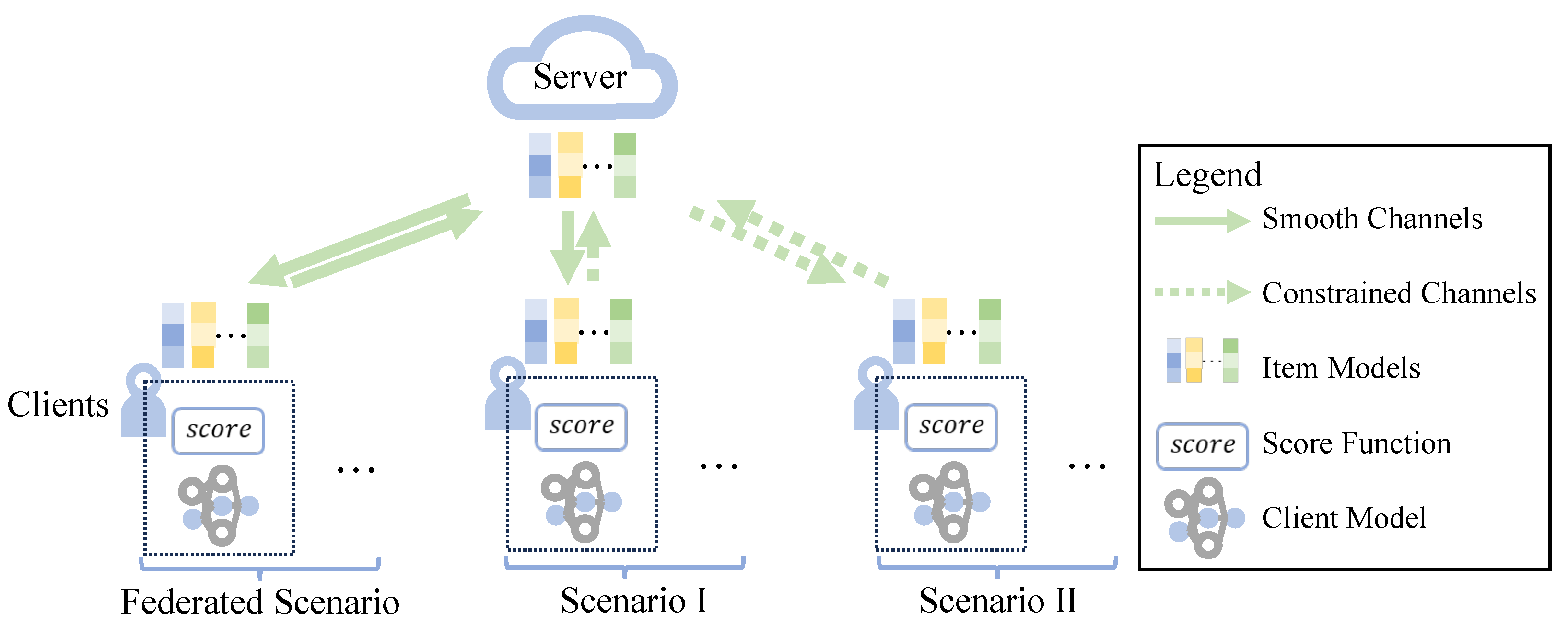
We analyze the learning curves and focus on HR@10, NDCG@10 and the associated communication rounds required to achieve the performance. PFedGMF denotes FedGMF utilizing DPM, and the same applies to PFedNCF and PFedRECON. For consistency in notation, we denote PFedRec as PFedMF. FedMF-I2CG represents FedMF employing I2CG, with similar notations applying to others. For brevity, we only present the learning curves of PFedMF/FedMF.
4.2.1. RQ1: Impacts on Convergence Speed and Recommendation Performance
We first focus on the relevant results of I2CG.
Figure 3 and
Table 4 show the impact of I2CG on FRSs with or without DPM. From the results, we observe that, whether FRSs adopt DPM or not, in most cases, the I2CG approach can effectively accelerate the convergence of HR and NDCG. For example, on Foursquare, when PFedMF employs I2CG, it only requires 84 communication rounds to reach convergence, which represents a 64.71% reduction in the number of communication rounds required compared to when I2CG is not employed, which necessitates 238 communication rounds. In a few instances, such as FedRECON on Lastfm-2K, the introduction of I2CG does not reduce the communication rounds needed for convergence (104 → 110). Introducing the I2CG strategy enables the utilization of local computation resources from communication-constrained clients, facilitating the comprehensive training of these clients, thereby accelerating overall model convergence rate.
The impact of I2CG on the model performance demonstrates variability across diverse FRSs, datasets and evaluation metrics. Specifically, on Lastfm-2K, the introduction of I2CG in PFedMF enhances HR from 0.8196 to 0.8540, representing a 5.2% increase. However, on MovieLens-100K, the introduction of I2CG in PFedMF results in a minor decrease in HR, from 0.7243 to 0.7211, a decline of 0.44%. Fortunately, the introduction of I2CG in experiments has never led to a significant decline in the recommendation performance. The reduction can be alleviated through the early-stop strategy which means removing I2CG from the system after proper rounds. Additionally, early-stop aids in minimizing the extra computation burden imposed by the I2CG approach. Further elaboration on this matter will be provided in
Section 4.2.3.
On one hand, I2CG can be seen as semi-federated learning whose clients do not upload the updated item models to the server for aggregation, resulting in a slight “drift” of the global item models compared to the global item models in federated learning incorporating both federated and I2CG clients. On the other hand, abstaining from uploading item models for aggregation could lead to a “delay” in global item models’ updating process compared to client models. During the next round of training, the “drift” and “delay” may have regularizing or negative effects on model performance. The direction of the impact may vary depending on the FRSs, datasets and evaluation metrics.
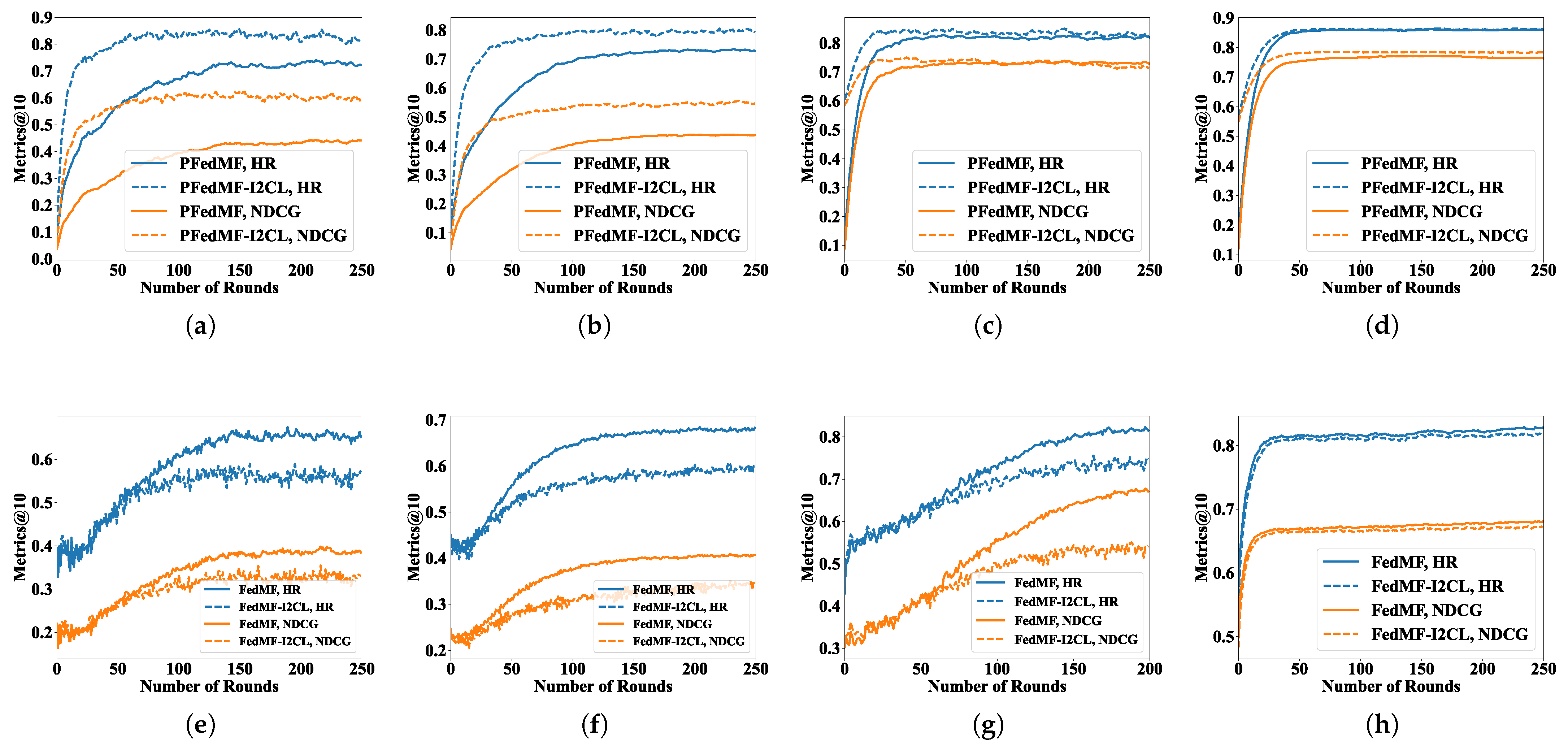
Now, we turn our attention to I2CL.
Figure 4a–d and
Table 5 show the impact of I2CL on FRSs with DPM. As
Figure 4a–d and
Table 5 show, the I2CL strategy markedly boosts the convergence speed of FRSs with DPM. For instance, on Lastfm-2K, the incorporation of I2CL significantly reduces the training rounds required for PFedRECON to reach convergence, decreasing from 198 to 47 rounds (−76.26%). In exceptional cases, such as on Foursquare, the training rounds needed of PFedMF remain unchanged.
Evidently, as dataset sparsity increases, the impact of I2CL in enhancing the model performance decreases. Considering PFedMF, for datasets with sparsity levels of 93.70% (MovieLens-100K), 95.53% (MovieLens-1M), 99.07% (Lastfm-2K), and 99.86% (Foursquare), the improvement rates of I2CL on HR are 16.10%, 8.15%, 1.66%, and 0.21%, respectively.
To explain the above observations, we consider pure local training, which does not leverage the FL paradigm and instead involves each client independently training using only its local data. In this scenario, client communication is absent, and the model is susceptible to overfitting to the local data. In FRS, an appropriate degree of pure local training can enhance the client model’s understanding of local data [
34], ultimately the improving model performance. In FRS, an appropriate degree of pure local training can enhance the client model’s understanding of local data [
34], ultimately improving the model performance. The introduction of I2CL essentially combines federated training with pure local training, where clients alternately engage in both types of training. For denser datasets, the local data contains more information, and the features extracted by the pure local training introduced by I2CL are more accurate, thereby enhancing the model performance. In contrast, I2CL in sparse datasets may have a minimal effect on improving the model performance, but it still advances the training process for communication-constrained clients, thereby accelerating the convergence of the entire system.
It should be noted that I2CL will damage the convergence speed and model performance on FRSs without DPM, as
Figure 4e–h shows. As FRSs without DPM rely on global item embeddings for prediction, I2CL results in a mismatch between purely locally trained client models and global item embeddings, thereby compromising the model performance. Consequently, I2CL not only fails to expedite the FRSs’ convergence but also diminishes their performance.
4.2.2. RQ2: Generality Across Various Communication Conditions and FRSs
In
Section 4.2.1, we have demonstrated the applicability of FedRecI2C for multiple FRSs. In practice, it is impractical to include all communication-constrained clients in I2C training during every communication round due to the complexities of real-world conditions. Consequently, we introduce the period parameter
p and client participation ratio
r for I2C, which not only align more closely with real-world communication conditions but also aim to achieve a balance between the convergence speed and additional computation costs. Taking FedMF/PFedMF on MovieLens-1M as an example, we investigate the impact of
p and
r on both the convergence speed and model performance.
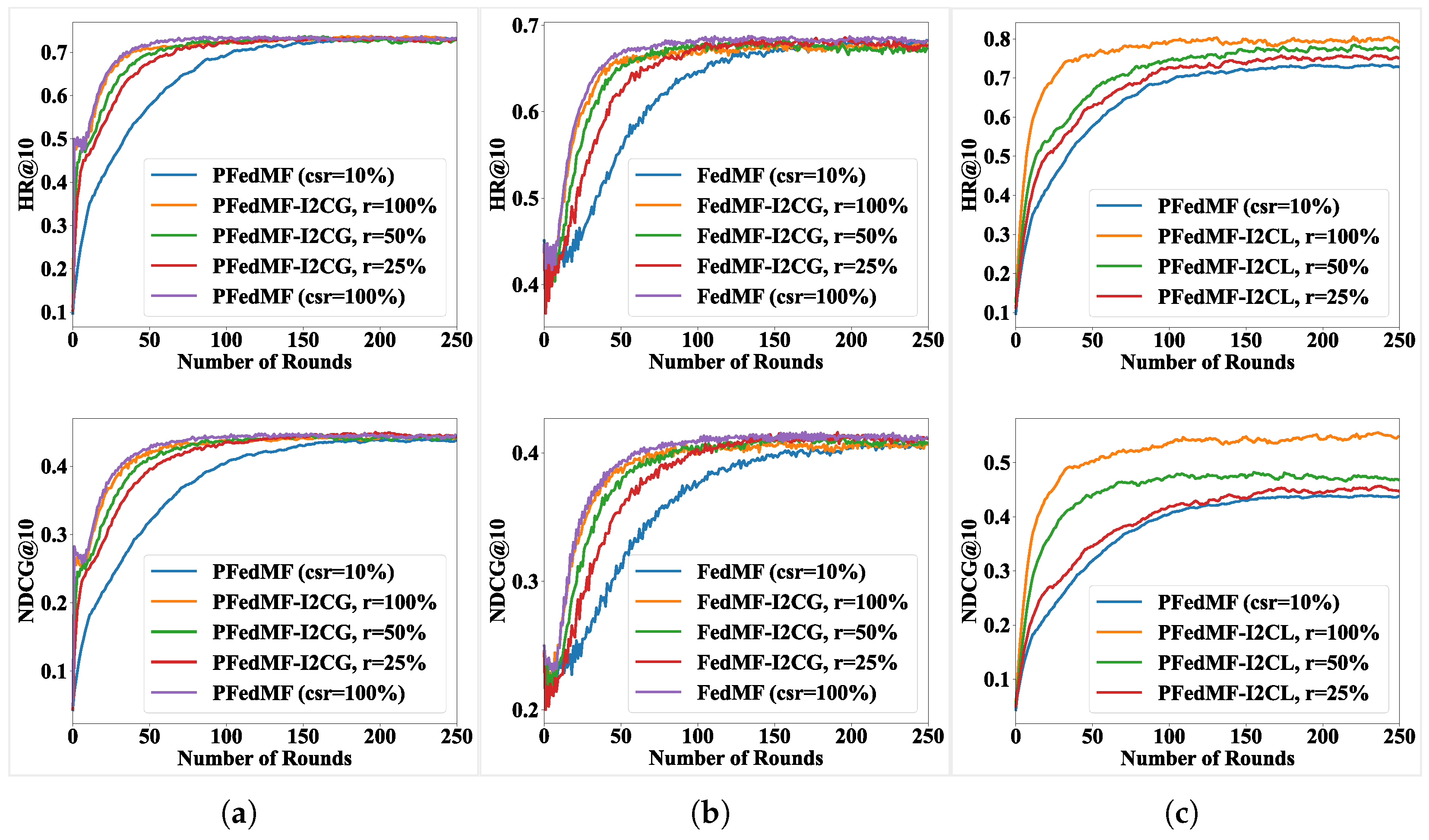
Figure 5 and
Figure 6 depict a scenario where 10% of clients undergo federated training, while the remainder can participate in I2C. In
Figure 5, I2C is configured with different
p. Specifically,
indicates that I2C runs in every communication round and so forth. In
Figure 6, we set different values of
r for clients, selecting
r = (100%, 50%, 25%) communication-constrained clients to perform I2C training.
As
Figure 5 and
Figure 6 show, when the frequency of I2C is higher, and with a larger proportion of clients under communication constraint participating in I2C training, faster convergence is achieved. But the influence of
p and
r on the model’s final performance is minimal for FRSs with I2CG.
In contrast to the FRSs (10% clients for FL), the introduction of I2CG (
p = 1) in FRSs leads to the remaining 90% of uploading-constrained clients implementing local training after obtaining item models from the server. This accelerates the training process of these clients. Compared with FRSs (100% clients for FL), implementing I2CG (
p = 1) reduces significant communication costs by sparing the 90% of clients from uploading item models while maintaining a comparable convergence speed, as evidenced by the purple and yellow curves in
Figure 5a,b.
Convergence acceleration still happens even with meaning implementing I2CG every ten rounds or % meaning only 25% communication-constrained clients executing I2CG training, while significantly reducing the associated computation overhead. Adjusting p or r can mitigate the additional computation cost associated with I2CG, which facilitates a tradeoff between additional computation overhead and convergence speed, tailored to specific requirements.
FRSs introducing I2CL essentially combine elements of federated training and pure local training. All clients alternate between federated training and pure local training, resulting in a dynamic equilibrium between the two. Federated training contributes to the generalization of item models, whereas pure local training enhances the fit of item models to clients’ local data. Over time, as federated training and pure local training achieve dynamic equilibrium, the entire system converges. As in
Figure 5c and
Figure 6c, the larger the
p or
r, the higher the proportion of pure local training in the total number of client training rounds. Higher
p or
r favor pure local training, facilitating rapid convergence and achieving superior performance. In contrast, lower
p or
r favor federated training, resulting in slower convergence but improved generalization capabilities.
As shown by the red curves in
Figure 5c, when
, communication-constrained clients undergo I2CL every five rounds, and in the following four rounds they may participate in federated training or rest. Each time I2CL is performed, the system’s performance will experience a surge, indicating a shift towards pure local training balance; in training rounds without I2CL, the learning curves will fall downwards to the balance of federated learning (blue curve); the system finally reaches a dynamic balance between the two.
4.2.3. RQ3: Impact of the Early-Stop Strategy on FedRecI2C
In FedRecI2C, the early-stop strategy refers to removing the I2C training for communication-constrained clients from the system after a suitable number of communication rounds, whereas the federated training for communication-capable clients persists.
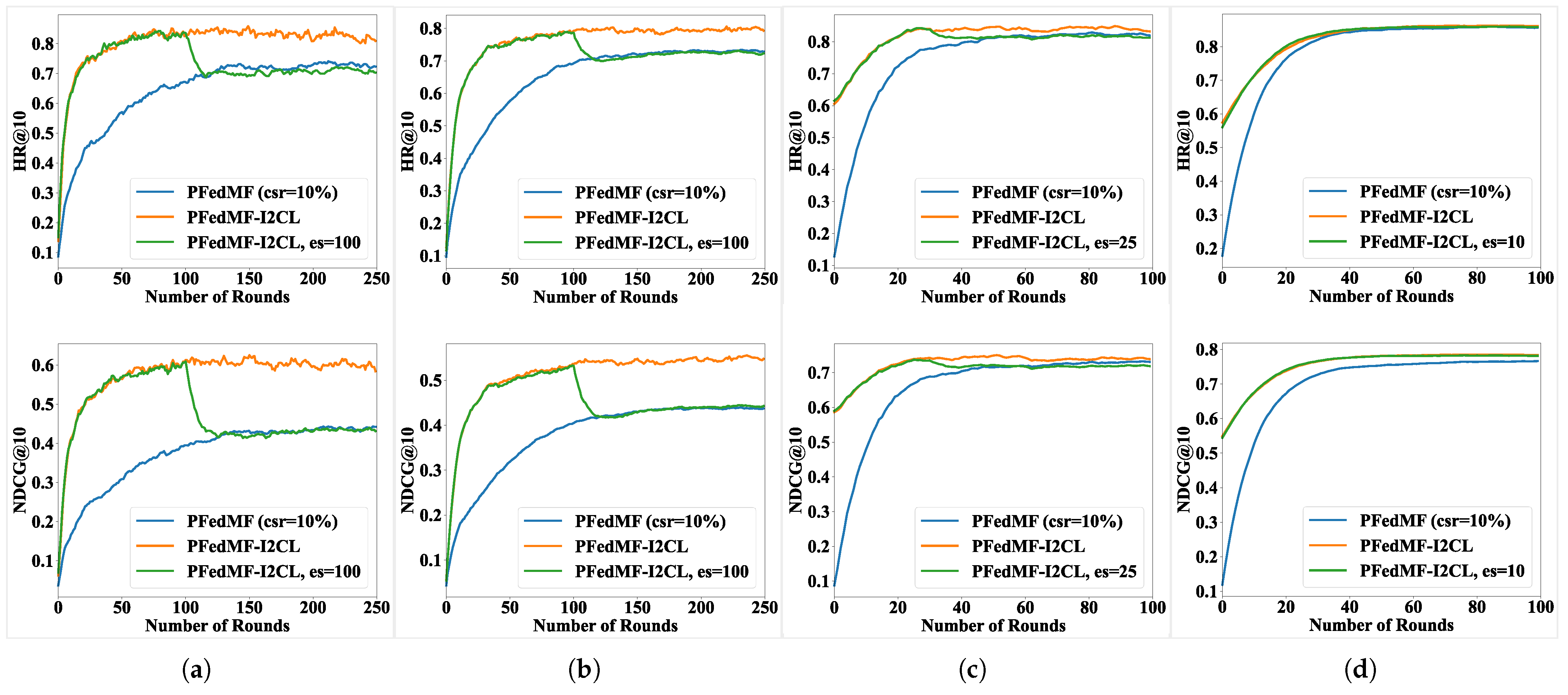
According to
Figure 7, early-stop slightly affects the final performance of FRSs with I2CG and the direction of this impact depends on the FRS and the dataset. Specifically, regardless of whether it is PFedMF-I2CG or FedMF-I2CG, early-stop moderately inhibits the performance decline on the MovieLens-100K dataset, with earlier cessation yielding a more pronounced effect. Premature early-stop may compromise the performance of PFedMF-I2CG (on Lastfm-2K) and FedMF-I2CG (Foursquare), which otherwise benefit from I2CG. Furthermore, choosing the right timing for early-stop and halting I2CG promptly can effectively minimize the extra computational burden imposed by I2CG. For example, consider the case in
Figure 7e. Here, we focus on FedMF-I2CG on the MovieLens-100K dataset. When we remove I2CG after the 50th communication round (es = 50), two main results occur. Firstly, the final model performance is superior compared to the scenario without early-stop. Secondly, there is a conservation of resources. Specifically, communication resources for downloading the global item models from the server are saved. Also, the computation resources required for local updates during the subsequent 200 communication rounds for communication-constrained clients are conserved.
As discussed in
Section 4.2.2, PFedMF-I2CL integrates both federated training and pure local training, ultimately achieving a dynamic equilibrium between the two. If pure local training is halted before the convergence of the system, the model’s performance will degrade to that of FL (
= 10%), as shown in
Figure 8a–c. However, as
Figure 8d shows, the removal of I2CL at the communication round of 10 does not diminish the performance of PFedMF-I2CL, which demonstrates the uniqueness of the Foursquare dataset. This observation may be attributed to the unique distribution characteristics of the Foursquare dataset, which motivates us to investigate the impact of early-stop on the performance of I2CL across more datasets in our future work.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}