
A Review of Research on Secure Aggregation for Federated Learning


Abstract
1. Introduction
- In the discussion of security, only the means of attack and the defense methods that can be used are analyzed, and there is no systematic categorization of defense methods based on privacy-preserving mechanisms [12].
- This work classifies federated learning from the perspective of secure aggregation, provides a detailed overview of privacy-preserving mechanisms currently applied in federated learning, and categorizes existing secure aggregation schemes based on these mechanisms.
- This work evaluates the resource consumption, protected models, accuracy, and network structures of different schemes, with vertical comparisons of secure aggregation algorithms under the same privacy-preserving mechanism and horizontal comparisons across distinct mechanisms.
- This work examines the future research directions of secure aggregation and the associated challenges.
2. Federated Learning
2.1. Definition of Federated Learning
- Initialization: At the t-th round of communication, the client downloads the latest model, , from the server for initialization.
- Local training: Each client, , iteratively trains on its own local dataset, , and hyperparameters, . The local model, , is updated according to and sent to the server.
- Model aggregation: The server aggregates the collected local models into a global model for the global model update.
2.2. Classification of Federated Learning
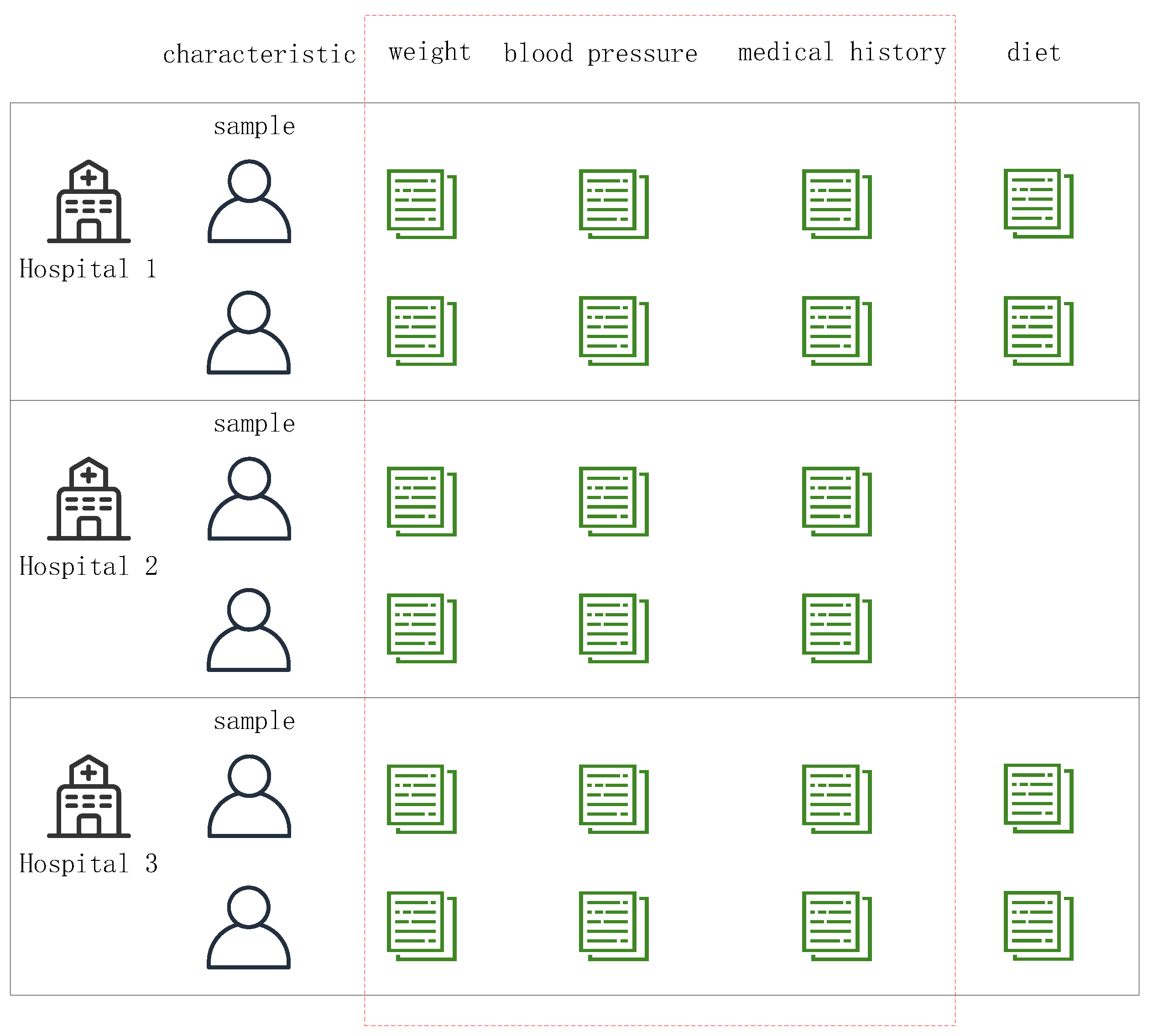
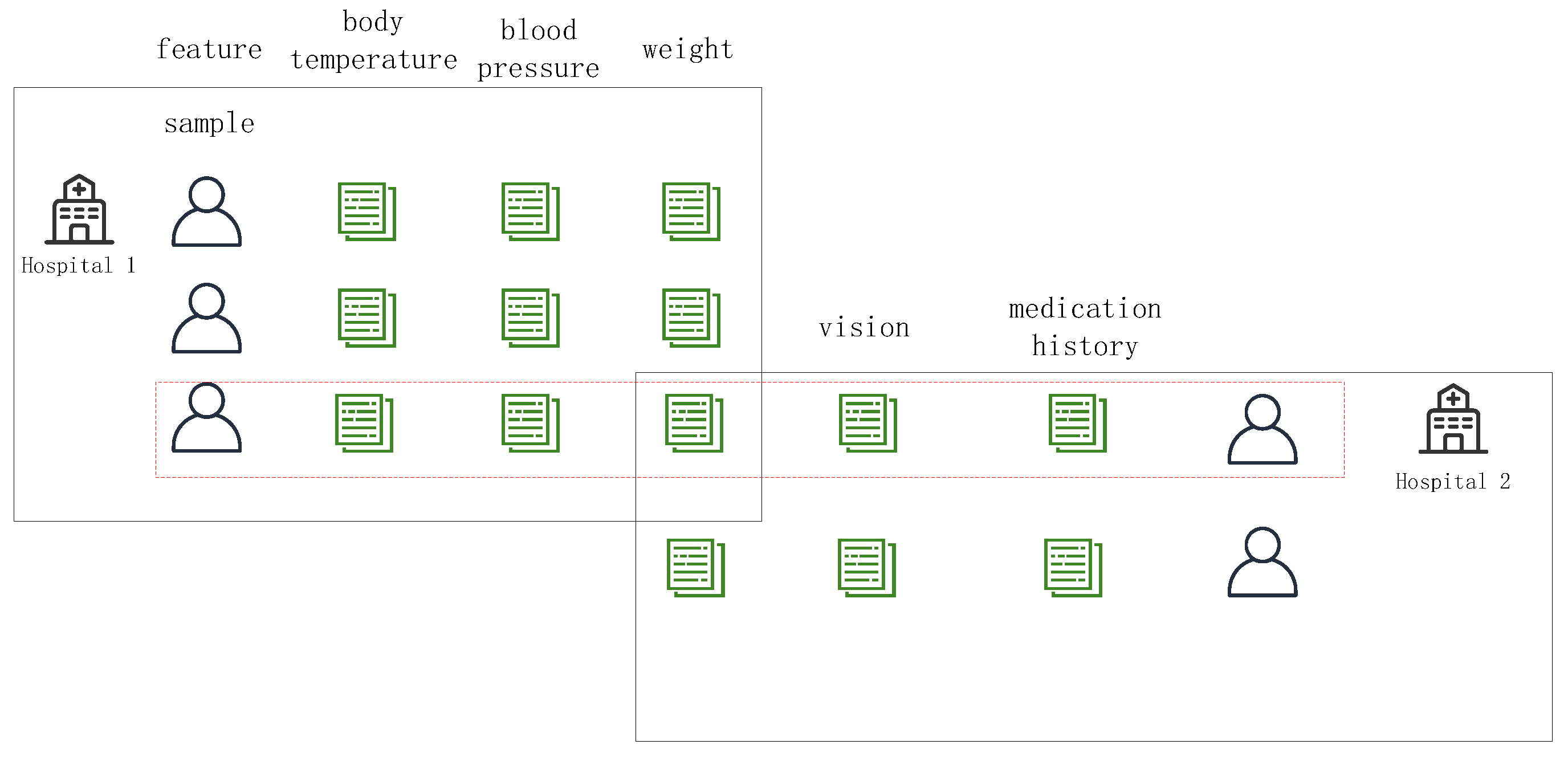
2.2.1. Data Partition
2.2.2. Client Size
2.2.3. Network Structure
2.3. Applications
2.3.1. Mobile Device
2.3.2. Agriculture
2.3.3. Healthcare
2.3.4. Renewable Energy
3. Privacy-Preserving Mechanisms
3.1. Homomorphic Encryption
- Partially homomorphic encryption (PHE): Permits an unlimited number of operations, but restricts them to a single type, such as addition or multiplication.
- Somewhat homomorphic encryption (SWHE): Permits certain types of operations but limits the number of uses, such as allowing only one multiplication.
- Fully homomorphic encryption (FHE): Allows infinite types of algorithmic operations and an infinite number of times.
- Paillier partially homomorphic encryption: The Paillier encryption algorithm is an asymmetric encryption algorithm with additive homomorphism properties and consists of three main steps:
- 1.
- Key generation: (1) Randomly select large primes such that p is not equal to q. (2) Calculate , , is the least common multiple. (3) Randomly select , and calculate the auxiliary value . Here, , is the multiplicative group modulo . (4) Use as the public key and as the private key.
- 2.
- Encryption: For plaintext , randomly select and compute the ciphertext .
- 3.
- Decryption: For ciphertext , compute the intermediate value required to restore the plaintext .
- ElGamal partially homomorphic encryption: The ElGamal encryption algorithm is a public key encryption scheme with multiplicative homomorphism properties, comprising three main steps:
- 1.
- Key generation: (1) Choose a large prime p and a generator g of the multiplicative group . (2) Select a private key . (3) Calculate and use as the public key.
- 2.
- Encryption: For plaintext , randomly select an ephemeral key , compute , , and represent the ciphertext as the pair
- 3.
- Decryption: Using the private key x, compute the shared secret , and then restore the plaintext , where is the modular inverse of s modulo p.
- CKKS Fully Homomorphic Encryption: The CKKS encryption algorithm is a fully homomorphic encryption algorithm designed for approximate computation, consisting of the following five main steps:
- 1.
- Key generation: (1) Parameter selection: Defining the ring polynomial , which serves as the polynomial modulus in the CKKS encryption scheme. is the modular inverse of s modulo p. N is a power of 2, and X is a formal variable. Choose a set of prime moduli to control noise growth. Define the scaling factor to map floating-point numbers to integer polynomials. Select a noise distribution, such as a discrete Gaussian distribution, to generate a small noise polynomial e. (2) Generating keys: Generate private key , where s is a small polynomial randomly selected from the ring. Generate public keys ,, where a is a random polynomial, and e is noise.
- 2.
- Data encoding: (1) Data vectorization: Encodes the plaintext data to be encrypted by the user as a polynomial . (2) Scaling polynomials: Scale the polynomial by a factor of ,
- 3.
- Encryption: Generate ciphertext , , , r is a random polynomial, , are noise polynomials.
- 4.
- Decryption: Decrypt the ciphertext using private key s,.
- 5.
- Plaintext recovery: , after which it is converted to plaintext data .
3.2. Secure Multi-Party Computation
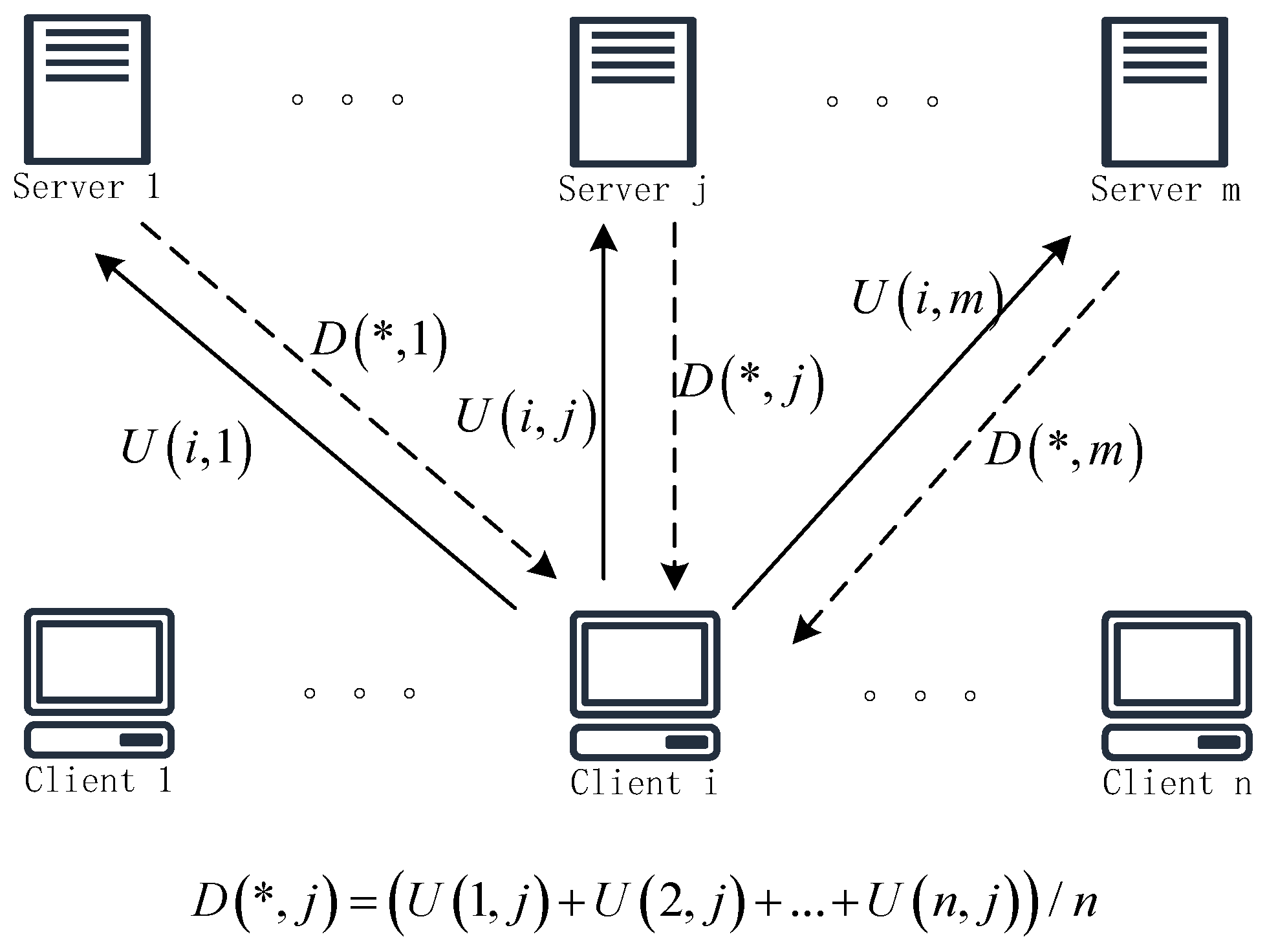
- Shamir’s secret sharing: In 1979, Adi Shamir proposed a secret sharing scheme rooted in the Lagrange interpolation theorem. The scheme leverages polynomial operations over finite fields to securely distribute a secret among multiple parties. Specifically, the Shamir secret sharing scheme for works as follows: To share the secret, s, a trusted dealer first selects a large prime number, p, such that . Then, random elements are chosen from the finite field to construct a polynomial , . Then, the trusted dealer selects n distinct non-zero elements from the finite field , computes , and assigns the share to . In the secret reconstruction phase, at least t shares from the participants are required to reconstruct the secret. The reconstruction formula is as follows:
- Verifiable secret sharing: A verifiable secret-sharing scheme is an enhancement of the traditional secret-sharing scheme, addressing the issue of malicious or deceptive behavior that may occur among participants in the traditional approach. This improvement makes the scheme more suitable for federated learning environments, where malicious clients and servers may exist. In scenarios where not all participants are necessarily honest, verifiable secret sharing allows honest participants to use cryptographic tools, such as commitment schemes or zero-knowledge proofs, to validate the consistency of secret shares provided by others. When dishonest participants are present, a verifiable secret-sharing scheme with fault-tolerance mechanisms enables the remaining participants to recover the secret value by adhering to the protocol rules.
- Additive secret sharing: In additive secret sharing, all secret sharing processes are implemented using additive methods, where the secret s is represented as . The secret distributor assigns the secret shares m and d to the participants. Each participant receives their respective secret shares as follows:Participants calculate as follows:The secret can be recovered by using the reconstruction formula for any t participants.
3.3. Differential Privacy
- Laplace mechanism [51]: DP is achieved by adding noise drawn from the Laplace distribution to the input or output. The probability density of the Laplace distribution is as follows:The sensitivity of the query function in the Laplace mechanism is defined as follows:Based on the above, the definition of Laplace DP can be stated as follows: Assume a query function , , where represents Laplace random noise. The random algorithm is defined to satisfy -differential privacy.
- Gaussian mechanism [52]: The Gaussian mechanism is used to achieve DP by adding Gaussian noise to the input or output. The Gaussian distribution is mathematically defined as follows:The sensitivity of the query function in the Gaussian mechanism is defined as follows:Based on the above, the definition of Gaussian differential privacy can be stated as follows: Assume a query function , , where for any , , and . Then, the randomized algorithm satisfies -differential privacy.
- Exponential mechanism [53]: The exponential mechanism is designed for non-numerical DP, and its sensitivity is defined as follows:where D is the dataset, q is the quality function that evaluates the quality score of each output result on the dataset, and r is the output result. When the randomized algorithm outputs r with a probability proportional to , then satisfies -differential privacy.
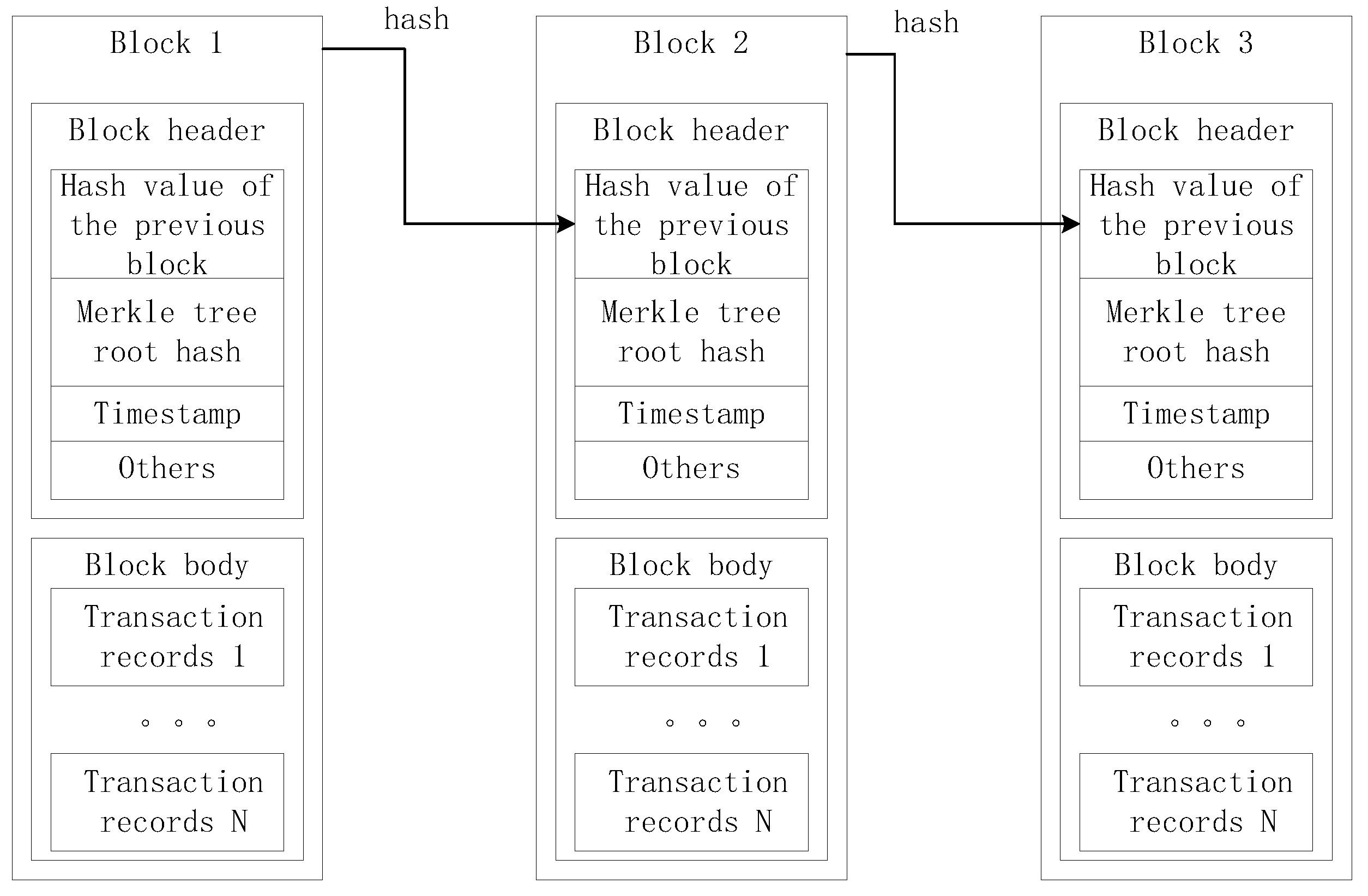
3.4. Blockchain
- Proof-of-work (PoW): Originally implemented in Bitcoin, the PoW algorithm addresses the issue of consensus through a computational puzzle that is difficult to solve but easy for others to verify. The core idea is to demonstrate validity through computational effort. PoW uses the process of solving puzzles to determine member selection. While PoW enables blockchain membership selection, it demands significant computation, leading to high resource consumption and low transaction throughput [54,55,56].
- Proof-of-stake (PoS): The core idea of PoS [57] is that a node demonstrates ownership of virtual resources by staking assets. This ownership determines its eligibility to participate in the consensus process and its level of influence. However, the security of PoS depends on the distribution of assets and places nodes with more assets in a more influential position in system operations.
- Delegated proof-of-stake (DPoS): DPoS [58] is a variant of proof-of-stake that introduces a democratic, voting-based membership selection process. Nodes holding stakes vote to select a delegate node, which enables the delegate node to verify and produce blocks.
- Practical Byzantine fault tolerant (PBFT): PBFT [59] is a mechanism that remains operational even in the presence of faulty nodes. The PBFT algorithm consists of three primary phases, as follows: the pre-preparation phase, the preparation phase, and the submission phase. The pre-preparation and preparation phases establish a total order of messages, while the preparation and submission phases guarantee consistent request ordering across all nodes.
4. Aggregation Techniques for Federated Learning
4.1. Fundamental Aggregation Algorithms
- FedAvg: The FedAvg [60] algorithm is a classic federated learning aggregation algorithm, where a subset of clients is randomly selected for aggregation in each training round. During aggregation, client parameters are weighted and averaged, with weights determined by the client’s data volume relative to the total data volume. FedAvg has efficient communication, supports non-independent and non-identically distributed (non-IID) data, and achieves high accuracy. However, when the degree of non-IID data distribution is too high, model convergence slows down. Furthermore, security considerations are lacking, failing to ensure participant trustworthiness. FedAvg updates the global model using the following equation:where is the aggregated global model, represents the set of selected clients, denotes the locally updated model for client k after local training, and is the weight factor.
- FedProx: FedProx [61] generalizes and reparameterizes FedAvg to address local optimization challenges in stochastic gradient descent (SGD)-based algorithms. It introduces a correction term to the client-side loss function, improving model performance and enhancing convergence speed. The correction term is defined as , the L2 norm of the difference between the local model and the global model, where is the penalty constant for the regularization term, designed to penalize clients with large deviations from the global model, thereby constraining the behavior of clients participating in training.
- Scaffold: Scaffold [62] is an update process that corrects both the global and local models by calculating the differences between the server-side and client-side control variables. This method effectively addresses the client drift problem caused by data heterogeneity in FedAvg. The model update in Scaffold consists of the following four steps:
- The client-side local model is updated as follows:
- The client-side control variable is updated as follows:
- The server global model is updated as follows:
- The server control variable is updated as follows:where represents the learning rate, K denotes the number of local update steps, is the gradient computation function, S stands for the selected client set, and N is the total number of clients.
- FedBN: FedBN [63] trains a local model on each client and incorporates a batch normalization (BN) layer for normalization. FedBN is designed to address the heterogeneity of federated learning data, particularly the feature drift issue. The FedBN normalization layer algorithm is as follows:where t is the training period, k is the client serial number, l is the number of neural network layers, and P is the set of clients.
- FedDF: FedDF [64] applies the concept of distillation to model fusion. Each client trains a local model, which is subsequently fused through distillation. FedDF is designed to address model heterogeneity and data heterogeneity with a certain level of robustness. The FedDF distillation algorithm is as follows:where represents the Kullback–Leibler divergence, is the softmax function, is the step size, and denotes the output of the k-th client model in the t-th round at the d-th batch.
4.2. Secure Aggregation Algorithms
4.2.1. Secure Aggregation Based on Homomorphic Encryption
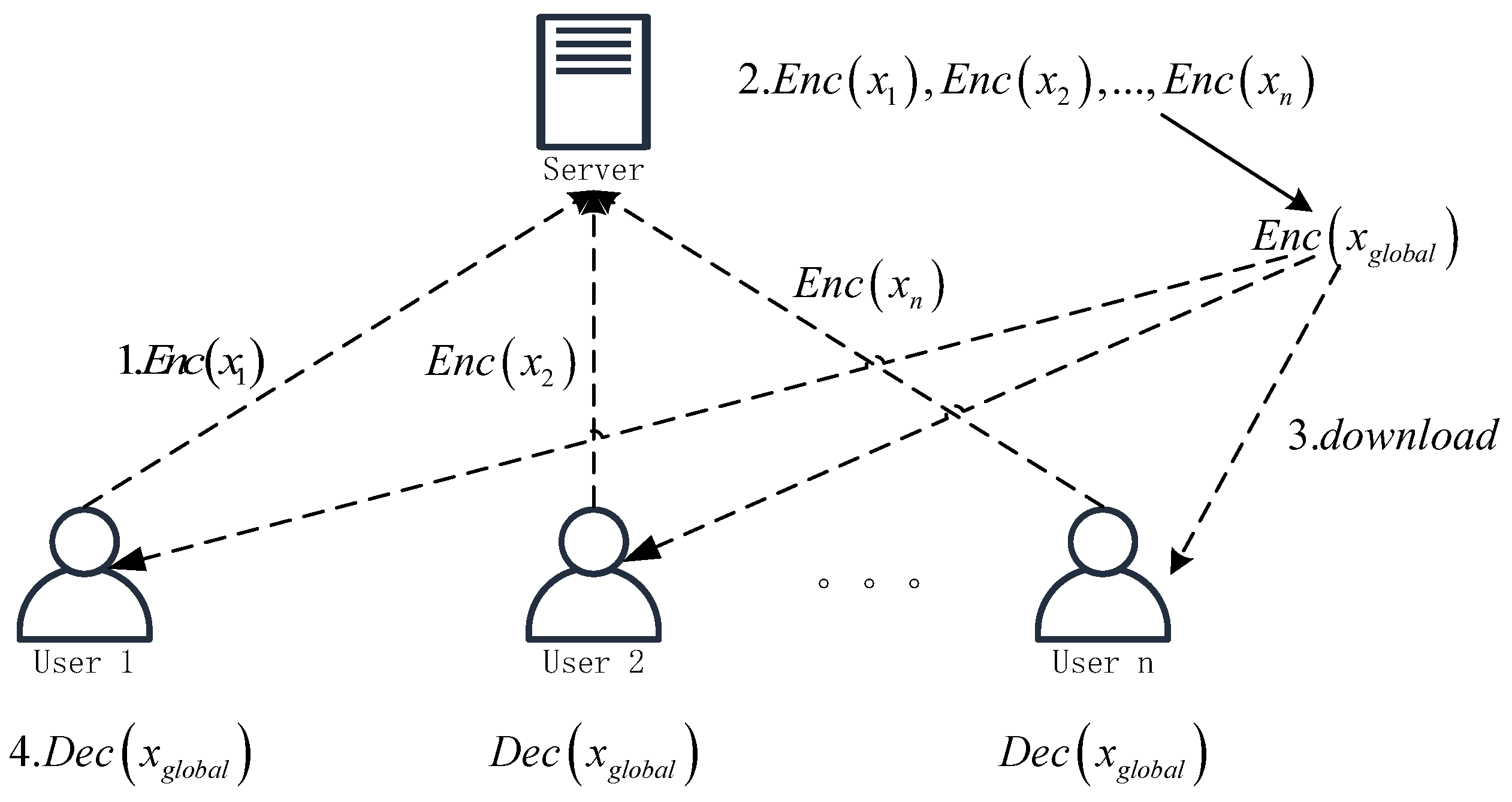
- Each user locally encrypts the trained model using homomorphic encryption to obtain , where represents the trained model data. The encrypted data is then uploaded to the server.
- The server performs the aggregation operation directly on the encrypted data to obtain the global model.
- The user downloads the global model.
- The user decrypts the global model locally using their private key.
4.2.2. Secure Aggregation Based on Secure Multi-Party Computation
4.2.3. Secure Aggregation Based on Differential Privacy
- Local differential privacy (LDP): Local differential privacy is designed for scenarios with untrusted servers, where each client adds perturbation noise to its data before sending it to the central server. By ensuring that the added noise satisfies the client’s differential privacy requirements, the client’s privacy remains protected regardless of the actions or behaviors of other clients or the server.
- Global differential privacy (GDP): Global differential privacy is typically employed in scenarios involving a trusted server, where the server adds differential privacy-compliant noise during the aggregation process. This approach protects user privacy while enabling the construction of a more practical model by introducing controlled noise into the global model maintained on the server.
- Distributed differential privacy (DDP): Distributed differential privacy does not require a trusted server and aims to achieve strong privacy guarantees with minimal noise addition. The system must pre-determine the noise budget required for each training round to ensure sufficient privacy protection. In each round, the noise addition task is allocated evenly among clients, each of which adds the minimum necessary noise to perturb its model update. Subsequently, the client’s update is masked before transmission to ensure that the server learns only the aggregated result. Distributed differential privacy typically incurs substantial communication overhead.
4.2.4. Secure Aggregation Based on Blockchain
- Initialization: The task publisher initializes the parameters of the global model and publishes them to the blockchain.
- Model download: Each client obtains the global model and determines whether to proceed to the next training round.
- Model training: Each client trains local models on its local data.
- Data transmission: All trained local models are uploaded and recorded in a blockchain block.
- Model aggregation: The selected consensus node uses the consensus algorithm to aggregate the local models and generate the global model.
- Global model update: The resulting global model is updated and recorded in a block, which is then appended to the blockchain.
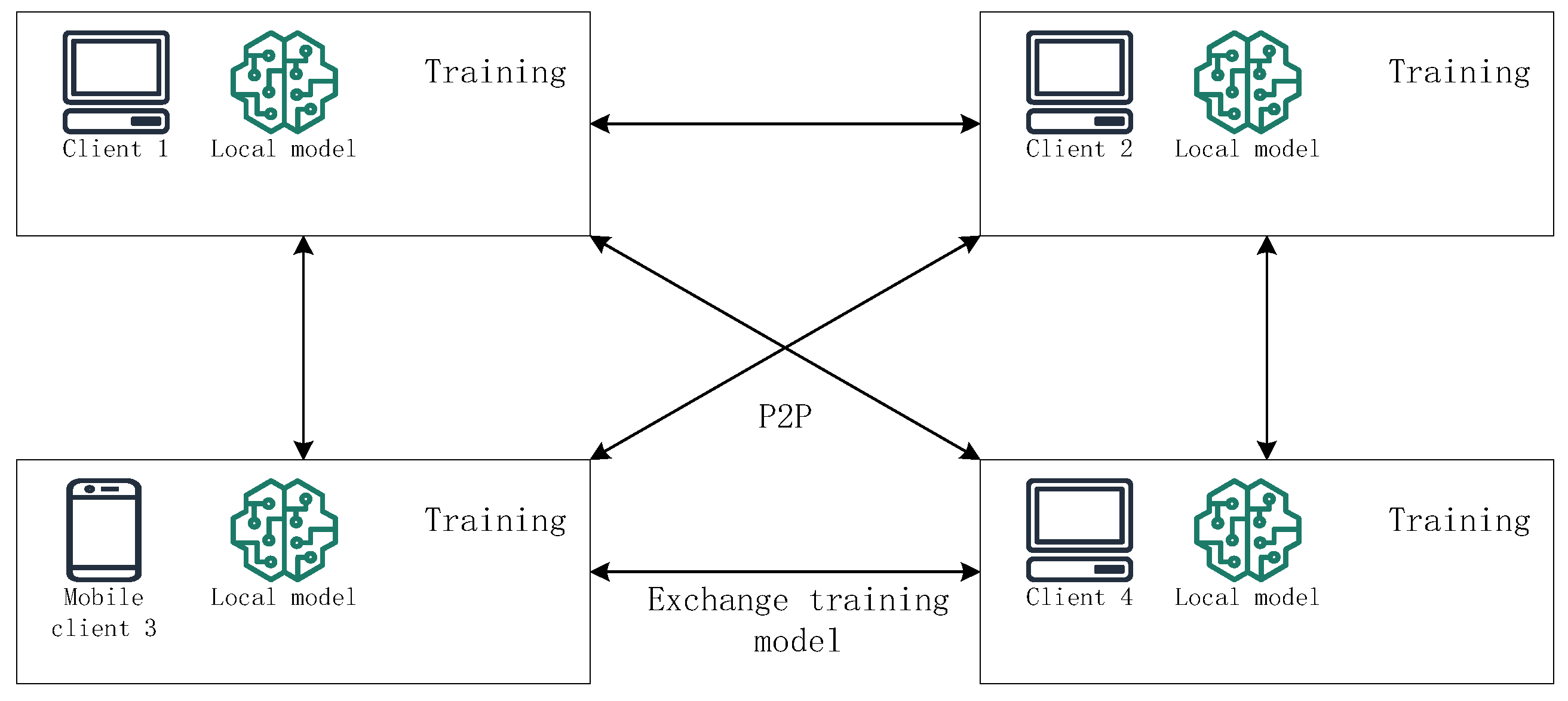
- Full decentralization: In fully decentralized federated learning, each node can act as a consensus node, playing the role of a central server to lead a training round, with a probability proportional to its available resources.
- Partial decentralization: In partially decentralized federated learning, the system balances computational cost and security by algorithmically selecting candidate blocks or designating nodes responsible for selecting candidate blocks to achieve an optimal trade-off.
4.3. Discussions
5. Challenges and Future Directions
5.1. Global Model Quality
5.2. Security
5.3. Adaptability
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Deng, L.; Yu, D. Deep learning: Methods and applications. Found. Trends Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef]
- Khan, S.; Yairi, T. A review on the application of deep learning in system health management. Mech. Syst. Signal Process. 2018, 107, 241–265. [Google Scholar] [CrossRef]
- Chen, C.; Zhu, W.; Steibel, J.; Siegford, J.; Han, J.; Norton, T. Classification of drinking and drinker-playing in pigs by a video-based deep learning method. Biosyst. Eng. 2020, 196, 1–14. [Google Scholar] [CrossRef]
- Liu, J.; Abbas, I.; Noor, R.S. Development of deep learning-based variable rate agrochemical spraying system for targeted weeds control in strawberry crop. Agronomy 2021, 11, 1480. [Google Scholar] [CrossRef]
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshad, H. State-of-the-art in artificial neural network applications: A survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef] [PubMed]
- Stoica, I.; Song, D.; Popa, R.A.; Patterson, D.; Mahoney, M.W.; Katz, R.; Joseph, A.D.; Jordan, M.; Hellerstein, J.M.; Gonzalez, J.E.; et al. A berkeley view of systems challenges for ai. arXiv 2017, arXiv:1712.05855. [Google Scholar] [CrossRef]
- Konečnỳ, J.; McMahan, H.B.; Ramage, D.; Richtárik, P. Federated optimization: Distributed machine learning for on-device intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar] [CrossRef]
- McMahan, H.B.; Moore, E.; Ramage, D.; y Arcas, B.A. Federated learning of deep networks using model averaging. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- Zhang, C.; Xie, Y.; Bai, H.; Yu, B.; Li, W.; Gao, Y. A survey on federated learning. Knowl.-Based Syst. 2021, 216, 106775. [Google Scholar] [CrossRef]
- Wen, J.; Zhang, Z.; Lan, Y.; Cui, Z.; Cai, J.; Zhang, W. A survey on federated learning: Challenges and applications. Int. J. Mach. Learn. Cybern. 2023, 14, 513–535. [Google Scholar] [CrossRef]
- Li, Q.; Wen, Z.; Wu, Z.; Hu, S.; Wang, N.; Li, Y.; Liu, X.; He, B. A survey on federated learning systems: Vision, hype and reality for data privacy and protection. IEEE Trans. Knowl. Data Eng. 2021, 35, 3347–3366. [Google Scholar] [CrossRef]
- Lyu, L.; Yu, H.; Ma, X.; Chen, C.; Sun, L.; Zhao, J.; Yang, Q.; Yu, P.S. Privacy and robustness in federated learning: Attacks and defenses. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 8726–8746. [Google Scholar] [CrossRef]
- Qu, Y.; Uddin, M.P.; Gan, C.; Xiang, Y.; Gao, L.; Yearwood, J. Blockchain-enabled federated learning: A survey. ACM Comput. Surv. 2022, 55, 1–35. [Google Scholar] [CrossRef]
- Fu, J.; Hong, Y.; Ling, X.; Wang, L.; Ran, X.; Sun, Z.; Wang, W.H.; Chen, Z.; Cao, Y. Differentially private federated learning: A systematic review. arXiv 2024, arXiv:2405.08299. [Google Scholar] [CrossRef]
- Qi, P.; Chiaro, D.; Guzzo, A.; Ianni, M.; Fortino, G.; Piccialli, F. Model aggregation techniques in federated learning: A comprehensive survey. Future Gener. Comput. Syst. 2024, 150, 272–293. [Google Scholar] [CrossRef]
- Moshawrab, M.; Adda, M.; Bouzouane, A.; Ibrahim, H.; Raad, A. Reviewing federated learning aggregation algorithms; strategies, contributions, limitations and future perspectives. Electronics 2023, 12, 2287. [Google Scholar] [CrossRef]
- Yang, W.; Zhang, Y.; Ye, K.; Li, L.; Xu, C.Z. FFD: A federated learning based method for credit card fraud detection. In Big Data–BigData 2019; Chen, K., Seshadri, S., Zhang, L.J., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 18–32. [Google Scholar]
- Yang, F.; Sun, J.; Cheng, J.; Fu, L.; Wang, S.; Xu, M. Detection of starch in minced chicken meat based on hyperspectral imaging technique and transfer learning. J. Food Process Eng. 2023, 46, e14304. [Google Scholar] [CrossRef]
- Zhang, Z.; Lu, Y.; Yang, M.; Wang, G.; Zhao, Y.; Hu, Y. Optimal training strategy for high-performance detection model of multi-cultivar tea shoots based on deep learning methods. Sci. Hortic. 2024, 328, 112949. [Google Scholar] [CrossRef]
- Zhu, H.; Wang, D.; Wei, Y.; Zhang, X.; Li, L. Combining Transfer Learning and Ensemble Algorithms for Improved Citrus Leaf Disease Classification. Agriculture 2024, 14, 1549. [Google Scholar] [CrossRef]
- Ahmed, S.; Qiu, B.; Ahmad, F.; Kong, C.W.; Xin, H. A state-of-the-art analysis of obstacle avoidance methods from the perspective of an agricultural sprayer UAV’s operation scenario. Agronomy 2021, 11, 1069. [Google Scholar] [CrossRef]
- Mansour, Y.; Mohri, M.; Ro, J.; Suresh, A.T. Three approaches for personalization with applications to federated learning. arXiv 2020, arXiv:2002.10619. [Google Scholar] [CrossRef]
- Hard, A.; Rao, K.; Mathews, R.; Ramaswamy, S.; Beaufays, F.; Augenstein, S.; Eichner, H.; Kiddon, C.; Ramage, D. Federated learning for mobile keyboard prediction. arXiv 2018, arXiv:1811.03604. [Google Scholar]
- Yu, T.; Li, T.; Sun, Y.; Nanda, S.; Smith, V.; Sekar, V.; Seshan, S. Learning context-aware policies from multiple smart homes via federated multi-task learning. In Proceedings of the 2020 IEEE/ACM Fifth International Conference on Internet-of-Things Design and Implementation (IoTDI), Sydney, NSW, Australia, 21–24 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 104–115. [Google Scholar]
- Amiri, M.M.; Gündüz, D. Federated learning over wireless fading channels. IEEE Trans. Wirel. Commun. 2020, 19, 3546–3557. [Google Scholar] [CrossRef]
- Yi, L.; Shi, X.; Wang, N.; Zhang, J.; Wang, G.; Liu, X. Fedpe: Adaptive model pruning-expanding for federated learning on mobile devices. IEEE Trans. Mob. Comput. 2024, 23, 10475–10493. [Google Scholar] [CrossRef]
- Zhu, W.; Sun, J.; Wang, S.; Shen, J.; Yang, K.; Zhou, X. Identifying field crop diseases using transformer-embedded convolutional neural network. Agriculture 2022, 12, 1083. [Google Scholar] [CrossRef]
- Ren, Y.; Huang, X.; Aheto, J.H.; Wang, C.; Ernest, B.; Tian, X.; He, P.; Chang, X.; Wang, C. Application of volatile and spectral profiling together with multimode data fusion strategy for the discrimination of preserved eggs. Food Chem. 2021, 343, 128515. [Google Scholar] [CrossRef]
- Yang, N.; Chang, K.; Dong, S.; Tang, J.; Wang, A.; Huang, R.; Jia, Y. Rapid image detection and recognition of rice false smut based on mobile smart devices with anti-light features from cloud database. Biosyst. Eng. 2022, 218, 229–244. [Google Scholar] [CrossRef]
- Awais, M.; Li, W.; Hussain, S.; Cheema, M.J.M.; Li, W.; Song, R.; Liu, C. Comparative evaluation of land surface temperature images from unmanned aerial vehicle and satellite observation for agricultural areas using in situ data. Agriculture 2022, 12, 184. [Google Scholar] [CrossRef]
- Tang, L.; Syed, A.U.A.; Otho, A.R.; Junejo, A.R.; Tunio, M.H.; Hao, L.; Asghar Ali, M.N.H.; Brohi, S.A.; Otho, S.A.; Channa, J.A. Intelligent Rapid Asexual Propagation Technology—A Novel Aeroponics Propagation Approach. Agronomy 2024, 14, 2289. [Google Scholar] [CrossRef]
- Guo, Y.; Gao, J.; Tunio, M.H.; Wang, L. Study on the identification of mildew disease of cuttings at the base of mulberry cuttings by aeroponics rapid propagation based on a BP neural network. Agronomy 2022, 13, 106. [Google Scholar] [CrossRef]
- Peng, Y.; Wang, A.; Liu, J.; Faheem, M. A comparative study of semantic segmentation models for identification of grape with different varieties. Agriculture 2021, 11, 997. [Google Scholar] [CrossRef]
- El-Mesery, H.S.; Qenawy, M.; Ali, M.; Hu, Z.; Adelusi, O.A.; Njobeh, P.B. Artificial intelligence as a tool for predicting the quality attributes of garlic (Allium sativum L.) slices during continuous infrared-assisted hot air drying. J. Food Sci. 2024, 89, 7693–7712. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Du, X.; Wang, Y.; Mao, H. Multi-machine collaboration realization conditions and precise and efficient production mode of intelligent agricultural machinery. Int. J. Agric. Biol. Eng. 2024, 17, 27–36. [Google Scholar] [CrossRef]
- Zhu, S.; Wang, B.; Pan, S.; Ye, Y.; Wang, E.; Mao, H. Task allocation of multi-machine collaborative operation for agricultural machinery based on the improved fireworks algorithm. Agronomy 2024, 14, 710. [Google Scholar] [CrossRef]
- Lakhiar, I.A.; Yan, H.; Zhang, C.; Wang, G.; He, B.; Hao, B.; Han, Y.; Wang, B.; Bao, R.; Syed, T.N.; et al. A review of precision irrigation water-saving technology under changing climate for enhancing water use efficiency, crop yield, and environmental footprints. Agriculture 2024, 14, 1141. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, X.; Zhang, H.; Zhang, B.; Zhang, J.; Hu, X.; Du, X.; Cai, J.; Jia, W.; Wu, C. UAV-Based Multispectral Winter Wheat Growth Monitoring with Adaptive Weight Allocation. Agriculture 2024, 14, 1900. [Google Scholar] [CrossRef]
- Wang, B.; Deng, J.; Jiang, H. Markov transition field combined with convolutional neural network improved the predictive performance of near-infrared spectroscopy models for determination of aflatoxin B1 in maize. Foods 2022, 11, 2210. [Google Scholar] [CrossRef]
- Suryavanshi, A.; Mehta, S.; Gupta, A.; Aeri, M.; Jain, V. Agriculture Farming Evolution: Federated Learning CNNs in Combatting Watermelon Leaf Diseases. In Proceedings of the 2024 Asia Pacific Conference on Innovation in Technology (APCIT), Mysore, India, 26–27 July 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar]
- Szegedi, G.; Kiss, P.; Horváth, T. Evolutionary federated learning on EEG-data. In Proceedings of the ITAT 2019-Information Technologies—Applications and Theory, Donovaly, Slovakia, 20–24 September 2019; pp. 71–78. [Google Scholar]
- Kim, Y.; Sun, J.; Yu, H.; Jiang, X. Federated tensor factorization for computational phenotyping. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 887–895. [Google Scholar]
- Lee, J.; Sun, J.; Wang, F.; Wang, S.; Jun, C.H.; Jiang, X. Privacy-preserving patient similarity learning in a federated environment: Development and analysis. JMIR Med. Inform. 2018, 6, e7744. [Google Scholar] [CrossRef]
- Liu, D.; Dligach, D.; Miller, T. Two-stage federated phenotyping and patient representation learning. Proc. Conf. Comput. Linguist. Meet. 2019, 2019, 283–291. [Google Scholar]
- Li, Y.; Wang, R.; Li, Y.; Zhang, M.; Long, C. Wind power forecasting considering data privacy protection: A federated deep reinforcement learning approach. Appl. Energy 2023, 329, 120291. [Google Scholar] [CrossRef]
- Wang, H.; Shen, H.; Li, F.; Wu, Y.; Li, M.; Shi, Z.; Deng, F. Novel PV power hybrid prediction model based on FL Co-Training method. Electronics 2023, 12, 730. [Google Scholar] [CrossRef]
- Goldwasser, S.; Micali, S.; Rackoff, C. The knowledge complexity of interactive proof-systems. In Providing Sound Foundations for Cryptography: On the Work of Shafi Goldwasser and Silvio Micali; Association for Computing Machinery: New York, NY, USA, 2019; pp. 203–225. [Google Scholar]
- Chaum, D.L. Untraceable electronic mail, return addresses, and digital pseudonyms. Commun. ACM 1981, 24, 84–90. [Google Scholar] [CrossRef]
- Rabin, M.O. Fingerprinting by Random Polynomials; Technical Report; Harvard University: Cambridge, MA, USA, 1981. [Google Scholar]
- Dwork, C. Differential privacy. In International Colloquium on Automata, Languages, and Programming; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1–12. [Google Scholar]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Proceedings of the Theory of Cryptography: Third Theory of Cryptography Conference, TCC 2006, New York, NY, USA, 4–7 March 2006; Proceedings 3. Springer: Berlin/Heidelberg, Germany, 2006; pp. 265–284. [Google Scholar]
- Dwork, C.; Roth, A. The algorithmic foundations of differential privacy. Found. Trends® Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- McSherry, F.; Talwar, K. Mechanism design via differential privacy. In Proceedings of the 48th Annual IEEE Symposium on Foundations of Computer Science (FOCS’07), Providence, RI, USA, 21–23 October 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 94–103. [Google Scholar]
- Cachin, C.; Vukolić, M. Blockchain consensus protocols in the wild. arXiv 2017, arXiv:1707.01873. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, L.; Battino, M.; Farag, M.A.; Xiao, J.; Simal-Gandara, J.; Gao, H.; Jiang, W. Blockchain: An emerging novel technology to upgrade the current fresh fruit supply chain. Trends Food Sci. Technol. 2022, 124, 1–12. [Google Scholar] [CrossRef]
- Gervais, A.; Karame, G.O.; Wüst, K.; Glykantzis, V.; Ritzdorf, H.; Capkun, S. On the security and performance of proof of work blockchains. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 3–16. [Google Scholar]
- Saad, S.M.S.; Radzi, R.Z.R.M. Comparative review of the blockchain consensus algorithm between proof of stake (pos) and delegated proof of stake (dpos). Int. J. Innov. Comput. 2020, 10, 27–32. [Google Scholar] [CrossRef]
- Pîrlea, G.; Sergey, I. Mechanising blockchain consensus. In Proceedings of the 7th ACM SIGPLAN International Conference on Certified Programs and Proofs, Los Angeles, CA, USA, 8–9 January 2018; pp. 78–90. [Google Scholar]
- Castro, M.; Liskov, B. Practical byzantine fault tolerance and proactive recovery. ACM Trans. Comput. Syst. (TOCS) 2002, 20, 398–461. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Artificial Intelligence and Statistics; PMLR: Birmingham, UK, 2017; pp. 1273–1282. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.; Stich, S.; Suresh, A.T. Scaffold: Stochastic controlled averaging for federated learning. In International Conference on Machine Learning; PMLR: Birmingham, UK, 2020; pp. 5132–5143. [Google Scholar]
- Li, X.; Jiang, M.; Zhang, X.; Kamp, M.; Dou, Q. Fedbn: Federated learning on non-iid features via local batch normalization. arXiv 2021, arXiv:2102.07623. [Google Scholar]
- Lin, T.; Kong, L.; Stich, S.U.; Jaggi, M. Ensemble distillation for robust model fusion in federated learning. Adv. Neural Inf. Process. Syst. 2020, 33, 2351–2363. [Google Scholar]
- Fang, H.; Qian, Q. Privacy preserving machine learning with homomorphic encryption and federated learning. Future Internet 2021, 13, 94. [Google Scholar] [CrossRef]
- Liu, Y.; Ma, Z.; Liu, X.; Ma, S.; Nepal, S.; Deng, R.H.; Ren, K. Boosting privately: Federated extreme gradient boosting for mobile crowdsensing. In Proceedings of the 2020 IEEE 40th International Conference on Distributed Computing Systems (ICDCS), Singapore, 29 November–1 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–11. [Google Scholar]
- Tang, F.; Wu, W.; Liu, J.; Wang, H.; Xian, M. Privacy-preserving distributed deep learning via homomorphic re-encryption. Electronics 2019, 8, 411. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, X.; Liu, J.K.; Xiang, Y. DeepPAR and DeepDPA: Privacy preserving and asynchronous deep learning for industrial IoT. IEEE Trans. Ind. Inform. 2019, 16, 2081–2090. [Google Scholar] [CrossRef]
- Wang, B.; Li, H.; Guo, Y.; Wang, J. PPFLHE: A privacy-preserving federated learning scheme with homomorphic encryption for healthcare data. Appl. Soft Comput. 2023, 146, 110677. [Google Scholar] [CrossRef]
- Aono, Y.; Hayashi, T.; Wang, L.; Moriai, S. Privacy-preserving deep learning via additively homomorphic encryption. IEEE Trans. Inf. Forensics Secur. 2017, 13, 1333–1345. [Google Scholar] [CrossRef]
- Yu, S.X.; Chen, Z. Efficient secure federated learning aggregation framework based on homomorphic encryption. J. Commun. 2023, 44, 14. [Google Scholar]
- Li, Q.; Cai, R.; Zhu, Y. GHPPFL: A Privacy Preserving Federated Learning Based On Gradient Compression and Homomorphic Encryption in Consumer App Security. IEEE Trans. Consum. Electron. 2025. early access. [Google Scholar] [CrossRef]
- Fang, C.; Guo, Y.; Hu, Y.; Ma, B.; Feng, L.; Yin, A. Privacy-preserving and communication-efficient federated learning in Internet of Things. Comput. Secur. 2021, 103, 102199. [Google Scholar] [CrossRef]
- Li, Y.; Li, H.; Xu, G.; Huang, X.; Lu, R. Efficient privacy-preserving federated learning with unreliable users. IEEE Internet Things J. 2021, 9, 11590–11603. [Google Scholar] [CrossRef]
- Truex, S.; Baracaldo, N.; Anwar, A.; Steinke, T.; Ludwig, H.; Zhang, R.; Zhou, Y. A hybrid approach to privacy-preserving federated learning. In Proceedings of the 12th ACM Workshop on Artificial Intelligence and Security, London, UK, 15 November 2019; pp. 1–11. [Google Scholar]
- Mandal, K.; Gong, G. PrivFL: Practical privacy-preserving federated regressions on high-dimensional data over mobile networks. In Proceedings of the 2019 ACM SIGSAC Conference on Cloud Computing Security Workshop, London, UK, 11 November 2019; pp. 57–68. [Google Scholar]
- Yang, W.; Liu, B.; Lu, C.; Yu, N. Privacy preserving on updated parameters in federated learning. In Proceedings of the ACM Turing Celebration Conference-China, Hefei, China, 22–24 May 2020; pp. 27–31. [Google Scholar]
- Zhang, L.; Xu, J.; Vijayakumar, P.; Sharma, P.K.; Ghosh, U. Homomorphic encryption-based privacy-preserving federated learning in IoT-enabled healthcare system. IEEE Trans. Netw. Sci. Eng. 2022, 10, 2864–2880. [Google Scholar] [CrossRef]
- Shen, C.; Zhang, W.; Zhou, T.; Zhang, L. A Security-Enhanced Federated Learning Scheme Based on Homomorphic Encryption and Secret Sharing. Mathematics 2024, 12, 1993. [Google Scholar] [CrossRef]
- Lai, C.; Zhao, Y.; Zheng, D. A Privacy Preserving and Verifiable Federated Learning Scheme Based on Homomorphic Encryption. Net-Info Secur. 2024, 24, 93–105. [Google Scholar]
- Xu, D.; Yuan, S.; Wu, X. Achieving differential privacy in vertically partitioned multiparty learning. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 5474–5483. [Google Scholar]
- Park, J.; Lim, H. Privacy-preserving federated learning using homomorphic encryption. Appl. Sci. 2022, 12, 734. [Google Scholar] [CrossRef]
- Froelicher, D.; Troncoso-Pastoriza, J.R.; Pyrgelis, A.; Sav, S.; Sousa, J.S.; Bossuat, J.P.; Hubaux, J.P. Scalable privacy-preserving distributed learning. arXiv 2020, arXiv:2005.09532. [Google Scholar] [CrossRef]
- Stripelis, D.; Saleem, H.; Ghai, T.; Dhinagar, N.; Gupta, U.; Anastasiou, C.; Ver Steeg, G.; Ravi, S.; Naveed, M.; Thompson, P.M.; et al. Secure neuroimaging analysis using federated learning with homomorphic encryption. In Proceedings of the 17th International Symposium on Medical Information Processing and Analysis, Campinas, Brazil, 17–19 November 2021; SPIE: Bellingham, WA, USA, 2021; Volume 12088, pp. 351–359. [Google Scholar]
- Ma, J.; Naas, S.A.; Sigg, S.; Lyu, X. Privacy-preserving federated learning based on multi-key homomorphic encryption. Int. J. Intell. Syst. 2022, 37, 5880–5901. [Google Scholar] [CrossRef]
- Hijazi, N.M.; Aloqaily, M.; Guizani, M.; Ouni, B.; Karray, F. Secure federated learning with fully homomorphic encryption for IoT communications. IEEE Internet Things J. 2023, 11, 4289–4300. [Google Scholar] [CrossRef]
- Fereidooni, H.; Marchal, S.; Miettinen, M.; Mirhoseini, A.; Möllering, H.; Nguyen, T.D.; Rieger, P.; Sadeghi, A.R.; Schneider, T.; Yalame, H.; et al. SAFELearn: Secure aggregation for private federated learning. In Proceedings of the 2021 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 27 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 56–62. [Google Scholar]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October– 3 November 2017; pp. 1175–1191. [Google Scholar]
- Choi, B.; Sohn, J.Y.; Han, D.J.; Moon, J. Communication-computation efficient secure aggregation for federated learning. arXiv 2020, arXiv:2012.05433. [Google Scholar]
- Liu, Z.; Guo, J.; Lam, K.Y.; Zhao, J. Efficient dropout-resilient aggregation for privacy-preserving machine learning. IEEE Trans. Inf. Forensics Secur. 2022, 18, 1839–1854. [Google Scholar] [CrossRef]
- Jin, X.; Yao, Y.; Yu, N. Efficient secure aggregation for privacy-preserving federated learning based on secret sharing. JUSTC 2024, 54, 0104-1–0104-16. [Google Scholar] [CrossRef]
- Ghavamipour, A.R.; Zhao, B.Z.H.; Turkmen, F. Privacy-preserving, dropout-resilient aggregation in decentralized learning. arXiv 2024, arXiv:2404.17984. [Google Scholar]
- Liu, Z.; Lin, H.Y.; Liu, Y. Long-term privacy-preserving aggregation with user-dynamics for federated learning. IEEE Trans. Inf. Forensics Secur. 2023, 18, 2398–2412. [Google Scholar] [CrossRef]
- Maurya, A.; Haripriya, R.; Pandey, M.; Choudhary, J.; Singh, D.P.; Solanki, S.; Sharma, D. Federated Learning for Privacy-Preserving Severity Classification in Healthcare: A Secure Edge-Aggregated Approach. IEEE Access 2025, 13, 102339–102358. [Google Scholar] [CrossRef]
- Xu, G.; Li, H.; Liu, S.; Yang, K.; Lin, X. VerifyNet: Secure and verifiable federated learning. IEEE Trans. Inf. Forensics Secur. 2019, 15, 911–926. [Google Scholar] [CrossRef]
- Brunetta, C.; Tsaloli, G.; Liang, B.; Banegas, G.; Mitrokotsa, A. Non-interactive, secure verifiable aggregation for decentralized, privacy-preserving learning. In Australasian Conference on Information Security and Privacy; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 510–528. [Google Scholar]
- Eltaras, T.; Sabry, F.; Labda, W.; Alzoubi, K.; Ahmedeltaras, Q. Efficient verifiable protocol for privacy-preserving aggregation in federated learning. IEEE Trans. Inf. Forensics Secur. 2023, 18, 2977–2990. [Google Scholar] [CrossRef]
- Guo, X.; Liu, Z.; Li, J.; Gao, J.; Hou, B.; Dong, C.; Baker, T. VeriFL: Communication-efficient and fast verifiable aggregation for federated learning. IEEE Trans. Inf. Forensics Secur. 2020, 16, 1736–1751. [Google Scholar] [CrossRef]
- Fu, A.; Zhang, X.; Xiong, N.; Gao, Y.; Wang, H.; Zhang, J. VFL: A verifiable federated learning with privacy-preserving for big data in industrial IoT. IEEE Trans. Ind. Inform. 2020, 18, 3316–3326. [Google Scholar] [CrossRef]
- Sotthiwat, E.; Zhen, L.; Li, Z.; Zhang, C. Partially encrypted multi-party computation for federated learning. In Proceedings of the 2021 IEEE/ACM 21st International Symposium on Cluster, Cloud and Internet Computing (CCGrid), Melbourne, Australia, 10–13 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 828–835. [Google Scholar]
- Li, S.; Yao, D.; Liu, J. Fedvs: Straggler-resilient and privacy-preserving vertical federated learning for split models. In International Conference on Machine Learning; PMLR: Birmingham, UK, 2023; pp. 20296–20311. [Google Scholar]
- Boer, D.; Kramer, S. Secure sum outperforms homomorphic encryption in (current) collaborative deep learning. arXiv 2020, arXiv:2006.02894. [Google Scholar]
- Kanagavelu, R.; Wei, Q.; Li, Z.; Zhang, H.; Samsudin, J.; Yang, Y.; Goh, R.S.M.; Wang, S. CE-Fed: Communication efficient multi-party computation enabled federated learning. Array 2022, 15, 100207. [Google Scholar] [CrossRef]
- Kadhe, S.; Rajaraman, N.; Koyluoglu, O.O.; Ramchandran, K. Fastsecagg: Scalable secure aggregation for privacy-preserving federated learning. arXiv 2020, arXiv:2009.11248. [Google Scholar]
- Wang, D.; Zhang, L. Federated learning scheme based on secure multi-party computation and differential privacy. Comput. Sci. 2022, 49, 297–305. [Google Scholar]
- Schlitter, N. A protocol for privacy preserving neural network learning on horizontal partitioned data. PSD 2008.
- Urabe, S.; Wang, J.; Kodama, E.; Takata, T. A high collusion-resistant approach to distributed privacy-preserving data mining. Inf. Media Technol. 2007, 2, 821–834. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, J.; Zhao, Y.; Chen, B. An efficient federated learning scheme with differential privacy in mobile edge computing. In Proceedings of the Machine Learning and Intelligent Communications: 4th International Conference, MLICOM 2019, Nanjing, China, 24–25 August 2019; Proceedings 4. Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 538–550. [Google Scholar]
- Wang, C.; Ma, C.; Li, M.; Gao, N.; Zhang, Y.; Shen, Z. Protecting data privacy in federated learning combining differential privacy and weak encryption. In Proceedings of the Science of Cyber Security: Third International Conference, SciSec 2021, Virtual Event, 13–15 August 2021; Revised Selected Papers 4. Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 95–109. [Google Scholar]
- Kasula, V.K.; Yenugula, M.; Konda, B.; Yadulla, A.R.; Tumma, C.; Rakki, S.B. Federated Learning with Secure Aggregation for Privacy-Preserving Deep Learning in IoT Environments. In Proceedings of the 2025 IEEE Conference on Computer Applications (ICCA), Yangon, Myanmar, 18 March 2025; IEEE: Piscataway, NJ, USA, 2025; pp. 1–7. [Google Scholar]
- Ling, X.; Fu, J.; Wang, K.; Liu, H.; Chen, Z. Ali-dpfl: Differentially private federated learning with adaptive local iterations. In Proceedings of the 2024 IEEE 25th International Symposium on a World of Wireless, Mobile and Multimedia Networks (WoWMoM), Perth, Australia, 4–7 June 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 349–358. [Google Scholar]
- Liu, X.; Zhou, Y.; Wu, D.; Hu, M.; Wang, J.H.; Guizani, M. FedDP-SA: Boosting Differentially Private Federated Learning via Local Dataset Splitting. IEEE Internet Things J. 2024, 11, 31687–31698. [Google Scholar] [CrossRef]
- Liu, J.; Lou, J.; Xiong, L.; Liu, J.; Meng, X. Projected federated averaging with heterogeneous differential privacy. Proc. VLDB Endow. 2021, 15, 828–840. [Google Scholar] [CrossRef]
- Yu, L.; Liu, L.; Pu, C.; Gursoy, M.E.; Truex, S. Differentially private model publishing for deep learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 332–349. [Google Scholar]
- Zhang, L.; Zhu, T.; Xiong, P.; Zhou, W.; Yu, P.S. A robust game-theoretical federated learning framework with joint differential privacy. IEEE Trans. Knowl. Data Eng. 2022, 35, 3333–3346. [Google Scholar] [CrossRef]
- Truex, S.; Liu, L.; Chow, K.H.; Gursoy, M.E.; Wei, W. LDP-Fed: Federated learning with local differential privacy. In Proceedings of the Third ACM International Workshop on Edge Systems, Analytics and Networking, Heraklion, Greece, 27 April 2020; pp. 61–66. [Google Scholar]
- Wang, B.; Chen, Y.; Jiang, H.; Zhao, Z. Ppefl: Privacy-preserving edge federated learning with local differential privacy. IEEE Internet Things J. 2023, 10, 15488–15500. [Google Scholar] [CrossRef]
- Cheu, A.; Smith, A.; Ullman, J.; Zeber, D.; Zhilyaev, M. Distributed differential privacy via shuffling. In Proceedings of the Advances in Cryptology–EUROCRYPT 2019: 38th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Darmstadt, Germany, 19–23 May 2019; Proceedings, Part I. Springer International Publishing: Berlin/Heidelberg, Germany, 2019; Volume 38, pp. 375–403. [Google Scholar]
- Jiang, Z.; Wang, W.; Chen, R. Dordis: Efficient Federated Learning with Dropout-Resilient Differential Privacy. In Proceedings of the Nineteenth European Conference on Computer Systems, Athens, Greece, 22–25 April 2024; pp. 472–488. [Google Scholar]
- Scott, M.; Cormode, G.; Maple, C. Aggregation and transformation of vector-valued messages in the shuffle model of differential privacy. IEEE Trans. Inf. Forensics Secur. 2022, 17, 612–627. [Google Scholar] [CrossRef]
- Hamouda, D.; Ferrag, M.A.; Benhamida, N.; Seridi, H. PPSS: A privacy-preserving secure framework using blockchain-enabled federated deep learning for industrial IoTs. Pervasive Mob. Comput. 2023, 88, 101738. [Google Scholar] [CrossRef]
- Dillenberger, D.N.; Novotny, P.; Zhang, Q.; Jayachandran, P.; Gupta, H.; Hans, S.; Verma, D.; Chakraborty, S.; Thomas, J.J.; Walli, M.M.; et al. Blockchain analytics and artificial intelligence. IBM J. Res. Dev. 2019, 63, 5:1–5:14. [Google Scholar] [CrossRef]
- Ma, C.; Li, J.; Shi, L.; Ding, M.; Wang, T.; Han, Z.; Poor, H.V. When federated learning meets blockchain: A new distributed learning paradigm. IEEE Comput. Intell. Mag. 2022, 17, 26–33. [Google Scholar] [CrossRef]
- Feng, L.; Zhao, Y.; Guo, S.; Qiu, X.; Li, W.; Yu, P. BAFL: A blockchain-based asynchronous federated learning framework. IEEE Trans. Comput. 2021, 71, 1092–1103. [Google Scholar] [CrossRef]
- Nguyen, H.; Nguyen, T.; Lovén, L.; Pirttikangas, S. Wait or Not to Wait: Evaluating Trade-Offs between Speed and Precision in Blockchain-based Federated Aggregation. arXiv 2024, arXiv:2406.00181. [Google Scholar] [CrossRef]
- Cui, L.; Su, X.; Ming, Z.; Chen, Z.; Yang, S.; Zhou, Y.; Xiao, W. CREAT: Blockchain-assisted compression algorithm of federated learning for content caching in edge computing. IEEE Internet Things J. 2020, 9, 14151–14161. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, J.; Jiang, L.; Tan, R.; Niyato, D.; Li, Z.; Lyu, L.; Liu, Y. Privacy-preserving blockchain-based federated learning for IoT devices. IEEE Internet Things J. 2020, 8, 1817–1829. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Zhang, K.; Maharjan, S.; Zhang, Y. Blockchain and federated learning for 5G beyond. IEEE Netw. 2020, 35, 219–225. [Google Scholar] [CrossRef]
- Zhou, S.; Huang, H.; Chen, W.; Zhou, P.; Zheng, Z.; Guo, S. Pirate: A blockchain-based secure framework of distributed machine learning in 5G networks. IEEE Netw. 2020, 34, 84–91. [Google Scholar] [CrossRef]
- Li, Y.; Chen, C.; Liu, N.; Huang, H.; Zheng, Z.; Yan, Q. A blockchain-based decentralized federated learning framework with committee consensus. IEEE Netw. 2020, 35, 234–241. [Google Scholar] [CrossRef]
- Zhou, M.; Yang, Z.; Yu, H.; Yu, S. VDFChain: Secure and verifiable decentralized federated learning via committee-based blockchain. J. Netw. Comput. Appl. 2024, 223, 103814. [Google Scholar] [CrossRef]
- Yang, Z.; Shi, Y.; Zhou, Y.; Wang, Z.; Yang, K. Trustworthy federated learning via blockchain. IEEE Internet Things J. 2022, 10, 92–109. [Google Scholar] [CrossRef]
- Qin, Z.; Yan, X.; Zhou, M.; Deng, S. BlockDFL: A Blockchain-based Fully Decentralized Peer-to-Peer Federated Learning Framework. In Proceedings of the ACM on Web Conference 2024, Singapore, 13–17 May 2024; pp. 2914–2925. [Google Scholar]
- Chen, R.; Dong, Y.; Liu, Y.; Fan, T.; Li, D.; Guan, Z.; Liu, J.; Zhou, J. FLock: Robust and Privacy-Preserving Federated Learning based on Practical Blockchain State Channels. In Proceedings of the ACM on Web Conference 2025, Sydney, NSW, Australia, 28 April–2 May 2025; pp. 884–895. [Google Scholar]
- Elsherbiny, O.; Gao, J.; Ma, M.; Guo, Y.; Tunio, M.H.; Mosha, A.H. Advancing lettuce physiological state recognition in IoT aeroponic systems: A meta-learning-driven data fusion approach. Eur. J. Agron. 2024, 161, 127387. [Google Scholar] [CrossRef]
- Mohamed, T.M.K.; Gao, J.; Tunio, M. Development and experiment of the intelligent control system for rhizosphere temperature of aeroponic lettuce via the Internet of Things. Int. J. Agric. Biol. Eng. 2022, 15, 225–233. [Google Scholar] [CrossRef]
- Ding, C.; Wang, L.; Chen, X.; Yang, H.; Huang, L.; Song, X. A blockchain-based wide-area agricultural machinery resource scheduling system. Appl. Eng. Agric. 2023, 39, 1–12. [Google Scholar] [CrossRef]
- Adade, S.Y.S.S.; Lin, H.; Johnson, N.A.N.; Nunekpeku, X.; Aheto, J.H.; Ekumah, J.N.; Kwadzokpui, B.A.; Teye, E.; Ahmad, W.; Chen, Q. Advanced Food Contaminant Detection through Multi-Source Data Fusion: Strategies, Applications, and Future Perspectives. Trends Food Sci. Technol. 2024, 156, 104851. [Google Scholar] [CrossRef]
- Li, Y.; Xu, L.; Lv, L.; Shi, Y.; Yu, X. Study on modeling method of a multi-parameter control system for threshing and cleaning devices in the grain combine harvester. Agriculture 2022, 12, 1483. [Google Scholar] [CrossRef]
- Zhou, X.; Zhao, C.; Sun, J.; Cao, Y.; Yao, K.; Xu, M. A deep learning method for predicting lead content in oilseed rape leaves using fluorescence hyperspectral imaging. Food Chem. 2023, 409, 135251. [Google Scholar] [CrossRef] [PubMed]
- Gao, J.; Hou, B.; Guo, X.; Liu, Z.; Zhang, Y.; Chen, K.; Li, J. Secure aggregation is insecure: Category inference attack on federated learning. IEEE Trans. Dependable Secur. Comput. 2021, 20, 147–160. [Google Scholar] [CrossRef]
- Wang, Z.; Huang, Y.; Song, M.; Wu, L.; Xue, F.; Ren, K. Poisoning-assisted property inference attack against federated learning. IEEE Trans. Dependable Secur. Comput. 2022, 20, 3328–3340. [Google Scholar] [CrossRef]
- Lyu, L.; Yu, H.; Yang, Q. Threats to federated learning: A survey. arXiv 2020, arXiv:2003.02133. [Google Scholar] [CrossRef]
- Zhou, X.; Sun, J.; Tian, Y.; Lu, B.; Hang, Y.; Chen, Q. Hyperspectral technique combined with deep learning algorithm for detection of compound heavy metals in lettuce. Food Chem. 2020, 321, 126503. [Google Scholar] [CrossRef]
- Raza, A.; Saber, K.; Hu, Y.; L. Ray, R.; Ziya Kaya, Y.; Dehghanisanij, H.; Kisi, O.; Elbeltagi, A. Modelling reference evapotranspiration using principal component analysis and machine learning methods under different climatic environments. Irrig. Drain. 2023, 72, 945–970. [Google Scholar] [CrossRef]
- Lin, H.; Pan, T.; Li, Y.; Chen, S.; Li, G. Development of analytical method associating near-infrared spectroscopy with one-dimensional convolution neural network: A case study. J. Food Meas. Charact. 2021, 15, 2963–2973. [Google Scholar] [CrossRef]
- Zhang, D.; Lin, Z.; Xuan, L.; Lu, M.; Shi, B.; Shi, J.; He, F.; Battino, M.; Zhao, L.; Zou, X. Rapid determination of geographical authenticity and pungency intensity of the red Sichuan pepper (Zanthoxylum bungeanum) using differential pulse voltammetry and machine learning algorithms. Food Chem. 2024, 439, 137978. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, M.; Xu, B.; Sun, J.; Mujumdar, A.S. Artificial intelligence assisted technologies for controlling the drying of fruits and vegetables using physical fields: A review. Trends Food Sci. Technol. 2020, 105, 251–260. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Scheme | Algorithm | Protected Model | Network Structure | Resource Requirement |
|---|---|---|---|---|---|
| Partially Homomorphic Encryption | [65,66,67,68,69,70,71,72] | Paillier | Local | Centralization | Acceptable |
| [73] | ElGamal | Local | Centralization | Lightweight | |
| [74,75] | threshold Paillier | Local | Centralization | High cost | |
| [76] | Joye-Libert | Local and Global | Centralization | Lightweight | |
| [77] | RSA/Paillier | Local | Trusted party and server | Acceptable | |
| [78,79,80] | threshold ElGamal | Local | Trusted party and server | Acceptable | |
| [81,82] | Others | Local and Global | Centralization | High cost | |
| Fully Homomorphic Encryption | [83,84,85] | CKKS | Local and Global | Centralization | High cost |
| [86,87] | Others | Local | Centralization | High cost |
| Type | Scheme | Support for User Disconnection | Protected Model | Network Structure | Resource Requirement |
|---|---|---|---|---|---|
| Shamir | [89,90,91] | Support | Local | Centralization | Lightweight |
| [92] | Support | Local | Decentralization | High cost | |
| [93,94] | Support | Local and Global | Centralization | Acceptable | |
| Verifiable Secret Sharing | [95] | Support | Local and Global | Trusted party and server | High cost |
| [96] | Support | Local and Global | Decentralization | High cost | |
| [97,98] | Support | Local and Global | Centralization | Lightweight | |
| [99] | Not supported | Local and Global | Centralization | Lightweight | |
| Additive Secret Sharing | [100] | Not supported | Local | Centralization | Acceptable |
| [102,103] | Not supported | Local | Decentralization | Acceptable | |
| [101,104] | Support | Local | Centralization | Lightweight | |
| [105] | Support | Local and Global | Centralization | Acceptable |
| Type | Scheme | Framework | Protected Model | Network Structure | Resource Requirement |
|---|---|---|---|---|---|
| Laplace Mechanism | [108] | LDP | Local | Decentralization | Lightweight |
| [109] | LDP | Local and Global | Centralization | Lightweight | |
| [110] | LDP | Local | Centralization | Lightweight | |
| Gaussian Mechanism | [111,112] | LDP | Local | Centralization | Lightweight |
| [113] | LDP | Local and Global | Centralization | Lightweight | |
| [114] | GDP | Global | Centralization | Acceptable | |
| Exponential Mechanism | [115] | GDP | Global | Centralization | Lightweight |
| [116,117] | LDP | Local | Centralization | Lightweight | |
| Others | [118,119,120] | DDP | Local and Global | Centralization | Acceptable |
| Type | Scheme | Model Accuracy | Protected Model | Network Structure | Resource Requirement |
|---|---|---|---|---|---|
| PoW | [123] | Increase | Local and Global | Full Decentralization | High cost |
| [124] | Increase 12.1% compared to FedAvg | Local and Global | Full Decentralization | High cost | |
| [125] | Increase | Local and Global | Full Decentralization | High cost | |
| PoS or DPoS | [126,127,128] | Increase | Local and Global | Partial Decentralization | Acceptable |
| Committee Consensus Algorithm | [129,130] | Increase | Local and Global | Partial Decentralization | Acceptable |
| [131] | No decline | Local and Global | Partial Decentralization | Acceptable | |
| PBFT | [132,133,134] | Increase | Local and Global | Full Decentralization | Acceptable |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Luo, Y.; Li, T. A Review of Research on Secure Aggregation for Federated Learning. Future Internet 2025, 17, 308. https://doi.org/10.3390/fi17070308
Zhang X, Luo Y, Li T. A Review of Research on Secure Aggregation for Federated Learning. Future Internet. 2025; 17(7):308. https://doi.org/10.3390/fi17070308
Chicago/Turabian StyleZhang, Xing, Yuexiang Luo, and Tianning Li. 2025. "A Review of Research on Secure Aggregation for Federated Learning" Future Internet 17, no. 7: 308. https://doi.org/10.3390/fi17070308
APA StyleZhang, X., Luo, Y., & Li, T. (2025). A Review of Research on Secure Aggregation for Federated Learning. Future Internet, 17(7), 308. https://doi.org/10.3390/fi17070308