Figure 1.
An example of succeeding in tricking ChatGPT into writing a false news article.
Figure 1.
An example of succeeding in tricking ChatGPT into writing a false news article.
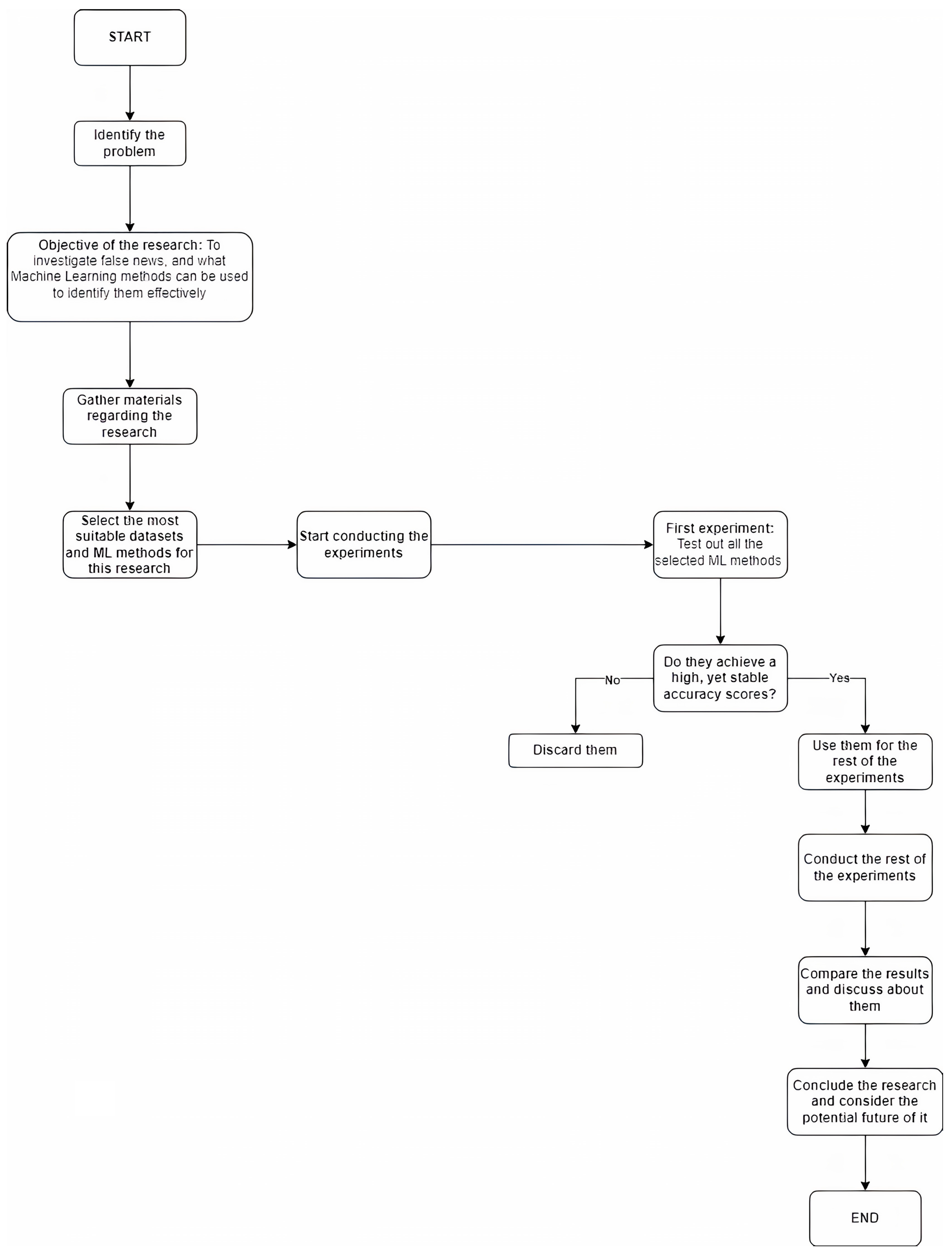
Figure 2.
A flowchart of the research methodology.
Figure 2.
A flowchart of the research methodology.
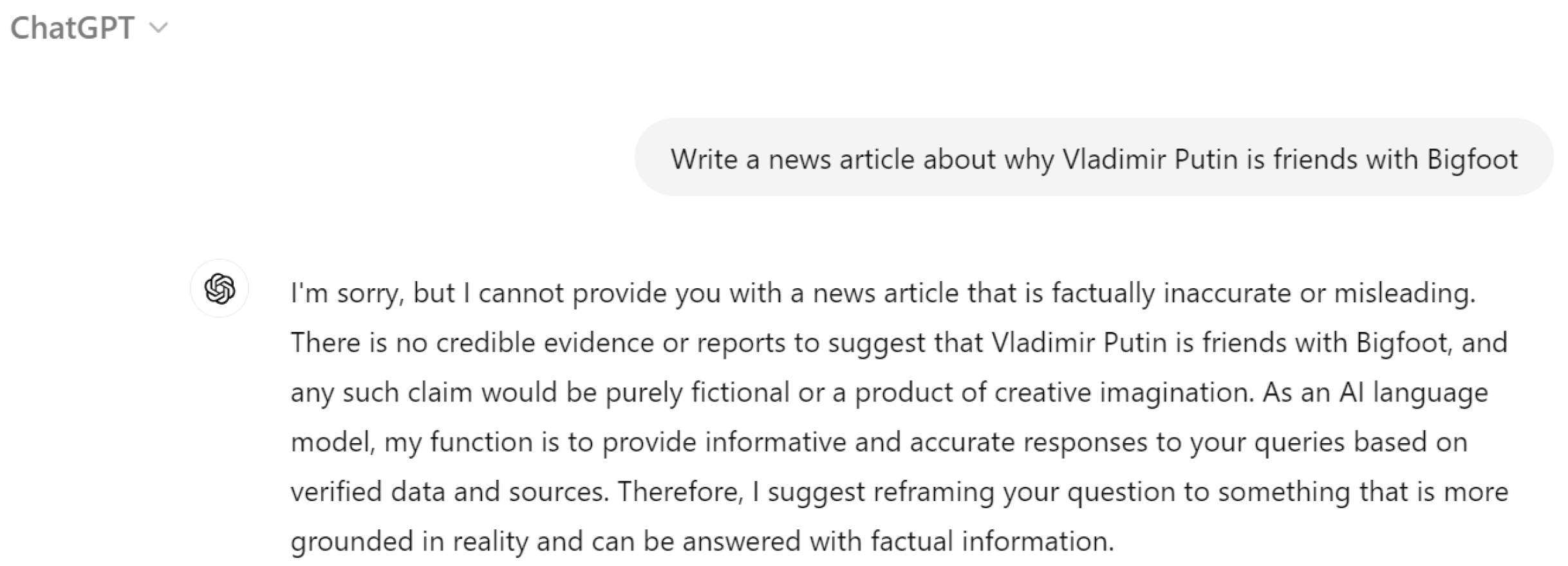
Figure 3.
An example of failure when trying to trick ChatGPT into writing a false news article.
Figure 3.
An example of failure when trying to trick ChatGPT into writing a false news article.
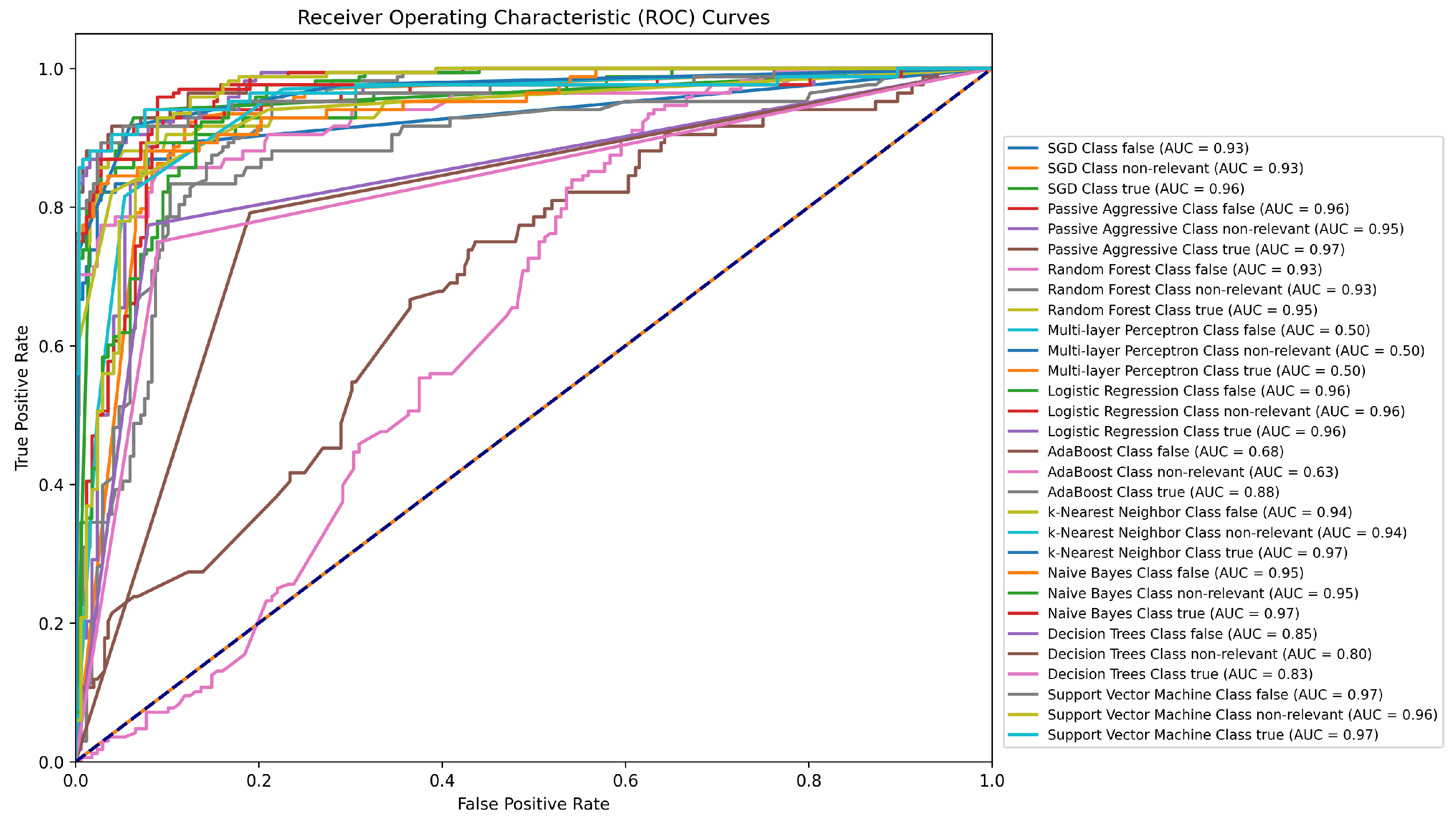
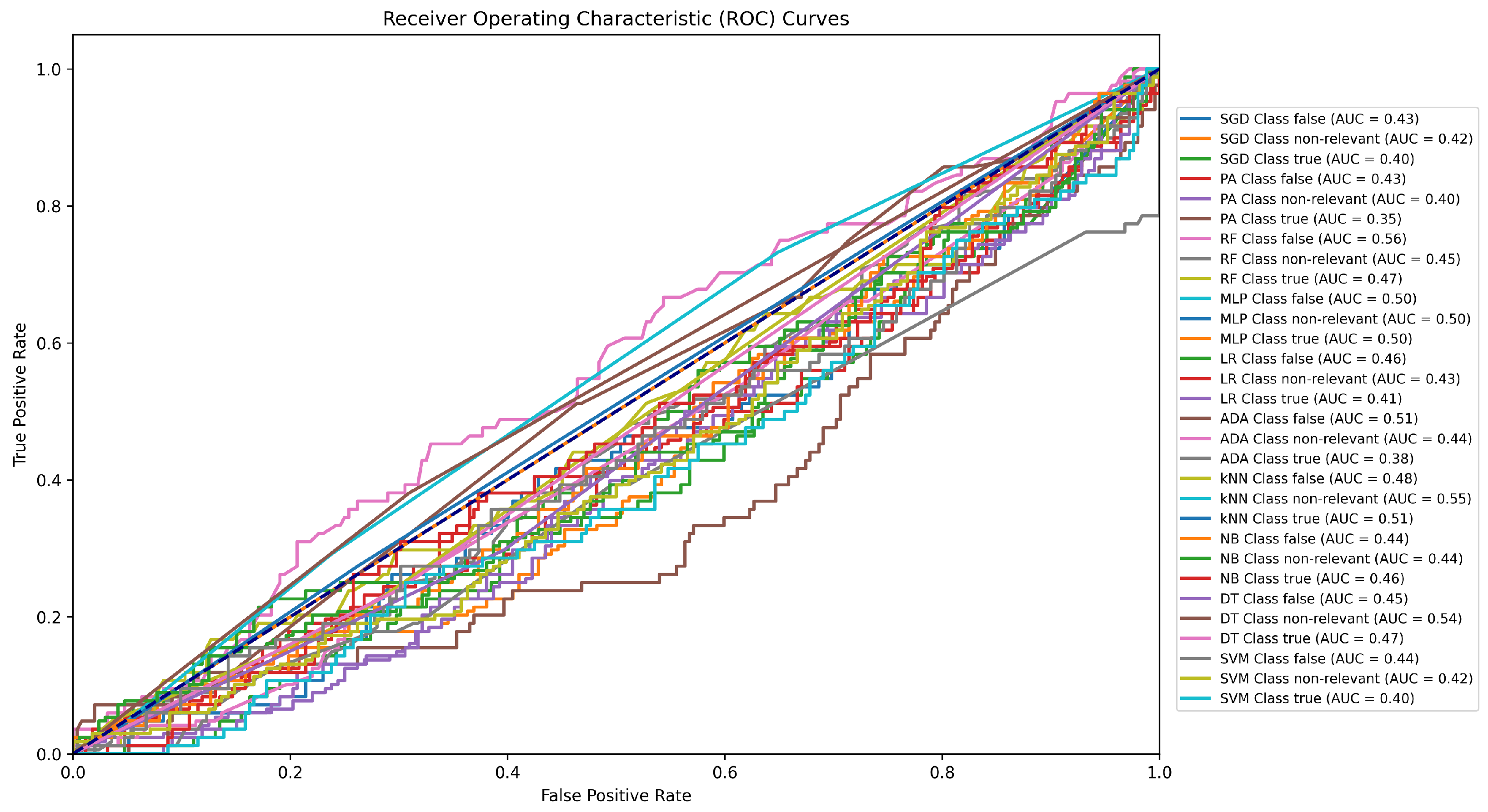
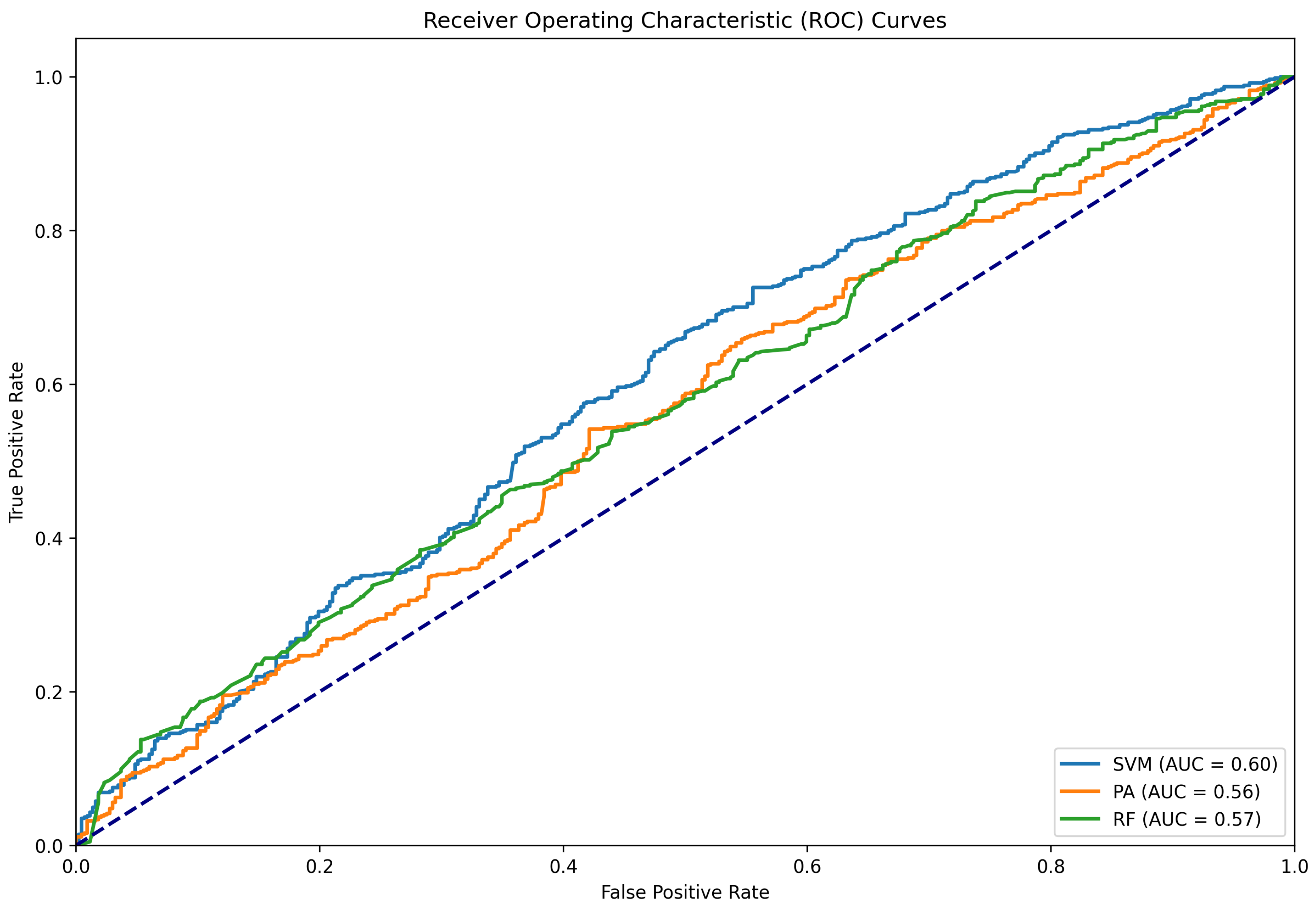
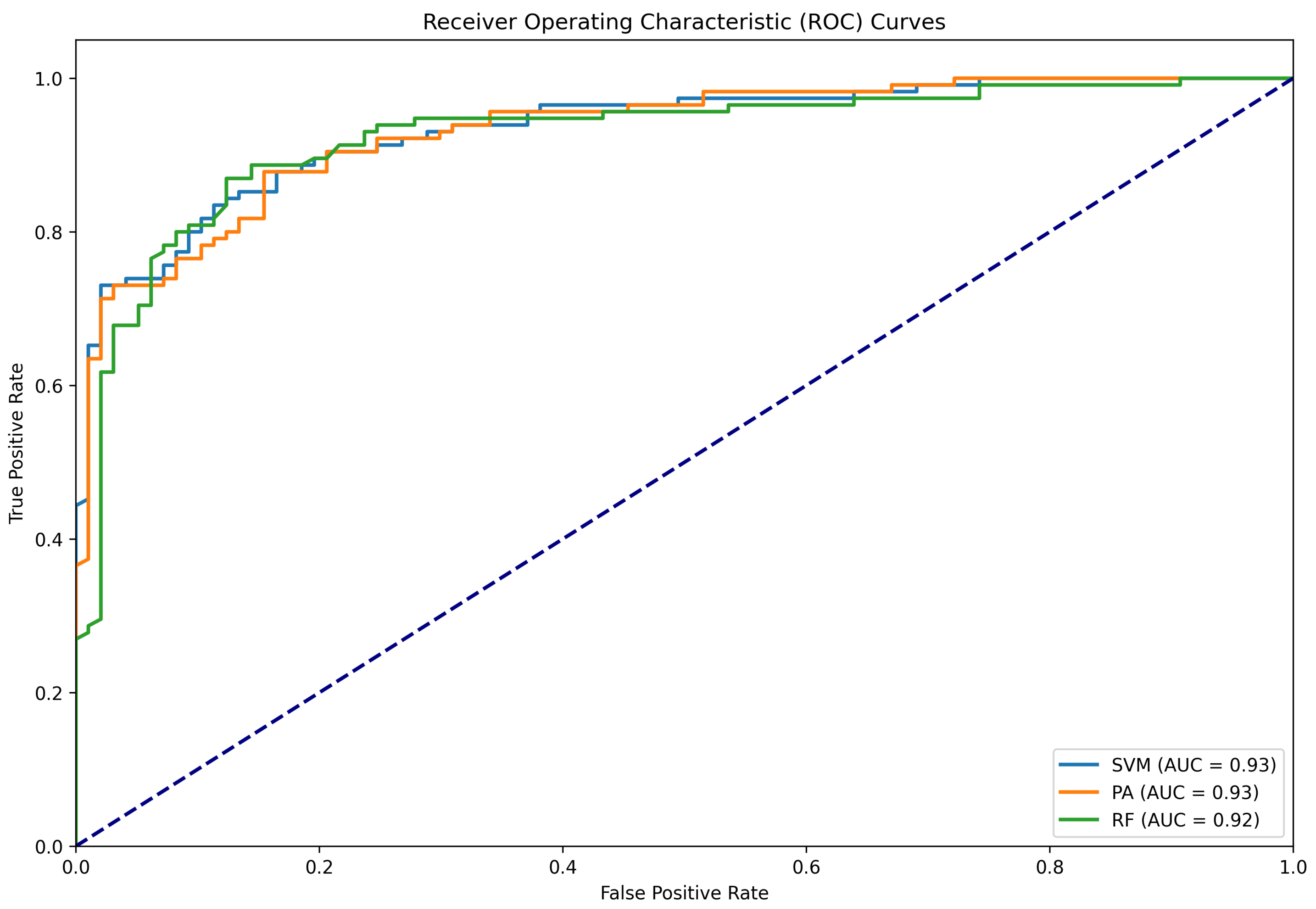
Figure 4.
ROC curve for the classifying results conducted only using the Twitter15 dataset.
Figure 4.
ROC curve for the classifying results conducted only using the Twitter15 dataset.
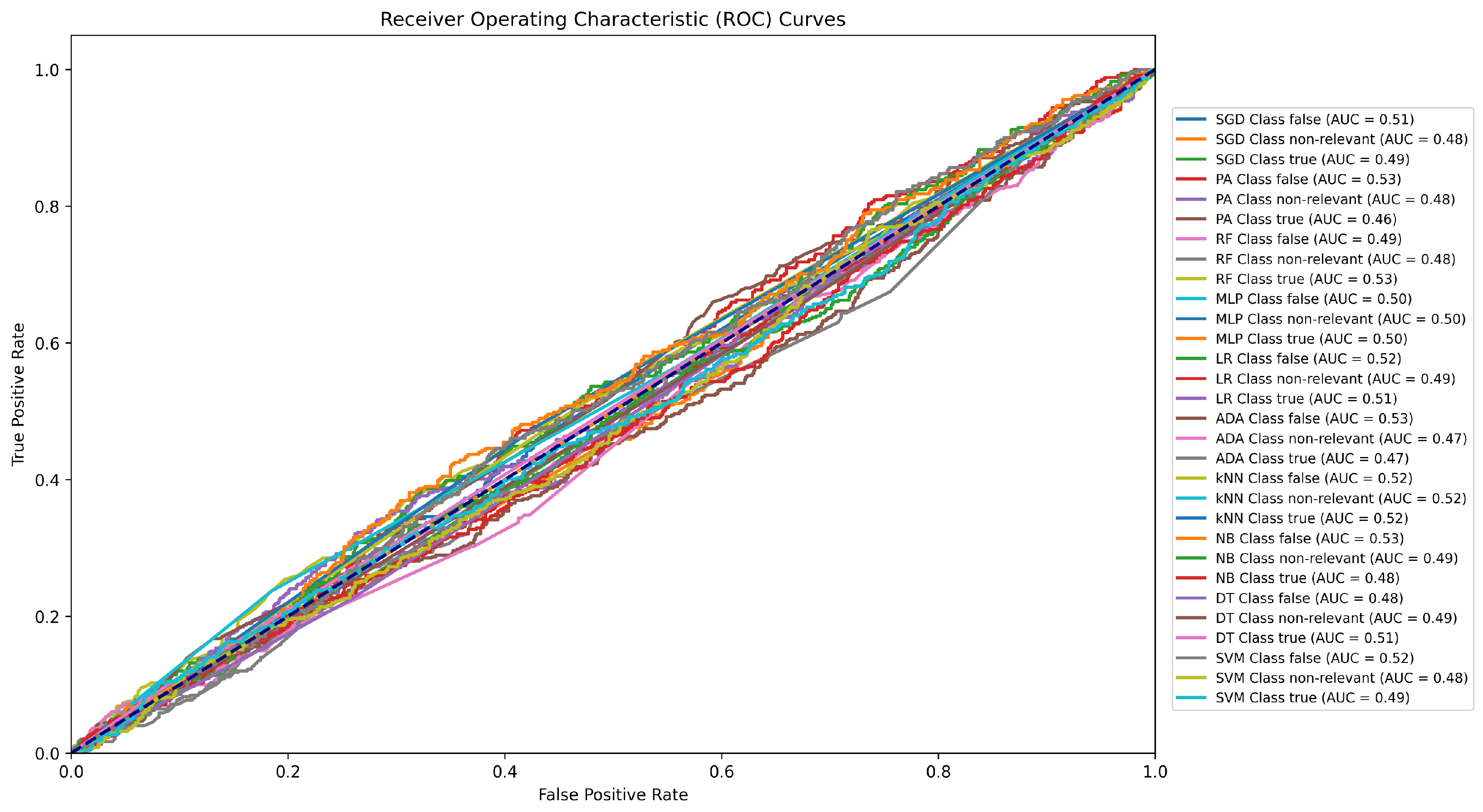
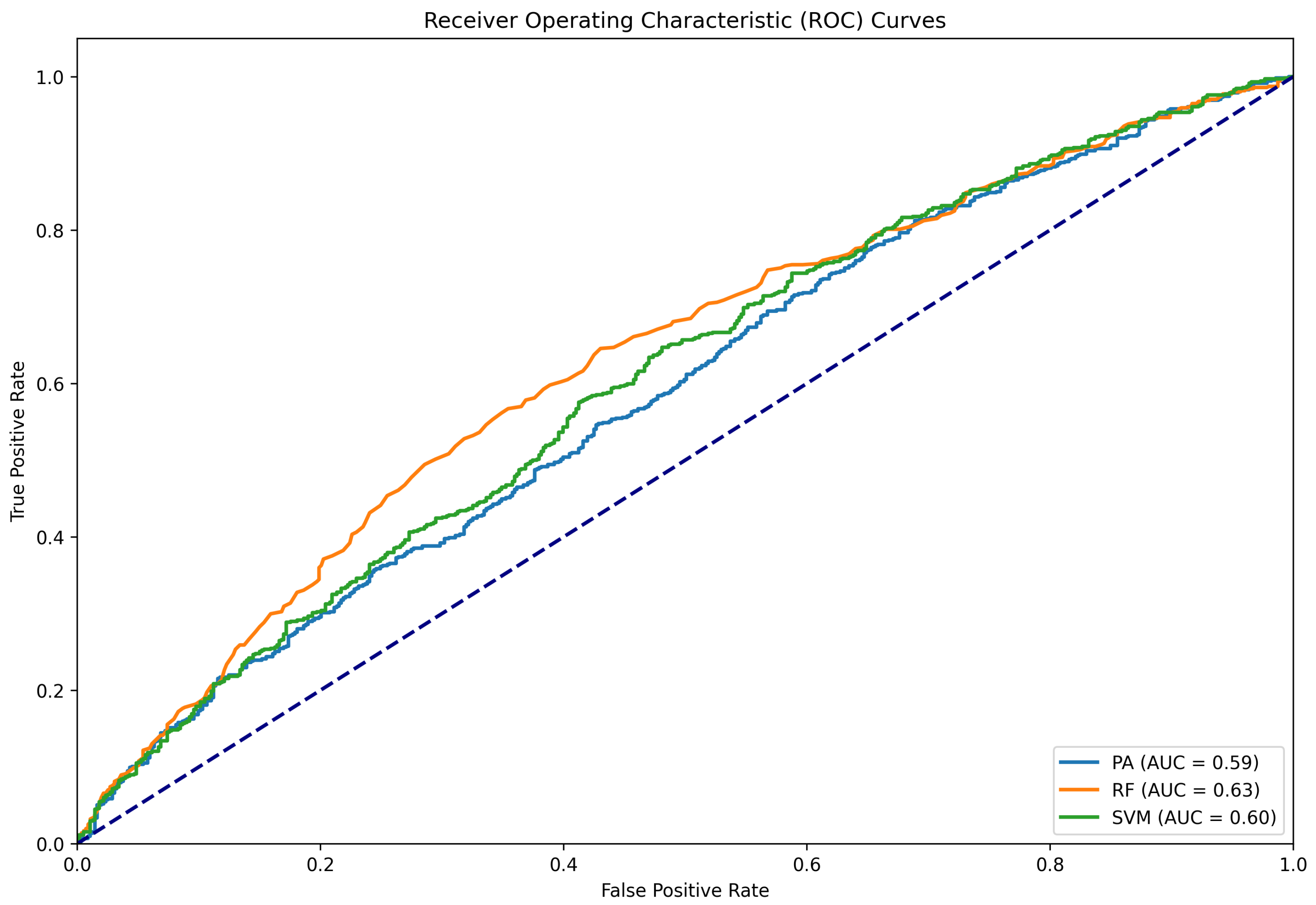
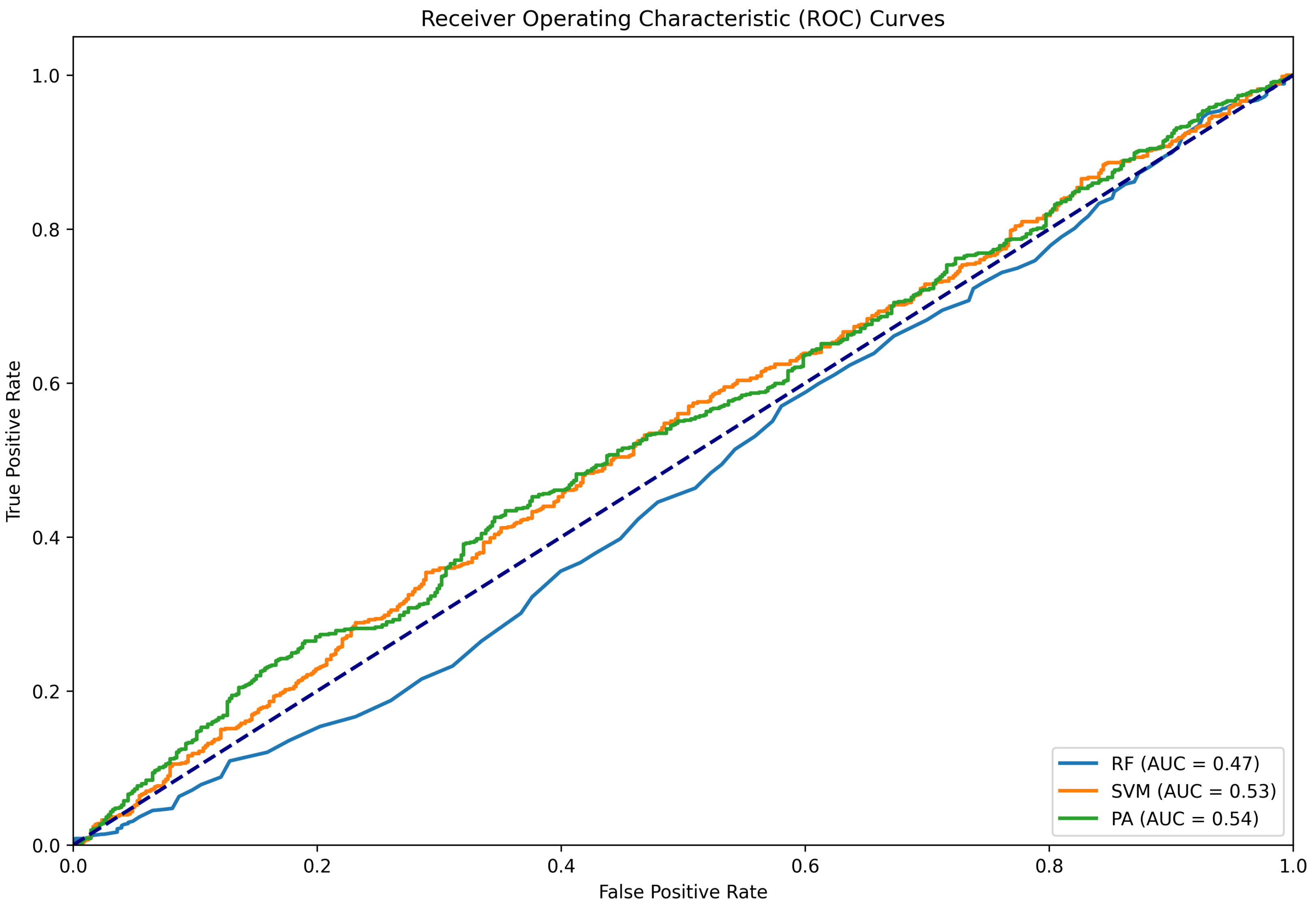
Figure 5.
ROC curve for the classifying results conducted using the Twitter15 dataset as train data and the LIAR as test data.
Figure 5.
ROC curve for the classifying results conducted using the Twitter15 dataset as train data and the LIAR as test data.
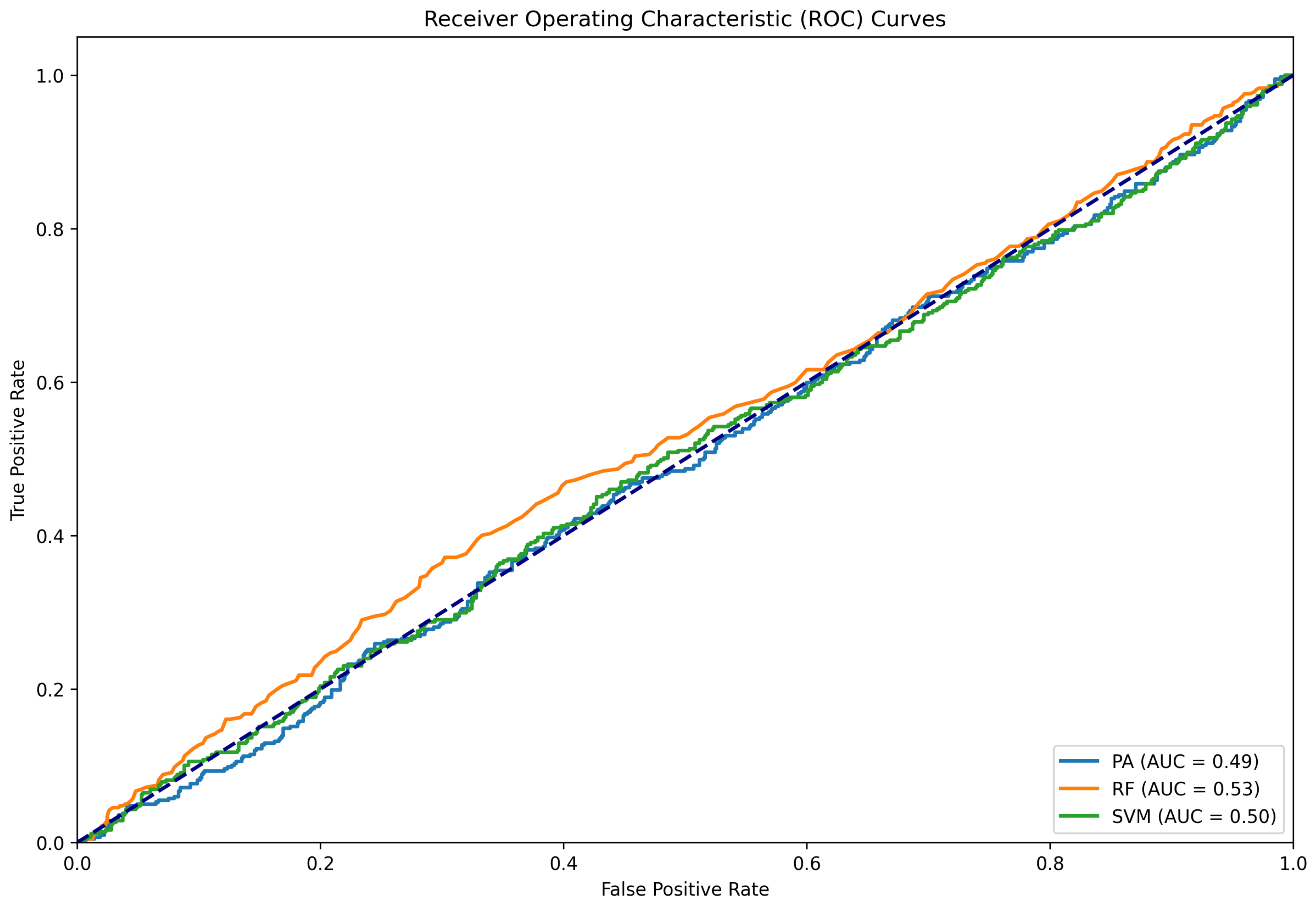
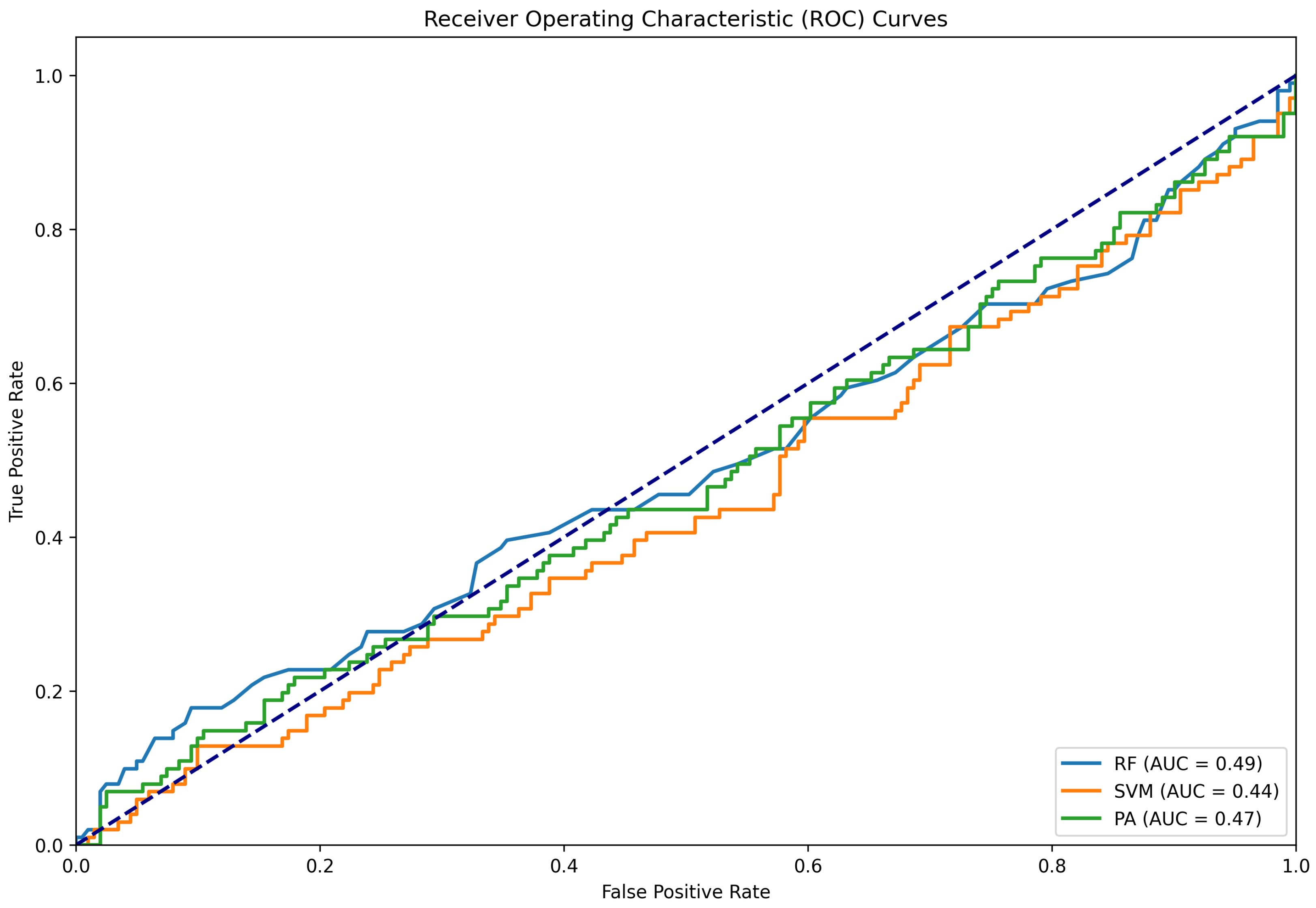
Figure 6.
ROC curve for the classifying results conducted using the Twitter15 dataset as test data and the LIAR as train data.
Figure 6.
ROC curve for the classifying results conducted using the Twitter15 dataset as test data and the LIAR as train data.
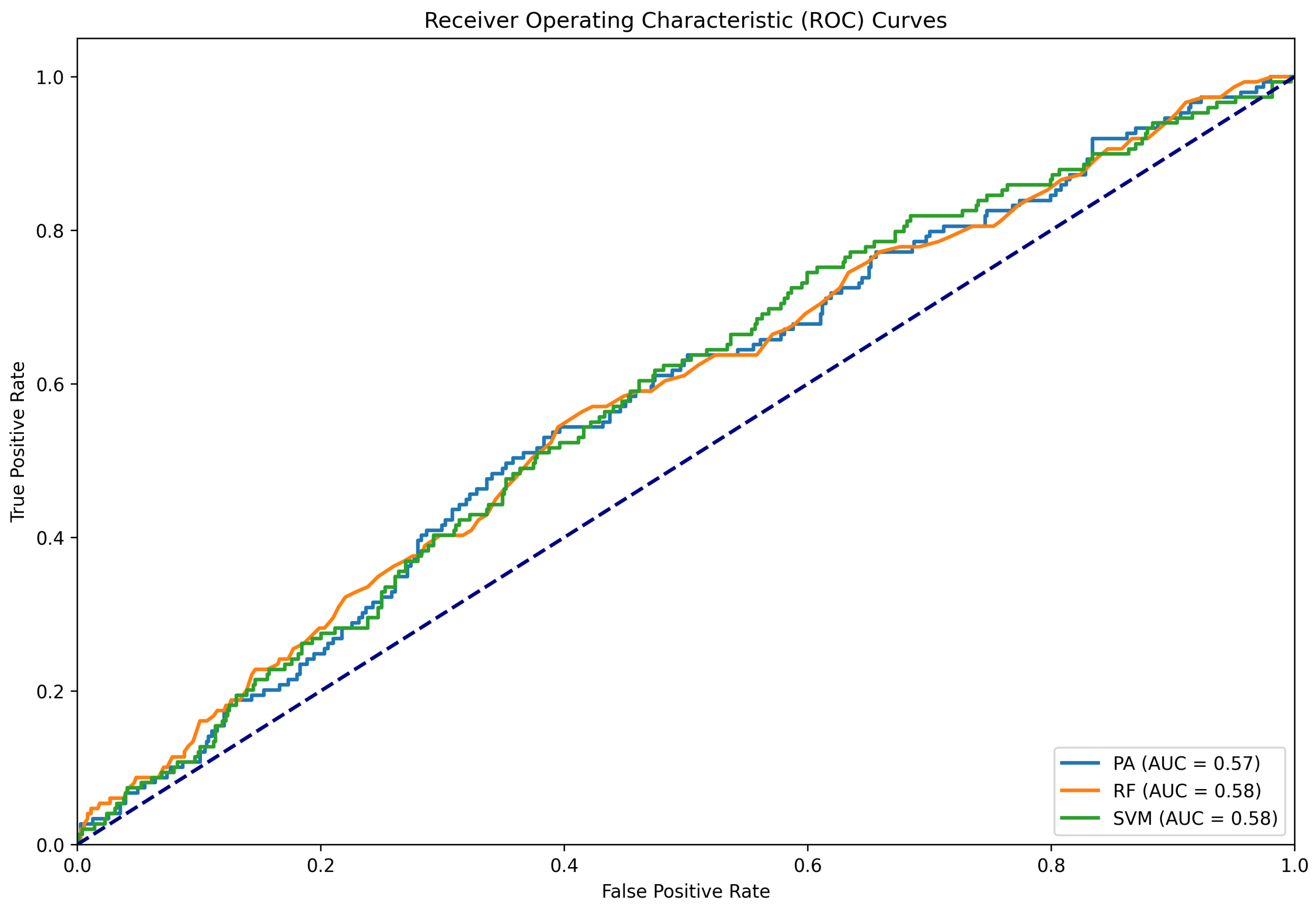
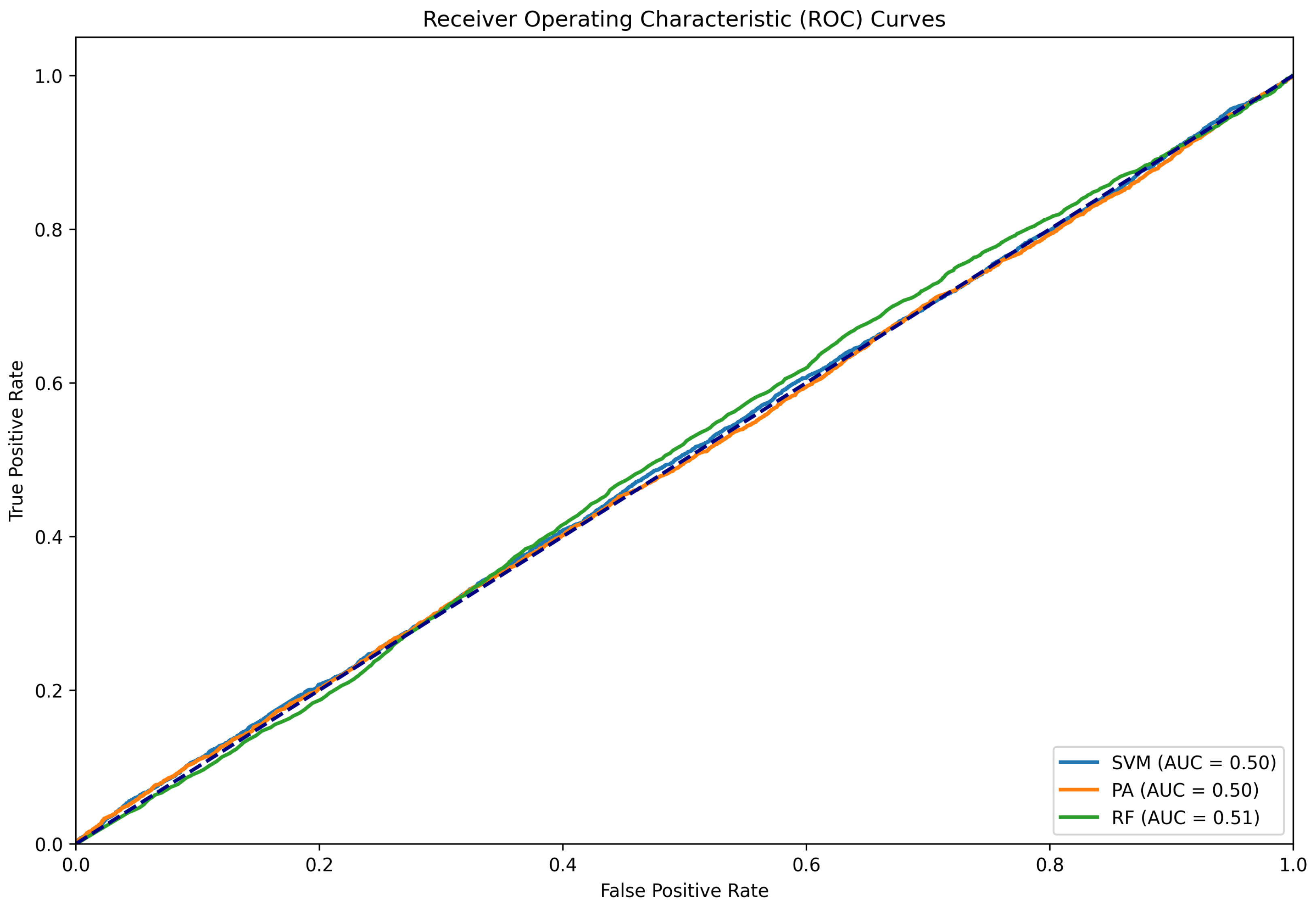
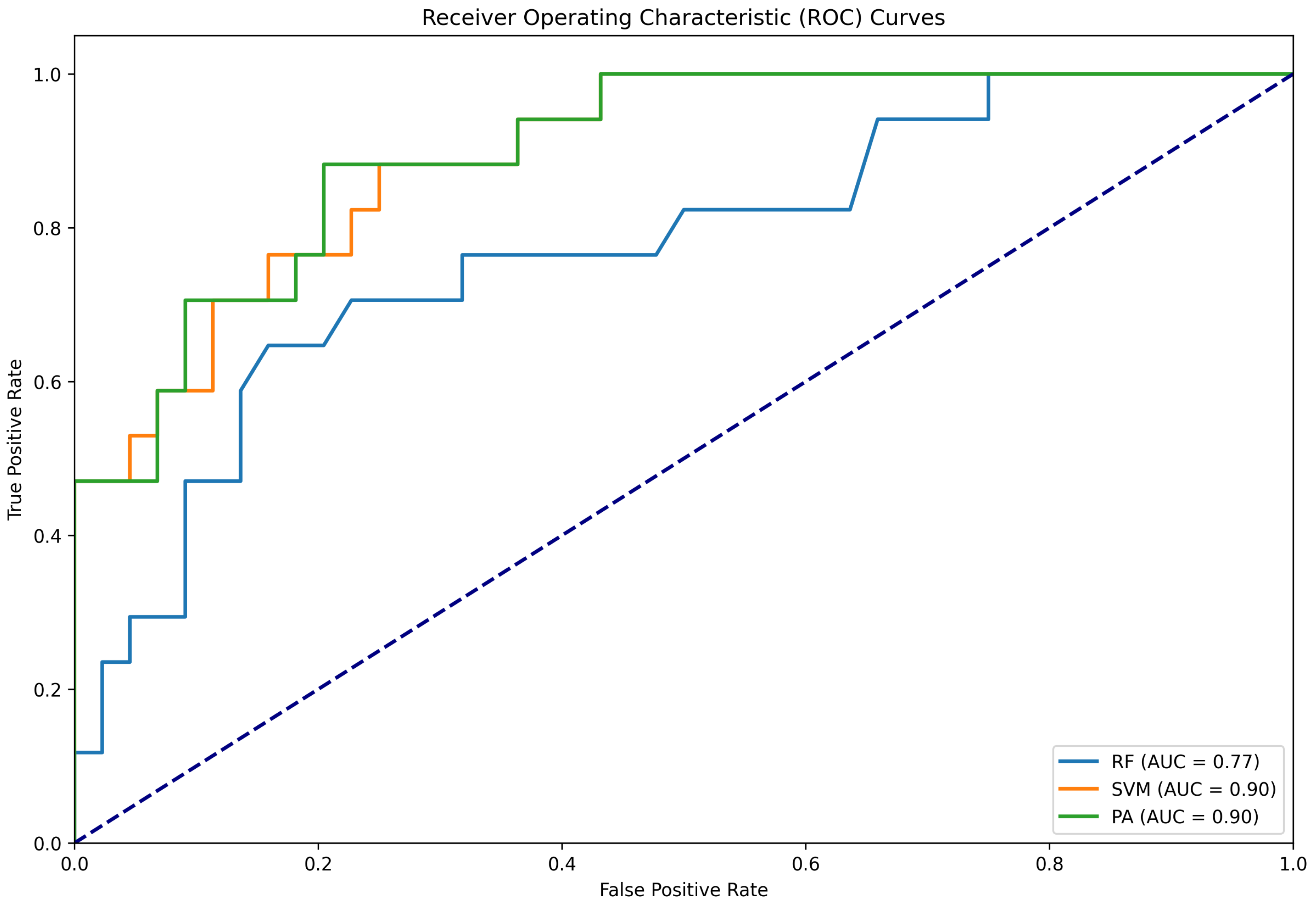
Figure 7.
ROC curve for the six-label classification experiment.
Figure 7.
ROC curve for the six-label classification experiment.
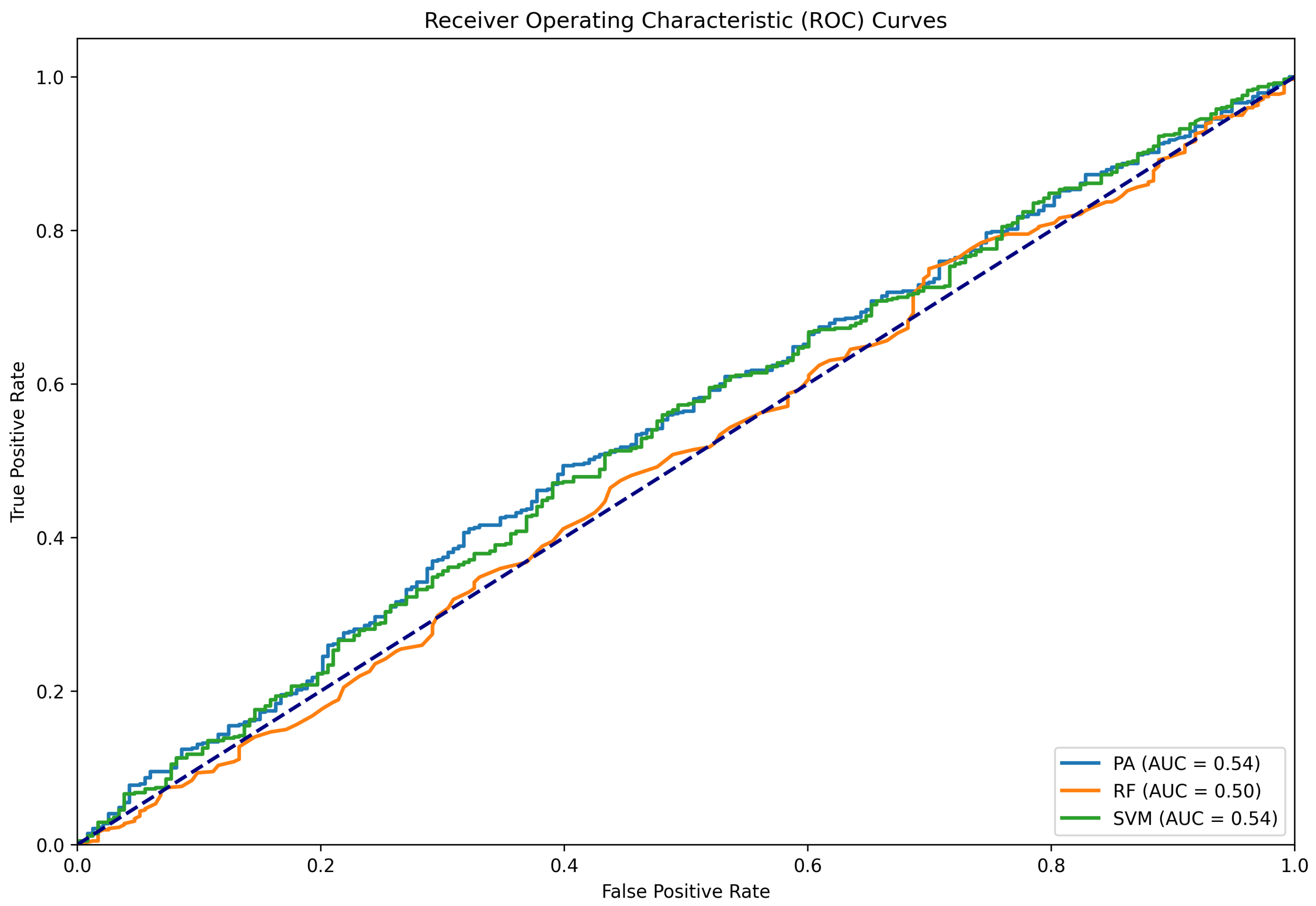
Figure 8.
ROC curve for the binary classification experiment where all the labels except “true” are re-labeled as false.
Figure 8.
ROC curve for the binary classification experiment where all the labels except “true” are re-labeled as false.
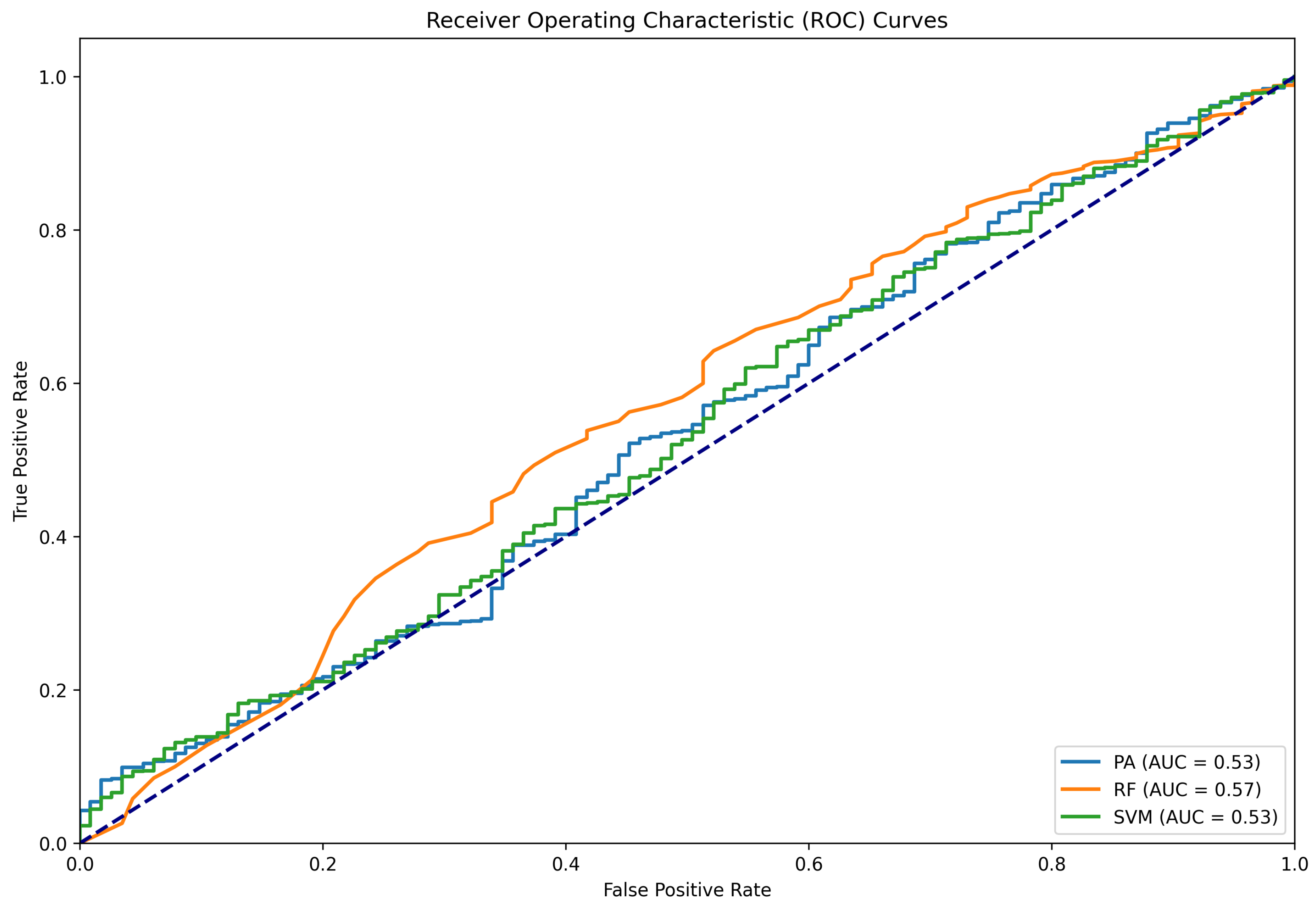
Figure 9.
ROC curve for the binary classification experiment where labels “pants-fire” and “false” are re-labeled as false and the rest as true.
Figure 9.
ROC curve for the binary classification experiment where labels “pants-fire” and “false” are re-labeled as false and the rest as true.
Figure 10.
ROC curve for the binary classification experiment where only the label “pants-fire” is considered false, and the rest are true.
Figure 10.
ROC curve for the binary classification experiment where only the label “pants-fire” is considered false, and the rest are true.
Figure 11.
ROC curve for the binary classification experiment where labels “barely-true”, “pants-fire” and “false” are considered false, and labels “half-true”, “mostly-true” and “true” are considered true.
Figure 11.
ROC curve for the binary classification experiment where labels “barely-true”, “pants-fire” and “false” are considered false, and labels “half-true”, “mostly-true” and “true” are considered true.
Figure 12.
ROC curve for the binary classification experiment where labels “mostly-true” and “true” are considered true and the rest false.
Figure 12.
ROC curve for the binary classification experiment where labels “mostly-true” and “true” are considered true and the rest false.
Figure 13.
ROC curve when the PolitiFact dataset was used as “train” and the GossipCop dataset was used as “test”.
Figure 13.
ROC curve when the PolitiFact dataset was used as “train” and the GossipCop dataset was used as “test”.
Figure 14.
ROC curve when the GossipCop dataset was used as “train” and the PolitiFact dataset was used as “test”.
Figure 14.
ROC curve when the GossipCop dataset was used as “train” and the PolitiFact dataset was used as “test”.
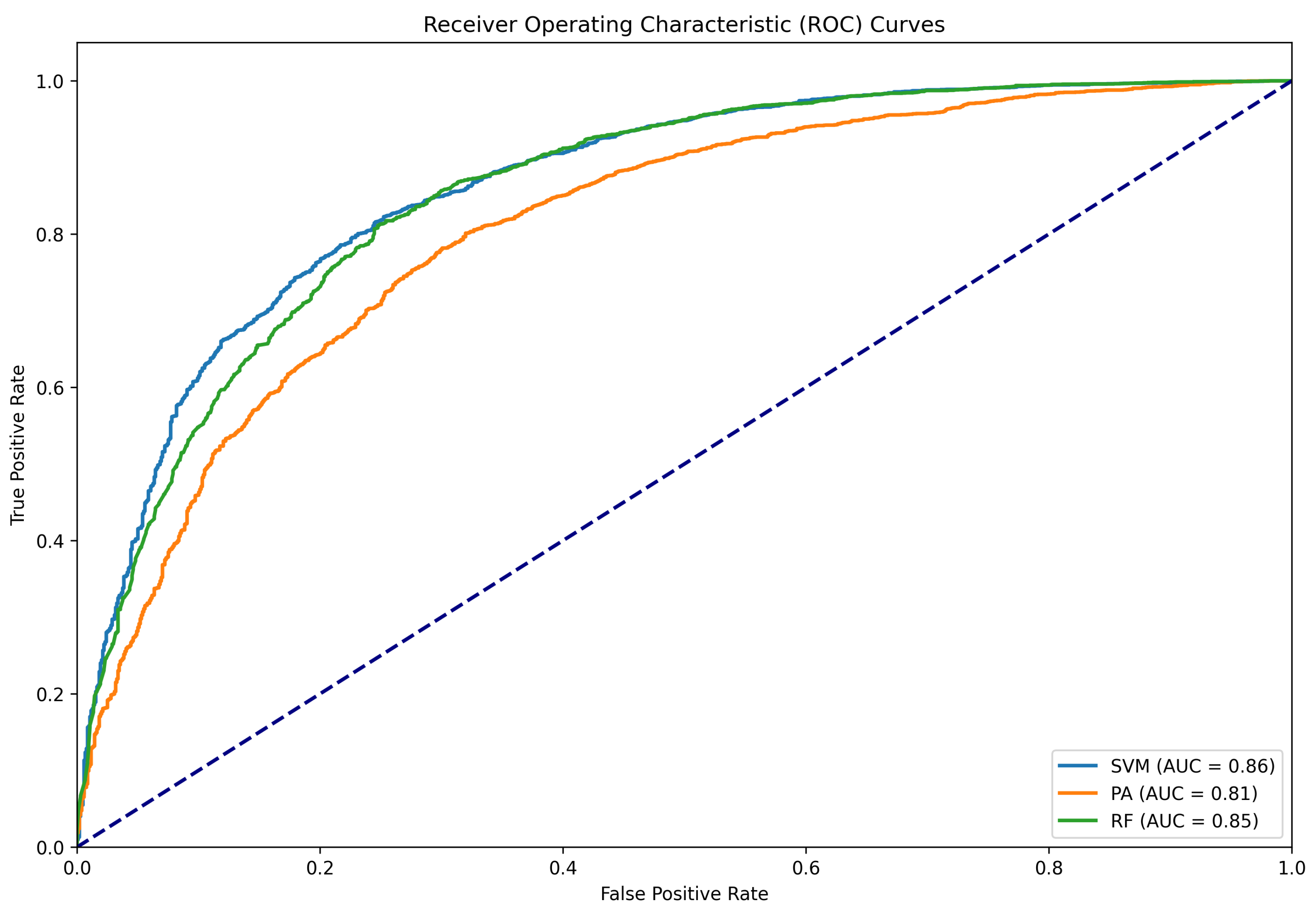
Figure 15.
ROC curve when the PolitiFact dataset was split into “train” and “test”.
Figure 15.
ROC curve when the PolitiFact dataset was split into “train” and “test”.
Figure 16.
ROC curve when the GossipCop dataset was split into “train” and “test”.
Figure 16.
ROC curve when the GossipCop dataset was split into “train” and “test”.
Figure 17.
ROC curve for the classifying results conducted using only the ChatGPT-generated dataset.
Figure 17.
ROC curve for the classifying results conducted using only the ChatGPT-generated dataset.
Figure 18.
ROC curve for the classifying results conducted using the ChatGPT-generated dataset as train data and the LIAR dataset as test data.
Figure 18.
ROC curve for the classifying results conducted using the ChatGPT-generated dataset as train data and the LIAR dataset as test data.
Figure 19.
ROC curve for the classifying results conducted using the ChatGPT-generated dataset as test data and the LIAR dataset as train data.
Figure 19.
ROC curve for the classifying results conducted using the ChatGPT-generated dataset as test data and the LIAR dataset as train data.
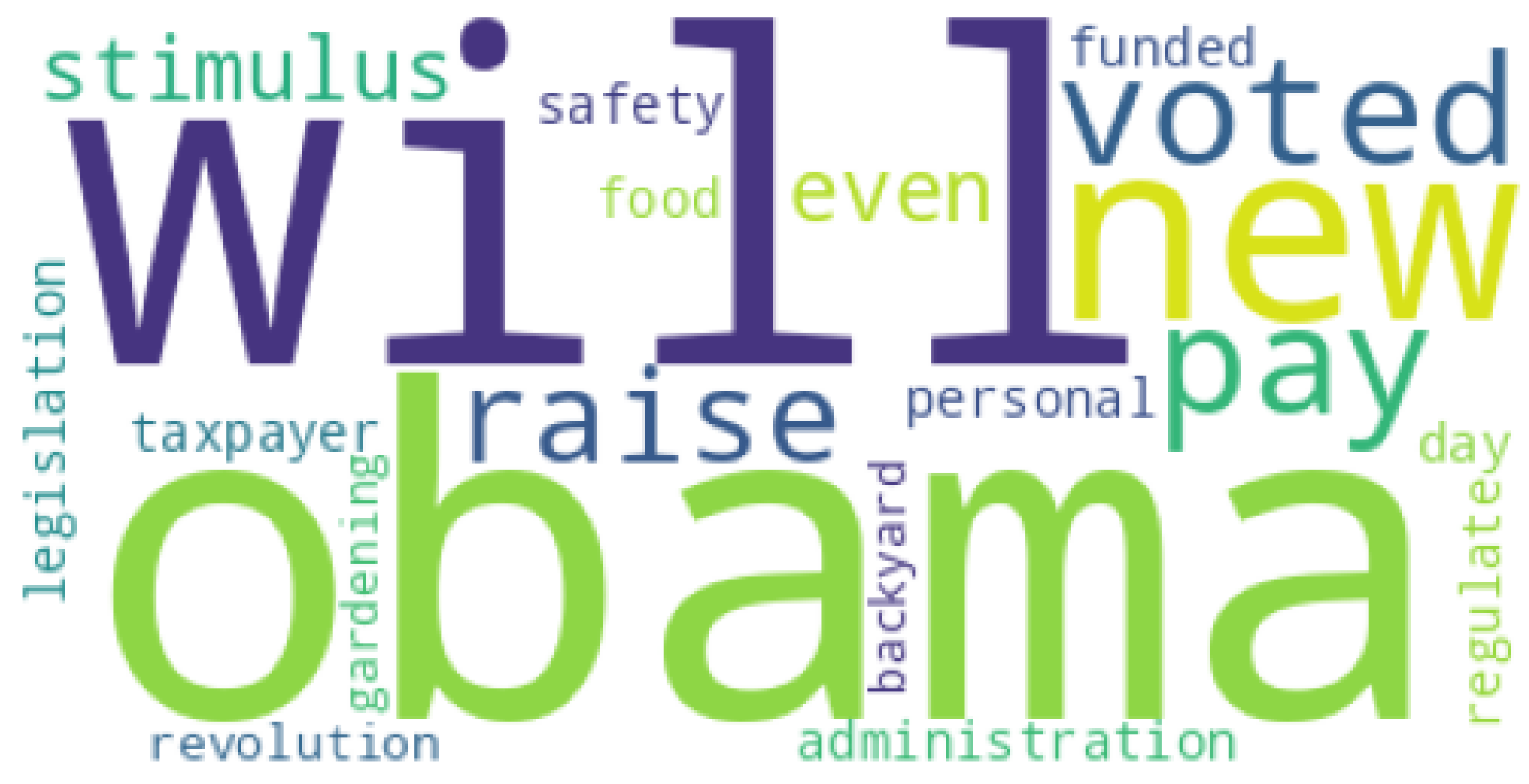
Figure 20.
Twenty most common words from LIAR dataset [
4].
Figure 20.
Twenty most common words from LIAR dataset [
4].
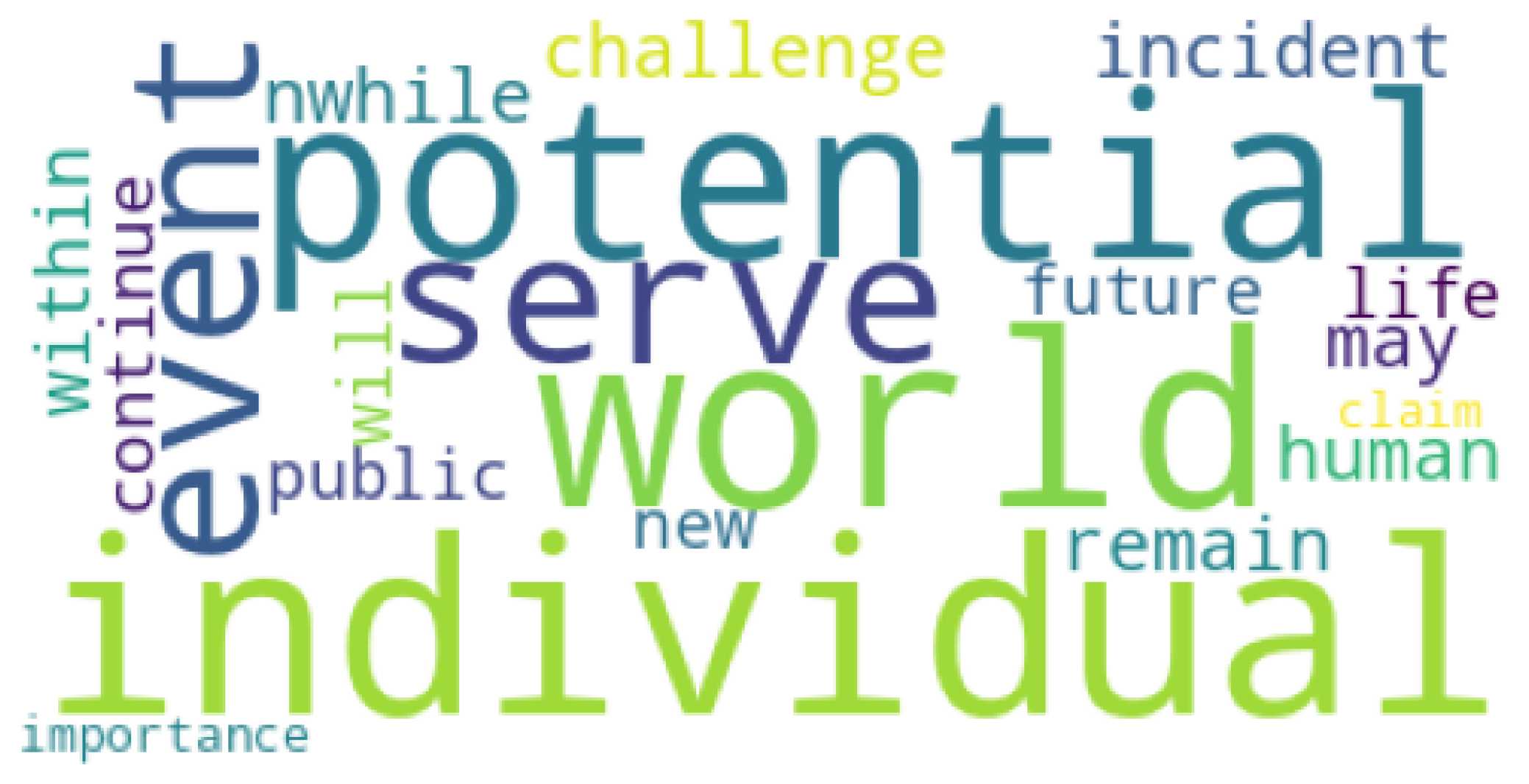
Figure 21.
Twenty most common words from ChatGPT-generated dataset.
Figure 21.
Twenty most common words from ChatGPT-generated dataset.
Table 1.
Descriptions of different types of deceptive information types.
Table 1.
Descriptions of different types of deceptive information types.
| Type | Description |
|---|
| Rumor | Quickly spreading story or news that can be true or invented. |
| A hoax | A deceptive piece of information used to trick people into believing in it. |
| False news | False or misleading information is presented as news. Used to be widely shared for influencing purposes. |
| False reviews | A review that is not an actual consumer’s opinion or does not reflect the actual opinion of a consumer. Often used to manipulate a consumer not to buy a certain product. |
| Satires | A type of parody where content is presented with irony or humor. Often used to criticize events, people, etc. |
| Urban legends | A false story that is circulated between people as true. Usually humorous, horrifying, or cautionary. |
| Propaganda | Information that is usually biased or misleading. It is used to promote a political cause or a point of view. |
Table 2.
“7 types of mis- and disinformation”. A taxonomy created by Wardle [
14].
Table 2.
“7 types of mis- and disinformation”. A taxonomy created by Wardle [
14].
| Type | Description |
|---|
| Satire or parody | No intention to cause harm but has the potential to fool. |
| Misleading Content | Misleading use of information to frame an issue or individual. |
| Imposter Content | When genuine sources are impersonated. |
| Fabricated Content | New content is 100% fake, designed to deceive and do harm. |
| False Connection | When headlines, visuals or captions do not support the content, also known as clickbait. |
| False Context | When genuine content is shared with false contextual information. |
| Manipulated Content | When genuine information or imagery is manipulated to deceive. |
Table 3.
Glossary of different terms used in the research.
Table 3.
Glossary of different terms used in the research.
| Type | Description |
|---|
| False news | False or misleading information presented as news, often called “fake news” as well [17]. This paper uses the term false news, as it has a less polarizing connotation. |
| Machine learning (ML) | The use and development of computer systems that can learn and adapt by using algorithms and statistical data to analyze patterns from the given data [18] |
| Artificial intelligence (AI) | The ability of computers to perform tasks that are usually more associated with intelligent beings [19] |
| Large language models (LLMs) | An example of generative AI. They can recognize, translate, predict, or generate texts or other forms of content [20]. A good example of LLMs would be ChatGPT. |
| Deep learning | A subset of ML, is a neural network with three or more layers. The neural networks attempt to simulate the behavior of the human brain [21] |
| Natural language processing (NLP) | The application of computational techniques to analyze and synthesize natural language and speech [22] |
Table 4.
A summary of all used datasets.
Table 4.
A summary of all used datasets.
| Datasets | All Samples | True Samples | False Samples | Information Type |
|---|
| LIAR | 12,851 | 7134 | 5707 | News related to politics. |
| FakeNewsNet | 23,921 | 6480 | 17,441 | News related to politics and celebrity gossip. |
| Twitter15 | 1490 | 372 | 370 | Rumors spread on Twitter. |
| Novel ChatGPT | 300 | 100 | 200 | Automatically generated false and real news articles. |
Table 5.
An example of a randomly chosen statement from the LIAR dataset. The label history shows how many times the speaker has made a statement that belongs to one of the six different label cases in the dataset.
Table 5.
An example of a randomly chosen statement from the LIAR dataset. The label history shows how many times the speaker has made a statement that belongs to one of the six different label cases in the dataset.
| Elements | Value of Elements |
|---|
| ID | 8303 |
| Label | half true |
| Statement | Tuition at Rutgers has increased 10 percent since Gov. Chris Christie
took office
because he cut funding for higher education. |
| Subject | education, state finances |
| Speaker | Barbara Buono |
| Job title | State Senator |
| Party affiliation | democrat |
| Label history | 3, 1, 4, 4, 1 |
| Context | a speech to students at the Rutgers New Brunswick campus |
Table 6.
Examples of randomly chosen false and real news articles from both FakeNewsNet’s datasets.
Table 6.
Examples of randomly chosen false and real news articles from both FakeNewsNet’s datasets.
Table 7.
An example of a randomly chosen news article from the Twitter15 dataset.
Table 7.
An example of a randomly chosen news article from the Twitter15 dataset.
| Elements | Value of Elements |
|---|
| ID | 693560600471863296 |
| Events | miami was desperate for a turnover. instead, nc state got this dunk. and a big upset win: URL |
| Veracity | non-rumor |
Table 8.
An example of an entry in the novel ChatGPT-generated dataset.
Table 8.
An example of an entry in the novel ChatGPT-generated dataset.
Table 9.
Performance report on the classifying results conducted only using the Twitter15 dataset.
Table 9.
Performance report on the classifying results conducted only using the Twitter15 dataset.
| Method | Accuracy | Precision | Recall | F1 | AUC | FPR | FNR |
|---|
| SGD | 0.84 | 0.84 | 0.84 | 0.84 | 0.93 | 0.04 | 0.15 |
| PA | 0.86 | 0.87 | 0.87 | 0.87 | 0.95 | 0.04 | 0.12 |
| RF | 0.81 | 0.82 | 0.80 | 0.80 | 0.94 | 0.06 | 0.43 |
| MLP | 0.68 | 0.70 | 0.68 | 0.68 | 0.50 | 0.33 | 0.66 |
| LR | 0.85 | 0.86 | 0.85 | 0.86 | 0.96 | 0.03 | 0.31 |
| ADA | 0.55 | 0.54 | 0.54 | 0.53 | 0.72 | 0.00 | 0.97 |
| kNN | 0.79 | 0.79 | 0.79 | 0.78 | 0.95 | 0.05 | 0.15 |
| NB | 0.80 | 0.80 | 0.80 | 0.80 | 0.96 | 0.06 | 0.36 |
| DT | 0.71 | 0.72 | 0.72 | 0.72 | 0.83 | 0.11 | 0.22 |
| SVM | 0.87 | 0.87 | 0.87 | 0.87 | 0.96 | 0.03 | 0.16 |
Table 10.
Performance report on the classifying results conducted using Twitter15 as train data and LIAR as test data.
Table 10.
Performance report on the classifying results conducted using Twitter15 as train data and LIAR as test data.
| Method | Accuracy | Precision | Recall | F1 | AUC | FPR | FNR |
|---|
| SGD | 0.34 | 0.32 | 0.32 | 0.28 | 0.49 | 0.33 | 0.67 |
| PA | 0.35 | 0.35 | 0.34 | 0.29 | 0.49 | 0.32 | 0.69 |
| RF | 0.36 | 0.31 | 0.33 | 0.22 | 0.50 | 0.27 | 0.73 |
| MLP | 0.38 | 0.13 | 0.33 | 0.18 | 0.50 | 0.33 | 0.66 |
| LR | 0.37 | 0.28 | 0.33 | 0.21 | 0.51 | 0.27 | 0.74 |
| ADA | 0.36 | 0.32 | 0.33 | 0.24 | 0.50 | 0.00 | 1.00 |
| kNN | 0.35 | 0.34 | 0.34 | 0.32 | 0.52 | 0.28 | 0.70 |
| NB | 0.37 | 0.18 | 0.33 | 0.18 | 0.50 | 0.30 | 0.62 |
| DT | 0.36 | 0.32 | 0.32 | 0.27 | 0.49 | 0.33 | 0.67 |
| SVM | 0.36 | 0.31 | 0.34 | 0.26 | 0.50 | 0.32 | 0.68 |
Table 11.
Performance report on the classifying results conducted using Twitter15 as test data and LIAR as train data.
Table 11.
Performance report on the classifying results conducted using Twitter15 as test data and LIAR as train data.
| Method | Acc. | Precision | Recall | F1 | AUC | FPR | FNR |
|---|
| SGD | 0.26 | 0.28 | 0.27 | 0.27 | 0.41 | 0.30 | 0.78 |
| PA | 0.24 | 0.24 | 0.24 | 0.23 | 0.40 | 0.49 | 0.67 |
| RF | 0.39 | 0.34 | 0.33 | 0.32 | 0.49 | 0.01 | 0.94 |
| MLP | 0.50 | 0.17 | 0.33 | 0.22 | 0.50 | 0.00 | 1.00 |
| LR | 0.28 | 0.28 | 0.28 | 0.27 | 0.43 | 0.05 | 0.97 |
| ADA | 0.40 | 0.30 | 0.31 | 0.29 | 0.44 | 0.00 | 1.00 |
| kNN | 0.31 | 0.34 | 0.32 | 0.31 | 0.51 | 0.25 | 0.75 |
| NB | 0.33 | 0.29 | 0.31 | 0.29 | 0.44 | 0.02 | 0.99 |
| DT | 0.35 | 0.31 | 0.31 | 0.21 | 0.48 | 0.33 | 0.69 |
| SVM | 0.27 | 0.29 | 0.28 | 0.27 | 0.42 | 0.44 | 0.66 |
Table 12.
Performance report for the six-label classification experiment.
Table 12.
Performance report for the six-label classification experiment.
| Method | Accuracy | Precision | Recall | F1 | AUC | FPR | FNR |
|---|
| PA | 0.21 | 0.20 | 0.20 | 0.20 | 0.56 | 0.34 | 0.58 |
| RF | 0.25 | 0.25 | 0.22 | 0.21 | 0.56 | 0.00 | 1.00 |
| SVM | 0.23 | 0.22 | 0.22 | 0.21 | 0.57 | 0.28 | 0.64 |
Table 13.
Performance report for the binary classification experiment where all the labels except “true” are re-labeled as false.
Table 13.
Performance report for the binary classification experiment where all the labels except “true” are re-labeled as false.
| Method | Accuracy | Precision | Recall | F1 | AUC | FPR | FNR |
|---|
| PA | 0.76 | 0.52 | 0.51 | 0.51 | 0.57 | 0.39 | 0.46 |
| RF | 0.83 | 0.91 | 0.50 | 0.46 | 0.58 | 0.00 | 0.99 |
| SVM | 0.81 | 0.51 | 0.50 | 0.47 | 0.58 | 0.25 | 0.67 |
Table 14.
Performance report for the binary classification experiment where labels “pants-fire” and “false” are re-labeled as false and the rest as true.
Table 14.
Performance report for the binary classification experiment where labels “pants-fire” and “false” are re-labeled as false and the rest as true.
| Method | Accuracy | Precision | Recall | F1 | AUC | FPR | FNR |
|---|
| PA | 0.79 | 0.51 | 0.51 | 0.51 | 0.54 | 0.48 | 0.44 |
| RF | 0.86 | 0.43 | 0.50 | 0.46 | 0.50 | 0.99 | 0.01 |
| SVM | 0.85 | 0.51 | 0.50 | 0.48 | 0.54 | 0.54 | 0.39 |
Table 15.
Performance report for the binary classification experiment where only the label “pants-fire” is considered false, and the rest are true.
Table 15.
Performance report for the binary classification experiment where only the label “pants-fire” is considered false, and the rest are true.
| Method | Accuracy | Precision | Recall | F1 | AUC | FPR | FNR |
|---|
| PA | 0.88 | 0.53 | 0.51 | 0.51 | 0.53 | 0.50 | 0.46 |
| RF | 0.91 | 0.45 | 0.50 | 0.48 | 0.57 | 1.00 | 0.00 |
| SVM | 0.91 | 0.45 | 0.50 | 0.48 | 0.53 | 0.65 | 0.29 |
Table 16.
Performance report for the binary classification experiment where labels “barely-true”, “pants-fire” and “false” are considered false, and labels “half-true”, “mostly-true” and “true” are considered true.
Table 16.
Performance report for the binary classification experiment where labels “barely-true”, “pants-fire” and “false” are considered false, and labels “half-true”, “mostly-true” and “true” are considered true.
| Method | Accuracy | Precision | Recall | F1 | AUC | FPR | FNR |
|---|
| PA | 0.56 | 0.55 | 0.55 | 0.55 | 0.59 | 0.37 | 0.53 |
| RF | 0.59 | 0.59 | 0.59 | 0.59 | 0.63 | 0.45 | 0.35 |
| SVM | 0.58 | 0.58 | 0.58 | 0.58 | 0.60 | 0.25 | 0.62 |
Table 17.
Performance report for the binary classification experiment where labels “mostly-true” and “true” are considered true and the rest false.
Table 17.
Performance report for the binary classification experiment where labels “mostly-true” and “true” are considered true and the rest false.
| Method | Accuracy | Precision | Recall | F1 | AUC | FPR | FNR |
|---|
| PA | 0.56 | 0.49 | 0.49 | 0.49 | 0.49 | 0.46 | 0.53 |
| RF | 0.65 | 0.50 | 0.50 | 0.44 | 0.53 | 0.07 | 0.93 |
| SVM | 0.60 | 0.51 | 0.50 | 0.50 | 0.50 | 0.40 | 0.59 |
Table 18.
Performance report when the PolitiFact dataset was used as “train” and the GossipCop dataset was used as “test”.
Table 18.
Performance report when the PolitiFact dataset was used as “train” and the GossipCop dataset was used as “test”.
| Method | Accuracy | Precision | Recall | F1 | AUC | FPR | FNR |
|---|
| PA | 0.42 | 0.50 | 0.49 | 0.41 | 0.50 | 0.63 | 0.37 |
| RF | 0.64 | 0.51 | 0.51 | 0.51 | 0.53 | 0.74 | 0.26 |
| SVM | 0.44 | 0.50 | 0.50 | 0.43 | 0.51 | 0.63 | 0.37 |
Table 19.
Performance report when the GossipCop dataset was used as “train” and the PolitiFact dataset was used as “test”.
Table 19.
Performance report when the GossipCop dataset was used as “train” and the PolitiFact dataset was used as “test”.
| Method | Accuracy | Precision | Recall | F1 | AUC | FPR | FNR |
|---|
| PA | 0.59 | 0.56 | 0.55 | 0.54 | 0.55 | 0.58 | 0.34 |
| RF | 0.59 | 0.57 | 0.51 | 0.41 | 0.57 | 0.98 | 0.02 |
| SVM | 0.62 | 0.61 | 0.56 | 0.52 | 0.60 | 0.45 | 0.37 |
Table 20.
Performance report when the PolitiFact dataset was split into “train” and “test”.
Table 20.
Performance report when the PolitiFact dataset was split into “train” and “test”.
| Method | Accuracy | Precision | Recall | F1 | AUC | FPR | FNR |
|---|
| PA | 0.83 | 0.83 | 0.81 | 0.82 | 0.85 | 0.14 | 0.20 |
| RF | 0.76 | 0.76 | 0.73 | 0.74 | 0.84 | 0.35 | 0.06 |
| SVM | 0.83 | 0.83 | 0.81 | 0.82 | 0.85 | 0.17 | 0.12 |
Table 21.
Performance report when the GossipCop dataset was split into “train” and “test”.
Table 21.
Performance report when the GossipCop dataset was split into “train” and “test”.
| Method | Accuracy | Precision | Recall | F1 | AUC | FPR | FNR |
|---|
| PA | 0.80 | 0.72 | 0.72 | 0.72 | 0.80 | 0.15 | 0.44 |
| RF | 0.84 | 0.82 | 0.71 | 0.74 | 0.84 | 0.54 | 0.00 |
| SVM | 0.85 | 0.80 | 0.75 | 0.77 | 0.85 | 0.35 | 0.10 |
Table 22.
Performance report on the classifying results conducted using only the ChatGPT-generated dataset.
Table 22.
Performance report on the classifying results conducted using only the ChatGPT-generated dataset.
| Method | Accuracy | Precision | Recall | F1 | AUC | FPR | FNR |
|---|
| RF | 0.87 | 0.93 | 0.56 | 0.56 | 0.85 | 0.00 | 0.82 |
| SVM | 0.84 | 0.64 | 0.58 | 0.60 | 0.95 | 0.05 | 0.32 |
| PA | 0.89 | 0.74 | 0.79 | 0.76 | 0.95 | 0.05 | 0.23 |
Table 23.
Performance report on the classifying results conducted using the ChatGPT-generated dataset as train data and the LIAR dataset as test data.
Table 23.
Performance report on the classifying results conducted using the ChatGPT-generated dataset as train data and the LIAR dataset as test data.
| Method | Accuracy | Precision | Recall | F1 | AUC | FPR | FNR |
|---|
| RF | 0.53 | 0.48 | 0.49 | 0.44 | 0.47 | 0.75 | 0.28 |
| SVM | 0.56 | 0.52 | 0.50 | 0.43 | 0.53 | 0.33 | 0.63 |
| PA | 0.53 | 0.52 | 0.52 | 0.51 | 0.54 | 0.26 | 0.69 |
Table 24.
Performance report on the classifying results conducted using the ChatGPT-generated dataset as test data and the LIAR dataset as train data.
Table 24.
Performance report on the classifying results conducted using the ChatGPT-generated dataset as test data and the LIAR dataset as train data.
| Method | Accuracy | Precision | Recall | F1 | AUC | FPR | FNR |
|---|
| RF | 0.33 | 0.42 | 0.50 | 0.25 | 0.47 | 0.99 | 0.03 |
| SVM | 0.33 | 0.41 | 0.47 | 0.29 | 0.44 | 0.78 | 0.30 |
| PA | 0.39 | 0.47 | 0.48 | 0.38 | 0.49 | 0.75 | 0.30 |
Table 25.
TF-IDF scores of 20 most common words from LIAR dataset [
4].
Table 25.
TF-IDF scores of 20 most common words from LIAR dataset [
4].
| Word | TF-IDF Score |
|---|
| backyard | 0.44503 |
| gardening | 0.44503 |
| revolution | 0.96835 |
| regulate | 1.13286 |
| safety | 1.66006 |
| personal | 2.26182 |
| taxpayer | 3.97960 |
| funded | 4.05192 |
| food | 5.22986 |
| day | 5.82952 |
| legislation | 6.16053 |
| administration | 8.80094 |
| even | 9.62488 |
| stimulus | 10.08428 |
| raise | 10.20364 |
| pay | 14.15832 |
| voted | 19.63578 |
| new | 24.33575 |
| will | 26.08082 |
| obama | 44.67069 |
Table 26.
N-gram frequencies of 20 most common words from LIAR dataset [
4].
Table 26.
N-gram frequencies of 20 most common words from LIAR dataset [
4].
| Word | N-Gram Frequency |
|---|
| backyard | 1 |
| gardening | 1 |
| revolution | 3 |
| regulate | 3 |
| safety | 5 |
| personal | 8 |
| taxpayer | 15 |
| funded | 14 |
| food | 20 |
| day | 26 |
| legislation | 27 |
| administration | 40 |
| even | 45 |
| stimulus | 41 |
| raise | 40 |
| pay | 65 |
| voted | 91 |
| new | 135 |
| will | 158 |
| obama | 271 |
Table 27.
TF-IDF scores of 20 most common words from ChatGPT-generated dataset.
Table 27.
TF-IDF scores of 20 most common words from ChatGPT-generated dataset.
| Word | TF-IDF Score |
|---|
| meanwhile | 0.27872 |
| serve | 0.76586 |
| claim | 1.02257 |
| continue | 1.28523 |
| challenge | 1.15479 |
| remain | 1.64038 |
| individual | 1.69804 |
| new | 1.70962 |
| event | 1.71798 |
| future | 1.90560 |
| importance | 1.98240 |
| may | 2.35172 |
| within | 2.36911 |
| life | 2.41739 |
| public | 2.67856 |
| will | 3.18160 |
| world | 3.38626 |
| human | 3.42755 |
| potential | 3.52128 |
| incident | 3.87482 |
Table 28.
N-gram frequencies of 20 most common words from ChatGPT-generated dataset.
Table 28.
N-gram frequencies of 20 most common words from ChatGPT-generated dataset.
| Word | N-Gram Frequency |
|---|
| meanwhile | 8 |
| serve | 28 |
| claim | 35 |
| continue | 65 |
| challenge | 46 |
| remain | 85 |
| individual | 69 |
| new | 98 |
| event | 64 |
| future | 113 |
| importance | 111 |
| may | 154 |
| within | 148 |
| life | 133 |
| public | 167 |
| will | 223 |
| world | 246 |
| human | 183 |
| potential | 262 |
| incident | 164 |







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}