Abstract
Digital forensics systems are complex applications consisting of numerous individual components that demand substantial computing resources. By adopting the concept of microservices, forensics applications can be divided into smaller, independently managed services. In this context, cloud resource orchestration platforms like Kubernetes provide augmented functionalities, such as resource scaling, load balancing, and monitoring, supporting every stage of the application’s lifecycle. This article explores the deployment of digital forensics applications over a microservice-based architecture. Leveraging resource scaling and persistent storage mechanisms, we introduce a vertical scaling mechanism for compute-intensive forensics applications. A practical evaluation of digital forensics applications in competition investigations was performed using datasets from the private cloud of the Hellenic Competition Commission. The numerical results illustrate that the processing time of CPU-intensive tasks is reduced significantly using dynamic resource scaling, while data integrity and security requirements are fulfilled.
1. Introduction
According to National Institute of Standards and Technology (NIST), digital forensics is a subdomain of forensics science that encompasses the acquisition, retrieval, preservation, and analysis of electronic data that can be useful in criminal investigations and prosecutions [1]. These data, crucial for both legal and cybersecurity contexts, can be collected from various types of resources, e.g., computers, mobile phones, cloud services, social media, and Internet of Things (IoT) [2]. Within cybersecurity, digital forensics and incident response focus on the identification, investigation, and remediation of cyberattacks. The deployment of forensics applications in the computing and network elements of modern 5G communication systems offers a dual benefit. It can enhance the monitoring of infrastructure health and significantly boost the system’s overall performance by enabling prompt detection and response to malicious activities or abnormal behavior [3].
Nowadays, since most human activities create digital traces due to the wide usage of electronic devices, any crime probably leaves some digital evidence [4]. With this capacity, digital forensics tools are incorporated into the investigation of a broad spectrum of cybercrime, such as online fraud, cyber-bullying, pornography, cartel screening, and economic competition-related violations [5,6]. Depending on the nature of the crime, a set of devices must be examined and various digital forensics tools can be utilized to collect digital evidence in a legally acceptable way to be admissible at the court. Thus, different digital forensics models exist based on the timing and nature of the investigation [7]. In particular, the models can be categorized into the following types: (i) proactive (or live) data forensics frameworks, which focus on gathering volatile evidence (RAM, network traffic, active sessions, etc.) from running devices and monitoring the status of computing and network infrastructure to detecting suspicious activities, and (ii) reactive (or traditional) data forensics, which follow the occurrence of a stored or archived event (on a hard drive, etc.) and attempt to create a Chain of Custody (CoC) to link suspects to incidents [8].
The biggest challenge of modern digital forensics frameworks is the efficient analysis of data. Typically, the data volume collected during an incident is large, resulting in time-consuming data preparation and interpretation processes that require considerable human resources. To mitigate this, numerous commercial and open-source forensics tools are designed to support the work of case handlers and Information Technology (IT) specialists in two key areas. First, these tools ensure that the collection and analysis of the digital evidence comply with the legal requirements regarding admissibility, authenticity, completion, reliability, and believability [9]. Second, robust digital forensics applications offer a range of advanced functionalities, such as intelligent keyword searching, visualizations, summaries, and automated reports, which aid case handlers throughout the investigation [10].
However, unlocking the full potential of these capabilities requires IT personnel to follow a rigorous workflow that includes data curation, document indexing, artifact recovery, and image processing [11]. Significantly, these tasks are increasingly integrated into Artificial Intelligence (AI) components of forensics tools, enabling the development of specialized models for identifying criminal activities [12]. Given that many of these high-level processes rely heavily on data science techniques like information retrieval, data mining, pattern recognition [13], image recognition [14], and Natural Language Processing (NLP) [15], they demand substantial computational resources.
Consequently, forensics tools require high computational power and storage capacity to process large datasets efficiently, while their resource management remains a challenge [16]. On the other hand, cloud computing and virtualization technologies offer well-established resource orchestration and management solutions that can meet the functional and performance requirements of network applications [17]. In addition, the conceptual architecture of microservices enables the creation of tailor-made applications based on discrete components, each responsible for a specific task. The combination of these technologies provides a promising approach to address the resource management issues faced by digital forensics tools, helping to streamline the analysis process and optimize resource utilization. We argue that the digital forensics ecosystem can benefit from the adoption of the microservices concept, which allows greater adaptability and interoperability. In parallel, this framework ensures the essential dynamical computing, storage, and network resources, facilitating the deployment of complex applications that accelerate data processing and enhance analytical capabilities, while adhering to high isolation and security standards.
This article proposes a microservice-based architecture for digital forensics applications, which is crucial for investigating electronic evidence and detecting anti-competitive practices in competition cases. With the increasing reliance on digital communications, competition and regulatory authorities often encounter complex cases involving collusion, price-fixing, and abuse of dominant market positions [18]. Digital forensics techniques help in extracting, preserving, and analyzing data from various sources (email clients, messaging apps, cloud storage, corporate networks, wearables, etc.), which is instrumental in uncovering evidence that may be otherwise concealed. By employing contemporary forensics tools, competition investigators can trace communication patterns, reconstruct events, and identify key actors involved in anti-competitive conduct, thereby strengthening the legal process and promoting a fair market environment.
Digital forensics is also of primary importance for competition economics by providing the tools and methodologies necessary to uncover and analyze digital evidence in cases related to antitrust violations and market manipulation. In an increasingly data-driven economy, digital forensics techniques enable authorities and experts to investigate vast volumes of digital records, including emails, server logs, financial transactions, and communication data, to identify evidence of anti-competitive agreements. By leveraging advanced data analytics, forensic investigators can trace hidden patterns, detect illicit agreements, and evaluate market behaviors that may harm consumers or stifle competition. Digital forensics not only strengthen the enforcement of competition laws, but also support a fair and transparent marketplace by ensuring accountability and compliance in the digital domain. Through a competition policy use case, we make the following contributions of the microservice-based architecture for digital forensics applications deployed over a private cloud infrastructure:
- Modern forensics applications consist of several distinct components. The proposed architecture enables the customization of service workflows, including AI-based processes.
- The processing of digital evidence includes compute-intensive tasks, such as data acquisition, data carving, document indexing, and image processing. The proposed microservice architecture enables dynamic resource orchestration and provisioning, while satisfying essential computational, network, and security requirements.
- The performance of the proposed framework is assessed using real, anonymized data from the private cloud of the Hellenic Competition Commission, employing a commercial forensic software.
The rest of this article is structured as follows. Section 2 presents the most related studies in digital forensics and cloud orchestration, while Section 3 describes the basic stages of the digital investigation process. Section 4 provides the details of the proposed architecture for dynamic digital forensics applications. Section 5 illustrates the efficacy of the proposed approach in a realistic private cloud environment. Finally, Section 6 concludes and discusses possible future work directions.
2. Related Work
This section presents a comprehensive overview of the most relevant studies in the literature. These studies consider the general requirements of digital forensics and focus on cloud computing, which is the dominant service delivery architecture today.
The authors of [9] analyzed the legal challenges of digital and cloud forensics, such as (i) “data territoriality—the loss of location challenge”, (ii) “the challenge of cloud content ownership”, and (iii) “the challenge of user authentication and data preservation”, and presented judicial opinions on cloud forensics from the European and USA legal framework. Akremi et al. [7] proposed a conceptual digital forensics model for deploying forensic applications over a service-oriented architecture. The authors provided a useful categorization of digital forensics and analyzed a forensic model that includes assets, attributes, threats, metrics, and solutions. Furthermore, they discussed the requirements of digital forensics Web applications within a service-oriented architecture.
Several surveys present challenges and features of the digital forensics landscape. The authors of [19] provided an analytical study of digital forensics regarding database, mobile, network, and IoT subdomains, and discussed future directions, including (i) the development of metamodeling languages for the digital forensics domain, (ii) the formulation of data representation and structured queries, (iii) the standardization of domain-specific ontologies, and (iv) the integration and harmonization of different domain frameworks into a unified one. Similarly, Casino et al. [2] presented challenges of the digital forensics domain. On top of that, this survey discussed various forensic frameworks and processing models that include all steps of a digital investigation, from evidence acquisition to reporting and presentation. Finally, it discussed future trends in forensic readiness and standards, immutability, ethics in criminal investigation, and explainability. Malik et al. [1] focused on cloud digital forensics by presenting procedures and tools to ensure the integrity of collected evidence, and discussed the main challenges based on the steps of the forensic procedure, including identification, collection, analysis, and presentation. Finally, regarding competition investigation, the survey of [20] presents a set of data screening tools that can evaluate the behavior of market and companies to detect cartels. The authors presented an in-depth analysis and classification of the existing studies, which include probabilistic, network, Machine Learning (ML), and various other methods.
Since digital forensics is a vital part of various types of investigations, different forensic procedures are utilized. The investigators leverage AI-based applications to process large datasets automatically. Vasilaras et al. [10] focused on AI-powered applications for mobile forensics. They evaluated commercial software tools, enhanced with ML functionalities, and discussed the ethical and technical challenges of AI in digital investigations. The authors of [3] described an architecture for covering aspects of data management and processing in the lawful interception ecosystem over 5G infrastructure. They proposed the adoption of several promising technologies, such as quantum ML and authentication, 5G network slicing management, and Radio Access Network (RAN) orchestration. Finally, Wen et al. [21] proposed a cloud-based framework for dealing with large datasets. Based on Hadoop, this framework includes various forensic applications and facilitates investigators in creating customized workflows and defining their requirements in XML configuration files. The framework allows for the selection of the appropriate applications, generates the corresponding map-reduce drivers and sets up the workflow in the cloud infrastructure automatically.
Cloud resource orchestration and virtualization are well-studied research problems. In the dawn of the 5G era, based on virtualization technology, many resource management frameworks have been developed and facilitate the automated deployment and operation of network applications. As applications increasingly rely on cloud infrastructure and become more complex, dynamic resource orchestration is essential to meet the performance requirements of the applications. Towards this direction, a resource orchestration mechanism should address application placement, resource scaling, load balancing, and admission control as the workload and network conditions change continuously. For example, ACRA [22] is a resource allocation and admission control mechanism for cloud-based virtualized applications. This mechanism relies on Kalman filter prediction and a feedback controller for allocating computing resources to Virtual Machines (VMs) and adjusting the admitted requests. With the advent of edge computing, Kubernetes (https://kubernetes.io) (accessed date 12 March 2025) (K8s) is the most-used open-source system for automating deployment, scaling, and management of containerized applications. Given the functionalities of K8s, Dimolitsas et al. [23] proposed an autoscaling mechanism for containerized applications, which relies on ARIMA predictor and a multi-criteria decision-making mechanism.
This paper aspires to introduce the concept of microservices for digital forensics applications. With this capacity, we propose a microservice-based resource orchestration mechanism for deploying various digital forensics applications that have several data integrity requirements and require dynamic resource scaling due to computing-intensive tasks.
3. Digital Investigations
This section provides an overview of the electronic discovery (e-discovery) process that can be followed in a competition or regulatory environment. Figure 1 illustrates an indicative CoC, ensuring that data remain unaltered, secure, and properly documented during the Electronic Discovery Reference Model (EDRM) (https://edrm.net/edrm-model) (accessed date 12 March 2025) process. More specifically, at the beginning of a dawn raid, the investigators work to identify the IT infrastructure of the company and focus on specific data types of interest. Then, depending on the case’s needs, they may acquire physical (forensic) images, logical images, or collect hand-picked data utilizing specific keywords (targeted images), adhering to GDPR guidelines. The process of data collection and the generation of digital signatures via cryptographic hash functions (e.g., MD5, SHA-1) to ensure data consistency is meticulous and can take several days [24]. Once collected, the data are secured in encrypted external storage devices and transferred to facilities. After a Legal Professional Privilege (LPP) process to safeguard confidential communications, documents, or personal data from subsequent procedures, the data are stored in ISO 27001-certified infrastructure. Afterward, the Electronically Stored Information (ESI) must be processed and transformed into an appropriate format to serve as valid input for forensic tools. This stage involves several demanding tasks, including data extraction, cleaning, and indexing, which are both time- and resource-intensive. Following preparation, the digital evidence is shared with the case handlers, who can then assess it using the appropriate functionalities of forensic applications to support their investigation, ultimately guiding to the legal and economic review.
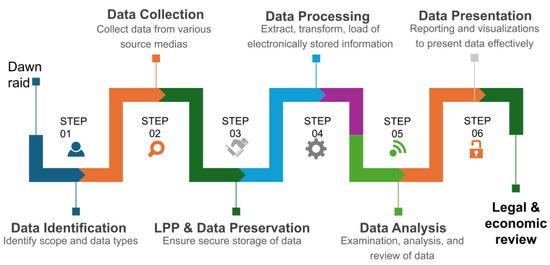
Figure 1.
The steps of a Chain of Custody for competition purposes that tracks the movement of electronic evidence throughout its lifecycle.
From an economic perspective, cartel detection involves identifying and analyzing collusive behavior among firms against consumers, typically to increase profits at the expense of consumers and overall market efficiency [25]. Economists and competition authorities use various tools and methods to detect cartels, as they operate secretly and their activities are considered illegal in most jurisdictions. Additionally, cartel detection and digital forensics are increasingly intertwined, especially in the modern era where digital communication and Big Data play a crucial role in business operations [26]. Digital forensics provide tools and techniques to uncover evidence of collusion, which is critical for detecting and prosecuting cartels. Resulting from the EDRM framework, forensic tools operate in three key phases of the digital evidence, i.e., collection, preservation, and analysis, to support effective investigation of illegal activities and anti-competitive practices [27]. In the context of cartel detection, digital forensics can help in (i) uncovering electronic communications (e.g., emails, chats, etc.) that reveal collusion, (ii) analyzing metadata to establish timelines and connections between parties, (iii) recovering deleted or hidden data that may contain evidence of illegal agreements, and (iv) providing admissible evidence for legal proceedings.
Depending on the nature of the investigation, the case handlers can use various forensics applications with different analytical capabilities. Forensic software usually focus on specific steps of the CoC and a single type of hardware device. Therefore, forensics applications can be categorized using four primary criteria: (i) function (purpose), (ii) device type, (iii) hosting Operating System (OS), and (iv) licensing. The function criterion considers the CoC step that the application provides its main functionalities, e.g., data acquisition, data processing, or forensic analysis. Forensics applications are often tailored to specific types of devices, hardware or software. These can include mobile devices, cloud infrastructure, memory or hard disks, and server logs or databases. Moreover, the forensics applications are designed for a specific OS, e.g., Windows, Linux, Android systems, or can be cross-platform, capable of running on multiple OS. Finally, regarding licensing, forensic software can be either commercial or open-source. Table 1 includes a list of widely used digital forensics applications and summarizes their main features and capabilities.

Table 1.
Comparison of digital forensics applications by function, device type, hosting OS, and licensing.
4. Microservice-Based Architecture
This section presents the details of the proposed architecture for deploying and managing various digital forensics applications. Virtualization and containerization are two leading technologies for delivering modern cloud services. Both provide many automated functionalities to support every stage of the lifecycle of end-to-end services, including instantiation, update, and termination. However, there are important differences between these technologies that make them more appropriate for specific types of applications. VMs require more computing resources (CPU and memory) because they run on their operating system, and their startup time is long. In parallel, VMs provide full isolation. On the contrary, containers are lightweight because they share the host operating system, and their instantiation time is short. Moreover, the isolation of the containerized application is at the process level. According to the features above, VMs are more suitable for static cloud applications, while containers are appropriate for dynamic and IoT applications. To this end, we select Kubernetes, the most popular framework for cloud and IoT applications, as the resource orchestration platform due to its built-in capabilities on automating deployment and resource management for containerized applications.
In the K8s platform, complex applications are broken down into microservices, which perform a specific task. This improves the resource management of every service based on performance and security requirements. The basic components of K8s ecosystem that are included in the proposed architecture are defined below:
- Pod: The elementary functional unit including one or more containers and their shared volumes.
- Service: Abstracts a set of pods that are components of an application.
- Node: A (virtual or physical) computing machine, where pods are deployed. It is part of a cluster.
- Cluster: A superset of nodes, which can be easily added or removed based on the workload demands.
- Deployment: The process that manages the resources of the pods dedicated to an application. The Deployment Descriptor includes all parameters for creating or modifying instances of the pods that hold containerized applications.
- Kubernetes API server: Exposes a RESTful interface to all Kubernetes resources, serves as the frontend of the Kubernetes control plane, and communicates with the Application Programming Interfaces (APIs) of Kubernetes to perform all the core functionalities.
- Ingress Controller: An API object that provides external access to the services in a cluster, typically through HTTP requests. Ingress controller can provide load balancing, SSL termination, and name-based virtual hosting functionalities.
- Volume: A directory accessible to all containers running in a pod. In contrast to the container-local filesystem, the data in volumes are preserved across container restarts and can be transferred in case of migration.
K8s assigns to every pod a unique IP address and a single DNS name for a set of pods of an application, which is useful for applying load balancing techniques among them. Following the network slicing rationale, K8s uses services as an abstract way to create and connect the individual components of an application running on its cluster. Figure 2 illustrates the nested application deployment in a K8s cluster using the abstractive method of the K8s service.
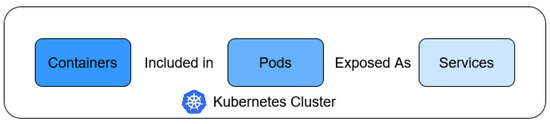
Figure 2.
Application deployed to Kubernetes cluster.
The pod’s resources and the attributes of the mechanisms (autoscalers, ingress controllers) in K8s are declared in the Deployment Descriptors. These descriptors are submitted to the Kubernetes API server for the configuration of pods, services, and other K8s functional components. The Deployment Descriptors are either YAML or JSON objects that describe the resources, which we aim to use or customize along with the functionalities of K8s objects, to fit the needs of a digital forensics platform. In this deployment object, we first define the API version to communicate with the Kubernetes API server, as long as the name and the label of the containerized application match. Then, we define the number of running pods (replicas) to handle the incoming workload. For each pod, the limits of resources in terms of CPU and RAM are defined, along with the initial requested values. As a result, when a pod is instantiated, it is assigned the requested values of resources and thus can scale vertically towards these limits. This allows us to perform vertical scaling of the running pods according to the number of requests that the specific application targets serve. Finally, the port that the container is listening for requests is defined. Typically, a pod includes many containers managed as a single entity. Without loss of generality, in our case, we assume that a pod hosts only one container.
Subsequently, we present the core elements of the microservice-based architecture for digital forensics applications. The proposed architecture aspires to provide fully automated management of the application lifecycle. Towards this direction, the architecture includes components that provide dynamic resource orchestration and authorization mechanisms to ensure high performance and data integrity. More specifically, the architecture provides an autoscaling mechanism suitable for compute-intensive tasks. In general, the scaling mechanism of a resource orchestration platform regulates the resources of a containerized application according to a set of predefined performance metrics and a resource scheduling algorithm. There are two scaling techniques, the horizontal [23] and the vertical one [43]. Horizontal scaling (scale in/out) refers to the dynamic resource adaption of a pod by creating multiple replicas. On the other hand, vertical scaling (scale up/down) refers to the dynamic change in the resource limits of the pod without creating replicas. In our case, we consider vertical scaling for the deployed forensic applications, because they are stateful applications and horizontal scaling requires complicated data management, which is not recommended for our case. In terms of data security, since only a selected group of case handlers should have access to the collected data, an authorization mechanism is essential to grant and maintain proper access control. Furthermore, in a real-world scenario, case handlers often collaborate and need to process and analyze digital evidence concurrently. Under this setting, to prevent data loss or data modification, it is essential to utilize a storage mechanism that ensures persistent data volumes, allowing data to be stored independently of which pod has access to it. To realize the above requirements, the implementation of the architecture relies on the capabilities of widely used open-source software tools.
Figure 3 illustrates the components of the architecture and the flow of the control and data plane. In this figure, solid and dashed lines correspond to plane and control data transfer, respectively. Firstly, the incoming requests are admitted by the app Ingress Control, which is responsible for routing the external traffic from K8s platform to the pods. In the case of many pod replicas, this component combined with K8s Load Balancer can perform traffic balancing based on various techniques. As already described, digital forensics applications are deployed in a pod and many pods can be hosted in a compute node. The Prometheus monitoring system (https://prometheus.io) (accessed date 12 March 2025) can be responsible for collecting various performance metrics from pods, such as processing time, CPU, and memory utilization and latency. Using the Prometheus Adapter, custom performance metrics can be defined and collected from the pods. In addition, these metrics can be used for scaling decisions and visualizing the status of the pods in real-time. The Custom Metrics Adapter retrieves monitoring data, which combine utilization, cost, and performance metrics, and forwards them to the Vertical Pod Autoscaler (VPA), which is responsible for updating the resources of a pod. Based on the custom metrics, VPA computes the pod’s resources. The actual implementation of the scaling decision is performed through deployment, which includes all the parameters of the running pod. The most important attribute of the deployment is the resource limits, which are responsible for vertical pod scaling. Regarding resource scaling, two controlling parameters, namely Request and Limits, configure the allocated CPU and memory to the pod. Request (either CPU or memory) defines the minimum amount of resources that containers of the pod need. In parallel, based on this information, K8s decides on which node to place the pod. Limit (either CPU or memory) defines the maximum amount of resources that a specific container can consume. Although the above parameters define the resource range that containers consume, there is still a risk that VPA recommends resources greater than those available in the cluster. To overcome this limitation, LimitRange policy allows us to constrain the pod’s resource allocation to a maximum value, usually the total available resources.
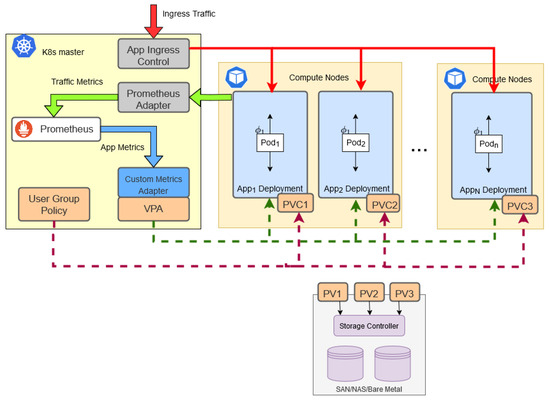
Figure 3.
A microservice-based architecture for digital forensics applications.
Regarding data integrity, the most crucial element in CoC, K8s provides a secure storage mechanism through persistent volumes. A PersistentVolume (PV) is a storage block in the cluster provided statically or dynamically. The PV subsystem provides an API for users and administrators that configures how storage is provided and consumed. Contrary to volumes, PVs are independent from any pod that uses them. Users and pods are allowed to consume PVs through PersistentVolumeClaims (PVCs), which request specific size and access modes (e.g., ReadWriteOnce, ReadOnlyMany, ReadWriteMany, or ReadWriteOncePod). This mechanism allows for the creation of bindings between PVs and PVCs with specific user access privileges in a secure way that protects from data loss. In the proposed architecture, the User Group Policy component provides access to a specific group of users by configuring a PVC. Through this claim, a pod hosting a forensic application is bound to a PV, where digital evidence is stored. In such a way, the case handlers have direct data access and parallel processing is feasible.
Last but not least, we must refer to the agile application’s lifecycle support of the proposed architecture. K8s is an open-source platform with wide adoption and support by the academic and industrial community. This ensures the long-term deployment of digital forensics applications following the microservice concepts. Furthermore, considering that public cloud infrastructure is not an applicable option for public regulatory authorities, like competition commissions, open-source resource orchestration tools like Kubernetes is a viable alternative for maintaining private cloud infrastructure.
5. Evaluation
In this section, we evaluate the efficacy of the microservice-based architecture for digital forensics applications using real, anonymized data from the private cloud of the Hellenic Competition Commission. The following paragraphs present the setup and the results of the experiments. In the experiments, we utilized a server with an Intel Xeon Silver 4210 CPU featuring 40 cores, 64 GB RAM, and a NETGEAR NAS storage system of 4.9 TB capacity. In three VMs, we deployed a Kubernetes cluster (v1.29.0), which included the K8s master node and two compute nodes. To evaluate the resource scaling mechanism of the proposed architecture, we used the TOVEK Tools software (v7.7.3) [32], which provided advanced capabilities on large amounts of text data using specialized modules for the indexing of sources, context and content analysis, and generation of graphs and interactive reports. This software can be deployed on a network storage (functioning like a server) to host its knowledge management and information analysis features. The client is installed as a desktop application on the local machines of selected case handlers, enabling efficient searching and the ability to answer complex queries fast, without the need to store the entire dataset locally. The network application is containerized in a pod, while its resources are scaled up or down based on the workload demand. For evaluation purposes, we used the TOVEK Index Manager to create indexes of large datasets, which is a CPU-intensive and time-consuming task.
To evaluate the resource scaling mechanism of the architecture, we considered four different resource profiles of pods. The resource profile of a pod specifies the CPU and memory resources that are recorded as the resource limits of the Deployment Descriptor. The scaling decision is based only on CPU utilization since memory utilization is stable and independent of the dataset size. For data indexing, we utilized five anonymized datasets of different sizes from the Hellenic Competition Commission, which have been used as digital evidence in a past case. Every dataset contains various types of files, such as emails, Microsoft Office files (i.e., Word, Excel, PowerPoint), images, and scanned documents. Using persistent volumes, the datasets were stored and bound with specific pods to prevent any data loss and guarantee data integrity. Table 2 includes the details of the resource profiles and datasets. Leveraging the VPA functionalities, we ran two different experimental setups to evaluate the scaling decision. For the first experimental setup, an indexing task is executed under different pods’ resource profiles. For the second set of experiments, we simultaneously ran two indexing tasks within a single pod. For both cases, the performance metric is the completion time of the indexing task (indexing time).
Table 2.
Resource profile naming conventions and dataset descriptions used in experiments.
In the first set of experiments, we focus on the effect of allocated CPU cores on the completion time of a single indexing task running in the pod. Figure 4 illustrates the completion time of the indexing tasks of various datasets, which were executed in pods with different resource profiles. Initially, it is observed that the indexing time decreases as the CPU cores increase. Indicatively, the indexing time of data-XL executed on an 8-core pod (prof4) is almost three times shorter than the completion time in a 2-core pod (prof1). However, it is worth mentioning that the improvement of indexing time is smaller as the allocated resources increase. As shown in Figure 4, for data-XL, the reduction in the indexing time for the pod with profiles prof3 and prof4 is less than . This can be explained by the thread parameter of TOVEK Tools software, which limits the number of CPU cores that are used for parallel task processing. If the allocated CPU cores exceed the value of this parameter, the indexing time will not be further improved. These two remarks highlight that vertical scaling significantly improves the required time for CPU-intensive tasks, like document indexing. Furthermore, leveraging the automated functionalities of VPA or another customized scaling algorithm, this performance improvement can be achieved on-demand, based on the dynamic workload needs.
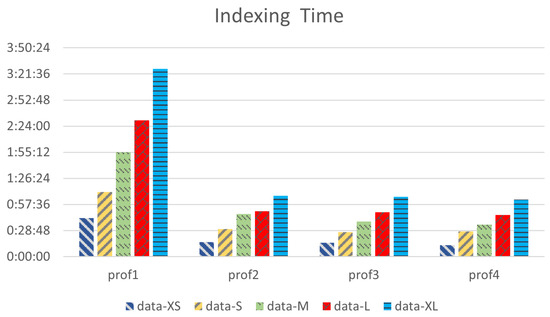
Figure 4.
Indexing time of different datasets under resource profiles.
In the second set of experiments, we examined the effect of multiple indexing tasks on the completion time of the indexing task. Figure 5 illustrates the completion time of two indexing tasks, which were executed simultaneously in a pod. In Figure 5a, two indexing tasks using datasets data-S and data-M are executed in a 4-core pod (prof2). Compared with the indexing time recorded in the first setup of experiments (Figure 4), the indexing time of data-S is almost double, while the completion time of data-S has been increased by . This large increase in indexing time is due to the lack of computing resources to execute these tasks concurrently. Next, as Figure 5b illustrates, we ran two indexing tasks with datasets data-M and data-XL in an 8-core pod (prof4). In this case, for data-M, the indexing time has been increased by , while the increase in indexing time of data-XL is only . Compared with the indexing time of a single task (Figure 4), the increase in data-XL is significantly smaller than that observed for data-M. This happened because the last task finished earlier and all CPU resources were available for the indexing of data-XL. Independent of the magnitude of the increase, we conclude that the concurrent execution of indexing tasks deteriorates the application’s performance in terms of the completion time, due to resource scarcity.
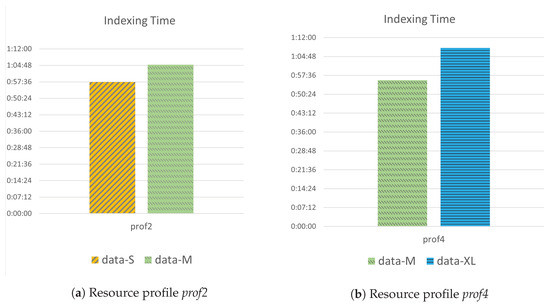
Figure 5.
Indexing time of simultaneous tasks under different resource profiles.
6. Conclusions
This article proposed a microservice-based architecture for digital forensics applications. The architecture enables the automated resource orchestration of applications, while it ensures the integrity of the acquired datasets. Under this setting, we exploited the integrated vertical scaling and persistent storage mechanisms of Kubernetes orchestration platform to enhance the performance of compute-intensive forensic analysis. Using real and anonymized datasets from the Hellenic Competition Commission, along with the TOVEK Tools software, the numerical results illustrate the benefits of vertical scaling, indicating a significant reduction in the processing time of CPU-intensive tasks, such as document indexing, without data loss.
In our future plans, we aim to enhance the functionalities of the proposed architecture to support AI-powered investigation tasks. These data-driven processes involve various components with increased computing demands. For instance, model training requires many computing resources and can be either centralized or distributed (federated). Additionally, the performance of a model may depend on the end-device it runs on. Thus, models with different complexity (e.g., architectural layers) can be trained to trade off accuracy, computing effort, and latency. Towards this direction, microservices enable the efficient break down of AI-based applications to smaller services and facilitate fine-grained management of their performance. To meet the performance requirements, sophisticated resource scaling algorithms for microservices can guarantee optimal resource allocation under varying workload demands.
Author Contributions
Conceptualization, all; methodology, F.N., K.K. and D.D.; validation, F.N. and D.D.; visualization, F.N., K.K. and D.D.; writing—original draft preparation, all. All authors have read and agreed to the published version of the manuscript. The views expressed in this paper are those of the authors and do not represent the views of their affiliated organizations. Any errors are the authors’ alone.
Funding
This research received no external funding.
Data Availability Statement
The data of this study are strictly confidential and unavailable due to legal and organizational restrictions imposed by the Hellenic Competition Commission.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| NIST | National Institute of Standards and Technology |
| IoT | Internet of Things |
| ML | Machine Learning |
| AI | Artificial Intelligence |
| NLP | Natural Language Processing |
| EDRM | Electronic Discovery Reference Model |
| VM | Virtual Machine |
| K8s | Kubernetes |
| CoC | Chain of Custody |
| VPA | Vertical Pod Autoscaler |
| PV | Persistent Volume |
| PVCs | PersistentVolumeClaims |
References
- Malik, A.W.; Bhatti, D.S.; Park, T.J.; Ishtiaq, H.U.; Ryou, J.C.; Kim, K.I. Cloud digital forensics: Beyond tools, techniques, and challenges. Sensors 2024, 24, 433. [Google Scholar] [CrossRef] [PubMed]
- Casino, F.; Dasaklis, T.K.; Spathoulas, G.P.; Anagnostopoulos, M.; Ghosal, A.; Borocz, I.; Solanas, A.; Conti, M.; Patsakis, C. Research trends, challenges, and emerging topics in digital forensics: A review of reviews. IEEE Access 2022, 10, 25464–25493. [Google Scholar] [CrossRef]
- Kourtis, M.A.; Xilouris, G.; Chochliouros, I.; Kourtis, A. Quantum Computing and Lawful Interception Applications. In Proceedings of the International Conference on Information Technology & Systems, Cusco, Peru, 24–26 April 2023; Springer: Cham, Switzerland, 2023; pp. 363–373. [Google Scholar]
- Reedy, P. Interpol review of digital evidence for 2019–2022. Forensic Sci. Int. Synerg. 2023, 6, 100313. [Google Scholar] [PubMed]
- Holt, T.; Bossler, A.; Seigfried-Spellar, K. Cybercrime and Digital Forensics: An Introduction; Routledge: Abingdon-on-Thames, UK, 2022. [Google Scholar]
- Montero, D. Screening Data as Evidence in EU Cartel Investigations. 2023. Available online: https://www.concorrencia.pt/sites/default/files/documentos/Diego%20Montero%20-%20Screening%20data%20as%20evidence%20in%20EU%20cartel%20investigations (accessed on 12 March 2025).
- Akremi, A.; Sallay, H.; Rouached, M.; Bouaziz, R. Applying digital forensics to service oriented architecture. Int. J. Web Serv. Res. 2020, 17, 17–42. [Google Scholar]
- Alharbi, S.; Weber-Jahnke, J.; Traore, I. The proactive and reactive digital forensics investigation process: A systematic literature review. In Proceedings of the Information Security and Assurance: International Conference—ISA 2011, Brno, Czech Republic, 15–17 August 2011; Springer: Cham, Switzerland, 2011; pp. 87–100. [Google Scholar]
- Karagiannis, C.; Vergidis, K. Digital evidence and cloud forensics: Contemporary legal challenges and the power of disposal. Information 2021, 12, 181. [Google Scholar] [CrossRef]
- Vasilaras, A.; Papadoudis, N.; Rizomiliotis, P. Artificial intelligence in mobile forensics: A survey of current status, a use case analysis and AI alignment objectives. Forensic Sci. Int. Digit. Investig. 2024, 49, 301737. [Google Scholar]
- Kwon, M.J.; Lee, W.; Nam, S.H.; Son, M.; Kim, C. SAFIRE: Segment Any Forged Image Region. arXiv 2024, arXiv:2412.08197. [Google Scholar]
- Irons, A.; Lallie, H.S. Digital forensics to intelligent forensics. Future Internet 2014, 6, 584–596. [Google Scholar] [CrossRef]
- Kong, C.; Luo, A.; Wang, S.; Li, H.; Rocha, A.; Kot, A.C. Pixel-inconsistency modeling for image manipulation localization. IEEE Trans. Pattern Anal. Mach. Intell. 2025. [Google Scholar] [CrossRef] [PubMed]
- Lou, Z.; Cao, G.; Guo, K.; Yu, L.; Weng, S. Exploring multi-view pixel contrast for general and robust image forgery localization. IEEE Trans. Inf. Forensics Secur. 2025, 20, 2329–2341. [Google Scholar] [CrossRef]
- Ukwen, D.O.; Karabatak, M. Review of NLP-based systems in digital forensics and cybersecurity. In Proceedings of the 2021 9th International Symposium on Digital Forensics and Security (ISDFS), Elazig, Turkey, 28–29 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–9. [Google Scholar]
- Lee, J.; Un, S. Digital forensics as a service: A case study of forensic indexed search. In Proceedings of the 2012 International Conference on ICT Convergence (ICTC), Jeju, Republich of Korea, 15–17 October 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 499–503. [Google Scholar]
- Dechouniotis, D.; Athanasopoulos, N.; Leivadeas, A.; Mitton, N.; Jungers, R.; Papavassiliou, S. Edge computing resource allocation for dynamic networks: The DRUID-NET vision and perspective. Sensors 2020, 20, 2191. [Google Scholar] [CrossRef] [PubMed]
- Carugati, C. The Generative AI challenges for competition authorities. Intereconomics 2024, 59, 14–21. [Google Scholar]
- Al-Dhaqm, A.; Ikuesan, R.A.; Kebande, V.R.; Abd Razak, S.; Grispos, G.; Choo, K.K.R.; Al-Rimy, B.A.S.; Alsewari, A.A. Digital forensics subdomains: The state of the art and future directions. IEEE Access 2021, 9, 152476–152502. [Google Scholar]
- OECD. Data Screening Tools for Competition Investigations; Competition Policy Roundtable Background Note; OECD: Paris, France, 2022. [Google Scholar]
- Wen, Y.; Man, X.; Le, K.; Shi, W. Forensics-as-a-service (faas): Computer forensic workflow management and processing using cloud. In Proceedings of the Fifth International Conferences on Pervasive Patterns and Applications, Valencia, Spain, 27 May–1 June 2013; pp. 1–7. [Google Scholar]
- Dechouniotis, D.; Leontiou, N.; Athanasopoulos, N.; Bitsoris, G.; Denazis, S. ACRA: A unified admission control and resource allocation framework for virtualized environments. In Proceedings of the 2012 8th International Conference on Network and Service Management (CNSM) and 2012 Workshop on sYstems Virtualiztion Management (SVM), Las Vegas, NV, USA, 22–26 October 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 145–149. [Google Scholar]
- Dimolitsas, I.; Spatharakis, D.; Dechouniotis, D.; Papavassiliou, S. AHP4HPA: An AHP-based Autoscaling Framework for Kubernetes Clusters at the Network Edge. In Proceedings of the GLOBECOM 2022–2022 IEEE Global Communications Conference, Rio de Janeiro, Brazil, 4–8 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2566–2571. [Google Scholar]
- John, J.L. Digital Forensics and Preservation; Citeseer: Princeton, NJ, USA, 2012. [Google Scholar]
- Stefanović, S. Cartels in the Digital Era: Challenges and Obstacles. Facta-Univ.-Law Politics 2023, 21, 1–10. [Google Scholar]
- Beth, H.; Gannon, O. Cartel screening–can competition authorities and corporations afford not to use big data to detect cartels? Compet. Law Policy Debate 2022, 7, 77–88. [Google Scholar] [CrossRef]
- Volpin, C.; Ohno, T. Digital Evidence Gathering in Cartel Investigations. SSRN 2020, 3917878. [Google Scholar] [CrossRef]
- Magnet Axiom Cyber. Available online: https://www.magnetforensics.com/products/magnet-axiom-cyber/ (accessed on 13 January 2025).
- Magnet Axiom Outrider. Available online: https://www.magnetforensics.com/products/magnet-outrider/ (accessed on 13 January 2025).
- X-Ways Forensics. Available online: https://www.x-ways.net/forensics/index-m.html (accessed on 13 January 2025).
- X-Ways Investigator. Available online: https://www.x-ways.net/investigator/index-m.html (accessed on 13 January 2025).
- Burita, L.; Halouzka, K. The Effective Working with Tovek Tools. In Proceedings of the Management Challenges in a Network Economy: Proceedings of the MakeLearn and TIIM International Conference, Lublin, Poland, 17–19 May 2017; pp. 185–194. [Google Scholar]
- OpenText Forensic. Available online: https://www.opentext.com/products/forensic (accessed on 13 January 2025).
- Autopsy Digital Forensics. Available online: https://www.sleuthkit.org/autopsy/ (accessed on 13 January 2025).
- The Sleuth Kit (TSK). Available online: https://www.sleuthkit.org/sleuthkit/ (accessed on 5 February 2025).
- FTK Forensic Toolkit. Available online: https://www.exterro.com/digital-forensics-software/forensic-toolkit (accessed on 13 January 2025).
- Cellebrite Physical Analyzer. Available online: https://cellebrite.com/en/physical-analyzer/ (accessed on 13 January 2025).
- Cellebrite UFED Cloud. Available online: https://cellebrite.com/wp-content/uploads/2020/05/ProductOverview_Cellebrite_UFEDCloud_web.pdf (accessed on 13 January 2025).
- Oxygen Forensic. Available online: https://www.oxygenforensics.com/en/products/oxygen-analytic-center/ (accessed on 13 January 2025).
- Logicube Falcon-NEO2. Available online: https://www.logicube.com/shop/forensic-falcon-neo2/ (accessed on 14 January 2025).
- Paladin Toolbox. Available online: https://sumuri.com/product/paladin-lts/ (accessed on 14 January 2025).
- Digital Forensics Framework (DFF). Available online: https://github.com/arxsys/dff (accessed on 14 January 2025).
- Dechouniotis, D.; Leontiou, N.; Athanasopoulos, N.; Christakidis, A.; Denazis, S. A control-theoretic approach towards joint admission control and resource allocation of cloud computing services. Int. J. Netw. Manag. 2015, 25, 159–180. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).