
MonkeyPox2022Tweets: A Large-Scale Twitter Dataset on the 2022 Monkeypox Outbreak, Findings from Analysis of Tweets, and Open Research Questions


Abstract
1. Introduction
- It presents an open-access dataset of 556,427 Tweet IDs of the same number of Tweets about monkeypox that were posted on Twitter from 7 May 2022 to 9 October 2022. The dataset is available at https://doi.org/10.7910/DVN/CR7T5E. The earliest date was selected as 7 May 2022, as the first case of the 2022 monkeypox outbreak was recorded on this date. 9 October 2022 was the most recent date at the time of resubmission of this paper after the second review round. The dataset is compliant with the privacy policy, developer agreement, and guidelines for content redistribution of Twitter, as well as with the FAIR principles (Findability, Accessibility, Interoperability, and Reusability) principles for scientific data management. A comparative study is also presented that compares this dataset with 36 prior works in this field that focused on the development of Twitter datasets to further uphold the novelty, relevance, and usefulness of this dataset.
- It presents the findings from a comprehensive content analysis of these Tweets. The findings show that:
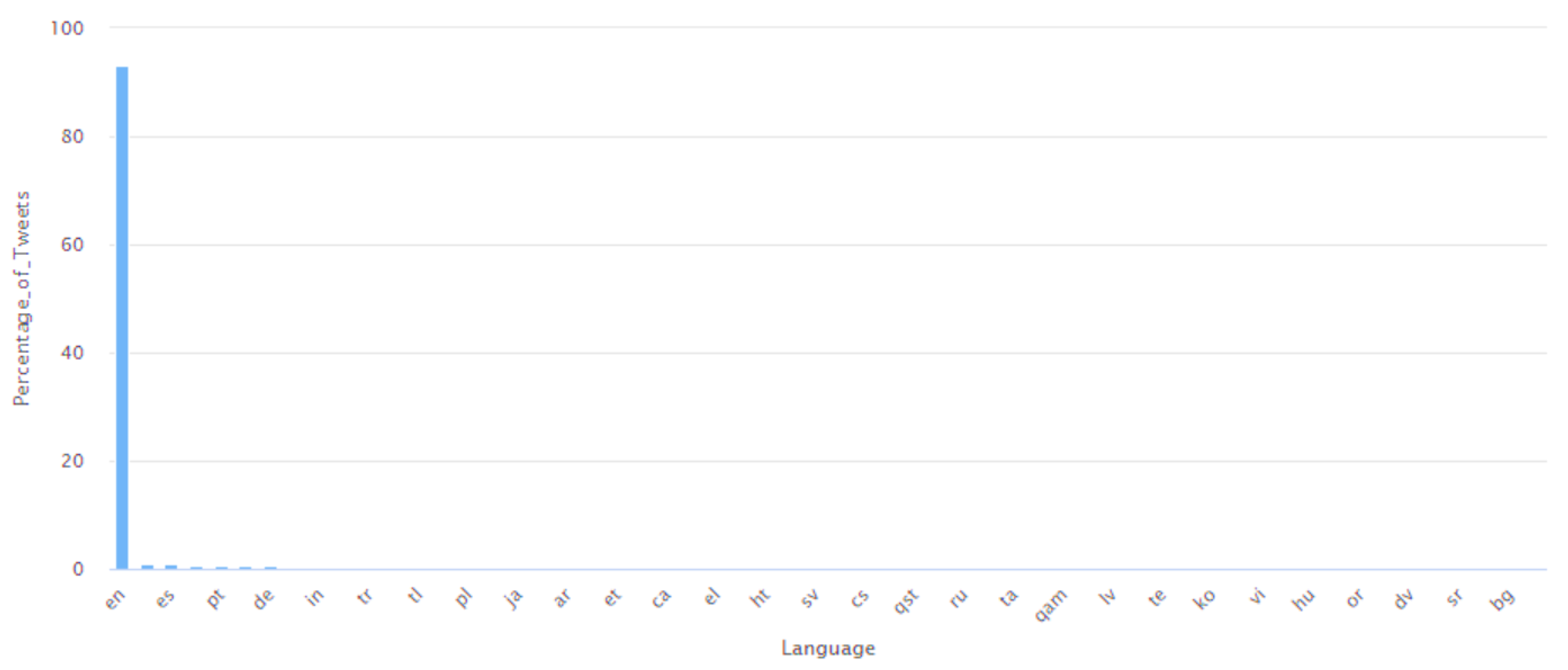
- All the 34 languages supported by the Twitter API have been used to post Tweets about the outbreak. However, English has been the most used language.
- The day WHO declared monkeypox as a GPHE, about 40,000 Tweets related to monkeypox were posted in a span of just 24 h.
- A total of 5470 distinct hashtags have been used in Tweets about this outbreak, of which #monkeypox is the most used hashtag as compared to all other variations of the spelling in terms of use of uppercase or lowercase characters, such as #MonkeyPox, #monkeyPox, #MONKEYPOX, etc.
- Twitter for iPhone has been the leading source that has been used to post Tweets about monkeypox since the first case of this outbreak. It is followed by Twitter for Android, the Twitter Web App, and other sources.
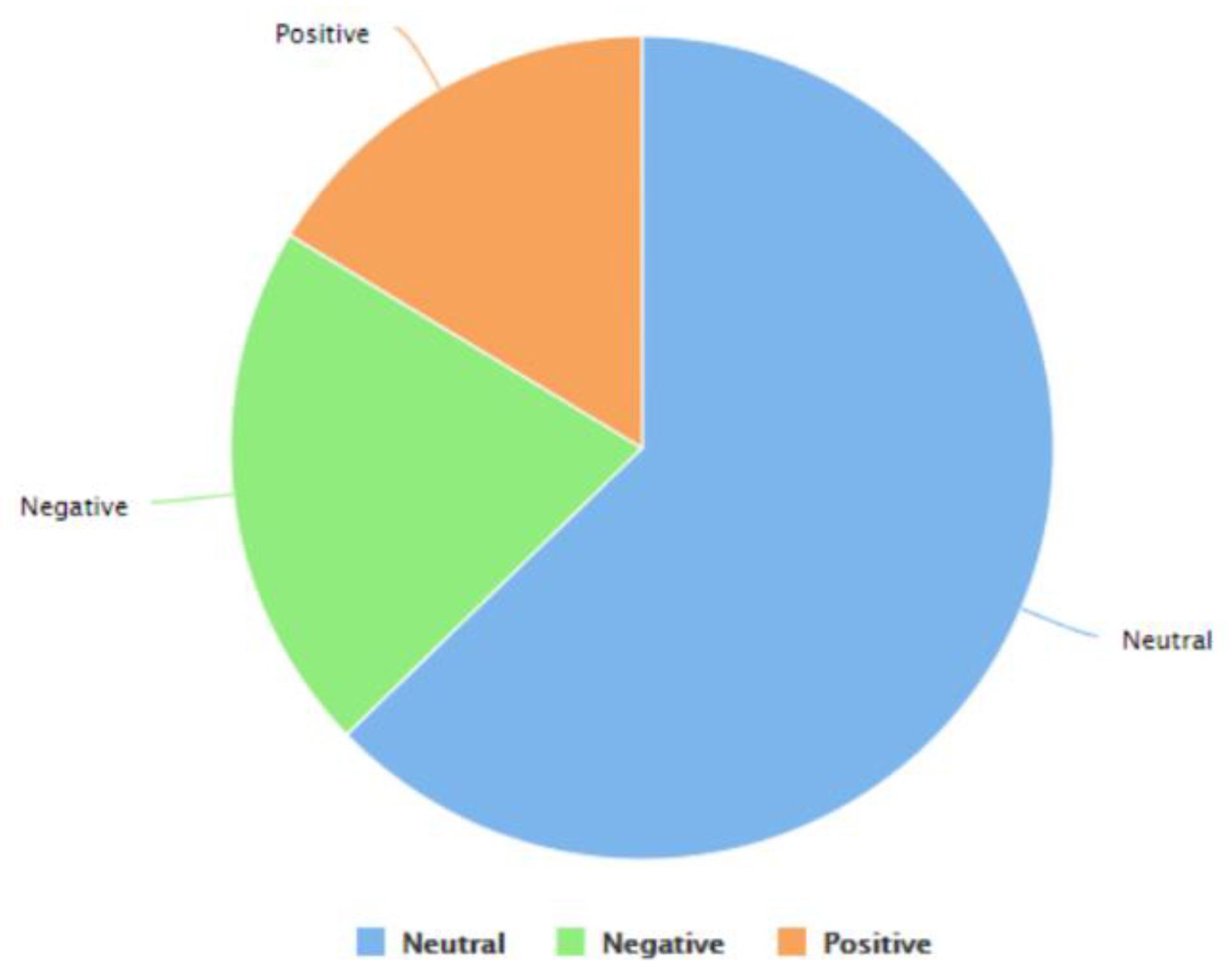
- The paper also presents the findings of sentiment analysis of the Tweets of this dataset. The findings of this study show that despite a lot of discussions, debate, opinions, information, and misinformation on Twitter on various topics in this regard, such as monkeypox and the LGBTQI+ community, monkeypox and COVID-19, vaccines for monkeypox, etc., a “neutral” sentiment is present in most of the Tweets. It is followed by “negative” and “positive” sentiments, respectively.
- Finally, to support research and development in this field, a list of 50 open research questions in the areas of Big Data, Data Mining, Machine Learning, Natural Language Processing, and Information Retrieval with a specific focus on this outbreak is presented that may be studied, analyzed, and investigated using this dataset.
2. Literature Review
2.1. Works on the Development of Twitter Datasets and Use-Cases
2.2. Works related to the 2022 Monkeypox Outbreak
2.3. Works on the Analysis of Tweets Related to Virus Outbreaks, Pandemics, and Epidemics
3. Methodology
3.1. Steps for the Development of this Dataset
3.1.1. Compliance with Twitter Policies
3.1.2. Compliance with Fair Policies for Scientific Data Management
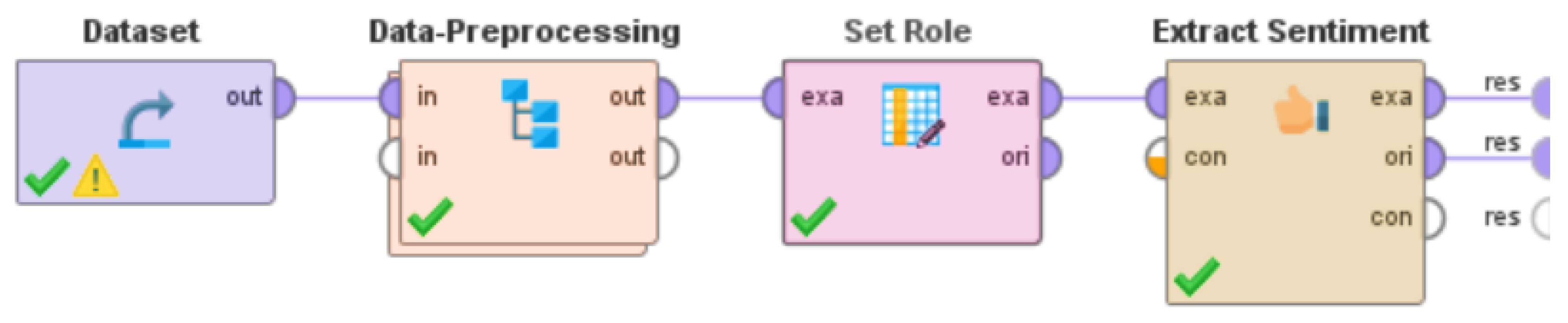
3.2. Steps for Performing Content Analysis of the Tweets of this Dataset
3.3. Steps for Performing Sentiment Analysis of the Tweets of this Dataset
4. Results and Discussions
4.1. Description of the Dataset, Usage Instructions, and Comparison with Other Twitter Datasets
4.1.1. Usage Instructions
- Installation: The desktop version of Hydrator [140] should be downloaded and installed.
- Twitter Connection: The Hydrator app should be connected to an active Twitter account. This can be performed by clicking on the “Link Twitter Account” button on the app’s interface.
- Dataset File Upload: This step involves uploading a dataset file to the Hydrator app for hydration. Only one file can be added at a time. This can be performed by clicking the “Add” button on the Hydrator app’s interface and then selecting one of the dataset files (for example, TweetIDs_Part3.txt) from the local computer. Upon successful file upload, the Hydrator app will show the exact number of Tweet IDs present in the uploaded file. In this case (for TweetIDs_Part3.txt), it will show 17,585.
- Inputting Dataset Information: This step involves providing certain information about the uploaded dataset file (such as Title, Creator, Publisher, and URL) to the Hydrator app.
- Completion of Dataset Upload: After completing Step 4, to complete the process of uploading the dataset to the app, the “Add Dataset” button on the app’s interface should be clicked.
- Start Hydration: After successful completion of Step 5, the Hydrator app will automatically redirect to the “Datasets” tab. In this tab, the “Start” button should be clicked to initiate the process of hydrating all the Tweet IDs present in the dataset file.
- Export Results: The progress indicator on the “Datasets” tab would indicate the successful completion of the hydration of all the Tweet IDs after the process has been completed. Thereafter, the Hydrator app allows the results to be saved in the form of either a. jsonl or .CSV file on the local computer.
4.1.2. Comparison with Other Twitter Datasets
4.2. Results of Content Analysis of the Tweets in this Dataset
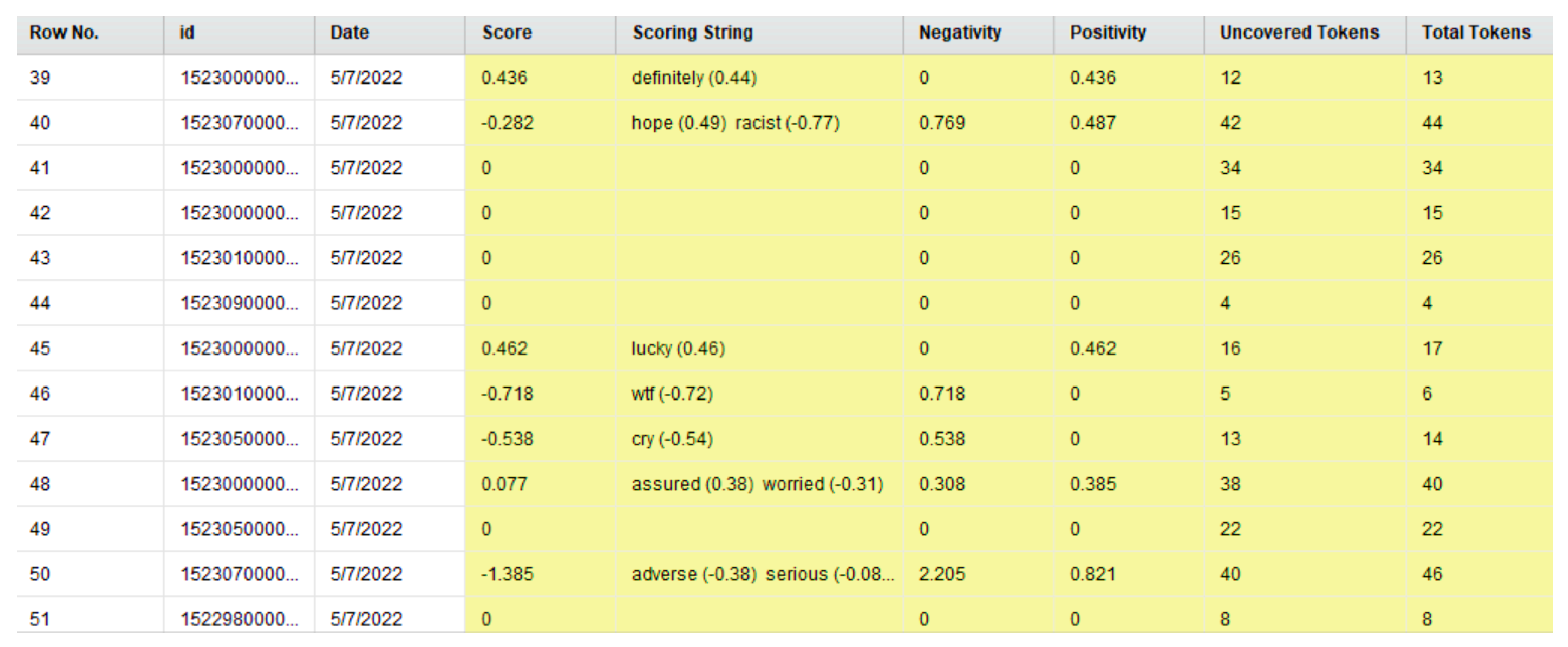
4.3. Results of Sentiment Analysis of the Tweets in This Dataset
4.4. Open Research Questions
- What is the overall sentiment (positive, negative, or neutral) of the general public related to the outbreak as expressed on Twitter?
- Are there any specific aspects or subject matters related to the outbreak (such as vaccines, treatments, and protocols to reduce the spread) that are consistently associated with a positive (or negative) sentiment on Twitter?
- Is there any correlation between the word counts of Tweets about monkeypox and the associated sentiment?
- What are some of the commonly used hashtags and trends in the same related to Tweets about the outbreak?
- Are any of the commonly used hashtags in Tweets about the outbreak associated with a specific sentiment?
- Have there been any trending discussions on Twitter related to one or more matters (such as new protocols to reduce the spread or treatments) concerning the outbreak?
- Has Twitter played a role in the development and spread of any conspiracy theories about monkeypox?
- Are any political leaders or popular personalities using Twitter to spread misinformation or fake news related to monkeypox?
- How is Twitter being used by news organizations, including regional media, local media, national media, and broadcast news agencies, in the dissemination of the latest developments related to the outbreak?
- What were the specific characteristics of the Tweets (character count, embedded URLs, date, time stamp, etc.) about monkeypox that was retweeted the most?
- Can the Tweets be analyzed to develop a machine learning classifier that would indicate the accuracy of information about monkeypox expressed in these Tweets from different sources?
- What are some of the concerns or needs, or complaints about the outbreak expressed by people on Twitter from different geographic regions?
- Is there any pattern of emoji usage in the Tweets about monkeypox since the beginning of the outbreak?
- Is there any correlation between the number of Tweets about monkeypox from a geographic region and the number of cases in the same region?
- What is the best time to Tweet (in terms of highest user engagement and impressions) about a new policy, measure, protocol, or news about monkeypox?
- Can the content of the Tweets be studied to investigate any potential online stigmatization, discrimination, and/or hate faced by any diversity group, such as the LGBTQI+ community?
- Do the Tweets reveal any form of panic behavior (such as the panic buying of certain products, as was observed during COVID-19) in regions with a high number of cases?
- Is there any feedback that individuals infected with the virus have communicated on Twitter related to the treatment they received?
- Can the Tweets be studied to infer stress or anxiety in individuals tweeting about the virus who are experiencing one or more symptoms after getting infected?
- What are some of the most popular news outlets from which news has been shared the most on Twitter in the context of the sharing and exchange of information about monkeypox?
- Can the Tweets be analyzed to develop different user personas in terms of the underlining views, opinions, and perspectives about monkeypox expressed in the Tweets?
- Can the Point of Interest (POI) of the Tweets [157] be studied to track high-level location information about a place to understand the location-specific opinions, perspectives, or attitudes of the public towards monkeypox?
- How can important Tweets [160] about monkeypox be identified and classified in real-time?
- Have verified accounts on Twitter played any role in disseminating relevant or irrelevant information [161] about monkeypox since the beginning of the outbreak?
- Can the gratification theory [164] be applied to these Tweets to deduce any factors or information about the outbreak that gratify Twitter users as expressed in their Tweets?
- Can the specific information about monkeypox expressed in the Tweets (such as medical opinion, treatment advice, etc.) be studied to determine the profession [165] of the Twitter users who posted those Tweets?
- Can the Latent Dirichlet Allocation (LDA) model [166] be used to develop an approach that can be applied to Tweets about the outbreak to deduce the credibility of information expressed in every Tweet?
- Can the Self-Exciting Point Process Model for Predicting Tweet Popularity (SEISMIC) [167] be used on this dataset of Tweets to develop an approach to predict the popularity of Tweets about monkeypox?
- How can spam accounts and bot accounts be detected that might be responsible for posting spam or incorrect information related to the outbreak?
- Is there any correlation between posting and/or retweeting research papers [168] about monkeypox and the citations of these papers?
- What are some of the most common domains (such as biorxiv.org, nature.com, science.org, etc.) that are associated with research papers on monkeypox that have been retweeted the most?
- Is there any correlation between tagging users while tweeting any new information [169] about the outbreak with the dissemination of that information?
- What is the overall stance of the general public, as expressed on Twitter, towards the recent developments related to vaccines and treatments for monkeypox?
- Can a classifier be developed to classify the Tweets into useful and useless suggestions and/or recommendations on factors or topics (such as reducing the spread of the virus) related to the outbreak?
- Can the iFACT framework [170] be applied to the Tweets to identify, assess, and evaluate the underlying factual information about monkeypox?
- What are the kinds of “events” [171] in the context of the outbreak that has been expressed in Tweets?
- Has there been any form of deception (both positive and negative deception) [172] in the context of sharing information related to the outbreak on Twitter?
- What are some of the trending topics [173] on Twitter about the outbreak?
- What are some of the “alarming” and “reassuring” information [174] about monkeypox that has been tweeted so far?
- Can a machine learning-based classifier be developed to detect instances of euphoria or delusion [175] in the context of information seeking and sharing on Twitter related to the outbreak?
- What are some of the common perceptions [176] of the public related to the recommended vaccines or treatments for monkeypox?
- Have any Twitter users posted a “regrettable” Tweet [177] about monkeypox that might cause any harm or damage to their reputation?
- Can concepts of topic extraction and sentiment analysis of Tweets be used to develop a followee recommendation model [178] for Twitter users actively involved in communicating and sharing information about the outbreak?
- What are the values of different Tweets [179] that have been posted about the outbreak so far?
- Is there any correlation between the degree of readability of Tweets [180] about the outbreak and the number of comments and/or retweets of those respective Tweets?
- What is the age group of Twitter users who have posted the most Tweets about monkeypox?
- What are some of the fake news trends on Twitter related to the outbreak?
5. Conclusions and Scope of Future Work
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- McCollum, A.M.; Damon, I.K. Human Monkeypox. Clin. Infect. Dis. 2014, 58, 260–267. [Google Scholar] [CrossRef] [PubMed]
- von Magnus, P.; Andersen, E.K.; Petersen, K.B.; Birch-Andersen, A. A Pox-like Disease in Cynomolgus Monkeys. Acta Pathol. Microbiol. Scand. 2009, 46, 156–176. [Google Scholar] [CrossRef]
- Breman, J.G.; Kalisa-Ruti; Steniowski, M.V.; Zanotto, E.; Gromyko, A.I.; Arita, I. Human Monkeypox, 1970–1979. Bull. World Health Organ. 1980, 58, 165–182. [Google Scholar] [PubMed]
- Charniga, K.; Masters, N.B.; Slayton, R.B.; Gosdin, L.; Minhaj, F.S.; Philpott, D.; Smith, D.; Gearhart, S.; Alvarado-Ramy, F.; Brown, C.; et al. Estimating the Incubation Period of Monkeypox Virus during the 2022 Multi-National Outbreak. medRxiv 2022, arXiv:2022.06.22.22276713. [Google Scholar]
- Jezek, Z.; Szczeniowski, M.; Paluku, K.M.; Mutombo, M. Human Monkeypox: Clinical Features of 282 Patients. J. Infect. Dis. 1987, 156, 293–298. [Google Scholar] [CrossRef] [PubMed]
- Perez Duque, M.; Ribeiro, S.; Martins, J.V.; Casaca, P.; Leite, P.P.; Tavares, M.; Mansinho, K.; Duque, L.M.; Fernandes, C.; Cordeiro, R.; et al. Ongoing Monkeypox Virus Outbreak, Portugal, 29 April to 23 May 2022. Euro Surveill. 2022, 27, 2200424. [Google Scholar] [CrossRef]
- Antinori, A.; Mazzotta, V.; Vita, S.; Carletti, F.; Tacconi, D.; Lapini, L.E.; D’Abramo, A.; Cicalini, S.; Lapa, D.; Pittalis, S.; et al. Epidemiological, Clinical and Virological Characteristics of Four Cases of Monkeypox Support Transmission through Sexual Contact, Italy, May 2022. Euro Surveill. 2022, 27, 2200421. [Google Scholar] [CrossRef]
- Hammerschlag, Y.; MacLeod, G.; Papadakis, G.; Adan Sanchez, A.; Druce, J.; Taiaroa, G.; Savic, I.; Mumford, J.; Roberts, J.; Caly, L.; et al. Monkeypox Infection Presenting as Genital Rash, Australia, May 2022. Euro Surveill. 2022, 27, 2200411. [Google Scholar] [CrossRef]
- Huhn, G.D.; Bauer, A.M.; Yorita, K.; Graham, M.B.; Sejvar, J.; Likos, A.; Damon, I.K.; Reynolds, M.G.; Kuehnert, M.J. Clinical Characteristics of Human Monkeypox, and Risk Factors for Severe Disease. Clin. Infect. Dis. 2005, 41, 1742–1751. [Google Scholar] [CrossRef]
- Adler, H.; Gould, S.; Hine, P.; Snell, L.B.; Wong, W.; Houlihan, C.F.; Osborne, J.C.; Rampling, T.; Beadsworth, M.B.; Duncan, C.J.; et al. Clinical Features and Management of Human Monkeypox: A Retrospective Observational Study in the UK. Lancet Infect. Dis. 2022, 22, 1153–1162. [Google Scholar] [CrossRef]
- Learned, L.A.; Reynolds, M.G.; Wassa, D.W.; Li, Y.; Olson, V.A.; Karem, K.; Stempora, L.L.; Braden, Z.H.; Kline, R.; Likos, A.; et al. Extended Interhuman Transmission of Monkeypox in a Hospital Community in the Republic of the Congo, 2003. Am. J. Trop. Med. Hyg. 2005, 73, 428–434. [Google Scholar] [CrossRef] [PubMed]
- Centers for Disease Control and Prevention (CDC) Multistate Outbreak of Monkeypox--Illinois, Indiana, and Wisconsin, 2003. MMWR Morb. Mortal. Wkly. Rep. 2003, 52, 537–540.
- Public Health England. Monkeypox Case Confirmed in England. 2019. Available online: https://www.gov.uk/government/news/monkeypox-case-confirmed-in-england (accessed on 30 July 2022).
- Erez, N.; Achdout, H.; Milrot, E.; Schwartz, Y.; Wiener-Well, Y.; Paran, N.; Politi, B.; Tamir, H.; Israely, T.; Weiss, S.; et al. Diagnosis of Imported Monkeypox, Israel, 2018. Emerg. Infect. Dis. 2019, 25, 980–983. [Google Scholar] [CrossRef] [PubMed]
- CDC. 2022 Monkeypox Outbreak Global Map. Available online: https://www.cdc.gov/poxvirus/monkeypox/response/2022/world-map.html (accessed on 22 August 2022).
- Saxena, S.K.; Ansari, S.; Maurya, V.K.; Kumar, S.; Jain, A.; Paweska, J.T.; Tripathi, A.K.; Abdel-Moneim, A.S. Re-Emerging Human Monkeypox: A Major Public-Health Debacle. J. Med. Virol. 2022, 2, 902. [Google Scholar] [CrossRef]
- Isidro, J.; Borges, V.; Pinto, M.; Ferreira, R.; Sobral, D.; Nunes, A.; Snatos, D.; Borrego, M.J.; Nuncio, S.; Pelerito, A.; et al. First Draft Genome Sequence of Monkeypox Virus Associated with the Suspected Multi-Country Outbreak, May 2022 (Confirmed Case in Portugal). Available online: https://virological.org/t/first-draft-genome-sequence-of-monkeypox-virus-associated-with-the-suspected-multi-country-outbreak-may-2022-confirmed-case-in-portugal/799 (accessed on 30 July 2022).
- Mauldin, M.R.; McCollum, A.M.; Nakazawa, Y.J.; Mandra, A.; Whitehouse, E.R.; Davidson, W.; Zhao, H.; Gao, J.; Li, Y.; Doty, J.; et al. Exportation of Monkeypox Virus from the African Continent. J. Infect. Dis. 2022, 225, 1367–1376. [Google Scholar] [CrossRef]
- Grover, N.; Rigby, J. WHO Calls Emergency Meeting as Monkeypox Cases Top 100 in Europe. Reuters 2022. [Google Scholar]
- Grover, N. Unlikely Monkeypox Outbreak Will Lead to Pandemic, WHO Says. Reuters 2022. [Google Scholar]
- Kelleher, S.R. CDC Raises Monkeypox Travel Alert to Level 2. Available online: https://www.forbes.com/sites/suzannerowankelleher/2022/06/07/cdc-raises-monkeypox-travel-alert-to-level-2/?sh=269eee1e3f93 (accessed on 30 July 2022).
- Kozlov, M. Monkeypox Declared a Global Emergency: Will It Help Contain the Outbreak? Nature 2022. [Google Scholar] [CrossRef]
- Kimball, S. Monkeypox Eradication Unlikely in the U.S. as Virus Could Spread Indefinitely, CDC Says. Available online: https://www.cnbc.com/2022/10/01/monkeypox-unlikely-to-be-eliminated-in-the-us-cdc-says.html (accessed on 22 August 2022).
- Murugesu, J.A. Monkeypox emergency. New Sci. 2022, 255, 7. [Google Scholar] [CrossRef]
- Mega, E.R. Why Scientists Fear Monkeypox Spreading in Wild Animals. Nature 2022. [Google Scholar] [CrossRef]
- CDC. Treatment Information for Healthcare Professionals. Available online: https://www.cdc.gov/poxvirus/monkeypox/clinicians/treatment.html (accessed on 30 July 2022).
- Available online: https://assets.publishing.service.gov.uk/government (accessed on 30 July 2022).
- SIGA. Receives Approval from the FDA for Intravenous (IV) Formulation of TPOXX® (Tecovirimat). Available online: https://investor.siga.com/news-releases/news-release-details/siga-receives-approval-fda-intravenous-iv-formulation-tpoxxr (accessed on 30 July 2022).
- CDC. Vaccines. Available online: https://www.cdc.gov/poxvirus/monkeypox/vaccines/index.html (accessed on 22 August 2022).
- Gilchrist, K. Belgium Becomes First Country to Introduce Mandatory Monkeypox Quarantine as Global Cases Rise. Available online: https://www.cnbc.com/2022/05/23/belgium-introduces-mandatory-monkeypox-quarantine-as-global-cases-rise.html (accessed on 30 July 2022).
- Bahl, R. Monkeypox Vaccine: U.S. Orders 500,000 Jynneos Doses as Cases Rise. Available online: https://www.healthline.com/health-news/monkeypox-vaccine-existing-vaccines-provide-strong-protection-one-fda-approved (accessed on 30 July 2022).
- MSN. Toronto to Offer Monkeypox Vaccine Clinics Targeting High-Risk Communities. Available online: https://www.msn.com/en-ca/news/canada/toronto-to-offer-monkeypox-vaccine-clinics-targeting-high-risk-communities/ar-AAYlYhH (accessed on 30 July 2022).
- With, A.M. Push for Targeted Monkeypox Vaccine Rollout in France, Denmark. Available online: https://www.rfi.fr/en/europe/20220525-push-for-targeted-monkeypox-vaccine-rollout-in-france-denmark (accessed on 30 July 2022).
- Monkeypox: German Panel Recommends Vaccine for Risk Groups. Available online: https://www.dw.com/en/monkeypox-german-panel-recommends-vaccine-for-risk-groups/a-62084728 (accessed on 30 July 2022).
- UK Health Authority Advises Self-Isolation for Monkeypox Infections. Available online: https://www.thesundaily.my/world/uk-health-authority-advises-self-isolation-for-monkeypox-infections-NE9314681 (accessed on 30 July 2022).
- da Costa, V.C.F.; Oliveira, L.; de Souza, J. Internet of Everything (IoE) Taxonomies: A Survey and a Novel Knowledge-Based Taxonomy. Sensors 2021, 21, 568. [Google Scholar] [CrossRef] [PubMed]
- Perrin, A.; Smith, A.; Duggan, M.; Greenwood, S.; Porteus, M.; Page, D. Social Media Usage. Available online: https://www.secretintelligenceservice.org/wp-content/uploads/2016/02/PI_2015-10-08_Social-Networking-Usage-2005-2015_FINAL.pdf (accessed on 30 July 2022).
- Noor Al-Deen, H.S.; Hendricks, J.A. Social Media: Usage and Impact; Lexington Books: Laham, MD, USA, 2011; ISBN 9780739167304. [Google Scholar]
- Kavada, A. Social Media as Conversation: A Manifesto. Soc. Media Soc. 2015, 1, 205630511558079. [Google Scholar] [CrossRef]
- Smith, A.; Brenner, J. Twitter Use 2012. Available online: https://www.pewinternet.org/wp-content/uploads/sites/9/media/Files/Reports/2012/PIP_Twitter_Use_2012.pdf (accessed on 30 July 2022).
- Morgan-Lopez, A.A.; Kim, A.E.; Chew, R.F.; Ruddle, P. Predicting Age Groups of Twitter Users Based on Language and Metadata Features. PLoS ONE 2017, 12, e0183537. [Google Scholar] [CrossRef] [PubMed]
- Iqbal, M. Twitter Revenue and Usage Statistics. 2022. Available online: https://www.businessofapps.com/data/twitter-statistics (accessed on 30 July 2022).
- Ring, T. Twitter Adds Link for Accurate Info on Monkeypox. Available online: https://www.advocate.com/health/2022/8/16/twitter-adds-link-accurate-info-monkeypox (accessed on 22 August 2022).
- Cao, S. Medical Experts Are Becoming Influencers amid All the Anxiety over Monkeypox. Available online: https://www.buzzfeednews.com/article/stefficao/monkeypox-influencers-medical-expert-hysteria (accessed on 22 August 2022).
- Wiggins, C. Rep. Marjorie Taylor Greene Tweets Monkeypox Disinformation. Available online: https://www.advocate.com/news/2022/7/25/rep-marjorie-taylor-greene-tweets-monkeypox-disinformation (accessed on 22 August 2022).
- McGee, K. UT-Dallas Is Investigating a Professor’s Homophobic Tweet with Misinformation about Monkeypox. The Texas Tribune 2022. Available online: https://www.texastribune.org/2022/07/20/ut-dallas-monkeypox-lgbtq/ (accessed on 22 August 2022).
- Niemietz, B. Prominent Medical Writer’s Typo Warns Sex with ‘Me’ Can Lead to Monkeypox. Daily News. 2022. Available online: https://www.nydailynews.com/news/national/ny-medical-writer-benjamin-ryan-monkeypox-20220721-lyzp26f7obhgtc2nnplvxiumtm-story.html (accessed on 22 August 2022).
- Mulki, H.; Haddad, H.; Bechikh Ali, C.; Alshabani, H. L-HSAB: A Levantine Twitter Dataset for Hate Speech and Abusive Language. In Proceedings of the Third Workshop on Abusive Language Online, Florence, Italy, 1 August 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 111–118. [Google Scholar]
- Urchs, S.; Wendlinger, L.; Mitrovic, J.; Granitzer, M. MMoveT15: A Twitter Dataset for Extracting and Analysing Migration-Movement Data of the European Migration Crisis 2015. In Proceedings of the 2019 IEEE 28th International Conference on Enabling Technologies: Infrastructure for Collaborative Enterprises (WETICE), Napoli, Italy, 12–14 June 2019; pp. 146–149. [Google Scholar]
- Meng, L.; Dong, Z.S. Natural Hazards Twitter Dataset. arXiv 2020, arXiv:2004.14456. [Google Scholar]
- Mulki, H.; Ghanem, B. Let-Mi: An Arabic Levantine Twitter Dataset for Misogynistic Language. arXiv 2021, arXiv:2103.10195. [Google Scholar]
- Manolescu, M.; University of Tübingen, Germany; Çöltekin, Ç. ROFF—A Romanian Twitter Dataset for Offensive Language. In Proceedings of the Conference Recent Advances in Natural Language Processing—Deep Learning for Natural Language Processing Methods and Applications, Varna, Bulgaria, 1–3 September 2021. [Google Scholar]
- Sech, J.; DeLucia, A.; Buczak, A.L.; Dredze, M. Civil Unrest on Twitter (CUT): A Dataset of Tweets to Support Research on Civil Unrest. In Proceedings of the Sixth Workshop on Noisy User-Generated Text (W-NUT 2020), https://aclanthology.org/volumes/2020.wnut-1/, Online, 19 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 215–221. [Google Scholar]
- Thakur, N. Twitter Big Data as a Resource for Exoskeleton Research: A Large-Scale Dataset of about 140,000 Tweets from 2017–2022 and 100 Research Questions. Analytics 2022, 1, 72–97. [Google Scholar] [CrossRef]
- Mutlu, E.C.; Oghaz, T.; Jasser, J.; Tutunculer, E.; Rajabi, A.; Tayebi, A.; Ozmen, O.; Garibay, I. A Stance Data Set on Polarized Conversations on Twitter about the Efficacy of Hydroxychloroquine as a Treatment for COVID-19. Data Brief 2020, 33, 106401. [Google Scholar] [CrossRef]
- Klein, A.Z.; Gonzalez-Hernandez, G. An Annotated Data Set for Identifying Women Reporting Adverse Pregnancy Outcomes on Twitter. Data Brief 2020, 32, 106249. [Google Scholar] [CrossRef]
- Sarker, A.; Gonzalez, G. A Corpus for Mining Drug-Related Knowledge from Twitter Chatter: Language Models and Their Utilities. Data Brief 2017, 10, 122–131. [Google Scholar] [CrossRef]
- Riccosan; Saputra, K.E.; Pratama, G.D.; Chowanda, A. Emotion Dataset from Indonesian Public Opinion. Data Brief 2022, 43, 108465. [Google Scholar] [CrossRef]
- Grace, R. Crisis Social Media Data Labeled for Storm-Related Information and Toponym Usage. Data Brief 2020, 30, 105595. [Google Scholar] [CrossRef] [PubMed]
- Thakur, N. A Large-Scale Dataset of Twitter Chatter about Online Learning during the Current COVID-19 Omicron Wave. Data 2022, 7, 109. [Google Scholar] [CrossRef]
- Gaikwad, M.; Ahirrao, S.; Phansalkar, S.; Kotecha, K. Multi-Ideology ISIS/Jihadist White Supremacist (MIWS) Dataset for Multi-Class Extremism Text Classification. Data 2021, 6, 117. [Google Scholar] [CrossRef]
- Putra, O.V.; Wasmanson, F.M.; Harmini, T.; Utama, S.N. Sundanese Twitter Dataset for Emotion Classification. In Proceedings of the 2020 International Conference on Computer Engineering, Network, and Intelligent Multimedia (CENIM), Surabaya, Indonesia, 17–18 November 2020. [Google Scholar]
- Averza, A.A. Twitter Dataset—Over 200,000 Tweets Containing the Word “Vaccine” for Research Porpuses. 2022. Available online: https://ieee-dataport.org/documents/twitter-dataset-over-200000-tweets-containing-word-vaccine-research-porpuses (accessed on 22 August 2022).
- Pranesh, R.R.; Kumar, S.; Shekhar, A. TweetBLM: A Hate Speech Dataset and Analysis of BlackLivesMatter-Related Microblogs on Twitter. 2020. Available online: https://zenodo.org/record/4000539#.Y0W3F3bMLEY.
- Thakur, N.; Han, C.Y. An Exploratory Study of Tweets about the SARS-CoV-2 Omicron Variant: Insights from Sentiment Analysis, Language Interpretation, Source Tracking, Type Classification, and Embedded URL Detection. COVID 2022, 2, 76. [Google Scholar] [CrossRef]
- RESILTECH s.r.l. Dataset of Tweets, Used to Detect Hazardous Events at the Baths of Diocletian Site in Rome. 2019. Available online: https://zenodo.org/record/3258416#.Y0W4anbMLEY.
- Jules, B. BestofThrowBackBlackTwitter. 2019. Available online: https://zenodo.org/record/4976950#.Y0W6SXbMLEY.
- Kora, R.; Mohammed, A. Corpus on Arabic Egyptian Tweets. 2019. Available online: https://doi.org/10.7910/DVN/LBXV9O. [CrossRef]
- Garain, A. COVID-19 Tweets Dataset for Spanish Language. 2020. Available online: https://ieee-dataport.org/open-access/covid-19-tweets-dataset-spanish-language (accessed on 22 August 2022).
- Garain, A. COVID-19 Tweets Dataset for Bengali Language. 2020. Available online: https://ieee-dataport.org/open-access/covid-19-tweets-dataset-bengali-language (accessed on 22 August 2022).
- Garain, A. English Language Tweets Dataset for COVID-19. 2020. Available online: https://ieee-dataport.org/open-access/english-language-tweets-dataset-covid-19 (accessed on 22 August 2022).
- Nawwar, A. #IndonesiaHumanRightsSOS Twitter Hashtag Tweets Dataset. 2020. Available online: https://zenodo.org/record/4362505#.Y0W1XnbMLEY.
- Jules, B. Dataset of Tweets with #Blackwomanhood. 2018. Available online: https://zenodo.org/record/4944545#.Y0W4yXbMLEY.
- Jules, B. Dataset of Tweets with #MarchForBlackWomen. 2017. Available online: https://zenodo.org/record/5018193#.Y0W5TXbMLEY.
- Jules, B. Dataset of Tweets with #BlackTheory. 2017. Available online: https://zenodo.org/record/4950437#.Y0W7SHbMLEY.
- Jules, B. Dataset of Tweets with #DuragFest. 2018. Available online: https://zenodo.org/record/4938042#.Y0W7SnbMLEY.
- Jules, B. Dataset of Tweets with #BringBackOurInternet. 2017. Available online: https://zenodo.org/record/4973415#.Y0W70nbMLEY.
- Jules, B. Dataset of Tweets with #WOCAffirmation. 2017. Available online: https://zenodo.org/record/4993283#.Y0W8t3bMLEY.
- Jules, B. Dataset of Tweets with #AskTimothy. 2018. Available online: https://zenodo.org/record/4958263#.Y0W-zHbMLEY.
- Wrubel, Laura (George Washington University) WITBragDay Tweet Ids. 2017. Available online: https://doi.org/10.7910/DVN/IRNS5Z. [CrossRef]
- Maria, A. Dataset of Tweets with #preuambicio 2021/03/04 to 2021/05/21. 2021. Available online: https://doi.org/10.7910/DVN/DVXTCX. [CrossRef]
- Maria, A. Dataset of Tweets with #MiPrimerRecuerdoFeminista 2020.03.06–2020.03.11. 2020. Available online: https://doi.org/10.7910/DVN/3GAZGD. [CrossRef]
- Jules, B. Dataset of Tweets with the phrase—“I Voted For Trump”. 2017. Available online: https://zenodo.org/record/4940956#.Y0W9eHbMLEY.
- Weissenbacher, D.; Sarker, A.; Klein, A.; O’Connor, K.; Magge, A.; Gonzalez-Hernandez, G. Deep Neural Networks Ensemble for Detecting Medication Mentions in Tweets. J. Am. Med. Inform. Assoc. 2019, 26, 1618–1626. [Google Scholar] [CrossRef]
- Sarker, A.; Gonzalez-Hernandez, G.; Ruan, Y.; Perrone, J. Machine Learning and Natural Language Processing for Geolocation-Centric Monitoring and Characterization of Opioid-Related Social Media Chatter. JAMA Netw. Open 2019, 2, e1914672. [Google Scholar] [CrossRef]
- Klein, A.Z.; Sarker, A.; Cai, H.; Weissenbacher, D.; Gonzalez-Hernandez, G. Social Media Mining for Birth Defects Research: A Rule-Based, Bootstrapping Approach to Collecting Data for Rare Health-Related Events on Twitter. J. Biomed. Inform. 2018, 87, 68–78. [Google Scholar] [CrossRef]
- Al-Garadi, M.A.; Yang, Y.-C.; Cai, H.; Ruan, Y.; O’Connor, K.; Graciela, G.-H.; Perrone, J.; Sarker, A. Text Classification Models for the Automatic Detection of Nonmedical Prescription Medication Use from Social Media. BMC Med. Inform. Decis. Mak. 2021, 21, 27. [Google Scholar] [CrossRef]
- Al-Garadi, M.A.; Yang, Y.-C.; Lakamana, S.; Lin, J.; Li, S.; Xie, A.; Hogg-Bremer, W.; Torres, M.; Banerjee, I.; Sarker, A. Automatic Breast Cancer Cohort Detection from Social Media for Studying Factors Affecting Patient-Centered Outcomes. In Artificial Intelligence in Medicine; Springer International Publishing: Cham, Germany, 2020; pp. 100–110. ISBN 9783030591366. [Google Scholar]
- Tekumalla, R.; Banda, J.M. Using Weak Supervision to Generate Training Datasets from Social Media Data: A Proof of Concept to Identify Drug Mentions. Neural Comput. Appl. 2021, 1–9. [Google Scholar] [CrossRef]
- Farooq, H.; Naveed, H. GPADRlex: Grouped Phrasal Adverse Drug Reaction Lexicon. In Proceedings of the 2019 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Dalian, China, 20–23 September 2019. [Google Scholar]
- Glandt, K.; Khanal, S.; Li, Y.; Caragea, D.; Caragea, C. Stance Detection in COVID-19 Tweets. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 1596–1611. [Google Scholar]
- Kumari, R.; Ashok, N.; Ghosal, T.; Ekbal, A. Misinformation Detection Using Multitask Learning with Mutual Learning for Novelty Detection and Emotion Recognition. Inf. Process. Manag. 2021, 58, 102631. [Google Scholar] [CrossRef]
- Kumari, R.; Ashok, N.; Ghosal, T.; Ekbal, A. A Multitask Learning Approach for Fake News Detection: Novelty, Emotion, and Sentiment Lend a Helping Hand. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzen, China, 18–22 September 2021; pp. 1–8. [Google Scholar]
- Hua, Y.; Jiang, H.; Lin, S.; Yang, J.; Plasek, J.M.; Bates, D.W.; Zhou, L. Using Twitter Data to Understand Public Perceptions of Approved versus Off-Label Use for COVID-19-Related Medications. J. Am. Med. Inform. Assoc. 2022, 29, 1668–1678. [Google Scholar] [CrossRef] [PubMed]
- Do, T.T.; Nguyen, D.; Le, A.; Nguyen, A.; Nguyen, D.; Hoang, N.; Le, U.; Tran, T. Understanding Public Opinion on Using Hydroxychloroquine for COVID-19 Treatment via Social Media. arXiv 2022, arXiv:2201.00237. [Google Scholar]
- Ceslov, R. Detecting Stance on COVID-19 Vaccine in a Polarized Media. 2021. Available online: https://academicworks.cuny.edu/gc_etds/4616/ (accessed on 22 August 2022).
- Miura, F.; van Ewijk, C.E.; Backer, J.A.; Xiridou, M.; Franz, E.; Op de Coul, E.; Brandwagt, D.; van Cleef, B.; van Rijckevorsel, G.; Swaan, C.; et al. Estimated Incubation Period for Monkeypox Cases Confirmed in the Netherlands, May 2022. Euro Surveill. 2022, 27, 2200448. [Google Scholar] [CrossRef] [PubMed]
- Bragazzi, N.L.; Khamisy-Farah, R.; Tsigalou, C.; Mahroum, N.; Converti, M. Attaching a Stigma to the LGBTQI+ Community Should Be Avoided during the Monkeypox Epidemic. J. Med. Virol. 2022. [Google Scholar] [CrossRef]
- Dashraath, P.; Nielsen-Saines, K.; Mattar, C.; Musso, D.; Tambyah, P.; Baud, D. Guidelines for Pregnant Individuals with Monkeypox Virus Exposure. Lancet 2022, 400, 21–22. [Google Scholar] [CrossRef]
- Kampf, G. Efficacy of Biocidal Agents and Disinfectants against the Monkeypox Virus and Other Orthopoxviruses. J. Hosp. Infect. 2022, 127, 101–110. [Google Scholar] [CrossRef]
- Nörz, D.; Pfefferle, S.; Brehm, T.T.; Franke, G.; Grewe, I.; Knobling, B.; Aepfelbacher, M.; Huber, S.; Klupp, E.M.; Jordan, S.; et al. Evidence of Surface Contamination in Hospital Rooms Occupied by Patients Infected with Monkeypox, Germany, June 2022. Euro Surveill. 2022, 27, 2200477. [Google Scholar] [CrossRef]
- Abbas, S.; Karam, S.; Schmidt-Sane, M.; Palmer, J. Social Considerations for Monkeypox Response; Institute of Development Studies: Brighton, UK, 2022. [Google Scholar]
- Mungmunpuntipantip, R.; Wiwanitkit, V. Diarrhea and Monkeypox: A Consideration. Rev. Esp. Enferm. Dig. 2022, in press. [Google Scholar] [CrossRef]
- Sallam, M.; Al-Mahzoum, K.; Dardas, L.A.; Al-Tammemi, A.B.; Al-Majali, L.; Al-Naimat, H.; Jardaneh, L.; AlHadidi, F.; Al-Salahat, K.; Al-Ajlouni, E.; et al. Knowledge of Human Monkeypox and Its Relation to Conspiracy Beliefs among Students in Jordanian Health Schools: Filling the Knowledge Gap on Emerging Zoonotic Viruses. Medicina 2022, 58, 924. [Google Scholar] [CrossRef]
- Md, A.P.; Ahsan, M.; Ramiz Uddin, M.; Luna, S.A. Monkeypox Image Data Collection. arXiv 2022, arXiv:2206.01774. [Google Scholar]
- Malik, A.A.; Winters, M.S.; Omer, S.B. Attitudes of the US General Public towards Monkeypox. bioRxiv 2022, arXiv:2022.06.20.22276527. [Google Scholar]
- Sypsa, V.; Mameletzis, I.; Tsiodras, S. Transmission Potential of Human Monkeypox in Mass Gatherings. bioRxiv 2022, arXiv:2022.06.21.22276684. [Google Scholar] [CrossRef] [PubMed]
- Kim, E.H.-J.; Jeong, Y.K.; Kim, Y.; Kang, K.Y.; Song, M. Topic-Based Content and Sentiment Analysis of Ebola Virus on Twitter and in the News. J. Inf. Sci. 2016, 42, 763–781. [Google Scholar] [CrossRef]
- Odlum, M.; Yoon, S. What Can We Learn about the Ebola Outbreak from Tweets? Am. J. Infect. Contro. 2015, 43, 563–571. [Google Scholar] [CrossRef]
- Su, C.-J.; Yon, J.A.Q. Sentiment Analysis and Information Diffusion on Social Media: The Case of the Zika Virus. Int. J. Inf. Educ. Technol. 2018, 8, 685–692. [Google Scholar] [CrossRef][Green Version]
- Barata, G.; Shores, K.; Alperin, J.P. Local Chatter or International Buzz? Language Differences on Posts about Zika Research on Twitter and Facebook. PLoS ONE 2018, 13, e0190482. [Google Scholar] [CrossRef]
- Yang, J.-A.J. Spatial-Temporal Analysis of Information Diffusion Patterns with User-Generated Geo-Social Contents from Social Media. 2017. Available online: https://www.proquest.com/openview/34ee11be7a87469d16f0ae25d1bc99aa/ (accessed on 22 August 2022).
- Alessa, A.; Faezipour, M. Tweet Classification Using Sentiment Analysis Features and TF-IDF Weighting for Improved Flu Trend Detection. In Machine Learning and Data Mining in Pattern Recognition; Springer International Publishing: Cham, Switzerland, 2018; pp. 174–186. ISBN 9783319961354. [Google Scholar]
- Hellsten, I.; Jacobs, S.; Wonneberger, A. Active and Passive Stakeholders in Issue Arenas: A Communication Network Approach to the Bird Flu Debate on Twitter. Public Relat. Rev. 2019, 45, 35–48. [Google Scholar] [CrossRef]
- Kaushik, N.; Bhatia, M.K. Twitter Sentiment Analysis Using K-Means and Hierarchical Clustering on COVID Pandemic. In Advances in Intelligent Systems and Computing; Springer Singapore: Singapore, 2022; pp. 757–769. ISBN 9789811625930. [Google Scholar]
- Jain, R.; Bawa, S.; Sharma, S. Sentiment Analysis of COVID-19 Tweets by Machine Learning and Deep Learning Classifiers. In Advances in Data and Information Sciences; Springer Singapore: Singapore, 2022; pp. 329–339. ISBN 9789811656880. [Google Scholar]
- Marcec, R.; Likic, R. Using Twitter for Sentiment Analysis towards AstraZeneca/Oxford, Pfizer/BioNTech and Moderna COVID-19 Vaccines. Postgrad. Med. J. 2022, 98, 544–550. [Google Scholar] [CrossRef]
- Bokaee Nezhad, Z.; Deihimi, M.A. Twitter Sentiment Analysis from Iran about COVID 19 Vaccine. Diabetes Metab. Syndr. 2022, 16, 102367. [Google Scholar] [CrossRef]
- Agustiningsih, K.K.; Utami, E.; Alsyaibani, M.A. Sentiment Analysis of COVID-19 Vaccines in Indonesia on Twitter Using Pre-Trained and Self-Training Word Embeddings. J. Ilmu Komput. Dan Inf. 2022, 15, 39–46. [Google Scholar] [CrossRef]
- Ponmani, K.; Thangaraj, M. Clustering Based Sentiment Analysis on Twitter Data for COVID-19 Vaccines in India. Int. J. Health Sci. 2022, 4732–4748. [Google Scholar] [CrossRef]
- Parameshwar Hegde, N.; Vikkurty, S.; Kandukuri, G.; Musunuru, S.; Hegde, G.P. Employee Sentiment Analysis towards Remote Work during COVID-19 Using Twitter Data. Int. J. Intell. Eng. Syst. 2022, 15, 75–84. [Google Scholar] [CrossRef]
- Waheeb, S.A.; Khan, N.A.; Shang, X. Topic Modeling and Sentiment Analysis of Online Education in the COVID-19 Era Using Social Networks Based Datasets. Electronics 2022, 11, 715. [Google Scholar] [CrossRef]
- Jyothsna; Rohini; Paulose, J. Sentiment Analysis on COVID-19 Related Social Distancing across the Globe Using Twitter Data. ECS Trans. 2022, 107, 3995–4001. [Google Scholar] [CrossRef]
- Bahekar, K.B.; Gautam, P.; Sharma, S. Sentiment Analysis on Wearing Mask during COVID-19 Pandemic in India: A Case Study on Twitter. ECS Trans. 2022, 107, 7165–7178. [Google Scholar] [CrossRef]
- Hikmah, K.; Fauzan, A.C.; Harliana, H. Sentiment Analysis of Vaccine Booster during Covid-19: Indonesian Netizen Perspective Based on Twitter Dataset. J. Teknol. Komput. Dan Sist. Inf. 2022, 5, 102–106. [Google Scholar] [CrossRef]
- Standard Search API. Available online: https://developer.twitter.com/en/docs/twitter-api/v1/tweets/search/api-reference/get-search-tweets (accessed on 31 July 2022).
- How to Use Advanced Search. Available online: https://help.twitter.com/en/using-twitter/twitter-advanced-search (accessed on 22 August 2022).
- Mierswa, I.; Wurst, M.; Klinkenberg, R.; Scholz, M.; Euler, T. YALE: Rapid Prototyping for Complex Data Mining Tasks. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD ’06, Philadelphia, PA, USA, 20–23 August 2006; ACM Press: New York, NY, USA, 2006. [Google Scholar]
- RapidMiner GmbH Search Twitter. RapidMiner Documentation. Available online: https://docs.rapidminer.com/latest/studio/operators/data_access/applications/twitter/search_twitter.html (accessed on 31 July 2022).
- Privacy Policy. Available online: https://twitter.com/en/privacy/previous/version_15 (accessed on 31 July 2022).
- Developer Agreement and Policy. Available online: https://developer.twitter.com/en/developer-terms/agreement-and-policy (accessed on 31 July 2022).
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for Scientific Data Management and Stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef]
- Hutto, C.; Gilbert, E. VADER: A Parsimonious Rule-Based Model for Sentiment Analysis of Social Media Text. ICWSM 2014, 8, 216–225. [Google Scholar] [CrossRef]
- Woeginger, G.J. Space and Time Complexity of Exact Algorithms: Some Open Problems. In Parameterized and Exact Computation; Springer: Berlin/Heidelberg, Germany, 2004; pp. 281–290. ISBN 9783540230717. [Google Scholar]
- Thakur, N. MonkeyPox2022Tweets: A Large-Scale Twitter Dataset on the 2022 MonkeyPox Out-break, Findings from Analysis of Tweets, and Open Research Questions, version 1. 2022. Available online: https://zenodo.org/record/6635559#.Y0X_J3bMLEY.
- Thakur, N. MonkeyPox2022Tweets: The First Public Twitter Dataset on the 2022 MonkeyPox Outbreak. Preprints 2022. [Google Scholar]
- Hydrator: Turn Tweet IDs into Twitter JSON & CSV from Your Desktop. Available online: https://github.com/DocNow/hydrator (accessed on 31 July 2022).
- Tekumalla, R.; Banda, J.M. Social Media Mining Toolkit (SMMT). Genomics Inform. 2020, 18, e16. [Google Scholar] [CrossRef]
- Twarc: A Command Line Tool (and Python Library) for Archiving Twitter JSON. Available online: https://github.com/DocNow/twarc (accessed on 31 July 2022).
- Hydrator. Available online: https://github.com/DocNow/hydrator/releases (accessed on 31 July 2022).
- Warren, E. Strengthening Research through Data Sharing. N. Engl. J. Med. 2016, 375, 401–403. [Google Scholar] [CrossRef]
- Fecher, B.; Friesike, S.; Hebing, M. What Drives Academic Data Sharing? PLoS ONE 2015, 10, e0118053. [Google Scholar] [CrossRef] [PubMed]
- Logan, J.A.R.; Hart, S.A.; Schatschneider, C. Data Sharing in Education Science. AERA Open 2021, 7, 233285842110064. [Google Scholar] [CrossRef]
- Thakur, N. MonkeyPox2022Tweets: MonkeyPox2022Tweets: A Large-Scale Twitter Dataset on the 2022 MonkeyPox Outbreak, Findings from Analysis of Tweets, and Open Research Questions, version 3. Available online: https://zenodo.org/record/6898178#.Y0YgcnbMLEY.
- Supported Languages and Browsers. Available online: https://developer.twitter.com/en/docs/twitter-for-websites/supported-languages (accessed on 31 July 2022).
- Twitter for IOS. Available online: https://apps.apple.com/us/app/twitter/id333903271 (accessed on 31 July 2022).
- Twitter for Android. Available online: https://play.google.com/store/apps/details?id=com.twitter.android&hl=en_US&gl=US (accessed on 31 July 2022).
- Twitter Website. Available online: https://twitter.com/home (accessed on 31 July 2022).
- TweetDeck Website. Available online: https://tweetdeck.twitter.com/ (accessed on 22 August 2022).
- He, L.; He, C.; Reynolds, T.L.; Bai, Q.; Huang, Y.; Li, C.; Zheng, K.; Chen, Y. Why Do People Oppose Mask Wearing? A Comprehensive Analysis of U.S. Tweets during the COVID-19 Pandemic. J. Am. Med. Inform. Assoc. 2021, 28, 1564–1573. [Google Scholar] [CrossRef] [PubMed]
- Al-Ramahi, M.; Elnoshokaty, A.; El-Gayar, O.; Nasralah, T.; Wahbeh, A. Public Discourse against Masks in the COVID-19 Era: Infodemiology Study of Twitter Data. JMIR Public Health Surveill. 2021, 7, e26780. [Google Scholar] [CrossRef] [PubMed]
- Nagel, A.C.; Tsou, M.-H.; Spitzberg, B.H.; An, L.; Gawron, J.M.; Gupta, D.K.; Yang, J.-A.; Han, S.; Peddecord, K.M.; Lindsay, S.; et al. The Complex Relationship of Realspace Events and Messages in Cyberspace: Case Study of Influenza and Pertussis Using Tweets. J. Med. Internet Res. 2013, 15, e237. [Google Scholar] [CrossRef]
- Zhang, K.; Song, W.; Liu, L.; Zhao, X.; Du, C. Bidirectional Long Short-Term Memory for Sentiment Analysis of Chinese Product Reviews. In Proceedings of the 2019 IEEE 9th International Conference on Electronics Information and Emergency Communication (ICEIEC), Beijing, China, 12–14 July 2019; pp. 1–4. [Google Scholar]
- Deepa, M.D.; Al, E. Bidirectional Encoder Representations from Transformers (BERT) Language Model for Sentiment Analysis Task: Review. Turk. J. Comput. Math. Educ. 2021, 12, 1708–1721. [Google Scholar] [CrossRef]
- Li, T.; Gu, J.-C.; Zhu, X.; Liu, Q.; Ling, Z.-H.; Su, Z.; Wei, S. DialBERT: A Hierarchical Pre-Trained Model for Conversation Disentanglement. arXiv 2020, arXiv:2004.03760. [Google Scholar]
- Kotsiantis, S.B.; Zaharakis, I.D.; Pintelas, P.E. Machine Learning: A Review of Classification and Combining Techniques. Artif. Intell. Rev. 2006, 26, 159–190. [Google Scholar] [CrossRef]
- Li, W.; Serdyukov, P.; de Vries, A.P.; Eickhoff, C.; Larson, M. The Where in the Tweet. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management—CIKM ’11, Glasgow, UK, 24–28 October 2011; ACM Press: New York, NY, USA, 2011. [Google Scholar]
- Liu, I.L.B.; Cheung, C.M.K.; Lee, M.K.O. Understanding Twitter Usage: What Drive People Continue to Tweet. In Proceedings of the PACIS 2010—14th Pacific Asia Conference on Information Systems, Taipei, Taiwan, 9–12 July 2010; pp. 928–939. [Google Scholar]
- Cheng, Z.; Caverlee, J.; Lee, K. You Are Where You Tweet: A Content-Based Approach to Geo-Locating Twitter Users. In Proceedings of the 19th ACM international conference on Information and knowledge management—CIKM ’10, Toronto, ON, Canada, 26–30 October 2010; ACM Press: New York, NY, USA, 2010. [Google Scholar]
- Uysal, I.; Croft, W.B. User Oriented Tweet Ranking: A Filtering Approach to Microblogs. In Proceedings of the 20th ACM international conference on Information and knowledge management—CIKM ’11, Glasgow, UK, 24–28 October 2011; ACM Press: New York, NY, USA, 2011. [Google Scholar]
- Tao, K.; Abel, F.; Hauff, C.; Houben, G.-J. What Makes a Tweet Relevant for a Topic? Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.309.8507&rep=rep1&type=pdf (accessed on 22 August 2022).
- Pujazon-Zazik, M.; Park, M.J. To Tweet, or Not to Tweet: Gender Differences and Potential Positive and Negative Health Outcomes of Adolescents’ Social Internet Use. Am. J. Mens. Health 2010, 4, 77–85. [Google Scholar] [CrossRef]
- Merler, M.; Cao, L.; Smith, J.R. You Are What You Tweet…pic! Gender Prediction Based on Semantic Analysis of Social Media Images. In Proceedings of the 2015 IEEE International Conference on Multimedia and Expo (ICME), Turin, Italy, 29 June–3 July 2015; pp. 1–6. [Google Scholar]
- Han, S.; Min, J.; Lee, H. Antecedents of Social Presence and Gratification of Social Connection Needs in SNS: A Study of Twitter Users and Their Mobile and Non-Mobile Usage. Int. J. Inf. Manage. 2015, 35, 459–471. [Google Scholar] [CrossRef]
- Hu, T.; Xiao, H.; Nguyen, T.-V.T.; Luo, J. What the Language You Tweet Says about Your Occupation. arXiv 2017, arXiv:1701.06233. [Google Scholar] [CrossRef]
- Ito, J.; Song, J.; Toda, H.; Koike, Y.; Oyama, S. Assessment of Tweet Credibility with LDA Features. In Proceedings of the 24th International Conference on World Wide Web—WWW ’15 Companion, Florence, Italy, 18–22 May 2015; ACM Press: New York, NY, USA, 2015. [Google Scholar]
- Zhao, Q.; Erdogdu, M.A.; He, H.Y.; Rajaraman, A.; Leskovec, J. SEISMIC: A Self-Exciting Point Process Model for Predicting Tweet Popularity. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD ’15, Sydney, Australia, 10–13 August 2015; ACM Press: New York, NY, USA, 2015. [Google Scholar]
- Tonia, T.; Van Oyen, H.; Berger, A.; Schindler, C.; Künzli, N. If I Tweet Will You Cite? The Effect of Social Media Exposure of Articles on Downloads and Citations. Int. J. Public Health 2016, 61, 513–520. [Google Scholar] [CrossRef]
- Haugh, B.R.; Watkins, B. Tag Me, Tweet Me If You Want to Reach Me: An Investigation into How Sports Fans Use Social Media. Int. J. Sport Communication 2016, 9, 278–293. [Google Scholar] [CrossRef]
- Lim, W.Y.; Lee, M.L.; Hsu, W. IFACT: An Interactive Framework to Assess Claims from Tweets. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; ACM: New York, NY, USA, 2017. [Google Scholar]
- Morabia, K.; Bhanu Murthy, N.L.; Malapati, A.; Samant, S. SEDTWIk: Segmentation-Based Event Detection from Tweets Using WIkipedia. In Proceedings of the 2019 Conference of the North, Minneapolis, Minnesota, 3–5 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 77–85. [Google Scholar]
- Alowibdi, J.S.; Buy, U.A.; Yu, P.S.; Ghani, S.; Mokbel, M. Deception Detection in Twitter. Soc. Netw. Anal. Min. 2015, 5, 32. [Google Scholar] [CrossRef]
- Classification and Ranking of Trending Topics in Twitter Using Tweets Text. J. Crit. Rev. 2020, 7, 895–899. [CrossRef]
- Vemprala, N.; Akello, P.; Valecha, R.; Rao, H.R. An Exploratory Analysis of Alarming and Reassuring Messages in Twitterverse during the Coronavirus Epidemic. In Proceedings of the American Conference on Information Systems 2020, Salt Lake City, UT, USA, 10–14 August 2020. [Google Scholar]
- Akpojivi, U. Euphoria and Delusion of Digital Activism: Case Study of #ZumaMustFall. In Advances in Social Networking and Online Communities; IGI Global: Hershey, PA, USA, 2018; pp. 179–202. ISBN 9781522528548. [Google Scholar]
- Culotta, A.; Cutler, J. Mining Brand Perceptions from Twitter Social Networks. Mark. Sci. 2016, 35, 343–362. [Google Scholar] [CrossRef]
- Zhou, L.; Wang, W.; Chen, K. Identifying Regrettable Messages from Tweets. In Proceedings of the 24th International Conference on World Wide Web—WWW ’15 Companion, Florence, Italy, 18–22 May 2015; ACM Press: New York, NY, USA, 2015. [Google Scholar]
- Yamamoto, Y.; Kumamoto, T.; Nadamoto, A. Followee Recommendation Based on Topic Extraction and Sentiment Analysis from Tweets. In Proceedings of the 17th International Conference on Information Integration and Web-based Applications & Services, Brussels, Belgium, 11–13 December 2015; ACM: New York, NY, USA, 2015. [Google Scholar]
- Yan, J.L.S.; Kaziunas, E. What Is a Tweet Worth? Measuring the Value of Social Media for an Academic Institution. In Proceedings of the 2012 iConference on—iConference ’12, Toronto, ON, Canada, 7–10 February 2012; ACM Press: New York, NY, USA, 2012. [Google Scholar]
- Davis, S.W.; Horváth, C.; Gretry, A.; Belei, N. Say What? How the Interplay of Tweet Readability and Brand Hedonism Affects Consumer Engagement. J. Bus. Res. 2019, 100, 150–164. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
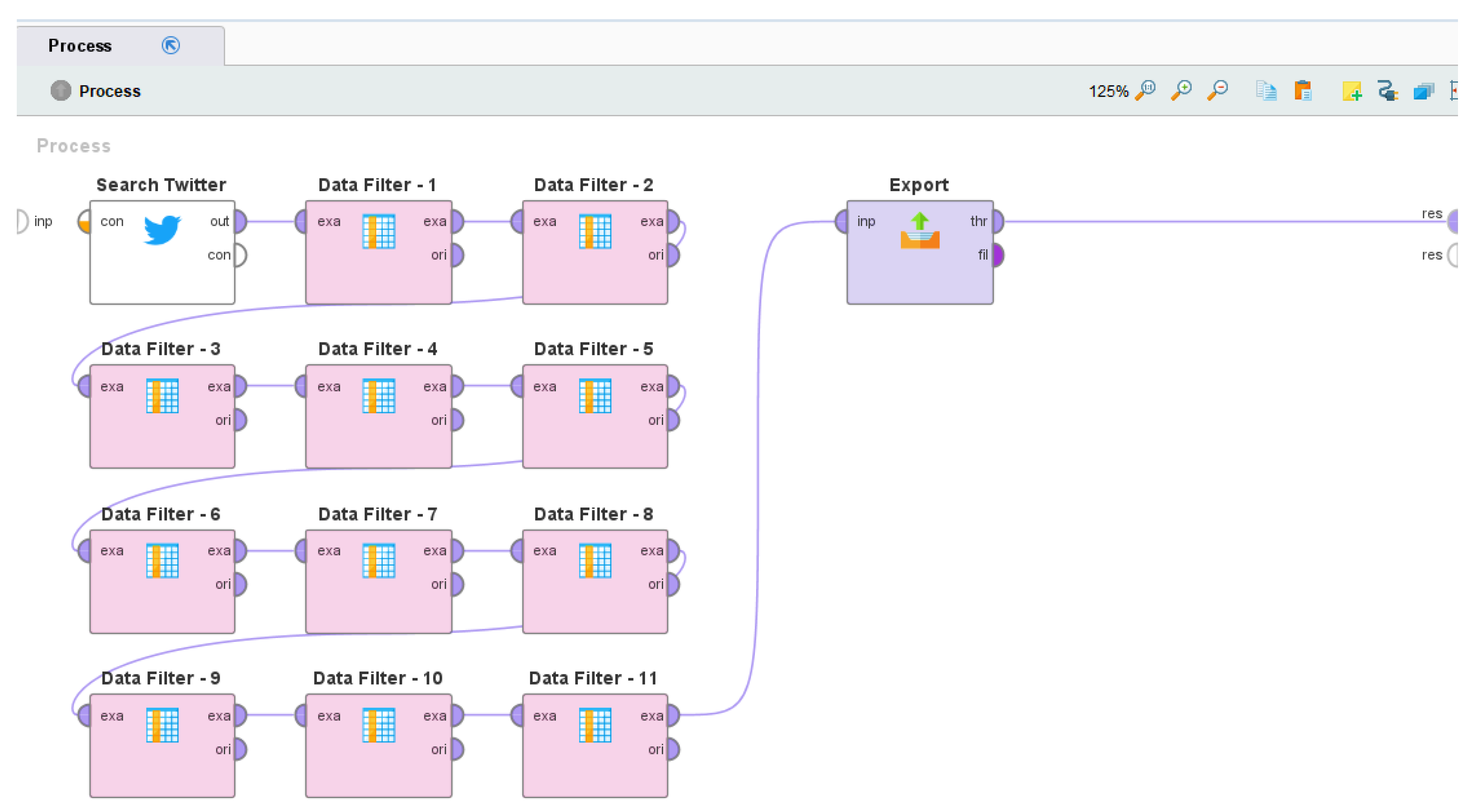
| Operator Name | Description |
|---|---|
| Search Twitter | Searches relevant tweets from Twitter by connecting with the Twitter API and by complying with the Twitter API’s standard search policies |
| Data Filter-1 | Removes the attribute that contains the date and time when the Tweet was posted |
| Data Filter-2 | Removes the attribute that contains the Twitter username of the user who posted the Tweet |
| Data Filter-3 | Removes the attribute that contains the Twitter User ID of the user who posted the Tweet |
| Data Filter-4 | Removes the attribute that contains the Twitter username of the user whose Tweet was replied to (if the tweet was a reply) in the current tweet |
| Data Filter-5 | Removes the attribute that contains the Twitter user ID of the user whose Tweet was replied to (if the tweet was a reply) in the current Tweet |
| Data Filter-6 | Removes the attribute that contains the language of the Tweet |
| Data Filter-7 | Removes the attribute that contains the source of the tweet, such as an Android source, Twitter website, etc. |
| Data Filter-8 | Removes the attribute that contains the complete text of the Tweet, including embedded URLs |
| Data Filter-9 | Removes the attribute that contains the geo-location (latitude) of the user posting the Tweet |
| Data Filter-10 | Removes the attribute that contains the geo-location (longitude) of the user posting the Tweet |
| Data Filter-11 | Removes the attribute that contains the retweet count of the Tweet |
| Export | Exports the result as a .csv file on the local computer |
| Filename | No. of Tweet IDs | Date Range of the Tweet IDs |
|---|---|---|
| TweetIDs_Part1.txt | 13,926 | 7 May 2022 to 21 May 2022 |
| TweetIDs_Part2.txt | 17,705 | 21 May 2022 to 27 May 2022 |
| TweetIDs_Part3.txt | 17,585 | 27 May 2022 to 5 June 2022 |
| TweetIDs_Part4.txt | 19,718 | 5 June 2022 to 11 June 2022 |
| TweetIDs_Part5.txt | 46,718 | 12 June 2022 to 30 June 2022 |
| TweetIDs_Part6.txt | 138,711 | 1 July 2022 to 23 July 2022 |
| TweetIDs_Part7.txt | 105,890 | 24 July 2022 to 31 July 2022 |
| TweetIDs_Part8.txt | 93,959 | 1 August 2022 to 9 August 2022 |
| TweetIDs_Part9.txt | 50,832 | 10 August 2022 to 24 August 2022 |
| TweetIDs_Part10.txt | 39,042 | 25 August 2022 to 19 September 2022 |
| TweetIDs_Part11.txt | 12,341 | 20 September 2022 to 9 October 2022 |
| Description of the Twitter Dataset | Number of Tweet IDs |
|---|---|
| Tweets with #preuambicio [81] | 643 |
| Tweets with #Blackwomanhood [73] | 919 |
| Tweets with #MiPrimerRecuerdoFeminista [82] | 1238 |
| Tweets with #BlackTheory [75] | 1430 |
| Tweets with #DuragFest [76] | 1705 |
| Tweets about Sundanese (the second-largest tribe in Indonesia) [62] | 2518 |
| Tweets about the European migration crisis [49] | 3275 |
| Tweets about civil unrest [53] | 4381 |
| Tweets involving offensive language [52] | 5000 |
| Tweets with #AskTimothy [79] | 5680 |
| Tweets involving hate speech and abusive language [48] | 5846 |
| Tweets reporting adverse pregnancy outcomes [56] | 6487 |
| Tweets involving misogynistic language [51] | 6550 |
| Tweets involving opinions of the Indonesian public on different matters [58] | 7080 |
| Tweets about BlackLivesMatter [64] | 9165 |
| Tweets about the efficacy of hydroxychloroquine as a treatment for COVID-19 [55] | 14,374 |
| Tweets with #MarchForBlackWomen [74] | 18,646 |
| Tweets about COVID-19 (posted in Spanish) [69] | 18,958 |
| Tweets about a severe storm and F1 tornado that struck Central Pennsylvania [59] | 22,706 |
| Tweets about COVID-19 (posted in Bengali) [70] | 36,117 |
| Tweets containing Multi-Ideology ISIS/Jihadist White Supremacy-based content [61] | 40,000 |
| Tweets in the Arabic language [68] | 40,000 |
| Tweets about natural hazards [50] | 49,816 |
| Tweets with #WITBragDay [80] | 52,457 |
| Tweets about Online Learning during the COVID-19 Omicron wave [60] | 52,984 |
| Tweets with #WOCAffirmation [78] | 80,339 |
| Tweets with #BringBackOurInternet [77] | 81,419 |
| Tweets with #IndonesiaHumanRightsSOS [72] | 106,903 |
| Tweets about exoskeletons [54] | 138,584 |
| Tweets containing the phrase—“I Voted For Trump” [83] | 140,000 |
| Tweets containing the word “vaccine” [63] | 220,085 |
| Tweets about COVID-19 (posted in English) [71] | 226,668 |
| Tweets containing drug-related knowledge [57] | 267,215 |
| Tweets about hazardous events at the Baths of Diocletian site in Rome [66] | 276,865 |
| Tweets about memes from Black Twitter [67] | 402,650 |
| Tweets about the COVID-19 Omicron variant [65] | 522,886 |
| Twitter Dataset on the 2022 Monkey Outbreak [this work] | 556,427 |
| Characteristic Feature | Statistics |
|---|---|
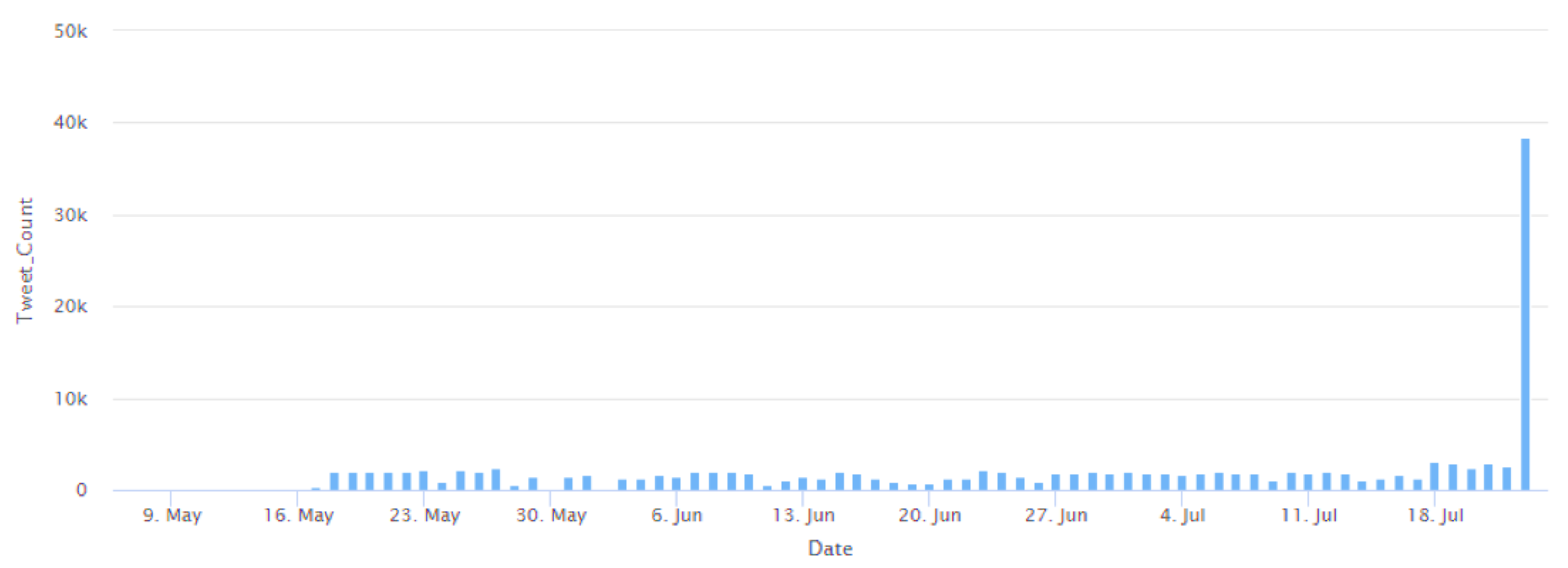
| Distinct dates when the Tweets were posted | 78 |
| Date when the maximum number of Tweets were posted | 23 July 2022 |
| Number of Tweets posted on 23 July 2022 | 38.417 |
| Distinct languages in which the Tweets are available | 34 |
| Most common language used for posting the Tweets | English |
| Total number of different hashtags present in all the Tweets | 5470 |
| Most commonly used hashtag | #monkeypox |
| Percentage of Tweets posted using an iPhone (Twitter for iPhone) | 46.2% |
| Percentage of Tweets posted using an Android Phone (Twitter for Android) | 22.4% |
| Percentage of Tweets posted using the Twitter Website (Twitter Web App) | 20.0% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thakur, N. MonkeyPox2022Tweets: A Large-Scale Twitter Dataset on the 2022 Monkeypox Outbreak, Findings from Analysis of Tweets, and Open Research Questions. Infect. Dis. Rep. 2022, 14, 855-883. https://doi.org/10.3390/idr14060087
Thakur N. MonkeyPox2022Tweets: A Large-Scale Twitter Dataset on the 2022 Monkeypox Outbreak, Findings from Analysis of Tweets, and Open Research Questions. Infectious Disease Reports. 2022; 14(6):855-883. https://doi.org/10.3390/idr14060087
Chicago/Turabian StyleThakur, Nirmalya. 2022. "MonkeyPox2022Tweets: A Large-Scale Twitter Dataset on the 2022 Monkeypox Outbreak, Findings from Analysis of Tweets, and Open Research Questions" Infectious Disease Reports 14, no. 6: 855-883. https://doi.org/10.3390/idr14060087
APA StyleThakur, N. (2022). MonkeyPox2022Tweets: A Large-Scale Twitter Dataset on the 2022 Monkeypox Outbreak, Findings from Analysis of Tweets, and Open Research Questions. Infectious Disease Reports, 14(6), 855-883. https://doi.org/10.3390/idr14060087