
An Effective Grouping Method for Privacy-Preserving Bike Sharing Data Publishing



Abstract
:1. Introduction
2. Background and Related Works
2.1. Privacy-Preserving Context
2.2. Privacy-Preserving Data Publishing
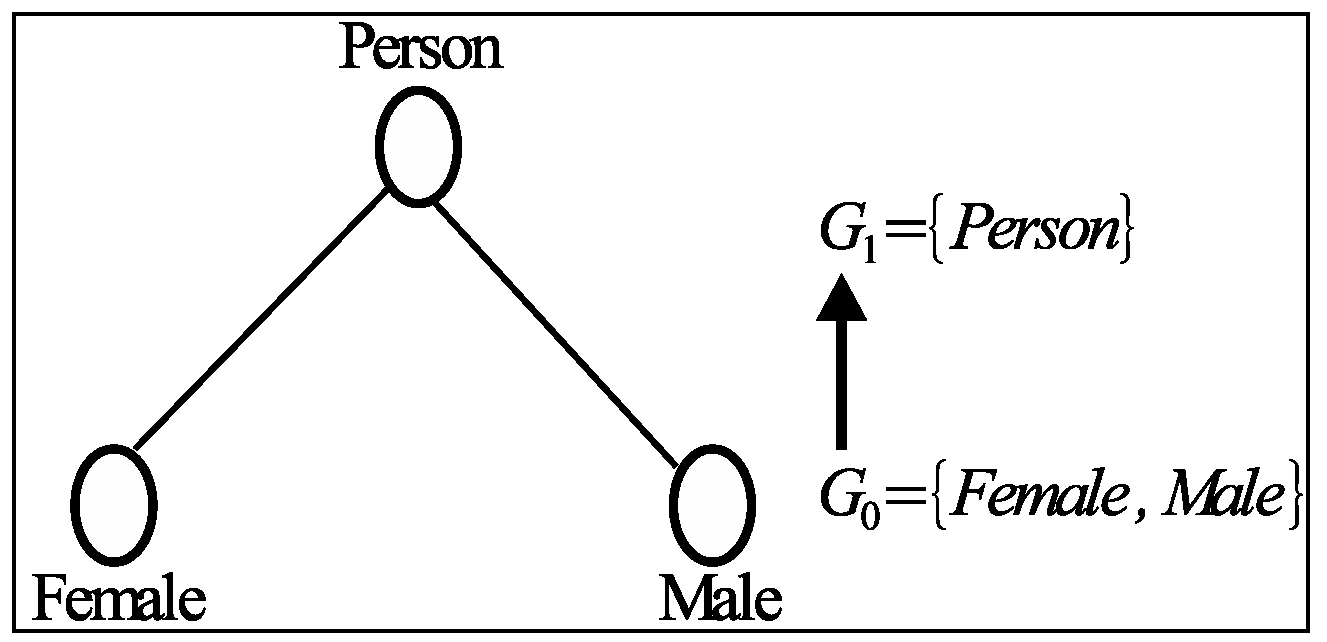
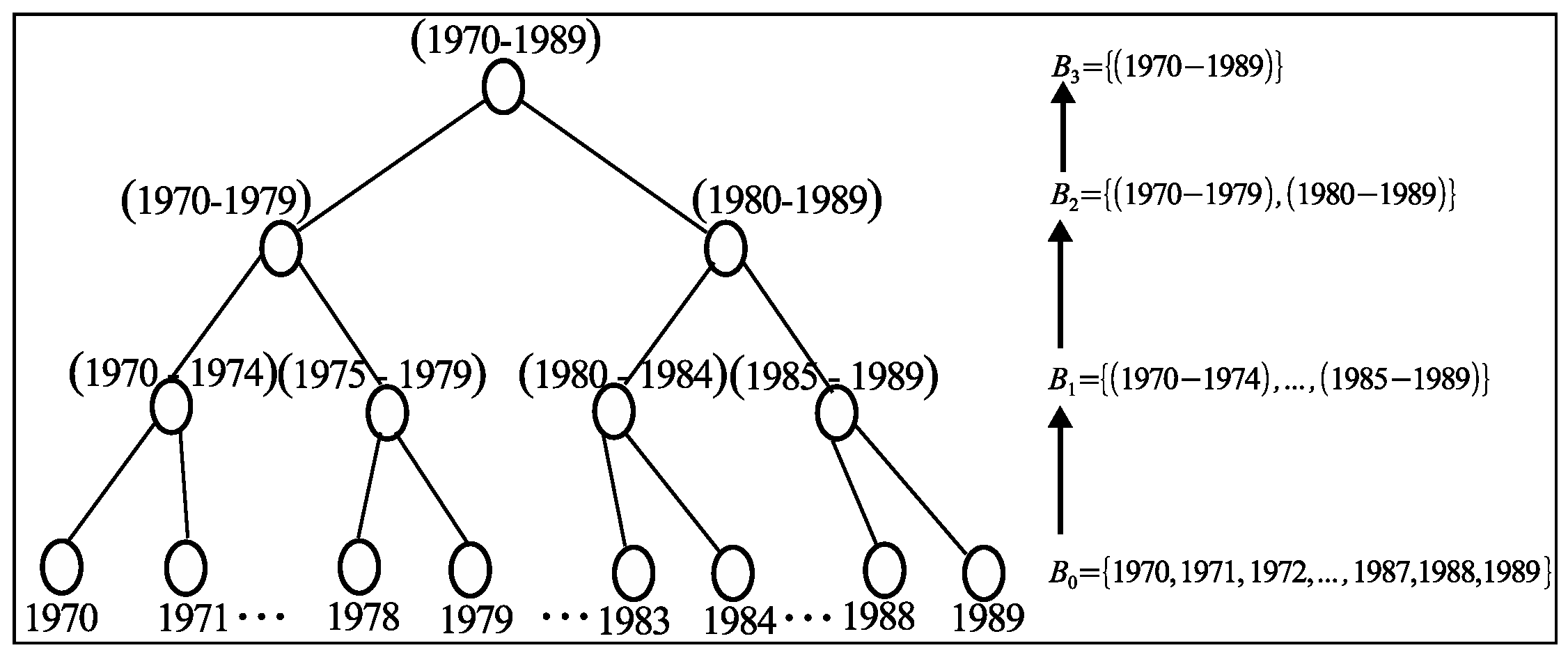
2.3. Anonymization Techniques
2.4. Background Knowledge and Privacy Threats
2.5. Problems in Bike Sharing Data Publishing
3. Methodology
3.1. Preliminaries and Problem Definitions
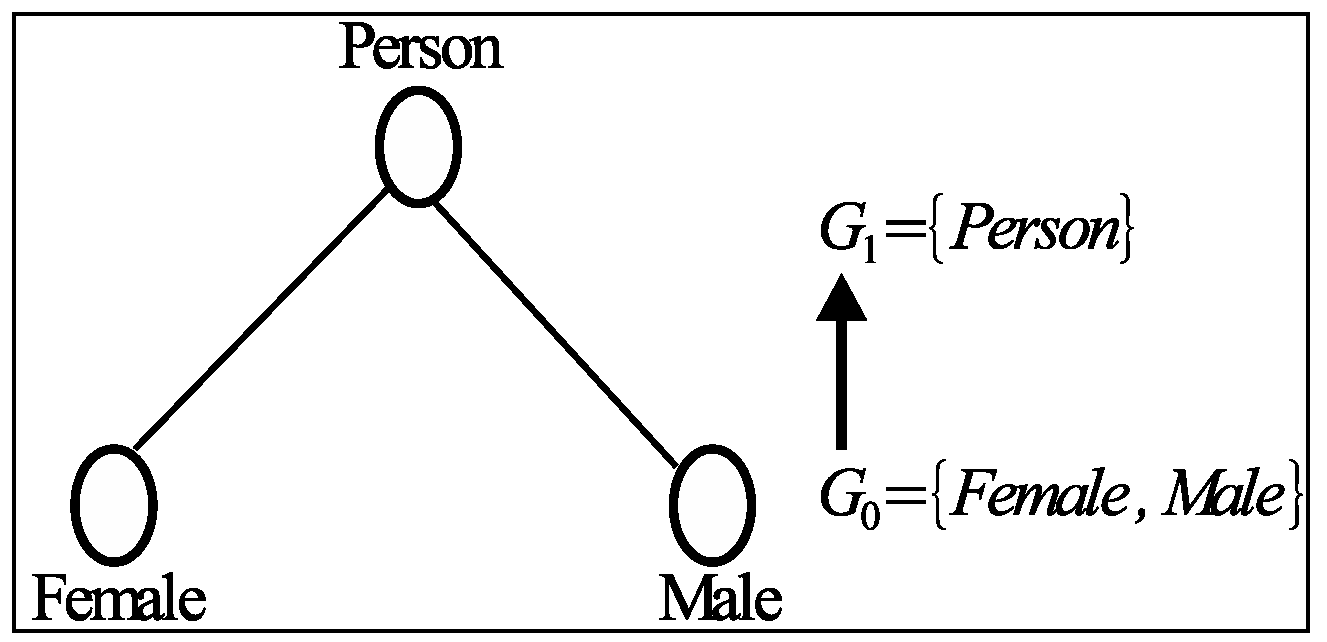
3.2. Grouping Methods
3.3. Algorithms
| Algorithm 1 Anonymization |
| Input: Bike Sharing Data set T |
| Output: Anonymized Data set T* |
| 1: For a given dataset T generates an anonymized table T*, which will satisfy the privacy concept with the privacy requirement R of l-diversity; |
| 2: B = ∅; |
| 3: for each tuples in T do |
| 4: group tuples into i buckets as in Mondrian [58]. |
| 5: permute attribute values in each bucket |
| 6: Privacy Check |
| 7: ; |
| return T*. |
| Algorithm 2 Privacy Check(B, R) |
| Input: Bucket B |
| Output: TRUE, if the bucket satisfies privacy requirement R |
| 1: for each tuple in bucket B do |
| 2: Check the l-diversity of every tuple to satisfy privacy requirement R as in [19]; |
| return TRUE. |
3.3.1. Anonymization Algorithm
3.3.2. Privacy Check Algorithm
3.3.3. Time Complexity
3.4. Discussion on the Anonymization Techniques
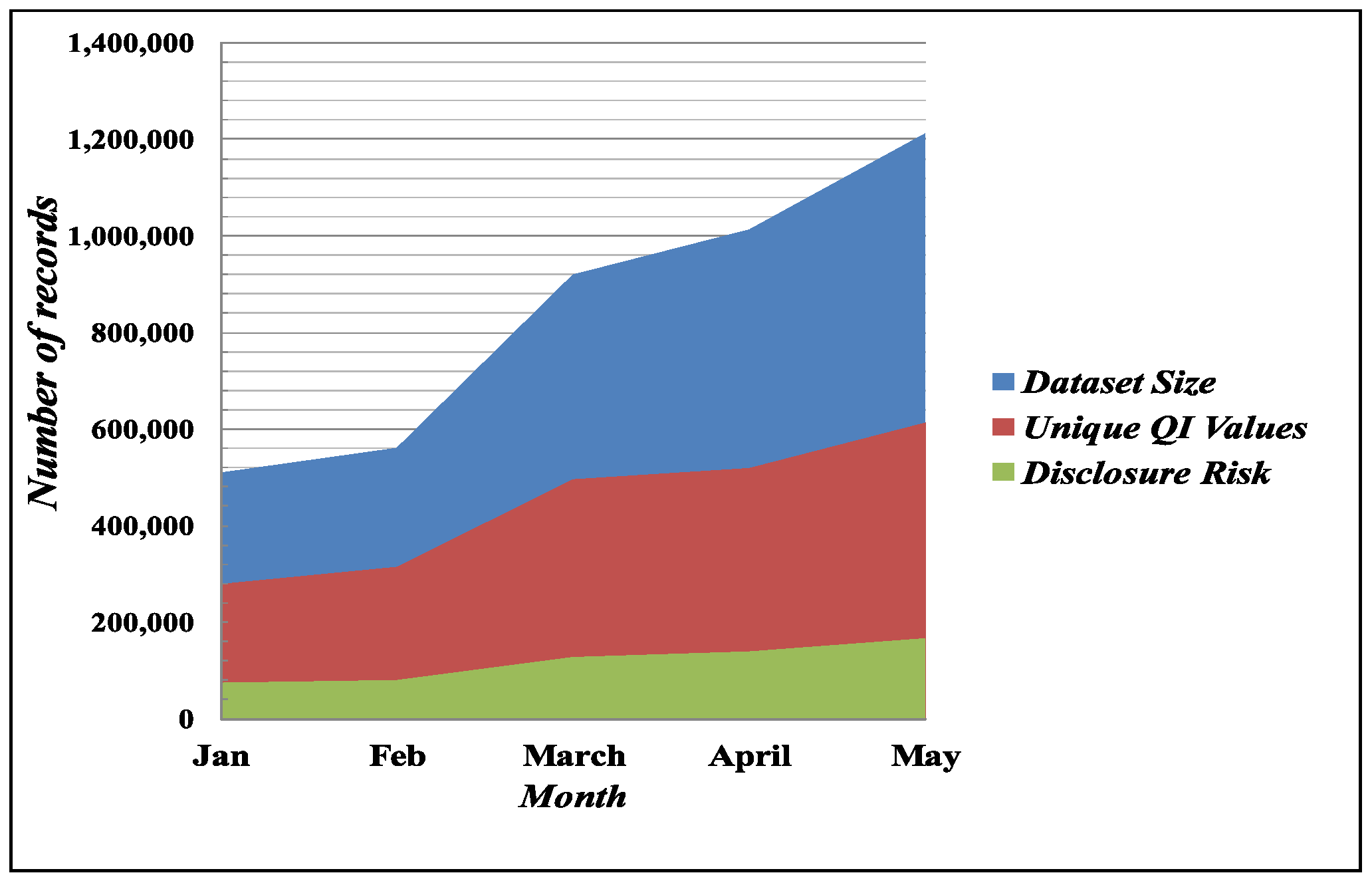
4. Experimental Analysis
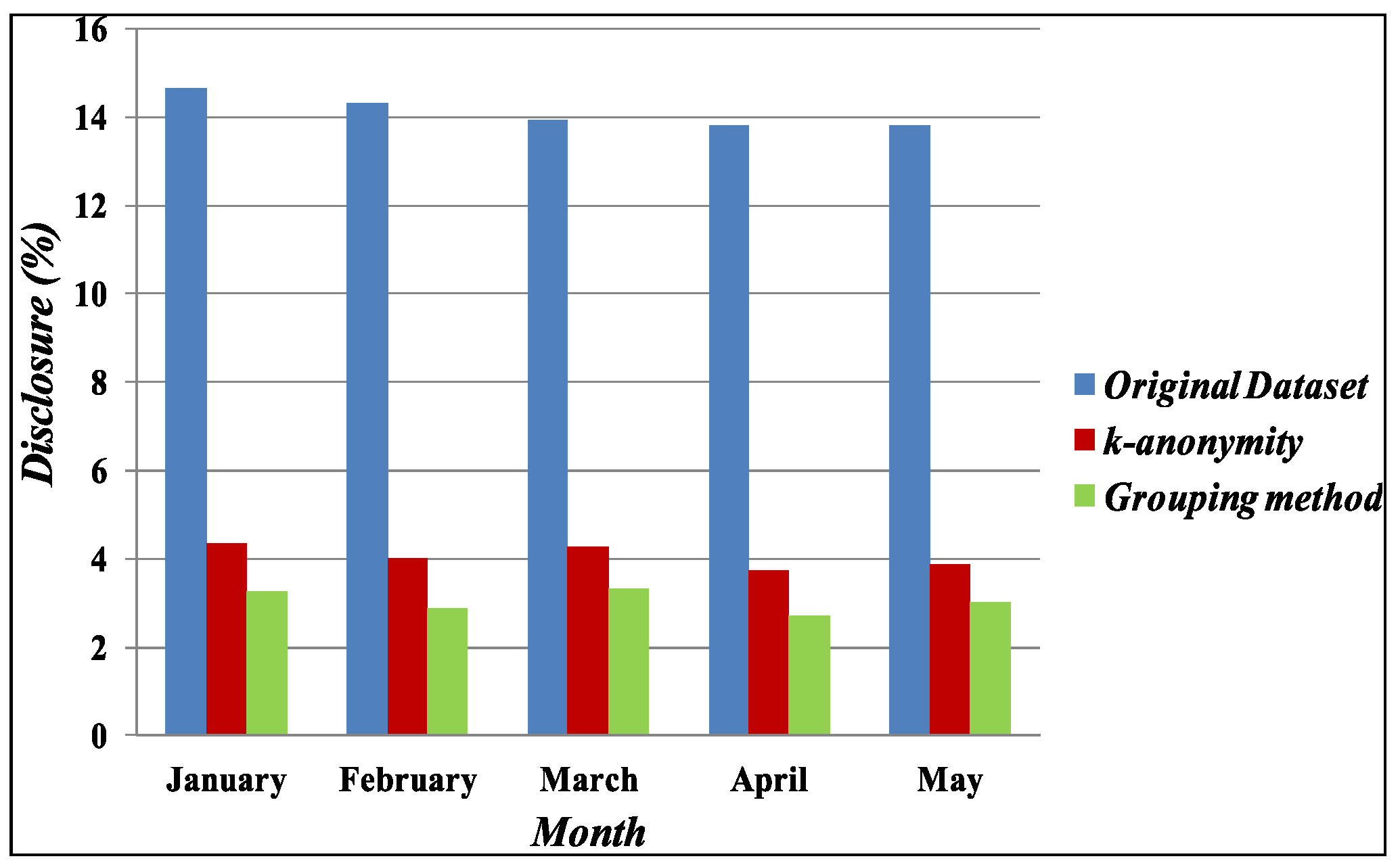
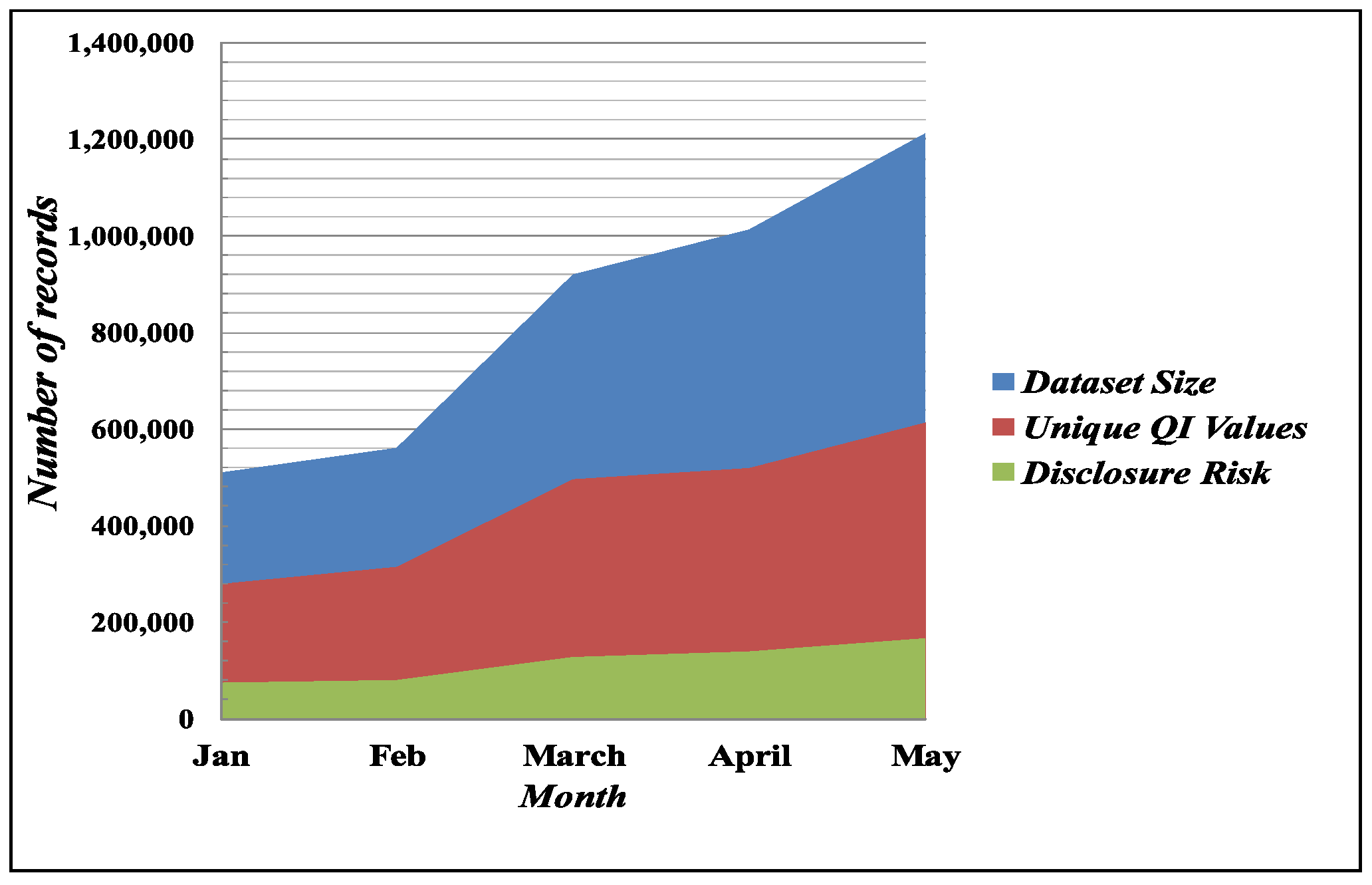
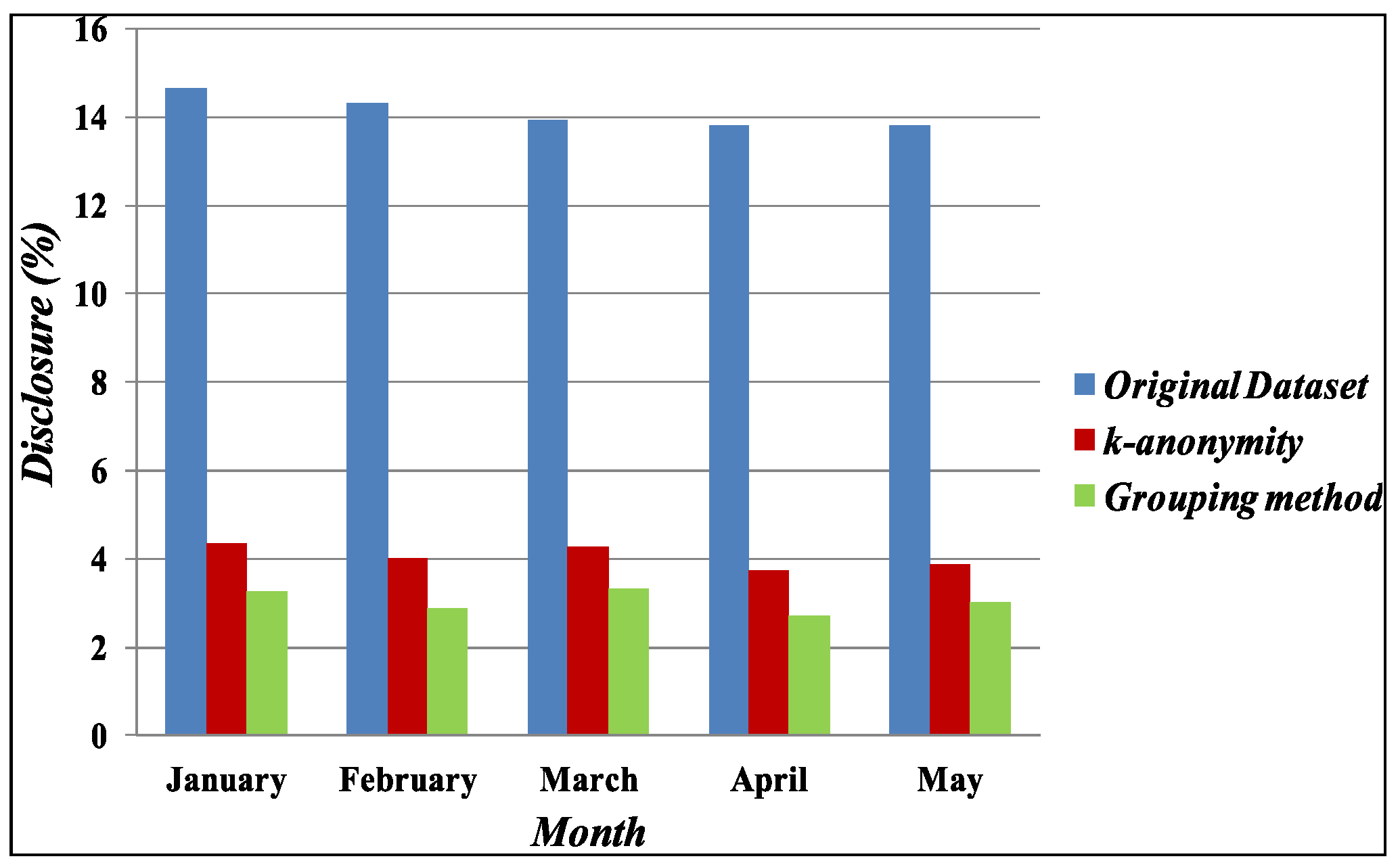
4.1. Disclosure
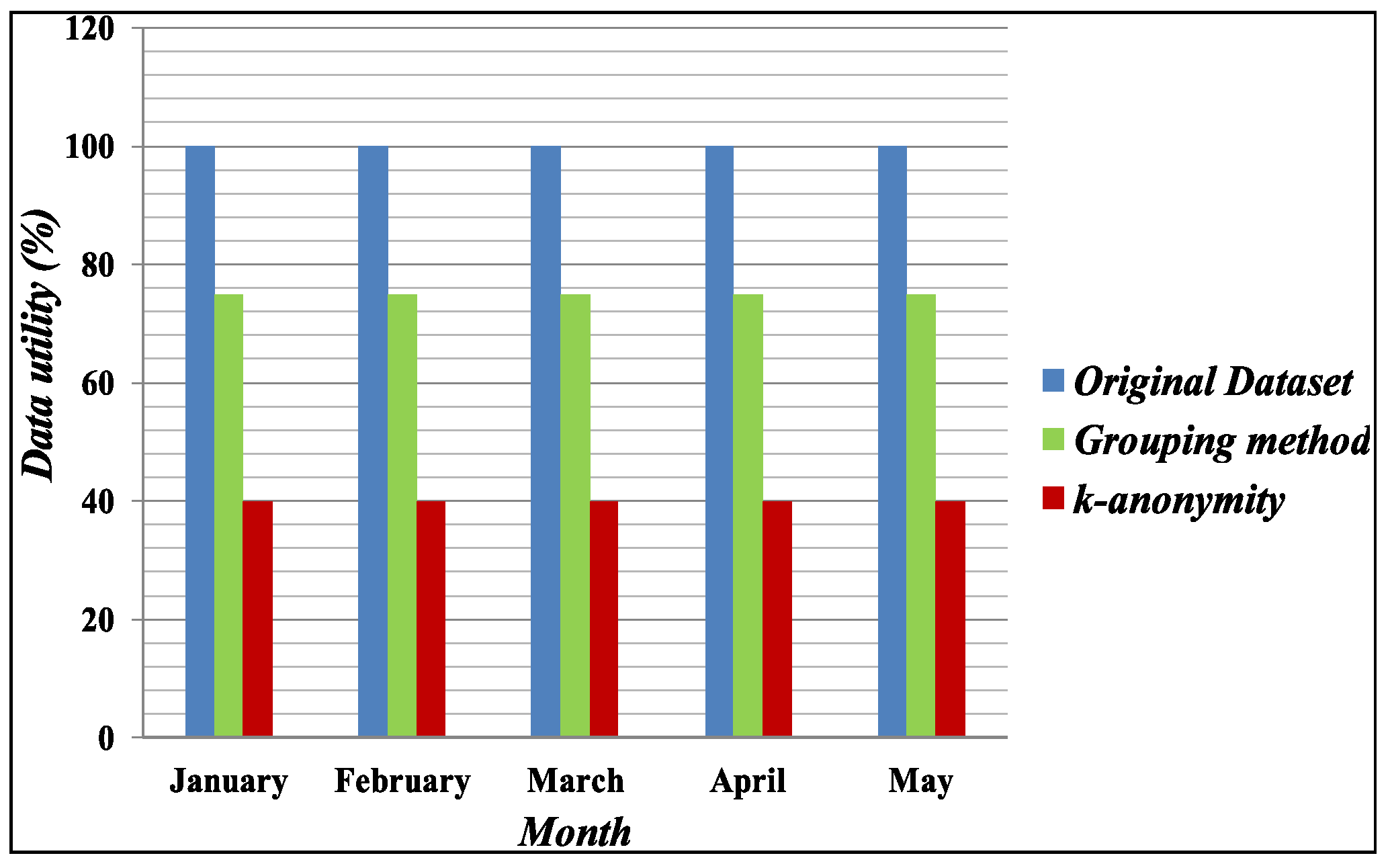
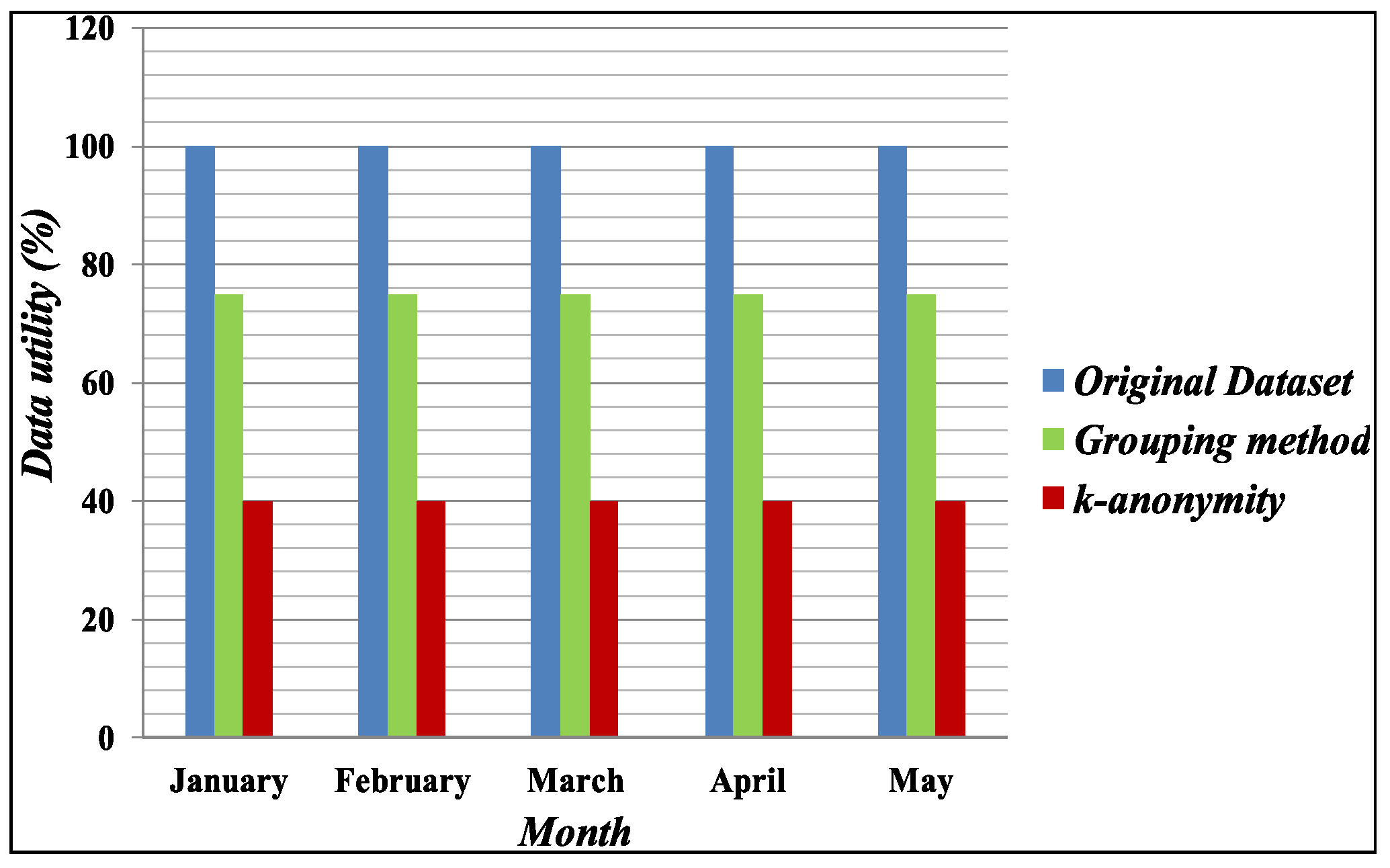
4.2. Data Utility Comparison
4.2.1. Data Utility
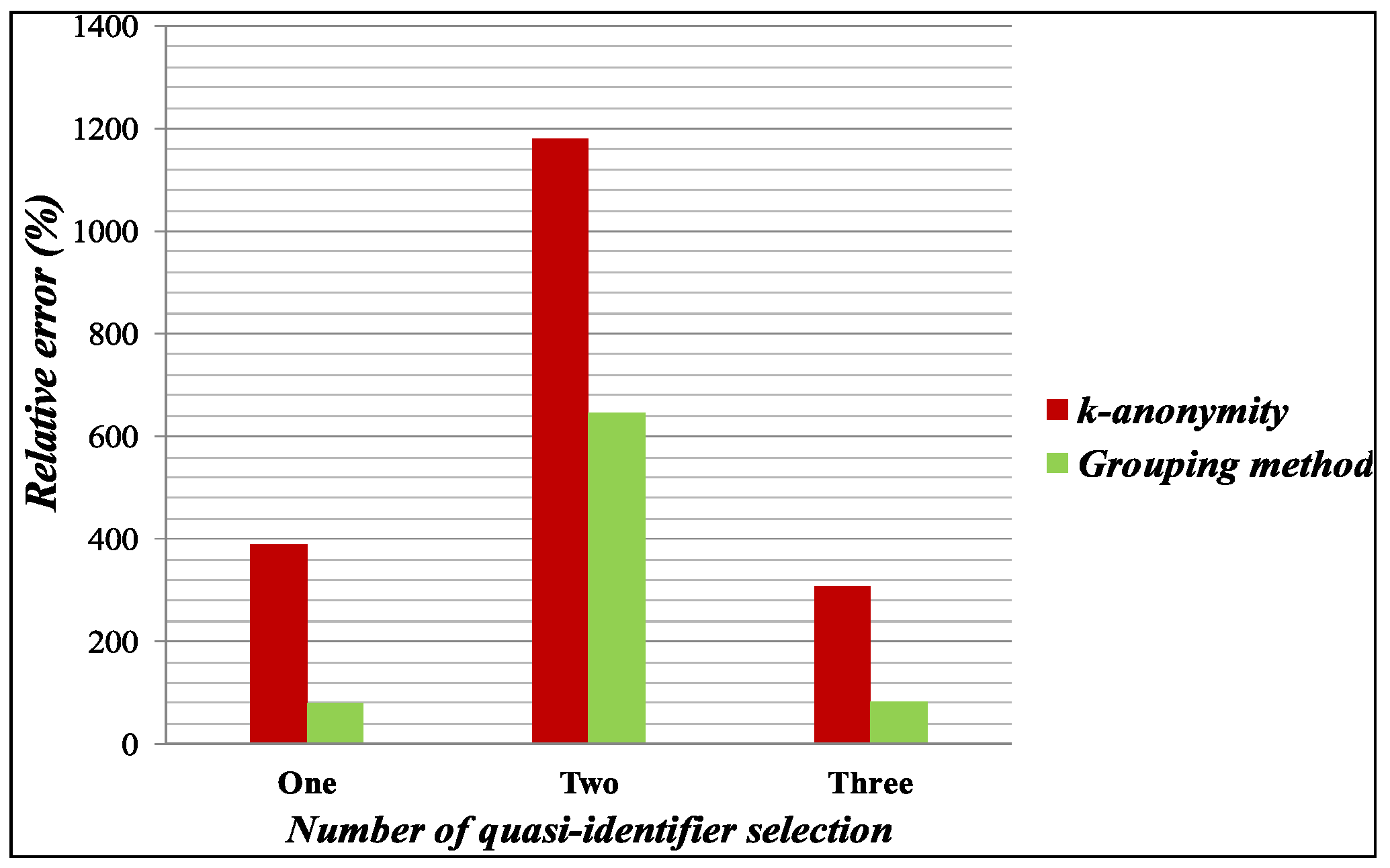
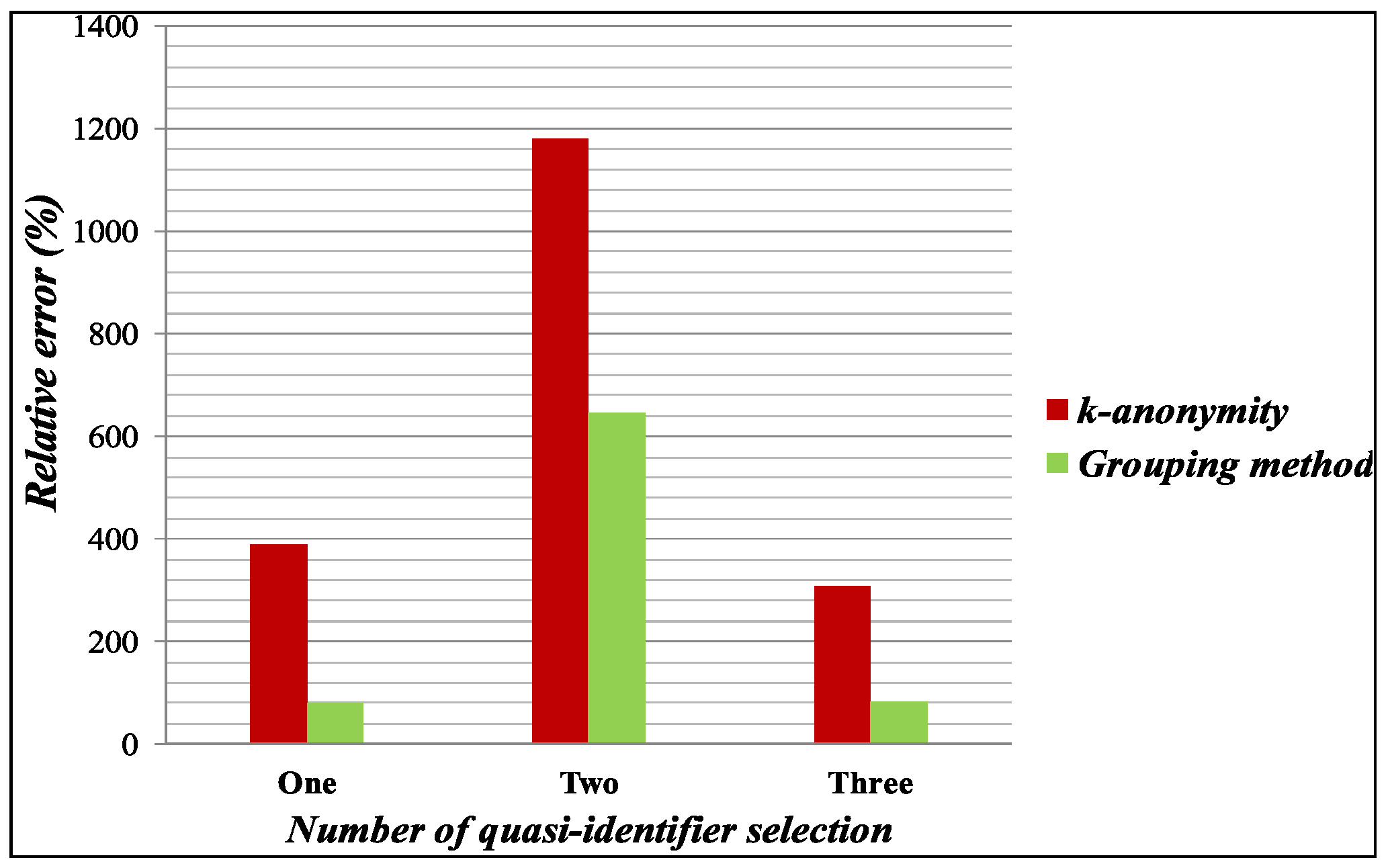
4.2.2. Aggregate Query Error
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Fishman, E.; Washington, S.; Haworth, N. Bikeshare’s impact on active travel: Evidence from the united states, great britain, and australia. J. Transp. Health 2015, 2, 135–142. [Google Scholar] [CrossRef]
- Scheepers, E.; Wendel-Vos, W.; van Kempen, E.; Panis, L.I.; Maas, J.; Stipdonk, H.; Moerman, M.; den Hertog, F.; Staatsen, B.; van Wesemael, P.; et al. Personal and environmental characteristics associated with choice of active transport modes versus car use for different trip purposes of trips up to 7.5 kilometers in the netherlands. PLoS ONE 2013, 8, e73105. [Google Scholar] [CrossRef] [PubMed]
- Chourabi, H.; Nam, T.; Walker, S.; Gil-Garcia, J.R.; Mellouli, S.; Nahon, K.; Pardo, T.A.; Scholl, H.J. Understanding smart cities: An integrative framework. In Proceedings of the 2012 45th Hawaii International Conference on System Science (HICSS), Maui, HI, USA, 4–7 January 2012; pp. 2289–2297. [Google Scholar]
- Meijer, A.; Bolívar, M.P.R. Governing the smart city: A review of the literature on smart urban governance. Int. Rev. Adm. Sci. 2016, 82, 392–408. [Google Scholar]
- Dyson, L. Beyond Transparency: Open Data and the Future of Civic Innovation; Code for America Press: San Francisco, CA, USA, 2013. [Google Scholar]
- Dobre, C.; Xhafa, F. Pervasive Computing: Next Generation Platforms for Intelligent Data Collection; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- Douriez, M.; Doraiswamy, H.; Freire, J.; Silva, C.T. Anonymizing nyc taxi data: Does it matter? In Proceedings of the 2016 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Montreal, QC, Canada, 17–19 October 2016; pp. 140–148. [Google Scholar]
- The Home of the U.S. Government’s Open Data. 2017. Available online: https://www.data.gov (accessed on 14 October 2017).
- Lu, R.; Lin, X.; Shen, X. Spoc: A secure and privacy-preserving opportunistic computing framework for mobile-healthcare emergency. IEEE Trans. Parallel Distrib. Syst. 2013, 24, 614–624. [Google Scholar] [CrossRef]
- Castiglione, A.; DAmbrosio, C.; De Santis, A.; Castiglione, A.; Palmieri, F. On secure data management in health-care environment. In Proceedings of the 2013 Seventh International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing (IMIS), Taichung, Taiwan, 3–5 July 2013; pp. 666–671. [Google Scholar]
- Gligoric, N.; Dimcic, T.; Drajic, D.; Krco, S.; Chu, N. Application-layer security mechanism for m2m communication over sms. In Proceedings of the 2012 20th Telecommunications Forum (TELFOR), Belgrade, Serbia, 20–22 November 2012; pp. 5–8. [Google Scholar]
- Pizzolante, R.; Carpentieri, B.; Castiglione, A.; Castiglione, A.; Palmieri, F. Text compression and encryption through smart devices for mobile communication. In Proceedings of the 2013 Seventh International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing (IMIS), Taichung, Taiwan, 3–5 July 2013; pp. 672–677. [Google Scholar]
- Sweeney, L. K-anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef]
- Li, J.; Baig, M.M.; Sattar, A.S.; Ding, X.; Liu, J.; Vincent, M. A hybrid approach to prevent composition attacks for independent data releases. Inf. Sci. 2016, 367–368, 324–336. [Google Scholar] [CrossRef]
- Narayanan, A.; Shmatikov, V. Shmatikov how to break anonymity of the netflix prize dataset. arXiv, 2006; arXiv:cs/0610105. [Google Scholar]
- Citi Bike Daily Ridership and Membership Data. Available online: https://www.citibikenyc.com/system-data (accessed on 3 April 2017).
- Aïvodji, U.M.; Gambs, S.; Huguet, M.-J.; Killijian, M.-O. Meeting points in ridesharing: A privacy-preserving approach. Transp. Res. Part C Emerg. Technol. 2016, 72, 239–253. [Google Scholar] [CrossRef]
- Bayardo, R.J.; Agrawal, R. Data privacy through optimal k-anonymization. In Proceedings of the 21st International Conference on Data Engineering, 2005, ICDE 2005, Tokoyo, Japan, 5–8 April 2005; pp. 217–228. [Google Scholar]
- Li, T.; Li, N.; Zhang, J.; Molloy, I. Slicing: A new approach for privacy preserving data publishing. IEEE Trans. Knowl. Data Eng. 2012, 24, 561–574. [Google Scholar] [CrossRef]
- Hasan, T.; Jiang, Q.; Luo, J.; Li, C.; Chen, L. An effective value swapping method for privacy preserving data publishing. Secur. Commun. Netw. 2016, 9, 3219–3228. [Google Scholar] [CrossRef]
- Kambourakis, G. Anonymity and closely related terms in the cyberspace: An analysis by example. J. Inf. Secur. Appl. 2014, 19, 2–17. [Google Scholar] [CrossRef]
- Pfitzmann, A.; Köhntopp, M. Anonymity, unobservability, and pseudonymity—A proposal for terminology. In Designing Privacy Enhancing Technologies; Springer: Berlin/Heidelberg, Germany, 2001; pp. 1–9. [Google Scholar]
- Pfitzmann, A.; Hansen, M. A Terminology for Talking About Privacy by Data Minimization: Anonymity, Unlinkability, Undetectability, Unobservability, Pseudonymity, and Identity Management. 2010. Available online: http://dud.inf.tu-dresden.de/literatur/Anon_Terminology_v0.34.pdf (accessed on 14 October 2017).
- Hansen, M.; Smith, R.; Tschofenig, H. CA Privacy terminology and concepts. In Internet Draft, March 2012; Technical Report; Network Working Group, IETF: Fremont, CA, USA, 2011. [Google Scholar]
- Gehrke, J. Models and methods for privacypreserving data publishing and analysis. In Proceedings of the 22nd International Conference on Data Engineering (ICDE), Atlanta, GA, USA, 3–7 April 2006; Volume 105. [Google Scholar]
- Yang, Z.; Zhong, S.; Wright, R.N. Anonymity-preserving data collection. In Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining, Chicago, IL, USA, 21–24 August 2005; pp. 334–343. [Google Scholar]
- Wong, R.C.-W.; Fu, A.W.-C. Privacy-preserving data publishing: An overview. Synth. Lect. Data Manag. 2010, 2, 1–138. [Google Scholar] [CrossRef]
- Taric, G.J.; Poovammal, E. A survey on privacy preserving data mining techniques. Indian J. Sci. Technol. 2017, 8. [Google Scholar] [CrossRef]
- Samarati, P.; Sweeney, L. Generalizing data to provide anonymity when disclosing information. PODS 1998, 98, 188. [Google Scholar] [CrossRef]
- Kwan, M.-P.; Casas, I.; Schmitz, B. Protection of geoprivacy and accuracy of spatial information: How effective are geographical masks? Int. J. Geogr. Inf. Sci. 2004, 39, 15–28. [Google Scholar] [CrossRef]
- Machanavajjhala, A.; Kifer, D.; Gehrke, J.; Venkitasubramaniam, M. L-diversity: Privacy beyond k-anonymity. ACM Trans. Knowl. Discov. Data 2007, 1, 3. [Google Scholar] [CrossRef]
- Dwork, C. Differential privacy. In IN ICALP; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1–12. [Google Scholar]
- Gambs, S.; Killijian, M.-O.; del Prado Cortez, M.N. Show me how you move and i will tell you who you are. In Proceedings of the 3rd ACM SIGSPATIAL International Workshop on Security and Privacy in GIS and LBS, San Jose, CA, USA, 2 November 2010; pp. 34–41. [Google Scholar]
- Gonzalez, M.C.; Hidalgo, C.A.; Barabasi, A.-L. Understanding individual human mobility patterns. Nature 2008, 453, 779–782. [Google Scholar] [CrossRef] [PubMed]
- Song, C.; Qu, Z.; Blumm, N.; Barabási, A.-L. Limits of predictability in human mobility. Science 2010, 327, 1018–1021. [Google Scholar] [CrossRef] [PubMed]
- Hasan, T.; Jiang, Q. A general framework for privacy preserving sequential data publishing. In Proceedings of the 31st International Conference on Advanced Information Networking and Applications Workshops (WAINA), Taipei, Taiwan, 27–29 March 2017; pp. 519–524. [Google Scholar]
- Ganta, S.R.; Kasiviswanathan, S.P.; Smith, A. Composition attacks and auxiliary information in data privacy. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 265–273. [Google Scholar]
- Wang, K.; Fung, B. Anonymizing sequential releases. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 414–423. [Google Scholar]
- Xiao, X.; Tao, Y. M-invariance: Towards privacy preserving re-publication of dynamic datasets. In Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data, Beijing, China, 11–14 June 2007; pp. 689–700. [Google Scholar]
- Dwork, C. Differential privacy: A survey of results. In 5th International Conference on Theory and Applications of Models of Computation; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1–19. [Google Scholar]
- Mohammed, N.; Chen, R.; Fung, B.; Yu, P.S. Differentially private data release for data mining. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 493–501. [Google Scholar]
- Li, H.; Xiong, L.; Zhang, L.; Jiang, X. Dpsynthesizer: Differentially private data synthesizer for privacy preserving data sharing. Proc. VLDB Endow. 2014, 7, 1677–1680. [Google Scholar] [CrossRef] [PubMed]
- Dong, B.; Wang, W. Frequency-hiding dependency-preserving encryption for outsourced databases. In Proceedings of the IEEE 33rd International Conference on Data Engineering (ICDE), San Diego, CA, USA, 19–22 April 2017; pp. 721–732. [Google Scholar]
- Dong, B.; Wang, W.; Yang, J. Secure data outsourcing with adversarial data dependency constraints. In Proceedings of the IEEE 2nd International Conference on Big Data Security on Cloud (BigDataSecurity), IEEE International Conference on High Performance and Smart Computing (HPSC), and IEEE International Conference on Intelligent Data and Security (IDS), New York, NY, USA, 9–10 April 2016; pp. 73–78. [Google Scholar]
- Dong, B.; Liu, R.; Wang, W.H. Prada: Privacy-preserving data-deduplication-as-a-service. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 1559–1568. [Google Scholar]
- Wang, X. Intelligent multi-camera video surveillance: A review. Pattern Recogn. Lett. 2013, 34, 3–19. [Google Scholar] [CrossRef]
- Albano, P.; Bruno, A.; Carpentieri, B.; Castiglione, A.; Castiglione, A.; Palmieri, F.; Pizzolante, R.; Yim, K.; You, I. Secure and distributed video surveillance via portable devices. J. Ambient Intell. Hum. Comput. 2014, 5, 205–213. [Google Scholar] [CrossRef]
- Yadav, D.K.; Singh, K.; Kumari, S. Challenging issues of video surveillance system using internet of things in cloud environment. In International Conference on Advances in Computing and Data Sciences; Springer: Singapore, 2016; pp. 471–481. [Google Scholar]
- Albano, P.; Bruno, A.; Carpentieri, B.; Castiglione, A.; Castiglione, A.; Palmieri, F.; Pizzolante, R.; You, I. A secure distributed video surveillance system based on portable devices. In CD-ARES; Springer: Berlin/Heidelberg, Germany, 2012; pp. 403–415. [Google Scholar]
- Yao, C.; Wang, X.S.; Jajodia, S. Checking for k-anonymity violation by views. In Proceedings of the 31st International Conference on Very Large Data Bases, Trondheim, Norway, 30 August–2 September 2005; pp. 910–921. [Google Scholar]
- Yang, B.; Nakagawa, H.; Sato, I.; Sakuma, J. Collusion-resistant privacy-preserving data mining. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 25–28 July 2010; pp. 483–492. [Google Scholar]
- Wong, R.C.-W.; Fu, A.W.-C.; Liu, J.; Wang, K.; Xu, Y. Global privacy guarantee in serial data publishing. In Proceedings of the IEEE 26th International Conference on Data Engineering (ICDE), Long Beach, CA, USA, 1–6 March 2010; pp. 956–959. [Google Scholar]
- Zhang, S.; Freundschuh, S.M.; Lenzer, K.; Zandbergen, P.A. The location swapping method for geomasking. Cartogr. Geogr. Inf. Sci. 2017, 44, 22–34. [Google Scholar] [CrossRef]
- Li, H.; Zhu, H.; Du, S.; Liang, X.; Shen, X. Privacy leakage of location sharing in mobile social networks: Attacks and defense. IEEE Trans. Dependable Secur. Comput. 2016. [Google Scholar] [CrossRef]
- Hasan, T.; Jiang, Q.; Li, C.; Chen, L. An effective model for anonymizing personal location trajectory. In Proceedings of the 6th International Conference on Communication and Network Security, Singapore, 26–29 November 2016; ACM: New York, NY, USA; pp. 35–39. [Google Scholar]
- Cramér, H. Mathematical Methods of Statistics (PMS-9); Princeton University Press: Princeton, NJ, USA, 2016; Volume 9. [Google Scholar]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 344. [Google Scholar]
- LeFevre, K.; DeWitt, D.J.; Ramakrishnan, R. Mondrian multidimensional k-anonymity. In Proceedings of the 22nd International Conference on Data Engineering, Atlanta, GA, USA, 3–7 April 2006; p. 25. [Google Scholar]
- Geeen, K.; Tashman, L. Percentage error: What denominator? Foresight Int. J. Appl. Forecast. 2009, 12, 36–40. [Google Scholar]
- Zhang, Q.; Koudas, N.; Srivastava, D.; Yu, T. Aggregate query answering on anonymized tables. In Proceedings of the IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, 15–20 April 2007; pp. 116–125. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Birth Year | Gender | Start Station | End Station | Start Time | End Time |
|---|---|---|---|---|---|
| 1970 | M | E 47 St & Park Ave | W 49 St & 8 Ave | 4/1/2016 6:53 | 4/1/2016 6:59 |
| 1970 | M | W 49 St & 8 Ave | E 47 St & Park Ave | 4/1/2016 16:12 | 4/1/2016 16:19 |
| 1986 | F | E 17 St & Broadway | E 27 St & 1 Ave | 4/5/2016 13:48 | 4/5/2016 13:56 |
| 1986 | F | E 27 St & 1 Ave | E 17 St & Broadway | 4/6/2016 0:16 | 4/6/2016 0:25 |
| 1970 | M | E 47 St & Park Ave | W 49 St & 8 Ave | 4/7/2016 18:49 | 4/7/2016 18:55 |
| 1988 | M | Broadway & E 22 St | E 20 St & 2 Ave | 4/7/2016 6:06 | 4/7/2016 6:11 |
| 1970 | M | W 49 St & 8 Ave | E 47 St & Park Ave | 4/7/2016 17:56 | 4/7/2016 18:02 |
| 1981 | M | 8 Ave & W 52 St | W 63 St & Broadway | 4/7/2016 6:47 | 4/7/2016 6:52 |
| 1986 | F | E 27 St & 1 Ave | E 17 St & Broadway | 4/20/2016 0:06 | 4/20/2016 0:15 |
| 1988 | M | E 20 St & 2 Ave | Broadway & E 22 St | 4/20/2016 8:41 | 4/20/2016 8:45 |
| 1983 | M | Carlton Ave & Flushing Ave | Front St & Gold St | 4/20/2016 11:16 | 4/20/2016 11:20 |
| 1983 | F | W 21 St & 6 Ave | E 20 St & 2 Ave | 4/21/2016 7:53 | 4/21/2016 8:00 |
| Birth Year | Gender | Start Station | End Station | Start Time | End Time |
|---|---|---|---|---|---|
| (1970–1988) | Person | [E 47 St & Park Ave, Broadway & E 22 St, W 49 St & 8 Ave] | [W 49 St & 8 Ave, E 20 St & 2 Ave, E 47 St & Park Ave] | 4/1/2016 6:53 | 4/1/2016 6:59 |
| (1970–1988) | Person | [E 47 St & Park Ave, Broadway & E 22 St, W 49 St & 8 Ave] | [W 49 St & 8 Ave, E 20 St & 2 Ave, E 47 St & Park Ave] | 4/7/2016 6:49 | 4/7/2016 6:55 |
| (1970–1988) | Person | [E 47 St & Park Ave, Broadway & E 22 St, W 49 St & 8 Ave] | [W 49 St & 8 Ave, E 20 St & 2 Ave, E 47 St & Park Ave] | 4/7/2016 18:06 | 4/7/2016 18:11 |
| (1970–1988) | Person | [E 47 St & Park Ave, Broadway & E 22 St, W 49 St & 8 Ave] | [W 49 St & 8 Ave, E 20 St & 2 Ave, E 47 St & Park Ave] | 4/7/2016 17:56 | 4/7/2016 18:02 |
| (1970–1986) | Person | [E 20 St & 2 Ave, Carlton Ave & Flushing Ave, W 49 St & 8 Ave, E 17 St & Broadway] | [Broadway & E 22 St, Front St & Gold St, E 47 St & Park Ave, E 27 St & 1 Ave] | 4/20/2016 8:41 | 4/20/2016 8:45 |
| (1970–1986) | Person | [E 20 St & 2 Ave, Carlton Ave & Flushing Ave, W 49 St & 8 Ave, E 17 St & Broadway] | [Broadway & E 22 St, Front St & Gold St, E 47 St & Park Ave, E 27 St & 1 Ave] | 4/20/2016 11:16 | 4/20/2016 11:20 |
| (1970–1986) | Person | [E 20 St & 2 Ave, Carlton Ave & Flushing Ave, W 49 St & 8 Ave, E 17 St & Broadway] | [Broadway & E 22 St, Front St & Gold St, E 47 St & Park Ave, E 27 St & 1 Ave] | 4/1/2016 16:12 | 4/1/2016 16:19 |
| (1970–1986) | Person | [E 20 St & 2 Ave, Carlton Ave & Flushing Ave, W 49 St & 8 Ave, E 17 St & Broadway] | [Broadway & E 22 St, Front St & Gold St, E 47 St & Park Ave, E 27 St & 1 Ave] | 4/5/2016 13:48 | 4/5/2016 13:56 |
| (1970–1986) | Person | [E 27 St & 1 Ave, 8 Ave & W 52 St, W 21 St & 6 Ave] | [E 17 St & Broadway, W 63 St & Broadway, E 20 St & 2 Ave] | 4/6/2016 0:16 | 4/6/2016 0:25 |
| (1970–1986) | Person | [E 27 St & 1 Ave,8 Ave & W 52 St, W 21 St & 6 Ave] | [E 17 St & Broadway,W 63 St & Broadway, E 20 St & 2 Ave] | 4/7/2016 6:47 | 4/7/2016 6:52 |
| (1970–1986) | Person | [E 27 St & 1 Ave, 8 Ave & W 52 St, W 21 St & 6 Ave] | [E 17 St & Broadway, W 63 St & Broadway, E 20 St & 2 Ave] | 4/20/2016 0:06 | 4/20/2016 0:15 |
| (1970–1986) | Person | [E 27 St & 1 Ave,8 Ave & W 52 St, W 21 St & 6 Ave] | [E 17 St & Broadway, W 63 St & Broadway, E 20 St & 2 Ave] | 4/21/2016 7:53 | 4/21/2016 8:00 |
| Birth Year | Gender | (Start Station, End Station) | (Start Time, End Time) |
|---|---|---|---|
| 1983 | Person | (E 20 St & 2 Ave, Broadway & E 22 St) | (4/7/2016 6:49, 4/7/2016 6:55) |
| 1988 | Person | (E 47 St & Park Ave, W 49 St & 8 Ave) | (4/20/2016 8:41, 4/20/2016 8:45) |
| 1970 | Person | (8 Ave & W 52 St, W 63 St & Broadway) | (4/20/2016 11:16, 4/20/2016 11:20) |
| 1988 | Person | (Carlton Ave & Flushing Ave, Front St & Gold St) | (4/7/2016 18:06, 4/7/2016 18:11) |
| 1981 | Person | (E 47 St & Park Ave, W 49 St & 8 Ave) | (4/7/2016 6:47, 4/7/2016 6:52) |
| 1970 | Person | (Broadway & E 22 St, E 20 St & 2 Ave) | (4/1/2016 6:53, 4/1/2016 6:59) |
| 1986 | Person | (E 17 St & Broadway, E 27 St & 1 Ave) | (4/5/2016 13:48, 4/5/2016 13:56) |
| 1970 | Person | (W 49 St & 8 Ave, E 47 St & Park Ave) | (4/7/2016 17:56, 4/7/2016 18:02) |
| 1983 | Person | (W 49 St & 8 Ave, E 47 St & Park Ave) | (4/1/2016 16:12, 4/1/2016 16:19) |
| 1986 | Person | (W 21 St & 6 Ave, E 20 St & 2 Ave) | (4/21/2016 7:53, 4/21/2016 8:00) |
| 1970 | Person | (E 27 St & 1 Ave, E 17 St & Broadway) | (4/6/2016 0:16, 4/6/2016 0:25) |
| 1986 | Person | (E 27 St & 1 Ave, E 17 St & Broadway) | (4/20/2016 0:06, 4/20/2016 0:15) |
| Attribute | Type | Number of Unique Values | |
|---|---|---|---|
| 1 | Birth Year | Continuous | 87 |
| 2 | Gender | Categorical | 2 |
| 3 | Start Station | Categorical | 475 |
| 4 | End Station | Categorical | 483 |
| 5 | Start Time | Date | 2,331,112 |
| 6 | End Time | Date | 2,330,582 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hasan, A.S.M.T.; Jiang, Q.; Li, C. An Effective Grouping Method for Privacy-Preserving Bike Sharing Data Publishing. Future Internet 2017, 9, 65. https://doi.org/10.3390/fi9040065
Hasan ASMT, Jiang Q, Li C. An Effective Grouping Method for Privacy-Preserving Bike Sharing Data Publishing. Future Internet. 2017; 9(4):65. https://doi.org/10.3390/fi9040065
Chicago/Turabian StyleHasan, A S M Touhidul, Qingshan Jiang, and Chengming Li. 2017. "An Effective Grouping Method for Privacy-Preserving Bike Sharing Data Publishing" Future Internet 9, no. 4: 65. https://doi.org/10.3390/fi9040065
APA StyleHasan, A. S. M. T., Jiang, Q., & Li, C. (2017). An Effective Grouping Method for Privacy-Preserving Bike Sharing Data Publishing. Future Internet, 9(4), 65. https://doi.org/10.3390/fi9040065