GHEFL: Grouping Based on Homomorphic Encryption Validates Federated Learning

Abstract
1. Introduction
- We propose GHEFL, a verifiable federated learning scheme. This scheme allows each participant to verify the correctness of the aggregation process, preventing malicious servers from tampering with parameters uploaded by participants. Additionally, it prevents servers from returning incorrect aggregated results.
- We adopt a dual-server architecture to replace the single-server architecture commonly used in traditional federated learning. This approach reduces the risk of performance degradation caused by the computational and storage overload of a single server, while also preventing malicious attempts by a single server to extract participants’ private information.
- In our scheme, we introduce a grouping mechanism by dividing participants into groups according to specific rules. Local parameter aggregation is first performed within each group and then the aggregated parameters are uploaded to the server on a group-by-group basis for global aggregation. This approach ensures the security of participant data and minimizes the information exchange between participants and the server compared to traditional federated learning.
2. Scheme Statement
2.1. System Architecture
- Participants: Participants receive the initial model parameters, train the local model on their local datasets at a specified learning rate, and then upload the local model parameters along with auxiliary computation information to the cloud server for aggregation. During this process, participants may choose to apply masking techniques to safeguard local model parameters and related private information.
- Servers: The cloud servers are responsible for receiving the local model parameters and auxiliary information uploaded by participants and aggregating them based on the proposed aggregation rules. Subsequently, the global aggregation results are returned to each participant for iterative training until model convergence.
2.2. Threat Model
- The malicious server attempts to extract user data or privacy information from the learning process by analyzing the model parameters uploaded by participants, thereby compromising the security of the protocol [26];
- The malicious server attempts to return incorrect aggregated results, thereby affecting the training of the global model [29];
- The malicious server attempts to falsify the aggregation results to bypass participant verification, causing participants to accept incorrect aggregation results and thereby disrupting model training [31].
2.3. Design Goals
3. Preliminaries
3.1. Party Grouping
3.2. Secret Sharing
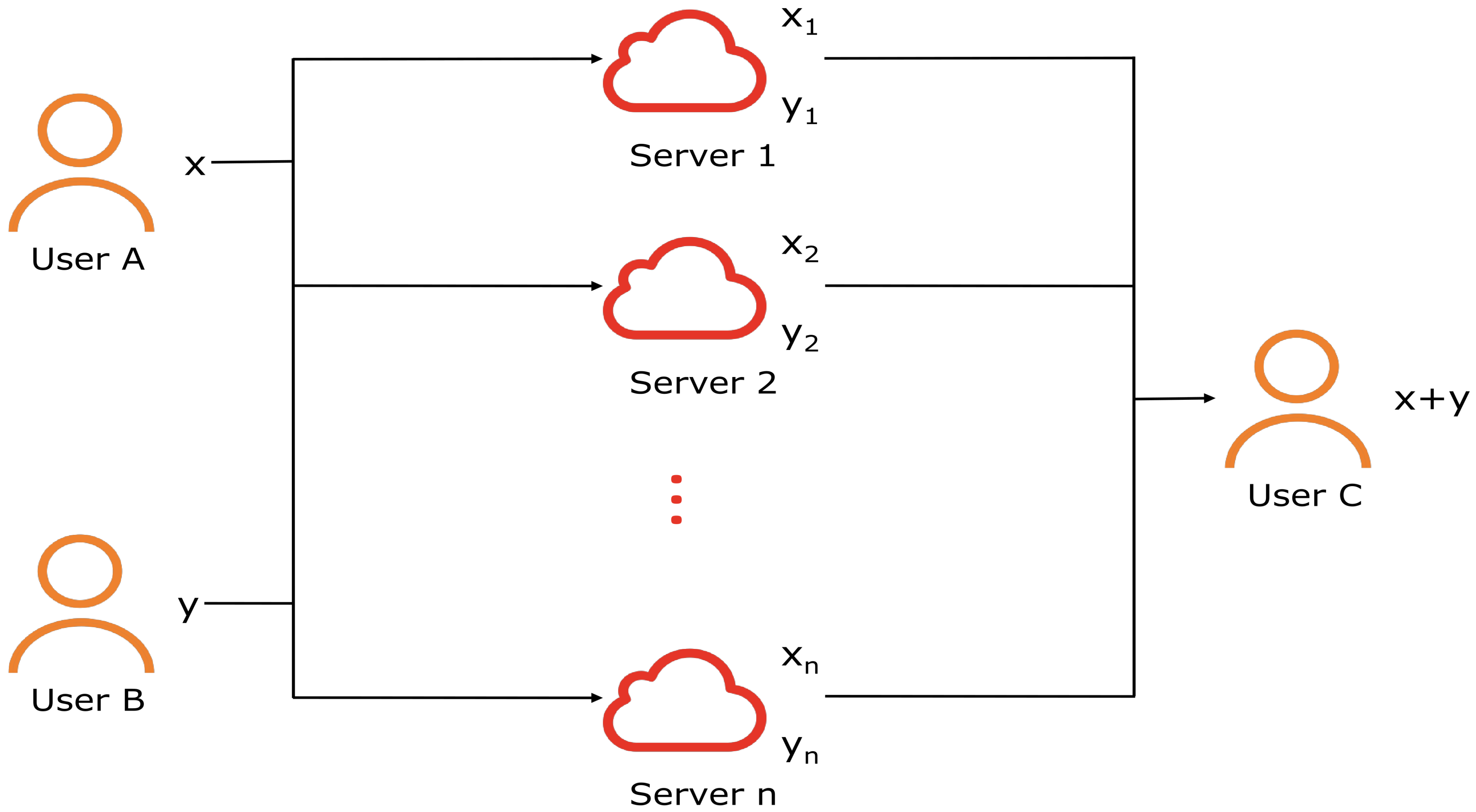
- Additive secret sharing: Suppose there are three users A, B, and C, at this point. Additive secret sharing can make C obtain the value of without knowing the local data x of user A or the local data y of user B. Initially, N cloud servers are selected and denoted as . Subsequently, users A and B randomly partition their local data x and y into n segments, respectively, such that and . The corresponding segments and are then assigned to the ith server, where . User C sends computation requests to each cloud server, and the cloud server computes , subsequently transmitting the result back to user C. After receiving it, user C calculates the sum locally: . The specific process is shown in Figure 3.
- Multiplicative secret sharing: This primarily utilizes the multiplication triple , which consists of two random numbers, a and b, to achieve secure computation.
- Threshold secret sharing: Threshold secret sharing based on polynomials randomly splits a secret s into n parts, such that , and distributes these parts to n users. A threshold is set, meaning that as long as any t users are selected from the n users, the original secret s can be reconstructed using the shares they hold: .
3.3. Homomorphic Encryption
- Semi-homomorphic encryption: Also known as partially homomorphic encryption, this supports only specific types of computations on ciphertexts, such as addition only, multiplication only, or a finite number of addition and multiplication operations. Taking additive homomorphism as an example, plaintexts a and b are encrypted using the encryption algorithm to obtain their corresponding ciphertexts and . Performing an addition operation on these ciphertexts yields , which is equal to the result of encrypting the sum of the two plaintexts, . That is, additive homomorphism satisfies . Common semi-homomorphic encryption schemes include the RSA algorithm, ElGamal algorithm, and Paillier algorithm.
- Fully homomorphic encryption: Unlike semi-homomorphic encryption algorithms that support only partial computations, this enables arbitrary computations on ciphertext data. Common fully homomorphic encryption schemes include the BGV scheme, BFV scheme, CKKS scheme, and others.
4. The Proposed Scheme
| Algorithm 1 The detailed procedures of GHEFL. |
| Input: learning rate , number of iterations T, loss function , users , data sets . Output: a secure global model W.
|
4.1. System Initialization
4.2. Local Model Training and Parameter Uploading
- Local model training phaseEach participant begins local training using the initial model parameters on its local dataset based on the stochastic gradient descent (SGD) algorithm to obtain its local model parameters , as shown below:where .
- Parameter upload stageThe first participant in each group utilizes a pseudo-random generator to produce a random number , which serves as a mask for the local model parameters to obtain the obfuscated local model parametersand sends to the next participant for aggregationThe process is repeated until the last participant’s local model parameter in the group also participates in the aggregation, resulting in the local model parameter for the current group.k denotes the total number of participants in the current subgroup.The first participant in each group homomorphically encrypts to obtain , which is then sent to the dual servers in a secret sharing manner, with each server receiving a share as and , where ; the last participant in each group homomorphically encrypts using to obtain the validation labelThe local model parameters and the validation label are sent to the dual servers in a secret sharing manner, with the servers receiving their respective shares as , , , and , where . After receiving their respective shares, the servers proceed to the next step. In this step, the operation of adding masks is performed exclusively by the first participant of each group and the operation of homomorphic encryption is performed only by the first and last participants within each group.
4.3. The Servers Compute and Return the Aggregated Results
4.4. Correctness Verification of Aggregation Results
5. Evaluation
5.1. Basic Configurations
5.2. Datasets
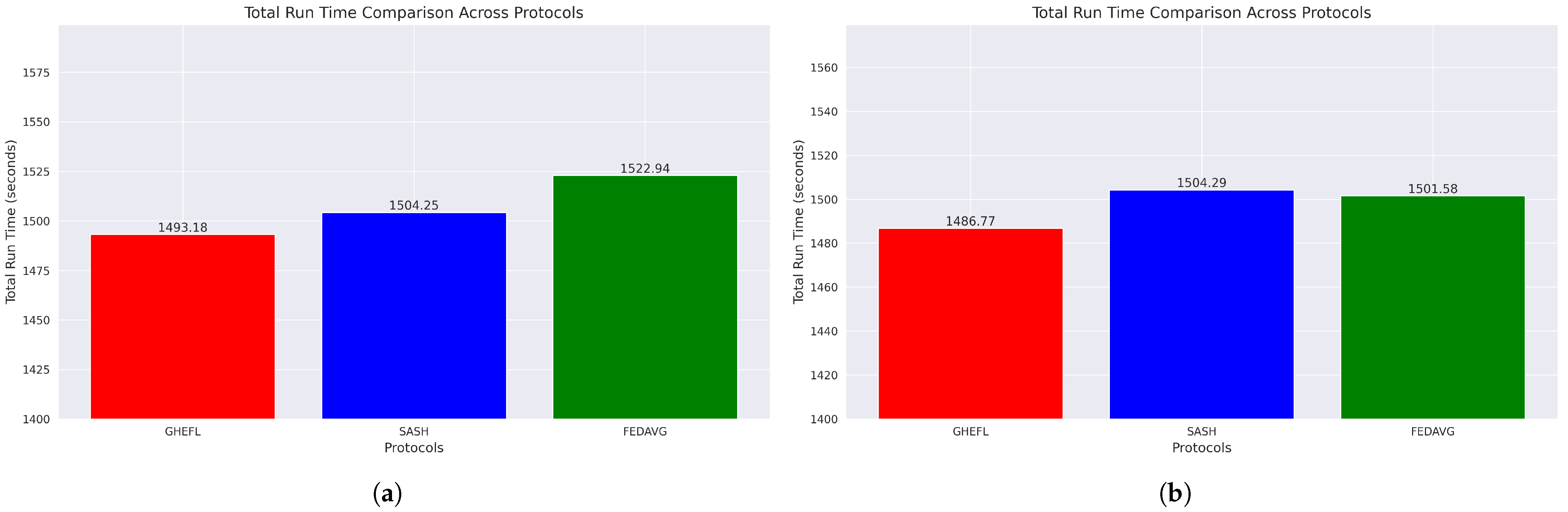
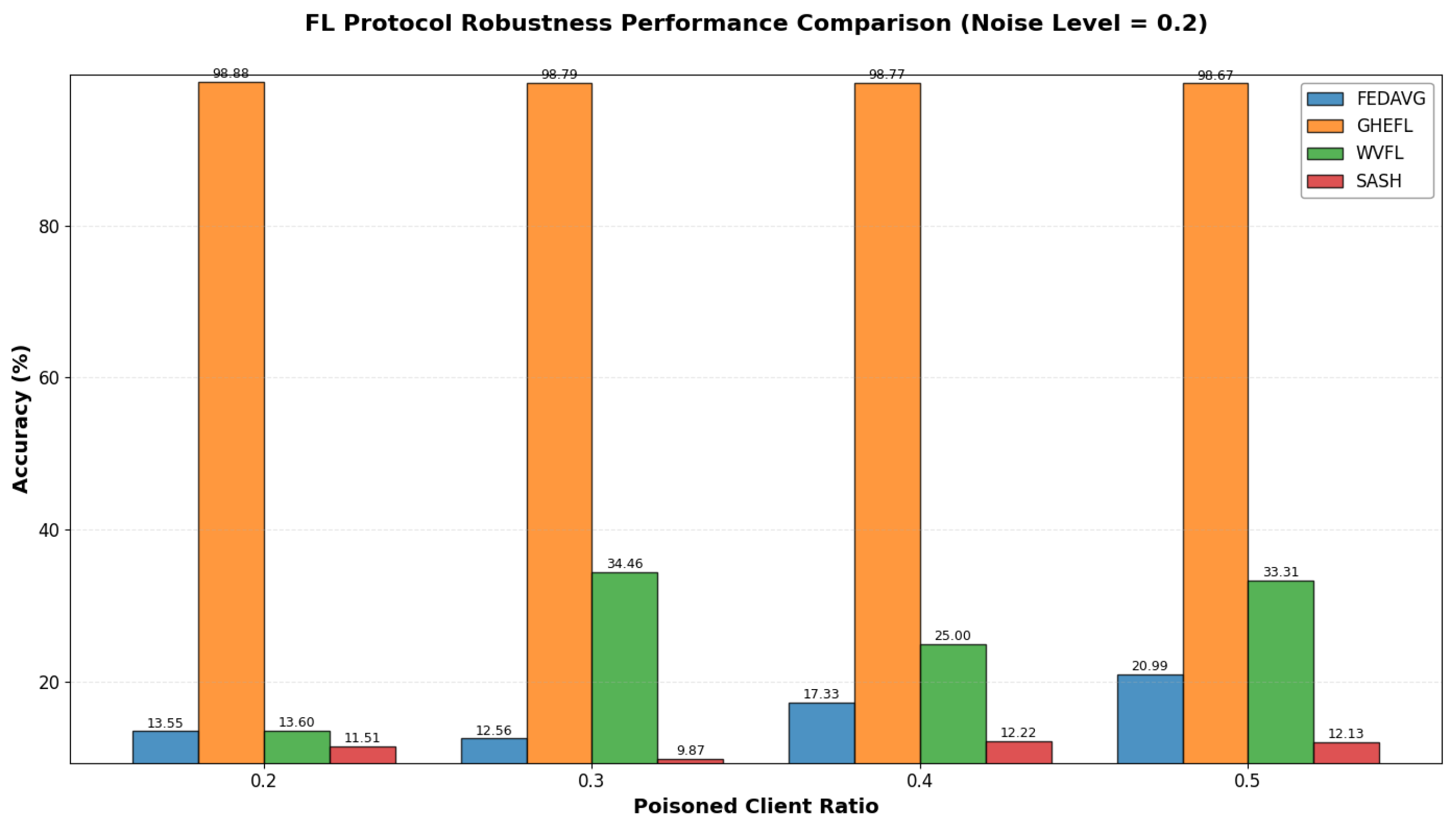
5.3. Experimental Results
5.4. Functionality
5.5. Theoretical Evaluation
- Security: The security mechanism of the verification protocol in this scheme relies on the dual-server architecture and the security guarantees provided by cryptographic techniques, specifically secret sharing and homomorphic encryption. The dual-server architecture, combined with the security of secret sharing, ensures that even if both servers act maliciously and collude, they cannot obtain or tamper with the local model parameters and related information of any participant. Furthermore, the homomorphic and one-way properties of homomorphic encryption ensure that each participant can successfully complete the final verification without gaining access to the information of other participants.
- Low Interaction: In federated learning, it is common for the server to send masks to two participants, allowing one to obfuscate parameters for privacy protection using the mask while the other removes the mask’s influence. This process incurs significant communication overhead, and when the number of participants is large, network bottlenecks become unavoidable. Additionally, the server must manage a large number of random values, resulting in a heavy workload. In this scheme, the server selects a random seed and transmits it only to the first user in each group, significantly reducing the information exchange between the server and participants and decreasing the server’s workload in managing random values. Moreover, using the same random seed ensures consistency in random value generation across participants. Furthermore, having the last participant in each group secretly share the aggregated parameters with the dual servers also reduces communication interactions between participants and servers.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Le, J.; Zhang, D.; Lei, X.; Jiao, L.; Zeng, K.; Liao, X. Privacy-preserving federated learning with malicious clients and honest-but-curious servers. IEEE Trans. Inf. Forensics Secur. 2023, 18, 4329–4344. [Google Scholar] [CrossRef]
- Gordon, L.A.; Loeb, M.P. The economics of information security investment. ACM Trans. Inf. Syst. Secur. (TISSEC) 2002, 5, 438–457. [Google Scholar] [CrossRef]
- Gal-Or, E.; Ghose, A. The economic incentives for sharing security information. Inf. Syst. Res. 2005, 16, 186–208. [Google Scholar] [CrossRef]
- Chen, M.; Shlezinger, N.; Poor, H.V.; Eldar, Y.C.; Cui, S. Communication-efficient federated learning. Proc. Natl. Acad. Sci. USA 2021, 118, e2024789118. [Google Scholar] [CrossRef] [PubMed]
- Liu, T.; Wang, Z.; He, H.; Shi, W.; Lin, L.; An, R.; Li, C. Efficient and secure federated learning for financial applications. Appl. Sci. 2023, 13, 5877. [Google Scholar] [CrossRef]
- Zhang, H.; Hong, J.; Dong, F.; Drew, S.; Xue, L.; Zhou, J. A privacy-preserving hybrid federated learning framework for financial crime detection. arXiv 2023, arXiv:2302.03654. [Google Scholar]
- Taha, Z.K.; Yaw, C.T.; Koh, S.P.; Tiong, S.K.; Kadirgama, K.; Benedict, F.; Tan, J.D.; Balasubramaniam, Y.A. A survey of federated learning from data perspective in the healthcare domain: Challenges, methods, and future directions. IEEE Access 2023, 11, 45711–45735. [Google Scholar] [CrossRef]
- Xu, J.; Glicksberg, B.S.; Su, C.; Walker, P.; Bian, J.; Wang, F. Federated learning for healthcare informatics. J. Healthc. Informatics Res. 2021, 5, 1–19. [Google Scholar] [CrossRef]
- Liu, F.; Wu, X.; Ge, S.; Fan, W.; Zou, Y. Federated learning for vision-and-language grounding problems. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11572–11579. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Lim, W.Y.B.; Luong, N.C.; Hoang, D.T.; Jiao, Y.; Liang, Y.C.; Yang, Q.; Niyato, D.; Miao, C. Federated learning in mobile edge networks: A comprehensive survey. IEEE Commun. Surv. Tutorials 2020, 22, 2031–2063. [Google Scholar] [CrossRef]
- Kang, J.; Xiong, Z.; Niyato, D.; Zou, Y.; Zhang, Y.; Guizani, M. Reliable federated learning for mobile networks. IEEE Wirel. Commun. 2020, 27, 72–80. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Ding, M.; Pathirana, P.N.; Seneviratne, A.; Li, J.; Poor, H.V. Federated learning for internet of things: A comprehensive survey. IEEE Commun. Surv. Tutorials 2021, 23, 1622–1658. [Google Scholar] [CrossRef]
- Zhang, C.; Xie, Y.; Bai, H.; Yu, B.; Li, W.; Gao, Y. A survey on federated learning. Knowl.-Based Syst. 2021, 216, 106775. [Google Scholar] [CrossRef]
- Khalfoun, B.; Ben Mokhtar, S.; Bouchenak, S.; Nitu, V. EDEN: Enforcing location privacy through re-identification risk assessment: A federated learning approach. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 1–25. [Google Scholar] [CrossRef]
- Kawa, D.; Punyani, S.; Nayak, P.; Karkera, A.; Jyotinagar, V. Credit risk assessment from combined bank records using federated learning. Int. Res. J. Eng. Technol. (IRJET) 2019, 6, 1355–1358. [Google Scholar]
- KhoKhar, F.A.; Shah, J.H.; Khan, M.A.; Sharif, M.; Tariq, U.; Kadry, S. A review on federated learning towards image processing. Comput. Electr. Eng. 2022, 99, 107818. [Google Scholar] [CrossRef]
- Hu, Z.; Xie, H.; Yu, L.; Gao, X.; Shang, Z.; Zhang, Y. Dynamic-aware federated learning for face forgery video detection. ACM Trans. Intell. Syst. Technol. (TIST) 2022, 13, 1–25. [Google Scholar] [CrossRef]
- Xie, C.; Koyejo, S.; Gupta, I. Asynchronous federated optimization. arXiv 2019, arXiv:1903.03934. [Google Scholar]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November2017; pp. 1175–1191. [Google Scholar]
- Wang, H.; Yurochkin, M.; Sun, Y.; Papailiopoulos, D.; Khazaeni, Y. Federated learning with matched averaging. arXiv 2020, arXiv:2002.06440. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Acar, D.A.E.; Zhao, Y.; Navarro, R.M.; Mattina, M.; Whatmough, P.N.; Saligrama, V. Federated learning based on dynamic regularization. arXiv 2021, arXiv:2111.04263. [Google Scholar]
- Karimi, B.; Li, P.; Li, X. Fed-LAMB: Layer-wise and dimension-wise locally adaptive federated learning. In Proceedings of the Uncertainty in Artificial Intelligence. PMLR, Pittsburgh, PA, USA, 31 July–4 August 2023; pp. 1037–1046. [Google Scholar]
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1322–1333. [Google Scholar]
- Shokri, R.; Shmatikov, V. Privacy-preserving deep learning. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1310–1321. [Google Scholar]
- Chen, J.H.; Chen, M.R.; Zeng, G.Q.; Weng, J.S. BDFL: A Byzantine-Fault-Tolerance Decentralized Federated Learning Method for Autonomous Vehicle. IEEE Trans. Veh. Technol. 2021, 70, 8639–8652. [Google Scholar] [CrossRef]
- Hao, M.; Li, H.; Xu, G.; Chen, H.; Zhang, T. Efficient, private and robust federated learning. In Proceedings of the 37th Annual Computer Security Applications Conference, Virtual, 6–10 December 2021; pp. 45–60. [Google Scholar]
- Xia, F.; Cheng, W. A survey on privacy-preserving federated learning against poisoning attacks. Cluster Computing 2024, 27, 13565–13582. [Google Scholar] [CrossRef]
- Ma, X.; Zhou, Y.; Wang, L.; Miao, M. Privacy-preserving Byzantine-robust federated learning. Comput. Stand. Interfaces 2022, 80, 103561. [Google Scholar] [CrossRef]
- Luo, X.; Tang, B. Byzantine Fault-Tolerant Federated Learning Based on Trustworthy Data and Historical Information. Electronics 2024, 13, 1540. [Google Scholar] [CrossRef]
- Xu, G.; Li, H.; Liu, S.; Yang, K.; Lin, X. VerifyNet: Secure and verifiable federated learning. IEEE Trans. Inf. Forensics Secur. 2019, 15, 911–926. [Google Scholar] [CrossRef]
- Gao, H.; He, N.; Gao, T. SVeriFL: Successive verifiable federated learning with privacy-preserving. Inf. Sci. 2023, 622, 98–114. [Google Scholar] [CrossRef]
- Fu, A.; Zhang, X.; Xiong, N.; Gao, Y.; Wang, H.; Zhang, J. VFL: A verifiable federated learning with privacy-preserving for big data in industrial IoT. IEEE Trans. Ind. Informatics 2020, 18, 3316–3326. [Google Scholar] [CrossRef]
- Cramer, R.; Damgård, I.; Maurer, U. General secure multi-party computation from any linear secret-sharing scheme. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Bruges, Belgium, 14–18 May 2000; pp. 316–334. [Google Scholar]
- Acar, A.; Aksu, H.; Uluagac, A.S.; Conti, M. A survey on homomorphic encryption schemes: Theory and implementation. ACM Comput. Surv. (Csur) 2018, 51, 1–35. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Solution | Techniques | Multi-Servers | Verifiable | Data Privacy | Security | Support for Participants Dropout |
|---|---|---|---|---|---|---|
| FedAvg | - |  | | | |  |
| G-VCFL | - | | | | | |
| VeriFL | Secret Sharing + Homomorphic Hash | | | | | |
| VerifyNet | Secret Sharing + Homomorphic Hash | | | | | |
| VERSA | Secret Sharing | | | | | |
| SASH | Secret Sharing | | | | | |
| GHEFL(This work) | Secret Sharing + Homomorphic Encryption | | | | | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, Y.; Tan, W.; Fan, L.; Chen, Y.; Lai, X.; Weng, J. GHEFL: Grouping Based on Homomorphic Encryption Validates Federated Learning. Future Internet 2025, 17, 128. https://doi.org/10.3390/fi17030128
Kang Y, Tan W, Fan L, Chen Y, Lai X, Weng J. GHEFL: Grouping Based on Homomorphic Encryption Validates Federated Learning. Future Internet. 2025; 17(3):128. https://doi.org/10.3390/fi17030128
Chicago/Turabian StyleKang, Yulin, Wuzheng Tan, Linlin Fan, Yinuo Chen, Xinbin Lai, and Jian Weng. 2025. "GHEFL: Grouping Based on Homomorphic Encryption Validates Federated Learning" Future Internet 17, no. 3: 128. https://doi.org/10.3390/fi17030128
APA StyleKang, Y., Tan, W., Fan, L., Chen, Y., Lai, X., & Weng, J. (2025). GHEFL: Grouping Based on Homomorphic Encryption Validates Federated Learning. Future Internet, 17(3), 128. https://doi.org/10.3390/fi17030128