Abstract
In recent years, advancements in artificial intelligence, speech, and natural language processing technology have enhanced spoken dialogue systems (SDSs), enabling natural, voice-based human–computer interaction. However, discrete, token-based LLMs in emotionally adaptive SDSs focus on lexical content while overlooking essential paralinguistic cues for emotion expression. Existing methods use external emotion predictors to compensate for this but introduce computational overhead and fail to fully integrate paralinguistic features with linguistic context. Moreover, the lack of high-quality emotional speech datasets limits models’ ability to learn expressive emotional cues. To address these challenges, we propose EmoSDS, a unified SDS framework that integrates speech and emotion recognition by leveraging self-supervised learning (SSL) features. Our three-stage training pipeline enables the LLM to learn both discrete linguistic content and continuous paralinguistic features, improving emotional expressiveness and response naturalness. Additionally, we construct EmoSC, a dataset combining GPT-generated dialogues with emotional voice conversion data, ensuring greater emotional diversity and a balanced sample distribution across emotion categories. The experimental results show that EmoSDS outperforms existing models in emotional alignment and response generation, achieving a minimum 2.9% increase in text generation metrics, enhancing the LLM’s ability to interpret emotional and textual cues for more expressive and contextually appropriate responses.
1. Introduction
Over the past decade, advances in artificial intelligence, speech processing, and natural language processing have transformed the capabilities of spoken dialogue systems (SDS), enabling more natural and human-like interactions. A typical SDS architecture follows a cascaded pipeline structure consisting of three components: an automatic speech recognition (ASR) module, a large language model (LLM), and a text-to-speech synthesis (TTS) module. The ASR module transcribes spoken language into text, which is then processed by the LLM to understand contextual meaning and generate an appropriate response. Finally, the TTS module converts the generated text back into speech. In this framework, each component is often pre-trained on large datasets and subsequently fine-tuned to enhance performance for specific tasks or domains.
Recent advancements have introduced end-to-end SDSs by leveraging self-supervised learning (SSL) speech representations, called SSL features, that effectively capture linguistic information such as lexical and semantic cues [1,2,3]. These representations are quantized into discrete tokens, serving as inputs to speech-language multimodal LLMs, which align speech features with the LLM’s content feature space, enabling direct speech-to-text conversion without requiring a dedicated ASR module or additional adaptors. This approach improves efficiency while maintaining high recognition accuracy.
However, discrete, token-based LLMs primarily emphasize lexical content while overlooking critical paralinguistic cues in human speech. These cues, including intonation, pitch, loudness, speech rate, and rhythm, along with literal semantics, are essential for conveying both emotions and nuanced meanings. While linguistic context contributes to emotion recognition, prosodic and acoustic features play a dominant role. Failure to incorporate emotional cues can lead to misinterpretations, causing the LLM to respond with inappropriate emotions and context, such as interpreting sarcasm as a sincere statement or failing to recognize frustration, ultimately reducing the naturalness of and engagement in the dialogue [4]. As shown in Figure 1, the same textual content can convey different meanings depending on the emotional prosody of the utterance.
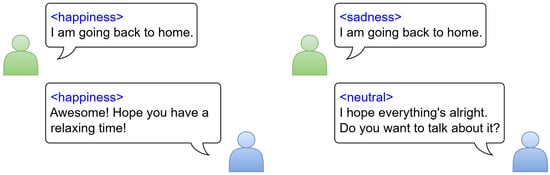
Figure 1.
Example conversations that convey different semantic meanings depending on the emotion.
Recent studies have explored the development of emotionally adaptive SDSs capable of better recognizing speaker emotions and generating responses accordingly [5,6,7,8]. These systems aim to produce contextually appropriate and emotionally expressive responses by extracting emotional embeddings from speech using a pretrained external emotion encoder [7,8,9]. However, effectively incorporating emotional context in speech-driven scenarios remains challenging. Most existing approaches rely primarily on speech-based emotional embeddings, which may result in incomplete emotion modeling due to the limited incorporation of contextual meaning. Furthermore, these methods, despite enabling emotional adaptation with minimal architectural modifications, introduce additional computational overhead due to their reliance on external emotion encoders. Consequently, they often struggle to fully integrate the rich paralinguistic features that constitute emotional expression with linguistic context. Addressing these limitations requires models that can more effectively incorporate contextual information to enhance emotional understanding and response generation.
Another challenge in the development of emotionally adaptive spoken dialogue systems is the scarcity of high-quality datasets. StyleTalk [8] and DailyTalk [10] are the most widely used publicly available speech conversation datasets annotated with emotion labels. However, these datasets often exhibit limitations such as insufficient emotional expressiveness in speech, a limited number of speakers or samples, and severe data imbalance across emotion categories, as shown in Figure 6 and Table 3. Empirically, we found that these issues hinder the LLM’s ability to effectively capture emotional cues from speech, leading to biased response generation and reducing the overall robustness of emotion-aware dialogue modeling.
In this paper, we propose EmoSDS, an Emotional Spoken Dialogue System that leverages self-supervised speech representations to unify speech and emotion recognition within a single framework. Unlike conventional approaches that rely on cascaded ASR and external emotion encoders, EmoSDS directly processes speech features within the LLM, enabling the simultaneous capture of both linguistic content and emotional cues.
To achieve this, we leverage the structured representation properties of SSL features [1]. Specifically, we apply k-means clustering to SSL features to obtain discrete linguistic tokens, while utilizing the residuals as continuous paralinguistic embeddings to preserve emotional and prosodic attributes. This approach enables a speech-language multimodal architecture that effectively integrates paralinguistic features and linguistic tokens eliminating the need for external emotion encoders. By leveraging the strong representational capabilities of the LLM, EmoSDS captures fine-grained emotional expressions, enhancing the naturalness of generated responses. Furthermore, we adopt a multi-stage training strategy to enable the LLM to learn progressively, starting with fundamental tasks, such as ASR and speech emotion recognition (SER), and moving onto more complex objectives, including response emotion conditioning and text generation. Specifically, we introduce a three-stage training pipeline: in Stage 1, the model is trained on the ASR task; in Stage 2, it learns both ASR and SER; and in Stage 3, it incorporates response emotion conditioning and text generation. This structured training approach allows the LLM to gradually learn linguistic and paralinguistic features, resulting in more emotionally aligned and contextually rich responses.
Finally, to mitigate the scarcity of high-quality emotional speech conversation datasets, we utilize the emotional speech database (ESD) [11] with GPT-4o-mini [12] to generate diverse emotional conversations, constructing an expanded emotional speech conversation dataset, EmoSC. This dataset not only improves emotional expressiveness but also increases the number of samples across different emotion categories, ensuring a more balanced and comprehensive dataset for training. As a result, the system can generate more emotionally nuanced and contextually appropriate responses.
The experimental results demonstrate that EmoSDS effectively recognizes both linguistic and emotional features from speech inputs and outperforms baseline systems in response emotion and text generation quality. Furthermore, comparative analyses show that our newly introduced dataset improves the diversity and balance of generated response emotions, enabling the system to engage in more emotionally expressive and contextually sensitive conversations.
Our contribution can be summarized as follows:
- We propose EmoSDS, an Emotional Spoken Dialogue System that unifies speech and emotion recognition within a single LLM, enabling an end-to-end speech understanding while effectively capturing both linguistic content and emotional cues by incorporating continuous paralinguistic features.
- We introduce a three-stage training pipeline that progressively improves the LLM’s learning of content and emotional representations for more expressive and contextually aligned responses.
- We propose EmoSC, a balanced emotional speech dataset that enhances expressiveness and supports diverse, emotionally rich dialogue generation.
2. Related Work
2.1. Speech-Language Multimodal LLM
Research into speech-language multimodal LLMs aims to bridge the representational gap between speech and text processing, leveraging their complementary strengths. These models seek to align speech and text feature spaces, enabling the seamless integration of spoken and written language processing. The joint speech and language model (SLM) [13] introduced a simple adapter mechanism to align speech and text representations, demonstrating the feasibility of integrating pretrained speech and language models to improve performance across various spoken language tasks. Similarly, SpeechGPT [2] and AudioPALM [3] extended LLM capabilities by tokenizing speech features as discrete tokens using a speech representation model and k-means clustering, allowing the LLM to process speech in a structured manner. Spectron [14] uses a single model that takes in spectrograms and outputs raw spectrograms but with the cost of increased latency. Align-SLM [15] applied reinforcement learning with preference data to further enhance speech-language alignment, optimizing response quality for finer linguistic control and improving the coherence and accuracy of spoken dialogue generation.
2.2. Emotionally Adaptive Spoken Dialogue System
Research on emotionally adaptive spoken dialogue systems focuses on enabling LLMs to recognize both the content and emotional features of speech, allowing them to generate emotionally adaptive responses. ParalinGPT [7] introduced a three-category emotion-aware dialogue model (positive, negative, neutral) to generate emotion-sensitive responses. Similarly, Spoken-LLM [8] expanded on this by utilizing a wider range of emotion categories and introducing the StyleTalk dataset for emotion-sensitive training. However, both models follow a cascaded architecture that relies on an additional emotion encoder, which increases computational complexity and retains the limitations of cascaded pipelines. Some recent models have attempted to move away from cascaded architectures. E-chat [16] integrated an ASR pipeline by leveraging an adapter module to project speech features into the LLM’s text latent space. However, this approach still lacks robust emotion recognition capabilities and does not have control over response emotions, limiting its ability to generate emotionally adaptive dialogues. Similarly, StyleTalker [9] directly feeds speech embeddings from an ASR model into the LLM, but has limitations in capturing emotional features from input speech. This prevents the system from fully utilizing emotional cues inherent in speech, resulting in emotionally inconsistent responses.
2.3. Self-Supervised Speech Representations
Recent advancements in SSL for speech processing have significantly improved representation learning, leading to the widespread adoption of pretrained SSL-based speech encoders in spoken dialogue systems [2,3]. SSL models are trained on large-scale, unlabeled speech data, allowing them to learn generalized speech representations across multiple layers, which can be fine-tuned for various downstream tasks.
SSL features, obtained from SSL models such as HuBERT [17] and WavLM [18], have demonstrated the capability to linearly predict various speech attributes, including phonetic content and speaker characteristics [19]. These features naturally form clusters corresponding to phonetic units, making them effective for content extraction in applications such as voice conversion and speech-to-text modeling [18,20,21,22,23,24].
A widely adopted approach for processing SSL features is k-means quantization (KQ) [2], which applies k-means clustering to the SSL features extracted from the training set to construct a codebook, a 2D matrix consisting of cluster centroid values. Through this process, continuous speech content is quantized while filtering out other acoustic information, enabling a structured linguistic representation in models trained on SSL features.
Recent studies have further investigated the properties of SSL features, revealing that the residual embeddings of quantization retain prosody, timbre, and other acoustic attributes [1]. Specifically, SSL features extracted from the sixth layer of WavLM have been shown to contain rich acoustic information, and their residuals preserve essential paralinguistic cues. These findings underscore the effectiveness of SSL features in capturing both phonetic and paralinguistic attributes, which are crucial for expressive spoken dialogue systems.
3. Methods
In the following sections, we describe (1) the architecture leveraged in EmoSDS, (2) our three-stage training pipeline, and (3) the dataset generation process for EmoSC.
3.1. EmoSDS
We propose EmoSDS, which integrates speech emotion recognition (SER) within a speech-language multimodal architecture, enabling end-to-end speech understanding. Our approach directly incorporated continuous paralinguistic features into the LLM, eliminating the need for an intermediate external emotion encoder. We extracted both linguistic and paralinguistic features from an SSL encoder using k-means quantization and a subtraction operation. The linguistic features were obtained through k-means quantization, while the paralinguistic features were derived from the quantization residuals obtained by subtracting the quantized representations from the original SSL features. These extracted features were then passed directly to the LLM, which was fine-tuned for ASR and SER tasks. This enabled the model to learn both content and emotional nuances, producing expressive and contextually appropriate responses. As a result, EmoSDS enhanced the naturalness of generated dialogues by capturing fine-grained emotional expressions.
The overall model architecture is illustrated in Figure 2. Our framework consisted of three primary components: a WavLM speech encoder, a K-means quantization module, and an LLM backbone. The speech encoder processed speech inputs to produce SSL representations, from which we extracted content features through a quantization and downsampling procedure. Residual features were subsequently derived by subtracting these content features from the original SSL representations.
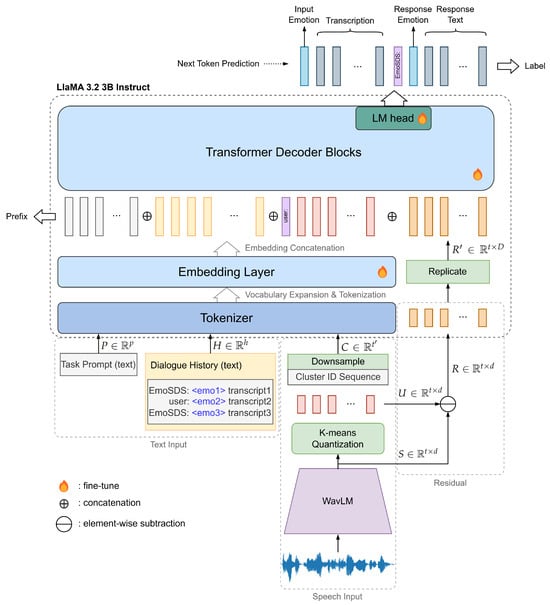
Figure 2.
Overall architecture of EmoSDS.
The LLM backbone internally comprised four subcomponents: a tokenizer, an embedding layer, transformer decoder blocks, and an LM head. The tokenizer converted textual inputs (such as text prompts and dialogue history) and speech cluster ID sequences into token sequences. These tokens were then mapped to embeddings via the embedding layer and concatenated with the residual embeddings. The transformer decoder blocks processed the combined embeddings and, finally, the LM head generated the most probable next token. For the LLM backbone, we used the LlaMA 3.2 3B Instruct model (https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct, accessed on 8 January 2025), which has been fine-tuned on various instruction-following tasks, and for the speech encoder, we used a pretrained WavLM-large model [18]. In the following subsections, we explain the details of each part of our architecture.
3.1.1. Speech Input Processing and Residual Extraction
The speech input was processed using the WavLM model to extract feature representations from its 6th transformer layer, denoted as , where t represents the number of frames and d denotes the speech feature dimension. The 6th layer of WavLM encoded both linguistic and paralinguistic features, incorporating rich acoustic information [1,20]. However, as these features were inherently continuous, while LLMs operate in a discrete feature space, a discretization process was necessary to bridge this gap. To achieve this, we applied k-means clustering, pretrained on the 6th layer of WavLM with 1000 clusters, to quantize the extracted speech representations. This quantization process captured essential linguistic content information, leveraging the structural properties of SSL features while transforming them into a form compatible with the LLM.
This process produced two outputs: a sequence of cluster embeddings , representing the quantized feature representations in the continuous space, and a corresponding sequence of cluster IDs, where each ID encoded the discrete cluster index assigned to each frame based on the clustering process.
To eliminate redundancy, consecutive duplicate cluster IDs were removed, resulting in a downsampled discrete unit sequence , formally defined as
where N denotes the total number of clusters and represents the number of downsampled frames.
To extract emotional features, we computed a residual embedding sequence by performing element-wise subtraction between the quantized embedding sequence U and pre-quantized embedding sequence S:
3.1.2. Text Input Processing
For text inputs, such as task prompts and dialogue history, tokenization was performed to enable the LLM to process textual information. Tokenization converts raw text into discrete numerical representations that models can understand and manipulate. Typically, the LLM utilized a subword tokenization method, referred to as byte-pair encoding (BPE), which segmented words into smaller subword units based on frequency statistics gathered during the tokenizer training phase. For example, the sentence “Transcribe the speech into written text” might be represented with BPE as follows: [“Trans”, “cribe”, “the”, “speech”, “into”, “writ”, “ten”, “text”]. This approach ensured the effective handling of rare or unseen words by reducing vocabulary size, maintaining flexibility, and mitigating the issue of out-of-vocabulary tokens.
3.1.3. Vocabulary Expansion and Tokenization
Text prompts were converted into tokens from the original vocabulary of the LLM. However, to enable the LLM to handle speech cluster IDs as additional tokens, it was necessary to expand the vocabulary. Alongside cluster IDs, emotion class tokens were introduced during training, serving as ground-truth labels for emotion prediction and enabling the LLM to better comprehend emotional context. Additionally, speaker ID tokens were introduced to distinguish between the model itself (“EmoSDS”) and the conversational partner (“user”) during dialogue generation, facilitating speaker-aware response generation. The details of this training process are provided in Section 3.2. Let V denote the original LLM vocabulary of size and let M and K represent the number of emotion class tokens and speaker ID tokens, respectively. The vocabulary is expanded by introducing a new set of speech unit tokens, emotion class tokens, and speaker ID tokens, forming an updated vocabulary , where
The final expanded vocabulary is then defined as
3.1.4. Embedding Concatenation
To construct the final input for the transformer decoder blocks, tokens obtained from text and speech prompts were first concatenated along the temporal axis. Both speech cluster tokens (C) and textual tokens were then transformed into corresponding embeddings via the embedding layer. Subsequently, the residual embeddings (R) were appended to the end of this embedding sequence. To match the dimension of R with the LLM’s hidden dimension, we replicated R three times along the feature dimension axis, forming . During training, this input segment was referred to as the prefix, and labels corresponding to each training stage were concatenated to the prefix before being fed into the LLM.
3.1.5. Training Objective
The LLM was trained using a next-token prediction objective, aiming to minimize the negative log-likelihood of predicting each subsequent token based on the preceding tokens. Consider an input sequence composed of a task prompt , a cluster ID sequence , and residual embeddings concatenated into a single sequence. The LLM input sequence can thus be formulated as
where represents the total prefix length and denotes the total number of tokens in the sample.
Since the goal of training was to predict the label portion of the sequence based on the prefix portion, the loss function was calculated on the label segment. The final LM head, comprising a linear layer followed by a softmax function, output the conditional probability distribution for the next token, given the previous tokens. The model was then optimized by minimizing the negative log-likelihood loss:
where d is the number of training samples in dataset D, represents the LLM parameters, and denotes the i-th token in sample .
3.2. Three-Stage Training Pipeline
To enable the LLM to effectively learn both linguistic and emotional features from speech, a progressive training strategy was employed. This training process consisted of three stages: the first focused on ASR, the second integrated both ASR and SER, and the final stage incorporated ASR, SER, and emotion-aware response generation. In the initial stage, the model was trained to recognize linguistic content from quantized speech representations. In the subsequent stage, paralinguistic features, including emotional cues, were introduced, enabling the model to associate prosodic and acoustic variations with their corresponding text. In the final stage, the model generated emotionally adaptive responses by conditioning the predicted input emotion and linguistic content. Through this structured training pipeline, the model incrementally acquired both content and emotional representations, enhancing its ability to generate expressive responses.
In the following subsections, we provide a detailed training strategy of each stage.
3.2.1. Stage 1: ASR Task
In the first stage, the model was trained to transcribe speech content using only the quantized input C. The loss was computed on the label portion, corresponding to the transcription of the input speech. To ensure that the model effectively captured linguistic content from C, only the lower six layers of the LLM were fine-tuned, which included the embedding layer, the LM head, and the first six transformer decoder layers.
3.2.2. Stage 2: ASR + SER Task
In the second stage, the input consisted of both token embeddings of C and residual embeddings , allowing the model to incorporate emotional attributes from speech. The training objective remained the same, following the next-token prediction loss function, with the label format modified to include emotion class tokens:
<input emotion> transcription.
By incorporating emotion tokens alongside linguistic content, the model learned to associate speech characteristics with emotional states. To facilitate this learning, five emotion class tokens were introduced into the vocabulary, the same classes utilized in the ESD dataset:
<anger>, <happiness>, <neutral>, <surprise>, and <sadness>.
As in the first stage, only the lower six layers of the LLM were fine-tuned in the second stage.
Additionally, prompt augmentation was applied in both Stage 1 and Stage 2 using GPT-4o, generating variations in training prompts to enhance diversity across ASR and SER tasks. Details of this augmentation process are provided in Section 3.3.
3.2.3. Stage 3: ASR + SER + Response Emotion and Text Generation
In the final stage, the model was trained to generate emotionally expressive responses. The label format was extended to incorporate both input emotion, response emotion, and generated text, following the structure
<input emotion> transcription <EmoSDS>: <response emotion> response text
At this stage, the entire LLM was fine-tuned, allowing the model to jointly optimize linguistic understanding, emotion recognition, and response generation. To enhance its ability to distinguish between conversational participants, special speaker ID tokens were introduced:
<user> and <EmoSDS>.
Additionally, dialogue history was incorporated by introducing history tokens into the prefix, modifying the total prefix length for the j-th sample as
By incorporating dialogue history, the model generated responses that were both contextually coherent and emotionally aligned, leveraging learned representations of both linguistic and paralinguistic cues.
3.3. EmoSC
The publicly available speech conversation datasets, such as StyleTalk [8] and DailyTalk [10], often exhibit limitations in emotional expressiveness or suffer from an insufficient number of samples per emotion category. We empirically found that these limitations hinder the LLM’s ability to effectively capture emotional cues from speech, leading to biased emotional responses (see Section 5.2 for details).
To overcome these shortcomings, a new dataset, EmoSC, was introduced. EmoSC was constructed based on three key principles: (1) a balanced distribution of emotion categories across samples, (2) real-world speech samples with clearly expressed emotions, and (3) multiple samples containing different emotions but identical text content. Rather than collecting speech data from scratch, the dataset was built upon the Emotional Speech Database (ESD) [11], which consists of 350 parallel utterances spoken by 10 English and 10 Chinese speakers, totaling over 29 h of speech data. Since the dataset was intended to be used for English-language applications, only the data from the 10 English speakers in ESD were used. The parallel nature of ESD, where each text is spoken in five different emotional tones, was leveraged to augment the dataset with GPT-generated dialogue history corresponding to each emotion–text pair. This augmentation enabled the construction of dialogue samples where the same utterance was expressed in five distinct emotions.
For each emotion–text pair in ESD, the GPT-4o-mini model was used to generate conversation history. The prompting strategy was adapted from [8] to construct system and user prompts, with the full prompt structure provided in Figure 3.

Figure 3.
Full prompt for dialogue generation. Each system message and user message was sent to the GPT-4o-mini as a prompt.
In the system prompt, explicit rules were defined to guide the model’s behavior. Specifically, the model was instructed to consider only five predefined emotions and to adhere to common-sense reasoning when generating dialogue histories. Each dialogue turn was structured in the following format: <speaker>: <emotion> <text>. Additionally, it was requested that the model output its responses in dictionary format to facilitate straightforward parsing.
The user prompt explicitly instructed the model to accomplish three tasks: (1) predict an appropriate emotion and corresponding response text based on the provided dialogue history, as well as the current emotion and text; (2) suggest an alternative emotion for the current text that conveyed a different nuance while retaining the original wording; and (3) based on this alternative emotion, generate a new appropriate emotion and associated response text.
An example of a generated dialogue is illustrated in Figure 4. Since the GPT-generated dialogues existed only in text format, each generated emotion–text pair was mapped to its corresponding speech sample from ESD, forming the final speech conversation dataset.

Figure 4.
Example of generated dialogue. The 3 turns in the above indicate the dialogue history. The current turn texts and emotions were selected from ESD dataset, while history and response texts and emotions were generated by GPT-4o-mini.
4. Experiment
4.1. Baseline
To evaluate the performance of the proposed model, comparisons were made against Spoken-LLM [8] and StyleTalker [9], which are trained on the StyleTalk and DailyTalk datasets, respectively. Spoken-LLM employs a cascaded architecture, whereas StyleTalker follows an end-to-end approach that eliminates the need for intermediate ASR. The quality of the generated responses was assessed by comparing outputs from the proposed model with those from the baseline models when trained on the same dataset. For Spoken-LLM, we also compared F1 scores for response emotion prediction.
To assess performance in recognizing input emotion, an external emotion recognition model was used as a baseline, and its results were compared with those of EmoSDS across three datasets. XLSR-53 [25] with a two-layer linear classifier was used, following fine-tuning on each dataset. The pretrained model was obtained from (https://huggingface.co/ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition, accessed on 17 February 2025) and training was conducted with a batch size of 4, a learning rate of 0.0001, and 10 epochs, selecting the checkpoint with the lowest validation loss for evaluation.
4.2. Dataset
The proposed model was trained in three stages, each utilizing different datasets corresponding to ASR training, ASR + SER training, and ASR + SER + response generation. In the first stage, training was conducted using the LibriSpeech dataset [26], which consists of approximately 1000 h of audiobook speech. The train-clean-100 subset, containing 100 h of speech from 251 speakers, was used for training. In the second stage, training was performed on the ESD dataset [11], which provides emotionally labeled speech samples. To ensure a balanced emotion distribution, each emotion category was sampled in equal proportions. In the final stage, the model was trained on the EmoSC dataset. The final dataset comprised 14,748 training samples, with 250 evaluation and test samples each, maintaining a uniform emotion distribution across all splits.
For comparison with baseline models, the proposed model was also trained on the StyleTalk and DailyTalk datasets. The first stage remained identical across all training setups, using the LibriSpeech dataset, while, in the second and third stages, models were separately trained on each dataset. The train–validation–test split for StyleTalk and DailyTalk followed the splits used in the Spoken-LLM and StyleTalker studies to ensure fair comparisons. Since the unfiltered set of StyleTalk is not publicly available, comparisons were conducted only on the filtered subset. In the DailyTalk dataset, samples labeled as “no emotion” were converted to “neutral”.
4.3. Evaluation Metrics
The semantic quality of generated responses was evaluated using widely adopted text generation metrics. Bilingual evaluation understudy (BLEU) [27] measured n-gram overlap between generated and reference text, with BLEU-4 used for assessment. Recall-oriented understudy for gisting evaluation (ROUGE) [28] evaluated recall-based text similarity, applying the longest common subsequence measure. Bidirectional Encoder Representations from Transformers Score (BERTScore) [29] calculated semantic similarity using contextual embeddings from a pretrained transformer model, with F1 scores reported.
For SER performance evaluation, the weighted F1 score was used to account for class imbalance in emotion distribution. ASR performance was assessed using word error rate (WER) and character error rate (CER).
To evaluate response emotion diversity and consistency with input emotion, the output emotion distribution given an input emotion was computed for the StyleTalk, DailyTalk, and EmoSC datasets. This analysis enabled comparison of the quality and diversity of emotional responses across different datasets.
4.4. Implementation Details
During training, in Stage 1 (ASR task) and Stage 2 (ASR + SER task), we introduced prompt diversity using the GPT-4o-mini model. Specifically, we generated 100 different prompts for the ASR and ASR + SER tasks. We leveraged and modified the prompts in [2] for GPT-4o-mini. Examples of prompts per stage can be found in Figure 5. In model architecture, the SSL feature dimension d was set to 1024. For all training stages, we used bfloat16 precision and a gradient accumulation step of 32. The batch size per device was set to 2 for Stages 1 and 2 and 1 for the final stage. The maximum sequence length was 3072 tokens, except for Stage 1, where it was set to 2048. We trained the model for 10 epochs in Stage 1, while Stages 2 and 3 were trained for 5 epochs each. We used a cosine annealing scheduler with an initial learning rate of and a warmup ratio of 0.1.

Figure 5.
In Stage 3, each sample was presented with a predefined prompt. The emotion examples in the prompt were replaced with the corresponding emotion categories from DailyTalk, StyleTalk, and EmoSC.
5. Results
5.1. Evaluation of EmoSDS
5.1.1. Emotion Recognition Performance
Table 1 presents the input emotion recognition performance of EmoSDS and the emotion predictor across different datasets. The emotion predictor (Section 4.1) was fine-tuned on each dataset. The results indicate that EmoSDS achieved comparable or superior performance to the emotion predictor, demonstrating its ability to effectively capture emotional cues from speech. Specifically, EmoSDS outperformed the emotion predictor on both StyleTalk (91.1% vs. 90.0%) and DailyTalk (55.4% vs. 45.4%), suggesting its robustness in recognizing emotions even in datasets with varying levels of emotional expressiveness. On EmoSC, our model achieved comparable accuracy to the emotion predictor, attaining 98.0% and 98.7%, respectively.

Table 1.
Emotion F1 scores of EmoSDS and emotion predictor.
5.1.2. Response Generation Quality
EmoSDS was trained on three datasets for evaluation: StyleTalk, DailyTalk, and EmoSC. Table 2 presents the BLEU, BERTScore, and ROUGE-L scores across the datasets. EmoSDS trained on StyleTalk outperformed Spoken-LLM by 5.6% in BLEU and 11.3% in BERTScore and achieved more than twice the ROUGE-L score. On DailyTalk, EmoSDS maintained high text generation quality with the BLEU (8.3%) and BERTScore (89.9%) and more than doubled the ROUGE-L score of StyleTalker (16.1%). EmoSDS trained on EmoSC achieved the highest performance, with BLEU (10.4%), ROUGE-L (40.5%), and the highest Resp. F1 (48.6%), indicating superior emotional adaptability. The consistently high performance across all metrics highlights the effectiveness of EmoSDS in generating structurally coherent and emotionally aligned responses. These results suggest that our proposed method enhances both linguistic coherence and emotional appropriateness, leading to more contextually relevant and emotionally expressive responses.
Table 2.
Response generation results on each dataset. An upward arrow (↑) indicates a higher value, signifying better performance.
5.2. Evaluation of EmoSC
5.2.1. Datasets Analysis
Table 3 and Figure 6 present the statistics and emotion distributions of StyleTalk, DailyTalk, and EmoSC. StyleTalk consisted of 2696 samples from nine speakers, with neutral and friendly emotions dominating, while cheerful and unfriendly emotions were underrepresented (Figure 6a). DailyTalk, despite its 21,232 samples, had only two speakers and exhibited severe class imbalance, with happiness comprising the majority (17,480 samples), while anger, fear, and disgust were significantly underrepresented (Figure 6b). In contrast, EmoSC, the largest dataset with 32,203 samples from 10 speakers, maintained a well-balanced emotion distribution, reducing class bias and enhancing generalization (Figure 6c).
Table 3.
Data statistics of each dataset.
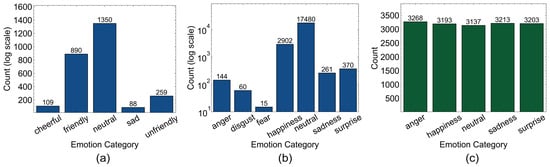
Figure 6.
Emotion distributions of three datasets. The numbers are unique speech samples of each emotion category. (a) StyleTalk, (b) DailyTalk, and (c) EmoSC.
To assess how distinguishable emotions were in speech, we fine-tuned an emotion predictor (Section 4.1) using a balanced dataset by manually splitting the data. EmoSC achieved the highest classification accuracy (97.0%), confirming clearly separable emotional cues. StyleTalk (91.1%), despite its smaller size, also demonstrated well-defined emotions. DailyTalk, with the lowest accuracy (60.7%), had less distinct emotional expressions.
5.2.2. Speech and Emotion Recognition Performance Across Datasets
Table 4 presents the SER and ASR performance of EmoSDS fine-tuned on each dataset. EmoSC achieved the highest accuracy according to F1 (98.0%), WER (0.1%), and CER (0.1%), demonstrating the benefits of conducting training on a well-balanced, emotionally expressive dataset. StyleTalk also performed well, achieving high F1 (91.1%), though its WER (9.6%) and CER (6.6%) indicated slightly lower transcription accuracy.
Table 4.
Stage 3: SER and ASR results on each dataset. An upward arrow (↑) indicates a higher value, signifying better performance, while a downward arrow (↓) indicates the opposite.
In contrast, DailyTalk recorded the lowest F1 score (55.4%), with higher WER (13.0%) and CER (7.6%), suggesting reduced emotional distinctiveness and a more challenging recognition task. The smaller sample size in both StyleTalk and DailyTalk further hindered speech recognition performance.
Figure 7 illustrates confusion matrices for SER performance. StyleTalk and EmoSC exhibited strong alignment with ground truth labels, confirming well-separated emotional categories. In contrast, DailyTalk showed frequent misclassifications, particularly among neutral, happiness, and sadness categories, further supporting its weak emotional distinctiveness and data sparsity.
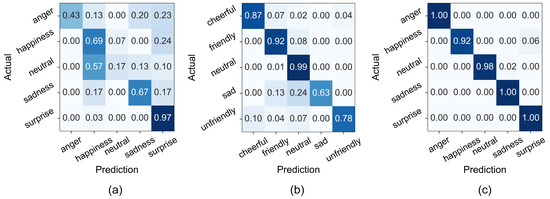
Figure 7.
Input emotion prediction confusion matrices. (a) DailyTalk, (b) StyleTalk, and (c) EmoSC.
These results confirm that large and emotionally expressive datasets enhance both SER and ASR performance, whereas datasets with imbalanced emotions and limited samples hinder accurate recognition.
5.2.3. Emotional Adaptability in Response Generation
In natural emotional conversations, responses do not always need to match the speaker’s emotion exactly. For example, when a speaker expresses sadness, a neutral response offering comfort may be more appropriate. Therefore, an effective emotional spoken dialogue system (SDS) should be able to generate emotionally diverse responses that are contextually relevant to the input emotion. Figure 8 illustrates the distribution of response emotions based on input emotions.
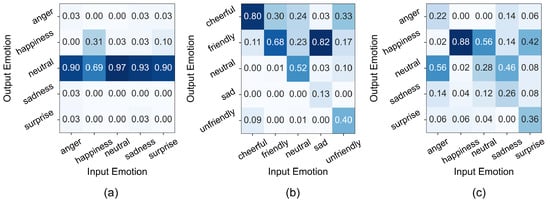
Figure 8.
Output emotion distributions for input emotions. (a) DailyTalk, (b) StyleTalk, and (c) EmoSC.
We observe that in DailyTalk, the model tended to overfit to a small subset of response emotions, reducing emotional diversity. This skewed distribution was likely caused by an imbalanced training set, where certain emotions were underrepresented, and a lack of alignment between input and response emotions. As a result, the model struggled to exhibit emotionally adaptive behavior, indicating that the dialogue quality in DailyTalk may not have been sufficient for training emotionally aware SDS models.
In StyleTalk, we observe that the model exhibited limitations in producing emotionally adaptive responses. For instance, it frequently generated “friendly” responses to “sad” input emotions or “cheerful” responses to “unfriendly” inputs, lacking emotional variability.
In contrast, our dataset enabled the model to generate a wider range of response emotions, demonstrating emotionally adaptive behavior. This was likely because the dataset contained a sufficient number of samples across all emotion categories that also had better emotionally adaptive responses, allowing the LLM to learn diverse emotional conversations and generate responses that better aligned with common sense interactions. Examples of generated responses from EmoSDS are provided in Figure 9.

Figure 9.
Example response outputs of EmoSDS. The input was delivered as cluster ID sequences. The examples were selected from the EmoSC test set.
5.3. Ablation Study
To evaluate the effectiveness of the three-stage training pipeline, we conducted an ablation study by removing Stage 1 and Stage 2 during the training of the EmoSC dataset. Additionally, the impact of residual input was examined by training the model using only discrete content tokens. Table 5 presents the results, highlighting the contributions of each training stage and the role of residual input in capturing paralinguistic features.
Table 5.
Ablation study results for the three-stage training pipeline and the impact of residual input. An upward arrow (↑) indicates a higher value, signifying better performance, while a downward arrow (↓) indicates the opposite.
Removing residual input resulted in a substantial decline in emotion recognition performance (input acc.: 58.4%), while text recognition remained relatively stable (BLEU: 9.7%, BERTScore: 87.8%). The slight increase in WER (0.6%) and CER (0.4%) indicated that textual information alone was insufficient for capturing emotional nuances. These findings demonstrate that residual input is critical for encoding paralinguistic cues, which are essential for distinguishing emotional variations beyond lexical content. Consequently, this enabled the model to effectively recognize emotions even when the same content was spoken with different emotional states, as in the EmoSC dataset.
The absence of both Stage 1 and Stage 2 resulted in notable performance degradation across all metrics (input acc.: 90.0%, BLEU: 8.5%, ROUGE-L: 38.9%), confirming the necessity of structured training. Removing Stage 1 slightly reduced emotion recognition (input acc.: 96.0%) while increasing WER (1.9%) and CER (1.1%), indicating its role in enhancing transcription accuracy. In contrast, removing Stage 2 had minimal impact on input acc. (96.4%) but slightly lowered BLEU (10.1%), suggesting that it refines text generation.
The full EmoSDS pipeline achieved the highest performance (input acc.: 98.0%, BLEU: 10.4%, ROUGE-L: 40.5%), demonstrating that residual input and structured training improve both emotion recognition and response generation. These findings confirm that training on emotionally diverse datasets with residual input enhances the model’s ability to capture both content and paralinguistic information.
6. Conclusions
This paper presented EmoSDS, an Emotional Spoken Dialogue System that unifies speech and emotion recognition within a single LLM-based framework. Unlike conventional SDS architectures that rely on cascaded ASR or external emotion encoders, EmoSDS directly feeds self-supervised speech representations into the LLM, enabling end-to-end speech understanding while effectively capturing both linguistic content and emotional cues.
Our approach leverages structured SSL feature representations, where discrete linguistic tokens are extracted through k-means clustering, and continuous residual embeddings preserve paralinguistic attributes. This enables the seamless integration of emotional and prosodic information, eliminating the need for external emotion encoders. To further enhance performance, we introduced a three-stage training pipeline, progressively training the model on ASR, SER, and response generation, allowing for the better learning of linguistic and paralinguistic features.
Through extensive evaluations, we demonstrated that EmoSDS achieves state-of-the-art performance in both emotion recognition and response generation. Our results show that residual input is essential for capturing paralinguistic cues, significantly improving emotion recognition accuracy, particularly in datasets where the same content is spoken with different emotional states. Additionally, stage-wise training enhances both transcription accuracy and emotional expressiveness, resulting in more coherent and emotionally adaptive responses. Furthermore, our findings indicate that LLMs can effectively process continuous paralinguistic features, leveraging prosodic variations to improve emotional understanding and response generation.
To address the scarcity of high-quality emotional speech conversation datasets, we introduced EmoSC, a balanced, emotional speech dataset constructed using GPT-4o-mini and the ESD corpus. EmoSC significantly improves emotion recognition robustness, reduces data imbalance, and enhances the LLM’s ability to generate diverse and emotionally nuanced responses.
Our findings confirm that emotionally expressive datasets and structured training pipelines are critical for advancing spoken dialogue systems. By integrating continuous paralinguistic features and multi-stage learning, EmoSDS bridges the gap between linguistic understanding and emotional expressiveness, offering a more natural and engaging conversational experience.
Future research can explore a fully end-to-end approach that eliminates not only the ASR front-end but also the LLM-TTS pipeline, enabling direct speech-to-speech interaction. Additionally, leveraging LLM methods capable of processing continuous paralinguistic features could extend the model’s applicability to more diverse and generalizable speech-related tasks, such as speaker recognition, speaker diarization, pitch estimation, and energy prediction, which are challenging for discrete, token-based LLMs. This could lead to a highly generalized speech-language multimodal LLM capable of capturing richer acoustic and linguistic information.
Furthermore, our current framework is constrained to five discrete emotion categories. Expanding to a broader set of emotions or adopting continuous emotional representation could enhance the expressiveness and adaptability of the model, further improving its real-world applicability in emotion-aware dialogue systems.
Author Contributions
Methodology: J.L. and Y.S.; software: J.L.; validation: J.L. and Y.S.; formal analysis: J.L., Y.S., J.K. and Y.-J.S.; investigation: J.L.; resources: J.L. and Y.S.; data curation: J.L. and Y.S.; writing—original draft preparation: Y.S. and J.L.; writing—review and editing: J.L., Y.S., J.K. and Y.-J.S.; visualization: J.L.; supervision: Y.-J.S.; project administration: Y.S. and Y.-J.S.; funding acquisition: Y.-J.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partly supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (2022R1A6A1A03052954), Institute of Information & Communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (MSIT) (no. RS-2019-II191906, Artificial Intelligence Graduate School Program (POSTECH)), and the Korea Institute of Energy Technology Evaluation and Planning (KETEP) grant funded by the Ministry of Trade, Industry & Energy (MOTIE) of the Republic of Korea (no. 20214810100010).
Data Availability Statement
The data and code presented in this study are openly available at https://github.com/pepero8/EmoSDS (accessed on 19 March 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Sim, Y.; Yoon, J.; Suh, Y.J. SKQVC: One-Shot Voice Conversion by K-Means Quantization with Self-Supervised Speech Representations. arXiv 2024, arXiv:2411.16147. [Google Scholar]
- Zhang, D.; Li, S.; Zhang, X.; Zhan, J.; Wang, P.; Zhou, Y.; Qiu, X. Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities. arXiv 2023, arXiv:2305.11000. [Google Scholar]
- Rubenstein, P.K.; Asawaroengchai, C.; Nguyen, D.D.; Bapna, A.; Borsos, Z.; Quitry, F.d.C.; Chen, P.; Badawy, D.E.; Han, W.; Kharitonov, E.; et al. Audiopalm: A large language model that can speak and listen. arXiv 2023, arXiv:2306.12925. [Google Scholar]
- Zhao, W.; Zhao, Y.; Lu, X.; Wang, S.; Tong, Y.; Qin, B. Is ChatGPT equipped with emotional dialogue capabilities? arXiv 2023, arXiv:2304.09582. [Google Scholar]
- Liu, R.; Wei, J.; Jia, C.; Vosoughi, S. Modulating language models with emotions. arXiv 2021, arXiv:2108.07886. [Google Scholar]
- Varshney, D.; Ekbal, A.; Bhattacharyya, P. Modelling context emotions using multi-task learning for emotion controlled dialog generation. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Online, 19–23 April 2021; pp. 2919–2931. [Google Scholar]
- Lin, G.T.; Shivakumar, P.G.; Gandhe, A.; Yang, C.H.H.; Gu, Y.; Ghosh, S.; Stolcke, A.; Lee, H.y.; Bulyko, I. Paralinguistics-enhanced large language modeling of spoken dialogue. In Proceedings of the ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; IEEE: New York, NY, USA, 2024; pp. 10316–10320. [Google Scholar]
- Lin, G.T.; Chiang, C.H.; Lee, H.y. Advancing large language models to capture varied speaking styles and respond properly in spoken conversations. arXiv 2024, arXiv:2402.12786. [Google Scholar]
- Li, Y.A.; Jiang, X.; Darefsky, J.; Zhu, G.; Mesgarani, N. Style-talker: Finetuning audio language model and style-based text-to-speech model for fast spoken dialogue generation. arXiv 2024, arXiv:2408.11849. [Google Scholar]
- Lee, K.; Park, K.; Kim, D. Dailytalk: Spoken dialogue dataset for conversational text-to-speech. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: New York, NY, USA, 2023; pp. 1–5. [Google Scholar]
- Zhou, K.; Sisman, B.; Liu, R.; Li, H. Emotional voice conversion: Theory, databases and ESD. Speech Commun. 2022, 137, 1–18. [Google Scholar] [CrossRef]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Wang, M.; Han, W.; Shafran, I.; Wu, Z.; Chiu, C.C.; Cao, Y.; Chen, N.; Zhang, Y.; Soltau, H.; Rubenstein, P.K.; et al. Slm: Bridge the thin gap between speech and text foundation models. In Proceedings of the 2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Taipei, Taiwan, 16–20 December 2023; IEEE: New York, NY, USA, 2023; pp. 1–8. [Google Scholar]
- Nachmani, E.; Levkovitch, A.; Hirsch, R.; Salazar, J.; Asawaroengchai, C.; Mariooryad, S.; Rivlin, E.; Skerry-Ryan, R.; Ramanovich, M.T. Spoken Question Answering and Speech Continuation Using Spectrogram-Powered LLM. arXiv 2023, arXiv:2305.15255. [Google Scholar]
- Lin, G.T.; Shivakumar, P.G.; Gourav, A.; Gu, Y.; Gandhe, A.; Lee, H.Y.; Bulyko, I. Align-SLM: Textless Spoken Language Models with Reinforcement Learning from AI Feedback. arXiv 2024, arXiv:2411.01834. [Google Scholar]
- Xue, H.; Liang, Y.; Mu, B.; Zhang, S.; Chen, M.; Chen, Q.; Xie, L. E-chat: Emotion-sensitive Spoken Dialogue System with Large Language Models. In Proceedings of the 2024 IEEE 14th International Symposium on Chinese Spoken Language Processing (ISCSLP), Beijing, China, 7–10 November 2024; IEEE: New York, NY, USA, 2024; pp. 586–590. [Google Scholar]
- Hsu, W.N.; Bolte, B.; Tsai, Y.H.H.; Lakhotia, K.; Salakhutdinov, R.; Mohamed, A. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3451–3460. [Google Scholar]
- Chen, S.; Wang, C.; Chen, Z.; Wu, Y.; Liu, S.; Chen, Z.; Li, J.; Kanda, N.; Yoshioka, T.; Xiao, X.; et al. Wavlm: Large-scale self-supervised pre-training for full stack speech processing. IEEE J. Sel. Top. Signal Process. 2022, 16, 1505–1518. [Google Scholar]
- Pasad, A.; Chou, J.C.; Livescu, K. Layer-wise analysis of a self-supervised speech representation model. In Proceedings of the 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Cartagena, Colombia, 13–17 December 2021; IEEE: New York, NY, USA, 2021; pp. 914–921. [Google Scholar]
- Baas, M.; van Niekerk, B.; Kamper, H. Voice conversion with just nearest neighbors. arXiv 2023, arXiv:2305.18975. [Google Scholar]
- Dunbar, E.; Hamilakis, N.; Dupoux, E. Self-supervised language learning from raw audio: Lessons from the zero resource speech challenge. IEEE J. Sel. Top. Signal Process. 2022, 16, 1211–1226. [Google Scholar] [CrossRef]
- Li, J.; Tu, W.; Xiao, L. Freevc: Towards high-quality text-free one-shot voice conversion. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: New York, NY, USA, 2023; pp. 1–5. [Google Scholar]
- Polyak, A.; Adi, Y.; Copet, J.; Kharitonov, E.; Lakhotia, K.; Hsu, W.N.; Mohamed, A.; Dupoux, E. Speech resynthesis from discrete disentangled self-supervised representations. arXiv 2021, arXiv:2104.00355. [Google Scholar]
- Li, J.; Guo, Y.; Chen, X.; Yu, K. SEF-VC: Speaker Embedding Free Zero-Shot Voice Conversion with Cross Attention. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; IEEE: New York, NY, USA, 2024; pp. 12296–12300. [Google Scholar]
- Conneau, A.; Baevski, A.; Collobert, R.; Mohamed, A.; Auli, M. Unsupervised cross-lingual representation learning for speech recognition. arXiv 2020, arXiv:2006.13979. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An asr corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015; IEEE: New York, NY, USA, 2015; pp. 5206–5210. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), Stroudsburg, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. BERTScore: Evaluating Text Generation with BERT. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).