
Optimizing Trajectories for Rechargeable Agricultural Robots in Greenhouse Climatic Sensing Using Deep Reinforcement Learning with Proximal Policy Optimization Algorithm †




Abstract

1. Introduction
Related Work
2. Materials and Methods
2.1. Background
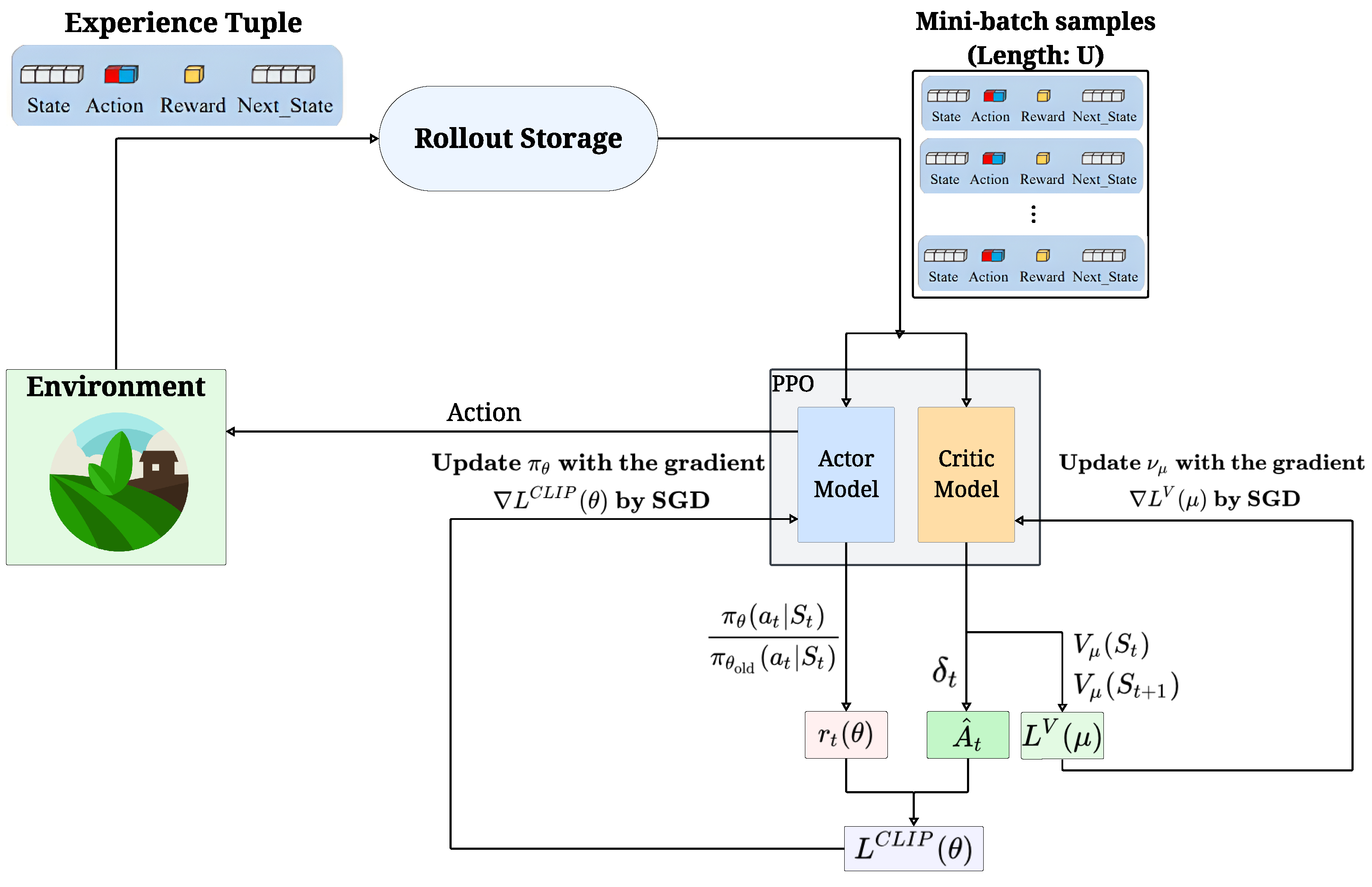
- Environment interaction and experience collection—Given the modeled environment E, the action model takes an action in E, obtaining in response from E the following experience tuple: , where is the current state, is the action taken, is the reward received by performing in , and is the reached state. This interaction continues for a fixed number of steps, generating a sequence of experiences, also called a trajectory of experiences.
- Rollout storage (trajectory memory)—The sequence of collected experience tuples are temporarily stored in a component called rollout storage. This component acts as a buffer that holds the sequence of experiences generated by the agent’s current policy . It is an essential element of the PPO because the algorithm uses this collected data for multiple learning updates before discarding them and collecting a new trajectory.
- PPO components: actor and critic models—The PPO block contains the two core learning models.
- Actor model (or policy model): It can be considered as the agent’s decision-maker. It receives information about the current state and decides which action to take. Its goal is to develop a stochastic policy , which is essentially a set of rules or probabilities that dictate the best action for any given state. Indeed, given the state as input, it produces the probabilities of taking each different action . The parameter represents the knowledge it has learned so far.
- Critic model (or value model): This acts as the agent’s evaluator. It assesses how good a particular state is, or how good a particular action taken in a state is. It learns to estimate the expected future reward () achievable from the current state . The parameter represents the learned evaluation knowledge.
- Data preparation for learning—Once an iteration has been completed, the two models can be updated. This update exploits the data collected inside the rollout storage component and requires the computation of the following parameters:
- Policy ratio : For each action , the algorithm calculates the probability of taking that action under the current policy and compares it to the probability under the old policy . This comparison produces the importance sampling ratio (), defined as follows:This ratio is a key factor in PPO stability, ensuring that updates do not deviate too far from the old policy.
- Temporal Difference (TD) error : The estimates provided by the critic network are used to calculate the TD error, which measures the difference between the expected return and the actual value observed. It is typically calculated as:where is the discount factor used to modulate the role of future rewards with respect to the current one.
- Advantage estimation : Using the TD errors, the Generalized Advantage Estimation (GAE) is calculated. This provides a more accurate measure of how much better a chosen action was compared to the average expected outcome from that state. It is a crucial input for updating the actor model.
- Model updates (optimization)—The prepared data is then used to update both the actor and critic models. A batch of samples, referred to as mini-batch samples (length: U), is drawn from the rollout storage for these updates.
- Critic model update: The objective of the critic model is to minimize its value loss, denoted as . This loss measures the squared difference between the predicted values () and the actual returns. The parameter characterizing this network is then updated using its gradient, , typically through an optimization algorithm like Stochastic Gradient Descent (SGD).
- Actor model update: The objective of the actor model is to minimize its clipped policy loss, denoted as . This is the core of PPO. It uses the importance sampling ratio and the advantage estimation to construct a loss function that encourages beneficial actions while preventing large, destabilizing changes to the policy. In particular, the clipping mechanism within this loss computation ensures that the ratio always stays within a certain range. The simplified policy loss can be seen as:where is the clipping hyperparameter. The parameter characterizing this network is updated using its gradient, , typically through an optimization algorithm like SGD. An entropy bonus (not explicitly shown in the formula but often added) is also typically included to encourage exploration.
2.2. Problem Formalization and Proposed Method
- 1.
- If and and are not empty, then the elements of are less than all the elements of .
- 2.
- If and and are not empty, then is also not empty.
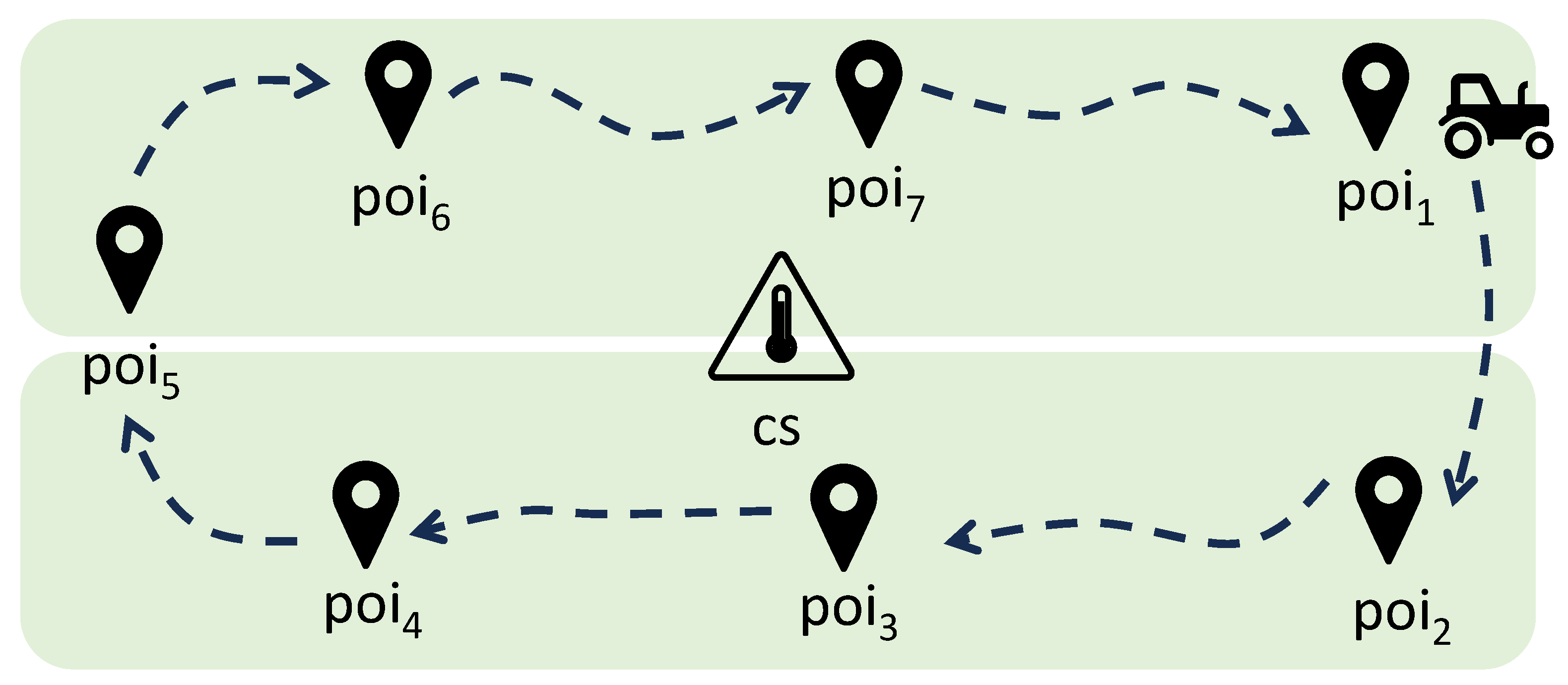
- An agricultural robot periodically describes a trajectory during its farming operations that potentially touches all elements of a set of predefined and well-identified PoIs. The visit order is not predefined, and there are no precedence constraints. Moreover, some PoIs in could be skipped during a specific trajectory.
- Each PoI could be reached directly or indirectly by passing through other PoIs, so there could be more than one path connecting the same pair of PoIs.
- There is no fixed direction in visiting PoIs; namely, the robot can go forward and backward among the PoIs.
- The robot is equipped with a device able to sample some climatic variables during the execution of its tasks. The measuring activity is done during farming operations. Therefore, we assume the presence of a function t, which returns for each PoI p the time required to complete the farming operations, including the measuring task. Since the assumed temporal granularity defines a resolution of one minute, the duration for each becomes the number of minutes needed to complete the task.
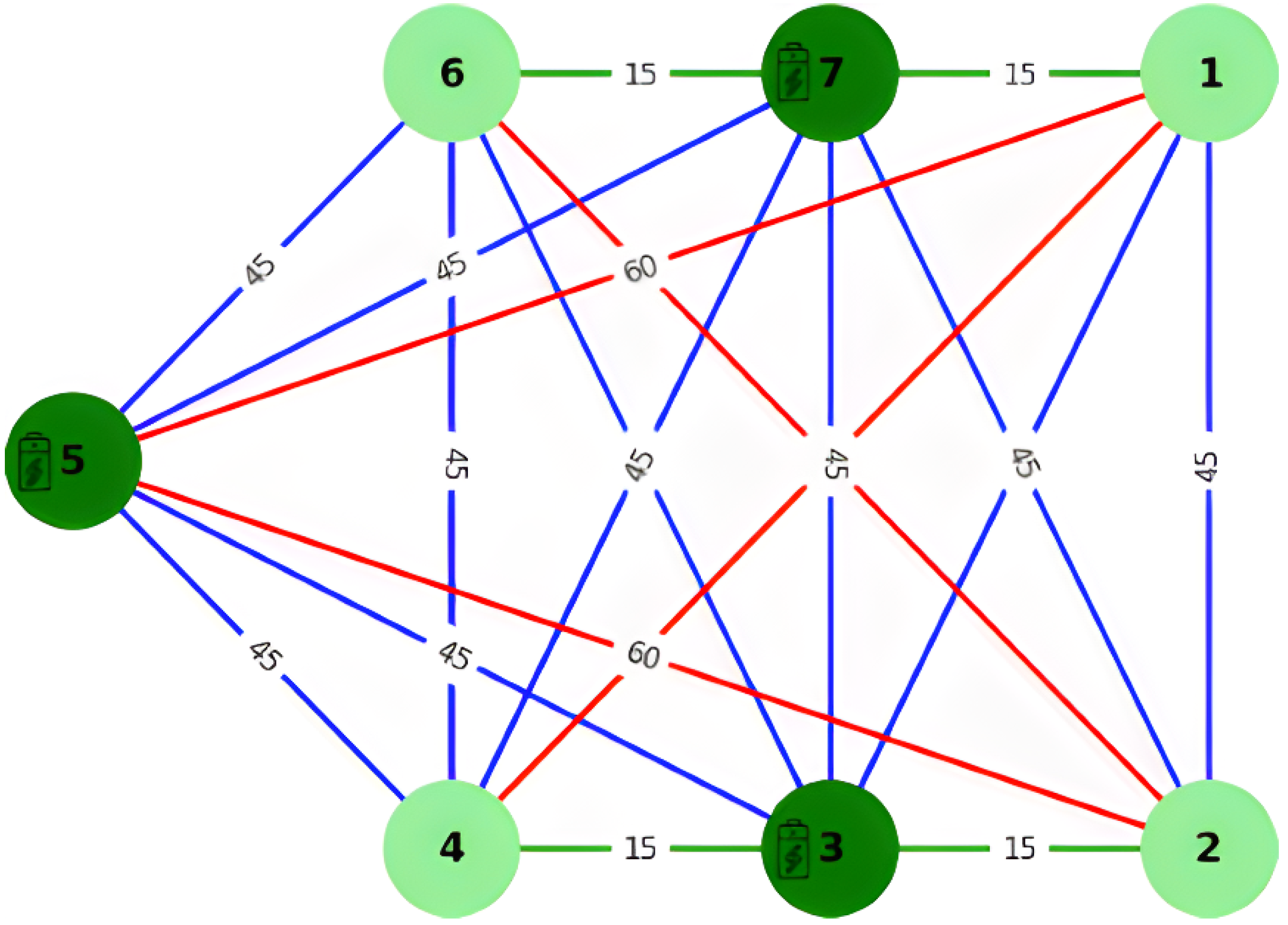
- The movement from one PoI to another PoI requires some time, which is represented by a function m that returns for each pair of PoIs the amount of time needed to perform such a movement. Again, since we consider a temporal granularity of one minute, m returns the number of minutes needed to complete such movement.
- The robot has a limited amount of energy charge, which is also consumed by moving among PoIs, so it needs to be recharged periodically. For the sake of simplicity, we assume that the available and consumed energy is expressed as an integer representing the battery life in terms of minutes.
- Some PoIs contain a charging station in which the robot battery can be charged. The charging activity takes some time to complete, and it does not overlap with farming/measuring operations. For the sake of simplicity, we assume that the charging time depends only on the current capabilities of the charging station, but the model is general enough to include a more complex function that also depends on the charging conditions, like the current battery level. In other words, in practical scenarios, the charging time will depend on the battery level at the moment of recharge, and the robot may require less time to recharge if the battery is not fully depleted. Future work could focus on incorporating a dynamic charging time model based on the robot’s actual battery level, enabling more accurate energy management. Integrating variable charging times into the trajectory planning algorithm will improve scheduling efficiency and leads to more realistic and effective operational strategies. In any case, the time required to complete a charging operation is represented by the number of minutes needed to complete it.
- The farming/measuring operations are orthogonal to charging operations, and a robot can stop in a PoI to either measure, charge, or do both.
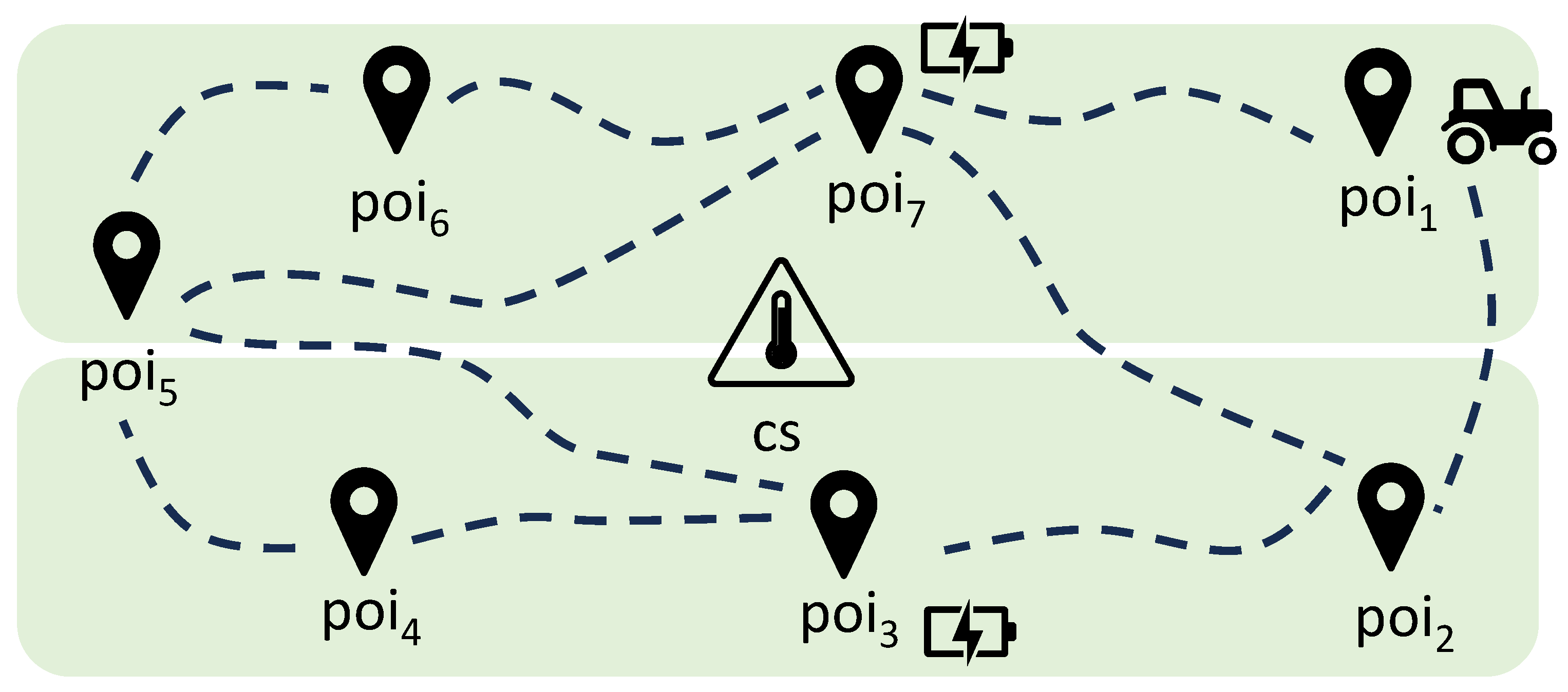
- V is the set of nodes representing the PoIs.
- is the set of bi-directional edges representing the paths connecting the nodes.
- is a labeling function assigning a label to each node , defined as follows:
- –
- is the identifier of the PoI.
- –
- is the function that represents the time required to complete the measuring task together with the farming task inside p. The notation is used in place of for not cluttering the notation,
- –
- indicates whether a given PoI p contains a charging station, i.e., means that p does not contain a charging station, while represents the time required for the charging operation.
- is a function that assigns a label to each edge as follows:
- –
- is the function that represents the time required by the robot to move between two adjacent PoIs. In the following, to not clutter the notation, we will use to denote the time spent to move from PoI to PoI . Since the edges are bi-directional, we assume that
- –
- is the function that represents the energy required by the robot to move between two adjacent PoIs, i.e., is the energy to be consumed to move from PoI to PoI . Since the edges are bi-directional, we assume that
- 1.
- Promote safety and avoid critical conditions
- Avoiding Stagnation: A significant penalty is applied if the agent stays in the same place. This is captured by in Equation (5), which checks if p and q represent the same PoI.
- Battery Management: Severe penalties are given for critical battery levels (i.e., it is too low to reach a charger, or it is empty). Conversely, a positive reward is provided for successfully reaching a charging station, especially when the battery is low. A penalty is also applied when the battery drops below a warning threshold, prompting the agent to seek charging early. These considerations about the battery level are captured by the term in Equation (5), which is based on the value returned by the function in Definition 8.
- 2.
- Performance Optimization
- Temperature Considerations: The reward for visiting a new location is based on the difference between the temperature that was previously measured or estimated there and the temperature that is expected at that location when the agent arrives. A larger difference in temperature indicates a greater importance of visiting that specific location, thus resulting in a higher reward for its selection. This is captured by the term in Equation (5).
- Time and Resource Efficiency: The agent is penalized for the time taken for actions and the resources consumed, encouraging faster and more efficient operations. This is captured by the term in Equation (5), which measures the energy required to move from p to q.
2.3. Implementation Details
2.3.1. Framework and Libraries
2.3.2. PPO Configuration
- Policy and Value Networks: The actor model outputs logits for a discrete action space, while the critic model estimates the scalar state value . Orthogonal initialization is used for all layers.
- Generalized Advantage Estimation (GAE): Employed to compute advantages, reduce variance, and improve learning stability.
- Clipped Surrogate Objective: The policy loss is calculated using the PPO clipped objective to ensure conservative policy updates.
- Entropy Regularization: An entropy bonus is added to the loss function to promote exploration.
- Gradient Clipping: Applied to all gradients with a configurable maximum norm to maintain stability.
- Learning Rate Annealing: The learning rate decays linearly over the training iterations.
2.3.3. Environment and Reward Shaping
2.3.4. Training Protocol
2.3.5. PPO Hyperparameters
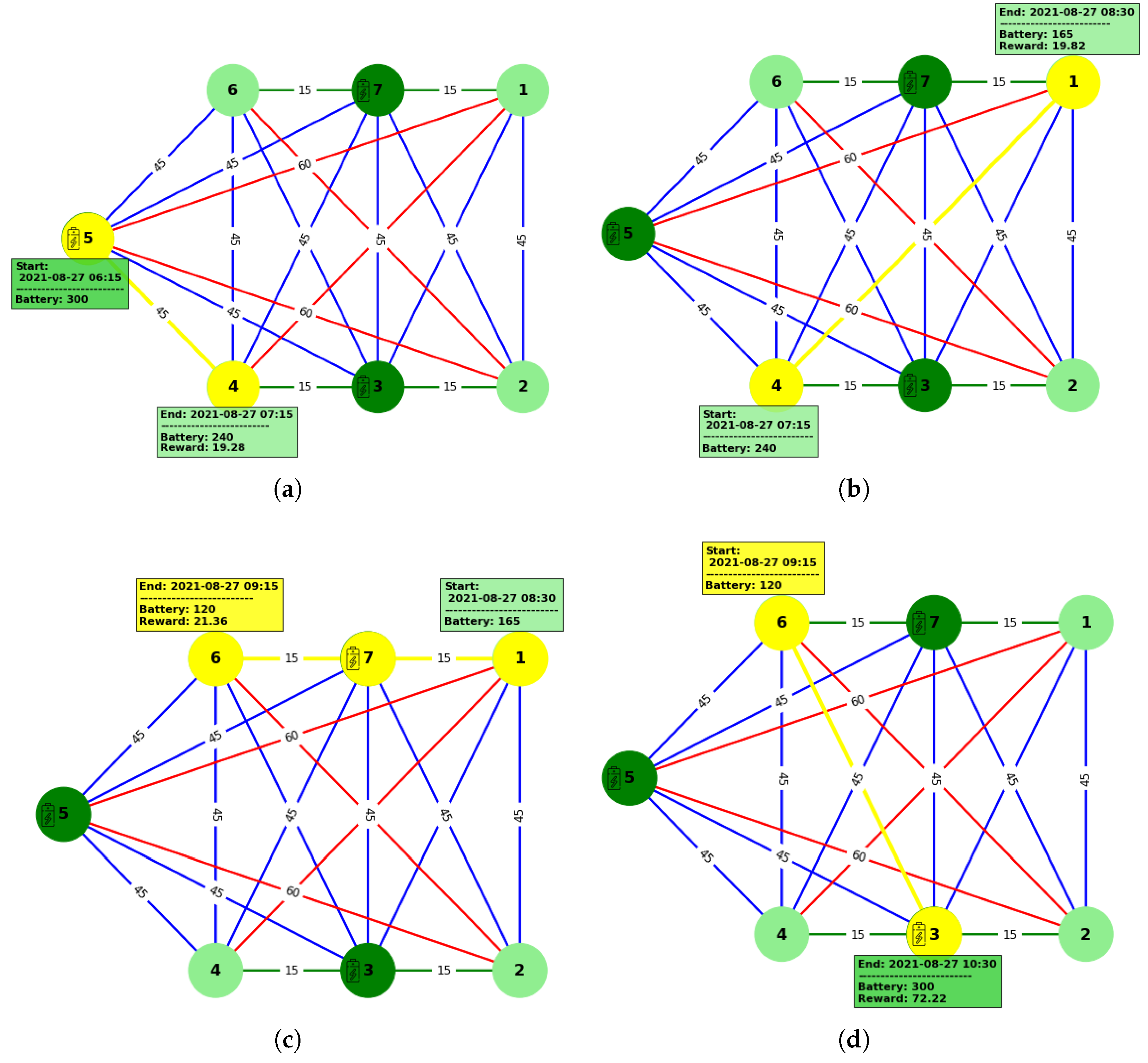
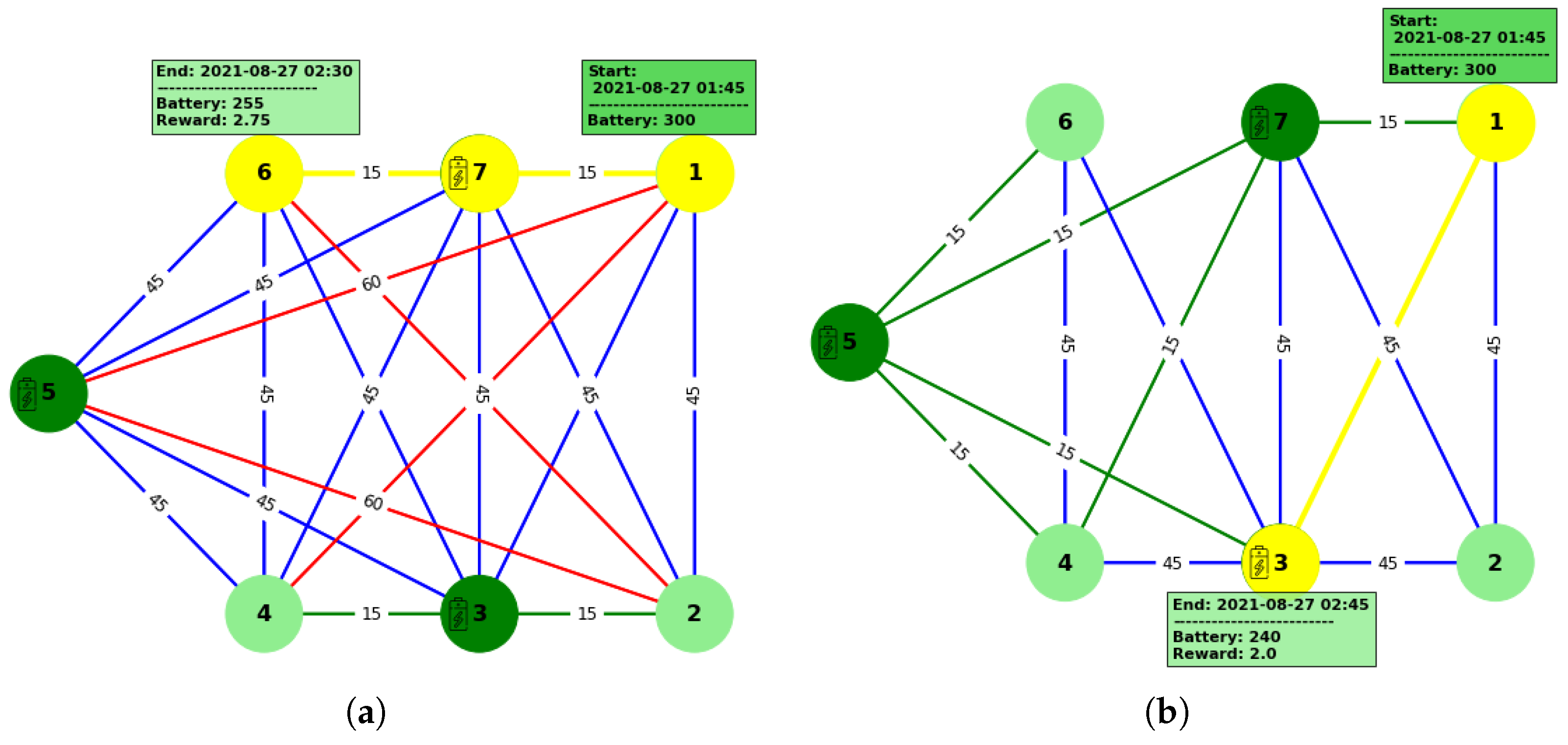
3. Results and Discussion
3.1. Application Setup
3.2. Experimental Results and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| PoIs | Points of Interest |
| PPO | Proximal Policy Optimization |
| RNN | Recurrent Neural Network |
| RL | Reinforcement Learning |
| WSN | Wireless Sensor Network |
| CFD | Computational Fluid Dynamics |
| CO2 | Carbon Dioxide |
| LSTM | Long Short-Term Memory |
| DRL | Deep Reinforcement Learning |
| TRPO | Trust Region Policy Optimization |
| DL | Deep Learning |
| MAPE | Mean Absolute Percentage Error |
| MAE | Mean Absolute Error |
| MSE | Mean Squared Error |
References
- Revathi, S.; Sivakumaran, N.; Radhakrishnan, T. Design of solar-powered forced ventilation system and energy-efficient thermal comfort operation of greenhouse. Mater. Today Proc. 2021, 46, 9893–9900. [Google Scholar] [CrossRef]
- Jolliet, O. HORTITRANS, a model for predicting and optimizing humidity and transpiration in greenhouses. J. Agric. Eng. Res. 1994, 57, 23–37. [Google Scholar] [CrossRef]
- Van Pee, M.; Janssens, K.; Berckmans, D.; Lemeur, R. Dynamic Measurement and Modelling of Climate Gradients Around a Plant for mIcro-Environment Control; Number 456 in Acta Horticulturae; International Society for Horticultural Science: The Hague, The Netherlands, 1998; pp. 399–406. Available online: https://www.actahort.org/books/456/456_48.htm (accessed on 28 June 2025).
- Zhao, Y.; Teitel, M.; Barak, M. SE—Structures and Environment: Vertical Temperature and Humidity Gradients in a Naturally Ventilated Greenhouse. J. Agric. Eng. Res. 2001, 78, 431–436. [Google Scholar] [CrossRef]
- Roy, J.; Boulard, T.; Kittas, C.; Wang, S. PA—Precision Agriculture: Convective and Ventilation Transfers in Greenhouses, Part 1: The Greenhouse considered as a Perfectly Stirred Tank. Biosyst. Eng. 2002, 83, 1–20. [Google Scholar] [CrossRef]
- Kittas, C.; Bartzanas, T.; Jaffrin, A. Temperature Gradients in a Partially Shaded Large Greenhouse equipped with Evaporative Cooling Pads. Biosyst. Eng. 2003, 85, 87–94. [Google Scholar] [CrossRef]
- Chen, C. Prediction of longitudinal variations in temperature and relative humidity eor evaporative cooling greenhouses. Agric. Eng. J. 2003, 12, 143–164. [Google Scholar]
- Kittas, C.; Bartzanas, T. Greenhouse microclimate and dehumidification effectiveness under different ventilator configurations. Build. Environ. 2007, 42, 3774–3784. [Google Scholar] [CrossRef]
- Bojacá, C.R.; Gil, R.; Cooman, A. Use of geostatistical and crop growth modelling to assess the variability of greenhouse tomato yield caused by spatial temperature variations. Comput. Electron. Agric. 2009, 65, 219–227. [Google Scholar] [CrossRef]
- Lopez-Martinez, J.; Blanco, J.; Perez, J. Distributed network for measuring climatic parameters in heterogeneous environments: Application in a greenhouse. Comput. Electron. Agric. 2018, 145, 105–121. [Google Scholar] [CrossRef]
- Hamrita, T. A wireless sensor network for precision irrigation in Tunisia. Int. J. Distrib. Sens. Netw. 2005, 1, 67–74. [Google Scholar]
- Teitel, M.; Wenger, E. Air exchange and ventilation efficiencies of a non-span greenhouse with one inflow and one outflow through longitudinal side openings. Biosyst. Eng. 2014, 119, 98–107. [Google Scholar] [CrossRef]
- Pahuja, R. An intelligent wireless sensor and actuator network system for greenhouse microenvironment control and assessment. J. Biosyst. Eng. 2017, 42, 23–43. [Google Scholar] [CrossRef]
- Rosas, J.; Palma, L.B.; Antunes, R.A. An Approach for Modeling and Simulation of Virtual Sensors in Automatic Control Systems Using Game Engines and Machine Learning. Sensors 2024, 24, 7610. [Google Scholar] [CrossRef] [PubMed]
- Brentarolli, E.; Migliorini, S.; Quaglia, D.; Tomazzoli, C. Mapping Micro-Climate in a Greenhouse Through a Context-Aware Recurrent Neural Network. In Proceedings of the 2023 IEEE Conference on AgriFood Electronics (CAFE), Torino, Italy, 25–27 September 2023; pp. 113–117. [Google Scholar] [CrossRef]
- Tomazzoli, C.; Brentarolli, E.; Quaglia, D.; Migliorini, S. Estimating Greenhouse Climate Through Context-Aware Recurrent Neural Networks Over an Embedded System. IEEE Trans. AgriFood Electron. 2024, 2, 554–562. [Google Scholar] [CrossRef]
- Brentarolli, E.; Migliorini, S.; Quaglia, D.; Tomazzoli, C. Greenhouse Climatic Sensing through Agricultural Robots and Recurrent Neural Networks. In Proceedings of the 2023 IEEE International Workshop on Metrology for Agriculture and Forestry, Pisa, Italy, 6–8 November 2023. [Google Scholar]
- Sharifi, A.; Migliorini, S.; Quaglia, D. Optimizing the Trajectory of Agricultural Robots in Greenhouse. In Proceedings of the 8th International Conference on Control, Automation and Diagnosis, ICCAD 2024, Paris, France, 15–17 May 2024. [Google Scholar]
- Akyildiz, I.; Su, W.; Sankarasubramaniam, Y.; Cayirci, E. Wireless sensor networks: A survey. Comput. Netw. 2002, 38, 393–422. [Google Scholar] [CrossRef]
- Gonda, L.; Cugnasca, C. A Proposal of Greenhouse Control Using Wireless Sensor Networks. In Proceedings of the Computers in Agriculture and Natural Resources—Proceedings of the 4th World Congress, Orlando, FL, USA, 24–26 July 2006. [Google Scholar] [CrossRef]
- Chaudhary, D.; Nayse, S.; Waghmare, L. Application of Wireless Sensor Networks for Greenhouse Parameter Control in Precision Agriculture. Int. J. Wirel. Mob. Netw. 2011, 3, 140–149. [Google Scholar] [CrossRef]
- Srbinovska, M.; Gavrovski, C.; Dimcev, V. Environmental parameters monitoring in precision agriculture using wireless sensor networks. J. Clean. Prod. 2015, 88, 297–307. [Google Scholar] [CrossRef]
- Guzmán, C.H.; Carrera, J.L.; Durán, H.A.; Berumen, J.; Ortiz, A.A.; Guirette, O.A.; Arroyo, A.; Brizuela, J.A.; Gómez, F.; Blanco, A.; et al. Implementation of Virtual Sensors for Monitoring Temperature in Greenhouses Using CFD and Control. Sensors 2019, 19, 60. [Google Scholar] [CrossRef]
- Davis, P. A technique of adaptive control of the temperature in a greenhouse using ventilator adjustments. J. Agric. Eng. Res. 1984, 29, 241–248. [Google Scholar] [CrossRef]
- Sánchez-Molina, J.; Rodríguez, F.; Guzmán, J.; Arahal, M. Virtual sensors for designing irrigation controllers in greenhouses. Sensors 2012, 12, 15244–15266. [Google Scholar] [CrossRef]
- Roldán, J.; Joosen, G.; Sanz, D.; del Cerro, J.; Barrientos, A. Mini-UAV based sensory system for measuring environmental variables in greenhouses. Sensors 2015, 15, 3334–3350. [Google Scholar] [CrossRef] [PubMed]
- Pawlowski, A.; Guzman, J.; Rodríguez, F.; Berenguel, M.; Sánchez, J.; Dormido, S. Simulation of greenhouse climate monitoring and control with wireless sensor network and event-based control. Sensors 2009, 9, 232–252. [Google Scholar] [CrossRef] [PubMed]
- Lin, B.; Recke, B.; Knudsen, J.K.; Jørgensen, S.B. A systematic approach for soft sensor development. Comput. Chem. Eng. 2007, 31, 419–425. [Google Scholar] [CrossRef]
- Prasad, V.; Schley, M.; Russo, L.P.; Wayne Bequette, B. Product property and production rate control of styrene polymerization. J. Process Control 2002, 12, 353–372. [Google Scholar] [CrossRef]
- Park, S.; Han, C. A nonlinear soft sensor based on multivariate smoothing procedure for quality estimation in distillation columns. Comput. Chem. Eng. 2000, 24, 871–877. [Google Scholar] [CrossRef]
- Radhakrishnan, V.; Mohamed, A. Neural networks for the identification and control of blast furnace hot metal quality. J. Process Control 2000, 10, 509–524. [Google Scholar] [CrossRef]
- Reichrath, S.; Davies, T. Using CFD to model the internal climate of greenhouses: Past, present and future. Agronomie 2002, 22, 3–19. [Google Scholar] [CrossRef]
- De la Torre-Gea, G.; Soto-Zarazúa, G.; López-Crúz, I.; Torres-Pacheco, I.; Rico-García, E. Computational fluid dynamics in greenhouses: A review. Afr. J. Biotechnol. 2011, 10, 17651–17662. [Google Scholar] [CrossRef]
- Sonoda, A.; Takayama, Y.; Sugawara, A.; Nishi, H. Greenhouse Heat Map Generation with Deep Neural Network Using Limited Number of Temperature Sensors. In Proceedings of the IECON 2022–48th Annual Conference of the IEEE Industrial Electronics Society, Brussels, Belgium, 17–20 October 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Molina-Aiz, F.; Fatnassi, H.; Boulard, T.; Roy, J.; Valera, D. Comparison of finite element and finite volume methods for simulation of natural ventilation in greenhouses. Comput. Electron. Agric. 2010, 72, 69–86. [Google Scholar] [CrossRef]
- Tong, G.; Christopher, D.; Li, B. Numerical modelling of temperature variations in a Chinese solar greenhouse. Comput. Electron. Agric. 2009, 68, 129–139. [Google Scholar] [CrossRef]
- Deltour, J.; De Halleux, D.; Nijskens, J.; Coutisse, S.; Nisen, A. Dynamic modelling of heat and mass transfer in greenhouses. In Proceedings of the Symposium Greenhouse Climate and Its Control, Wageningen, The Netherlands, 19–24 May 1985; pp. 119–126. [Google Scholar]
- Longo, G.; Gasparella, A. Comparative experimental analysis and modelling of a flower greenhouse equipped with a desiccant system. Appl. Therm. Eng. 2012, 47, 54–62. [Google Scholar] [CrossRef]
- Cheng, X.; Li, D.; Shao, L.; Ren, Z. A virtual sensor simulation system of a flower greenhouse coupled with a new temperature microclimate model using three-dimensional CFD. Comput. Electron. Agric. 2021, 181, 105934. [Google Scholar] [CrossRef]
- Usman, A.; Rafiq, M.; Saeed, M.; Nauman, A.; Almqvist, A.; Liwicki, M. Machine learning computational fluid dynamics. In Proceedings of the 2021 Swedish Artificial Intelligence Society Workshop (SAIS), Lulea, Sweden, 14–15 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–4. [Google Scholar]
- Brentarolli, E.; Locatelli, S.; Nicoletto, C.; Sambo, P.; Quaglia, D.; Muradore, R. A spatio-temporal methodology for greenhouse microclimatic mapping. PLoS ONE 2024, 19, e0310454. [Google Scholar] [CrossRef] [PubMed]
- Laidi, R.; Djenouri, D.; Balasingham, I. On Predicting Sensor Readings With Sequence Modeling and Reinforcement Learning for Energy-Efficient IoT Applications. IEEE Trans. Syst. Man, Cybern. Syst. 2022, 52, 5140–5151. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Uttrani, S.; Rao, A.K.; Kanekar, B.; Vohra, I.; Dutt, V. Assessment of Various Deep Reinforcement Learning Techniques in Complex Virtual Search-and-Retrieve Environments Compared to Human Performance. In Applied Cognitive Science and Technology: Implications of Interactions Between Human Cognition and Technology; Mukherjee, S., Dutt, V., Srinivasan, N., Eds.; Springer Nature: Singapore, 2023; pp. 139–155. [Google Scholar] [CrossRef]
- Bettini, C.; Wang, X.S.; Jajodia, S. Temporal Granularity. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer: Boston, MA, USA, 2009; pp. 2968–2973. [Google Scholar] [CrossRef]
- Enderton, H. Elements of Set Theory; Elsevier Science: Amsterdam, The Netherlands, 1977. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Meaning |
|---|---|
| temporal domain | |
| set of PoIs | |
| V | set of nodes representing PoIs |
| E | set of edges between PoIs |
| set of PoIs | |
| node labeling | |
| time for measuring in | |
| time for charging in | |
| edge labeling | |
| time for moving from to | |
| energy consumed for moving from to | |
| robot trajectory | |
| measuring trajectory | |
| charging trajectory | |
| time for completing | |
| x | contextual measure |
| contextual dimensions | |
| context | |
| reward for going from p to q | |
| charging level of the robot | |
| ℓ | position of the robot |
| checks if |
| PoI | Proposed Work | Previous Work [18] | Baseline Method [17] | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| # Visits | MAPE% | MAE | MSE | # Visits | MAPE% | MAE | MSE | # Visits | MAPE% | MAE | MSE | |||
| 1 | 419 | 5.1 | 0.93 | 2.2 | 343 | 7.7 | 1.3 | 4.4 | 560 | 8.8 | 1.4 | 4.1 | ||
| 2 | 395 | 5.5 | 1.0 | 2.5 | 241 | 5.7 | 1.0 | 2.6 | 560 | 6.1 | 1.2 | 2.6 | ||
| 3 | 396 | 5.6 | 1.0 | 2.6 | 323 | 7.2 | 1.3 | 4.6 | 520 | 8.6 | 1.5 | 4.7 | ||
| 4 | 356 | 5.9 | 1.2 | 3.2 | 53 | 7.3 | 1.3 | 4.6 | 560 | 8.3 | 1.5 | 4.8 | ||
| 5 | 383 | 5.2 | 1.0 | 2.6 | 62 | 6.8 | 1.3 | 3.6 | 520 | 7.5 | 1.4 | 3.8 | ||
| 6 | 384 | 5.8 | 1.2 | 3.7 | 87 | 8.2 | 1.6 | 6.0 | 560 | 8.3 | 1.6 | 5.3 | ||
| 7 | 405 | 5.1 | 1.0 | 2.5 | 161 | 6.8 | 1.3 | 4.7 | 560 | 6.9 | 1.3 | 3.7 | ||
| All | 2738 | 5.4 | 1.1 | 2.7 | 1270 | 7.1 | 1.3 | 4.3 | 3840 | 7.8 | 1.4 | 4.1 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharifi, A.; Migliorini, S.; Quaglia, D. Optimizing Trajectories for Rechargeable Agricultural Robots in Greenhouse Climatic Sensing Using Deep Reinforcement Learning with Proximal Policy Optimization Algorithm. Future Internet 2025, 17, 296. https://doi.org/10.3390/fi17070296
Sharifi A, Migliorini S, Quaglia D. Optimizing Trajectories for Rechargeable Agricultural Robots in Greenhouse Climatic Sensing Using Deep Reinforcement Learning with Proximal Policy Optimization Algorithm. Future Internet. 2025; 17(7):296. https://doi.org/10.3390/fi17070296
Chicago/Turabian StyleSharifi, Ashraf, Sara Migliorini, and Davide Quaglia. 2025. "Optimizing Trajectories for Rechargeable Agricultural Robots in Greenhouse Climatic Sensing Using Deep Reinforcement Learning with Proximal Policy Optimization Algorithm" Future Internet 17, no. 7: 296. https://doi.org/10.3390/fi17070296
APA StyleSharifi, A., Migliorini, S., & Quaglia, D. (2025). Optimizing Trajectories for Rechargeable Agricultural Robots in Greenhouse Climatic Sensing Using Deep Reinforcement Learning with Proximal Policy Optimization Algorithm. Future Internet, 17(7), 296. https://doi.org/10.3390/fi17070296