
The Thomas More Lists: A Phonemically Balanced Dutch Monosyllabic Speech Audiometry Test


Abstract
:1. Introduction
2. Materials and Methods
2.1. Development of the Audio Materials
2.2. Design and Validation of the Speech Lists
3. Results
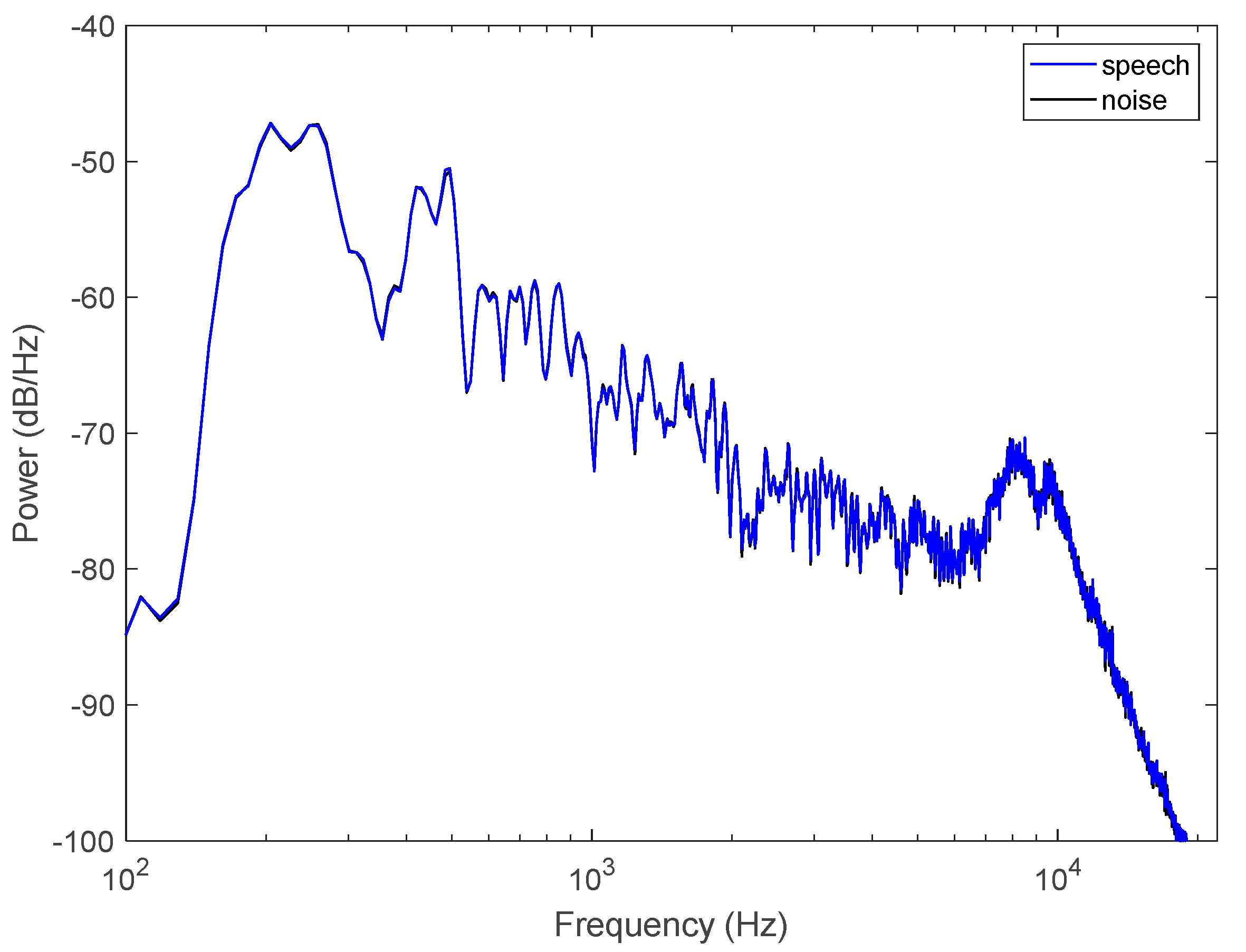
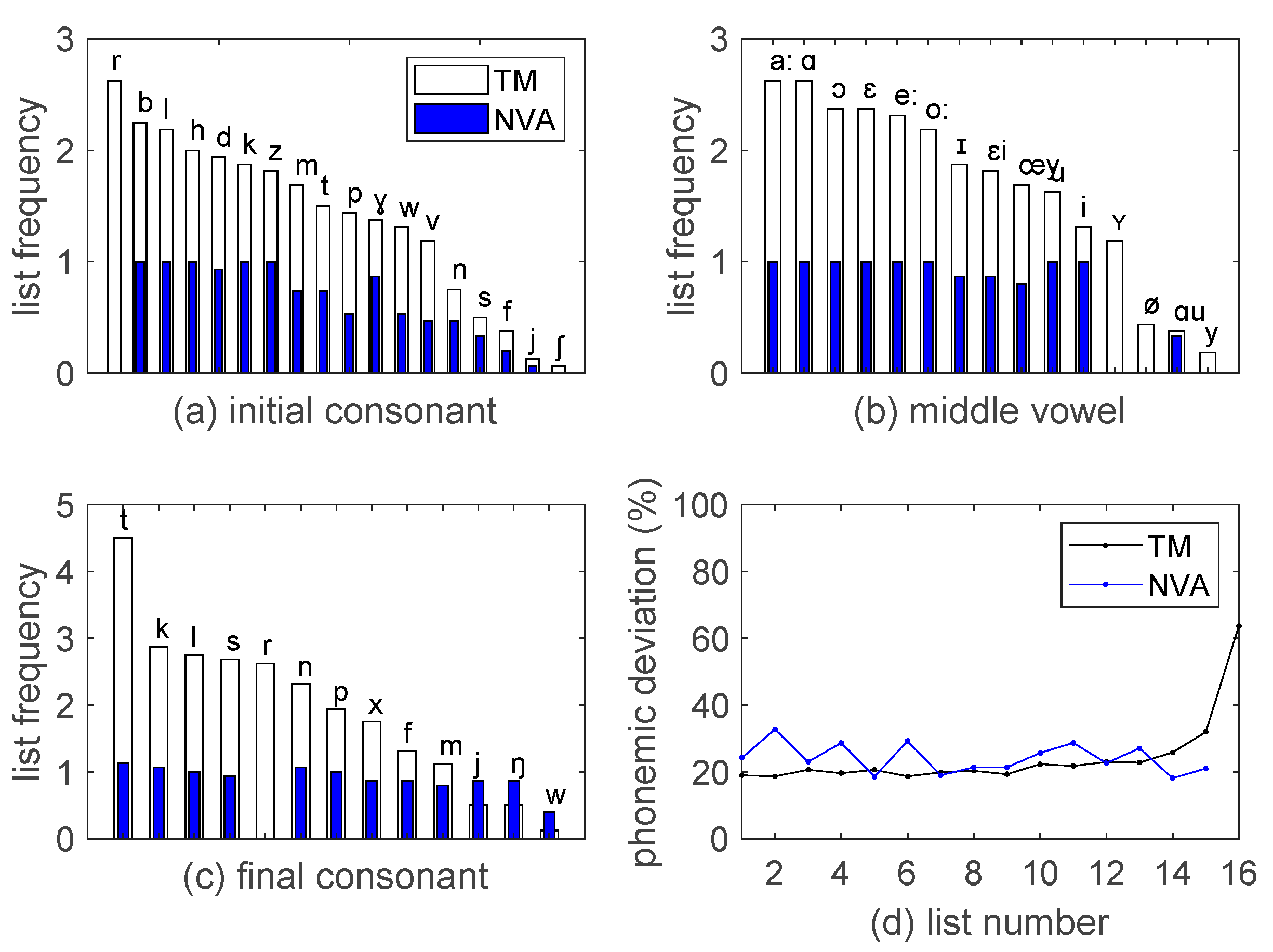
3.1. Spectrum and Phonemic Distribution
3.2. Reference Speech Recognition Curves
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CVC | Consonant-vowel-consonant |
| CI | Cochlear implant |
| IPA | International Phonetic Alphabet |
| NVA | Nederlandse Vereniging Audiology (Dutch association of Audiology) lists |
| PAT | phoneme allocation table |
| SRT, SRTq, SRTn | Speech recognition threshold level. Subscript indicates in quiet or in noise |
References
- Luyckx, K.; Kloots, H.; Coussé, E.; Gillis, S. Klankfrequenties in het Nederlands. In Tussen Taal, Spelling en Onderwijs: Essays bij het Emeritaat van Frans Daems; Sandra, D., Rymenans, R., Cuvelier, P., van Petegem, P., Eds.; Academia Press: Cambridge, MA, USA, 2007; pp. 141–154. [Google Scholar]
- Hammer, A.; Coene, M.; Govaerts, P. Zinnen of woorden? Een bespreking van het spraakmateriaal binnen de Nederlandse en Vlaamse spraakaudiometrie. Stem-Spraak-Taalpathologie 2013, 18, 1–12. [Google Scholar]
- Bosman, A.J.; Smoorenburg, G.F. Woordenlijst Voor Spraakaudiometrie; CD Released under the Auspices of the Dutch Audiology Association; Dutch Audiology Association: Rotterdam, The Netherlands, 1992. [Google Scholar]
- Wouters, J.; Damman, W.; Bosman, A.J. Vlaamse opname van woordenlijsten voor spraakaudiometrie. Logopedie 1994, 7, 28–34. [Google Scholar]
- Manjula, P.; Antony, J.; Kumar, K.S.; Geetha, C. Development of Phonemically Balanced Word Lists for Adults in the Kannada Language. J. Hear. Sci. 2015, 5, 22–30. [Google Scholar]
- Schlauch, R.S.; Anderson, E.S.; Micheyl, C. A demonstration of improved precision of word recognition scores. J. Speech Lang. Hear. Res. 2014, 57, 543–555. [Google Scholar] [CrossRef] [PubMed]
- Thornton, A.R.; Raffin, M.J. Speech discrimination scores modeled as a binomial variable. J. Speech Hear. Res. 1978, 21, 507–518. [Google Scholar] [CrossRef] [PubMed]
- Gelfand, S.A. Optimizing the reliability of speech recognition scores. J. Speech Lang. Hear. Res. 1998, 41, 1088–1092. [Google Scholar] [CrossRef] [PubMed]
- Boothroyd, A.; Nittrouer, S. Mathematical treatment of context effects in phoneme and word recognition. J. Acoust. Soc. Am. 1988, 84, 101–114. [Google Scholar] [CrossRef] [PubMed]
- Bosman, A.J. Speech Perception by the Hearing Impaired. Ph.D. Thesis, Rijksuniversiteit Utrecht, Utrecht, The Netherlands, 1989. [Google Scholar]
- Hudgins, C.V.; Hawkins, J.E.; Karlin, J.E.; Stevens, S.S. The development of recorded auditory tests for measuring hearing loss for speech. Laryngoscope 1947, 57, 57–89. [Google Scholar] [CrossRef] [PubMed]
- Lyregaard, P. Chapter 2: Towards a theory of speech audiometry tests. In Speech Audiometry, 2nd ed.; Martin, M., Ed.; Whurr Publishers Ltd.: London, UK, 1997; pp. 33–62. [Google Scholar]
- Martin, F.N.; Champlin, C.A.; Perez, D.D. The question of phonetic balance in word recognition testing. J. Am. Acad. Audiol. 2000, 11, 489–493. [Google Scholar] [CrossRef] [PubMed]
- Black, J.W. Accompaniments of word intelligibility. J. Speech Hear. 1952, 17, 409–418. [Google Scholar] [CrossRef] [PubMed]
- Howes, D. On the relation between the intelligibility and frequency of occurrence of English words. J. Acoust. Soc. Am. 1957, 29, 296–305. [Google Scholar] [CrossRef]
- Brysbaert, M.; Keuleers, E.; Mandera, P.; Stevens, M. Woordenkennis van Nederlanders en Vlamingen anno 2013: Resultaten van het Groot Nationaal Onderzoek Taal; Ghent University, Dutch Organization for Scientific Research: Ghent, Belgium, 2013; Available online: http://crr.ugent.be/papers/Woordenkennis_van_Nederlanders_en_Vlamingen_anno_2013.pdf (accessed on 16 May 2021).
- Berg, T. On the Relationship between Type and Token Frequency. J. Quant. Linguist. 2014, 21, 199–222. [Google Scholar] [CrossRef]
- Fei, J.I.; Aiting, C.; Yang, Z.; Xin, X.I.; Dongyi, H. Development of a script of phonemically balanced monosyllable lists of Mandarin-Chinese. J. Otol. 2010, 5, 8–19. [Google Scholar] [CrossRef] [Green Version]
- Audacity® Software Is Copyright © 1999–2021 Audacity Team. The Name Audacity® Is a Registerd Trademark. Available online: https://www.audacityteam.org/copyright/ (accessed on 17 April 2022).
- Bosman, A.J.; Wouters, J.; Damman, W. Realisatie van een cd voor spraakaudiometrie in Vlaanderen. Logop. Foniatr. 1995, 67, 218–225. [Google Scholar]
- Coene, M.; Van der Lee, A.; Govaerts, P.J. Spoken word recognition errors in speech audiometry: A measure of hearing performance? BioMed Res. Int. 2015, 2015, 932519. [Google Scholar] [CrossRef] [PubMed] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Speech Recognition Score % | Quiet (dBSPL) | In Noise (dBSNR) | ||
|---|---|---|---|---|
| Phoneme | Word | Phoneme | Word | |
| 30 | 16.2 | 22.6 | −10.7 | −6.4 |
| 40 | 18.3 | 24.7 | −9.1 | −5.0 |
| 50 | 20.3 | 26.6 | −7.7 | −3.6 |
| 60 | 22.2 | 28.5 | −6.3 | −2.2 |
| 70 | 24.4 | 30.5 | −4.7 | −0.8 |
| 80 | 27.0 | 33.0 | −2.8 | 1.0 |
| 90 | 30.8 | 36.8 | 0.0 | 3.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vanpoucke, F.; De Sloovere, M.; Plasmans, A. The Thomas More Lists: A Phonemically Balanced Dutch Monosyllabic Speech Audiometry Test. Audiol. Res. 2022, 12, 404-413. https://doi.org/10.3390/audiolres12040041
Vanpoucke F, De Sloovere M, Plasmans A. The Thomas More Lists: A Phonemically Balanced Dutch Monosyllabic Speech Audiometry Test. Audiology Research. 2022; 12(4):404-413. https://doi.org/10.3390/audiolres12040041
Chicago/Turabian StyleVanpoucke, Filiep, Marleen De Sloovere, and Anke Plasmans. 2022. "The Thomas More Lists: A Phonemically Balanced Dutch Monosyllabic Speech Audiometry Test" Audiology Research 12, no. 4: 404-413. https://doi.org/10.3390/audiolres12040041
APA StyleVanpoucke, F., De Sloovere, M., & Plasmans, A. (2022). The Thomas More Lists: A Phonemically Balanced Dutch Monosyllabic Speech Audiometry Test. Audiology Research, 12(4), 404-413. https://doi.org/10.3390/audiolres12040041