

A Novel TLS-Based Fingerprinting Approach That Combines Feature Expansion and Similarity Mapping


Abstract
1. Introduction
- We conducted a critical literature review, evaluating active scanning techniques that can be used to generate server fingerprints.
- We applied the information gathered in the literature review to the design and development of an active scanning fingerprint that increases the granularity of current techniques, improving the ability to detect malicious domains hosted on CDNs where feature similarity is high.
- We enhanced the applicability and security of fingerprinting by introducing a suitable similarity-mapping approach, making it difficult to subvert hash-based fingerprints with minuscule adjustments or manipulations.
- We critically evaluated the results and findings from the practical experiments.
2. Related Work
2.1. Active Fingerprinting
2.2. TLS Fingerprinting and the CDN Problem
2.3. TLS Fingerprint Enrichment
3. Methodology
3.1. Data Acquisition
3.2. Tooling
3.3. Process Flow
3.4. Active Scanning
3.5. Fingerprint Post-Processing
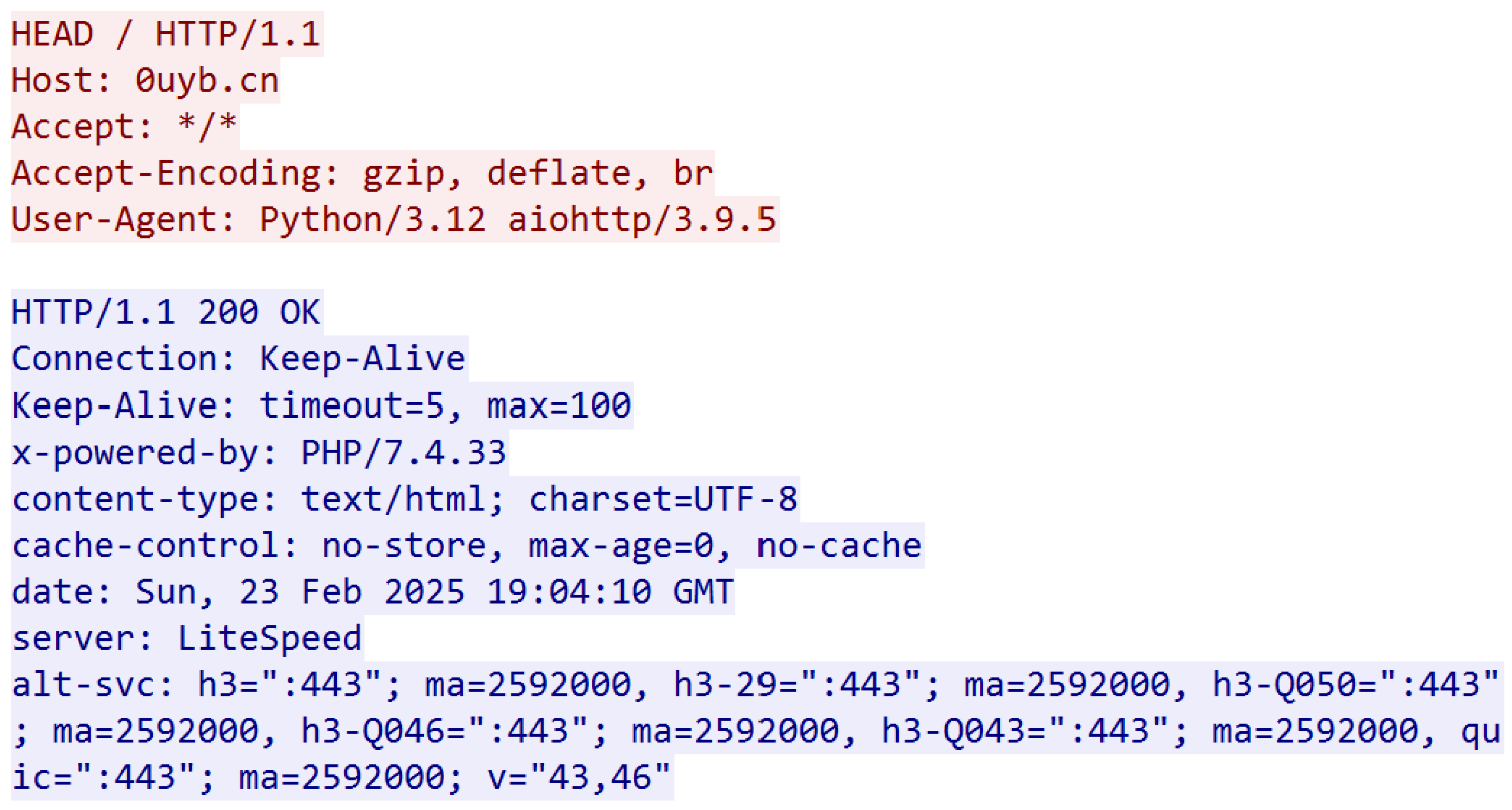
3.6. HTTP Header Enrichment
3.7. Feature Vector Generation
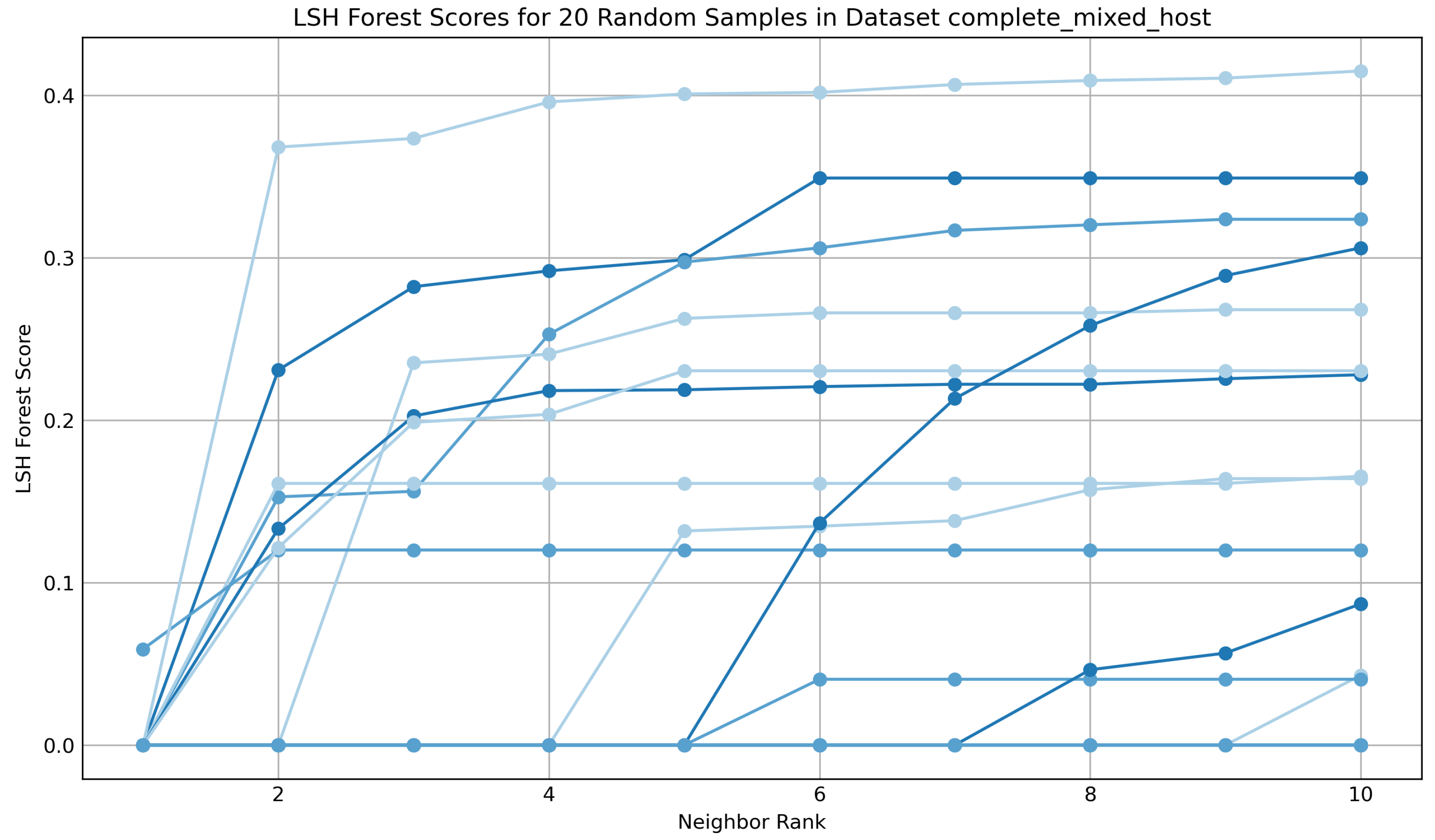
3.8. Similarity Mapping
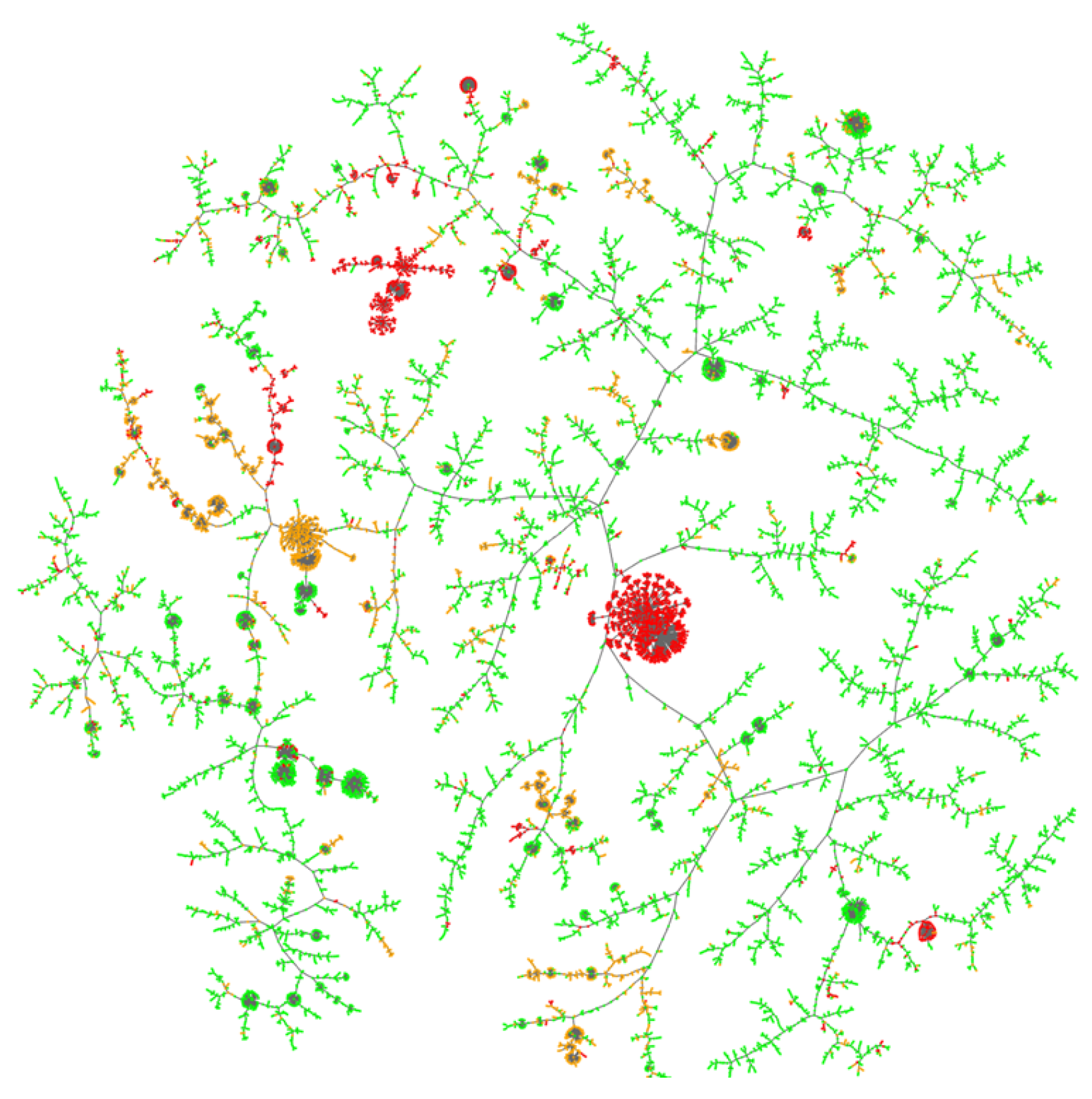
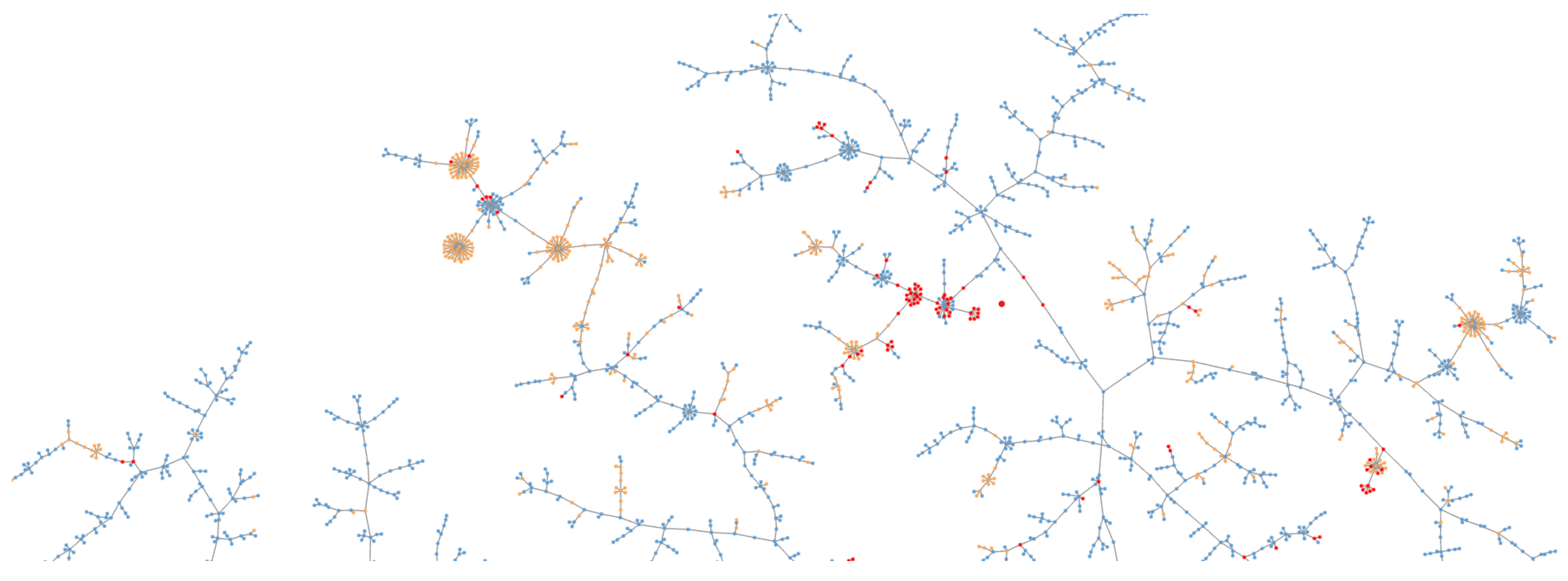
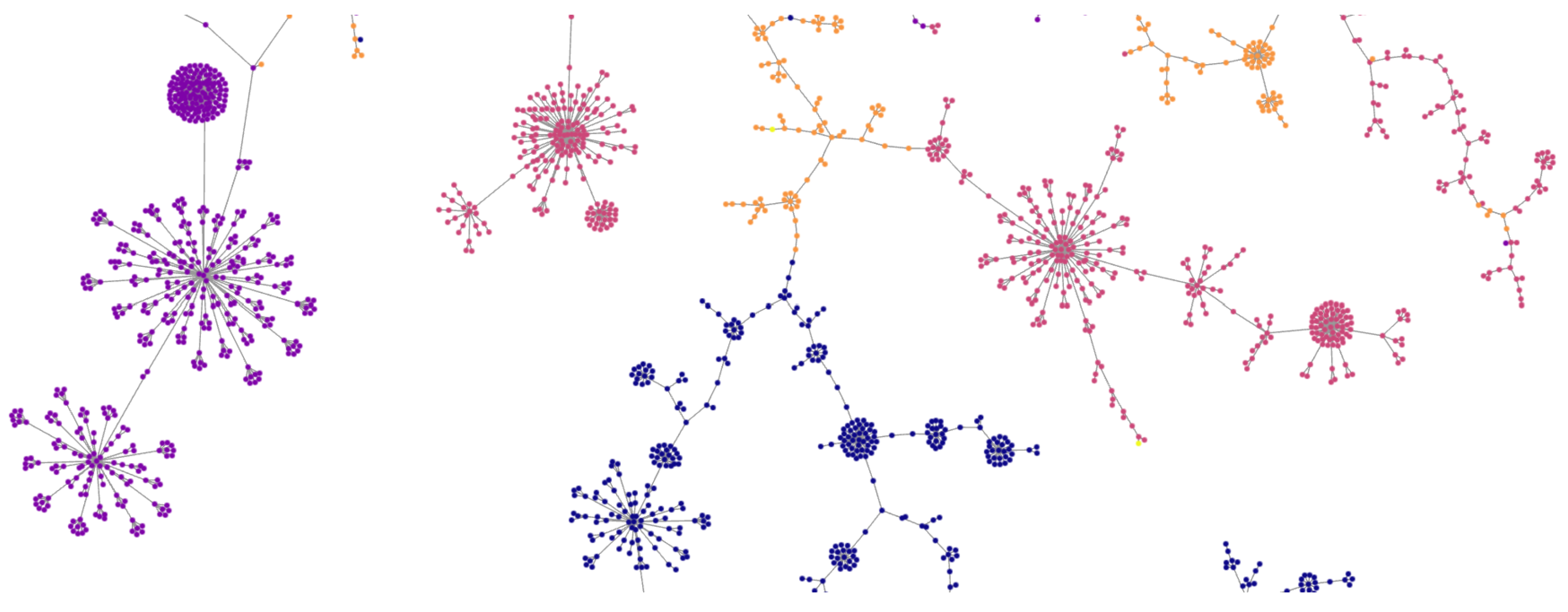
3.9. Similarity Visualisation with Tree MAP
Similarity Resilience
4. Evaluation
4.1. Granularity Comparisons
4.2. Evaluation of Similarity
4.3. Visualisation of the Datasets
4.3.1. Initial Verification Through Security Platforms
4.3.2. Further Indication Analysis
4.3.3. Dataset A—Mixed Host
4.3.4. Dataset B—Cloudflare CDN
4.4. Data Set C—Malicious
5. Discussion
6. Conclusions
Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Internet Organised Crime Threat Assessment (IOCTA) 2024. 2024. Available online: https://www.europol.europa.eu/publication-events/main-reports/internet-organised-crime-threat-assessment-iocta-2024 (accessed on 2 February 2025).
- Begou, N.; Vinoy, J.; Duda, A.; Korczyński, M. Exploring the Dark Side of AI: Advanced Phishing Attack Design and Deployment Using ChatGPT. In Proceedings of the 2023 IEEE Conference on Communications and Network Security (CNS), Orlando, FL, USA, 2–5 October 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Rescorla, E. The Transport Layer Security (TLS) Protocol Version 1.3; Request for Comments; Internet Engineering Task Force: Bangkok, Thailand, 2018; p. 160. [Google Scholar] [CrossRef]
- Warburton, D. The 2021 TLS Telemetry Report. Available online: https://www.f5.com/labs/articles/threat-intelligence/the-2021-tls-telemetry-report (accessed on 1 August 2024).
- Oh, C.; Ha, J.; Roh, H. A Survey on TLS-Encrypted Malware Network Traffic Analysis Applicable to Security Operations Centers. Appl. Sci. 2022, 12, 155. [Google Scholar] [CrossRef]
- Shamsimukhametov, D.; Kurapov, A.; Liubogoshchev, M.; Khorov, E. Is Encrypted ClientHello a Challenge for Traffic Classification? IEEE Access 2022, 10, 77883–77897. [Google Scholar] [CrossRef]
- Sosnowski, M.; Zirngibl, J.; Sattler, P.; Carle, G.; Grohnfeldt, C.; Russo, M.; Sgandurra, D. Active TLS Stack Fingerprinting: Characterizing TLS Server Deployments at Scale. In Proceedings of the Network Traffic Measurement and Analysis Conference (TMA), Enschede, The Netherlands, 27–30 June 2022. [Google Scholar]
- Althouse, J.; Smart, A.; Nunnally, R.; Brady, M. Easily Identify Malicious Servers on the Internet with JARM. 2020. Available online: https://engineering.salesforce.com/easily-identify-malicious-servers-on-the-internet-with-jarm-e095edac525a/ (accessed on 8 July 2024).
- Papadogiannaki, E.; Ioannidis, S. Pump up the JARM: Studying the Evolution of Botnets Using Active TLS Fingerprinting. In Proceedings of the 2023 IEEE Symposium on Computers and Communications (ISCC), Tunis, Tunisia, 9–12 July 2023; pp. 764–770, ISSN 2642-7389. [Google Scholar] [CrossRef]
- Matoušek, P.; Burgetová, I.; Ryšavý, O.; Victor, M. On Reliability of JA3 Hashes for Fingerprinting Mobile Applications. In Proceedings of the Digital Forensics and Cyber Crime: 11th EAI International Conference, ICDF2C 2020, Boston, MA, USA, 15–16 October 2020; Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering. Goel, S., Gladyshev, P., Johnson, D., Pourzandi, M., Majumdar, S., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 1–22. [Google Scholar]
- Van Der Mandele, A.; Ghendini, A.; Wood, C.; Mehra, R. Encrypted Client Hello—The Last Puzzle Piece to Privacy. 2023. Available online: https://blog.cloudflare.com/announcing-encrypted-client-hello/ (accessed on 8 July 2024).
- Bhandari, H.; Viggiano, J. The 2022 Web Almanac: CDN; Technical Report, HTTP Archive; 2022; Volume 4, Available online: https://almanac.httparchive.org/en/2022/cdn (accessed on 8 July 2024).
- Siby, S.; Barman, L.; Wood, C.; Fayed, M.; Sullivan, N.; Troncoso, C. Evaluating practical QUIC website fingerprinting defenses for the masses. Proc. Priv. Enhancing Technol. 2023, 4, 79–95. [Google Scholar] [CrossRef]
- Tang, Z.; Wang, Q.; Li, W.; Bao, H.; Liu, F.; Wang, W. HSLF: HTTP Header Sequence Based LSH Fingerprints for Application Traffic Classification. In Proceedings of the Computational Science—ICCS 2021, Kraków, Poland, 16–18 June 2021; Paszynski, M., Kranzlmüller, D., Krzhizhanovskaya, V.V., Dongarra, J.J., Sloot, P.M.A., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 41–54. [Google Scholar]
- McGahagan, J.; Bhansali, D.; Gratian, M.; Cukier, M. A Comprehensive Evaluation of HTTP Header Features for Detecting Malicious Websites. In Proceedings of the 2019 15th European Dependable Computing Conference (EDCC), Naples, Italy, 17–20 September 2019; pp. 75–82. [Google Scholar] [CrossRef]
- Al-Hakimi, S.; Bax, F. Hunting for Malicious Infrastructure Using Big Data. SNE Master Research Projects 2020–2021, University of Amsterdam. Available online: https://rp.os3.nl/2020-2021/p54/report.pdf (accessed on 12 August 2024).
- Bortolameotti, R.; van Ede, T.; Continella, A.; Hupperich, T.; Everts, M.H.; Rafati, R.; Jonker, W.; Hartel, P.; Peter, A. HeadPrint: Detecting anomalous communications through header-based application fingerprinting. In Proceedings of the 35th Annual ACM Symposium on Applied Computing, New York, NY, USA, 30 March–3 April 2020; SAC ’20. pp. 1696–1705. [Google Scholar] [CrossRef]
- Pochat, V.L.; Van Goethem, T.; Tajalizadehkhoob, S.; Korczyński, M.; Joosen, W. Tranco: A Research-Oriented Top Sites Ranking Hardened Against Manipulation. In Proceedings of the 2019 Network and Distributed System Security Symposium, San Diego, CA, USA, 24–27 February 2019. [Google Scholar]
- Deniz, F.; Nabeel, M.; Yu, T.; Khalil, I.M. MANTIS: Detection of Zero-Day Malicious Domains Leveraging Low Reputed Hosting Infrastructure. arXiv 2025, arXiv:2502.09788. [Google Scholar]
- Tilborghs, S. Flagging 13 Million Malicious Domains in 1 Month with Newly Observed Domains. Akamai Secur. Res. 2022, 28. [Google Scholar]
- URLhaus. Malware URL Exchange. Available online: https://urlhaus.abuse.ch/ (accessed on 1 August 2024).
- Hunt.io. Proactive Infrastructure Hunting. Available online: https://hunt.io/ (accessed on 1 August 2024).
- Cert.pl. Research and Academic Computer Network. Available online: https://hole.cert.pl/domains (accessed on 1 August 2024).
- OpenPhish.io. Actionable Intelligence Data on Active Phishing Threats. Available online: https://www.openphish.com/ (accessed on 1 August 2024).
- Shreshtait. Stop Internet Threats such as Phishing, Ransomware, DGA, Botnets Real-Time. Available online: https://shreshtait.com/blog/2024/02/recently-registered-domains-download/ (accessed on 1 August 2024).
- Blechschmidt. A High-Performance DNS Stub Resolver for Bulk Lookups and Reconnaissance. Available online: https://github.com/blechschmidt/massdns (accessed on 1 August 2024).
- Sosnowski, M.; Zirngibl, J.; Sattler, P.; Carle, G.; Grohnfeldt, C.; Russo, M.; Sgandurra, D. EFACTLS: Effective Active TLS Fingerprinting for Large-scale Server Deployment Characterization. IEEE Trans. Netw. Serv. Manag. 2024, 21, 2582–2595. [Google Scholar] [CrossRef]
- Broder, A. On the resemblance and containment of documents. In Proceedings of the Compression and Complexity of SEQUENCES 1997 (Cat. No.97TB100171), Salerno, Italy, 13 June 1997; IEEE: New York, NY, USA, 1997; pp. 21–29. [Google Scholar] [CrossRef]
- Broder, A.Z.; Charikar, M.; Frieze, A.M.; Mitzenmacher, M. Min-Wise Independent Permutations. J. Comput. Syst. Sci. 2000, 60, 630–659. [Google Scholar] [CrossRef]
- Probst, D.; Reymond, J.L. Visualization of very large high-dimensional datasets as minimum spanning trees. J. Cheminformat. 2020, 12, 12. [Google Scholar] [CrossRef] [PubMed]
- Bullock, M.; Lechowski, M.; Mehra, R. New Standards for a Faster and More Private Internet. 2024. Available online: https://blog.cloudflare.com/new-standards/#encrypted-client-hello-ech (accessed on 3 February 2025).
- Anderson, B.; Paul, S.; McGrew, D.A. Deciphering Malware’s use of TLS (without Decryption). arXiv 2016, arXiv:1607.01639. [Google Scholar] [CrossRef]
- URLQuery. Website Malware Analysis and Malicious Content Detection. Available online: https://urlquery.net (accessed on 28 July 2024).

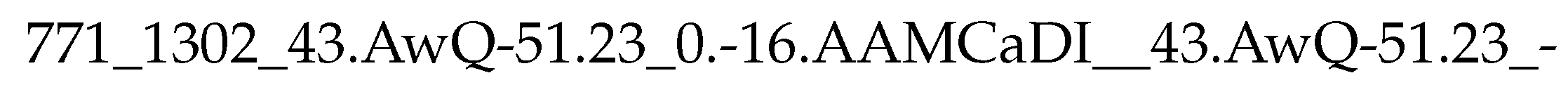







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Extension | JARM | Active TLS |
|---|---|---|---|
| 1 | max_fragment_length | ||
| 7 | client_authentication | ||
| 8 | server_authentication | ||
| 9 | cert_type | ||
| 10 | supported_groups | ||
| 11 | ec_point_formats | ||
| 13 | signature_algorithms | ||
| 15 | heartbeat | ||
| 16 | application_layer_protocol_negotiation | ||
| 19 | client_certificate_type | ||
| 20 | server_certificate_type | ||
| 23 | extended_master_secret | ||
| 24 | token_binding | ||
| 27 | compress_certificate | ||
| 28 | record_size_limit | ||
| 35 | session_ticket | ||
| 43 | supported_versions | ||
| 45 | psk_key_exchange_modes | ||
| 47 | certificate_authorities | ||
| 50 | signature_algorithms_cert | ||
| 51 | key_share (only selected group) | ||
| 65281 | renegotiation_info |
| Dataset | Location | Category |
|---|---|---|
| Tranco LJNY4 [18] | https://tranco-list.eu access on 2 March 2025 | Good |
| UrlHaus [21] | https://urlhaus.abuse.ch access on 2 March 2025 | Bad |
| Hunt.io [22] | https://hunt.io access on 2 March 2025 | Bad |
| Cert.pl [23] | https://hole.cert.pl access on 2 March 2025 | Bad |
| OpenPhish [24] | https://openphish.com access on 2 March 2025 | Bad |
| Shreshtait [25] | https://shreshtait.com access on 2 March 2025 | Unknown |
| TLS Fingerprint (SHA256) | HTTP Headers (MMH3) |
|---|---|
| 71a72d0a2d5478cafb7fc513fe120129a4db5f5dd21671ded5314034b0b72124 | 3898065973 |
| ab545fcff96261433c531d79bd9035d8db4a13b7faef85f5e4283d66ad5ed49d | 3898065973 |
| ab545fcff96261433c531d79bd9035d8db4a13b7faef85f5e4283d66ad5ed49d | 3898065973 |
| 71a72d0a2d5478cafb7fc513fe120129a4db5f5dd21671ded5314034b0b72124 | 2350846486 |
| ab545fcff96261433c531d79bd9035d8db4a13b7faef85f5e4283d66ad5ed49d | 1200561793 |
| Dataset | Sample Size (n) | Dimensionality (d) | Improvement |
|---|---|---|---|
| Mixed Host | 17,711 | 2124 features | 4–199% |
| Cloudflare CDN | 5368 | 847 features | 66.7–4523.7% |
| Malicious | 4475 | 306 features | 4–118% |
| Total Nodes: | 211 |
| Known Good: | 32 |
| Known Bad: | 166 |
| Unknown: | 13 |
| Newly identified malicious domains: | 27 |
| Area with 91.47% confirmed malicious nodes and 12 distinct fingerprints. | |
| Of the total good or unknown domains, 60% were reclassified to bad. | |
| Total Nodes: | 85 |
| Known Good: | 25 |
| Known Bad: | 30 |
| Unknown: | 30 |
| Newly identified malicious domains: | 40 |
| Area with 82.35% confirmed malicious nodes and nine distinct fingerprints. | |
| Of the total good or unknown domains, 72.72% were reclassified to bad. | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thomson, A.; Maglaras, L.; Moradpoor, N. A Novel TLS-Based Fingerprinting Approach That Combines Feature Expansion and Similarity Mapping. Future Internet 2025, 17, 120. https://doi.org/10.3390/fi17030120
Thomson A, Maglaras L, Moradpoor N. A Novel TLS-Based Fingerprinting Approach That Combines Feature Expansion and Similarity Mapping. Future Internet. 2025; 17(3):120. https://doi.org/10.3390/fi17030120
Chicago/Turabian StyleThomson, Amanda, Leandros Maglaras, and Naghmeh Moradpoor. 2025. "A Novel TLS-Based Fingerprinting Approach That Combines Feature Expansion and Similarity Mapping" Future Internet 17, no. 3: 120. https://doi.org/10.3390/fi17030120
APA StyleThomson, A., Maglaras, L., & Moradpoor, N. (2025). A Novel TLS-Based Fingerprinting Approach That Combines Feature Expansion and Similarity Mapping. Future Internet, 17(3), 120. https://doi.org/10.3390/fi17030120