
Effectiveness of Green Infrastructure Location Based on a Social Well-Being Index


Abstract
:1. Introduction
- -
- How does GI influence residents’ satisfaction with livability?
- -
- Which attributes of sociodemographic and regional characteristics are most sensitive for adopting GI?
- -
- How do we maximize the model’s application in the realm of urban studies?
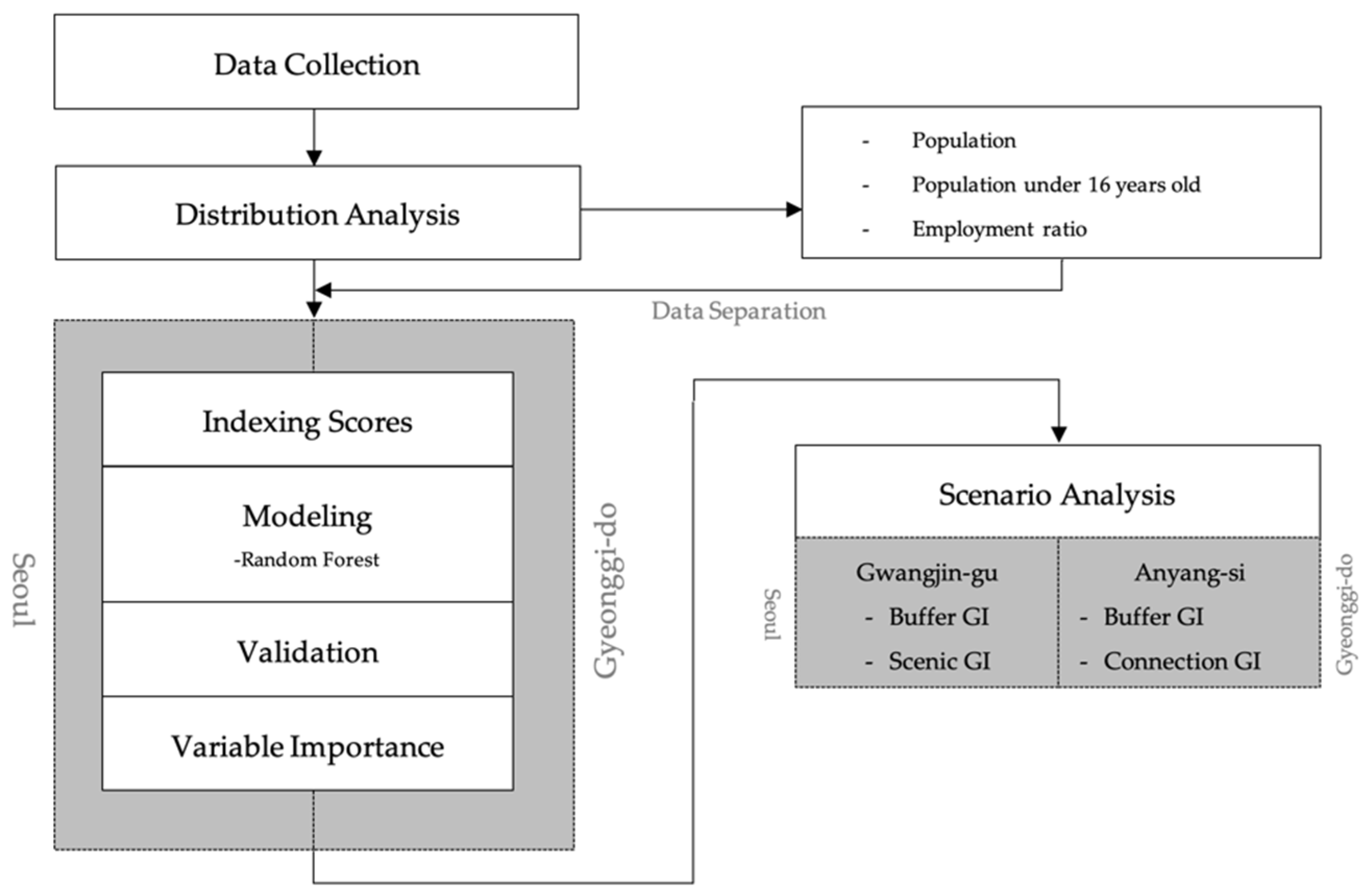
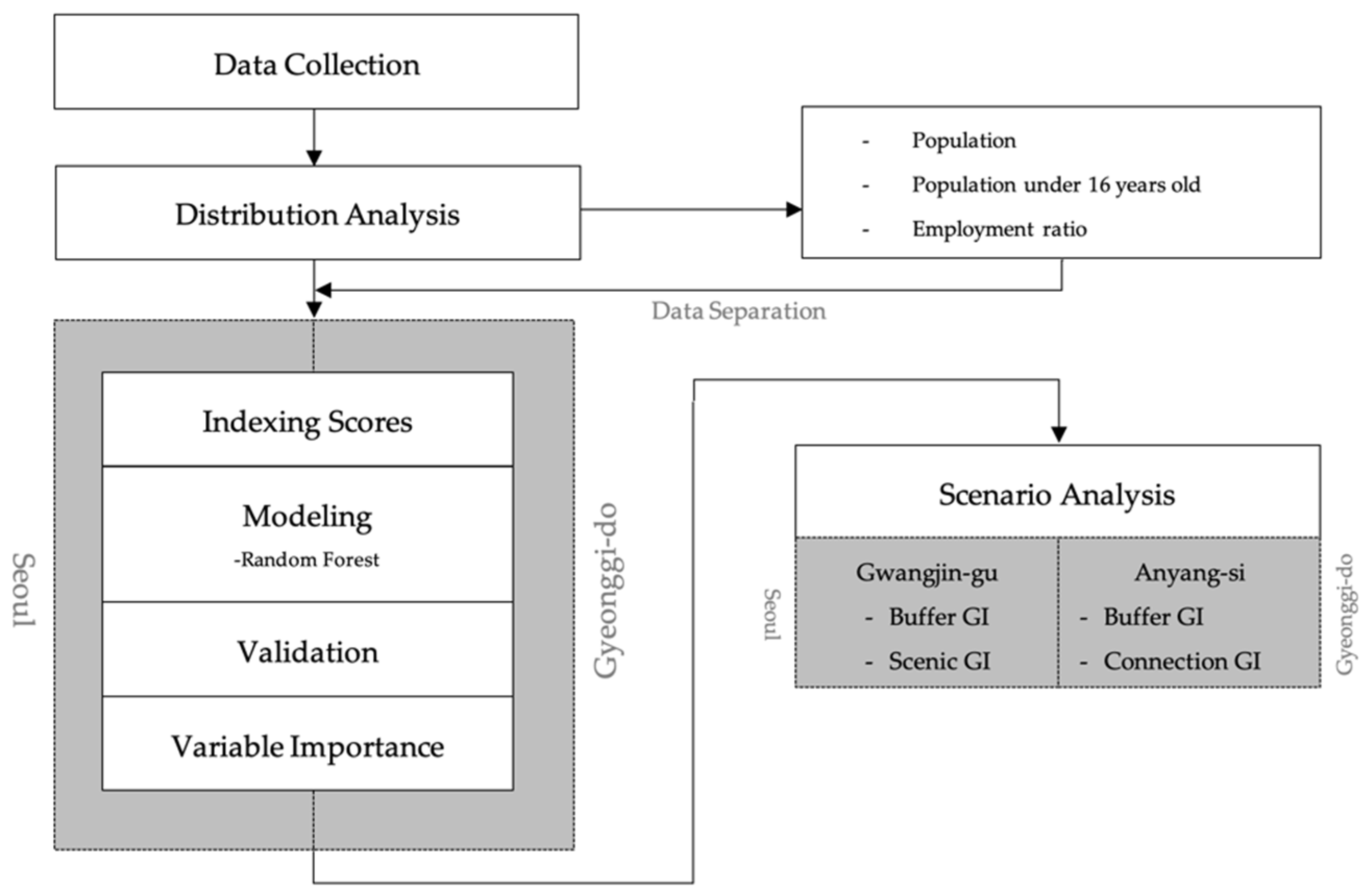
2. Materials and Method
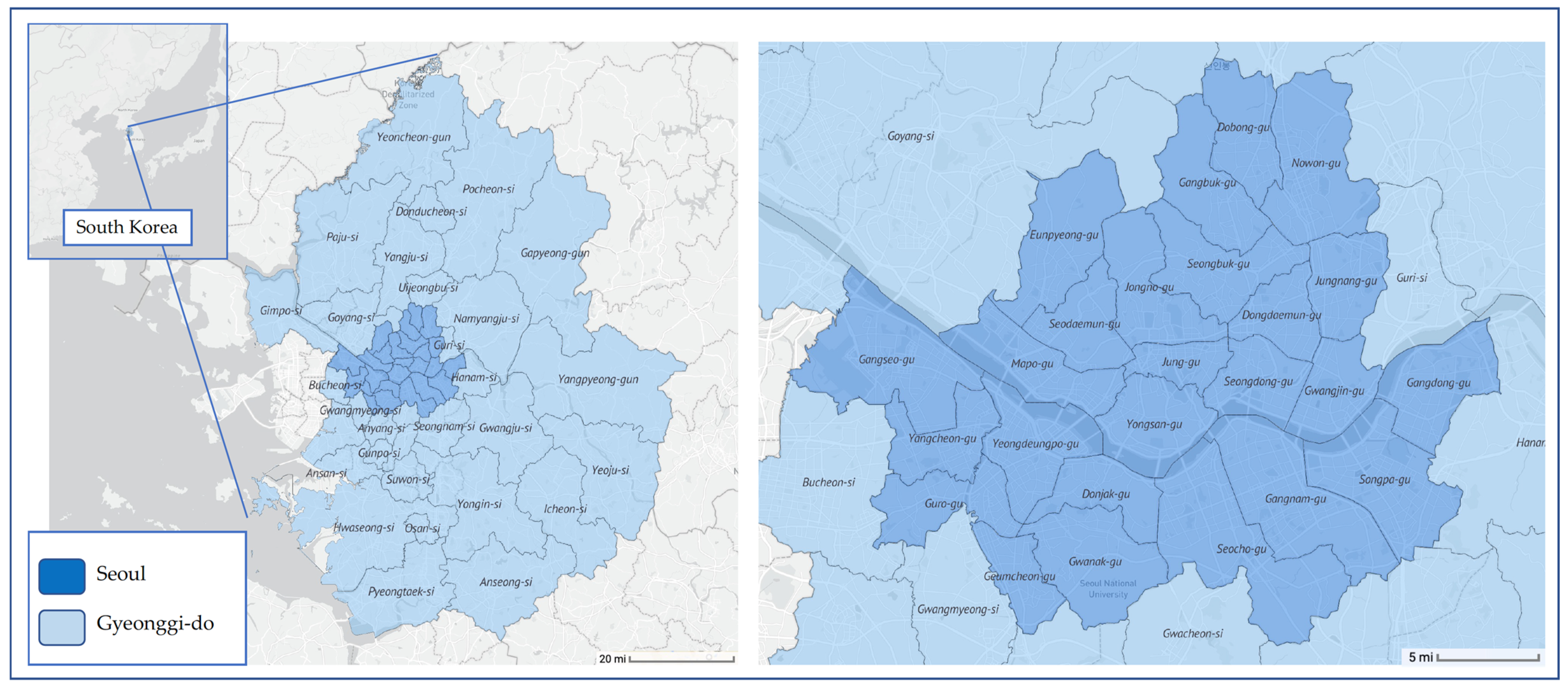
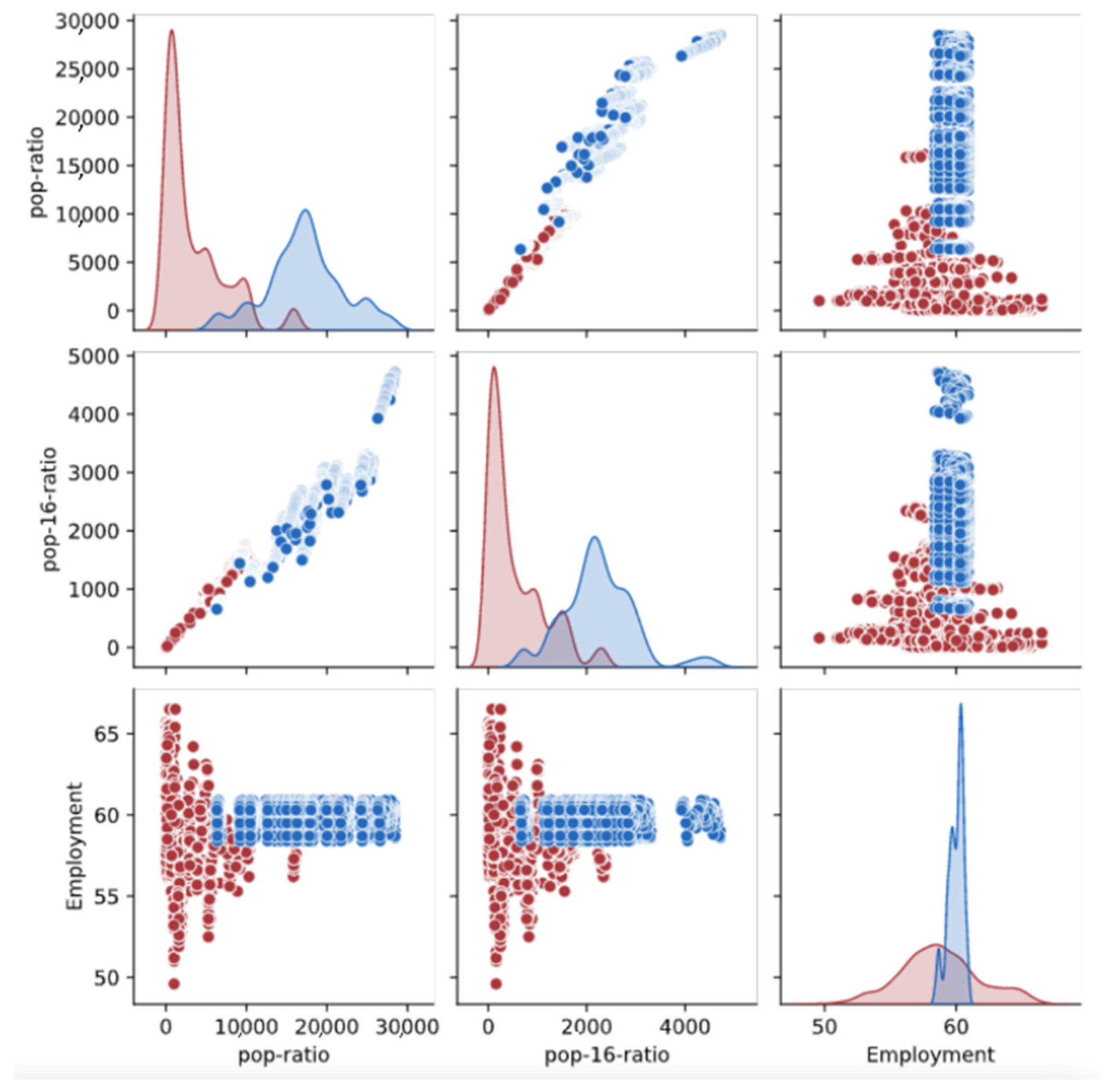
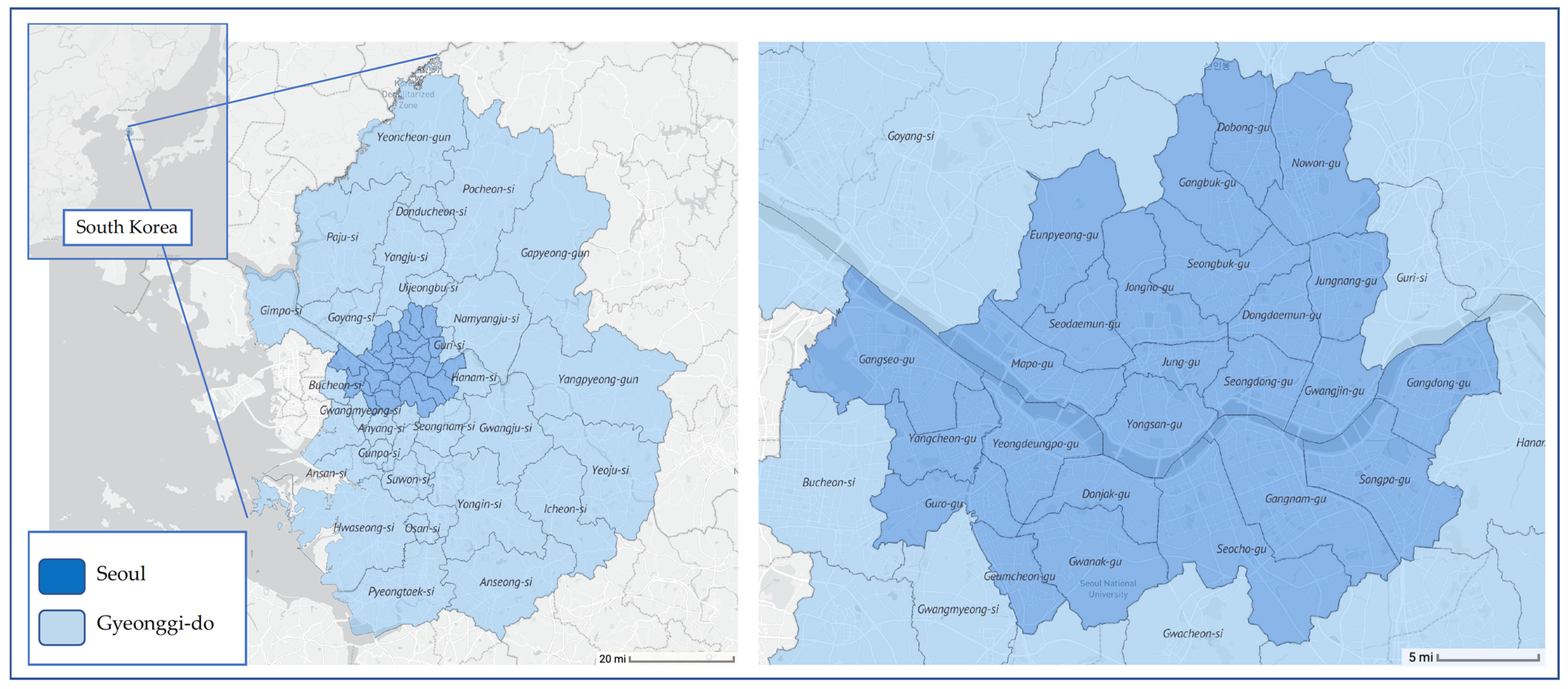
2.1. Materials
2.2. Model Method
2.2.1. Social Well-Being Index
2.2.2. Random Forest Regressor: Rule-Based Bootstrap Aggregation
2.2.3. Interpretation of ML Models
3. Model Results
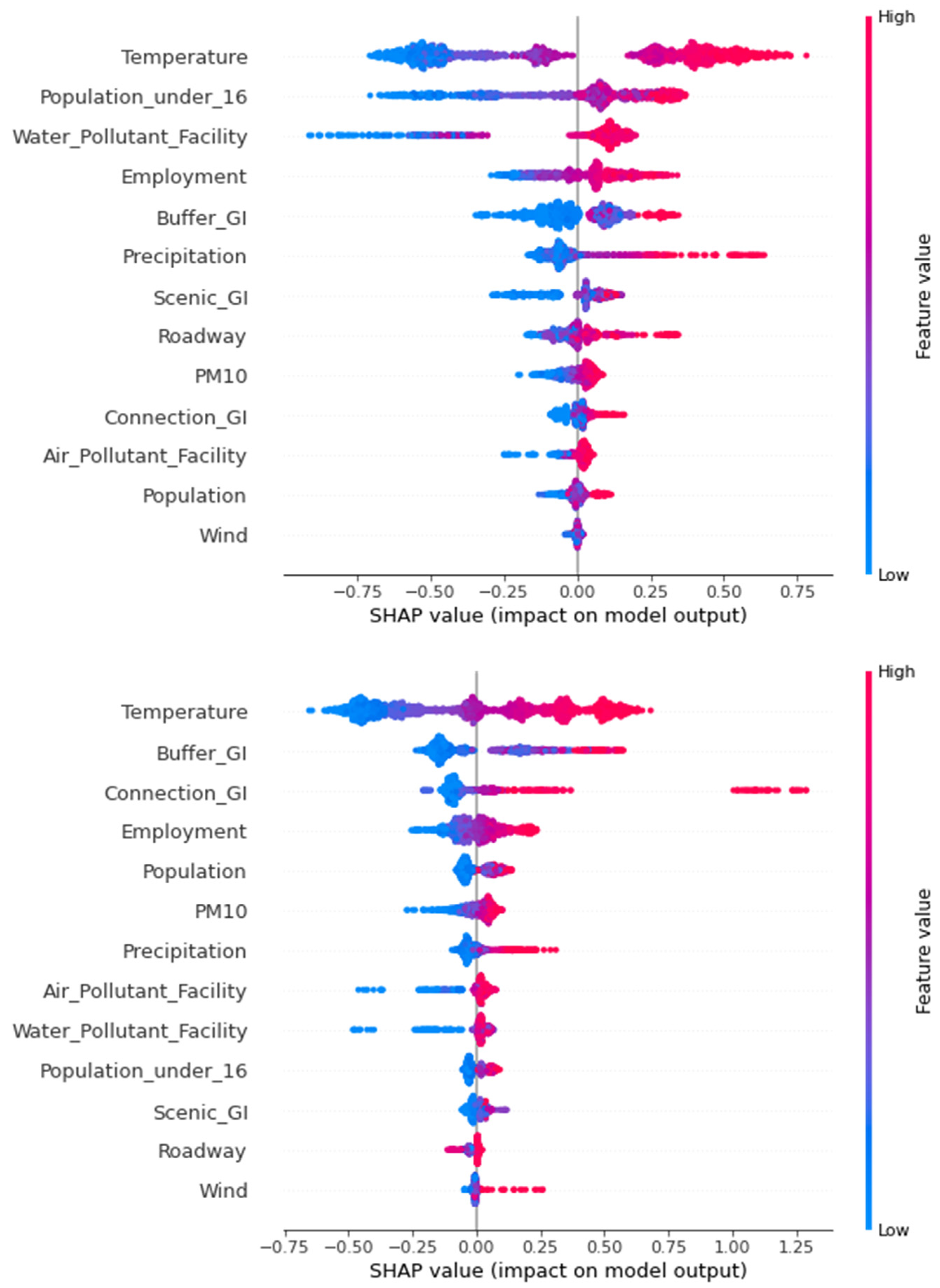
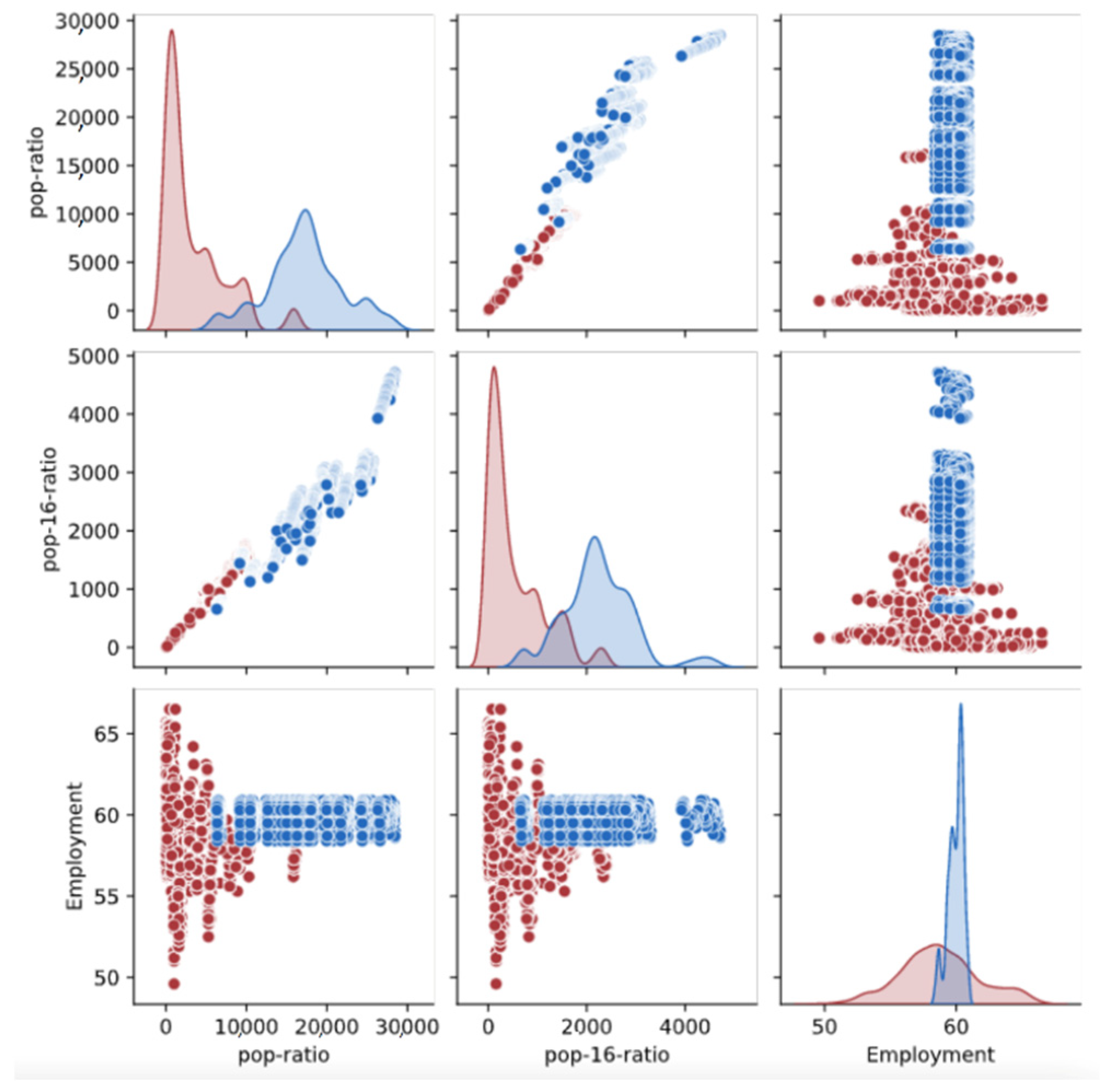
3.1. Relative Importance of Variable
3.2. Green Infrastructure Index Distribution
4. Scenario Analysis and Discussion
4.1. Scenario Analysis: Potential Impacts of GI on Social Well-Being Index
4.2. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Allen Klaiber, H.; Phaneuf, D.J. Valuing Open Space in a Residential Sorting Model of the Twin Cities. J. Environ. Econ. Manag. 2010, 60, 57–77. [Google Scholar] [CrossRef]
- Pauleit, S.; Ambrose-Oji, B.; Andersson, E.; Anton, B.; Buijs, A.; Haase, D.; Elands, B.; Hansen, R.; Kowarik, I.; Kronenberg, J.; et al. Advancing Urban Green Infrastructure in Europe: Outcomes and Reflections from the GREEN SURGE Project. Urban For. Urban Green. 2019, 40, 4–16. [Google Scholar] [CrossRef]
- Department for Transportation, Local Government and the Regions. Towards an Urban Renaissance; Taylor & Francis: Abingdon, UK, 1999. [Google Scholar]
- Imrie, R.; Raco, M. Urban Renaissance—New Labour, Community, and Urban Policy; The Policy Press: Bristol, UK, 2003. [Google Scholar]
- European Commission; Expert Group on the Urban Environment. European Sustainable Cities; Nuclear Safety and Civil Protection: Brussels, Belgium, 1996. [Google Scholar]
- United Nations. The Sustainable Development Goals Report; The Department of Economic and Social Affairs: New York, NY, USA, 2020. [Google Scholar]
- Department of Economics and Social Affairs. The Future Is Now—Science for Achieving Sustainable Development; United Nations: New York, NY, USA, 2019. [Google Scholar]
- Derrible, S. Urban Engineering for Sustainability; The MIT Press: Cambridge, MA, USA, 2019; ISBN 978-0-262-04344-1. [Google Scholar]
- City of Portland. Portland’s Green Infrastructure: Quantifying the Health, Energy and Community Livability Benefits; City of Portland: Portland, WA, USA, 2010; p. 101. [Google Scholar]
- Votsis, A. Planning for Green Infrastructure: The Spatial Effects of Parks, Forests, and Fields on Helsinki’s Apartment Prices. Ecol. Econ. 2017, 132, 279–289. [Google Scholar] [CrossRef] [Green Version]
- Botkin, D.B.; Beveridge, C.E. Cities as Environment. Urban Ecosyst. 1997, 1, 3–19. [Google Scholar] [CrossRef]
- Sandström, U.G. Green Infrastructure Planning in Urban Sweden. Plan. Pract. Res. 2002, 17, 373–385. [Google Scholar] [CrossRef]
- United States Environmental Protection Agency (US EPA). Benefits of Green Infrastructure; US EPA: Washington, DC, USA, 2021.
- Tzoulas, K.; Korpela, K.; Venn, S.; Yli-Pelkonen, V.; Kaźmierczak, A.; Niemela, J.; James, P. Promoting Ecosystem and Human Health in Urban Areas Using Green Infrastructure: A Literature Review. Landsc. Urban Plan. 2007, 81, 167–178. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Plantinga, A.J. The Influence of Public Open Space on Urban Spatial Structure. J. Environ. Econ. Manag. 2003, 46, 288–309. [Google Scholar] [CrossRef]
- Mell, I.C. Can Green Infrastructure Promote Urban Sustainability? Proc. Inst. Civ. Eng. Eng. Sustain. 2009, 162, 23–34. [Google Scholar] [CrossRef]
- Sung, H.-C.; Hwang, S. A Preliminary Study on Assessment of Urban Parks and Green Zones of Ecological Attributes and Responsiveness to Climate Change. J. Korea Soc. Environ. Restor. Technol. 2013, 16, 107–117. [Google Scholar] [CrossRef]
- Zhang, Y.; Murray, A.T.; Turner, B.L. Optimizing Green Space Locations to Reduce Daytime and Nighttime Urban Heat Island Effects in Phoenix, Arizona. Landsc. Urban Plan. 2017, 165, 162–171. [Google Scholar] [CrossRef]
- Meerow, S.; Newell, J.P. Spatial Planning for Multifunctional Green Infrastructure: Growing Resilience in Detroit. Landsc. Urban Plan. 2017, 159, 62–75. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, R.; Grekousis, G.; Liu, Y.; Yuan, Y.; Li, Z. Neighbourhood Greenness and Mental Wellbeing in Guangzhou, China_ What Are the Pathways? Landsc. Urban Plan. 2019, 190, 9. [Google Scholar] [CrossRef]
- Neema, M.N.; Ohgai, A. Multitype Green-Space Modeling for Urban Planning Using GA and GIS. Environ. Plan. B Plan. Des. 2013, 40, 447–473. [Google Scholar] [CrossRef]
- Yuan, Z.; Tiemao, S.; Chang, G. Multi-Objective Optimal Location Planning of Urban Parks. In Proceedings of the 2011 International Conference on Electronics, Communications and Control (ICECC), Ningbo, China, 9–11 September 2011; pp. 918–921. [Google Scholar]
- Maruani, T.; Amit-Cohen, I. Open Space Planning Models: A Review of Approaches and Methods. Landsc. Urban Plan. 2007, 81, 1–13. [Google Scholar] [CrossRef]
- Thompson, C.W. Urban Open Space in the 21st Century. Landsc. Urban Plan. 2002, 60, 59–72. [Google Scholar] [CrossRef]
- BenDor, T.; Westervelt, J.; Song, Y.; Sexton, J.O. Modeling Park Development through Regional Land Use Change Simulation. Land Use Policy 2013, 30, 1–12. [Google Scholar] [CrossRef]
- Kim, H.; Tran, T. An Evaluation of Local Comprehensive Plans Toward Sustainable Green Infrastructure in US. Sustainability 2018, 10, 4143. [Google Scholar] [CrossRef] [Green Version]
- Campagnaro, T.; Sitzia, T.; Cambria, V.E.; Semenzato, P. Indicators for the Planning and Management of Urban Green Spaces: A Focus on Public Areas in Padua, Italy. Sustainability 2019, 11, 7071. [Google Scholar] [CrossRef] [Green Version]
- Lee, D.; Oh, K. The Green Infrastructure Assessment System (GIAS) and Its Applications for Urban Development and Management. Sustainability 2019, 11, 3798. [Google Scholar] [CrossRef] [Green Version]
- Zhou, C.; Wu, Y. A Planning Support Tool for Layout Integral Optimization of Urban Blue–Green Infrastructure. Sustainability 2020, 12, 1613. [Google Scholar] [CrossRef] [Green Version]
- Lai, S.; Leone, F.; Zoppi, C. Assessment of Municipal Masterplans Aimed at Identifying and Fostering Green Infrastructure: A Study Concerning Three Towns of the Metropolitan Area of Cagliari, Italy. Sustainability 2019, 11, 1470. [Google Scholar] [CrossRef] [Green Version]
- Giles-Corti, B.; Broomhall, M.H.; Knuiman, M.; Collins, C.; Douglas, K.; Ng, K.; Lange, A.; Donovan, R.J. How Important Is Distance To, Attractiveness, and Size of Public Open Space? Am. J. Prev. Med. 2005, 28, 169–176. [Google Scholar] [CrossRef]
- Liang, X.; Tian, H.; Li, X.; Huang, J.-L.; Clarke, K.C.; Yao, Y.; Guan, Q.; Hu, G. Modeling the Dynamics and Walking Accessibility of Urban Open Spaces under Various Policy Scenarios. Landsc. Urban Plan. 2021, 207, 103993. [Google Scholar] [CrossRef]
- Chiesura, A. The Role of Urban Parks for the Sustainable City. Landsc. Urban Plan. 2004, 68, 129–138. [Google Scholar] [CrossRef]
- Roe, M.; Mell, I. Negotiating Value and Priorities: Evaluating the Demands of Green Infrastructure Development. J. Environ. Plan. Manag. 2013, 56, 650–673. [Google Scholar] [CrossRef]
- Lee, D.; Derrible, S. Predicting Residential Water Demand with Machine-Based Statistical Learning. J. Water Resour. Plan. Manag. 2020, 146, 04019067. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. JMLR 2011, 12, 2825–2830. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning with Applications in R, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 112, ISBN 978-1-4614-7138-7. [Google Scholar]
- Abhijith, K.V. Air Pollution Abatement Performances of Green Infrastructure in Open Road and Built-up Street Canyon Environments—A Review. Atmos. Environ. 2017, 162, 71–86. [Google Scholar] [CrossRef]
- De Groot, R.S. Functions of Nature: Evaluation of Nature in Environmental Planning Management and Decision-Making; Wolters-Noordhoff BV: Toronto, ON, Canada, 1992; ISBN 90-01-35594-3. [Google Scholar]
- Seoul Metropolitan Governments. Urban Planning-Seoul’s Unique, Sustainable Urban Planning; Seoul Solution: Seoul, Korea, 2021. [Google Scholar]
- OECD. How’s Life in Your Region? Measuring Regional and Local Well-Being for Policy Making; OECD: Paris, France, 2014. [Google Scholar]
- Byun, M.; Choi, J.; Park, M.; Lee, H. The Quality of Life in Megacity and Seoul-Specific Happiness Indicator; Seoul Research Institute: Seoul, Korea, 2015. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006; ISBN 978-0-387-31073-2. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer Series in Statistics; Springer: New York, NY, USA, 2009; ISBN 978-0-387-84858-7. [Google Scholar]
- Lee, D.; Mulrow, J.; Haboucha, C.J.; Derrible, S.; Shiftan, Y. Attitudes on Autonomous Vehicle Adoption Using Interpretable Gradient Boosting Machine. Transp. Res. Rec. 2019, 2673, 865–878. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Statist. 2001, 29. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30, pp. 4765–4774. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Description | Time Range | Mean | S.D. | Min. | Max. |
|---|---|---|---|---|---|---|
| Demographic characteristics | ||||||
| Pop | Total population | Year | 404,873.60 | 252,774.03 | 43,824 | 1,203,285 |
| Pop_16 | Number of the population age 16 or under | Year | 61,644.73 | 43,861.39 | 5020 | 213,391 |
| Emp | Employment ratio (employed/total population) | Year | 59.31 | 2.37 | 49.6 | 66.5 |
| Green Infrastructure characteristics | ||||||
| Buffer_gi | Buffer Green Infrastructure area (m2) | Year | 573,978.77 | 815,943.75 | 0 | 4,504,737 |
| Scenic_gi | Scenic Green Infrastructure area (m2) | Year | 494,455.95 | 2,672,348.84 | 0 | 34,908,592 |
| Connection_gi | Connection Green Infrastructure area (m2) | Year | 93,391.83 | 427,795.86 | 0 | 3,939,590 |
| Built environment characteristics | ||||||
| Water_pol_fac | Number of water pollution facilities | Year | 320.99 | 409.81 | 19 | 2775 |
| Air_pol_fac | Number of air pollution facilities | Year | 314.86 | 530.14 | 2 | 3231 |
| Road | Road coverage (km2) | Year | 11.65 | 10.21 | 0.11 | 28.83 |
| Climate characteristics | ||||||
| temp | Temperature (°C) | Month | 12.51 | 10.12 | −8.5 | 29.3 |
| wind | Wind speed (m/s) | Month | 1.54 | 0.58 | 0 | 6.8 |
| precipitation | Precipitation (mm/day) | Month | 85.07 | 108.34 | 0 | 1076.50 |
| PM10 | Particulate Matters (<10 micrometers, micrograms/m2) | Month | 47.39 | 15.81 | 6 | 124 |
| Analysis Cases | GI Type | Gwangjin-gu (Seoul) | Anyang-si (Gyeonggi-do) | |||
|---|---|---|---|---|---|---|
| Ratio | Index Rank | Ratio | Index Rank | |||
| Base case (December 2019) | Buffer | 0.099% | 10 | 0.551% | 28 | |
| Scenic | 0.011% | 0.219% | ||||
| Connection | 0.000% | 0.043% | ||||
| Scenario cases | Mean ratio | Buffer | 0.506% | 9 | 0.520% | 28 |
| Scenic | 0.151% | 0.219% | ||||
| Connection | 0.000% | 0.055% | ||||
| 150% of the mean ratio | Buffer | 0.759% | 8 | 0.780% | 26 | |
| Scenic | 0.226% | 0.219% | ||||
| Connection | 0.000% | 0.083% | ||||
| Maximum ratio | Buffer | 2.467% | 1 | 1.969% | 6 | |
| Scenic | 1.062% | 0.219% | ||||
| Connection | 0.000% | 0.506% | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ko, S.; Lee, D. Effectiveness of Green Infrastructure Location Based on a Social Well-Being Index. Sustainability 2021, 13, 9620. https://doi.org/10.3390/su13179620
Ko S, Lee D. Effectiveness of Green Infrastructure Location Based on a Social Well-Being Index. Sustainability. 2021; 13(17):9620. https://doi.org/10.3390/su13179620
Chicago/Turabian StyleKo, Sanghyeon, and Dongwoo Lee. 2021. "Effectiveness of Green Infrastructure Location Based on a Social Well-Being Index" Sustainability 13, no. 17: 9620. https://doi.org/10.3390/su13179620
APA StyleKo, S., & Lee, D. (2021). Effectiveness of Green Infrastructure Location Based on a Social Well-Being Index. Sustainability, 13(17), 9620. https://doi.org/10.3390/su13179620