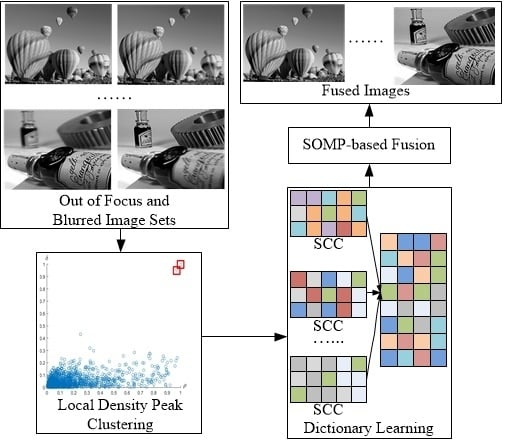
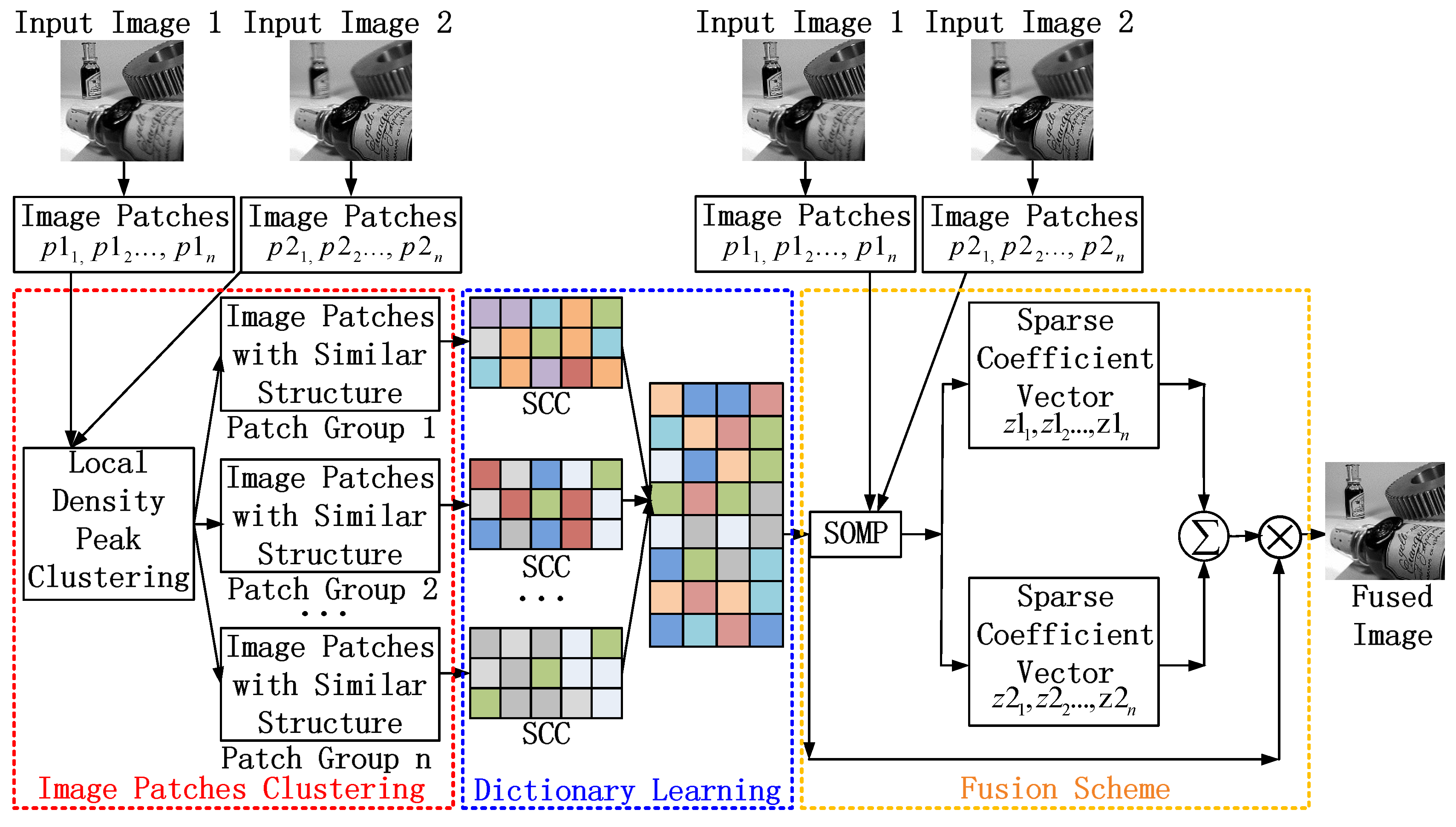
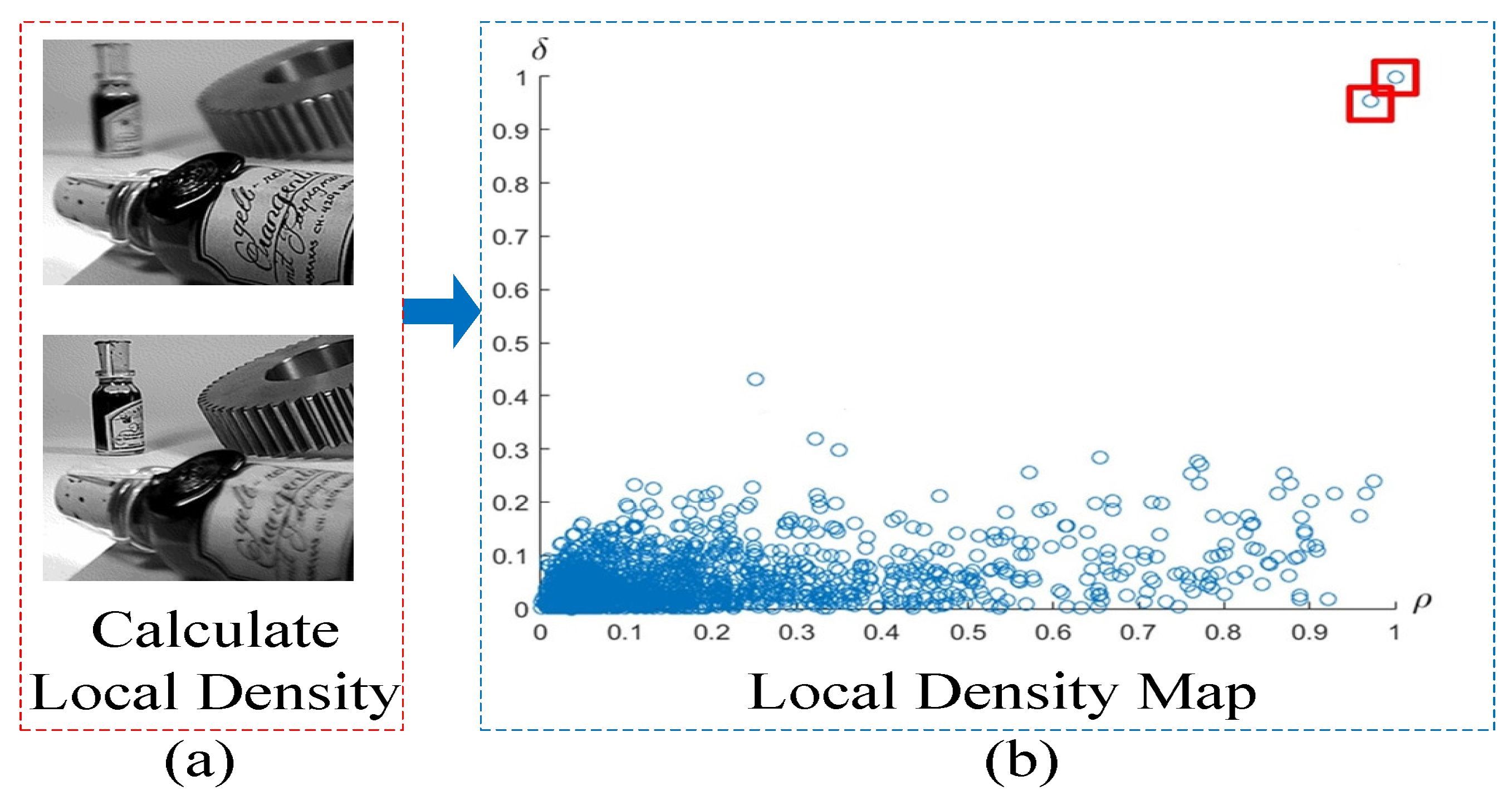
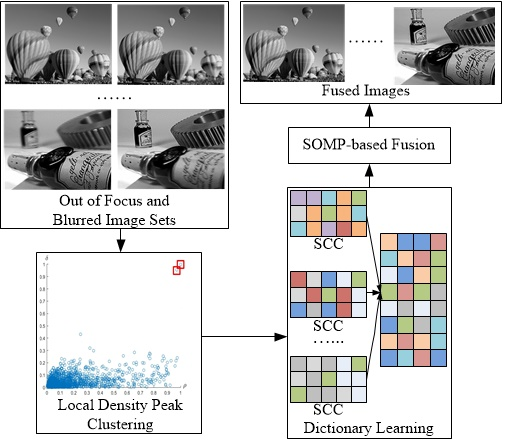
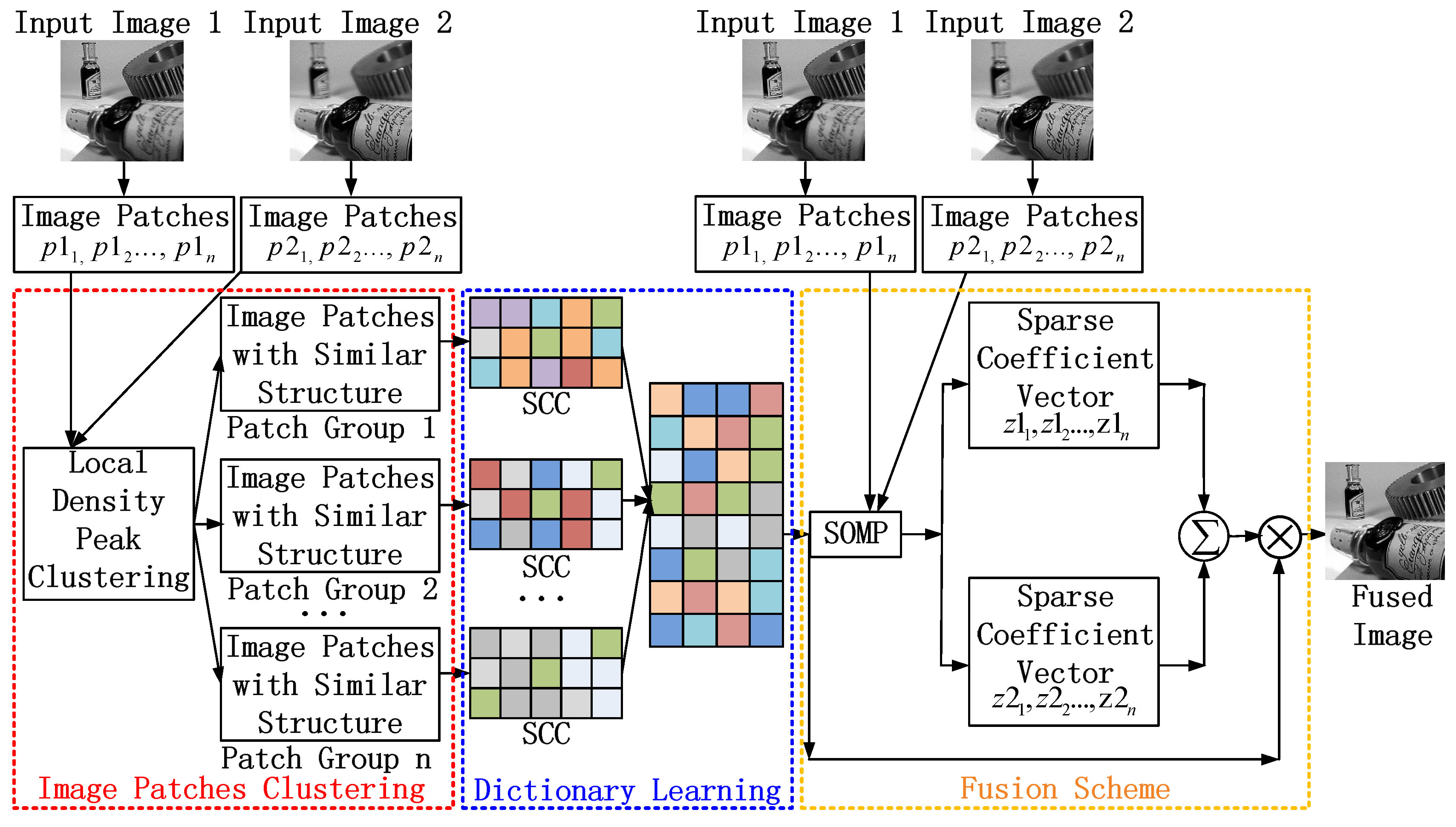
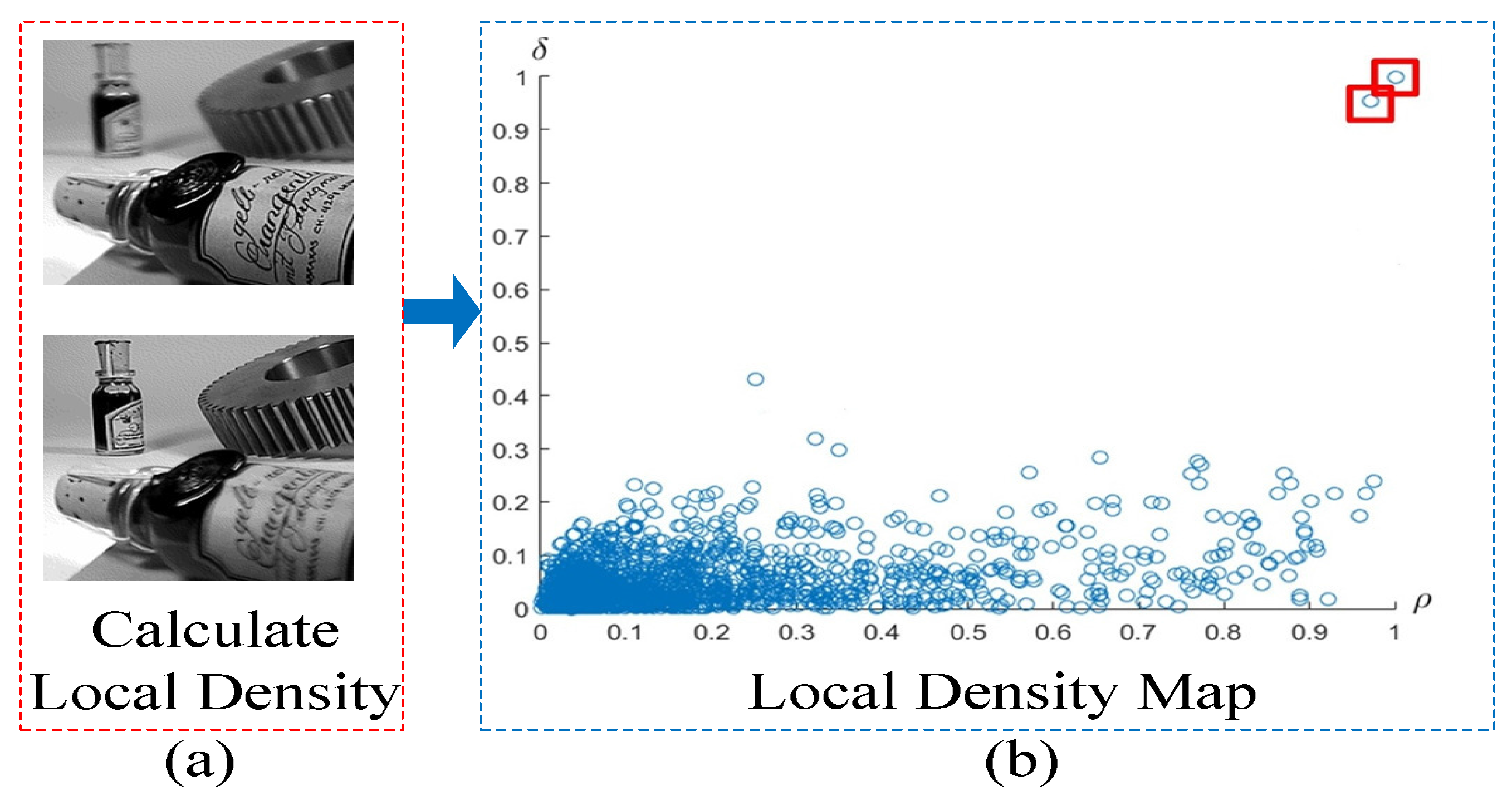
The proposed multi-focus image fusion method is applied to standard multi-focus images from public website [
29]. All standard multi-focus images used in this paper are free to use for research purposes. The images from the image fusion library have the size of 256 × 256 pixels or 320 × 240 pixels. The fused images are evaluated by comparing them to the fused images of other existing methods. In this paper, four pairs of images are used as a case study to simulate the proposed multi-focus image fusion method. To simulate a real world environment, four pairs of images have two scenes. One is an outdoor scene, such as a hot-air balloon and leopard shown in
Figure 3a,b respectively. The other is an indoor scene, such as a lab and bottle shown in
Figure 3c,d respectively. These four pairs of original images are from the same sensor modality. Since each image focuses on a different object, there are two images for each scene. The out-of-focus regions in the original images are blurred.
3.1. Experiment Setup
The quality of the proposed image fusion scheme is evaluated against the other seven popular multi-focus fusion methods. These multi-focus fusion methods consist of popular spatial-based image fusion methods, like Laplacian energy (LE) [
8]; four states of art MST methods, including disperse wavelet transform (DWT) [
30], dual-tree complex wavelet transform (DT-CWT) [
31], curvelet (CVT) [
13], non-subsampled contourlet (NSCT) [
9]; two sparse representation methods, including sparse representation with a fixed DCT dictionary (SR-DCT) [
21] and sparse representation with a trained dictionary by K-SVD (SR-KSVD) [
32]. The objective evaluation of fused image includes edge intensity (EI) [
33], edge retention
[
34], mutual information (MI) [
35,
36], and visual information fidelity (VIF) [
37]. Then it compares the dictionary construction time of the proposed method with K-SVD [
32], which is the most popular dictionary construction method. All experiments are implemented using Matlab, version 2014a; MathWorks: Natick, MA, 2014. and Visual Studio, version Community 2013; Microsoft: Redmond, WA, 2013. mixed programming on an Intel(R) Core(TM), version i7-4720HQ; Intel: Santa Clara, CA, 2015. CPU @ 2.60GHz Laptop with 12.00 GB RAM.
3.1.1. Edge Intensity
The quality of the fused image is measured by the local edge intensity
L in image
I [
38]. It folds a Gaussian kernel
G with the image
I to get a smoothed image. Then it obtains the edge intensity image by subtracting the smoothed image from the original image. The spectrum of the edge intensities depends on the width of the Gaussian kernel
G.
The fused image H is calculated by image and the weighted average of local edge intensities.
3.1.2. Mutual Information
MI for images can be formalized as Equation (
14) [
35].
where
L is the number of gray-level,
is the gray histogram of image A and F. The
and
are edge histogram of image A and F. For a fused image, the MI of the fused image can be calculated by Equation (
15).
where
represents the MI value between input image A and fused image F;
represents the MI value of input image B and fused image F.
3.1.3.
The
metric is a gradient-based quality index to measure how well the edge information of source images conducted to the fused image [
34]. It is calculated by:
where
,
and
are the edge strength and orientation preservation values at location (i,j).
can be computed similarly to
.
and
are the importance weights of
and
respectively.
3.1.4. Visual Information Fidelity
VIF is the novel full reference image quality metric. VIF quantifies the mutual information between the reference and test images based on natural scene statistics (NSS) theory and human visual system (HVS) model. It can be expressed as the ratio between the distorted test image information and the reference image information, the calculation equation of VIF is shown in Equation (
17).
where
and
represent the mutual information, which are extracted from a particular subband in the reference and the test images respectively.
denotes N elements from a random field,
and
are visual signals at the output of HVS model from the reference and the test images respectively.
An average VIF value of each input image and integrated image is used to evaluate the fused image. The evaluation function of VIF for image fusion is shown in Equation (18) [
37].
where
is the VIF value between input image A and fused image F;
is the VIF value between input image B and fused image F.
3.2. Image Quality Comparison
To show the efficiency of the proposed method, the quality comparison of fused images is demonstrated. Four pairs of multi-focused images of a hot-air balloon, leopard, lab, and bottle are employed for quality comparison. It compares the quality of fused image based on visual effect, the accuracy of focused region detection, and the objective evaluations. The different images are used to show the differences between fused images and corresponding source images. This paper increases the contrast and brightness of difference images for printable purposes. All difference images are adjusted by using the same parameters.
In the first comparison experiment, the "hot-air balloon" images are a pair of multi-focused images. The source multi-focused images are shown in
Figure 4a,b. In
Figure 4a, the biggest hot-air balloon on the bottom left is out of focus, the rest of the hot-air balloons are in focus. In contrast, in
Figure 4b, the biggest hot-air balloon is in focus, but the rest of balloons are out of focus. LE, DWT, DT-CWT, CVT, NSCT, SR-DCT, SR-KSVD and the proposed method are employed to merge two multi-focused images into a clear one, respectively. The corresponding fusion results are shown in
Figure 4c–j respectively. The difference images of LE, DWT, DT-CWT, CVT, NSCT, SR-DCT, SR-KSVD and the proposed method do the matrix subtraction with the source images shown in
Figure 4a,b. The corresponding subtracted results are shown in
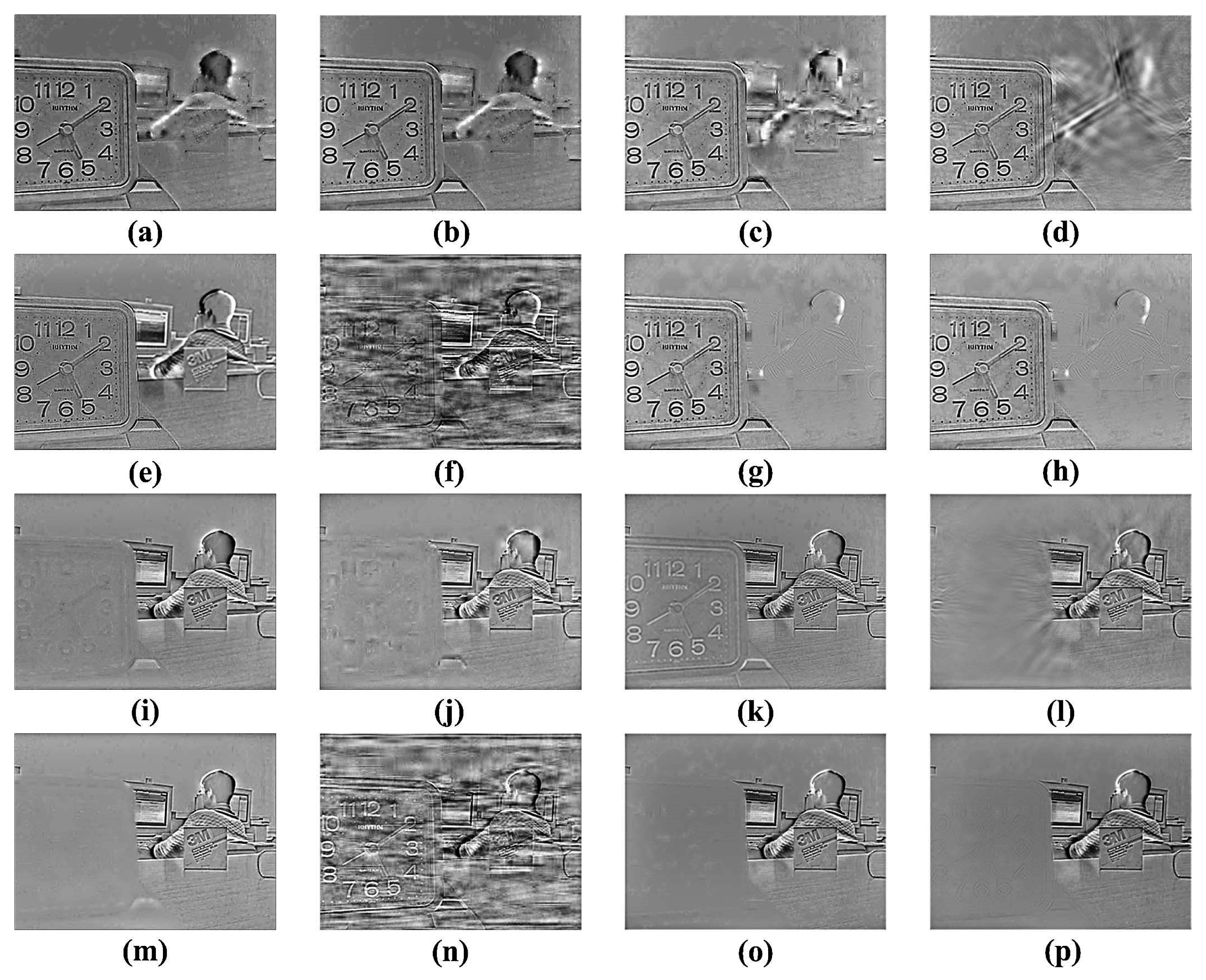
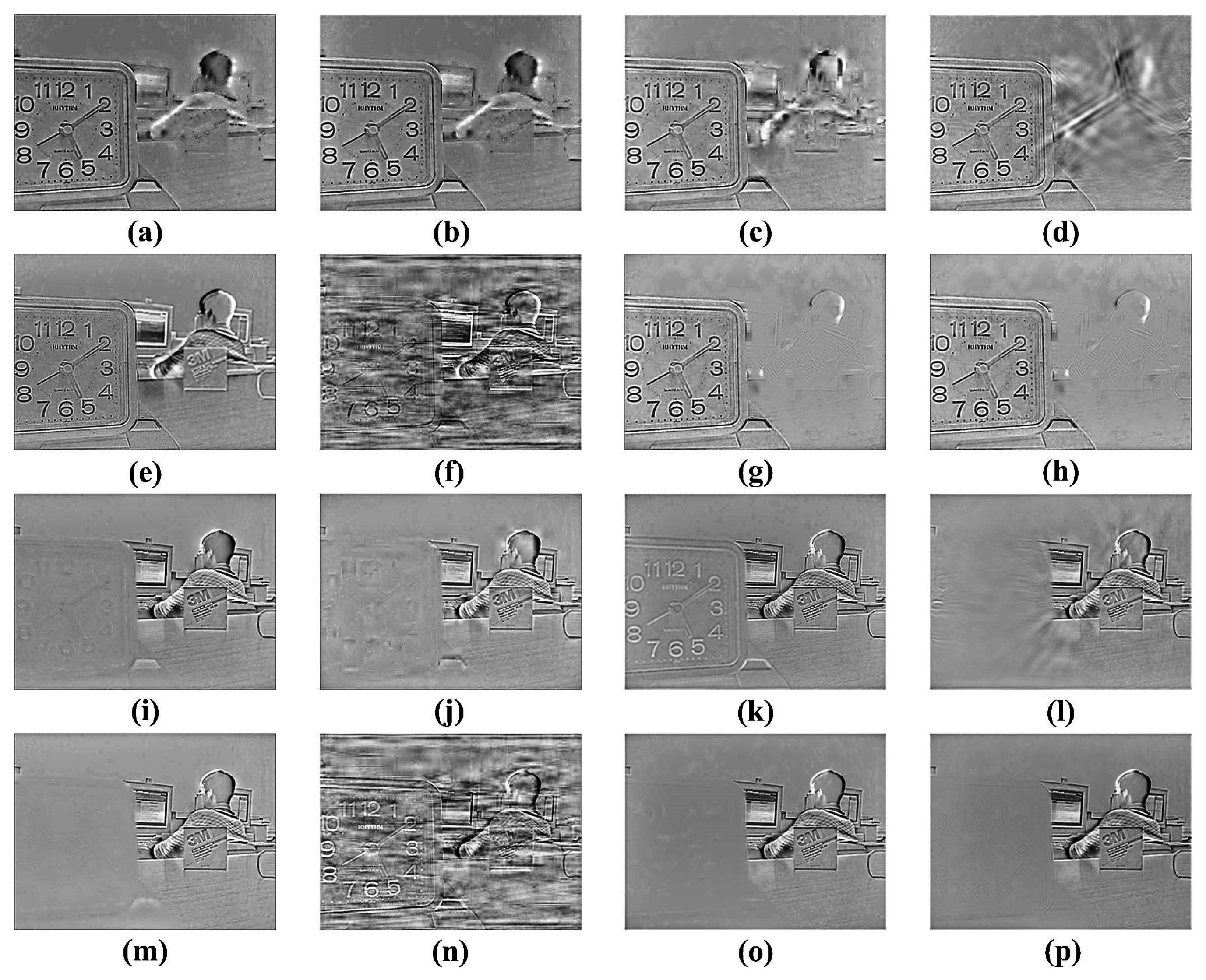
Figure 5a–h,i–p respectively.
Figure 5a–h are the difference images between
Figure 4a and
Figure 4c–j, and
Figure 5i–p are the difference images between
Figure 4b and
Figure 4c–j. The difference images of LE, DWT, DT-CWT, CVT, NSCT, SR-DCT, SR-KSVD and the proposed method are the matrix subtraction results of the corresponding fused images and source images shown in
Figure 4a,b.
There are a lot of noises in
Figure 4h, which are acquired by SR-DCT. The rest of integrated images in
Figure 4 are similar. Difference images, that show hot-air balloons of LE, DWT, and DT-CWT on the left side respectively, do not get all the edge information in
Figure 5a–c.
Similarly,
Figure 5i–k shows that the biggest hot-air balloons of LE, DWT, and DT-CWT on the bottom left, respectively, are not totally focused. Due to the misjudgement of focused areas, the fused "hot-air balloon" images of LE, DWT, DT-CWT, and SR-DCT have shortcomings. Compared with source images, the rest of the methods do great job in identifying the focused area. To further compare the quality of fused images, objective metrics are used.
Table 1 shows the objective evaluations. Compared with the rest of the image fusion methods, the proposed method SR-SCC gets the largest value in MI and VIF. LE and DT-CWT get the largest value in EI and
respectively, but they provide an inaccurate decision in detecting the focused region. The proposed method has the best overall performance of multi-focus image fusion in the "hot-air balloon" scene among all eight methods, according to the quality of fused image, accuracy of locating focused region, and objective evaluations.
Similarly, the source images of the other three comparison experiments, as "leopard", "lab" and "bottle", are shown in
Figure 6,
Figure 7 and
Figure 8a,b respectively. In a set of source images, two images (a) and (b) focus on different items. The source images are fused by LE, DWT, DT-CWT, CVT, NSCT, SR-DCT, SR-KSVD, and the proposed method to get a totally focused image, and the corresponding fusion results are shown in
Figure 6,
Figure 7 and
Figure 8c–j respectively. The difference between fused images and their corresponding source images are shown in
Figure 9,
Figure 10 and
Figure 11a–h,i–p respectively.
Objective metrics of multi-focus "leopard", "lab", and "bottle" fusion experiments are shown in
Table 2,
Table 3 and
Table 4 respectively to evaluate the quality of fused images.
Multi-focus "leopard" fusion: The proposed method SR-SCC achieves the largest value in MI and VIF. LE obtains the largest value in EI index, but it makes inaccurate decision in detecting the focused region. SR-KSVD shows great performance in , and the result of proposed method is only 0.0002 smaller than SR-KSVD. According to the quality of visual image, the accuracy of focused region, and objective evaluations, the proposed method does a better job than the rest of the methods.
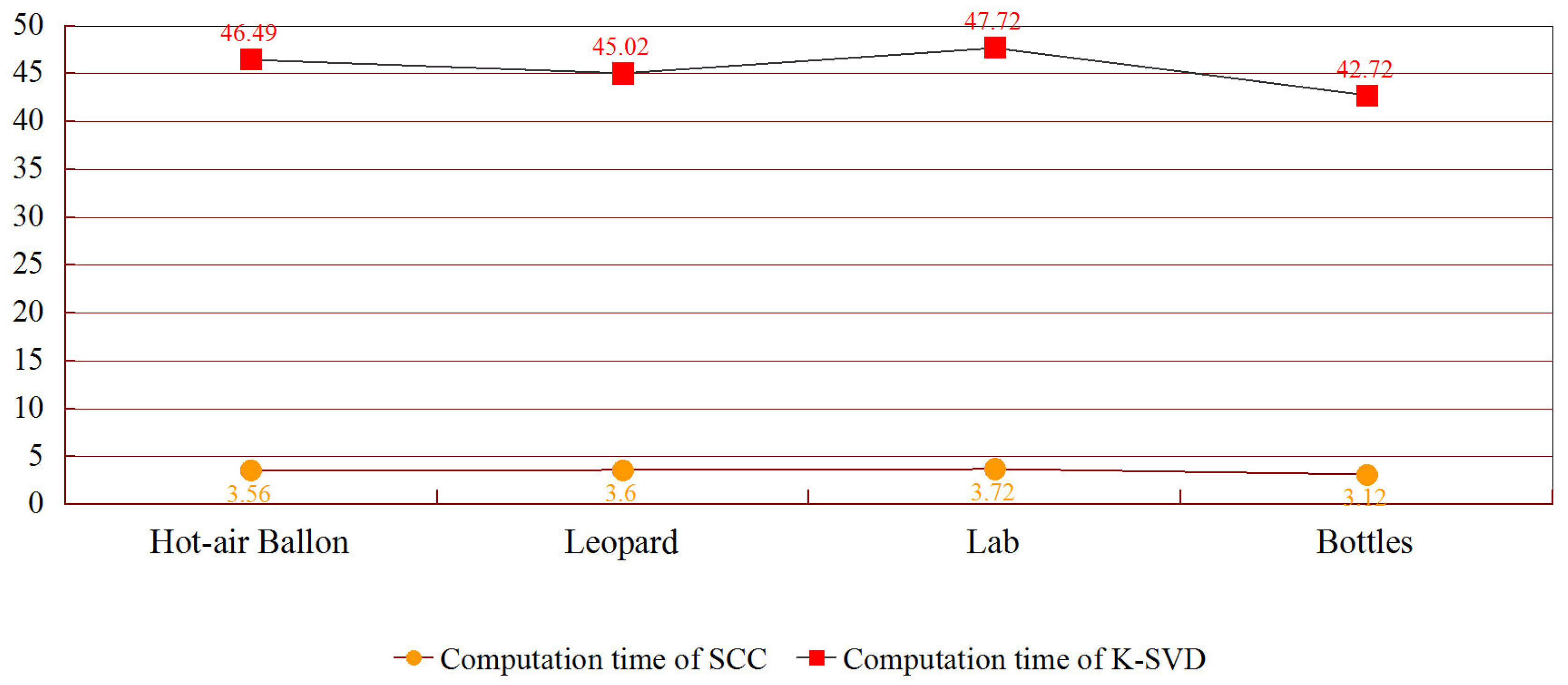
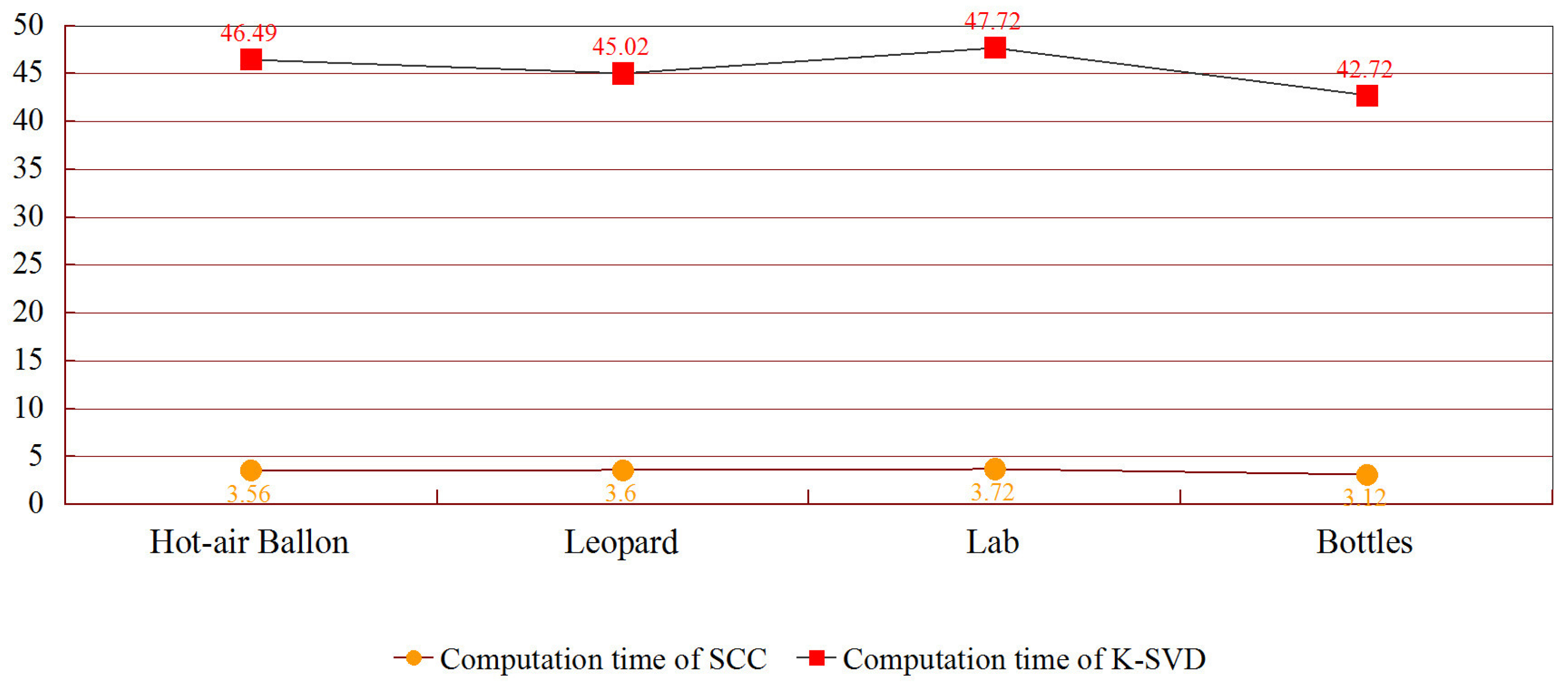
Multi-focus "lab" fusion: The proposed method SR-SCC achieves the largest value in and VIF. DWT obtains the largest value of EI index, but it cannot distinguish the correct focused areas. SR-KSVD has the best performance in MI. The proposed method and SR-KSVD show great performance of visual effect in focused area, distinguishing focused area, and objective evaluation. Compared with SR-KSVD, the proposed method dramatically reduces computation costs in dictionary construction. So the proposed method has the best overall performance among all comparison methods.
Multi-focus "bottle" fusion: DWT obtains the largest value in EI, but it does not get an accurate focused area. The proposed method achieves SR-SCC with the largest values of the rest of the objective evaluations. So the proposed method has the best overall performance compared with other methods in the "bottle" scene.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}