
FODIT: A Filter-Based Module for Optimizing Data Storage in B5G IoT Environments

 , , and
, , and
Abstract
1. Introduction
2. Background
2.1. IoT Architecture in B5G Environments
2.2. Filters
Cuckoo Filter
| Algorithm 1 Insert (x) |
|
| Algorithm 2 Search (x) |
|
| Algorithm 3 Delete (x) |
|
3. Related Work
4. Analysis of Storage in IoT Environments
- Local databases provide on-premises storage solutions, allowing IoT devices to store and manage data without relying on external networks [41]. This approach ensures low-latency access and enhanced security, as data remains within a controlled environment. However, scalability is a major limitation, as the storage capacity is constrained by the physical hardware available. Additionally, local databases may face challenges in data synchronization and remote accessibility, making them less suitable for large-scale, distributed IoT systems.
- Cloud-based storage solutions offer scalable, on-demand storage managed by third-party providers. This model enables seamless data access, redundancy, and backup capabilities, making it ideal for IoT applications that require high availability [42]. The key benefits of cloud storage include elastic scalability, reduced infrastructure costs, and remote accessibility. Nevertheless, reliance on cloud services introduces concerns regarding data privacy, network dependency, and latency. Additionally, subscription costs and compliance with data regulations must be carefully managed when adopting cloud-based solutions.
- DLT such as blockchain [43], offers a decentralized approach to data storage, enhancing security and transparency. In an IoT context, DLT ensures data integrity, immutability, and traceability, which are crucial for applications requiring high levels of trust. However, DLT-based storage systems often face scalability challenges, as maintaining a distributed ledger across multiple nodes demands significant computational and storage resources [44]. Furthermore, the transaction processing time in blockchain-based systems can introduce latency, making it less suitable for real-time IoT applications [8,45].
5. FODIT Overview
5.1. Architecture Overview
- Transaction confirmation is received within the maximum time window defined for the temporary structure. In this case, the data is removed from the temporary structure and inserted into the filter.
- Transaction confirmation is not received within the defined time window. In this case, the data is discarded from the temporary structure and is not inserted into the filter.
5.2. Workflow
- IoT devices (): This represents a set of n electronic devices. Through these devices, a data collection denoted by is generated and subsequently stored in the server provider .
- Server provider (): The server provider is an entity responsible for storing and managing the data collection . In this paper, may refer to a local database, cloud storage, or a DLT.
- Insertion algorithm (): This is the algorithm used to perform data insertion in the FODIT module. It takes the data collection , acquired from the IoT devices D, as input. Let ; then x is inserted into the cuckoo filter using Algorithm 1. It is important to note that the cuckoo filter does not store the data x directly; instead, it stores a fingerprint , computed as shown in Equation (2), to optimize storage. Once the fingerprint is inserted into the filter, the data x is stored in the server provider , completing the insertion process. For the particular case where is the DLT, the insertion algorithm first stores the data in the structure . If the data x is correctly recorded in the DLT, then the data is inserted into the filter and is deleted from the structure .
- Query algorithm (): This algorithm performs the data query operation in the FODIT module. Let z be the data item to be retrieved from . The algorithm takes z as input and invokes the search function , as described in Algorithm 2, to check for the presence of z in the cuckoo filter . If z is found in the filter, it can be retrieved from ; otherwise, z is not present in . The complete process is summarized in Algorithm 5.
| Algorithm 4 Insertion Algorithm |
|
| Algorithm 5 Query algorithm |
|
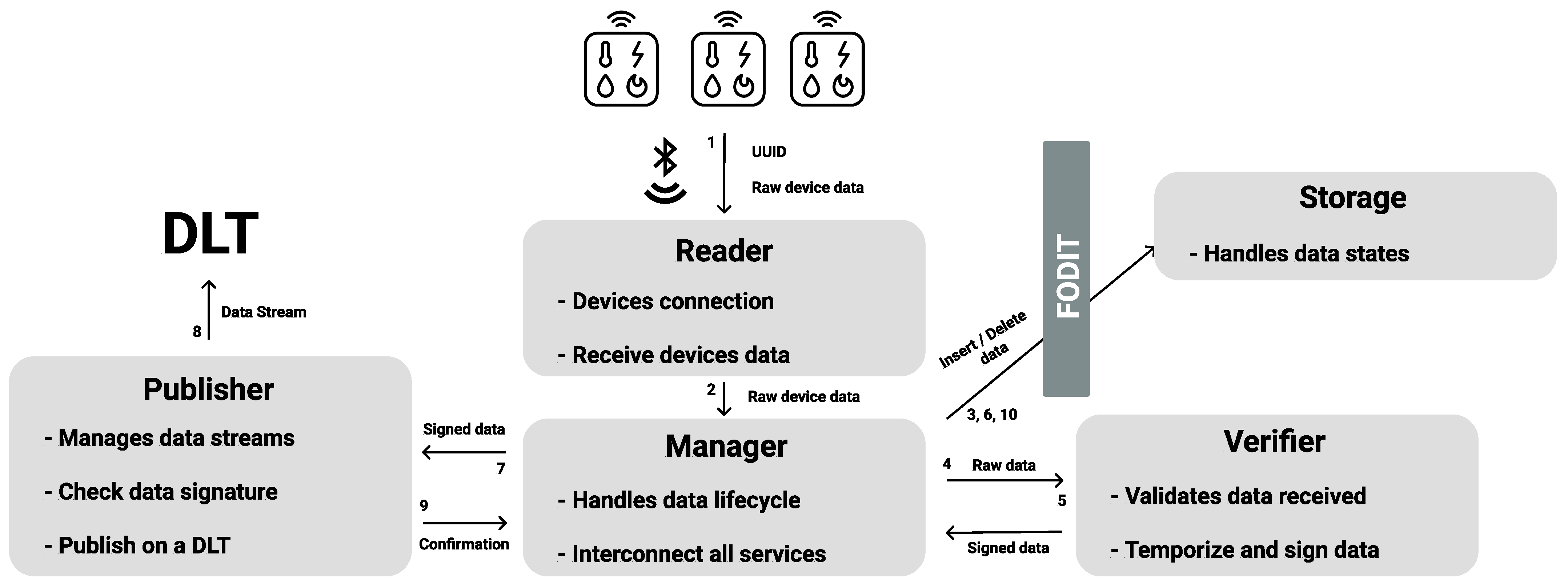
5.3. Integrating FODIT in Phonendo
- Reader: Responsible for establishing connections with various IoT devices and collecting their data.
- Manager: Acts as the orchestration layer of the framework, coordinating all services and managing the data flow.
- Verifier: Verifies the integrity of incoming data and appends a digital signature to ensure its authenticity before storage.
- Storage: Handles the persistence of the system state, which can be managed either locally, DB, or via a cloud-based storage service, DaaS.
- Publisher: Oversees the management of data streams, verifying their digital signatures and publishing validated data to a DLT when required.
6. Evaluation
6.1. Case Studies
6.2. Experiments and Results
- CPU: Core™ i7-7500U Intel® processor 2.70 GHz × 4
- OS: Ubuntu 22.04.2 LTS
- Compiler: gcc 7.4.0
- Local Databases Manager: MongoDB 6.0 LTS
- Cloud Computing Service: AWS RDS-PostgreSQL 10.9
- DLT: IOTA Tangle [47]
6.2.1. Experiment 1
6.2.2. Experiment 2
6.3. False Positives Analysis
6.4. Discussion
6.5. Study Limitations
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| B5G | Beyond 5G |
| IoT | Internet of Things |
| DB | Database |
| DaaS | Database as a Service |
| DLTs | Distributed Ledger Technologies |
| FFBF | Fuzzy-Folded Bloom Filter |
| FODIT | Filter-Based Optimization for Data Storage in IoT |
| mMTC | Massive Machine-Type Communications |
| PDS | Probabilistic Data Structure |
| CF | Cuckoo Filter |
| IF | Insertion Filter function |
| SF | Search Filter function |
| DF | Deletion Filter function |
References
- Ahmed, E.; Yaqoob, I.; Gani, A.; Imran, M.; Guizani, M. Internet-of-things-based smart environments: State of the art, taxonomy, and open research challenges. IEEE Wirel. Commun. 2016, 23, 10–16. [Google Scholar] [CrossRef]
- Elmustafa, S.A.A.; Mujtaba, E.Y. Internet of things in smart environment: Concept, applications, challenges, and future directions. World Sci. News 2019, 134, 1–51. [Google Scholar]
- Ben-Daya, M.; Hassini, E.; Bahroun, Z. Internet of things and supply chain management: A literature review. Int. J. Prod. Res. 2019, 57, 4719–4742. [Google Scholar] [CrossRef]
- Babangida, L.; Perumal, T.; Mustapha, N.; Yaakob, R. Internet of Things (IoT) based activity recognition strategies in smart homes: A review. IEEE Sens. J. 2022, 22, 8327–8336. [Google Scholar] [CrossRef]
- Babayigit, B.; Abubaker, M. Industrial internet of things: A review of improvements over traditional scada systems for industrial automation. IEEE Syst. J. 2023, 18, 120–133. [Google Scholar] [CrossRef]
- Rejeb, A.; Rejeb, K.; Treiblmaier, H.; Appolloni, A.; Alghamdi, S.; Alhasawi, Y.; Iranmanesh, M. The Internet of Things (IoT) in healthcare: Taking stock and moving forward. Internet Things 2023, 22, 100721. [Google Scholar] [CrossRef]
- Muñoz-Higueras, C.; Serradilla-Gil, A.M.; Moreno-Colmenero, P.; Quesada-Real, F.J. Integrating IoT and DLT to Enhance Patient Wait Time Traceability in Radiotherapy Oncology. In Proceedings of the International Conference on Ubiquitous Computing and Ambient Intelligence, Belfast, UK, 2–5 December 2014; Springer: Berlin/Heidelberg, Germany, 2024; pp. 932–942. [Google Scholar]
- Ramos-Cruz, B.; Quesada-Real, F.J.; Rodriguez-Garcia, M.; Andreu-Pérez, J.; Martínez, L. Combining Distributed Ledger Technologies and Differentially Private Sketching Techniques for Securing Health Monitoring. In Proceedings of the International Conference on Ubiquitous Computing and Ambient Intelligence, Belfast, UK, 2–5 December 2014; Springer: Berlin/Heidelberg, Germany, 2024; pp. 920–931. [Google Scholar]
- Stojkoska, B.L.R.; Trivodaliev, K.V. A review of Internet of Things for smart home: Challenges and solutions. J. Clean. Prod. 2017, 140, 1454–1464. [Google Scholar] [CrossRef]
- Zanella, A.; Bui, N.; Castellani, A.; Vangelista, L.; Zorzi, M. Internet of things for smart cities. IEEE Internet Things J. 2014, 1, 22–32. [Google Scholar] [CrossRef]
- Mehmood, Y.; Ahmad, F.; Yaqoob, I.; Adnane, A.; Imran, M.; Guizani, S. Internet-of-things-based smart cities: Recent advances and challenges. IEEE Commun. Mag. 2017, 55, 16–24. [Google Scholar] [CrossRef]
- Attar, H.; Alghanim, M.; Ababneh, J.; Rezaee, K.; Alrosan, A.; Deif, M.A. B5g applications and emerging services in smart IoT environments. Int. J. Crowd Sci. 2025, 9, 79–95. [Google Scholar] [CrossRef]
- Lessi, C.C.; Gavrielides, A.; Solina, V.; Qiu, R.; Nicoletti, L.; Li, D. 5G and beyond 5G technologies enabling industry 5.0: Network applications for robotics. Procedia Comput. Sci. 2024, 232, 675–687. [Google Scholar] [CrossRef]
- Qi, Q.; Chen, X.; Zhong, C.; Zhang, Z. Integrated sensing, computation and communication in B5G cellular Internet of Things. IEEE Trans. Wirel. Commun. 2020, 20, 332–344. [Google Scholar] [CrossRef]
- Uddin, H.; Gibson, M.; Safdar, G.A.; Kalsoom, T.; Ramzan, N.; Ur-Rehman, M.; Imran, M.A. IoT for 5G/B5G applications in smart homes, smart cities, wearables and connected cars. In Proceedings of the 2019 IEEE 24th International Workshop on Computer Aided Modeling and Design of Communication Links and Networks (CAMAD), Limassol, Cyprus, 11–13 September 2019; IEEE: Piscataway, NY, USA, 2019; pp. 1–5. [Google Scholar]
- Popovski, P.; Trillingsgaard, K.F.; Simeone, O.; Durisi, G. 5G wireless network slicing for eMBB, URLLC, and mMTC: A communication-theoretic view. IEEE Access 2018, 6, 55765–55779. [Google Scholar] [CrossRef]
- Pokhrel, S.R.; Ding, J.; Park, J.; Park, O.; Choi, J. Towards enabling critical mMTC: A review of URLLC within mMTC. IEEE Access 2020, 8, 131796–131813. [Google Scholar] [CrossRef]
- Khan, B.S.; Jangsher, S.; Ahmed, A.; Al-Dweik, A. URLLC and eMBB in 5G industrial IoT: A survey. IEEE Open J. Commun. Soc. 2022, 3, 1134–1163. [Google Scholar] [CrossRef]
- Kong, X.; Wu, Y.; Wang, H.; Xia, F. Edge computing for internet of everything: A survey. IEEE Internet Things J. 2022, 9, 23472–23485. [Google Scholar] [CrossRef]
- Xu, W.; Yang, Z.; Ng, D.W.K.; Levorato, M.; Eldar, Y.C.; Debbah, M. Edge learning for B5G networks with distributed signal processing: Semantic communication, edge computing, and wireless sensing. IEEE J. Sel. Top. Signal Process. 2023, 17, 9–39. [Google Scholar] [CrossRef]
- Rafique, W.; Barai, J.; Fapojuwo, A.O.; Krishnamurthy, D. A survey on beyond 5g network slicing for smart cities applications. IEEE Commun. Surv. Tutor. 2024, 27, 595–628. [Google Scholar] [CrossRef]
- Morocho-Cayamcela, M.E.; Lee, H.; Lim, W. Machine learning for 5G/B5G mobile and wireless communications: Potential, limitations, and future directions. IEEE Access 2019, 7, 137184–137206. [Google Scholar] [CrossRef]
- Bloom, B.H. Space/time trade-offs in hash coding with allowable errors. Commun. ACM 1970, 13, 422–426. [Google Scholar] [CrossRef]
- Fan, B.; Andersen, D.G.; Kaminsky, M.; Mitzenmacher, M.D. Cuckoo filter: Practically better than bloom. In Proceedings of the 10th ACM International on Conference on emerging Networking Experiments and Technologies, Sydney, Australia, 2–5 December 2014; pp. 75–88. [Google Scholar]
- Moya, F.; Quesada, F.J.; Martínez, L.; Estrella, F.J. Phonendo: A Platform for Publishing Wearable Data on Distributed Ledger Technologies. Wirel. Netw. 2024, 30, 6507–6521. [Google Scholar] [CrossRef]
- Wu, W.; Zhou, C.; Li, M.; Wu, H.; Zhou, H.; Zhang, N.; Shen, X.S.; Zhuang, W. AI-native network slicing for 6G networks. IEEE Wirel. Commun. 2022, 29, 96–103. [Google Scholar] [CrossRef]
- Alsenwi, M.; Tran, N.H.; Bennis, M.; Pandey, S.R.; Bairagi, A.K.; Hong, C.S. Intelligent resource slicing for eMBB and URLLC coexistence in 5G and beyond: A deep reinforcement learning based approach. IEEE Trans. Wirel. Commun. 2021, 20, 4585–4600. [Google Scholar] [CrossRef]
- Singh, A.; Garg, S.; Kaur, R.; Batra, S.; Kumar, N.; Zomaya, A.Y. Probabilistic data structures for big data analytics: A comprehensive review. Knowl.-Based Syst. 2020, 188, 104987. [Google Scholar] [CrossRef]
- Bonomi, F.; Mitzenmacher, M.; Panigrahy, R.; Singh, S.; Varghese, G. An improved construction for counting bloom filters. In Proceedings of the Algorithms–ESA 2006: 14th Annual European Symposium, Zurich, Switzerland, 11–13 September 2006; Proceedings 14; Springer: Berlin/Heidelberg, Germany, 2006; pp. 684–695. [Google Scholar]
- Naor, M.; Yogev, E. Sliding bloom filters. In Proceedings of the International Symposium on Algorithms and Computation, Hong Kong, China, 16–18 December 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 513–523. [Google Scholar]
- Singh, A.; Garg, S.; Batra, S.; Kumar, N.; Rodrigues, J. Bloom filter based optimization scheme for massive data handling in IoT environment. Future Gener. Comput. Syst. 2017, 82, 440–449. [Google Scholar] [CrossRef]
- Podnar Zarko, I.; Pripuzic, K.; Serrano, M.; Hauswirth, M. IoT data management methods and optimisation algorithms for mobile publish/subscribe services in cloud environments. In Proceedings of the 2014 European Conference on Networks and Communications (EuCNC), Bologna, Italy, 23–26 June 2014; pp. 1–5. [Google Scholar]
- Jeong, J.; Joo, J.W.J.; Lee, Y.; Son, Y. Secure Cloud Storage Service Using Bloom Filters for the Internet of Things. IEEE Access 2019, 7, 60897–60907. [Google Scholar] [CrossRef]
- Singh, A.; Garg, S.; Kaur, K.; Batra, S.; Kumar, N.; Raymond Choo, K. Fuzzy-Folded Bloom Filter-as-a-Service for Big Data Storage in the Cloud. IEEE Trans. Ind. Inform. 2019, 15, 2338–2348. [Google Scholar] [CrossRef]
- Pintilei, M.A.; Schreiner, C.; Socotar, D. Exploring Data Compression: Solutions to Optimize Efficiency and Improve Performance. In Proceedings of the 2024 IEEE International Conference And Exposition On Electric And Power Engineering (EPEi), Iasi, Romania, 17–19 October 2024; pp. 280–286. [Google Scholar] [CrossRef]
- Yu, J.; Shen, W.; Zhang, X. Cloud storage auditing and data sharing with data deduplication and private information protection for cloud-based EMR. Comput. Secur. 2024, 144, 103932. [Google Scholar] [CrossRef]
- Aladiyan, A. Efficient Data Structures and Algorithms for Cloud Computing Platforms. In Proceedings of the 2024 4th International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), Greater Noida, India, 14–15 May 2024; pp. 1717–1721. [Google Scholar] [CrossRef]
- Idrees, S.K.; Azar, J.; Couturier, R.; Idrees, A.K.; Gechter, F. SZ4IoT: An adaptive lightweight lossy compression algorithm for diverse IoT devices and data types. J. Supercomput. 2025, 81, 392. [Google Scholar] [CrossRef]
- Altowaijri, S.M. Efficient Data Aggregation and Duplicate Removal Using Grid-Based Hashing in Cloud-Assisted Industrial IoT. IEEE Access 2024, 12, 145350–145365. [Google Scholar] [CrossRef]
- Kumar, M.; Singh, A. Bloom filter empowered smart storage/access in IoMT [edge-fog-cloud] hierarchy for health-care data ingestion. Concurr. Comput. Pract. Exp. 2024, 36, e8012. [Google Scholar] [CrossRef]
- Cooper, J.; James, A. Challenges for database management in the internet of things. IETE Tech. Rev. 2009, 26, 320–329. [Google Scholar] [CrossRef]
- Wu, J.; Ping, L.; Ge, X.; Wang, Y.; Fu, J. Cloud storage as the infrastructure of cloud computing. In Proceedings of the 2010 International Conference on Intelligent Computing and Cognitive Informatics, Kuala Lumpur, Malaysia, 22–23 June 2010; IEEE: Piscataway, NY, USA, 2010; pp. 380–383. [Google Scholar]
- Nakamoto, S. Bitcoin Whitepaper. Available online: https://bitcoin.org/bitcoin.pdf (accessed on 25 June 2025).
- Farahani, B.; Firouzi, F.; Luecking, M. The convergence of IoT and distributed ledger technologies (DLT): Opportunities, challenges, and solutions. J. Netw. Comput. Appl. 2021, 177, 102936. [Google Scholar] [CrossRef]
- Quesada-Real, F.J.; Moya-Pérez, F.; Rodriguez-Garcia, M.; Dutta, B. A Transparent and Ecologically Sustainable DLT-based Approach for Tendering Processes. J. Univers. Comput. Sci. JUCS 2025, 31, 277–297. [Google Scholar] [CrossRef]
- Moya, F.; Quesada, F.J.; Martínez, L.; Estrella, F.J. CertifioT: An IoT and DLT-based solution for enhancing trust and transparency in data certification. In Proceedings of the International Conference on Ubiquitous Computing and Ambient Intelligence, Riviera Maya, Mexico, 25 November 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 127–138. [Google Scholar]
- Popov, S. The tangle. White Pap. 2018, 1, 30. [Google Scholar]
- Popov, S.; Lu, Q. IOTA: Feeless and free. IEEE Blockchain Tech. Briefs 2019, 6, 964. [Google Scholar]
- Bose, P.; Guo, H.; Kranakis, E.; Maheshwari, A.; Morin, P.; Morrison, J.; Smid, M.; Tang, Y. On the false-positive rate of Bloom filters. Inf. Process. Lett. 2008, 108, 210–213. [Google Scholar] [CrossRef]






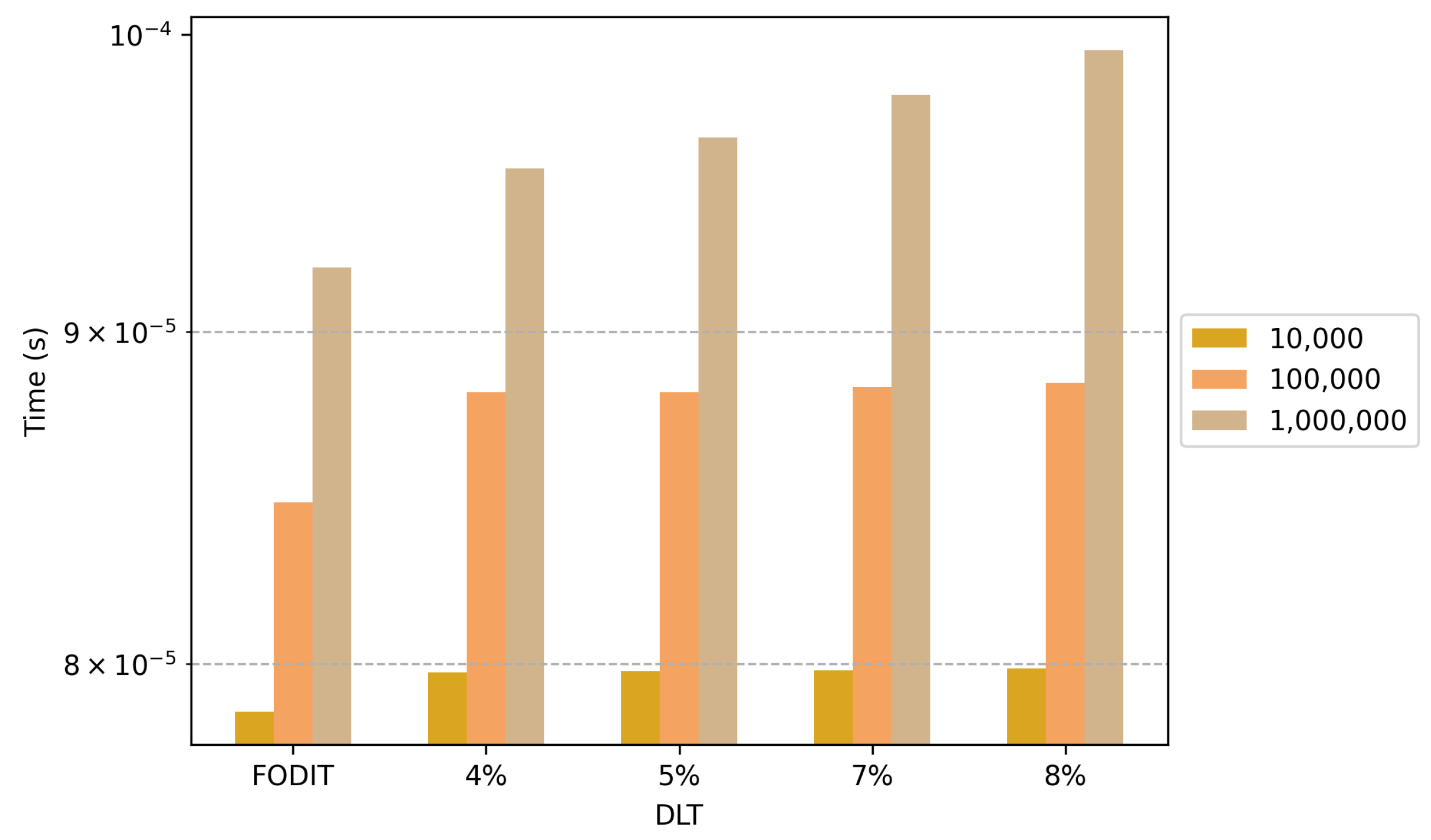


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Bloom Filter | Counting Bloom Filter | Sliding Bloom Filter | Cuckoo Filter |
|---|---|---|---|---|
| Supports Deletions | No | Yes | No | Yes |
| False Positives | n | |||
| Insertion Speed | ||||
| Query Speed | ||||
| Deletion Speed | Not supported | Not supported | ||
| Implementation | Simple | Moderate (counter management) | Complex (window management) | Moderate (cuckoo hashing) |
| Scalability | Limited (fixed size) | Limited (counter overhead) | Better (sliding window) | Best (resizable, low overhead) |
| Storage | Pros | Cons |
|---|---|---|
| Local DB | Low latency High security Network independence | Limited scalability Sync complexity Limited remote access |
| Cloud storage | Scalable Cost-efficient Remote access B5G-enhanced bandwidth | Latency Privacy concerns Network reliance Subscription cost |
| DLT | Immutable Decentralized trust Transparent | High overhead Scalability issues Transaction latency |
| Storage | Data | Classical | FODIT | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Duplicates (4%) | Duplicates (5%) | Duplicates (7%) | Duplicates (8%) | Not Duplicates | Filter | AuxS | Total | ||
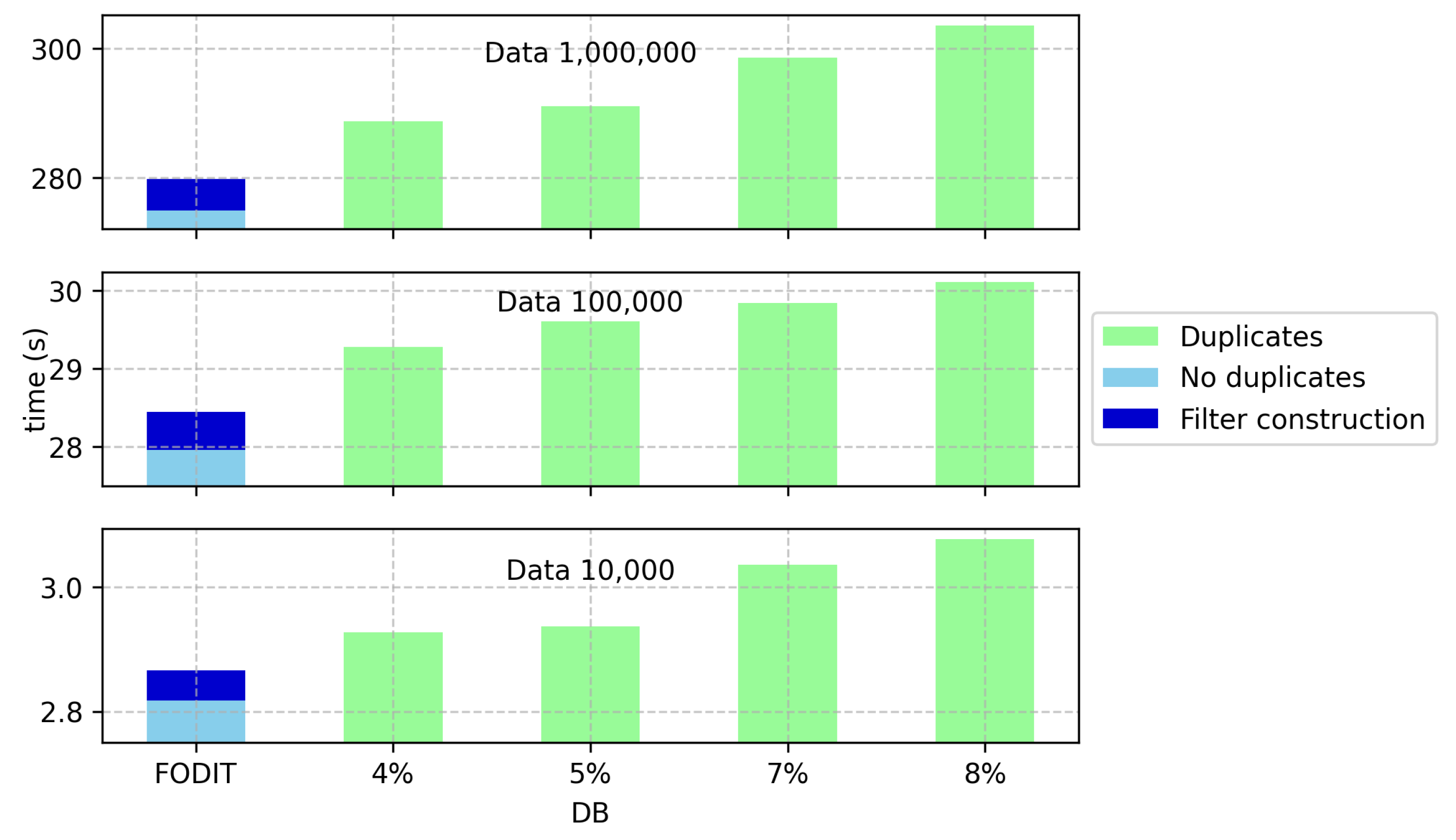
| DB | 10,000 | 2.9277 | 2.9367 | 3.0359 | 3.0776 | 2.8172 | 0.0492 | 0 | 2.8664 |
| 100,000 | 29.2806 | 29.6053 | 29.8442 | 30.1098 | 27.9589 | 0.4877 | 0 | 28.4466 | |
| 1,000,000 | 288.6968 | 291.0532 | 298.5853 | 303.6195 | 274.8504 | 4.9137 | 0 | 279.7637 | |
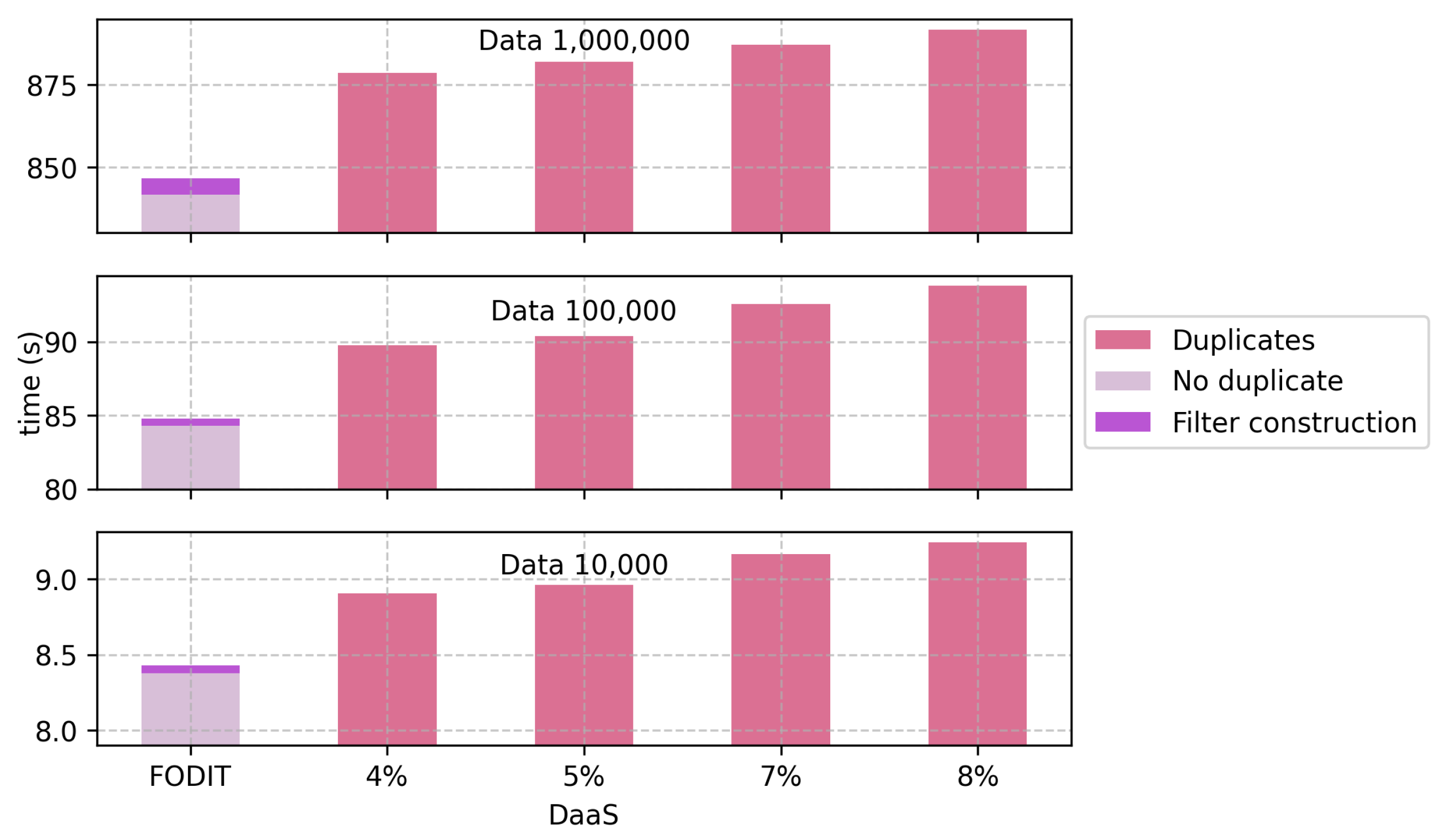
| DaaS | 10,000 | 8.9053 | 8.9604 | 9.1657 | 9.2461 | 8.3792 | 0.0492 | 0 | 8.4284 |
| 100,000 | 89.7634 | 90.3721 | 92.5781 | 93.7923 | 84.2795 | 0.4877 | 0 | 84.7672 | |
| 1,000,000 | 878.5982 | 881.9156 | 887.2513 | 891.7634 | 841.7258 | 4.9137 | 0 | 846.6395 | |
| DLT | 10,000 | 345.0824 | 350.1425 | 360.5115 | 378.1140 | 331.81 | 0.0492 | 0.0151 | 331.8743 |
| 100,000 | 3485.3322 | 3536.2650 | 3605.1156 | 3656.8780 | 3367.8715 | 0.4877 | 0.3327 | 3368.6919 | |
| 1,000,000 | 37,268.8992 | 37,731.7741 | 38,372.4992 | 39,054.037 | 35,835.48 | 4.9137 | 2.1324 | 35,842.5261 | |
| Data | Classical | FODIT | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Duplicates (4%) | Time | Duplicates (5%) | Time | Duplicates (7%) | Time | Duplicates (8%) | Time | Time | ||
| DB | 10,000 | 10,400 | 3.05175 × 10−5 | 10,500 | 3.3140 × 10−5 | 10,700 | 4.0292 × 10−5 | 10,800 | 4.12695 × 10−5 | 3.0279 × 10−5 |
| 100,000 | 104,000 | 4.2676 × 10−5 | 105,000 | 4.3869 × 10−5 | 107,000 | 4.4562 × 10−5 | 108,000 | 4.5776 × 10−5 | 4.1246 × 10−5 | |
| 1,000,000 | 1,040,000 | 5.3153 × 10−5 | 1,050,000 | 5.4527 × 10−5 | 1,070,000 | 5.5936 × 10−5 | 1,080,000 | 5.6523 × 10−5 | 5.2193 × 10−5 | |
| DaaS | 10,000 | 10,400 | 5.8275 × 10−5 | 10,500 | 5.9173 × 10−5 | 10,700 | 6.1293 × 10−5 | 10,800 | 6.2371 × 10−5 | 5.4682 × 10−5 |
| 100,000 | 104,000 | 6.2454 × 10−5 | 105,000 | 6.3587 × 10−5 | 107,000 | 6.5729 × 10−5 | 108,000 | 6.6192 × 10−5 | 5.8935 × 10−5 | |
| 1,000,000 | 1,040,000 | 8.0145 × 10−5 | 1,050,000 | 8.1937 × 10−5 | 1,070,000 | 8.3475 × 10−5 | 1,080,000 | 8.3876 × 10−5 | 6.8942 × 10−5 | |
| DLT | 10,000 | 10,400 | 7.9766 × 10−5 | 10,500 | 7.9802 × 10−5 | 10,700 | 7.9826 × 10−5 | 10,800 | 7.9866 × 10−5 | 7.866 × 10−5 |
| 100,000 | 104,000 | 8.8083 × 10−5 | 105,000 | 8.8100 × 10−5 | 107,000 | 8.8257 × 10−5 | 108,000 | 8.8376 × 10−5 | 8.4714 × 10−5 | |
| 1,000,000 | 1,040,000 | 9.5363 × 10−5 | 1,050,000 | 9.6423 × 10−5 | 1,070,000 | 9.7891 × 10−5 | 1,080,000 | 9.9452 × 10−5 | 9.208 × 10−5 | |
| FPR | Percentage | Length f |
|---|---|---|
| 1% | 10 bits | |
| 0.1% | 13 bits | |
| 0.01% | 17 bits | |
| 0.001% | 20 bits | |
| 0.0001% | 23 bits | |
| 0.00001% | 27 bits | |
| 0.000001% | 30 bits | |
| 0.0000001% | 33 bits | |
| 0.00000001% | 37 bits | |
| ⋮ | ⋮ | ⋮ |
| % | 256 bits |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramos-Cruz, B.; Quesada-Real, F.J.; Andreu-Pérez, J.; Zaqueros-Martinez, J. FODIT: A Filter-Based Module for Optimizing Data Storage in B5G IoT Environments. Future Internet 2025, 17, 295. https://doi.org/10.3390/fi17070295
Ramos-Cruz B, Quesada-Real FJ, Andreu-Pérez J, Zaqueros-Martinez J. FODIT: A Filter-Based Module for Optimizing Data Storage in B5G IoT Environments. Future Internet. 2025; 17(7):295. https://doi.org/10.3390/fi17070295
Chicago/Turabian StyleRamos-Cruz, Bruno, Francisco J. Quesada-Real, Javier Andreu-Pérez, and Jessica Zaqueros-Martinez. 2025. "FODIT: A Filter-Based Module for Optimizing Data Storage in B5G IoT Environments" Future Internet 17, no. 7: 295. https://doi.org/10.3390/fi17070295
APA StyleRamos-Cruz, B., Quesada-Real, F. J., Andreu-Pérez, J., & Zaqueros-Martinez, J. (2025). FODIT: A Filter-Based Module for Optimizing Data Storage in B5G IoT Environments. Future Internet, 17(7), 295. https://doi.org/10.3390/fi17070295