Figure 1.
Architecture diagram of this paper.
Figure 1.
Architecture diagram of this paper.
Figure 2.
Distribution of converted labels containing benign traffic.
Figure 2.
Distribution of converted labels containing benign traffic.
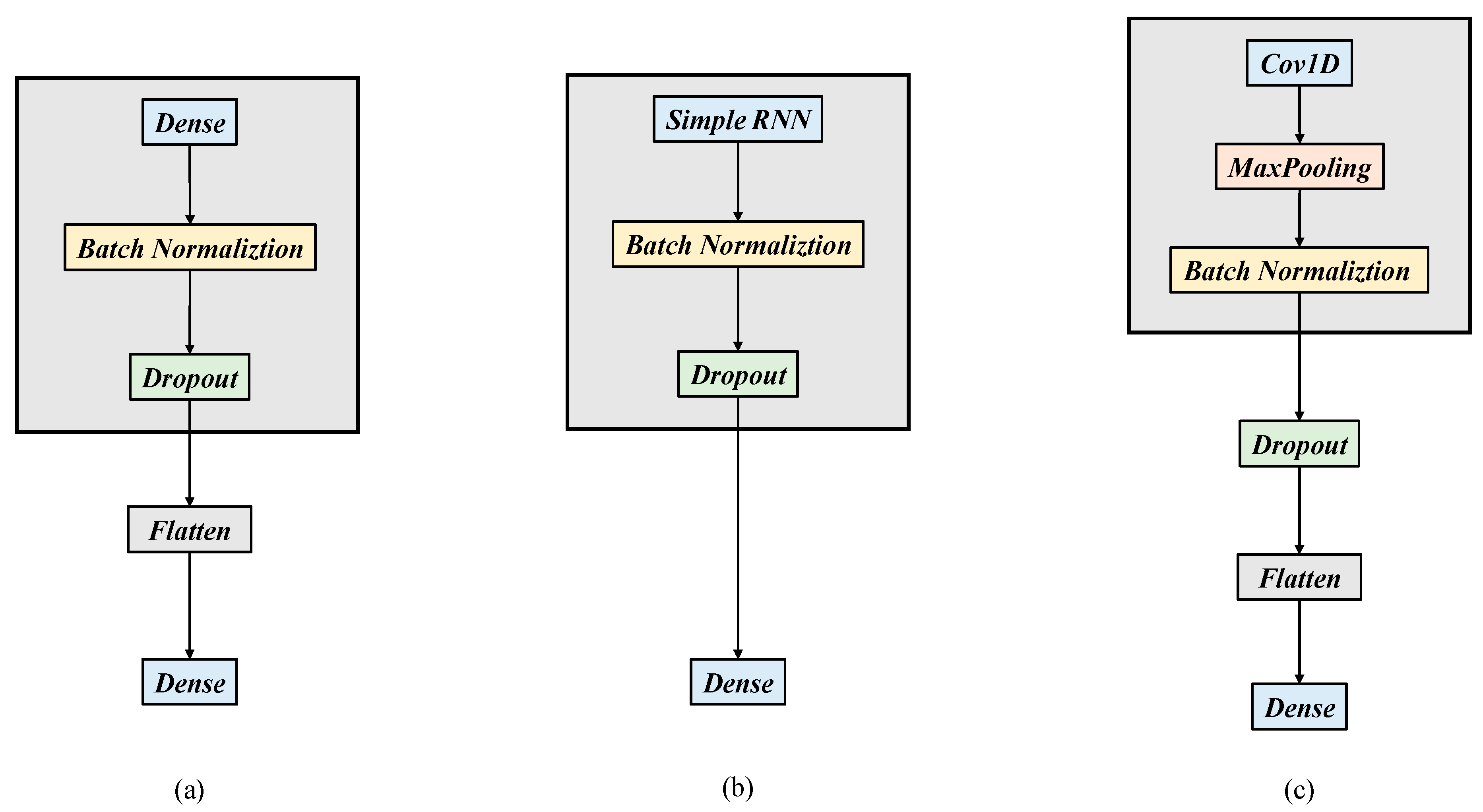
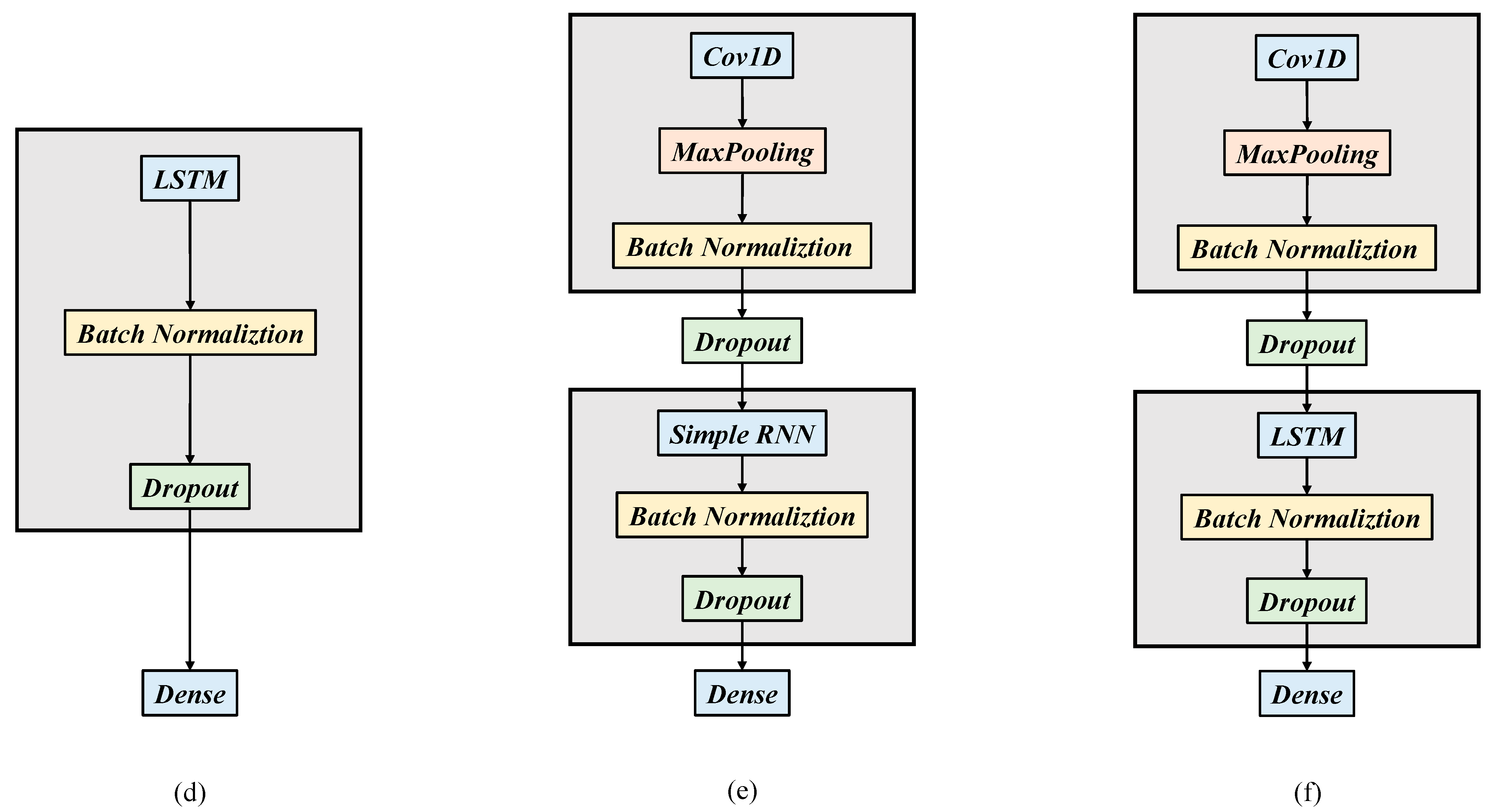
Figure 3.
(a) Architecture diagram of DNN, (b) architecture diagram of RNN, (c) architecture diagram of CNN, (d) architecture diagram of LSTM, (e) architecture diagram of CNN + RNN, and (f) architecture diagram of CNN + LSTM.
Figure 3.
(a) Architecture diagram of DNN, (b) architecture diagram of RNN, (c) architecture diagram of CNN, (d) architecture diagram of LSTM, (e) architecture diagram of CNN + RNN, and (f) architecture diagram of CNN + LSTM.
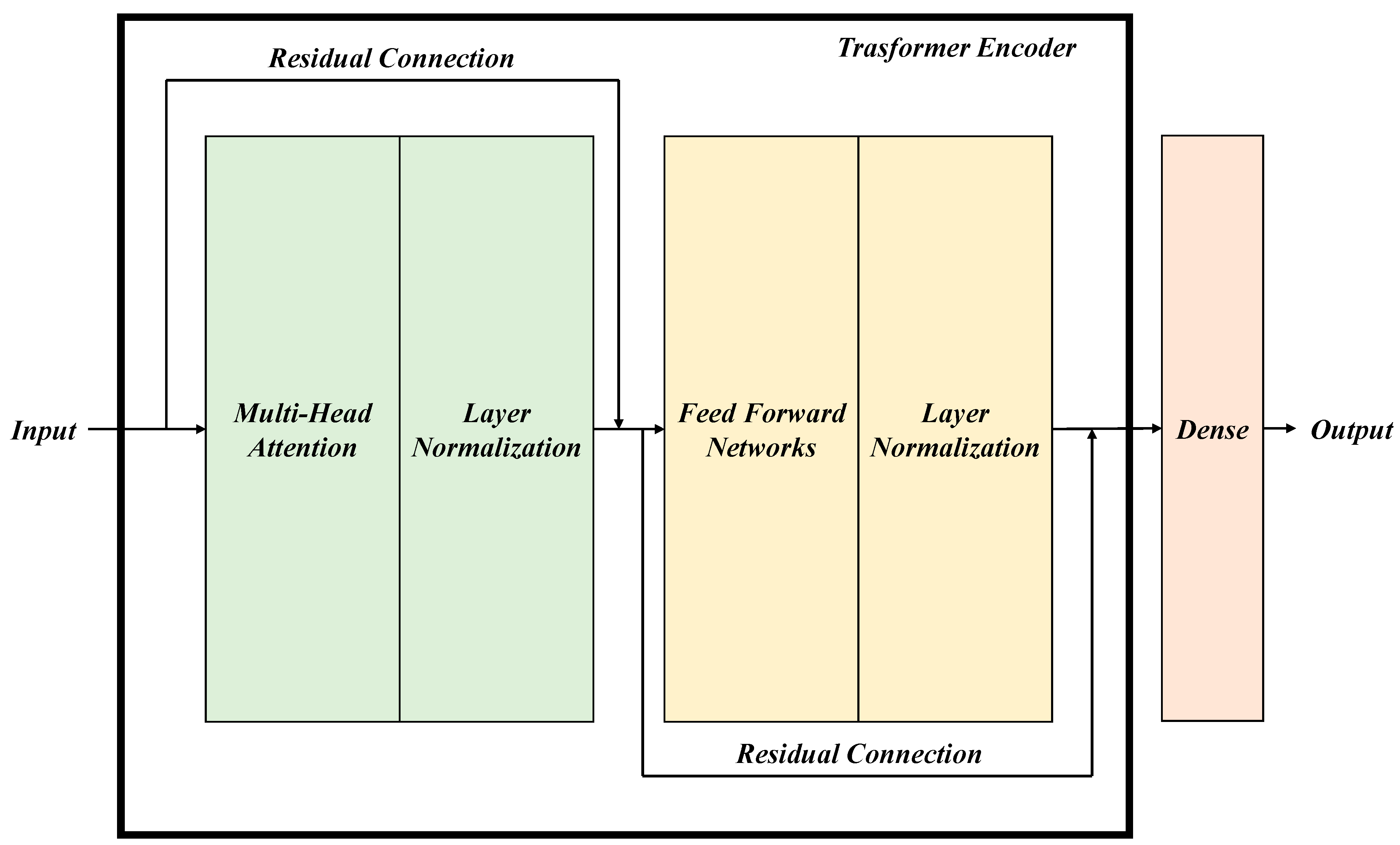
Figure 4.
Transformer encoder architecture diagram.
Figure 4.
Transformer encoder architecture diagram.
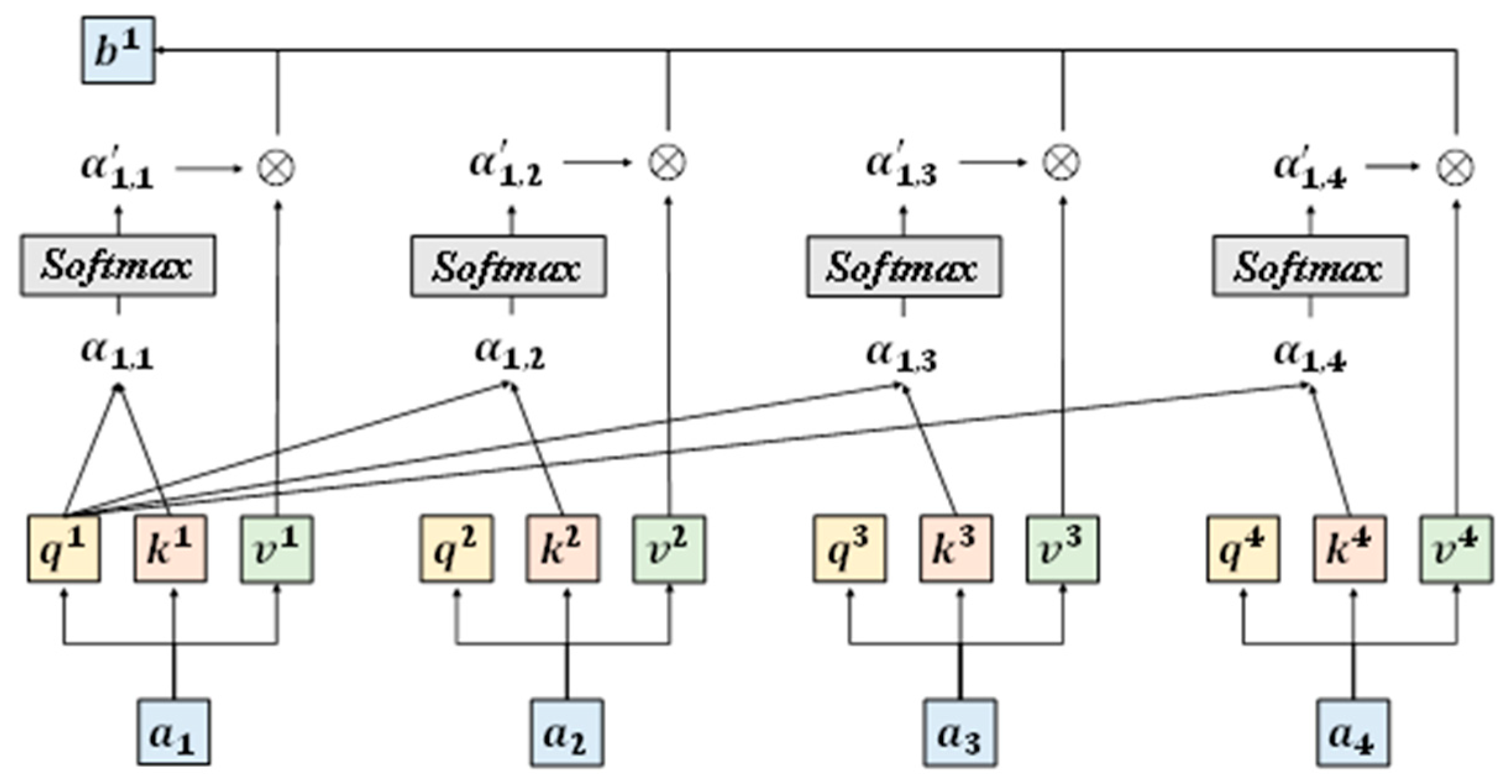
Figure 5.
The schematic diagram of finding one of the outputs .
Figure 5.
The schematic diagram of finding one of the outputs .
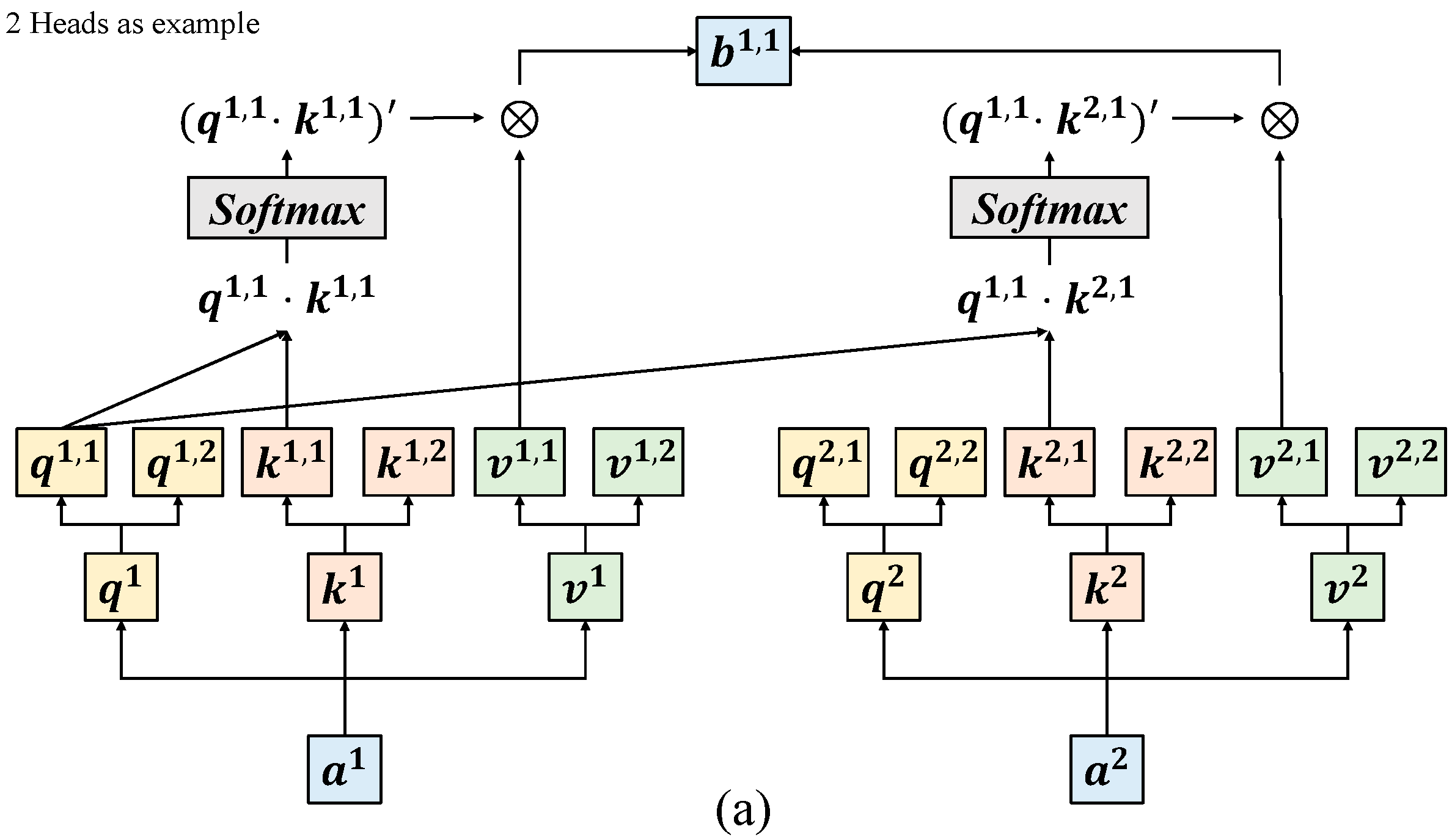
Figure 6.
(a) The schematic diagram of finding one of the output ; (b) the schematic diagram of finding one of the output ; and (c) the schematic diagram of adding two results.
Figure 6.
(a) The schematic diagram of finding one of the output ; (b) the schematic diagram of finding one of the output ; and (c) the schematic diagram of adding two results.
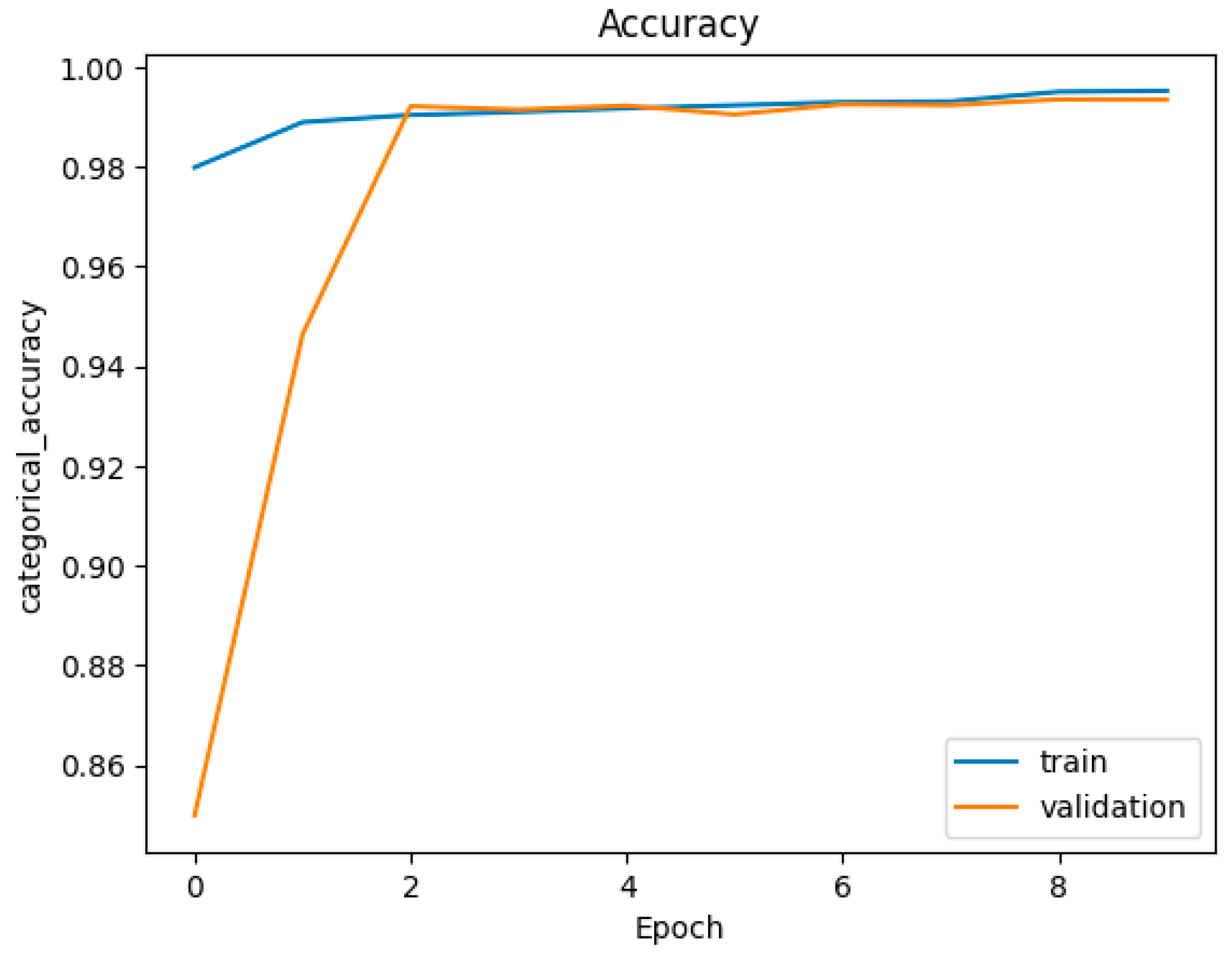
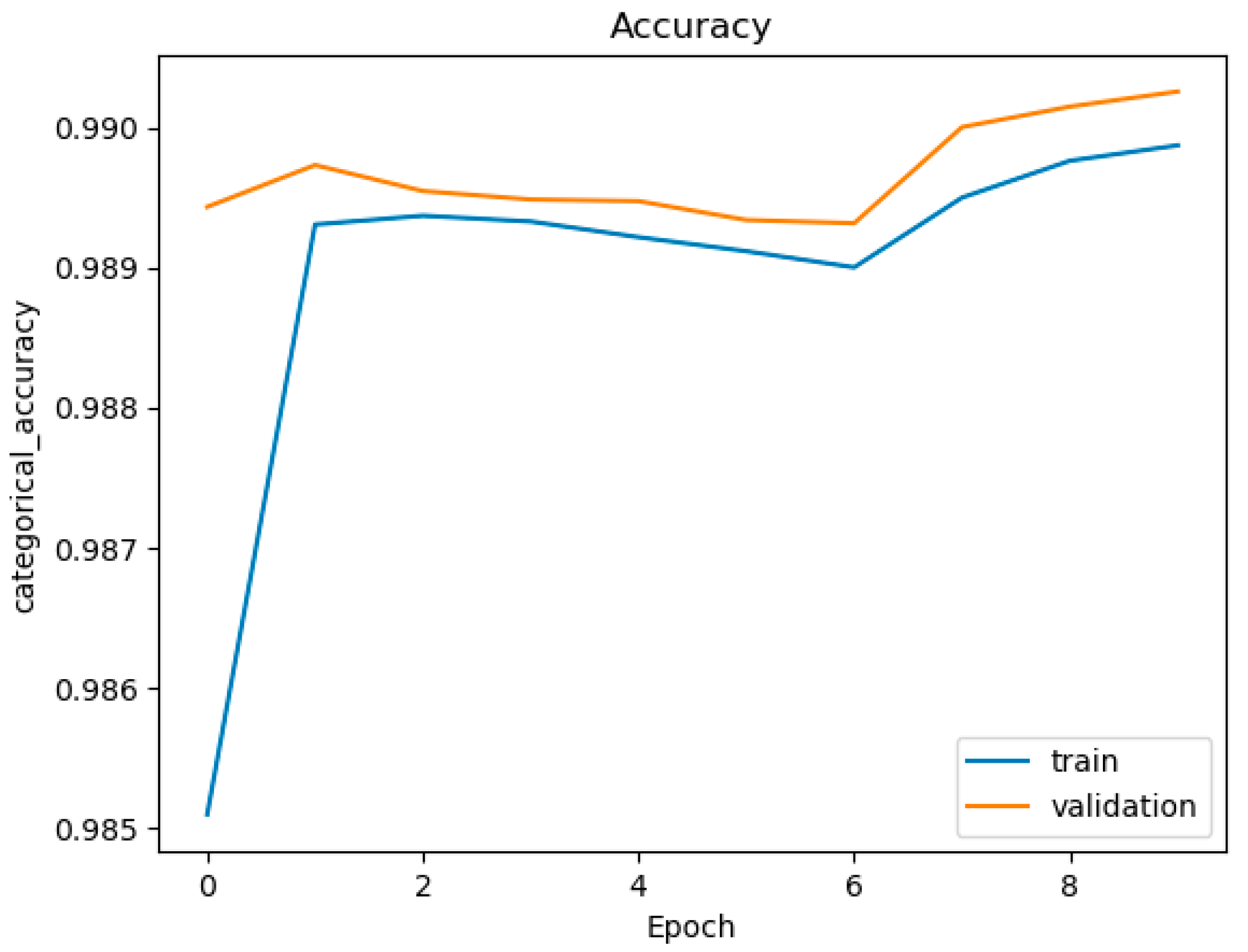
Figure 7.
Accuracy figure of DNN with (layer = 3, Node = 768, multi-class).
Figure 7.
Accuracy figure of DNN with (layer = 3, Node = 768, multi-class).
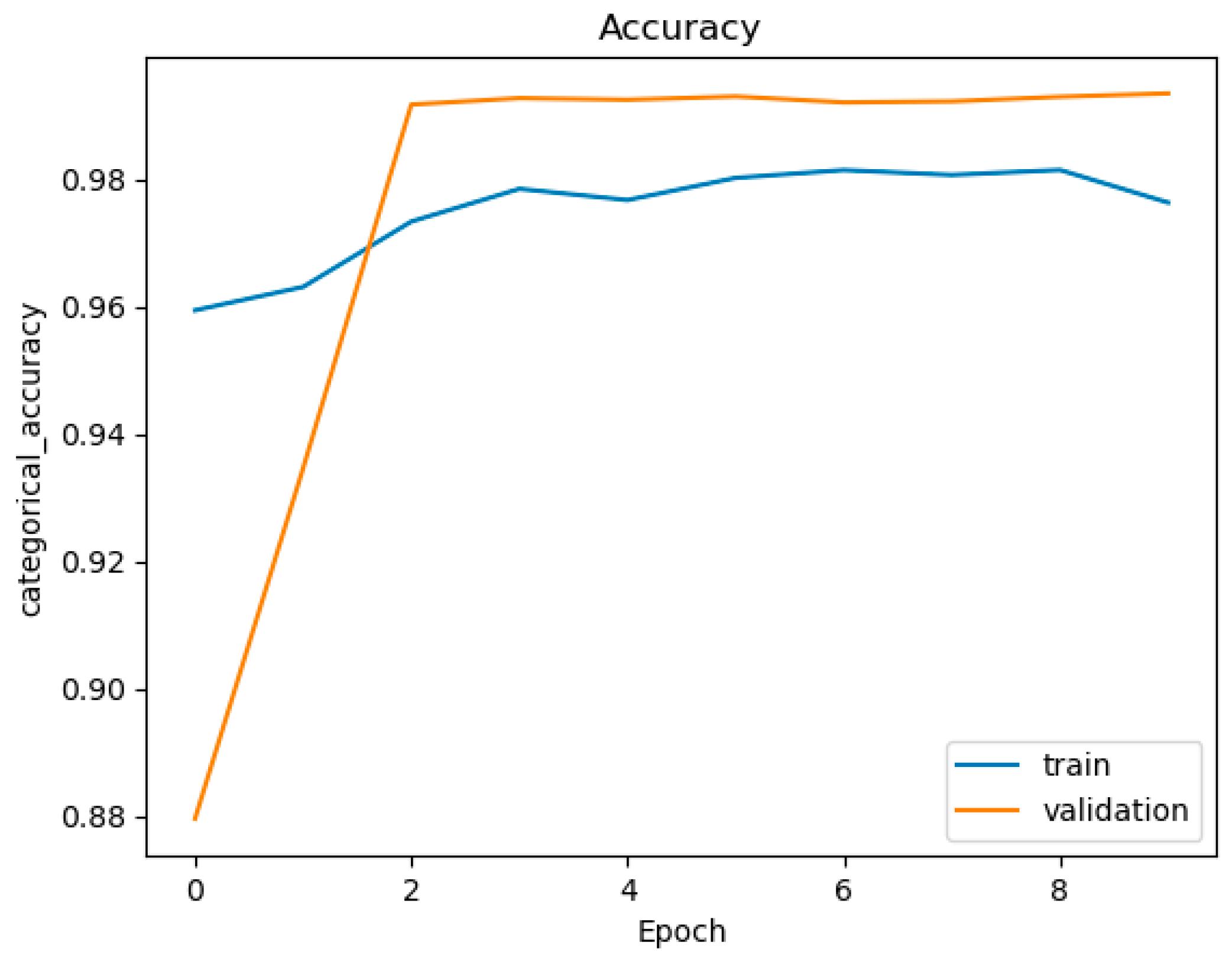
Figure 8.
Accuracy figure of RNN (with layer = 3, node = 768, multi-class classification).
Figure 8.
Accuracy figure of RNN (with layer = 3, node = 768, multi-class classification).
Figure 9.
Accuracy figure of CNN (with layer = 3, node = 768, multi-class classification).
Figure 9.
Accuracy figure of CNN (with layer = 3, node = 768, multi-class classification).
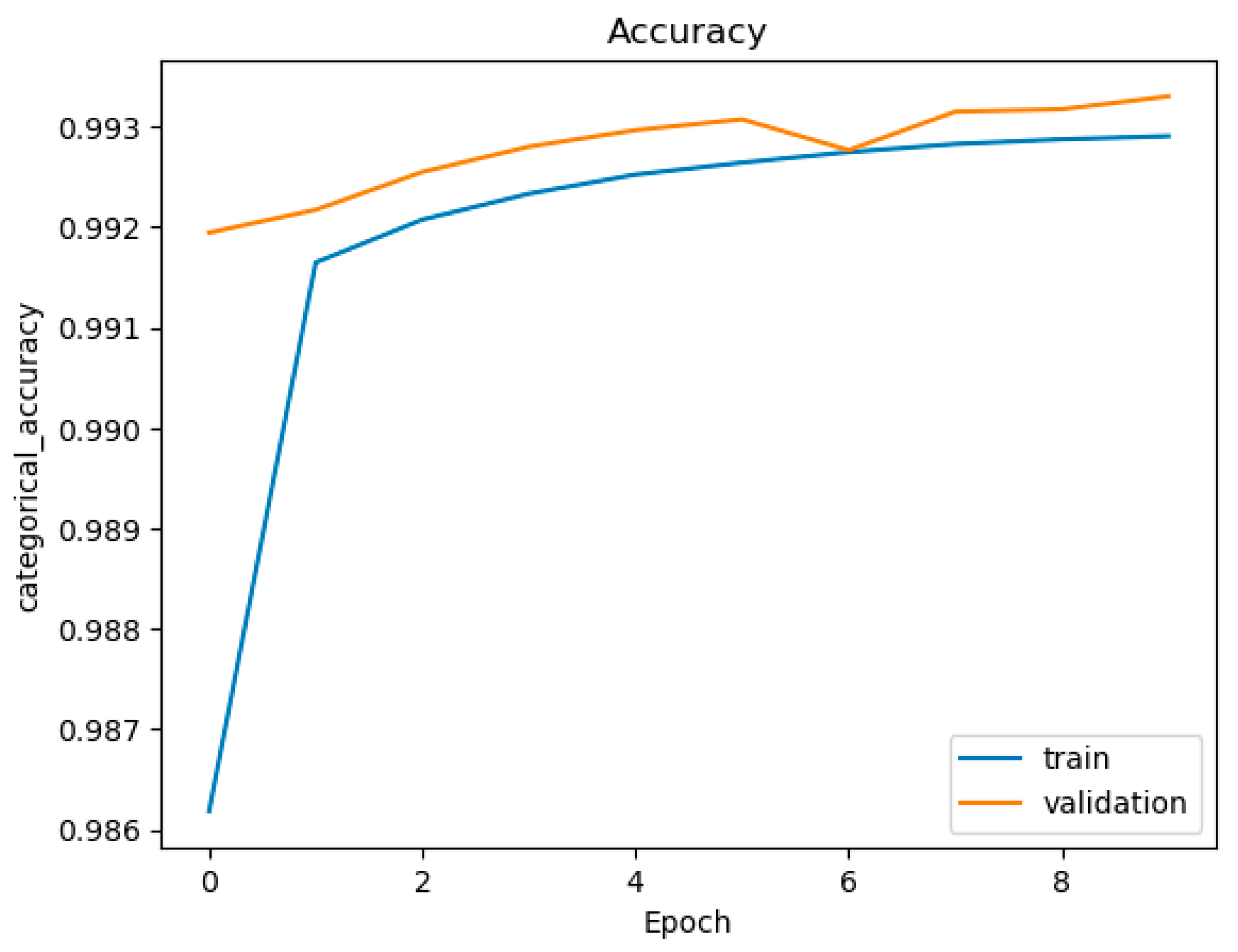
Figure 10.
Accuracy figure of LSTM (with layer = 3, node = 768, multi-class classification).
Figure 10.
Accuracy figure of LSTM (with layer = 3, node = 768, multi-class classification).
Figure 11.
Accuracy figure of CNN + RNN (with layer = 3, node = 768, multi-class classification).
Figure 11.
Accuracy figure of CNN + RNN (with layer = 3, node = 768, multi-class classification).
Figure 12.
Accuracy figure of CNN + LSTM (with layer = 3, node = 768, multi-class classification).
Figure 12.
Accuracy figure of CNN + LSTM (with layer = 3, node = 768, multi-class classification).
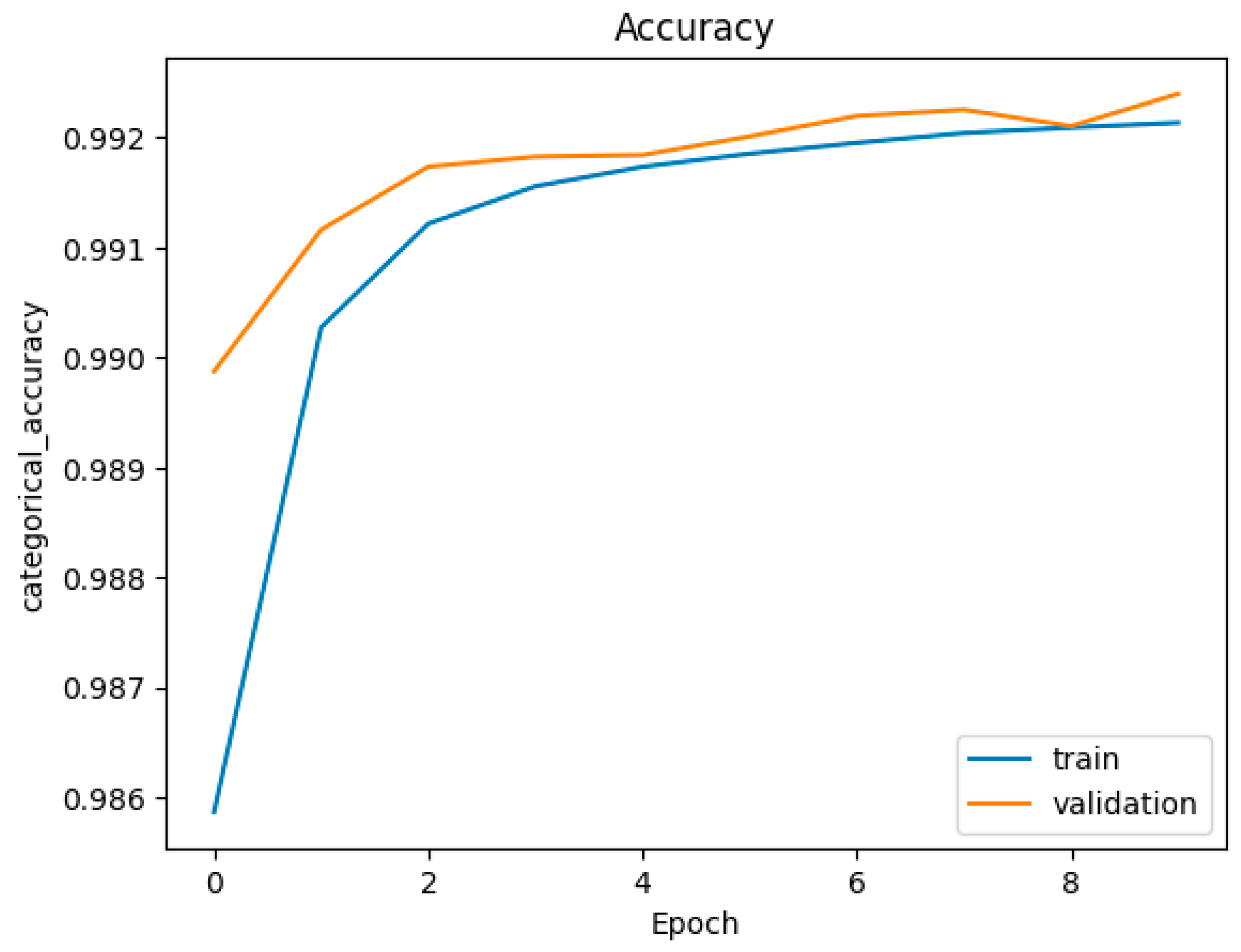
Figure 13.
Accuracy figure of Transformer (with Dense Dimension = 2048, Number of Heads = 1, Number of Layers = 1, multi-class classification).
Figure 13.
Accuracy figure of Transformer (with Dense Dimension = 2048, Number of Heads = 1, Number of Layers = 1, multi-class classification).
Table 1.
Related works/baseline schemes.
Table 1.
Related works/baseline schemes.
| Paper | Dataset | Classification | DL Method | Accuracy | Inference Time 1 |
|---|
| [1] | CIC-IoT-2023 | Binary | DNN based on Federated Learning | 99.00% | |
| [6] | CIC-IDS-2018 | Binary, Multi-class | DNN, RNN, CNN, LSTM,
CNN + LSTM, and CNN + RNN | 98.85% | Multi-Class:
LSTM: 3.451 (ms)
CNN + LSTM: 4.31 (ms) |
| [7] | ToN-IoT | Binary | LSTM, RNN, and Transformer | 87.79% | Binary Class
LSTM: 27 (s)
RNN: 35 (s) |
| [9] | CIC-IoT-2023 | Multi-class | Deep Reinforcement Learning | 95.60% | |
| [10] | CIC-IoT-2023 | Multi-class | LTSM | 98.75% | |
| [11] | CIC-IoT-2023 | Not Mentioned | Gradient Boost, MLP,
Logistic Regression, and KNN | 95.00% | |
| [13] | CIC-IoT-2023 | Binary, Multi-class | DNN | 99.44%, 99.11% | |
| [8] | KD999 | Multi-class | CNN, Autoencoder, FCN
RNN, U-Net, TCN, and TCN + LSTM | 97.7% | Multi-Class
CNN: 5 (min/epoch)
TCN + LSTM: 11 (min/epoch) |
Table 2.
The number of each label containing benign traffic.
Table 2.
The number of each label containing benign traffic.
| Label | Quantitys | Label | Quantitys | Label | Quantitys |
|---|
| DDoS-ICMP_Flood | 7,200,504 | Mirai-greeth_flood | 991,866 | DoS-HTTP_Flood | 71,864 |
| DDoS-UDP_Flood | 5,412,287 | Mirai-udpplain | 890,576 | Vulnerability Scan | 37,382 |
| DDoS-TCP_Flood | 4,497,667 | Mirai-greip_flood | 751,682 | DDoS-SlowLoris | 23,246 |
| DDoS-PSHACK_Flood | 4,094,755 | DDoS-ICMP_Fragmentation | 452,489 | DictionaryBruteForce | 13,064 |
| DDoS-SYN_Flood | 4,059,190 | MITM-ArpSpoofing | 307,593 | BrowserHijacking | 5859 |
| DDoS-RSTFINFlood | 4,045,190 | DDoS-UDP_Fragmentation | 286,925 | CommandInjection | 5409 |
| DDoS-SynonymousIP_Flood | 3,598,138 | DDoS-ACK_Fragmentation | 285,104 | SQL Injection | 5245 |
| DoS-UDP_Flood | 3,318,595 | Recon-HostDiscovery | 178,911 | XSS | 3946 |
| DoS-TCP_Flood | 2,671,445 | Recon-OSScan | 134,378 | Backdoor_Malware | 3218 |
| DoS-SYN_Flood | 2,028,834 | Recon-PortScan | 98,259 | Recon-PingSweep | 2262 |
| Benign | 1,098,195 | DDoS-HTTP_Flood | 71,864 | Uploading_Attack | 1252 |
Table 3.
The features used in CIC-IoT-2023.
Table 3.
The features used in CIC-IoT-2023.
| Feature | Name |
|---|
| 1 | Flow duration |
| 2 | Header Length |
| 3 | Protocol |
| 4 | Type |
| 5 | Duration |
| 6 | Rate Mrate Drate |
| 7 | fin flag number |
| 8 | syn flag number |
| 9 | rst flag number |
| 10 | psh flag number |
| 11 | ack flag number |
| 12 | ece flag number |
| 13 | cwr flag number |
| 14 | ack count |
| 15 | syn count |
| 16 | fin count |
| 17 | urg count |
| 18 | rst count |
| 19 | HTTP |
| 20 | HTTPS |
| 21 | DNS |
| 22 | Telnet |
| 23 | SMTP |
| 24 | SSH |
| 25 | IRC |
| 26 | TCP |
| 27 | UDP |
| 28 | DHCP |
| 29 | ARP |
| 30 | ICMP |
| 31 | IPv |
| 32 | LLC |
| 33 | Tot sum |
| 34 | Min |
| 35 | Max |
| 36 | AVG |
| 37 | Std |
| 38 | Tot size |
| 39 | IAT |
| 40 | Number |
| 41 | Magnitude |
| 42 | Radius |
| 43 | Covariance |
| 44 | Variance |
| 45 | Weight |
| 46 | Flow duration |
Table 4.
The number of neurons and units of each of the neural networks.
Table 4.
The number of neurons and units of each of the neural networks.
| Layers | Neurons | Units |
|---|
| 1 | 256 | 256 |
| 512 | 512 |
| 768 | 768 |
| 3 | 256 | 64 + 64 + 128 |
| 512 | 128 + 128 + 256 |
| 768 | 256 + 256 + 256 |
Table 5.
Number of parameters and nodes of DNN.
Table 5.
Number of parameters and nodes of DNN.
| Layers | Neurons | Parameters |
|---|
| Binary | Multi-Class |
|---|
| 1 | 256 | 13,313 | 15,112 |
| 512 | 26,625 | 30,216 |
| 768 | 39,937 | 45,320 |
| 3 | 256 | 19,521 | 19,976 |
| 512 | 63,617 | 64,520 |
| 768 | 146,945 | 148,744 |
Table 6.
Number of parameters and nodes of RNN.
Table 6.
Number of parameters and nodes of RNN.
| Layers | Neurons | Parameters |
|---|
| Binary | Multi-Class |
|---|
| 1 | 256 | 78,849 | 80,648 |
| 512 | 288,769 | 292,360 |
| 768 | 629,761 | 635,144 |
| 3 | 256 | 44,097 | 44,552 |
| 512 | 161,921 | 162,824 |
| 768 | 343,553 | 345,352 |
Table 7.
Number of parameters and nodes of CNN.
Table 7.
Number of parameters and nodes of CNN.
| Layers | Neurons | Parameters |
|---|
| Binary | Multi-Class |
|---|
| 1 | 256 | 13,313 | 15,112 |
| 512 | 26,625 | 30,216 |
| 768 | 39,937 | 45,320 |
| 3 | 256 | 19,521 | 19,976 |
| 512 | 63,617 | 64,520 |
| 768 | 146,945 | 148,744 |
Table 8.
Number of parameters and nodes of LSTM.
Table 8.
Number of parameters and nodes of LSTM.
| Layers | Neurons | Parameters |
|---|
| Binary | Multi-Class |
|---|
| 1 | 256 | 311,553 | 313,352 |
| 512 | 1,147,393 | 1,150,984 |
| 768 | 2,507,521 | 2,512,904 |
| 3 | 256 | 173,121 | 173,576 |
| 512 | 354,433 | 619,528 |
| 768 | 1,364,225 | 1,366,024 |
Table 9.
Number of parameters and nodes of CNN + RNN.
Table 9.
Number of parameters and nodes of CNN + RNN.
| Layers | Neurons | Parameters |
|---|
| Binary | Multi-Class |
|---|
| 1 | 256 | 78,849 | 133,160 |
| 512 | 288,769 | 365,864 |
| 768 | 629,761 | 729,640 |
| 3 | 256 | 44,097 | 86,568 |
| 512 | 161,921 | 215,336 |
| 768 | 343,553 | 397,864 |
Table 10.
Number of parameters and nodes of CNN + LSTM.
Table 10.
Number of parameters and nodes of CNN + LSTM.
| Layers | Neurons | Parameters |
|---|
| Binary | Multi-Class |
|---|
| 1 | 256 | 420,041 | 428,840 |
| 512 | 1,346,849 | 1,350,440 |
| 768 | 2,790,945 | 2,796,328 |
| 3 | 256 | 246,625 | 247,080 |
| 512 | 756,641 | 757,544 |
| 768 | 1,479,713 | 1,481,512 |
Table 11.
Number of parameters of Transformer.
Table 11.
Number of parameters of Transformer.
Dense Dimension
(FFN) | Number of Heads | Number of Layers
(Encoder) | Parameters |
|---|
| Binary | Multi-Class |
|---|
| 256 | 1 | 1 | 32,733 | 33,062 |
| 128 | | | 20,829 | 21,158 |
| 512 | | | 56,541 | 56,870 |
| 1024 | | | 104,157 | 104,486 |
| 2048 | | | 199,389 | 199,718 |
| | 2 | | 41,335 | 41,664 |
| | 4 | | 58,539 | 58,868 |
| | 8 | | 94,947 | 93,276 |
| | | 2 | 41,381 | 41,710 |
| | | 4 | 58,677 | 59,006 |
| | | 8 | 94,269 | 93,598 |
Table 12.
Number of parameters of Transformer.
Table 12.
Number of parameters of Transformer.
| Project | Properties |
|---|
| OS | Windows 11 |
| CPU | Intel® Core™ i7-13700 Processor |
| GPU | NVIDA Geforce RTX 4080 |
| Memory | 128 GB |
| Disk | 1TB SSD |
| Python | 3.7.16 |
| NVIDIA CUDA | 11.3.1 |
| Framework | Tensorflow-gpu 2.5 & 2.6 |
Table 13.
Number of parameters of Transformer.
Table 13.
Number of parameters of Transformer.
| Hyperparameter | Value |
|---|
| Batch Size | 1024 |
| Epochs | 10 |
| Learning Rate | 0.001 |
| Dropout | 0.1 |
Table 14.
The accuracy results of DNN.
Table 14.
The accuracy results of DNN.
| Layers | Neurons | Accuracy (%) |
|---|
| Binary | Multi-Class |
|---|
| 1 | 256 | 99.48 | 97.35 |
| 512 | 99.47 | 97.73 |
| 768 | 99.53 | 99.13 |
| 3 | 256 | 99.56 | 99.16 |
| 512 | 99.56 | 99.23 |
| 768 | 99.56 | 99.36 |
Table 15.
The evaluation results of DNN.
Table 15.
The evaluation results of DNN.
| Layer | Node | Precision (%) | Recall (%) | F1-Score (%) |
|---|
| Binary | Multi-Class | Binary | Multi-Class | Binary | Multi-Class |
|---|
| 1 | 256 | 99.51 | 97.35 | 99.48 | 97.35 | 99.49 | 97.30 |
| 512 | 99.51 | 97.74 | 99.48 | 97.73 | 99.49 | 97.66 |
| 768 | 99.49 | 99.12 | 99.47 | 99.13 | 99.48 | 99.10 |
| 3 | 256 | 99.54 | 99.17 | 99.53 | 99.16 | 99.54 | 99.12 |
| 512 | 99.57 | 99.24 | 99.56 | 99.23 | 99.56 | 99.18 |
| 768 | 99.57 | 99.35 | 99.56 | 99.36 | 99.57 | 99.32 |
Table 16.
The accuracy results of RNN.
Table 16.
The accuracy results of RNN.
| Layers | Neurons | Accuracy (%) |
|---|
| Binary | Multi-Class |
|---|
| 1 | 256 | 99.49 | 99.21 |
| 512 | 99.49 | 99.22 |
| 768 | 99.48 | 99.24 |
| 3 | 256 | 99.53 | 99.26 |
| 512 | 99.50 | 99.27 |
| 768 | 99.50 | 99.28 |
Table 17.
The evaluation results of RNN.
Table 17.
The evaluation results of RNN.
| Layer | Node | Precision (%) | Recall (%) | F1-Score (%) |
|---|
| Binary | Multi-Class | Binary | Multi-Class | Binary | Multi-Class |
|---|
| 1 | 256 | 99.51 | 99.21 | 99.49 | 99.21 | 99.50 | 99.17 |
| 512 | 99.50 | 99.23 | 99.49 | 99.22 | 99.49 | 99.19 |
| 768 | 99.51 | 99.23 | 99.48 | 99.24 | 99.49 | 99.21 |
| 3 | 256 | 99.54 | 99.26 | 99.53 | 99.26 | 99.53 | 99.21 |
| 512 | 99.50 | 99.27 | 99.50 | 99.27 | 99.50 | 99.24 |
| 768 | 99.52 | 99.28 | 99.50 | 99.28 | 99.51 | 99.23 |
Table 18.
The evaluation results of CNN.
Table 18.
The evaluation results of CNN.
| Layer | Node | Precision (%) | Recall (%) | F1-Score (%) |
|---|
| Binary | Multi-Class | Binary | Multi-Class | Binary | Multi-Class |
|---|
| 1 | 256 | 99.51 | 99.21 | 99.49 | 99.21 | 99.50 | 99.17 |
| 512 | 99.50 | 99.23 | 99.49 | 99.22 | 99.49 | 99.19 |
| 768 | 99.51 | 99.23 | 99.48 | 99.24 | 99.49 | 99.21 |
| 3 | 256 | 99.54 | 99.26 | 99.53 | 99.26 | 99.53 | 99.21 |
| 512 | 99.50 | 99.27 | 99.50 | 99.27 | 99.50 | 99.24 |
| 768 | 99.52 | 99.28 | 99.50 | 99.28 | 99.51 | 99.23 |
Table 19.
The evaluation results of CNN.
Table 19.
The evaluation results of CNN.
| Layer | Node | Precision (%) | Recall (%) | F1-Score (%) |
|---|
| Binary | Multi-Class | Binary | Multi-Class | Binary | Multi-Class |
|---|
| 1 | 256 | 99.30 | 96.11 | 99.27 | 96.06 | 99.28 | 95.93 |
| 512 | 99.29 | 97.83 | 99.27 | 97.73 | 99.28 | 97.64 |
| 768 | 99.31 | 91.95 | 99.24 | 90.91 | 99.27 | 89.88 |
| 3 | 256 | 99.50 | 99.18 | 99.48 | 99.19 | 99.48 | 99.15 |
| 512 | 99.51 | 99.21 | 99.48 | 99.23 | 99.49 | 99.1 |
| 768 | 99.52 | 99.23 | 99.48 | 99.25 | 99.50 | 99.21 |
Table 20.
The accuracy results of LSTM.
Table 20.
The accuracy results of LSTM.
| Layers | Neurons | Accuracy (%) |
|---|
| Binary | Multi-Class |
|---|
| 1 | 256 | 99.51 | 99.28 |
| 512 | 99.51 | 99.28 |
| 768 | 99.50 | 99.28 |
| 3 | 256 | 99.54 | 99.32 |
| 512 | 99.54 | 99.21 |
| 768 | 99.52 | 99.34 |
Table 21.
The evaluation results of LSTM.
Table 21.
The evaluation results of LSTM.
| Layer | Node | Precision (%) | Recall (%) | F1-Score (%) |
|---|
| Binary | Multi-Class | Binary | Multi-Class | Binary | Multi-Class |
|---|
| 1 | 256 | 99.52 | 99.27 | 99.51 | 99.28 | 99.51 | 99.24 |
| 512 | 99.53 | 99.28 | 99.51 | 99.28 | 99.52 | 99.25 |
| 768 | 99.53 | 99.28 | 99.50 | 99.28 | 99.51 | 99.24 |
| 3 | 256 | 99.55 | 99.31 | 99.54 | 99.32 | 99.54 | 99.28 |
| 512 | 99.55 | 99.31 | 99.54 | 99.31 | 99.54 | 99.28 |
| 768 | 99.54 | 99.32 | 99.54 | 99.34 | 99.52 | 99.31 |
Table 22.
The accuracy results of CNN + RNN.
Table 22.
The accuracy results of CNN + RNN.
| Layers | Neurons | Accuracy (%) |
|---|
| Binary | Multi-Class |
|---|
| 1 | 256 | 99.37 | 99.15 |
| 512 | 99.29 | 99.19 |
| 768 | 99.45 | 99.11 |
| 3 | 256 | 99.46 | 99.16 |
| 512 | 99.42 | 99.07 |
| 768 | 99.15 | 99.03 |
Table 23.
The evaluation results of CNN + RNN.
Table 23.
The evaluation results of CNN + RNN.
| Layer | Node | Precision (%) | Recall (%) | F1-Score (%) |
|---|
| Binary | Multi-Class | Binary | Multi-Class | Binary | Multi-Class |
|---|
| 1 | 256 | 99.44 | 99.15 | 99.37 | 99.15 | 99.39 | 99.10 |
| 512 | 99.36 | 99.19 | 99.29 | 99.19 | 99.32 | 99.15 |
| 768 | 99.48 | 99.12 | 99.45 | 99.11 | 99.47 | 99.04 |
| 3 | 256 | 99.48 | 99.15 | 99.46 | 99.16 | 99.47 | 99.12 |
| 512 | 99.43 | 99.07 | 99.42 | 99.07 | 99.43 | 99.00 |
| 768 | 99.23 | 99.02 | 99.15 | 99.03 | 99.18 | 98.98 |
Table 24.
The accuracy results of CNN + LSTM.
Table 24.
The accuracy results of CNN + LSTM.
| Layers | Neurons | Accuracy (%) |
|---|
| Binary | Multi-Class |
|---|
| 1 | 256 | 99.56 | 99.33 |
| 512 | 99.46 | 98.70 |
| 768 | 99.55 | 99.34 |
| 3 | 256 | 99.53 | 99.31 |
| 512 | 99.49 | 99.26 |
| 768 | 99.48 | 99.26 |
Table 25.
The evaluation results of CNN + LSTM.
Table 25.
The evaluation results of CNN + LSTM.
| Layer | Node | Precision (%) | Recall (%) | F1-Score (%) |
|---|
| Binary | Multi-Class | Binary | Multi-Class | Binary | Multi-Class |
|---|
| 1 | 256 | 99.57 | 99.31 | 99.56 | 99.33 | 99.56 | 99.30 |
| 512 | 9.57 | 98.70 | 99.56 | 98.70 | 99.56 | 98.66 |
| 768 | 99.57 | 99.33 | 99.55 | 99.34 | 99.56 | 99.31 |
| 3 | 256 | 99.55 | 99.29 | 99.53 | 99.31 | 99.54 | 99.28 |
| 512 | 99.49 | 99.25 | 99.49 | 99.26 | 99.49 | 99.22 |
| 768 | 99.48 | 99.25 | 99.48 | 99.26 | 99.48 | 99.22 |
Table 26.
The accuracy results of Transformer.
Table 26.
The accuracy results of Transformer.
Dense Dimension
(FFN) | Number of Heads | Number of Layers
(Encoder) | Accuracy (%) |
|---|
| Binary | Multi-Class |
|---|
| 256 | 1 | 1 | 99.51 | 99.12 |
| 128 | | | 99.50 | 97.54 |
| 512 | | | 99.51 | 99.40 |
| 1024 | | | 99.51 | 99.36 |
| 2048 | | | 99.52 | 99.21 |
| | 2 | | 99.50 | 99.19 |
| | 4 | | 99.50 | 98.96 |
| | 8 | | 99.51 | 99.32 |
| | | 2 | 99.50 | 99.34 |
| | | 4 | 99.49 | 99.23 |
| | | 8 | 99.48 | 99.24 |
Table 27.
The precision of Transformer.
Table 27.
The precision of Transformer.
Dense Dimension
(FFN) | Number of Heads | Number of Layers
(Encoder) | Binary | Multi-Class |
|---|
| 256 | 1 | 1 | 99.52 | 94.03 |
| 128 | | | 99.53 | 98.72 |
| 512 | | | 99.52 | 99.27 |
| 1024 | | | 99.54 | 99.31 |
| 2048 | | | 99.54 | 99.33 |
| | 2 | | 99.53 | 98.88 |
| | 4 | | 99.52 | 99.23 |
| | 8 | | 99.53 | 95.03 |
| | | 2 | 99.53 | 99.25 |
| | | 4 | 99.52 | 99.32 |
| | | 8 | 99.49 | 99.11 |
Table 28.
The recall of Transformer.
Table 28.
The recall of Transformer.
Dense Dimension
(FFN) | Number of Heads | Number of Layers
(Encoder) | Binary | Multi-Class |
|---|
| 256 | 1 | 1 | 99.50 | 93.68 |
| 128 | | | 99.51 | 98.72 |
| 512 | | | 99.51 | 99.27 |
| 1024 | | | 99.52 | 99.43 |
| 2048 | | | 99.52 | 99.33 |
| | 2 | | 99.50 | 98.88 |
| | 4 | | 99.50 | 94.94 |
| | 8 | | 99.51 | 98.88 |
| | | 2 | 99.50 | 99.24 |
| | | 4 | 99.49 | 99.30 |
| | | 8 | 99.48 | 99.11 |
Table 29.
Time consumption of each model (per sample).
Table 29.
Time consumption of each model (per sample).
| Model | Binary Testing Time (μs) | Multi-Class Testing Time (μs) |
|---|
| DNN | 3.8 | 3.8 |
| RNN | 7 | 7 |
| CNN | 12.3 | 12.3 |
| LSTM | 8 | 8 |
| CNN + RNN | 15 | 15 |
| CNN + LSTM | 18 | 18 |
| Transformer | 5 | 5 |
Table 30.
Confusion matrix figure of DNN (with layer = 3, node = 768, multi-class classification).
Table 30.
Confusion matrix figure of DNN (with layer = 3, node = 768, multi-class classification).
| Actual | Benign Traffic | 1,073,132 | 87 | 287 | 8001 | 30 | 3 | 16,647 | 8 |
| DDos | 47 | 83,980,302 | 2712 | 1338 | 0 | 0 | 12 | 149 |
| Dos | 22 | 18,808 | 8,071,716 | 79 | 0 | 0 | 34 | 7915 |
| Recon | 82,758 | 5445 | 105 | 220,880 | 1550 | 138 | 43,664 | 15 |
| Web-Based | 5367 | 0 | 7 | 3462 | 3193 | 12 | 12,787 | 1 |
| Brute Force | 2508 | 0 | 2 | 1938 | 15 | 3749 | 4852 | 0 |
| Spoofing | 56,557 | 132 | 141 | 13,208 | 91 | 945 | 415,405 | 25 |
| Mirai | 9 | 13,504 | 289 | 1175 | 0 | 0 | 18 | 2,619,129 |
| | Benign Traffic | DDos | Dos | Recon | Web-Based | Brute Force | Spoofing | Mirai |
Table 31.
Confusion matrix figure of RNN (with layer = 3, node = 768, multi-class classification).
Table 31.
Confusion matrix figure of RNN (with layer = 3, node = 768, multi-class classification).
| Actual | Benign Traffic | 1,057,073 | 7 | 4 | 17,204 | 40 | 1 | 23,866 | 0 |
| DDos | 51 | 83,980,261 | 2463 | 1198 | 0 | 0 | 96 | 491 |
| Dos | 26 | 7272 | 8,083,199 | 32 | 0 | 0 | 46 | 163 |
| Recon | 83,296 | 1312 | 37 | 236,622 | 196 | 9 | 33,083 | 10 |
| Web-Based | 8200 | 0 | 0 | 5175 | 2746 | 0 | 8708 | 0 |
| Brute Force | 4089 | 0 | 0 | 3834 | 29 | 2298 | 2812 | 2 |
| Spoofing | 108,726 | 24 | 7 | 24,986 | 220 | 14 | 352,524 | 3 |
| Mirai | 18 | 350 | 56 | 11 | 0 | 0 | 33 | 2,633,656 |
| | Benign Traffic | DDos | Dos | Recon | Web-Based | Brute Force | Spoofing | Mirai |
| Predicted |
Table 32.
Confusion matrix figure of CNN (with layer = 3, node = 768, multi-class classification).
Table 32.
Confusion matrix figure of CNN (with layer = 3, node = 768, multi-class classification).
| Actual | Benign Traffic | 1,034,444 | 14 | 7 | 22,362 | 127 | 47 | 41,192 | 2 |
| DDos | 83 | 83,979,984 | 3238 | 764 | 0 | 0 | 63 | 428 |
| Dos | 36 | 6228 | 8,084,368 | 20 | 0 | 0 | 37 | 49 |
| Recon | 78,798 | 2093 | 40 | 236,729 | 790 | 161 | 35,930 | 24 |
| Web-Based | 6077 | 1 | 2 | 5485 | 2960 | 7 | 10,297 | 0 |
| Brute Force | 3564 | 0 | 0 | 3584 | 78 | 2401 | 3437 | 0 |
| Spoofing | 101,541 | 23 | 4 | 24,349 | 880 | 98 | 359,605 | 4 |
| Mirai | 5 | 380 | 63 | 6 | 0 | 0 | 16 | 2,633,654 |
| | Benign Traffic | DDos | Dos | Recon | Web-Based | Brute Force | Spoofing | Mirai |
| Predicted |
Table 33.
Confusion matrix figure of LSTM (with layer = 3, node = 768, multi-class classification).
Table 33.
Confusion matrix figure of LSTM (with layer = 3, node = 768, multi-class classification).
| Actual | Benign Traffic | 1,049,179 | 16 | 3 | 17,245 | 244 | 34 | 31,472 | 2 |
| DDos | 46 | 83,980,598 | 2405 | 1335 | 2 | 0 | 47 | 136 |
| Dos | 24 | 6531 | 8,084,054 | 28 | 1 | 0 | 37 | 63 |
| Recon | 68,011 | 723 | 29 | 247,281 | 1212 | 179 | 37,128 | 2 |
| Web-Based | 5230 | 1 | 0 | 4826 | 5520 | 16 | 9235 | 1 |
| Brute Force | 3258 | 1 | 0 | 3384 | 142 | 2864 | 3415 | 0 |
| Spoofing | 88,611 | 29 | 30 | 21,880 | 1797 | 170 | 373,965 | 22 |
| Mirai | 11 | 865 | 38 | 19 | 0 | 0 | 25 | 2,633,166 |
| | Benign Traffic | DDos | Dos | Recon | Web-Based | Brute Force | Spoofing | Mirai |
| Predicted |
Table 34.
Confusion matrix figure of CNN + RNN (with layer = 3, node = 768, multi-class classification).
Table 34.
Confusion matrix figure of CNN + RNN (with layer = 3, node = 768, multi-class classification).
| Actual | Benign Traffic | 1,043,235 | 67 | 3 | 20,089 | 81 | 2 | 34,715 | 3 |
| DDos | 108 | 83,962,688 | 160,078 | 3626 | 0 | 2 | 290 | 1768 |
| Dos | 42 | 29,673 | 8,058,272 | 1521 | 3 | 0 | 47 | 1180 |
| Recon | 95,693 | 4048 | 638 | 217,211 | 55 | 14 | 36,490 | 416 |
| Web-Based | 7995 | 7 | 0 | 5812 | 1501 | 0 | 9513 | 1 |
| Brute Force | 4772 | 1 | 0 | 3641 | 5 | 1904 | 2741 | 0 |
| Spoofing | 131,007 | 95 | 0 | 27,761 | 203 | 0 | 327,415 | 23 |
| Mirai | 29 | 10,576 | 1292 | 1130 | 0 | 2 | 161 | 2,620,934 |
| | Benign Traffic | DDos | Dos | Recon | Web-Based | Brute Force | Spoofing | Mirai |
| Predicted |
Table 35.
Confusion matrix figure of CNN + LSTM (with layer = 3, node = 768, multi-class classification).
Table 35.
Confusion matrix figure of CNN + LSTM (with layer = 3, node = 768, multi-class classification).
| Actual | Benign Traffic | 1,042,720 | 31 | 6 | 25,929 | 367 | 26 | 29,116 | 0 |
| DDos | 33 | 83,980,794 | 2611 | 778 | 0 | 3 | 83 | 258 |
| Dos | 15 | 6435 | 8,084,207 | 10 | 1 | 0 | 30 | 40 |
| Recon | 66,965 | 1731 | 27 | 251,565 | 1386 | 155 | 32,689 | 47 |
| Web-Based | 4273 | 6 | 1 | 6214 | 5465 | 10 | 8410 | 0 |
| Brute Force | 3036 | 1 | 0 | 3710 | 177 | 2740 | 3400 | 0 |
| Spoofing | 93,724 | 109 | 28 | 26,392 | 2532 | 77 | 363,638 | 4 |
| Mirai | 7 | 368 | 31 | 70 | 0 | 0 | 103 | 2,633,545 |
| | Benign Traffic | DDos | Dos | Recon | Web-Based | Brute Force | Spoofing | Mirai |
| Predicted |
Table 36.
Confusion matrix figure of Transformer (with layer = 3, node = 768, multi-class classification).
Table 36.
Confusion matrix figure of Transformer (with layer = 3, node = 768, multi-class classification).
| Actual | Benign Traffic | 1,050,021 | 1264 | 1 | 23,943 | 61 | 11 | 22,828 | 66 |
| DDos | 13 | 83,975,357 | 2031 | 3208 | 1 | 0 | 688 | 3262 |
| Dos | 46 | 25,250 | 8,064,500 | 498 | 0 | 0 | 60 | 384 |
| Recon | 59,531 | 2309 | 2 | 257,601 | 28 | 7 | 35,007 | 80 |
| Web-Based | 5513 | 23 | 0 | 4960 | 7361 | 0 | 6971 | 1 |
| Brute Force | 3300 | 6 | 0 | 2589 | 2 | 2318 | 4848 | 1 |
| Spoofing | 68,286 | 613 | 0 | 23,988 | 379 | 333 | 392,815 | 90 |
| Mirai | 3 | 7796 | 79 | 212 | 0 | 0 | 262 | 2,625,772 |
| | Benign Traffic | DDos | Dos | Recon | Web-Based | Brute Force | Spoofing | Mirai |
| Predicted |










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}