


A Deep Learning Framework for Enhanced Detection of Polymorphic Ransomware



Abstract
1. Introduction
1.1. Problem and Motivation
- Process-centric methods analyze running programs, but they often need complete data to work, which makes early detection difficult.
- Data-centric approaches monitor user files for unusual changes. However, they frequently produce too many false alarms because they cannot easily tell the difference between normal file changes and malicious ransomware activity. This leads to slow responses.
- Ransomware’s polymorphic nature (meaning it can constantly change its appearance) and its ability to mimic legitimate software further complicate early detection. The critical pre-encryption phase is especially challenging; it is so brief and elusive that traditional analysis struggles to collect enough data for timely and accurate detection [13,14].
- Their Minimax loss function struggles to accurately model the complex differences between real and synthetic ransomware data, particularly during that critical pre-encryption phase.
- GANs are also vulnerable to the “curse of dimensionality,” meaning they need effective ways to select important features. Traditional feature selection methods often are not adaptable enough to keep up with evolving ransomware [16].
1.2. Research Questions and Objectives
1.2.1. Research Questions
- To what extent does GAN-based data augmentation mitigate pre-encryption data scarcity and enhance ransomware early detection?
- How can mutual information feature selection techniques be integrated into a DBN-based ransomware detection model to enable dynamic feature relevance reassessment with the incorporation of new data?
- How can an uncertainty-based estimation approach be utilized to determine the optimal number of training epochs for a DBN-based ransomware detection model?
1.2.2. Objectives
- Introduce an enhanced GAN-based data augmentation module with a novel Bi-Gradual Minimax loss function. Existing GAN models struggle to accurately bridge the gap between real and synthetic data distributions, especially with scarce pre-encryption data. Our new loss function, employing a gradual up-weighting coefficient, minimizes this divergence, enabling the generation of highly realistic artificial ransomware attack patterns. This directly tackles data scarcity, a major obstacle to early detection, and is expected to significantly improve accuracy.
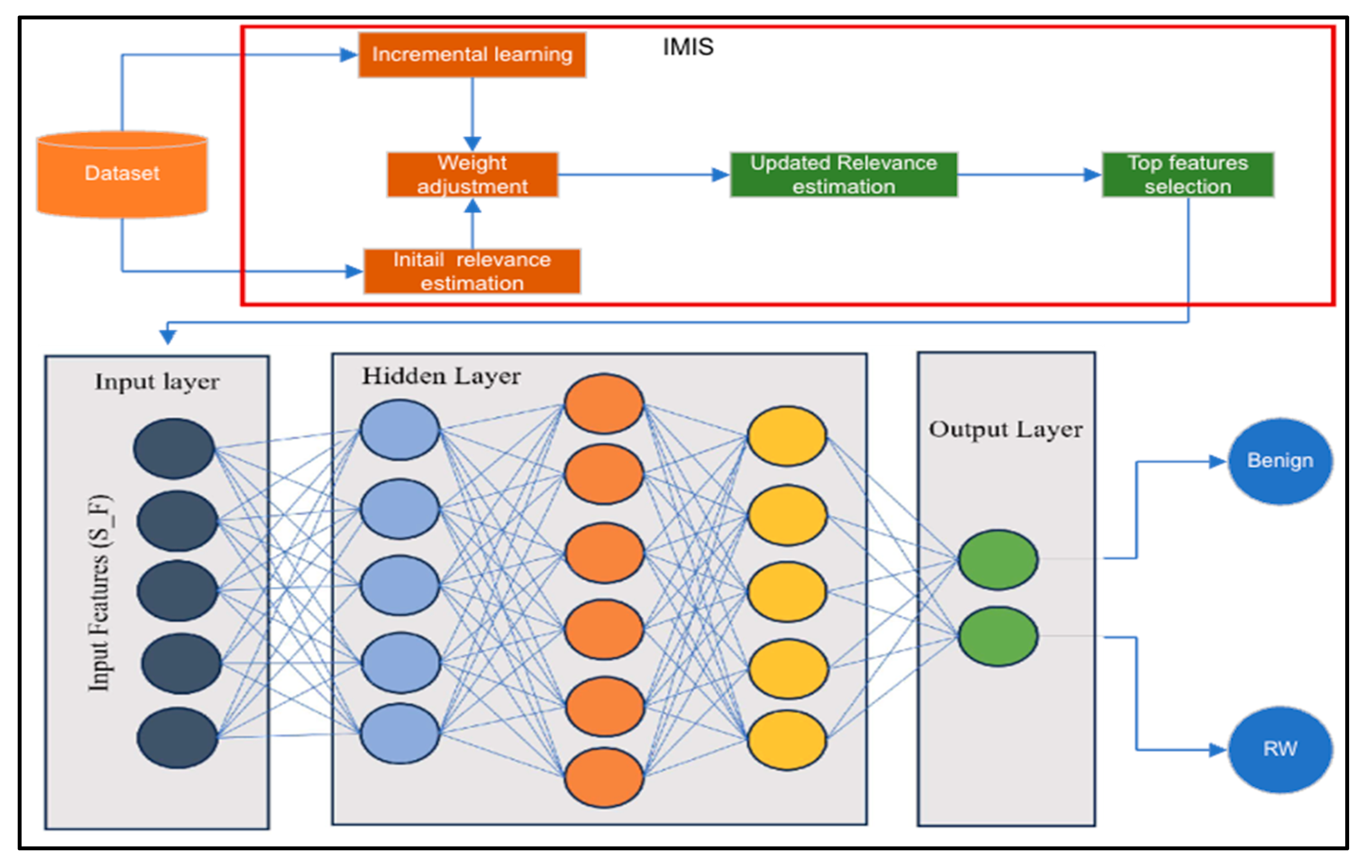
- Propose an Incremental Mutual Information Selection (IMIS) technique to enhance model adaptability. Traditional feature selection methods often become outdated due to the dynamic nature of ransomware. IMIS dynamically reassesses feature relevance as new data integrates into our custom DBN-based model. This on-the-fly adaptation allows continuous learning and improved detection accuracy against evolving threats, ensuring long-term effectiveness.
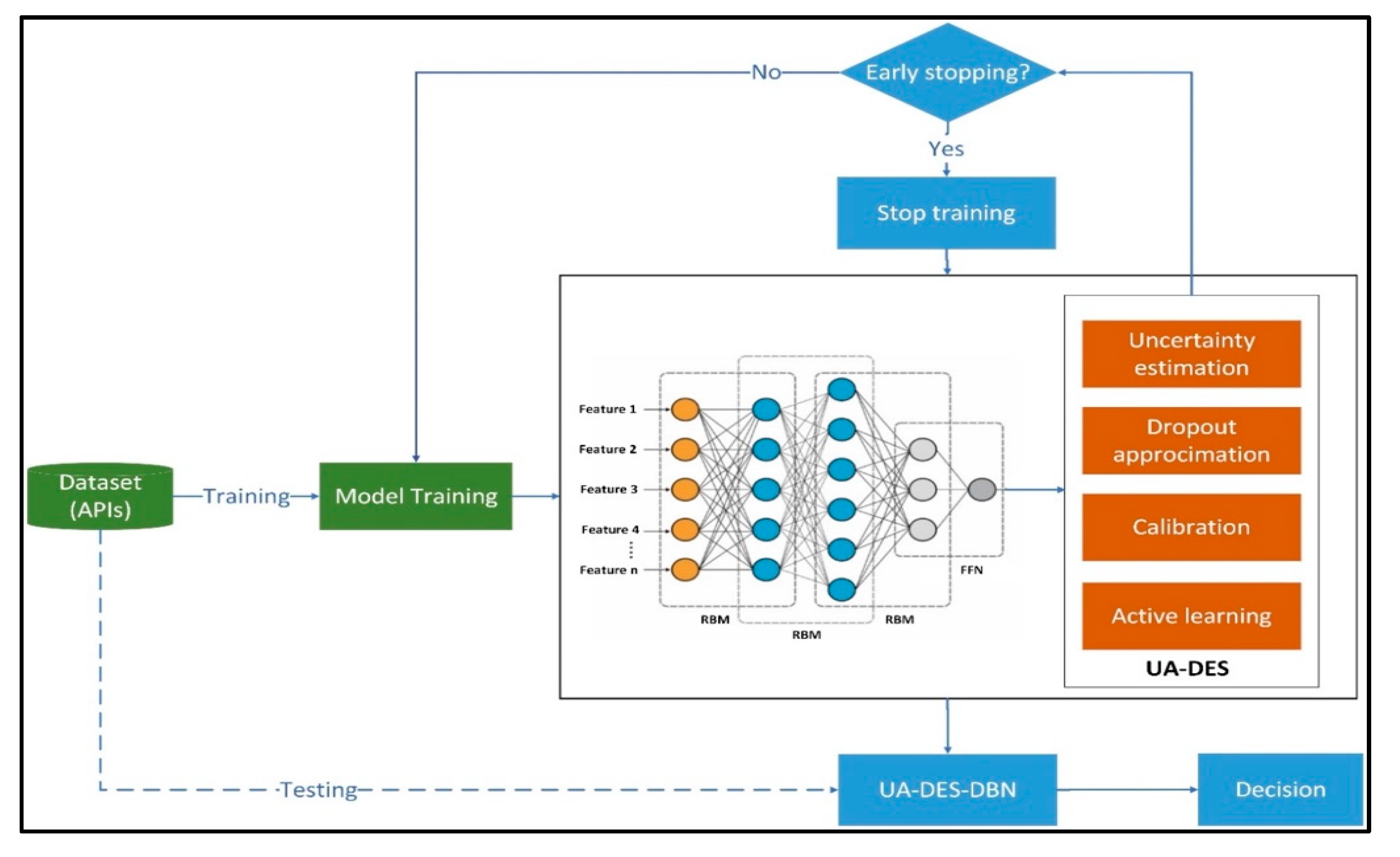
- Present an Uncertainty-Aware Dynamic Early Stopping (UA-DES) criterion and method to optimize DBN training. Overfitting is a common challenge in DBN training, particularly in determining optimal epochs. Existing dynamic approaches often fall short due to the inherent variability of ransomware behavior. By leveraging Bayesian approximation to accurately estimate uncertainty, UA-DES aims to determine the optimal number of training epochs, leading to improved model generalization, best-in-class prediction performance, and effective overfitting prevention.
1.3. Early Detection Value Proposition
- Realistic Ransomware Pattern Generation: A novel Bi-Gradual Minimax Loss function uses a gradual up-weighting coefficient to enable the GAN to produce highly realistic artificial ransomware attack patterns.
- Dynamic Feature Adaptation: An Incremental Mutual Feature Selection (IMIS) technique allows the model to continuously adapt to evolving ransomware behaviors by reassessing feature relevance.
- Optimized Training for Timely Detection: The Uncertainty-Aware Dynamic Early Stopping (UA-DES) technique, based on Bayesian approximation, precisely determines the optimal training epochs for the DBN, ensuring efficient and early detection.
- First-of-its-Kind Taxonomy of Ransomware Attack Success Factors: This work introduces a groundbreaking categorization of factors contributing to successful ransomware attacks, particularly within industrial SCADA environments. This offers essential insights for risk mitigation and targeted defense [11,14].
- Comprehensive Ransomware Attack Model for Industrial Systems: We have developed a detailed model illustrating ransomware’s operational mechanisms in industrial systems, crucial for designing effective prevention and mitigation strategies.
- Advanced Situational Awareness for Prediction: The framework enhances the ability to predict ransomware attacks by integrating diverse evidence, enabling proactive intervention. It also establishes a benchmark for evaluating future ransomware prediction methodologies in Industrial Control Systems (ICSs) [10].
1.4. Overview of the 3-Phase Framework
- What it does: Uses a GAN to create synthetic, yet realistic, ransomware attack patterns.
- Why it is important: Real-world pre-encryption ransomware data is scarce. GANs help overcome this data insufficiency, allowing the detection model to be trained on a much larger and more diverse set of potential attack scenarios. The framework employs a “Bi-Gradual Minimax loss function” to make the synthetic data even more accurate.
- What it does: Employs an IMIS technique to identify and prioritize the most important “features” or indicators of ransomware behavior.
- Why it is important: Ransomware constantly evolves, meaning what was a useful indicator yesterday might not be today. IMIS dynamically reassesses which features are most relevant as new data becomes available, ensuring the detection model focuses on the most current and effective signals, while also avoiding redundant information.
- What it does: Trains a DBN using the augmented data and selected features. It introduces a UA-DES criterion.
- Why it is important: Training deep learning models can lead to “overfitting,” where the model becomes too good at recognizing the training data but performs poorly on new, unseen data. UA-DES helps determine the optimal point to stop training, preventing overfitting and improving the model’s ability to accurately detect new and evolving ransomware threats. It does this by considering the uncertainty in the model’s predictions.
1.5. Example Use Case
- Scenario: The security team has logs from a few past ransomware incidents, but these are limited, especially for the very early, pre-encryption stages.
- Framework in Action: The GAN component of the framework would take these limited real-world ransomware logs and generate thousands of synthetic but highly realistic “pre-encryption” ransomware behaviors. These synthetic logs would include subtle system changes, file access patterns, or network communication anomalies that might occur just before encryption. This massively expands the training data available to the security team’s detection system.
- Scenario: As new, real-world (or even synthetic) data comes in from various sources—perhaps from threat intelligence feeds about emerging ransomware or from internal simulations—the security team needs to know which indicators are still relevant. For example, a previous ransomware might have always accessed a specific registry key, but a new variant might not.
- Framework in Action: The IMIS component would continuously analyze all the available data (real and synthetic). It would dynamically identify which specific actions, API calls, or network patterns are currently the strongest indicators of ransomware behavior, and which ones are becoming less relevant for detection. For instance, it might determine that unusual file system enumeration combined with specific network beaconing is a very strong indicator for a new variant, while a previously important indicator (like a specific DLL injection) is now less reliable. The system automatically prioritizes these most relevant “features” for the detection model.
- Scenario: The security team wants their SCADA system’s security software to detect ransomware as early as possible, without generating too many false alarms (e.g., stopping a legitimate system update). They also need the model to be robust and adaptable.
- Framework in Action: The DBN, trained on the GAN-augmented data and using the IMIS-selected features, would constantly monitor the water treatment plant’s SCADA systems. The UA-DES part of the framework ensures the DBN is trained just enough to be highly accurate but not so much that it overfits (leading to false positives). If the DBN detects a sequence of behaviors (based on the dynamically selected features) that strongly resembles ransomware, it would trigger an alert. For example, it might flag a sudden, unusual attempt to access specific operational data files followed by an attempt to modify system services, even if the exact pattern has not been seen before but falls within the learned “ransomware behavior space.” This early alert allows the security team to intervene before any critical systems are encrypted or damaged.
1.6. Multi-Step Deep Learning Approach
2. Related Work
2.1. Ransomware Attacks and Trends
2.2. Ransomware Success Factors
2.2.1. Operational-Related Factors
2.2.2. Resource-Related Factors
- Data Vulnerabilities: IoT and SCADA devices collect and transmit critical data used in control systems. Ransomware attacks targeting these data storages can encrypt or hijack (inject false data) operational data, which damages systems. Data servers, Human–Machine interfaces, and connected networks within SCADA systems are particularly sensitive due to their exposure to external networks [50,51].
- Service Disruption: Resource-limited devices often cannot easily recover from service disruptions caused by ransomware. Locking up ransomware, which disables device services without encryption, is a common tactic against such systems. Also, attackers can easily disable critical services required for operational decision-making [52].
- Lack of Expertise: Industrial systems like SCADA devices often run on specific operating systems that have not undergone enough research by the cybersecurity community. This lack of focus creates vulnerabilities that attackers exploit through zero-day attacks. The low interest in securing SCADA systems among researchers and industry professionals makes the issue bigger, and that can make them attractive targets [53].
2.3. Current Detection and Prevention Methods
2.3.1. Ransomware Prevention
2.3.2. Gaps in Ransomware Prediction and Detection
2.4. Addressing Prevention Gaps
3. Methodology
3.1. Phase 1: GAN Pre-Encryption Data Augmentation
3.2. Phase 2: Incremental Mutual Information Selection (IMIS)
3.3. Phase 3: Deep Belief Network-Based Ransomware Detection Model
4. Experimental Evaluation and Analysis
- Phase 1 uses a Bi-Gradual Minimax GAN (BGM-GAN) to generate synthetic ransomware attack patterns, overcoming data scarcity.
- Phase 2 employs the IMIS technique to dynamically select relevant features and adapt to evolving ransomware.
- Phase 3 utilizes a DBN with a UA-DES technique to optimize training and prevent overfitting.
4.1. Dataset, Environment, and Metrics
4.2. Phase 1
4.2.1. GANs Generative Adversarial NWs
Refined Minimax Loss: The Enhanced Bi-Gradual Approach
4.2.2. Early Detection with Feature Selection
4.2.3. Performance Evaluation
- Experimental Facilities
- Corpus of crypto-ransomware binaries
- Data Engineering
- Feature selection
- Compilation and comparison of results
4.3. Phase 2
- Correlation Coefficient Calculation
- Correlation-Based Adjustment of the Weighting Factor
- Threshold-Based Adjustment Function for Weighting Factor Stability
4.3.1. IMIS-DBN Integration
| Algorithm 1. Incremental Mutual Information Selection (IMIS) [70]. |
| Input: |
| Data_Batches: Stream of data batches from devices |
| Target_Class: The class variable for intrusion detection (e.g., normal or attack) |
| Alpha: Weighting factor for balancing historical and new data (initially set) |
| Threshold: Threshold for significant change in mutual information |
| Output: |
| Selected_Features: Set of features selected for intrusion detection |
| Procedure IMIS (Data_Batches, Target_Class, Alpha, Threshold): |
| Initialize Historical_MI as an empty dictionary |
| Initialize Selected_Features as an empty set |
| for each Batch in Data_Batches: |
| Current_MI = CalculateMutualInformation(Batch, Target_Class) |
| Historical_MI = UpdateFeatureRelevance(Historical_MI, Current_MI, Alpha) |
| Selected_Features = SelectAndUpdateFeatures(Historical_MI, Selected_Features, Threshold) |
| Yield Selected_Features |
| Procedure CalculateMutualInformation(Batch, Target_Class): |
| return {Feature: ComputeMutualInformation(Feature, Target_Class) for Feature in Batch} |
| Procedure UpdateFeatureRelevance(Historical_MI, Current_MI, Alpha): |
| return {Feature: Alpha ∗ Historical_MI.get(Feature, 0) + (1 − Alpha) ∗ MI for Feature, MI in Current_MI.items()} |
| Procedure SelectAndUpdateFeatures(Historical_MI, Selected_Features, Threshold): |
| return {Feature for Feature, MI in Historical_MI.items() if MI > Threshold or Feature in Selected_Features} |
4.3.2. Training for Adaptive Detection
4.3.3. Performance Evaluation of IMIS
4.4. Phase 3
4.4.1. UA-DES: Mathematical Steps and Algorithm
- Step 1. Bayesian Performance Modeling
- Performance Evaluation Based on Posterior Distribution:
- Uncertainty Estimation:
- Step 2. Bayesian Approximation via Dropout: Stochastic Inference in DBNs
- Step 3. Calibration for Reliable Probability Estimates
- Step 4. Active Learning Framework
- Step 5. Dynamic Stopping Criteria
| Algorithm 2. UA-DES and DBN Integration Pseudocode [70]. | |
| Initialize DBN model | |
| Initialize training parameters (epochs, learning rate, etc.) | |
| Initialize early stopping params (thrshld for perf improve, uncertainty thrshld, calibr qual. thrshld) | |
| 1. | For each epoch in training: |
| 2. | Train DBN on training dataset |
| 3. | Evaluate DBN on validation dataset |
| 4. | Calculate performance metric (e.g., accuracy, F1-score) |
| 5. | # Dropout as Bayesian approximation for uncertainty estimation |
| 6. | Perform dropout simulations on validation dataset |
| 7. | Calculate mean and standard deviation of performance metric across simulations |
| 8. | # Calibration of probability estimates |
| 9. | Calibrate model outputs on validation dataset |
| 10. | Calculate calibration quality (e.g., Expected Calibration Error) |
| 11. | # Active learning for data efficiency |
| 12. | If epoch % active_learning_interval == 0: |
| 13. | Identify and prioritize uncertain samples in training dataset |
| 14. | Retrain DBN model including prioritized samples |
| 15. | # Dynamic stopping criterion VALIDATION based on perf improvement, uncertainty, and calibration |
| 16. | If (performance improvement < performance improvement threshold) And |
| 17. | (standard deviation of performance metric < uncertainty threshold) And |
| 18. | (calibration quality > calibration quality threshold) Then |
| 19. | Stop the training |
4.4.2. Improved Detection Capability
4.4.3. Overall Results and Discussion
5. Conclusions
6. Future Research
6.1. Risk of Generating Misleading Samples
6.2. Empirical Diversity of Attack Behavior
6.3. Computational Efficiency
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AAA-ODBN | Artificial Algae Optimization Algorithm with Optimal Deep Belief Network |
| API | Application Programming Interface |
| AV | Anti-Virus |
| C2 | Command and Control |
| CISA | Cybersecurity and Infrastructure Security Agency |
| CNN | Convolutional Neural Network |
| DBN | Deep Belief Network |
| DNN | Deep Neural Network |
| DoR | Denial-of-Resources |
| DPBD-FE | Dynamic Pre-encryption Boundary Delineation and Feature Extraction |
| DR | Detection Rates |
| ECE | Expected Calibration Error |
| FNR | False Negative Rate |
| FPR | False Positive Rate |
| GAN | Generative Adversarial Network |
| HMI | Human–Machine Interface |
| IC3 | FBI’s Internet Crime Complaint Center |
| ICS | Industrial Control System |
| IDPS | Intrusion Detection and Prevention System |
| IDS | Intrusion Detection System |
| IMI | Incremental Mutual Information |
| FW | Firewall |
| IMIS | Incremental Mutual Information Selection |
| IOC | Indicator of Compromise |
| IoMT | Internet of Medical Things |
| IoT | Internet of Things |
| LSTM | Long Short-Term Memory |
| Malware | Malicious Software |
| MIFS | Mutual Information Feature Selection |
| NIST | National Institute of Standards & Technology |
| NLL | Negative Log-Likelihood |
| OT | Operational Technology |
| PE | Portable Executable |
| PRDL | Polymorphic Ransomware Deep Learning |
| RaaS | Ransomware-as-a-Service |
| RBM | Restricted Boltzmann Machine |
| ReLU | Rectified Linear Unit |
| SCADA | Supervisory Control and Data Acquisition |
| SVM | Support Vector Machine |
| TS | Temperature Scaling |
| TTP | Tactics, Techniques, and Procedures |
| UA-DES | Uncertainty-Aware Dynamic Early Stopping |
| VMI | Virtual Machine Introspection |
| PLC | Programmable Logic Controller |
Appendix A. Case Studies
High-Impact Ransomware Attacks on Critical Infrastructure
Appendix B. Code Samples
Appendix B.1. Data Augmentation Using BBM-GAN

Appendix B.2. Code Sample for Feature Selection Using IMIS

Appendix B.3. Code Sample of UEA-DES for Early Stopping

Appendix C. Representative Data Samples
- Cryptography APIs: These APIs are used to encrypt user files, rendering them inaccessible without the decryption key.
- ○
- CryptEncrypt/CryptDecrypt: Functions for encrypting and decrypting data using a specified algorithm and key.
- ○
- OpenSSL EVP_EncryptInit_ex/EVP_EncryptUpdate/EVP_EncryptFinal_ex: Functions for initializing, updating, and finalizing encryption operations.
- File System APIs: These APIs are used to locate and access files for encryption, overwrite files with encrypted content, and sometimes delete original unencrypted files to prevent recovery.
- ○
- CreateFile/WriteFile/ReadFile: Functions for creating, writing to, and reading from files,
- ○
- FindFirstFile/FindNextFile: Functions for enumerating files in a directory,
- ○
- DeleteFile:Functionfordeletingfiles.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Rank | Feature Name | Feature Type |
|---|---|---|
| 1 | CryptEncrypt | Crypto APIs |
| 2 | CreateFile | File access APIs |
| 3 | CryptGenKey | Crypto APIs |
| 4 | WinHttpConnect | Network APIs |
| 5 | FindFirstFileEXA | File access APIs |
| 6 | CryptDestroyKey | Crypto APIs |
| 7 | WinHttpOpenRequest | Network APIs |
| 8 | FindNextFileA | File access APIs |
| 9 | CryptGenRandom | Crypto APIs |
| 10 | DeleteFile | File access APIs |
References
- Benmalek, M. Ransomware on cyber-physical systems: Taxonomies, case studies, security gaps, and open challenges. Internet Things Cyber-Phys. Syst. 2024, 4, 186–202. [Google Scholar] [CrossRef]
- Cen, M.; Jiang, F.; Qin, X.; Jiang, Q.; Doss, R. Ransomware early detection: A survey. Comput. Netw. 2024, 239, 110138. [Google Scholar] [CrossRef]
- Roseline, S.A.; Geetha, S. A comprehensive survey of tools and techniques mitigating computer and mobile malware attacks. Comput. Electr. Eng. 2021, 92, 107143. [Google Scholar] [CrossRef]
- Li, D.; Li, Q. Adversarial Deep Ensemble: Evasion Attacks and Defenses for Malware Detection. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3886–3900. [Google Scholar] [CrossRef]
- Al-Rimy, B.A.S.; Maarof, M.A.; Shaid, S.Z.M. Ransomware threat success factors, taxonomy, and countermeasures: A survey and research directions. Comput. Secur. 2018, 74, 144–166. [Google Scholar] [CrossRef]
- Gulmez, S.; Kakisim, A.G.; Sogukpinar, I. XRan: Explainable deep learning-based ransomware detection using dynamic analysis. Comput. Secur. 2024, 139, 103703. [Google Scholar] [CrossRef]
- Oz, H.; Aris, A.; Levi, A.; Uluagac, A.S. A survey on ransomware: Evolution, taxonomy, and defense solutions. ACM Comput. Surv. (CSUR) 2022, 54, 1–37. [Google Scholar] [CrossRef]
- Beaman, C.; Barkworth, A.; Akande, T.D.; Hakak, S.; Khan, M.K. Ransomware: Recent advances, analysis, challenges and future research directions. Comput. Secur. 2021, 111, 102490. [Google Scholar] [CrossRef] [PubMed]
- Urooj, U.; Al-rimy, B.A.S.; Zainal, A.; Ghaleb, F.A.; Rassam, M.A. Ransomware Detection Using the Dynamic Analysis and Machine Learning: A Survey and Research Directions. Appl. Sci. 2022, 12, 172. [Google Scholar] [CrossRef]
- Gazzan, M.; Sheldon, F.T. Opportunities for early detection and prediction of ransomware attacks against industrial control systems. Future Internet 2023, 15, 144. [Google Scholar] [CrossRef]
- Alqahtani, A.; Gazzan, M.; Sheldon, F.T. A proposed crypto-ransomware early detection (CRED) model using an integrated deep learning and vector space model approach. In Proceedings of the 2020 10th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 6–8 January 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 275–279. [Google Scholar]
- Urooj, U.; Maarof, M.A.B.; Al-rimy, B.A.S. A proposed adaptive pre-encryption crypto-ransomware early detection model. In Proceedings of the 2021 3rd International Cyber Resilience Conference (CRC), Langkawi Island, Malaysia, 29–31 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Al-Rimy, B.A.S.; Maarof, M.A.; Alazab, M.; Shaid, S.Z.M.; Ghaleb, F.A.; Almalawi, A.; Ali, A.M.; Al-Hadhrami, T. Redundancy coefficient gradual up-weighting-based mutual information feature selection technique for crypto-ransomware early detection. Future Gener. Comput. Syst. 2021, 115, 641–658. [Google Scholar] [CrossRef]
- Alqahtani, A.; Sheldon, F.T. A survey of crypto ransomware attack detection methodologies: An evolving outlook. Sensors 2022, 22, 1837. [Google Scholar] [CrossRef] [PubMed]
- Al-rimy, B.A.S.; Maarof, M.A.; Shaid, S.Z.M. Crypto-ransomware early detection model using novel incremental bagging with enhanced semi-random subspace selection. Future Gener. Comput. Syst. 2019, 101, 476–491. [Google Scholar] [CrossRef]
- Urooj, U.; Al-Rimy, B.A.S.; Zainal, A.B.; Saeed, F.; Abdelmaboud, A.; Nagmeldin, W. Addressing Behavioral Drift in Ransomware Early Detection Through Weighted Generative Adversarial Networks. IEEE Access 2023, 12, 3910–3925. [Google Scholar] [CrossRef]
- Alabdulwahab, S.; Kim, Y.-T.; Seo, A.; Son, Y. Generating Synthetic Dataset for ML-Based IDS Using CTGAN and Feature Selection to Protect Smart IoT Environments. Appl. Sci. 2023, 13, 10951. [Google Scholar] [CrossRef]
- Lall, S.; Ray, S.; Bandyopadhyay, S. Generating Realistic Cell Samples for Gene Selection in scRNA-seq Data: A Novel Generative Framework. bioRxiv 2021. [Google Scholar] [CrossRef]
- Liu, Q.; Liang, T.; Dinavahi, V. Deep Learning for Hardware-Based Real-Time Fault Detection and Localization of All Electric Ship MVDC Power System. IEEE Open J. Ind. Appl. 2020, 1, 194–204. [Google Scholar] [CrossRef]
- Wang, S.L.; Zhao, C.; Huang, L.; Li, Y.; Li, R. Current Status, Application, and Challenges of the Interpretability of Generative Adversarial Network Models. Comput. Intell. 2022, 39, 283–314. [Google Scholar] [CrossRef]
- Alalhareth, M.; Hong, S.-C. An Adaptive Intrusion Detection System in the Internet of Medical Things Using Fuzzy-Based Learning. Sensors 2023, 23, 9247. [Google Scholar] [CrossRef] [PubMed]
- Zhu, T.; Kuang, L.; Daniels, J.; Herrero, P.; Li, K.; Georgiou, P. IoMT-enabled real-time blood glucose prediction with deep learning and edge computing. IEEE Internet Things J. 2022, 10, 3706–3719. [Google Scholar] [CrossRef]
- Xue, L.; Sun, G. Design and implementation of a malware detection system based on network behavior. Secur. Commun. Netw. 2015, 8, 459–470. [Google Scholar] [CrossRef]
- Robinson, M. The SCADA threat landscape. In Proceedings of the 1st International Symposium for ICS & SCADA Cyber Security Research 2013 (ICS-CSR 2013), Leicester, UK, 16–17 September 2013; 2013; Volume 1, pp. 30–41. [Google Scholar]
- Hansen, S.S.; Larsen, T.M.T.; Stevanovic, M.; Pedersen, J.M. An approach for detection and family classification of malware based on behavioral analysis. In Proceedings of the 2016 International Conference on Computing, Networking and Communications (ICNC), Kauai, HI, USA, 15–18 February 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Milošević, N. History of malware. arXiv 2013, arXiv:1302.5392. [Google Scholar]
- Galal, H.S.; Mahdy, Y.B.; Atiea, M.A. Behavior-based features model for malware detection. J. Comput. Virol. Hacking Tech. 2016, 12, 59–67. [Google Scholar] [CrossRef]
- del Rey, A.M. Mathematical modeling of the propagation of malware: A review. Secur. Commun. Netw. 2015, 8, 2561–2579. [Google Scholar] [CrossRef]
- Song, S.; Kim, B.; Lee, S. The effective ransomware prevention technique using process monitoring on android platform. Mob. Inf. Syst. 2016, 2016, 2946735. [Google Scholar] [CrossRef]
- Mercaldo, F.; Nardone, V.; Santone, A.; Visaggio, C.A. Ransomware Steals Your Phone. Formal Methods Rescue It. In Formal Techniques for Distributed Objects, Components, and Systems: 36th IFIP WG 6.1 International Conference, FORTE 2016, Held as Part of the 11th International Federated Conference on Distributed Computing Techniques, DisCoTec 2016, Heraklion, Crete, Greece, 6–9 June 2016 Proceedings; Albert, E., Lanese, I., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 212–221. [Google Scholar]
- Yang, T.; Yang, Y.; Qian, K.; Lo, D.C.-T.; Qian, Y.; Tao, L. Automated Detection and Analysis for Android Ransomware. In Proceedings of the 2015 IEEE 17th International Conference on High Performance Computing and Communications, 2015 IEEE 7th International Symposium on Cyberspace Safety and Security, and 2015 IEEE 12th International Conference on Embedded Software and Systems, New York, NY, USA, 24–26 August 2015; pp. 1338–1343. [Google Scholar] [CrossRef]
- Andronio, N.; Zanero, S.; Maggi, F. HELDROID: Dissecting and detecting mobile ransomware. In Proceedings of the 18th International Symposium on Research in Attacks, Intrusions, and Defenses, RAID 2015, Kyoto, Japan, 2–4 November 2015; Volume 9404, pp. 382–404. [Google Scholar]
- Scaife, N.; Carter, H.; Traynor, P.; Butler, K.R. CryptoLock (and Drop It): Stopping Ransomware Attacks on User Data. In Proceedings of the 2016 IEEE 36th International Conference on Distributed Computing Systems (ICDCS), Nara, Japan, 27–30 June 2016. [Google Scholar]
- Kharraz, A.; Robertson, W.; Balzarotti, D.; Bilge, L.; Kirda, E. Cutting the gordian knot: A look under the hood of ransomware attacks. In Proceedings of the 12th International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment, DIMVA 2015, Milano, Italy, 9–10 July 2015; Volume 9148, pp. 3–24. [Google Scholar]
- Cabaj, K.; Gawkowski, P.; Grochowski, K.; Kosik, A. Developing malware evaluation infrastructure. In Proceedings of the 2016 Federated Conference on Computer Science and Information Systems (FedCSIS), Gdańsk, Poland, 11–14 September 2016; pp. 981–989. [Google Scholar]
- Symantec. Ransomware and Businesses 2016. In An ISTR Special Report; Symantec Corporation: Tempe, AZ, USA, 2016. In An ISTR Special Report; Symantec Corporation: Tempe, AZ, USA, 2016. [Google Scholar]
- O’Gorman, G.; McDonald, G. Ransomware: A Growing Menace; Symantec Corporation: Tempe, AZ, USA, 2012. [Google Scholar]
- Savage, P.C.K.; Lau, H. The evolution of ransomware. In Security Response; Symantec Corporation: Tempe, AZ, USA, 2015. [Google Scholar]
- Bhardwaj, A.; Subrahmanyam, G.; Avasthi, V.; Sastry, H. Ransomware: A Rising Threat of new age Digital Extortion. arXiv 2015, arXiv:1512.01980. [Google Scholar]
- Young, A.L. Cryptoviral extortion using Microsoft’s Crypto API. Int. J. Inf. Secur. 2006, 5, 67–76. [Google Scholar] [CrossRef]
- Young, A.L. Building a Cryptovirus Using Microsoft’s Cryptographic API. In Proceedings of the Information Security: 8th International Conference, ISC 2005, Singapore, 20–23 September 2005; Zhou, J., Lopez, J., Deng, R.H., Bao, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 389–401. [Google Scholar]
- Kumar, S.M.; Kumar, M.R. Cryptoviral Extortion: A virus based approach. Int. J. Comput. Trends Technol. (IJCTT) 2013, 4, 149–1153. [Google Scholar]
- Canham, M.; Posey, C.; Strickland, D.; Constantino, M.J. Phishing for Long Tails: Examining Organizational Repeat Clickers and Protective Stewards. Sage Open 2021, 11, 2158244021990656. [Google Scholar] [CrossRef]
- Salahdine, F.; Kaabouch, N. Social engineering attacks: A survey. Future Internet 2019, 11, 89. [Google Scholar] [CrossRef]
- Luo, X.; Liao, Q. Awareness education as the key to ransomware prevention. Inf. Syst. Secur. 2007, 16, 195–202. [Google Scholar] [CrossRef]
- Zhang-Kennedy, L.; Assal, H.; Rocheleau, J.; Mohamed, R.; Baig, K.; Chiasson, S. The aftermath of a crypto-ransomware attack at a large academic institution. In Proceedings of the 27th {USENIX} Security Symposium ({USENIX} Security 18), Baltimore, MD, USA, 15–17 August 2018; pp. 1061–1078. [Google Scholar]
- de Leon, D.C.; Bhandari, V.A.; Jillepalli, A.; Sheldon, F.T. Using a knowledge-based security orchestration tool to reduce the risk of browser compromise. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016; IEEE: Piscataway, NJ, USA; pp. 1–8. [Google Scholar]
- Upadhyay, D.; Sampalli, S. SCADA (Supervisory Control and Data Acquisition) systems: Vulnerability assessment and security recommendations. Comput. Secur. 2020, 89, 101666. [Google Scholar] [CrossRef]
- Ahmed, Y.A.; Koçer, B.; Huda, S.; Al-rimy, B.A.S.; Hassan, M.M. A system call refinement-based enhanced Minimum Redundancy Maximum Relevance method for ransomware early detection. J. Netw. Comput. Appl. 2020, 167, 102753. [Google Scholar] [CrossRef]
- Fovino, I.N.; Carcano, A.; Masera, M.; Trombetta, A. An experimental investigation of malware attacks on SCADA systems. Int. J. Crit. Infrastruct. Prot. 2009, 2, 139–145. [Google Scholar] [CrossRef]
- Ashrafuzzaman, M.; Das, S.; Chakhchoukh, Y.M.; Shiva, S.; Sheldon, F.T. Detection of Stealthy False Data Injection Attacks in Smart Grid using Ensemble-based Machine Learning. Comput. Secur. 2020, 97, 101994. [Google Scholar] [CrossRef]
- Zimba, A.; Wang, Z.; Chen, H. Multi-stage crypto ransomware attacks: A new emerging cyber threat to critical infrastructure and industrial control systems. ICT Express 2018, 4, 14–18. [Google Scholar] [CrossRef]
- Al-rimy, B.A.S.; Maarof, M.A.; Shaid, S.Z.M. A 0-day aware crypto-ransomware early behavioral detection framework. In Proceedings of the International Conference of Reliable Information and Communication Technology, Johor, Malaysia, 23–24 April 2017; Springer: Berlin/Heidelberg, Germany; pp. 758–766. [Google Scholar]
- Van Nhuong, N.; Nhi, V.T.Y.; Cam, N.T.; Phu, M.X.; Tan, C.D. SSSM-semantic set and string matching based malware detection. In Proceedings of the 7th IEEE Symposium on Computational Intelligence for Security and Defense Applications, CISDA 2014, a Noi, Vietnam, 14–17 December 2015; Institute of Electrical and Electronics Engineers Inc.: Piscataway Township, NJ, USA, 2015. [Google Scholar] [CrossRef]
- Poonia, A.S.; Singh, S. Malware detection by token counting. In Proceedings of the 2014 International Conference on Contemporary Computing and Informatics, IC3I 2014, Mysore, India, 27–29 November 2014; Institute of Electrical and Electronics Engineers Inc.: Piscataway Township, NJ, USA, 2015; pp. 1285–1288. [Google Scholar] [CrossRef]
- Kumar, C.U.O.; Kishore, S.; Geetha, A. Debugging using MD5 process firewall. In Proceedings of the 2014 International Conference on Contemporary Computing and Informatics, IC3I 2014, Mysore, India, 27–29 November 2014; Institute of Electrical and Electronics Engineers Inc.: Piscataway Township, NJ, USA, 2015; pp. 1279–1284. [Google Scholar] [CrossRef]
- Prelipcean, D.B.; Popescu, A.S.; Gavrilut, D.T. Improving Malware Detection Response Time with Behavior-Based Statistical Analysis Techniques. In Proceedings of the 17th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing, SYNASC 2015, Timisoara, Romania, 21–24 September 2015; Volume 2016, pp. 232–239. [Google Scholar] [CrossRef]
- Bridges, L. The changing face of malware. Netw. Secur. 2008, 2008, 17–20. (In English) [Google Scholar] [CrossRef]
- Pluskal, O. Behavioural malware detection using efficient SVM implementation. In Research in Adaptive and Convergent Systems, RACS 2015; Association for Computing Machinery, Inc.: New York, NY, USA, 2015; pp. 296–301. [Google Scholar] [CrossRef]
- Jillepalli, A.A.; Sheldon, F.T.; de Leon, D.C.; Haney, M.; Abercrombie, R.K. Security management of cyber physical control systems using NIST SP 800-82r2. In Proceedings of the 2017 13th International Wireless Communications and Mobile Computing Conference (IWCMC), Valencia, Spain; 26–30 June 2017; IEEE: Piscataway, NJ, USA; pp. 1864–1870.
- Le Guernic, C.; Legay, A. Ransomware and the Legacy Crypto API. In Risks and Security of Internet and Systems, Proceedings of the 11th International Conference, CRiSIS 2016, Roscoff, France, 5–7 September 2016, Revised Selected Papers; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10158, p. 11. [Google Scholar]
- Christensen, J.B.; Beuschau, N. Ransomware Detection and Mitigation Tool. Master’s Thesis, Technical University of Denmark, Lyngby, Denmark, 2017. [Google Scholar]
- Chen, Z.-G.; Kang, H.-S.; Yin, S.-N.; Kim, S.-R. Automatic Ransomware Detection and Analysis Based on Dynamic API Calls Flow Graph. In Proceedings of the International Conference on Research in Adaptive and Convergent Systems, Krakow, Poland, 6–10 August 2017. [Google Scholar]
- Sgandurra, D.; Muñoz-González, L.; Mohsen, R.; Lupu, E.C. Automated Dynamic Analysis of Ransomware: Benefits, Limitations and use for Detection. arXiv 2016, arXiv:1609.03020. [Google Scholar]
- Ioanid, A.; Scarlat, C.; Militaru, G. The Effect of Cybercrime on Romanian SMEs in the Context of Wannacry Ransomware Attacks. In Proceedings of the 12th European Conference on Innovation and Entrepreneurship ECIE 2017, Paris, France, 21–22 September 2017; p. 307. [Google Scholar]
- Pandey, S.K.; Mehtre, B.M. Performance of malware detection tools: A comparison. In Proceedings of the 2014 IEEE International Conference on Advanced Communication, Control and Computing Technologies, ICACCCT 2014, Online, 8–10 May 2015; Institute of Electrical and Electronics Engineers Inc.: Piscataway Township, NJ, USA; pp. 1811–1817. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, J.; Zhu, S. Dual Generative Adversarial Networks Based Unknown Encryption Ransomware Attack Detection. IEEE Access 2022, 10, 900–913. [Google Scholar] [CrossRef]
- Yadav, P.; Menon, N.; Ravi, V.; Vishvanathan, S.; Pham, T.D. EfficientNet convolutional neural networks-based Android malware detection. Comput. Secur. 2022, 115, 102622. [Google Scholar] [CrossRef]
- Su, X.; Shi, W.; Qu, X.; Zheng, Y.; Liu, X. DroidDeep: Using Deep Belief Network to characterize and detect android malware. Soft Comput. 2020, 24, 6017–6030. [Google Scholar] [CrossRef]
- Gazzan, M.; Sheldon, F.T. Novel Ransomware Detection Exploiting Uncertainty and Calibration Quality Measures Using Deep Learning. Information 2024, 15, 262. [Google Scholar] [CrossRef]
- Gavel, S.; Raghuvanshi, A.S.; Tiwari, S. Maximum correlation based mutual information scheme for intrusion detection in the data networks. Expert Syst. Appl. 2022, 189, 116089. [Google Scholar] [CrossRef]
- Gazzan, M.; Sheldon, F.T. An Incremental Mutual Information-Selection Technique for Early Ransomware Detection. Information 2024, 15, 262. [Google Scholar] [CrossRef]
- Zakaria, W.Z.A.; Alta, N.M.K.M.; Abdollah, M.F.; Abdollah, O.; Yassin, S.W.M.S. Early Detection of Windows Cryptographic Ransomware Based on Pre-Attack API Calls Features and Machine Learning. J. Adv. Res. Appl. Sci. Eng. Technol. 2024, 39, 110–131. [Google Scholar] [CrossRef]
- Alqahtani, A.; Sheldon, F.T. e MIFS: A Normalized Hyperbolic Ransomware Deterrence Model Yielding Greater Accuracy and Overall Performance. Sensors 2024, 24, 1728. [Google Scholar] [CrossRef] [PubMed]
- Bold, R.; Al-Khateeb, H.; Ersotelos, N. Reducing False Negatives in Ransomware Detection: A Critical Evaluation of Machine Learning Algorithms. Appl. Sci. 2022, 12, 12941. [Google Scholar] [CrossRef]
- Al-Garadi, M.A.; Mohamed, A.; Al-Ali, A.; Du, X.; Ali, I.; Guizani, M. A Survey of Machine and Deep Learning Methods for Internet of Things (IoT) Security. IEEE Commun. Surv. Tutor. 2020, 22, 1646–1685. [Google Scholar] [CrossRef]
- Liu, Y.; Tantithamthavorn, C.; Li, L.; Liu, Y. Deep Learning for Android Malware Defenses: A Systematic Literature Review. ACM Comput. Surv. 2022, 55, 1–36. [Google Scholar] [CrossRef]
- Uysal, D.T.; Yoo, P.D.; Taha, K. Data-Driven Malware Detection for 6G Networks: A Survey From the Perspective of Continuous Learning and Explainability via Visualisation. IEEE Open J. Veh. Technol. 2023, 4, 61–71. [Google Scholar] [CrossRef]
- Shemitha, P.A.; Dhas, J.P.M. Crow Search With Adaptive Awareness Probability-Based Deep Belief Network for Detecting Ransomware. Int. J. Pattern Recognit. Artif. Intell. 2022, 36, 2251010. [Google Scholar] [CrossRef]
- Lansky, J.; Ali, S.; Mohammadi, M.; Majeed, M.K.; Karim, S.H.T.; Rashidi, S.; Hosseinzadeh, M.; Rahmani, A.M. Deep Learning-Based Intrusion Detection Systems: A Systematic Review. IEEE Access 2021, 9, 101574–101599. [Google Scholar] [CrossRef]
- Radoglou-Grammatikis, P.; Sarigiannidis, P.; Diamantoulakis, P.; Lagkas, T.; Saoulidis, T.; Fountoukidis, E.; Karagiannidis, G. Strategic Honeypot Deployment in Ultra-Dense Beyond 5G Networks: A Reinforcement Learning Approach. IEEE Trans. Emerg. Top. Comput. 2024, 12, 643–655. [Google Scholar] [CrossRef]
- Banaamah, A.M.; Ahmad, I. Intrusion Detection in IoT Using Deep Learning. Sensors 2022, 21, 8417. [Google Scholar] [CrossRef] [PubMed]
- Cao, F. Intrusion Anomaly Detection Based on Pseudo-Count Exploration. Available online: https://www.researchgate.net/publication/372378041_Intrusion_Anomaly_Detection_Based_on_Pseudo-Count_Exploration (accessed on 10 July 2025).
- Ferrag, M.A.; Janicke, H.; Smith, R. Deep Learning Techniques for Cyber Security Intrusion Detection: A Detailed Analysis. In Proceedings of the 6th International Symposium for ICS & SCADA Cyber Security Research 2019, Athens, Greece, 9–12 September 2019. [Google Scholar] [CrossRef]
- Cho, H.; Kim, Y.-J.; Lee, E.; Choi, D.; Lee, Y.J.; Rhee, W. Basic Enhancement Strategies When Using Bayesian Optimization for Hyperparameter Tuning of Deep Neural Networks. IEEE Access 2020, 8, 52588–52608. [Google Scholar] [CrossRef]
- Dorka, N.; Boedecker, J.; Burgard, W. Adaptively Calibrated Critic Estimates for Deep Reinforcement Learning. IEEE Robot. Autom. Lett. 2023, 8, 624–631. [Google Scholar] [CrossRef]
- Rezaeezade, A.; Batina, L. Regularizers to the Rescue: Fighting Overfitting in DeepLearning-based Side-Channel Analysis. J. Cryptogr. Eng. 2022, 14, 609–629. [Google Scholar] [CrossRef]
- Choi, H.; Lee, H. Exploiting All Samples in Low-Resource Sentence Classification: Early Stopping and Initialization Parameters. J. Cryptogr. Eng. 2021, 14, 609–629. [Google Scholar] [CrossRef]
- Wang, H.; Li, T.H.; Zhang, Z.; Chen, T.; Liang, H.; Sun, J. Early Stopping for Deep Image Prior. arXiv 2021, arXiv:2112.06074. [Google Scholar]
- El-Ghamry, A.; Darwish, A.; Hassanien, A.E. An optimized CNN-based intrusion detection system for reducing risks in smart farming. Internet Things 2023, 22, 100709. [Google Scholar] [CrossRef]
- Jothi, B.; Pushpalatha, M. WILS-TRS—A novel optimized deep learning based intrusion detection framework for IoT networks. Pers. Ubiquitous Comput. 2023, 27, 1285–1301. [Google Scholar] [CrossRef]
- Sharma, A.; Gupta, B.B.; Singh, A.K.; Saraswat, V. A novel approach for detection of APT malware using multi-dimensional hybrid Bayesian belief network. Int. J. Inf. Secur. 2023, 22, 119–135. [Google Scholar] [CrossRef]
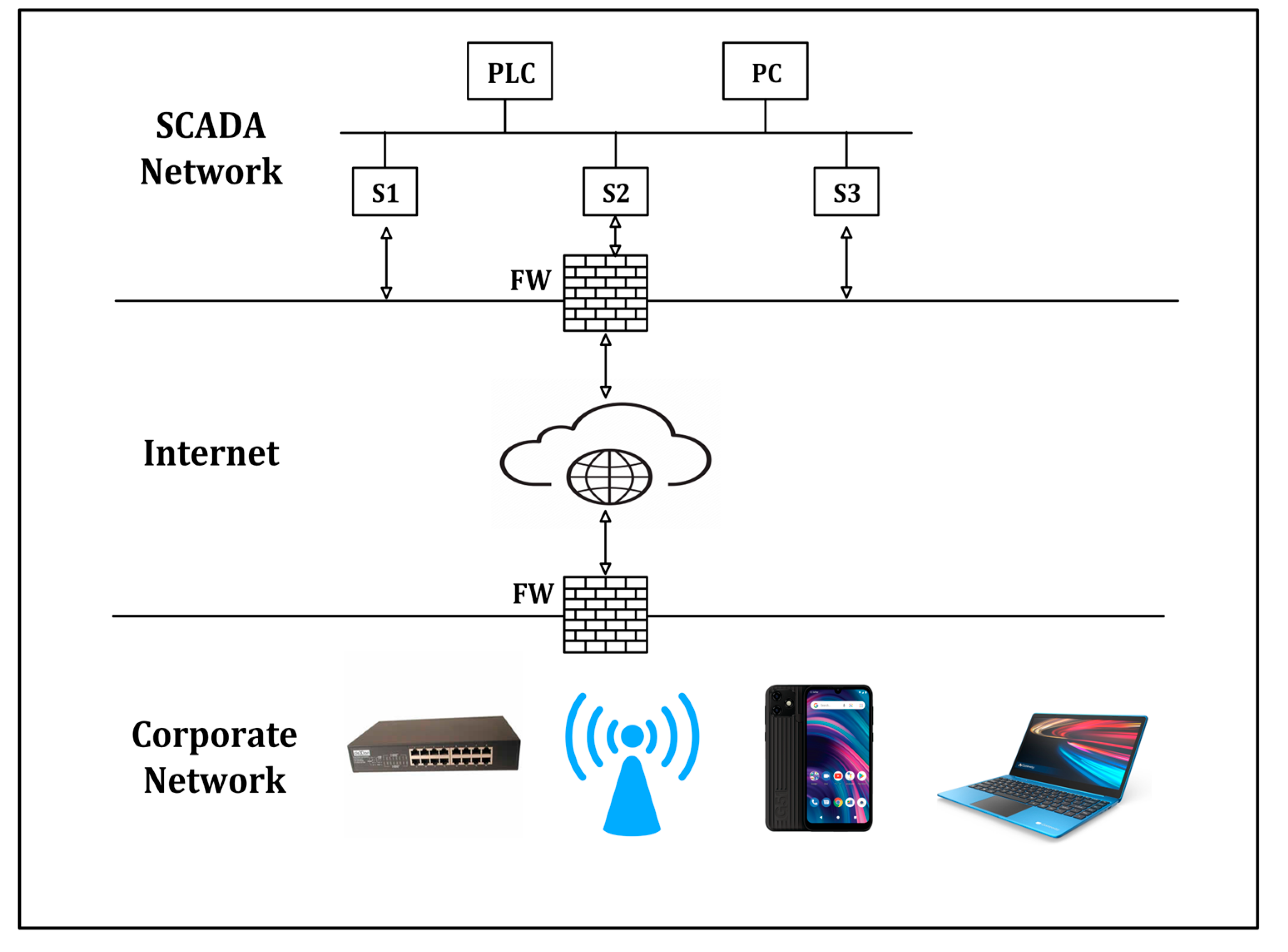












| Author | Problem | Solution | Method | Tools | Empirical | Limitation |
|---|---|---|---|---|---|---|
| [33] | The detection of ransomware based on past attack data is not suitable to detect novel, zero-day attacks, which are common nowadays. | The behavioral patterns extracted from the dynamic analysis of ransomware during the execution time were used to train a prediction model. | Support vector machines (SVM) were used to build the prediction model based on the behavioral data. | ScikitLearn, and Pandas | Yes | This approach also uses historical behavior to predict future ones. This is not suitable for evasive ransomware that uses obfuscation and polymorphism to change its behavior from time to time. |
| [34] | Advanced malware can obfuscate much of its traces through many mechanisms, such as metamorphic engines. Therefore, the detection of such malware has become a significant challenge for malware analysis mechanisms. | A regression model to predict advanced malware based on a selected set of significant features extracted from a dataset of malware runtime data. | The dataset is created by executing real-world malware samples and capturing the behavioral data into trace files. | N/A | Yes | The model was trained using historical data of existing and known malware samples. The dataset does not contain the future behaviors necessary for accurate prediction models. |
| [35] | Sophisticated Android malware families often implement techniques aimed at avoiding detection. Split-personality malware, for example, behaves benignly when it detects that it is running on an analysis environment such as a malware sandbox, and maliciously when running on a real user’s device. | Exploiting sandbox detecting heuristic prediction to predict and automatically generate bytecode patches. | An Andronew, a heuristic approach, was used based on API calls collected during the execution time of the malware. | Sandbox | Yes | The heuristics were performed based on historical data, which limits the ability of this approach to predict the future behavior of malware |
| [41] | Zero-day malware attacks are challenging due to the polymorphic nature of the malware. | Generating synthesized malware samples based on existing malware signatures derived from the static analysis of malware payloads. | GAN algorithm to generate artificial malware samples. | Keras, and Tensorflow | Yes | The static analysis adopted by the study does not reveal the behavioral aspect of the malware as polymorphism works during the runtime. In addition, the packing and encryption techniques used by sophisticated malware prevent the static analysis from exploring the malware features. |
| [42] | Existing malware detection is not accurate enough. | A cluster-based detection engine that is trained based on artificial patterns represents the trending of malware behavior. | GAN algorithm to create malware patterns. | N/A | N/A | There was no evidence of the applicability and efficacy of the model. |
| [7] | Malware authors have the ability to reveal the features used by detection models. | MalGAN model that attacks black-box machine-learning detection models. | A substitute detector to fit the black-box malware detection system. | N/A | Yes | The data used for model training were general and limited to malware operational behavior. The context was not captured. |
| [43] | The ransomware changes its behavior which makes it difficult to detect. | The study studies data collected from the ransomware process and its interaction with the file system. | It used malware development toolkits to create ransomware samples. | ADMMutate, Clet, and Phatbot | Yes | The study is limited to the ability of the tools to manually create samples, which makes it impractical to have a diversified dataset. |
| [44] | Detecting novel malware attacks is difficult as the behavior changes continuously. | The model examines the patterns in the data and studies the evolution of the malware behavior. | It used a collection of data from previous malware infections to train a logistic regression algorithm. | N/A | Yes | Relying on the evolution of the attack behavior to forecast future attacks is not sufficient to visualize the sophisticated malware attacks. |
| [46] | The new types of malware tend to be more difficult to detect than older ones. This has made content-based, signature-based, and pattern-matching techniques less effective in detecting and preventing ransomware attacks. | Utilized the neural network algorithm to predict the future occurrences of ransomware and malware attacks over time. | Time-series regression-based neural network algorithm model. | TensorFlow, Keras, NumPy, Matplotlib, and Pandas | Yes | The model concentrates solely on data pertaining to processing operations, disregarding the context in which the process was executed. |
| [47] | Existing ransomware attack predictions are not tailored for IoT systems that are diverse and resource-constrained environments. | A technique for predicting ransomware using contextual data and utilizing a context ontology to gather information characteristics of ransomware attacks against the IoT. | An ontology approach with SVM. | N/A | Yes | Relying only on contextual data and ignoring the behavioral data is insufficient for modeling the characteristics of the evasive malware attacks. |
| [49] | Detection solutions alone are no longer enough to protect against malware due to the increasing rate of zero-day attacks. | An early prediction of malware attacks in Android devices was proposed. By capturing the implicit contextual relations between various data, the model predicts the suspicious behavior of a running process using data collected during the early stages of the attack within the same session. | LSTM and ensemble learning. | N/A | Yes | This approach is inadequate in terms of the necessary data required for an accurate prediction and is unable to anticipate the future behavior of the malware. |
| [49] | Due to the obfuscation techniques employed by advanced malware, detection is no longer enough, and there is a need for methodologies to predict future behavior instead. | A rapid sequence snapshot analysis was used to make the prediction decisions. | A set of random snapshots were taken from the APIs and permission data and used to train an ensemble LSTM model that is used for the prediction. | Tensorflow | Yes | The LSTM was trained on historical data only, which assumes that these historical attack patterns are likely to reoccur in future attacks. This does not hold, especially with the use of obfuscation and polymorphic strategies adopted by the malware to change the attack behavior. |
| [59] | Existing approaches to detect the malware need to collect enough data which takes more time, during which the sabotage has likely already been inflicted by the time of detection. | Predicting the behavior based on a short snapshot of behavioral data. | An ensemble RNN. The method was able to predict the attack within 5 s with an accuracy of around 94%. | Keras, and Tensorflow | Yes | The method relies on historical data to predict the behavior. This approach is not suitable for obfuscated behavior that tries to show a major difference between past and future attacks. |
| Family | Samples | Family | Samples |
|---|---|---|---|
| Cryptolocker | 741 | Cerber | 263 |
| Cryptowall | 706 | Filecryptor | 772 |
| Cryrar | 583 | Crypt | 789 |
| Locky | 567 | CTB_Locker | 560 |
| Petya | 593 | Satana | 289 |
| Reventon | 617 | CryptXXX | 651 |
| Teslactypt | 398 | Sage | 187 |
| WannaCry | 436 | ||
| Epochs | E30 | E90 | E150 | E210 | |
|---|---|---|---|---|---|
| Features | |||||
| 5 | 0.890 | 0.934 | 0.942 | 0.926 | |
| 10 | 0.908 | 0.951 | 0.954 | 0.957 | |
| 15 | 0.898 | 0.937 | 0.950 | 0.961 | |
| 20 | 0.915 | 0.956 | 0.956 | 0.962 | |
| 25 | 0.910 | 0.941 | 0.971 | 0.969 | |
| 30 | 0.927 | 0.931 | 0.980 | 0.967 | |
| 35 | 0.936 | 0.938 | 0.979 | 0.981 | |
| 40 | 0.937 | 0.953 | 0.976 | 0.986 | |
| 45 | 0.939 | 0.946 | 0.981 | 0.992 | |
| 50 | 0.938 | 0.922 | 0.984 | 0.995 | |
| Number of Epochs | Training Time (s) | Number of Epochs | Training Time (s) |
|---|---|---|---|
| 30 | 70 s | 150 | 307 s |
| 90 | 189 s | 210 | 431 s |
| Technique | Per-Call Execution Time (s) | Per-Call Execution Time (min) | Train Time (min) |
|---|---|---|---|
| IMIS | 0.01 s | 3.5 m | 19 m |
| RCGU | 0.054 s | 10.8 m | 33 m |
| EMRMR | 0.063 s | 12.6 m | 37 m |
| MIFS | 0.03 s | 6.0 m | 28 m |
| JMI | 0.07 s | 4.0 m | 24 m |
| Type | Features | Rank |
|---|---|---|
| Crypto APIs | CryptEncrypt | 1 |
| CryptGenKey | 3 | |
| CryptDestroyKey | 6 | |
| BCryptGenRandom | 9 | |
| File access APIs | CreateFile | 2 |
| FindFirstFileEXA | 5 | |
| FindNextFileA | 8 | |
| DeleteFile | 10 | |
| Network APIs | WinHttpConnect | 4 |
| WinHttpOpenRequest | 7 |
| Type | Features |
|---|---|
| Crypto APIs | CryptEncrypt|CryptGenKey|CryptDestroyKey|CryptGenRandom |
| File Access APIs | CreateFile|FindFirstFileEXA|FindNextFileA|DeleteFile |
| Network APIs | WinHttpConnect|WinHttpOpenRequest |
| Fig/Tab | Phase | Comparison Details | Metrics | Value Proposition |
|---|---|---|---|---|
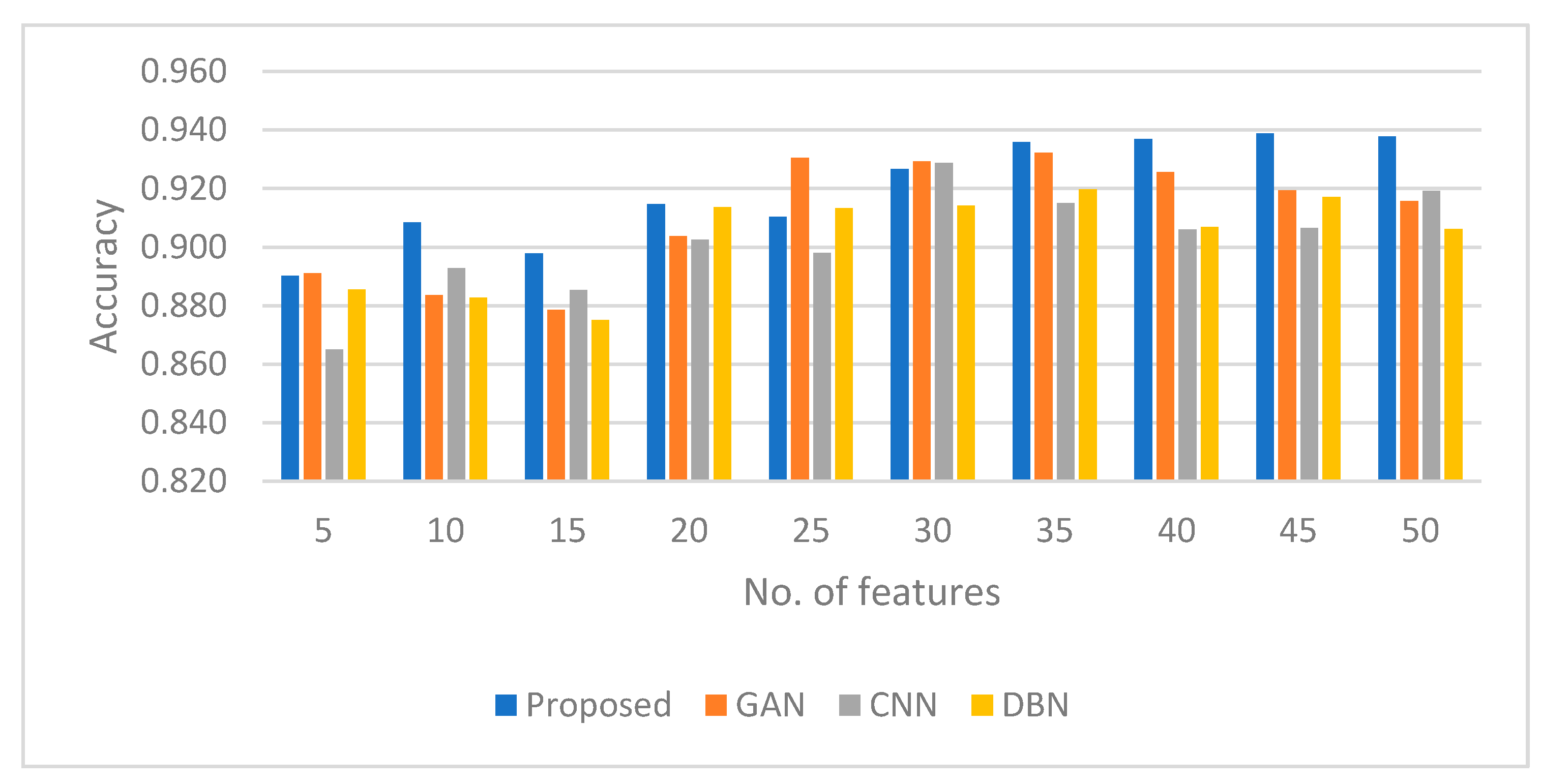
| Figure 4, Figure 5, Figure 6 and Figure 7 | Phase 1 | Models: BGM-GAN (Proposed) vs. standard GAN, CNN, DBN. | Accuracy | BGM-GAN consistently outperforms the other models across all training epochs, achieving a peak accuracy of 0.995 with 50 features at 210 epochs. |
| Variable: Performance across 5–50 features at 30, 90, 150, and 210 training epochs. | ||||
| Figure 8 | Phase 1 | Models: BGM-GAN (Proposed) vs. standard GAN, CNN, DBN. | Recall (TPR) | BGM-GAN demonstrates a superior recall rate compared to existing techniques across varying feature counts and epochs. |
| Variable: Averaged performance across epochs. | ||||
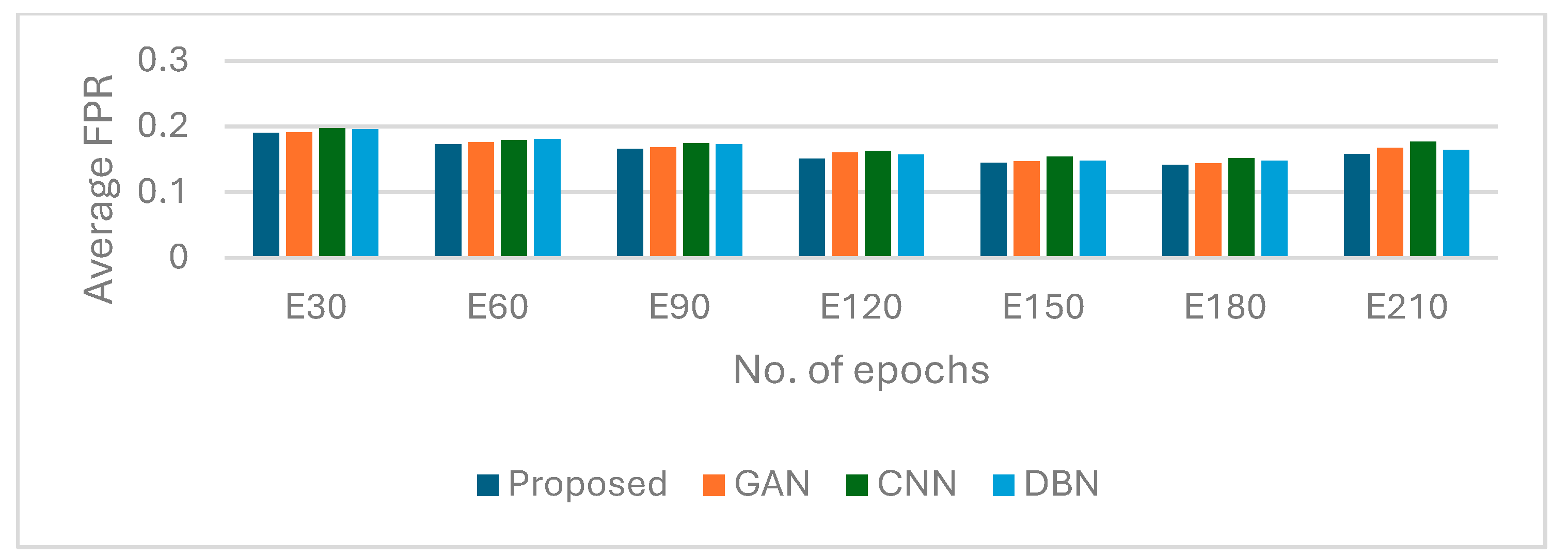
| Figure 9 | Phase 1 | Models: BGM-GAN (Proposed) vs. standard GAN, CNN, DBN. | False Positive Rate (FPR) | BGM-GAN achieves a lower false positive rate than comparison models, indicating higher precision. |
| Variable: Averaged performance across epochs. | ||||
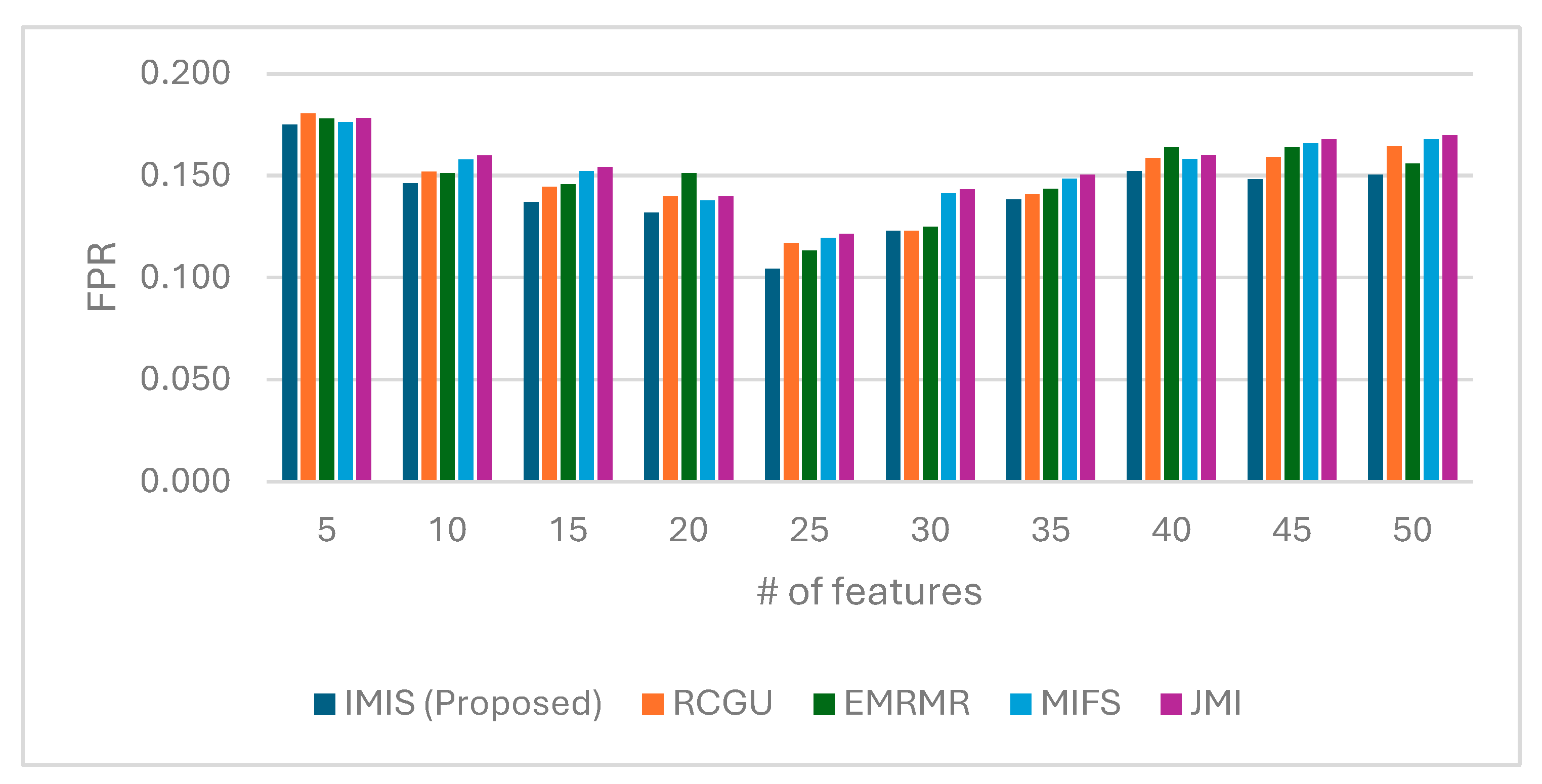
| Figure 11, Figure 12, Figure 13 and Figure 14 | Phase 2 | Models: IMIS (Proposed) vs. RCGU, EMRMR, MIFS, JMI. | Accuracy, FPR, DR, F1-Score | IMIS consistently outperforms other feature selection methods, achieving a peak accuracy of 0.979 and the best balance of precision and recall (F1-score). |
| Variable: Performance across 5–50 features. | ||||
| Table 6 | Phase 2 | Models: IMIS (Proposed) Versus RCGU, EMRMR, MIFS, JMI. | Computational Efficiency | IMIS is the most computationally efficient method, with the shortest execution time and lowest total runtime. |
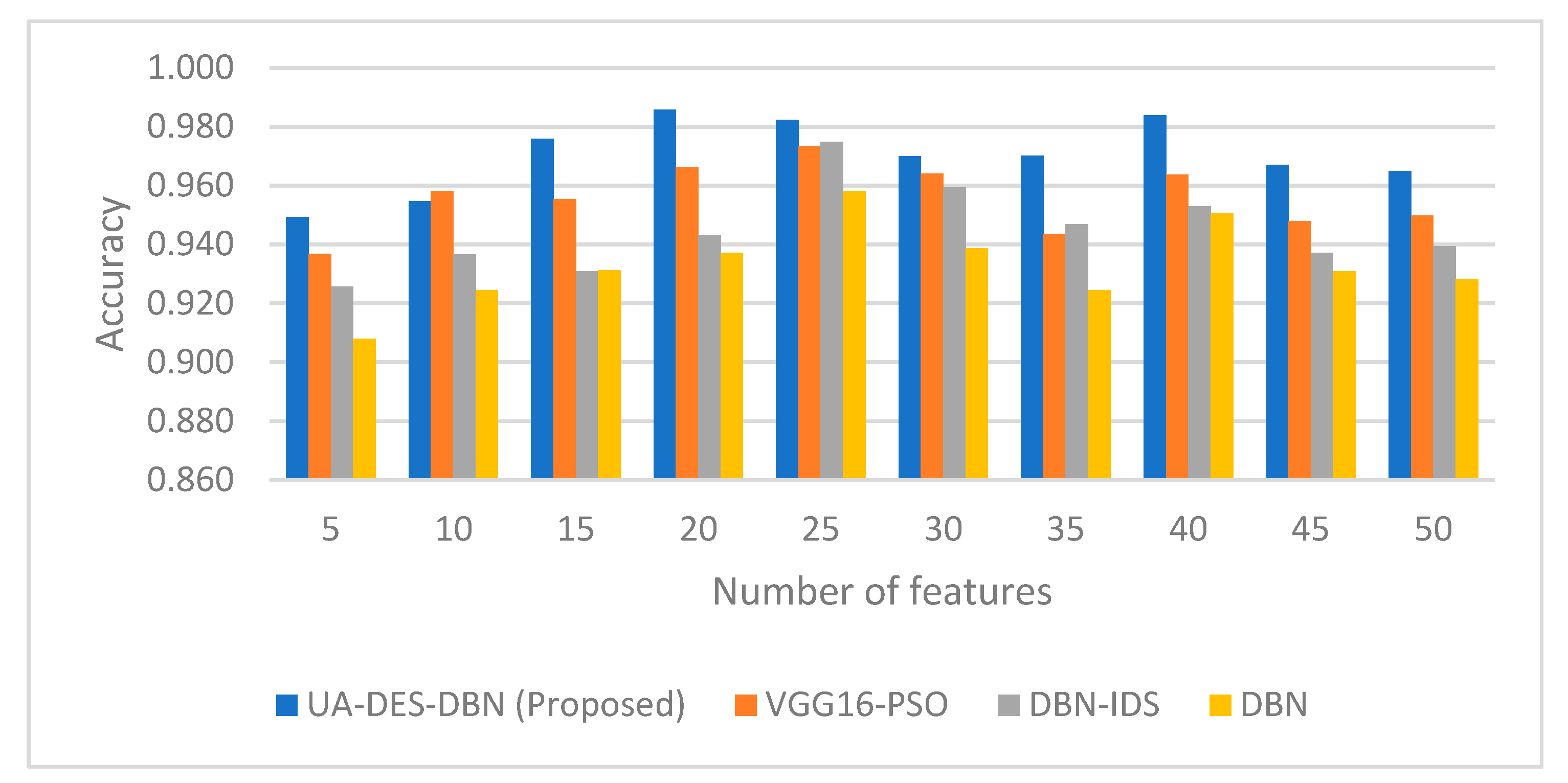
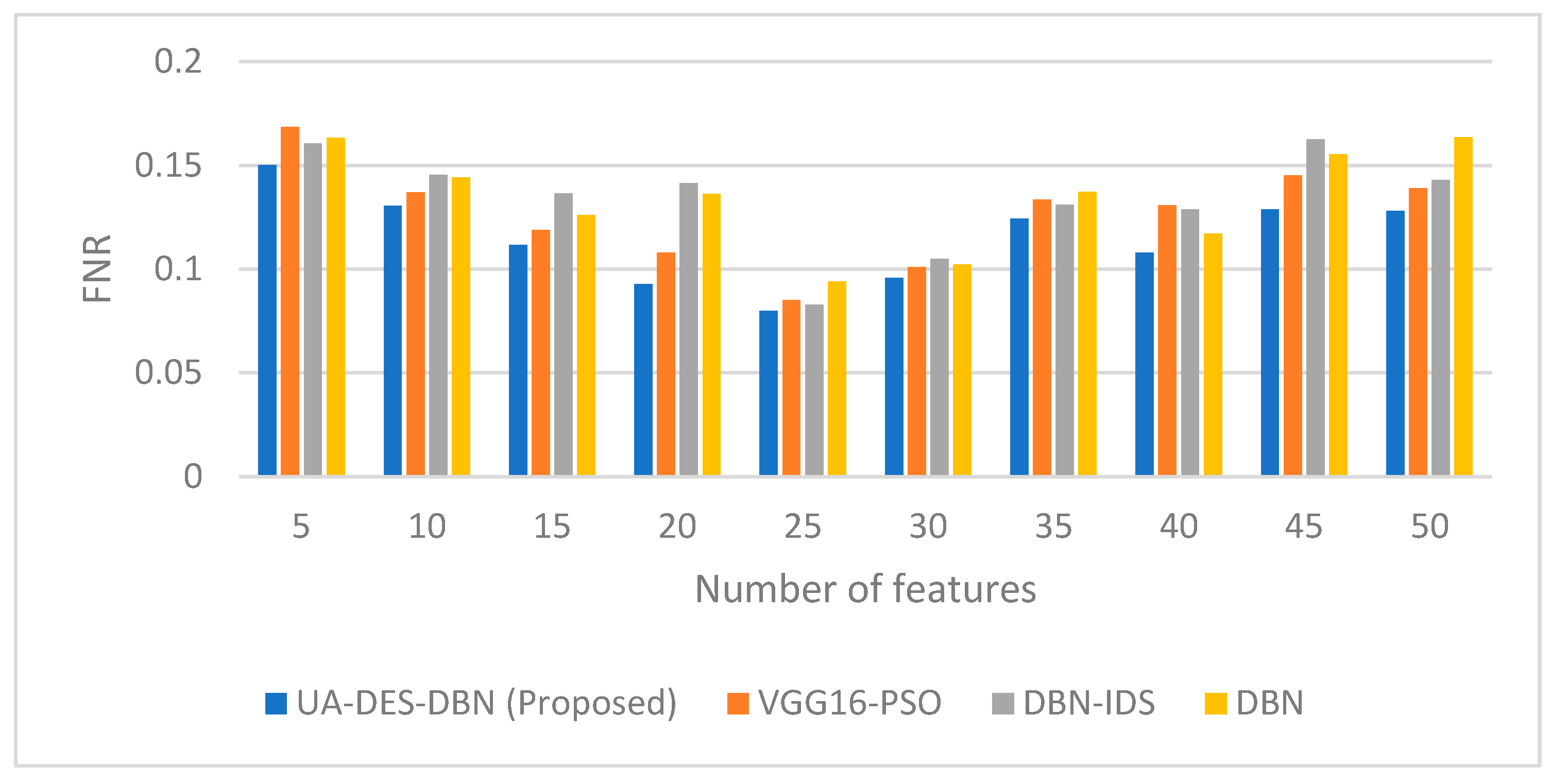
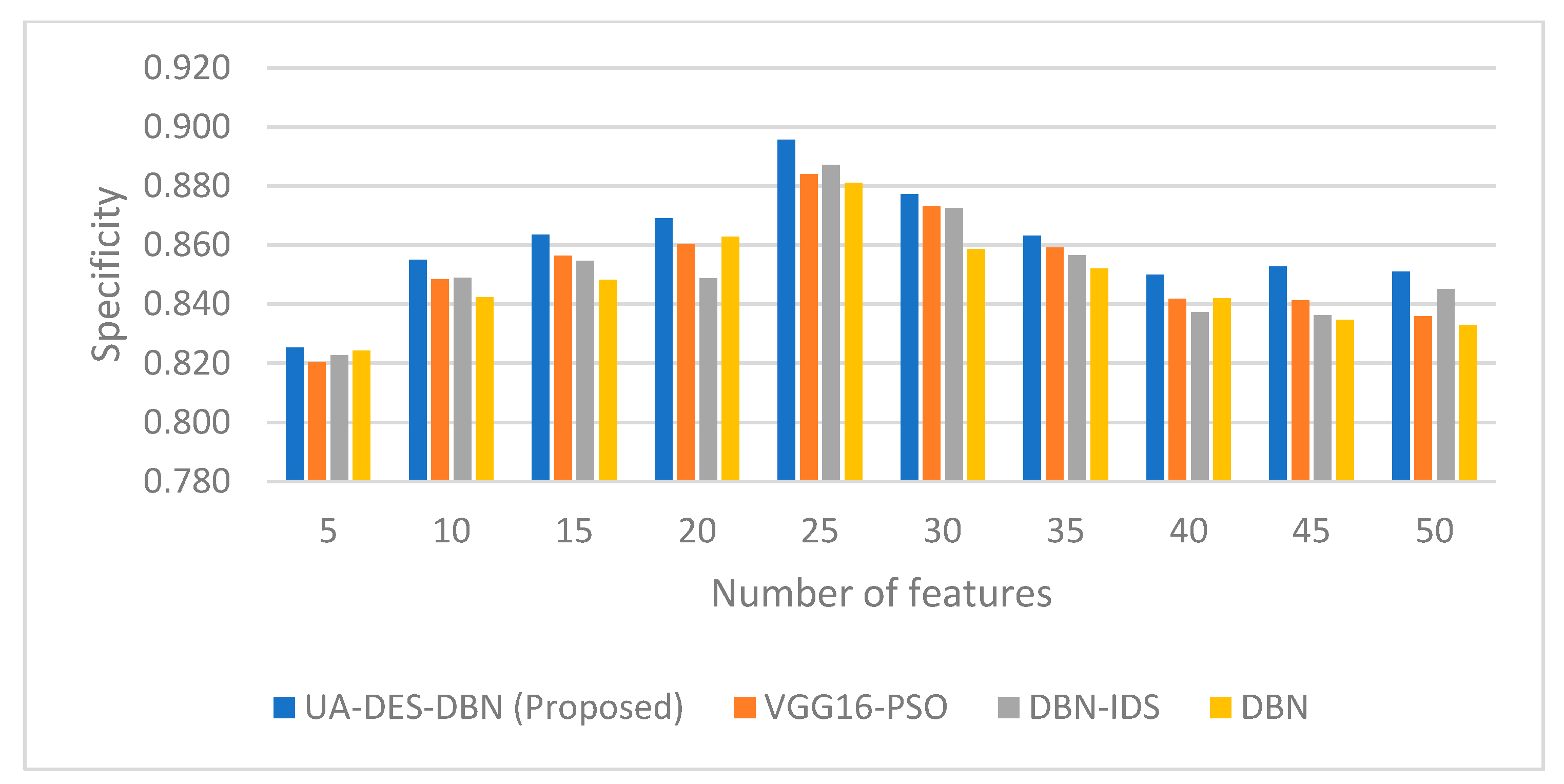
| Figure 16, Figure 17, Figure 18, Figure 19, Figure 20 and Figure 21 | Phase 3 | Models: UA-DES-DBN (Proposed) vs. VGG16-PSO, DBN-IDS, DBN. | Accuracy, FPR, DR, F1-Score, FNR, Specificity | UA-DES-DBN model achieves superior performance, with a peak accuracy of 0.986, a lower FPR, and a higher F1-score than comparison models. |
| Variable: Performance across 5–50 input features. |
| Motivation | Component | Contribution | Limitation |
|---|---|---|---|
| Lack of data during pre-encryption phase | BGM-GAN | Generates synthetic ransomware attack patterns to augment early-phase data. | Effectiveness depends on the quality and diversity of initial real samples. |
| Static feature selection struggles to adapt to evolving threats | IMIS | Dynamically selects and updates relevant features in real-time. | May struggle with noisy or redundant features. |
| Risk of overfitting in deep detection models | DBN + UA-DES | Learns hierarchical patterns and employs uncertainty-aware stopping to optimize training. | Requires tuning and high computational resources. |
| Absence of a unified, adaptive detection approach | Integrated 3-phase framework | Combines augmentation, adaptive learning, and uncertainty-aware training for enhanced early detection. | Currently evaluated on Windows PE files; may need generalization for other environments. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gazzan, M.; Alobaywi, B.; Almutairi, M.; Sheldon, F.T. A Deep Learning Framework for Enhanced Detection of Polymorphic Ransomware. Future Internet 2025, 17, 311. https://doi.org/10.3390/fi17070311
Gazzan M, Alobaywi B, Almutairi M, Sheldon FT. A Deep Learning Framework for Enhanced Detection of Polymorphic Ransomware. Future Internet. 2025; 17(7):311. https://doi.org/10.3390/fi17070311
Chicago/Turabian StyleGazzan, Mazen, Bader Alobaywi, Mohammed Almutairi, and Frederick T. Sheldon. 2025. "A Deep Learning Framework for Enhanced Detection of Polymorphic Ransomware" Future Internet 17, no. 7: 311. https://doi.org/10.3390/fi17070311
APA StyleGazzan, M., Alobaywi, B., Almutairi, M., & Sheldon, F. T. (2025). A Deep Learning Framework for Enhanced Detection of Polymorphic Ransomware. Future Internet, 17(7), 311. https://doi.org/10.3390/fi17070311