
Pressure Injury Prediction in Intensive Care Units Using Artificial Intelligence: A Scoping Review




Abstract
1. Introduction
- What artificial intelligence tools are used in predicting the risk of pressure injuries in critically ill patients admitted to intensive care units?
- What are the results of using artificial intelligence tools in predicting pressure injuries in critically ill patients admitted to intensive care units?
- What variables are identified by artificial intelligence tools in predicting pressure injuries in critically ill patients admitted to intensive care units?
- What are the implications for nursing practice of using artificial intelligence tools in predicting pressure injuries in critically ill patients admitted to intensive care units?
2. Materials and Methods
2.1. Eligibility Criteria
- Participants: This review considered studies that include adult critically ill patients. No restrictions were applied regarding gender, ethnicity, or other personal characteristics. A critically ill person is defined as someone experiencing a critical illness, with a potentially reversible health condition characterized by vital organ dysfunction and a high risk of imminent death if appropriate care is not provided [45].
- Concept: Studies addressing AI for predicting PIs were considered. AI is understood as the simulation of human intelligence by a system or machine [30]. This concept includes, but is not limited to, ML, deep learning, neural networks, and natural language processing. Studies that address other types of instruments or tools will be excluded. A PI is an injury or ulceration caused by prolonged pressure on the skin and tissues when one stays in one position for a long period of time, such as lying in bed. Additionally, pressure injuries caused by medical devices, known as ‘medical device-related pressure injuries’, which typically develop in different locations than traditional PIs, will also be considered [6].
- Context: Regarding context, studies conducted in adult, specific, or multipurpose ICUs within public or private hospitals were included, without geographic or cultural limitations. Pediatric and neonatal ICUs were excluded. An ICU is an organized system for providing care to critically ill patients, offering intensive and specialized medical and nursing care, enhanced monitoring capabilities, and multiple modalities of physiological organ support to sustain life during acute organ system failure [10].
2.2. Types of Sources
2.3. Search Strategy
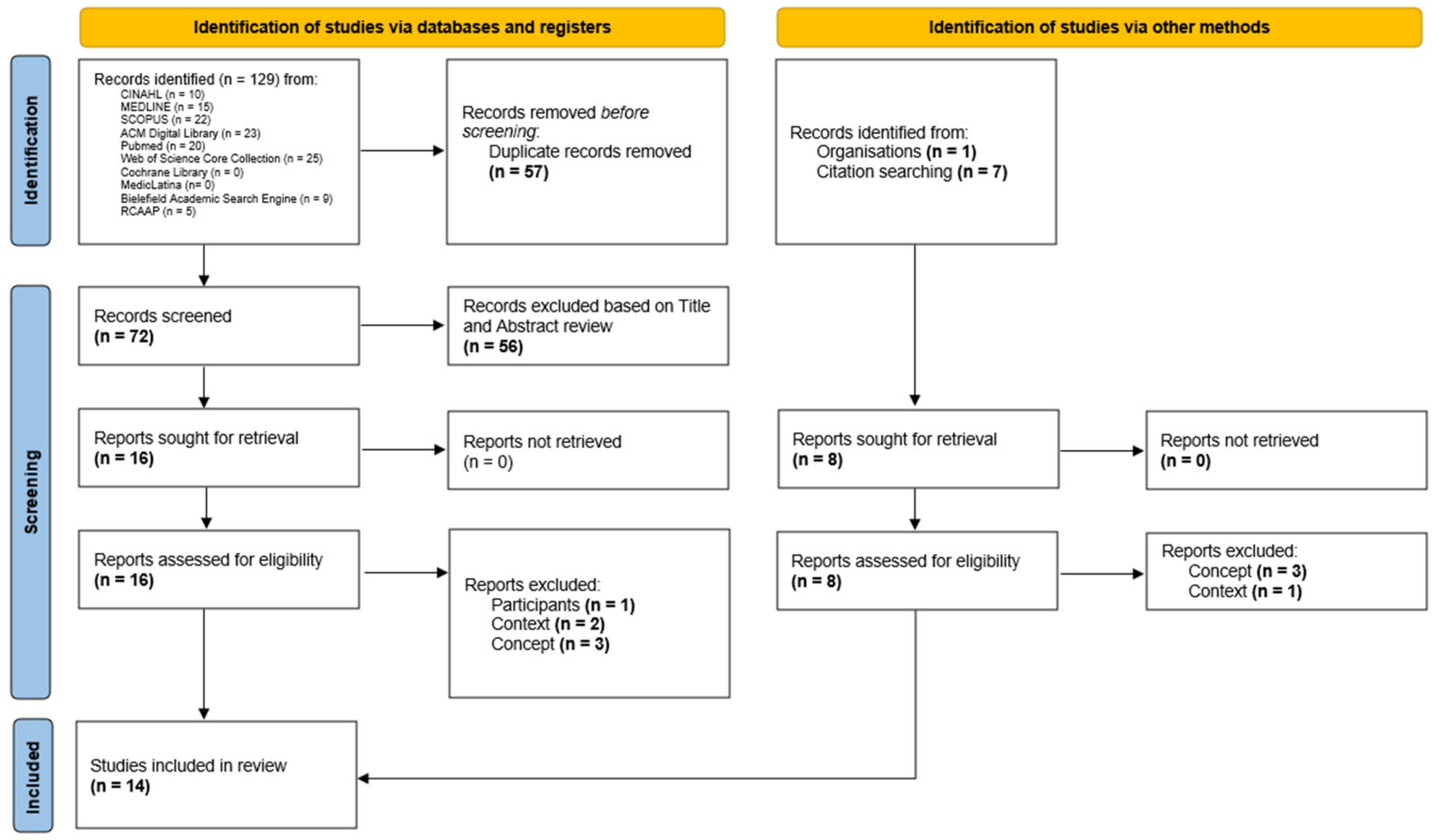
2.4. Source of Evidence Selection
2.5. Data Extraction
2.6. Ethical Considerations
3. Results
3.1. Characteristics of Included Papers
3.2. Prediction Model Design
3.3. Variables
- Clinical Measures—Covers parameters such as blood pressure (systolic, diastolic, and mean), heart rate, oxygen saturation (SpO2), temperature, Glasgow Coma Scale, APACHE, and MEWS scores [21,32,51,53,54,58]. These measures play a key role in capturing the patient’s disease severity for hemodynamic and neurological conditions;
- Laboratory Results—Includes variables such as albumin, hemoglobin, glucose, creatinine, lactate, bilirubin, arterial PaO2, PaCO2, and pH [32,51,53,54,56,58]. These variables were often highlighted as significant predictors due to their ability to reflect the patient’s nutritional, metabolic and inflammatory status;
- Interventions—Variables related to clinical interventions, such as the use of ventilation (invasive or non-invasive), Continuous Renal Replacement Therapy (CRRT), Extracorporeal membrane oxygenation (ECMO), and parenteral nutrition [32,51,55,58,60]. These variables reflect the impact of therapeutic interventions on risk of injury development;
- Nursing Assessments—Includes variables from the Braden scale (total score and subscales such as sensory perception, activity, mobility, nutrition, skin moisture, and friction/shear) [32,33,51,52,55,57,58,59,60], repositioning practices, and skin assessment (e.g., fragile skin or skin tears) [32,58,59];
3.4. Model Performance
3.5. Results of Implementation
4. Discussion
4.1. Performance Analisys of AI Models
4.2. Key Variables in Prediction Models
4.3. Clinical Implementation and Implications
4.4. Strengths and Limitations
4.5. Future Research Directions
- External Validation and Multicenter Studies—Prospective, multicenter trials across diverse ICU settings are essential to ensure predictive models’ generalizability and real-world applicability. Diagnostic randomized controlled trials are critical for evaluating their true clinical effectiveness beyond retrospective metrics [69,70];
- Incorporation of Underutilized Variables—Future models should include repositioning frequency, support surface use, perioperative variables, skin care interventions, and staff workload metrics, alongside physiological and laboratory data, to improve specificity and relevance;
- Standardization of Metrics—Uniform reporting and performance metrics are needed to enable cross-study comparisons, enhance evidence synthesis, and improve model refinement;
- Real-Time Integration—Dynamic models with continuous monitoring, such as time-series analysis, should be integrated into EHRs for seamless, proactive care;
- Addressing Ethical and Human Factors—Models must be interpretable and user-friendly to foster trust and adoption among clinicians. Ethical concerns, such as algorithmic bias and transparency, must also be addressed to ensure equitable implementation.
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Public Involvement Statement
Guidelines and Standards Statement
Use of Artificial Intelligence
Acknowledgments
Conflicts of Interest
References
- Gefen, A.; Soppi, E. The Pathophysiological Links between Pressure Ulcers and Pain and the Role of the Support Surface in Mitigating Both. Wounds Int. 2020, 11, 38–44. [Google Scholar]
- Rondinelli, J.; Zuniga, S.; Kipnis, P.; Kawar, L.N.; Liu, V.; Escobar, G.J. Hospital-Acquired Pressure Injury: Risk-Adjusted Comparisons in an Integrated Healthcare Delivery System. Nurs. Res. 2018, 67, 16–25. [Google Scholar] [CrossRef] [PubMed]
- Roussou, E.; Fasoi, G.; Stavropoulou, A.; Kelesi, M.; Vasilopoulos, G.; Gerogianni, G.; Alikari, V. Quality of Life of Patients with Pressure Ulcers: A Systematic Review. Med. Pharm. Rep. 2023, 96, 123–130. [Google Scholar] [CrossRef] [PubMed]
- Padula, W.V.; Delarmente, B.A. The National Cost of Hospital-acquired Pressure Injuries in the United States. Int. Wound J. 2019, 16, 634–640. [Google Scholar] [CrossRef]
- Han, Y.; Jin, Y.; Jin, T.; Lee, S.-M.; Lee, J.-Y. Impact of Pressure Injuries on Patient Outcomes in a Korean Hospital: A Case-Control Study. J. Wound Ostomy Cont. Nurs. 2019, 46, 194–200. [Google Scholar] [CrossRef]
- European Pressure Ulcer Advisory Panel; National Pressure Injury Advisory Panel; Pan Pacific Pressure Injury Alliance (Eds.) Prevention and Treatment of Pressure Ulcers/Injuries: Clinical Practice Guideline: The International Guideline, 3rd ed.; EPUAP—European Pressure Ulcer Advisory Panel: Helsinki, Finland, 2019; ISBN 978-0-6480097-8-8. [Google Scholar]
- Edsberg, L.E.; Black, J.M.; Goldberg, M.; McNichol, L.; Moore, L.; Sieggreen, M. Revised National Pressure Ulcer Advisory Panel Pressure Injury Staging System: Revised Pressure Injury Staging System. J. Wound Ostomy Cont. Nurs. 2016, 43, 585–597. [Google Scholar] [CrossRef]
- Al Mutairi, K.B.; Hendrie, D. Global Incidence and Prevalence of Pressure Injuries in Public Hospitals: A Systematic Review. Wound Med. 2018, 22, 23–31. [Google Scholar] [CrossRef]
- Li, Z.; Lin, F.; Thalib, L.; Chaboyer, W. Global Prevalence and Incidence of Pressure Injuries in Hospitalised Adult Patients: A Systematic Review and Meta-Analysis. Int. J. Nurs. Stud. 2020, 105, 103546. [Google Scholar] [CrossRef]
- Marshall, J.C.; Bosco, L.; Adhikari, N.K.; Connolly, B.; Diaz, J.V.; Dorman, T.; Fowler, R.A.; Meyfroidt, G.; Nakagawa, S.; Pelosi, P.; et al. What Is an Intensive Care Unit? A Report of the Task Force of the World Federation of Societies of Intensive and Critical Care Medicine. J. Crit. Care 2017, 37, 270–276. [Google Scholar] [CrossRef]
- Chaboyer, W.P.; Thalib, L.; Harbeck, E.L.; Coyer, F.M.; Blot, S.; Bull, C.F.; Nogueira, P.C.; Lin, F.F. Incidence and Prevalence of Pressure Injuries in Adult Intensive Care Patients: A Systematic Review and Meta-Analysis. Crit. Care Med. 2018, 46, e1074–e1081. [Google Scholar] [CrossRef]
- Serrano, M.L.; Méndez, M.I.G.; Cebollero, F.M.C.; Rodríguez, J.S.L. Risk Factors for Pressure Ulcer Development in Intensive Care Units: A Systematic Review. Med. Intensiv. 2017, 41, 339–346. [Google Scholar] [CrossRef]
- Labeau, S.O.; Afonso, E.; Benbenishty, J.; Blackwood, B.; Boulanger, C.; Brett, S.J.; Calvino-Gunther, S.; Chaboyer, W.; Coyer, F.; Deschepper, M.; et al. Prevalence, Associated Factors and Outcomes of Pressure Injuries in Adult Intensive Care Unit Patients: The DecubICUs Study. Intensive Care Med. 2021, 47, 160–169. [Google Scholar] [CrossRef] [PubMed]
- Coleman, S.; Nixon, J.; Keen, J.; Wilson, L.; McGinnis, E.; Dealey, C.; Stubbs, N.; Farrin, A.; Dowding, D.; Schols, J.M.; et al. A New Pressure Ulcer Conceptual Framework. J. Adv. Nurs. 2014, 70, 2222–2234. [Google Scholar] [CrossRef] [PubMed]
- Alshahrani, B.; Sim, J.; Middleton, R. Nursing Interventions for Pressure Injury Prevention among Critically Ill Patients: A Systematic Review. J. Clin. Nurs. 2021, 30, 2151–2168. [Google Scholar] [CrossRef]
- Tschannen, D.; Anderson, C. The Pressure Injury Predictive Model: A Framework for Hospital-acquired Pressure Injuries. J. Clin. Nurs. 2020, 29, 1398–1421. [Google Scholar] [CrossRef]
- Norton, D. Calculating the Risk: Reflections on the Norton Scale. Decubitus 1989, 2, 24–31. [Google Scholar]
- Bergstrom, N.; Braden, B.J.; Laguzza, A.; Holman, V. The Braden Scale for Predicting Pressure Sore Risk. Nurs. Res. 1987, 36, 205–210. [Google Scholar] [CrossRef]
- Waterlow, J. Pressure Sores: A Risk Assessment Card. Nurs. Times 1985, 81, 49–55. [Google Scholar]
- Cox, J. Predictive Power of the Braden Scale for Pressure Sore Risk in Adult Critical Care Patients: A Comprehensive Review. J. Wound Ostomy Cont. Nurs. 2012, 39, 613. [Google Scholar] [CrossRef]
- Ladios-Martin, M.; Fernández-de-Maya, J.; Ballesta-López, F.-J.; Belso-Garzas, A.; Mas-Asencio, M.; Cabañero-Martínez, M.J. Predictive Modeling of Pressure Injury Risk in Patients Admitted to an Intensive Care Unit. Am. J. Crit. Care 2020, 29, e70–e80. [Google Scholar] [CrossRef]
- Picoito, R.; Lapuente, S.; Ramos, A.; Rabiais, I.; Deodato, S.; Nunes, E. Risk Assessment Instruments for Pressure Ulcer in Adults in Critical Situation: A Scoping Review. Rev. Lat.-Am. Enferm. 2023, 31, e3983. [Google Scholar] [CrossRef]
- Ranzani, O.T.; Simpson, E.S.; Japiassú, A.M.; Noritomi, D.T.; Amil Critical Care Group. The Challenge of Predicting Pressure Ulcers in Critically Ill Patients. A Multicenter Cohort Study. Ann. Am. Thorac. Soc. 2016, 13, 1775–1783. [Google Scholar] [CrossRef] [PubMed]
- Wei, M.; Wu, L.; Chen, Y.; Fu, Q.; Chen, W.; Yang, D. Predictive Validity of the Braden Scale for Pressure Ulcer Risk in Critical Care: A Meta-Analysis. Nurs. Crit. Care 2020, 25, 165–170. [Google Scholar] [CrossRef]
- Vocci, M.C.; Lopes Saranholi, T.; Amante Miot, H.; Fernandes Abbade, L.P. Intensive Care Pressure Injuries: A Cohort Study Using the CALCULATE and Braden Scales. Adv. Ski. Wound Care 2022, 35, 1–8. [Google Scholar] [CrossRef]
- Jackson, C. The Revised Jackson/Cubbin Pressure Area Risk Calculator. Intensive Crit. Care Nurs. 1999, 15, 169–175. [Google Scholar] [CrossRef]
- de Souza, G.K.C.; Kaiser, D.E.; Morais, P.P.; Boniatti, M.M. Assessment of the Accuracy of the CALCULATE Scale for Pressure Injury in Critically Ill Patients. Aust. Crit. Care 2023, 36, 195–200. [Google Scholar] [CrossRef]
- Leal-Felipe, M.d.L.Á.; Arroyo-López, M.d.C.; Robayna-Delgado, M.d.C.; Gómez-Espejo, A.; Perera-Díaz, P.; Chinea-Rodríguez, C.D.; García-Correa, N.; Jiménez-Sosa, A. Predictive Ability of the EVARUCI Scale and COMHON Index for Pressure Injury Risk in Critically Ill Patients: A Diagnostic Accuracy Study. Aust. Crit. Care 2018, 31, 355–361. [Google Scholar] [CrossRef]
- Moore, Z.E.; Patton, D. Risk Assessment Tools for the Prevention of Pressure Ulcers. Cochrane Database Syst. Rev. 2019, 1, 1–41. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, X.; Cao, X.; Huang, C.; Liu, E.; Qian, S.; Liu, X.; Wu, Y.; Dong, F.; Qiu, C.-W.; et al. Artificial Intelligence: A Powerful Paradigm for Scientific Research. Innovation 2021, 2, 100179. [Google Scholar] [CrossRef]
- Raju, D.; Su, X.; Patrician, P.A.; Loan, L.A.; McCarthy, M.S. Exploring Factors Associated with Pressure Ulcers: A Data Mining Approach. Int. J. Nurs. Stud. 2015, 52, 102–111. [Google Scholar] [CrossRef]
- Cho, I.; Park, I.; Kim, E.; Lee, E.; Bates, D.W. Using EHR Data to Predict Hospital-Acquired Pressure Ulcers: A Prospective Study of a Bayesian Network Model. Int. J. Med. Inform. 2013, 82, 1059–1067. [Google Scholar] [CrossRef] [PubMed]
- Kaewprag, P.; Newton, C.; Vermillion, B.; Hyun, S.; Huang, K.; Machiraju, R. Predictive Models for Pressure Ulcers from Intensive Care Unit Electronic Health Records Using Bayesian Networks. BMC Med. Inform. Decis. Mak. 2017, 17, 65. [Google Scholar] [CrossRef] [PubMed]
- Çayirtepe, Z.; Şenel, A.C. Risk Management In Intensive Care Units With Artificial Intelligence Technologies: Systematic Review of Prediction Models Using Electronic Health Records. J. Basic Clin. Health Sci. 2022, 6, 958–976. [Google Scholar] [CrossRef]
- Ade, R.R.; Deshmukh, P.R. Methods for Incremental Learning: A Survey. Int. J. Data Min. Knowl. Manag. Process 2013, 3, 119–125. [Google Scholar] [CrossRef]
- Bradley, A.P. The Use of the Area under the ROC Curve in the Evaluation of Machine Learning Algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef]
- Yang, S.; Berdine, G. The Receiver Operating Characteristic (ROC) Curve. Southwest Resp. Crit. Care Chron. 2017, 5, 34. [Google Scholar] [CrossRef]
- Berrar, D.; Flach, P. Caveats and Pitfalls of ROC Analysis in Clinical Microarray Research (and How to Avoid Them). Brief. Bioinform. 2012, 13, 83–97. [Google Scholar] [CrossRef]
- Fan, J.; Upadhye, S.; Worster, A. Understanding Receiver Operating Characteristic (ROC) Curves. Can. J. Emerg. Med. 2006, 8, 19–20. [Google Scholar] [CrossRef]
- Barghouthi, E.D.; Owda, A.Y.; Asia, M.; Owda, M. Systematic Review for Risks of Pressure Injury and Prediction Models Using Machine Learning Algorithms. Diagnostics 2023, 13, 2739. [Google Scholar] [CrossRef]
- Zhou, Y.; Yang, X.; Ma, S.; Yuan, Y.; Yan, M. A Systematic Review of Predictive Models for Hospital-acquired Pressure Injury Using Machine Learning. Nurs. Open 2023, 10, 1234–1246. [Google Scholar] [CrossRef]
- Peters, M.D.J.; Marnie, C.; Tricco, A.C.; Pollock, D.; Munn, Z.; Alexander, L.; McInerney, P.; Godfrey, C.M.; Khalil, H. Updated Methodological Guidance for the Conduct of Scoping Reviews. JBI Evid. Synth. 2020, 18, 2119–2126. [Google Scholar] [CrossRef] [PubMed]
- Peters, M.D.J.; Godfrey, C.; McInerney, P.; Khalil, H.; Larsen, P.; Marnie, C.; Pollock, D.; Tricco, A.C.; Munn, Z. Best Practice Guidance and Reporting Items for the Development of Scoping Review Protocols. JBI Evid. Synth. 2022, 20, 953. [Google Scholar] [CrossRef] [PubMed]
- Tricco, A.C.; Lillie, E.; Zarin, W.; O’Brien, K.K.; Colquhoun, H.; Levac, D.; Moher, D.; Peters, M.D.J.; Horsley, T.; Weeks, L.; et al. PRISMA Extension for Scoping Reviews (PRISMA-ScR): Checklist and Explanation. Ann. Intern. Med. 2018, 169, 467–473. [Google Scholar] [CrossRef] [PubMed]
- Kayambankadzanja, R.K.; Schell, C.O.; Gerdin Wärnberg, M.; Tamras, T.; Mollazadegan, H.; Holmberg, M.; Alvesson, H.M.; Baker, T. Towards Definitions of Critical Illness and Critical Care Using Concept Analysis. BMJ Open 2022, 12, e060972. [Google Scholar] [CrossRef]
- Ouzzani, M.; Hammady, H.; Fedorowicz, Z.; Elmagarmid, A. Rayyan—A Web and Mobile App for Systematic Reviews. Syst. Rev. 2016, 5, 210. [Google Scholar] [CrossRef]
- Takats, S.; Stillman, D.; Cheslack-Postava, F.; Abaev, B.; Bagdonas, M.; Jellinek, A.; Najdek, T.; Dima, P.; Rentka, M.; Vasilakis, M.; et al. Zotero, version 7.0.13; Corporation for Digital Scholarship: Vienna, VA, USA, 2025; Available online: https://www.zotero.org/ (accessed on 21 February 2025).
- Page, M.J.; Mckenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 Statement: An Updated Guideline for Reporting Systematic Reviews. BMJ 2021, 372, n71. [Google Scholar] [CrossRef]
- Pollock, D.; Peters, M.D.J.; Khalil, H.; McInerney, P.; Alexander, L.; Tricco, A.C.; Evans, C.; de Moraes, É.B.; Godfrey, C.M.; Pieper, D.; et al. Recommendations for the Extraction, Analysis, and Presentation of Results in Scoping Reviews. JBI Evid. Synth. 2023, 21, 520. [Google Scholar] [CrossRef]
- Arksey, H.; O’Malley, L. Scoping Studies: Towards a Methodological Framework. Int. J. Soc. Res. Methodol. 2005, 8, 19–32. [Google Scholar] [CrossRef]
- Kim, M.; Kim, T.-H.; Kim, D.; Lee, D.; Kim, D.; Heo, J.; Kang, S.; Ha, T.; Kim, J.; Moon, D.H.; et al. In-Advance Prediction of Pressure Ulcers via Deep-Learning-Based Robust Missing Value Imputation on Real-Time Intensive Care Variables. J. Clin. Med. 2024, 13, 36. [Google Scholar] [CrossRef]
- Kaewprag, P.; Newton, C.; Vermillion, B.; Hyun, S.; Huang, K.; Machiraju, R. Predictive Modeling for Pressure Ulcers from Intensive Care Unit Electronic Health Records. AMIA Jt. Summits Transl. Sci. Proc. 2015, 2015, 82–86. [Google Scholar]
- Alderden, J.; Pepper, G.A.; Wilson, A.; Whitney, J.D.; Richardson, S.; Butcher, R.; Jo, Y.; Cummins, M.R. Predicting Pressure Injury in Critical Care Patients: A Machine-Learning Model. Am. J. Crit. Care 2018, 27, 461–468. [Google Scholar] [CrossRef] [PubMed]
- Cramer, E.M.; Seneviratne, M.G.; Sharifi, H.; Ozturk, A.; Hernandez-Boussard, T. Predicting the Incidence of Pressure Ulcers in the Intensive Care Unit Using Machine Learning. eGEMS 2019, 7, 49. [Google Scholar] [CrossRef] [PubMed]
- Hyun, S.; Moffatt-Bruce, S.; Cooper, C.; Hixon, B.; Kaewprag, P. Prediction Model for Hospital-Acquired Pressure Ulcer Development: Retrospective Cohort Study. JMIR Med. Inform. 2019, 7, e13785. [Google Scholar] [CrossRef]
- Choi, B.K.; Kim, M.S.; Kim, S.H. Risk Prediction Models for the Development of Oral-Mucosal Pressure Injuries in Intubated Patients in Intensive Care Units: A Prospective Observational Study. J. Tissue Viability 2020, 29, 252–257. [Google Scholar] [CrossRef]
- Vyas, K.; Samadani, A.; Milosevic, M.; Ostadabbas, S.; Parvaneh, S. Additional Value of Augmenting Current Subscales in Braden Scale with Advanced Machine Learning Technique for Pressure Injury Risk Assessment. In Proceedings of the 2020 IEEE International Conference on Bioinformatics and Biomedicine, BIBM 2020, Seoul, Republic of Korea, 16–19 December 2020; pp. 2993–2995. [Google Scholar] [CrossRef]
- Alderden, J.; Drake, K.P.; Wilson, A.; Dimas, J.; Cummins, M.R.; Yap, T.L. Hospital Acquired Pressure Injury Prediction in Surgical Critical Care Patients. BMC Med. Inform. Decis. Mak. 2021, 21, 12. [Google Scholar] [CrossRef]
- Alderden, J.; Kennerly, S.M.; Wilson, A.; Dimas, J.; McFarland, C.; Yap, D.Y.; Zhao, L.; Yap, T.L. Explainable Artificial Intelligence for Predicting Hospital-Acquired Pressure Injuries in COVID-19-Positive Critical Care Patients. Comput. Inform. Nurs. 2022, 40, 659–665. [Google Scholar] [CrossRef]
- Šín, P.; Hokynková, A.; Marie, N.; Andrea, P.; Krč, R.; Podroužek, J. Machine Learning-Based Pressure Ulcer Prediction in Modular Critical Care Data. Diagnostics 2022, 12, 850. [Google Scholar] [CrossRef]
- Ho, J.C.; Sotoodeh, M.; Zhang, W.; Simpson, R.L.; Hertzberg, V.S. An AdaBoost-Based Algorithm to Detect Hospital-Acquired Pressure Injury in the Presence of Conflicting Annotations. Comput. Biol. Med. 2024, 168, 107754. [Google Scholar] [CrossRef]
- Tang, Z.; Li, N.; Xu, J. Construction of a Risk Prediction Model for Intraoperative Pressure Injuries: A Prospective, Observational Study. J. PeriAnesthesia Nurs. 2021, 36, 473–479. [Google Scholar] [CrossRef]
- Primiano, M.; Friend, M.; McClure, C.; Nardi, S.; Fix, L.; Schafer, M.; Savochka, K.; McNett, M. Pressure Ulcer Prevalence and Risk Factors among Prolonged Surgical Procedures in the OR. AORN J. 2011, 94, 555–566. [Google Scholar] [CrossRef]
- van der Meijden, S.L.; Hond, A.A.H.d.; Thoral, P.J.; Steyerberg, E.W.; Kant, I.M.J.; Cinà, G.; Arbous, M.S. Intensive Care Unit Physicians’ Perspectives on Artificial Intelligence–Based Clinical Decision Support Tools: Preimplementation Survey Study. JMIR Hum. Factors 2023, 10, e39114. [Google Scholar] [CrossRef] [PubMed]
- Hassan, E.A.; El-Ashry, A.M. Leading with AI in Critical Care Nursing: Challenges, Opportunities, and the Human Factor. BMC Nurs. 2024, 23, 752. [Google Scholar] [CrossRef] [PubMed]
- Khosravi, M.; Zare, Z.; Mojtabaeian, S.M.; Izadi, R. Artificial Intelligence and Decision-Making in Healthcare: A Thematic Analysis of a Systematic Review of Reviews. Health Serv. Res. Manag. Epidemiol. 2024, 11, 23333928241234863. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, M.I.; Spooner, B.; Isherwood, J.; Lane, M.; Orrock, E.; Dennison, A. A Systematic Review of the Barriers to the Implementation of Artificial Intelligence in Healthcare. Cureus 2023, 15, e46454. [Google Scholar] [CrossRef]
- Ahmad, O.F.; Stoyanov, D.; Lovat, L.B. Barriers and Pitfalls for Artificial Intelligence in Gastroenterology: Ethical and Regulatory Issues. Tech. Innov. Gastrointest. Endosc. 2020, 22, 80–84. [Google Scholar] [CrossRef]
- Altman, D.G.; Vergouwe, Y.; Royston, P.; Moons, K.G.M. Prognosis and Prognostic Research: Validating a Prognostic Model. BMJ 2009, 338, b605. [Google Scholar] [CrossRef]
- di Ruffano, L.F.; Hyde, C.J.; McCaffery, K.J.; Bossuyt, P.M.M.; Deeks, J.J. Assessing the Value of Diagnostic Tests: A Framework for Designing and Evaluating Trials. BMJ 2012, 344, e686. [Google Scholar] [CrossRef]

{kind=link}
| Author | Prediction Models | Best Performing Model |
|---|---|---|
| Cho et al. 2013 [32] | Bayesian Networks | Bayesian Networks |
| Kaewprag et al. 2015 [52] | Logistic Regression; Support Vector Machine; Decision Tree; Random Forest; k-nearest neighbors; Naïve Bayes | Logistic Regression |
| Kaewprag et al. 2017 [33] | Bayesian Networks | Bayesian Networks |
| Alderden et al. 2018 [53] | Random Forest | Random Forest |
| Cramer et al. 2019 [54] | Logistic Regression; Elastic Net; Support Vector Machine; Random Forest; GBM; Neural Networks | Logistic Regression |
| Hyun et al. 2019 [55] | Logistic Regression | Logistic Regression |
| Choi et al. 2020 [56] | Naïve Bayes | Naïves Bayes |
| Ladíos-Martin et al. 2020 [21] | Logistic Regression; Bayes Point Machine; Averaged Perception; Boosted Decision Tree; Boosted Decision Forest; Decision Jungle; Locally Deep Support Vector Machine; Neural Networks; Support Vector Machine | Logistic Regression |
| Vyas et al. 2020 [57] | XGBoost | XGBoost |
| Alderden et al. 2021 [58] | Neural Networks; Random Forest; GBM; AdaBoost; Logistic Regression | GBM |
| Alderden et al. 2022 [59] | K-nearest neighbors; Logistic Regression; Multi-layer Perceptron; Naïve Bayes; Random Forest; Support Vector Machine | Ensemble SuperLearner |
| Šín et al. 2022 [60] | K-nearest neighbors; Logistic Regression; Multi-layer Perceptron; Naïve Bayes; Random Forest; Support Vector Machine | Random Forest |
| Ho et al. 2024 [61] | AdaBoost; Decision Tree; Logistic Regression; K-nearest neighbors; Multi-layer Perceptron; Random Forest; Support Vector Machine; GBM; MedaBoost | MedaBoost |
| Kim et al. 2024 [51] | RNN; GRU; LSTM; Logistic Regression; Decision Tree; Random Forest; XGBoost; GRU-D; GRU-D++ | GRU-D++ |
| Author | Model | ACC | AUROC | SEN | SPE | PPV | NPV |
|---|---|---|---|---|---|---|---|
| Cho et al. 2013 [32] | Bayesian Networks | - | 0.85 | 0.82 | 0.76 | 0.36 | 0.96 |
| Kaewprag et al. 2015 [52] | Logistic Regression | - | 0.83 | 0.16 | 0.99 | 0.56 | 0.93 |
| Kaewprag et al. 2017 [33] | Bayesian Networks | - | 0.83 | 0.46 | 0.91 | 0.29 | 0.95 |
| Alderden et al. 2018 [53] | Random Forest | - | 0.79 | - | - | - | - |
| Cramer et al. 2019 [54] | Logistic Regression | - | - | 0.71 | - | 0.09 | - |
| Hyun et al. 2019 [55] | Logistic Regression | 0.92 | 0.74 | 0.65 | 0.69 | 0.21 | 0.96 |
| Choi et al. 2020 [56] | Naïves Bayes | - | 0.82 | 0.6 | 0.89 | 0.23 | 0.98 |
| - | 0.68 | 0.85 | 0.76 | 0.37 | 0.97 | ||
| Ladíos-Martin et al. 2020 [21] | Logistic Regression | 0.87 | 0.88 | 0.75 | 0.88 | 0.22 | 0.99 |
| Vyas et al. 2020 [57] | XGBoost | 0.95 | - | 0.84 | 0.97 | 0.87 | 0.97 |
| Alderden et al. 2021 [58] | GBM | - | 0.82 | - | - | - | - |
| Alderden et al. 2022 [59] | Ensemble SuperLearner | - | 0.81 | - | - | - | - |
| Šín et al. 2022 [60] | Random Forest | 0.96 | 0.99 | 0.92 | - | 0.95 | - |
| Ho et al. 2024 [61] | MedaBoost | - | 0.9 | - | - | - | - |
| Kim et al. 2024 [51] | GRU-D++ | - | 0.95 | - | - | - | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alves, J.; Azevedo, R.; Marques, A.; Encarnação, R.; Alves, P. Pressure Injury Prediction in Intensive Care Units Using Artificial Intelligence: A Scoping Review. Nurs. Rep. 2025, 15, 126. https://doi.org/10.3390/nursrep15040126
Alves J, Azevedo R, Marques A, Encarnação R, Alves P. Pressure Injury Prediction in Intensive Care Units Using Artificial Intelligence: A Scoping Review. Nursing Reports. 2025; 15(4):126. https://doi.org/10.3390/nursrep15040126
Chicago/Turabian StyleAlves, José, Rita Azevedo, Ana Marques, Rúben Encarnação, and Paulo Alves. 2025. "Pressure Injury Prediction in Intensive Care Units Using Artificial Intelligence: A Scoping Review" Nursing Reports 15, no. 4: 126. https://doi.org/10.3390/nursrep15040126
APA StyleAlves, J., Azevedo, R., Marques, A., Encarnação, R., & Alves, P. (2025). Pressure Injury Prediction in Intensive Care Units Using Artificial Intelligence: A Scoping Review. Nursing Reports, 15(4), 126. https://doi.org/10.3390/nursrep15040126