1. Introduction
The proliferation of disinformation on social media has become a global concern, given the scale and potentially harmful impact of false news on public opinion, political processes, and public health. In this context, automatic detection of misleading content has gained prominence as a key tool to mitigate these effects [
1,
2]. Several studies have demonstrated that the dissemination of false news differs significantly from that of factual information, not only in terms of factual accuracy but also in terms of linguistic style, emotional appeal, and propagation dynamics [
3,
4,
5]. In particular, false content often exploits emotional triggers to spread more rapidly and widely on social networks. These messages frequently employ inflammatory language to manipulate readers, evoking negative emotions such as fear, anger, or surprise [
1,
6]. In contrast, news from reliable sources tends to evoke predominantly positive emotions, reflecting a distinct engagement pattern compared to that observed in misleading content.
We adopt standard distinctions in the information-disorder literature [
7]:
misinformation denotes false or misleading content shared without intent to deceive;
disinformation denotes false or misleading content shared with manipulative intent; and
fake news is used colloquially to refer to such content in social platforms. In this study, we do not adjudicate authorial intent at the message level. Instead, we follow a common operational practice and use a
source-level proxy for manipulative intent: messages are labeled as disinformation when they originate from outlets rated
Low or
Very Low in factual reporting by Media Bias/Fact Check (MBFC), categories that reflect recurrent publication of fabricated or misleading claims (see
Section 3.1). Messages from outlets rated
High or
Very High are treated as reliable. This makes our object of study precise and reproducible while acknowledging that “intent” is inferred at the source level rather than asserted per message.
Despite the evident role of emotions in the viral spread of false news, most traditional detection approaches do not explicitly consider the emotional patterns of content, focusing instead on textual attributes, user characteristics, or propagation structures [
4,
5]. Moreover, prior work typically treats emotion as a static property (e.g., overall polarity or bag-of-emotions) rather than modelling how emotions unfold within a message, which theory and evidence suggest is critical for manipulation and engagement [
8,
9]. To address this gap, the present study proposes the use of emotional sequences—that is, the temporal order of emotions expressed in a text—as a new discriminatory signal for identifying disinformation on social media. Specifically, we operationalize emotional sequencing at the subsentence level and show that temporal progressions provide discriminative information beyond aggregate sentiment or emotion counts.
On the one hand, this study is important because understanding how emotions evolve within deceptive messages can reveal the subtle mechanisms through which readers’ attention and trust are manipulated. By capturing the temporal evolution of emotions, this research provides interpretable signals that complement black-box detection models and contribute to a deeper comprehension of how emotional manipulation sustains the virality of misinformation. From a societal standpoint, such insights are critical for designing interventions that promote digital literacy and resilience against manipulative communication strategies [
8,
9].
On the other hand, the novelty of this work lies in introducing the emotional sequence dimension into disinformation detection, whereas prior research has largely focused on static emotion frequencies or overall sentiment polarity. By analyzing how emotions unfold and transition within messages, this study adds a temporal-emotional perspective that has not been systematically explored before. This approach extends traditional content analysis by showing that emotional progression—not merely emotional intensity—can serve as a structural marker of manipulation in online discourse.
The contribution of this study lies in integrating the temporal emotional dimension into the disinformation detection framework, filling a gap in the existing literature. Most previous research has focused on static content attributes, user credibility metrics, or network diffusion patterns [
10], without thoroughly addressing how emotions unfold throughout false narratives. By exploring sequential emotional patterns, this study provides evidence that temporal emotional signals can enhance the identification of misleading content. Thus, the results complement traditional detection approaches and reinforce the importance of incorporating emotional aspects into automated models, opening new perspectives for addressing the spread of disinformation on social media.
2. Related Work
The automatic detection of disinformation has gained significant attention in recent years due to the growing impact of fake news on public opinion, political processes, and public health. Several studies have demonstrated that the dissemination of disinformation differs significantly from reliable information, not only in terms of factual content but also in linguistic style, emotional appeal, and propagation dynamics [
2,
3,
4,
11]. False information tends to spread faster, more widely, and more deeply across social networks, often exploiting emotions such as fear, anger, and surprise. In contrast, reliable news typically evokes emotions such as trust and anticipation and circulates more moderately and selectively within online ecosystems [
4,
12].
Among the key factors driving the virality of fake news, the role of emotions stands out. The seminal work of Vosoughi et al. [
4] demonstrated that false rumors frequently evoke fear, disgust, and surprise, whereas truthful information tends to elicit joy, trust, and anticipation. This systematic divergence in emotional appeal has led to the development of computational approaches that incorporate emotional signals as features for disinformation detection. This view is supported by Liu et al. [
12], who emphasized that emotions play a central role in the diffusion and acceptance of disinformation across social platforms, highlighting that emotional patterns serve as critical signals for distinguishing fake and real content.
Building on this premise, Giachanou et al. [
13] proposed a Long Short-Term Memory (LSTM) model that directly integrates emotional signals extracted from text to differentiate between credible and non-credible claims. The integration of emotions into the classification process was shown to significantly enhance the performance of credibility detection systems. Expanding on this analysis, Ghanem et al. [
5] investigated emotional patterns across different types of disinformation, including propaganda, clickbait, satire, and hoaxes. Their findings revealed distinct emotional profiles for each type, highlighting that emotional manipulation is tailored to the specific objectives of each disinformation genre.
Furthering this emotional perspective, Zhang et al. [
14] introduced the concept of
dual emotion, exploring not only the emotions conveyed directly in the content (publisher emotion) but also the emotions expressed in user responses (social emotion). Their work demonstrated that the interplay between these two layers of emotion provides additional signals for distinguishing fake news from reliable content. This dual-emotion approach was further extended by Guo et al. [
15], who proposed the TieFake model, incorporating both textual and emotional similarity between news titles and bodies to enhance detection performance.
Beyond content-based approaches, psycholinguistic features and user behaviors have also been leveraged to enhance disinformation detection. Giachanou et al. [
16] developed the CheckerOrSpreader model, a convolutional neural network-based framework that profiles users as either fake news spreaders or fact-checkers based on linguistic patterns and personality traits. This user-centric approach complements content-based methods by highlighting the importance of user profiling in disinformation detection, demonstrating that the propagation of fake news is not only a textual phenomenon but also reflects behavioral patterns.
The importance of user-level features is further reinforced by Butt et al. [
17], who conducted a psycholinguistic analysis of rumor tweets and their replies. They identified linguistic and emotional differences between rumor and non-rumor content, demonstrating that emotional signals and user responses contribute complementary information for rumor detection. Their findings support the need for multi-dimensional approaches that combine content, user behavior, and interaction patterns.
Cognitive factors also play a crucial role in the dissemination and acceptance of fake news. Santos et al. [
18] reviewed cognitive biases such as confirmation bias and the availability heuristic, emphasizing how emotionally charged content interacts with these cognitive shortcuts to enhance belief and sharing of false information. Although cognitive processes are not directly modeled in this study, they provide a theoretical foundation for understanding why emotionally sequenced narratives are particularly effective in disinformation campaigns.
The evolving nature of disinformation narratives is also a topic of interest. Introne et al. [
19] examined the narrative structure of conspiracy theories in anti-vaccine discussions, illustrating how these narratives adapt over time in response to external events. This process, which combines emotional manipulation with dynamic narrative framing, highlights the importance of understanding how emotions are organized and evolve within disinformation content. The present study builds upon this work by focusing specifically on emotional sequences within fake news messages, aiming to uncover recurrent patterns of emotional progression.
The significance of integrating emotional progression with credibility assessment is also highlighted by Giachanou et al. [
20], who developed emoCred, an LSTM-based model that incorporates emotional signals extracted from text to classify claims as credible or non-credible. Their work demonstrated that the inclusion of emotional signals significantly improved classification performance, especially when combined with psycholinguistic features.
More recently, Liu et al. [
21] proposed an emotion-aware fake news detection approach based on graph neural networks (GNNs), demonstrating that incorporating emotional transitions within propagation networks enhances the detection of fake news. This emphasis on emotional progression aligns directly with the present study, which focuses on the sequential dynamics of emotions within disinformation content itself, rather than just in user interactions.
Comprehensive reviews such as those by Zhou and Zafarani [
3] and Ruffo et al. [
22] have highlighted the need for multi-disciplinary approaches that combine linguistic, emotional, social, and network-based features to capture the complexity of online disinformation. These reviews emphasize the importance of explainability in detection models, ensuring that both researchers and practitioners can understand the reasoning behind model predictions. Another study [
23] has shown that there is a significant connection between the identification of fake news and its potentially damaging impact, and therefore, the time available to detect it. The present study contributes to this body of research by proposing a method that explicitly models emotional sequences, providing interpretable insights into how disinformation narratives manipulate emotional responses over time.
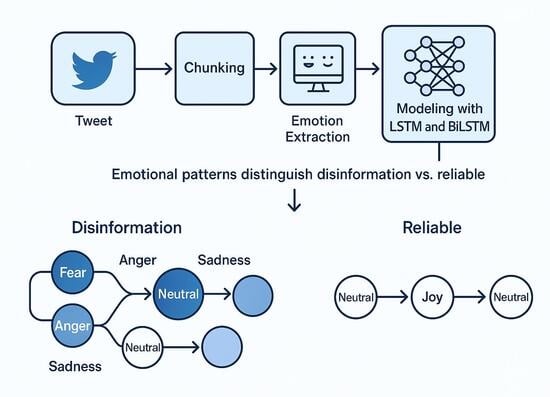
This study builds upon this extensive body of work by introducing a novel approach to analyzing emotional sequences in fake news messages. Using semantic chunking, subsentence-level emotion recognition, and frequent sequential pattern mining via the PrefixSpan algorithm, the present research aims to uncover the underlying emotional structures that characterize disinformation. By focusing on the temporal and sequential dynamics of emotions, this study contributes to advancing the state of the art, offering new insights into how emotional manipulation is systematically organized to enhance the persuasive power and virality of fake news in social media environments.
Complementary lines of work formalize veracity via fact-checked benchmarks and rumor-classification schemes, and model diffusion with graph-based architectures [
24,
25]. Our contribution is orthogonal: we focus on
content-internal emotional sequencing as a discriminative signal, rather than network structure or
post-hoc fact verification.
3. Data and Preprocessing
3.1. Dataset Construction
To investigate the hypothesis introduced in
Section 1, we constructed a dataset combining Natural Language Processing techniques with sequential pattern analysis.
The dataset construction was based on the Media Bias/Fact Check (MBFC) platform, founded in 2015 by Dave M. Van Zandt, which systematically evaluates media outlets according to political bias and factual accuracy. Each outlet is assessed through the linguistic framing of headlines and articles, the quality of cited sources, and the consistency of factual reporting. MBFC classifies sources from Very Low (highly unreliable) to Very High (consistently factual), offering a reliable foundation for selecting sources with contrasting credibility levels.
From the MBFC resource, six categories of disinformation sources were selected: Pseudoscience, Political News, General News, Conspiracy, PAC SuperPAC, and Political Advocacy. To allow for direct comparison, five categories of reliable news sources were also selected: General News, Political News, Pro-Science, Political Advocacy, and PAC SuperPAC. The selection of these categories enabled direct comparisons between disinformation and reliable producers within the same coverage type. Notably, Pseudoscience and Conspiracy serve as counterparts to Pro-Science, creating a balanced framework for analysis.
Disinformation sources were chosen from outlets classified as Very Low or Low in MBFC’s Factual Reporting Rating, while reliable sources were drawn from those rated High or Very High. Priority was given to high-traffic sources to ensure representativeness. Sources lacking an official Twitter account or with fewer than 1000 followers between November 2024 and January 2025 were excluded to maintain sample consistency. For each disinformation outlet, a matching reliable outlet was selected in the same category, ensuring an approximately balanced number of tweets per class.
Between 1000 and 3000 tweets were collected from each source using the TwExportly extension, which retrieves posts in reverse chronological order. Empty tweets and those containing only user mentions were removed. Each message was then segmented into smaller textual units, and automatic recognition models were applied to identify the emotions expressed in each segment, enabling subsequent sequential emotion analysis. The final dataset comprised 45,060 tweets from disinformation sources and 49,536 from reliable ones, totaling 94,596 messages.
Unlike earlier drafts that described MBFC and data collection separately, all relevant methodological details are now integrated here for coherence. The unified description highlights how credibility classification, tweet extraction, and emotion segmentation form a single methodological pipeline.
3.2. Processing and Improvements
The dataset (94,596 records, including tweets, retweets, and replies) underwent several preprocessing stages. Text cleaning involved the removal of links, mentions, and special characters. Stopwords were kept for sentiment and emotion analyses but excluded from word cloud generation. Emojis were converted into their textual representations using the demoji library to preserve emotional context. Among disinformation sources, 60.4% of messages correspond to original tweets (27,195), 20.2% to retweets (9102), and 19.4% to replies (8762). In contrast, reliable sources show a higher proportion of original tweets (76.9%; 38,078), with 16.0% retweets (7917) and 7.1% replies (3541). These differences indicate that disinformation messages circulate proportionally more through retweets and replies than reliable news, reflecting distinct diffusion patterns and engagement behaviors.
Figure 1 and
Figure 2 display the number of tweets, retweets, and replies across categories.
3.2.1. Reproducibility and Availability
All code, configuration files, and datasets used in this paper are publicly available online (
https://github.com/vieirasre/emotional-sequence-disinformation accessed on 22 September 2025). The repository includes scripts for data collection (source lists and filters), preprocessing (cleaning, emoji handling), sentiment and emotion inference, sequence mining (PrefixSpan), association rules (Apriori), and modeling pipelines, together with exact parameter files and random seeds.
3.2.2. Labeling Protocol
We do not perform per-message human annotation in this study; labels derive from a
source-level protocol using MBFC factual-reporting ratings (Low/Very Low ⇒ disinformation; High/Very High ⇒ reliable). Consequently, inter-annotator agreement is not applicable.
Section 3 details source selection criteria (MBFC categories, traffic priority, public Twitter handle, ≥1000 followers, extraction window, and exclusions).
4. Sentiment and Emotional Analysis
4.1. Sentiment Analysis
Sentiment analysis plays a central role in this study, serving as a preliminary layer for investigating the affective patterns expressed in messages from both reliable sources and disinformation outlets. Previous studies demonstrate that fake news, in contrast to verified news, tends to exploit negative and polarizing sentiments to amplify its reach and viral potential. Therefore, identifying and quantifying sentiment polarity contributes to understanding the role of emotional manipulation in the strategies used to spread deceptive content.
The literature highlights that disinformation messages consistently exhibit a higher prevalence of negative sentiments, such as fear, anger, and disgust, while messages from reliable sources display a more neutral or mildly positive polarity, characterized by sentiments such as trust and anticipation. This difference in polarity, observed both in the content itself and in user reactions, has already been used in various studies as a relevant indicator for distinguishing between false and true content. Studies such as those by [
3,
16] show that sentiment polarity, particularly when combined with linguistic and psycholinguistic features, significantly enhances the accuracy of fake news detection models.
Widely used tools, such as VADER, designed specifically for short texts in social media, and HowNet, applied in Chinese-language contexts, are frequently employed to calculate the sentiment polarity of messages. These tools classify texts as positive, negative, or neutral, enabling the integration of sentiment polarity into machine learning models aimed at disinformation detection.
4.1.1. Methodology and Tools
Three distinct methods were employed for sentiment analysis: TextBlob, VADER, and a pre-trained model specifically designed for tweet sentiment analysis, identified as
https://huggingface.co/cardiffnlp/twitter-roberta-base-sentiment-latest (accessed on 22 July 2025). This model, built on the RoBERTa architecture, was trained on approximately 124 million tweets published between January 2018 and December 2021, and subsequently fine-tuned for sentiment classification using the TweetEval benchmark [
26].
Following these analyses, a manual evaluation was conducted on a random sample of 50 tweets. This process confirmed that the pre-trained model demonstrated superior performance, achieving 60% agreement with human evaluation, while TextBlob and VADER reached 24% and 34%, respectively. We present the results of that evaluation in
Figure 3. Hence,
Figure 3 explains what each method tends to predict, while the above values in the text describe which method is closer to human evaluation.
4.1.2. Sentiment Analysis Results
The comparative analysis of sentiment between tweets from reliable sources and those from disinformation outlets reveals consistent differences. Tweets from disinformation sources exhibit a higher proportion of
negative sentiment, while tweets from reliable sources predominantly display
positive sentiment (
Figure 4).
Additionally, among fake news tweets,
neutral and
negative sentiments appear with similar frequency, both significantly surpassing the occurrence of positive sentiment. In contrast, among reliable news tweets, the majority of messages are classified as
neutral, followed by a considerable proportion of
positive messages, with negative sentiment occurring far less frequently (
Figure 5).
These results are consistent with previous research findings, which highlight the predominance of negative sentiments in disinformation content and the adoption of a more neutral or mildly positive tone in messages from reliable sources.
4.2. Emotion Recognition and Sequence Extraction
The spread of disinformation on social media does not occur randomly or in a disorganized manner. Studies indicate that fake news messages often employ a strategic emotional progression to capture the reader’s attention, modulate their cognitive and affective reactions, and ultimately influence the dissemination of the content [
5,
14,
20]. Previous research shows that false rumors tend to evoke emotions such as fear, disgust, and surprise, while true information triggers emotions such as joy, trust, and anticipation [
4]. This emotional manipulation, especially when organized into a coherent sequence, is a key factor in understanding how fake narratives spread faster and more broadly than factual content [
3].
Additionally, recent research reinforces that disinformation messages not only evoke more intense emotions but also frequently organize these emotions into specific sequences that amplify their persuasive effectiveness. For example, some messages begin by evoking surprise, followed by fear or anger, and conclude with a call to action that leverages distrust or indignation [
14]. This sequential emotional structure facilitates virality by encouraging greater reader engagement, making them more likely to share the content before critically reflecting on its veracity [
14,
22].
The use of emotional sequences as distinguishing markers of fake news has also been explored in computational models. Recent works proposed the use of Long Short-Term Memory (LSTM) networks capable of incorporating emotional signals directly extracted from the text to differentiate between true and false messages [
13]. These models demonstrated that the order and transitions between emotions throughout a text provide important clues for the detection of disinformation, further supporting the relevance of analyzing emotional sequences as a methodological strategy to capture the underlying structure of deceptive messages [
5].
This section describes the process of recognizing emotions in social media messages and extracting the subsequent emotional sequences. By analyzing these sequences, it becomes possible to identify recurring patterns and understand how different types of disinformation structure emotional progressions to maximize their impact.
Semantic Chunking and Emotion Labeling
To investigate emotional progression in disinformation messages, a methodological approach was adopted combining semantic chunking, automatic emotion recognition, and sequential pattern mining. The first step involved the semantic segmentation of each message, splitting the original text into smaller units called subsentences. This segmentation was performed using a hybrid approach based on both punctuation marks and coordinating and subordinating conjunctions, ensuring that each subsentence maintained minimal semantic coherence while enabling fine-grained emotional analysis across the message.
With the subsentences identified, each was processed through an emotion recognition pipeline using the DistilRoBERTa-base model, specifically fine-tuned for emotion classification in English [
27]. This model was selected for its strong performance in recognizing emotions in short texts, making it particularly suitable for social media content. For each subsentence, the model produced a probability distribution across seven emotional categories: anger, disgust, fear, joy, neutral, sadness, and surprise. The dominant emotion—the one with the highest probability—was selected to represent that subsentence.
The final emotional sequence for each tweet was composed by concatenating the ordered emotions of all subsentences, preserving the original chronological and discursive order of the text. To ensure analytical relevance, a filtering criterion was applied: only sequences containing at least three distinct emotions were retained, ensuring that the sequences analyzed were sufficiently diverse and complex to reveal meaningful emotional patterns. This criterion aligns with prior research highlighting the importance of emotional diversity in distinguishing fake from reliable news [
14].
With the emotional sequences cleaned and structured, the PrefixSpan algorithm was applied for frequent sequence mining. PrefixSpan discovers frequent sequential patterns by projecting databases with respect to shared prefixes and recursively growing patterns only from frequent extensions, which avoids the generation of large candidate sets and progressively reduces the search space. Unlike earlier approaches, it does not require a predefined list of candidate patterns, which makes it both efficient and scalable for temporal sequence mining. These properties make PrefixSpan particularly suitable for identifying recurring emotional regularities directly from the data [
3,
28].
This methodological pipeline—composed of semantic segmentation, emotion recognition using a neural model, and sequential pattern mining was applied to both the subset of tweets classified as disinformation and the subset classified as reliable news. This comparative approach aims to reveal whether there are distinct emotional structures associated with each type of content. The sequences identified and the patterns extracted are analyzed in the following section, with a focus on understanding how emotional progression relates to discursive strategies in both reliable and fake news messages.
Figure 6 illustrates the methodological pipeline, from semantic segmentation to sequential pattern extraction using the PrefixSpan algorithm.
Implementation details: emotion inference uses DistilRoBERTa-base fine-tuned for seven emotions [
27]; chunking relies on punctuation and coordinating/subordinating conjunctions (rules included in repo); PrefixSpan is executed with the minimum support and minimum length settings reported in the text, and Apriori uses the thresholds reported in
Section 4.6. Exact library versions, CLI calls, and seeds are in the repository.
4.3. General Patterns in Fake News
The analysis of emotional sequences in fake news messages aims not only to identify the most common emotions in this type of content, but also to understand how these emotions are connected throughout the discourse, forming characteristic emotional patterns. A total of 193,683 emotions were identified across subsequences extracted from tweets classified as fake news. The initial analysis of the isolated frequency of each emotion already reveals a clear predominance of neutral segments, as seen in
Table 1, interspersed with emotionally charged passages.
The high presence of neutral emotions (66.47%) indicates that a significant portion of fake news messages consists of emotionally neutral segments, interspersed with emotionally charged sections. It is also noteworthy that the overall presence of anger (8.91%) is approximately twice that of joy (4.66%), highlighting a relatively greater emphasis on content associated with indignation and conflict compared to positive emotions.
The analysis of sequences containing three or more distinct emotions allows us to observe how these emotions are organized throughout the discourse. These sequences reveal the typical emotional progression found in fake news messages, in which high-arousal negative emotions frequently alternate with neutral segments, creating variations in intensity throughout the message.
Table 2 presents the 10 most frequent emotional sequences in fake news.
In addition to sequences with three or more emotions, it is relevant to observe direct transitions between pairs of consecutive emotions, which offer complementary insights into short-term emotional links.
Table 3 presents the 10 most frequent binary transitions, excluding sequences involving the neutral emotion.
Direct transitions between negative emotions, especially between fear and anger, appear frequently among the most common combinations. This direct alternation between alert emotions and indignation draws attention by indicating a possible emphasis on high-impact emotional content. The presence of transitions involving sadness and disgust suggests that these emotions also play a relevant role in the messages analyzed, particularly in content addressing negative situations or emotionally impactful events.
Another relevant aspect identified is the presence of a subset of messages that display emotional progressions containing four or more distinct emotions within a single sequence. This type of sequence represents a smaller fraction of the total patterns found, but its recurrence among the most frequent patterns suggests that some fake news messages adopt more complex emotional strategies, guiding the reader through a longer and more varied emotional trajectory.
The most common combinations among these long sequences are presented in
Table 4, and involve transitions between fear, anger, sadness, and neutral. These patterns may reflect an attempt to structure messages in a way that captures and holds the reader’s attention through a succession of contrasting emotional stimuli. The alternation between high-arousal emotions (fear and anger) and lower-arousal emotions (sadness and neutral) suggests the presence of an intentional emotional progression, with planned variations in emotional tone throughout the narrative.
The results presented indicate that, in fake news messages, the emotional flow is characterized by a combination of neutral segments and cycles of high emotional arousal, frequently structured in progressions that alternate between fear, anger, and sadness, with varying levels of complexity that include both short transitions and longer, more diverse sequences.
Fake News by Subcategory
The analysis of emotional sequences containing three or more distinct emotions revealed that, although neutral and anger are consistently dominant across all fake news categories, there are notable variations in the third most frequent emotion within each subcategory. These differences suggest the use of specific emotional strategies tailored to the narrative structure of each type of disinformation.
In the General News category, fear stands out as the most prominent emotion after neutrality and anger. This pattern suggests that seemingly neutral or informative content is often structured to induce concern or a sense of threat. PAC SuperPAC exhibits a more restricted emotional profile, but with fear and joy as the most frequent additional emotions. The presence of joy may be linked to the promotion of positive messages about specific candidates or political agendas, suggesting optimistic scenarios in case of electoral success. In the political categories—Political News and Political Advocacy—there is a clear predominance of sadness and fear in the sequences. This combination reinforces a discourse centered on indignation, threat, and loss, which is typical of emotionally charged and polarized narratives. Within the Pseudoscience & Conspiracy group, internal distinctions are significant. Conspiracy is marked by a high frequency of disgust, reflecting a narrative structure oriented toward moral repulsion and rejection, often associated with conspiracy theories and attacks on groups or institutions. Pseudoscience, on the other hand, is characterized by the intense use of sadness, suggesting narratives driven by disillusionment, frustration, or a sense of loss. In both, fear remains a strong component, reinforcing an alarmist tone.
These observations confirm that, while anger and neutral tone are general features, the third most dominant emotion varies significantly across disinformation genres, functioning as an emotional “signature” specific to each type of fake news.
4.4. General Patterns in Reliable News
The analysis of emotional sequences in messages classified as reliable news revealed patterns that, in several aspects, differ from those observed in fake news. As shown in
Table 5, a total of 205,912 emotions were segmented into subsequences extracted from 36,695 reliable tweets, reflecting the larger number of reliable messages in the dataset.
The high presence of neutral emotions (75.95%) is even more pronounced in reliable news than in fake news (66.47%). This result suggests that reliable messages tend to contain a higher proportion of segments classified as neutral. Positive emotions, such as joy, also appear with relatively higher frequency (6.42%) compared to fake news (4.66%). On the other hand, emotions such as anger and fear, although present, appear in smaller proportions in reliable news.
The analysis of sequences containing three or more distinct emotions allows us to observe how these emotions are linked throughout the discourse.
Table 6 presents the 10 most frequent emotional sequences in reliable news.
The most frequent sequences in reliable news present an alternation between positive and negative emotions, with emphasis on combinations involving joy, sadness, and fear. This alternation suggests a more balanced emotional progression, in which different emotional valences appear throughout the discourse, possibly reflecting the coverage of complex events with different emotional tones.
The analysis of direct transitions between pairs of consecutive emotions also reveals relevant aspects of the emotional dynamics in reliable news.
Table 7 presents the 10 most frequent binary transitions, excluding sequences that involve the neutral emotion.
The most frequent transitions reflect greater emotional diversity in reliable news, with frequent combinations between positive and negative emotions. The presence of transitions between fear, sadness, and anger indicates that, even in reliable texts, negative emotions are present, although in a less concentrated form than in fake news.
The analysis of emotional sequences in tweets classified as reliable news revealed that all identified sequences contain at most three distinct emotions. No cases of progressions with four or more different emotions were found in the entire dataset. This result directly contrasts with what was observed in fake news, where longer and more diverse emotional chains consistently appeared among the most frequent patterns.
This finding suggests that, in reliable tweets, emotional progression tends to be more linear or concentrated in a limited set of emotions, which may reflect a more straightforward discursive construction, without the need to guide the reader through a prolonged emotional trajectory. The absence of long and diverse sequences suggests that the emotional flow in reliable news is more likely associated with the presentation of facts and specific events, rather than an attempt to amplify or manipulate emotional reactions through variation and contrast.
Reliable News by Subcategory
The emotional sequences identified in the reliable news categories reveal patterns that are notably different from those found in fake news, both in their structure and emotional progression. Among the five subcategories analyzed, three of them (Pro-Science, Political News, and General News) exhibit remarkably similar emotional configurations.
These three categories are characterized by sequences involving combinations of joy, sadness, and fear, often interspersed with neutral segments. Common structures include transitions between joy and sadness (e.g., joy → sadness → neutral), fear and sadness, as well as joy and surprise. These patterns suggest that reliable news tends to present emotionally balanced narratives, alternating between positive and negative emotions in a way that reflects the complexity of factual reporting.
In contrast, the PAC SuperPAC category exhibits a structure that closely resembles that of fake news in the same subcategory. The most frequent sequences include transitions among fear, anger, and sadness—a configuration typically associated with emotionally charged or persuasive content. This similarity may reflect the nature of political advocacy and campaign messaging, even when disseminated by reliable sources.
The Political Advocacy category stands apart from the others. Although joy is present in the sequences, it tends to appear in isolation or accompanied only by neutral segments, rather than forming more complex emotional progressions. This lack of varied combinations with other emotional types indicates a less structured emotional narrative, potentially reflecting a different communication strategy or lower reliance on emotional modulation.
Overall, while some reliable news categories display consistent emotional structuring that aligns with informative and balanced communication, others show traces of more emotionally polarized patterns, underscoring the influence of thematic context on emotional sequencing.
4.5. Comparison Between Emotional Patterns in Fake News and Reliable News
In addition to these structural differences, the contrast between fake and reliable news becomes even more evident when analyzed by subcategory. As illustrated in
Figure 7, emotional compositions vary across thematic domains, yet the distinction between fake and reliable content remains consistent. In all five matched subcategories—General News, Political News, PAC SuperPAC, Political Advocacy, and Pseudoscience vs. Pro-Science—fake news systematically exhibits higher relative proportions of high-intensity negative emotions, particularly anger and fear. In all five matched subcategories—General News, Political News, PAC SuperPAC, Political Advocacy, and Pseudoscience vs. Pro-Science—fake news shows higher relative proportions of high-intensity negative emotions, particularly anger and fear. Reliable news shows comparatively higher proportions of joy and lower levels of anger.
4.6. Association Rules: Emotion and Veracity
This section explores the relationship between emotional patterns and message veracity through the extraction of association rules. The Apriori algorithm was applied to identify frequent combinations of emotions that, when present within a sequence, are strongly associated with either fake news or reliable news. The goal was to investigate whether certain emotional configurations, previously observed in the sequential analyses, could serve as sufficiently strong patterns to discriminate between disinformative and trustworthy content.
For the discovery of rules associated with fake news, a minimum support of 2% and a minimum confidence of 75% were established. These thresholds were set based on the size of the dataset and aimed to balance between capturing relevant patterns and avoiding overly sparse or excessively frequent rules. The application of these metrics resulted in nine main rules, presented in
Table 8, all with a lift greater than 1.77, reinforcing the association between the identified emotions and disinformation.
Among the most relevant rules for fake news, patterns such as disgust, fear, and anger (, , ) stand out, along with combinations involving surprise and neutral. These results corroborate the previous sequential analyses, where high-arousal negative emotions, such as anger and fear, predominated in the most complex emotional chains. The high lift of these rules indicates that the extracted emotional combinations do not occur by chance but systematically contribute to distinguishing fake news from reliable news.
In contrast, when applying Apriori to detect patterns associated with reliable news, even after reducing the minimum support to 1%, only three rules were found, listed in
Table 9. All of these presented confidence below 63% and a lift close to 1.08, suggesting a weak association between the predominant emotions (
joy and
neutral) and the trustworthiness of the content. This result reinforces that reliable news shows less dependence on specific emotional patterns for dissemination, aligning with previous analyses that indicated a simpler and more linear emotional structure in these messages.
Overall, the findings from this section confirm that emotions such as anger, fear, sadness, disgust, and surprise form relevant combinations for identifying fake news, complementing the sequential analysis previously presented. Reliable news, on the other hand, maintains a more neutral and emotionally less intense profile, with less complex emotional patterns.
5. Modeling and Validation
In this section, we evaluate the predictive power of emotional sequences as standalone features for disinformation detection. The analysis aims to determine whether temporal emotion patterns—independent of textual, user, or network information—encode sufficient signal to discriminate between fake and reliable news. We describe the sequence-based modeling framework, the training and evaluation procedures, and the external validation strategy used to assess generalization.
5.1. Sequence-Based Modeling with LSTM
One of the main goals of this work is to develop a model capable of classifying tweets as fake news or reliable news based exclusively on the sequence of emotions extracted from the messages. To this end, different neural network architectures were tested, focusing on sequential modeling and the identification of emotional patterns characteristic of disinformation.
The dataset was stratified to respect both the class distribution (fake/reliable) and the thematic subcategories present (such as politics, conspiracy theories, among others). The test set was exclusively reserved for final evaluation, while the training and validation sets were used for hyperparameter selection and identification of the most promising architectures. Train/validation/test splits follow an 80/10/10 policy with fixed random seed 42 (provided in the repo configs).
Initially, unidirectional LSTM networks were trained with multiple combinations of hyperparameters such as the number of units, embedding dimensions, learning rate, and batch size. We also investigated whether adding confidence scores attributed to each emotion would improve model performance, but experiments showed that their inclusion reduced predictive capacity. Next, we explored the combination of convolutional layers with LSTM to capture local emotional patterns before sequential modeling. Although the results were comparable, the next approach aimed to deepen the sequence modeling. BiLSTM networks were used under the hypothesis that future emotions could influence message interpretation—especially in ambiguous or manipulative content. This stage involved hundreds of variations and significantly higher training time. Finally, a Transformer encoder-based architecture was implemented, without causal attention, to test whether the temporal order of emotions was essential. As the encoder observes the sequence globally, its performance would indicate whether overall presence of specific emotional patterns is more relevant than their order.
5.2. Evaluation Steps and Performance Results
5.2.1. Step 1—Initial Evaluation on Validation
For each architecture, the best hyperparameter configurations were recorded based on the F1-score obtained during validation.
Table 10 presents the top-performing models for each architecture.
Legend of filenames:
Pure LSTM → model_IDS _lstm256 _batch128 _emb16 _lr0001;
Pure BiLSTM → model_IDS _bilstm128 _batch32 _emb32 _lr00025;
CNN + LSTM → model_IDS_cnnmultik_lstm64_batch256 _emb32_lr00025;
Transformer Encoder → model_IDS_transformer_emb128 _head2_ff32_lr0001;
LSTM with Emotion Scores → model_IDS_lstm256_batch32 _emb32_lr00025.
Note: Model names indicate the architecture and selection criterion. The best results were obtained with combinations of LSTM units, embedding dimensions (emb), batch size, learning rate (lr), attention heads (head), and feed-forward size (ff), as specified in the model filenames.
Additionally, the best individual values for each metric among all tested combinations using unidirectional LSTM were identified, as shown in
Table 11:
Legend of filenames:
LSTM (highest accuracy) → model_IDS_lstm256 _batch128 _emb16 _lr0001;
LSTM (highest precision) → model_IDS_lstm128 _batch32 _emb32 _lr001;
LSTM (highest recall) → model_IDS_lstm32 _batch64 _emb32 _lr00.
5.2.2. Step 2—Evaluation on Test Data
The selected models underwent a second evaluation step using the test set, with the goal of assessing their performance on previously unseen data. The results obtained guided the selection of models to be fine-tuned in the following step.
Table 12 presents the performance metrics for the evaluated models. Each threshold was adjusted to maximize the F1-score for the
fake class. The comparison reinforces the robustness of the selected architectures, particularly those based on LSTM and BiLSTM.
These complementary profiles provided insights into each architecture’s behavior, guiding the selection of models for the next step. Given the similarity between F1-score and AUC results, the models modelo_IDS_lstm256 _batch128 _emb16 _lr0001 (selected for its accuracy and AUC) and modelo_IDS_bilstm128 _batch32 _emb32 _lr00025 (selected for its F1-score) were chosen for further refinement.
5.2.3. Step 3—Model Adjustment with Class Weights
In this phase, the LSTM and BiLSTM models selected before were fine-tuned using class weights to address class imbalance. The training hyperparameters remained unchanged, but a higher penalty was applied to errors in the minority class (fake), with the aim of improving recall without significantly compromising precision.
The results on the validation set are presented in
Table 13. The LSTM model achieved a precision of 0.5443, recall of 0.7322, F1-score of 0.6244, and accuracy of 0.6265. The BiLSTM model obtained a precision of 0.5541, recall of 0.6776, F1-score of 0.6097, and accuracy of 0.6321. These results indicate that class weighting was effective in increasing the sensitivity to the fake class, especially in the LSTM model, which maintained a strong balance between precision and recall.
5.2.4. Step 4—Final Evaluation on Test Set
The adjusted models were then re-evaluated on the test set.
Table 14 presents the final metrics, which confirmed that applying class weighting was effective in improving recall for the
fake class without a significant loss in precision. Although the models are not outstanding in absolute terms, they represent the best performance achieved in this study for the task of disinformation detection based on emotional sequences. Moreover, these configurations yielded the highest F1-scores observed throughout the entire experimentation process.
Both architectures achieved area under the curve (AUC) values close to 0.70, as shown in
Figure 8, indicating a moderate ability to distinguish between content labeled as fake news and reliable news based solely on emotional sequences. Although the performances are not outstanding in absolute terms, the results suggest that sequential modeling of emotions provides relevant discriminative information, representing a promising approach to be further explored in broader scenarios or with longer text formats.
5.3. External Validation
We evaluate the generalisability of the emotional-sequence findings on an independent corpus. In order to assess the robustness and generalizability of the emotional patterns identified through the PrefixSpan and Apriori methods, an external validation was conducted using the dataset
Fake News Detection Datasets, available on the Kaggle platform. This independent corpus, composed of texts labeled as either fake or real news and collected from multiple sources, provides a consolidated basis for testing the replicability of the patterns observed in the main analysis [
29,
30].
All texts were processed using the same methodological protocol previously applied, including semantic segmentation, emotion labeling, and extraction of emotional subsequences. After filtering texts longer than 512 tokens to ensure compatibility with the emotion classification model, 19,229 fake news samples and 17,047 real news samples were. A total of 388,195 emotional subsequences were extracted from fake news and 282,343 from real news.
The emotion distribution analysis revealed that the neutral emotion appeared in approximately 54.9% of the emotional subsequences extracted from reliable news, compared to 53.5% in fake news. This represents a relative difference of 1.4 percentage points in favor of truthful content, suggesting a stronger tendency toward neutrality in credible messages.
Among the most frequent emotional sequences extracted from fake news, combinations involving
fear,
anger, and
neutral were predominant.
Table 15 indicates that when the neutral emotion is excluded, the most recurrent patterns consisted of fear, sadness, and anger—showing strong consistency with the results obtained in the original dataset. Emotions such as
disgust and
surprise also emerged but less frequently, usually combined with fear or anger, reinforcing the presence of emotionally intense and negatively valenced patterns in disinformation.
Conversely, emotional sequences from reliable news displayed structural similarities, including frequent combinations of fear, anger, and sadness. However, they differed from fake news through the presence of joy in combination with fear, sadness, and anger, particularly in sequences of at least three distinct emotions without neutrality. This indicates a more emotionally diverse configuration in truthful messages, in contrast with the predominantly negative arrangements found in fake news.
Association rules generated via the Apriori algorithm further supported these distinctions. In fake news, rule sets with high confidence levels (above 85%) were identified, predominantly composed of anger, surprise, and disgust, frequently combined with neutrality. In contrast, the rules extracted from real news exhibited lower confidence levels (around 49%), with most rules ranging between 44% and 48%. These involved combinations primarily composed of fear, sadness, and neutral, suggesting more dispersed emotional structures and less consistent associative patterns.
Together, the contrast in emotional sequence composition and association patterns between fake and reliable content underscores the relevance of emotional structure as a discriminatory signal. The prevalence of negatively valenced combinations in disinformation points to a possible strategy of emotional manipulation, whereas the greater relative presence of neutrality in real news may reflect a more balanced and fact-oriented communication style, valuable for the development of automatic detection systems.
A comparative analysis with the original dataset confirms that the external validation supports and reinforces the core conclusions of this study. In both corpora, fake news consistently exhibit emotionally intense patterns predominantly composed of fear, anger, and sadness, while reliable news shows a higher relative presence of neutral emotions and more emotionally diverse sequences, including joy. The recurrence of similar association rules and sequential structures across datasets indicates that the observed emotional configurations are not exclusive to a single source or collection method, but rather reflect generalizable characteristics of disinformation and trustworthy content. This alignment across independent datasets strengthens the evidence for using emotional sequencing as a discriminative feature in disinformation detection models.
6. Results
This section summarizes the main empirical findings reported in
Section 4 and
Section 5, highlighting only the most salient quantitative differences between disinformation and reliable content.
6.1. Descriptive Analysis
We first summarise descriptive patterns in the dataset (
Section 3). Disinformation sources produced proportionally fewer original tweets and more replies/retweets than reliable sources (60.4% vs. 76.9% originals), indicating higher interaction/recirculation dynamics for disinformation. Category-level volumes are shown in
Figure 1 and
Figure 2.
6.2. Comparative Quantitative Findings
Tweets from disinformation sources exhibit a higher proportion of negative sentiment, while tweets from reliable sources predominantly display positive and neutral sentiment. Among fake news tweets, neutral and negative sentiments appear with similar frequency, both clearly exceeding the occurrence of positive sentiment. In contrast, among reliable news tweets, most messages are classified as neutral, followed by a substantial proportion of positive messages, and only a smaller proportion expresses negative sentiment.
In the analysis of emotional sequences extracted from fake news messages, a total of 193,683 emotions were identified across subsequences. Neutral segments account for 66.47% of all labeled subsentences, followed by anger (8.91%), sadness (6.47%), fear (5.91%), joy (4.66%), disgust (3.83%), and surprise (3.72%). In reliable news, 205,912 emotions were identified, with an even higher proportion of neutral segments (75.95%), followed by joy (6.42%), sadness (4.90%), fear (4.28%), anger (3.92%), surprise (2.82%), and disgust (1.71%).
When examining the most frequent multi-emotion sequences (three or more distinct emotions), fake news shows recurring progressions combining high-intensity negative emotions. The most common patterns include transitions such as Fear → Anger → Neutral, Fear → Neutral → Anger, and Neutral → Anger → Sadness. In reliable news, the most frequent multi-emotion sequences include combinations such as Joy → Sadness → Neutral, Fear → Sadness → Neutral, and Fear → Anger → Neutral, which often alternate between emotions of different valence.
Direct emotion-to-emotion transitions were also quantified. In fake news, the most frequent binary transitions (excluding neutral) include Fear → Anger, Anger → Sadness, Sadness → Anger, and Anger → Fear, indicating frequent proximity of high-arousal negative emotions. In reliable news, common binary transitions include Fear → Sadness, Joy → Sadness, Fear → Anger, and Sadness → Joy. These transitions show recurrent alternation between distinct emotions.
Longer emotion progressions were also quantified. In fake news, sequences containing four or more distinct emotions were not only present but among the most frequent patterns. Examples include Fear → Anger → Sadness → Neutral and Fear → Neutral → Anger → Sadness. In contrast, in reliable news, no sequences containing four or more distinct emotions were observed. All identified sequences in reliable tweets contained at most three distinct emotions.
Category-level comparisons were also computed. In disinformation content:
General News is marked by frequent use of fear alongside anger.
PAC SuperPAC shows fear and joy as frequent additional emotions.
Political News and Political Advocacy display high proportions of sadness and fear.
Conspiracy shows elevated disgust, while Pseudoscience shows elevated sadness.
In reliable content:
Pro-Science, Political News, and General News tend to exhibit recurring combinations of joy, sadness, and fear, often mixed with neutral segments.
PAC/SuperPAC content shows more transitions among fear, anger, and sadness.
Political Advocacy displays less emotional variety, with joy often appearing in isolation or with neutral segments.
Finally, the association rules analysis quantified which emotion combinations are statistically linked to disinformation. For fake news, rules containing combinations such as {disgust, fear, anger} and {surprise, anger} achieve high confidence and lift values, indicating that these co-occurring emotions are strongly associated with fake news samples. In contrast, for reliable news, the strongest rules—typically involving neutral and joy—yielded lower confidence and lift.
7. Discussion
The results presented in
Section 4,
Section 5 and
Section 6 show that disinformation content is characterized by emotionally dense and cyclic sequences dominated by fear, anger, and sadness, whereas reliable news displays more linear and balanced emotional progressions. This contrast suggests that deceptive messages deliberately exploit high-arousal negative emotions to attract attention, sustain engagement, and reinforce ideological alignment. Such patterns are consistent with prior research indicating that emotional intensity, particularly fear and anger, increases message diffusion and perceived credibility [
1,
4]. Taken together, these findings dovetail with evidence that affectively charged content captures attention and travels farther online [
8], and with recent accounts of emotion
dynamics—rather than static polarity—shaping manipulation and engagement on social platforms [
9]. In our setting, the prevalence of high-arousal negative emotions within disinformation is not only higher in proportion, but also organized in recurrent progressions, suggesting a deliberate affective scaffolding aimed at sustaining arousal across the message.
From a theoretical standpoint, these findings align with affective models of misinformation spread, which emphasize emotional contagion and the use of affective framing to guide readers through escalating emotional states [
8,
9]. Prior studies have shown that fake news often amplifies affective polarization by triggering emotional resonance rather than factual reasoning [
14,
20]. Our sequential approach extends this perspective by demonstrating that not only the presence but also the temporal order of emotions contributes to the persuasive structure of disinformation. Conceptually, this extends polarity-based accounts by showing that
order and
transitions (e.g., fear → anger, anger → sadness) are themselves informative units of analysis. Empirically, two observations support this claim: (i) complex chains (≥4 distinct emotions) emerge among the most frequent patterns only in disinformation, and (ii) association rules with high lift for disinformation systematically combine high-arousal negatives (anger, fear) with surprise/disgust. Both patterns are consistent with the idea that sequential affect can steer appraisal and action tendencies in ways that static sentiment scores cannot capture [
8].
Moreover, our results nuance the simple “more emotion ⇒ more diffusion” narrative. Reliable news exhibits higher neutrality and a more balanced alternation with joy, and the corresponding association rules are weaker and less specific—supporting the view that calibrated emotional tone serves informative aims, whereas disinformation relies on more targeted affective escalation [
9]. In this sense, our analysis supports and sharpens prior claims by linking diffusion-prone negativity to a
sequential mechanism (affective escalation and cycling) rather than to aggregate intensity alone.
The identification of recurrent progressions—such as fear→anger→sadness—also speaks to the rhetorical organization of deceptive narratives. Sequences that begin with attention-capturing emotions (surprise/fear), pivot to mobilizing anger, and resolve into sadness (loss/inevitability) mirror persuasive arcs described in the literature on moral–emotional communication and online mobilization [
8,
31]. This mapping lends a process-level interpretation to our statistical patterns: emotional sequencing appears to function as a scaffold for attention, appraisal, and call-to-action within a post.
This temporal patterning resonates with models of narrative persuasion and rhetorical framing in online discourse [
3,
22]. By quantifying how emotions unfold within deceptive content, the present work provides empirical grounding for theories that view disinformation as an emotionally driven communicative strategy. In particular, the sequential evidence clarifies where our contribution sits relative to existing knowledge: prior work has shown that (i) negative, moralized, and novel content diffuses more widely; we add that (ii)
how emotions unfold within a single message—its ordered transitions and complexity—offers an interpretable, content-internal marker of manipulation that complements user/propagation features. This helps reconcile mixed results from static sentiment features in detection models by revealing that the discriminative signal partly resides in temporal structure.
Overall, these results position emotional sequencing as a complementary analytical dimension for understanding manipulative communication on social media. While existing approaches have focused on user networks and diffusion structures, our findings reveal that emotional flow within individual posts already encodes meaningful cues about deceptive intent. Future research should combine emotional trajectories with multimodal or propagation-based models to examine how emotional manipulation interacts with structural and social mechanisms of misinformation diffusion. We also note two scope clarifications for external validity. First, linguistic realization of emotions may vary across languages and cultural contexts; testing whether similar progressions emerge in non-English corpora is a natural next step [
9]. Second, longer-form and multimodal settings (e.g., articles, images, video) may enable richer affective arcs; validating whether sequence complexity scales with narrative length would further connect content-level sequencing to downstream engagement and diffusion [
8].
8. Conclusions
Summary of contributions. This study investigated emotional sequencing as a structural feature for identifying disinformation on social media. This pattern is consistent with evidence that false news spreads farther and faster than true news on Twitter, partly due to its greater novelty and affective appeal [
4]. Theoretically, the findings demonstrate that the
temporal organization of affect—rather than aggregated sentiment alone—offers a distinctive lens to interpret how manipulative narratives evolve. Practically, emotional sequences provide compact and interpretable descriptors that can complement existing linguistic and network-based detectors in newsroom tools, social-media monitoring, and platform moderation systems.
The research presented addressed the detection of disinformation on social media through the analysis of emotional sequences, an aspect that has been sparsely explored in the literature. By constructing a diverse dataset and applying advanced Natural Language Processing and sequential pattern mining techniques, it was possible to identify that the emotional pattern of disinformation messages is substantially different from truthful content, with a notable prevalence of negative emotions and an alternation of more complex emotional states. Sentiment analysis and emotion recognition within the subcategories of fake news provided a more detailed understanding of the emotional behavior in these messages, highlighting their role in manipulating and spreading disinformation.
While the results show promising gains in detection, it is important to note that the model’s performance can be enhanced by integrating other contextual and linguistic features, making it more robust across varied scenarios. Emotional sequences, while an important tool, should be combined with other data sources, such as user behavior or structural characteristics of content, to achieve more precise results. This work contributes to the advancement of the field by proposing a novel approach to emotion analysis in texts and opens avenues for future investigations that explore new combinations of emotional, behavioral, and contextual features, aiming to improve disinformation detection models on digital platforms.
Limitations. The study faced practical and methodological constraints, including limited data volume due to API restrictions and hardware capacity, and the brevity of tweets, which restricts complex emotional arcs. The reliance on seven basic emotion categories, although widely accepted, may oversimplify nuanced emotional expressions. These limitations highlight the need for caution when generalising results to broader contexts or longer text forms.
Future research directions. Building upon the present findings, future work should (i) expand emotion taxonomies to include mixed and ambiguous states (e.g., confusion, irony, disbelief), (ii) test emotional sequencing in longer and multimodal content, such as articles and videos, (iii) integrate user credibility and diffusion-pattern metrics to connect emotional flow with propagation dynamics, and (iv) evaluate emotional-sequence features on fact-checked benchmark datasets and explore their integration with graph/diffusion models to assess complementarity. Advances in multimodal and cross-lingual models could also enable the inclusion of visual and auditory emotional cues, enhancing the scope and applicability of this approach.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}