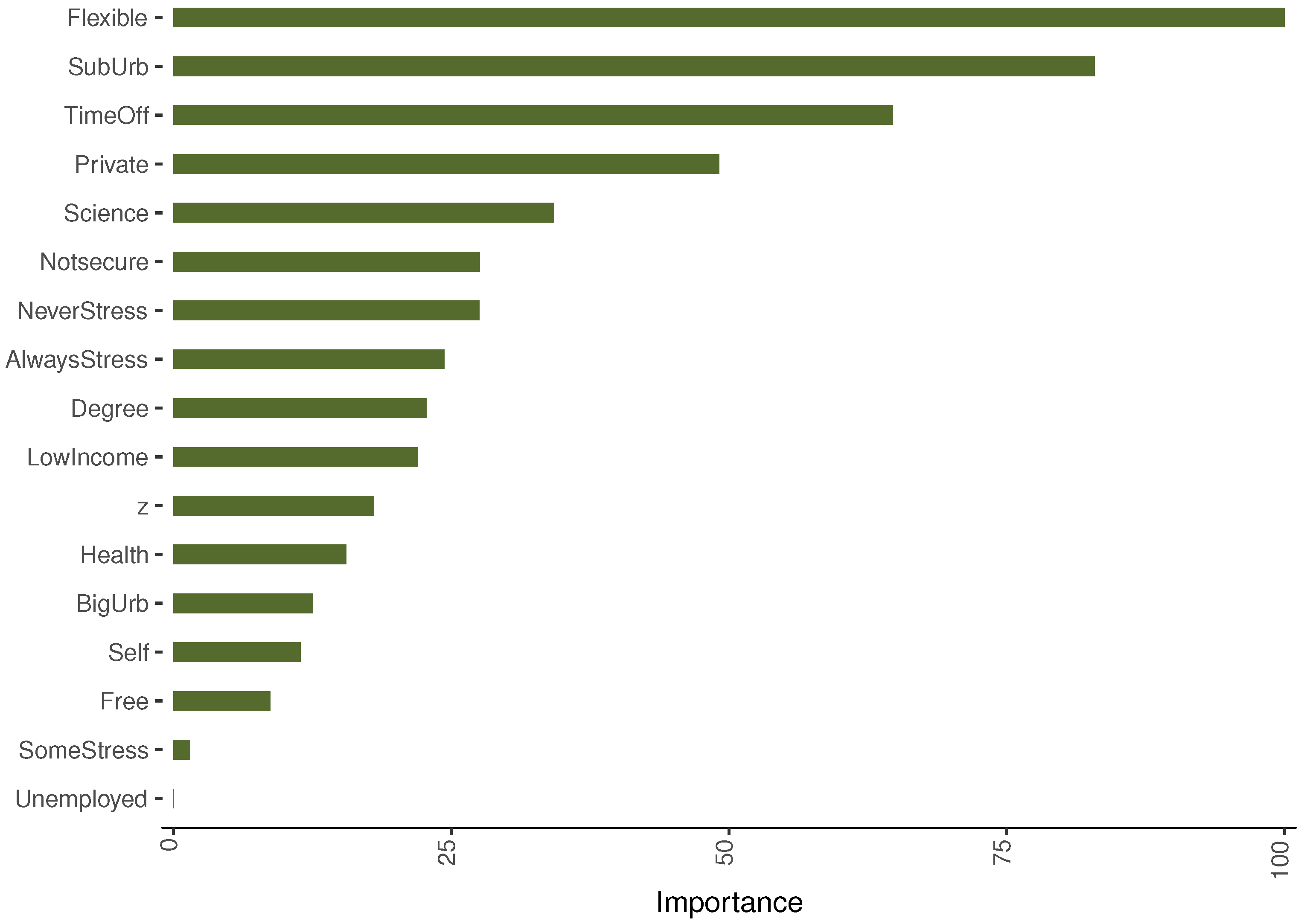{kind=link}
{kind=link}
{kind=link}
| Name | Description | Reference Category |
|---|---|---|
| Regional patent applications per million inhabitants in 2006. Source: Eurostat. | ||
| Average hours worked per week by the respondents. Source: ISSP 2005-Work Orientations III. | ||
| Share of respondents who are either completely free to decide the start and end times of their work or who have some freedom to decide within certain limits. | Share of respondents whose starting and finishing times are decided by the employer. Source: ISSP 2005-Work Orientations III. | |
| Share of respondents who have complete or some freedom to organise their daily work. | Share of respondents who have no freedom to organise their daily work. Source: ISSP 2005-Work Orientations III. | |
| Share of respondents who either disagree or strongly disagree that their job is secure. | Share of respondents who either agree, strongly agree, or neither agree or disagree that their job is secure. Source: ISSP 2005-Work Orientations III. | |
| Share of respondents who state that their work is “never” or “hardly ever” stressful. | Share of respondents who state that their work is “always” or “often” stressful (same reference dummy as the variable SomeStress). Source: ISSP 2005-Work Orientations III. | |
| Share of respondents who state that their work is “sometimes” stressful. | Share of respondents who state that their work is “always” or “often” stressful (same reference dummy as the variable NeverStress). Source: ISSP 2005-Work Orientations III. | |
| The share of respondents whose occupations belong to the category “physical, mathematical and engineering science professionals” listed under the International Standard Classification of Occupations 1988 (ISCO-88) as used in ISSP 2005. | Share of respondents in all other occupations. Source: ISSP 2005-Work Orientations III. | |
| Share of respondents who work for private, non-public, or non-government firms. | Share of respondents who work for the government or publicly owned firms (same reference dummy with the variable Self). Source: ISSP 2005-Work Orientations III. | |
| Share of respondents who are self-employed. | Share of respondents who work for the government or publicly owned firms (same reference dummy as the variable Private). Source: ISSP 2005-Work Orientations III. | |
| Share of respondents who have completed at least a university degree. | Share of respondents with education levels less than a university degree. Source: ISSP 2005-Work Orientations III. | |
| Share of respondents who are unemployed. | The share of respondents who have another employment status. Source: ISSP 2005-Work Orientations III. | |
| Share of respondents who either disagree or strongly disagree that their income is high. | Share of respondents who either agree, strongly agree, or neither agree or disagree that their income is high. Source: ISSP 2005-Work Orientations III. | |
| Share of respondents who live in an urbanised area/big city. | Share of respondents who live in either a town or small city, country village, or farm or home in the country (same reference dummy as the variable SuBurb). Source: ISSP 2005-Work Orientations III. | |
| Share of respondents who live in a suburban area or on the outskirts of a big city. | Share of respondents who live in either a town or small city, country village, or farm or home in the country (same reference dummy as the variable BigUrb). Source: ISSP 2005-Work Orientations III. | |
| Share of respondents who state that taking time off during work hours is either “not too difficult” or “not difficult at all”. | Share of respondents who state that taking time off during work hours is either “very difficult” or “somewhat difficult”. Source: ISSP 2005-Work Orientations III. | |
| The share of respondents who belong to the occupations under the category “life science and health professionals” (excluding “nursing and midwifery professionals”) listed under the International Standard Classification of Occupations 1988 (ISCO-88) as used in ISSP 2005. | Share of respondents in all other occupations. Source: ISSP 2005-Work Orientations III. |
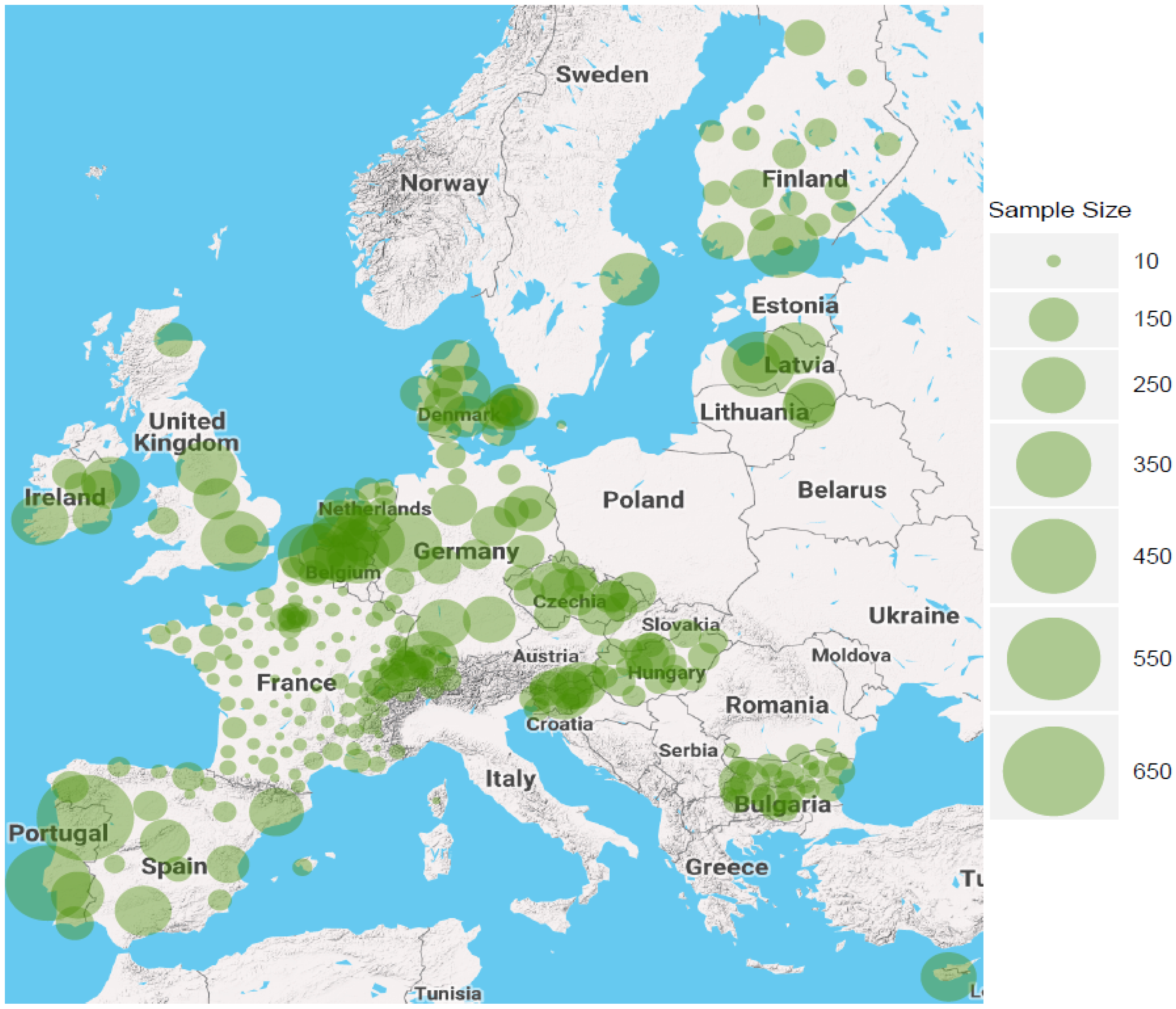
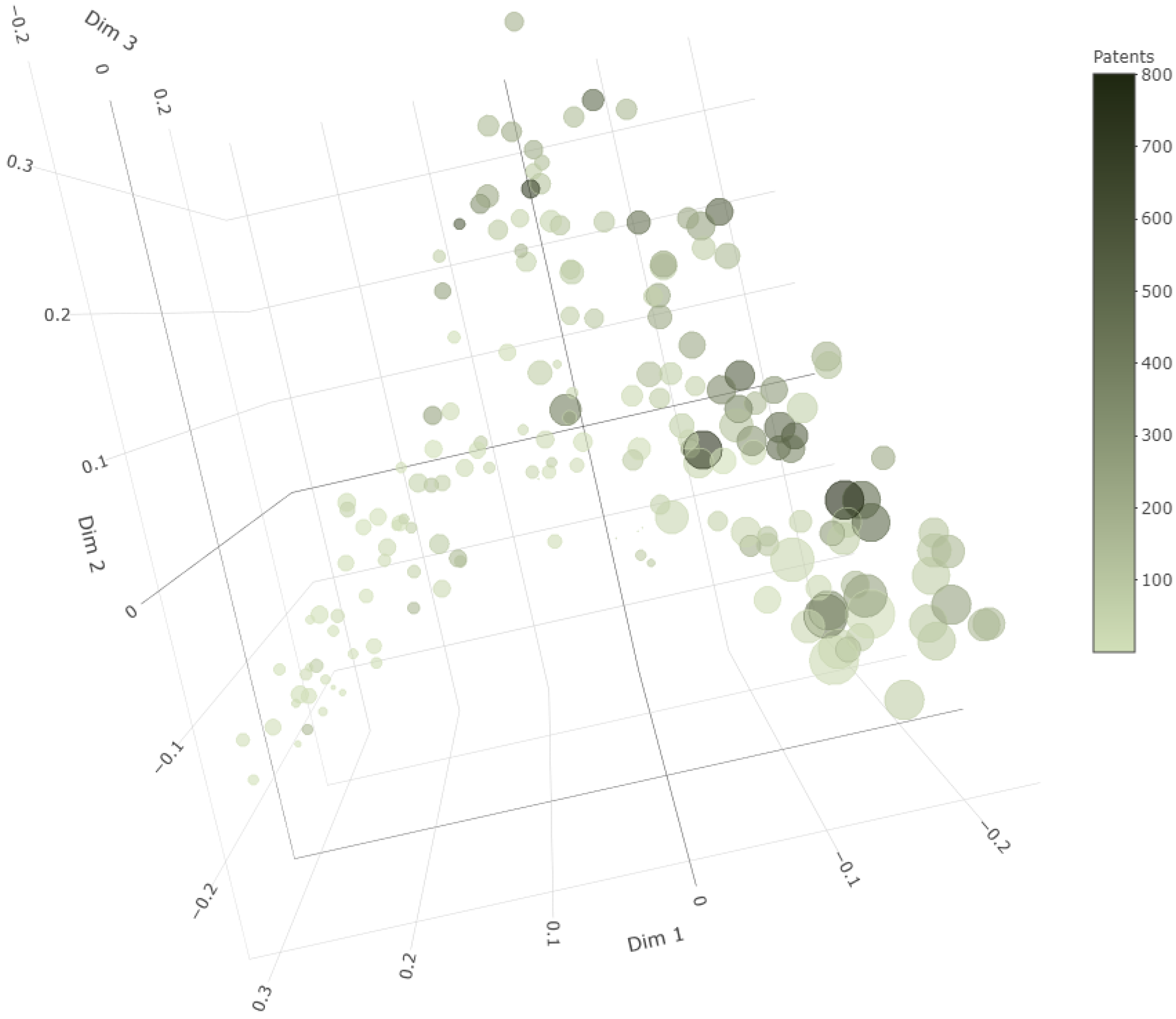
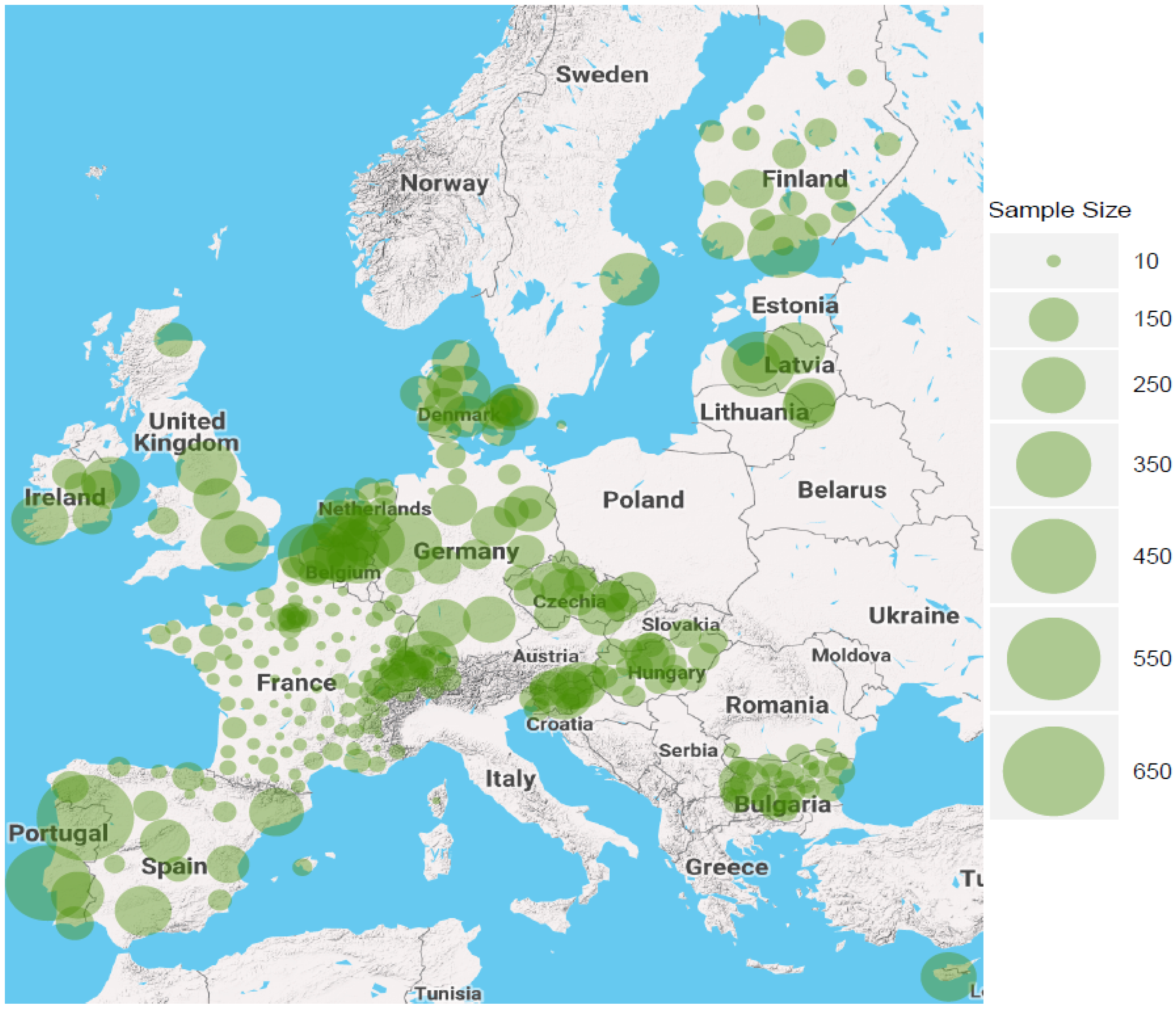
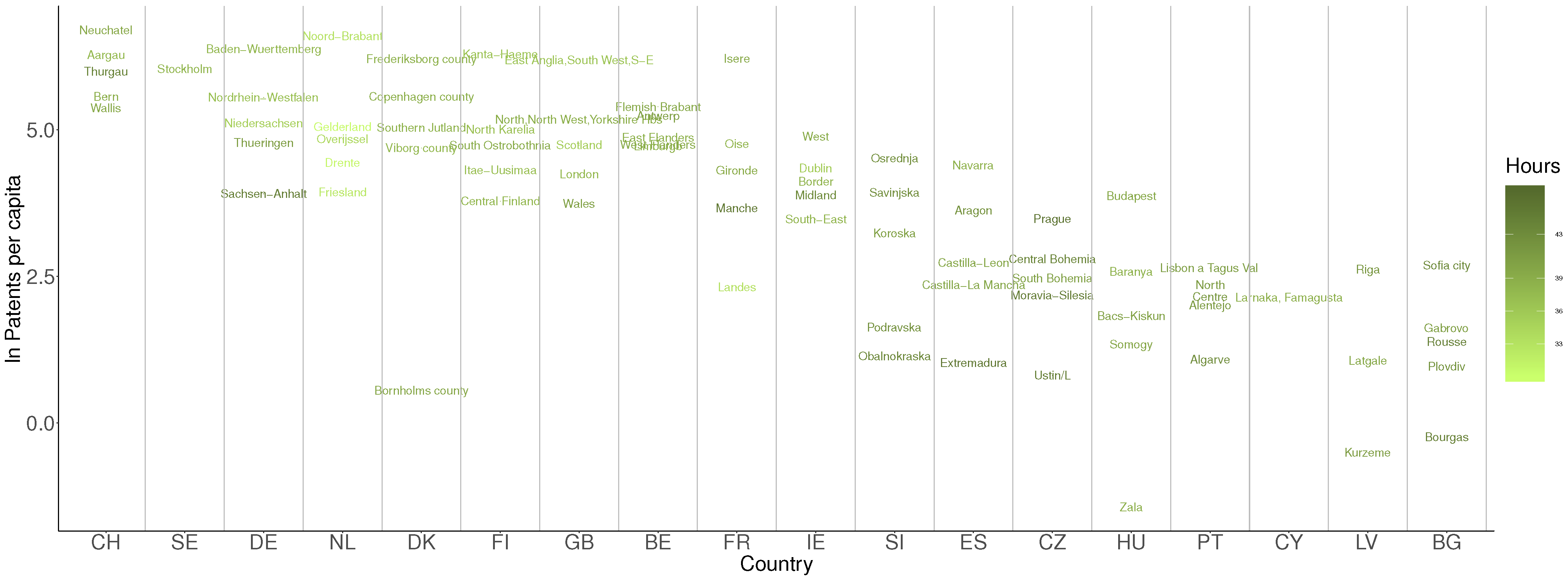
4. Data and Descriptive Statistics
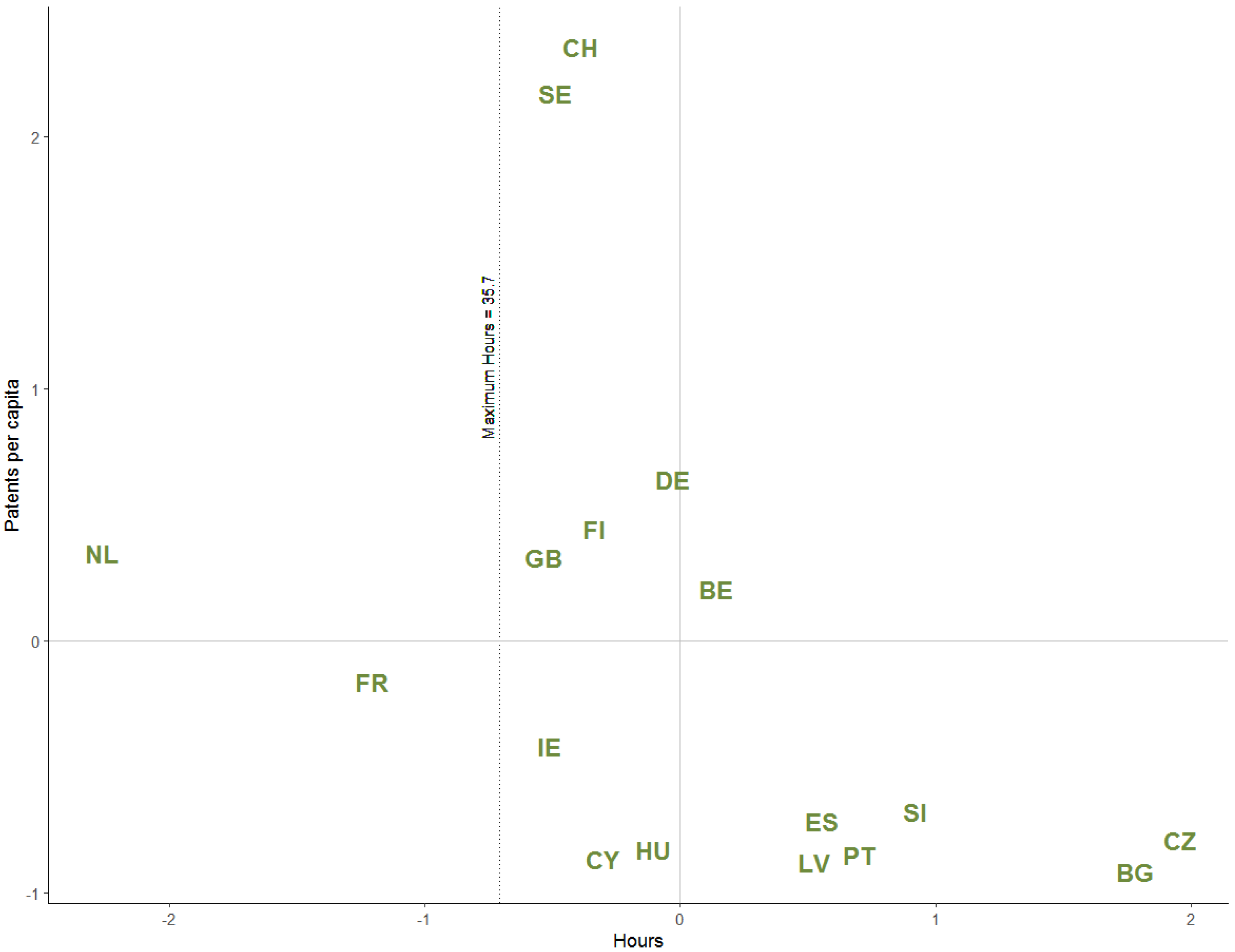
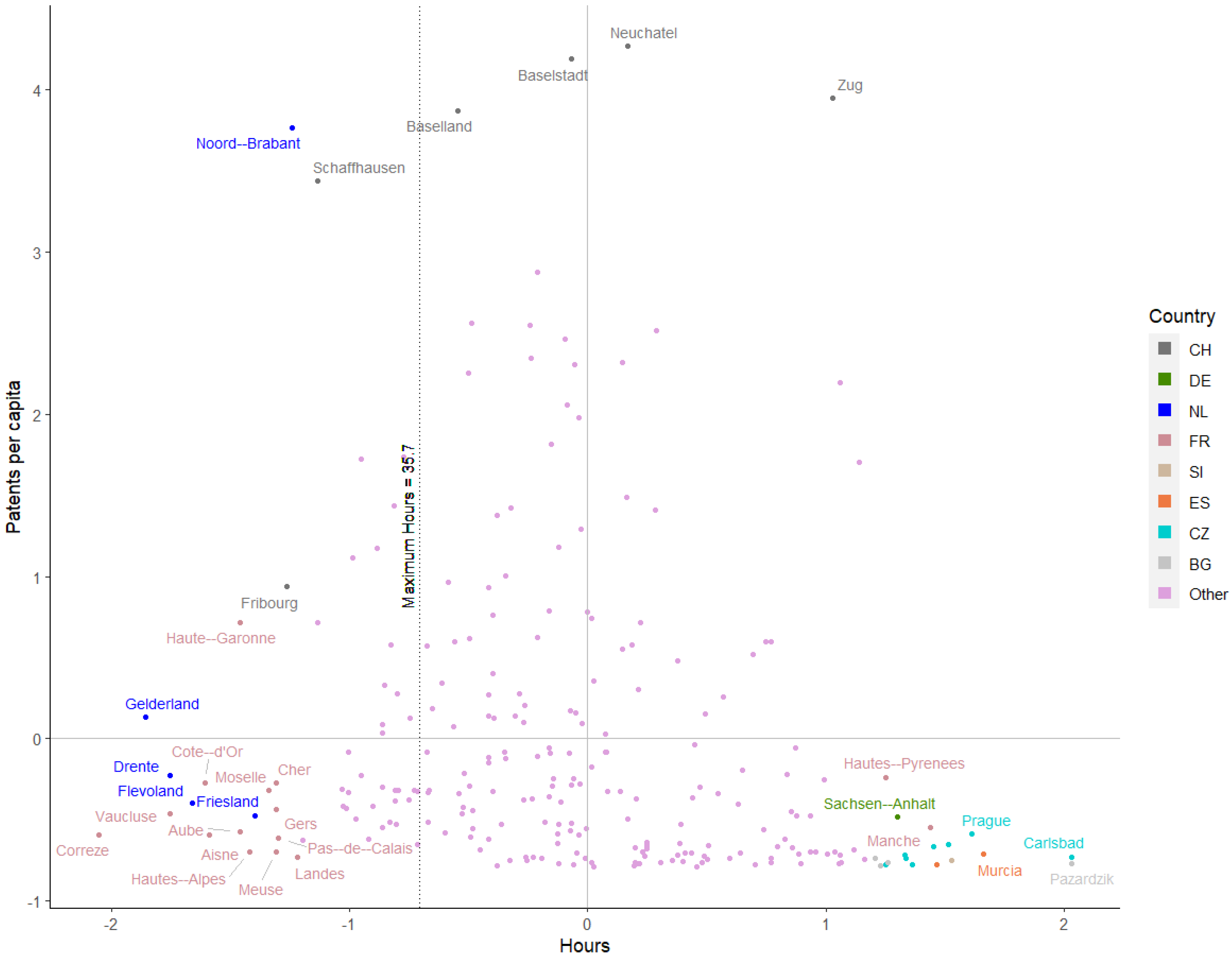
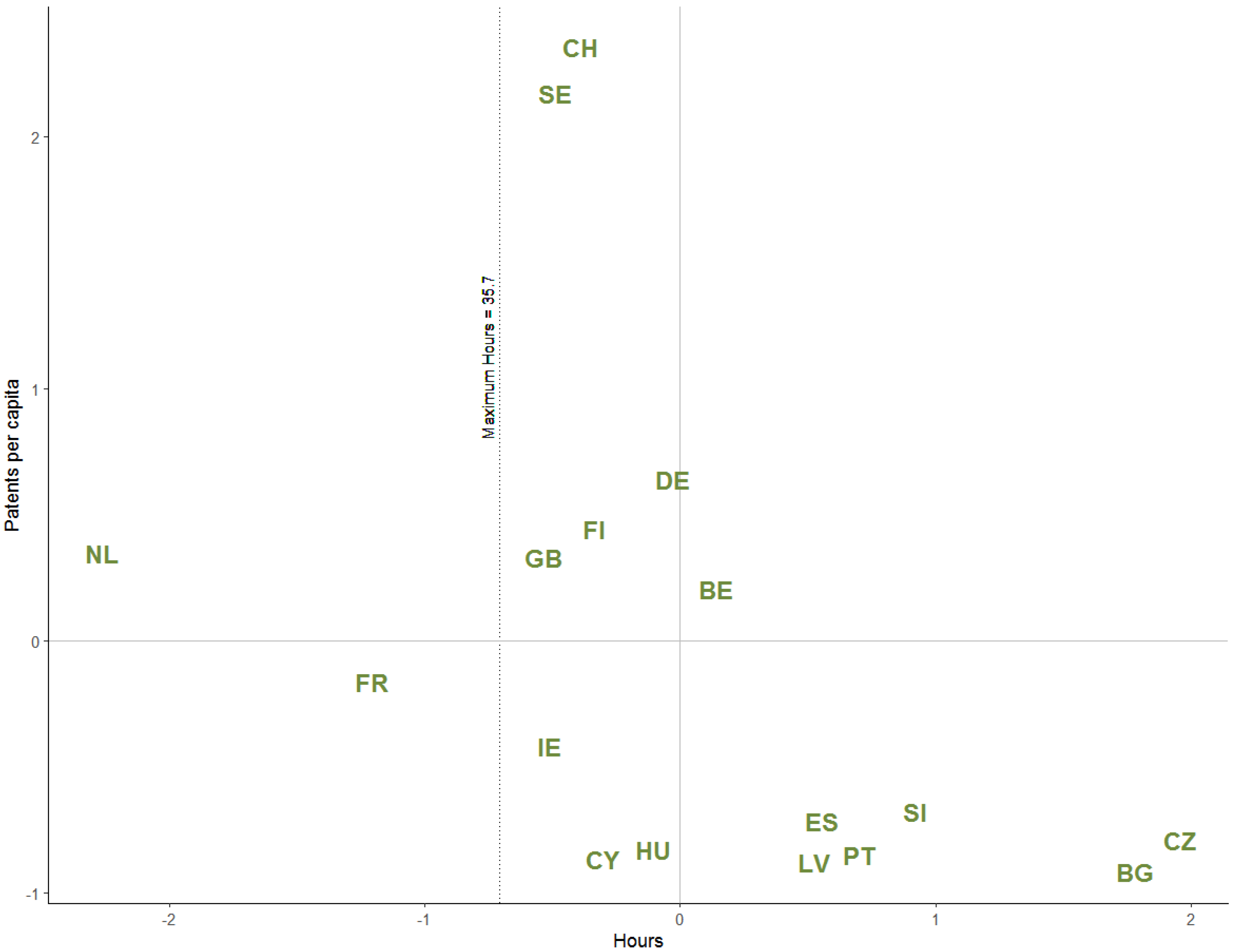
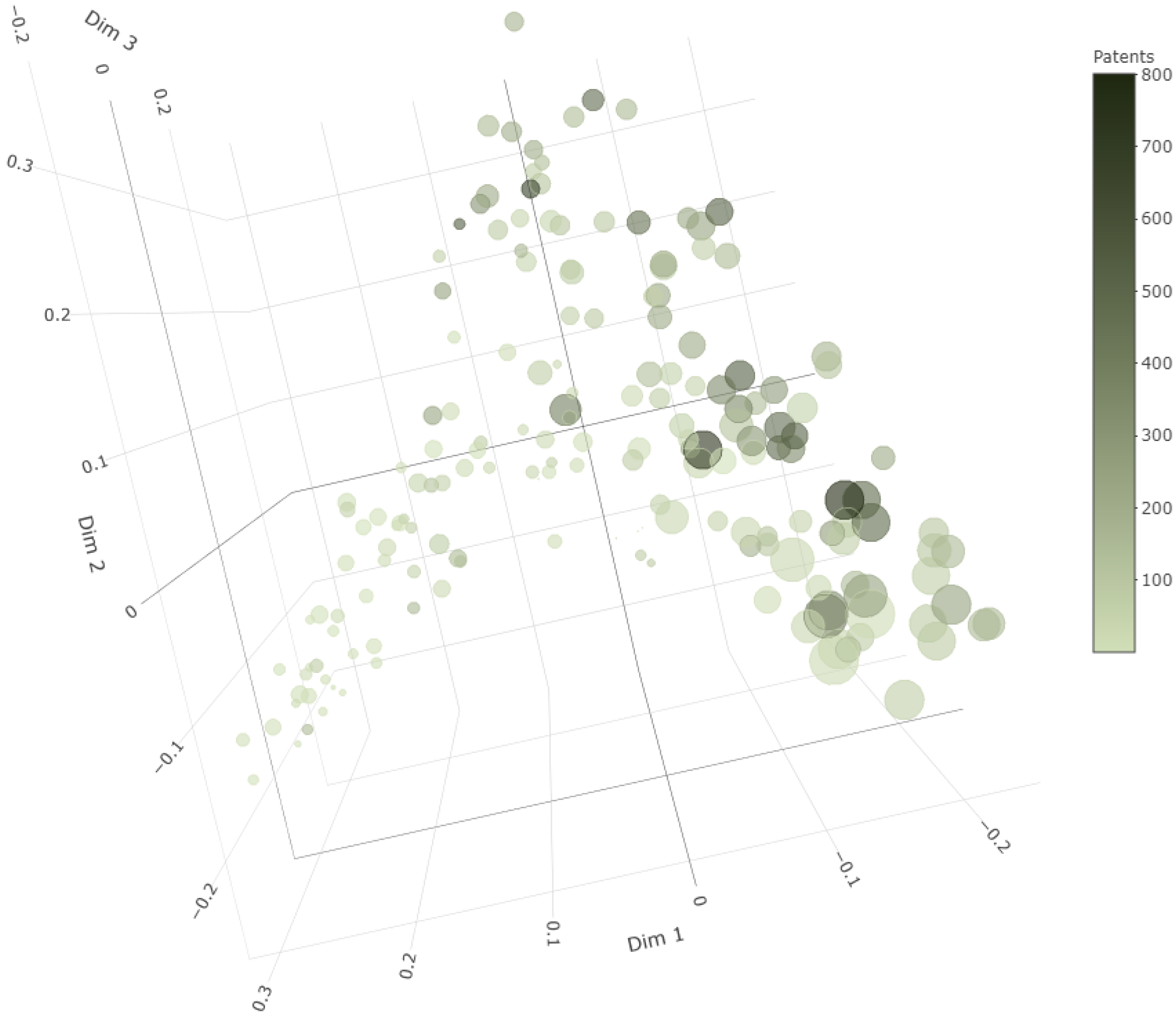
5. Spatial Econometric Estimation Results
Results of the Spatial and Non-Spatial Models
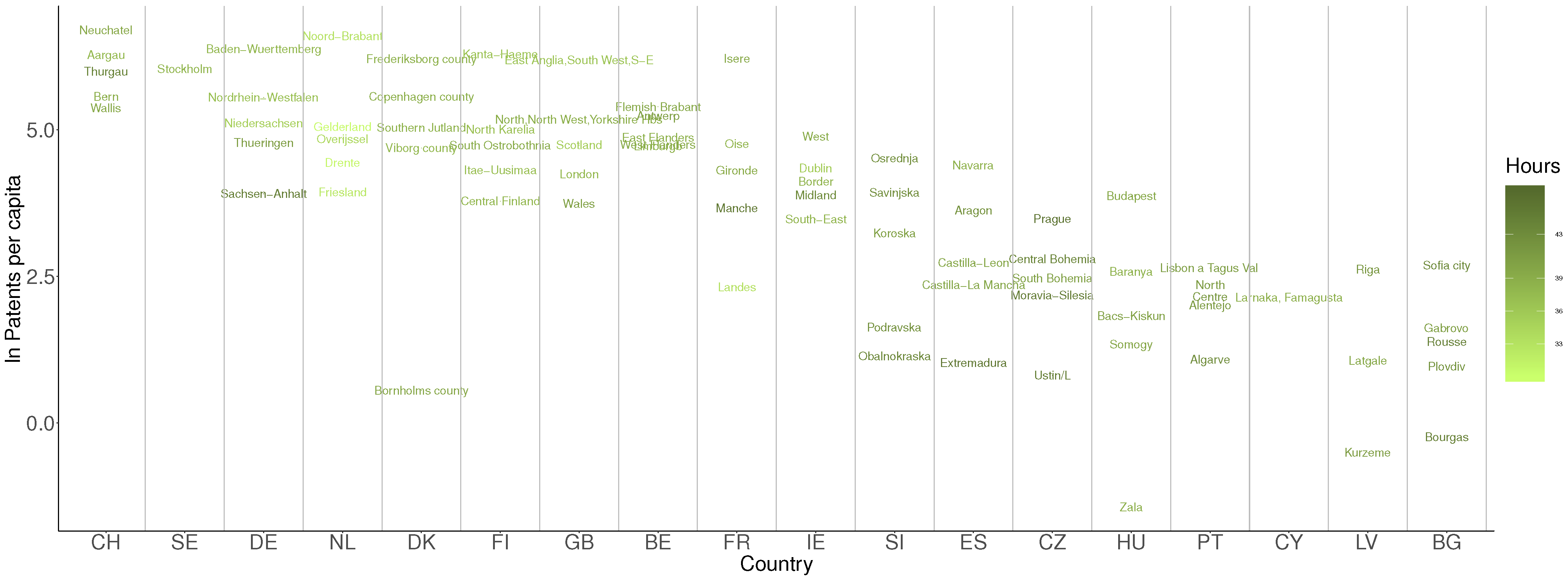
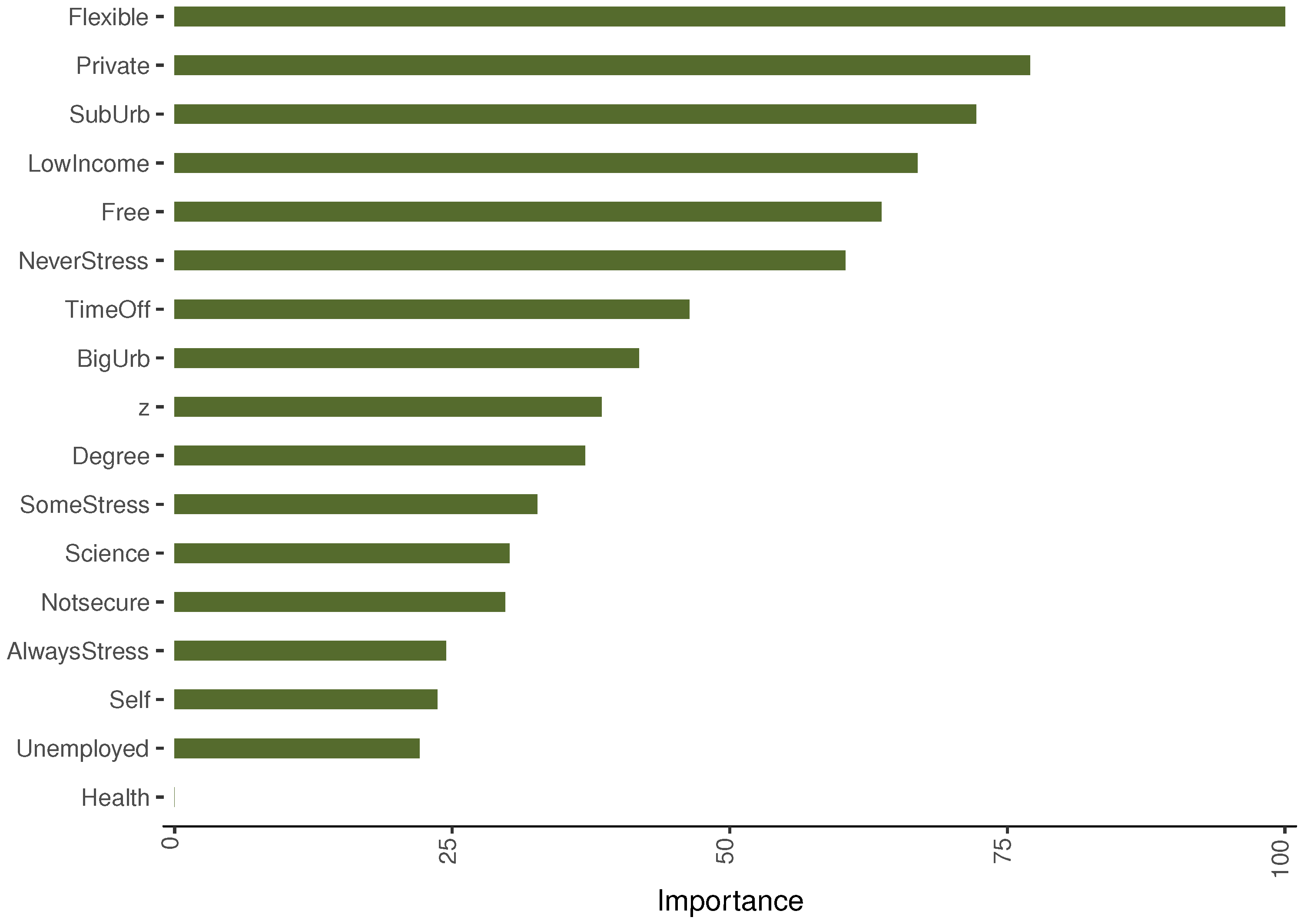
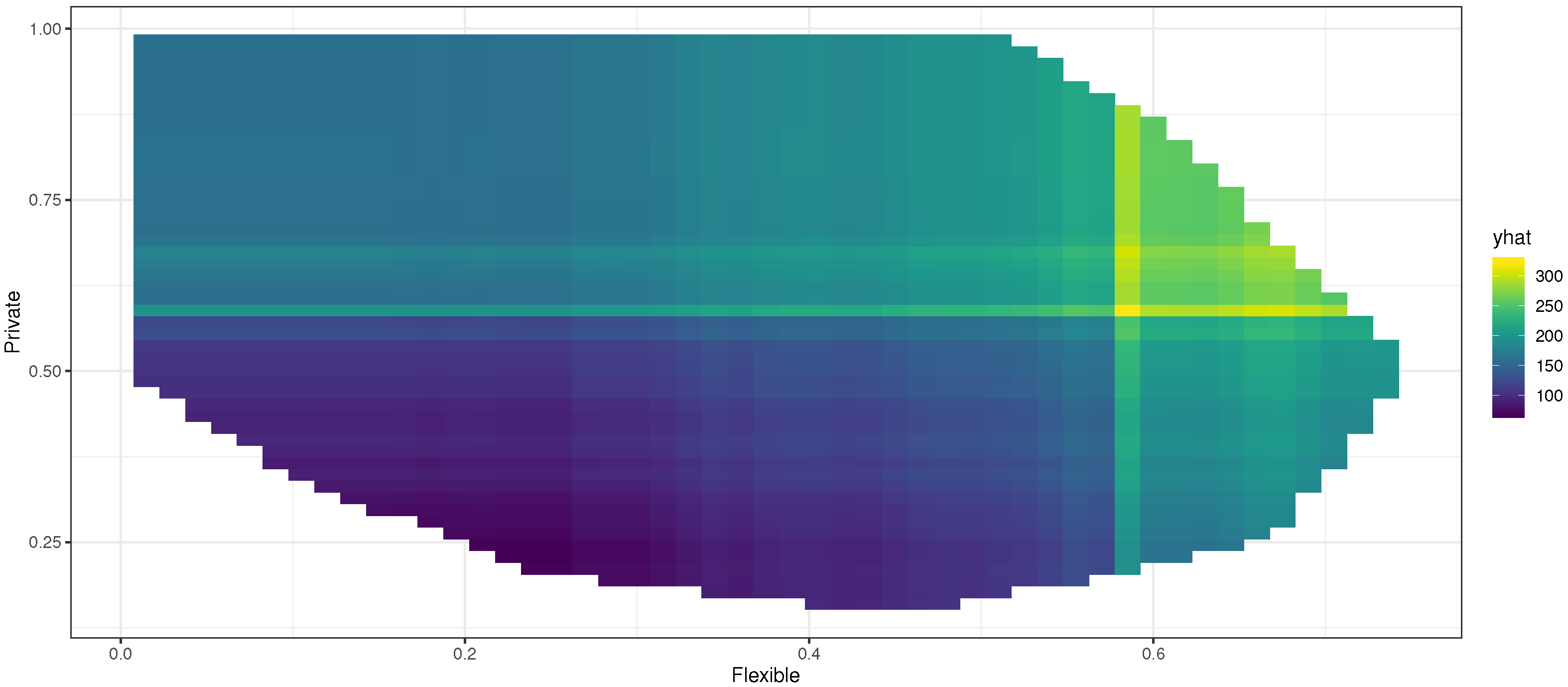
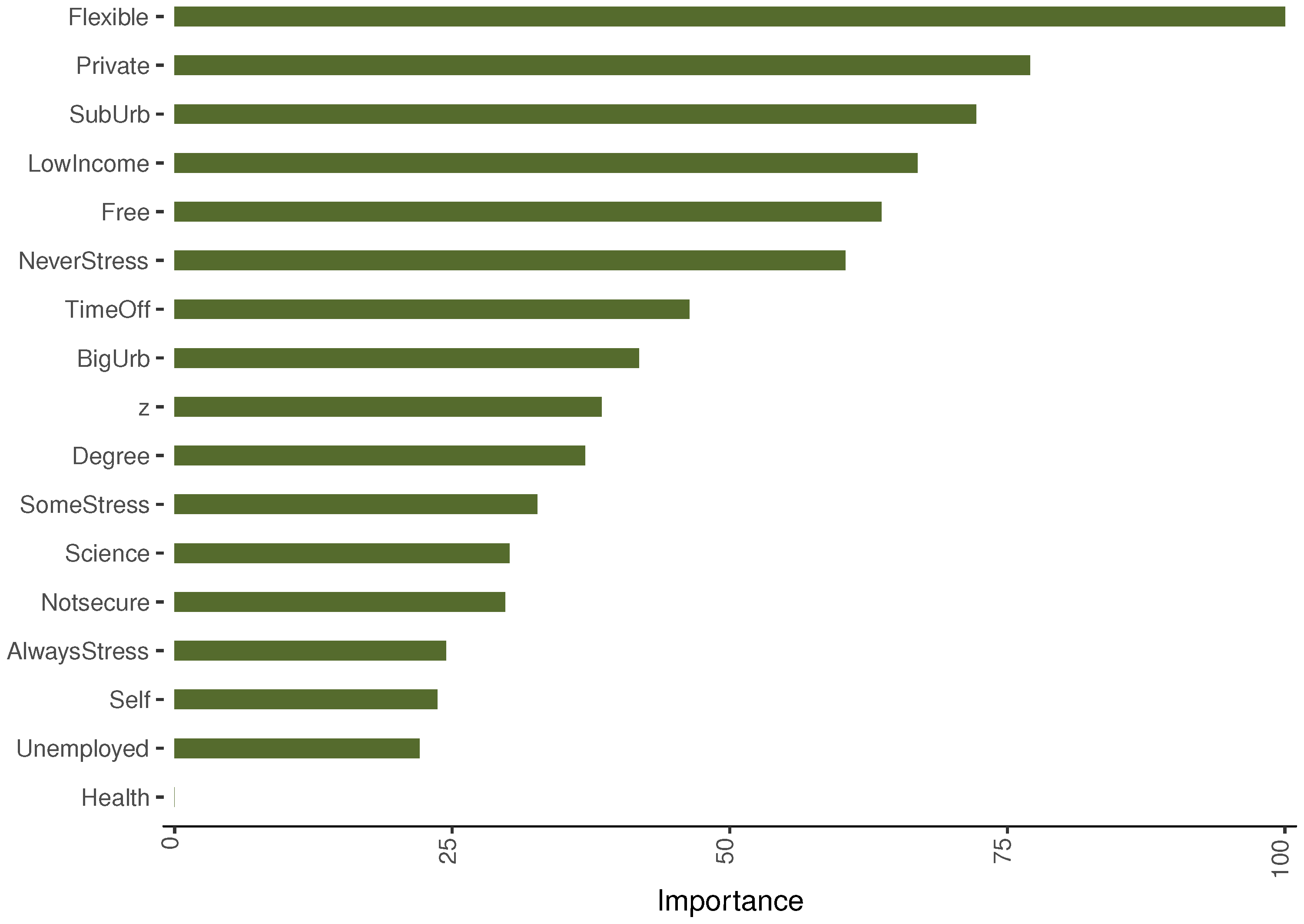
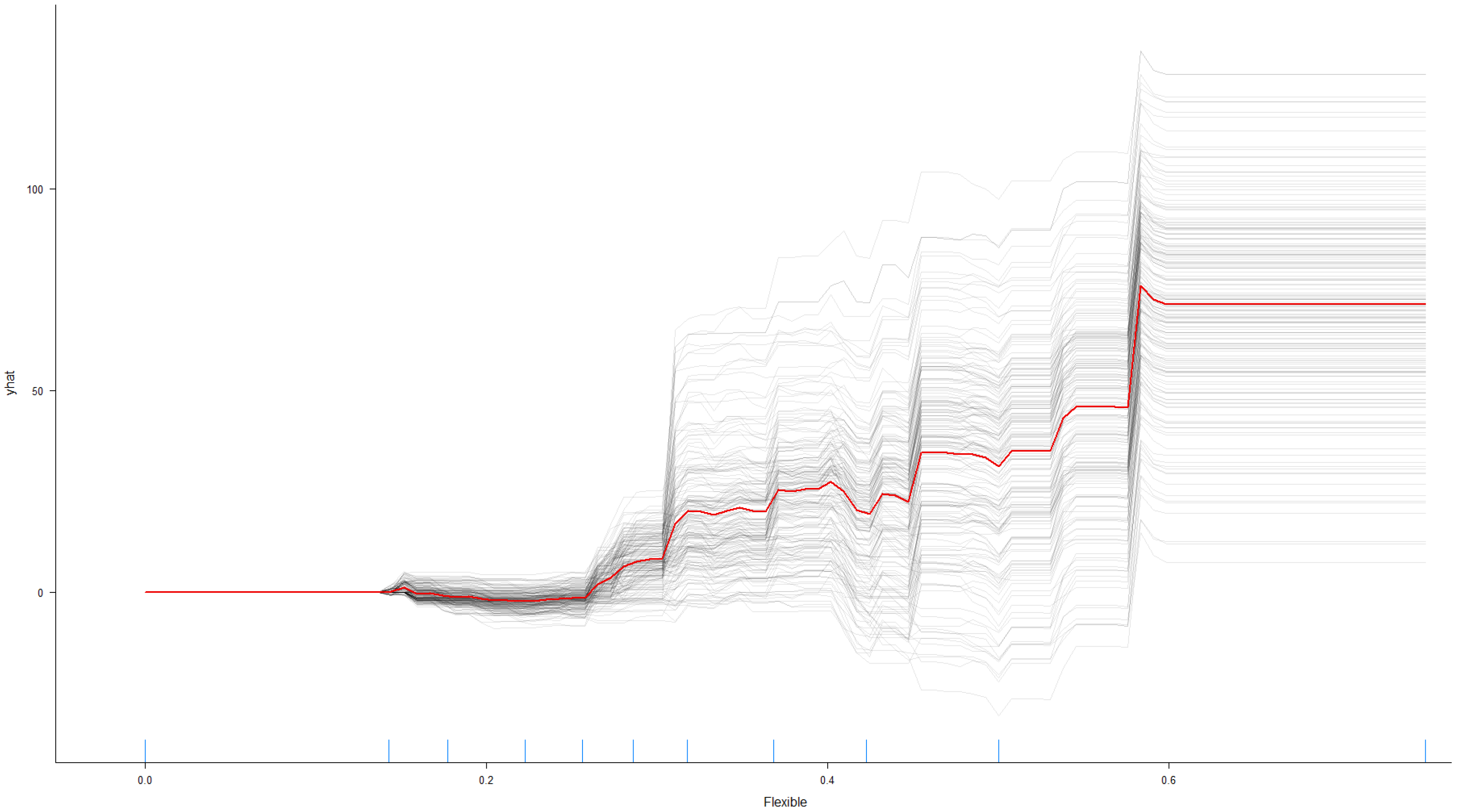
6. Machine Learning Applications
6.1. The Base Regression Tree Model
Regression Tree Results
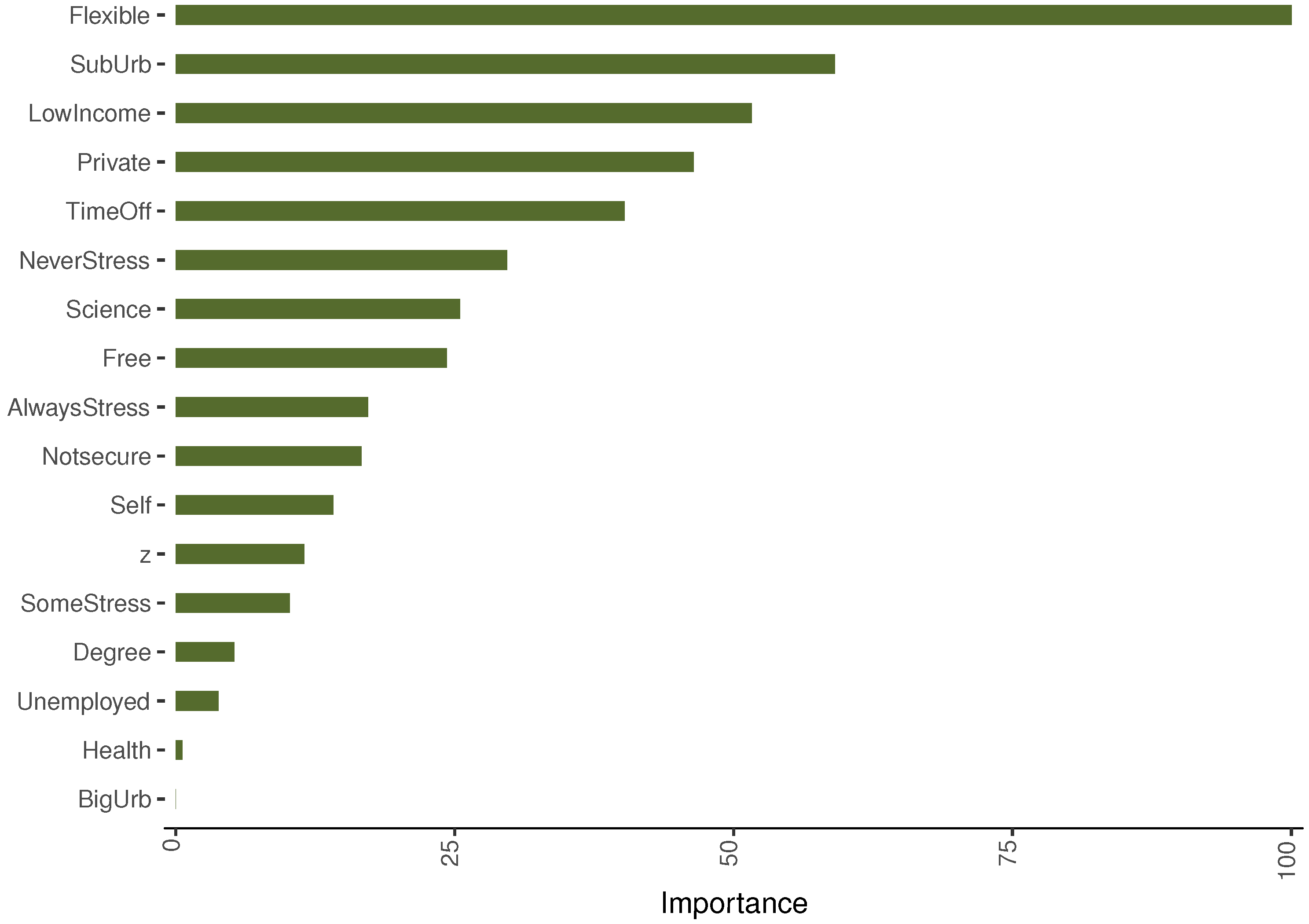
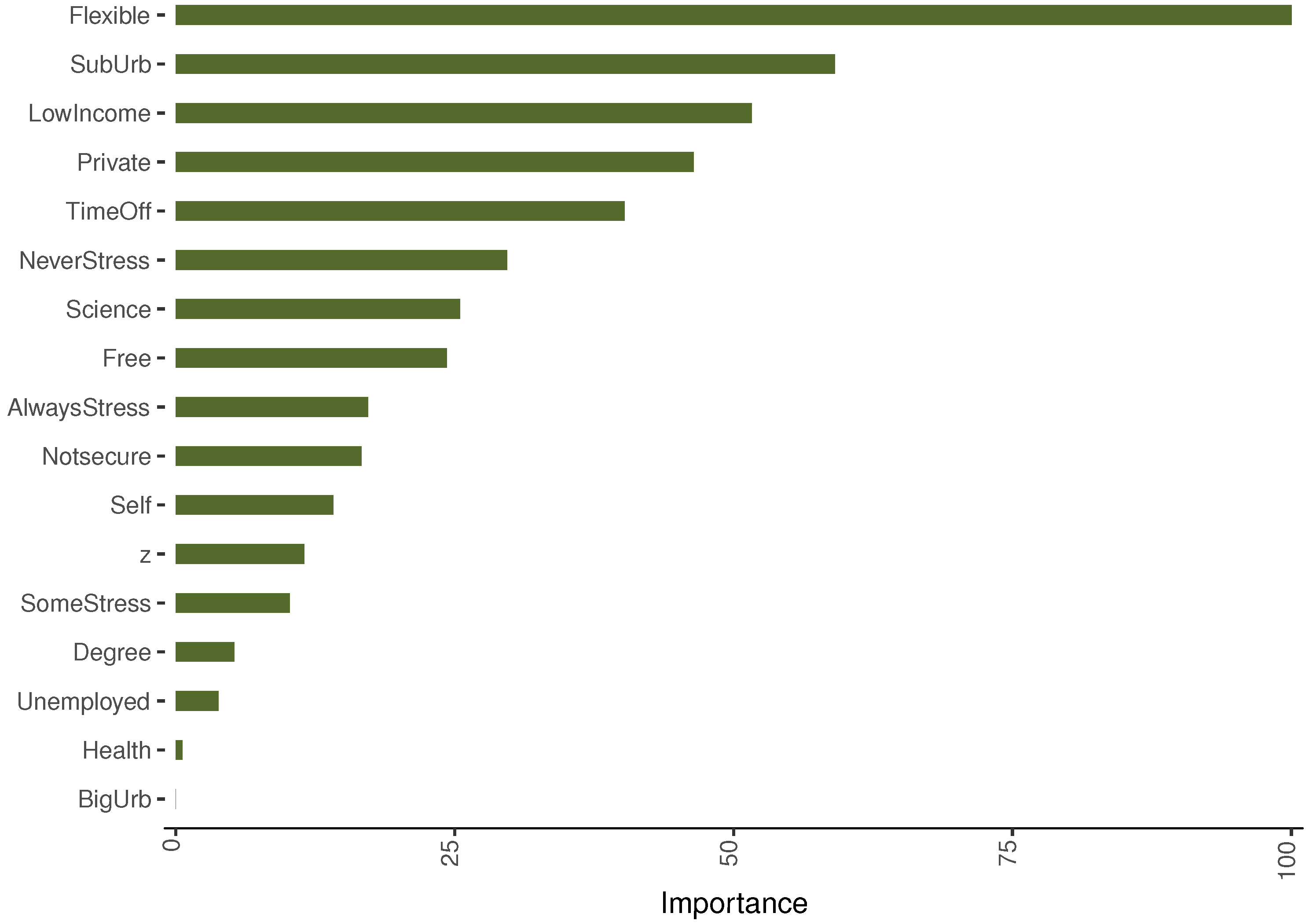
6.2. Bootstrap Aggregation
Bootstrap Aggregation Results
6.3. Random Forest
Random Forest Results
6.4. Stochastic Gradient Boosting Machine
GBM and S-GBM Results
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bilbao-Osorio, B.; Rodríguez-Pose, A. From R&D to innovation and economic growth in the EU. Growth Chang. 2004, 35, 434–455. [Google Scholar]
- Xiong, A.; Xia, S.; Ye, Z.P.; Cao, D.; Jing, Y.; Li, H. Can innovation really bring economic growth? The role of social filter in China. Struct. Chang. Econ. Dyn. 2020, 53, 50–61. [Google Scholar] [CrossRef]
- Asheim, B.T.; Coenen, L. Knowledge bases and regional innovation systems: Comparing Nordic clusters. Res. Policy 2005, 34, 1173–1190. [Google Scholar] [CrossRef]
- Etzkowitz, H.; Klofsten, M. The innovating region: Toward a theory of knowledge-based regional development. R D Manag. 2005, 35, 243–255. [Google Scholar] [CrossRef]
- Camps, S.; Marques, P. Exploring how social capital facilitates innovation: The role of innovation enablers. Technol. Forecast. Soc. Chang. 2014, 88, 325–348. [Google Scholar] [CrossRef]
- Gao, Y.; Zhao, X.; Xu, X.; Ma, F. A study on the cross level transformation from individual creativity to organizational creativity. Technol. Forecast. Soc. Chang. 2021, 171, 120958. [Google Scholar] [CrossRef]
- Koh, A.-T. Linking learning, knowledge creation, and business creativity: A preliminary assessment of the East Asian quest for creativity. Technol. Forecast. Soc. Chang. 2000, 64, 85–100. [Google Scholar] [CrossRef]
- Li, G.-C.; Lai, R.; D’Amour, A.; Doolin, D.M.; Sun, Y.; Torvik, V.I.; Amy, Z.Y.; Fleming, L. Disambiguation and co-authorship networks of the US patent inventor database (1975–2010). Res. Policy 2014, 43, 941–955. [Google Scholar] [CrossRef]
- Barge-Gil, A.; JesusNieto, M.; Santamaria, L. Hidden innovators: The role of non-R&D activities. Technol. Anal. Strateg. Manag. 2011, 23, 415–432. [Google Scholar]
- Chesbrough, H.W. Open Innovation: The New Imperative for Creating and Profiting from Technology; Harvard Business Press: Boston, MA, USA, 2003. [Google Scholar]
- Hervás-Oliver, J.L.; Parrilli, M.D.; Rodríguez-Pose, A.; Sempere-Ripoll, F. The drivers of SME innovation in the regions of the EU. Res. Policy 2021, 50, 104316. [Google Scholar] [CrossRef]
- Santamaría, L.; Nieto, M.J.; Barge-Gil, A. Beyond formal R&D: Taking advantage of other sources of innovation in low-and medium-technology industries. Res. Policy 2009, 38, 507–517. [Google Scholar]
- Kourtit, K.; Nijkamp, P. Creative actors and historical–cultural assets in urban regions. Reg. Stud. 2018, 53, 977–990. [Google Scholar] [CrossRef]
- Dainow, E. A Concise History of Computers, Smartphones, and the Internet; CreateSpace Independent Publishing Platform: Scotts Valley, CA, USA, 2017. [Google Scholar]
- Thulin, E.; Vilhelmson, B.; Johansson, M. New telework, time pressure, and time use control in everyday life. Sustainability 2019, 11, 3067. [Google Scholar] [CrossRef] [Green Version]
- Sarwar, M.; Soomro, T.R. Impact of smartphone’s on society. Eur. J. Sci. Res. 2013, 98, 216–226. [Google Scholar]
- Derks, D.; van Duin, D.; Tims, M.; Bakker, A.B. Smartphone use and work-home interference: The moderating role of social norms and employee work engagement. J. Occup. Organ. Psychol. 2014, 88, 155–177. [Google Scholar] [CrossRef] [Green Version]
- International Labour Organization. Teleworking arrangements during the COVID-19 crisis and beyond. In Proceedings of the 2nd Employment Working Group Meeting under the 2021 Italian Presidency of the G20, online, 14–16 April 2021. [Google Scholar]
- Celbiş, M.G.; Crombrugghe, D. Internet infrastructure and regional convergence: Evidence from Turkey. Pap. Reg. Sci. 2018, 97, 387–409. [Google Scholar] [CrossRef]
- Türk, U. A multilevel analysis of the contextual effects in distance education outcomes during COVID-19. East. J. Eur. Stud. 2021, 12, 149–169. [Google Scholar] [CrossRef]
- Kratzer, J.; Meissner, D.; Roud, V. Open innovation and company culture: Internal openness makes the difference. Technol. Forecast. Soc. Chang. 2017, 119, 128–138. [Google Scholar] [CrossRef]
- Ponsiglione, C.; Quinto, I.; Zollo, G. Regional innovation systems as complex adaptive systems: The case of lagging European regions. Sustainability 2018, 10, 2862. [Google Scholar] [CrossRef] [Green Version]
- Türkeli, S.; Wong, P.-H.; Yitbarek, E.A. Multiplex learning: An evidence-based approach to design policy learning networks in Sub-Saharan Africa for the SDGs. In Africa and the Sustainable Development Goals; Springer: Berlin/Heidelberg, Germany, 2020; pp. 279–292. [Google Scholar]
- Laursen, K.; Foss, N.J. Human resource management practices and innovation. In The Oxford Handbook of Innovation Management; Dodgson, M., Gann, D., Phillips, N., Eds.; Oxford University Press: Oxford, UK, 2014; pp. 505–529. [Google Scholar]
- Arvanitis, S. Modes of labor flexibility at firm level: Are there any implications for performance and innovation? Evidence for the Swiss economy. Ind. Corp. Chang. 2005, 14, 993–1016. [Google Scholar] [CrossRef]
- Burtch, G.; Carnahan, S.; Greenwood, B.N. Can you gig it? An empirical examination of the gig economy and entrepreneurial activity. Manag. Sci. 2018, 64, 5497–5520. [Google Scholar] [CrossRef] [Green Version]
- Arvanitis, S.; Seliger, F.; Stucki, T. The relative importance of human resource management practices for innovation. Econ. Innov. New Technol. 2016, 25, 769–800. [Google Scholar] [CrossRef]
- Birkinshaw, J.; Hamel, G.; Mol, M.J. Management innovation. Acad. Manag. Rev. 2008, 33, 825–845. [Google Scholar] [CrossRef]
- Kianto, A.; Sáenz, J.; Aramburu, N. Knowledge-based human resource management practices, intellectual capital and innovation. J. Bus. Res. 2017, 81, 11–20. [Google Scholar] [CrossRef]
- Suominen, A.; Toivanen, H.; Seppänen, M. Firms’ knowledge profiles: Mapping patent data with unsupervised learning. Technol. Forecast. Soc. Chang. 2017, 115, 131–142. [Google Scholar] [CrossRef] [Green Version]
- Ballestar, M.T.; Doncel, L.M.; Sainz, J.; Ortigosa-Blanch, A. A novel machine learning approach for evaluation of public policies: An application in relation to the performance of university researchers. Technol. Forecast. Soc. Chang. 2019, 149, 119756. [Google Scholar] [CrossRef]
- Kim, T.S.; Sohn, S.Y. Machine-learning-based deep semantic analysis approach for forecasting new technology convergence. Technol. Forecast. Soc. Chang. 2020, 157, 120095. [Google Scholar] [CrossRef]
- Schumpeter, J.A. The Theory of Economic Development; Transaction Publishers: London, UK, 1934. [Google Scholar]
- Fagerberg, J.; Srholec, M. National innovation systems, capabilities and economic development. Res. Policy 2008, 37, 1417–1435. [Google Scholar] [CrossRef]
- Kourtit, K.; Nijkamp, P.; Lowik, S.; Van Vught, F.; Vulto, P. From islands of innovation to creative hotspots. Reg. Sci. Policy Pract. 2011, 3, 145–161. [Google Scholar] [CrossRef]
- Lundvall, B.-Å. National Systems of Innovation: Toward a Theory of Innovation and Interactive Learning; Pinter Publishers: London, UK, 1992. [Google Scholar]
- Nelson, R.R. National Innovation Systems: A Comparative Analysis; Oxford University Press: New York, NY, USA, 1993. [Google Scholar]
- Leydesdorff, L.; Etzkowitz, H. The triple helix as a model for innovation studies. Sci. Public Policy 1998, 25, 195–203. [Google Scholar]
- Cooke, P.; Uranga, M.G.; Etxebarria, G. Regional innovation systems: Institutional and organisational dimensions. Res. Policy 1997, 26, 475–491. [Google Scholar] [CrossRef]
- Amabile, T.M.; Conti, R.; Coon, H.; Lazenby, J.; Herron, M. Assessing the work environment for creativity. Acad. Manag. J. 1996, 39, 1154–1184. [Google Scholar]
- Laursen, K.; Foss, N.J. New human resource management practices, complementarities and the impact on innovation performance. Camb. J. Econ. 2003, 27, 243–263. [Google Scholar] [CrossRef]
- Krammer, S.M. Human resource policies and firm innovation: The moderating effects of economic and institutional context. Technovation 2021, 2, 102366. [Google Scholar] [CrossRef]
- Seeck, H.; Diehl, M.R. A literature review on HRM and innovation–taking stock and future directions. Int. J. Hum. Resour. Manag. 2017, 28, 913–944. [Google Scholar] [CrossRef]
- Strobel, N.; Kratzer, J. Obstacles to innovation for SMEs: Evidence from Germany. Int. J. Innov. Manag. 2017, 21, 1750030. [Google Scholar] [CrossRef]
- Michie, J.; Sheehan, M. Labour market deregulation, ‘flexibility’ and innovation. Camb. J. Econ. 2003, 27, 123–143. [Google Scholar] [CrossRef]
- Zhou, H.; Dekker, R.; Kleinknecht, A. Flexible labor and innovation performance: Evidence from longitudinal firm-level data. Ind. Corp. Chang. 2011, 20, 941–968. [Google Scholar] [CrossRef]
- Hoxha, S.; Kleinknecht, A. When labour market rigidities are useful for innovation: Evidence from German IAB firm-level data. Res. Policy 2020, 49, 104066. [Google Scholar] [CrossRef]
- Hoxha, S.; Kleinknecht, A. Do trustful labor–Management relations enhance innovation? Evidence from German WSI data. Rev. Soc. Econ. 2021, 79, 261–285. [Google Scholar] [CrossRef]
- Freeman, C.; Soete, L. The Economics of Industrial Innovation, 3rd ed.; MIT Press: Cambridge, MA, USA, 1997. [Google Scholar]
- Celbis, M.G.; Turkeli, S. Does Too Much Work Hamper Innovation? Evidence for Diminishing Returns of Work Hours for Patent Grants. J. Glob. Policy Gov. 2015, 17, 97–116. [Google Scholar]
- Cui, D.; Wei, X.; Wu, D.; Cui, N.; Nijkamp, P. Leisure time and labor productivity: A new economic view rooted from sociological perspective. Economics 2019, 13, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Jones, C.I. R&D-based models of economic growth. J. Political Econ. 1995, 103, 759–784. [Google Scholar]
- Amabile, T.M.; Hadley, C.N.; Kramer, S.J. Creativity under the gun. Harv. Bus. Rev. 2002, 80, 52–63. [Google Scholar]
- OECD. Enhancing Productivity in UK Core Cities; OECD: Paris, France, 2020. [Google Scholar]
- Glaeser, E.L.; Gottlieb, J.D. The wealth of cities: Agglomeration economies and spatial equilibrium in the United States. J. Econ. Lit. 2009, 47, 983–1028. [Google Scholar] [CrossRef] [Green Version]
- Özgüzel, C. Agglomeration Effects in a Developing Country: Evidence from Turkey; Mimeo, Paris School of Economics halshs-02878368; Economic Research Forum: Giza, Egypt, 2020. [Google Scholar]
- Celbiş, M.G. A machine learning approach to rural entrepreneurship. Pap. Reg. Sci. 2021, 100, 1079–1104. [Google Scholar] [CrossRef]
- Dakhli, M.; DeClercq, D. Human capital, social capital, and innovation: A multi-country study. Entrep. Reg. Dev. 2004, 16, 107–128. [Google Scholar] [CrossRef]
- Gu, Y.; Hu, L.; Zhang, H.; Hou, C. Innovation ecosystem research: Emerging trends and future research. Sustainability 2021, 13, 11458. [Google Scholar] [CrossRef]
- Szirmai, A.; Naudé, W.; Goedhuys, M. Entrepreneurship, Innovation, and Economic Development; Oxford University Press: Oxford, UK, 2011. [Google Scholar]
- ISSP 2005-Work Orientations III Variable Report Documentation Release 2013/07/22. GESIS—Leibniz Institute for the Social Sciences. Archive-Study-No. ZA4350 Version 2.0.0. 2005. Available online: https://www.gesis.org/en/issp/modules/issp-modules-by-topic/work-orientations/2005 (accessed on 20 September 2021).
- Buesa, M.; Heijs, J.; Baumert, T. The determinants of regional innovation in Europe: A combined factorial and regression knowledge production function approach. Res. Policy 2010, 39, 722–735. [Google Scholar] [CrossRef]
- Bergamini, E.; Zachmann, G. Exploring EU’s regional potential in low-carbon technologies. Sustainability 2021, 13, 32. [Google Scholar] [CrossRef]
- LeSage, J.; Pace, R.K. Introduction to Spatial Econometrics; Chapman and Hall/CRC: Boca Raton, FL, USA, 2009. [Google Scholar]
- Anselin, L. Spatial Econometrics: Methods and Models; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1988. [Google Scholar]
- Celbiş, M.G.; Wong, P.-H.; Guznajeva, T. Regional integration and the economic geography of Belarus. Eurasian Geogr. Econ. 2018, 59, 462–495. [Google Scholar] [CrossRef]
- Feldman, M.P. The new economics of innovation, spillovers and agglomeration: A review of empirical studies. Econ. Innov. New Technol. 1999, 8, 5–25. [Google Scholar] [CrossRef]
- Fingleton, B.; López-Bazo, E. Empirical growth models with spatial effects. Pap. Reg. Sci. 2006, 85, 177–198. [Google Scholar] [CrossRef]
- Ertur, C.; Koch, W. Growth, technological interdependence and spatial externalities: Theory and evidence. J. Appl. Econom. 2007, 22, 1033–1062. [Google Scholar] [CrossRef] [Green Version]
- Caragliu, A.; Nijkamp, P. The impact of regional absorptive capacity on spatial knowledge spillovers: The Cohen and Levinthal model revisited. Appl. Econ. 2012, 44, 1363–1374. [Google Scholar] [CrossRef]
- Caragliu, A.; Nijkamp, P. Space and knowledge spillovers in European regions: The impact of different forms of proximity on spatial knowledge diffusion. J. Econ. Geogr. 2016, 16, 749–774. [Google Scholar] [CrossRef]
- DeDominicis, L.; Florax, R.J.; deGroot, H.L. Regional clusters of innovative activity in Europe: Are social capital and geographical proximity key determinants? Appl. Econ. 2013, 45, 2325–2335. [Google Scholar] [CrossRef]
- Fischer, M.M. Regions, technological interdependence and growth in Europe. Rom. J. Reg. Sci. 2009, 3, 1–17. [Google Scholar]
- Ponds, R.; van Oort, F.; Frenken, K. Innovation, spillovers and university–Industry collaboration: An extended knowledge production function approach. J. Econ. Geogr. 2009, 10, 231–255. [Google Scholar] [CrossRef]
- Petruzzelli, A.M. The impact of technological relatedness, prior ties, and geographical distance on university–industry collaborations: A joint-patent analysis. Technovation 2011, 31, 309–319. [Google Scholar] [CrossRef]
- Elhorst, J.P. Specification and estimation of spatial panel data models. Int. Reg. Sci. Rev. 2003, 26, 244–268. [Google Scholar] [CrossRef]
- Ord, K. Estimation methods for models of spatial interaction. J. Am. Stat. Assoc. 1975, 70, 120–126. [Google Scholar] [CrossRef]
- Elhorst, J.P. Applied spatial econometrics: Raising the bar. Spat. Econ. Anal. 2010, 5, 9–28. [Google Scholar] [CrossRef]
- Beugelsdijk, S. Strategic human resource practices and product innovation. Organ. Stud. 2008, 29, 821–847. [Google Scholar] [CrossRef]
- Bloch, C.; Bugge, M.M. Public sector innovation—From theory to measurement. Struct. Chang. Econ. Dyn. 2013, 27, 133–145. [Google Scholar] [CrossRef] [Green Version]
- D’Este, P.; Rentocchini, F.; Vega-Jurado, J. The role of human capital in lowering the barriers to engaging in innovation: Evidence from the Spanish innovation survey. Ind. Innov. 2014, 21, 1–19. [Google Scholar] [CrossRef]
- Beaudry, C.; Schiffauerova, A. Who’s right, Marshall or Jacobs? The localization versus urbanization debate. Res. Policy 2009, 38, 318–337. [Google Scholar] [CrossRef] [Green Version]
- Shearmur, R.; Doloreux, D. How open innovation processes vary between urban and remote environments: Slow innovators, market-sourced information and frequency of interaction. Entrep. Reg. Dev. 2016, 28, 337–357. [Google Scholar] [CrossRef]
- Chung, S. Building a national innovation system through regional innovation systems. Technovation 2002, 22, 485–491. [Google Scholar] [CrossRef]
- Breiman, L. Statistical modeling: The two cultures (with comments and a rejoinder by the author). Stat. Sci. 2001, 16, 199–231. [Google Scholar] [CrossRef]
- Imbens, G.; Athey, S. Breiman’s two cultures: A perspective from econometrics. Obs. Stud. 2021, 7, 127–133. [Google Scholar] [CrossRef]
- Atkinson, E.J.; Therneau, T.M. An Introduction to Recursive Partitioning Using the RPART Routines; Mayo Foundation: Rochester, NY, USA, 2000. [Google Scholar]
- Breiman, L.; Cutler, A. Random Forests. Available online: https://www.stat.berkeley.edu/~breiman/RandomForests/cc_home.htm (accessed on 1 February 2020).
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y. xgboost: Extreme Gradient Boosting; R Package Version 0.4-2; 2015; pp. 1–4. Available online: http://www.milbo.org/rpart-plot/index.html (accessed on 20 September 2021).
- Milborrow, S. R Package ‘Rpart. Plot’; 2019; Available online: https://github.com/dmlc/xgboost (accessed on 20 September 2021).
- Greenwell, B.M. pdp: An R package for constructing partial dependence plots. R J. 2017, 9, 421–436. [Google Scholar] [CrossRef] [Green Version]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: New York, NY, USA, 2013. [Google Scholar]
- Varian, H.R. Big data: New tricks for econometrics. J. Econ. Perspect. 2014, 28, 3–28. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Wadsworth and Brooks: Monterey, CA, USA, 1984. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning; Springer Series in Statistics; Springer: New York, NY, USA, 2001. [Google Scholar]
- Collignon, O.; Han, J.; An, H.; Oh, S.; Lee, Y. Comparison of the modified unbounded penalty and the LASSO to select predictive genes of response to chemotherapy in breast cancer. PLoS ONE 2018, 13, e0204897. [Google Scholar] [CrossRef]
- Jin, S.; Noh, M.; Lee, Y. H-Likelihood Approach to Factor Analysis for Ordinal Data. Struct. Equ. Model. 2018, 25, 530–540. [Google Scholar] [CrossRef]
- Jin, S.; Noh, M.; Yang-Wallentin, F.; Lee, Y. Robust nonlinear structural equation modeling with interaction between exogenous and endogenous latent variables. Struct. Equ. Model. 2021, 28, 1–10. [Google Scholar] [CrossRef]
- Mullainathan, S.; Spiess, J. Machine learning: An applied econometric approach. J. Econ. Perspect. 2017, 31, 87–106. [Google Scholar] [CrossRef] [Green Version]
- Wong, P.H.; Kourtit, K.; Nijkamp, P. The ideal neighbourhoods of successful ageing: A machine learning approach. Health Place 2021, 72, 102704. [Google Scholar] [CrossRef] [PubMed]
- Athey, S.; Imbens, G.W. Machine learning methods that economists should know about. Annu. Rev. Econ. 2019, 11, 685–725. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Svetnik, V.; Liaw, A.; Tong, C.; Wang, T. Application of Breiman’s Random Forest to modeling structure-activity relationships of pharmaceutical molecules. In Multiple Classifier Systems; Lecture Notes in Computer Science; Springer: Berlin/ Heidelberg, Germany, 2004; Volume 3077, pp. 334–343. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 5, 1189–1232. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Schonlau, M. Boosted regression (boosting): An introductory tutorial and a stata plugin. Stata J. 2005, 5, 330–354. [Google Scholar] [CrossRef]
- Goldstein, A.; Kapelner, A.; Bleich, J.; Pitkin, E. Peeking inside the black box: Visualizing statistical learning with plots of individual conditional expectation. J. Comput. Graph. Stat. 2015, 24, 44–65. [Google Scholar] [CrossRef]
- Armbruster, B.B. Metacognition in creativity. In Handbook of Creativity: Perspectives on Individual Differences; Glover, J., Ronning, R., Reynolds, C., Eds.; Springer: Boston, MA, USA, 1989; pp. 177–182. [Google Scholar]
- Elsbach, K.D.; Hargadon, A.B. Enhancing creativity through “mindless” work: A framework of workday design. Organ. Sci. 2006, 17, 470–483. [Google Scholar] [CrossRef] [Green Version]




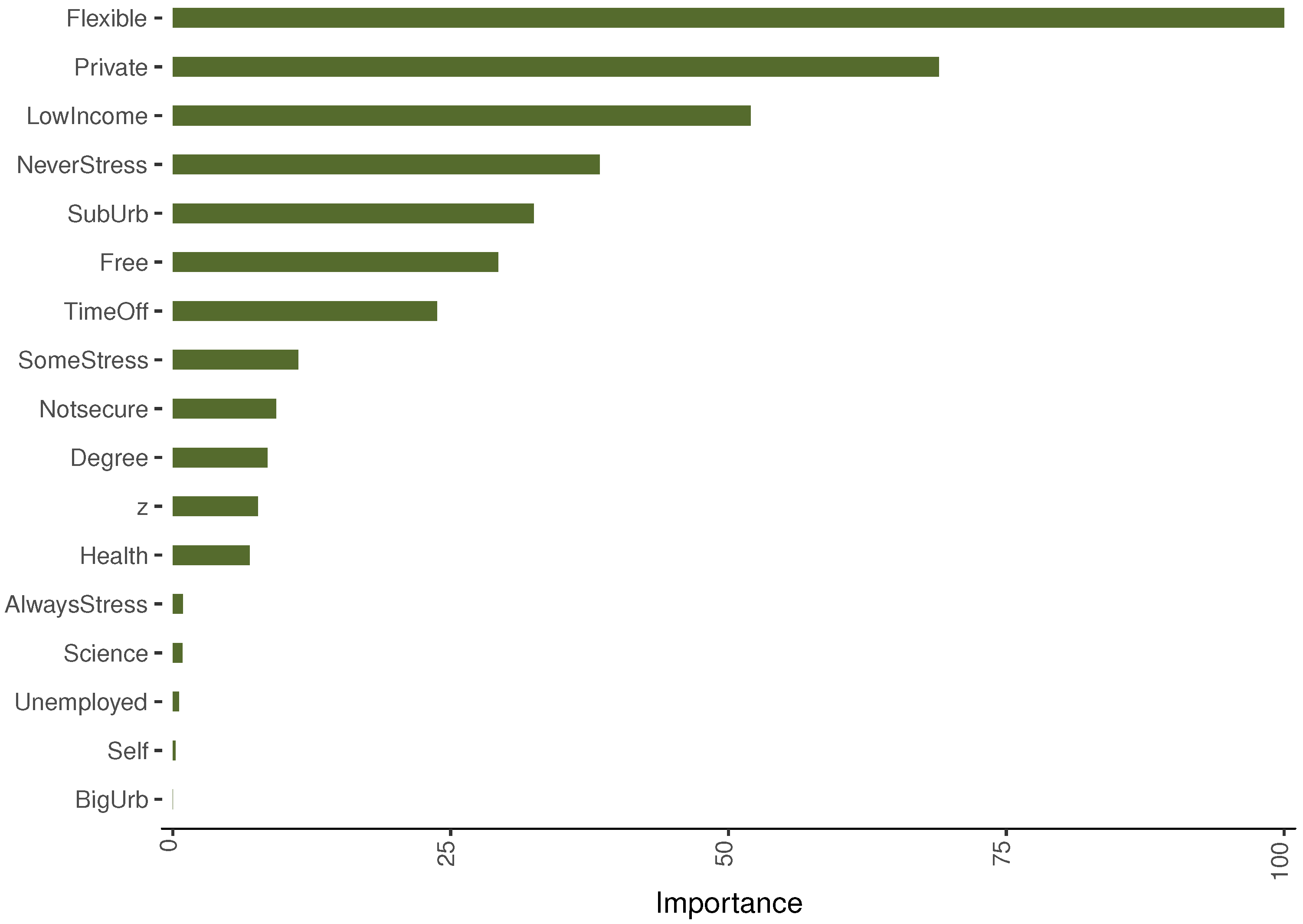


| Variable | Obs | Mean | Std. Dev. | Min | Max |
|---|---|---|---|---|---|
| PatCap | 264 | 127.07 | 160.93 | 0.24 | 813.33 |
| Hours | 301 | 38.88 | 4.49 | 10 | 55.91 |
| Flexible | 301 | 0.3 | 0.15 | 0 | 0.83 |
| Free | 301 | 0.45 | 0.18 | 0.02 | 1 |
| NotSecure | 301 | 0.13 | 0.09 | 0 | 0.5 |
| NeverStress | 301 | 0.12 | 0.09 | 0 | 0.75 |
| SomeStress | 301 | 0.25 | 0.12 | 0 | 0.8 |
| Science | 301 | 0.02 | 0.04 | 0 | 0.23 |
| Private | 301 | 0.56 | 0.17 | 0 | 1 |
| Self | 301 | 0.09 | 0.09 | 0 | 1 |
| Degree | 301 | 0.15 | 0.12 | 0 | 0.75 |
| Unemployed | 301 | 0.06 | 0.06 | 0 | 0.31 |
| LowIncome | 301 | 0.3 | 0.14 | 0 | 1 |
| BigUrb | 301 | 0.2 | 0.23 | 0 | 1 |
| SubUrb | 301 | 0.1 | 0.17 | 0 | 0.86 |
| TimeOff | 301 | 0.38 | 0.16 | 0 | 1 |
| Health | 301 | 0.01 | 0.03 | 0 | 0.25 |
| Non-Spatial | SAR | |||
|---|---|---|---|---|
| 0.181 *** | 0.177 ** | |||
| (0.050) | (0.069) | |||
| −0.003 *** | −0.002 *** | |||
| (0.001) | (0.001) | |||
| −0.051 *** | −0.049 *** | |||
| (0.015) | (0.018) | |||
| 0.171 | 0.103 | 0.057 | −0.009 | |
| (0.717) | (0.717) | (0.596) | (0.591) | |
| 0.387 | 0.450 | 0.339 | 0.402 | |
| (0.889) | (0.880) | (0.725) | (0.724) | |
| −0.315 | −0.423 | −0.318 | −0.421 | |
| (0.650) | (0.636) | (0.618) | (0.614) | |
| −0.446 | −0.508 | −0.377 | −0.424 | |
| (0.839) | (0.796) | (0.756) | (0.730) | |
| 0.272 | 0.224 | 0.144 | 0.114 | |
| (0.788) | (0.738) | (0.573) | (0.543) | |
| 3.129 ** | 3.280 ** | 3.063 ** | 3.212 ** | |
| (1.307) | (1.324) | (1.431) | (1.422) | |
| 0.851 ** | 0.875 ** | 0.821 ** | 0.841 ** | |
| (0.372) | (0.360) | (0.392) | (0.391) | |
| −0.572 | −0.383 | −0.404 | −0.238 | |
| (0.671) | (0.633) | (0.638) | (0.624) | |
| 1.589 *** | 1.650 *** | 1.466 *** | 1.525 *** | |
| (0.610) | (0.613) | (0.563) | (0.564) | |
| −2.188 | −2.738 | −2.418 | −2.928 | |
| (2.778) | (2.824) | (1.958) | (1.924) | |
| −0.525 | −0.593 | −0.528 | −0.587 | |
| (0.556) | (0.534) | (0.493) | (0.484) | |
| 1.005 *** | 1.001 *** | 1.035 *** | 1.031 *** | |
| (0.351) | (0.349) | (0.292) | (0.292) | |
| 0.546 * | 0.541 * | 0.466 | 0.463 | |
| (0.285) | (0.289) | (0.316) | (0.315) | |
| −0.071 | −0.017 | 0.006 | 0.055 | |
| (0.625) | (0.604) | (0.604) | (0.595) | |
| −2.636 | −2.645 | −2.426 | −2.413 | |
| (2.155) | (2.080) | (2.070) | (2.042) | |
| 0.738 | 4.082 *** | −0.585 | 2.681 ** | |
| (1.386) | (0.775) | (1.818) | (1.160) | |
| 0.399 *** | 0.392 *** | |||
| (0.151) | (0.151) | |||
| Maximum Hours | 35.9 | 35.7 | ||
| Maximum Daily Hours (5-Day) | 7.2 | 7.1 | ||
| RMSE | 117.4 | 118.3 | 114.2 | 114.8 |
| Observations | 253 | 253 | 253 | 253 |
| R | 0.780 | 0.781 | ||
| Log Likelihood | −273.294 | −272.748 | ||
| Wald Test p-value | 0.027 | 0.009 | ||
| LR Test p-value | 0.033 | 0.037 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Celbiş, M.G.; Wong, P.-H.; Kourtit, K.; Nijkamp, P. Innovativeness, Work Flexibility, and Place Characteristics: A Spatial Econometric and Machine Learning Approach. Sustainability 2021, 13, 13426. https://doi.org/10.3390/su132313426
Celbiş MG, Wong P-H, Kourtit K, Nijkamp P. Innovativeness, Work Flexibility, and Place Characteristics: A Spatial Econometric and Machine Learning Approach. Sustainability. 2021; 13(23):13426. https://doi.org/10.3390/su132313426
Chicago/Turabian StyleCelbiş, Mehmet Güney, Pui-Hang Wong, Karima Kourtit, and Peter Nijkamp. 2021. "Innovativeness, Work Flexibility, and Place Characteristics: A Spatial Econometric and Machine Learning Approach" Sustainability 13, no. 23: 13426. https://doi.org/10.3390/su132313426
APA StyleCelbiş, M. G., Wong, P.-H., Kourtit, K., & Nijkamp, P. (2021). Innovativeness, Work Flexibility, and Place Characteristics: A Spatial Econometric and Machine Learning Approach. Sustainability, 13(23), 13426. https://doi.org/10.3390/su132313426