Ontology Design for Solving Computationally-Intensive Problems on Heterogeneous Architectures

 , ,
, ,
Abstract
:1. Introduction
2. Related Work
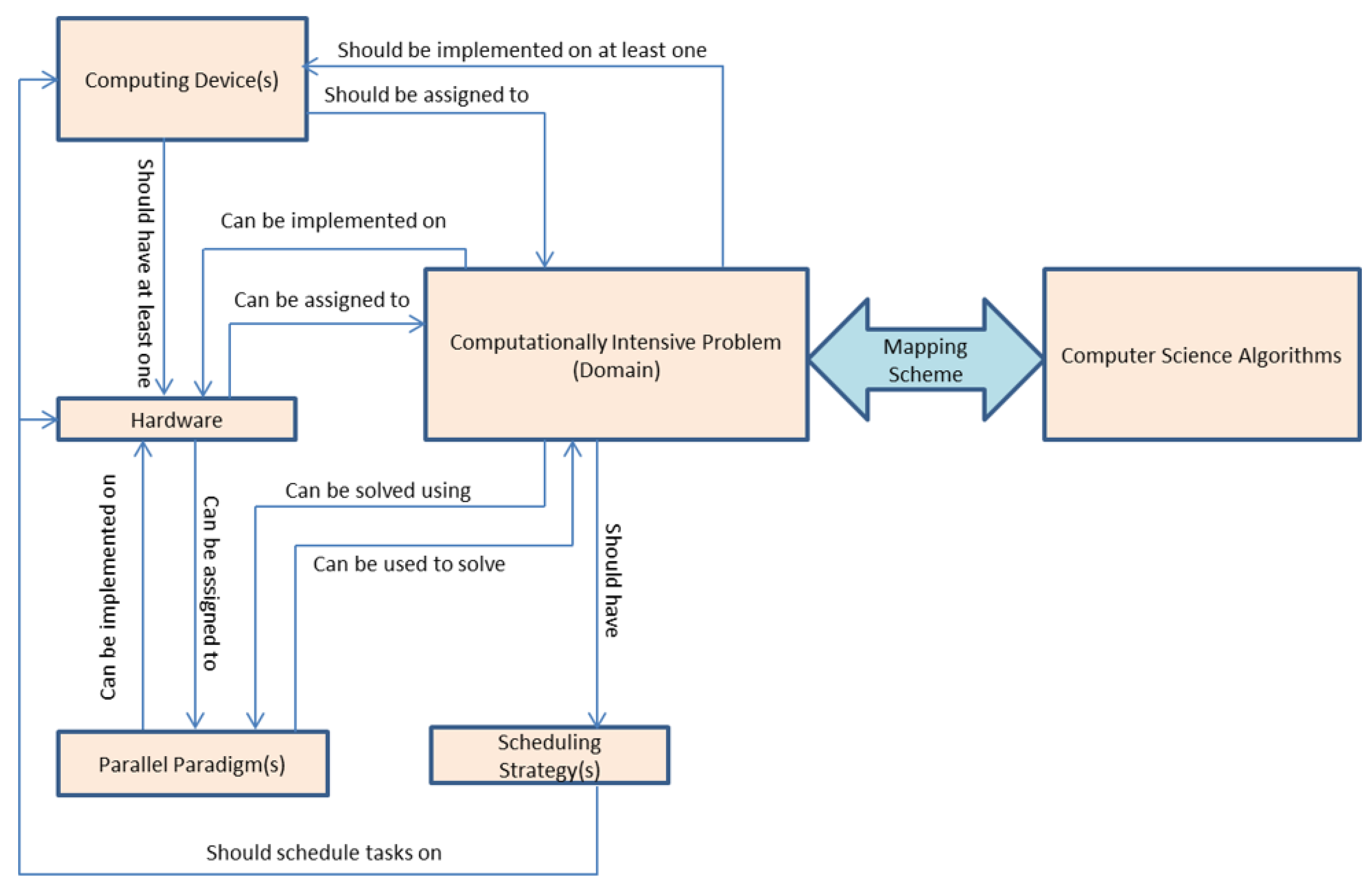
3. Ontology Structure
4. Ontology Basics
4.1. Named Classes
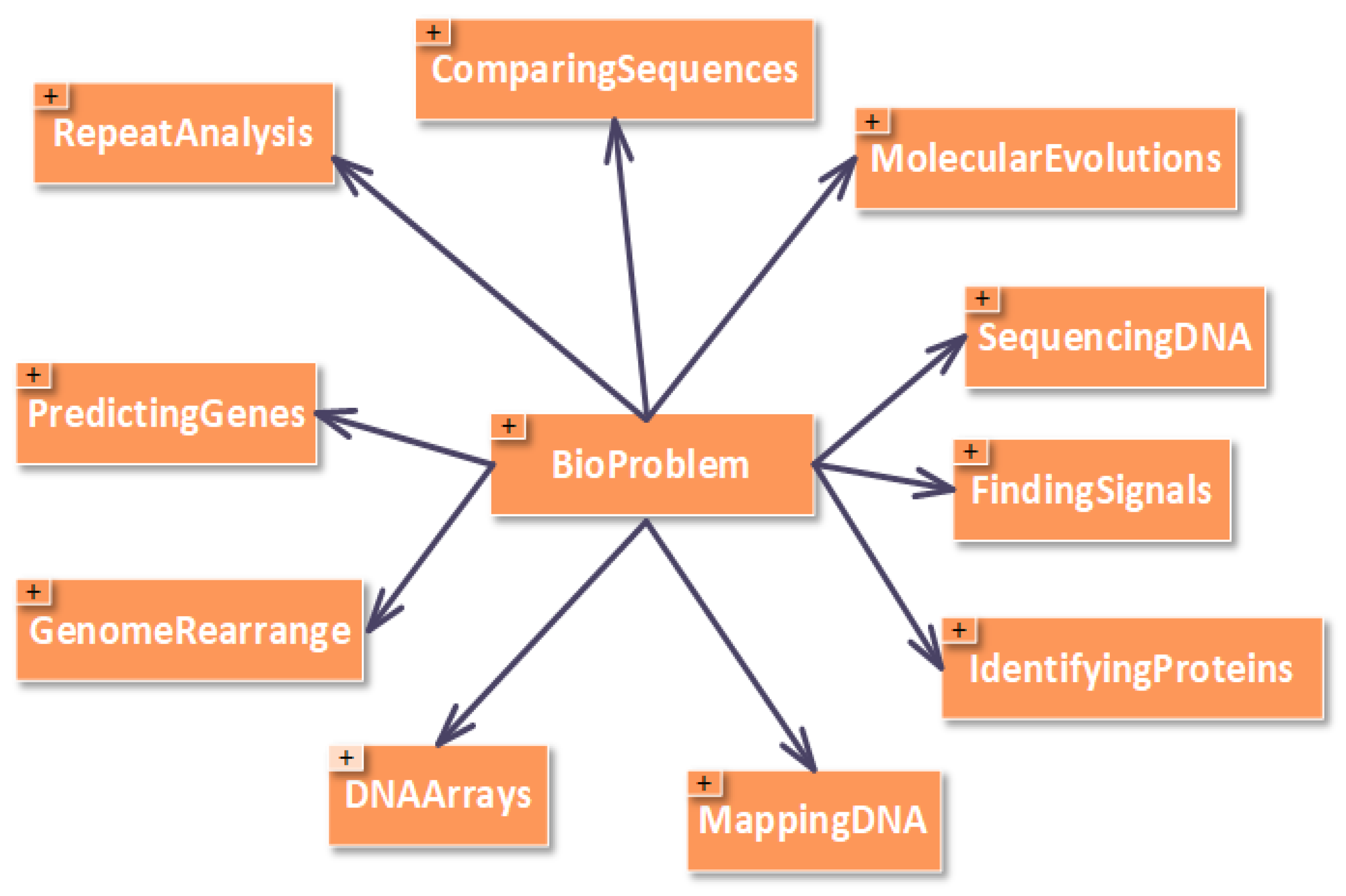
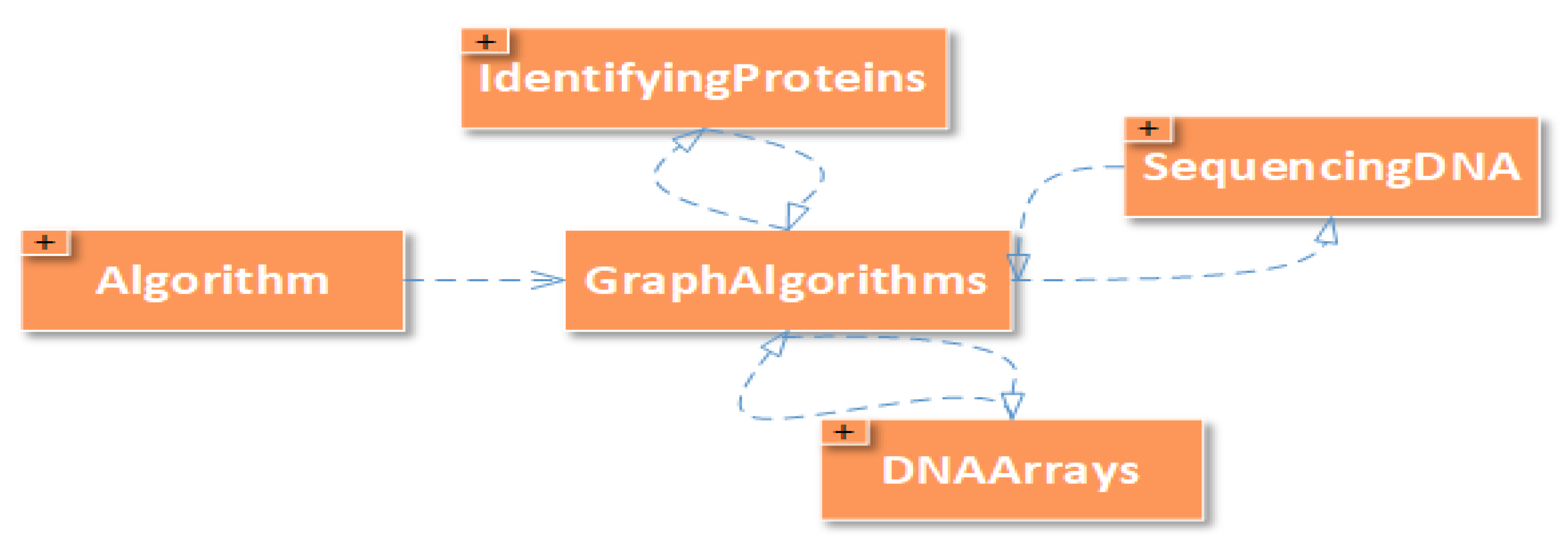
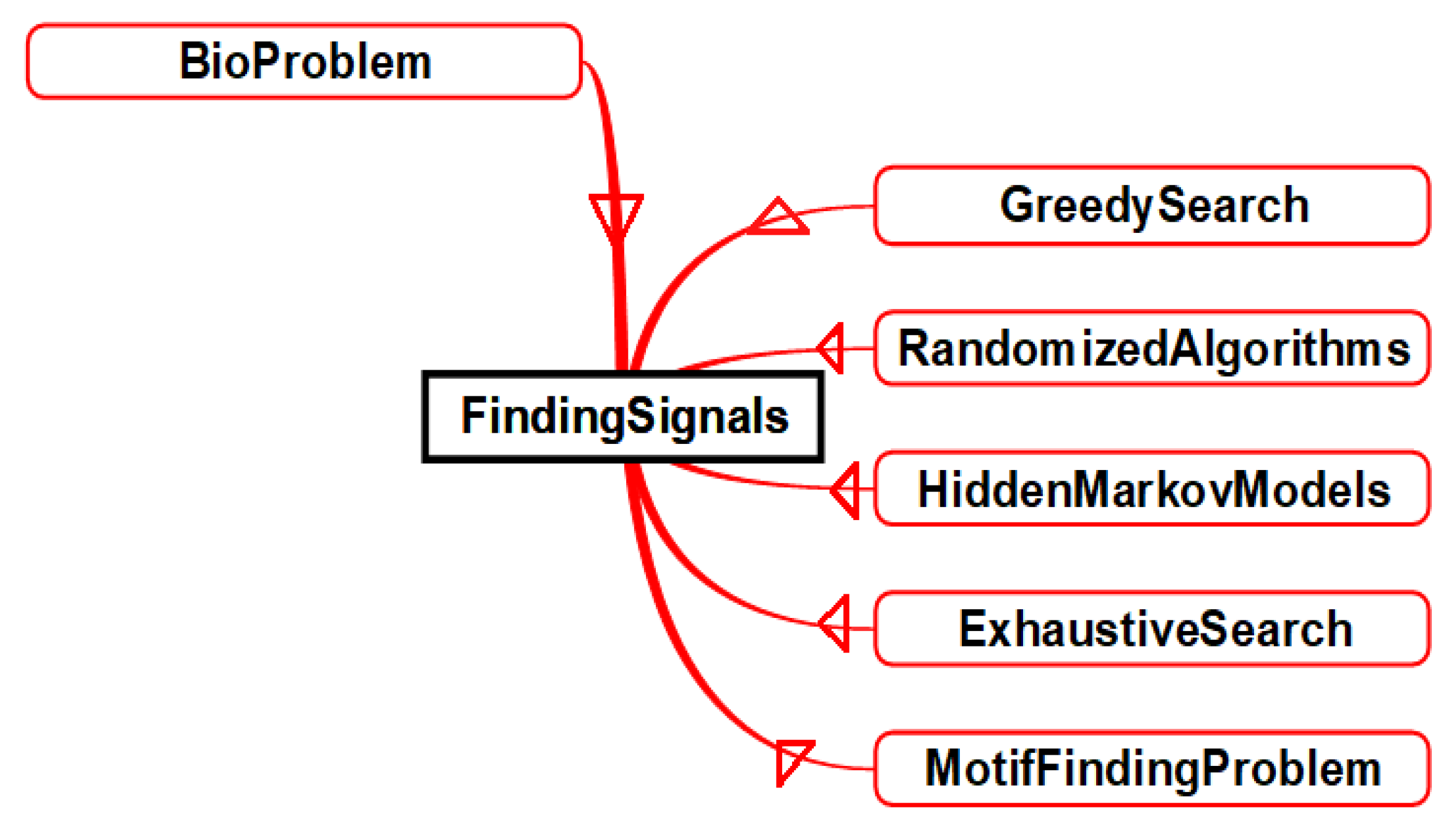
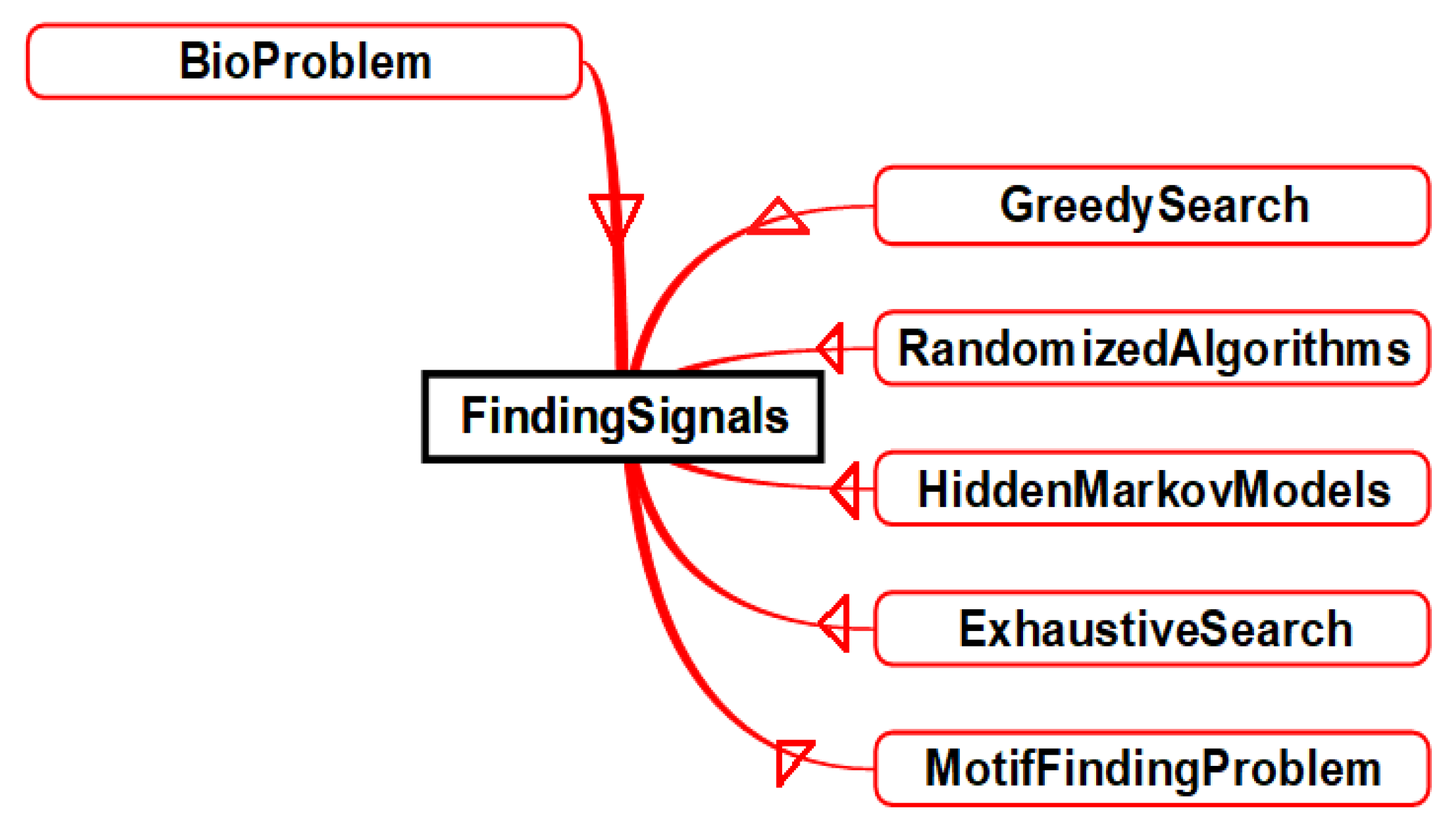
- BioProblem class has a set of bio problems such as “Comparing Sequences”, “DNA Arrays”, “Finding Signals”, “Genome Rearrangements”, “Identifying Proteins”, “Mapping DNA”, “Molecular Evolutions”, “Predicting Genes”, “Repeat Analysis”, and “Sequencing DNA”. This is shown in Figure 2. Defining these classes can help domain experts in finding the best scheduling strategy as a solution for integrated problem of bio and HPC domains.
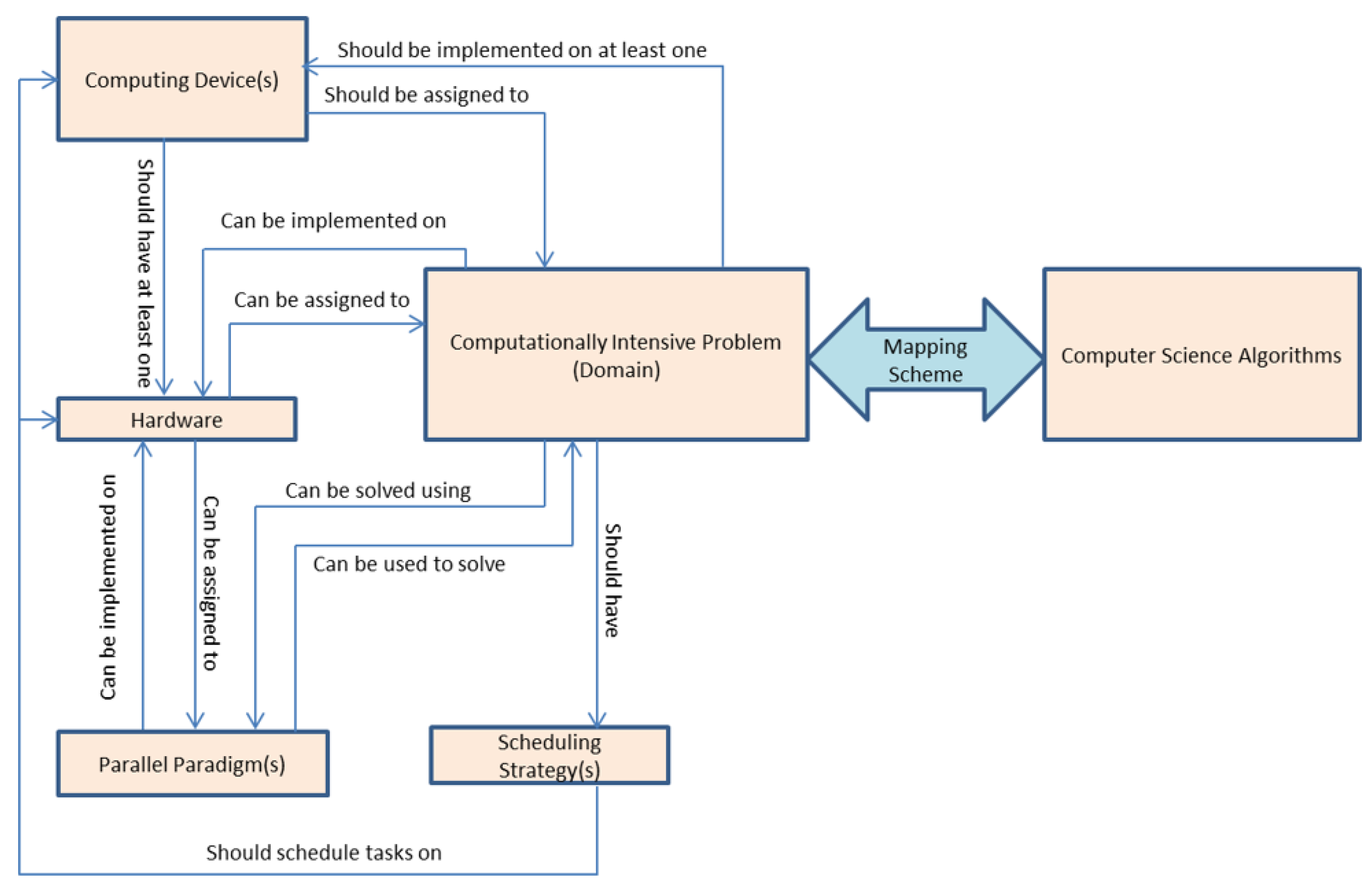
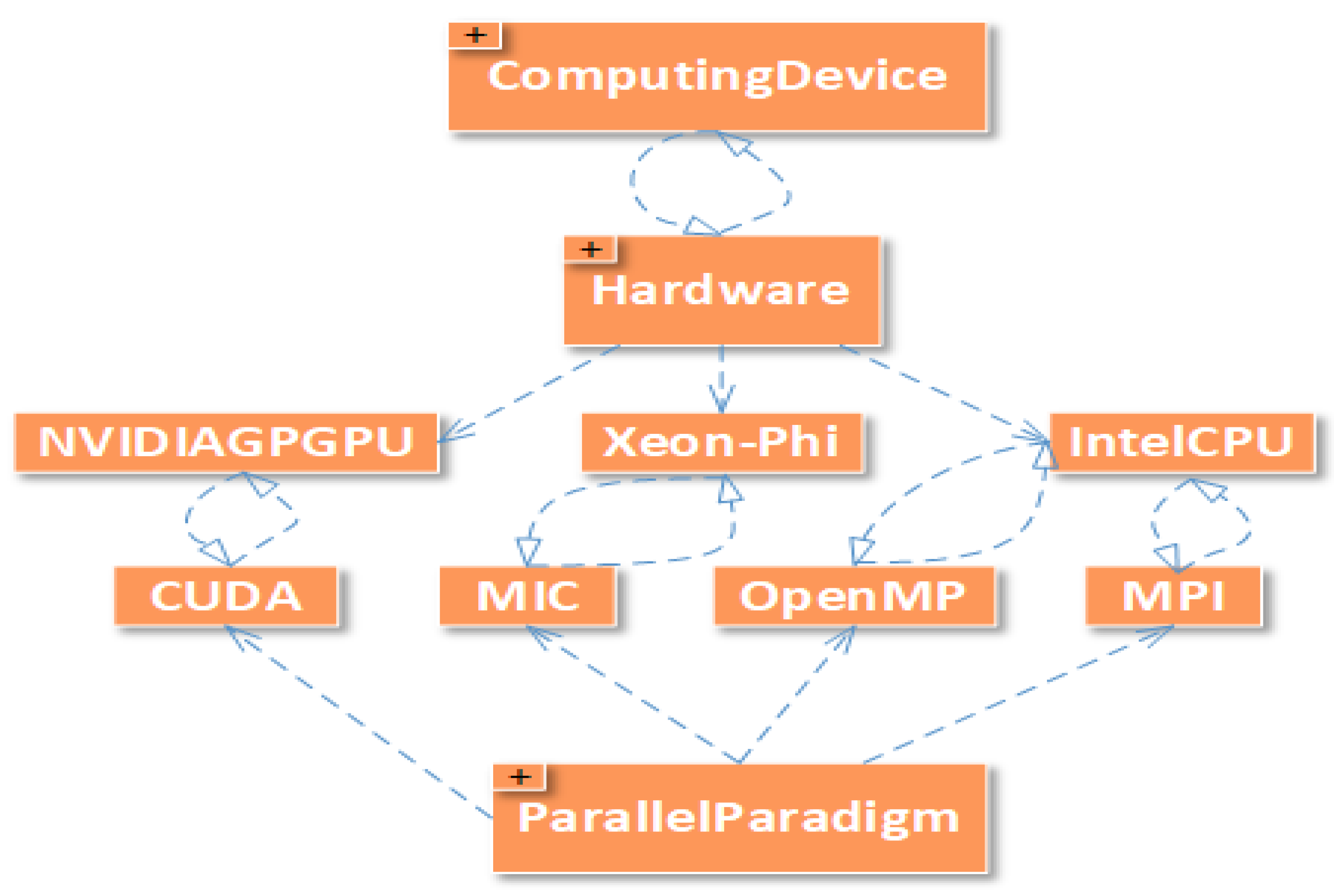
- BioProblem class has a relation with SchedulingStrategy, Hardware, ComputingDevice, and ParallelParadigm classes, such that the BioProblem needs ComputingDevice equipped with at least hardware architecture to run the job on it. ParallelParadigm is needed to write code that best fits the selected hardware. SchedulingStrategy is used to schedule the tasks on the hardware of the ComputingDevice.
4.2. Object Properties
- Property “hasAlgorithm”This property assigns an algorithm (from the computer science domain) to solve a given bio problem. “IsAlgorithmOf” is an inverse property of it.
- Property “hasHardware”This property assigns a hardware architecture on which the algorithm will run to solve a given bio problem. “IsHardwareOf” is an inverse property of it.
- Property “hasParallelParadigm”This property assigns a parallel paradigm used to write an algorithm to solve a given bio problem. “IsParallelParadigmOf” is an inverse property of it.
- Property “hasSchedulingStrategy”This property assigns the scheduling strategy used to deploy the hardware used to solve a given bio problem. “IsSchedulingStrategyOf” is the inverse of it.
- Property “hasComputingDevice”This property assigns at least one computing device to solve a given bio problem. “IsComputingDevice” is the inverse of it.
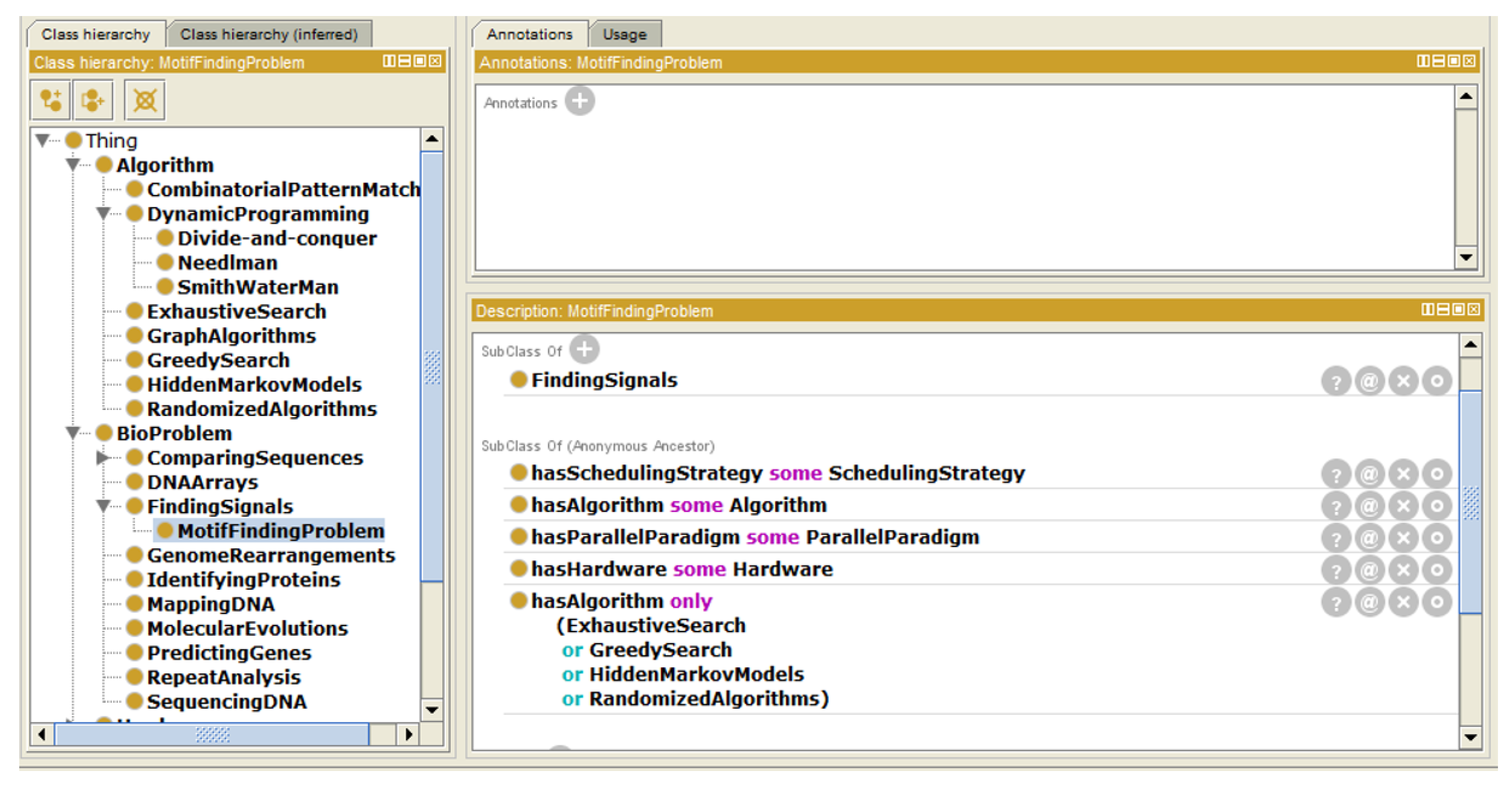
- Property “hasParameters”This property assigns the parameters required for each algorithm. For example, a motif-finding problem has L, d, n, and T, where: L is the length of motif, d is the permitted mutation, n is the number of characters in each sequence, and T is the number of sequences. These parameters are all of the type ‘integer’.
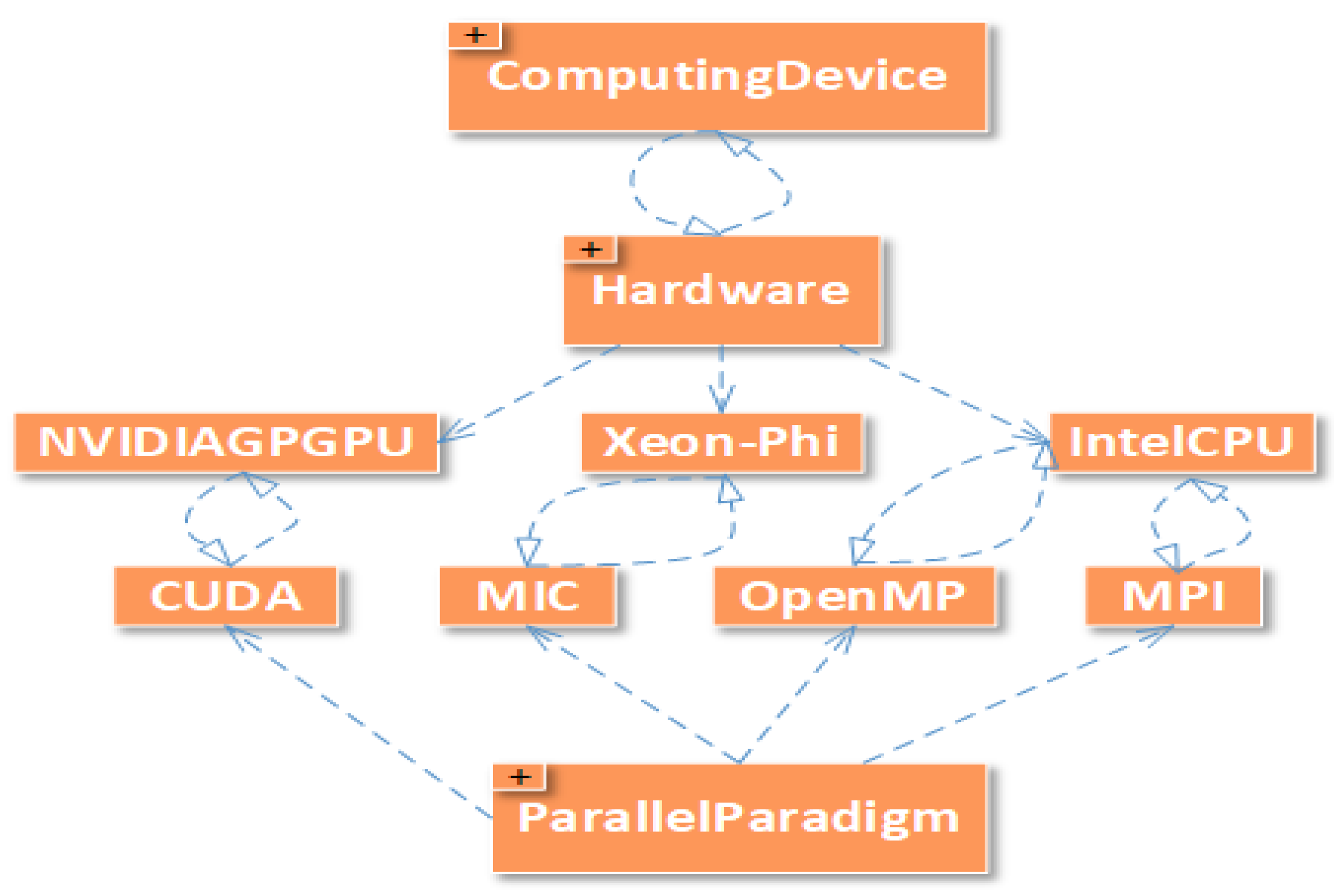
- Property “hasArchitecture”This property assigns at least architecture to a computing device. Each computing device can be equipped with one or more architectures.
4.3. Instances
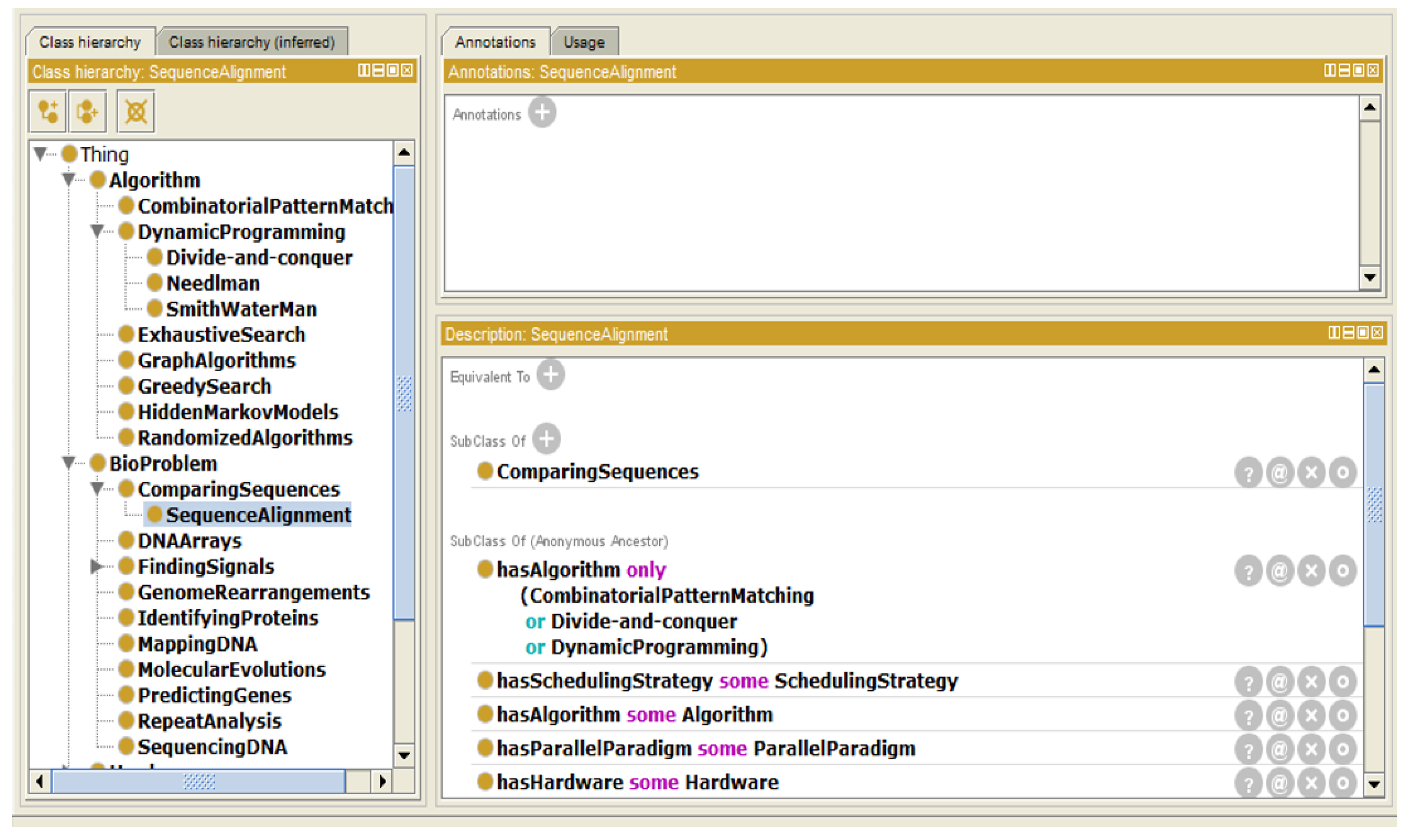
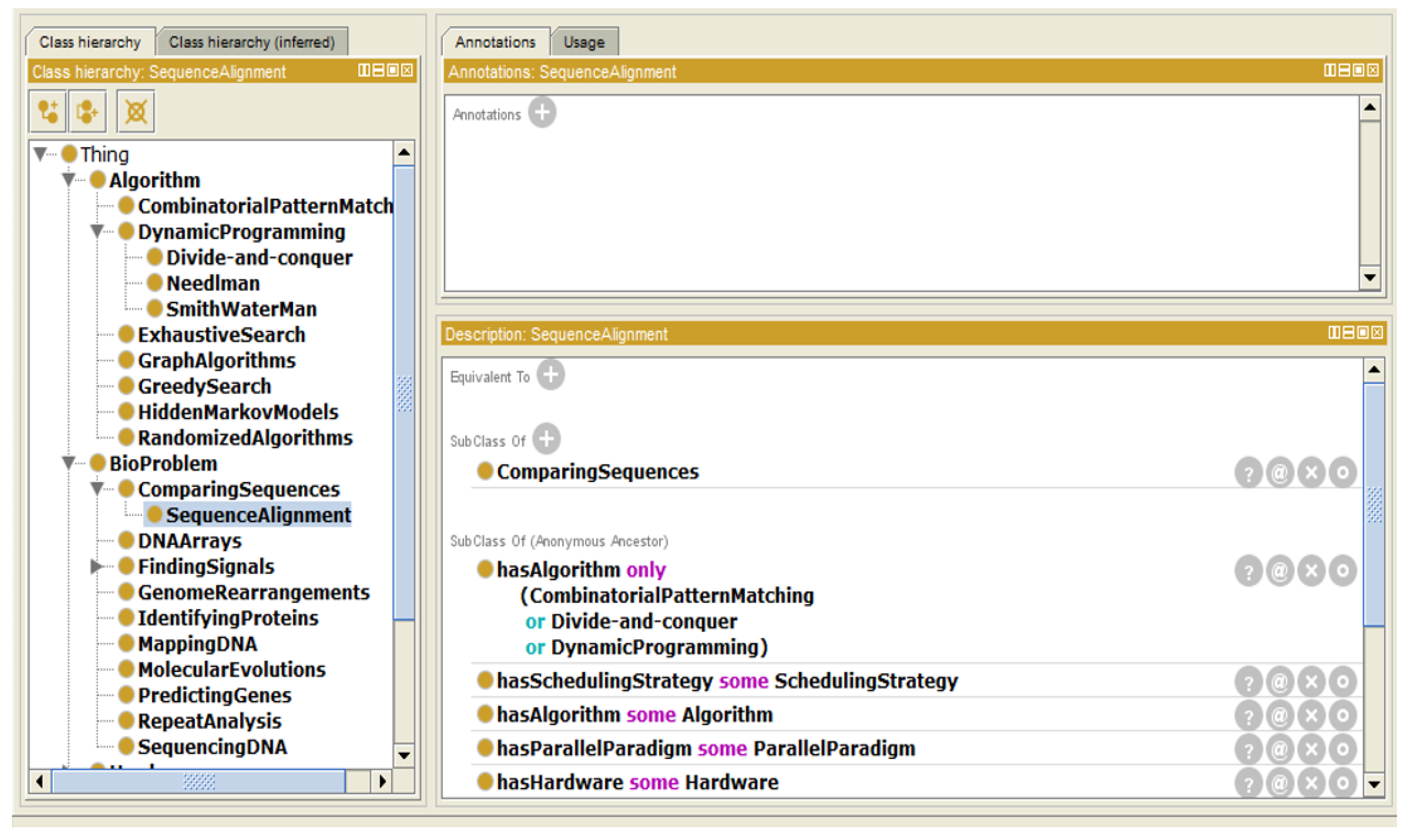
- Instance “SequenceAlignment”The DNA sequence alignment is one of the most famous bio problems. It is classified under “ComparingSequences”. It can be solved using either combinatorial pattern matching or divide-and-conquer or dynamic programming algorithms (as shown in Figure 4).
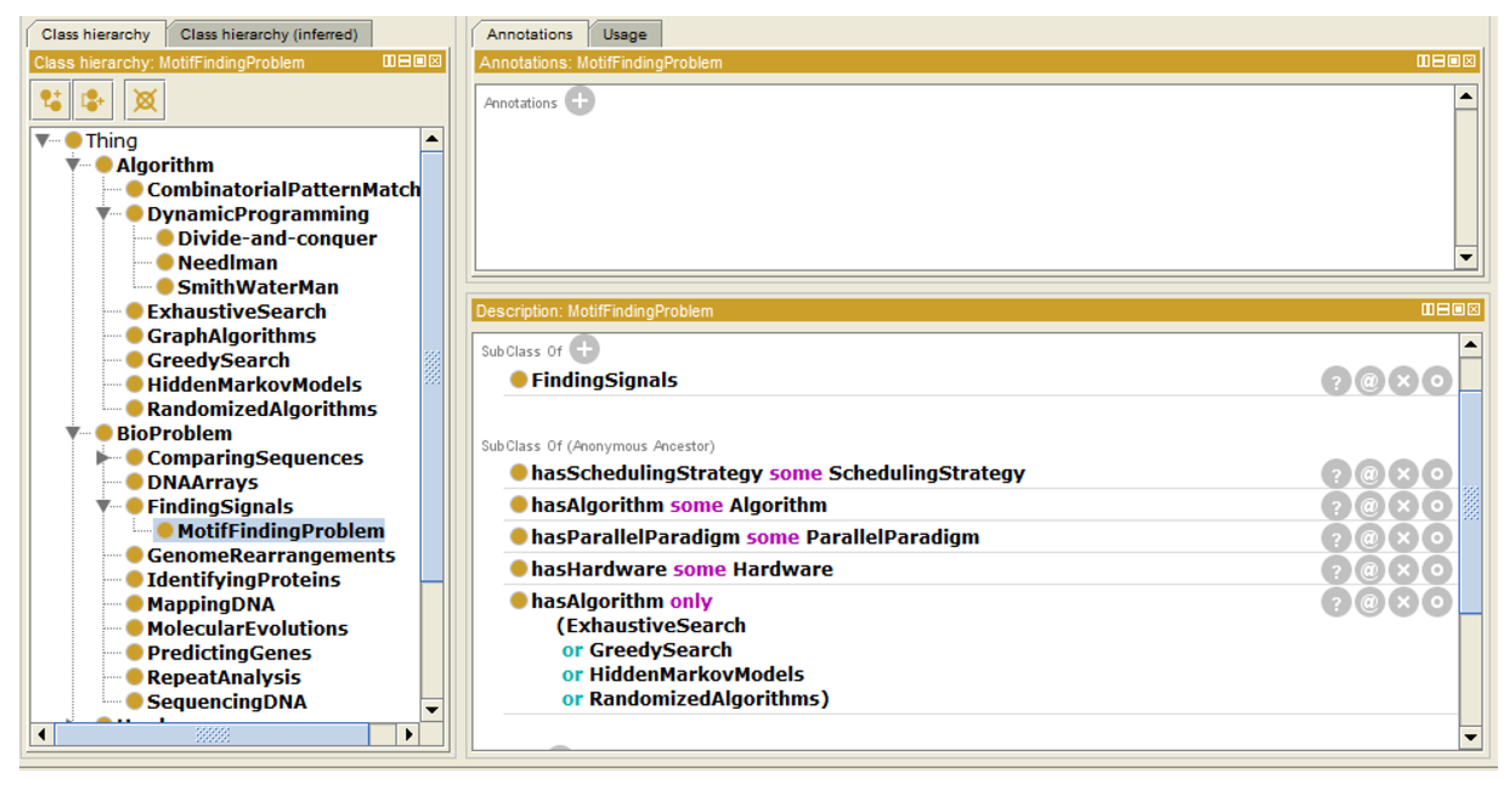
- Instance “MotifFindingProblem”The motif-finding problem is one of the most famous bio problems. It is classified under “FindingSignals”. It can be solved using exhaustive or greedy searches, hidden Markov models or randomized algorithms (as described in Figure 5).
4.4. Axioms
5. Evaluation of the Flexibility
- Finding an optical path from source to destination that passes through multiple links, all of which have the same free spectrum range. This problem can be solved using either the exhaustive search algorithm, the heuristic algorithm or linear programming techniques.
- Finding a set of links that constitute an optical path, on condition that all the links have enough free contiguous spectra. This problem can be solved by using the computer science algorithm known as an exhaustive search.
- Load balancing of traffic to minimize spectrum fragmentation. This can be solved by a sorting algorithm or a binary search algorithm.
5.1. Motif Finding Problem
- Computing device and its hardware used in solving the problem (IntelCPU and NVIDIAGPGPU and Xeon-Phi)
- Parallel computing paradigm used on each architecture (MPI and OpenMP on IntelCPU, CUDA on NVIDIAGPGPU, and MIC on Xeon-Phi)
- Scheduling strategy used to solve the problem (Speed-based)
- Computer algorithm used to solve the problem (exhaustive search)
5.2. Optical Path Finding
- G is a directed graph
- V is the set of nodes in the graph
- A is the set of unidirectional arcs connecting the graph nodes
- T is the traffic demand matrix
- Each demand is assigned a contiguous spectrum (spectrum contiguity constraint)
- Each demand is assigned the same spectrum across all links of its path (spectrum continuity constraint)
- Demands that share the same link are assigned non-overlapping spectrum parts
- Computing device and its hardware used in solving the problem (IntelCPU and NVIDIAGPGPU)
- Parallel computing paradigm used on each architecture (OpenMP on IntelCPU and CUDA on NVIDIAGPGPU)
- Scheduling strategy used to solve the problem (Speed-based)
- Computer algorithm used to solve the problem (exhaustive search)
5.3. A Case Study of Bioinformatics Problem
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Compton, M.; Barnaghi, P.; Bermudez, L.; Garcıa-Castro, R.; Corcho, O.; Cox, S.; Graybeal, J.; Hauswirth, M.; Henson, C.; Herzog, A.; et al. The SSN Ontology of the W3C Semantic Sensor Network Incubator Group. Web Semant. Sci. Serv. Agents World Wide Web 2012, 17, 25–32. [Google Scholar]
- Keet, C.M.; Ławrynowicz, A.; d’Amato, C.; Kalousis, A.; Nguyen, P.; Palma, R.; Stevens, R.; Hilario, M.H. The Data Mining OPtimization Ontology. Web Semant. Sci. Serv. Agents World Wide Web 2015, 32, 43–53. [Google Scholar] [CrossRef]
- Baker, C.; Shaban-Nejad, A.; Su, X.; Haarslev, V.; Butler, G. Semantic Web Infrastructure for Fungal Enzyme Biotechnologists. Web Semant. Sci. Serv. Agents World Wide Web 2006, 4, 168–180. [Google Scholar] [CrossRef]
- Shekarpour, S.; Marx, E.; Ngomo, A.C.N.; Auer, S. SINA: Semantic Interpretation of User Queries for Question Answering on Interlinked Data. Web Semant. Sci. Serv. Agents World Wide Web 2015, 30, 39–51. [Google Scholar]
- Heino, N.; Pan, J.Z. RDFS Reasoning on Massively Parallel Hardware. In Proceedings of the 11th International Semantic Web Conference (ISWC2012), Boston, MA, USA, 11–15 November 2012. [Google Scholar]
- Atahary, T.; Taha, T.M.; Douglass, S. Hardware Accelerated Cognitively Enhanced Complex Event Processing Architecture. In Proceedings of the 2013 14th ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing, Honolulu, HI, USA, 1–3 July 2013; pp. 283–288. [Google Scholar]
- Miksa, T. Using ontologies for verification and validation of workflow-based experiments. Web Semant. Sci. Serv. Agents World Wide Web 2017, 43, 25–45. [Google Scholar] [CrossRef]
- Koumenides, C.; Alani, H.; Shadbolt, N.; Salvadores, M. Global Integration of Public Sector Information. In Proceedings of the WebSci10: Extending the Frontiers of Society On-Line, Raleigh, NC, USA, 26–27 April 2010. [Google Scholar]
- Höchtl, J.; Reichstädter, P. Linked Open Data—A Means for Public Sector Information Management. In Electronic Government and the Information Systems Perspective; Andersen, K.N., Francesconi, E., Groenlund, A., van Engers, T.M., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6866, pp. 330–343. [Google Scholar]
- Bechhofer, S.K.; Stevens, R.D.; Lord, P.W. GOHSE: Ontology Driven Linking of Biology Resources. Web Semant. Sci. Serv. Agents World Wide Web 2006, 4, 155–163. [Google Scholar] [CrossRef]
- Jonquet, C.; LePendu, P.; Falconer, S.; Coulet, A.; Noy, N.F.; Musen, M.A.; Shah, N.H. NCBO Resource Index: Ontology-Based Search and Mining of Biomedical Resources,information retrieval, biomedical data and ontologies. Web Semant. Sci. Serv. Agents World Wide Web 2011, 9, 316–324. [Google Scholar] [CrossRef] [PubMed]
- Uschold, M. Building Ontologies: Towards a Unified Methodology; Technical Report; University of Edinburgh: Edinburgh, UK, 1996. [Google Scholar]
- Bock, J. Parallel Computation Techniques for Ontology Reasoning. In The Semantic Web—ISWC 2008, Proceedings of the 7th International Semantic Web Conference, ISWC 2008, Karlsruhe, Germany, 26–30 October 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 901–906. [Google Scholar]
- Arguello, M.; Gacitua, R.; Osborne, J.; Peters, S.; Ekin, P.; Sawyer, P. Skeletons and Semantic Web Descriptions to Integrate Parallel Programming into Ontology Learning Frameworks. In Proceedings of the 2009 11th International Conference on Computer Modelling and Simulation, Cambridge, UK, 25–27 March 2009; pp. 640–645. [Google Scholar]
- Gonidis, F.; Paraskakis, I.; Simons, A.J.H. On the Role of Ontologies in the Design of Service Based Cloud Applications. In Euro-Par 2014: Parallel Processing Workshops, Proceedings of the Euro-Par 2014 International Workshops, Porto, Portugal, 25–26 August 2014; Revised Selected Papers; Springer International Publishing: Cham, Switzerland, 2014; Part II; pp. 1–12. [Google Scholar]
- Ali, A.; Shamsuddin, S.; Eassa, F. Ontology-based cloud services representation. Res. J. Appl. Sci. Eng. Technol. 2014, 8, 83–94. [Google Scholar] [CrossRef]
- Chuprina, S. Steps towards Bridging the HPC and Computational Science Talent Gap Based on Ontology Engineering Methods. Procedia Comput. Sci. 2015, 51, 1705–1713. [Google Scholar] [CrossRef]
- Ren, Y.; Pan, J.Z.; Lee, K. Parallel ABox Reasoning of EL Ontologies. In Proceedings of the First Joint International Conference of Semantic Technology (JIST 2011), Hangzhou, China, 4–7 December 2011. [Google Scholar]
- Pattuelli, M.C.; Miller, M. Semantic network edges: A human-machine approach to represent typed relations in social networks. J. Knowl. Manag. 2015, 19, 71–81. [Google Scholar] [CrossRef]
- Zhang, Y.; Luo, X.; Zhao, Y.; Zhang, H.C. An ontology-based knowledge framework for engineering material selection. Adv. Eng. Inform. 2015, 29, 985–1000. [Google Scholar] [CrossRef]
- Kabir, M.A.; Han, J.; Colman, A.; Aljohani, N.R.; Basheri, M.; Aslam, M.A. Ontological Reasoning about Situations from Calendar Events. In On the Move to Meaningful Internet Systems: OTM 2016 Conferences, Proceedings of the Confederated International Conferences: CoopIS, C&TC, and ODBASE 2016, Rhodes, Greece, 24–28 October 2016; Springer: Cham, Switzerland, 2016; pp. 810–826. [Google Scholar]
- Faheem, H.M.; Park, S.J.; Shires, D.R. A New Scheduling Strategy for Solving the Motif Finding Problem on Heterogeneous Architectures. Int. J. Comput. Appl. 2014, 101, 27–31. [Google Scholar]
- Fayez, M.; Katib, I.; Rouskas, G.N.; Faheem, H.M. Spectrum Assignment in Mesh Elastic Optical Networks. In Proceedings of the 2015 24th International Conference on Computer Communication and Networks (ICCCN), Las Vegas, NV, USA, 3–6 August 2015; pp. 1–6. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Concept Name | Axiom Description | Logical Expression |
|---|---|---|
| Algorithm | A collection of computer algorithms such that an algorithm is a software procedure or formula used to solve a specific problem in this domain, based on conducting a sequence of specified actions. | |
| Computationally_ Intensive_Problem | A generic term to describe any problem in any domain that needs intensive computations. | |
| Computing_Device | A device that should contain at least one physical hardware processor. | |
| Hardware | A generic term to express the processors used in performing the computations. | |
| IntelCPU | A traditional type of central processing unit developed by Intel. | |
| NVIDIAGPGPU | A general-purpose graphics processor unit developed by NVIDIA. | |
| Xeon-Phi | Term for many core processors or coprocessors developed by Intel. | |
| ParallelParadigm | A paradigm used to parallelize sequential code. | |
| MPI | A Message Passing Interface parallel computing paradigm that supports distributed memory multiprocessing. | Memory |
| OpenMP | An Open Multi-Processing parallel computing paradigm that supports shared memory multiprocessing. | |
| CUDA | A Compute Unified Device Architecture parallel computing paradigm used on NVIDIA GPGPUs. | |
| MIC | A Many Integrated Core Architecture parallel computing paradigm used on Xeon-Phi coprocessors. | |
| SchedulingStrategy | A scheduling strategy is used to assign suitable hardware resources to perform the jobs in a way to achieve a certain goal such as speeding up, load balancing, or optimization of power consumption, etc. | |
| FIFO | A First-In-First-Out scheduling strategy. | |
| HEFT | A Heterogeneous Earliest Finish Time scheduling strategy. | |
| PEFT | A Predictable Earliest Finish Time scheduling strategy. | tFinishTime |
| Speed-based | A scheduling strategy that assigns data sets to be processed based on the speed of the processors being used to solve a problem. |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Faheem, H.M.; König-Ries, B.; Aslam, M.A.; Aljohani, N.R.; Katib, I. Ontology Design for Solving Computationally-Intensive Problems on Heterogeneous Architectures. Sustainability 2018, 10, 441. https://doi.org/10.3390/su10020441
Faheem HM, König-Ries B, Aslam MA, Aljohani NR, Katib I. Ontology Design for Solving Computationally-Intensive Problems on Heterogeneous Architectures. Sustainability. 2018; 10(2):441. https://doi.org/10.3390/su10020441
Chicago/Turabian StyleFaheem, Hossam M., Birgitta König-Ries, Muhammad Ahtisham Aslam, Naif Radi Aljohani, and Iyad Katib. 2018. "Ontology Design for Solving Computationally-Intensive Problems on Heterogeneous Architectures" Sustainability 10, no. 2: 441. https://doi.org/10.3390/su10020441
APA StyleFaheem, H. M., König-Ries, B., Aslam, M. A., Aljohani, N. R., & Katib, I. (2018). Ontology Design for Solving Computationally-Intensive Problems on Heterogeneous Architectures. Sustainability, 10(2), 441. https://doi.org/10.3390/su10020441