
Map Construction Based on LiDAR Vision Inertial Multi-Sensor Fusion


Abstract
:1. Introduction
- (1)
- Before the LiDAR feature extraction, the point clouds are screened to eliminate the points that do not meet the conditions, so as to effectively reduce the loss of computing resources.
- (2)
- The visual features filtered through the intensity value of the point clouds are used to supplement the laser point cloud features, improving the accuracy of positioning and mapping.
- (3)
- A close-coupled LiDAR vision inertial system based on factor graph optimization is proposed in order to realize multi-sensor information fusion and construct a three-dimensional point cloud map with high robustness in real-time.
2. Previous Work
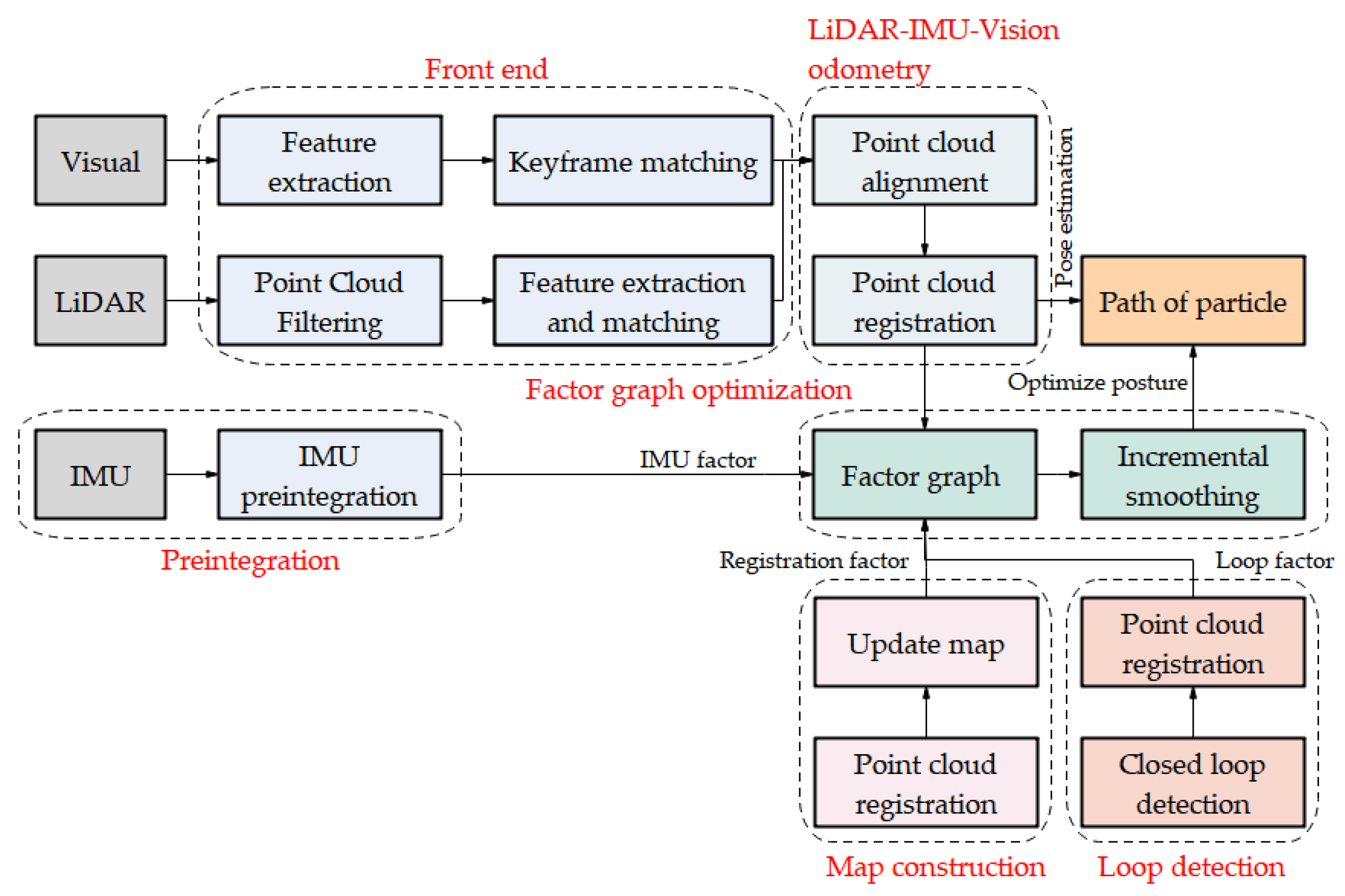
3. Methods
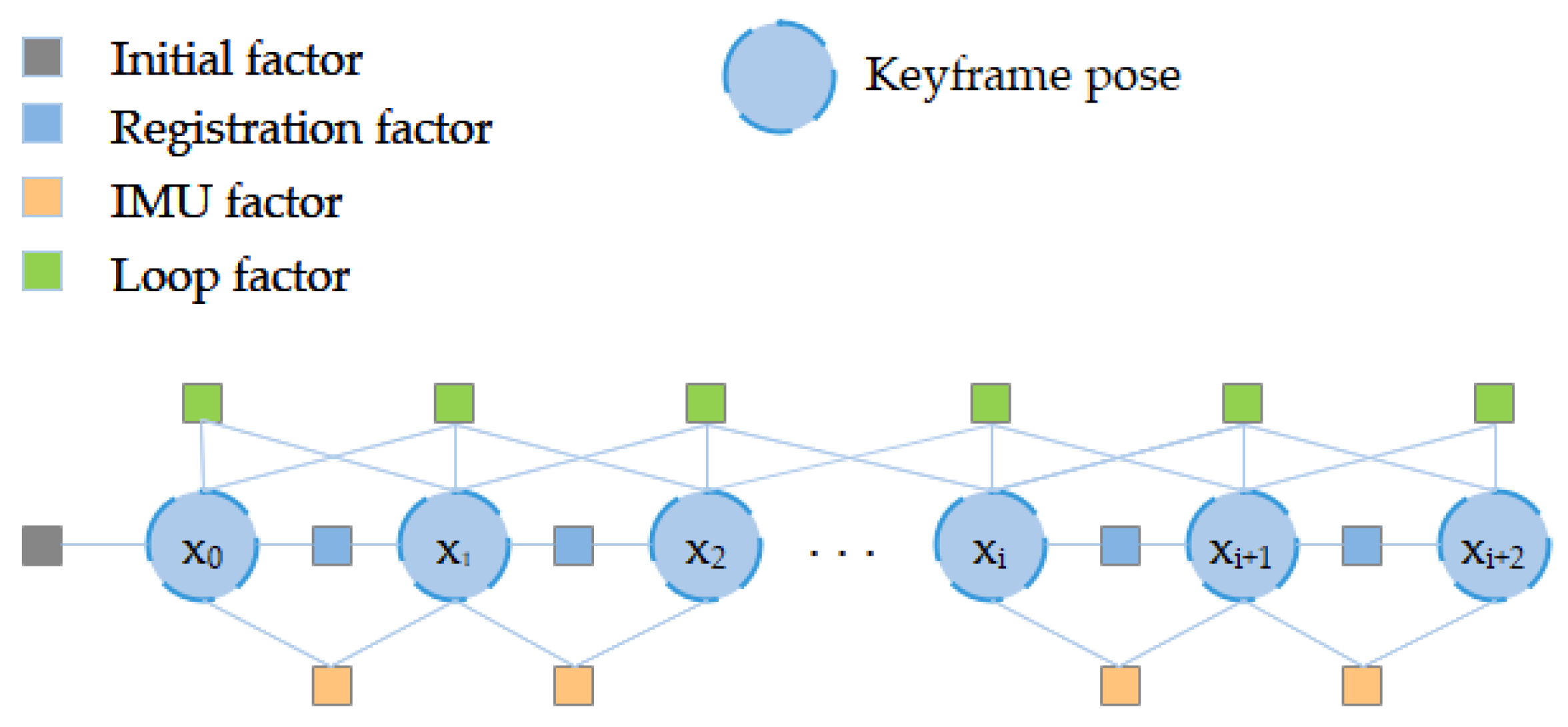
3.1. State Estimation Based on Factor Graph Optimization
3.2. Vision and LiDAR Front End
3.2.1. Visual Front End
3.2.2. LiDAR Front End
- (1)
- In order to improve the accuracy of the positioning and mapping, the point cloud scanned by LiDAR is processed, and the irrelevant point clouds are eliminated by the following rules.The points at the edge of the LiDAR angle of view are eliminated.
- (2)
- Eliminate the points with particularly large or small reflection intensities. Excessive intensity will lead to the saturation or distortion of the receiving circuit, and a too-small intensity will lead to the reduction of the signal-to-noise ratio, both of which will reduce the ranging accuracy.
- (3)
- Eliminate the points hidden behind the object, otherwise it will lead to the wrong edge features.
3.3. IMU Pre-Integration
3.4. LiDAR-IMU-Vision Odometry
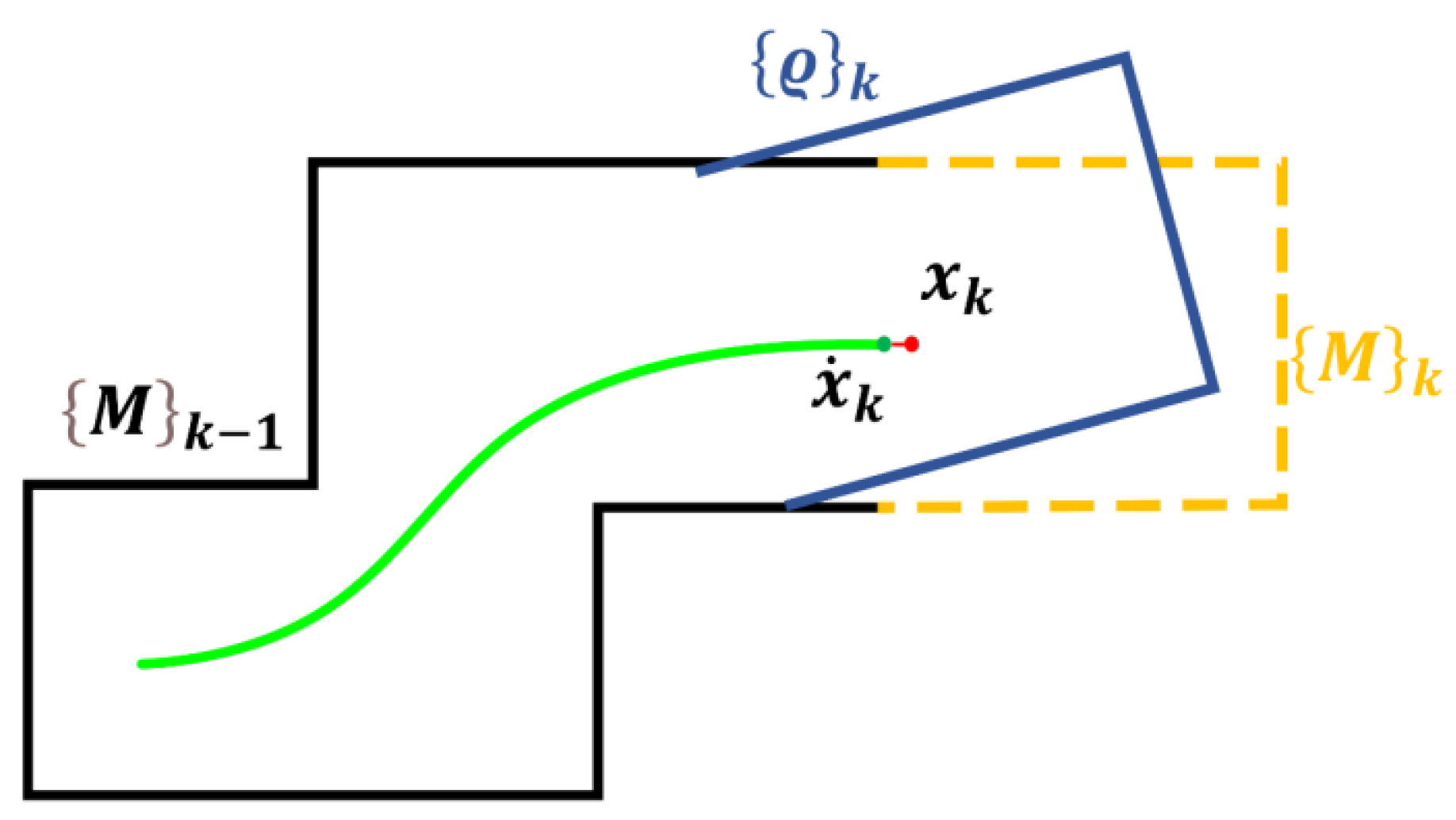
3.5. Map Construction
3.6. Closed Loop Detection
3.7. Factor Graph Optimization
4. Experimental Verification
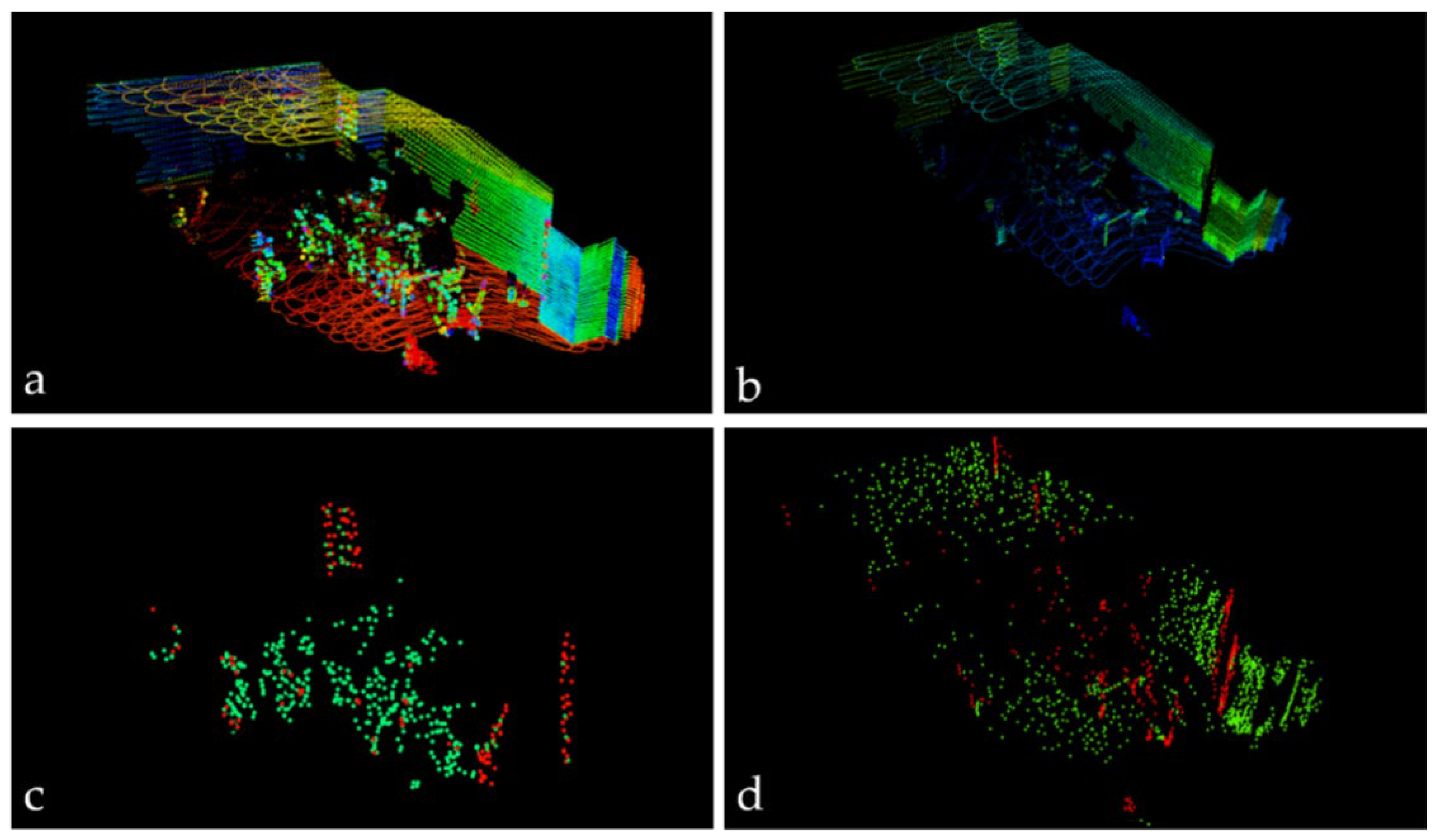
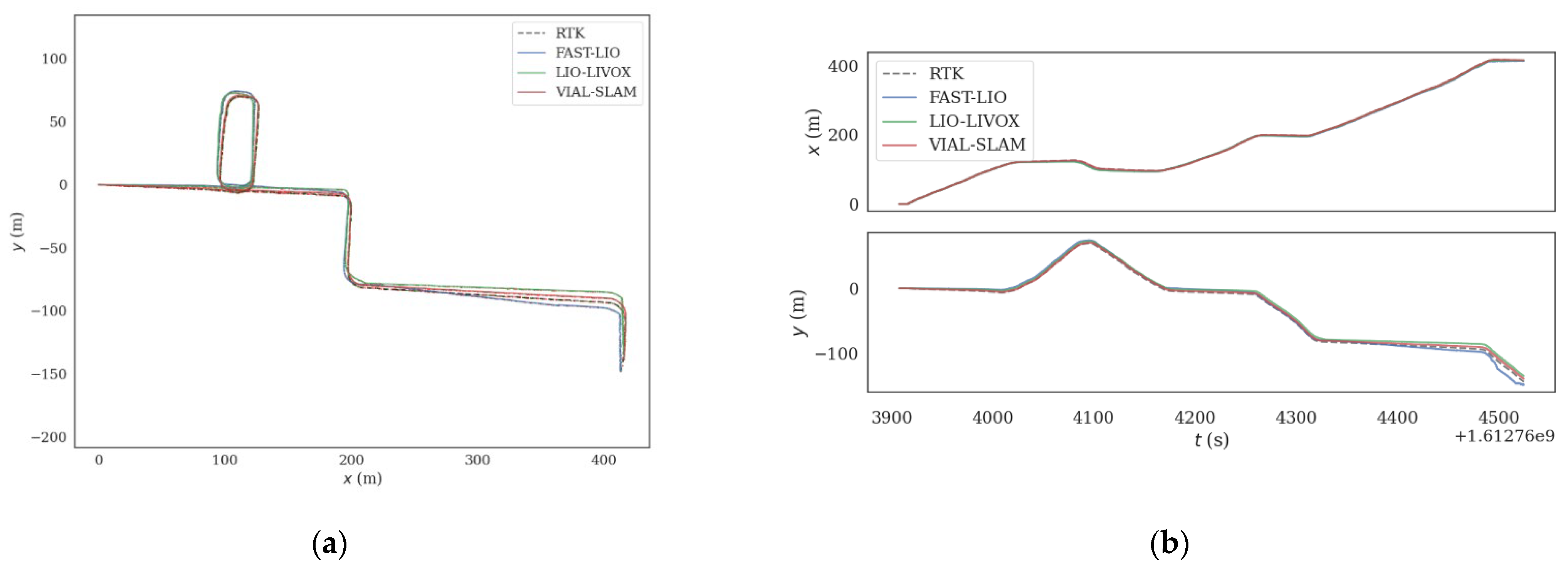
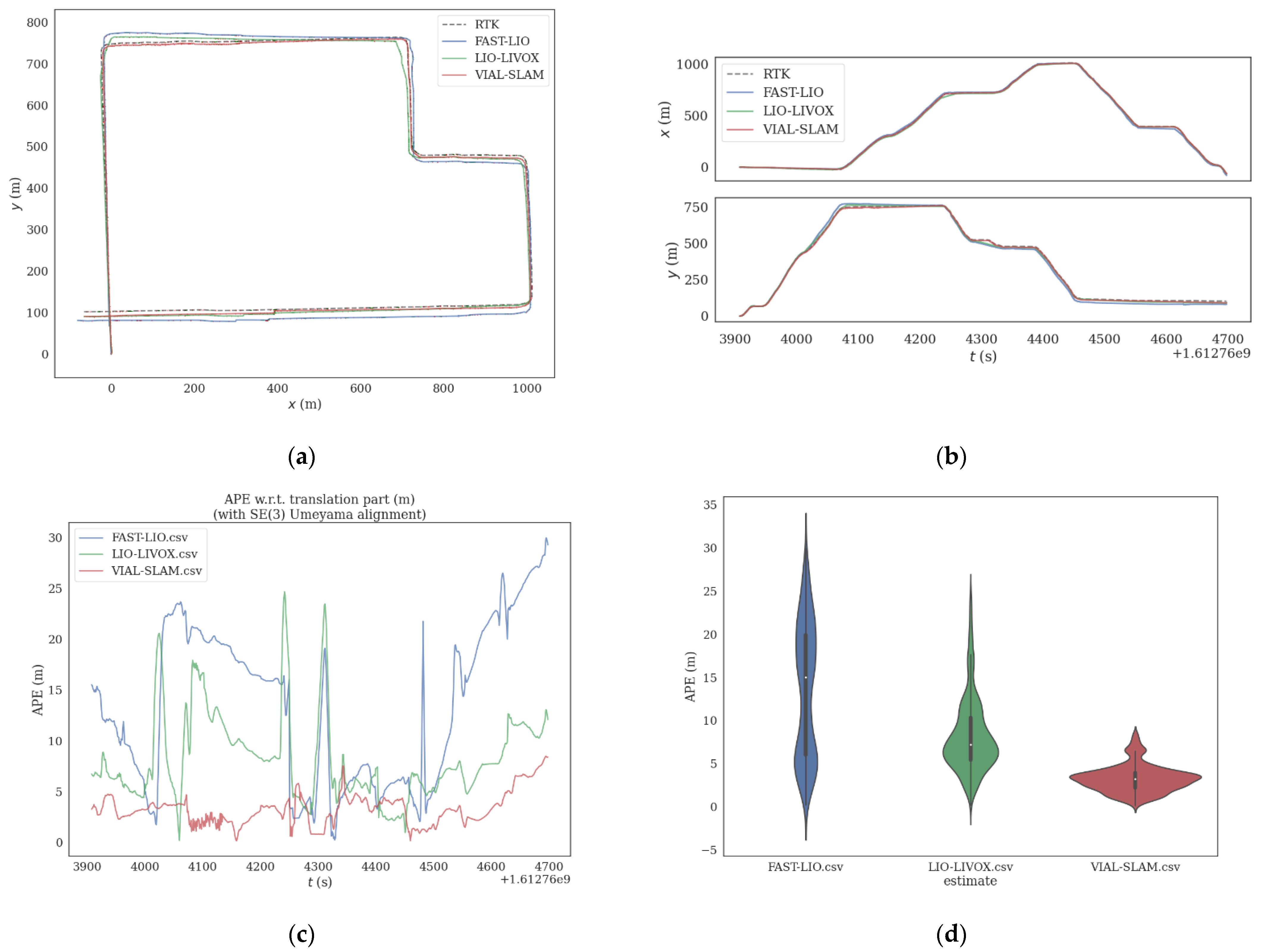
4.1. School Environment Test
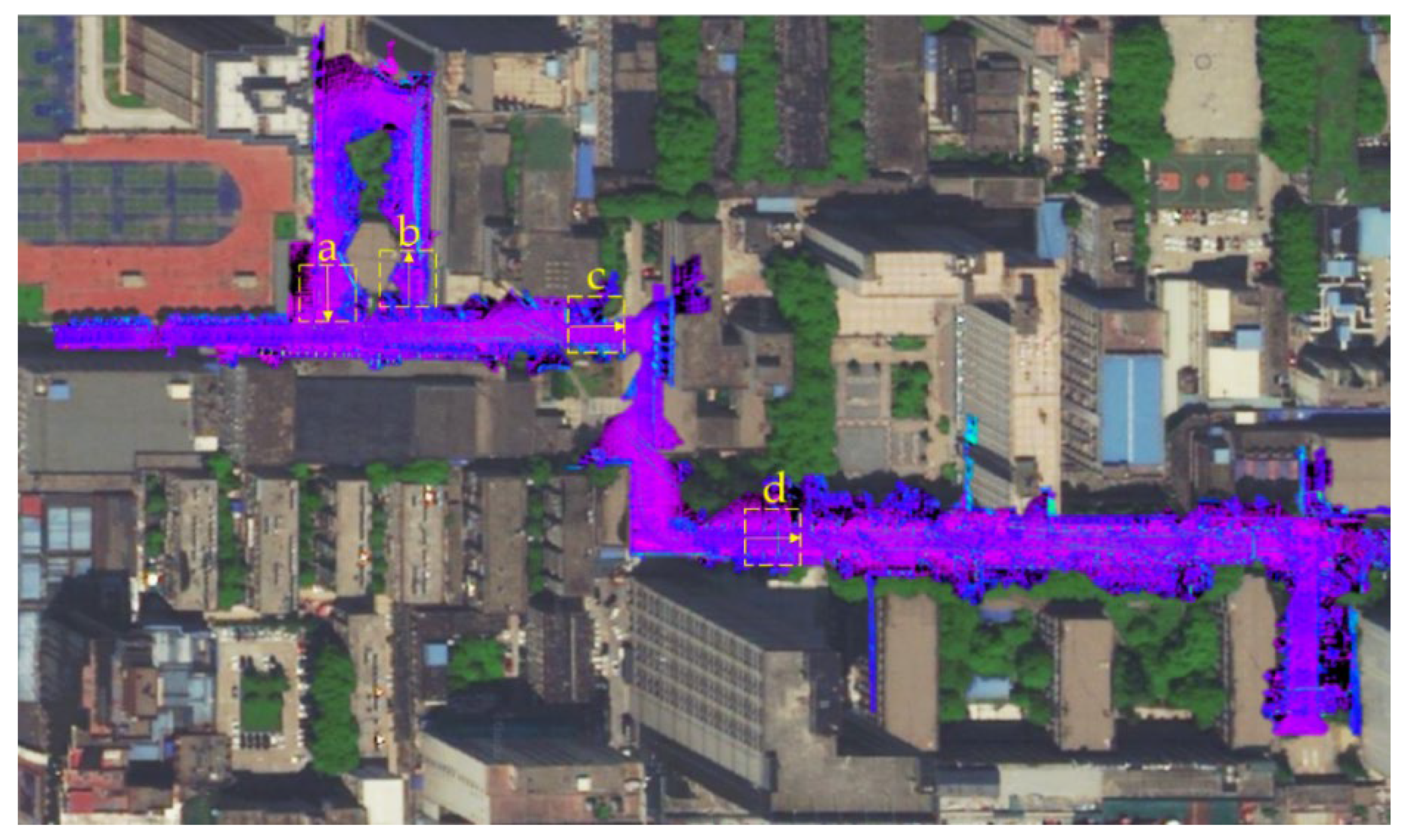
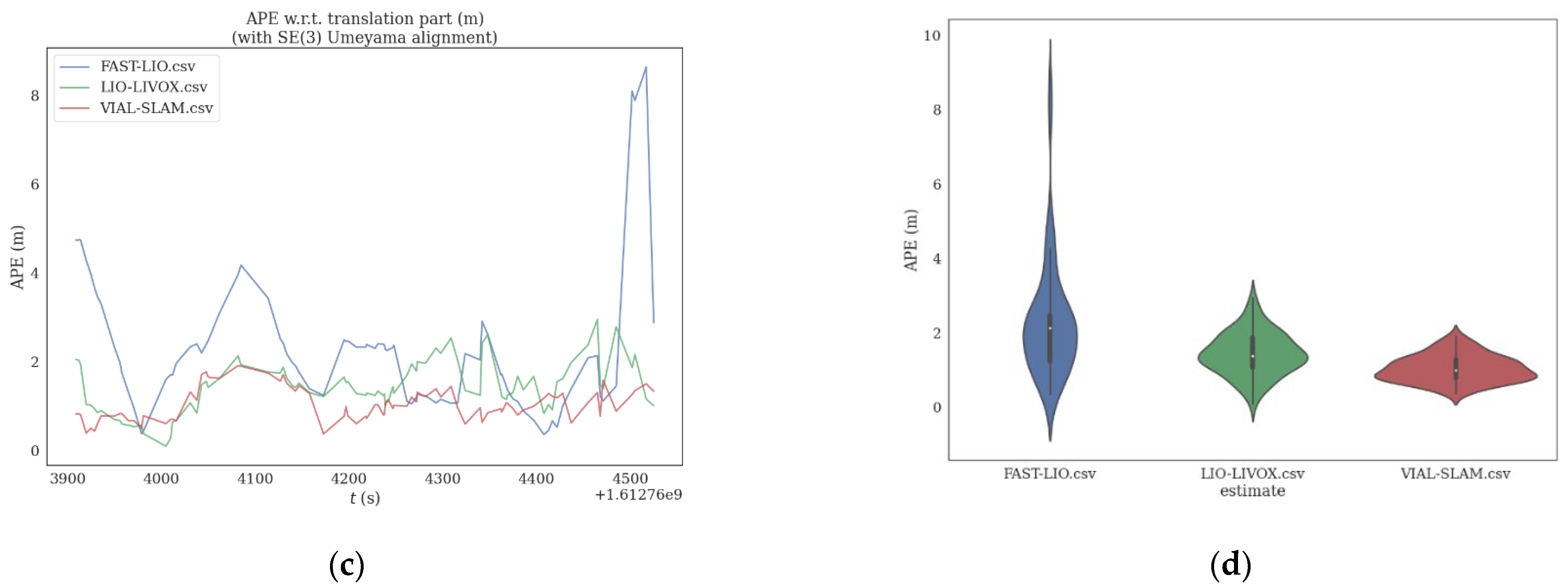
4.2. Real Urban Road Environment Test
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, J.; Li, T.; Yang, T.; Zhao, L.; Huang, S. 2D Laser SLAM with Closed Shape Features: Fourier Series Parameterization and Submap Joining. IEEE Robot. Autom. Lett. 2021, 6, 1527–1534. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV 2011), Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef] [Green Version]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef] [Green Version]
- Usenko, V.; Engel, J.; Stückler, J.; Cremers, D. Direct visual-inertial odometry with stereo cameras. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1885–1892. [Google Scholar]
- Qin, T.; Cao, S.; Pan, J.; Shen, S. A general optimization-based framework for global pose estimation with multiple sensors. arXiv 2019, arXiv:1901.03642. [Google Scholar]
- Campos, C.; Elvira, R.; Rodriguez, J.J.G.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual–Inertial, and Multimap SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S. Vins-mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Singh, S. Low-drift and Real-Time Lidar Odometry and Mapping. Auton. Robot 2017, 41, 401–416. [Google Scholar] [CrossRef]
- Shan, T.; Englot, B. LeGO-LOAM: Lightweight and Ground-Optimized Lidar Odometry and Mapping on Variable Ter-rain. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4758–4765. [Google Scholar]
- Shan, T.; Englot, B.; Meyers, D.; Wang, W.; Ratti, C.; Rus, D. LIO-SAM: Tightly-coupled Lidar Inertial Odometry via Smoothing and Mapping. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Las Vegas, NV, USA, 25–29 October 2020. [Google Scholar]
- Ye, H.; Chen, Y.; Liu, M. Tightly coupled 3d lidar inertial odometry and mapping. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 3144–3150. [Google Scholar]
- Zhao, S.; Fang, Z.; Li, H.L.; Scherer, S. A robust laser-inertial odometry and mapping method for large-scale highway environ-ments. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 1285–1292. [Google Scholar]
- Geneva, P.; Eckenhoff, K.; Yang, Y.; Huang, G. LIPS: Lidar-Inertial 3d plane slam. In Proceedings of the 2018 IEEE/RSJ International Conference on In-telligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 123–130. [Google Scholar]
- Bry, A.; Bachrach, A.; Roy, N. State estimation for aggressive flight in GPS-denied environments using onboard sensing. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 1–8. [Google Scholar]
- Debeunne, C.; Vivet, D. A review of visual-LiDAR fusion based simultaneous localization and mapping. Sensors 2020, 20, 2068. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, J.; Singh, S. Visual-lidar odometry and mapping: Low-drift, robust, and fast. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 2174–2181. [Google Scholar]
- Seo, Y.; Chou, C.C. A tight coupling of vision-lidar measurements for an effective odometry. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1118–1123. [Google Scholar]
- Jiang, G.; Yin, L.; Jin, S.; Tian, C.; Ma, X.; Ou, Y. A Simultaneous Localization and Mapping (SLAM) Framework for 2.5D Map Building Based on Low-Cost LiDAR and Vision Fusion. Appl. Sci. 2019, 9, 2105. [Google Scholar] [CrossRef] [Green Version]
- Lin, J.; Zhang, F. Loam livox: A fast, robust, high-precision LiDAR odometry and mapping package for LiDARs of small FoV. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 3126–3131. [Google Scholar]
- Chen, S.; Zhou, B.; Jiang, C.; Xue, W.; Li, Q. A LiDAR/Visual SLAM Backend with Loop Closure Detection and Graph Optimization. Remote Sens. 2021, 13, 2720. [Google Scholar] [CrossRef]
- Wang, W.; Liu, J.; Wang, C.; Lin, B.; Zhang, C. DV-LOAM: Direct visual lidar odometry and mapping. Remote Sens. 2021, 13, 3340. [Google Scholar] [CrossRef]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. Brief: Binary Robust Independent Elementary Features; European conference on computer vision; Springer: Berlin/Heidelberg, Germany, 2010; pp. 778–792. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Error Term | VIAL-SLAM | LIO-LIVOX | FAST-LIO |
|---|---|---|---|
| Root mean square error | 0.67 m | 1.49 m | 2.92 m |
| Mean error | 0.56 m | 1.35 m | 2.49 m |
| Error ratio | 0.095% | 0.213% | 0.417% |
| Error Term | VIAL-SLAM | LIO_LIVOX | FAST-LIO |
|---|---|---|---|
| Root mean square error | 3.54 m | 9.18 m | 15.77 m |
| Mean error | 3.08 m | 7.92 m | 13.5 m |
| Error ratio | 0.107% | 0.278% | 0.478% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Lei, L.; Ma, X.; Zhou, R.; Shi, Z.; Guo, Z. Map Construction Based on LiDAR Vision Inertial Multi-Sensor Fusion. World Electr. Veh. J. 2021, 12, 261. https://doi.org/10.3390/wevj12040261
Zhang C, Lei L, Ma X, Zhou R, Shi Z, Guo Z. Map Construction Based on LiDAR Vision Inertial Multi-Sensor Fusion. World Electric Vehicle Journal. 2021; 12(4):261. https://doi.org/10.3390/wevj12040261
Chicago/Turabian StyleZhang, Chuanwei, Lei Lei, Xiaowen Ma, Rui Zhou, Zhenghe Shi, and Zhongyu Guo. 2021. "Map Construction Based on LiDAR Vision Inertial Multi-Sensor Fusion" World Electric Vehicle Journal 12, no. 4: 261. https://doi.org/10.3390/wevj12040261
APA StyleZhang, C., Lei, L., Ma, X., Zhou, R., Shi, Z., & Guo, Z. (2021). Map Construction Based on LiDAR Vision Inertial Multi-Sensor Fusion. World Electric Vehicle Journal, 12(4), 261. https://doi.org/10.3390/wevj12040261