1. Introduction
With the rapid development of smart cities, massive amounts of data are being generated across various sectors, including judicial, governmental, healthcare, elderly care, and transportation systems [
1]. Among these diverse data types, digital images play a vital role and are extensively used as digital evidence in urban management scenarios such as video surveillance, news reporting, and legal proceedings. However, the advancement of image processing technologies has significantly lowered the barriers for malicious actors to manipulate or forge digital images. This growing vulnerability underscores the increasing importance of source camera identification, which enables the verification of an image’s origin and contributes to ensuring its authenticity and integrity [
2].
Source camera identification approaches are generally divided into two categories. The first category is the active approach, which relies on information embedded in the image to verify its source. Celik et al. proposed a lossless authentication watermarking framework [
3]. Yang et al. developed a lossless visible watermarking scheme considering human visual features [
4], and Chen et al. introduced a chaotic watermarking scheme based on semi-fragile watermarking [
5]. The second category is the passive forensic approach, which relies on camera fingerprints, such as pattern noise (e.g., photo response non-uniformity (PRNU) noise), to identify the source camera. This noise arises from sensor responses and internal image signal processing [
6,
7]. Cao et al. detected image demosaicing regularities [
8], and Taspinar et al. proposed a spatial domain averaging technique to enhance efficiency by reducing denoising times [
9]. Other works, such as those by Rao et al. [
10], Thai et al. [
11], and Chen et al. [
12], have focused on suppressing correlated noises, using heteroscedastic noise models, and incorporating privacy-preserving methods to improve source camera identification performance.
Although the above methods contribute significantly to source camera identification, active approaches relying solely on embedded information are often considered unreliable [
11], while passive methods dependent on intrinsic features may fail to achieve sufficient accuracy under complex image processing techniques [
13]. To address these challenges, we propose a novel hybrid fingerprint model that integrates both active and passive forensic approaches, combining embedded information with intrinsic camera features. The proposed method improves the reliability and accuracy of source camera identification by taking advantage of the complementary strengths of the active approach and the passive forensic approach, thus overcoming the limitations of each when used independently. Unlike existing methods, our hybrid fingerprint model adapts to varying image processing scenarios, providing a more robust and accurate solution for source camera identification.
Traditional source camera identification methods usually make a judgment about images by performing the identification process only once [
14,
15,
16]. However, modern image-processing techniques, such as tampering and compression, pose significant challenges to the reliability of such methods. Furthermore, the privacy of sensitive images, such as those involving military, political, or personal data, must also be safeguarded during the identification process. To address these issues, we propose a distributed source camera identification scheme with a privacy-preserving strategy, which not only improves reliability but also protects sensitive information.
In the digital era, the widespread use of image acquisition devices and social media platforms facilitates the sharing of digital images, but post-processing operations such as image scaling and JPEG compression [
17,
18,
19] can degrade camera fingerprints, reducing the effectiveness of traditional identification methods. Therefore, it is crucial to consider the impact of such processing techniques on source camera identification.
In this paper, we first develop a novel hybrid fingerprint model by combining camera intrinsic features with a specifically designed tag. To safeguard both the content and source of the images, we implement a privacy-preserving strategy. Following this strategy, we design a hybrid fingerprint model within an encrypted environment. Finally, we present the proposed distributed source camera identification scheme. Based on the binary hypothesis testing theory, we present a generalized likelihood ratio test (GLRT) to detail the source camera identification process performed by a single secondary user. The proposed scheme not only enhances identification accuracy, but also ensures the protection of sensitive information throughout the identification process.
2. Problem Formulation and System Model
2.1. Problem Formulation
With the increasing prevalence of digital images, source camera identification has gained critical importance in the field of image forensics [
20]. Digital images are now widely used as digital evidence by various official entities, including courts of law, government agencies, police investigations, and news outlets, playing a significant role in their decision-making processes [
21]. Due to the rapid development of network technology and the great advances in image editing tools, illegal attackers can easily edit, alter, or forge images, leading to questions about the reliability and trustworthiness of digital images [
22]. As a result, the need for reliable methods to verify the authenticity and source of digital images has become more urgent than ever. Source camera identification techniques serve as an essential tool for determining the specific camera model or device that captured an image, ensuring the authenticity and trustworthiness of digital evidence. However, traditional identification methods usually make a decision by analyzing the image only once, which may lead to missed detections or false alarms. To address the above limitations, we propose a novel distributed source camera identification framework. This approach enhances the accuracy and robustness of the identification process by leveraging the collaborative efforts of multiple secondary users. Through this distributed framework, we aim to provide a more reliable method for determining the source of digital images, ultimately improving the validity of digital evidence in critical applications.
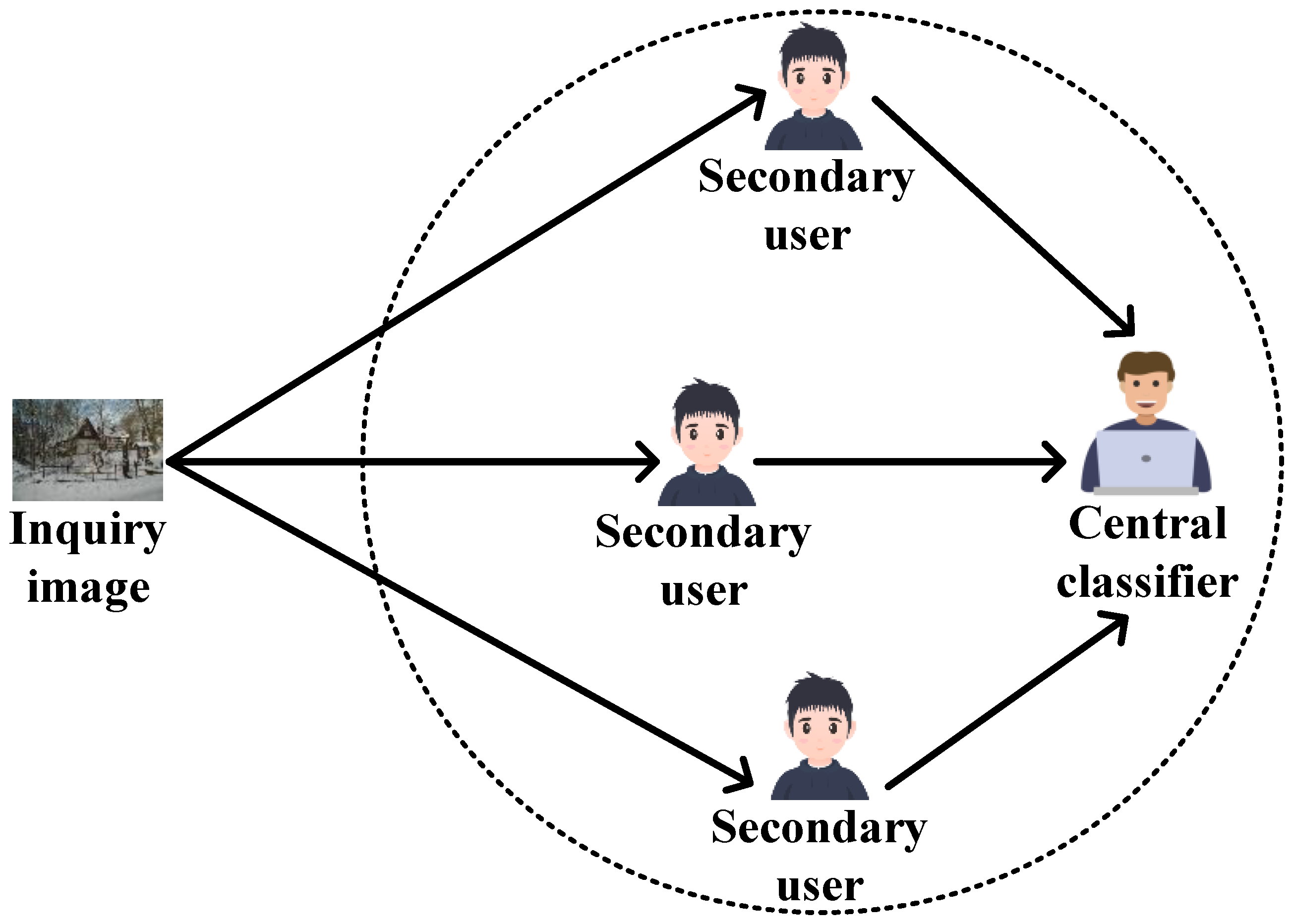
As shown in
Figure 1, we design a distributed source camera identification framework containing a central classifier and three secondary users. All three secondary users are assumed to be trustworthy. To compare with the fingerprint of the inquiry image, each secondary user first separately extracts the camera fingerprint from images taken by a specific known camera model, where the images used to extract the camera fingerprint are different for each secondary user. Then, each secondary user individually makes a preliminary judgment for the same inquiry image by using a specialized source camera identification technique (i.e., the GLRT designed in
Section 3.2.2) to evaluate whether the image is from a specific known camera model. The secondary users send their respective binary judgments (1 means the image is from a known camera, 0 means the image is not from a known camera) to the central classifier. The central classifier receives and fuses the decision information from all the secondary users and makes the final judgment based on the “
n-out-of
K” voting rule (
Section 3.1) to infer whether the image is from a specific camera model.
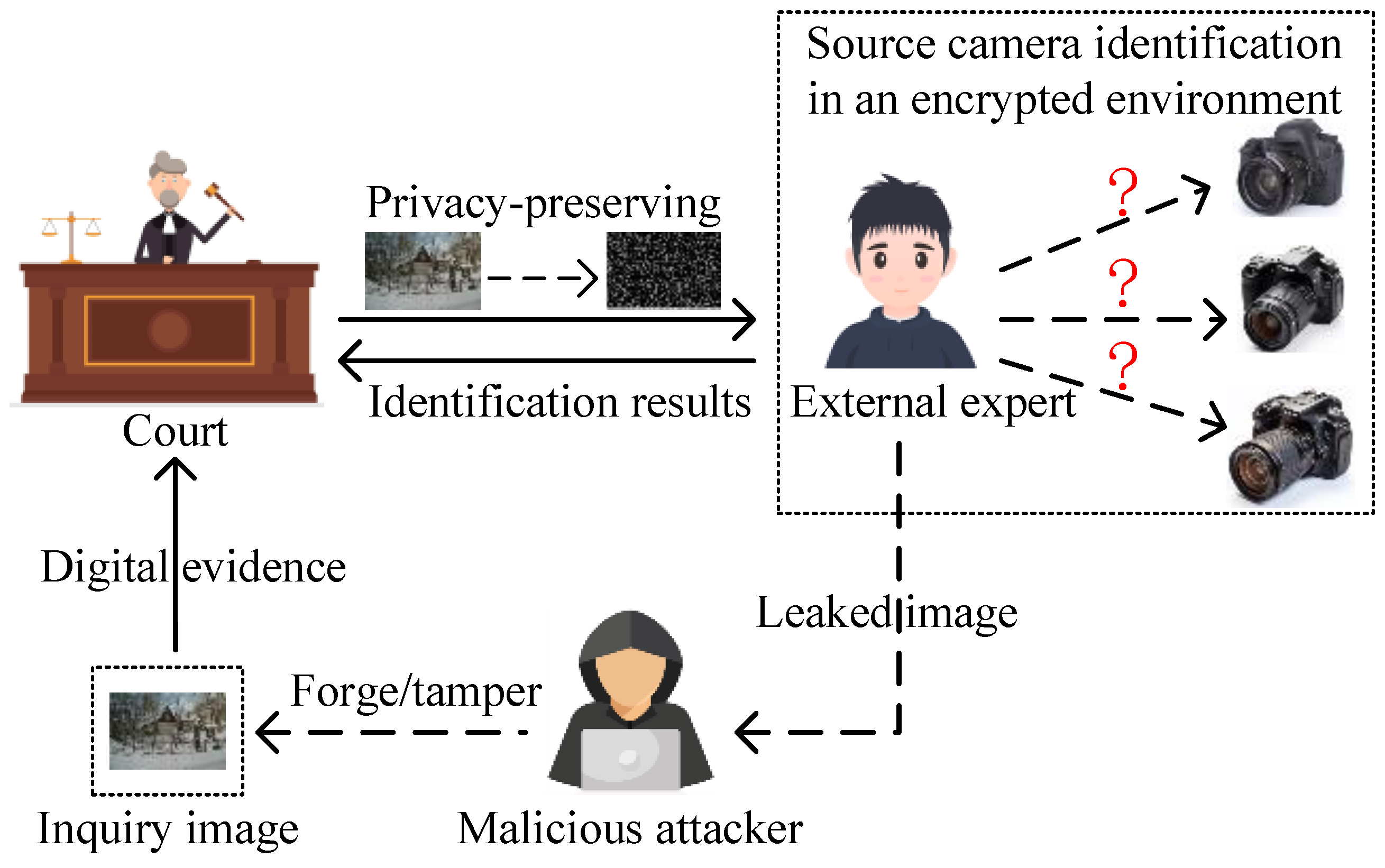
As illustrated in
Figure 2, we present a real-world application scenario demonstrating the process by which a single secondary user identifies the source camera of an image. In such cases, digital images may be transmitted as evidence to official institutions, such as courts, particularly in sensitive cases like military operations or child pornography. Indeed, malicious attackers can potentially tamper with or falsify digital images, thereby compromising the credibility of the images. Consequently, when images are used as evidence, it becomes essential for courts to verify the authenticity of the image source to uphold the integrity of the digital evidence. However, courts typically lack the expertise and computational resources required for source camera identification. At this point, engaging external experts is regarded as an effective solution to the above problems [
23]. Nevertheless, external experts are not official entities, and thus relying on the experts may expose inquiry image information to potential malicious attackers, increasing the risk of unauthorized disclosure. To mitigate the above risk and protect the privacy of the images, the courts must employ a privacy-preserving strategy (i.e., the strategy designed in
Section 2.2.2). Specifically, before transmitting the inquiry image to the expert, the court encrypts both the image content and the camera fingerprints. In the encrypted environment, the external expert utilizes advanced source camera identification techniques, such as the GLRT described in
Section 3.2.2, to determine the original camera model used to capture the image. The expert then sends the identification results back to the court, allowing the institution to make a more informed decision regarding the reliability of the digital evidence. By relying on the identification results from the expert, the court can more accurately assess the authenticity of the image and thus make a well-founded judgment.
2.2. System Model
2.2.1. Unencrypted Hybrid Fingerprint Model
A noise model can characterize an image because it is related to the image acquisition and post-acquisition processes. The classical noise model usually uses two parameters to characterize camera fingerprints. One of the most widely used statistical noise model is
where
represents the
i-th pixel of an image,
, and
I denotes the number of pixels.
is the variance of the
i-th pixel.
is the expectation of the
i-th pixel.
represent the camera fingerprints.
is the quantized noise with step
, and we set
in this paper [
12].
We note that the fingerprints
of different camera models have little difference, which leads to insufficient differentiation between different camera models. Moreover, the statistical noise model
cannot identify different devices of a specific camera model. To solve the above two problems, we introduce a tag into the statistical noise model to propose a new hybrid fingerprint model, which is
where
denotes the
k-th pixel of an image,
, and
K is the number of pixels.
is the variance of the
k-th pixel.
represents the expectation of the
k-th pixel.
denote the camera fingerprints and
. The designed tag is a zero-mean Gaussian noise that is embedded into the image during the fingerprint extraction process. Denoting the tag as
g, it follows the distribution:
where
represents the variance of the tag.
We chose zero-mean Gaussian noise as the artificial tag primarily due to its well-understood statistical properties, compatibility with existing statistical noise models, and ease of integration into the pixel-wise variance framework. Gaussian noise preserves the assumption of normality commonly used in likelihood-based detectors such as GLRT, thereby maintaining theoretical consistency. While we considered alternative synthetic patterns such as uniform noise, Laplacian noise, and deterministic pseudo-random sequences, these either deviated from the Gaussianity assumption crucial for likelihood computation, or exhibited inferior performance in empirical identification tasks. As a result, Gaussian noise was selected as a suitable and effective design choice for the hybrid fingerprint model.
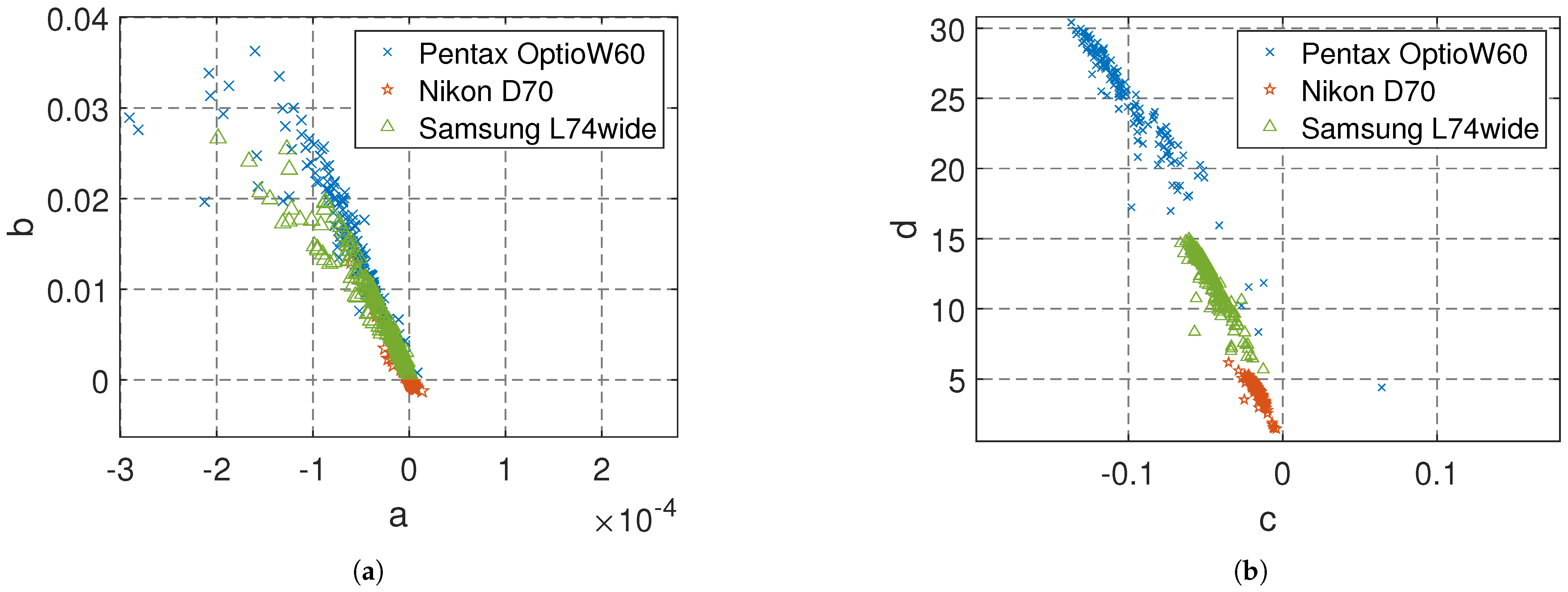
Note that our designed tag helps to improve the identification rate between different camera models when conducting source camera identification. Moreover, our proposed scheme also enables the identification of different devices of a specific camera model. To prove the above two statements, we randomly selected several camera models from the Dresden dataset [
24]. First, we conducted an ablation study to explicitly evaluate the impact of introducing the tag into the fingerprint extraction process. Specifically, we plot in
Figure 3a,b the results of camera fingerprints extracted from different camera models under the original statistical noise model and our proposed hybrid fingerprint model, respectively. In
Figure 3a, the camera fingerprints
obtained without the tag show significant overlap across different camera models, indicating poor separability. In contrast,
Figure 3b shows the camera fingerprints
extracted using the hybrid fingerprint model, where the overlap areas are substantially reduced. This comparison clearly demonstrates that the addition of the designed tag led to more compact and distinguishable fingerprint distributions. The ablation study confirmed that the improved identification performance can be primarily attributed to the inclusion of the artificial tag, rather than changes to other components of the pipeline. To further prove that the hybrid fingerprint model
can achieve identification of different devices of a specific camera model, we take the Fujifilm FinePixJ50 as an example in
Figure 4a. As shown in
Figure 4b, the overlap area between the camera fingerprints
of three different devices is small, so our hybrid fingerprint model can also identify different devices of a specific camera model. In summary, our hybrid fingerprint model achieved superior performance in identifying both different camera models and different devices of the same model.
2.2.2. Privacy-Preserving Strategy
To protect the privacy of the image content and camera model identity, we use a privacy-preserving strategy, consisting of two steps: pixel positional scrambling encryption, and noise linear mapping encryption. Furthermore, the encryption security of this privacy-preserving strategy has been verified in previous studies [
12], proving that this method can adequately protect image content and camera fingerprint information from malicious attackers.
Pixel position scrambling encryption: Pixel position scrambling encryption is employed to safeguard the authentic content of images by concealing their original structure. As illustrated in
Figure 5, when comparing the image before and after encryption, it is evident that pixel position scrambling effectively preserves the privacy of the image content. This encryption technique obfuscates the image content by rearranging the original pixel sequence into a random, disordered configuration. Importantly, as illustrated in
Figure 6, the camera fingerprint remains consistent before and after encryption, confirming that the scrambling process does not alter the original value of the camera fingerprint. Therefore, the scrambling encryption technique serves to effectively protect image content, without compromising the performance of source camera identification.
Noise linear mapping encryption: Although pixel position scrambling encryption effectively safeguards the image content, it does not alter the values of camera fingerprints. As a result, while the scrambling encryption offers content protection, it does not safeguard information about the image’s origin. To address the above limitations, we apply a noise linear mapping encryption method to encrypt the camera fingerprints, thus enhancing the image source protection. Since the camera fingerprint is extracted from the image noise based on our hybrid fingerprint model
, encrypting the camera fingerprint
is equivalent to encrypting the image noise. Therefore, we multiply the image noise by a linear coefficient to protect the image source. The above operation modifies the camera fingerprint values
, effectively concealing the authentic camera fingerprint, and thus avoiding the risk of leaking the authentic image source. As demonstrated in
Figure 4, both the original and encrypted camera fingerprint exhibit distinguishable characteristics between different devices of the same camera model. Consequently, the noise linear mapping encryption does not degrade the performance of source camera identification, ensuring that protection of the image source is achieved without compromising identification accuracy.
2.2.3. Encrypted Hybrid Fingerprint Model
We adopt the above privacy-preserving strategy that involves pixel position scrambling encryption and noisy linear mapping encryption to secure the image data. In this approach, the pixel position scrambling encryption does not alter the values of the original camera fingerprints
, ensuring that the hybrid fingerprint model remains unaffected. Therefore, in the encrypted environment, we focus solely on the impact of coefficient changes introduced by the noisy linear mapping encryption within our hybrid fingerprint model. Specifically, we define
and
as the noise before and after encryption of the
k-th pixel in an image, respectively. The relationship between between
and
can be written as
where
is a linear coefficient. Specifically, the linear coefficient
serves as a critical parameter for encrypting image noise. It is exclusively determined and maintained by official institutions and is not disclosed to any third parties, thereby ensuring the security of the encryption process. The official institution randomly sets the linear coefficients of different camera models, which can effectively change the noise characteristics of the image, and thus protect the image source. Note that the linear coefficients used in noise linear mapping encryption should be distinct depending on different camera models or devices. In addition, when identifying whether an image is from a specific camera model or device, the linear coefficient
used to encrypt the image must be consistent with the linear coefficient
of the corresponding camera model or device.
Based on (
4), the noise
of each pixel is multiplied by a linear coefficient
. Thus, the encrypted hybrid fingerprint model can be further written as
where
is the variance of the
k-th pixel after encryption.
is the encrypted camera fingerprint.
3. Identification Scheme with Privacy-Preserving
In this section, we first present the overall framework for distributed source camera identification, where multiple secondary users work collaboratively to improve the accuracy and reliability of the identification results. Then, we illustrate the process of source camera identification based on GLRT by a single secondary user.
3.1. Identification of Multiple Secondary Users
Binary hypothesis testing is a statistical decision-making method used to select the most likely hypothesis from two possible hypotheses. In source camera identification, to determine whether a given image comes from a known camera model, we typically model the task as a binary hypothesis testing problem. One hypothesis () represents the case where the image originates from a known camera model, while the other hypothesis () suggests that the image comes from an unknown camera model. The goal of binary hypothesis testing is to calculate the likelihood of the data and decide which camera model the image is more likely to belong to.
We consider a camera identification network consisting of
K camera fingerprint extraction modules (secondary users) and a central classifier, as shown in
Figure 1. We assume that each fingerprint extraction module independently extracts fingerprint information from the inquiry images and then sends local decisions to the central classifier, which can fuse all available decision information to infer whether an image is from a known camera model. We define
and
as two different camera models. Hypothesis
means that the image is from camera model
, and hypothesis
represents that the image is from camera model
. Meanwhile, we define
,
, as an image. Actually, the nature of source camera identification is a binary hypothesis testing problem, which can be formulated as
where the image
M is horizontally divided into
H non-overlapping sections, with each section containing
pixels
;
represents the pixel in the
h-th section with index
i pixels in the
h-th section;
is the mean value of all the pixels in the
h-th section; and
denotes the variance derived from the hybrid fingerprint model.
For source camera identification, True Positive Rate (TPR) and False Alarm Rate (FAR) are two crucial evaluation metrics that measure the effectiveness of identification methods. TPR represents the proportion of correctly identified true positives (i.e., images correctly classified as being from the source camera) out of all actual positive instances. A higher TPR indicates that the identification approach is effective at correctly identifying images from the source camera. FAR measures the proportion of false positives (i.e., images incorrectly classified as being from the source camera) out of all actual negative instances. A lower FAR indicates a better results in terms of minimizing false alarms or incorrect identifications. In this paper, we utilize TPR and FAR as two of our primary evaluation metrics. The specific formulas can be calculated as
where TP represents True Positives, the number of images correctly identified as being from the known camera and FN means False Negatives, the number of images incorrectly identified as not being from the known camera.
where FP denotes False Positives, the number of images incorrectly identified as being from the source camera and TN represents True Negatives, the number of images correctly identified as not being from the source camera.
In collaborative source camera identification, each collaborative module makes a binary decision based on its locally extracted camera fingerprint information. Then, each collaborative module sends one bit of the decision
(1 means that the image is from a known camera
and 0 means that the image is not from the known camera
) to the public classifier. At the public classifier, all 1-bit decisions are fused together according to a logic rule, denoted as
where
and
represent the inference drawn by the central classifier about whether or not an image is from a specific known camera model, respectively. The threshold
n is defined as an integer that denotes the “
n-out-of-
K” voting rule [
25].
We can see that the OR rule applies when
and the AND rule applies when
. Considering that the OR rule determines an image to be captured by camera model
as long as one of the auxiliary users makes a decision of 1-bit, this may lead to a false judgment. Meanwhile, the AND rule requires all secondary users to make the same decision, which can easily lead to a missed detection. Furthermore, considering application in large-scale datasets, we discuss the computational time and memory required when using different numbers of secondary users in the distributed scheme. As shown in
Table 1, with the increase in the number of secondary users, the scale of the distributed framework grows, leading to an increase in both computational time and memory usage. For example, under the same conditions, when using three secondary users, the system’s computational time and memory usage are 1.54 h and 10.91 GB, respectively; whereas, with 12 secondary users, the computational time and memory usage increase to 6.17 h and 44.11 GB, respectively. Since the distributed scheme with three auxiliary users was sufficient for the scale of the classical datasets we used, and considering the computational overhead, we only use three auxiliary users in this paper, i.e.,
. Based on
, setting
strikes a balance between the OR and AND rules, reducing computational complexity and improving system efficiency, while maintaining good identification performance. Therefore, we set
in this paper, i.e., the public classifier identifies an image as captured by camera model
only when the decisions of at least two secondary users indicate that the image is from the known camera model
.
3.2. Identification of Single Secondary User
3.2.1. Likelihood Ratio Test in Ideal Scenarios
By comparing the likelihood of data under two hypotheses, the Likelihood Ratio Test (LRT) is a classical method for solving binary hypothesis testing problems. Specifically, the LRT calculates the ratio of likelihood functions under the two hypotheses and compares it with a predefined threshold. If the ratio exceeds the threshold, hypothesis
is accepted; otherwise, hypothesis
is accepted. According to the Neyman–Pearson lemma [
27], the LRT provides an optimal decision rule under ideal conditions, where model parameters are known, and it is effective in addressing tasks such as source camera identification. In this paper, according to hypothesis testing theory and the privacy-preserving strategy, source camera identification can be regarded as a binary hypothesis testing problem in an encrypted environment. In an ideal scenario where all parameters are known, we apply the likelihood ratio test (LRT) to solve different situations. Specifically, the LRT can be defined as
where
denotes the likelihood ratio (LR) of the image
. The threshold
is set empirically. The LR of
can be formulized as
where log(·) represents the natural logarithm function,
and
indicate the variances of
and
corresponding to hypotheses
and
, respectively.
In order to analytically evaluate the statistical performance of
, the statistical properties of the likelihood ratio
are examined, which can be represented as a statistical model.
where
and
represent the expectation and variance of
under hypothesis
, respectively, as detailed in [
12].
Considering the inherent variability of natural images, the likelihood ratio
is normalized under the hypothesis, and can be expressed as follows:
The expression for
given in Equation (
10) can be redefined as follows:
where the threshold
is set empirically.
3.2.2. Generalized Likelihood Ratio Test in Real Scenarios
In practical applications, the parameters of all camera models are typically unknown, so the LRT proposed for ideal scenarios is not applicable in real-world situations. The Generalized Likelihood Ratio Test (GLRT) is an extension of the LRT, designed for cases where parameters are not fully known. In the GLRT, because certain parameters (such as the noise characteristics or statistical distribution parameters of the camera model) may be unknown, it estimates these unknown parameters by maximizing the likelihood function, and then computes the likelihood ratio. Unlike the LRT, the GLRT provides effective inference when parameters are partially unknown, making it especially suitable for the complex scenarios encountered in real-world applications.
In this paper, we assume that the camera model
is known, and that the camera fingerprint
can be accurately estimated from images of model
. Specifically, we randomly select 10 images from the known camera model
and estimate the camera fingerprint
in advance. Therefore, in this paper, the task is to determine whether an image comes from the known camera model
, where
denotes the encrypted image
M. Based on existing research (e.g., [
28,
29]), the GLRT is considered the most effective method to address source camera identification in real-world scenarios. The GLRT can be expressed as
where
denotes the generalized likelihood ratio (GLR) of the image
.
is a preset threshold set empirically.
According to (
15), the GLR of
can be written as
where
and
denote the estimated variances under hypothesis
and
, respectively. The local expectation
and
denotes the denoised pixel in the
h-th part with index
i of image
. Based on our hybrid fingerprint model,
corresponds to
and
can be acquired through maximum likelihood (ML) estimation, formulated as
where
means the noise in the
h-th part with index
i of image
and
.
In addition, the variation in the estimated unknown fingerprint parameters under
conditions was considered to fully evaluate the statistical performance of GLRT for source camera identification. The GLR
under hypothesis
can be expressed as
where
and
represent the expectation and variance of the GLR
, as detailed in [
12].
In order to avoid the image content affecting the selection of thresholds, we use a normalization process for
.
is normalized to obtain the GLR
under hypothesis
, then we have
where
and
denote the expectation and variance of
, respectively.
and
can be obtained from parameter estimation [
12] based on our hybrid fingerprint model.
According to
in (
19),
in (
15) can be reformulated as
where the threshold
is set within a reasonable range based on empirical values.
4. Numerical Results
We first describe the experimental setup and the four datasets used in our experiments. Then, to evaluate the performance of our proposed distributed forensics approach in solving the image source camera identification problem, we present a series of numerical experiments on multiple datasets.
4.1. Experimental Setup
All experiments were conducted on a system featuring dual Intel Xeon Gold 5118 CPUs operating at 2.30 GHz (2.29 GHz per processor) with 64 GB of RAM via MATLAB R2021b. The system was equipped with four NVIDIA GeForce RTX 2080 Ti GPUs, each possessing 11 GB of memory. In this paper, the experimental performance is illustrated mainly through Receiver Operating Characteristic (ROC) curves and tables. For the evaluation metrics, FAR denotes the false alarm rate and TPR denotes the true positive rate, i.e., the likelihood of correct detection of a result. Some experimental parameters could be set reasonably in advance; for example, the parameter H of the non-overlapping segment was set to 256.
4.2. Datasets Used
In this paper, we used six datasets: the Dresden [
24] dataset, which has been extensively used in previous camera forensics research, and five datasets containing smartphone cameras (ALASKA [
26]; SOCRatES [
30]; Forchheim [
31]; SIHDR [
32]; VISION [
33]), three of which also contain images that have been processed by multiple online social networking platforms. The smartphone camera dataset was particularly important considering the rapid growth and popularity of today’s online social networking platforms, as well as the fact that the vast majority of captured images come from smartphones. We summarize the relevant content and features of each dataset below.
The Dresden [
24] dataset comprises over 16,000 images captured using 73 distinct digital cameras across 25 camera models. This classical dataset showcases a variety of lighting conditions and diverse scene compositions, including both indoor and outdoor environments, as well as settings featuring public places and natural elements like trees. To better simulate real-world scenarios, the dataset incorporates a range of camera settings, such as variations in focal length and the use of flash. To validate the performance of our proposed distributed source camera identification scheme, we used real JPEG images from the Dresden dataset to conduct experiments. All images were captured at the highest resolution and maximum JPEG quality factor. We randomly selected different camera models for the experiment and used all images from the selected camera models.
The Alaska [
26] dataset provides a comprehensive collection of 80,000 images captured by over 40 different cameras, ranging from smartphones and tablets to both low-end cameras and high-end full-frame digital single-lens reflex models. The dataset is designed to reflect a wide variety of real-world scenarios, encompassing highly heterogeneous image processing conditions. To facilitate use, especially for various study tasks, Alaska offers several preprocessed subsets. These subsets include uncompressed color and grayscale images available in standardized sizes of 512 × 512 and 256 × 256 pixels, as well as JPEG-compressed images with varying quality factors, ranging from 75 to 100. This diversity allows for flexibility in experimenting with different compression levels and resolutions, making the dataset a versatile tool for research in image processing and forensic analysis.
The SOCRatES [
30] dataset is a comprehensive dataset consisting of approximately 9700 images, captured using 103 different smartphones from 15 different brands and around 60 unique models. What sets SOCRatES apart from previously published datasets is its unique data collection process, where smartphone owners themselves captured the images, introducing a high degree of diversity and realism. With its wide range of 103 devices, SOCRatES holds the distinction of being the largest dataset for source camera identification in terms of sensor variety. Specifically designed to support the development and benchmarking of image forensic techniques on smartphones, this dataset is particularly valuable for addressing the source camera identification problem, although its applications extend beyond this.
The Forchheim [
31] dataset comprises approximately 4000 images sourced from 25 distinct smartphone camera models. This extensive collection showcases a diverse range of scene content and varying capture conditions, including indoor versus outdoor settings, day versus night scenarios, and close-up versus distant shots. By capturing multiple images of the same scene across different devices, the dataset effectively minimizes the influence of content variability, which can often obscure camera model identification processes. Furthermore, the dataset includes versions of these images that have undergone post-processing via five popular social media platforms (i.e., WhatsApp, Facebook, Instagram, Telegram, and Twitter). This dataset having multi-platform images is important because users often share images through these platforms, and images from different platforms reflect a variety of real-world usage patterns. Therefore, the application of camera model identification to post-processed images can provide valuable insights into more realistic application scenarios, thereby increasing the relevance and applicability of the research results obtained from this dataset.
The SIHDR [
32] dataset comprises 5415 images captured using 23 mobile devices under various conditions. All devices were set to their default camera configurations, and images were taken without the use of flash, in a range of environments, including both indoor and outdoor settings. Wu et al. [
13] further expanded the SIHDR dataset by introducing nine widely used social media platforms (Twitter, Telegram, WhatsApp, Instagram, Facebook, Weibo, QQ, Dingding, and WeChat), simulating image transmission across these platforms. This extension allows for a more comprehensive evaluation of the robustness of source camera identification approaches in real-world scenarios.
The Vision [
33] dataset comprises a total of 34,427 images, both in their original formats and in versions shared through social media platforms such as Facebook and WhatsApp. These media files were collected from 35 portable devices across 11 major brands. The VISION dataset serves as a benchmark for evaluating various image forensic tools. The dataset includes two main categories of images: ‘Flat’, which features scenes like skies or walls with minimal texture, and ‘Nat’, which includes more diverse scenes without restrictions on orientation or content. Of the 11,732 original images, 7565 were shared through Facebook and WhatsApp, bringing the total image count to 34,427. For Facebook, two separate albums were created to host the ‘Nat’ images—one for high-quality (FBH) and one for low-quality (FBL) versions, as permitted by the platform. This setup allows for a comprehensive evaluation of image forensics across different compression and sharing settings.
As shown in
Table 2, we introduce a summary of the number of images, camera models, and distinct camera devices included in the datasets used for the experiments.
4.3. Results and Discussion
To comprehensively evaluate the performance of the proposed distributed source camera identification approach, we considered several distinct scenarios. These included different identification environments, such as conventional settings and privacy-preserving contexts, as well as extensive testing across multiple datasets. Additionally, we assessed the approach in a real-world scenario, using images processed by various popular social media platforms to simulate practical conditions. To further illustrate the benefits of the distributed method, we compared its performance in both single-user and multi-user settings, highlighting the advantages of utilizing multiple secondary users in the identification process. In this work, we selected the method proposed by Chen et al. [
12] as the primary baseline for comparison, because it represents one of the most recent and state-of-the-art approaches in the field of source camera identification, particularly in encrypted environments. Furthermore, Chen et al.’s method has already been used in extensive experiments and comprehensive comparisons with several widely used and representative methods, such as those based on PRNU. These results have consistently demonstrated the superior performance of their approach over previous baselines. Therefore, to avoid redundancy and unnecessary duplication of prior comparative studies, and to maintain a focused, fair, and meaningful evaluation, we adopted Chen et al.’s method as the sole baseline in our experiments. This choice allowed us to directly assess the advantages of our proposed method against a strong and well-established benchmark, ensuring a clear and rigorous evaluation.
4.3.1. Single Secondary User Identification Performance in an Unencrypted Environment
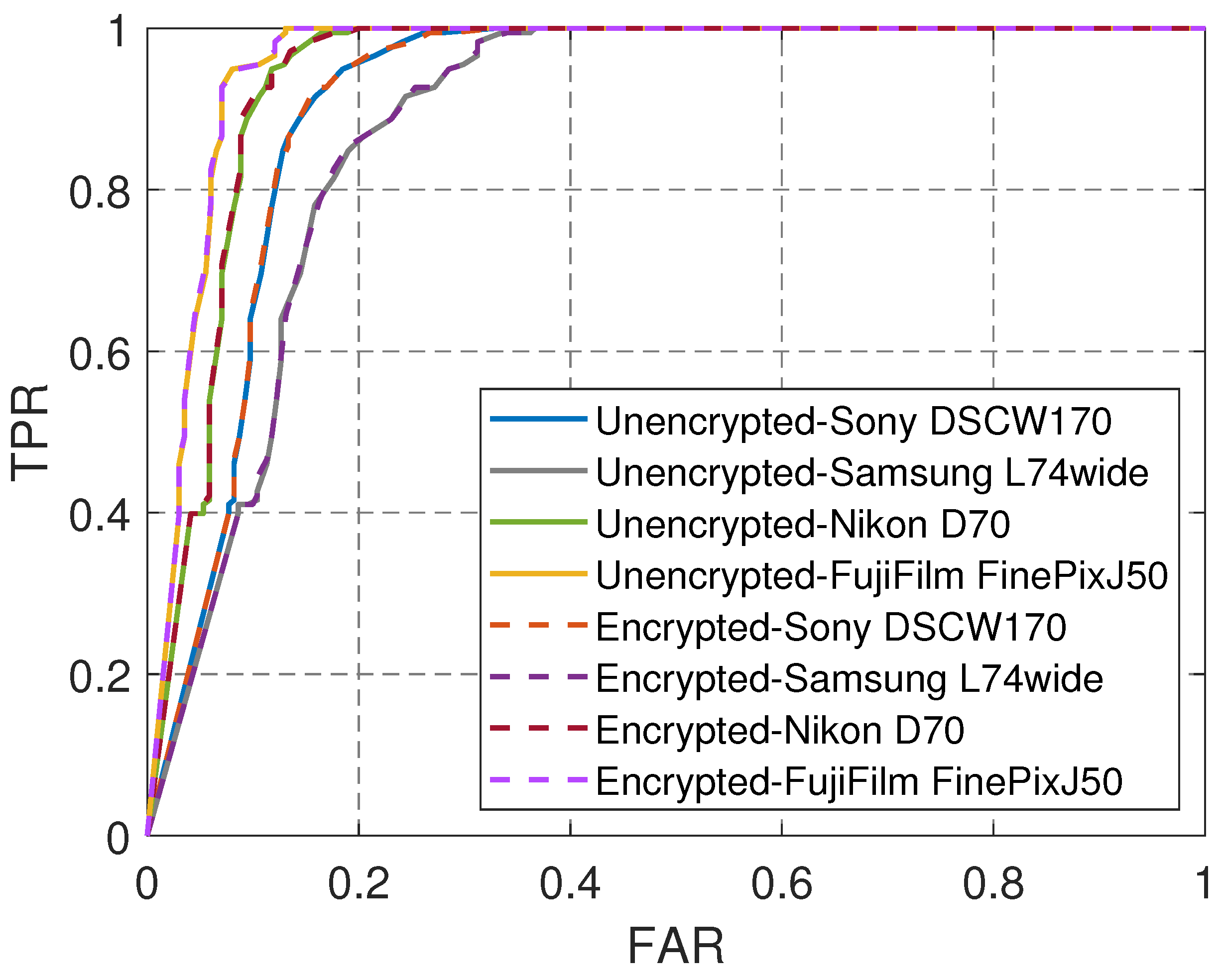
In this experiment, we focused on evaluating the effectiveness of the proposed hybrid fingerprint model for camera identification, considering only a single secondary user and without incorporating a privacy-preserving strategy. The performance of our model was compared to the statistical noise model proposed by Chen et al. As illustrated in
Figure 7, we randomly selected several camera models from the Dresden dataset to verify the identification performance. In this setup, Pentax was chosen as the target camera model
, while Sony, Samsung, Nikon, and Fujifilm served as non-target models
. The goal was to determine whether an image was captured using a Pentax or not.
Figure 7 provides a detailed comparison of the experimental results between the existing method by Chen et al. [
12] and our proposed approach under the same conditions. Notably, the Area Under the Curve (AUC) values obtained by our method consistently outperformed those of Chen et al. across four different scenarios. This demonstrates the superiority of our proposed scheme in achieving more accurate camera identification results. The results in
Figure 7 further highlight that combining unique camera fingerprints with our carefully designed tag enhanced the performance of identifying the camera model that captured the image. These findings validate the advantages of our hybrid fingerprint model in distinguishing between camera models, showcasing its potential for more reliable source camera identification.
4.3.2. Single Secondary User Identification Performance in Different Identification Environments
With the growing popularity of social media platforms and the rapid development of image processing tools, it has become increasingly easy for malicious attackers to tamper with, forge, and distribute images. When digital images are used as forensic evidence, both the image content and source are often highly sensitive, especially in security and legal contexts. Therefore, protecting the privacy of images during the source camera identification process is critical. To address this, we implemented the privacy-preserving strategy described in
Section 2.2.2, ensuring that image privacy is maintained throughout the identification process. To demonstrate that the privacy-preserving strategy does not affect the identification performance, and considering that the GLRT theoretically relies on specific statistical assumptions (e.g., the noise obeys a normal distribution and the variance is known), we further empirically validated the encrypted image data to assess whether these statistical assumptions still held in the privacy-preserving environment. In our experiments, Canon served as the known camera model
, while Sony, Samsung, Nikon, and Fuji were used as unknown camera models
. For each case, we determined whether the images originated from the Canon camera, comparing results in both before and after encryption environments. The ROC curves, shown in
Figure 8, visualize the identification results before and after applying the privacy-preserving strategy. As seen in
Figure 8, the AUC for the four different cases were similar before and after encryption. This results indicates that the privacy-preserving strategy did not affect the identification performance. Thus, the strategy can be used to protect the authentic content and source of images during the source camera identification process.
4.3.3. Single Secondary User Source Device Identification Performance in an Encrypted Environment
With the popularity of low-cost image acquisition devices and the widespread use of different devices with the same camera model, accurately distinguishing digital images captured by different devices of the same model has become critically important in the field of image forensics. Even among devices of the same model, each camera can introduce unique characteristics during the image capture process, such as variations in sensor noise, lens imperfections, or other subtle manufacturing discrepancies. These device-specific traits generate distinctive fingerprints that allow for the precise identification of the specific device used to capture a given image, rather than merely identifying the camera model.
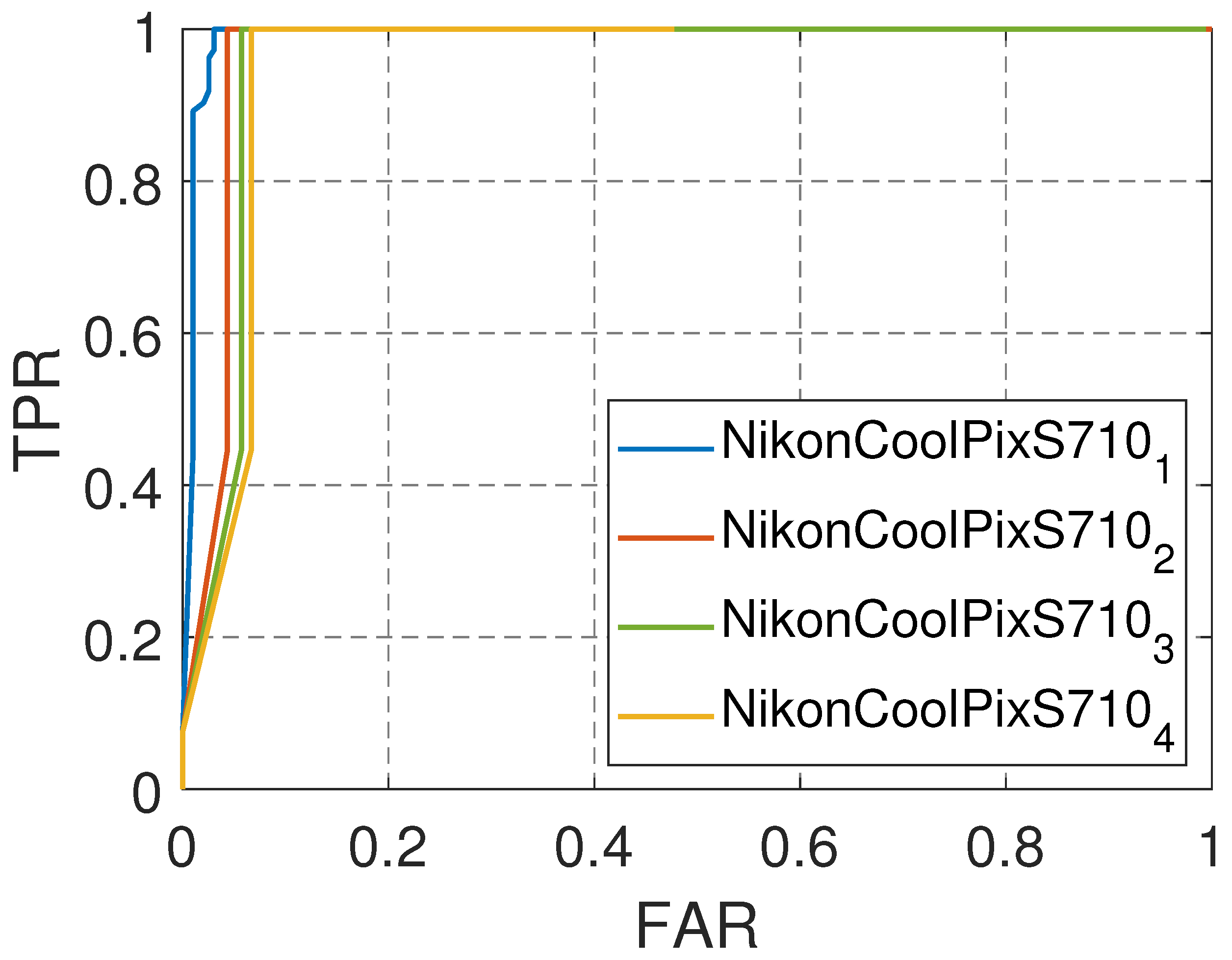
In our study, as illustrated in
Figure 9, we used Nikon as a case study, conducting experiments with multiple devices of the same camera model to evaluate the efficacy of our proposed method for source device identification. We did not compare our results with those of Chen et al., because their source camera identification method does not extend to the identification of specific devices within the same model. The Receiver Operating Characteristic (ROC) curve was employed to evaluate the performance of our approach, where a curve closer to the upper left corner indicates a higher TPR and lower FPR, corresponding to a larger AUC and better identification performance. As shown in
Figure 9, the proposed method achieved high AUC values when distinguishing between different devices of the same camera model, highlighting its effectiveness in source device identification. It is worth noting that device aging and sensor degradation over time may affect the physical-layer fingerprint of a camera, and the differences between devices of the same model are typically more subtle than those between different models. Therefore, the strong identification performance across multiple devices of the same model further demonstrates the robustness and practicality of the proposed approach.
4.3.4. Single Secondary User Identification Performance on Different Social Media Platforms
With the rapid advancement of the Internet, social media platforms have become the primary means of sharing images. Therefore, forensic efforts to identify the source camera model are increasingly focused on images that have been transmitted through these platforms. However, during transmission, each platform applies its own set of post-processing operations, such as JPEG compression and image rescaling, with the specific parameters for these processes typically unknown. These unknown and platform-specific operations can significantly alter the statistical characteristics of an image, potentially deviating the image data from its original distribution. Such alterations introduce substantial challenges for source camera identification, especially for methods that rely on fine-grained sensor noise patterns or statistical assumptions.Therefore, to ensure the practical applicability of the proposed method, it was essential to evaluate its robustness under real-world conditions involving post-processed images.
To address the above challenges, we performed a series of experiments using the Forchheim dataset. This dataset includes both original images captured by smartphones and corresponding versions that have been post-processed by various social media platforms. As depicted in
Figure 10, we first evaluated the identification task performed by a single secondary user, comparing source camera identification across the same set of images having undergone different post-processing steps. The results in
Figure 10 show that, in all six experimental scenarios, our method consistently achieved a higher AUC compared to the method of Chen [
12]. Furthermore, the variations in identification accuracy for the same image processed by different platforms can be attributed to the unique effects of these platforms’ processing operations on the original sensor noise of the image. Despite these variations, the findings from
Figure 10 demonstrate that our proposed method remained robust in the face of real-world post-processing, maintaining reliable performance even when images have been altered by social media platforms.
4.3.5. Comparison Considering Single and Multiple Secondary Users
In source camera identification, traditional methods typically rely on a single secondary user to perform the identification task. While single-user identification can produce reasonable results, it is limited by the information and computational resources available to that one user, which can result in reduced accuracy, especially when handling complex datasets or images impacted by noise, compression, and other post-processing effects. To address these limitations, we propose a distributed source camera identification scheme that utilizes multiple secondary users working collaboratively. By combining the resources and perspectives of multiple secondary users, the distributed approach enables us to capture the unique characteristics of camera fingerprints more effectively, even in challenging environments. Additionally, the distributed method enhances the overall reliability of the identification process, as the consensus drawn from multiple users helps to mitigate the impact of noise and other distortions, reducing the likelihood of errors.
The accuracy results for each secondary user and the central classifier in the distributed source camera identification scheme are detailed in
Table 3 across six datasets: Dresden, ALASKA, SOCRatES, Forchheim, SIHDR, and VISION. Note that bold text in the table indicates the best result among all methods for each indicator in this paper. The results indicate that the central classifier consistently achieved an accuracy equal to or higher than that of individual secondary users across all datasets, demonstrating superior performance and stability. Notably, the central classifier matched the accuracy of the secondary users on the Forchheim and VISION datasets, achieving scores of 0.9925 and 0.9999, respectively. However, the central classifier surpassed some secondary users on the Dresden, ALASKA, SOCRatES, and SIHDR datasets, achieving accuracies of 0.9822, 0.9793, 0.9886, and 0.9750, respectively. In fact, in the digital forensics field, even subtle improvements in identification accuracy are critical for ensuring fair and reliable outcomes in decision-making processes. Therefore, the results in
Table 3 highlight the robustness and efficacy of our proposed distributed approach in maintaining a high identification accuracy across diverse datasets.
4.3.6. Evaluation of Multiple Secondary Users on Different Datasets
To demonstrate the generalizability and effectiveness of the proposed distributed source camera identification method, it was essential to evaluate its performance across a variety of datasets. Each dataset represents different shooting conditions and camera models, reflecting the diversity encountered in real-world scenarios. By conducting experiments on original images from four distinct datasets (i.e., Dresden, Alaska, Forchheim, and Vision), we aimed to validate the robustness and adaptability of the method across different environments.
Table 4 presents the experimental results comparing our proposed distributed source camera identification scheme with the method by Chen et al. across six distinct datasets. The results demonstrate that our method significantly outperformed Chen et al.’s approach on all datasets. Specifically, our approach achieved higher accuracy rates, with values of 0.9822 on the Dresden dataset, 0.9793 on the ALASKA dataset, 0.9886 on the SOCRatES dataset, 0.9925 on the Forchheim dataset, 0.9750 on the SIHDR dataset, and 0.9999 on the VISION dataset. In contrast, Chen et al.’s method showed lower accuracy across these datasets, particularly on the SOCRatES and SIHDR datasets, where the accuracy values were 0.2614 and 0.45, respectively. The results in
Table 4 illustrate the robustness and superior performance of our method across a diverse range of datasets and challenging image conditions.
4.3.7. Effectiveness of Multiple Secondary Users on Different Social Media Platforms
To further demonstrate the robustness of our proposed distributed source camera identification method, we conducted a series of experiments using images processed through various social media platforms.
Table 5 shows the results of source camera identification on digital images from the VISION dataset, which have been subjected to various post-processing operations on different social media platforms. As shown in
Table 5, in the NatFBH and NatWA categories, our method achieved near-perfect accuracy (0.9999), which demonstrates the robustness of our method under different image conditions. However, in the NatFBL category, our method obtained a slightly lower accuracy of 0.8855 compared to 0.9912 for Chen et al. This is due to the fact that different social media platforms may exhibit distinct characteristics in terms of image processing and sharing. For example, images on NatFBL may undergo different compression algorithms, resolutions, or color treatments compared to other platforms. As a result, the method proposed by Chen et al. might be better suited to the specific image characteristics of NatFBL. Nevertheless, the overall average accuracy of our method was 0.9618, which demonstrates the better stability of our method in general. The results in
Table 5 highlight the effectiveness of our proposed scheme, even when dealing with images of varying quality that have undergone unknown operations.
Similarly,
Table 6 summarizes the results obtained from experiments conducted on the Forchheim dataset, which includes images processed by a variety of social media platforms. Our method consistently outperformed the approach proposed by Chen et al. in most categories, except for the Facebook category. In the Facebook case, Chen et al.’s method slightly surpassed ours, achieving an accuracy of 0.9925, whereas our method recorded an accuracy of 0.9173. The slightly lower performance of our approach on the Facebook platform was due to similar reasons as those observed for NatFBL in
Table 5. However, our method achieved a good accuracy of 0.9999 for images processed by Instagram, Twitter, Telegram, and Whatsapp. Moreover, the overall mean accuracy of our method was 0.9834, surpassing the average accuracy of 0.8947 achieved by Chen et al. The results in
Table 6 further highlight the adaptability and robustness of our distributed source camera identification method in real-world scenarios.
5. Discussion
In this paper, we primarily investigated how to enhance the reliability and accuracy of source camera identification techniques, and validated our scheme on several well-established image datasets. However, when considering the future expansion of the framework’s application, several key issues still need further exploration.
First, regarding dataset diversity, the current evaluation was primarily based on certain widely used classic image datasets. However, in real-world applications, we may encounter images with extreme distortions, such as compression artifacts, low lighting, or adversarial modifications. Therefore, future research should focus on exploring these special cases, to more comprehensively assess the robustness of the framework. Furthermore, images from rare or outdated camera models are typically excluded from mainstream datasets, which may lead to biases in the framework towards certain camera types or brands, potentially causing systemic discrepancies and affecting the fairness of the identification process. To address the above issues, future studies should consider creating synthetic datasets or incorporating images from underrepresented regions and manufacturers, thereby improving the framework’s generalizability and practicality.
Second, the potential enhancement of source camera identification performance through image cropping could be considered. Current research primarily relies on identifying the source camera of complete digital images, which may not fully leverage the feature information from local regions within the image. More importantly, local regions of the image may be forged or tampered with, affecting the overall authenticity of the image. Therefore, future research could explore various image cropping strategies, considering dividing the image into multiple local regions for independent identification, and then combining the results from each cropped region to infer the source of the entire image. This approach could not only help better identify the integrity and authenticity of the image, but also effectively enhance the robustness of the framework, preventing misjudgments caused by local tampering or distortion.
Third, ethical issues need to be given high priority. For instance, malicious actors could misuse this technology for unauthorized surveillance or to falsely attribute images in legal cases, leading to privacy violations or wrongful accusations. Therefore, future work should delve into privacy-preserving strategies to ensure that the framework complies with relevant privacy protection regulations (such as GDPR or other regional laws) to avoid potential legal and social risks, especially in sensitive application scenarios.
Overall, future research should focus on expanding the framework’s applicability, enhancing dataset diversity, exploring reasonable image cropping strategies, and thoroughly considering the ethical and legal implications, ensuring that source camera identification technology is comprehensively safeguarded in terms of fairness, privacy protection, and practical utility.
6. Conclusions
By jointly utilizing the unique physical layer fingerprint features of cameras and our carefully designed tag, we proposed a new source camera identification scheme with privacy preservation. Based on our hybrid fingerprint model and privacy-preserving strategy, we also developed a GLRT for a single assisted user to identify the source camera of an image in an encrypted environment. The experimental results in this paper show that the authentic content and source of the images could be protected by the privacy-preserving strategy. Meanwhile, the identification performance was enhanced by combining the physical layer fingerprint features of the camera and our carefully designed tag. Finally, by combining the preliminary identification results from multiple secondary users, the distributed source camera identification scheme had a higher reliability.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}