
Sound Quality Factors Inducing the Autonomous Sensory Meridian Response
Abstract
1. Introduction
2. Method
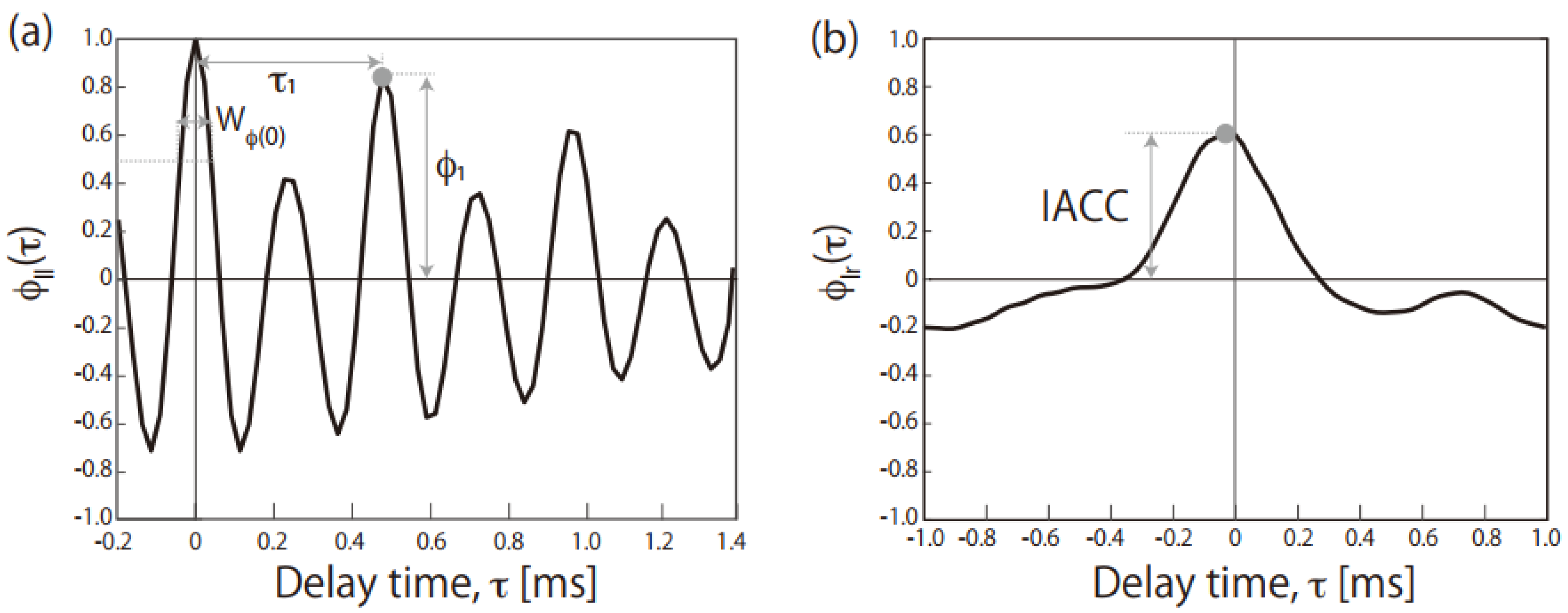
2.1. ASMR Triggers and Sound Quality Parameters
2.2. Participants
2.3. Tasks and Procedures
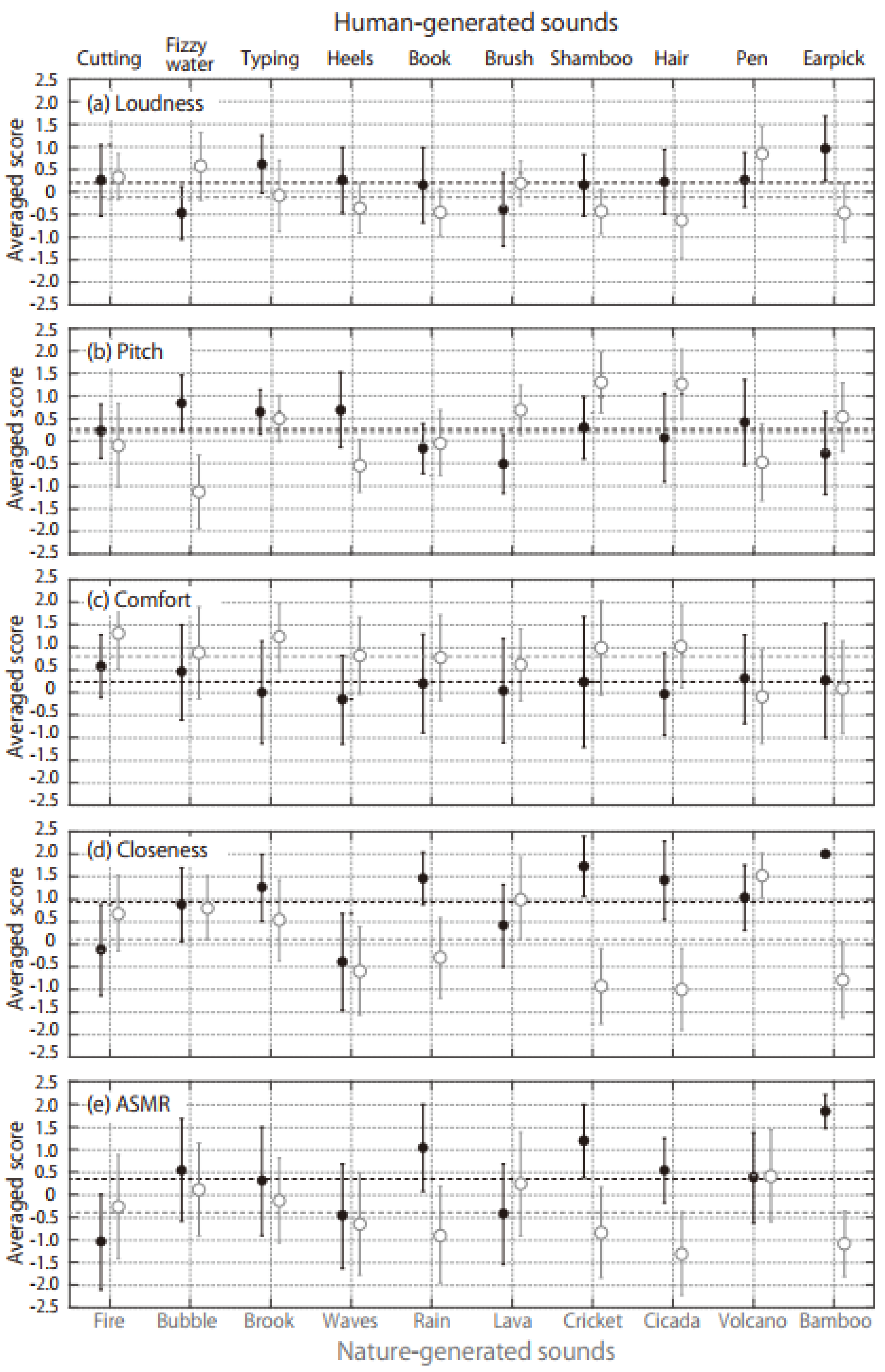
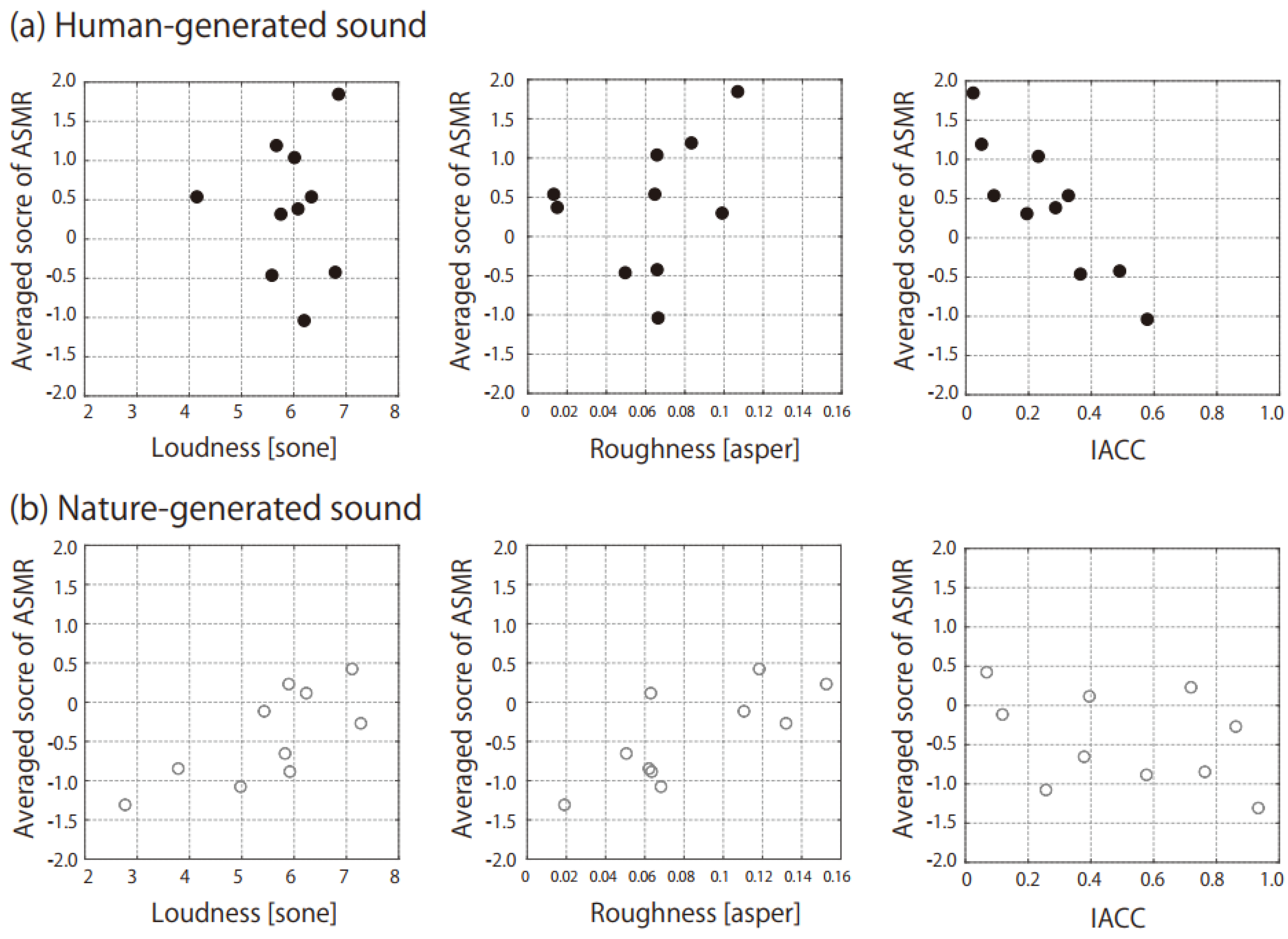
3. Results
4. Discussion
5. Conclusions
- (1)
- Human-generated sounds are more likely to trigger stronger ASMRs than nature-generated sounds.
- (2)
- Among possible ASMR auditory triggers, sounds perceived to be close to the listener are more likely to evoke the ASMR sensation.
- (3)
- In the case of nature-generated sounds, the ASMR triggers with higher loudness and roughness among Zwicker parameters are more likely to evoke the ASMR sensation.
- (4)
- In the case of human-generated sounds, the ASMR triggers with a lower IACC among the ACF/IACF parameters are more likely to evoke the ASMR sensation.
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Barratt, E.L.; Davis, N.J. Autonomous Sensory Meridian Response (ASMR): A flow-like mental state. PeerJ 2015, 3, e851. [Google Scholar] [CrossRef] [PubMed]
- McErlean, A.B.J.; Banissy, M.J. Increased misophonia in self-reported Autonomous Sensory Meridian Response. PeerJ 2018, 6, e5351. [Google Scholar] [CrossRef] [PubMed]
- McGeoch, P.D.; Rouw, R. How everyday sounds can trigger strong emotion: ASMR, misophonia and the feeling of wellbeing. BioEssays. 2020, 42, 2000099. [Google Scholar] [CrossRef] [PubMed]
- Tada, K.; Hasegawa, R.; Kondo, H. Sensitivity to everyday sounds: ASMR, misophonia, and autistic traits. Jpn. J. Psychol. 2022, 93, 263–269. [Google Scholar] [CrossRef]
- Jastreboff, M.M.; Jastreboff, P.J. Components of decreased sound tolerance: Hyperacusis, misophonia, phonophobia. ITHS News Lett. 2001, 2, 5–7. [Google Scholar]
- Jastreboff, P.J.; Jastreboff, M.M. Treatments for decreased sound tolerance (hyperacusis and misophonia). In Seminars in Hearing; Thieme Medical Publishers: New York, NY, USA, 2014; Volume 35, pp. 105–120. [Google Scholar]
- Møller, A.R. Misophonia, phonophobia, and ‘exploding head’ syndrome. In Textbook of Tinnitus; Møller, A.R., Langguth, B., DeRidder, D., Kleinjung, T., Eds.; Springer: New York, NY, USA, 2011; pp. 25–27. [Google Scholar]
- Wu, M.S.; Lewin, A.B.; Murphy, T.K.; Storch, E.A. Misophonia: Incidence, phenomenology, and clinical correlates in an undergraduate student sample. J. Clin. Psychol. 2014, 70, 994–1007. [Google Scholar] [CrossRef]
- Barratt, E.L.; Spence, C.; Davis, N.J. Sensory determinants of the autonomous sensory meridian response (ASMR): Understanding the triggers. PeerJ. 2017, 5, e3846. [Google Scholar] [CrossRef]
- Fredborg, B.; Clark, J.; Smith, S.D. An examination of personality traits associated with autonomous sensory meridian response (ASMR). Front. Psychol. 2017, 8, 247. [Google Scholar] [CrossRef]
- Poerio, G.L.; Blakey, E.; Hostler, T.J.; Veltri, T. More than a feeling: Autonomous sensory meridian response (ASMR) in characterized by reliable changes in affect and physiology. PLoS ONE 2018, 13, e0196645. [Google Scholar] [CrossRef]
- Smith, S.D.; Fredborg, B.; Kornelsen, J. Functional connectivity associated with different categories of autonomous sensory meridian response (ASMR) triggers. Conscious. Cogn. 2020, 85, 103021. [Google Scholar] [CrossRef]
- Swart, T.R.; Bowling, N.C.; Banissy, M.J. ASMR-experience questionnaire (AEQ): A data-driven step towards accurately classifying ASMR responders. Br. J. Psychol. 2022, 113, 68–83. [Google Scholar] [CrossRef]
- Zwicker, E.; Fastl, H. Psychoacoustics: Facts and Models; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- ISO 532-1; Acoustics—Methods for Calculating Loudness—Part 1: Zwicker Method. International Organization for Standardization: Geneva, Switzerland, 2017.
- DIN 45692; Measurement Technique for the Simulation of the Auditory Sensation of Sharpness. German Institute for Standardization: Berlin, Germany, 2009.
- Ando, Y. 5. Prediction of subjective preference in concert halls. In Concert Hall Acoustics; Springer: Berlin/Heidelberg, Germany, 1995; pp. 70–88. [Google Scholar]
- Cariani, P.A.; Delgutte, B. Neural correlates of the pitch of complex tones. I. Pitch and pitch salience. J. Neurophysiol. 1996, 76, 1698–1716. [Google Scholar] [CrossRef] [PubMed]
- Cariani, P.A.; Delgutte, B. Neural correlates of the pitch of complex tones. II. Pitch shift, pitch ambiguity, phase invariance, pitch circularity, rate pitch, and the dominance. J. Neurophysiol. 1996, 76, 1717–1734. [Google Scholar] [CrossRef] [PubMed]
- Sato, S.; You, J.; Jeon, J.Y. Sound quality characteristics of refrigerator noise in real living environments with relation to psychoacoustical and autocorrelation function parameters. J. Acoust. Soc. Am. 2007, 122, 314–325. [Google Scholar] [CrossRef] [PubMed]
- Soeta, Y.; Shimokura, R. Sound quality evaluation of air-conditioner noise based on factors of the autocorrelation function. Appl. Acoust. 2017, 124, 11–19. [Google Scholar] [CrossRef]
- Ando, Y. Autocorrelation-based features for speech representation. Acta Acust. United Acust. 2015, 101, 145–154. [Google Scholar] [CrossRef]
- Shimokura, R.; Akasaka, S.; Nishimura, T.; Hosoi, H.; Matsui, T. Autocorrelation factors and intelligibility of Japanese monosyllables in individuals with sensorineural hearing loss. J. Acoust. Soc. Am. 2017, 141, 1065. [Google Scholar] [CrossRef]
- Kitamura, T.; Shimokura, R.; Sato, S.; Ando, Y. Measurement of temporal and spatial factors of a flushing toilet noise in a downstairs bedroom. J. Temp. Des. Archit. Environ. 2002, 2, 13–19. [Google Scholar]
- Fujii, K.; Soeta, Y.; Ando, Y. Acoustical properties of aircraft noise measured by temporal and spatial factors. J. Sound Vib. 2001, 241, 69–78. [Google Scholar] [CrossRef]
- Fujii, K.; Atagi, J.; Ando, Y. Temporal and spatial factors of traffic noise and its annoyance. J. Temp. Des. Archit. Environ. 2002, 2, 33–41. [Google Scholar]
- Soeta, Y.; Shimokura, R. Survey of interior noise characteristics in various types of trains. Appl. Acoust. 2013, 74, 1160–1166. [Google Scholar] [CrossRef]
- Smith, S.D.; Fredborg, B.K.; Kornelsen, J. An examination of the default mode network in individuals with autonomous sensory meridian response (AMSR). Soc. Neurosci. 2017, 12, 361–365. [Google Scholar] [CrossRef] [PubMed]
- Lochte, B.C.; Guillory, S.A.; Richard, C.A.H.; Kelly, W.M. An fMRI investigation of neural correlates underlying the autonomous sensory median response (ASMR). BioImpacts 2018, 8, 295–304. [Google Scholar] [CrossRef]
- Audio Toolbox. Available online: https://jp.mathworks.com/help/audio/index.html?s_tid=CRUX_lftnav (accessed on 23 September 2022).
- Nikolov, M.E.; Blagoeva, M.E. Proximity effect frequency characteristics of directional microphones. In Proceedings of the Audio Engineering Society Convention 108, Paris, French, 19–22 February 2000. [Google Scholar]
- Fujii, K.; Hotehama, T.; Kato, K.; Shimokura, R.; Okamoto, Y.; Suzumura, Y.; Ando, Y. Spatial distribution of acoustical parameters in concert halls: Comparison of different scattered reflections. J. Temp. Des. Archit. Environ. 2004, 4, 59–68. [Google Scholar]
- Kurozumi, K.; Ohgushi, K. The relationship between the cross correlation coefficient of two-channel acoustic signals and sound image quality. J. Acoust. Soc. Am. 1983, 74, 1726–1733. [Google Scholar] [CrossRef]
- Gerzon, M.A. Signal processing for simulating realistic stereo images. In Proceedings of the Audio Engineering Society Convention 93, San Francisco, CA, USA, 1–4 October 1992. [Google Scholar]
- Kendall, G.S. The decorrelation of audio signals and its impact on spatial imagery. Comput. Music J. 1995, 19, 71–87. [Google Scholar] [CrossRef]
- Koyama, S.; Furuya, K.; Hiwasaki, Y.; Haneda, Y. Reproducing virtual sound sources in front of a loudspeaker array using inverse wave propagator. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 1746–1758. [Google Scholar] [CrossRef]
- Jeon, S.W.; Park, Y.C.; Youn, D.H. Auditory distance rendering based on ICPD control for stereophonic 3D audio system. IEEE Signal Process. Lett. 2015, 22, 529–533. [Google Scholar] [CrossRef]
- Bernstein, R.E.; Angell, K.L.; Dehle, C.M. A brief course of cognitive behavioral therapy for the treatment of misophonia: A case example. Cogn. Behav. Ther. 2013, 6, e10. [Google Scholar] [CrossRef]
- Dozier, T.H. Counterconditioning treatment for misophonia. Clin. Case Stud. 2015, 14, 374–387. [Google Scholar] [CrossRef]
- Dozier, T.H. Treating the initial physical reflex of misophonia with the neural repatterning technique: A counterconditioning procedure. Psychol. Thought 2015, 8, 189–210. [Google Scholar] [CrossRef]
- McGuire, J.F.; Wu, M.S.; Storch, E.A. Cognitive-behavioral therapy for 2 youths with Misophonia. J. Clin. Psychiatry 2015, 76, 573–574. [Google Scholar] [CrossRef] [PubMed]
- Reid, A.M.; Guzick, A.G.; Gernand, A.; Olsen, B. Intensive cognitive-behavioral therapy for comorbid misophonic and obsessive-compulsive symptoms: A systematic case study. J. Obsessive Compuls. Relat. Disord. 2016, 10, 1–9. [Google Scholar] [CrossRef]
- Schröder, A.E.; Vulink, N.C.; van Loon, A.J.; Denys, D.A. Cognitive behavioral therapy is effective in misophonia: An open trial. J. Affect. Disord. 2017, 217, 289–294. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Sound Source | Zwicker’s Parameters | ACF/IACF Parameters | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Short Title | Contents | Loudness [sone] | Sharpness [acum] | Roughness [asper] | Fluctuation Strength [vacil] | τ1 [ms] | ϕ1 | WΦ(0) [ms] | IACC | |
| Human-generated sound | Cutting | Cutting vegetable | 6.20 | 1.63 | 0.07 | 1.31 | 2.52 | 0.20 | 0.26 | 0.58 |
| Fizzwater | Stirring carbonated water | 4.15 | 3.25 | 0.06 | 0.02 | 0.22 | 0.29 | 0.06 | 0.09 | |
| Typing | Typing a keyboard | 5.75 | 2.22 | 0.10 | 0.59 | 0.86 | 0.15 | 0.09 | 0.19 | |
| Heels | Footsteps of high heels | 5.58 | 1.58 | 0.05 | 0.43 | 1.56 | 0.19 | 0.36 | 0.37 | |
| Book | Flipping a book | 6.01 | 1.94 | 0.07 | 0.06 | 1.40 | 0.13 | 0.13 | 0.23 | |
| Brush | Brushing something | 6.79 | 1.78 | 0.07 | 0.05 | 1.99 | 0.15 | 0.14 | 0.49 | |
| Shampoo | Washing hair with shampoo | 5.67 | 2.33 | 0.08 | 0.33 | 1.92 | 0.04 | 0.10 | 0.05 | |
| Hair | Cutting hair | 6.34 | 2.17 | 0.01 | 0.39 | 0.93 | 0.42 | 0.09 | 0.33 | |
| Pen | Writing with pen | 6.08 | 2.54 | 0.01 | 0.39 | 0.42 | 0.29 | 0.06 | 0.29 | |
| Earpick | Earpick | 6.86 | 1.30 | 0.11 | 0.74 | 6.45 | 0.05 | 0.40 | 0.02 | |
| Nature-generated sound | Fire | Building a fire | 7.28 | 1.88 | 0.13 | 0.03 | 3.32 | 0.11 | 0.12 | 0.86 |
| Bubble | Bubbles under water | 6.23 | 0.70 | 0.06 | 0.07 | 6.74 | 0.21 | 0.77 | 0.40 | |
| Brook | Murmur of a brook | 5.43 | 1.87 | 0.11 | 0.07 | 1.70 | 0.13 | 0.15 | 0.12 | |
| Waves | Sound of waves | 5.83 | 1.43 | 0.05 | 0.06 | 3.63 | 0.05 | 0.30 | 0.38 | |
| Rain | Sound of rain | 5.92 | 2.11 | 0.06 | 0.10 | 3.63 | 0.05 | 0.30 | 0.58 | |
| Lava | Lava flowing | 5.90 | 2.53 | 0.15 | 0.02 | 0.68 | 0.09 | 0.07 | 0.72 | |
| Cricket | Bell-ringing cricket | 3.78 | 3.19 | 0.06 | 0.02 | 0.48 | 0.84 | 0.07 | 0.76 | |
| Cicada | Evening cicada | 2.77 | 2.69 | 0.02 | 0.02 | 0.28 | 0.95 | 0.09 | 0.93 | |
| Volcano | Bubbles of mud volcano | 7.11 | 1.46 | 0.12 | 0.29 | 1.65 | 0.15 | 0.22 | 0.07 | |
| Bamboo | Wind through bamboo forest | 4.98 | 3.13 | 0.07 | 0.06 | 3.76 | 0.02 | 0.06 | 0.26 | |
| Zwicker’s Parameters | ACF/IACF Parameters | Subjective Judgements | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Loudness | Sharpness | Roughness | Fluctuation Strength | τ1 | ϕ1 | WΦ(0) | IACC | Subjective Loudness | Pitch | Comfort | Closeness | |
| ASMR (Total) | 0.42 | −0.21 | 0.27 | 0.15 | 0.12 | −0.36 | 0.06 | −0.67 ** | 0.64 ** | −0.29 | −0.38 | 0.93 ** |
| ASMR (Human) | 0.04 | 0.11 | 0.32 | −0.30 | 0.39 | −0.32 | −0.04 | −0.89 ** | 0.38 | −0.20 | 0.02 | 0.93 ** |
| ASMR (Nature) | 0.73 * | −0.61 | 0.77 ** | 0.47 | 0.14 | −0.46 | 0.34 | −0.41 | 0.92 ** | −0.53 | −0.17 | 0.96 ** |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shimokura, R. Sound Quality Factors Inducing the Autonomous Sensory Meridian Response. Audiol. Res. 2022, 12, 574-584. https://doi.org/10.3390/audiolres12050056
Shimokura R. Sound Quality Factors Inducing the Autonomous Sensory Meridian Response. Audiology Research. 2022; 12(5):574-584. https://doi.org/10.3390/audiolres12050056
Chicago/Turabian StyleShimokura, Ryota. 2022. "Sound Quality Factors Inducing the Autonomous Sensory Meridian Response" Audiology Research 12, no. 5: 574-584. https://doi.org/10.3390/audiolres12050056
APA StyleShimokura, R. (2022). Sound Quality Factors Inducing the Autonomous Sensory Meridian Response. Audiology Research, 12(5), 574-584. https://doi.org/10.3390/audiolres12050056