A Distributed Infrastructure for Metadata about Metadata: The HDMM Architectural Style and PORTAL-DOORS System

Abstract
:1. Introduction
2. Related Work
2.1. Metadata Management Systems
2.2. Neuroinformatics Systems
3. A New Approach

4. Hierarchically Distributed Mobile Metadata (HDMM) as an Architectural Style
- Distributed infrastructure: Pervasively distributed and shared infrastructure, content, and control of content including distributed and shared control over both the contribution and distribution of the content defined as the mobile metadata records.
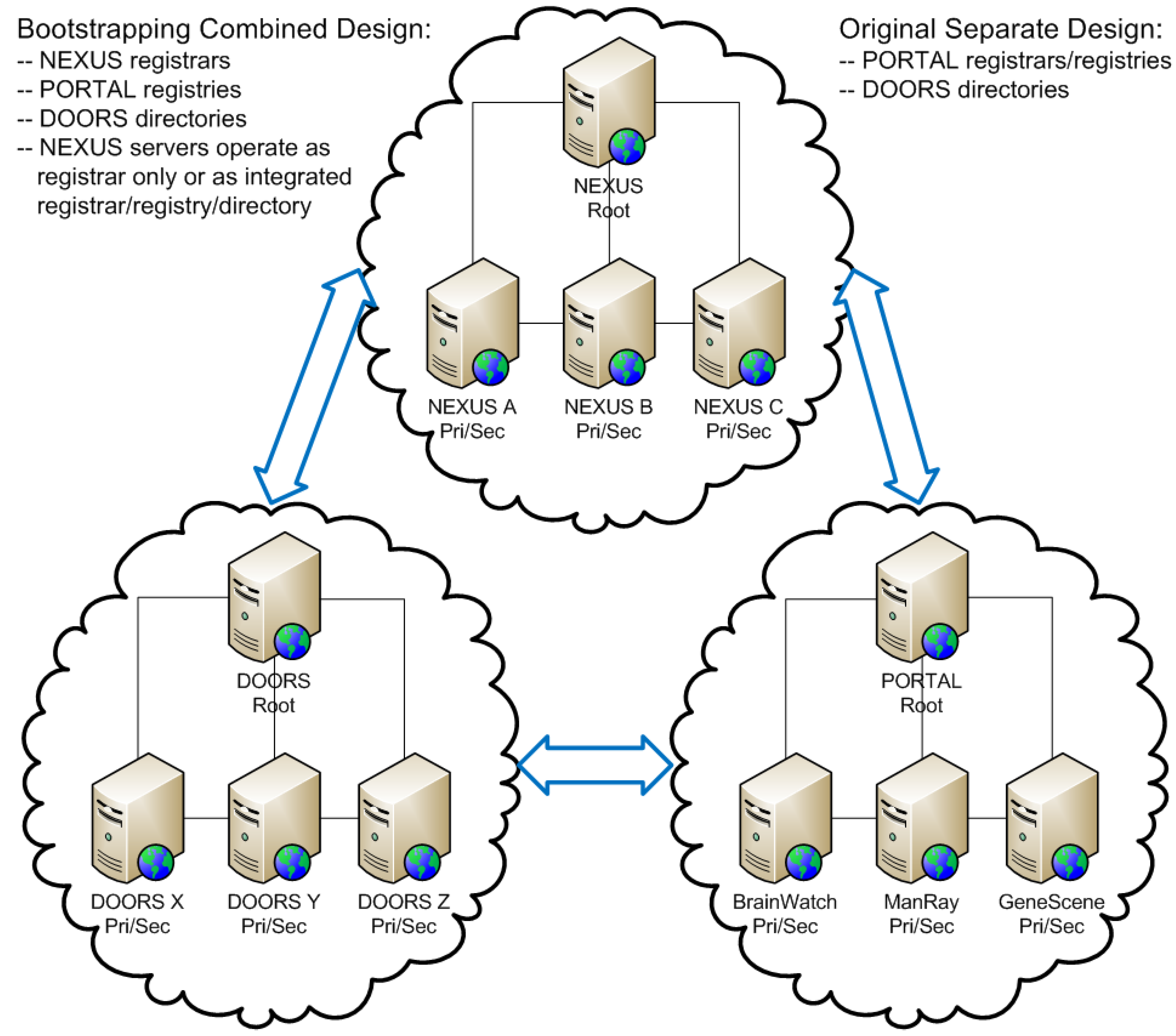
- Hierarchical authorities: A hierarchy of both authoritative and non-authoritative servers (root, primary, secondary, forwarding and caching) enabling global interoperable communication and exchange of the mobile metadata records while permitting independent administrative control of local policies governing the publication and distribution of the metadata records.
- Mobile metadata: A focus on moving the mobile metadata for who what where as fast as possible with pervasive distribution and redistribution from servers in response to requests from clients that access non-authoritative local forwarding and caching servers updated regularly by the authoritative servers.
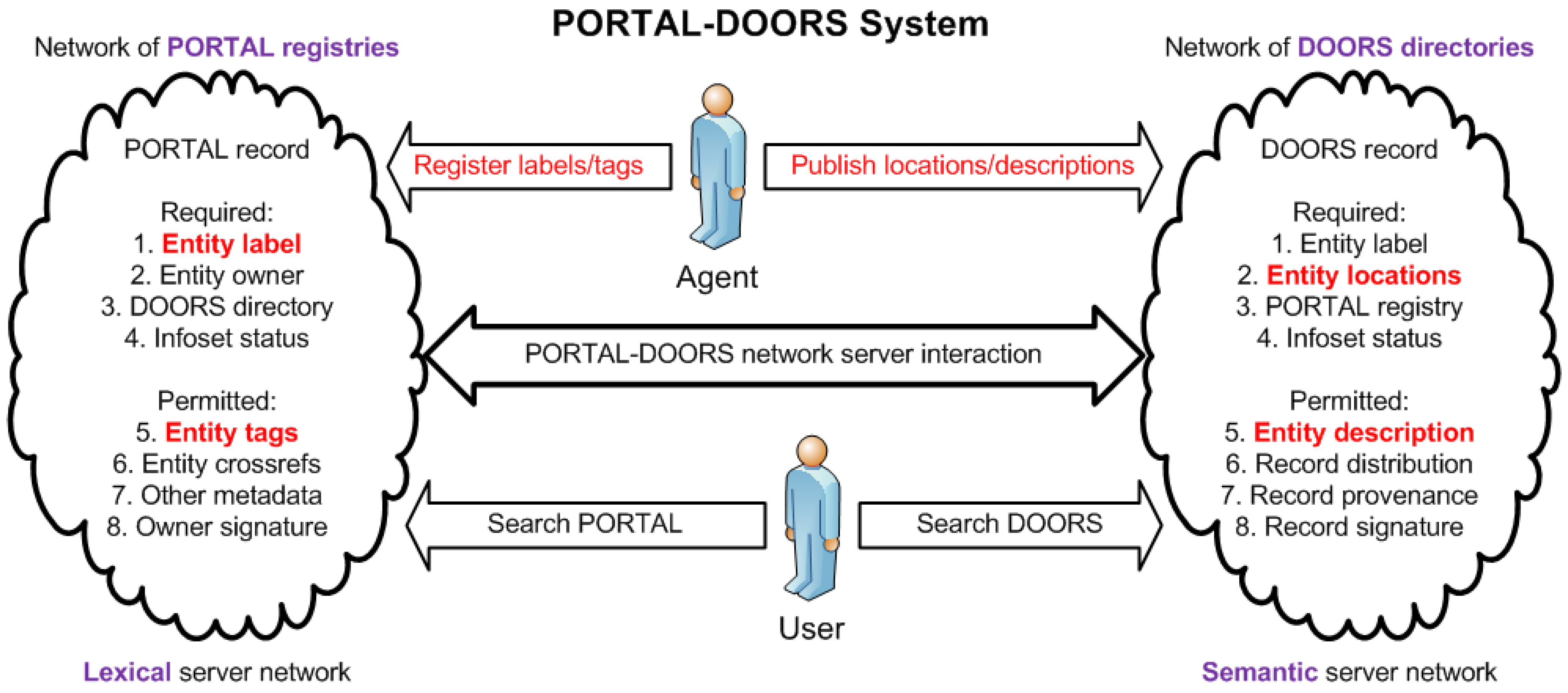
- Separated concerns: A separation of concerns with registries for identifying resources and directories for locating resources that have been globally uniquely identified in the registries.
- Unrestricted identification: A relative freedom of choice in the selection of identifiers with purposeful absence of any requirement to use the same root name or label for all identifiers, thus enabling essentially unrestricted choice of naming or labeling schemes for identification and thereby avoiding monopolistic control by any single organization.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
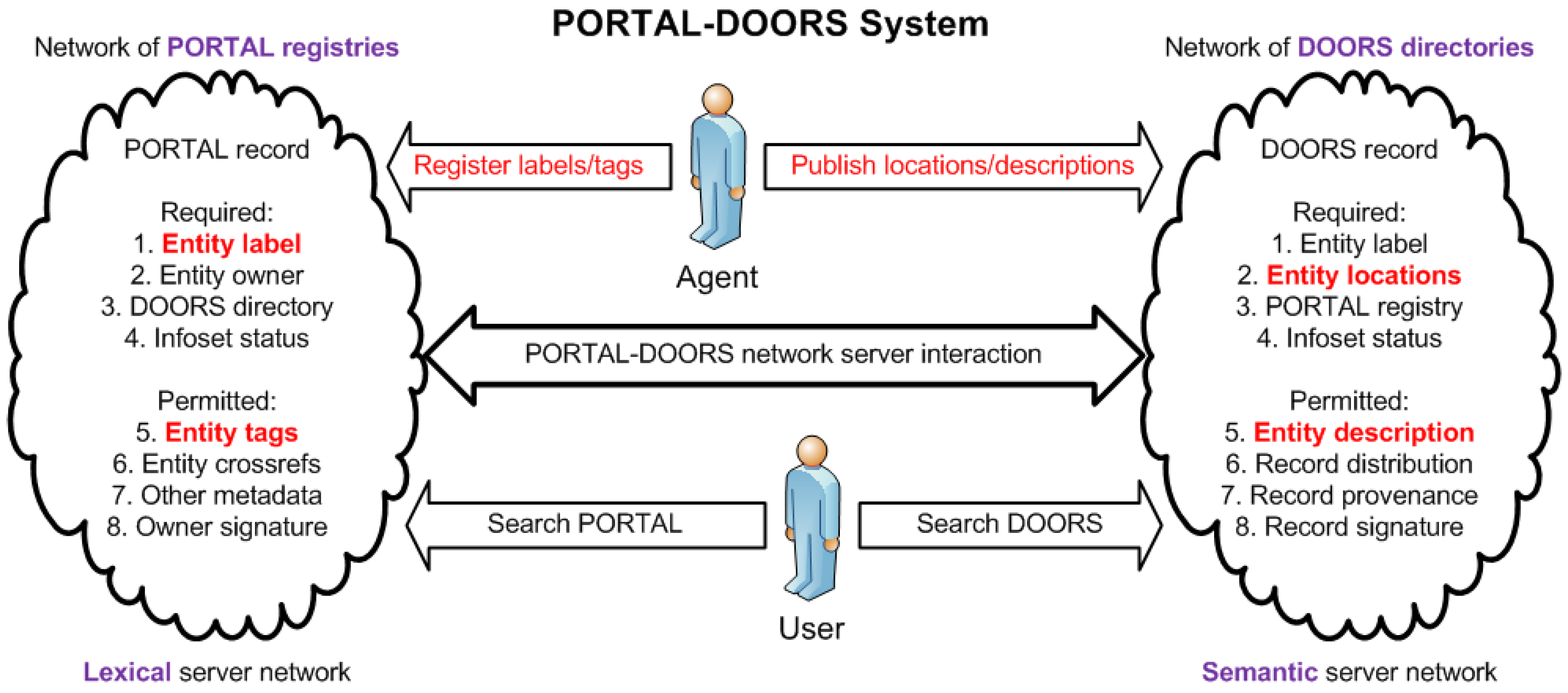
{kind=link}
| IRIS-DNS System | PORTAL-DOORS System | |
| Dynamic metaphor | A distributed communications network brain of nodal neurons continuously updating, exchanging, and integrating messages about ‘who what where’ | |
| Static metaphor | A simple phonebook | A sophisticated library card catalogue |
| Registering system | IRIS registries | PORTAL registries |
| – Entity registered | domain | resource |
| – Identified by | unique name | unique label with optional tags |
| Publishing system | DNS directories | DOORS directories |
| – Attributes published | address and aliases | locations and descriptions |
| – Specified by | IP numbers | URIs, URLs, RDF triples referencing OWL ontologies |
| Entity identification | Hierarchical URL | Non-hierarchical URI |
| Record distribution | Hierarchical request forwarding and response caching | Hierarchical request forwarding and response caching |
| Serves original web | Yes, via mapping of character name to numeric address | Yes, via mapping of character label to URL for IRIS-DNS |
| Serves semantic web | No, because IRIS-DNS does not use RDF triples | Yes, via mapping of character label to semantic description |
| Crosslinks entities | No | Yes, via mappings within DOORS descriptions to other resources |
| Crosslinks systems | No | Yes, via mappings within PORTAL crossreferences to other systems |
5. Architectural Design of the PORTAL-DOORS System
5.1. Core Design
- A distributed network of registries and directories for resource metadata oriented by problem domain or specialist community rather than by technology format of the resource.
- A hierarchical system enabling local independence of communities while simultaneously maintaining global interoperability and compatibility for communication between and search amongst different specialty communities.
- A hybridized architecture with both XML Schemas and terminologies serving the original web and also RDF triples and OWL ontologies serving the semantic web to bridge and transition from the original web to the semantic web.
- Pervasively distributed and shared infrastructure permitting use of any micro-format, terminology or ontology to promote democratization and evolutionary adoption (i.e., survival of the fittest, not necessarily the first).
- Hierarchical authorities (root, primary, secondary, forwarding, caching) and globally unique identifiers to prevent namespace conflicts when identifying resources while maintaining autonomy of local communities with control over local policies.
- Designed to accomodate any resource — whether abstract or concrete, offline or online, semantic or non-semantic — with either non-semantic descriptions using tags referencing terminologies or semantic descriptions using RDF triples referencing ontologies.
- Supported with cross-references to other systems whether legacy or contemporaneous.

5.2. New Multilevel Metadata Design
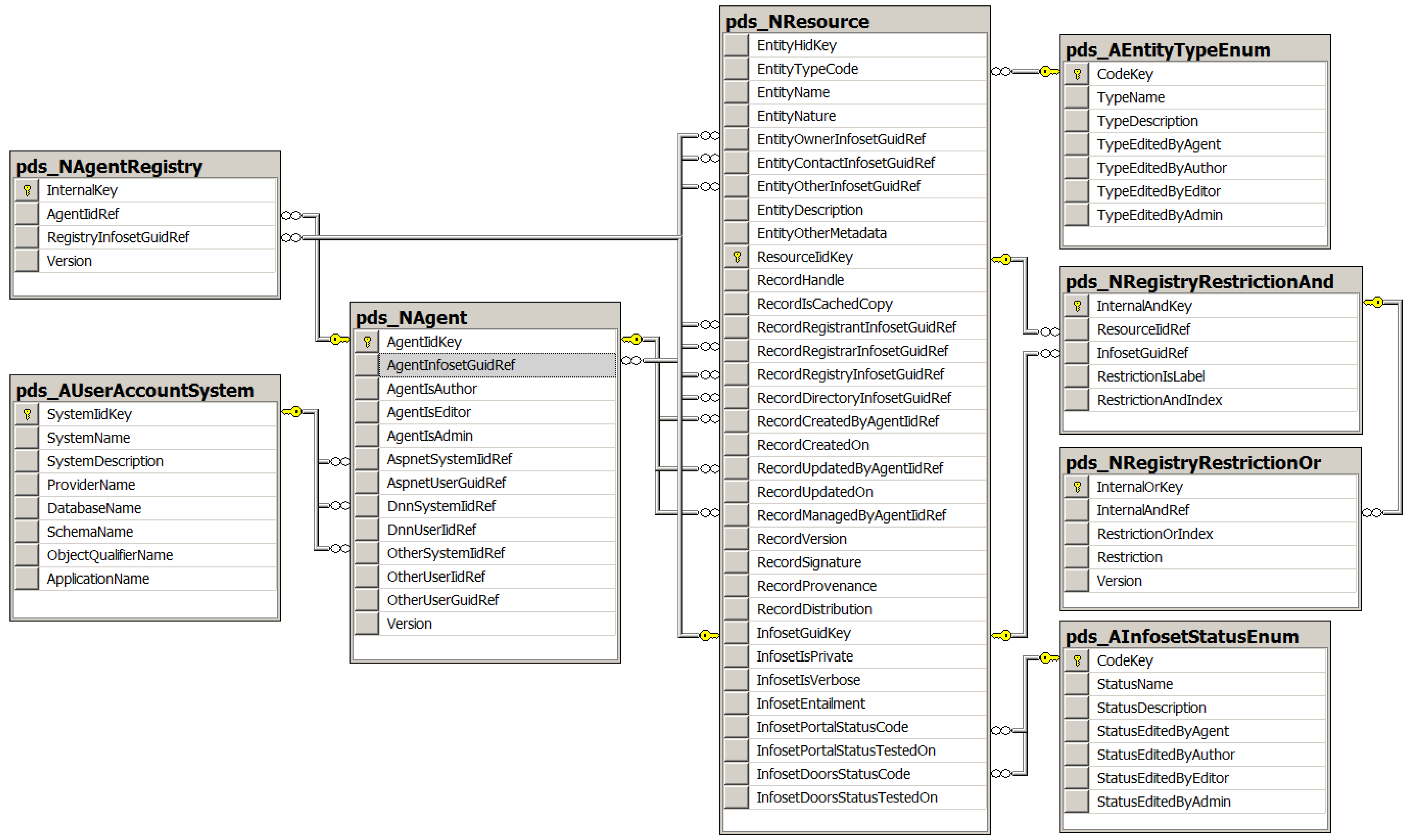
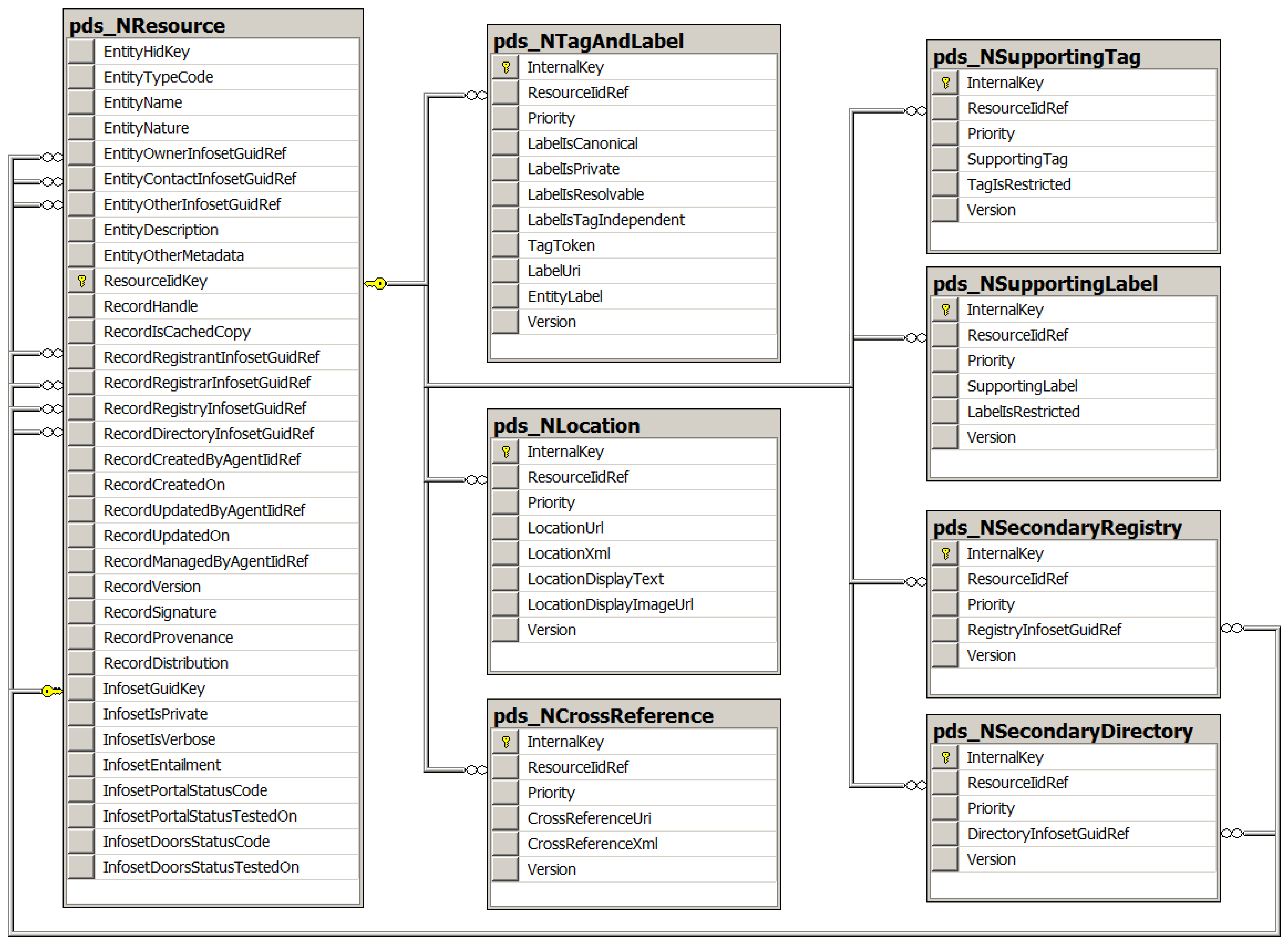
- Resource entity: The object of interest considered by the registrant to be the resource whether concrete or abstract, online or offline, semantic or lexical, real or virtual. This resource entity may be registered at a particular PORTAL registry only if it satisfies the registration requirements of that PORTAL registry. Depending upon the problem-oriented specialty domain of the PORTAL registry and its registration policies, examples may include persons, patients, investigators, authors, or organizations; online virtual entities or offline physical entities; data services, data storage tools, and data records (independent of and unrelated to any PORTAL-DOORS metadata record); analysis services and data processing tools; authored information, books, journals, papers, web sites, and web pages; and many other examples and categories within any field of interest defined by the administrators of the particular PORTAL registry.
- Resource record: The database object containing information about the resource entity for the purpose of persistent storage. This resource record is stored in a database at a PDS server (a PORTAL, DOORS, or NEXUS server). Note that for the same resource entity, the information stored in a resource record at a PORTAL, DOORS, or NEXUS server will be different, and may also be different within each of the networks of PORTAL, DOORS, and NEXUS servers depending on their operation as authoritative primary or non-authoritative secondary and caching servers.
- Resource infoset: The memory object containing information about the resource entity for the purpose of managing, displaying, and analyzing the information about the resource entity of interest. This resource infoset is assembled by the responding PDS server that gathers all of the relevant information from possibly multiple distributed records located at various different PORTAL, DOORS, and NEXUS servers.
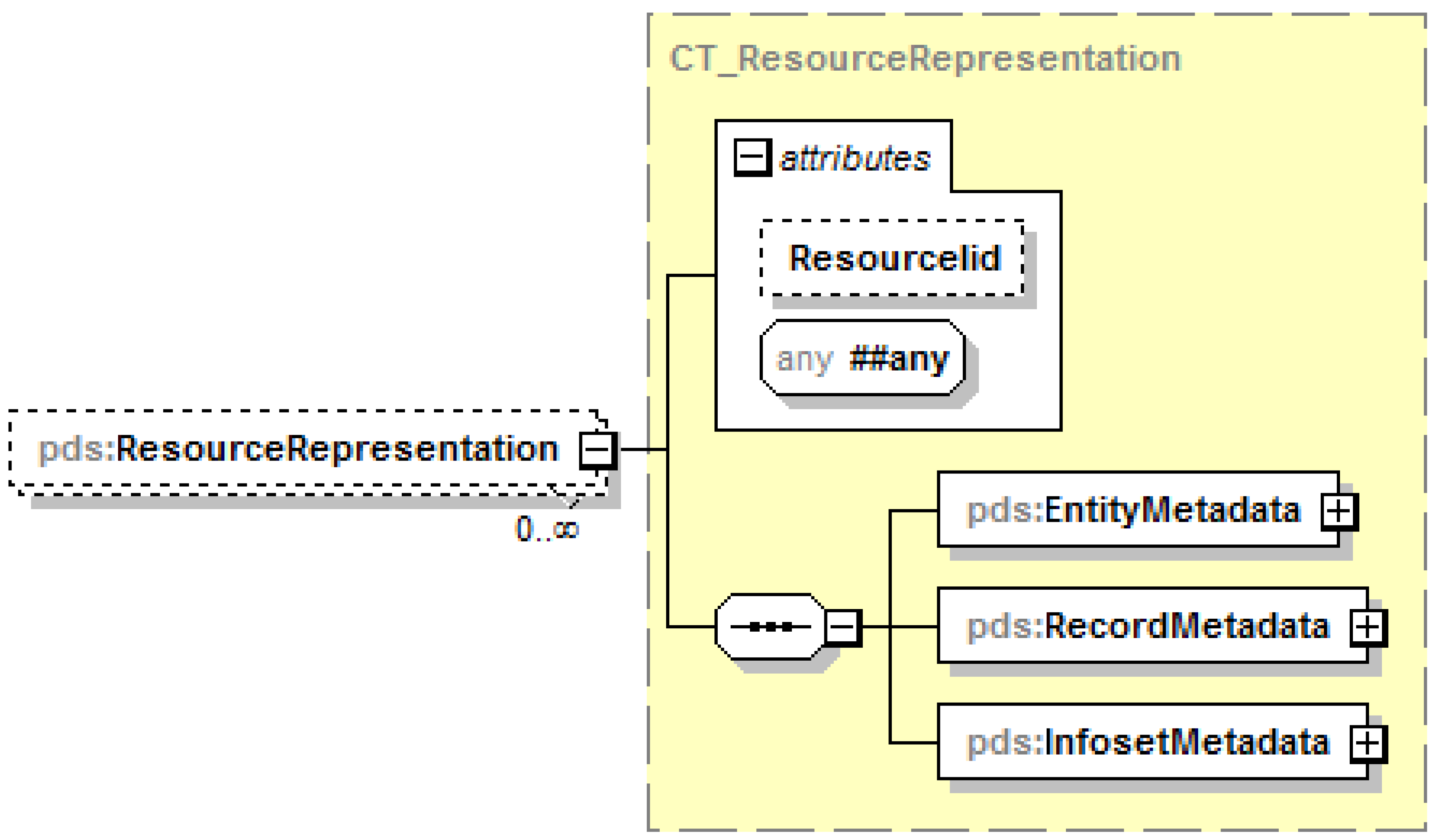
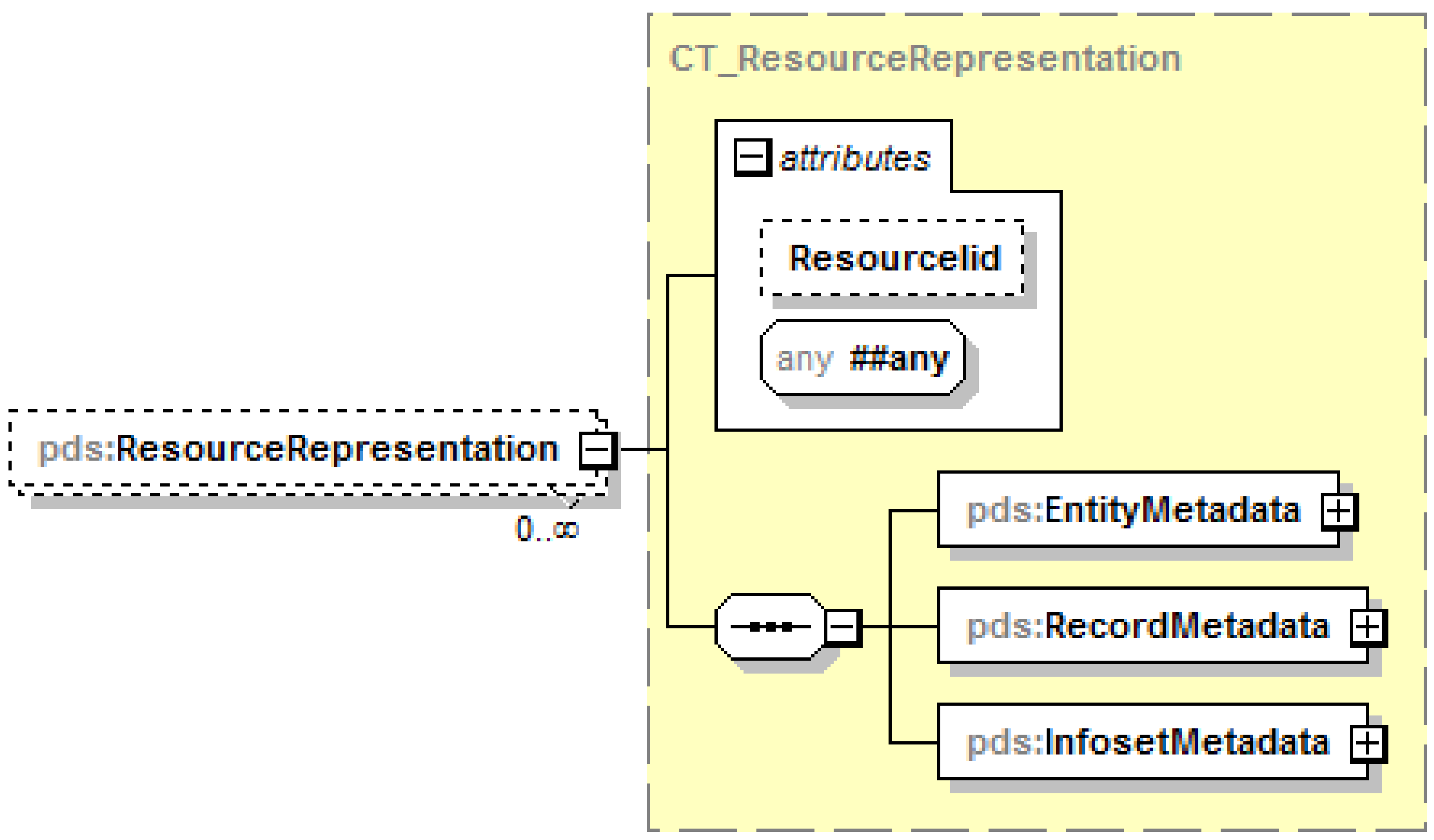
- Resource representation: The serialized object, obtained from the memory object, representing all of the information collected and assembled about the resource entity for the purpose of interoperable information exchange compliant with the PDS interface. One or more of these resource representations are sent by the PDS server in response to requests from clients if the server is configured to return a response without a message envelope.
- Resource message: The message object containing one or more serialized resource representations within an envelope for the purpose of interoperable information exchange compliant with the PDS interface. This resource message is exchanged between different PDS servers and/or is sent by the targeted PDS server in response to requests from clients.
- Entity metadata: All metadata pertaining to the entity itself including tags, labels, locations and description of the entity as well as references to the owner and contact for the entity; corresponds to PDS schema element EntityMetadata and considered primary or Level 1 metadata about the entity itself.
- Record metadata: All metadata pertaining to the stored records about the entity and the process of registering and managing the records including timestamps for creating and updating the records, references to the governing registries and directories, as well as references to the registrant and agents for the records; note that the registrant and agent for the records may be different from the owner and contact for the entity; corresponds to PDS schema element RecordMetadata and considered secondary or Level 2 metadata about the Level 1 metadata.
- Infoset metadata: All metadata pertaining to the dynamic infoset about the entity assembled from the distributed stored records including status, validation timestamps if validated, and any entailments if inferred by a reasoning engine; corresponds to PDS schema element InfosetMetadata and considered tertiary or Level 3 metadata about the Level 1 and Level 2 metadata.
- Representation metadata: Current design limited to use with only an identifier as an attribute on a wrapper element collating the three elements EntityMetadata, RecordMetadata, and InfosetMetadata respectively for the primary, secondary, and tertiary metadata; corresponds to PDS schema type ResourceRepresentation with element instances PORTAL, DOORS, and NEXUS.
- Message metadata: All metadata pertaining to the messaging envelope and the process of exchanging messages throughout the PORTAL-DOORS System; design based on using an analogy with the IRIS-DNS System; corresponds to PDS schema element PDS as the root element for all PDS messages.
5.3. Other New Design Features
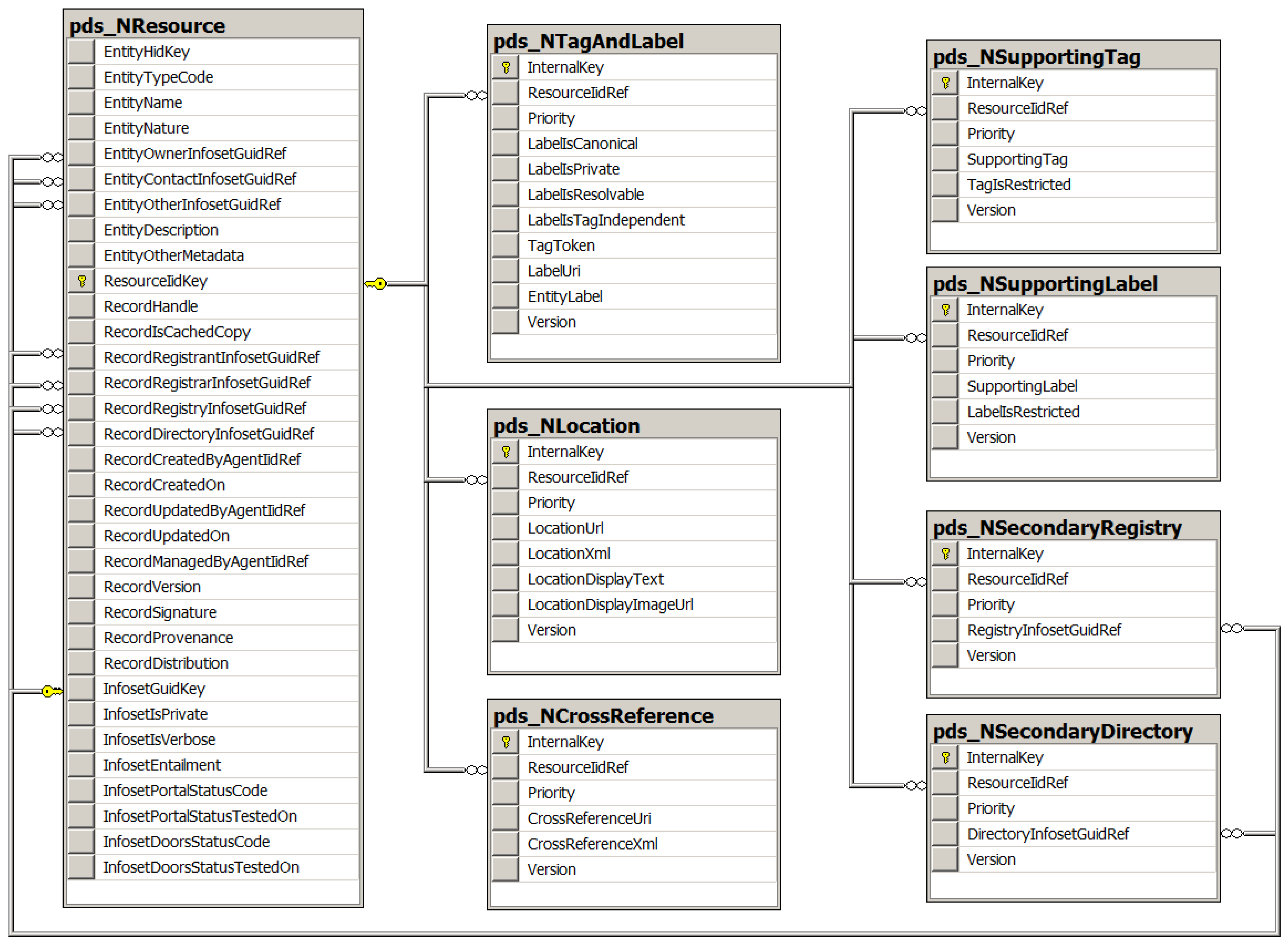
- Aliases: The original design of PDS as published in [1] specified use of a URI or IRI as the globally unique identifier, called a label, for any resource registered in the system. The current revision reported here now allows multiple labels for any given resource and distinguishes between a single required canonical label and multiple permitted alias labels for the resource. All labels, whether canonical or alias, for all resources must always be globally unique throughout the system. Thus the original design requirement for uniqueness of labels has not been violated by this revision.
- Priorities: A number of the metadata fields, such as alias labels, supporting tags, supporting labels, locations, crossreferences, secondary registries and secondary directories permit multiple instances of the field for the same given resource. The current revision of PDS now allows for priorities to be assigned to these instances so that they can be ranked in order. A priority is defined to be a single-byte integer rank in the range from 0 to 255 with precedence order in natural counting order, i.e., first 0 and last 255. In the case of multiple instances of labels for a resource, the canonical label is always identified by the assigned priority 0 with all other alias labels assigned any priority in the range from 1 to 255.
- Metaresources: The original blueprint design [1] also specified that resources can only be registered and managed by owners of the resources. This design principle yields a system that does not allow anonymous public editing of resources which is contrary to the policies adopted by many wiki systems. However, it is possible to design an extension of the initial PORTAL-DOORS System that maintains the original principle while also enabling secondary resources to be registered and managed by individuals who are not the owners of the primary resource. These secondary resources about primary resources are called metaresources. The secondary metaresources are declared by specifying their entity type as a special type called meta-entity. Secondary metaresources are required to maintain a reference to their targeted primary resources. This approach assures that all metaresources about the same targeted resource can refer consistently to that resource yet be managed independently of it as the primary resource and of each other as the other secondary resources. A scientific journal article as primary resource with multiple reviews as secondary metaresources constitute a simple example. All of the referees who write the secondary reviews and the authors who write the article should have control over their own resources without interference by others.
- Agents: The original description of PDS [1] distinguished between the roles of users and owners of resources and resource metadata. This terminology must be refined when considering the design of an implementation for a web site application or service. Therefore, the term resource owner now refers to the collection of person(s) and/or organization(s) presumed to own the resource while the term resource agent refers to the person who registers, manages and edits the information about the resource and who is presumed to be acting on behalf of the resource owner. As before, the term resource user refers to the person who anonymously consumes information from PDS. Thus, users have read privileges throughout PDS, whereas agents have read/write privileges at those registries and directories where they have been explicitly granted write privileges for creating and editing records. For the reference implementation described in Section 6, agents may edit information in author, editor, or administrator modes if granted access to these successively higher privileges. The reference implementation adopts the following conventions: In author mode, the agent may edit only records initially entered by the agent. In editor mode, the agent may edit any records in the same registry. In administrator mode, the agent may edit any registry or directory records accessible via the same registrar.
6. Implementation and Application of the PORTAL-DOORS System
6.1. Implementation of Current Version 0.6
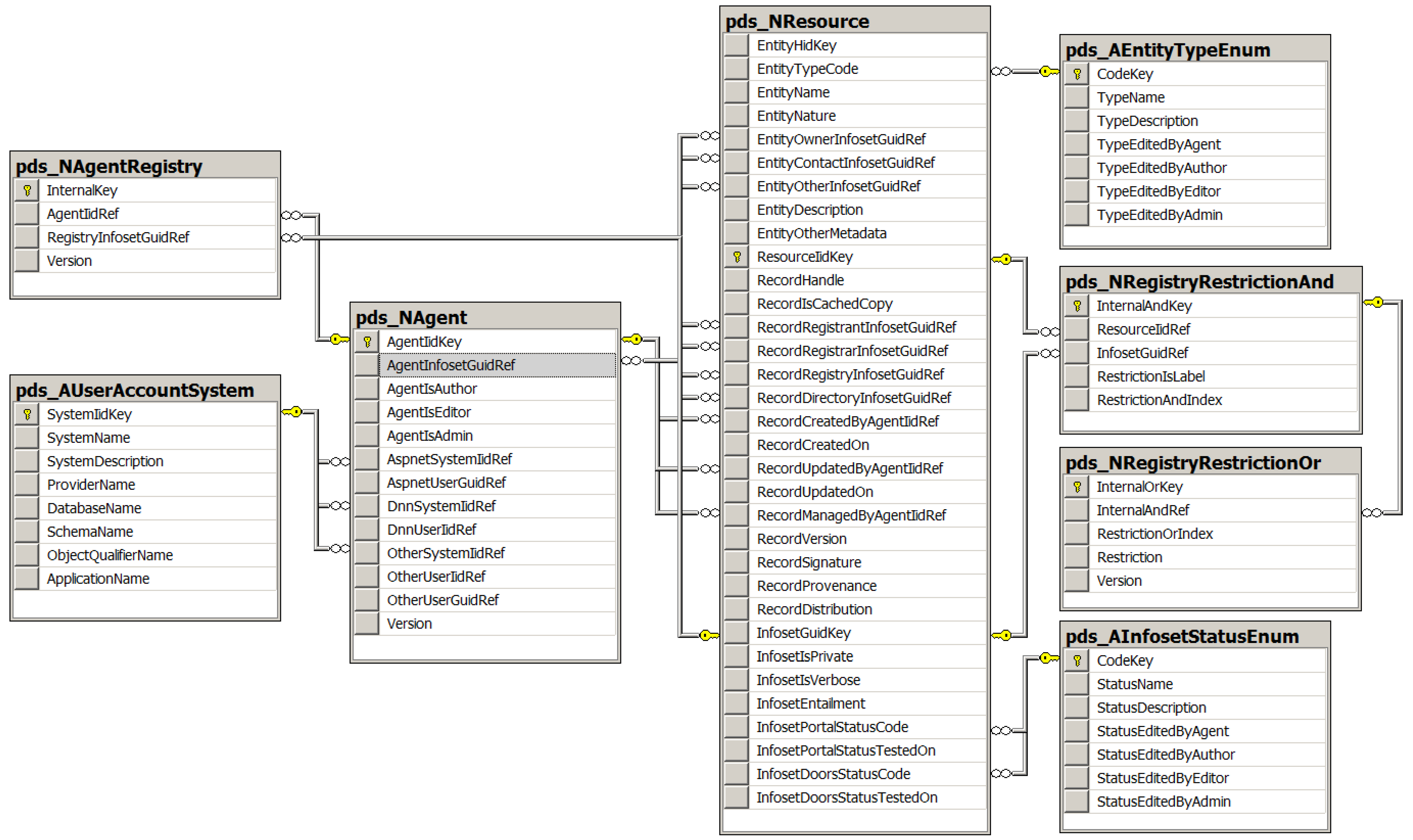
- /nexus/resrep/find?{parameter=value}
- /nexus/resrep/search?{parameter=value}
- /nexus/resrep/{entityTypeName}/{entityPrincipalTag}
- /{registryPrincipalTag}/{entityPrincipalTag}
6.2. Infrastructure System versus Tools and Applications versus Content
6.3. General Usage Scenarios for the PORTAL-DOORS System
- Minimal use of required elements for both PORTAL registries and DOORS directories: This scenario essentially reduces use of the system to an alternative equivalent to the use of PURLs [50] (and other similar services). However, it does so without requiring use of a pre-determined URL identifier root like purl.oclc.org and instead allowing use of any identification scheme as long as it is a URI or IRI.
- Maximal use of permitted elements for PORTAL registries but minimal use of required elements for DOORS directories: This scenario enables exploiting the full metadata management facilities of the PORTAL non-semantic services (which include provisions for tags, micro-formats, cross-references, etc) without any obligation to use the DOORS semantic services (that necessitate use of the RDF/OWL/SPARQL stack of technologies and tools). This scenario enables resource agents to publish metadata now in non-semantic formats and defer until later any possible transition to semantic formats which would then be facilitated by the prior staging in the non-semantic formats.
- Minimal use of required elements for PORTAL registries but maximal use of permitted elements for DOORS directories: This scenario serves those situations where there is no barrier to transition the metadata from original web formats to semantic web formats, and the resource owner and agent do not wish to maintain the metadata in both semantic and non-semantic formats. This scenario requires that the resource agent registering and publishing the metadata already has access to established ontologies that can be referenced by semantic tools for describing the resource.
- Maximal use of permitted elements for both PORTAL registries and DOORS directories: This usage scenario provides the significant benefit of exposing as much metadata as possible to as many clients as possible including both older non-semantic as well as newer semantic tools and applications.
- Complete development of a specification model for the PORTAL-DOORS System as the interoperable informatics infrastructure using the Hierarchically Distributed Mobile Metadata (HDMM) architectural style for a distributed network of registries and directories.
- Complete implementation of a reference model with XML Schemas for the interoperable communication interface standards and with RESTful web services for the transport protocol.
- Build open source software clients and servers for multiple platforms, operating systems and programming languages according to the detailed roadmap (see Sec. 6.5) for continuing development of the previously published designs and prototypes.
6.4. Specific Use Cases for the PORTAL-DOORS System
- Assisting with organization of the ‘bioinformatics resourceome’ and the description, discovery and use of resources for e-science and e-medicine in health care and life sciences (see [1] Sec. III).
- Cataloguing resources for biomedical computing (see [1] Sec. IV and VIII).
- Cataloguing patents and trademarks and relating them to products and services for e-business (see [1] Sec. IX).
- Assisting with semantic search, decision support and knowledge management applications in translational research and drug discovery for personalized medicine (see [1] Sec. XI).
6.5. Development Roadmap for the PORTAL-DOORS System
- Version 0.5: Implementation as an AJAXified web application with back-end database and front-end web browser client for partial PORTAL server functionality and partial DOORS server functionality. Version 0.5.4 was the last 0.5.* version published on 3/29/2009.
- Version 0.6: Implementation as RESTful web services with both ASP.net based clients enhanced with user-friendly graphical user interfaces and editors for managing (entering and updating) data records at PORTAL-DOORS servers on Microsoft Windows platforms. The current version 0.6.4 is operational as a RESTful web service for user access and an AJAXified web application for agent access.
- Version 0.7: Completion and revision of lexical PORTAL functionality including interoperability with terminology tools.
- Version 0.8: Completion and revision of semantic DOORS functionality including interoperability with ontology tools.
- Version 0.9: Implementation as RESTful web services with JAVA based servers and clients for Linux and Mac OS X platforms.
- Version 1.0: Official release of PORTAL-DOORS System models and schemas for an authoritative server at a single site for all platforms.
- Version 2.0: Multi-site functionality (including security) for distributed interacting authoritative servers.
- Version 3.0: Multi-site functionality (including provenance) for distributed interacting non-author-itative servers operating with request forwarding and response caching amongst the distributed servers.
7. Discussion
- Should search be pursued via hierarchical, peer-to-peer, or alternative network paths?
- Which search path is best when attempting to locate a resource known to exist somewhere?
- Which search path is best when attempting to establish the existence of a resource not known to exist a priori?
- Which search path is best for a commoditized resource for which any instance will satisfice?
- Which search path is best for a uniquely individual resource for which only the unique instance will suffice?
HDMM Conjecture: Semantic HDMM networks should scale more efficiently than semantic peer-to-peer networks and thus should be more useful for searching by various query criteria for an unknown resource entity at an unknown resource location, i.e., when existence of the resource is not known a priori.
8. Conclusion
Acknowledgements
References
- Taswell, C. DOORS to the Semantic Web and Grid with a PORTAL for Biomedical Computing. IEEE Trans. Inform. Technol. Biomed. 2008, 12, 191–204, In the Special Section on Bio-Grid. [Google Scholar] [CrossRef] [PubMed]
- Taswell, C. Corrections to “DOORS to the Semantic Web and Grid With a PORTAL for Biomedical Computing”. IEEE Trans. Inform. Technol. Biomed. 2008, 12, 411. [Google Scholar] [CrossRef]
- Beck, J.R.; Adams, R.M. The cancer Biomedical Informatics Grid (caBIG): Enabling the patient-centric molecular medicine revolution. Technical report. National Cancer Institute: Bethesda, MD, USA, 2005; Slide presentation dated 10/15/2005. [Google Scholar]
- Marshall, C.C.; Shipman, F.M. Which semantic web? HYPERTEXT ’03: Proceedings of the 14th ACM Conference on Hypertext and Hypermedia; ACM: New York, NY, USA, 2003; pp. 57–66. [Google Scholar]
- Mowshowitz, A.; Kumar, N. And Then There Were Three. IEEE Computer 2009, 42, 108-107. [Google Scholar] [CrossRef]
- Berti-Equille, L.; Sarma, A.D.; Xin.; Dong.; Marian, A.; Srivastava, D. Sailing the Information Ocean with Awareness of Currents: Discovery and Application of Source Dependence. Proceedings of CIDR 2009. 2009. [Google Scholar]
- Acemoglu, D.; Ozdaglar, A.E.; ParandehGheibi, A. Spread of (Mis)Information in Social Networks. Working paper series, Social Science Research Network eLibrary, 2009. [Google Scholar]
- Taylor, R.N.; Medvidovic, N.; Dashofy, E.M. Software Architecture: Foundations, Theory, and Practice; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2010. [Google Scholar]
- Taswell, C. PORTAL-DOORS Infrastructure System for Translational Biomedical Informatics on the Semantic Web and Grid. In Proceedings of the American Medical Informatics Association Summit on Translational Bioinformatics, San Francisco, CA, 2008; p. 43.
- Zhuge, H.; Xing, Y.; Shi, P. Resource space model, OWL and database: Mapping and integration. ACM Trans. Internet Technol. 2008, 8, 1–31. [Google Scholar] [CrossRef]
- Taswell, C. Alternative Bootstrapping Design for the PORTAL-DOORS Cyberinfrastructure with Self-Referencing and Self-Describing Features. In Semantic Web; Wu, G., Ed.; In-Teh: Vukovar, Croatia, 2009; chapter 2; pp. 29–37. [Google Scholar]
- Eccles, J.R.; Saldanha, J.W. Metadata-based generation and management of knowledgebases from molecular biologal databases. Comp. Meth. Prog. Bio. 1990, 32, 115–123. [Google Scholar] [CrossRef]
- Sienknecht, T.F.; Friedrich, R.J.; Martinka, J.J.; Friedenbach, P.M. The implications of distributed data in a commercial environment on the design of hierarchical storage management. Performance Evaluation 1994, 20, 3–25. [Google Scholar] [CrossRef]
- Nadkarni, P.M. QAV: Querying entity-attribute-value metadata in a biomedical database. Comp. Meth. Prog. Bio. 1997, 53, 93–103. [Google Scholar] [CrossRef]
- de Carvalho Moura, A.M.; da Costa Pereira, G.; Campos, M.L.M. A metadata approach to manage and organize electronic documents and collections on the web. J. Brazil. Comp. Soc. 2002, 8, 16–31. [Google Scholar] [CrossRef]
- Shaw, N.G.; Mian, A.; Yadav, S.B. A comprehensive agent-based architecture for intelligent information retrieval in a distributed heterogeneous environment. Decis. Sup. Sys. 2002, 32, 401–415. [Google Scholar] [CrossRef]
- Brandt, S.A.; Miller, E.L.; Long, D.D.E.; Xue, L. Efficient Metadata Management in Large Distributed Storage Systems. In Proceedings of the 20 th IEEE/11 th NASA Goddard Conference on Mass Storage Systems and Technologies (MSS03); IEEE Computer Society, 2003. [Google Scholar]
- Caldas, C.H.; Soibelman, L. Automating hierarchical document classification for construction management information systems. Automat. Constr. 2003, 12, 395–406. [Google Scholar] [CrossRef]
- Stevens, R.D.; Robinson, A.J.; Goble, C.A. myGrid: personalised bioinformatics on the information grid. Bioinformatics 2003, 19, i302–i304. [Google Scholar] [CrossRef] [PubMed]
- Arabshian, K.; Schulzrinne, H. GloServ: Global Service Discovery Architecture. In MobiQuitous 2004 First Annual International Conference on Mobile and Ubiquitous Systems; IEEE Computer Society: Los Alamitos, CA, USA, 2004; pp. 319–325. [Google Scholar]
- Cai, M.; Frank, M.; Yan, B.; MacGregor, R. A subscribable peer-to-peer RDF repository for distributed metadata management. J. Web Semant. 2004, 2, 109–130. [Google Scholar] [CrossRef]
- Jeong, D.; Baik, D.K. Incremental data integration based on hierarchical metadata registry with data visibility. Information Sciences 2004, 162, 147–181. [Google Scholar] [CrossRef]
- Zhu, Y.; Jiang, H.; Wang, J. Hierarchical Bloom filter arrays (HBA): a novel, scalable metadata management system for large cluster-based storage. In CLUSTER ’04: Proceedings of the 2004 IEEE International Conference on Cluster Computing; IEEE Computer Society: Washington, DC, USA, 2004; pp. 165–174. [Google Scholar]
- Mastroianni, C.; Talia, D.; Verta, O. A super-peer model for resource discovery services in large-scale Grids. Future Gener. Comput. Syst. 2005, 21, 1235–1248. [Google Scholar] [CrossRef]
- Nottelmann, H.; Fischer, G. Search and browse services for heterogeneous collections with the peer-to-peer network Pepper. Inform. Process. Manag. 2007, 43, 624–642. [Google Scholar] [CrossRef]
- Mastroianni, C.; Talia, D.; Verta, O. Designing an information system for Grids: Comparing hierarchical, decentralized P2P and super-peer models. Parallel Comput. 2008, 34, 593–611. [Google Scholar] [CrossRef]
- Nguyen, D.Q.; Sonnet, H. Multilevel metadata exploration using Meta-Previewer and Cascading-View widgets. In RIVF 2008 IEEE International Conference on Research, Innovation and Vision for the Future; 2008; pp. 298–305. [Google Scholar]
- Wang, J.; Feng, D.; Wang, F.; Lu, C. MHS: A distributed metadata management strategy. J. Syst. Software 2009, 82, 2004–2011. [Google Scholar] [CrossRef]
- Hartung, M.; Loebe, F.; Herre, H.; Rahm, E. Management of evolving semantic grid metadata within a collaborative platform. Information Sciences 180 (2010) 2010, 180, 1837–1849. [Google Scholar] [CrossRef]
- Teare, K.; Popp, N.; Ong, B. Navigating network resources based on metadata. US Patent 6151624, 2000. [Google Scholar]
- Call, C.G. Methods and apparatus for disseminating product information via the internet using universal product codes. US Patent 6154738, 2000. [Google Scholar]
- Dixon, C.J.; Pinckney, T. Website reputation product architecture. US Patent Application 11/342319, 2006. [Google Scholar]
- Akelbein, J.P.; Haustein, N. System and Method for Managing Data Using A Hierarchical Metadata Management System. US Patent Application 12/164197, 2009. [Google Scholar]
- Arabshian, K.; Schulzrinne, H. A Hybrid Hierarchical and Peer-to-Peer Ontology-based Global Service Discovery System. Technical Report CUCS-016-05. Columbia Univ: New York, NY, 2005. [Google Scholar]
- Milne, K.; Wing, P. A Brief Introduction to Enterprise Metadata Management for Microsoft SharePoint Server 2010 Developers. http://msdn.microsoft.com/en-us/library/ee832800(office.14).aspx accessed on 28 March 2010.
- Dolin, R.A. Pharos: A Scalable Distributed Architecture for Locating Heterogeneous Information Sources. PhD thesis, University of California, Santa Barbara, 1998. [Google Scholar]
- de Leeuw, J.; Meijer, E. (Eds.) Handbook of Multilevel Analysis; Springer Science+Business Media, LLC: New York, NY, USA, 2008.
- Rasbash, J.; Browne, W.J. Non-Hierarchical Multilevel Models. In Handbook of Multilevel Analysis; Springer Science+Business Media, LLC: New York, NY, USA, 2008; chapter 8; pp. 301–334. [Google Scholar]
- Taswell, C. Implementation of Prototype Biomedical Registries for PORTAL-DOORS. In Proceedings of the American Medical Informatics Association Summit on Translational Bioinformatics, San Francisco, CA, 2009. AMIA-0036-T2009.
- Taswell, C. Biomedical Informatics for Brain Imaging and Gene-Brain-Behavior Relationships. In W3C Semantic Web HCLSIG F2F Meeting 4/30-5/1; 2009. [Google Scholar]
- Taswell, C. Knowledge Engineering for PharmacoGenomic Molecular Imaging of the Brain. In Proceedings of SKG 2009 The 5th International Conference on Semantics, Knowledge, and Grid; IEEE Computer Society, 2009; pp. 26–33. [Google Scholar]
- Crasto, C.J. (Ed.) Neuroinformatics; Vol. 401, Methods in Molecular Biology; Humana Press Inc.: Totowa, NJ, USA, 2007.
- Cheung, K.H.; Lim, E.; Samwald, M.; Chen, H.; Marenco, L.; Holford, M.E.; Morse, T.M.; Mutalik, P.; Shepherd, G.M.; Miller, P.L. Approaches to neuroscience data integration. Brief. Bioinform. 2009, 10, 345–353. [Google Scholar] [CrossRef] [PubMed]
- Berners-Lee, T.; Hall, W.; Hendler, J.; Shadbolt, N.; Weitzner, D.J. Creating a science of the Web. Science 2006, 313, 769–771. [Google Scholar] [CrossRef] [PubMed]
- Taswell, C. The Hierarchically Distributed Mobile Metadata (HDMM) Style of Architecture for Pervasive Metadata Networks. In Proceedings of I-SPAN 2009 The 10th International Symposium on Pervasive Systems, Algorithms and Networks; IEEE Computer Society, 2009; pp. 315–320. [Google Scholar]
- Fielding, R.T.; Taylor, R.N. Principled design of the modern Web architecture. ACM Trans. Internet Technol. 2002, 2, 115–150. [Google Scholar] [CrossRef]
- Newton, A.; Sanz, M. RFC3981: IRIS: The Internet Registry Information Service (IRIS) Core Protocol. http://www.ietf.org/rfc/rfc3981.txt accessed on 19 October 2006.
- Mockapetris, P.V. STD13 RFC1035: Domain Names - Implementation and Specification. http://www.ietf.org/rfc/rfc1035.txt accessed on 19 October 2006.
- Lockery, D.; Peters, J.F.; Taswell, C. Clinical Telegaming PORTAL for Telerehabilitation Systems. Technical report. University of Manitoba: Canada, 2010. [Google Scholar]
- Shafer, K.; Weibel, S.; Jul, E.; Fausey, J. Introduction to Persistent Uniform Resource Locators. http://purl.oclc.org/docs/inet96.html accessed on 4 March 2007.
- Marchionini, G.; White, R.W. Information-Seeking Support Systems [Guest Editors’ Introduction]. IEEE Computer 2009, 42, 30–32. [Google Scholar] [CrossRef]
- Morville, P.; Rosenfeld, L. Information Architecture for the World Wide Web, 3rd ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2007. [Google Scholar]
- Schraefel, M.C. Building Knowledge: What’s beyond Keyword Search? IEEE Computer 2009, 42, 52–59. [Google Scholar] [CrossRef]
- Taswell, C. Use of the MeSH Thesaurus in the PORTAL-DOORS System. In Proceedings AMIA 2010 Symposium on Clinical Research Informatics, San Francisco CA, 2010; p. AMIA–033–C2010.
- Taswell, C. Use of NLM Medical Subject Headings with the MeSH2010 Thesaurus in the PORTAL-DOORS System. In Proceedings 8th HealthGrid 2010 Paris; 2010. [Google Scholar]
- Newman, M.E.J. The Structure and Function of Complex Networks. SIAM Rev. 2003, 45, 167–256. [Google Scholar] [CrossRef]
- Fujimoto, R.M.; Perumalla, K.; Park, A.; Wu, H.; Ammar, M.H.; Riley, G.F. Large-Scale Network Simulation: How Big? How Fast? In MASCOTS 2003 Proceedings of the 11th Annual IEEE/ACM International Symposium on Modeling, Analysis, and Simulation of Computer Systems; IEEE Computer Society: Los Alamitos, CA, USA, 2003; pp. 116–123. [Google Scholar]
- Nicol, D.M.; Liljenstam, M.; Liu, J. Advanced concepts in large-scale network simulation. In WSC ’05: Proceedings of the 37th conference on Winter simulation. Winter Simulation Conference; 2005; pp. 153–166. [Google Scholar]
- Wei, S.; Mirkovic, J. A realistic simulation of internet-scale events. In ValueTools ’06: Proceedings of the 1st International Conference on Performance Evaluation Methodolgies and Tools; ACM: New York, NY, USA, 2006; p. 28. [Google Scholar]
- Fujimoto, R.M.; Perumalla, K.S.; Riley, G.F. Network Simulation; Synthesis Lectures on Communication Networks, Morgan & Claypool Publishers: San Rafael, CA, USA, 2007. [Google Scholar]
- Carl, G.; Kesidis, G. Large-scale testing of the Internet’s Border Gateway Protocol (BGP) via topological scale-down. ACM Trans. Model. Comput. Simul. 2008, 18, 1–30. [Google Scholar] [CrossRef]
- Qiu, D.; Srikant, R. Modeling and performance analysis of BitTorrent-like peer-to-peer networks. In SIGCOMM ’04: Proceedings of the 2004 conference on Applications, technologies, architectures, and protocols for computer communications; ACM: New York, NY, USA, 2004; pp. 367–378. [Google Scholar]
- Bharambe, A.R.; Herley, C.; Padmanabhan, V.N. Analyzing and Improving a BitTorrent Networks Performance Mechanisms. In INFOCOM 2006. 25th IEEE International Conference on Computer Communications. Proceedings; 2006; pp. 1–12. [Google Scholar]
- Deaconescu, R.; Rughinis, R.; Tapus, N. A BitTorrent Performance Evaluation Framework. In ICNS ’09: Proceedings of the 2009 Fifth International Conference on Networking and Services; IEEE Computer Society: Washington, DC, USA, 2009; pp. 354–358. [Google Scholar]
© 2010 by the author. Licensee MDPI, Basel, Switzerland. This article is an Open Access article distributed under the terms and conditions of the Creative Commons Attribution license http://creativecommons.org/licenses/by/3.0/.
Share and Cite
Taswell, C. A Distributed Infrastructure for Metadata about Metadata: The HDMM Architectural Style and PORTAL-DOORS System. Future Internet 2010, 2, 156-189. https://doi.org/10.3390/fi2020156
Taswell C. A Distributed Infrastructure for Metadata about Metadata: The HDMM Architectural Style and PORTAL-DOORS System. Future Internet. 2010; 2(2):156-189. https://doi.org/10.3390/fi2020156
Chicago/Turabian StyleTaswell, Carl. 2010. "A Distributed Infrastructure for Metadata about Metadata: The HDMM Architectural Style and PORTAL-DOORS System" Future Internet 2, no. 2: 156-189. https://doi.org/10.3390/fi2020156
APA StyleTaswell, C. (2010). A Distributed Infrastructure for Metadata about Metadata: The HDMM Architectural Style and PORTAL-DOORS System. Future Internet, 2(2), 156-189. https://doi.org/10.3390/fi2020156