1. Introduction
The spread of misinformation online, most commonly known as fake news, is an important issue that has become more pronounced in the last two decades due to the prevalence of social media. Platforms like Twitter, Reddit, and Facebook have been commonly identified as the main channels for propagating misinformation and have been criticized for not acting on addressing the conditions that permit the circulation and amplification of false information [
1]. Such misinformation includes false claims and non-fact-checked news items, which originate from sources of questionable credibility [
2].
The problem of misinformation becomes critical when it pertains to healthcare and health issues, since it puts lives and public health at risk. One of the first cases of widely spread misinformation in the medical domain is the falsehood that the MMR vaccine (measles, mumps, and rubella) causes autism [
3]. The falsehood originated from a fraudulent article titled “Ileal-lymphoid-nodular hyperplasia, non-specific colitis, and pervasive developmental disorder in children” published in the prestigious
Lancet journal in 1998 [
4,
5]. This study turned tens of thousands of parents against the vaccine, and as a result, in 2020, many countries, including the United Kingdom, Greece, Venezuela, and Brazil, lost their measles elimination status. In 2020, twenty-two years after publishing this study,
Lancet retracted the paper [
6]. Examples of medical fake news that have spread on social media include the oncogenic effects of antihypertensive drugs, which caused several patients to stop using them, and misinformation about the Human Papillomavirus (HPV) vaccines, which resulted in half of the population in South Carolina not having completed the vaccination series [
5,
7].
The issue of fake news was exacerbated during the recent COVID-19 pandemic, where it became clear that the enemy was not only the virus but also the abundance of misinformation leaked on social media and the web, even from prominent public figures, endangering human lives (
https://www.europol.europa.eu/covid-19/covid-19-fake-news, accessed on 2 November 2023). The extent of online health misinformation led the World Health Organization (WHO) to declare an “infodemic”, that is, “an overabundance of information—some accurate and some not—that makes it hard for people to find trustworthy sources and reliable guidance when they need it” (
https://www.who.int/health-topics/infodemic, accessed on 2 November 2023). The repercussions of the infodemic are severe: it results in “an increase in erroneous interpretation of scientific knowledge, opinion polarization, escalating fear, and panic or decreased access to health care” [
4], and it is detrimental to public health, impacting healthcare utilization and cost and medical non-compliance [
8]. Indicatively, in a recent poll (
https://debeaumont.org/wp-content/uploads/2023/03/misinformation-poll-brief-FINAL.pdf, accessed on 10 December 2024), among 806 physicians, 3 out of 4 of the physicians said that medical misinformation has hindered their ability to treat COVID-19 patients. Half of them estimated that most of the information they receive from patients is misinformation, which also extends to areas such as weight loss, dietary supplements, mental health, and other vaccines.
As a response to this wave of dangerous misinformation, there was a call to arms to construct tools for weathering the infodemic. There was a strong effort from the scientific community to construct and make publicly available datasets with valid scholarly information relevant to the pandemic and coronaviruses in general. A well-known dataset is the COVID-19 Open Research Dataset (CORD-19) [
9] and the Covidex search engine [
10] built on top of it. Infodemic risk indices, such as those developed by the COVID-19 Infodemic Observatory (
https://covid19obs.fbk.eu/, accessed on 10 December 2024), offer a quantitative framework for assessing the prevalence and severity of misinformation. These indices aid in identifying high-risk regions, topics, and patterns, enabling targeted interventions to mitigate the spread of misleading information.
Most fact-checking organizations had to grow and dedicate more of their resources to COVID-19 misinformation [
11]. As a result, several fact-checking services were developed, aiming at assessing the validity of claims and the credibility of sources related to the pandemic. However, it has become increasingly challenging and expensive to identify fake news and claims through manual inspection, due to the speed at which information (both valid and non-valid) spreads in the media, and especially on social media. In a WHO survey on COVID-19 fact-checkers (WHO cooperates with a global network of 200 fact-checking organizations
https://covid19misinfo.org/fact-checking/covid-19-fact-checkers/, accessed on 10 December 2024), most fact-checking organizations reported that their leading challenge was keeping up with rapidly changing science and fact-checking health misinformation [
12].
The inability of manual approaches to deal with the scale of the problem highlights the importance of automatic, data-driven approaches that can complement or supplant manual efforts. The research efforts of the information technology scientific community for addressing misinformation focus on a variety of issues, such as automating claim detection and validation, detecting misinformation using the content and the propagation patterns, identifying users (malicious or not) that instigate or facilitate misinformation, as well as mitigating misinformation. Most of the approaches develop and apply state-of-the-art data science and machine learning techniques, trained on large amounts of data.
The research on misinformation is extremely broad, touching several scientific fields. Previous technical surveys on fact-checking and fake news provide a general overview of the current landscape but do not target the medical domain [
13,
14,
15]. The few surveys that explicitly focus on misinformation in the medical domain [
16,
17,
18,
19] provide a high-level approach that is relevant to a broad spectrum of researchers, stakeholders, and decision makers. This survey complements the previous works by focusing on the medical domain and exploring how the different fact-checking and fake news detection techniques have been adapted to this domain from a computer engineering perspective. To facilitate future research on the area, it thoroughly describes publicly available domain-specific datasets, paying special attention to the COVID-19 case.
We followed an exploratory (snowball) methodology for collecting papers on fact-checking and fake news detection on medical issues. The papers were gathered through Google Scholar by submitting appropriate queries such as “
medical fake news detection”, “
health misinformation detection on social media”, “
detection of COVID-19 vaccine misinformation”, “
medical fact check”, etc. We also used authoritative general surveys on fake news and fact-checking [
13,
14,
15] as a starting point for exploring the literature and identifying medical-related approaches. Finally, we explored the citations of the most cited papers in order to cover the most recent advancements in the area. In total, this survey references 190 scientific papers and describes 24 publicly available datasets and 11 fact-checking tools.
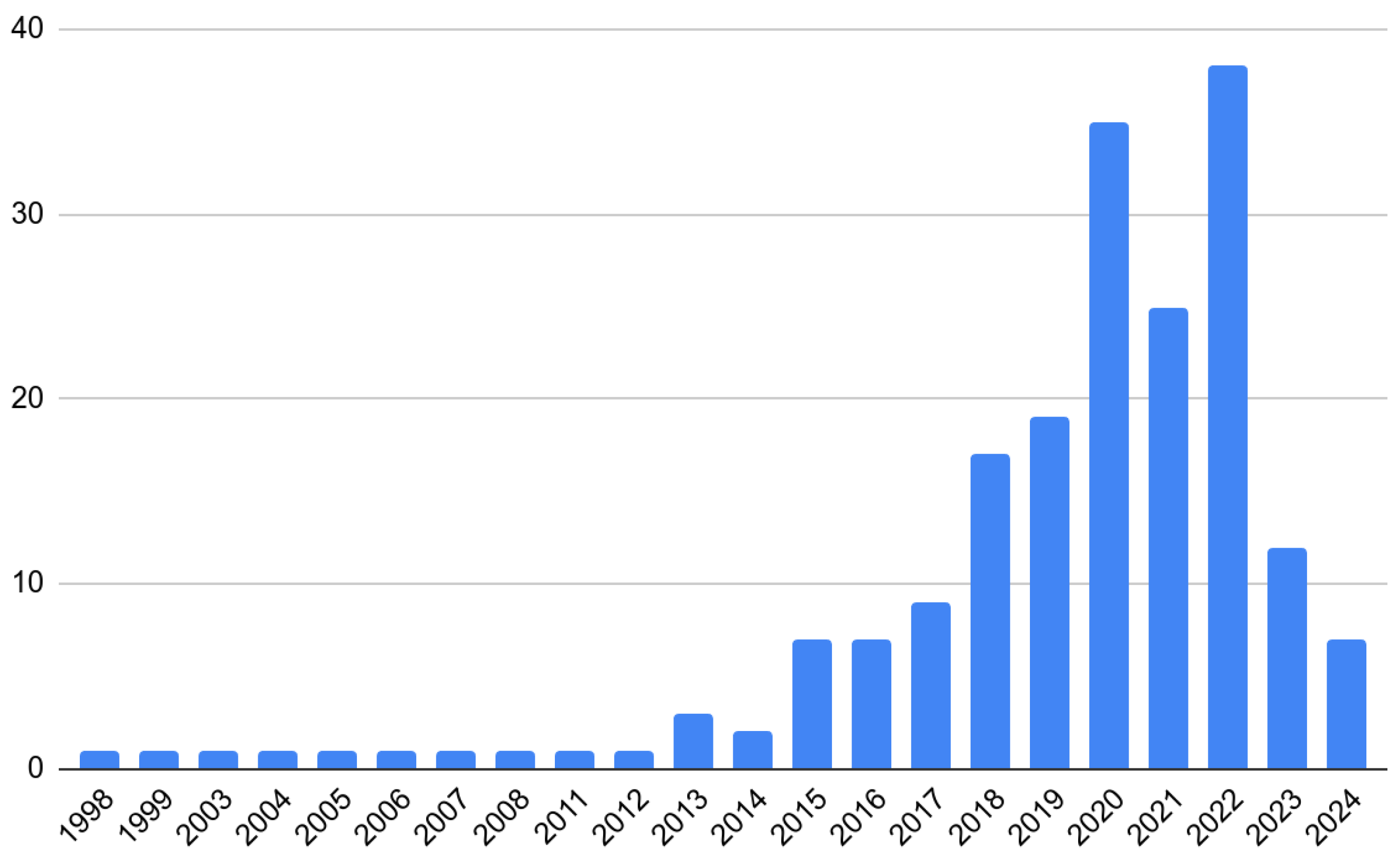
Figure 1 depicts the number of scientific papers per year referenced in this survey.
The rest of the survey is structured as follows.
Section 2 provides an overview of the domain and the corresponding definitions, while
Section 3 discusses manual and automatic approaches to fact-checking and some well-known fact-checking tools and services. The following sections discuss three types of automatic approaches for fake news detection in social media. The first one is based on the content of posts and comments (
Section 4), the second one on the propagation of posts in social networks (
Section 5), and the third one on the credibility of news sources (
Section 6).
Section 7 reports fake/valid news datasets originating from social platforms like Twitter and Reddit.
Section 8 provides a brief summary of available mitigation approaches, while
Section 9 discusses how popular platforms address the issue of fake news. Finally,
Section 10 provides a discussion and explores future directions, while
Section 11 concludes the survey.
2. Overview
In this section, we provide an overview of fake news and its intersections with related concepts such as disinformation and satire. On social media, the fake news lifecycle encompasses the phases of the creation, publication, and propagation, often leveraging cognitive biases to enhance its spread. In the health domain, misinformation—particularly concerning vaccines and COVID-19—proliferates due to limited scientific literacy and the influence of conspiracy theories. Detecting and mitigating fake news involves both manual and automated fact-checking, as well as algorithmic approaches that examine the content, propagation patterns, and sources of fake news. Below we discuss the above in more detail.
There is no universally accepted definition of fake news. An understanding of fake news is attained by considering the dimensions of authenticity, intention, and news content [
14,
20]. The
authenticity dimension refers to whether the factual claims in the news item are valid. The
intention dimension is about whether there is intention to deceive in creating or propagating the news item. Finally, the
news dimension refers to whether the content of the item is about news or not. In the case of social media, the news dimension is often not clear, since blogs and social platforms have allowed non-journalists to reach large audiences, challenging the traditional definition of what news is [
20].
There are many information disorders along the dimensions of authenticity and intention that overlap with fake news. The term
misinformation is used to characterize both intentionally and unintentionally false or misleading information, while the term
disinformation is used for false information that is purposely spread to deceive people [
21]. In this paper, we will consider mainly misinformation. Malinformation is the deliberate dissemination of true information (e.g., leaking private information) and it is not considered fake news [
22].
There is also a long list of other concepts in the authenticity, intention, and news spectrum related to fake news [
14,
20,
22]. Two such concepts are
satire and
parody that use humor or exaggeration to draw attention and often entertain. Both share the assumption that the users are aware that the presentation or the content is intentionally faux. Fake information may also be part of
advertising or
public relations when marketing or other persuasive messages are inserted into news articles. A somewhat similar case is
propaganda that refers to news items created by political entities to influence public perceptions. Other concepts include
hoaxes referring to half-truths made for fun,
rumors referring to ambiguous stories whose truthfulness never gets confirmed, and
clickbait referring to misleading headlines for engaging the audience.
When it comes to social networks, the lifecycle of fake news includes the phases of news creation, publishing on the network, and online propagation. The author of the news item is the person that first created the news item. The author may be a journalist writing a newspaper article, a scientist writing a scientific article, or in some cases, a normal user. The publisher is the person that first posted the item on the social network platform. In some cases, the publisher is also the author of the item. Propagation means any kind of reaction that leads to the item getting additional exposure. Depending on the media, reactions include repostings or retweets, commenting, and various other actions of endorsement or disapproval, such as likes, upvotes, or downvotes.
In particular, in the medical domain, misinformation is often created and spread by individuals with no scientific affiliation that assume the role of expert patients, promote individual autonomy, and challenge state actions [
19]. By promoting fear and anxiety, and through the horizontal diffusion of conspiracy theories, they are able to erode in an irreversible way the vertical health communication strategies.
Another major issue regarding medical information, and scientific information in general, is the fact that citizens often have a limited understanding of basic scientific facts and more broadly of the scientific process [
23]. Moreover, personal beliefs are often inconsistent with the best available science due to inaccurate perceptions, lack of scientific consensus, or adoption of conspiracy theories.
Fake news propagation in social media is also amplified by the fact that it is systemic according to [
24]. Fake news is designed in such a way so as to pass itself as news to the relevant targeted audience and in fact mislead it by exploiting the systemic features inherent in the channels of social media. Such features include various cognitive biases and heuristics that lead to increasing the spread of fake news propagation.
Various pilot studies have been conducted regarding the typology of health misinformation in social media. The authors of [
25] examined health-related misinformative posts from various social network platforms written in Polish during the period 2012–2017. In the initial screening, satire, parody, and propaganda were not detected, probably because they mainly apply to political news. However, 40% of the most frequently shared links contained text classified as fake news. The most fallacious content concerned vaccines while content about cardiovascular diseases was, in general, well sourced and informative. Another study of the sources and types of misinformation about COVID-19 highlighted the prevalence of fake news in social media [
26]. In this study, the identified common types of misinformation including false claims, conspiracy theories, and pseudoscientific health therapies, regarding the diagnosis, treatment, prevention, origin, and spread of the virus.
Finally, in a high-level overview survey on English social media [
18], the authors used the PubMed search engine to explore the prevalence of health misinformation and identify the medical topics that are more susceptible to fake information. They reported high misinformation content in the smoke, drug, and vaccine categories; moderate misinformation about diets and noncommunicable diseases and pandemics; and low misinformation in medical treatments and surgical treatments, since in this case most information is coming from official accounts.
In the following sections, we focus on fact-checking, fake news detection, and mitigation in social media platforms with emphasis on the medical domain.
Fact-checking is the process of verifying the accuracy and truthfulness of information that is presented as news or as factual. Fact-checking involves researching the claims being made, looking for credible sources of information, and comparing the information to other sources to ensure that it is accurate and truthful. We categorize fact-checking approaches into manual and automatic approaches and present a thorough analysis of the related methods. Fact-checking is important because it helps to prevent the spread of misinformation and it allows people to make informed decisions based on accurate information. We also discuss the available fact-checking tools and services.
In terms of fake news detection, we provide a systematic categorization and thorough description and analysis of fake news detection approaches. We categorize fake news detection approaches into those using (a) the content of the news item, (b) information about its propagation in the social platform, and (c) features of the source; that is, of the publisher or the social media users involved in the propagation. For each approach, we describe in depth the used methods, including the commonly used features in the case of traditional machine learning (ML) approaches and the involved pipelines in the case of deep learning (DL) approaches.
The three categories of fake news detection approaches are usually fused since the study of fake news in social media requires the use of both textual and structural information, along with the user context and preferences, the social context, and any spatio-temporal information available [
27,
28,
29]. For example, according to [
30], the analysis of health-related content that uses more informal language can benefit from propagation network and user profile features, while more formal medical content can benefit from linguistic–stylistic and linguistic–medical features. Moreover, the analysis of popular content that generates a high volume of social reactions can benefit from linguistic–emotional features [
30].
Fake news mitigation techniques aim mainly at the early detection of fake news and at limiting the spread of misinformation. They include approaches applied at the propagation and the source level. Finally, we describe in detail the available datasets related to medical fact-checking and fake news detection on social media.
3. Fact-Checking
In this section, we examine the concept of fact-checking, its historical role in journalism, and its growing relevance across diverse fields such as social media and scientific research. We delve into various fact-checking approaches, including manual methods—whether expert- or crowd-sourced—and automated techniques that identify and validate claims using sophisticated algorithms and comprehensive knowledge bases. This section concludes with a list and discussion of available online fact-checking tools.
Fact-checking is the process of verifying the factual accuracy of statements/claims. Historically, it has been associated with journalism, being an important process of media companies for verifying published information related to different types of claims (political, religious, social, etc.). The process of fact-checking is usually conducted either internally, using resources of the media company or through an external third party [
1].
In a similar manner, there is a verification and validation process of academic work in the scientific community, where the critical study of the prior literature, the soundness of the proposed approaches and methodologies, and the reproducibility and verifiability of the results are integral to academic research. However, the rise of==in algorithmically generated papers and fraudulent publications, as highlighted in [
31] that studies the prevalence of nonsensical algorithmically generated papers in the scientific literature, and in [
32] that assesses the retracted papers from cancer journals associated with “paper mills”, underscores the challenges in maintaining scientific integrity. These works discuss fraud detection in scientific content, which parallels the challenge of spotting fake medical misinformation in social networks and the need for automated approaches.
During the 2016 US elections, online media platforms were found susceptible to disseminating disinformation and misinformation [
33]. This made fact-checking a hot topic across the scientific community, journalists, and online social users. This trend was further amplified due to the pandemic misinformation. As a result, the number and size of fact-checking organizations have grown across the globe and social platforms have started to develop partnerships with them [
1]. In addition, the need for cutting-edge and credible scientific knowledge has made the scientific literature part of the fact-checking sources.
Publishing fact-checked information has a positive effect on correcting false and inaccurate information, discouraging bad actors from spreading misinformation. However, the fact-checked information does not necessarily prevail due to the persistent promotion of less accurate claims from highly influential groups [
34]. The same is also true for the medical domain, where the decrease in COVID-19 misperceptions thanks to fact-checking does not persist over time even after repeated exposure [
35]. As a result, fact-checked information is only part of the solution toward credible medical information, and it should be combined with the automatic fake news detection and mitigation approaches discussed in the next sections to be effective.
The process of fact-checking is either performed manually, by domain experts or workers in crowdsourcing platforms, or automatically. The two approaches are discussed in detail below, while a detailed description of the available online fact-checking tools is provided afterward.
3.1. Manual Fact-Checking
In manual fact-checking, the assessment of a claim as true or false is performed by people who read the articles that must be checked and decide whether the contained claims are true or false based on certain criteria, metrics, and research. Manual fact-checking is divided into expert-based and crowd-sourced-based fact-checking.
3.1.1. Expert-Based Fact-Checking
In expert-based fact-checking, the news is checked by experts of a domain, like the previously mentioned COVID-19 fact-checkers network. Usually, this team consists of journalists and domain experts. This method offers accurate fact-checking but is expensive and time-consuming. Moreover, it is difficult for a group of people to cover all the current affairs articles and keep up with rapidly changing domains like the COVID-19 pandemic everyday.
The most famous fact-checking site that makes use of an expert-based fact-checking method and was highly active during the pandemic is Politifact [
36], which contains a column about health news and a column about coronavirus. In Politifact, a team of experts studies daily transcripts, news stories, press releases, and campaign brochures to find the most significant claims. Politifact uses the Truth-O-Meter ratings that classify the claims into the following categories: true (accurate), mostly true (needs clarification), half-true (leaves out key details), mostly false (ignores critical facts), false (not accurate), and pants on fire (ridiculous claim).
Another platform is the Media Bias/Fact-Check [
37] where the team uses a 0–10 scale to rate sites for biased wording, headlines, actuality, sourcing, story choices, and political affiliation. The team sorted the various sources into the following bias categories: left, left center, right center, right, least biased, conspiracy pseudoscience, questionable Sources, pro-science, and satire.
Based on the work of expert fact-checkers, a number of datasets have been constructed for facilitating research for claim detection and verification. A well-known generic fake news dataset is FEVER [
38]. It consists of almost 200K claims manually verified against Wikipedia pages and classified as supported, refuted, or notenoughinfo. Datasets that focus on assessing the veracity of scientific claims include the SciFACT (
https://github.com/allenai/scifact, accessed on 10 December 2024) [
39] and the larger SciFACT-Open (
https://github.com/dwadden/scifact-open, accessed on 10 December 2024) [
40] datasets. These datasets include expert-written claims paired with evidence-containing abstracts annotated with veracity labels and rationales. Datasets that focus on the opposite task of non-claim detection also exist [
41]. Finally, there exists a dataset (
https://borealisdata.ca/dataset.xhtml?persistentId=doi:10.5683/SP2/VPYSIS, accessed on 3 November 2023) containing COVID-related claims that have been reviewed by fact-checking organizations around the world and retrieved by the Google Fact-Check Tools API (
https://toolbox.google.com/factcheck/explorer, accessed on 10 December 2024).
3.1.2. Crowd-Source-Based Fact-Checking
In crowd-sourced fact-checking, the detection of fake news is performed by a large population that rates the credibility of articles. This approach has been proposed by various organizations such as WikiTribune [
42] and is much more economical than expert-based fact-checking. However, it carries the risk that the rating population might introduce their own biases in the process.
The process consists of several steps. The first step is monitoring the news on TV, social media, newspapers, and websites and selecting the articles to be checked. When this selection is made by experts, the articles are filtered and balanced in order to be unbiased (e.g., they cover the whole political spectrum). This is a major differentiation from the case where the selection of articles is made up by the crowd since, in the latter case, it is difficult to certify that the selection of new claims is spread fairly across the news spectrum. The next step is researching the subject of the claims using multiple sources and assigning a rating to the news article. This step is difficult to be completed objectively by people who are not experts. There are concerns about the correctness of the rating, the availability of evidence, and the rater’s motivation. Another drawback of this approach is that it is difficult for volunteers to fact-check a claim that needs to be assessed rapidly, as in the case of the pandemic.
An example of a site that works with crowd-sourced fact-checking is Fiskkit [
43], where users can select articles, upload them to the site, and rate them sentence-by-sentence. Users can also apply tags that evaluate the article’s accuracy and see the ratings of other users.
Regarding available datasets, the Multi-Genre Natural Language Inference Corpus (MNLI) (
https://cims.nyu.edu/~sbowman/multinli/, accessed on 10 December 2024) is a crowd-sourced collection of 433 K sentence pairs annotated for textual entailment. In other words, the data consist of pairs (p and h), where p is the premise and h is the hypothesis, and labels in {entailment, contradiction, and neutral}, which report whether the hypothesis entails, contradicts, or is neutral toward the premise.
3.2. Automatic Fact-Checking
Manual fact-checking has satisfactory results, especially in the case of expert-based fact-checking. However, since the task of fact-checking is time-consuming, this method is not efficient for the rapidly changing domain of news and for keeping pace with the volume of new content on the web. Therefore, the scientific community has been exploring approaches to automate fact-checking by exploiting techniques and advancements from the domains of NLP and DL. The process of automatic fact-checking consists of two steps: (a) detecting the claims in the text and (b) assessing the validity of the claims by retrieving evidence.
3.2.1. Claim Detection
Regarding the detection of the claims contained in social media posts, comments, news, and web pages, it is important that the most check-worthy claims are selected. Such claims are those for which people show interest and are trending. The claims are usually collected from social media, where metadata like the number of likes and reposts are used as features to identify top claims [
30]. Other sources of claims can be found in Wikipedia (e.g., COVID-19 pandemic misconceptions) or in news websites and organizations.
In [
6], the authors annotate a corpus of 1200 tweets for implicit and explicit biomedical claims. Using this corpus, which is related to COVID-19, measles, cystic fibrosis, and depression, they developed deep learning models that automatically detect tweets containing claims. Their analysis showed that biomedical tweets are densely populated with claims. Despite the fact that the detection of claims was challenging, they report that deployed models provided an acceptable performance.
While most works focus on single claim sentence analysis, the work presented in [
44] introduces the NewsClaims dataset, a benchmark for attribute-aware claim detection considering topics related to COVID-19. Specifically, given a news article, the task is to identify the claim sentence to a set of predefined topics that contain factually verifiable topics, the claimer, the claim object, the stance of the claimer, and the exact claim boundaries. For claim sentence detection, they use Claimbuster (
https://idir.uta.edu/claimbuster/api/, accessed on 10 December 2024) [
45] along with pre-trained Natural Language Inference (NLI) models as zero-shot classifiers based on BART, where the claim sentence is the NLP premise and the hypothesis is constructed from each topic. The claim object task is modeled as a zero-shot or few-shot setting by converting it into a prompting task for pre-trained language models like GPT-3 (
https://lablab.ai/tech/gpt3, accessed on 10 December 2024). Stance detection is performed again through NLI, where the affirm and refute labels construct the hypothesis, taking as stance the corresponding higher entailment score. Claim boundary detection is performed using fine-tuned Bidirectional Encoder Representations from transformers (BERT) [
46] models, the Project Debater APIs [
47], and the PolNeAR (
https://github.com/networkdynamics/PolNeAR, accessed on 10 December 2024) popular news attribution corpus of annotated triples comprising the source, cue, and content for statements made in news. Finally, regarding claimer detection, they again leverage PolNeAR for building a claimer extraction baseline by fine-tuning a BERT model, along with a second baseline built upon Semantic Role Labeling (SRL), that outputs the predicate–argument structure of a sentence such as who did what to whom. The results showcase that the above tasks, except the task of stance detection, are difficult for current models, especially the task of claim sentence detection.
3.2.2. Claim Validation
For the assessment of the validity of a claim, an essential part is the retrieval of the evidence process. Evidence retrieval is the task of retrieving documents that support the prediction of a claim. During this process, information and proofs must be found around the claim, such as the text, tables, knowledge bases, images, and other metadata for evidence of the truth. A fundamental issue is finding trustworthy sources. For example, many fact-checking approaches make use of encyclopedias.
Table 1 reports some trustworthy sites for information and proof of medical claims.
After the retrieval of evidence, a fact-verification method has to conclude the validity of a claim. Usually, the verification of claims leverages NLI techniques [
48]. As already mentioned, the NLI task aims to classify the relationship between a pair of a premise (evidence) and a hypothesis (claim) as either entailment, contradiction, or neutral. However, in fact-verification systems, the usually multiple evidence pieces are found by the systems themselves. In addition, given a collection of false/true claims, the verification of a new information piece can also be modeled as an NLI task, where the goal is to detect entailment with one of the false/true collected claims [
49]. Another approach is described in [
50], where the authors present the ClaimGen-BART and Knowledge Base Informed Negations (KBIN) methods for generating claims and claim negations supported by the literature, using the BART pre-trained model [
51]. In [
39], the authors present the Kernel Graph Attention Network (KGAT), which conducts more fine-grained fact verification with kernel-based attention.
Regarding the medical domain, a COVID-19-specific dataset that has been constructed using automatic methods is COVID-Fact [
52], which contains 4086 claims concerning the pandemic, evidence for the claims, and contradictory claims refuted by evidence. The approach described in [
53] adapts the open-domain fact extraction and verification KGAT approach [
54] with in-domain language models based on the SciFACT and COVID-Fact datasets. Specifically, the in-domain language model transfers COVID domain knowledge into pre-trained language models with continuous training. The COVID medical token semantics are learned using mask language model-based training. In a similar manner, the authors of [
55] introduce the PubHealth dataset for public health fact-checking, which also includes explanations, and explore veracity prediction and explanation generation tasks using various pre-trained models. Their results show that training models on in-domain data improves the accuracy of veracity prediction and the quality of generated explanations compared to training generic language models without explanation.
In [
56], the authors introduce the HealthVer dataset for evidence-based fact-checking of health-related claims. The dataset was created using a three-step approach. The first step is to retrieve real-world claims from snippets returned by a search engine for questions about COVID-19. The next step is to retrieve and rank relevant scientific papers as evidence from the COVID-19 Open Research Dataset (CORD-19) [
9] using a T5 (
https://github.com/google-research/text-to-text-transfer-transformer, accessed on 10 December 2024) relevance-based model. The last step is to manually annotate the relations between each evidence statement and the associated claims. The conducted experiments showed that training deep learning models on real-world medical claims greatly improves performance compared to models trained on synthetic and open-domain claims.
In [
57], the authors evaluate baseline models for categorizing Reddit posts as containing claims, personal experiences, and/or questions. In addition, they evaluate various BERT models for extracting descriptions of populations, interventions, and outcomes, as well as for tagging claims, questions, and experiences. Finally, using snippets, they retrieve trustworthy (published) evidence relevant to a given claim. To this end, they introduce a heuristic supervision strategy that outperformed pre-trained retrieval models.
Knowledge Bases and Claim Validation
Another direction for assessing the validity of a claim and retrieving the corresponding evidence is by exploiting knowledge bases. A knowledge base (KB) is a collection of information and resources where human knowledge can be stored. A common way of representing it is by connecting two entities with a given relationship. These relationships can form a graph, the knowledge graph (KG), where the entities are represented as nodes and relationships are represented as edges. In this case, a fact is defined as a triple that has the form of (“subject” s, “predicate” p, and “object” o) and can be classified to different categories (e.g., numerical, object properties, etc.). Usually, the data modeling languages that are used for creating the graphs are the Resource Description Framework (RDF) (
https://www.w3.org/RDF/, accessed on 10 December 2024) or the more expressive Web Ontology Language (OWL) (
https://www.w3.org/OWL/, accessed on 10 December 2024) that also provides automatic reasoners. An example is the KG-Miner [
58], which can predict the truthfulness of a statement using discriminative predicate path mining.
Given a textual claim and a KG, the claim is converted to a triple by using NLP methods [
59,
60], and the validity of the fact is checked against the information contained in the graph. However, the KG is considered incomplete (the Open World Assumption), meaning that it does not contain all known true facts. As a result, a missing fact does not imply an invalid claim. The proposed methods in the literature try to overcome this issue.
There are three main approaches for checking the validity of a claim against an incomplete KB [
61]: (a) using external web resources as a way to find new fact triples that are missing from the KB and complement existing knowledge [
62]; (b) embedding-based [
63,
64] and path-based approaches [
58] that use graph embeddings and properties of the paths as features, respectively, for verifying facts; and (c) rule-based approaches that use rule-mining techniques to validate a fact [
65]. The first approach, which complements the KB with external knowledge, has been proven to be inaccurate due to the difficulty of the information extraction task (83.51% of fact triples extracted from Wikipedia using a BERT-model relation extraction approach were false [
61]). Embedding-based approaches, since they use a statistical approach, have the benefit that they can verify entity pair links that are not linked in the KG, covering more verifiable triples which are not verifiable by rule-based ones [
61]. On the other hand, since rule-based approaches use logical rules, their results are more interpretable, and they can easily verify some facts that the embedding approaches have trouble with [
64]. Finally, it has been shown that both the embedding-based and rule-based approaches can be used complementarily, offering a better performance than by using them separately [
61].
In the medical domain, there are various knowledge graphs that could be used for fact-checking claims, such as COVID-19, CovidGraph (
https://github.com/covidgraph/, accessed on 10 December 2024), literature-review-related ones [
66], oncological-specific KGs [
67], personalized medicine recommendation KBs [
68,
69], disease ontologies like ICD-9 (
https://bioportal.bioontology.org/ontologies/HOM-ICD9, accessed on 10 December 2024), and drug safety and interactions KBs like DrugBank (
https://go.drugbank.com/, accessed on 10 December 2024).
The SciClaim KG [
70] is a graph of scientific claims drawn from Social and Behavior Science (SBS), PubMed, and CORD19 papers. It incorporates coarse-grained entity spans (list of tokens) as nodes and relations as edges between them, and fine-grained attributes that modify entities and their relations. In total, it contains 12,738 labels that capture causal, comparative, predictive, statistical, and proportional associations over experimental variables, along with their qualifications, subtypes, and evidence. The schema is inferred using a transformer-based joint entity and relation extraction approach.
The UMLS (
https://www.nlm.nih.gov/research/umls/index.html, accessed on 10 December 2024) meta-thesaurus is a large biomedical knowledge base that unifies hundreds of different ontologies in biomedicine. UMLS is used as the source knowledge base for normalization and candidate selection for KBIN. Additionally, it is the knowledge base used to train the clinical concept embeddings cui2vec (
https://github.com/beamandrew/cui2vec, accessed on 10 December 2024) [
71], which are used for candidate concept selection in KBIN.
The public medical knowledge graph KnowLife (
http://knowlife.mpi-inf.mpg.de/, accessed on 10 December 2024) [
72] contains 25,334 entity names and 591,171 triples, and it is used among others by [
73] to extract six positive relations (i.e., Causes, Heals, CreateRiskFor, ReducesRiskFor, Alleviates, and Aggravates) and four negative relations (i.e., DoesNotCause, DoesNotHeal, DoesNotCreateRisk, and DoesNotReduceRiskFor). The approach uses an attention mechanism to calculate the importance of entities for each article, and the knowledge-guided article embeddings are used for misinformation detection.
A remark about the above methods is that although we assume that KBs and KGs contain only accurate information, this is usually not true. For example, Wikipedia, which is used as a source in the construction of various KGs, is known to contain various false facts in different time snapshots. For example, version 3.6 of the DBpedia KG, which is constructed using Wikipedia, has been found to be 80% correct [
74], while for most KGs, this accuracy is unknown.
3.3. Fact-Checking Tools
Table 2 lists the most popular fact-checking tools. For every tool, it reports whether it uses manual or automatic fact-checking techniques, the themes they are covering, and the rating scale they use for the credibility assessment of the news. Below we discuss the most prominent ones.
Snopes [
75] is one of the oldest fact-checking websites, which has been used as a source for validating and debunking urban legends and stories in American culture. It covers politics, health, and social issues. In 2020, Snopes was very active regarding the COVID-19 pandemic misinformation and had around 237 COVID-related fact-checked articles. Its rating scale consists of values like
True, Mostly True, Mixture, Mostly False, Unproven, etc.
Media Bias/Fact-Check [
37] examines bias in the media from all points of the political spectrum. It includes a “Daily Source Bias Check” that examines the truthfulness and bias of various news sources. It also includes a conspiracy/pseudoscience category that includes COVID-19-related news.
Another well-known fact-checker is Politifact [
36]. This service is devoted to fact-checking claims made by political pundits. Specifically, everyday journalists explore transcripts, speeches, news stories, press releases, and campaign brochures to identify statements that should be fact-checked. In order to decide which statements to check, they consider questions like “Is the statement rooted in a fact that is verifiable?” or “Is the statement likely to be passed on and repeated by others?” They cover politics and health topics, and they provide a scorecard that gives information about the statistics on the authenticity distribution of all statements related to a specific topic.
The Washington Post [
76] also provides a column discussing the factual accuracy of statements with zero to four Pinocchios. Full-fact [
77] is another fact-checker that uses a three-stage review fact-checking process that may also involve external academics (soon it will also apply automatic approaches). FactCheck [
78] consists of features like “Ask FactCheck”, with which users can ask questions that are usually based on rumors; “Viral Spiral”, which makes a list of the most popular myths that the site has debunked; and “Mailbag”, which includes readers’ opinions on the site’s claims.
Finally, Google Fact-Check [
79] is a search engine for fact-checks. It consists of the Fact-Check Markup tool, which provides structured markup, and the Fact-Check Explorer. The first one allows publishers to add claim-related markup into their web content, which will then be crawled and indexed by Google. The explorer allows users to query claims and returns whether they are true or false based on the indexed structured markup added by publishers and Google’s algorithms that evaluate the credibility of the sources.
4. Content-Based Methods
Content-based methods analyze the content of the various sources and their interaction, mainly in the form of text but also images, as a way to detect fake news [
80]. Specifically, they extract various features from news items, social media posts, user comments, and the content of external sources through hyperlinks and quotes [
81], which can be associated with fake news.
Before feature extraction, it is necessary to pre-process the data by using techniques such as tokenization, lowercase transformation, the removal of stop words, sentence segmentation, etc. Afterward, the extracted features can be used as the input to ML classifiers or can be concatenated or aggregated in neural network architectures like feedforward neural networks (FNNs), recurrent neural networks (RNNs), convolutional neural networks (CNNs), Long Short-Term Memory networks (LSTMs), Generative Adversarial Networks (GANs), Sequence-to-Sequence networks (Seq2Seq) like transformers, Graph Neural Networks (GNNs), etc. (see [
82,
83,
84,
85,
86]).
Below we describe the different types of content-based features commonly used in the literature. We consider the following categories: text representations, linguistic features, emotional features, entity-based features, stylistic features, topic extraction, user profile features, image-based features, and external features.
Table 3 offers an overview of all the available features.
4.1. Text Representations
Text representations address the fundamental problem of converting unstructured documents to mathematically computable forms, usually in the form of vectors. Commonly used approaches include the bag-of-words (BoW) approach, which weights the frequency of a word in a document [
30,
87], and the term frequency–inverse document frequency (TF-IDF) approach, which keeps the appearances of words in a document by the fraction of documents in the corpus that contain the word [
30,
87,
88,
89]. Approaches using n-grams, which are based on contiguous sequences of n ’items’ (words, letters, syllables, phonemes, etc.), are commonly used even in the context of medical fake news detection [
89].
More modern approaches use a latent space to create text embeddings over the content of the articles. Embeddings provide a way to translate a high-dimensional vector into a relatively low-dimensional one, placing semantically similar inputs close together in the embedding space. Usually, embeddings are learned over big corpora and datasets so that they can be reused across models, domains, and tasks. It has been shown that the effectiveness of word embeddings in encapsulating the semantic, syntactic, and context features affects the performance of the classification models [
90].
Text embeddings can be divided into non-contextual and contextual ones. Non-contextual ones, like word2vec [
91], GloVe [
92], and FastText [
93], learn word associations from a large corpus of text but do not capture information about the context in which they appear. They provide a single global representation for every word, even if words can be ambiguous and have various meanings. For example, in the context of medical fake news, the authors in [
83] use the GloVe pre-trained model to classify COVID-19 news by using various neural network architectures.
Contextual embeddings assign to each word a representation based on its context. In this way, they can capture uses of words across varied contexts and can encode knowledge that can be cross-lingual. In [
90], the authors evaluate non-contextual and contextual text-embedding approaches over various fake news datasets and showcase the importance of contextual embeddings. A large number of approaches that leverage latent features use pre-trained language models based on the popular BERT model [
46] and its derivatives (BART [
51], RoBERTa [
94], distilBERT [
95], Albert [
96], XLNet [
97], etc.). Such models can be fine-tuned over a collection of fake and valid news for classification reasons, as is the case of FakeBERT [
98], and offer an exceptional performance for the task at hand. Furthermore, they can be trained over datasets of a specific domain in order to identify the terminology, constructs, and peculiarities of this domain. An example of a pre-trained representation model in the medical domain is BioBert [
99], a BERT model for Biomedical Text Mining. This is the first domain-specific language representation model pre-trained on large-scale biomedical corpora (PubMed abstracts and PMC full-text articles). The reported results show that pre-training BERT on biomedical articles is crucial for several tasks in the medical domain. In the same manner, Med-BERT [
100], which has been trained in electronic health records, has shown an excellent performance in disease prediction tasks on two clinical databases. Another relevant BERT-based model is the scientific-BERT (SCIBERT) [
101], which was trained on the FakeHealth dataset that contains health-related annotated news from the news fact-checking site Snopes (
https://www.snopes.com/, accessed on 10 December 2024). Finally, BioGPT [
102] is a domain-specific generative transformer language model pre-trained on the large-scale biomedical literature.
Other strategies for fake news detection [
103,
104,
105,
106,
107,
108] use a combination of different types of pre-trained models over different domains and contexts. For example, in [
103], the authors propose a multi-context neural architecture with three pre-trained transformer-based models: BERT, BERTweet [
109], and COVID-Twitter-BERT [
110]. They show that their combination outperforms the use of a single model. The reason is that the hybrid model benefits from the different aspects that each model understands. Specifically, BERT understands the English language constructs, BERTweet the structures of tweets, and COVID-Twitter-BERT the COVID-19 scientific terms.
Finally, several knowledge-embedding models have been widely proposed in the bibliography. Such models include TransE [
111], TransD [
112], TransMS [
113], and TuckER [
114]. The performance of the above models has been explored in the context of Twitter COVID-19 misinformation detection as a graph link prediction problem in [
115,
116]. In [
73], medical knowledge graph embeddings are leveraged to guide article embedding using a graph attention network to differentiate misinformation from fact.
An important conclusion from the plethora of the aforementioned works is that exploiting pre-trained models benefits studies on other smaller or domain-specific datasets by offering an exceptional performance in various tasks while at the same time reducing data collection costs.
Table 4 summarizes the mentioned pre-trained models.
4.2. Linguistic Features
Linguistic features are characteristics that are used to classify phonemes or words, along with their inter-relationships. Of special importance in the context of fake news detection are morphological, syntactical, and grammatical features like Part-Of-Speech (POS) and noun phrases (NPs) [
30,
87,
89,
117,
118]. Various works showcase the importance of uncertainty constructs like possibility adverbs, conditional particles, and certainty constructs like demonstrative adjectives/pronouns and declarative conjunctions. For example, the authors in [
88] study the structural difference between fake and true news for the health domain. They claim that the size of the headline is a key element of a news article, and they analyze the presence of some common patterns like the use of demonstrative adjectives, numbers, modal words, questions, and superlative words. Similarly, the authors in [
119] report that the content provided by trustworthy sources tends to be expressed in a passive voice. Finally, the use of morphological Part-Of-Speech (POS) n-grams was not found to improve fake news detection over a TF-IDF baseline [
120].
4.3. Emotional Features
Sentiment analysis and emotion detection have also been studied in the context of fake news detection [
30,
87,
121,
122,
123,
124,
125,
126]. Sentiment analysis characterizes textual content as positive, negative, or neutral, while emotional detection identifies distinct human emotion types like depression, happiness, anger, etc. Fake news has been noted for producing feelings of fear and anxiety to news consumers [
123]. In the same manner, a high level of negativity and depression has been correlated with subjectivity [
122]. The polarity of the text has also been used for classifying fake and valid news since polarity indicates bias and questionable credibility and can be extracted using emotion analysis techniques [
122,
124].
There is a plethora of tools used for both sentiment detection and emotional analysis. Such resources include the NRC lexicon (
https://saifmohammad.com/WebPages/NRC-Emotion-Lexicon.htm, accessed on 10 December 2024), the MPQA subjectivity lexicon (
https://mpqa.cs.pitt.edu/, accessed on 10 December 2024), the Affective Norms for English words (ANEW) lexicon (
https://github.com/nisarg64/Sentiment-Analysis-ANEW, accessed on 10 December 2024), the SentiWordNet sentiment lexicon (
https://github.com/aesuli/SentiWordNet, accessed on 10 December 2024), the WordNet-Affect affective concept and words lexicon (
https://wndomains.fbk.eu/wnaffect.html, accessed on 10 December 2024), the text2emotion python package (
https://pypi.org/project/text2emotion/, accessed on 10 December 2024), the general NLP task TextBlob library (
https://textblob.readthedocs.io/en/dev/, accessed on 10 December 2024), and others.
Table 3.
Features used in content-based approaches.
Table 3.
Features used in content-based approaches.
| Textual Representations |
|---|
| BoW | [30,87] |
| TF-IDF | [30,87,88,89,105] |
| n-grams | [89] |
| Non-contextual embeddings | [30,83,89,90,104,121,127] |
| Contextual embeddings | [53,80,89,90,103,105,106,107,108,127,128,129] |
| Knowledge embeddings | [73,115,116] |
| Linguistic |
| PoS | [30,89,117,130] |
| Uncertainty constructs | [88,131] |
| Certainty constructs | [88] |
| Passive voice | [119] |
| Headline length | [88] |
| Emotional |
| Sentiment analysis | [30,122,123,124,125,126] |
| Subjectivity | [121] |
| Polarity | [122,124] |
| Entities |
| NER | [30,130] |
| Medical terms | [30] |
| Commercial terms | [30] |
| Hyperlinks | [88] |
| Hashtags | [132] |
| Direct quotes | [88] |
| Visual and textual entity inconsistencies | [133] |
| Stylistic |
| Complexity, readability, specificity, | [87,121,131,134] |
| informality, non-immediacy, diversity | |
| Misspellings | [87] |
| Topic Extraction |
| LDA | [135] |
| Markov chains | [136] |
| Image |
| Visual features | [133,137,138] |
| User Profiles |
| User description, timeline, | [117,128] |
| friends profile | |
| External |
| Fact-verification score | [128] |
| Credibility score | [139] |
| Stance detection | [140,141,142] |
Table 4.
Pre-trained models: general, fake-news-, medical-domain-, and social-media-related ones over various datasets.
Table 4.
Pre-trained models: general, fake-news-, medical-domain-, and social-media-related ones over various datasets.
| General |
|---|
| BERT | English Wikipedia, BooksCorpus | [46] |
| BART | English Wikipedia, BooksCorpus | [51] |
| RoBERTa | English Wikipedia, BooksCorpus, | [94] |
| | CC-News, OpenWebText, | |
| | and CommonCrawl Stories | |
| distilBERT | English Wikipedia, BooksCorpus | [95] |
| Albert | English Wikipedia, BooksCorpus | [96] |
| XLNet | English Wikipedia, BooksCorpus | [97] |
| Fake News |
| FakeBERT | 40K fake and valid news | [98] |
| Medical Domain |
| cui2vec | 20M clinical notes and | [71] |
| | 1.7M biomedical articles | |
| BioBert | PubMed abstracts and PMC articles | [99] |
| Med-BERT | Electronic health records | [100] |
| SCIBERT | FakeHealth dataset (news) | [101] |
| COVID-Twitter-BERT | 22.5M COVID-19 tweets | [110] |
| BioGPT | 15M PubMed abstracts | [102] |
| Social Media |
| BERTweet | 850M English tweets | [109] |
4.4. Entity-Based Features
News usually contains named entities, which can be important for understanding the news semantics and for detecting fake news. Such entities include categories like person, PersonType, location, organization, event, product, dates, and others. The process of identifying the named entities is called Named Entities Recognition (NER) (a list of NER tools is provided at
https://www.clarin.eu/resource-families/tools-named-entity-recognition, accessed on 10 December 2024). Biomedical NER has also been studied for recognizing diseases, drugs, surgery reports, anatomical parts, and examination documents [
143,
144,
145]. In addition, the previously presented language models can be fine-tuned for this specific task [
99,
146].
NER approaches are usually deployed in fake news classification as a feature that enriches the textual representation, sentiment, and linguistic features [
87,
130]. For example, in [
130] the authors use a combination of POS tagging and NER sequences to identify valid and fake news. The work described in [
30] uses linguistic–medical entities and specifically the fraction of medical terms in a document. Those are found using the MedMentions (
https://github.com/chanzuckerberg/MedMentions, accessed on 10 December 2024) NER model, which is specially trained on medical information, and consists of 4392 biomedical papers annotated with mentions of UMLS entities. They also exploit commercial terms since they are used for profit. As a result, the higher the number of commercial terms, the less credible the information [
147]. The authors in [
88] explore to what extent credible medical-related sources make use of quotations and hyperlinks in a news article by using the Stanford QuoteAnnotator (
https://github.com/muzny/quoteannotator, accessed on 10 December 2024). What they observed is that unreliable outlets use a smaller number of quotations compared to reliable ones. Regarding the hyperlinks, they concluded that a credible news article contains on average 1.6 more hyperlinks than non-credible articles. They also compare various classifiers using textual representations, the headline length, the number of direct quotes, and the number of hyperlinks and showcase the importance of direct quotes and hyperlinks for detecting fake news. Hashtags have also been found effective in identifying fake news, especially early in the propagation lifecycle [
132]. Finally, a multimodal approach that monitors inconsistencies between recognized entities in textual and image content, offering a potential indicator for multimodal fake news, is described in [
133].
4.5. Stylistic Features
Various stylistic capturing features of the content are considered to be disinformation-related by [
14] and are studied in various works [
87,
121,
134]. Such attributes are related to the quantity of information present in the text, its complexity (e.g., the ratio of characters and words in a message), its non-immediacy (deceivers tend to disassociate themselves from their deceptive messages for reducing accountability and responsibility for their statements [
148]), its diversification in terms of words, its uncertainty (e.g., lack of information, hedging, lexical ambiguity, and negation), its informality (e.g., presence of emoticons, slang, or colloquial words), its specificity (e.g., deciding when to convey general statements, elaborate on details, and gauging how much detail to convey), and its readability (the accessibility of a text showing how wide an audience it will reach) [
134]. Misspellings in a COVID-19 setting were studied in [
87].
4.6. Topic Extraction
Topic extraction methods have also been used in fake news detection approaches. Specifically, the approach described in [
135] uses the Latent Dirichlet Allocation (LDA) [
149] topic detection model to examine the influence of the article’s headline and the body both individually and collaboratively. These features are then used to enhance a BERT-based classifier. A Markov-inspired topic extraction approach has been used to identify trends in fake news agendas through fact-checking content over a time window [
136].
4.7. User Profile Features
The content of a user profile along with the user timeline are also important for fake news detection. For example, in [
128], the authors use the textual information of the user description along with other properties of the user account. In addition, the user timeline and the profile of the user’s friends have been studied [
117]. We discuss in more detail the user-related features in
Section 6.
4.8. Image-Based Features
Posts on social media are frequently accompanied by images or even sometimes consist of just plain images (e.g., memes). Image-containing posts generally target the emotions of the people, spread faster, and have a high level of retweets and shares. If images contain text (e.g., in the caption or inline), the previously discussed approaches can be applied in the extracted text. Else, more complicated deep learning pipelines [
138] can be deployed that flag fake posts with visual data embedded with text. Such approaches can even support the identification of tampered and out-of-context images. The already discussed work described in [
133] tries to identify inconsistencies between recognized entities in textual and image content. Finally, the authors in [
137] propose a multimodal fused encoder–decoder architecture to detect COVID-19 misinformation by investigating the cross-modal association between the visual and textual content that is embedded in multimodal news content. The challenging part of this method is to accurately assess the consistency between the visual and textual content. The deployed architecture uses (a) a multimodal feature encoder for the content (text and image) and user comments of input news articles, (b) a text-guided visual feature generator that is given features from the previous encoder and generates visual features based on the understanding of the news text, (c) an image-guided textual feature decoder to learn the corresponding guided textual feature information from the news images, and (d) a comment-driven explanation generator that leverages both the original and generated features to provide content and comment explanations on the results.
4.9. External
Finally, another category of works tries to incorporate external features using textual information. For example, in [
128], the text of tweets is used as a query in a popular web search engine to compute a fact-verification score. Specifically, the authors consider the results of popular news websites only as reliable and use the Levenshtein distance between the tweet text and the titles of the results to compute the fact-verification score. Another approach [
139] uses Wikipedia and Twitter among others to assess the credibility of web pages. In the same manner, the provided references to external resources (e.g., URLs) can be used in combination with other features (e.g., sentiment and linguistic) to identify the credibility of the referenced information by exploiting available fact-checking services like the Media Bias/Fact-Checking service (
https://mediabiasfactcheck.com/about/, accessed on 10 December 2024) and stance techniques [
140,
141].
5. Propagation-Based Methods
Propagation-based methods leverage the complex networks involved in and influencing the dissemination of news within social media platforms. These approaches analyze how misinformation spreads by examining user behavior, the structural and temporal dynamics of interactions, and the characteristics of both the users and their social connections. By studying engagement patterns, such as how quickly and widely false information circulates, these methods aim to identify signals that distinguish fake news from legitimate content.
An important network is the cascade network that captures the actual propagation of a news item in a social network. The cascade network is usually a tree whose nodes represent the users who are involved in spreading each news item. The root represents the publisher of the item, i.e., the user who first posted the item in the social network. There is a link from a node u to a node v if the user represented by u has spread the item posted by the user represented by v, for example, by retweeting, reposting, or liking the item. Spreading news in such networks indicates endorsement of the original item. Note that for a specific news item, there may be more than one publisher and thus multiple simultaneous cascades.
Another network directly capturing the propagation of an item is the discussion network. This is usually a tree whose nodes represent items related to the news item. The root represents the original news item, and there is a link for a node u to node v if the item represented by u is a reply or a comment to the item represented by node v. A common variation of the discussion network is one whose nodes represent the users that posted the items instead of the item itself. Spreading items in such networks indicates engagement with the original item but not necessarily an endorsement of it, since a reply or a comment may express a negative reaction.
Several other networks have also been studied; for example, networks that capture a friendship or follow relationships between the users spreading the news, as well as specialized healthcare social networks [
150]. We present some of them later in this section.
Propagation networks find many applications in the context of medical fake news. First, they have been exploited toward enhancing our understanding of the mechanisms driving the spread of fake news in a social network. Then, propagation networks are used to improve fake news detection. Furthermore, they help in building richer user and item profiles. For example, a friendship network can be used to build an enhanced profile for a user u that also incorporates information about the friends of u, or a discussion network can be used to augment the content of an item i with the content of replies to i. This can be achieved either through explicit aggregation or implicitly by using the propagation network to build, for example, a GNN architecture.
In the following, we first present propagation-based approaches that involve a feature-extraction process. Then, we present approaches that use latent features of the networks.
5.1. Propagation Network Features
Previous research looks into several features of the networks involved in the propagation of news items. Such features have been used to make important observations regarding the spread of fake news [
151,
152]. They have also been used as features for fake news detection [
30,
153]. In
Table 5, we report several features of propagation networks studied in the context of fake news [
30,
151,
152,
154,
155,
156]. Note that features can be computed not only at the whole graph but also at specific subgraphs.
The most common
structural features are size, depth, and breadth. Size counts the number of nodes, either the nodes representing distinct or the nodes representing non-distinct entities. In the case of tree-structured networks, depth is the maximum distance from the root to any of the leaves, while depth counts the number of nodes at a level of the tree. There are also features of individual nodes, such as the centrality of nodes, as measured by the degree centrality, closeness centrality, and betweenness centrality. Distance-based features consider the shortest path distances between pairs of nodes. One such feature is structural virality, defined as the average Wiener index, i.e., the average shortest path distance between all pairs of nodes [
157]. Structural virality tends to be maximized for large networks that have become that way through many small branching events over many generations. Other structural features are about the local structure of the graphs, captured, for example, using modularity.
Temporal features have also been considered. In this case, networks are annotated with time information; for example, in a cascade network, each node is annotated with the time when the corresponding item was posted. Common temporal features are lifespan, speed, and heat. Lifespan captures the duration of spreading a news item and can be measured as the difference between the time associated with the first and the last node. Speed refers to how fast information is spread and may be measured as the time needed to reach a specific number of users, a specific level of the tree, or the value of some other structural feature. Heat refers to the number of nodes, e.g., comments that appear within a specific time interval.
Several other types of features have also been studied besides structural and temporal ones. A family of such features looks at the users involved in the propagation and computes various statistics about the distribution of their features in the network, such as the percentage of bots. A fairly recent work studies the habitual nature of misinformation propagation. Specifically, Facebook users were found to automatically react to familiar platform cues, sharing misinformation out of habit [
156]. For example, headlines were presented in the standard manner (i.e., Facebook format of a photograph, source, and headline) with the sharing response arrow underneath, and users clicked the shared button habitually. Analogously, the distribution of content features, such as linguistic aspects and sentiment, have also been exploited [
154]. Finally, there are features about the relationships between the different networks involved. For example, one such feature is whether the likelihood of retweeting is larger between friends. There is also work that aims to understand how misinformation propagates in social networks by identifying influential nodes (e.g., see [
158]).
Various studies highlight the difference in structural, temporal, and other features between graphs related to fake and true news. The authors of [
151] used the retweet network of all fact-checked cascades on Twitter from 2006 to 2017. Their study showed that fake news was propagated six times faster than real news. Specifically, it was shown that it took the truth approximately six times as long as falsehood to reach 1500 people and 20 times as long as falsehood to reach a depth of ten. Falsehood was also diffused significantly more broadly and was retweeted by more unique users than the truth at every depth. False political news diffused deeper more quickly and reached more people faster. In addition, the inclusion of bots in social media accelerated the spread of both true and false news. However, it affected their spread roughly equally.
In the medical domain, work in [
152] constructed cascade networks of retweets during the Zika epidemic in 2016. They report statistically significant differences in nine network metrics between real and fake groups of cascade networks. Fake news cascade networks were in general more sophisticated than those of the real news. The metrics they consider are the number of nodes, number of distinct nodes, diameter, Wiener index, structural virality, out-degree distribution, largest betweenness centrality, modularity, and relation between follower networks and retweets, i.e., the difference in the probability of retweets between followers and non-followers.
In a recent study, the authors of [
30] examine and analyze several distinct groups of features (introduced in [
154]) and various machine learning techniques to assess misinformation in online medicine-related content. Amongst others, they are using propagation network features. They divided these features into four categories: structural features, temporal features, linguistic features, and engagement features. Structural features capture the network structure of users and can be depth, breadth, or out-degree. Temporal features include the duration of dissemination, the average speed of dissemination, and the average speed of response. Linguistic features are variables that capture the linguistic aspects of messages that interact with information dissemination. Finally, engagement features are variables that assess the level of appreciation. After the feature construction, they use binary classification to distinguish health information from misinformation. In their results, they report that the random forest classifier had the best performance among the rest.
Some propagation-based methods use trees or tree-like structures to capture the propagation of an article on social media. For instance, in [
153], the authors propose a graph-kernel-based hybrid SVM classifier that captures the high-order propagation patterns. Specifically, they model the message pattern propagation as a tree that reflects the relation between reposts and their authors. Moreover, they propose a random walk graph kernel to model the similarity of propagation trees. They combined the graph kernel with a radial basis function kernel to build a hybrid SVM classifier. The structural features used for classification were features such as the total number of nodes and the maximum or average degree of the graph. They achieved significantly better classification accuracy than other models for the early detection of false rumors.
5.2. Beyond Propagation Features
Recent research leverages complex graphs beyond the propagation networks to leverage rich contextual information about the news and users involved in spreading misinformation. Entities involved in the news propagation include the original news item, related posts, publishers, and users. Edges in the graphs correspond to the various relations between these entities. Initial feature representations of the nodes of the graphs are created using content and other features. These representations are then enhanced using the relations in the graphs. Approaches differ in the types of entities, relations, and graphs as well as in the methods used to create latent representations. Below we present some representative approaches that use such complex networks for fake news detection [
159,
160,
161,
162].
Hetero-SCAN [
159] builds a heterogeneous graph capturing various types of nodes and interactions. Specifically, the graph consists of three types of nodes: publishers who create the news, users who tweet the news, and news. There are four types of edges: citation edges between publishers, publish edges between publishers and news, tweet edges between users and news, and friendship edges between users. The graph is used to learn feature representations for the news nodes, which are used as input to a fake news classifier. Initial feature representations are constructed for the three types of nodes using appropriate text- and graph-embedding methods. Then, the feature representations for the news nodes are enriched using instances of two types of meta-paths: news → publishers → news and news → users → news. KG-based embeddings are used, in particular TransE, refined for this task. The premise behind using these specific meta-paths is that the validity of a specific news item is related to the authenticity of both its publishers and its users as well as the news that the publishers and users, respectively, publish and tweet.
The SOMPS-Net framework builds an end-to-end binary fake news classifier [
160]. The entities are news articles, tweets, and retweets of the articles, users, and publishers. SOMPS-Net consists of two components, the social interaction graph component (SIG) and the publisher and news statistics component (PNS). The SIG component has several subcomponents. Initial textual embeddings of each article and its related tweets and retweets are generated using GloVe. Feature vectors are constructed for the users based on information from their profile and history, such as the number of their tweets and friends. For each article, two social connectivity graphs are built, one with the users that tweeted about the article and one with the users that retweeted about it. There is an edge from a user
u to a user
v if
u follows
v weighted by the number of common followers and followees of
u and
v. A graph convolution layer is applied on the two graphs to obtain graph embeddings. A cross-attention component is then applied to capture the correlation between the news embeddings and the graph embeddings. The PNS component includes statistical features about the article, such as the total number of tweets, and some features of its publisher. The PNS feature vector is fused with the output of the SIG component, and the result is used to predict the validity of a news item.
Fake news detection is formulated as a binary graph classification problem in the Post-User Interaction Network (PSIN) model [
161]. The entities are news items, posts, and users. An interesting aspect of the approach is that they adopt an adversarial topic discriminator to improve the generalizability of the model to emerging topics. A heterogeneous directed graph is built for each news item. The graph includes two types of nodes: the users and the posts involved in the dissemination of the item. There are three types of edges: propagation edges between posts, follower edges between users, and post edges from users to posts. The heterogeneous graph along with the topic of a news item are given as input to a classifier that determines whether the item is fake or not. To process the graph, the graph is decomposed into three parts: the post-propagation tree, user social graph, and post-user interaction graph. Node representations are built using both textual features and meta-features (e.g., number of likes). Each part of the graph is processed individually, using appropriate graph attention (GAT) models. At the end, the concatenated and pooled representations are fed into a veracity classifier and an adversarial topic classifier.
A different approach is taken in [
162], where a new graph data structure, termed meta-graph, is proposed. The nodes of the meta-graph correspond to retweet cascades. Each cascade disseminates a root tweet along with the web and/or media URL(s) embedded in that tweet. There is an edge between two nodes (i.e., cascades) if there are common users in the two cascades. The node features contain information about the cascade graph structure, obtained by applying a graph-embedding algorithm to each individual cascade, textual information potentially including topic and sentiment, profile user information, and relational user information, extracted from the social network. The edge features encode relationships between cascades, such as structural similarity, number of common users, or content similarity. Two formulations of the problem of fake news detection are proposed. The first formulation is as a graph classification problem where each graph corresponds to a single cascade, i.e., the meta-graph is not used. The second formulation is as a node classification problem at the meta-graph level. The meta-graph node classification approach slightly outperforms the graph classification approach in accuracy. Various GNN-based classifiers are used in both approaches.
Complex networks are used to determine whether an item refers to a known misconception in [
115]. Specifically, given a set of misinformation targets (MisTs), each addressing a known misconception about the COVID-19 vaccines, the authors address the problem of discovering automatically which tweets contain misinformation and the one or more MisT they refer to. They construct a Misinformation Knowledge Graph (MKG) whose nodes are tweets that contain misinformation. An edge between two tweets indicates that they share the same misconception, and the tweets are labeled with the corresponding MisT. For each MisT, a separate, fully connected graph (FCG) is generated spanning all tweets that refer to this MisT. Then, the problem of discovering whether an unconnected tweet contains misinformation is cast as a link prediction problem: predict whether there is a link from the tweet to any FCG. Representations of the tweets are learned using several KG embedding models. To capture linguistic content, embeddings of MisTs and tweets are also created using COVID-Twitter-BERT-v2 and projected in the embedding space of the MKG. The link ranking functions from each KG embedding model are used for predicting a link between any tweet that may contain misinformation and tweets that share a known MisT.
Finally, an additional type of information that can be exploited is the fact that an item may take a different stance on a topic. To exploit this information, some approaches introduce stance networks where different types of edges are used to exploit agreement or disagreement between nodes (e.g., news items or users). For example, the approach proposed in [
163] exploits a signed network of tweets to predict the credibility of a tweet. Credibility is a numeric value in
with positive values corresponding to valid information and negative values to fake information. There are two types of edges: positive edges between tweets taking the same viewpoint and negative edges between tweets taking different viewpoints. Initial credibility values are assigned to some tweets. Then, credibility propagation is formulated as a graph optimization problem. The solution is based on the assumption that tweets with similar viewpoints should have similar credibility values while tweets with opposing viewpoints should have opposite credibility values.
Table 6 summarizes the approaches that exploit the network information.
6. Source-Based Methods
Most fake news detection algorithms focus on finding clues from the content of news, which is not always effective since fake news is intentionally written to mislead users by imitating valid news. Therefore, it is helpful to explore ancillary information to improve detection. One such piece of information is the credibility of the news sources. Source-based fake news detection uses methods to assess the credibility of the source of news. The source can refer to publishers, such as news portals that publish the news, and the social media users who either create new content or post existing news articles published by the publishers.
Thus, we divide source-based methods into two main categories based on the type of source: methods that focus on the credibility of publishers and methods that focus on the credibility of social media users [
14]. The latter also considers the case of social bots and trolls.
6.1. Publisher Credibility
Assessing the credibility of publishers is closely related to the problem of assessing the credibility of web domains. This is a problem that has been considered in the literature for ranking web pages [
164,
165] and fighting spam (e.g., see [
166,
167]). We aim to assess the credibility with respect to the truthfulness of the information.
Assessing the credibility of web domains relies on identifying characteristics and patterns that are associated with fake news. A variety of approaches has been considered, such as content analysis, link analysis, natural language processing, and machine learning algorithms. We distinguish two main categories of methods: methods that use content-based features and methods that use graph-based features.
Content-based features extract specific information from the text of websites to distinguish between valid and non-valid websites. For example, in [
139], to assess the credibility of a source, the authors extract features from a sample of the website articles, the corresponding Twitter account, the Wikipedia page, and the web traffic information to the domain. The study found that Twitter accounts had the most impactful features.
Graph-based features are used to analyze the structure of the network of web pages and the links between them. This can involve identifying patterns of link exchanges and websites that are highly connected to other websites that include fake news. Consequently, most graph-based fake website detection algorithms follow the Pagerank intuition by iteratively propagating scores through the links in the web graph.
Using the graph of web pages and links, it is also possible to detect communities of websites that are interconnected and may be involved in spreading fake news. The work in [
168] focuses on detecting fake news on web pages utilizing both graph and content-based features. They associate each domain with a group of Twitter users who tweet about it and create a graph by linking domains whose user sets have a Jaccard similarity above a specified threshold. Then, a classifier is used with three types of features: markup, readability, and morphological. The top features associated with real news include advanced HTML tags and high readability scores, while the top features for fake news include italic fonts and underscore.
Several studies have indicated that there is a tendency for news publishers (and journalists) to form homogeneous networks. These networks can be analyzed to identify patterns and assess the credibility of unknown authors or publishers. If an unknown author or publisher is found to be connected to a network of individuals that have spread misinformation, it may be reasonable to question their credibility [
14].
In [
169], the authors explore how the credibility of the news publishers relates to the communities they form. They collected publisher domains and articles from both mainstream outlets and alternative sources. They created a content-sharing directed network, where nodes are news sources and edges are articles copied between the sources. Edges are weighted by the number of articles copied and they are directed from the original source to the source that copied. To identify the communities in the network, they used the modularity maximization algorithm [
170]. The credibility of the news sources was then evaluated by using several tools, News Guard, Media Fact-Check, Allsides, and BuzzFeed. They combined the outcomes from these tools to generate a score ranging from −1 to 1. Sources with a score less than −0.6 were labeled as non-credible, those with a score more than 0.6 were labeled as credible, while sources in between were labeled as unknown. They then studied the relationship between the community structure in the network and the credibility of sources, and they identified four main behaviors: echo chambers, context mixing, competing narratives, and counter-narratives. They concluded that news publishers face challenges in maintaining their credibility. Alternative news sources tend to promote conflicting narratives, eroding trust in mainstream media. Some right-wing sources mix mainstream and conspiracy content, potentially lending false credibility to unreliable sources. News is homogeneous within communities, creating different spirals of sameness and amplifying alternative narratives.
6.2. Social Media Users
We now turn our attention to the credibility assessment of users in social media. We divide social media users into two categories: humans (normal, non-automated users) and bots (fully automated accounts).
The assessment of social media user credibility is based on a diverse range of source-based features, including
user,
content,
network,
behavioral, and
temporal characteristics. User features include basic information such as age, profile, and interests, while content features pertain to the textual information found in the user profile, posts, and comments. Behavioral features refer to the user behavior on the platform, such as their discussion initiation, interaction engagement, influential scope, and more. These features can provide insights into the user’s level of engagement with the platform and their role in the community. Timing features, such as interval entropy, can also be analyzed to determine if the user is sharing content in a manner consistent with typical human behavior.
Table 7 presents a summary of the most commonly used features in source-based methods.
In [
128], the authors propose an approach for the early detection of fake news about COVID-19 from social media, such as tweets in multiple indic languages besides English, using both
content and
source based features. To determine the credibility of the source, they use
user features from Twitter and
network features. Some of the features as reported in
Table 7 are the number of characters and the total number of URLs in the description of the user, whether the user has an official URL or not, the number of followers, the number of days since the user’s latest tweet, whether the user account is verified officially, etc. After experiments on various combinations of features and classifiers, they concluded that user features are effective at determining the credibility of the news that the user spreads.
Another approach [
173] focuses on
behavioral features of users in order to detect misinformation spreading on Zibizheng Ba, a Chinese forum about autism on Baidu Rieba. Specifically, they measured discussion initiation (the tendency of a user to initiate a new discussion); interaction engagement (how much a user is interacting with other users); influential scope (the communication ability of a user) that is measured by using the degree centrality in the social network of the user; and relation mediation (the ability to control communication in the community), measured by betweenness centrality and informational independence (the ability of the user to instantly communicate with others without going through many intermediaries) and by measuring closeness centrality.
Some other medical fake news detection approaches that make use of source-based methods examine the characteristics of users who are sharing unverified cures for various illnesses. In [
131], the authors focused on misinformation spread about cancer treatments by users on Twitter. They separate users into two groups, the
rumor group, with users that have posted some of the “treatments”, and the
control group, who have posted generally about cancer but none of these topics. They measure and compare
user features,
content features, and
temporal features. They observed that the most important and discriminative features of content-based features are readability, number of adverbs and numbers, user verification regarding the user features, and interval entropy regarding temporal features. Also, they concluded that most viral rumors were on “cures” that involved food or drink.
The importance of the knowledge background of a user when dealing with healthcare information dissemination is studied in [
172]. The authors analyze Twitter users and their content in the dissemination of medical news around mammography and the ensuing discussions. They separate users in non-healthcare, health organizations, commercial healthcare organizations, physicians, non-provider health professionals, media organizations, health advocates, cancer specialists, and non-physician providers. They use
user features like gender, age, location, and
content features to analyze and determine who is sharing information about medical topics that may not be valid or verified. They conclude that non-healthcare users are the primary drivers of such conversations and tend to make claims without providing any references.
6.3. Trolls
A
troll is an individual with antisocial behavior who intentionally creates posts and comments in social media to provoke emotional reactions from others. Such individuals often use aggressive or offensive language in order to slow down the natural progression of the conversation. The purpose of a troll is to offend people, dominate discussions, and manipulate the opinions of people [
174].
The prevalence of trolls has grown in recent years, causing concern for both individuals and society. Identifying trolls is a challenging task, as trolls go to great lengths to conceal their true identity and their actions. Many online communities such as Reddit have developed strategies to identify and remove harmful content like moderation teams that monitor and delete inappropriate messages manually [
174,
175]. US Congress also published a catalog of 2752 Twitter accounts which were allegedly linked with the Internet Research Agency, a Russian-based organization referred as a “troll farm” [
176,
177], in an effort to deter what was perceived as a systematic campaign for the mass manipulation of public opinion by Russia.
There has been considerable research effort on automatic troll detection approaches [
175,
176,
178,
179,
180]. Troll detection involves several methods such as analyzing the language used in posts or comments using NLP techniques to determine the sentiment and emotional tone of messages. User behavior analysis is another method that can be used as trolls often exhibit certain patterns of behavior, such as continuously posting negative comments or targeting specific users. Network analysis is also used as trolls often operate in groups or networks, and by analyzing social network connections, it is possible to identify groups of users engaging in trolling behavior [
174].
For instance, in [
178], the authors train a model on 335 Russian-sponsored troll accounts identified by Reddit. They demonstrated that troll accounts exhibit specific interaction patterns, such as a higher frequency of replies among each other, and submissions with the same title. They considered accounts from the top subreddits with trolls (r/News, r/Politics, and r/Bitcoin). They concluded that the most important features include the number of submissions, account age, fraction of submissions with the same title as known troll submissions, fraction of comments that reply to a troll account, etc.
In [
175], the TrollPacifier tool is proposed for detecting trolls. This model was trained on Twitter data using six groups of features: sentiment analysis, time and frequency of actions, text content and style, user behaviors, interactions with the community, and advertisement of external content. Community and advertisement groups of features were found to outperform the rest. Additionally, in [
179], the authors focused on troll detection in comments via sentiment analysis and user activity data on the Sina Weibo Chinese platform.
Trolls can also play a significant role in the spread of health misinformation on social media and lead to the confusion of the public. For example, during the COVID-19 pandemic, trolls were very active in spreading health misinformation on a wide range of topics, such as treatments, vaccines, and the origins of the virus [
181]. Due to the serious consequences of this kind of misinformation, several troll detection tools have focused on the health domain. For example, in [
181], the authors collect a variety of Twitter content features to detect whether a tweet was meant to troll. As features, they use trolling hashtags and specific strings that were commonly used to advance trolling topics, sentiment analysis features, and user behavioral features.
6.4. Social Bots
A bot is a software program designed to automate tasks or simulate human behavior on the internet. There is a wide range of different types of bots, such as spiders or crawlers, shopbots, knowbots, chatbots, and social bots.
A social bot is a type of bot that imitates human behavior in social media platforms. Social bots can be utilized for both positive and negative purposes [
182]. Some of the positive purposes are disseminating accurate and helpful information to a wide audience, promoting products or services in a cost-effective manner, and providing customer support [
183]. Also, social bots have helped in emergency management like in publishing earthquake warnings in Japan [
184].
However, they have also been used for negative purposes such as spreading misinformation and propaganda to manipulate public opinion, scamming people, and creating fake accounts to manipulate or increase follower counts. Social bots, in some cases, have some similarities with trolls. Both bots and trolls can be used to spread fake news and propaganda and influence public opinion. They are often designed to spread malicious software, create confusion and distraction, and manipulate social media discourse with rumors [
185]. They can infiltrate into a group of people and change their view of reality [
186]. Some notable examples are the role of social bots on the Brexit debate where they influenced users opinion about the election [
187] or the effect of social bots on Twitter during the 2016 U.S. election. Some studies claim that 64% to 79% of Donald Trump’s followers were fake. Such accounts made opinions appear more widespread [
188].
The effect of bots on health-related news can be really harmful. Bots can spread fake or misleading information about health topics and cures, which can lead to confusion and harm public health. During the COVID-19 pandemic, the majority of social bots were tweeting about COVID-19 [
189]. However, there is limited evidence regarding their stance on these topics. Some bots were spreading accurate up-to-date information about the pandemic and others were spreading misinformation, conspiracy theories, fake treatments, and rumors about the vaccine. It is shown that the activity level of social bots was consistent with that of human users [
190]. Nevertheless, in [
191], by utilizing a combination of machine learning and network science methods on a collection of tweets about the pandemic in the Philippines and the United States, the authors indicate a significant association between bot activity and increased levels of hate speech in both countries, particularly within densely populated and socially isolated communities. Additionally, they highlight the significance of adopting a global perspective in computational social science, especially in the midst of a worldwide pandemic and infodemic, which have universal yet unequal impacts on societies.
To detect bots, various techniques, similar to those used in troll detection, are employed [
189]. Profile metadata include account age and username, along with user activity, temporal patterns, and post content. Bots tend to retweet more frequently and have shorter time intervals between tweets. Additionally, network patterns, such as friend/follower connections, hashtag use, retweets, and mentions are used to identify social bots that exploit network homophily. Bot detection is getting harder as bots evolve and make it more difficult to distinguish them from human behavior [
186].
In [
192], the authors collected tweets and analyzed user activity by measuring the number of tweets, retweets, and replies. They also examined the types of software used to generate tweets (some users use Twitter clients, some others use cross-posting through other platforms, while commercial actors use marketing automation software). Finally, they developed a classifier that can identify social bots based on the user activity, which is measured as the sum of tweets, retweets, and replies posted by a user and visibility which is measured as the number of retweets and replies received by a user.
In [
171], the authors used two datasets, the COVID-19 dataset [
193] and a dataset with human accounts and three types of bots including a social spam bot, fake followers, and traditional Twitter spambots. This dataset consists of user features such as follower count, retweet count, reply count, number of shared URLs, etc. They used BERT to classify the origin posts into bot or not bot. They concluded that both bot and human accounts have very similar behavior in spreading fake or real news. Also, they observed that bots are not the primary source of fake news in the COVID-19 pandemic.
7. Datasets
In this section, we discuss publicly available datasets for fact-checking and fake news detection for the medical domain that could be helpful to researchers.
Table 8 lists 24 health-related fake news and fact-checking datasets that are publicly available. Most of these datasets were constructed from Twitter posts and user interactions that also exploit online news articles. The only exceptions are [
57,
194], which contain a collection of claims constructed from Reddit via r/coronavirus and submissions from various health-related subreddits correspondingly.
A crucial step in annotated datasets is how the annotation is conducted. There are two basic approaches to annotation, manual and automatic. In manual annotation, the annotation can be performed by experts of the domain [
11,
136,
195], which is an expensive and time-consuming process; by crowd-sourcing techniques like in [
194] or the highly moderated Reddit subreddits such as r/coronavirus that require sources of claims; and finally by the authors themselves using fact-checking services or a search engine [
25,
128,
196]. Regarding automatic approaches, some datasets have been annotated by using the inference capabilities of already-trained models [
6]. Other datasets have used DL retrieval models to manually annotate only a subset of the dataset, which includes the most relevant tweets to a misinformation target [
7]. Finally, the work in [
197] uses distant supervision, where a database or a KG is used to collect examples for the relations to be extracted. Then, based on these examples and whether they coexist in a sentence, the user post or news article can be annotated accordingly.
The performance of the various models and approaches proposed in the literature over these datasets spans across a variety of scores. For example, the F1 scores can range between 33 and 99%, reported in [
127] and [
193], respectively. This showcases the importance of the intrinsic properties of the datasets used for evaluation purposes (e.g., what sources they use, their size, how the dataset was labeled, etc.), and the task at hand (a binary or more refined classification like multiclass and multi-label classification).
Finally, most of the approaches introduce their own datasets, making the comparison between the various approaches difficult and inconsistent. As a result, the community involved in the domain of medical fake news detection needs a dataset that could be used as a benchmark for evaluation purposes.
Table 8.
Public datasets related to medical fact-checking, fake news detection, and social media (all websites accessed on 25 February 2025).
Table 8.
Public datasets related to medical fact-checking, fake news detection, and social media (all websites accessed on 25 February 2025).
| Work | Type | URL | Annotation | Characteristics |
|---|
| BioClaim [6] | -Biomedical claims
-Tweets | https://www.ims.uni-stuttgart.de/documents/ressourcen/korpora/bioclaim/WuehrlKlinger-Bioclaim2021.zip | Manual | A total of 1200 tweets of implicit and explicit biomedical claims (the latter also with span annotations for the claim phrase), including COVID-19, measles, cystic fibrosis, and depression |
| NewsClaims [44] | -COVID-19 claims
-News | https://github.com/blender-nlp/NewsClaims | Manual | A total of 889 claims annotated over 143 pieces of news, including claim sentences, claim objects, claim stances, claim span, and claimer detection |
| RedHOT [57] | -Health issue claims
-Reddit | https://github.com/sominw/redhot | Manual (crowd-sourced and experts) | A total of 22,000 posts from 24 medical condition subreddits, annotated as claims, personal experiences, and questions |
| PubHealth [55] | -Health issue claims
-Claims from fact-checking sites and news | https://github.com/neemakot/Health-Fact-Checking | Manual Automatic | A total of 27,578 fact-checked claims, 9023 claims from Associated Press and Reuters News, and 2700 claims from Health News Review. Labels are true, false, mixture, and unproven |
| HealthVer [56] | -Health issue claims
-Search engines snippets | https://github.com/sarrouti/HealthVer | Manual (authors) | A total of 14,330 evidence claim pairs, labeled as support, refute, and neutral |
| ANTi-Vax [198] | -COVID-19 vaccine misinformation
-Tweets | https://github.com/SakibShahriar95/ANTiVax | Manual (experts) | A total of 15 million COVID-19 vaccine-related tweets and 15 thousand labeled tweets for vaccine misinformation detection (binary classification) |
| CMU-MisCOV19 [195] | -COVID-19 vaccine misinformation
-Tweets | https://zenodo.org/record/4024154/files/CMU_MisCov19_dataset.csv.zip | Manual (authors) | A total of 4573 annotated tweets, comprising 3629 users. Labels are: irrelevant, conspiracy, true treatment, true prevention, fake cure, fake treatment, false fact or prevention, correction/calling out, sarcasm/satire, true public health, response, false public health response, politics, ambiguous/difficult to classify, commercial activity or promotion, emergency response, news, panic buying |
| ReCOVery [196] | -Spread of fake news
-News, tweets | https://github.com/apurvamulay/ReCOVery | Distant supervision | A total of 2029 news articles on coronavirus are finally collected in the repository along with 140,820 tweets, news content, and social information revealing how it spreads on social media, which covers textual, visual, temporal, and network information |
| Mega-COV [197] | -Large diverse, longitudinal, and multi-lingual COVID-19
-Tweets | https://github.com/UBC-NLP/megacov | None | The dataset is diverse (covers 268 countries), longitudinal (goes as far back as 2007), multilingual (comes in 100+ languages), and has a significant number of location-tagged tweets (≈169 M tweets) |
| CoAID [193] | -COVID-19 healthcare misinformation dataset
-News, media posts | https://github.com/cuilimeng/CoAID | None | It includes 5216 pieces of news, 296,752 related user engagements, 958 social platform posts about COVID-19, and ground truth labels |
| COVID-Fact [53] | -Claims concerning the COVID-19 pandemic from Reddit
-Claims | https://github.com/asaakyan/covidfact | Manual (crowd-sourced)
Automatic filtering for true claims and refuted claims | The COVID-Fact dataset contains 4086 real-world claims with the corresponding evidence documents and evidence sentences to support or refute the claims. There are 1296 supported claims and 2790 automatically generated refuted claims |
| FakeCovid [199] | -Multilingual cross-domain dataset for COVID-19
-News | https://github.com/Gautamshahi/FakeCovid | Manual (authors) | A total of 5182 fact-checked news articles for COVID-19, collected from 4 January 2020 to 15 May 2020. Articles annotated into 11 different categories |
| COVID19 Fake News Detection [200] | -Real and fake news on COVID-19
-Media posts, articles | https://github.com/parthpatwa/covid19-fake-news-detection | Manual (authors) | A total of 10,700 social media posts and articles |
| COVIDLIES [201] | -COVID-19-related misinformation
-Tweets | https://github.com/ucinlp/covid19-data | Manual (experts) | A total of 86 misconceptions and 6761 annotated tweet–misconception pairs |
| CoVaxLies [115] | -COVID-19 vaccines
-Tweets | https://github.com/Supermaxman/covid19-vaccine-twitter | Manual (experts) | A total of 7246 tweets paired with misinformation targets (MisTs) and stances |
| VaccineLies [7] | -COVID-19 and HPV vaccines
-Tweets | https://github.com/Supermaxman/vaccine-lies | Manual (experts) Automatic | A total of 14,642 tweets paired with misinformation targets (MisTs) and stances (a superset of CoVaxLies) |
| FakeHealth [117] | -Real and fake health stories and release
-News, tweet engagements | https://github.com/EnyanDai/FakeHealth | Manual (experts) | A total of 1690 stories (1218 real and 472 fake) and 606 releases (315 real and 291 fake) from HealthNewsReview.org; both news stories and news releases are evaluated by experts on 10 criteria. Ratings from 0 to 5 |
| COVID-19 Fake News Sentiment [124] | -COVID-19
-News | https://github.com/susanli2016/NLP-with-Python/blob/master/data/corona_fake.csv | Manual (authors) | Dataset consists of 586 true pieces of news and 578 fake pieces of news, and more than 1100 news articles and social media posts regarding COVID-19. The true news was gathered from Harvard Health Publishing, WHO, CDC, The New York Times, and so on. Fake news was gathered from social media (Facebook) posts and other medical sites |
| COVID-19 Disinformation [202] | -COVID-19
-Tweets | https://github.com/firojalam/COVID-19-disinformation | Manual (authors) | Annotated dataset of 16K tweets related to the COVID-19 infodemic in four languages (Arabic, Bulgarian, Dutch, and English), using a schema that combines the perspective of journalists, fact-checkers, social media platforms, policymakers, and society |
| MMCoVaR [203] | -COVID-19 vaccine
-News, tweets | https://drive.google.com/drive/folders/1LGfD0mdup7va_SME0sncg-h3ADoCZyEZ?usp=sharing (must request access) | Automatic | Multimodal dataset, 2593 articles annotated as reliable or non-reliable, and 24,184 Twitter posts |
| Covid-HeRA [127] | -COVID-19
-Tweets | https://github.com/TIMAN-group/covid19_misinformation | Automatic for binary
Manual (authors) for multiclass | A total of 62,286 tweets labeled as real news, possibly severe, highly severe, other, and refutes/rebuts (a subset of CoAID) |
| CoVaxNet [204] | -COVID-19 vaccine
-Tweets, fact-checked data, news (offline like local news), statistics | https://github.com/jiangbohan/CoVaxNet | Manual Automatic | A multi-source, multimodal, and multi-feature online and offline data repository. It contains 1,495,991 pro-vaccine and 335,229 anti-vaccine reports (labeled using keywords and hashtags) and 4263 COVID-19 vaccine-related fact-checking reports |
| WICO [205] | -COVID-19 and 5G
-Tweets | https://datasets.simula.no/wico-graph | Manual (authors) | Subgraphs of 3000 tweets that propagate 5G COVID-19 misinformation, other conspiracy theories, and tweets that do neither |
| MM-COVID [206] | -COVID-19
-News | https://github.com/bigheiniu/X-COVID | Manual | A total of 3981 fake and 7192 trustworthy multi-language and multimodal news, including temporal information |
8. Mitigation
Fake news and misinformation shared on social media can be very effective in shaping the opinions and beliefs of people. Medical fake news, in particular, is a serious danger to public health, as the spread of false information and lack of knowledge of the truth can put patients at risk. The proliferation of medical fake news can cause individuals to adopt dangerous health practices or avoid proven, life-saving medical treatments. As such, it is imperative that the spread of medical fake news on social media is effectively mitigated using robust solutions that can limit its impact on public health. The issue of mitigating fake news has garnered attention from researchers across various fields, including the social sciences and psychology. However, in this survey, we will only describe the technical approaches developed in the field of computer science.
One category of mitigation methods revolves around the user perspective, leveraging the diverse roles and positions users can have in the dissemination of fake news. Some users hold significant influence as opinion leaders and have a wide circle of followers while others act as correctors and contribute to fake news posts by attaching links and comments that counter the false information with facts and evidence [
14].
Other approaches involve the identification of sources that create and disseminate disinformation, which are afterward prevented from contaminating social media platforms, as described in
Section 6. Such approaches are characterized by their proactive nature and can be included in the early fake news detection methods as they aim to identify users who are at risk of engaging with fake news or have previously engaged with it and may do so again in the future. These techniques utilize content-based methods, like the ones described in
Section 4, to analyze the language and content patterns of news articles in the user history and their personal information. Through the application of these techniques, it becomes feasible to identify and remove fake users or restrict their movements on social media platforms. An important aspect of these techniques is the identification of influential spreaders. When blocking fake news in a social network, targeting these influential spreaders can lead to a more efficient intervention compared to those with insignificant social influence on others [
207].
The bot detection techniques described in
Section 6 also belong to this category. These methods focus on identifying and removing fake users that are designed to mimic human behavior and disseminate misinformation by detecting patterns of bot behavior, such as repeated postings of similar content or engagement with other bots. Once detected, these fake users can be removed from social media platforms, limiting their ability to spread false information [
171,
186,
192].
Also, the work in [
208] presents an innovative approach to effectively mitigate the problem of online misinformation. This study delves into the role of the “guardian”, online users who actively combat misinformation and fake news during online discussions by providing fact-checking URLs. The authors also introduce a novel fact-checking URL recommendation model, designed to motivate and empower guardians to engage even more actively in fact-checking activities.
Intervening based on network structure involves stopping the spread of fake news by blocking its propagation paths [
207]. This approach relies on analyzing the network structure of how fake news spreads and predicting how it will continue to spread. By identifying the key nodes in the network through which the fake news is likely to spread, these nodes can be blocked in order to prevent the spread of misinformation. These approaches employ diverse models, such as the Independent Cascade (IC) [
209,
210,
211] and Linear Threshold (LT) [
212,
213] models, to model the diffusion of information in the network. Also, network structural and temporal features are used in order to detect the propagation of fake news and slow it down.
Another approach to limit the propagation of fake news on social media aims to identify the smallest possible set of users in the network whose immunization can effectively diminish the spread of misinformation [
214]. To find these nodes, various methods and techniques are utilized in graphs. One such technique is the greedy method, which proceeds iteratively, selecting the best node that minimizes the network influence each time until the desired number of nodes is reached. Other techniques rely on heuristic methods. Additionally, measures such as centrality measures can be employed to estimate the magnitude of influence that a node has on other nodes in the network, which can help in identifying nodes with the highest influence to be immunized.
Detecting and monitoring communities in social networks is also crucial in identifying the ones where fake news is frequently shared and has the potential to spread beyond the community. In [
215], researchers developed a method to measure the influence of nodes within a community and calculate the probability of rumors spreading between them. They also suggested an algorithm that employs a dynamic blocking strategy to minimize the impact of rumors.
Some other network approaches focus on mitigating fake news by promoting real news by either targeting users who have already been exposed to false news or by strategically selecting initial users to disseminate true news in competition with false news. An example is the decontamination method described in [
216], which targets contaminated users (i.e., users who have been exposed to false news) for decontamination. The contaminated users are identified using greedy algorithms while the IC and LC models are used for the diffusion process. The process of selecting seed users continues until the expected objective of decontaminating a
-fraction of the contaminated users is reached. Another approach named the Competing Cascades method [
207] involves selecting
k seed users who will propagate the true news cascade. The objective is to maximize the influence of the true news cascade while minimizing the influence of the fake news cascade. The users who are exposed to both articles may be more likely to believe the true news article if it is shared by a trusted source or if it provides compelling evidence.
9. Current State of Popular Social Platforms in Combating Misinformation
Below, we discuss the strategies adopted by various social media platforms to address misinformation. While the exact details of their algorithms remain undisclosed, these measures indicate the general direction taken to mitigate the spread of fake news.
Since 2016, social media platforms have taken steps to curb the spread of misinformation, particularly after concerns that Facebook and Reddit may have influenced the outcome of the 2016 U.S. presidential election. In response to criticism, Facebook partnered with fact-checking organizations such as FactCheck.org, Snopes, and Politifact to verify content and limit the reach of false information [
217]. False information is ranked lower in the feed, while Facebook takes action against repeat offenders by reducing the distribution of false information and their ability to advertise. To further combat misinformation, Facebook deploys algorithms to find copies of misinformation with small differences and to identify whether a post contains claims that are commonly identified as misinformation by many fact-checkers. Users of the platform will be notified with more information over false information, while people who shared it will also be notified. Additionally, tools to identify posts that contain misinformation but for notifying fact-checkers if content that contains misinformation has been corrected or rated erroneously are also provided.
In 2020, Facebook enhanced its efforts by deploying AI-driven tools [
218] to detect and prevent misinformation at scale. Technologies like SimSearchNet++ enabled highly precise image matching, allowing the system to identify variations of known false content across Facebook and Instagram platforms. Additionally, Meta (Facebook was renamed to Meta in 2021) collaborated with 60 fact-checking organizations covering over 50 languages from around 130 countries to monitor COVID-19 misinformation [
219], using AI to detect and limit the spread of flagged content. By 2022, Meta continued leveraging AI for fact-checking, particularly to improve the accuracy of Wikipedia entries [
220] by maintaining and improving the quality of Wikipedia references through verifying the cited references.
Regarding Reddit and COVID-19, there was a notable movement named “going dark”, where various Reddit communities became inaccessible to outsiders as a protest toward COVID-19 skeptic Reddit communities (subreddits) [
221] that were spreading misinformation. As a response, Reddit banned those subreddits (e.g., r/NoNewNormal) and started to collaborate with third-party fact-checking organizations. In addition, Reddit employs a multi-layered moderation system that combines community-driven moderation with automated tools. Individual subreddits set their own rules, enforced by volunteer moderators, who flag misinformation using labels. The platform also uses automated tools to proactively detect content and behaviors that violate its policies, although the specifics of these tools remain undisclosed [
222]. Research has highlighted the effectiveness of Reddit’s community-based moderation approach in controlling misinformation [
223].
Regarding Twitter (Twitter was renamed to X in 2023), in 2020, it implemented content-monitoring systems to detect and label misleading information related to COVID-19, ensuring that such content was not amplified. The platform categorized misinformation into three types: misleading information, which was confirmed false by experts; disputed claims, where accuracy was contested; and unverified claims, which lacked confirmation at the time of sharing [
224]. In 2021, Twitter introduced Birdwatch, a community-driven initiative allowing users to identify and provide context for misleading tweets [
225]. Later that year, Twitter collaborated with Reuters and The Associated Press to improve information accuracy, with its Curation team sourcing reliable context for trending conversations [
226]. Currently, X employs community notes, enabling users to collaboratively add clarifications and context to tweets as a way to timely identify and reduce the propagation of fake news. Community notes have been extensively researched by the scientific community with mostly positive results [
227,
228,
229,
230,
231,
232,
233]. However, at least one study mentions that the community notes on X were often added to problematic posts too late to reduce engagement, because they came after false claims had already spread widely [
234].
Governments, particularly the European Union (EU), have pressured platforms to moderate misinformation. The EU Code of Practice on Disinformation [
235] is a voluntary framework aimed at combating disinformation by promoting fact-checking and transparency among online platforms. It has 48 signatories, including major platforms like Google, Meta, Microsoft, and TikTok, as well as fact-checking and civil society organizations. The Code is set to become a co-regulatory instrument under the Digital Services Act (DSA) by July 2025 [
236], following a formal assessment by the European Commission and the European Board for Digital Services. Signatories report their progress through a Transparency Center, and monitoring ensures the implementation of commitments, though platforms can opt out of specific measures if deemed irrelevant.
However, some platforms have retreated from their commitments [
237]:
X withdrew entirely in May 2023.
Meta announced in January 2025 it would stop third-party fact-checking for US users, citing a shift toward “restoring free speech” and updating its content-moderation policies.
Google rejected fact-checking commitments, arguing its existing moderation is sufficient, and instead allows users to add contextual notes to YouTube videos.
LinkedIn opted out, claiming the commitment did not align with its risk profile.
TikTok expressed willingness to commit but only if other platforms did the same.
Currently, the trend toward crowdsourced fact-checking is growing, with platforms like X and Google enabling users to add context to posts and videos. Meta is also exploring similar community-based systems, such as community notes, to replace third-party fact-checking in the US. These changes have sparked concerns from organizations like the European Fact-Checking Standards Network and Reporters Without Borders, who worry about the impact on misinformation and free speech. Meta’s shift includes reintroducing political content recommendations and relaxing restrictions on sensitive topics, raising further debate about its implications for online discourse.
It is also important to note that platforms like Twitter and Reddit have historically provided valuable data for research. However, recent changes have placed their APIs behind a paywall, significantly restricting access and impacting numerous research projects.
10. Discussion and Future Work
Fact-checking, especially in the rapidly evolving domain of medical misinformation, involves a delicate balance between speed, accuracy, and scalability. Manual fact-checking benefits from human expertise, the understanding of details, and higher accuracy, especially for complex or nuanced claims. However, it is time-consuming, expensive, and prone to bias, as human fact-checkers may unintentionally or intentionally introduce personal biases that affect the outcomes [
13,
15]. In contrast, automated fact-checking offers speed, scalability, and consistency, as it can quickly process large volumes of data and maintain a uniform approach in evaluating facts, free from human biases. Once developed, automated systems require fewer resources compared to the large teams needed for manual fact-checking. However, they often struggle with understanding nuanced contexts, sarcasm, or cultural references, and can produce false positives or negatives, especially when the algorithm is poorly trained or when claims require expert analysis. Moreover, different automated fact-checking methods come with their own strengths and limitations. Content-based methods analyze textual or visual elements to detect misinformation, offering independence from external metadata but struggling with subtle contextual manipulation and requiring extensive labeled data. Propagation-based methods leverage the spread patterns of information, making them effective against coordinated disinformation campaigns, yet they rely on large-scale social network data. Source-based methods assess the credibility of information sources, providing an efficient way to filter unreliable content but facing challenges when dealing with new or not widely recognized sources.
In recent years, research advances in addressing misinformation, and specifically health misinformation, were expedited due to the COVID-19 pandemic. However, there are still several open issues and major challenges in the domain of medical misinformation, including the following areas [
18]: (a) the identification of dominant health misinformation trends and their prevalence across different social platforms, (b) the mechanisms that allow the spread of health misinformation, (c) their impact on the development and reproduction of unhealthy and dangerous behaviors, and finally, (d) the development of strategies for fighting and reducing the negative impact of misinformation without reducing the inherent communicative potential to propagate health information. Addressing the various open problems in these areas requires the collaboration of
cross-discipline researchers, policymakers, and technology experts.
One challenge specific to the medical domain is the
inherent uncertainty of medical scientific knowledge and the fact that scientific knowledge
evolves over time [
238]. Medical facts are usually accompanied by probabilities and risk factors that may differ based on population demographics. Furthermore, medical knowledge evolves over time as new discoveries are made. This uncertainty poses additional challenges in communicating medical information to the public and provides a fertile ground for misinformation to grow. Uncertainty and temporality should be accounted for when designing approaches for fact-checking and misinformation detection or mitigation.
Another challenge is the fact that the approaches used for fake news fabrication and propagation in social media and networks are constantly improving. Aiming at accurately imitating the characteristics and features of valid news as closely as possible, the deployed strategies are becoming more complex and refined. The recent advancements in large language models (LLMs), which can be trained to follow the style and form of valid news will only complicate the problem [
239]. Consequently, the assumption that fake news has distinct characteristics that separate it from valid news weakens, as producers and promoters of fake news deploy more advanced techniques. There are similar challenges for propagation-based methods where bots can be adapted to imitate the structural, temporal, and propagation patterns of valid news propagation networks. However, faithfully reproducing human behavior is more complex, so these features can still preserve some of their discriminatory power.
An important future research direction for addressing this challenge is to incorporate available authoritative ground truth knowledge and apply symbolic logic in fake news detection. Specifically for the medical domain, hybrid approaches are needed that combine the constantly evolving machine learning approaches for detection, with the slower-evolving but high-quality and validated information stored in domain-specific knowledge bases. Such information usually originates from authoritative academic research and can be exploited by logic rules and reasoning. The fusion of the statistical learning capabilities of the deep neural networks with strict logic reasoning approaches and rules (e.g., [
240]) will lead to a representation learning system with a joint learning mechanism that will achieve joint inference and will enforce complicated correlations and constraints in the output space.
Regarding the focus of research on medical fake news, most work targets fake news detection. However, detection needs to be combined with mitigation approaches, which act as gatekeepers of misinformation propagation. Greater research emphasis is needed on the development, refinement, and real-world evaluation of such mitigation approaches.
In the same direction, the research community should work toward preemptive approaches that provide valid and fact-checked information, personalized to the current interests of users. The goal is to proactively inform a user about the facts of a misinformation-infested topic, which could potentially attract the attention of the user in the near future. This way, the user will have a critical and well-informed view if and when exposed to this misinformation. Furthermore, inoculated users will act as deterrents to the propagation and spread of misinformation in the social network.
The deployment of automated approaches, particularly in the sensitive domain of healthcare, raises significant ethical considerations. Since these tools rely on vast amounts of user data to detect and mitigate misinformation, they can infringe on individual privacy if not handled transparently and responsibly. Additionally, the risk of legitimate content being mistakenly flagged or suppressed poses a threat to freedom of speech and the potential for censorship. To address these challenges, using anonymized data when possible along with eXplainable AI (XAI) [
241] plays a crucial role in increasing public trust. By making the algorithms transparent and interpretable, XAI can help users understand why certain content is flagged, fostering accountability and reducing skepticism. However, balancing misinformation mitigation with freedom of speech remains a delicate task, and algorithms must be designed to prioritize fairness and transparency, ensuring that they do not disproportionately target specific viewpoints or communities. As a result, we advocate that there is a pressing need for approaches that provide transparency and integrate explainability and fairness guarantees to build a relationship of trust between the producers, the consumers, and the gatekeepers of the information flow (i.e., the social media platforms). The goal should be the creation of a healthy ecosystem around grounded information that does not hinder freedom of speech, democratic values, diversity, and exploration.
Finally, an important finding of this work is that there is not a single specific dataset in the domain of medical fake news that can be used as a benchmark. Most of the described approaches introduce their own customized datasets, making the comparison of the proposed methods difficult. Moreover, the quality of the gathered data and their annotation varies and is sometimes questionable. The research community should focus on collaboratively creating a reference dataset for the task of fake news detection in the medical domain. This dataset should incorporate rich data gathered from social media and the web and should satisfy the requirements of content-based, propagation-based, and source-based misinformation detection methods. The dataset should cover a broad range of medical topics, beyond COVID-19, such as smoking, drugs, diets, and self-treatment-related content. Finally, the important work of annotating the dataset with labels should be conducted by experts, incorporating data from authoritative expert-based manual fact-checking services.
11. Conclusions
Understanding, assessing, and countering health misinformation promises to empower healthcare providers and policymakers, safeguard the public trust in medical information science, enhance and promote health literacy, and ultimately contribute to improved health outcomes. While ongoing collaboration between researchers, policymakers, and healthcare providers is essential, technology offers the means to more objectively and reliably address misinformation.
In this comprehensive survey, we shed light on the pervasive issue of health misinformation online, with an emphasis on the COVID-19 pandemic. We provide an overview of the domain and examine notable instances of medical fake news and its consequences, highlighting the importance of addressing this critical challenge. We also provide an extensive analysis of manual and automatic methods for fact-checking, along with content, propagation, and source-based techniques for fake news detection and automated methods for misinformation mitigation. Moreover, we present existing publicly available datasets specifically tailored to fact-checking and fake news detection in the medical domain, and we detail a collection of well-known fact-checking tools. These resources serve as a foundation for further research and development in the field, enabling researchers and practitioners to refine and enhance the effectiveness of their approaches.
While significant progress has been made, it is crucial to acknowledge that the battle against health misinformation is an ongoing endeavor. Future directions include the integration of machine learning and natural language advancements, the more extensive deployment and exploitation of knowledge graphs, the exploration of novel detection techniques, the development of comprehensive curated datasets that can act as benchmarks, and the further development and refinement of mitigation and preemptive approaches.


 ,
, 

{kind=link}