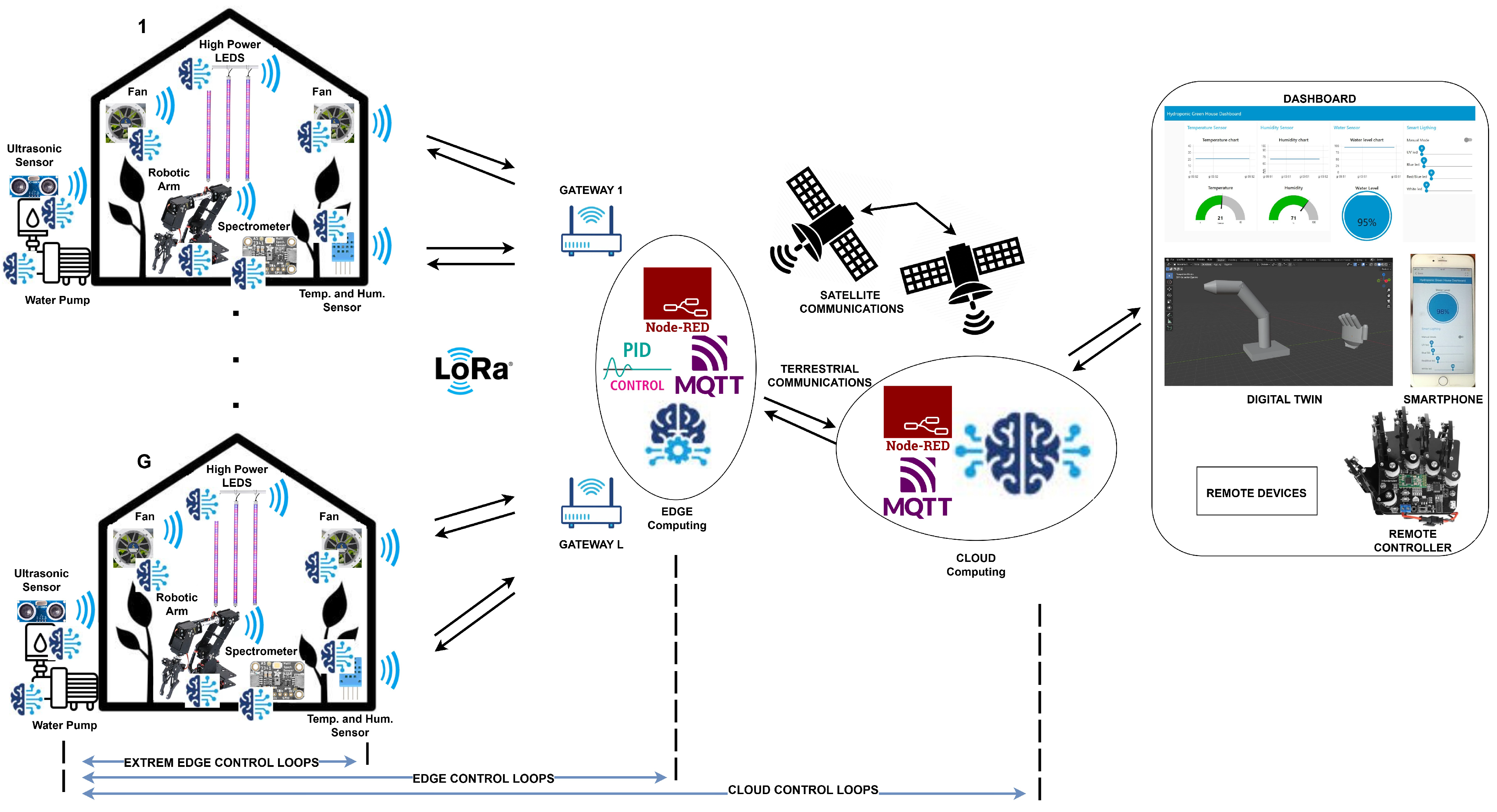
4.1. Network Architecture
The proposed network architecture comprises a certain number
G of greenhouses, each containing a series of extreme edge devices for sensing and actuation. This component is represented on the left side of
Figure 2, which illustrates the entire employed network architecture.
The extreme edge devices within the GHs communicate using LoRa modulation at 2.4 GHz, leveraging the capabilities of the latest SX1280 Semtech chip. Compared to other low-power consumption technologies such as ZigBee, SigFox, and IEEE 802.11ah (Wi-Fi HaLow) [
37,
38], LoRa offers several advantages: lower power consumption, greater robustness against interference, and a longer communication range of up to 10 km in line of sight [
31,
39]. This is particularly beneficial when GHs are installed in remote and/or rural areas far from the main building, where internet coverage is typically available. Moreover, employing LoRa at a 2.4 GHz frequency enables global compatibility and seamless usability without requiring special configurations or transmission authorization, unlike technologies operating in licensed spectrum.
For data processing and sharing, the concept of the cloud continuum is adopted, distributing computation across both the network edge and the centralized public cloud. Communication between these components occurs via the public internet, which is well known to utilize both terrestrial and satellite communications. This approach reduces communication latency for stringent actuation control loops by exploiting edge computing while simultaneously enabling more accurate decision-making and retrospective adjustment of prior decisions, due to the greater computational power offered by centralized cloud computing. The Node-RED low-code/no-code paradigm has been implemented both at the edge and in the cloud to facilitate the integration of new sensing and actuating devices into the GHs and to develop monitoring and control functions. The choice of using the computing server Node-RED is driven by its ability to facilitate data processing through an intuitive and fast block-based programming approach. As the transport protocol, Message Queuing Telemetry Transport (MQTT) has been employed among all entities in the network architecture: extreme edge devices, edge computing, cloud computing, and remote devices. This choice is justified by its simplicity of implementation and low processing overhead on the network [
40].
The proposed network architecture also enables human interaction via remote devices, such as dashboards for visualizing monitored data like temperature and humidity trends, water trunk levels and light intensity, and issuing manual commands to be executed in the GHs, digital twins of specific GH services for monitoring their status and prototyping new functionalities, and wearable controllers for transmitting commands to the extreme edge devices [
41].
In our application scenario, the developed network architecture consists of four distinct hydroponic greenhouses (
) and two gateways for LoRa coverage (
). Edge computing, incorporating the MQTT broker and Node-RED server, has been implemented on a Raspberry Pi 5 board, while cloud computing utilizes the public cloud Microsoft Azure. More specifically, the extreme edge devices installed in the GHs include [
12] high-power LEDs (UV, red, blue, and white), temperature and humidity sensors, ultrasonic sensors, spectrometers, fans, robotic arms, and water pumps. Each of the aforementioned sensors and actuators is connected to the gateway and directly to others through an STM32 microcontroller and an SX1280 module.
Through this network architecture, three types of control loops can be developed: extreme edge control loops, edge control loops, and cloud control loops. Typically, in other architectures, only edge and cloud loops are utilized, transferring sensor data from the GH to external computing units. This enhances control accuracy and decision-making through more complex algorithms, benefiting from higher computational power. However, it also increases the latency between sensing and actuation (such as cooling system activation, water pump control and illumination adjustment). In case of stringent latency requirements, the optimal approach is to employ extreme edge control loops with direct communication between sensors and actuators. In this case, computing and decision-making must be performed immediately on the microcontroller, which is the primary focus of this paper. Indeed, our work reduces the complexity of the NNs in terms of memory-allocated variables and the number of FLOPs required for microclimate prediction and classification.
4.2. Dataset Construction
To demonstrate the validity and improvements of our approach, we installed a Davis Vantage PRO 2 weather station sensor [
42] in each of the four GHs to collect temperature and humidity data with an accuracy of ±0.3 °C and ±2%, respectively. The four GHs contain cultivated tomato plants and are located in different areas of Pisa, Italy, which reduces the dependency between the collected data compared to having all GHs in the same location. Specifically, data were sampled every 15 min throughout the entirety of 2024, resulting in a dataset consisting of 35,136 samples per GH and monitored parameter, for a total of 281,088 recorded values.
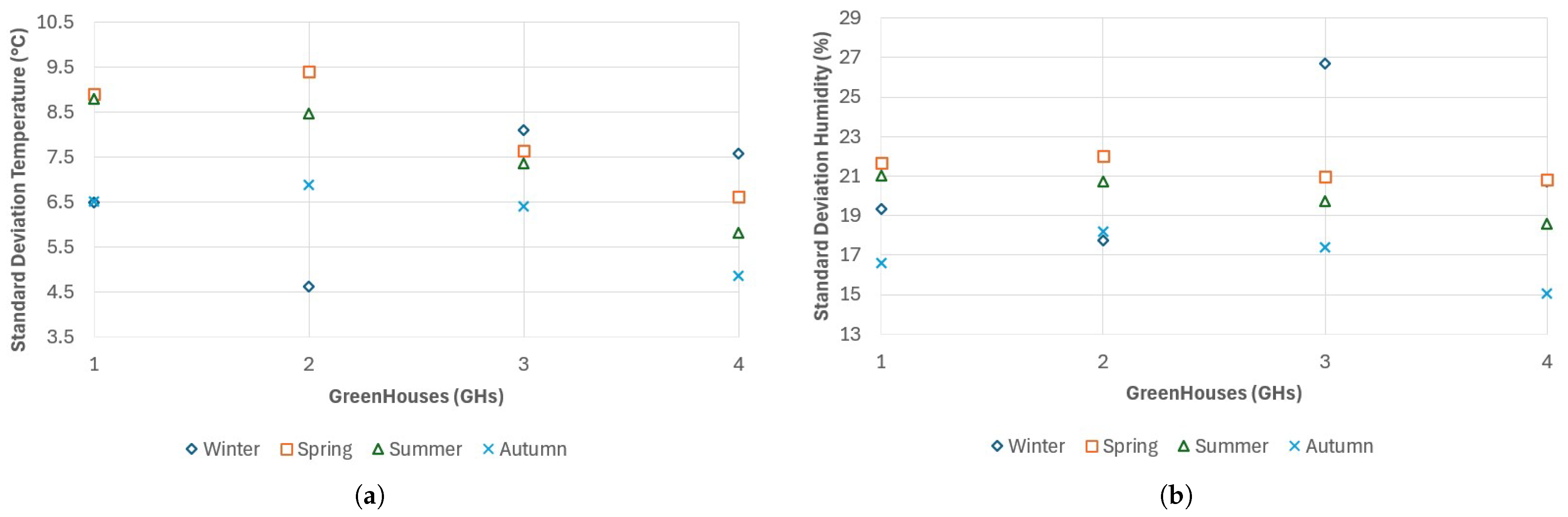
In
Figure 3, we illustrate the average temperature and humidity for the four distinct GHs (represented by different colors) across the four seasons.
From
Figure 3, it can be observed that the mean temperature varies significantly across seasons compared to the variation in mean humidity. Moreover, among the different GHs, the temperature variation is more pronounced during summer and winter, whereas the variability in humidity remains more uniform across the GHs.
Conversely,
Figure 4 shows the standard deviation of temperature and humidity across the GHs and throughout the seasons.
Regarding the standard deviation of temperature, it can be noted that the four GHs exhibit different behaviors. On the other hand, the humidity trend appears more uniform across the GHs, except for a peak during winter in GH3. Indeed, the fact that they are located in different areas reinforces the idea that the data from the various greenhouses are independent of one another.
Additionally,
Table 2 presents the minimum and maximum temperature and humidity values for each GH, as well as the global values for the dataset, which are later utilized in
Section 4.3.
4.3. Hybrid Neural Network and Fuzzy Proposed Approach
Our hybrid approach incorporates a NN for time series prediction, followed by a fuzzy layer to classify the NN’s output; specifically, greenhouse microclimate conditions. The primary objective is to reduce NN complexity while maintaining performance levels in a way that is comparable to those of a standard NN classifier. In particular, we have chosen a FFNN as our reference NN model, as explained in
Section 3.
The FFNN consists of an input layer, a hidden layer, and an output layer. The input layer receives past temperature and humidity values at hourly intervals. During the search for the optimal configuration, the number of input features will be varied, as discussed in
Section 5. Additionally, the size of the hidden layer, defined by the number of interconnected nodes between the input and output layers, will be adjusted in the experimental trials. Finally, the output layer generates two numerical outputs, corresponding to the predicted temperature and humidity for the next hour. These predicted values will then be processed by the fuzzy layer to produce the final microclimate classification.
Our proposed solution is compared to the standard approach, in which the NN directly outputs the final microclimate classification.
For training both the proposed and standard NN models, we employed the Levenberg–Marquardt algorithm [
34], which is commonly used for this purpose.
Regarding the activation function, our approach utilizes the ReLU function, as it provides the numerical temperature and humidity predictions required for the fuzzy layer. In contrast, the standard approach employs the sigmoid function, which outputs probabilities for microclimate classification.
For backpropagation, both approaches use MSE to compute the gradient of the loss function with respect to the selected weights and biases.
More specifically, our approach integrates numerical predictions from the FFNN with the concept of granular computing, in particular fuzzy sets, aiming not only to reduce the complexity and size of the NN architecture but also to enhance the interpretability and reliability of the predicted classifications.
Fuzzy sets are defined as follows [
43]:
Definition 1. Given a domain , with x being a generic element of , the fuzzy set A in is defined as the set of pairs , characterized by a membership function that associates a real number in the interval with each element of . The value of represents the degree of membership of x in A.
For , x definitely belongs to A.
For , x does not belong to A.
For , x partially belongs to A.
For the fuzzy sets, we employed triangular membership functions, as they provide a more accurate representation of phenomena exhibiting gradual and continuous variations. The triangular membership function is defined as follows:
where
a and
c define the base points of the triangle, while
b represents the peak position.
With reference to tomato plant cultivation, we set the optimal growth thresholds for temperature and humidity according to
Table 3, based on [
44].
Each cell follows the format [a, b, c], as in Equation (
5). Additionally,
and
represent the global minimum temperature and humidity values in the dataset, while
and
denote their respective global maximum values, as shown in
Table 2. In this way, each temperature and humidity value will be associated with a fuzzy set through a specific degree of membership for each membership function, ranging from zero to one. The membership functions constructed in this manner take into account all input values from the dataset, from the minimum to the maximum.
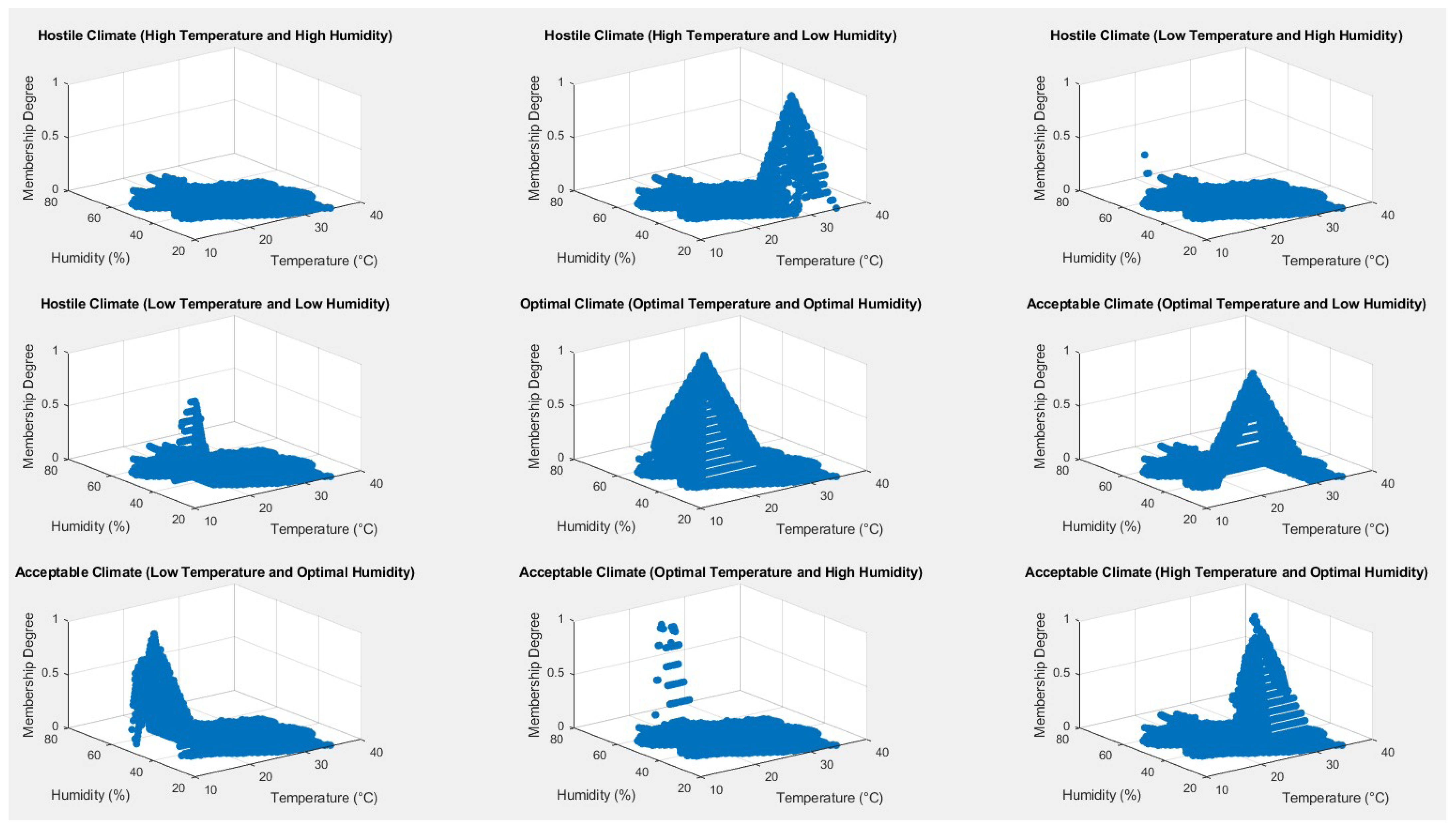
To resume, the fuzzy layer consists of six triangular membership functions, each corresponding to a different class of temperature and humidity: low temperature, optimal temperature, high temperature, low humidity, optimal humidity, and high humidity.
Using these six membership functions, we defined the final microclimate classifications based on a rule set that combines temperature and humidity membership functions. This rule set uses the values of the membership functions to determine their influence on the final classification. Specifically, the final classification is computed by finding the minimum of the membership degrees for each combination of temperature and humidity membership functions, resulting in nine decision classification degrees, corresponding to the entries of
Table 4, excluding Out of Knowledge (OOK). Among the nine decision classification degrees, the maximum is identified and selected as the final classification. If the maximum is zero, the system will return the OOK classification. As detailed in
Table 4, the possible final classifications are Optimal, Acceptable, Hostile microclimate conditions, and OOK prediction.
An additional advantage of the proposed approach is the ability to output an OOK classification, enhancing the reliability of classifications derived from the FFNN’s numerical predictions. It is well known that NNs always generate an output, even in cases where the prediction is unreliable. To mitigate this issue, our approach introduces a dedicated OOK classification when the predicted temperature and/or humidity values do not fall within any of the previously defined triangular fuzzy sets. This prevents the generation of misleading outputs outside the reliability ranges, i.e., the range of values present in the dataset used for training, from which the NN learned the temporal patterns.
Finally, to evaluate the overall performance of the proposed approach (FFNN + fuzzy) and the standard approach, we employed the
metric, defined by the following Equation (
6):
where
,
, and
.



 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}