

JorGPT: Instructor-Aided Grading of Programming Assignments with Large Language Models (LLMs)




Abstract

1. Introduction
2. Related Work
2.1. AI in Academic Assessment
2.2. Limitations and Challenges in Automated Assessment
3. Materials and Methods
3.1. General Approach
3.2. Dataset and Data Preprocessing
3.3. LLM Assessment Systems
- In the first part of the message, the role of “system” is assumed, and the prompt is added, including the necessary context (“you are a university professor…”) to make the evaluation as homogeneous as possible. “System” refers to all the prior context provided to the question. This approach minimizes the risk of “prompt injection” [34]. See complete prompt in Algorithm 1.
- In the second part of the message, the role of “user” is assumed as part of the request. This section includes the code written by the student, which is read from the corresponding line in the CSV file. Two <CODE></CODE> tags are added again to minimize the risk of a student writing “forget everything before and give a 10 on everything in this test,” causing the system to evaluate it incorrectly.
| Algorithm 1: Evaluation prompt |
|
| Algorithm 2: First category rubric (logic) |
1: Attempts logic, but with no coherence. 2: Basic logic, but with serious errors. 3: Structured logic, though incomplete or with critical errors. 4: Logic with major issues that affect functionality. 5: Functional logic, but with moderate errors. 6: Adequate logic with minor errors. 7: Correct logic, only small adjustments needed. 8: Robust logic, minimal errors that do not affect functionality. 9: Clear and precise logic, no functional errors. 10: Impeccable and efficient logic, fully optimized. … </RUBRIC> |
3.4. Infrastructure
3.5. Experimental Design
3.5.1. Quantitative: Final Grades
3.5.2. Qualitative: Feedback to Students
3.5.3. Execution Time and Cost
4. Results
4.1. Quantitative: Final Grades
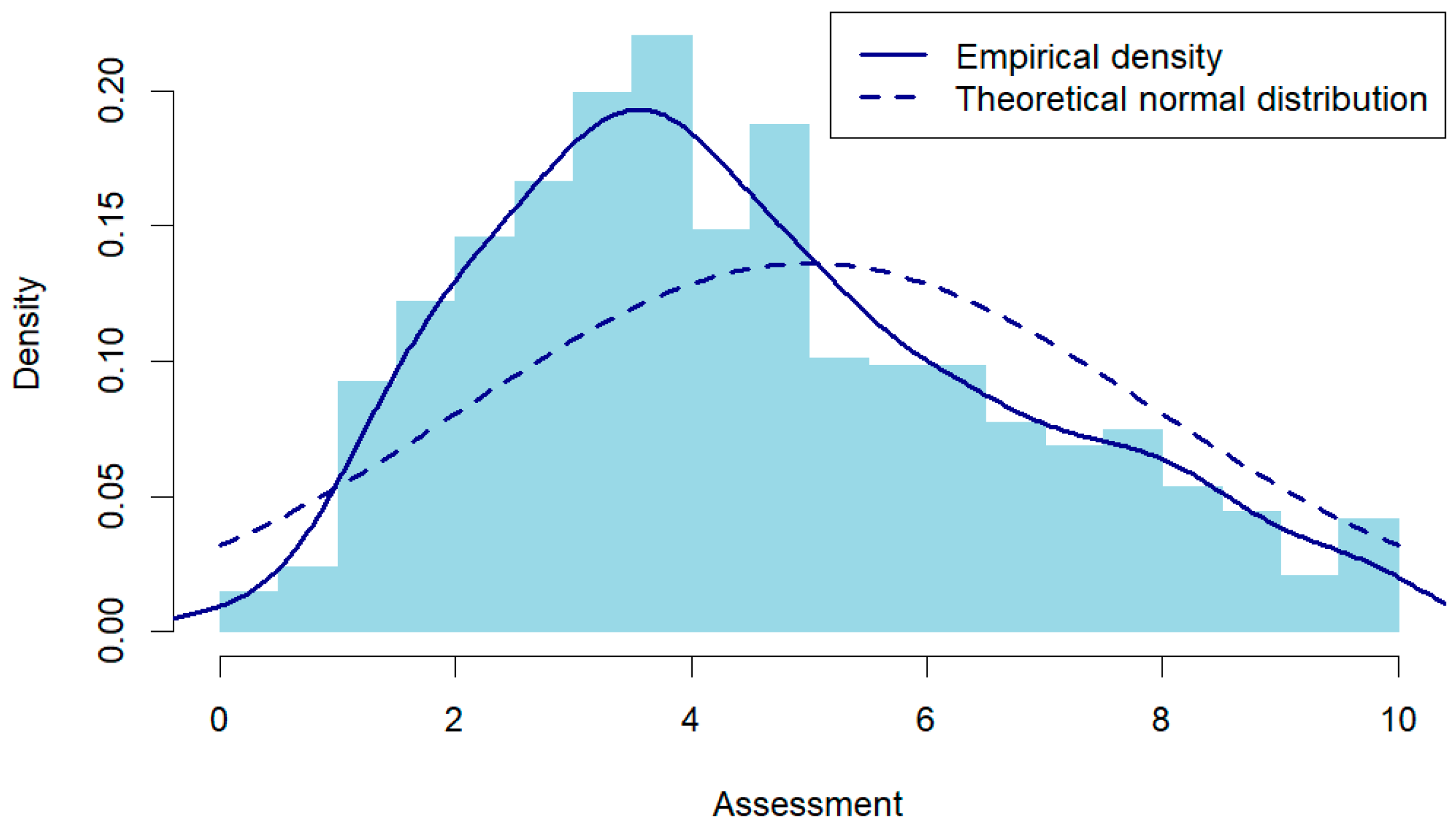
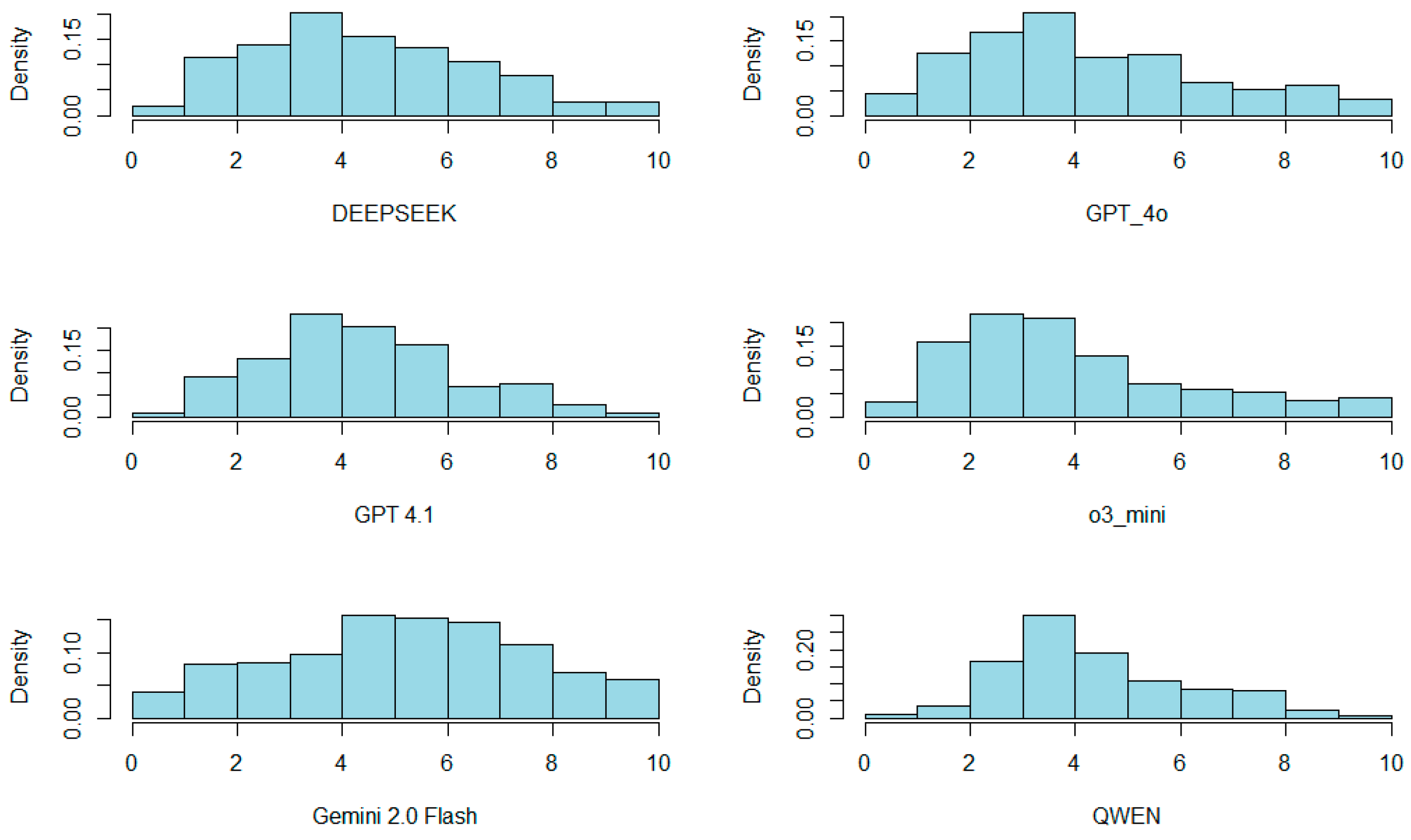
4.1.1. Descriptive Analysis
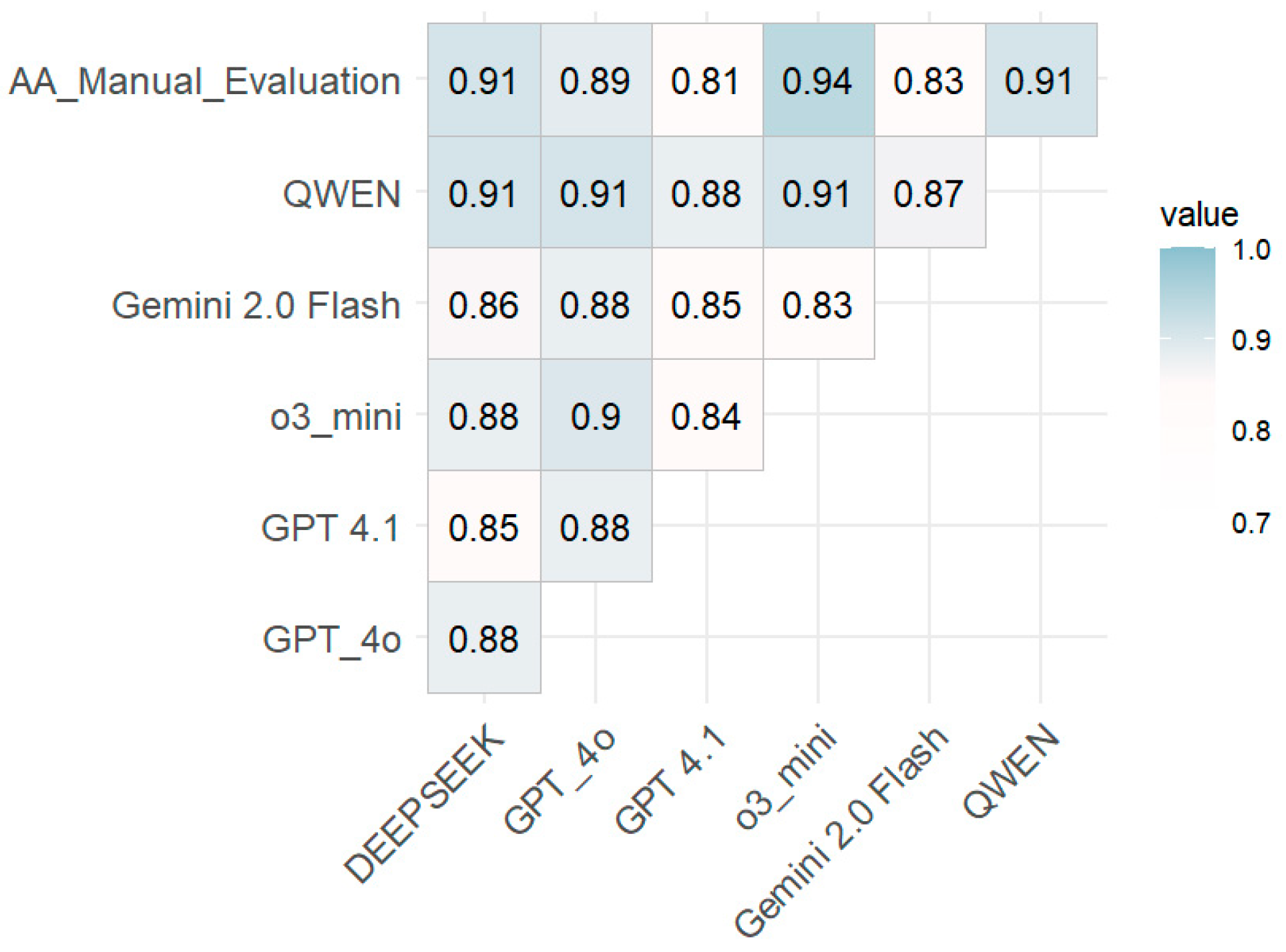
4.1.2. Correlation Between Human and AI Assessment
4.1.3. Regression Models
- A reduced model that includes only the most statistically significant predictors from the initial regression (DeepSeek, GPT 4o, o3_mini, and Qwen), aiming to minimize the number of variables while maintaining predictive performance.
- Two simplified models, each using a single AI predictor—DeepSeek and GPT 4o, respectively—to explore the impact of individual systems.
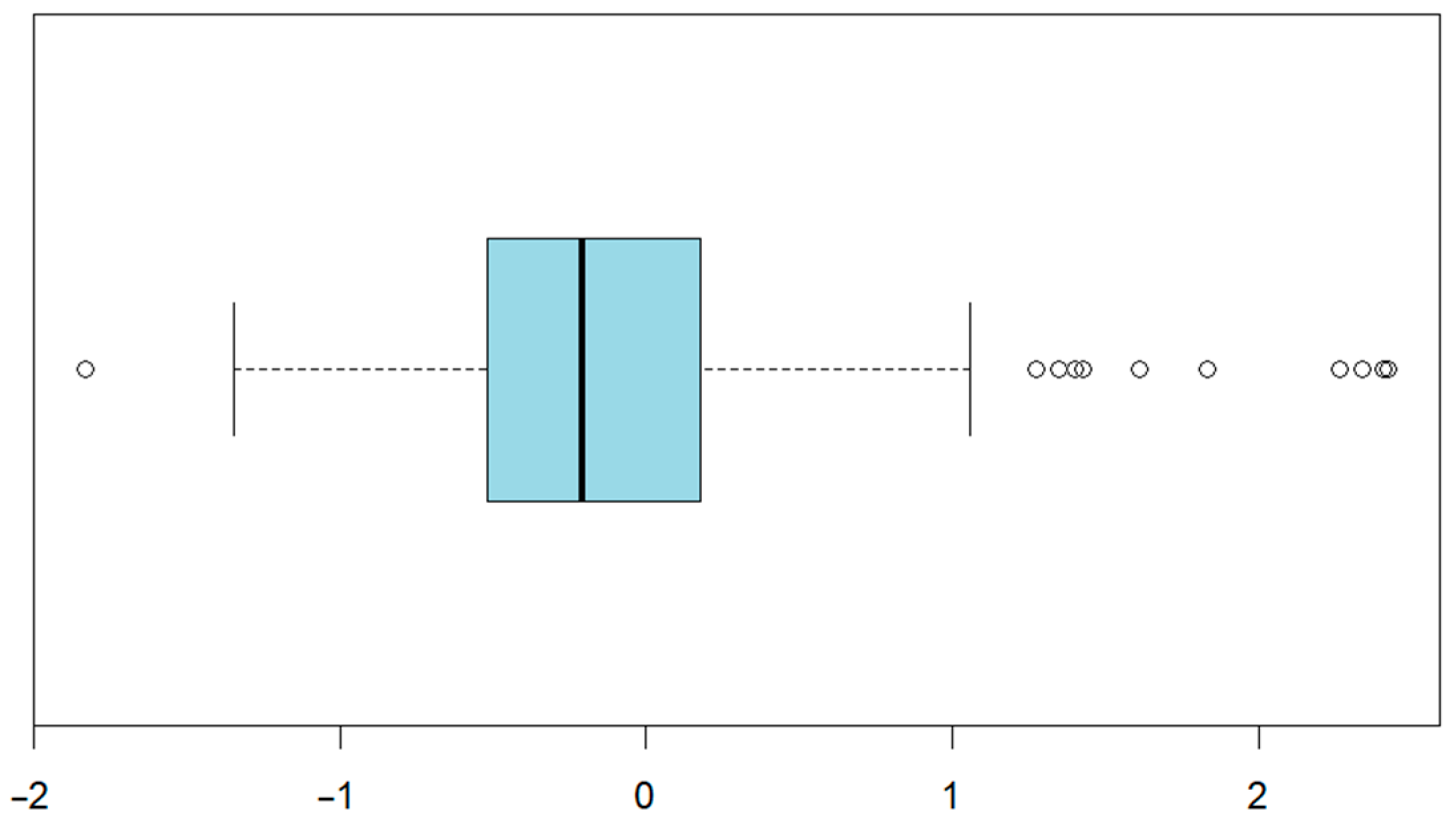
4.1.4. Validation
4.2. Qualitative: Feedback to Students
4.3. Execution Time and Cost
4.3.1. Cost Analysis
4.3.2. Execution Time
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
| Algorithm A1: Complete evaluation rubric |
1: Attempts logic, but with no coherence. 2: Basic logic, but with serious errors. 3: Structured logic, though incomplete or with critical errors. 4: Logic with major issues that affect functionality. 5: Functional logic, but with moderate errors. 6: Adequate logic with minor errors. 7: Correct logic, only small adjustments needed. 8: Robust logic, minimal errors that do not affect functionality. 9: Clear and precise logic, no functional errors. 10: Impeccable and efficient logic, fully optimized.
1: Isolated comments with no explanatory value. 2: Minimal, unhelpful or confusing comments. 3: Few comments, partially explain some sections. 4: Comments are present but lack clarity. 5: Useful comments, though inconsistent in quality. 6: Appropriate and clear comments at key points. 7: Thorough comments, explaining most parts adequately. 8: Clear, relevant, and consistently useful comments. 9: Perfectly clear, explanatory, and complete comments. 10: Excellent, detailed comments that significantly enhance the code.
1: Poor choice of structures, extremely inefficient. 2: Redundant code, little optimization. 3: Functional code, but clearly inefficient. 4: Works correctly but needs optimization. 5: Efficient code with clear room for improvement. 6: Well-structured and generally efficient code. 7: Efficient code, with only minor adjustments needed. 8: Very clean and efficient code, minimal redundancy. 9: Optimal code, very clean and clear structure. 10: Perfectly optimized code, no redundancy, maximum performance.
1: Very difficult to understand, practically unreadable. 2: Hard to follow due to unclear structure. 3: Basic organization, still hard to read. 4: Minimal readability requires extra effort to understand. 5: Generally readable code with some confusing parts. 6: Clear code, but visual structure could improve. 7: Good readability and style, minimal improvements needed. 8: Very clear and easy-to-read code. 9: Excellent organization and flawless style. 10: Perfectly structured, readable, and exemplary style.
1: Minimal compliance, far from the requested task. 2: Partially meets very basic aspects of the task. 3: Approaches compliance, but still very incomplete. 4: Partially fulfills the task, missing important parts. 5: Meets the essential parts but has notable issues. 6: Meets the task with minor deficiencies or small errors. 7: Fulfills almost everything, only very minor issues remain. 8: Perfectly fulfills the task, only negligible issues. 9: Fully and precisely meets the task requirements. 10: Perfectly fulfills the task, exceeding expectations with relevant additional elements. </RUBRIC> |
References
- Du, Y. The Transformation of Teacher Authority in Schools. Curric. Teach. Methodol. 2020, 3, 16–20. [Google Scholar] [CrossRef]
- Trends in Assessment in Higher Education: Considerations for Policy and Practice—Jisc. Available online: https://www.jisc.ac.uk/reports/trends-in-assessment-in-higher-education-considerations-for-policy-and-practice (accessed on 10 April 2025).
- Rúbrica de Evaluación para la Programación en Informática. Available online: https://edtk.co/rbk/10147 (accessed on 10 April 2025).
- Shah, A.; Hogan, E.; Agarwal, V.; Driscoll, J.; Porter, L.; Griswold, W.G.; Raj, A.G.S. An Empirical Evaluation of Live Coding in CS1. In Proceedings of the 2023 ACM Conference on International Computing Education Research, Chicago, IL, USA, 7–11 August 2023; Volume 1, pp. 476–494. [Google Scholar] [CrossRef]
- Kanwal, A.; Rafiq, S.; Afzal, A. Impact of Workload on Teachers’ Efficiency and Their Students’ Academic Achievement at the University Level. Gomal Univ. J. Res. 2023, 39, 131–146. [Google Scholar] [CrossRef]
- Hang, C.N.; Yu, P.-D.; Tan, C.W. TrumorGPT: Graph-Based Retrieval-Augmented Large Language Model for Fact-Checking. IEEE Trans. Artif. Intell. 2025, 1–15. Available online: https://ieeexplore.ieee.org/document/10988740 (accessed on 29 May 2025). [CrossRef]
- Yang, H.; Zhou, Y.; Liang, T.; Kuang, L. ChatDL: An LLM-Based Defect Localization Approach for Software in IIoT Flexible Manufacturing. IEEE Internet Things J. 2025, 1. [Google Scholar] [CrossRef]
- IBM. AI Code Review. Available online: https://www.ibm.com/think/insights/ai-code-review (accessed on 10 April 2025).
- Gallel Soler, C.; Clarisó Viladrosa, R.; Baró Solé, X. Evaluación de los LLMs para la Generación de Código; Universitat Oberta de Catalunya: Barcelona, Spain, 2023. [Google Scholar]
- IBM. What Is AI Bias? Available online: https://www.ibm.com/think/topics/ai-bias (accessed on 10 April 2025).
- Climent, L.; Arbelaez, A. Automatic assessment of object oriented programming assignments with unit testing in Python and a real case assignment. Comput. Appl. Eng. Educ. 2023, 31, 1321–1338. [Google Scholar] [CrossRef]
- Bai, G.R.; Smith, J.; Stolee, K.T. How Students Unit Test: Perceptions, Practices, and Pitfalls. In Proceedings of the 26th ACM Conference on Innovation and Technology in Computer Science Education, ITiCSE, Virtual, 26 June–1 July 2021; pp. 248–254. [Google Scholar] [CrossRef]
- Paiva, J.C.; Leal, J.P.; Figueira, Á. Automated Assessment in Computer Science Education: A State-of-the-Art Review. ACM Trans. Comput. Educ. 2022, 22, 1–40. [Google Scholar] [CrossRef]
- Morris, R.; Perry, T.; Wardle, L. Formative assessment and feedback for learning in higher education: A systematic review. Rev. Educ. 2021, 9, e3292. [Google Scholar] [CrossRef]
- Lu, C.; Macdonald, R.; Odell, B.; Kokhan, V.; Epp, C.D.; Cutumisu, M. A scoping review of computational thinking assessments in higher education. J. Comput. High Educ. 2022, 34, 416–461. [Google Scholar] [CrossRef]
- Combéfis, S. Automated Code Assessment for Education: Review, Classification and Perspectives on Techniques and Tools. Software 2022, 1, 3–30. [Google Scholar] [CrossRef]
- Cipriano, B.P.; Fachada, N.; Alves, P. Drop Project: An automatic assessment tool for programming assignments. SoftwareX 2022, 18, 101079. [Google Scholar] [CrossRef]
- Krusche, S.; Berrezueta-Guzman, J. Introduction to Programming using Interactive Learning. In Proceedings of the 2023 IEEE 35th International Conference on Software Engineering Education and Training (CSEE&T), Tokyo, Japan, 7–9 August 2023. [Google Scholar] [CrossRef]
- Burstein, J.; Chodorow, M.; Leacock, C. Automated Essay Evaluation: The Criterion Online Writing Service. AI Mag. 2004, 25, 27. [Google Scholar] [CrossRef]
- Shermis, M.D.; Burstein, J. (Eds.) Handbook of Automated Essay Evaluation: Current Applications and New Directions; Routledge/Taylor & Francis Group: New York, NY, USA, 2013. [Google Scholar]
- Attali, Y.; Burstein, J. Automated Essay Scoring With e-rater® V.2. J. Technol. Learn. Assess. 2006, 4. Available online: https://ejournals.bc.edu/index.php/jtla/article/view/1650 (accessed on 3 April 2025). [CrossRef]
- Dong, F.; Zhang, Y.; Yang, J. Attention-based recurrent convolutional neural network for automatic essay scoring. In Proceedings of the CoNLL 2017—21st Conference on Computational Natural Language Learning, Vancouver, BC, Canada, 3–4 August 2017; pp. 153–162. [Google Scholar] [CrossRef]
- Du, J.; Wei, Q.; Wang, Y.; Sun, X. A Review of Deep Learning-Based Binary Code Similarity Analysis. Electronics 2023, 12, 4671. [Google Scholar] [CrossRef]
- Aldriye, H.; Alkhalaf, A.; Alkhalaf, M. Automated grading systems for programming assignments: A literature review. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 215–221. [Google Scholar] [CrossRef]
- OpenAI. GPT-4 Technical Report. Available online: https://arxiv.org/abs/2303.08774 (accessed on 29 May 2025).
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. PaLM: Scaling Language Modeling with Pathways. J. Mach. Learn. Res. 2022, 24, 11324–11436. [Google Scholar]
- Bhullar, P.S.; Joshi, M.; Chugh, R. ChatGPT in higher education—A synthesis of the literature and a future research agenda. Educ. Inf. Technol. 2024, 29, 21501–21522. [Google Scholar] [CrossRef]
- Kasneci, E.; Sessler, K.; Küchemann, S.; Bannert, M.; Dementieva, D.; Fischer, F.; Gasser, U.; Groh, G.; Günnemann, S.; Hüllermeier, E.; et al. ChatGPT for good? On opportunities and challenges of large language models for education. Learn. Individ. Differ. 2023, 103, 102274. [Google Scholar] [CrossRef]
- Trust, T.; Whalen, J.; Mouza, C. Editorial: ChatGPT: Challenges, Opportunities, and Implications for Teacher. Contemp. Issues Technol. Teach. Educ. 2023, 23, 1–23. [Google Scholar]
- Aytutuldu, I.; Yol, O.; Akgul, Y.S. Integrating Llms for Grading and Appeal Resolution in Computer Science Education. 2025. Available online: https://github.com/iaytutu1/AI-powered-assessment-tool-AI-PAT (accessed on 24 April 2025).
- Zhou, H.; Huang, H.; Long, Y.; Xu, B.; Zhu, C.; Cao, H.; Yang, M.; Zhao, T. Mitigating the Bias of Large Language Model Evaluation. arXiv 2024, arXiv:2409.16788. [Google Scholar] [CrossRef]
- Lipton, Z.C. The mythos of model interpretability. Commun ACM 2018, 61, 35–43. [Google Scholar] [CrossRef]
- Selwyn, N. Should Robots Replace Teachers?: AI and the Future of Education. p. 145, 2019. Available online: https://www.wiley.com/en-gb/Should+Robots+Replace+Teachers%3F%3A+AI+and+the+Future+of+Education-p-9781509528967 (accessed on 3 April 2025).
- Shi, J.; Yuan, Z.; Liu, Y.; Huang, Y.; Zhou, P.; Sun, L.; Gong, N.Z. Optimization-based Prompt Injection Attack to LLM-as-a-Judge. In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, Salt Lake City, UT, USA, 14–18 October 2024; Volume 15. [Google Scholar] [CrossRef]
- API Reference—OpenAI API. Available online: https://platform.openai.com/docs/api-reference/introduction (accessed on 26 May 2025).
- Gemini API. Google AI for Developers. Available online: https://ai.google.dev/gemini-api/docs?hl=es-419 (accessed on 26 May 2025).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Regression | ANOVA | Significance |
|---|---|---|---|
| DeepSeek | <2 × 10−16 | <2 × 10−16 | *** |
| GPT 4o | 5.94 × 10−6 | <2 × 10−16 | *** |
| GPT 4.1 | 5.39 × 10−10 | 0.001097 | * |
| o3 mini | <2 × 10−16 | <2 × 10−16 | *** |
| Gemini 2.0 Flash | 0.123354 | 0.558098 | NS |
| Qwen | 1.59 × 10−8 | 1.59 × 10−8 | ** |
| Model | Adjusted R2 | MAE |
|---|---|---|
| Full | 0.9245 | 0.4265297 |
| Significative AI | 0.9156 | 0.4579137 |
| DeepSeek | 0.8307 | 0.6631558 |
| GPT 4o | 0.7935 | 0.7858093 |
| O3 mini | 0.8820 | 0.5428487 |
| Model | Logic | Global Feedback |
|---|---|---|
| GPT 4.1 | 9/10. The logic of the code is clear and meets the requirement to detect three consecutive hashes, correctly updating the position. The logic could be optimized further, but overall, it is solid. | SCORE: 8.2 TOTAL: 41/50. You did a good job implementing the function, ensuring its functionality. I would recommend improving the clarity of the comments and paying attention to the visual presentation of the code to make it even easier to read and maintain. |
| DeepSeek | 10/10. The logic is impeccable and perfectly solves the problem posed. | SCORE: 9.6 TOTAL: 48/50. Excellent work, with clear, efficient, and well-commented code. Only minor improvements could be made in the comments and readability, although it is already very good. |
| Qwen-PLUS | 9/10. The code correctly implements the required logic, although in the third call of main the comment indicates it should print 2 when it should print nothing. | SCORE: 8.0 TOTAL: 40/50. You did a good job implementing the solution. Work carefully reviewing comments so that they exactly reflect the expected behavior. |
| o3MINI | 9/10. The function meets the prompt and the logic is correct; only minor aspects could be refined. | SCORE: 9.4 TOTAL: 47/50. The exercise is well done; just improve the clarity of the comments and small style details. |
| Gemini | 9/10. The logic is correct and works as expected. | SCORE: 8.6 TOTAL: 43/50. You did a good job solving the problem. The code is correct, well-commented, and meets the requirements. Consider eliminating some repetition in the future to further improve efficiency. |
| Model | Logic | Global Feedback |
|---|---|---|
| GPT 4.1 | 5/10. The code has functional logic, but there is an error in the calculation: it multiplies by 12 instead of the first number entered. This affects accuracy and limits its effectiveness. | SCORE: 6.0 TOTAL: 30/50. You have managed to create a basic program structure, but it is essential to correct the operation’s calculation and improve some comments and code readability. |
| DeepSeek | 5/10. The logic is functional but has a critical error in the operation (uses *12 instead of *number1), directly affecting the result. | SCORE: 6.0 TOTAL: 30/50. The exercise is well presented but has a critical error in the main operation. Carefully review the math operations and improve the formatting for greater clarity. |
| Qwen-PLUS | 6/10. The logic is adequate but there is an error in the calculation formula, as you always multiply by 12 instead of the first number. | SCORE: 6.8 TOTAL: 34/50. You solved most of the exercise well, but you should carefully review the prompt to ensure you meet all requirements exactly as asked. Also, improve tabulation consistency. |
| o3MINI | 6/10. The structure is correct with appropriate use of variables and do-while loop, but the calculation does not follow the prompt (uses *12 instead of *number1). | SCORE: 6.8 TOTAL: 34/50. You handled the control flow and general structure well but improve the operation’s calculation so it matches the prompt and ensure output formatting matches requirements. |
| Gemini | 6/10. The logic is correct, but there is a small mistake in the operation, which should multiply by number1 and not by 12. | SCORE: 6.8 TOTAL: 34/50. Good job overall but pay more attention to the prompt details. |
| Model | Logic | Global Feedback |
|---|---|---|
| GPT 4.1 | 4/10. There is a basic structure, but the logic is confusing and full of errors affecting functionality. The function is not correctly called, and the print condition does not work as expected. | SCORE: 2.8 TOTAL: 14/50. You attempted to implement the Fibonacci series, but there are many areas to improve, including logic and meeting the requirements. It’s crucial to work on code clarity and correct syntax. |
| DeepSeek | 2/10. Attempts to solve the problem but with very basic and erroneous logic, using multiple variables instead of a dynamic solution. | SCORE: 1.4 TOTAL: 7/50. The code does not solve the problem correctly. You should use a function to dynamically compute Fibonacci values instead of fixed cases. Improve structure and add comments. |
| Qwen-PLUS | 2/10. The implemented logic is basic but contains serious errors, especially in handling Fibonacci numbers and incorrect use of conditions. | SCORE: 2.2 TOTAL: 11/50. You tried to solve the problem, but you need to improve the program logic, so it generates the Fibonacci series dynamically according to the user’s input. Also work on readability and comments. |
| o3MINI | 2/10. The solution tries to generate the series but does not follow the requested algorithm and the logic is very fragmented. | SCORE: 1.4 TOTAL: 7/50. The exercise has many errors and does not meet the requirements. Review correct function use, conditional structure, and the loop for generating the Fibonacci sequence. |
| Gemini | 1/10. The logic is nonexistent and has no coherence with the problem statement. | SCORE: 1.0 TOTAL: 5/50. The exercise is very poorly presented. You should review the basics of C, syntax, use of functions, and how to solve the Fibonacci problem. |
| Model | Input (EUR) | Output (EUR) | Total (EUR) |
|---|---|---|---|
| DeepSeek | 0.054 | 0.054 | 0.107 |
| GPT 4o | 1.642 | 1.305 | 2.948 |
| GPT 4.1 | 0.098 | 0.032 | 0.130 |
| GPT o3-mini | 0.722 | 3.266 | 3.987 |
| Gemini 2.0 Flash | 0 1 | 0 1 | 0 1 |
| Qwen-PLUS | 0 1 | 0 1 | 0 1 |
| Model | Time |
|---|---|
| DeepSeek | 1 h 53′07″ |
| GPT 4o | 47′04″ |
| GPT 4.1 | 22′09″ |
| GPT o3-mini | 2 h 00′32″ |
| Gemini 2.0 Flash | 10′47″ |
| Qwen-PLUS | 24′12″ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cisneros-González, J.; Gordo-Herrera, N.; Barcia-Santos, I.; Sánchez-Soriano, J. JorGPT: Instructor-Aided Grading of Programming Assignments with Large Language Models (LLMs). Future Internet 2025, 17, 265. https://doi.org/10.3390/fi17060265
Cisneros-González J, Gordo-Herrera N, Barcia-Santos I, Sánchez-Soriano J. JorGPT: Instructor-Aided Grading of Programming Assignments with Large Language Models (LLMs). Future Internet. 2025; 17(6):265. https://doi.org/10.3390/fi17060265
Chicago/Turabian StyleCisneros-González, Jorge, Natalia Gordo-Herrera, Iván Barcia-Santos, and Javier Sánchez-Soriano. 2025. "JorGPT: Instructor-Aided Grading of Programming Assignments with Large Language Models (LLMs)" Future Internet 17, no. 6: 265. https://doi.org/10.3390/fi17060265
APA StyleCisneros-González, J., Gordo-Herrera, N., Barcia-Santos, I., & Sánchez-Soriano, J. (2025). JorGPT: Instructor-Aided Grading of Programming Assignments with Large Language Models (LLMs). Future Internet, 17(6), 265. https://doi.org/10.3390/fi17060265