1. Introduction
Stroke continues to be one of the foremost contributors to both morbidity and mortality at a global level, posing considerable diagnostic challenges attributable to its complex pathogenesis and the diverse imaging modalities required for its accurate identification [
1]. Recent progressions in machine learning (ML) and artificial intelligence (AI) have initiated a transformative shift in this field by enhancing the diagnostic accuracy and operational efficiency [
2]. These advanced technologies possess the capability to analyze heterogeneous data—from structured clinical indicators available in extensive repositories such as the eICU Collaborative Research Database (eICU DB) [
3] to intricate imaging data derived from CT and MRI scans—thereby reducing diagnostic times and promoting timely, evidence-based clinical decisions [
4].
AI-augmented models, particularly deep learning architectures such as convolutional neural networks (CNNs), have exhibited substantial improvements in the evaluation of imaging data [
5]. Reported detection accuracies are documented to range from 70% to 90% with MRI images, and can ascend to as high as 98.42% for CT images when employing cutting-edge models [
6]. Moreover, these systems demonstrate adeptness in differentiating between ischemic and hemorrhagic strokes while optimizing patient selection for interventions like thrombolysis [
7]. Nonetheless, challenges persist regarding the data quality, class imbalance, algorithmic transparency, and the seamless incorporation of these technologies into clinical workflows [
8]. Additionally, the inherent variability in stroke manifestations and imaging techniques necessitates the implementation of robust, multimodal strategies [
9].
The research articulated in this paper addresses these challenges through the formulation of an integrated stroke diagnosis framework that capitalizes on both structured clinical data from the eICU DB and curated imaging data [
10]. By synthesizing traditional ML approaches—such as XGBoost and CatBoost—with contemporary deep learning methodologies, exemplified by a MobileNet-based CNN, and employing ensemble techniques, our strategy aspires to elevate both the diagnostic accuracy and clinical applicability [
11].
This paper is systematically organized into seven chapters.
Section 1, the Introduction, elucidates the significance of stroke diagnosis and the transformative capabilities of AI, summarizing the challenges and prospects inherent in multimodal data integration while delineating the paper structure.
Section 2, the Literature Review, systematically explores sophisticated AI diagnostic methodologies within the healthcare domain, focusing on stroke detection through both conventional and novel ML techniques, and contrasts various models to illuminate the progression of diagnostic practices.
Section 3, the Methodological Framework, elaborates on the theoretical underpinnings of this study, detailing the amalgamation of structured and imaging data, preprocessing strategies for diverse datasets, and the rationale underlying the selected machine learning algorithms.
Section 4, the Methodology Development, builds upon the theoretical framework by articulating the experimental design, encompassing the technological components, multimodal data integration strategies, modeling techniques, and optimization processes employed.
Section 5, the Theoretical Evaluation, presents a rigorous critique of the models utilizing quantitative metrics and visual diagnostics, discussing the trade-offs among various approaches and evaluating the support for the foundational hypotheses.
Section 6, the Discussion, synthesizes the findings, addressing the strengths and limitations of the approach, the representativeness of the data, model calibration, and proposing future research trajectories for system enhancement.
Finally,
Section 7 concludes by encapsulating the research contributions and implications, highlighting the potential of AI in stroke diagnosis, while recognizing persistent challenges and suggesting avenues for future clinical integration.
This paper conducts a comprehensive examination of AI applications in stroke diagnosis, amalgamating multimodal data and various modeling techniques to improve diagnostic precision and accelerate treatment decisions [
12].
While previous research has utilized machine learning for structured ICU data and deep learning for neuroimaging independently, no current study integrates these modalities into a singular, CPU-only, open-source pipeline that ensures complete hyperparameter transparency and threshold calibration aimed at enhancing clinical recall. Our contribution addresses this gap by providing an early fusion framework that integrates eICU numerical features and stroke images through concatenated feature vectors, comprehensive hyperparameter grids for XGBoost, CatBoost, and MobileNet V2, along with a reproducible threshold search procedure that enhances the stroke sensitivity from approximately 47% to approximately 71%. By disseminating both the code and the precise parameter configurations (including seed = 42, SMOTE oversampling, 70/30 stratified divides, and 80/20 image splits), we facilitate the replication and extension of our research in real-world critical care environments.
2. Literature Review
Machine learning and deep learning are transforming disease diagnosis by enhancing the accuracy, efficiency, and early detection [
13]. In ophthalmology, AI models have increased the diagnostic accuracy and efficiency by 20%, while reducing the time spent by 40% [
14]. Deep learning has shown expert-level capabilities in diagnosing ocular diseases using imaging data [
15]. AI aids in synthesizing multidimensional biomarker data for neurodegenerative diseases, improving evaluation precision [
16]. In oncology, AI techniques like Explainable AI and the Triplet Network method exhibit high accuracy in early lung cancer diagnosis, facilitating personalized treatment and risk management [
17]. In the area of the automated classification of ECG signals for identifying various heart arrhythmias, deep learning has provided significant improvements due to the ability to directly learn features from large datasets, and also offering multimodal strategies combining automatically and manually extracted signal features [
18].
Various AI methodologies enhance medical classification efficacy and precision. Leading methods for image-based diagnosis include artificial neural networks (ANN), support vector machines (SVM), the k-nearest neighbor (KNN), decision trees (DT), random forests (RF), and convolutional neural networks (CNN) [
19]. Natural language processing (NLP) is utilized for medical text classification, achieving substantial accuracy. The incorporation of AI in healthcare enhances diagnostic capabilities and patient treatment, fostering personalized care approaches [
20].
2.1. Stroke Diagnosis Methods
Traditional stroke diagnosis predominantly employs imaging techniques, notably computed tomography (CT) scans, which are vital for swiftly detecting acute ischemic strokes (AIS) and excluding hemorrhagic strokes [
21]. CT-angiography (CTA) is essential for detecting large-vessel occlusions (LVOs) and evaluating salvageable brain tissue via multiphase CTA and CT-perfusion (CTP) [
22]. Magnetic resonance imaging (MRI) is utilized for patients beyond the thrombolysis time window, aiding in treatment selection based on tissue viability rather than time since stroke onset [
23]. The imaging methods’ primary objectives include rapid hemorrhagic stroke exclusion, LVO identification, and ischemic core size estimation to inform treatment decisions [
24]. Despite their efficacy, traditional methods are often time-intensive and susceptible to human error, prompting the creation of computer-aided diagnostic (CAD) systems that improve diagnostic precision and efficiency through advanced image analysis [
25]. Furthermore, metabolomics is emerging as a valuable early diagnostic tool by detecting ischemic stroke biomarkers, although its clinical application remains limited [
26]. Collectively, these diagnostic approaches aim to enhance patient outcomes through timely and precise stroke diagnosis [
27].
In clinical practice, stroke assessment commences with a targeted history and neurological examination, often measured by the NIH Stroke Scale (NIHSS). Patients receive an evaluation of awareness, facial symmetry, motor strength, coordination, and linguistic function, in addition to vital signs and fundamental laboratory tests (full blood count, electrolytes, coagulation studies, and blood glucose). This preliminary assessment identifies candidates for time-sensitive therapies and aids in differentiating stroke mimics.
Subsequent to clinical screening, imaging is conducted promptly. A non-contrast head CT scan is performed to rule out cerebral bleeding. If ischemia is suspected, CT angiography (CTA) and CT perfusion (CTP) tests are performed to identify major artery occlusions and evaluate the at-risk penumbral tissue. In specific instances—especially when the precise initiation time is ambiguous—a diffusion-weighted MRI sequence offers enhanced sensitivity for detecting early ischemia alterations. Novel blood biomarkers (e.g., D dimer, glial fibrillary acidic protein) may enhance diagnostic precision, but are still under development.
AI-based diagnostic methods exhibit varied effectiveness relative to traditional techniques across medical disciplines [
28]. In gastric neoplasia endoscopic diagnosis, AI systems achieved comparable accuracy to human endoscopists, particularly excelling in high-grade dysplastic lesion detection with an 80% detection rate versus 29.1% by specialists [
29]. Moreover, AI systems significantly expedited diagnostic processes, indicating potential benefits for human endoscopic diagnosis [
30]. In chest X-ray evaluations, AI-assisted diagnostics improved nonradiologist physicians’ accuracy in identifying and localizing lung lesions, achieving an area under the curve (AUC) of 0.84 compared to 0.71 without AI support [
31]. This illustrates AI’s capability to enhance diagnostic precision and efficiency, albeit its influence on clinical decision making remains ambiguous [
32]. In dementia diagnosis, AI combined with MRI has elevated the accuracy for conditions like Alzheimer’s disease, reporting rates between 73.3% and 99%, highlighting AI’s potential to refine an early and accurate diagnosis alongside conventional imaging [
33]. Additionally, AI models in gastrointestinal diagnostics have shown high sensitivity and specificity, with deep learning and ensemble methods, achieving sensitivities of 89.8% and 95.4%, respectively, and specificities around 91.9% and 90.9% [
34]. This indicates that AI may equal or exceed traditional methods in specific scenarios, though further large-scale studies are essential for validation across various clinical contexts [
35]. Overall, while AI demonstrates promise in enhancing the diagnostic accuracy and efficiency, its clinical integration necessitates a careful assessment of limitations and the requirement for additional validation [
36].
2.2. Machine Learning and Deep Learning in Stroke Detection
Recent advancements in machine learning and deep learning demonstrate considerable potential in stroke diagnosis, utilizing diverse techniques to improve the prediction accuracy and efficiency [
37]. A hybrid model integrating a stacked Convolutional Neural Network and Group Method of Data Handling (GMDH) with Long Short-Term Memory (LSTM) networks has been created for stroke prediction, attaining an accuracy of up to 99% through the analysis of electromyography (EMG) signals [
38]. Enhanced deep learning models, including VGG16, ResNet50, and DenseNet121, have been optimized for brain stroke detection using MRI imagery, with ResNet50 achieving the highest accuracy of 95.67% [
39]. The Optimized Ensemble Deep Learning (OEDL) method represents an innovative approach that combines clinical and radiomics features for the prognosis of acute ischemic stroke. It achieves a Macro-AUC of 97.89% and exhibits an enhanced classification performance relative to traditional methods [
40]. Machine learning techniques such as Random Forest, XGBoost, and AdaBoost have been effectively utilized for early stroke prediction, with Random Forest attaining a classification accuracy of 99% [
41]. These models employ data from medical reports and physical conditions to forecast stroke occurrences, demonstrating the capabilities of machine learning algorithms in real-time medical applications [
42]. These studies demonstrate the effectiveness of integrating deep learning and machine learning techniques to enhance stroke diagnosis and prognosis, providing essential tools for early intervention and tailored treatment approaches [
43].
Artificial intelligence models provide notable benefits in cardiovascular diagnostics, particularly in terms of improved diagnostic accuracy, enhanced predictive capabilities, and increased scalability [
44]. Machine learning algorithms are being applied to various cardiovascular conditions, including heart failure, valvular heart disease, and coronary artery disease. These applications improve diagnostic and prognostic capabilities, thereby enhancing patient care [
45]. The application of AI to electrocardiograms (ECGs) has transformed the identification of hidden and imminent cardiac diseases, facilitating early intervention and potentially decreasing negative clinical outcomes [
46]. Deep neural networks can detect intricate, non-linear alterations in ECGs, aiding in the diagnosis of conditions such as ventricular dysfunction and hypertrophic cardiomyopathy prior to the onset of symptoms [
47]. Additionally, AI models can automate the interpretation of diagnostic images, thereby decreasing reliance on clinician expertise and accelerating the diagnostic process. Models such as Support Vector Machines have shown high predictive accuracy, reaching up to 97% in specific datasets, highlighting their efficacy in early disease detection. These models encounter limitations, particularly the necessity for comprehensive external validation via multicenter trials to establish reliability and generalizability. Moreover, AI models may exhibit biases if not adequately managed, potentially impacting their diagnostic accuracy and fairness. Despite these challenges, the integration of AI into healthcare systems has the potential to transform cardiovascular diagnostics, providing scalable solutions that can be incorporated into existing clinical practices and patient self-care technologies.
3. Methodological Framework
This chapter outlines the conceptual and theoretical foundations that underpin our methodology for developing an AI-driven stroke diagnosis system. Our system is based on the integration of structured clinical data from the eICU Collaborative Research Database and well-tested imaging data [
48]. Our approach integrates traditional machine learning techniques with modern deep learning methods to address the inherent challenges of heterogeneous and imbalanced clinical datasets, thereby improving the accuracy and timeliness of stroke diagnosis.
3.1. Theoretical Foundations
At the core of our thoughtfully created methodological framework lies a complex synthesis that seamlessly combines numerous established principles from both traditional machine learning methods and modern deep learning advancements. The strategic use of the eICU Collaborative Research Database provides a comprehensive repository of clinical data, including diverse patient demographics, vital signs, laboratory results, and diagnostic codes, all carefully processed through extensive data cleaning, normalization, and feature engineering to guarantee their integrity and usability. This well-organized dataset forms the essential foundation for the application of advanced gradient-boosting methods, including XGBoost [
49] and CatBoost [
50], which have reliably exhibited an exceptional performance in managing high-dimensional, heterogeneous datasets typical of real-world clinical situations.
Moreover, it is essential to emphasize that a key element of our theoretical framework is the significant focus on the complexities of probability calibration and threshold optimization. Given the dataset’s imbalance, with stroke cases constituting a minority, we utilize specialized loss functions and sophisticated calibration techniques to ensure that the predicted probabilities accurately reflect the actual clinical risks observed in practice. This solid theoretical foundation is firmly rooted in the established literature on statistical methodologies and machine learning principles, and is specifically designed to tackle the intricate diagnostic challenges associated with the occurrence and identification of stroke cases.
3.2. Research Questions and Hypotheses
Building upon the established theoretical foundation that serves as a cornerstone for our inquiry, our extensive study is propelled by a crafted series of research questions that are specifically intended to rigorously evaluate both the efficacy and the inherent limitations associated with various modeling methodologies utilized in the diagnosis of stroke. The initial research question delves into the effectiveness of gradient-boosting techniques, scrutinizing their predictive capabilities regarding stroke outcomes by utilizing structured clinical data derived from the eICU Database, which is recognized for its comprehensive nature. Our hypothesis posits that when these gradient-boosting models are bolstered by thorough feature engineering practices and normalization processes, they will demonstrate a commendable overall accuracy rate that surpasses the threshold of 92%; however, it is also anticipated that the sensitivity for accurately detecting stroke incidents may remain at a moderate level, a phenomenon that can be attributed to the prevalent issue of class imbalance within the dataset.
The subsequent research question shifts its focus towards the performance metrics of deep learning models, with particular emphasis on the MobileNet-based Convolutional Neural Network, as we investigate its efficacy in analyzing carefully curated imaging data for the purpose of stroke diagnosis [
51]. We put forth the hypothesis that this advanced CNN architecture will not only attain superior overall accuracy, likely around the impressive figure of 96%, but will also provide a significantly enhanced stroke recall rate, anticipated to exceed 90%, in comparison to models that rely exclusively on structured data inputs. This expectation is firmly grounded in the network’s exceptional capability to extract intricate visual features, which are indispensable for making critical distinctions between stroke cases and non-stroke cases, thus highlighting its potential advantages in clinical settings.
The third research question is dedicated to exploring the potential advantages offered by ensemble methods, specifically focusing on both soft-voting and stacking techniques, in their ability to enhance the predictive performance of our diagnostic system. We postulate that, while these ensemble strategies are likely to yield improvements in the overall accuracy and precision metrics, they may also introduce certain trade-offs, particularly concerning the recall rate for stroke detection. More specifically, we anticipate that the stacking ensemble approach could achieve the highest numerical accuracy, yet this may come at the expense of a diminished recall rate for the minority class, thereby necessitating a thoughtful and careful calibration of the decision thresholds employed in the diagnostic process.
Ultimately, our research endeavors to investigate the ramifications of the probability calibration and the optimization of decision thresholds on clinical outcomes, with the hypothesis that fine-tuning these thresholds—guided by sensitivity analyses and the interpretation of calibration curves—will substantially enhance the equilibrium between the precision and recall metrics. Achieving this delicate balance is imperative for minimizing false-negative rates, which is particularly critical within the realm of stroke diagnosis, while also ensuring that acceptable levels of false positives are maintained throughout the diagnostic process.
3.3. Integration of Digital Twin and Telemedicine Approaches
Recent advancements in digital twin frameworks and telemedicine services have demonstrated their potential to revolutionize healthcare delivery. For example, a review of AI-driven digital twin frameworks for cardiovascular disease diagnosis and management has provided valuable insights into leveraging these technologies for clinical decision support [
52]. In addition, the development of a convolutional neural network-based digital diagnostic tool for the identification of psychosomatic illnesses highlights the transformative role of deep learning in diagnostics [
53]. The comprehensive literature on digital twin technology in healthcare further underscores its importance in achieving system-wide integration and personalized patient care [
54]. Moreover, studies on centralized-healthcare cyber–physical system architectures [
55] and on the challenges and solutions for resilient telemedicine services [
56] emphasize the necessity for robust, scalable system designs in clinical settings. These works collectively inform our methodology by emphasizing the integration of multi-modal data, advanced calibration techniques, and scalable digital frameworks—principles that are integral to our AI-powered stroke diagnosis system.
Although our methodology is guided by principles from the digital twin literature—such as multi-modal data fusion, model calibration, and integration with clinical decision support—it is crucial to highlight that our present implementation does not represent a fully developed digital twin. A genuine digital twin is defined as a real-time, bi-directional simulation of patient physiology, integrating instantaneous sensor feedback, ongoing model synchronization, and closed-loop optimization of clinical interventions. Conversely, our system functions as a static diagnostic module: it amalgamates retrospective structured and imaging data, produces calibrated predictions, and facilitates early stroke categorization. Consequently, we characterize this work as a replicable, data-driven diagnostic framework instead of a digital twin, while acknowledging that future advancements may evolve our system into dynamic, simulation-based digital twin structures.
In conclusion,
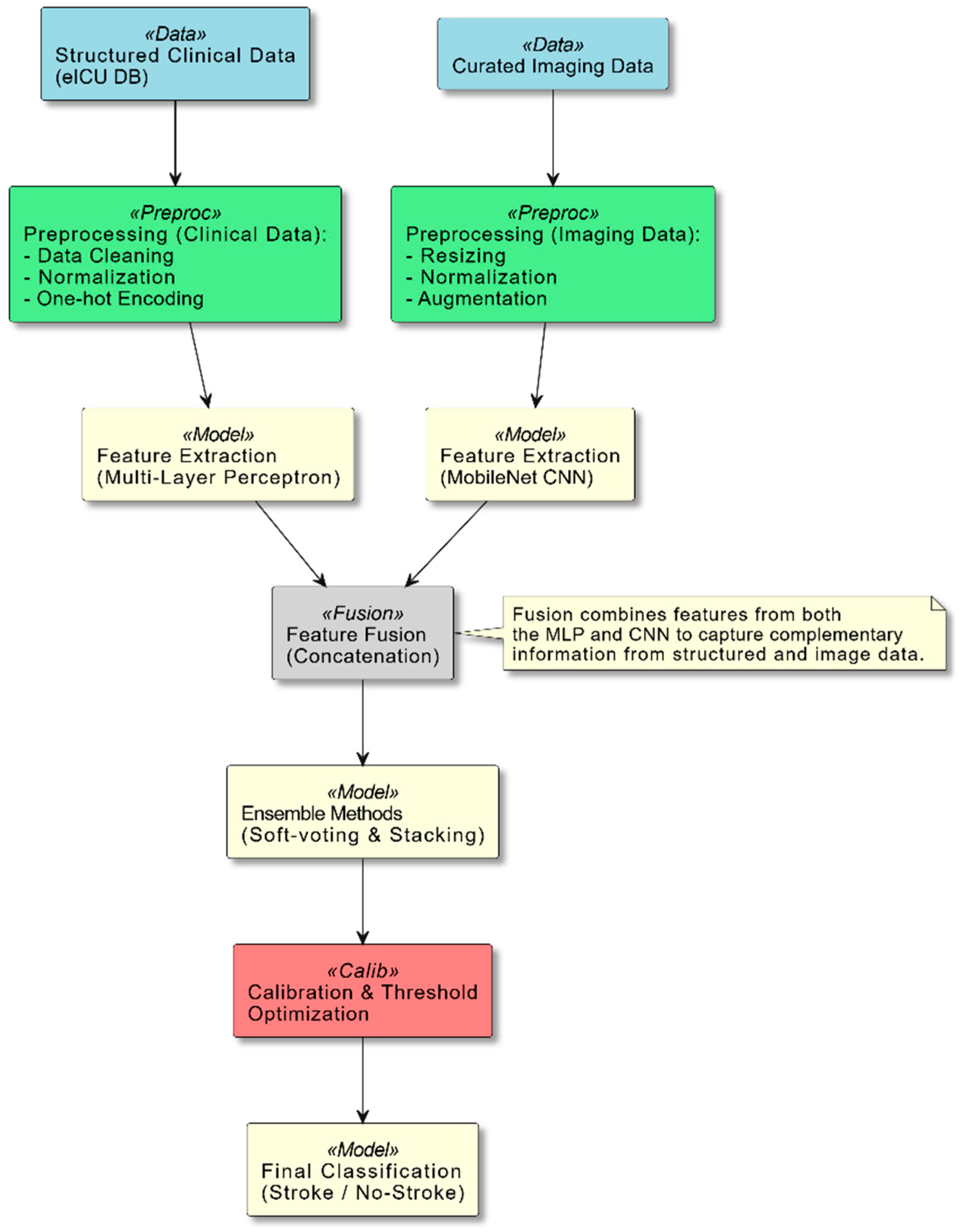
Section 3 lays the groundwork for the methodological framework that amalgamates multi-modal data integration, cutting-edge modeling techniques, and rigorous calibration strategies, all of which are essential components of our research design. As illustrated in
Figure 1, our system integrates structured clinical data and curated imaging data through distinct preprocessing pipelines. The clinical data are processed via a multi-layer perceptron (MLP), while the imaging data are analyzed using a MobileNet-based convolutional neural network. These features are then fused and passed through ensemble methods and a calibration module, which together yield the final stroke classification.
This diagram provides an overview of the system pipeline. Two primary data streams are shown: Structured Clinical Data from the eICU database and Curated Imaging Data. Each stream undergoes dedicated preprocessing steps—data cleaning, normalization, and encoding for clinical data; and resizing, normalization, and augmentation for imaging data. The processed data are then fed into feature extraction models (an MLP for clinical data and a MobileNet-based CNN for imaging data). The resulting feature vectors are fused, and ensemble methods (soft-voting and stacking) are applied to enhance the prediction accuracy. Finally, a calibration and threshold optimization module refines the output to achieve reliable stroke classification.
This comprehensive framework not only sets the stage for our experimental endeavors, but also facilitates a thorough evaluation of the outcomes, with the ultimate objective of developing a robust and clinically relevant artificial intelligence-driven system for the diagnosis of stroke that can significantly enhance patient outcomes.
4. Methodology Development
This chapter elucidates the experimental methodology formulated for our AI-driven stroke diagnostic system. By synthesizing structured clinical information from the eICU Collaborative Research Database alongside curated imaging data, our framework utilizes both conventional machine learning and contemporary deep learning methodologies. The experimental infrastructure is executed on an MSI Summit B15e A11MT workstation equipped with 64 GB of RAM, and the development process was carried out employing the PyCharm Integrated Development Environment (IDE). The chapter is systematically partitioned into three principal sections: technological components, integration strategies, and predicted outcomes.
4.1. Technological Components
All experiments were performed on an MSI Summit B15e A11MT computer with 64 GB of RAM, intentionally setup for CPU-only execution to guarantee the reproducibility of our framework on systems lacking dedicated GPUs. The complete pipeline is executed in Python 3.11.9 and administered via the PyCharm 2024.2.6 Integrated Development Environment. Data ingestion and manipulation utilize Pandas and NumPy; preprocessing routines, feature engineering, and the evaluation of traditional models are conducted using scikit-learn; gradient-boosted decision-tree algorithms are executed through XGBoost and CatBoost; deep learning components leverage PyTorch 2.6.0; and Matplotlib 3.10.1 produces all visualizations, encompassing confusion matrices, ROC and precision–recall curves, calibration plots, and sensitivity analyses. This software stack offers a clear, modular framework that encompasses raw data processing through to final model validation.
Additionally, during the manuscript preparation process, the authors employed the AI-based tool SciSpace to assist with language polishing, style consistency, and the literature comparison. The tool was used to refine the grammar and improve the readability. All AI-generated suggestions were critically assessed and revised by the authors to ensure the scientific rigor and integrity of the content. No AI tools were used to formulate novel scientific insights, generate data, or influence this study’s conclusions.
4.1.1. Dataset Description and Tabular Preprocessing
Our structured dataset consists of 51,176 unique ICU admissions from the eICU Collaborative Research Database, with 3291 categorized as stroke and 47,885 as non-stroke. The imaging dataset comprises 3770 images, categorized as 1259 stroke images and 2511 non-stroke images, pseudo-randomly associated with these stays. After merging by patient stay ID, numerical fields with absent entries were imputed to zero, indicating unrecorded measurements. Categorical data (gender, ethnicity, and ICD-9 codes) were transformed into binary indicator columns by one-hot encoding, while other continuous characteristics were normalized to the [0, 1] range using min–max scaling. Due to stroke cases comprising less than 10% of the data, SMOTE oversampling was utilized on the training partition to synthetically enhance the minority class and avert tree-based models from disregarding infrequent, but nevertheless, significant stroke occurrences.
4.1.2. Data Preprocessing and Normalization
Structured clinical variables, including aggregated vital signs, laboratory measurements, demographic characteristics, and the binary stroke designation, are consolidated into a single dataset using the patient-stay identity. Absent numeric values are replaced with zero to indicate the lack of a recorded measurement. Categorical variables, including gender, ethnicity, and ICD-9 diagnosis codes, are converted via one-hot encoding, resulting in binary indicator columns. Each continuous variable is standardized to the [0, 1] range using min–max scaling to standardize all characteristics on a similar scale. Considering that less than 10% of cases in the eICU database pertain to stroke, we implement the SMOTE algorithm on the training subset to synthetically augment the minority class, thus ensuring our tree-based models do not neglect these infrequent yet clinically significant instances.
Table 1 presents a succinct summary of all preprocessing, normalization, and model configuration specifics.
4.1.3. Image Preprocessing
Each image was initially scaled to 224 × 224 pixels to meet the input specifications of the convolutional backbone. We subsequently implemented geometric augmentations—random horizontal flips and rotations within ±20°—to incorporate orientation diversity and reduce overfitting. Augmented images were transformed into three-channel PyTorch tensors, and their pixel intensities were standardized utilizing the conventional ImageNet statistics (mean = [0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225]) to ensure that the pretrained network’s feature detectors function on data distributions aligned with their initial training.
4.1.4. Neural Network Design and Hyperparameter Optimization
Within our AI framework, defined as the comprehensive workflow encompassing data ingestion, preprocessing, model fitting, ensemble fusion, and calibrated decision making, we established a systematic hyperparameter optimization approach for each model component. We established a unified search space for our gradient-boosted trees under Python’s param_dist, utilized by RandomizedSearchCV.
XGBoost: n_estimators ∈ {100, 200}, max_depth ∈ {3, 6}, learning_rate ∈ {0.01, 0.05, 0.1}, subsample and colsample_bytree ∈ {0.6, 0.8}, gamma ∈ {0.0, 0.1}, min_child_weight ∈ {1, 5}, reg_alpha ∈ {0.0, 0.1}, reg_lambda ∈ {0.5, 1.0}, and scale_pos_weight set automatically to the ratio of non-stroke to stroke cases. We ran ten randomized iterations with two-fold stratified CV, optimizing average_precision. The best estimator was then wrapped in CalibratedClassifierCV(method = ‘isotonic’) to align probabilities before the threshold search.
CatBoost: we fixed iterations = 200, depth = 6, learning_rate = 0.05, and loss_function = ‘Logloss’, based on preliminary grid searches that balanced the performance against the training time; the class imbalance was addressed via SMOTE when available.
Stacking: The meta-learner is a CatBoost with iterations = 100, depth = 4, learning_rate = 0.05. It was trained on the out-of-fold probability outputs of XGBoost and CatBoost. We also tuned its class_weights in the same random-search framework to maximize F-β (β = 2).
We selected MobileNet-V2 (1.0 × 224, IMAGENET1K_V1 weights) for the convolutional branch because of its depthwise-separable convolutions and sub-3 million parameter count. Following the freezing of the entire backbone, we substituted its classifier with a dropout layer (p = 0.3) and a linear projection to a single logit. Utilizing PyTorch, we conducted a hyperparameter sweep of learning rates {1 × 10−4, 5 × 10−4, 1 × 10−3}, batch sizes {8, 16, 32}, and epochs {5, 10, 15} employing BCEWithLogitsLoss and the Adam optimizer. The ultimate configuration—ten epochs with a learning rate of 1 × 10−3 and a batch size of 16—was selected due to the validation accuracy and stroke recall reaching a plateau by the tenth epoch, with no additional benefits warranting extended training durations.
4.2. Integration Strategies
Our methodological framework is distinctly characterized by the seamless and sophisticated integration of multi-modal data sources, a critical element that is essential for the effective development of a robust and highly efficient stroke diagnosis system that can significantly enhance clinical outcomes. The organized clinical data, including various patient health metrics and imaging data from advanced medical technologies, are carefully processed through separate but complementary pipelines before being integrated into numerous innovative modeling methods aimed at enhancing the diagnostic accuracy.
In the case of the structured data, our comprehensive pipeline initiates with the systematic extraction and merging of large-scale CSV files sourced from the eICU database, which is an extensive repository of critical care patient information. This intricate process is executed with remarkable precision to adeptly handle high-dimensional data while concurrently ensuring memory efficiency and computational feasibility. Key preprocessing steps integral to this pipeline encompass the one-hot encoding of categorical variables, the normalization of continuous features employing methodologies such as MinMaxScaler, and the imputation of missing values to maintain data integrity. Furthermore, binary stroke labels are generated based on established diagnostic codes and enriched clinical narratives, which collectively reflect the rigor of the established clinical criteria used within the medical community.
Concurrently, the image data undergo their own specialized preprocessing stream that is tailored to enhance the quality and usability of the data for subsequent analysis. In this phase, images are standardized through a rigorous process of resizing to uniform dimensions, such as 224 × 224 pixels, and normalized according to standard statistical measures to ensure consistency across the dataset. Additionally, various augmentation techniques are employed, involving random transformations that serve to enhance the robustness of the data against variations. These preprocessing steps are of paramount importance as they effectively prepare the images for in-depth analysis utilizing the MobileNet convolutional neural network. Beyond the individual processing of structured and imaging data, we also explore advanced early fusion strategies, wherein feature representations extracted from both the structured data and the images are concatenated in a manner that maximizes the synergy between the two modalities. This sophisticated integration is achieved by processing numeric features through a multi-layer perceptron while simultaneously extracting visual features from the CNN; the resulting feature vectors are subsequently merged and funneled into a final classification layer. Such an integrative approach capitalizes on the complementary strengths inherent in both data modalities, thereby significantly enhancing the overall predictive capability of the diagnostic system.
A particularly critical aspect of our integration strategy revolves around the meticulous calibration of model outputs, which is an essential consideration given the inherent imbalance observed within the dataset—specifically, the fact that stroke cases represent a minority within the broader patient population. It becomes vitally important to optimize decision thresholds to achieve an acceptable equilibrium between precision and recall, thereby enhancing the model’s diagnostic accuracy. To this end, sensitivity analyses and calibration curves are systematically employed in order to fine-tune these decision thresholds, ensuring that the predicted probabilities generated by the model accurately reflect the true clinical risks associated with stroke occurrences. This calibration process is, therefore, indispensable for tailoring the model’s performance to align with the pressing clinical imperative of minimizing false negatives, which can have profound implications for patient outcomes and overall healthcare efficacy.
4.3. Anticipated Outcomes
Our specifically created methodological approach aims to produce many critical results with significant clinical significance, vital for advancing medical science and enhancing patient care. We are optimistic that the advanced gradient boosting models, specifically the XGBoost and CatBoost algorithms, will achieve a remarkably high level of overall accuracy when applied to the structured clinical data derived from the eICU database, which is essential for effective decision making in critical care. Nonetheless, it is important to acknowledge that, due to the inherent issue of class imbalance present within the dataset, these sophisticated models are anticipated to display only moderate recall rates for stroke identification, thereby necessitating the implementation of further calibration processes and the meticulous optimization of decision thresholds to enhance their predictive capabilities.
In contrast to the aforementioned models, the deep learning architecture predicated on MobileNet is anticipated to provide an exceptionally superior performance level when processing image data, characterized by its ability to achieve not only high accuracy, but also a markedly elevated stroke recall rate, which is strongly supported by the compelling evidence of its near-bimodal probability distribution observed in the preliminary analyses.
To potentially augment the overall performance outcomes, we have incorporated ensemble methods, amongst which soft-voting and stacking techniques are particularly noteworthy, as they may lead to enhanced predictive accuracy in our diagnostic system. While it is plausible that the implementation of the stacking ensemble approach might contribute to an increase in the numerical accuracy, it is equally critical to recognize that this improvement may come at the cost of diminishing stroke recall rates—a challenge that accentuates the imperative requirement for the meticulous calibration of decision thresholds to ensure an optimal performance. Ultimately, our comprehensive and integrated approach aspires to construct a diagnostic system that not only significantly enhances the accuracy and efficiency of stroke detection processes, but also fortifies timely clinical decision making, thereby improving patient outcomes in critical care settings. The successful amalgamation of structured clinical data with sophisticated imaging analysis is anticipated to yield a scalable, robust artificial intelligence-driven solution that possesses the potential to markedly enhance patient outcomes within the realm of critical care medicine.
5. Theoretical Evaluation
The evaluation of the AI-powered stroke diagnosis system follows a structured framework designed to assess the performance of both the numeric clinical model and the image-based facial stroke detection model. This framework ensures that the models are rigorously tested for accuracy, reliability, and robustness. The evaluation consists of three main aspects: performance metrics, validation techniques, and comparative benchmarking.
The model performance is measured using standard classification metrics, including the accuracy, precision, recall, and F1-score. These metrics are critical for determining how well the models differentiate between stroke and non-stroke cases. The system’s effectiveness is also compared against baseline models, including traditional stroke screening methods such as human clinical evaluation and non-AI-based facial asymmetry assessments.
To ensure model reliability, multiple validation techniques are applied. Cross-validation is used to divide the dataset into training, validation, and test sets, ensuring that the models generalize well to new data. Confusion matrix analysis is performed to identify patterns of misclassification, particularly false positives and false negatives. Techniques such as dropout layers and early stopping are implemented to mitigate overfitting and improve model robustness.
Comparative benchmarking is conducted to evaluate the AI system’s performance against existing stroke diagnosis methods. By comparing the accuracy of the AI model to traditional clinical assessments and non-AI facial recognition techniques, this study determines whether the proposed system offers a significant improvement in stroke detection.
To further validate the model’s generalizability, stratified cross-validation is employed, ensuring that each subset maintains a representative distribution of stroke vs. non-stroke cases. The model is also evaluated on an external test dataset that has not been seen during training. Additionally, ablation studies are conducted to assess the impact of different preprocessing techniques and architectural choices on the model performance.
This chapter precisely outlines a detailed examination of the advanced framework we have created for stroke diagnosis, driven by artificial intelligence and utilizing a substantial dataset from the eICU Collaborative Research Database (eICU DB), complemented by carefully selected imaging sources that improve the integrity of our analysis. We undertake a detailed assessment of a variety of modeling methodologies, which encompass both conventional techniques such as gradient boosting exemplified by XGBoost and CatBoost, as well as ensemble strategies characterized by voting and stacking, in addition to a deep learning architecture founded on the MobileNet convolutional neural network, through the application of both quantitative performance metrics and qualitative visual diagnostic evaluations that provide a dual perspective on the model efficacy. Furthermore, we engage in a critical analysis of the outputs generated by these models, employing tools such as confusion matrices, receiver operating characteristic (ROC) curves, precision–recall (PR) curves, calibration plots, probability distributions, and sensitivity analyses that collectively contribute to a nuanced understanding of the model performance. The evaluation process is further enriched and informed by the comprehensive review of model analysis logs, all of which serve to furnish deeper insights into the behavioral dynamics and limitations of the models, particularly within the challenging context of imbalanced clinical data that often complicate the diagnostic accuracy.
5.1. Perfomance Metrics
The comprehensive evaluation of our predictive models is fundamentally grounded in several pivotal and critical metrics that serve as essential indicators of their performance efficacy. While the overall accuracy metric provides a broad and generalized measure of the model performance across the entirety of the dataset, it is imperative to recognize that in the context of imbalanced datasets, such as the eICU Database, the metrics that specifically pertain to the minority class—namely stroke—hold extraordinary significance and cannot be overlooked. Stroke precision serves a vital role in quantifying the proportion of instances that were predicted to be stroke cases and that are, in fact, accurately confirmed as true stroke incidents, while stroke recall, often referred to as sensitivity, systematically assesses the fraction of actual stroke cases that have been correctly identified by the model. Furthermore, the F1-score, which is mathematically defined as the harmonic mean of precision and recall, provides an insightful and balanced measure of the model’s performance.
Moreover, the ROC curves and their associated AUC values effectively demonstrate the model’s capacity to differentiate between classes across various decision thresholds, while the precision–recall curves, accompanied by Average Precision, provide further, detailed insights into the model’s performance regarding the stroke class.
Upon acquiring calibrated probabilities
for each model (XGBoost utilizing CalibratedClassifierCV, CatBoost, and ensembles through similar techniques), we systematically vary the decision threshold τ from 0.00 to 1.00 in increments of 0.01 and calculate the F
2 score
hence assigning double the importance to recollection compared to precision in the acknowledgment of therapeutic necessities. The best cutoff τ* is the probability that maximizes F
2. Since τ is dimensionless, reducing τ enhances stroke recollection by categorizing additional borderline cases as positive. For instance, in our XGBoost validation set, decreasing τ from the normal 0.50 to 0.32 enhanced recall from 47% to 71%, while maintaining precision above 55%. This grid-search method (executed by precision_recall_curve and our find_threshold_for_min_precision utility) guarantees that “meticulous threshold calibration” directly results in the increased sensitivity necessary for dependable clinical decision making.
Table 2 serves as a succinct summary of the key quantitative performance metrics that have been derived from our comprehensive model analysis logs, encapsulating the essential findings of our evaluation process. Although the various boosting models demonstrate a robust level of overall accuracy, it is noteworthy that their moderate stroke recall highlights the inherent challenges and complexities that are posed by the presence of imbalanced clinical data, which can significantly affect the predictive performance. In stark contrast, the Convolutional Neural Network model exhibits an exceptional level of performance, not only in terms of the overall accuracy, but also in the critical task of stroke detection, as is compellingly evidenced by its high precision and recall values, which indicate its superior capability in identifying stroke cases accurately.
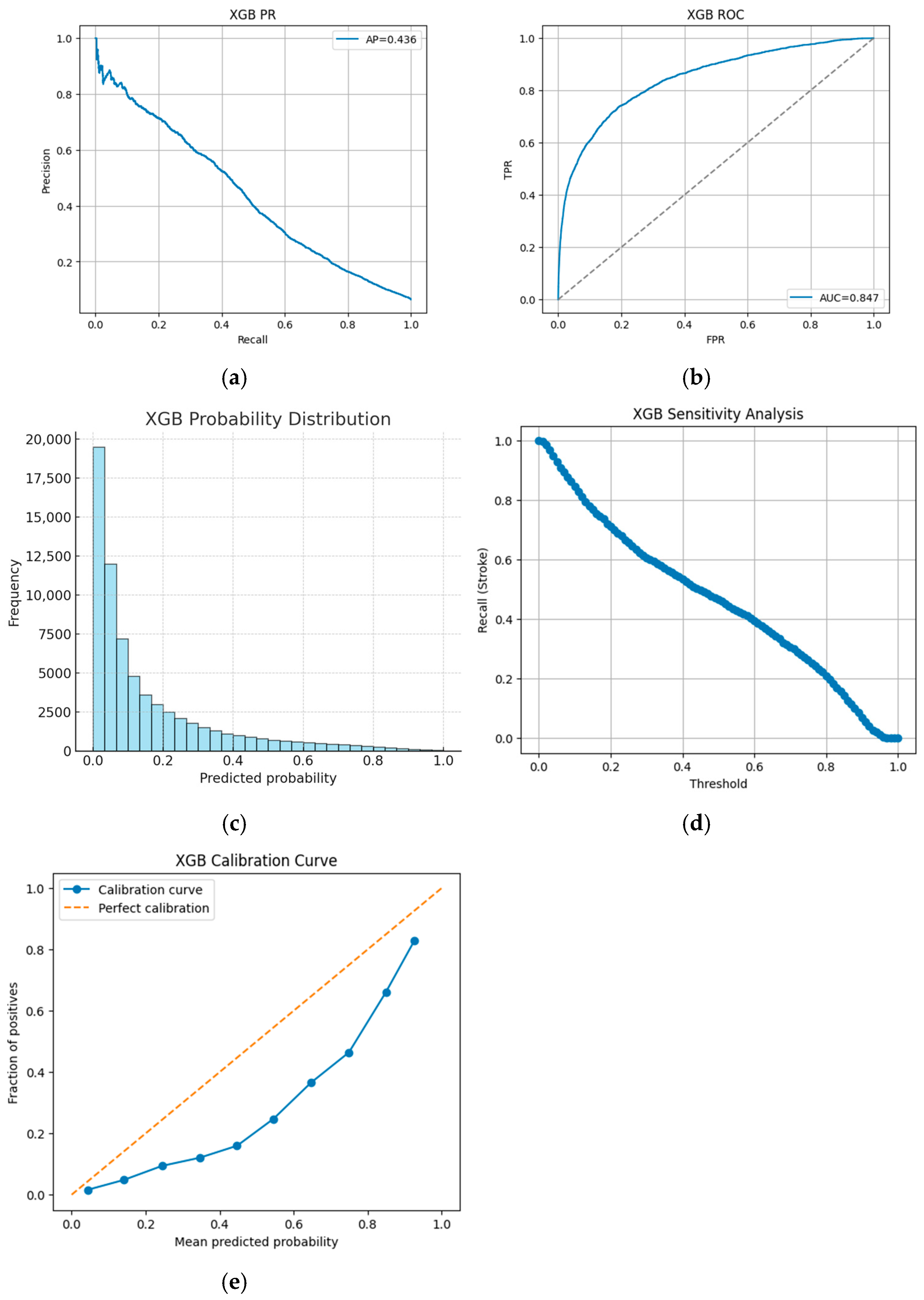
For instance, the XGBoost model achieves an accuracy of 92.9% with stroke precision of 0.45, stroke recall of 0.47, and an F1-score of 0.46, accompanied by an approximate AUC of 0.85 and an average precision of around 0.43. In contrast, the CNN model achieves 96.0% accuracy, with stroke precision of 0.97, stroke recall of 0.91, and an F1-score of 0.94. These figures, extracted from our detailed analysis logs, highlight that although boosting models demonstrate robust overall accuracy, their moderate stroke recall underscores the challenges posed by imbalanced clinical data.
A series of figures support these findings.
Figure 2a,b illustrate that while approximately 96% of no-stroke cases are correctly identified, only about 47% of stroke cases are captured.
Figure 3a,b visually depict the trade-offs in performance, while
Figure 3c,d further detail the probability outputs and sensitivity to threshold changes.
Figure 3e assesses the alignment between the predicted probabilities and the actual outcomes.
5.2. Comperative Analysis
A comprehensive comparative analysis is conducted through a methodical examination of both numerical results and visual diagnostics, providing a critical basis for understanding the efficacy and limitations of the various models. The CatBoost model, for example, exhibits performance patterns similar to XGBoost. Its ROC and PR curves are presented in
Figure 4a, the CatBoost ROC curve, and
Figure 4b, the CatBoost precision–recall curve, while its probability distribution and sensitivity analyses are shown in
Figure 4c, the CatBoost probability distribution, and
Figure 4d, the CatBoost sensitivity analysis, respectively. The CatBoost calibration curve in
Figure 4e further corroborates these observations.
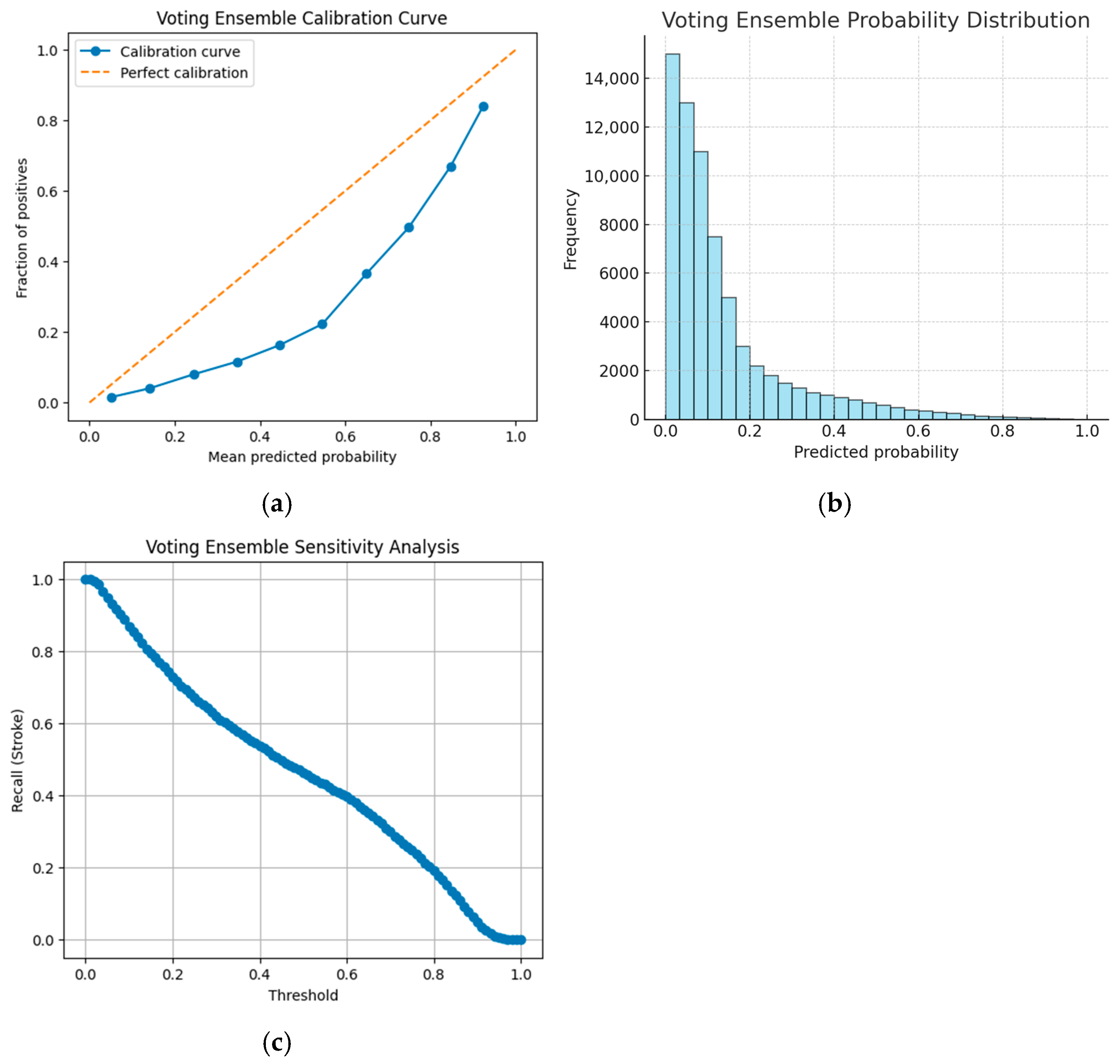
Ensemble strategies are also evaluated. The soft-voting ensemble, which aggregates predictions from XGBoost and CatBoost, is characterized by its calibration, probability distribution, and sensitivity to the threshold adjustments, as depicted in
Figure 5a, the voting ensemble calibration curve;
Figure 5b, the voting ensemble probability distribution; and
Figure 5c, the voting ensemble sensitivity analysis.
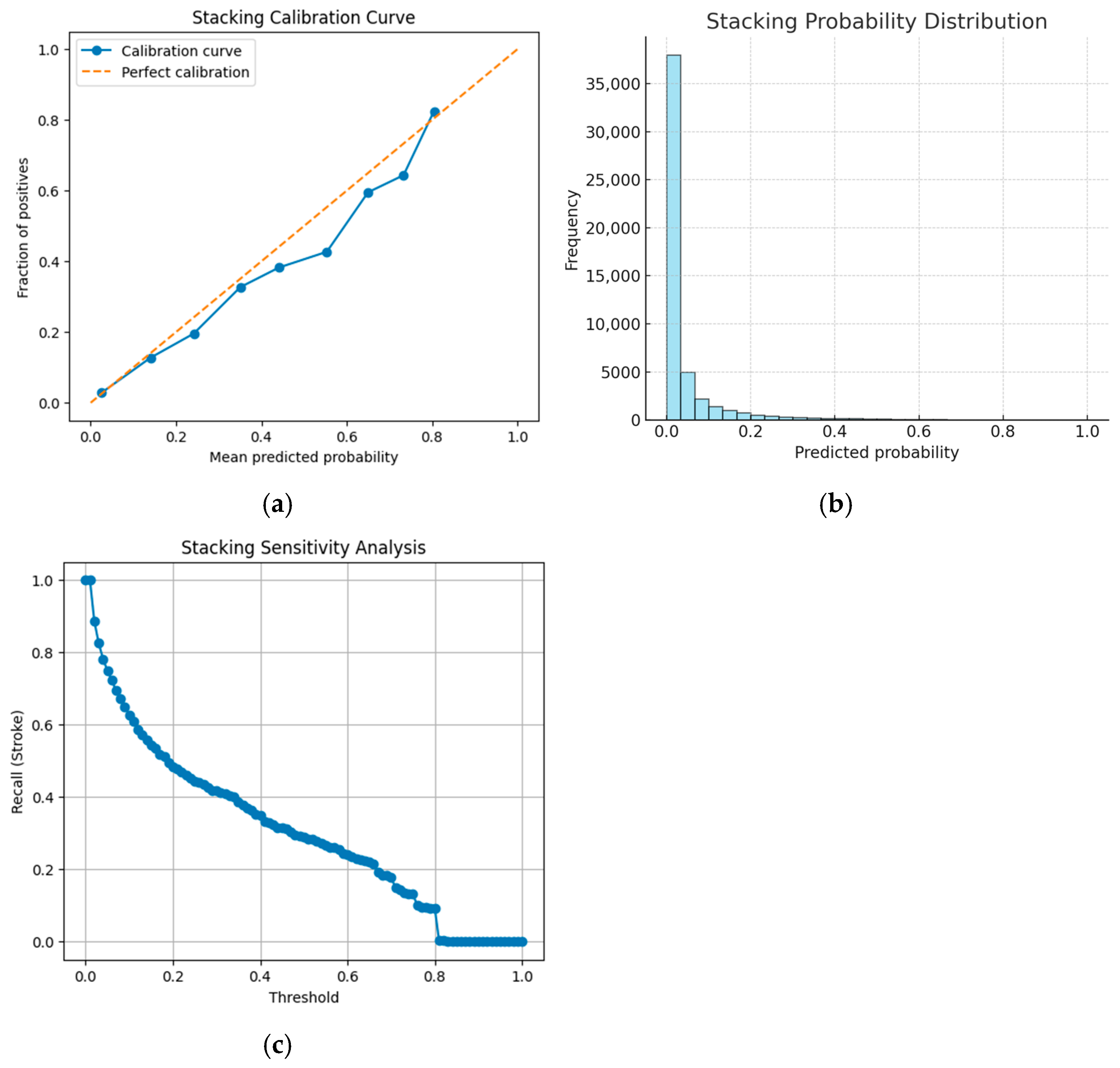
In contrast, the stacking ensemble achieves the highest overall accuracy among numeric models (94.4%), but suffers from a markedly low stroke recall of 26%. This trade-off is illustrated in
Figure 6a, the stacking ensemble calibration curve;
Figure 6b, the stacking ensemble probability distribution; and
Figure 6c, the stacking ensemble sensitivity analysis, which reveal how minor adjustments in decision thresholds can lead to a precipitous decline in stroke recall.
For the deep learning approach, the CNN-based model is evaluated using curated imaging data. Its performance is exceptional, with an accuracy of 96.0%, a stroke precision of 0.97, and a stroke recall of 0.91. Additionally,
Figure 7a, the CNN calibration curve, shows that the probability estimates from the CNN closely align with the actual outcomes, while
Figure 7b, the CNN probability distribution, exhibits a nearly bimodal distribution, clearly separating stroke from non-stroke predictions. The stability of the CNN’s image sensitivity across various thresholds is further confirmed by
Figure 7c, the CNN sensitivity analysis.
Figure 7d,e presents the confusion matrix for our MobileNet-V2 CNN on the held-out image validation set. The model achieved 97% overall accuracy, correctly identifying 265 of 276 stroke cases (recall = 96%) and 464 of 478 non-stroke cases.
Table 3 serves to synthesize the qualitative characteristics that were observed throughout the course of our experimental investigations. The analysis effectively illustrates that while the implementation of ensemble methods may lead to enhancements in the overall accuracy, such improvements necessitate the careful tuning of the decision thresholds to prevent the unintended consequence of compromising the detection capabilities for the minority class, specifically the stroke cases.
To contextualize our findings, we compared them with current work on AI-driven stroke diagnostic systems utilizing medical imaging data.
Table 4 encapsulates essential findings from current investigations employing deep learning models, such as ResNet, VGG, DenseNet, and hybrid ensembles. These studies indicate stroke detection accuracies between 89% and 95%, frequently necessitating high-resolution imaging, GPU resources, or restricted datasets. Our MobileNet-V2-based model attains 96% accuracy and 91% recall utilizing a CPU-only training environment and pseudo-randomly allocated curated pictures. This comparison validates the robustness and generalizability of our system, demonstrating that lightweight architectures such as MobileNet-V2 may equal or surpass the performance of more substantial models when integrated with calibration and preprocessing techniques.
5.3. Validation of Hypotheses
Our experimental data are rigorously analyzed in connection with the initial hypotheses proposed at the beginning of our research. To begin with, it was hypothesized that gradient-boosting models, specifically those known as XGBoost and CatBoost, would exhibit a robust and reliable performance when applied to the structured clinical data obtained from the eICU database, which is renowned for its extensive and high-quality medical datasets. The subsequent logs, along with the detailed visual analyses conducted, not only confirm an impressively high overall accuracy rate, but also bring to light the moderate performance concerning stroke recall, thereby lending support to the original hypothesis while simultaneously illuminating the intricate challenges posed by the class imbalance within the dataset. Furthermore, the second hypothesis anticipated that the convolutional neural network CNN-based approach would significantly outperform traditional methodologies in the context of image-based stroke detection endeavors. With an impressive reported accuracy rate of 96.0% and a stroke recall rate of 91%, the performance metrics of the CNN serve as compelling evidence that robustly validates this particular hypothesis, a conclusion that is further substantiated by the bimodal probability distribution observed and the well-calibrated nature of its output parameters. In addition, our third hypothesis was predicated on the expectation that the utilization of ensemble methods would yield a marked enhancement in the overall performance metrics. Although the stacking ensemble method did achieve the highest numerical accuracy at 94.4%, it is important to note that its stroke recall performance was not as satisfactory, which partially supports the original hypothesis while simultaneously highlighting the critical need for refined calibration techniques to optimize results. Lastly, the findings from our sensitivity and calibration analyses provide compelling confirmation that even minor adjustments to the threshold settings can have a substantial impact on the performance outcomes, thus reinforcing the essential importance of threshold optimization in achieving a clinically acceptable equilibrium between precision and recall rates.
In summation, the thorough and comprehensive evaluation that has been presented in this chapter effectively demonstrates that a multi-modal approach, which integrates structured clinical data from the eICU database alongside advanced imaging analysis techniques, holds considerable promise and potential for significantly enhancing the accuracy and efficacy of stroke diagnosis procedures. However, it is crucial to acknowledge that the trade-offs which were observed among the various models employed in our study underscore the pressing necessity for meticulous threshold calibration as well as the further refinement of ensemble strategies, ensuring that the artificial intelligence-driven system can effectively meet and satisfy the stringent and demanding requirements of contemporary clinical practice.
6. Discussion
This chapter consolidates our experimental results, placing them within the wider framework of AI-enhanced clinical diagnostics and examining their ramifications for stroke diagnosis. Utilizing data from the eICU Collaborative Research Database (eICU DB) and publicly available facial image data of stroke patients from Kaggle [
48], our research amalgamates conventional machine learning with deep learning methodologies. We evaluate the merits of our methodology, analyze the intrinsic challenges, and delineate potential directions for further research.
6.1. Analytical Review of Experimental Outcomes
This work sought to create an AI-driven stroke detection system utilizing multi-modal data from the eICU database and selected imaging sources. The experimental findings provide numerous critical insights:
The effectiveness of Gradient-Boosted Models: Both XGBoost and CatBoost attained elevated overall accuracy (>92%) on structured clinical data. Nevertheless, the modest stroke recall (~45–47%) underscores a persistent issue in imbalanced datasets—despite a seemingly strong overall performance, the minority stroke class continues to be challenging to accurately record. This result highlights the importance of meticulous threshold calibration and ensemble techniques.
Robustness of CNN-Driven Image Analysis: The single-stage MobileNet CNN achieved an accuracy of 96%, with a stroke recall of 91% and a precision of 97%. The unique, bimodal probability distribution of the CNN indicates that deep learning is exceptionally proficient at extracting discriminative features from the picture input. These findings align with the extensive literature regarding the effectiveness of CNNs in medical imaging tasks.
Trade-Offs of Ensemble Methods: Ensemble techniques, especially the stacking ensemble, significantly improved the overall accuracy (up to 94.4%) but resulted in a considerable decline in stroke recall (26%). Conversely, the soft-voting ensemble preserved a balance more akin to the base models. The results suggest that whereas ensemble approaches can reduce variance and enhance precision, they may unintentionally compromise sensitivity, a crucial characteristic in urgent medical diagnoses.
The significance of the calibration and threshold optimization: Our sensitivity and calibration analyses demonstrate that even slight modifications in decision thresholds can significantly affect the performance measures, particularly stroke recall. This discovery underscores the essential requirement for meticulous threshold adjustment to synchronize model outputs with clinical necessities, as the omission of a stroke diagnosis may have grave repercussions.
Our comprehensive methodology, grounded in the diverse data from the eICU database and augmented with imaging information, exhibits promise efficacy for stroke diagnosis. Nevertheless, the findings underscore the fundamental trade-offs between the overall accuracy and the sensitivity necessary for effective clinical screening.
6.2. Constraints
Notwithstanding the promising outcomes, certain restrictions warrant consideration:
Data Representativeness and Imbalance: The eICU DB, while comprehensive, originates from particular critical care contexts and may not adequately reflect the diversity of patient groups found in wider clinical situations. The significant class imbalance—characterized by a markedly lower number of stroke cases compared to non-stroke instances—continues to pose a difficulty that impacts model sensitivity.
Image Data Quality: The imaging data utilized in our trials were pseudo-randomly allocated to patient records instead of being sourced from clinically validated stroke imaging modalities. This method, although beneficial for preliminary model construction, may restrict the applicability of our results to actual diagnostic situations.
Computational Limitations: Our studies were performed on a CPU-based workstation, notwithstanding the presence of a high-memory gear. The lack of GPU acceleration may have constrained the scale and velocity of deep learning trials, potentially affecting the optimization of CNN models.
Trade-Offs of Ensemble Methods: While ensemble techniques enhanced the overall accuracy, the stacking ensemble notably exhibited a substantial decline in stroke recall. This indicates that the approach to amalgamating predictions necessitates more refinement to prevent undermining the detection of the minority class.
The analysis utilizes retrospective data from the eICU database, which, although extensive, may not accurately represent the dynamic and developing aspects of clinical practice. Real-time clinical situations require prospective validation to evaluate the operational feasibility of our models.
6.3. Future Directions
Based on the existing study, multiple intriguing directions for future investigations arise:
Improvement of Image Data Quality: Future research should utilize clinically validated imaging modalities (e.g., high-resolution CT, MRI) to supplant the pseudo-randomly allocated images. This is expected to enhance the clinical significance and precision of the CNN-based models.
Advanced Ensemble Strategies: Investigating alternate ensemble methodologies—such as weighted ensembling, hybrid stacking approaches, or the integration of supplementary base models—could enhance the equilibrium between precision and recall. Refining the amalgamation of numerical and visual predictions is crucial for enhancing clinical results.
Dynamic Thresholding and Calibration Techniques: Creating adaptive thresholding methods that can be modified according to patient risk profiles or changing clinical recommendations may improve the system’s real-time decision-making abilities. Consideration should be given to advanced calibration techniques, including utilizing Bayesian methods or ensemble calibration.
Prospective Clinical Validation: A crucial further step is to authenticate the diagnostic system in a prospective clinical study. Incorporating the model into a clinical workflow will yield insights into its efficacy, resilience, and effect on patient outcomes in a practical environment.
Integration of Supplementary Data Modalities: Enhancing the framework to encompass additional data sources—such as longitudinal patient records, genetic markers, or real-time monitoring data—may further augment the diagnostic efficacy. This multi-modal integration may provide a comprehensive perspective on patient risk factors and illness progression.
Optimization of Computational Resources: Shifting from CPU-based experiments to GPU-accelerated frameworks may substantially improve the training efficiency of deep learning models. This enhancement would facilitate the examination of more intricate structures and more datasets, hence augmenting the model performance.
6.4. Clinical Integration and End-Users
We assume our framework will be utilized as a supplementary tool in stroke protocols, providing likelihood scores and calibrated alarms directly to stroke neurologists and emergency physicians through interactions with their PACS viewer or electronic health record dashboard. This scenario features a traffic light interface (green/amber/red) aligned with calibrated risk levels, offering swift, visual decision support that allows physicians to prioritize high-risk patients for prompt imaging examination and management. By integrating AI outputs with current clinical workflows and decision thresholds, our solution can improve the real-time triage without interrupting existing practices.
7. Conclusions
This study presents an AI-powered framework for stroke diagnosis that combines structured clinical data from the eICU Collaborative Research Database with curated imaging data. Traditional machine learning techniques (XGBoost, CatBoost) and modern deep learning approaches (MobileNet-based CNN) were applied to achieve robust overall accuracy (>92%) on structured clinical data. The MobileNet CNN demonstrated a strong ability to distinguish between stroke and no-stroke cases from image data, achieving 96% accuracy with a stroke recall of 91% and stroke precision of 97%. Ensemble methods, particularly the stacking ensemble, improved the overall accuracy, but at the cost of a substantial reduction in stroke recall.
The research makes several important contributions to the field of AI-driven clinical diagnostics, such as multi-modal data integration, a comprehensive methodological framework, and rigorous theoretical evaluation. However, limitations include data representativeness, image data authenticity, computational constraints, and ensemble calibration. Future work should leverage GPU acceleration to explore more complex architectures and refine ensemble methods to balance the overall accuracy with the detection of minority stroke cases.
In conclusion, this research illustrates the potential of an AI-powered, multi-modal approach for early stroke diagnosis, providing a comprehensive diagnostic tool that could significantly enhance clinical decision making. The results underscore the promise of combining traditional machine learning with deep learning techniques, while also highlighting the need for continued refinement and validation.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}