Urban Real Estate Values and Ecosystem Disservices: An Estimate Model Based on Regression Analysis



Abstract
1. Introduction
- Provisioning. These are all the goods that derive from ecosystems and that man uses to satisfy his needs. This category includes: food, deriving from organized systems such as agriculture, breeding and waterculture, and from wild sources; water, also a support service for the development of life; timber, used as a building material as well as fuel; fibers in general, both those obtained from agricultural systems and those produced by animals; the fuels; etc.;
- Regulating, that are benefits deriving from the regulation of ecosystem processes, such as climate regulation, natural risk management and waste treatment;
- Cultural, mainly characterized by intangibility, among whom are included cultural identity and diversity, values of cultural and landscape heritage, spiritual and inspirational services, entertainment and tourism;
- Supporting, means those that support and allow the supply of all other types of services, such as the formation of the soil and the nutrient cycle.
2. Aim of the Paper
3. Essential Notions on Regression Analysis
- yi is the dependent variable;
- xpi are the independent variables or regressors;
- βi are the regression coefficients;
- β0 is the intercept and represents the point where the straight line crosses the ordinate axis;
- εi is the error.
- Y is a vector n × 1 of n observations of the dependent variable;
- X is a matrix n × (p + 1) of n observations of p + 1 regressors;
- ε is a vector n × 1 of n error terms;
- β is a vector (p + 1) × 1 of unknown regression coefficients.
- Assigned x1i, x2i, …, xpi, the conditioned distribution of εi has average zero;
- x1i, x2i, …, xpi, yi, with i = 1, …, n are independent and identically distributed (i.i.d.);
- x1i, x2i, …, xpi, yi and εi have four moments;
- Not perfect collinearity. When no regressor is linear combination of other regressors;
- Hypothesis of homoschedasticity;
- Variance of regression;
- Variance of residuals.
- represents the average of the values observed;
- represents the values observed;
- represents the expected theoretical values.
4. A Multiple Regression Model for Estimating Real Estate Values
- Living Surface (LSU) expressed in square meters;
- Number of Services (SERV) of the living unit;
- Conservation and Maintenance Level (CML) of the property. Usually this variable is appreciated by market operators according to a score rating scale, with 1 = poor, 3 = fair, 5 = good;
- Distance of the Apartment from the Ecosystem Service (DES), in meters;
- Floor Level (FLL) of the apartment;
- Panoramicity (PAN), according to the score rating scale usually used in the real estate agencies, 1 = bad, 3 = poor, 5 = fair, 7 = good, 9 = excellent;
- Lift Presence (LIFT), 0 = absent, 1 = present.
5. Case Study
9.75·LIFT
- The independent variables x1, x2, …, x7 are deterministic and the independence of the s conditional distributions (with s = number of observations = 60) is verified because the sampled values were measured without error and are independent of each other;
- The normality of the conditioned distributions and the linearity of the relationships among the variables are verified by the Q-Q plot method (Quantile-Quantile plot), according to which the observed (real) quantiles are compared with the expected quantiles in case the distribution is normal. Since the points are arranged along a straight line, it is possible to say that the distribution approximates the normal well. The reference graphic is in Figure 2;
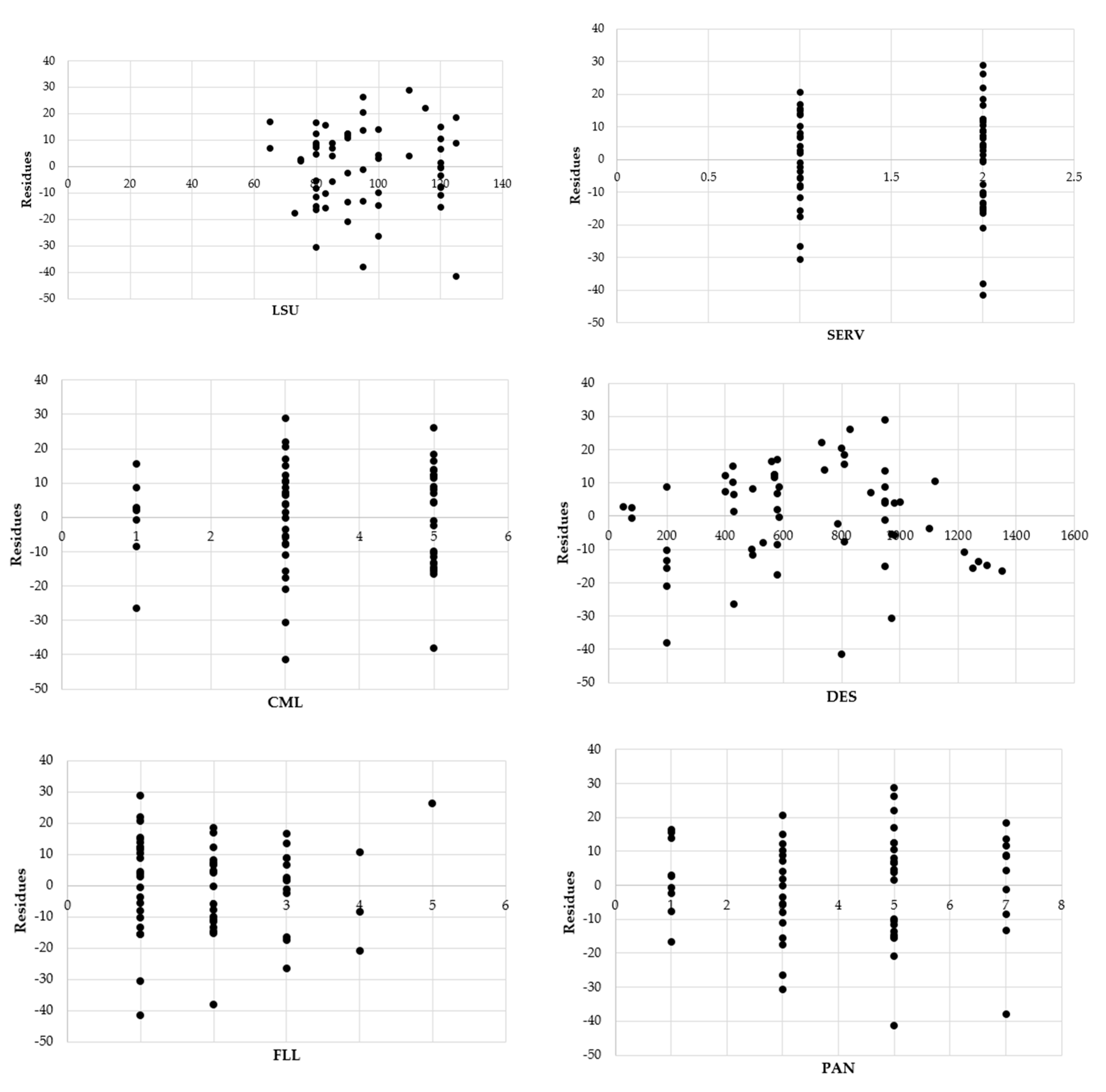
- The hypothesis of homoschedasticity is verified by analyzing the residues. In fact, with the only exception of the FLL variable, however significant for estimation reasons, the graphs of the residues are presented approximately as points clouds that are arranged randomly within a horizontal band, as shown in the graphs in Figure 3;
- H0: β1 = β2 = β3 = β4 = β5 = β6 = β7 = 0 (there is no linear relationship between the dependent variable and the explanatory variables);
- H1: βj ≠ 0 (there is a linear relationship between the dependent variable and at least one of the explanatory variables).
- Accept H1 if F > Fcrit, where Fcrit is the critical value on the right tail of a distribution F with p and n − p − 1 degrees of freedom;
- Otherwise accept H0.
- H0: βi = 0 (there is no linear relationship between the dependent variable P and the explanatory variable xi);
- H1: βi ≠ 0 (here is a linear relationship between xi and P).
- Accept H1 if t > tcrit, where tcrit is the critical value;
- Otherwise accept H0.
- Since t stat > tcrit with α = 0.05 (95%), the variables LSU, DES, PAN and LIFT have significant effects on the purchase price. So, taking into account the amount of the other variables, there is a linear relationship between each of the variables considered and the price P;
- Since t stat > tcrit with α = 0.5 (50%), the variable CML has effects on the price;
- The variables SERV and FLL have no evident effects on the purchase price, because t stat < tcrit for any level of α. However, these variables are taken into account in the analysis for extra-statistical considerations based on the importance from an estimative point of view.
6. Results and Discussions
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Farber, S.C.; Costanza, R.; Wilson, M.A. Economic and ecological concepts for valuing ecosystem services. Ecol. Econ. 2002, 41, 375–392. [Google Scholar] [CrossRef]
- UN. MEA Ecosystems and Human Well-being: Multiscale Assessment. Millennium Ecosystem Assessment Series; UN: Washington, DC, USA, 2006. [Google Scholar]
- Costanza, R.; d’Arge, R.; de Groot, R.; Farber, S.; Grasso, M.; Hannon, B.; Limburg, K.; Naeem, S.; O’Nell, R.V.; Paruelo, J.; et al. The value of the world’s ecosystem services and natural capital. Nature 1997, 387, 253–260. [Google Scholar] [CrossRef]
- Daily, G.C.; Soderquist, T.; Aniyar, S.; Arrow, K.; Dasgupta, P.; Ehrlich, P.R.; Folke, C.; Jansson, A.M.; Jansson, B.O.; Kautsky, N.; et al. The value of nature and the nature of value. Science 2000, 289, 395–396. [Google Scholar] [CrossRef] [PubMed]
- De Groot, R.S.; Wilson, M.A.; Boumans, R.M.J. A typology for the classification, description and valuation of ecosystem functions, goods and services. Special Issue: The Dynamics and Value of Ecosystem Services: Integrating Economic and Ecological Perspectives. Ecol. Econ. 2002, 41, 393–408. [Google Scholar] [CrossRef]
- Nesticò, A.; Guarini, M.R.; Morano, P.; Sica, F. An Economic Analysis Algorithm for Urban Forestry Projects. Sustainability 2019, 11, 314. [Google Scholar] [CrossRef]
- Nesticò, A.; Maselli, G. Sustainability indicators for the economic evaluation of tourism investments on islands. J. Clean. Prod. 2020, 248, 119217. [Google Scholar] [CrossRef]
- Del Giudice, V. L’analisi di Regressione Multipla Nella Stima per Valori Tipici, Ce.S.E.T. Seminari. Aspetti Evolutivi Della Scienza Estimativa. Seminario in Onore di Ernesto Marenghi; Firenze University Press: Firenze, Italy, 1995. [Google Scholar]
- Schimmenti, E.; Asciuto, A.; Mandanici, S.; Viviano, P. L’utilizzo della regressione multipla nelle indagini estimative condotte in mercati fondiari attivi: Il caso studio di oliveti e vigneti in un territorio siciliano. Aestimum. Apprais. Rural. Econ. 2012, 60, 53–84. [Google Scholar] [CrossRef]
- Isakson, H.R. Using Multiple Regression Analysis in Real Estate Appraisal. Apprais. J. 2001, 69, 424–430. [Google Scholar]
- Zheng, S.; Cao, J.; Kahn, M.E.; Sun, C. Real Estate Valuation and Cross-Boundary Air Pollution Externalities: Evidence from Chinese Cities. J. Real Estate Financ. Econ. 2013, 48, 398–414. [Google Scholar] [CrossRef]
- Liebelt, V.; Bartke, S.; Schwarz, N. Urban Green Spaces and Housing Prices: An Alternative Perspective. Sustainability 2019, 11, 3707. [Google Scholar] [CrossRef]
- Xu, L.; You, H.; Li, D.; Yu, K. Urban green spaces, their spatial pattern, and ecosystem service value: The case of Beijing. Habitat Int. 2016, 56, 84–95. [Google Scholar] [CrossRef]
- Isaac, D.; O’Leary, J. Property Valuation Principles, 2nd ed.; Palgrave MacMillan: London, UK, 2012. [Google Scholar]
- Kruskal, W.H.; Tanur, J.M. Linear Hypotheses. International Encyclopedia of Statistics; Free Press, Collier Macmillan: London, UK, 1978. [Google Scholar]
- Lindley, D.V. Regression and Correlation Analysis. In Series and Statistics; Eatwell, J., Milgate, M., Newman, P., Eds.; Time Palgrave MacMillan: London, UK, 1990. [Google Scholar]
- Birkes, D.; Dodge, Y. Alternative Methods of Regression; Yohn Wiley Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Morano, P. L’analisi di Regressione per le Valutazioni di Ordine Estimativo; Celid: Torino, Italy, 2002. [Google Scholar]
- Acciani, C. La Regressione Lineare Multipla Nelle Valutazioni Immobiliari; Edagricole: Bologna, Italy, 1996. [Google Scholar]
- Bencardino, M.; Nesticò, A. Demographic Changes and Real Estate Values. A Quantitative Model for Analyzing the Urban-Rural Linkages. Sustainability 2017, 9, 536. [Google Scholar] [CrossRef]
- De Luca, A. Le Applicazioni dei Metodi Statistici alle Analisi di Mercato. Manuale di Ricerche per il Marketing; FrancoAngeli: Milano, Italy, 2006. [Google Scholar]
- Damodar, N. Gujarati Essentials of Econometrics; McGraw-Hill Education: New York, NY, USA, 2009. [Google Scholar]
- Stock, J.H.; Watson, M.W. Introduzione All’econometria; Pearson: Torino, Italy, 2005. [Google Scholar]
- Gorla, M.S. Elementi di Statistica Applicata; Maggioli Editore: Rimini, Italy, 2011. [Google Scholar]
- Sen, A.; Srivastava, M. Regression Analysis: Theory, Methods and Applications; Springer: New York, NY, USA, 1990. [Google Scholar]
- Faraway, J. Linear Models with R; CRC Press: Boca Raton, FL, USA, 2004. [Google Scholar]
- Dobson, A.J.; Barnett, A.G. An Introduction to Generalized Linear Models, 3rd ed.; CRC Press: New York, NY, USA, 2008. [Google Scholar]
- Levine, M.D.; Krehbiel, T.C.; Berenson, M.L. Statistica; Apogeo editore: Milano, Italy, 2006. [Google Scholar]
- Morano, P. Un modello di regressione in presenza di outlier per l’analisi del mercato immobiliare. Estimo E Territ. 2001, 10, 19–35. [Google Scholar]
- Micelli, E. Qualità e Valori Immobiliari; Edagricole: Bologna, Italy, 1998. [Google Scholar]
- Agenzia del Territorio Manuale Operativo delle Stime Immobiliari; Agenzia del Territorio: Milano, Italy, 2012.
- De Mare, G.; Nesticò, A.; Tajani, F. The Rational Quantification of Social Housing. An Operative Research Model. ICCSA 2012, 7334, 27–43. [Google Scholar] [CrossRef]
- Epley, D.R.; Burns, W. The Correct use of Confidence Intervals and Regression Analysis in Determining the Value of Residential Homes. Real Estate Econ. 1978, 6, 70–85. [Google Scholar] [CrossRef]
- Waltl, S.R. Variation across Price Segments and Locations: A Comprehensive Quantile Regression Analysis of the Sydney Housing Market. Real Estate Econ. 2016, 47, 723–756. [Google Scholar] [CrossRef]
- Kim, H.; Hung, K.; Park, S.Y. Determinants of Housing Prices in Hong Kong: A Box-Cox Quantile Regression Approach. J. Real Estate Finan. Econ. 2015, 50, 270–287. [Google Scholar] [CrossRef]
- Zietz, J.; Zietz, E.N.; Sirmans, G.S. Determinants of House Prices: A Quantile Regression Approach. J. Real Estate Financ. Econ. 2008, 37, 317–333. [Google Scholar] [CrossRef]
- Rosen, S. Hedonic prices and implicit markets: Product differentiation in pure competition. J. Political Econ. 1974, 82, 34–55. [Google Scholar] [CrossRef]
- Witte, A.D.; Sumka, H.J.; Erekson, H. An Estimate of a Structural Hedonic Price Model of the Housing Market: An Application of Rosen’s Theory of Implicit Markets. Econometrica 1979, 47, 1151–1173. [Google Scholar] [CrossRef]
- Smith, T.R. Multiple regression and the appraisal of single residential properties. Apprais. J. 1971, 39, 277–284. [Google Scholar]
- Smith, B.A. Measuring the Value of Urban Amenities. J. Urban Econ. 1978, 5, 370–387. [Google Scholar] [CrossRef]
- Cohen, J.P.; Coughlin, C.C.; Clapp, J.M. Local Polynomial Regressions versus OLS for Generating Location Value Estimates. J. Real Estate Finan. Econ. 2017, 54, 365–385. [Google Scholar] [CrossRef]
- Simonotti, M. La Stima Immobiliare; UTET Libreria: Milano, Italy, 1997. [Google Scholar]
- Lindley, D.V. Regression and correlation analysis. In New Palgrave: A Dictionary of Economics; Mcmillan: New York, NY, USA, 1987. [Google Scholar]
- Simonotti, M. Un’applicazione Dell’analisi di Regressione Multipla Nella Stima di Appartamenti Genio Rurale; Edagricole: Bologna, Italy, 1991. [Google Scholar]
- Del Giudice, V. L’analisi di regressione multipla nella stima per valori tipici. Aestimum 2009, 15, 119–128. [Google Scholar] [CrossRef]
- Pavlov, A.D. Space-Varying Regression Coefficients: A Semi-parametric Approach Applied to Real Estate Markets. Real Estate Econ. 2003, 28, 249–283. [Google Scholar] [CrossRef]
- Lai, T.-Y.; Wang, K. Comparing the Accuracy of the Minimum-Variance Grid Method to Multiple Regression in Appraised Value Estimates. Real Estate Econ. 1996, 24, 531–549. [Google Scholar] [CrossRef]
- Antoniucci, V.; Marella, G. Small town resilience: Housing market crisis and urban density in Italy. Land Use Policy 2016, 59, 580–588. [Google Scholar] [CrossRef]
- Antoniucci, V.; Marella, G. Is social polarization related to urban density? Evidence from the Italian housing market. Landsc. Urban Plan. 2018, 177, 340–349. [Google Scholar] [CrossRef]
- Dolores, L.; Macchiaroli, M.; De Mare, G. Soglie monetarie per la vendita pubblica di spazi pubblicitari nel contratto di sponsorizzazione culturale. LaborEst 2019, 19, 5–9. [Google Scholar] [CrossRef]
- Nesticò, A.; Maselli, G. Declining discount rate estimate in the long-term economic evaluation of environmental projects. J. Environ. Account. Manag. 2020, 8, 93–110. [Google Scholar] [CrossRef]
- Ross, S.M. Introduzione alla statistica. Maggioli Editore: Rimini, Italy, 2014. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N. | P [€ × 1000] | LSU [m2] | SERV [n.] | CML | DES [m] | FLL | PAN | LIFT |
|---|---|---|---|---|---|---|---|---|
| 1 | 240 | 115 | 2 | 3 | 730 | 1 | 5 | 0 |
| 2 | 205 | 100 | 1 | 5 | 740 | 1 | 1 | 1 |
| 3 | 235 | 125 | 2 | 1 | 585 | 3 | 3 | 1 |
| 4 | 210 | 120 | 2 | 3 | 585 | 2 | 3 | 0 |
| 5 | 165 | 90 | 1 | 5 | 785 | 3 | 1 | 0 |
| 6 | 215 | 120 | 1 | 3 | 425 | 1 | 3 | 1 |
| 7 | 220 | 120 | 2 | 3 | 430 | 3 | 5 | 1 |
| 8 | 135 | 80 | 1 | 5 | 495 | 2 | 5 | 1 |
| 9 | 180 | 90 | 2 | 5 | 570 | 1 | 7 | 0 |
| 10 | 185 | 90 | 2 | 5 | 570 | 1 | 5 | 1 |
| 11 | 210 | 125 | 2 | 3 | 800 | 1 | 5 | 1 |
| 12 | 270 | 125 | 2 | 5 | 810 | 2 | 7 | 0 |
| 13 | 215 | 120 | 2 | 3 | 810 | 2 | 1 | 0 |
| 14 | 195 | 85 | 1 | 5 | 900 | 2 | 5 | 1 |
| 15 | 205 | 85 | 2 | 3 | 950 | 1 | 7 | 1 |
| 16 | 235 | 100 | 2 | 5 | 1000 | 1 | 7 | 1 |
| 17 | 170 | 80 | 2 | 5 | 950 | 2 | 5 | 1 |
| 18 | 220 | 95 | 1 | 5 | 950 | 3 | 7 | 0 |
| 19 | 265 | 110 | 2 | 3 | 950 | 1 | 5 | 1 |
| 20 | 105 | 83 | 2 | 5 | 200 | 1 | 5 | 0 |
| 21 | 120 | 95 | 2 | 5 | 200 | 2 | 7 | 1 |
| 22 | 105 | 73 | 1 | 3 | 580 | 3 | 3 | 0 |
| 23 | 140 | 65 | 1 | 3 | 580 | 2 | 5 | 1 |
| 24 | 135 | 80 | 1 | 3 | 970 | 1 | 3 | 0 |
| 25 | 180 | 85 | 1 | 3 | 980 | 2 | 3 | 1 |
| 26 | 130 | 80 | 2 | 3 | 400 | 2 | 3 | 0 |
| 27 | 130 | 100 | 1 | 1 | 430 | 3 | 3 | 0 |
| 28 | 120 | 90 | 2 | 3 | 200 | 4 | 5 | 1 |
| 29 | 165 | 100 | 2 | 5 | 490 | 2 | 5 | 0 |
| 30 | 205 | 120 | 1 | 3 | 530 | 1 | 3 | 1 |
| 31 | 150 | 80 | 2 | 5 | 560 | 3 | 1 | 0 |
| 32 | 185 | 90 | 2 | 5 | 570 | 1 | 5 | 1 |
| 33 | 200 | 95 | 1 | 3 | 800 | 1 | 3 | 0 |
| 34 | 230 | 95 | 2 | 5 | 830 | 5 | 5 | 1 |
| 35 | 175 | 83 | 1 | 1 | 810 | 1 | 1 | 1 |
| 36 | 140 | 80 | 2 | 5 | 200 | 3 | 7 | 1 |
| 37 | 145 | 80 | 1 | 1 | 580 | 4 | 7 | 1 |
| 38 | 180 | 80 | 2 | 5 | 950 | 2 | 5 | 0 |
| 39 | 215 | 95 | 1 | 5 | 950 | 3 | 7 | 1 |
| 40 | 240 | 110 | 2 | 3 | 950 | 1 | 5 | 1 |
| 41 | 120 | 83 | 2 | 5 | 200 | 1 | 5 | 1 |
| 42 | 135 | 95 | 2 | 5 | 200 | 2 | 7 | 0 |
| 43 | 125 | 75 | 1 | 1 | 580 | 3 | 3 | 0 |
| 44 | 120 | 65 | 1 | 3 | 580 | 2 | 5 | 0 |
| 45 | 170 | 80 | 1 | 3 | 970 | 1 | 3 | 1 |
| 46 | 180 | 85 | 1 | 3 | 980 | 2 | 3 | 0 |
| 47 | 135 | 80 | 2 | 3 | 400 | 2 | 3 | 0 |
| 48 | 210 | 120 | 1 | 3 | 425 | 1 | 3 | 0 |
| 49 | 215 | 120 | 2 | 3 | 430 | 3 | 5 | 1 |
| 50 | 145 | 80 | 1 | 5 | 495 | 2 | 5 | 0 |
| 51 | 225 | 90 | 2 | 3 | 1120 | 4 | 5 | 1 |
| 52 | 225 | 100 | 2 | 5 | 1300 | 2 | 5 | 0 |
| 53 | 255 | 120 | 1 | 3 | 1250 | 1 | 3 | 1 |
| 54 | 180 | 80 | 2 | 5 | 1350 | 3 | 1 | 0 |
| 55 | 215 | 90 | 2 | 5 | 1270 | 1 | 5 | 1 |
| 56 | 250 | 120 | 2 | 3 | 1220 | 2 | 3 | 0 |
| 57 | 255 | 120 | 1 | 3 | 1100 | 1 | 3 | 1 |
| 58 | 170 | 120 | 2 | 1 | 80 | 1 | 1 | 1 |
| 59 | 90 | 75 | 1 | 1 | 80 | 3 | 1 | 1 |
| 60 | 125 | 100 | 2 | 1 | 50 | 1 | 1 | 0 |
| LSU | SERV | CML | DES | FLL | PAN | LIFT | |
|---|---|---|---|---|---|---|---|
| LSU | 1 | ||||||
| SERV | 0.24 | 1 | |||||
| CML | −0.17 | 0.25 | 1 | ||||
| DES | 0.08 | −0.10 | 0.20 | 1 | |||
| FLL | −0.22 | 0.01 | −0.04 | −0.07 | 1 | ||
| PAN | −0.07 | 0.26 | 0.45 | 0.02 | 0.09 | 1 | |
| LIFT | 0.11 | −0.02 | −0.07 | 0.02 | −0.03 | 0.19 | 1 |
| Output | ||||||
|---|---|---|---|---|---|---|
| Multiple R | 0.95 | |||||
| R2 | 0.89 | |||||
| Adjusted R2 | 0.88 | |||||
| Standard Error | 16.07 | |||||
| Observations | 60 | |||||
| df | SS | MS | F | SignificanceF | ||
| Regression | 7 | 112,426 | 16,061 | 62 | 0 | |
| Residual | 52 | 13,429 | 258 | |||
| Total | 59 | 125,855 | ||||
| Coefficients | Standard Error | t Stat | Significance Value | Lower95% | Upper 95% | |
| Intercepts | −72.60 | 16.24 | −4.47 | 0.00 | −105.18 | −40.02 |
| LSU | 1.82 | 0.14 | 13.30 | 0.00 | 1.54 | 2.09 |
| SERV | 2.18 | 4.74 | 0.46 | 0.65 | −7.32 | 11.69 |
| CML | 1.56 | 1.86 | 0.84 | 0.40 | −2.17 | 5.29 |
| DES | 0.08 | 0.01 | 12.06 | 0.00 | 0.07 | 0.09 |
| FLL | 0.34 | 2.20 | 0.15 | 0.88 | −4.08 | 4.75 |
| PAN | 2.78 | 1.31 | 2.12 | 0.04 | 0.15 | 5.42 |
| LIFT | 9.75 | 4.35 | 2.24 | 0.03 | 1.02 | 18.48 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nesticò, A.; La Marca, M. Urban Real Estate Values and Ecosystem Disservices: An Estimate Model Based on Regression Analysis. Sustainability 2020, 12, 6304. https://doi.org/10.3390/su12166304
Nesticò A, La Marca M. Urban Real Estate Values and Ecosystem Disservices: An Estimate Model Based on Regression Analysis. Sustainability. 2020; 12(16):6304. https://doi.org/10.3390/su12166304
Chicago/Turabian StyleNesticò, Antonio, and Marianna La Marca. 2020. "Urban Real Estate Values and Ecosystem Disservices: An Estimate Model Based on Regression Analysis" Sustainability 12, no. 16: 6304. https://doi.org/10.3390/su12166304
APA StyleNesticò, A., & La Marca, M. (2020). Urban Real Estate Values and Ecosystem Disservices: An Estimate Model Based on Regression Analysis. Sustainability, 12(16), 6304. https://doi.org/10.3390/su12166304