Markup in Engineering Design: A Discourse


Abstract
:1. Introduction
2. Annotation and markup
- 1)
- Punctuational mark-up: where word, phrase, and sentence boundaries are identified by spaces, commas, full stops, and other punctuation characters inserted into the text.
- 2)
- Presentational mark-up: where the visual form of the document is specified directly.
- 3)
- Procedural mark-up: in which presentational instructions (or commands) for some particular processing system are embedded in the text.
- 4)
- Descriptive mark-up: the author identifies the element types as tokens, as often found in applications of SGML and XML, which approach documents as structured objects containing semantically interpretable parts.
- 5)
- Referential mark-up: refers to entities external to the document and is replaced by those entities during processing.
- 6)
- Meta-mark-up: provides a facility for controlling the interpretation of mark-up and for extending the vocabulary of descriptive mark-up languages (e.g. macros).
3. Markup languages
3.1. Markup languages for text documents
3.2. Markup languages for graphics and images
3.3. Markup languages for web applications

{kind=link}
{kind=link}
{kind=link}
| Language | Based on | Developer | Initial release | Major applications |
|---|---|---|---|---|
| Generalized Mark-up Language (GML) | _ | IBM | 1960s | Document |
| Standard Generalized Mark-up Language (SGML) | GML | ISO | 1986 | Document |
| HyperText Markup Language (HTML) | SGML | W3C & WHATWG | 1991 | The World Wide Web |
| eXtensible Markup Language (XML) | SGML | W3C | 1996 | Arbitrary data structures |
| Dimensional Mark-up Language (DML) | XML | NIST | _ | CAPP/CAM/CNC |
| Product Information Mark-up Language (PIML) | XML | Lee et al. | 2005 | PLM |
| eXtensible Rule Mark-up Language(XRML) | XML | Kang and Lee | 1998 | Web information |
| Motion Capture Mark-up Language (MCML) | XML | Chung and Lee | 2003 | Motion capture data |
| Scalable Vector Graphics (SVG) | XML | W3C | 2001 | 2D graphics |
| Vector Markup Language(VML) | XML | Autodesk, Hewlett-Packard, Macromedia, Microsoft, Visio | 1998 | Vector information together with additional markup |
| Precision Graphics Mark-up Language(PGML) | XML | Adobe Systems, IBM, Netscape, Sun Microsystems | -- | Vector graphics |
| X3D (eXtensible 3D) | XML/VRML | W3C/ISO | _ | 3D graphics |
| 3D XML | XML | Dassault Systemes | -- | 3D data |
| PLM XML | XML | UGS. | -- | PLM information |
| Description Framework (RDF) | W3C | 1999 | Web resources | |
| Web Ontology Language (OWL) | RDF/XML | W3C | 2002 | Web ontology language |
| Commerce XML (cXML) | XML | more than 40 companies | 1999 | e-commerce |
| Simple Object Access Protocol (SOAP) | XML | W3C/ Microsoft, IBM, DevelopMentor, UserLand Software) | 2003 | Web service |
| Web Service Description Language (WSDL) | XML | W3C /IBM, Microsoft, Ariba) | 2000 | Web services |
| Remote Procedure Calls (XML-RPC) | XML | Dave Winer of UserLand Software and Microsoft | 1998 | Internet |
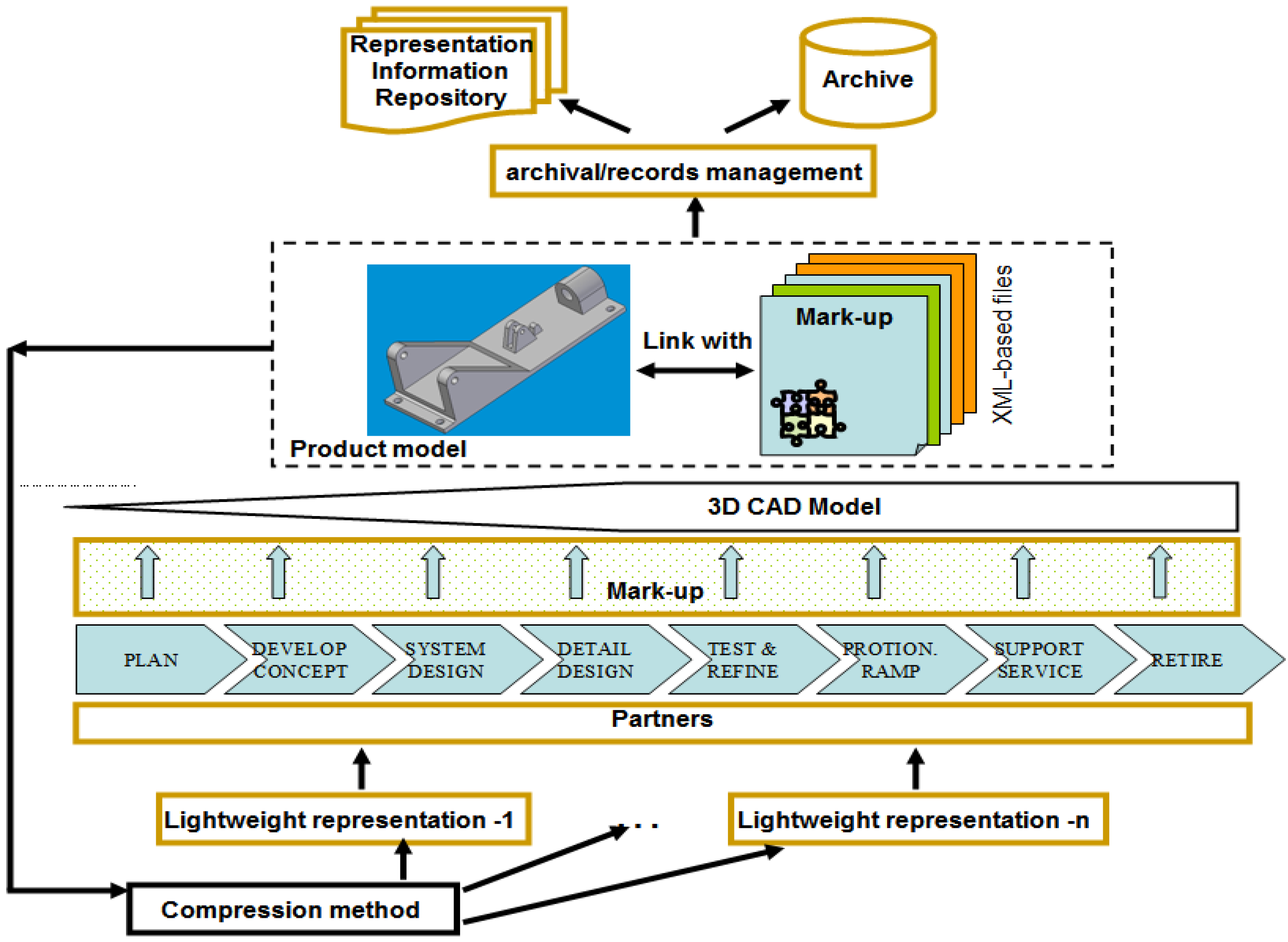
4. Mark-up strategy
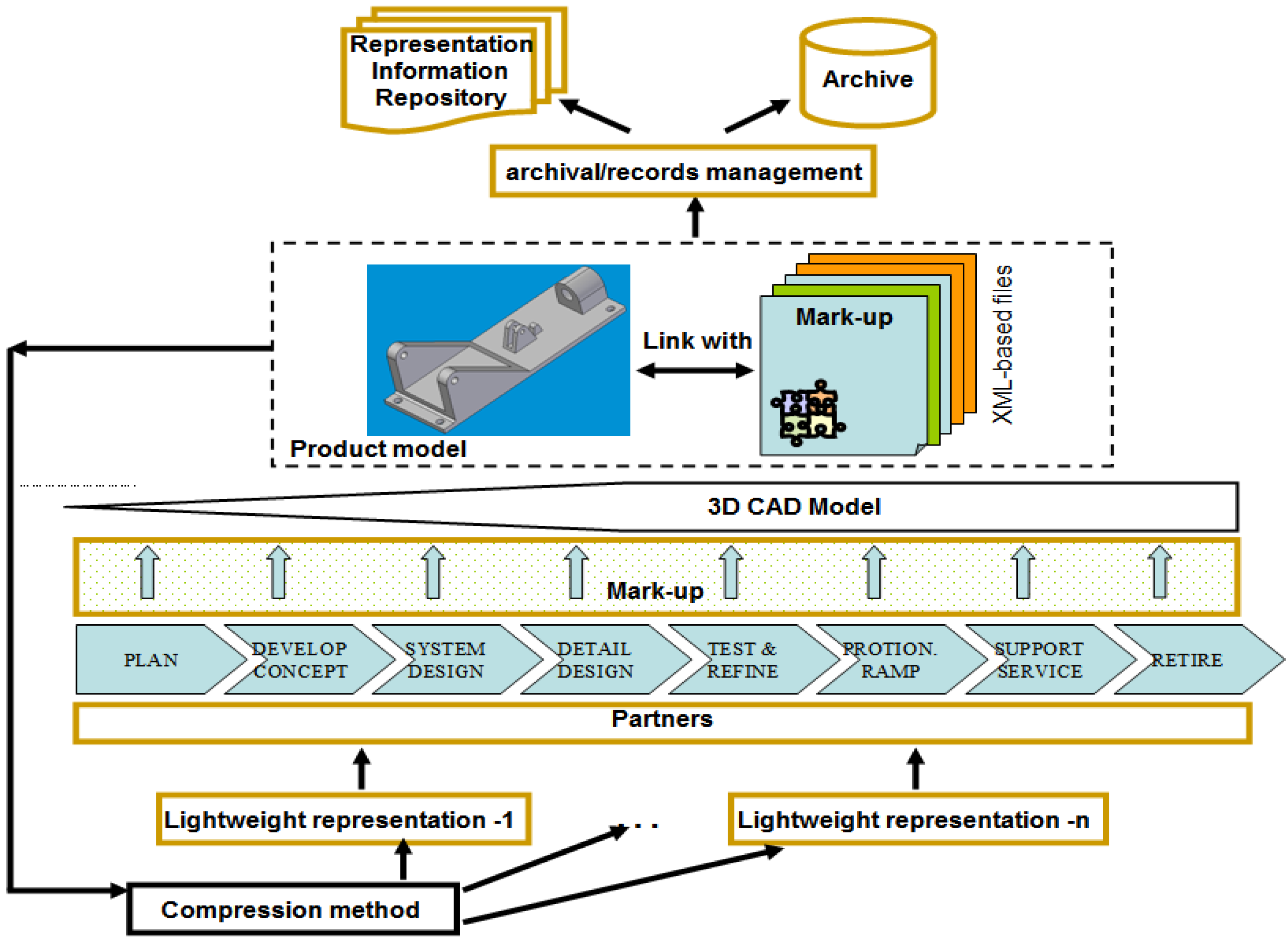
- It allows original digital object (i.e. including both documents and various digital model) progressively to expand to include extra information (e.g. semantic context and rationale behind) and metadata without changing the representation method used for the original object. Thus, it provides a good tool to support the continuous update of information throughout a product lifecycle.
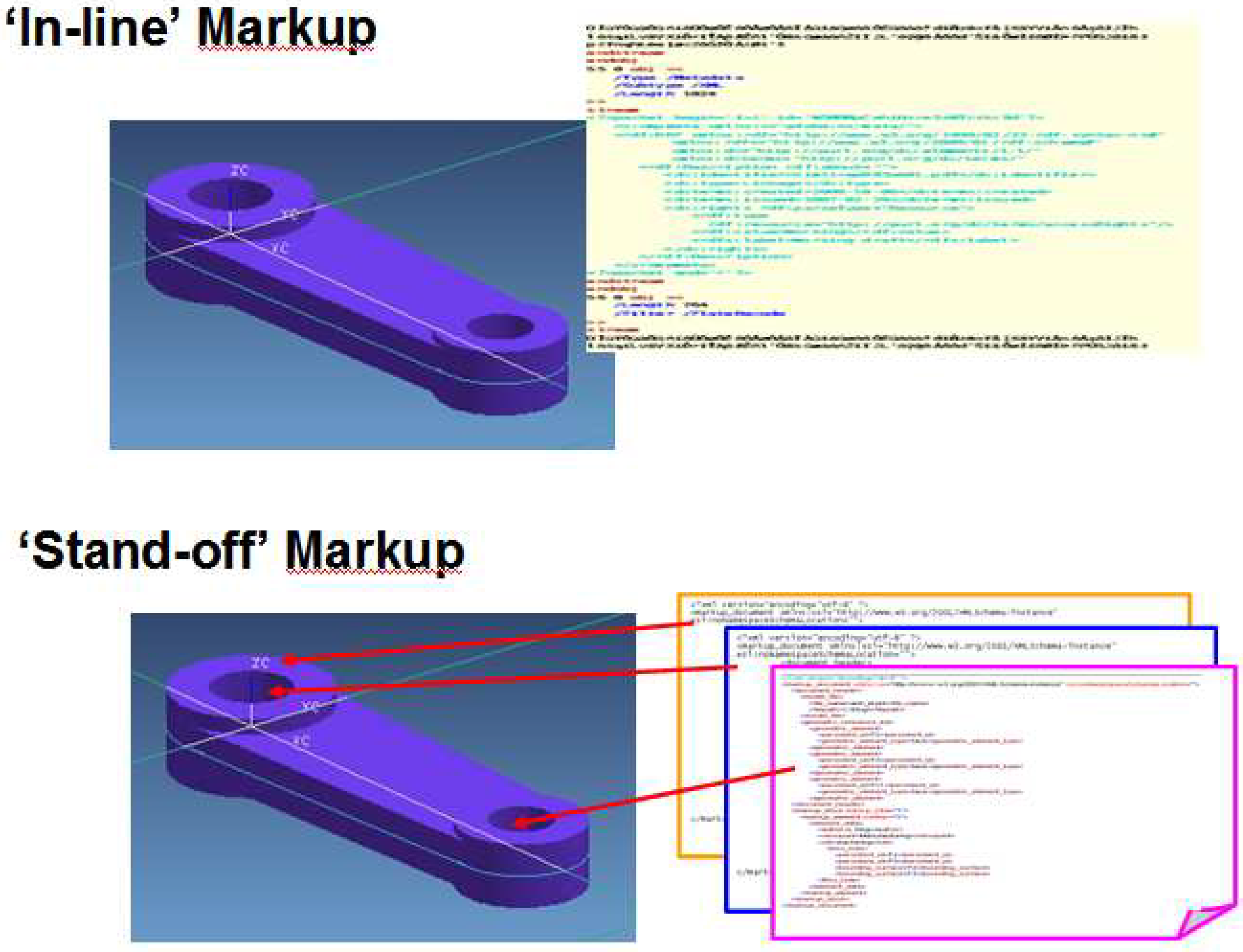
- Many layers of markup can be associated with the same object, allowing different viewpoints to be associated with, both concurrent viewpoints (e.g. cooperators or partners during the design phase) and successive (e.g. technology requirements from machining engineers or maintenance information from in-service phase). That is, with ‘stand-off’ markup, information from various viewpoints with different structures or formats can be carried, while the original object itself however, remains ‘light’ and can be passed with only the information necessary for a specific user or purpose.
- The information pertaining to one viewpoint can be put in a separate markup file; and multiple independent markup files can be safely applied to the same object. Thus, it allows context-specific information to be manipulated into different viewpoints, freely tailored to a reduced version for reasons of security/IP (Intellectual Property) and the requirements of different target users, and re-organized for various purposes and applications.
| Markup strategy | Advantages | Disadvantages |
|---|---|---|
| ‘in-line’ |
|
|
| ‘stand-off’ |
|
|
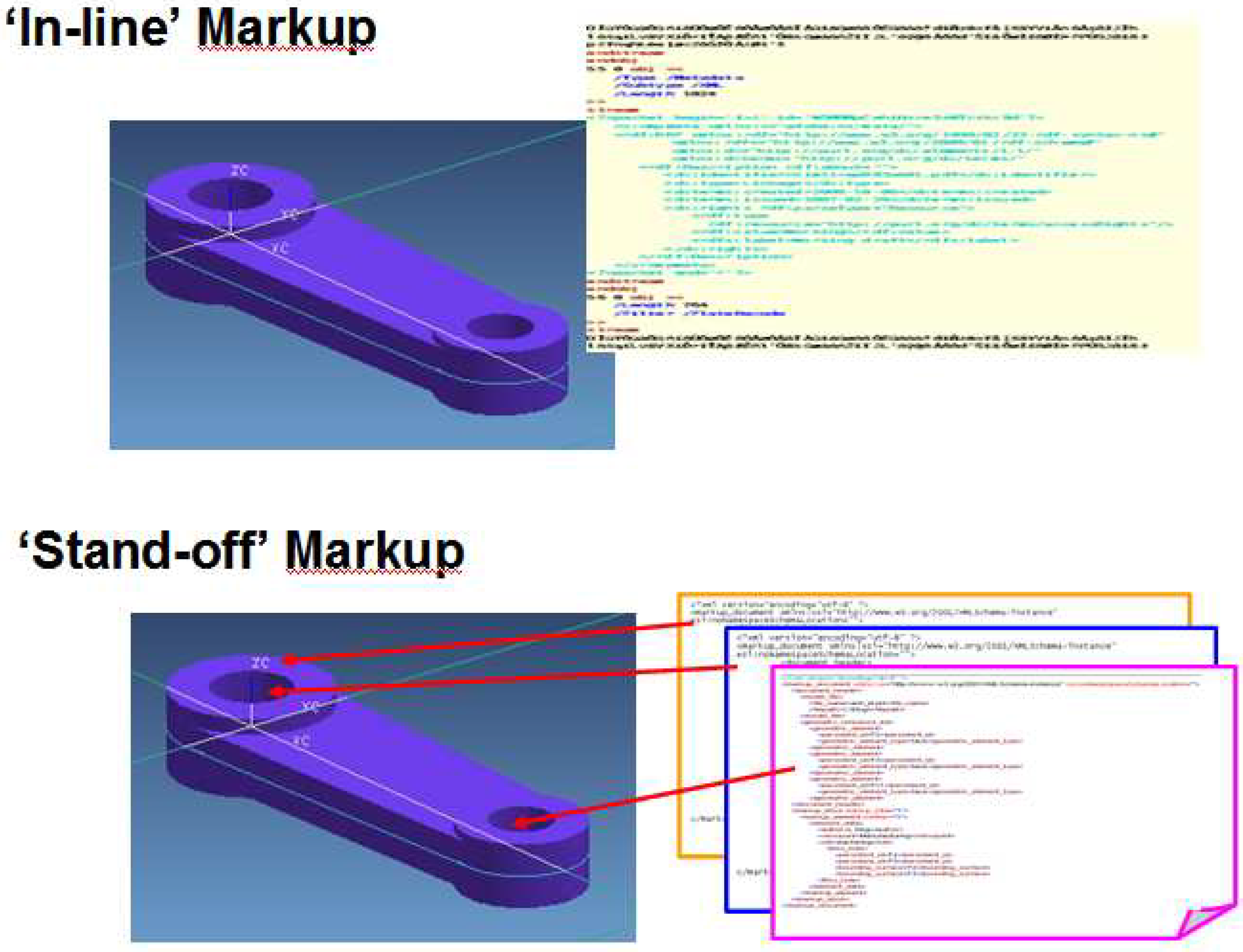
5. Applications of markup in Engineering Design
5.1. Markup for information management and retrieval
5.2. 3D annotation and markup in engineering design
- The ‘annotation’ functions provided are often limited to a single type (e.g. free-text, Uniform Resource Identifier (URI) or numerical format), they cannot satisfy the requirements of annotation schemes supporting context-specific information and multiple viewpoints.
- The content of the annotation is associated with specific product models. In other words, the annotation adopts ‘inline’ annotation strategy. This is easy to accomplish, but it does actually change the models, and it is only reusable for invariant topologies.
- It is difficult to place multiple independent sets of annotation in the same model, which hinders the annotation being re-organized and retrieval at later stage.
5.3. Annotation in collaborative design environment
5.4. Recent research direction
| Approach | Strategy | Technique | Targets | Applications | Markup languages involved |
|---|---|---|---|---|---|
| Work by Kim and Compton, 2004 [50] | In-line | Manual | Web-based document | Document management & retrieval | Unclear |
| Work by Soo et al. 2003 [51] | In-line | Automatic | Document | Document retrieval | RDF |
| ANITA by Gardoni 2005 [52], Frank and Gardoni 2005 [53] | In-line | Manual | Document (whole or parts) | Information retrieval | XML |
| KIM by Kiryakov et al. 2004 [54] | Stand-off | Automatic | Entity | Information retrieval | RDF |
| @WEB by Hignette et al. 2008 [55] | In-line | Semi-automatic | Data tables in documents | Information retrieval | Unclear |
| Work by Elinson and Nau, 1997 [57] | In-line | N/A | Graph representation of machining features | Feature classification | Unclear |
| Work by Hoffman and Joan-Arinyo, 1998 [58] | In-line | N/A | Product model | Multiple viewpoints | Unclear |
| CAD/CAM (e.g. AutoCAD 2008, SolidEdge V19, Pro/ENGINEER, NX5, CATIA V5R13), Microstation [59,60,61,62,63,64] | In-line | Manual | CAD models | Association of information | Unclear |
| LIMMA by Ding et al. 2009 [14] | Stand-off | Manual | CAD models | Multiple viewpoints | XML |
| EPM by Ding et al. 2009 [1] | Stand-off | Manual | CAD models | Information organization and retrieval in PLM | XML |
| TaDiMa by Fiorentino et al. 2009 [65] | In-line / stand-off | Automatic | Digital Master | Marketing and design review | HTML |
| Work by Pittarello and Faveri, 2006 [67] | In-line | N/A | X3D, semantic web | Navigational support | X3D/RDF/XML |
| Work by Ding et al. 2009 [68] | Stand-off | Manual | CAD models/ Lightweight representations | Management of lifecycle product information | XML |
| Vannotea by Schroeter et al. 2006 [69] | Stand-off | Manual | Images, video, 3D object, audio | Communication in collaboration | XML |
| Work by Lenne et al. 2009 [70] | In-line | Manual | 3D object | Communication and knowledge management | Unclear |
| Work by Hisarciklilar and Boujut, 2009 [71] | Stand-off | Manual | VRML | Communication in collaboration | VRML |
| Work by Matthews et al. 2009 [72] | Stand-off | Manual / Semi-automatic | CAD models | Support of design optimisation | XML |
| Work by Vucinic et al. 2009 [73] | In-line | N/A | X3D | Multidisciplinary engineering environments | X3D/OWL |
6. Summary and discussion
- 1)
- Annotation and markup have shown their advantages in various applications. XML, as one of most common markup languages, has been widely applied due to its characteristics, especially its extensibility, representation of semi-structure information, and support of re-organisation and multi-viewpoints. As shown in the review, the powers of XML have led to a large number of XML-based markup languages founded on various scenarios and applications, which have resulted in the problem of information interoperability when considered for future usage.
- 2)
- There are two basic types of markup methods: ‘in-line’ and ‘stand-off’. The ‘in-line’ method can be easily implemented using a text editor or a simple scripting language, and therefore it has been widely adopted, especially in document management. However, with high requirements to support multi-viewpoints and the introduction of 3D annotation, ‘stand-off’ method starts to show its potential. Although some technical issues like persistent references and maintenance of changes, have not yet been adequately solved, which hinders its applications in industry.
- 3)
- It is inspiring to see that annotations have played a key role in product development. The work on information retrieval comes not only from the engineering community, but also from computer science and IT industry. The current achievements encourage researchers to think about extending the application from document to 3D models and multimedia. Compared with document retrieval, the researches on 3D annotation started a little later, but the latest results, such as exploration of ‘stand-off’ annotation on 3D models, integration with PLM requirements and datasets, and applications in collaboration environment, have already shown their considerable impacts for industrial solutions. In addition, it can be seen that the 3D annotation is still an active area of research recently. The work on design methodology has just started. Therefore, results are still limited, but the potential for the future work is warranted. Some further research questions have already been identified: for example, how to integrate annotation techniques with current CAE supporting tools, how to combine the techniques with traditional design process and rationale capture tools, etc.
7. Future research directions
- 1)
- Persistent identification of geometry: The issue of the persistent identification of geometry, also called the ‘persistent naming problem’, was raised by Mun and Han [74]. The initial focus of the problem was how to identify the surviving entities of a pre-edit B-rep in the post-edit B-rep. Now, the persistent identification of geometry is becoming a key obstacle in translating annotations references between various 3D models formats, for example, how can annotations be shared among the users of the native CAD models and the users of the derived lightweight versions? To explore a solution, an experiment using UGS NX3 and Adobe Acrobat 3D 8.1 has been carried out [75]. The results show that the face labels in the original CAD model did survive during its translation to PRC format in PDF, meaning that all the faces of the product model could be persistently identified; it is therefore possible, at least in principle, that features based on a specific viewpoint could be constructed as combinations of the faces of the model. Correspondingly, if an original CAD model remains constant, the annotations could also survive within both the CAD model and the lightweight formats. Although the results are inspiring, there is a risk that the linkage between the CAD model and the annotation may be lost when the entity referred to is deleted in the CAD model. Obviously, an intensive exploration on the representations of 3D models and 3D annotation techniques needs to be carried out between academics, standards community and commercial industry.
- 2)
- Semi-automatic/automatic information capture tools: Most applications of annotation are still user-intervention-based. That is, it needs manual input. If the users forget to update their changes or neglect to retrieve the information to annotate, the annotation systems cannot work well and some of important information will be lost. Thus, dedicated information capture tools is worth exploring to support semi-automatic or automatic annotations. Some efforts on automatic information capture are being carried out by both academics and software industry. For example, the Simulation Process Studio (SPS) with UGS NX 3 Simulation [76] provides a palette of standard steps for users to drag and drop into the process with connecting lines defining the flow. The steps can then be saved as an XML file and made available to the standard Unigraphics NX application. Obviously, the results are still limited and more efforts are needed.
- 3)
- Enhancement of support for development methodology: As reviewed, recently, more and more researchers are transferring their attention to directly support design methodology, but the outputs of the work are still not enough. Further fundamental researches are required, including how to use annotation to help the capture of the design process, retrieval of rationale behind, and support of CAE tools. This would highlight that the work could be more meaningful if it integrates with latest design methodology and changes of working way (e.g. distributed cooperation). The latest work performed by Ding et al. [77] presented a general component-based approach to making records of transactional for design activities. In the proposed method, the activities are individually recorded in XML-based format, which can be assembled, tailored and transformed in different ways by XSL/XSLT. Therefore, it shifts design records to design reuse.
Acknowledgements
References
- Ding, L.; Matthews, J.; McMahon, C.A.; Mullineux, G. An Information Support Approach for Machine Design & Build Companies. Concurrent Eng. – Res. A. 2009, 17, 103–109. [Google Scholar] [CrossRef]
- Patel, M.; Ball, A.; Ding, L. Strategies for the Curation of CAD Engineering Models. Int. J. Digital Curation 2009, 4, 84–97. [Google Scholar] [CrossRef]
- Feilden, B.R. Engineering Design: Report of Royal Commission, 2nd Ed. ed; HMSO: London, UK, 1963. [Google Scholar]
- NX. http://www.plm.automation.siemens.com/en_gb/products/nx/index.shtml (accessed 10 February, 2010).
- AutoCAD. http://usa.autodesk.com/ (accessed 10 February, 2010).
- Pro/Engineer. http://www.ptc.com/products/proengineer/ (accessed 10 February, 2010).
- Clarkson, P.J.; Hamilton, J.R. Signposting, a Parameter-driven Task-based Model of the Design Process. Res Eng Des 2000, 12, 18–38. [Google Scholar] [CrossRef]
- Ryu, K.; Yücesan, E. CPM: A Collaborative Process Modeling for Cooperative Manufacturers. Adv. Eng. Inform. 2007, 21, 231–239. [Google Scholar] [CrossRef]
- Browning, T.R.; Fricke, E.; Negele, H. Key Concepts in Modeling Product Development Processes. Syst. Eng. 2006, 9, 104–128. [Google Scholar] [CrossRef]
- Bracewell, R.H.; Wallace, K.M. A Tool for Capturing Design Rationale. In Proceedings of the 14th International Conference on Engineering Design (ICED’03), Stockholm, Sweden, August 2003; pp. 185–186.
- Regli, W.C.; Hu, X.; Atwood, M.; Sun, W. A Survey of Design Rationale Systems: Approaches, Representation, Capture and Retrieval. Eng. Comput. 2000, 16, 209–235. [Google Scholar] [CrossRef]
- Li, W. D.; Qiu, Z. M. State-of-the-Art Technologies and Methodologies for Collaborative Product Development Systems. Int. J. Prod. Res. 2006, 44, 2525–2559. [Google Scholar] [CrossRef]
- Van der Aalst, W.M.P. Exploring the CSCW Spectrum using Process Mining. Adv. Eng. Inform. 2007, 21, 191–199. [Google Scholar] [CrossRef]
- Ding, L.; Davies, D.; McMahon, C.A. The Integration of Lightweight Representation and Annotation for Collaborative Design Representation. Res. Eng. Des. 2009, 19, 223–238. [Google Scholar] [CrossRef]
- Khare, R.; Rifkin, A. The Origin of Document Species. Comput. Networks ISDN 1998, 30, 389–397. [Google Scholar] [CrossRef]
- Coombs, J.H.; Renear, A.H.; DeRose, S.J. Mark-up Systems and the Future of Scholarly Text Processing. Commun. ACM 1987, 30, 933–947. [Google Scholar] [CrossRef]
- Liu, S.; McMahon, C.A.; Culley, S.J. A Review of Structured Document Retrieval (SDR) Technology to Improve Information Access Performance in Engineering Document Management. Comput. Ind. 2008, 59, 3–16. [Google Scholar] [CrossRef]
- Johnston, P. What you have always wanted to know that about SGML, HTML and XML but were afraid to ask: why mark-up matters. In Presented at Society of Archivists’ Diploma in Archive Administration Seminar, Edinburgh, UK, November 1998.
- Goldfarb, C. The SGML Handbook; Rubinsky, Y., Ed.; Clarendon Press: Oxford, UK, 1990. [Google Scholar]
- Brecher, C.; Vitr, M.; Wolf, J. Closed-loop CAPP/CAM/CNC Process Chain based on STEP and STEP-NC Inspection Tasks. Int. J. of Computer Integr. Manuf. 2006, 19, 570–580. [Google Scholar] [CrossRef]
- Lee, C.K.M.; Ho, G.T.S.; Lau, H.C.W.; Yu, K.M. A Dynamic Information Schema for Supporting Product Lifecycle Management. Expert Syst. Appl. 2006, 31, 30–40. [Google Scholar] [CrossRef]
- Kang, J.; Lee, J.K. Rule Identification from Web Pages by the XRML Approach. Decis. Support Syst. 2005, 41, 205–227. [Google Scholar] [CrossRef]
- Chung, H.S.; Lee, Y. MCML: Motion Capture Mark-up Language for Integration of Heterogeneous Motion Capture Data. Comp. Stand. Inter. 2004, 26, 113–130. [Google Scholar] [CrossRef]
- Wang, Y.; Ajoku, P.N.; Brustoloni, J.C.; Nnaji, B.Q. Intellectual Property Protection in Collaborative Design through Lean Information Modelling and Sharing. J. Comput. Inf. Sci. Eng. 2006, 6, 149–159. [Google Scholar] [CrossRef]
- Anwar, N.; Kanok-Nukulchai, W.; Batanov, D.N. Component-based, Information Oriented 3D Structural Engineering Applications. J. Comput. Civil Eng. 2005, 19, 45–57. [Google Scholar] [CrossRef]
- Swindells, N. Communication Materials Information: Product Data Technology for Materials. Int. Mater. Rev. 2002, 47, 31–46. [Google Scholar] [CrossRef]
- PGML, Precision Graphics Mark-up Language. www.w3.org/TR/1998/NOTE-PGML-19980410 (accessed 10 February, 2010).
- X3D, eXtensible 3D. www.web3d.org (accessed 10 February, 2010).
- Kim, C.Y.; Kim, N.; Kim, Y.; Kang, S.H.; O’Grady, P. Distributed Concurrent Engineering: Internet-based Interactive 3-D Dynamic Browsing and Mark-up of STEP Data. Concurrent Eng. – Res. A. 1998, 6, 53–70. [Google Scholar] [CrossRef]
- Li, W.D. A Web-based Service for Distributed Process Planning Optimisation. Comput. Ind. 2005, 56, 272–288. [Google Scholar] [CrossRef]
- Versprille, K. Dassault Systèmes’ Strategic Initiative: 3D XML for Sharing Product Information. In Presented at Technology Trends in PLM, Collaborative Product Development Associates, Stamford, CT, USA, July 2005.
- Open product lifecycle data sharing using XML, Write paper: PLM XML. http://www.plm.automation.siemens.com/en_us/Images/plm%20xml%20wp%20W%203_tcm1023-11521.pdf (accessed 10 February, 2010).
- Resource Description Framework (RDF). http://www.w3.org/RDF/ (accessed 10 February, 2010).
- OWL Web Ontology Language Overview. http://www.w3.org/TR/owl-features/ (accessed 10 February, 2010).
- Commerce XML Resources. http://www.cxml.org/ (accessed 10 February, 2010).
- SOAP, Simple Object Access Protocol. http://www.w3.org/2000/xp/Group/ (accessed 10 February, 2010).
- WSDL, Web Service Description Language. http://www.w3.org/2002/ws/desc/ (accessed 10 February, 2010).
- XML-RPC, XML—Remote Procedure Calls. http://www.xml-rpc.net/ (accessed 10 February, 2010).
- Umar, A. The Emerging Role of the Web for Enterprise Applications and ASPs. Proc. IEEE 2004, 92, 1420–1438. [Google Scholar] [CrossRef]
- Bussler, C. Semantic Web Services—Fundamentals and Advanced Topics. Lect. Notes Comput. Sci. 2004, 3263, 1–8. [Google Scholar]
- The Text Encoding Initiative (TEI) Consortium, Stand-off Markup. http://www.tei-c.org/Activities/SO/sow06.xml?style=printable (accessed 10 February, 2010).
- Thompson, H.S.; McKelvie, D. Hyperlink Semantics for Standoff Markup of Read-only Documents. In Proceedings of SGML Europe’97: The next decade – Pushing the Envelope, Barcelona, Spain, 1997; pp. 227–229.
- Davies, D.; McMahon, C.A. Multiple Viewpoint Design Modelling through Semantic Markup. In Proceedings of IDETC/CIE 2006, ASME 2006 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Philadelphia, Pennsylvania, USA, 2006.
- Alink, W. XIRAF: An XML-IR Approach to Digital Forensics. Master’s thesis, University of Twente, Enschede, The Netherlands, 2005. [Google Scholar]
- Taghva, K.; Condit, A.; Borsack, J. Autotag: A Tool for Creating Structured Document Collections from Printed Materials. http://www.isri.unlv.edu/publications/isripub/Taghva98b.pdf (accessed 10 February, 2010).
- Akhtar, S.; Reilly, R.G.; Dunnion, J. Auto-tagging of Text Documents into XML. Lect. Notes Comput. Sci. 2003, 2807, 20–26. [Google Scholar]
- Cui, H. ARTT: A General Approach to Automatic Mark-up of Taxonomic Descriptions with XML. http://www.cais-acsi.ca/proceedings/2005/cui_2005.pdf (accessed 10 February, 2010).
- Feldman, R.; Rosenfeld, B.; Fresko, M. TEG—a Hybrid Approach to Information Extraction. Know. Inf. Sys. 2006, 9, 1–18. [Google Scholar] [CrossRef]
- Vargas-Vera, M.; Motta, E.; Domingue, J.; Lanzoni, M.; Stutt, A.; Ciravegna, F. MnM: Ontology Driven Semi-automatic and Automatic Support for Semantic Mark-up. Lect. Notes Comput. Sci. 2002, 2473, 379–391. [Google Scholar] [CrossRef]
- Kim, M.; Compton, P. Evolutionary Document Management and Retrieval for Specialized Domains on the Web. Int. J. Hum.-Comput. Stud. 2004, 60, 201–241. [Google Scholar] [CrossRef]
- Soo, V.W.; Lee, C.Y.; Li, C.C.; Chen, S.L.; Chen, C.C. Automated Semantic Annotation and Retrieval Based on Sharable Ontology and Case-based Learning Techniques. In Proceedings of the 3rd ACM/IEEE-CS Joint Conference on Digital Libraries (JCDL’ 2003), Houston, TX, USA, May 2003; pp. 61–72.
- Gardoni, M. Concurrent Engineering in Research Projects to Support Information Content Management in a Collective Way. Concurrent Eng. – Res. A. 2005, 13, 135. [Google Scholar] [CrossRef]
- Frank, C.; Gardoni, M. Information Content Management with Shared Ontologies—at Corporate Research Centre of EADS. Int. J. Inf. Manage. 2005, 25, 55–70. [Google Scholar] [CrossRef]
- Kiryakov, A.; Popov, B.; Ognyanoff, D.; Manov, D.; Goranov, K.M. Semantic Annotation, Indexing, and Retrieval. J. Web Semantics 2004, 2, 49–79. [Google Scholar] [CrossRef]
- Hignette, G.; Buche, P.; Couvert, O.; Dibie-Barthélemy, J.; Doussot, D.; Haemmerlé, O.; Mettler, E.; Soler, L. Semantic Annotation of Web Data Applied to Risk in Food. Int. J. Food Microbiol. 2008, 128, 174–180. [Google Scholar] [CrossRef]
- American Society of Mechanical Engineers. An American National Standard: digital product definition data practices; ASME: New York, USA, 2003. [Google Scholar]
- Elinson, A.; Nau, D. S.; Regli, W. C. Feature-based Similarity Assessment of Solid Models. In Proceedings of the Fourth ACM Symposium on Solid Modeling and Applications, Atlanta, Georgia, USA, 1997; pp. 297–310.
- Hoffmann, C. M.; Joan-Arinyo, R. CAD and the Product Master Model. Comput.-Aided Des. 1998, 30, 905–918. [Google Scholar] [CrossRef]
- Fane, B. Autodesk AutoCAD 2008 (Cadalyst Labs Review) – New annotations are the name of the game. Cadalyst. April 2007. http://www.cadalyst.com/general-software/autodesk-autocad-2008-cadalyst-labs-review-6061 (accessed 10 February, 2010).
- Cohn, D. New Enhancements in Solid Edge. CADCAMNet. June 2006. http://www.plm.automation.siemens.com/en_us/Images/cadcamnet_solidedge_v19review_tcm1023-22637.pdf (accessed 10 February, 2010).
- Rowe, J. Cadalyst Labs Review: PTC Pro/ENGINEER Wildfire 3 Workflow efficiency and productivity take center stage. Cadalyst. September 2006. http://www.cadalyst.com/manufacturing/cadalyst-labs-review-ptc-proengineer-wildfire-3-10834 (accessed 10 February, 2010).
- Rowe, J. Cadalyst Labs Review: NX5, Part2 – Enhancements in software architecture enable major improvements in assemblies, visualization, and drawings. Cadalyst. December 2007. http://manufacturing.cadalyst.com/manufacturing/article/articleDetail.jsp?id=475124 (accessed 10 February, 2010).
- CATIA - 3D Functional Tolerancing and Annotations, 2(FTA), CATIA V5R19. http://www.catia.cz/fileadmin/Pictures_Menu/Catia/Catia_V5/Mechanical_Domain/pdf/FTA.pdf (accessed 10 February, 2010).
- Anderson, A. Microstation V8 – An Introduction to Computer Aided Design; Schroff Development Corporation: Mission, KS, USA, 2002. [Google Scholar]
- Fiorentino, M.; Monno, G.; Uva, A. E. Tangible Digital Master for Product Lifecycle Management in Augmented Reality. Int. J. Interact. Des. Manuf. 2009, 3, 121–129. [Google Scholar] [CrossRef]
- Ball, A.; Ding, L.; Patel, M. An Approach to Accessing Product Data across System and Software Revisions. Adv. Eng. Inform. 2008, 22, 222–235. [Google Scholar] [CrossRef]
- Pittarello, F.; Faveri, A.D. Semantic Description of 3D Environments : a Proposal Based on Web Standards. In Proceedings of the eleventh International Conference on 3D Web Technology, Columbia, Maryland, USA, 2006; pp. 85–95.
- Ding, L.; Ball, A.; Matthews, J.; McMahon, C.A.; Patel, M. Annotation of Lightweight Formats for Long-term Product Representations. Int. J. of Computer Integr. Manuf. 2009, 22, 1037–1053. [Google Scholar] [CrossRef]
- Schroeter, R.; Hunter, J.; Guerin, J.; Khan, I.; Henderson, M. A Synchronous Multimedia Annotation System for Secure Collaboratories. In Proceedings of the Second IEEE International Conference on e-Science and Grid Computing, Piscataway, USA, 2006; p. 41.
- Lenne, D.; Thouvenin, I.; Aubry, S. Supporting Design with 3D-annotations in a Collaborative Virtual Environment. Res. Eng. Des. 2009, 20, 149–155. [Google Scholar] [CrossRef]
- Hisarciklilar, O.; Boujut, J.F. An annotation model to reduce ambiguity in design communication. Res. Eng. Des. 2009, 20, 171–184. [Google Scholar] [CrossRef]
- Matthews, J.; Ding, L.; Feldman, J.; Mullineux, G. The Maintenance and Handling of Constraints in Machine Design. In Proceedings of the ASME 2009 International Design Engineering Technical Conferences & Computers and Information in Engineering Conference, IDETC/CIE 2009, San Diego, California, USA, August 30 – September 2, 2009. 10 pages on CD. ISBN 978-0-7918-3856-3.
- Vucinic, D.; Pesut, M.; Jovic, F.; Lacor, C. Exploring Ontology-based Approach for Facilitate Integration of Multi-physics and Visualization for Numerical Models. In Proceedings of the ASME 2009 International Design Engineering Technical Conferences & Computers and Information in Engineering Conference, IDETC/CIE 2009, San Diego, California, USA, August 30 – September 2, 2009. 10 pages on CD. ISBN 978-0-7918-3856-3.
- Mun, D.; Han, S. Identification of Topological Entities and Naming Mapping for Parametric CAD Model Exchanges. Int. J. CAD/CAM 2005, 5, 69–82. [Google Scholar]
- Ding, L.; Ball, A.; Patel, M.; Matthews, J.; Mullineux, G. Strategies for the Collaborative Use of CAD Product Models. In Proceedings of the 17th International Conference on Engineering Design (ICED'09), Stanford, CA, USA, August 2009; pp. 123–134, ISBN 978-1-904670-12-4.
- Simulation Process Studio. http://newsletter.plmworld.org/archive/Vol3No3/Ogilvie.php (accessed10 February, 2010).
- Ding, L.; Giess, M.; Goh, Y.M.; McMahon, C.A.; Thangarajah, U. Component-based Records: a Novel Method to Record Transaction Design Work. Adv. Eng. Inform. 2009, 23, 332–347. [Google Scholar] [CrossRef]
© 2010 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Ding, L.; Liu, S. Markup in Engineering Design: A Discourse. Future Internet 2010, 2, 74-95. https://doi.org/10.3390/fi2010074
Ding L, Liu S. Markup in Engineering Design: A Discourse. Future Internet. 2010; 2(1):74-95. https://doi.org/10.3390/fi2010074
Chicago/Turabian StyleDing, Lian, and Shaofeng Liu. 2010. "Markup in Engineering Design: A Discourse" Future Internet 2, no. 1: 74-95. https://doi.org/10.3390/fi2010074
APA StyleDing, L., & Liu, S. (2010). Markup in Engineering Design: A Discourse. Future Internet, 2(1), 74-95. https://doi.org/10.3390/fi2010074