1. Introduction
Geospatial research comprises substantial efforts in studying the dynamics of cities [
1,
2,
3,
4]. In general terms, humans exhibit regularity in their spatial, temporal, and social behaviors [
5,
6,
7,
8]; nevertheless, large-scale urban social systems are complex and challenging to model or represent [
9,
10]. The accelerated urbanization process of current society and the forecasts for a significant augment in urban populations are expected to enhance this complexity [
11]. To predict these systems requires a mathematical description of the patterns found in city data, forming the basis of models that can be used to anticipate trends, assess risks, and manage future events [
12]. The lack of data in this context has historically been a substantial problem [
13]; however, the increase in the availability of crowdsourced data over the last decade gives a rich and real-time data source of detailed images of urban systems [
3,
12]. Practitioners including geographers, social researchers, and data scientists consider social media to provide core source data for studying cities [
14]. To be sure, such information remains sparse in the geographical space, is incomplete in a time interval [
15,
16,
17], and might not be representative [
18]; still, this information is considered a complementary alternative to the gathered information through survey sampling techniques for analyzing human activity since it captures people’s perceptions and spatio-temporal changes more accurately [
1,
19,
20]. Such data have driven the development of specific methods in network analysis, data mining, and statistics in a new branch of knowledge called urban informatics or urban analytics [
21,
22].
However, the use of social networks and their data have not been explored in-depth in urban studies [
23,
24]. Currently, ubiquitous computing has permitted collecting a large amount of data shared by people about themselves [
25] and their interaction with the physical world [
26]. Those datasets are far from conventional in the sense of tabular or structured data, and data processing has not analyzed a significant amount of them because of the computational expense and the need for specific data analysis techniques [
27]. Thus, in this work, we aim to offer, to practitioners and urban researchers, a robust and straightforward methodological strategy for processing significant volumes of human-generated social media data by using efficiently performed and replicable methods that can include new data in the analysis as soon as additional information is available. This effort provides meaningful insights regarding city environments and a picture of the urban population dynamics through knowing the spatio-temporal changes where humans develop their activities [
28].
To this end, we suggest a spatio-temporal statistical approach to analyze the collective dynamics of urban environments through the analysis of locations and timestamps of geolocated tweets generated by people in cities. This approach involves the estimation of regression models to characterize the temporal trends of the usage of social media and the use of classification algorithms to identify spatio-temporal patterns of places where humans develop their activities. Our method mainly uses the tools of regression for count data, spatial point patterns, functional principal component analysis (FPCA), and hierarchical clustering. This alternative considers that social media usage is a proxy for when and where humans develop their activities that can impact and shape policies and action plans in cities. Thus, we aim to study the spatio-temporal components of the dynamics of human activities by investigating the distribution of locations and timestamps in geolocated tweets.
To evaluate our proposal, we collect geolocated tweets, accessing the Twitter application programming interface (API) on streaming, for a two-week period in the summer of 2017 in three urban scenarios, namely, Lisbon, London, and Manhattan. We first address the analysis of temporal trends in the usability of social networks at the city level with explanatory models for count data, such as Poisson and negative binomial regression. Those models allow for identifying factors that explain the changes in the number of geolocated tweets collected per hour as a function of the number of tweets in previous hours (autoregressive parameters) in addition to the hour of the day and the day of the week data (seasonal effects). We then study the hourly spatial distribution of the places where people perform social media activities. To do that, we label each location within the hour when the tweet was created to form a multitype spatial point pattern. We estimate second-order summary statistics for each type, such as Ripley’s K and pair-correlation functions. We then convert these summary statistics into functional curves by smoothing with the B-spline basis. We apply FPCA over curves and obtain the functional scores. We finally cluster those scores to obtain hours of the day with a similar spatial arrangement of places with events of Twitter activity.
On the other hand, although the analysis of content data has been a hot topic into the field of Twitter Analytics and urban informatics, it raises several constraints that can limit its scope and we want to avoid in our proposal. First, Twitter streaming API provides human-generated content that is not only text, which reduces the amount of data for analyzing in procedures of sentiment analysis, and thus, the representativeness of its results, for example, a significant amount of geotagged tweets come from third parties such as Instagram and Foursquare, among others. Second, the computational expense of text mining methods, the problems with the processing of textual information due to UTF-8 characters, study more than one language, and hashtag parsing [
29]. Finally, and perhaps the most critical, privacy concerns associated with the identification of the users [
4,
16,
19].
Our approach demonstrates that spatio-temporal statistical analysis provides valuable tools to analyze a significant amount of geolocated human-generated data and provides insights into how human activities occur in the cities. The obtained results in the studied urban environments highlight the presence of several types of patterns through time across space in the usage of social networks by humans. Then, considering those patterns as a reflection of population dynamics in the cities, this line of investigation can provide instruments to define public policies regarding the provision of services and infrastructures and the planning, management, and mitigation of risks. For example, identifying of places commonly visited by people and hours of the day when that happens can suggest changes in the frequency of service of public transport systems and define strategies for disaster management, among others [
30,
31,
32].
The current paper is prepared as follows. In
Section 2 we summarize the literature review of related studies.
Section 3 describes how to collect, organize, and prepare datasets to implement our data processing methodology. In
Section 4, we provide the statistical framework for regression models of count data, multitype spatial point patterns, and clustering over the scores of FPCA.
Section 5 presents the results of the method for the three studied urban environments. In
Section 6 we discuss and interpret our findings regarding previous studies.
Section 7 summarizes our conclusions and the limitations of our proposal.
2. Background and Related Work
Human activity understanding embraces activity recognition and activity pattern discovery. While the first one is related to the accurate detection of human activities based on a predefined activity model, the second one is more about uncovering hidden patterns from low-level sensor data without any predefined models or assumptions [
33]. On the other hand, Goodchild [
34] establishes humans can act as sensors of activities that occur in real life, and this allows for generating content with some associated geographical aspect. Thus, social media data and mainly location-based social networks (LBSN) have become an information source for studying and identifying human activity patterns. The analysis of LBSN data has been an active area of research in urban studies over the last decade which has allowed for developing applications in urban planning [
19,
30,
35,
36,
37], human activity [
1,
2,
17,
20,
38,
39], population dynamics [
24,
28,
40,
41], and event detection and disaster management [
4,
29,
31,
32,
42,
43], among others, as well as, implementing several analytical techniques.
Data analysis on LBSN can be divided into two main approaches, data mining and statistical methods, which are looking for identifying groups of spatio-temporal similar locations. From data mining, it stands out: self-organizing maps (SOM) [
19,
35], hierarchical SOM [
44], independent component analysis (ICA) [
17], density-based spatial clustering of Applications with Noise (DBSCAN) and ST-DBSCAN [
29,
43], and random forests [
40]. Meanwhile, from the branch of statistical analysis, it emerges ordinary least-squares (OLS) [
30], generalized additive models (GAM) [
32], local indicators of spatial association (LISA) [
24], space-time scan statistics (STSS) [
42], Gaussian mixture models (GMM) [
45], and kernel density estimation (KDE) [
1,
38]. Generally, both alternatives combine the discovery of patterns for the spatio-temporal locations, as well as, for the content data. This latter implies the use of probabilistic topic models such as latent Dirichlet allocation (LDA) algorithms.
Although the aforementioned studies provided promising results, there are still some limitations on them. For example, García-Palomares et al. [
30] normalized the number of geolocated tweets to use models under the statistical assumptions of the OLS; however, regression for count data captures the nature of the variable in the study directly. On the other hand, techniques such as DBSCAN and ST-DBSCAN do not include spatial, temporal, or spatio-temporal autocorrelation structures in the clustering process, while the statistical analysis of spatial and spatio-temporal point patterns estimates and uses autocorrelation structures to study the distribution of the events. Also, ST-DBSCAN depends on the selection of distance and tolerance parameters [
29]. Finally, in the case of LISA statistics, information is spatially aggregated in pixels without considering the temporal variations of the social media activity that causes modifiable area unit problem (MAUP) [
36]; then, for avoiding this issue, a better alternative is analyzing the locations and timestamps as points rather than spatial aggregations.
Hence, we wish to prove that statistical modelling—and mainly spatio-temporal statistics—is an alternative approach to study urban dynamics. It provides advantages such as (1) the possibilities to analyze significant volumes of human-generated data in cities, (2) a way to gain insight into human behavior almost in real time, and (3) tools to include implicitly and explicitly spatio-temporal correlation schemas in models and predictions. Besides, statistical modelling provides, by estimating the parameters of the models, a way to explain the processes that generate the data [
46]. In such a sense, our approach can be useful in monitoring, comparing, and simulating urban environments more reliably. In this context, techniques such as regression models for count data allow for the inclusion of specific temporal structures such as autoregressive and seasonality effects [
47]. On the other hand, the statistical analysis of spatial point patterns identifies schemas of spatial distribution through a set of summary measures defined for different spatial scales [
48,
49]. Furthermore, FPCA brings the possibility of reducing dimensionality, highlighting the relevant underlying characteristics in spatial summary measures [
50].
4. Statistical Framework and Methods
Our data analysis approach focuses on three main aspects. First, we implement several statistical methods to analyze the spatio-temporal distribution of human-generated social media data, followed by the processing of a significant amount of information almost in real time. Finally, we use easily implemented and reproducible techniques that allow for the inclusion of new data to the models as soon as further information is collected.
Additionally, we include in the analysis spatio-temporal structures that reflect the characteristics of human activity adequately. To this end, we decompose the statistical analysis into two parts (
see Figure 3): the study of the temporal distribution of the hourly number of geolocated tweets in a city and the description of the spatial distribution by hours of the places where people generated the collected tweets.
Many factors can explain the temporal changes in the amount of human-generated data in cities, and some of them can be more relevant to the understanding of human behaviors. For example, in the scope of urban planning and decision-making processes, we can rapidly obtain insights regarding urban dynamics through the identification and impact quantification of issues related to the day of the week, hour of the day, and other temporal trends, such as autoregressive and seasonal effects. In this sense, the regression techniques are flexible statistical methods that can provide valuable tools to study temporal variations in the frequency of social media use.
Although human activity exhibits a high degree of spatio-temporal regularity, the exact place and time of where and when people carry out their activities can neither be fixed nor established by some sampling mechanism. In that sense, the statistical analysis of spatial point patterns plays an important role to study the distribution of the locations where people generate social media data since such an analysis provides elements to describe if those locations present some particular spatial arrangement. Furthermore, determining the temporal variations of that distribution gives a vision of the dynamics of the activities in the urban spaces, e.g., how people move from residential areas in the mornings to working places throughout the day or the frequency of visits to places of interest in the cities. In addition, multivariate techniques allow for us to identify groups of hours that show a similar spatial distribution, ultimately displaying in a synthetic way pictures of urban human activity variations through the day.
This section first presents the main elements of the statistical methods that make up our methodological proposal. It then describes the essentials of regression models for the count data and establishes our procedure to estimate, select, and validate those type of models. We then explain the general framework of the statistical analysis of spatial point patterns. Finally, we address the functional data analysis (FDA) and its application in the context of the multitype spatial point patterns.
4.1. Regression Models for Count Data
We used regression techniques to explain the variations in the mean
of a variable (called
response variable) associated with a set of factors (called
explanatory variables ) and to quantify the magnitude of their effect through a collection of values called
parameters of the model [
59]. Classical regression models rely on the assumption that the response variable follows a Gaussian distribution [
60]. However, in our case, the response variable
,
represents the count of the number of geolocated tweets collected per hour, i.e., a non-negative, discrete variable. In this case, statistical modelling falls under the scope of generalized linear models (GLMs). Those models are a general framework that allows for the modelling of responses whose probability distribution belongs to the exponential family of distributions, such as binomial, Poisson, gamma, and negative binomial, among others [
61]. To formulate a GLM requires the specification of three elements [
62]. First, a
random component referred to the probability distribution of the response variable. Second, a
systematic part or
linear predictor that expresses the parameters of the model as a linear function of the explanatory variables,
. Finally, a monotone, differentiable
link function g that relates the mean of the response variable with the systematic part,
.
In the context of count data, it is common to assume that the random component follows a Poisson distribution when the mean and the variance of the response are equal or a negative binomial distribution when the variance is greater than the mean of the response (overdispersion) [
63]. In addition, it is customary to use the natural logarithm as the link function to ensure that the predictions of the mean of the response are non-negative [
64]. The estimation of the parameters of the model is made by maximum likelihood through the iteratively weighted least-squares (IWLS) algorithm [
65].
Let
,
be the number of geolocated tweets at the hour
t. We will assume those counts follow a Poisson or a negative binomial distribution with conditional mean
given by:
where
,
represents the parameters of the model,
I, the corresponding dummy variables for the day of the week and the hour of the day, and
, the counts of the number of the tweets in previous hours. Equation (
1) describes the
full model. We use that specification to estimate the parameters of two models, one for each type of response variable, following the procedure suggested by [
66]. We carry out a stepwise process to select explanatory variables based on the Bayesian information criterion (BIC) [
67]. The obtained models are compared to choose the best model regarding the probability distribution of the response variable by using a likelihood ratio contrast [
68]. We finally identify the preferred model and test for normality of the residuals using the Shapiro-Wilk test and for residual autocorrelation using empirical autocorrelation function plots.
4.2. Spatio-Temporal Analysis
Under the scope of spatial statistics, the analysis of spatial point patterns is the branch where the locations of the phenomenon of the study, called
events, are not fixed and themselves are the variable of interest [
69]. Thus, a set
,
, where
denotes the location of the
i-th event, is called a
spatial point pattern [
70]. From the statistical point of view, two types of measures summarize the pattern: (1)
first-order statistics characterize the mean of the process
, i.e., the number of events per unit of area, and (2)
second-order statistics outline the spatial autocorrelation between the events
[
71]. One of the primary objectives of the analysis relies on identifying whether the events exhibit spatial clustering or spatial regularity by using the second-order summary statistics [
48].
Second-order summary statistics are functions that express the degree of spatial relationship between the events of the pattern for several spatial scales [
46]. Conventionally, Ripley’s
K-function (
,
), Besag’s
L-function (
,
), and the pair-correlation function
g (
,
) are the essential elements for the analysis of point patterns. Thus, the evaluation of the characteristics of the process, such as complete spatial randomness (CSR), clustering, or regularity, is based on the empirical estimation and the values that these functions take. For instance, under CSR,
,
, and
[
49].
In many applications, the objective of the study is analyze the distribution of various types of points that come from the same origin or are of the same nature. The context might be the research of species in ecology, the characterization of different classes of crimes in a city, or analysis of case-control studies in epidemiology. In this context, each event is labelled with a mark
,
to identify its type, and then the set
is called a
multitype point pattern. Thus, multivariate statistical methods play an essential role in the data analysis since they provide elements for identifying groups of events with similar spatial distribution through the use of clustering algorithms in second-order summary statistics [
48].
The analysis implies the estimation of summary statistics for the formed pattern by each type of mark in several distances, e.g.,
,
. This estimation produces numerical realizations of
l non-observable functions. Although it would be possible to conduct this work by using classical multivariate analysis, the summary statistics are functions instead of single values [
49]. Then, techniques such as the FDA provides tools for understanding the spatial behavior of the pattern since it considers that observations are functions or single units rather than consecutive measurements [
72].
A dataset in the FDA is a sample of the following form [
73]:
where we have
l observed curves over the same interval
. The basic idea is that the objects of study are the smooth curves
defined for all values of
r but observed only at selected points
.
Then, the first step in the analysis involves converting the sample in Equation (
2) to functions by using smoothing techniques, which involves determining a set of
functional blocks or
basis functions ,
and a set of coefficients
,
to define each function as a linear combination of these basis functions; thus,
,
. Although several types of bases exist, it is common to use Fourier basis systems for periodic data or spline basis (
B-splines) for aperiodic data [
74].
Conventionally, by using least-squares or localized least-squares fits, it is possible to estimate the coefficients
,
. However, such methods are not efficient when observations exhibit a significant level of noise, causing their functional representation to exhibit multiple local fluctuations. Therefore, a
penalized smoothing approach is preferred to minimize the effect of the random variability. This approach uses many basis functions and penalizes the sum of the squares through a
smoothing parameter to enforce a tradeoff between overfitting and oversmoothing of the data to the smooth functions [
73].
Once a functional representation of the data is obtained, the FPCA is a valuable tool to explore and identify features in the curves and the number of types of them. As with the principal component analysis (PCA) used in classical multivariate methods, FPCA defines a new set of scalar variables
,
,
, called
scores, as linear combinations of the smooth functions. Thus, [
75],
where
is a weight function that maximizes
subject to the constraint
. This process defines an eigenequation:
with associated covariance function
. The solution of Equation (
5) gives the eigenvalues
and the scores. Following the PCA, the scores associated with the first eigenvalue retain the maximum variability of the smooth curves, and so on, with the next ones. Then, for subsequent analysis, it is customary to study the first
d principal components with
.
The format of the data (see
Table 2) is
, where each
denotes the location, and
h,
, the corresponding hour of the day of a tweet shared in city
W. We assume that these data constitute a full register of all events that happen within
W at hour
h. We consider this dataset as an hourly
multitype spatial point pattern.
Thus, we first estimate the Ripley’s
K-function for each hourly spatial point pattern using the following estimator:
where
is the area of the city,
is the number of tweets at hour
h,
is the distance between the geolocation of two collected tweets at hour
h,
takes the value 1 when the distance is less than or equal to
r or 0 otherwise, and
is an
edge correction weight defined by the geometry of the window and the number of the events in the point pattern [
46].
Based on the estimator (
6), we calculate Besag’s
L-function
,
for distances
,
, where
. To decrease the bias in the estimation of the function, we consider
values up to
of the smaller side length of the rectangle that circumscribes the window
W [
48]. From those estimations, we obtain a functional representation of the 24 curves through smoothing techniques with cubic
B-splines by imposing a roughness penalty based on a harmonic acceleration operator [
73]. We establish the number of the functional blocks by using the rule
[
74]. We posteriorly perform an FPCA over the smoothed functions and select as many scores as is necessary to obtain at least 70% of the retained variability. Finally, we perform hierarchical clustering on the selected scores with Ward’s procedure [
76], which allows for the detection of groups of similar second-order summary statistics, i.e., groups of hours with a similar spatial distribution of tweet locations.
5. Case Study
To evaluate our data analysis approach, we collected geolocated tweets in a two-week period from 28 July 2017, at 12:22:00 UTC/GMT+1 h to 14 August 2017, 12:21:59 UTC/GMT+1 for the metropolitan areas of Lisbon, London, and New York City.
Table 3 shows the geographical limits of the corresponding bounding boxes that establish the parameters of the query to connect the Twitter’s API in addition to the total number of downloaded tweets and the number of tweets after preprocessing the data. In the case of New York City and the metropolitan area of Lisbon, we restricted the study to the information coming from Manhattan Island and the municipality of Lisbon, to avoid the impact of bodies of water. Thus, we discarded tweets outside of the administrative boundaries of those cities. We collected 4373, 79,519, and 79,649 tweets for Lisbon, London, and Manhattan, respectively. For the subsequent analysis, we set
‘
2017-07-30 00:00:00’ and
‘
2017-08-13 00:00:00’. This step provided a study period of 336 h, between 0 and 335. We then processed 3626, 64,404, and 59,472 tweets in each urban scenario. We finally transformed the coordinates to the local CRS EPSG:3763 for Lisbon, EPSG:27700 for London, and EPSG:2263 for Manhattan.
Figure 4 and
Figure 5 show the bar charts of the temporal distribution of the collected tweets during the study period. We aggregated the tweets for the two-week period by hours of the day and days of the week. We found considerable differences between the amount of gathered information in each city, but their distribution throughout the day presented similar patterns of behavior. We discovered a sharp decrease in the usage of Twitter after midnight until early in the morning, followed by an increase that peaked in the evening. Those maximums did not occur at the same hour, lying between 19:00 and 21:00 in Lisbon, between 17:00 to 19:00 in London, and at 18:00 in Manhattan. Regarding the day of the week, the three cities showed marked variations: Lisbon had more social media activity from Tuesday to Thursday, London recorded more tweets on the weekends than on the weekdays, and there was no a considerable difference in the volume of human-generated data in Manhattan.
Figure 6 displays the three-count time series for the 336 h of analysis, revealing a daily seasonal effect in the frequency of interaction with social networks. Lisbon’s time series exhibits unusual activity: a high number of tweets in the evenings on 1 August, 3 August, and 9 August 2017.
For each city, we adjusted two count regression models based on Equation (
1) by considering Poisson and negative binomial responses.
Table 4 presents the statistics for the goodness of fit to the selected best model in each case. The likelihood ratio test shows that in all cases, the models have a better fit using a negative binomial distribution for the random component in the corresponding GLM. After performing the stepwise variable selection procedure, we concluded that the preferred models are suitable to explain the number of geolocated tweets per hour as a function of the examined explanatory variables since deviance statistics are statistically significant.
Table 5 presents the summary of the estimation for the selected negative binomial regression models. The results show that the parameters related to the day of the week are positively correlated with the Twitter activity from Tuesday to Thursday in Lisbon, from Thursday to Sunday in London, and with no influence in Manhattan. The models indicate that there is a notable correlation between the hour of the day and the amount of social media data shared by people. The pattern is almost the same in the three urban environments, with a negative association from midnight until early in the morning and a positive relationship that increases with the course of the day, peaking at 19:00 in Lisbon, 17:00 in London, and 18:00 in Manhattan. Additionally, some of the parameters related to the autoregressive effects were significant. In Lisbon, the number of tweets created 5 h before is negatively correlated with the activity for the current hour. In the case of London, an increase in the social media activity one hour and three hours before is likely to produce an increase in the number of tweets in the present time. In the same way as the selected model for Lisbon, the estimated model for London reported a negative relationship with the number of tweets five hours before and the activity at the current moment. For Manhattan, only the amount of the tweets in the two previous hours exhibits a positive correlation with the amount of interaction with Twitter in the current time. The stepwise procedure removed all the variables included for the seasonal autoregressive trends.
Figure 7 compares observed and fitted numbers of geolocated tweets over the observation period in the three cities. The predicted values obtained through the models adequately represent most of the trends that the data exhibit. We also evaluate the forecasts accuracy by summarizing the forecast errors of the estimated models for the two following days of the information, 13th and 14th August 2017, whose counts were not included in the estimation of the parameters of the models.
Table 6 presents the statistics of the fit: Pearson coefficient correlation, root mean squared error (RMSE), mean absolute error (MAE), mean absolute percentage error (MAPE), and symmetric mean absolute percentage error (sMAPE). The accuracy of forecasts with the estimated models shows that the fitted models for London and Manhattan are better than for Lisbon, despite the RMSE and MAE are lower in Lisbon, but those measures are absolute and cannot be compared between cities.
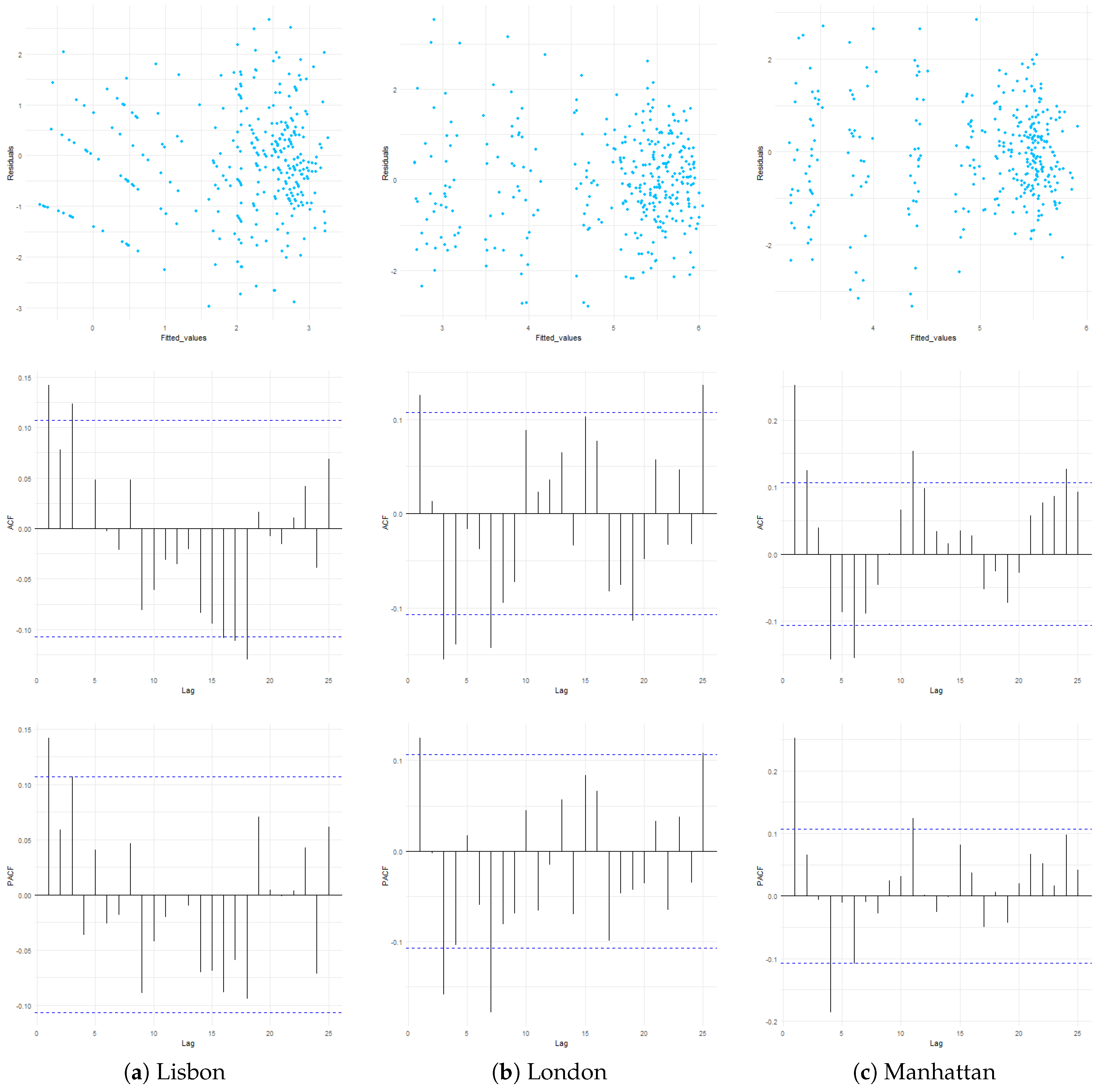
To evaluate the validity of the models and to identify departures from the statistical assumptions, we conducted a residual analysis. The results of the Shapiro-Wilk’s test are as follows: Lisbon:
,
p-value = 0.65; London:
,
p-value = 0.34; and Manhattan:
,
p-value = 0.27; these results indicate that there is no statistical evidence to reject the null hypothesis that states the residuals of the models follow a Gaussian probability distribution. Additionally,
Figure A1 shows the residuals versus the fitted values and autocorrelation function and partial autocorrelation function plots. We note that no apparent patterns arise from the relation between residuals and adjusted values and that the residual autocorrelation is not significant.
For each city, we built a multitype spatial point pattern, labelling each location with the hour when a user created the corresponding tweet.
Figure 4 shows the distribution of the number of events for each mark, displaying the dynamics of the social media activity through the day. We established the length of the smaller side of the rectangles that circumscribe the city of Lisbon, London’s metropolitan area, and the island of Manhattan. Based on those lengths, we defined the maximum distances (
) to estimate the
L-Besag function. We worked with a sequence of values from 0 meters up to
with intervals of 25 meters.
Table 7 shows a summary of the obtained ranges. We then estimated the centered version
of the function, for every hourly formed spatial point pattern, over the set of those distances.
We obtained the functional representation of those estimations by using functional blocks of 117, 451, and 304 for Lisbon, London, and Manhattan, respectively, and a roughness penalty with a smoothing parameter of
. We then calculated the FPCA over the smoothed curves and kept the first two principal scores since together they contributed more than 70% of the variability in the three scenarios. Additionally, to disclose more significant components of variation, we rotated the functional principal components with the VARIMAX rotation algorithm [
74]. Finally, we obtained a dendrogram by applying agglomerative hierarchical clustering through Ward’s method on the matrix of dissimilarities computed with the Euclidian distance between the scores.
Figure 8,
Figure 9 and
Figure 10 present the results of the spatio-temporal data analysis approach in the three studied urban scenarios. In the case of Lisbon, the smoothed functions reveal schemes of spatial clustering for almost all the considered distances and hours of the day, except for the case of the events registered at
04:00, whose curve decreases rapidly and reaches negative values after
km. In addition, those functional representations belonging to hours from midnight to early in the morning (light deep-sky-blue curves) are more irregular than those associated with later hours. The first two principal components retain
% and
% of the variability. As a functional principal component symbolizes variation over the average curve, the interpretation depends on this capability. Thus, since the first component takes negative values for distances up to 500 meters, approximately the variation of the mean of the hourly second-order summary statistics, the relationship is strongest for distances longer than this value, and the second component captures primarily variations in the hourly summaries up to
km. Panel (c) of
Figure 8 reveals that the spatial distribution, of the shared events at
04:00, is quite dissimilar in comparison with the behavior of the distributions for the other hours of the day. There are approximately three groups of hours for human activities, thus: (1) between
00:00 and
01:00, (2) from
02:00 to
07:00, and (3) at the rest of the hours.
The smoothed centered L-Besag functions for London show less irregularity than those for Lisbon. The curves also exhibit a pattern of spatial clustering for all distances and hours of the day. The functional representation for the hourly second-order summary statistics reveals marked differences between the curves associated with tweets generated in dawn hours to the curves from tweets shared in other periods of the day. The first two principal components explain % and % of the variability of the summary statistics. The first harmonic portrays a continuous increase of the variation of the mean function with the distance, mainly from 3 km. The distribution of the hours through the scatterplot of the first two functional principal components reveals that there are approximately four groups, three of them for early hours in the morning and the other for the rest of the day.
Similar to the other two cities, the obtained results for Manhattan indicate that the spatial arrangement of the collected geolocated tweets exhibits schemas of spatial clustering for every hour and for all distances. In addition, the smoothed curves that belong to hours after midnight until 05:00 exhibit more irregularity than those at other hours of the day. The first two harmonics explain % and % of the variability of the smoothed L-Besag’s functions. The first component reveals that the variation in the mean function of the second-order summary statistics is increasing for all distances higher than km, whereas the second component portrays increments of the variations up to km. The hourly data can be divided into four groups: one for activities performed from 00:00 to 02:00, another for 03:00 to 05:00, and the other two for later hours.
Finally, we obtained the intensity function of each mark of the multitype spatial point pattern by using bidimensional-KDE. We employed the quartic kernel and selected the bandwidth by using Scott’s method [
77]. We then standardized all the estimated values and normalized them to a scale of 0–1 by subtracting their minimum and then dividing by their range.
Figure 11,
Figure 12 and
Figure 13 display the estimations. In Lisbon, there is a persistent accumulation of the human-generated data in the southern area lying along the Tagus River; this location contains the main attractions within the city. On the other hand, London’s metropolitan area concentrates social media activity in the surrounding boroughs of the city of London, which contain tourist locations, large companies, and commercial areas. The island of Manhattan aggregates most of the Twitter activity in the direction southwest of Central Park to the limits with the Upper Bay and the Hudson River, in which Times Square, SoHo, and the Financial District, among other attractions, are located.
6. Discussion
We first examined the temporal distribution of the number of geolocated tweets per hour by using regression models for count data under the scope of the GLMs. We evaluated and found that in the three studied cities, the models have a better goodness of fit when we used the negative binomial distribution for the random component. This result implies that the counts exhibit a high heterogeneity, which reflects the complexity of the analyzed systems and agrees with as stated by [
9]. We additionally detected strong temporal trends related to the day of the week and the hour of the day that reinforce the idea that people who publish geolocated tweets tend to develop their activities approximately at the same times. França et al. [
1,
35,
44] studied social media data from London and Manhattan and identified areas with high social media activity and differences in behavior between weekdays and weekends and in hours of the day. However, those temporal patterns change between cities. Our results in the case of Manhattan show that the estimated model did not establish a significant difference in the days of the week, which is contrary to the findings in previous research. These divergences can be due to those aforementioned studies used a more extended period of data collection than ours, which allowed the authors to have a broader image of the urban dynamics, not just a two-week period in a summer, and their conclusions are based on frequencies while we used a more sophisticated approach that included regression modelling and statistical hypothesis testing. The dissimilarity of the frequency of people’s use of social media in the other two cities through the weekdays might be an effect of the unusual counts registered in the time series of Lisbon that increased the volume of human-generated data from Tuesday to Thursday. After a thorough review, we attribute the outlier occurring on 9 August 2017, at
19:00 to the prematch tweets of the Portuguese local soccer league between Benfica and Braga. Our approach also involved the estimation of parameters associated with autoregressive trends. The findings highlight that those temporal effects are also significant to explain the number of tweets and can be meaningful as a measure to anticipate the pressures of increasing the amount of human activity.
We then investigated the spatio-temporal distribution of the geolocated tweets. We linked elements of statistical analysis of spatial point patterns, FDA, and hierarchical clustering. We discovered that locations, where people create and share social media data, exhibit a pattern of spatial clustering for every hour during the day and for all considered spatial scales. This result agrees with the fact the people tend to visit the same places at the same times [
6,
7,
16]. Furthermore, we detected that those schemes of clustering change through the day, being more similar from
08:00 to midnight and highly unlikely between midnight and early hours in the morning. We also found that the measures of spatial correlation through the time tend to be more homogeneous in short distances, at 500 m, 3 km, and
km for Lisbon, London, and Manhattan, respectively. These values differ significantly with travel distance of 1.5 km reported in human mobility studies [
5,
6,
7]. The behavior of the smoothed second-order summary statistics showed more uniform curves in London and more erratic curves in Lisbon, which might be an effect of the number of gathered tweets in each city in the two-week period. The analysis also revealed that the places where people share content in Twitter are in the same areas at the same hours, which is a common feature in the social conduct of humans. The irregular shape of the curves for dawn hours retained most of the variability of the
L-Besag’s functions; as a consequence, this covered other relevant spatial effects that occur in different periods of the day.
We found some limitations in our research. One of the main issues was regarding the analysis of content data that has provided meaningful insights into the field of Twitter Analytics. The inclusion of semantics components of geolocated tweets in our approach would give additional information about the cities. However, that was not our primary goal. We aimed to understand the spatio-temporal distribution of where humans interact with their social networks as a proxy for human activity and avoid constraints related to the semantic analysis. On the other hand, the identification and elimination of shared content by machines, bots, and other sources that are not people is a complex task that restricts the analysis. Also, the short study period and the season when was located can distort the found patterns. The representativeness of the harvested sample through the Twitter API is just around one per cent of the overall activity. Finally, estimated models can vary greatly depending on population number, social structure, ethnicity, culture, traditions, and consumer preferences. Many control variables can enter modelling.
Our work has characterized the behavior of human-generated Twitter data in cities as a proxy for human activity. We have found temporal and spatial regularities, namely, autoregressive and long-term temporal trends, as well as, spatial clustering in various scales that can be used as a first step for developing more complex and reliable models to explain the underlying nature of urban dynamics, such as mechanistic models [
46]. This approach would face the problem to estimate parameters of spatio-temporal models in large datasets in which the Bayesian techniques have taken in a boom since they allow developing complex models without imposing simplified structures [
78]. Notably, the integrated nested Laplace approximations (INLA) has shown to be a fast and accurate algorithm in comparison with the conventional Markov chain Monte Carlo methods [
79,
80,
81] that can analyze social media data.
On the other hand, considering our results, we suggest that an approach based on epidemic data can more effectively accommodate the presence of outliers and might even be capable of predicting them. Epidemic data are conceived as realizations of spatio-temporal processes with autoregressive behavior which do not come from planned experiments. Its observations, number of events, are not independent, and phenomena are only partially observed [
82]. There is a high similarity with the distribution of the number of geolocated tweets. Those methods also include autoregressive trends and spatio-temporal structures in the estimation of the parameters of the models that might describe human social conduct more accurately. Our analysis has shown the data coming from the hours commonly dedicated to rest might hide spatio-temporal patterns in the behavior of the people in the cities at other times of the day. Therefore, we also suggest that to avoid the randomness associated with activity during those hours, the analysis of the human activity in cities should be restricted to the hours of the day where humans are more active and developing their daily life.
7. Conclusions
This research reviewed relevant literature in the field of human urban activity, social media analytics and summarized several components in its study, as well as reflections on the statistical methods to find urban patterns. It has been highlighted the potential opportunities and impact of the analytical approaches suggested for the analysis of Twitter data and the study of the spatio-temporal distributions related to the understanding of the human urban activity. These have mainly reflected on how the proposed methods address some of the current gaps in the field of statistical modelling of human activity regarding monitoring, modelling, and predicting urban dynamics patterns on a large-scale level.
We have proposed an alternative to studying the spatio-temporal distribution of geolocated tweets using statistical methods for answering several questions. It first focused on developing a meaningful approach to analyze a considerable amount of human-generated data. In that direction, it was found that regression modelling, spatial point patterns, FDA, and hierarchical methods can process data coming from social networks and discover and describe regularities in the distribution of the human activities in the cites.
Additionally, this work aimed to characterize temporal and spatial structures in the data to capture the spatio-temporal behavior of humans. The evaluated techniques showed that temporal trends and spatial autocorrelation are relevant to improve the goodness of fit in regression methods and adequately describe the spatial distribution of the places where people interact with social media, respectively. The analytical proposal was tested in three different cities to characterize and compare behaviors across those urban environments which allowed to gain information involving human conduct in cities with different structures and dynamics.
We have found that our approach was able to identify almost the same behaviors in a more straightforward way than alternatives developed in previous research. On the other hand, our proposal is looking for providing easily implemented and reproducible methods that can be automatized and thus, analyze a significant amount of geolocated data with the advantage of using more advanced techniques. Moreover, we included and statistically tested the effect of considering structures of spatio-temporal autocorrelation that might allow for predicting, monitoring and, simulating the activities accurately in the cities. For example, the inclusion of autoregressive parameters permits anticipates abnormal situations due to the pressure that immediate changes produce in the short-term forecasts.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}