

Active Queue Management in L4S with Asynchronous Advantage Actor-Critic: A FreeBSD Networking Stack Perspective



Abstract
1. Introduction
- How can the FreeBSD networking stack be modified to support L4S and integrate explicit congestion notification (ECN)?
- What performance improvements can be observed in terms of latency, loss, and throughput by implementing L4S in FreeBSD?
- How can the A3C algorithm be applied to dynamically adjust the base drop probability of L4S in response to varying network conditions?
- What is the impact of using A3C to optimize the base drop probability of L4S on the performance of real-time applications?
2. Background and Related Work
2.1. Active Queue Management
2.1.1. Controlled Delay (CoDel)
2.1.2. Proportional Integral Controller Enhanced (PIE)
2.1.3. Flow Queue-Controlled Delay (FQ-CoDel)
2.1.4. Flow Queue-Proportional Integral Controller Enhanced (FQ-PIE)
2.1.5. Low Latency, Low Loss, and Scalable Throughput (L4S)
2.2. Machine Learning-Based AQM Schemes
3. Research Design and Methodology
3.1. Using DualPi2 as an AQM in FreeBSD-L4S
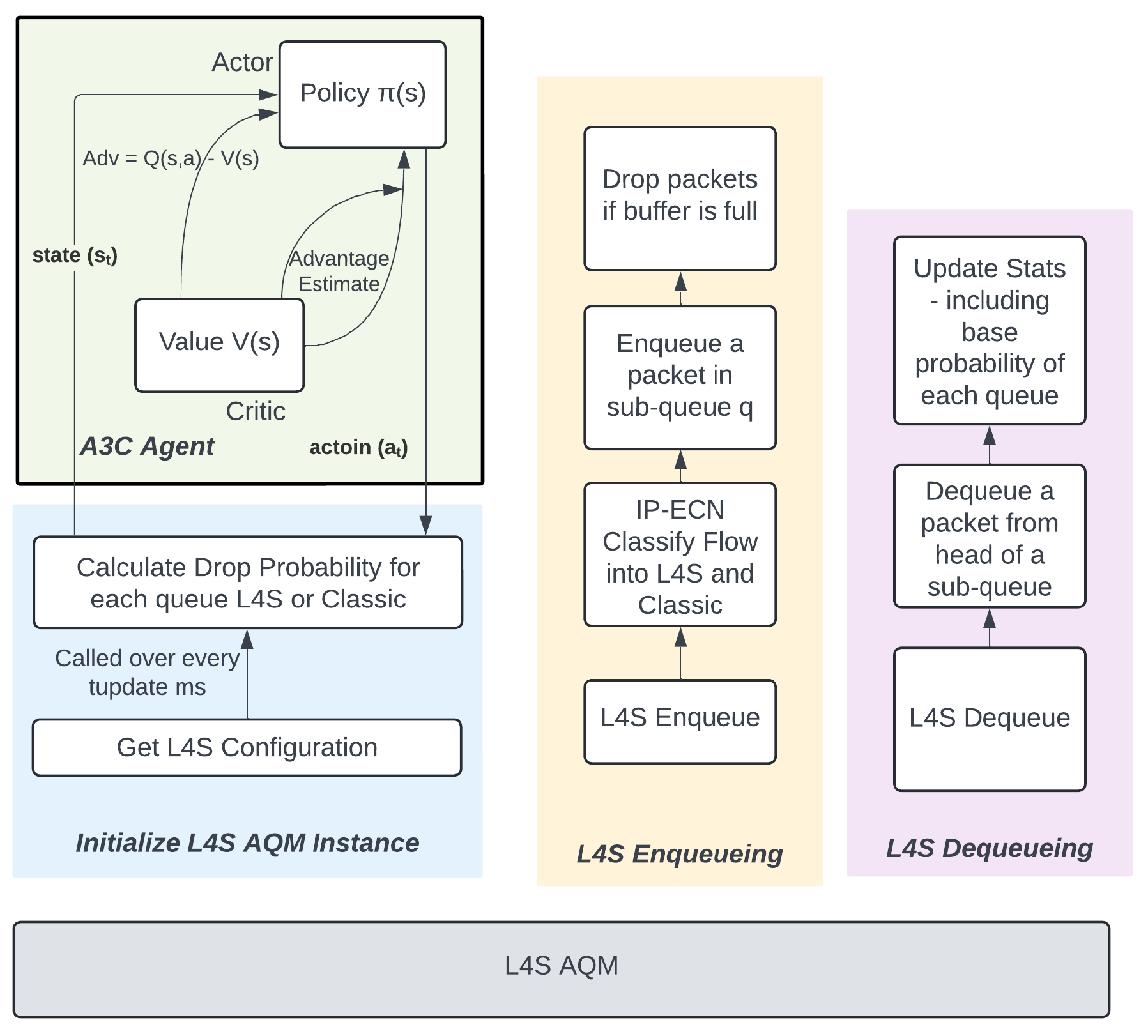
3.2. Asynchronous Advantage Actor-Critic (A3C) Model
3.2.1. Markov Decision Process
3.2.2. Actor-Critic Model
- -
- represents the parameters of the policy network, which outputs the policy .
- -
- represents the parameters of the value network, which outputs the value function
- -
- The state represents the environment at step t. It contains all the necessary information for the agent to decide that step.
- represents the probability of choosing action a given state s, as determined by the actor network with parameters .
- denotes the advantage function
- is an entropy term that encourages exploration by ensuring the policy does not become overly deterministic, with being a hyperparameter that influences the agent into prioritizing learning policies that consistently favor a specific action over another with greater probability.
| Algorithm 1: Actor Neural Network Architecture |
| state_input = Input((self.state_dim,)) dense_1 = Dense(32, activation=’relu’)(state_input) dense_2 = Dense(32, activation=’relu’)(dense_1) out_mu = Dense(self.action_dim, activation=’tanh’)(dense_2) mu_output = Lambda(lambda x: x * self.action_bound)(out_mu) std_output = Dense(self.action_dim, activation=’softplus’)(dense_2) return tf.keras.models.Model(state_input, [mu_output, std_output]) |
| Algorithm 2: Critic Neural Network Architecture |
| Input((self.state_dim,)), Dense(32, activation=’relu’), Dense(32, activation=’relu’), Dense(16, activation=’relu’), Dense(1, activation=’linear’) |
3.2.3. Training the Asynchronous Advantage Actor-Critic (A3C) model
| Algorithm 3: A3C Pseudocode |
|
3.2.4. Data Preparation
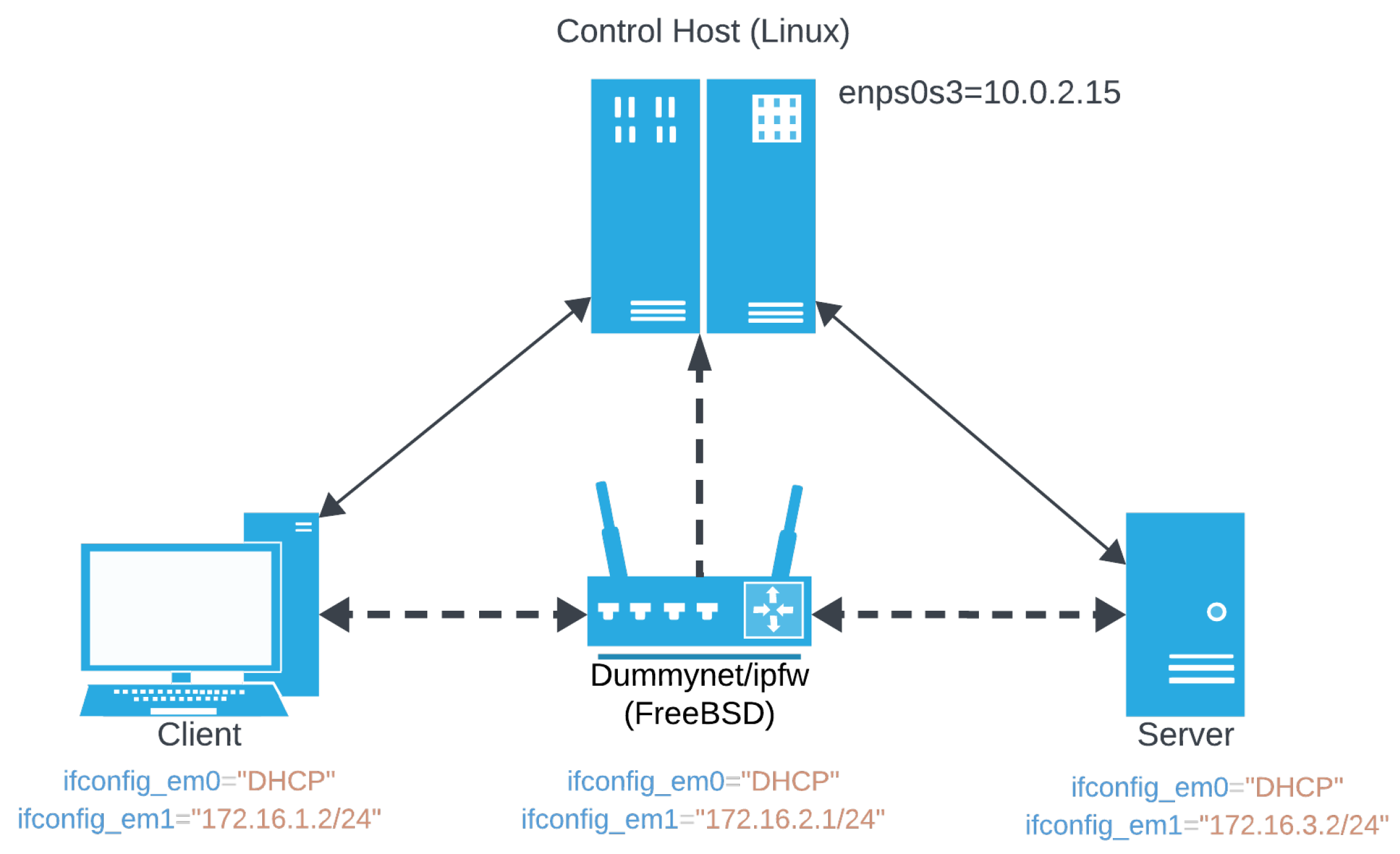
4. Implementation and Benchmarking of L4S in FreeBSD
- Limiting the number of flows or queues to the required amount
- Enqueuing and filtering packets based on their ECN flag
- Coupling the probabilities of the L4S and classic queues
4.1. Step 1: Limiting the Number of Flows or Queues to the Required Amount
| Algorithm 4: Assert code to use default queue size |
| static int l4s_config(struct dn_schk *_schk) {... struct dn_sch_l4s_parms *fqp_cfg; ...... /* L4S configurations */ ..... if (1) fqp_cfg->flows_cnt = l4s_sysctl.flows_cnt; ...... ..... } |
4.2. Step 2: Enqueuing and Filtering Packets Based on Their ECN Flag
| Algorithm 5: Packet Enqueuing in Queues |
| /* * Enqueue a packet into either L4S or Classic queues according to its ECN flag */ static int l4s_enqueue(struct dn_sch_inst *_si, struct dn_queue *_q, struct mbuf *m) { ................ /* classify a packet to queue number, which is half of the total queue size*/ idx = l4s_classify_flow(m, param->flows_cnt/2, si); struct ip *ip; ip = (struct ip *)mtodo(m, dn_tag_get(m)->iphdr_off); /* If the queue number is 0-2 given by Jenkin Hash and if ECN is enabled, * we will put the packet in the later half of the queue buffer meant for * L4S */ if (ip->ip_tos & IPTOS_ECN_MASK) != 0) idx=idx+(int)(param->flows_cnt / 2); drop = pie_enqueue(&flows[idx], m, si); ....................... } |
- l4s_classify_flow(m, param->flows_cnt / 2, si) is a function that classifies the packet m into a queue number using The Jenkins hash algorithm.
- param->flows_cnt / 2 is used as an argument to split the classification into L4S and native PIE queues.
- si is an additional parameter passed to the classification function.
- struct ip *ip; declares a pointer to an IP header structure.
- ip = (struct ip *)mtodo(m, dn_tag_get(m)->iphdr_off); extracts the IP header from the packet m using the offset provided by dn_tag_get(m)->iphdr_off.
- if ((ip->ip_tos & IPTOS_ECN_MASK) == IPTOS_ECN_ECT1) checks the explicit congestion notification (ECN) field in the IP header’s type of service (ToS) field.
- IPTOS_ECN_MASK is a mask to isolate the ECN bits.
- If the ECN field is not zero, the queue index idx is adjusted by adding half of the total flow count (param->flows_cnt / 2). This effectively classifies the packet into L4S queues based on its ECN status.
- drop = pie_enqueue(&flows[idx], m, si); enqueues the packet m into the queue indexed by idx in the flows array using the pie_enqueue function.
- &flows[idx] is a pointer to the specific queue.
- si is likely additional context or parameters needed for the enqueue operation.
- The result of the enqueue operation (whether the packet was dropped or successfully enqueued) is stored in the variable drop.
4.3. Step 3: Coupling the Probabilities of the L4S and Classic Queues
| Algorithm 6: Initializing variables for drop probabilities |
| uint32_t drop_prob_Pdash_flow_0; uint32_t drop_prob_Pdash_flow_1; uint32_t drop_prob_Pdash_flow_2; uint32_t drop_prob_Pl_flow_3; uint32_t drop_prob_Pl_flow_4; uint32_t drop_prob_Pl_flow_5; uint32_t P_Cmax; |
| Algorithm 7: Calculate the drop probabilities based on their queue type |
|
1 /* 2 * Enqueue a packet in queue q, subject to space and L4S queue management policy 3 * We will calculate its drop probability depending on its queue or flow index 4 * Update stats for the queue and the scheduler. 5 * Return 0 on success, 1 on drop. 6 */ 7 static int 8 pie_enqueue(struct l4s_flow *q, struct mbuf* m, struct l4s_si *si) 9 { 10 .... 11 int coupling_factor=2; 12 .... 13 int64_t prob; 14 uint32_t drop_prob_PCl_flow_3; 15 uint32_t drop_prob_PCl_flow_4; 16 uint32_t drop_prob_PCl_flow_5; 17 18 if(q->flow_index==0 || q->flow_index==1 || q->flow_index==2 ) 19 prob=(pst->drop_prob*pst->drop_prob)/PIE_MAX_PROB; 20 21 if(q->flow_index==3) 22 { 23 drop_prob_PCl_flow_3=drop_prob_Pdash_flow_0*coupling_factor; 24 if(drop_prob_Pl_flow_3<drop_prob_PCl_flow_3) 25 prob=drop_prob_PCl_flow_3; 26 else 27 prob=drop_prob_Pl_flow_3; 28 } 29 30 31 32 if(q->flow_index==4) 33 { 34 drop_prob_PCl_flow_4=drop_prob_Pdash_flow_1*coupling_factor; 35 if(drop_prob_Pl_flow_4<drop_prob_PCl_flow_4) 36 prob=drop_prob_PCl_flow_4; 37 else 38 prob=drop_prob_Pl_flow_4; 39 } 40 if(q->flow_index==5) 41 { 42 drop_prob_PCl_flow_5=drop_prob_Pdash_flow_2*coupling_factor; 43 if(drop_prob_Pl_flow_5<drop_prob_PCl_flow_5) 44 prob=drop_prob_PCl_flow_5; 45 else 46 prob=drop_prob_Pl_flow_5; 47 } 48 49 if(prob < 0) 50 prob = 0; 51 else if(prob > PIE_MAX_PROB) 52 prob = PIE_MAX_PROB; 53 54 ....... 55 } |
4.4. Step 4: Kernel Integration of L4S-Based AQM
- Implemented the L4S AQM scheduler within the ipfw module source code.
- Ensured that all necessary parameters and functionalities specific to the L4S algorithm were defined.
- Updated the relevant system files to reflect the addition of the new AQM scheduler.
- Made necessary adjustments to ensure compatibility and proper integration within the FreeBSD kernel.
- Executed the buildworld process to rebuild the FreeBSD world, incorporating the new AQM scheduler.
- This step recompiled all userland programs and utilities, ensuring they recognized and could utilize the new AQM parameters.
- Followed the buildkernel process to compile the updated kernel with the newly integrated L4S AQM.
- Installed the rebuilt kernel and rebooted the system to apply the changes.
5. Experimental Evaluation
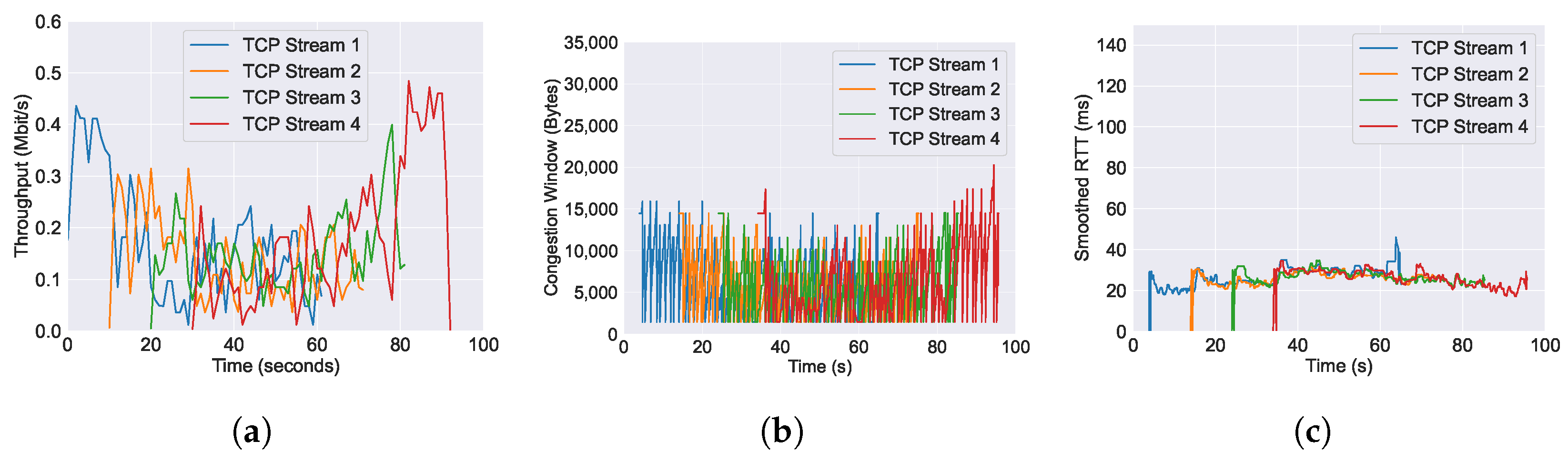
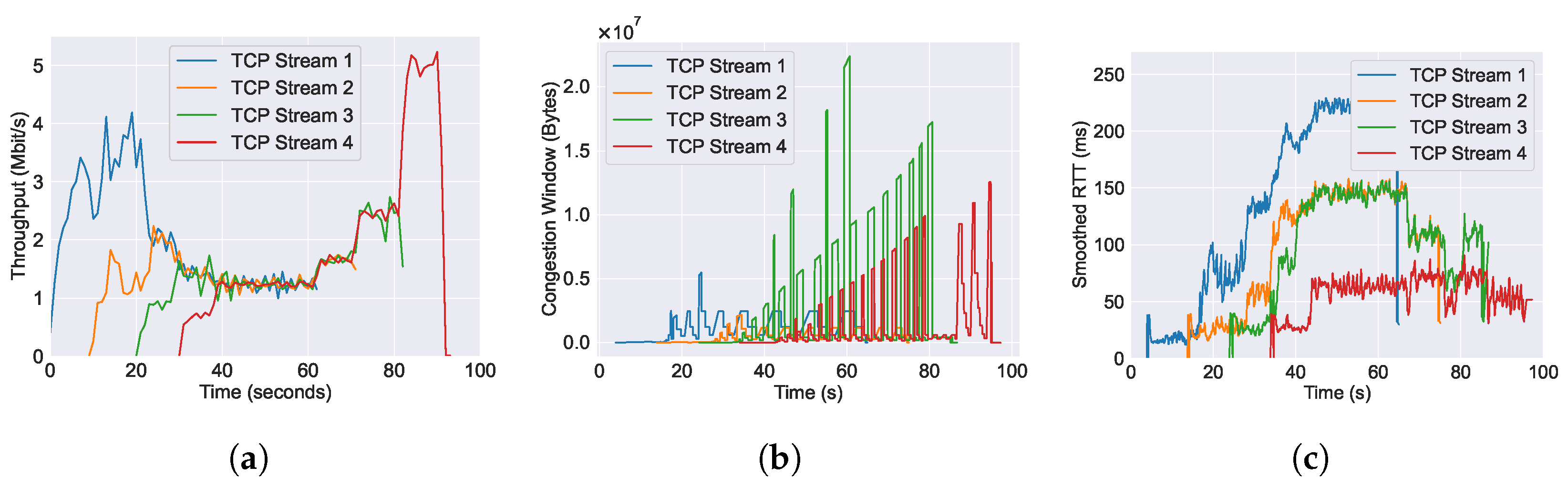
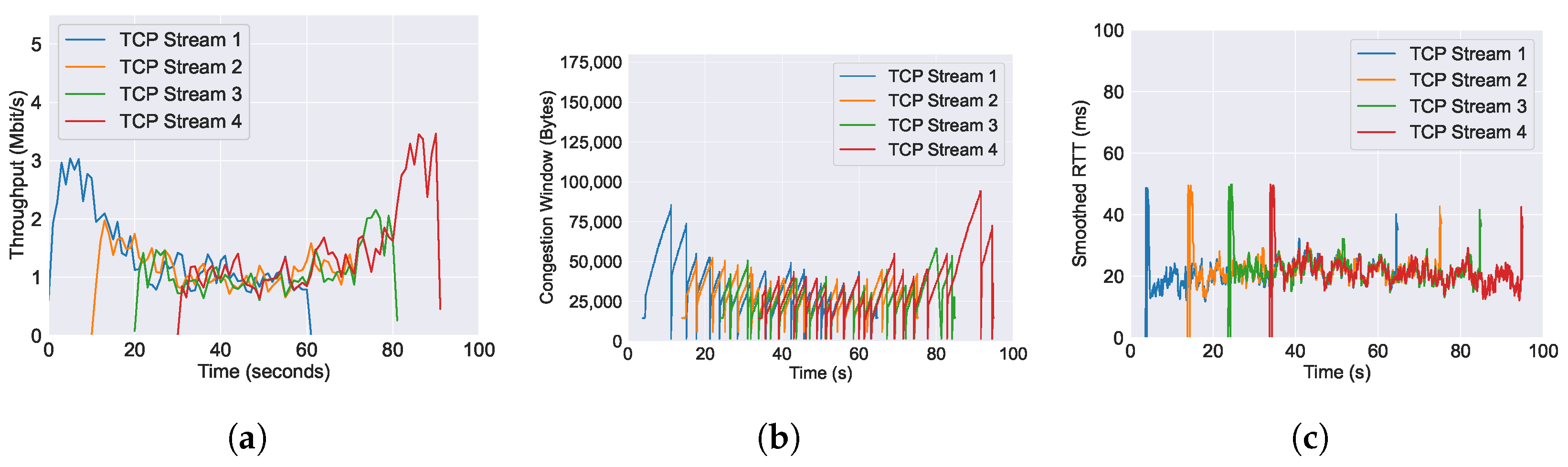
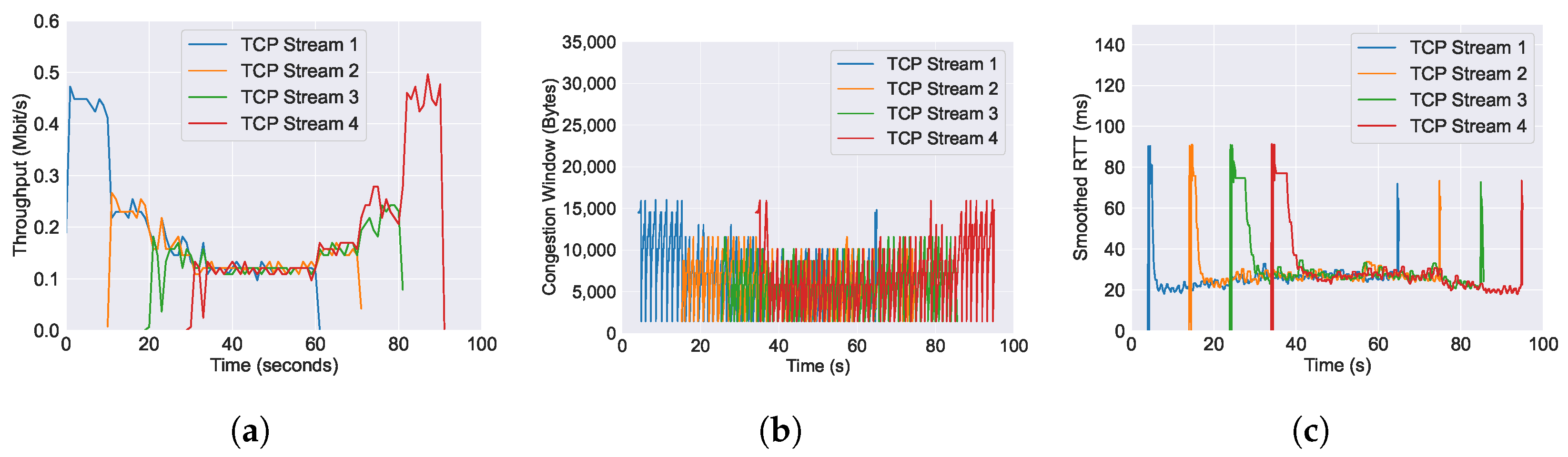
5.1. Evaluation and Benchmarking of AQM Algorithms
5.1.1. CoDel
5.1.2. PIE
5.1.3. FQ-CoDel
5.1.4. FQ-PIE
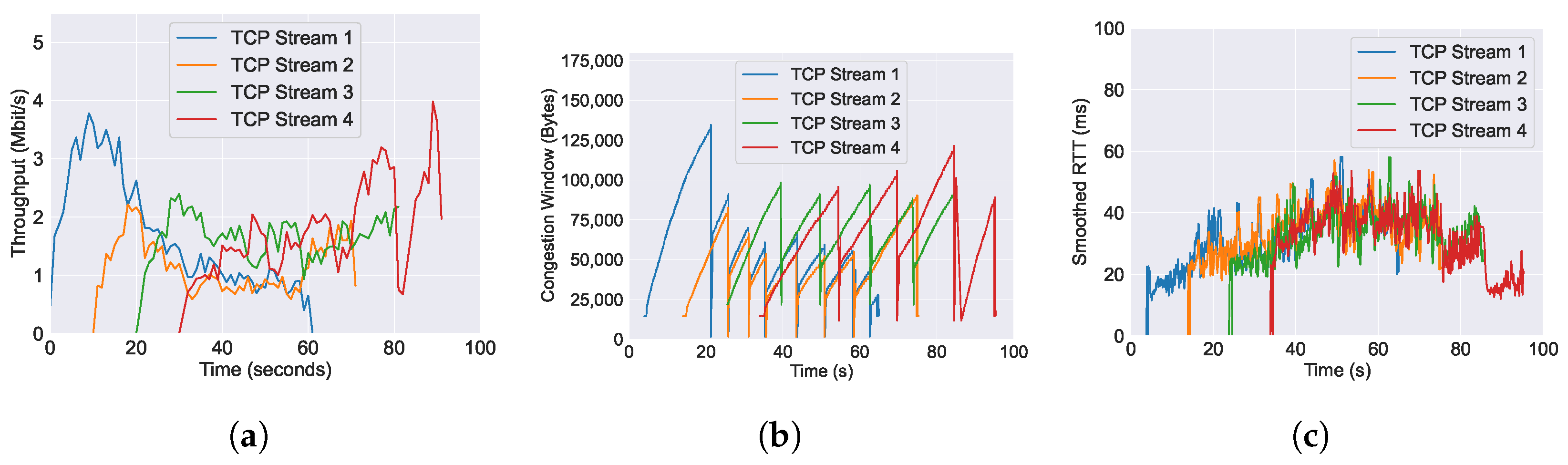
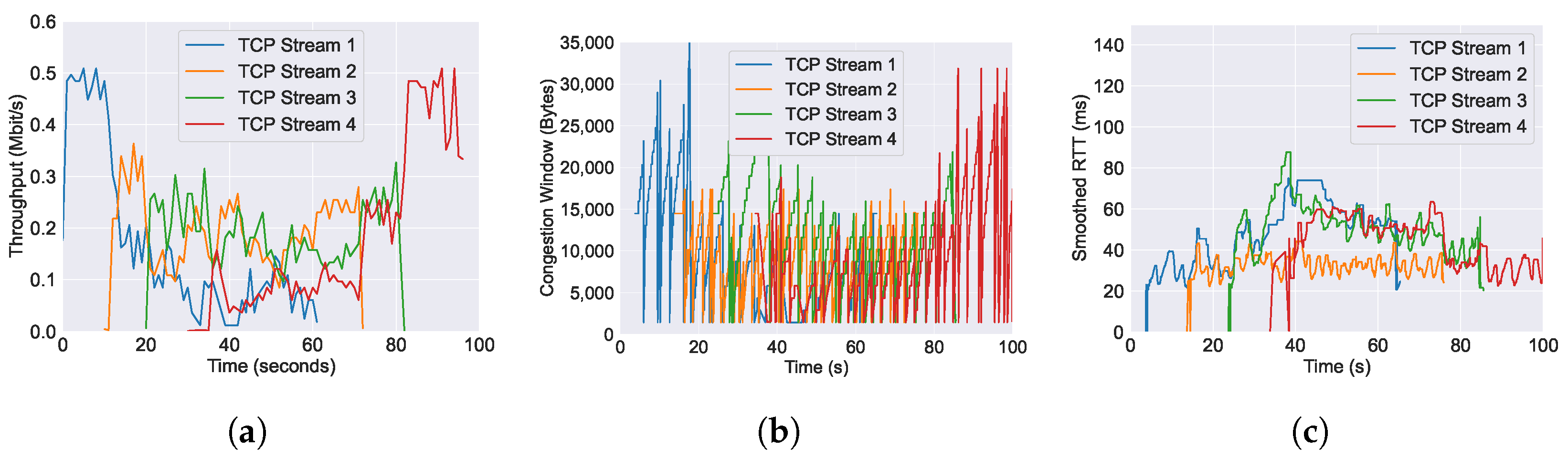
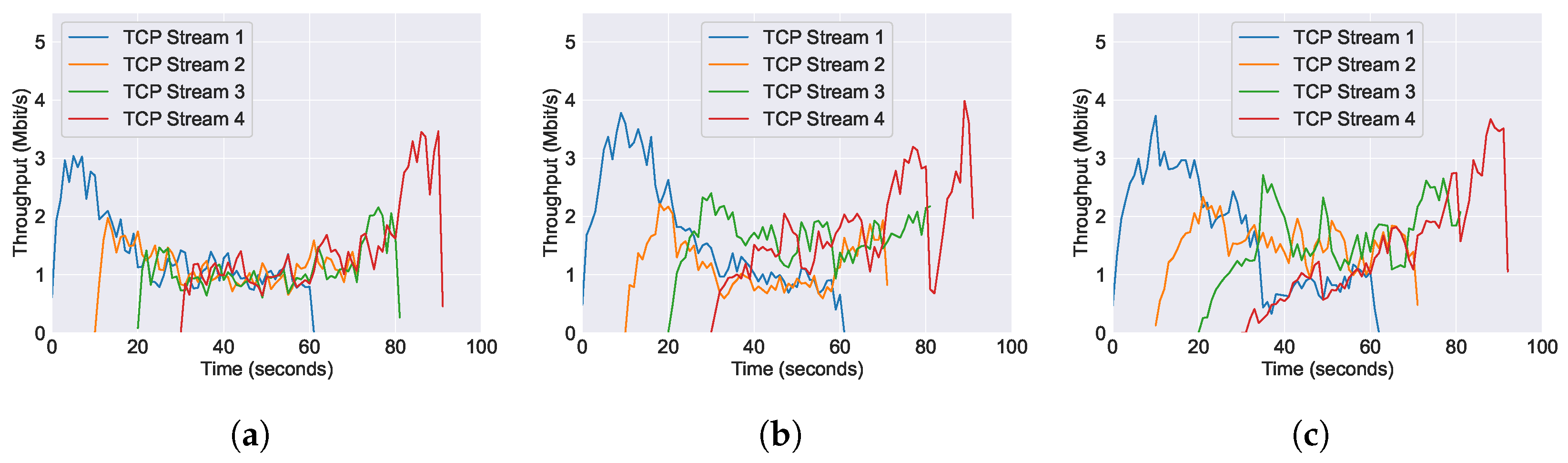
5.1.5. L4S
5.2. A3C-L4S Evaluation
5.2.1. Convergence of A3C Model
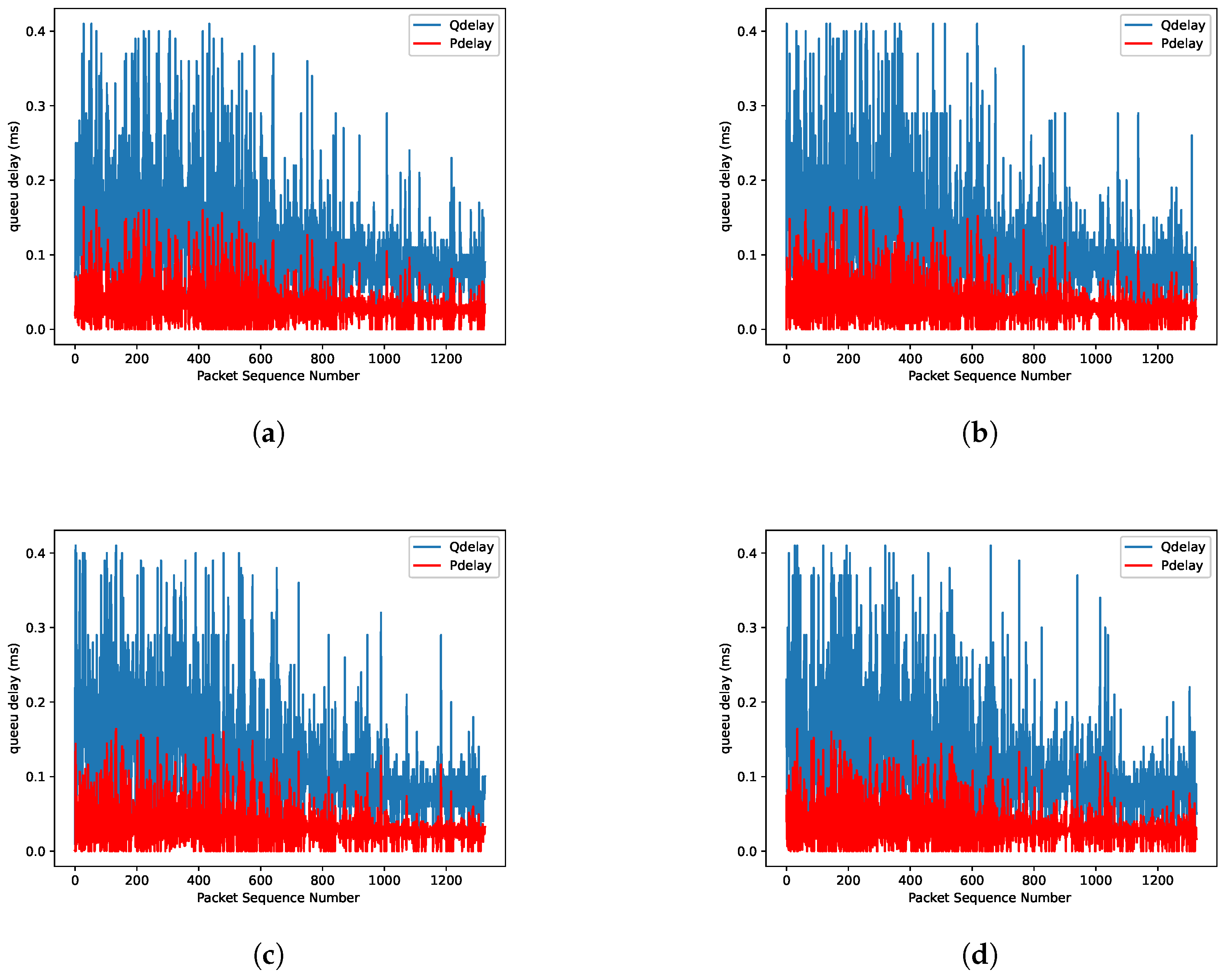
5.2.2. Comparing Predicted QDelay vs. Actual QDelay
5.2.3. Comparing Predicted QDelay vs. Actual QDelay with Varying Reward Scaling Factor
6. Results Analysis and Discussion
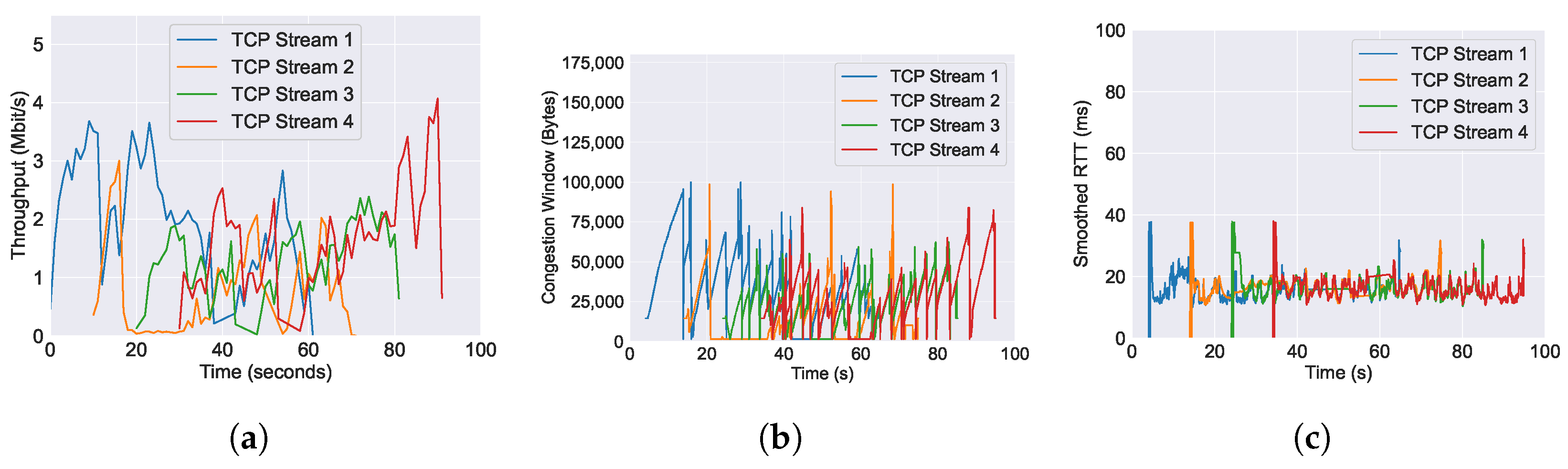
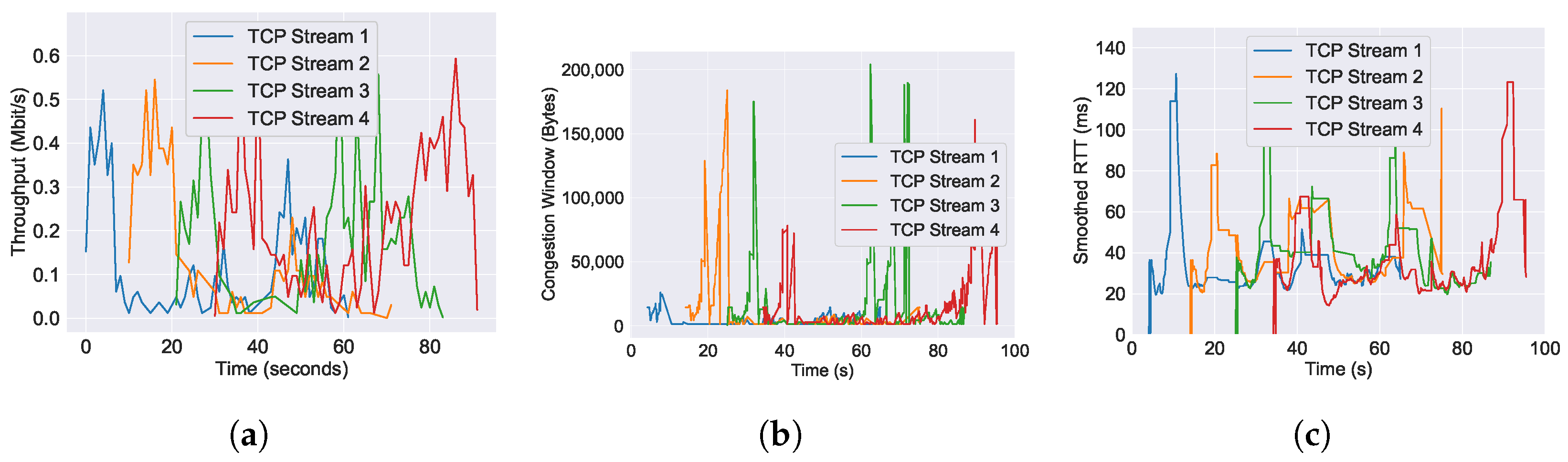
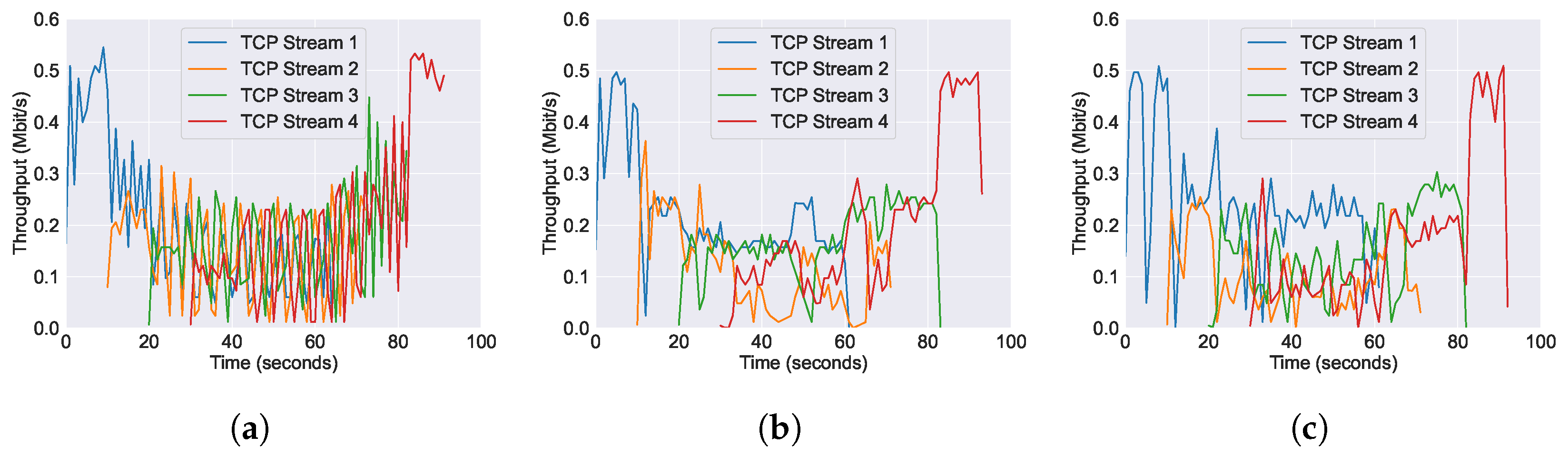
6.1. Performance of Throughput across Varying AQM Algorithms
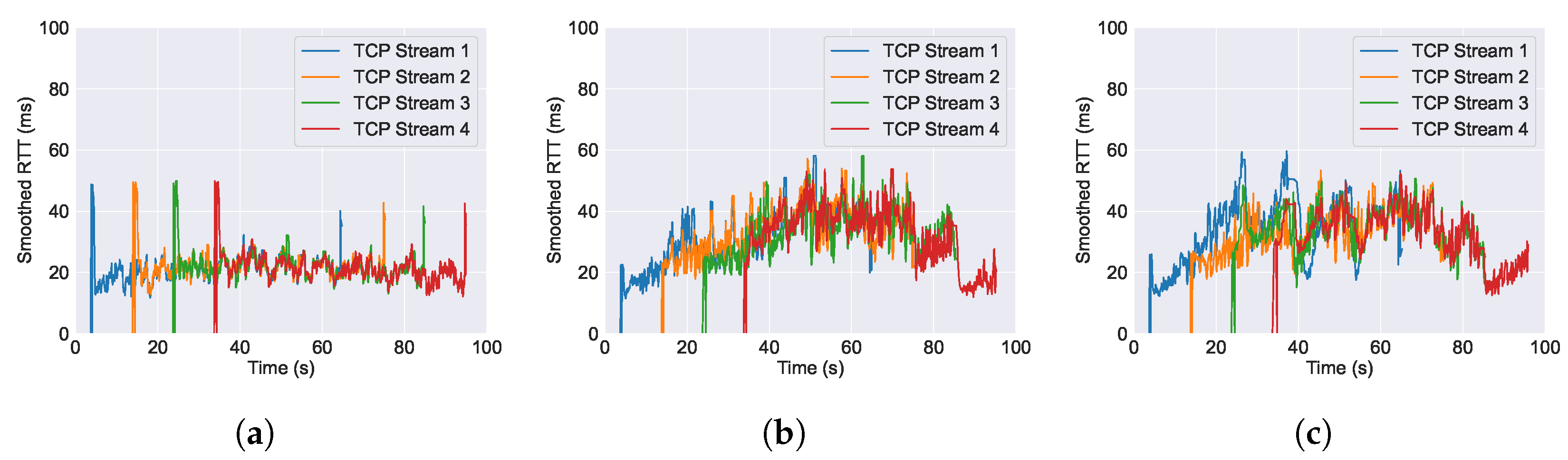
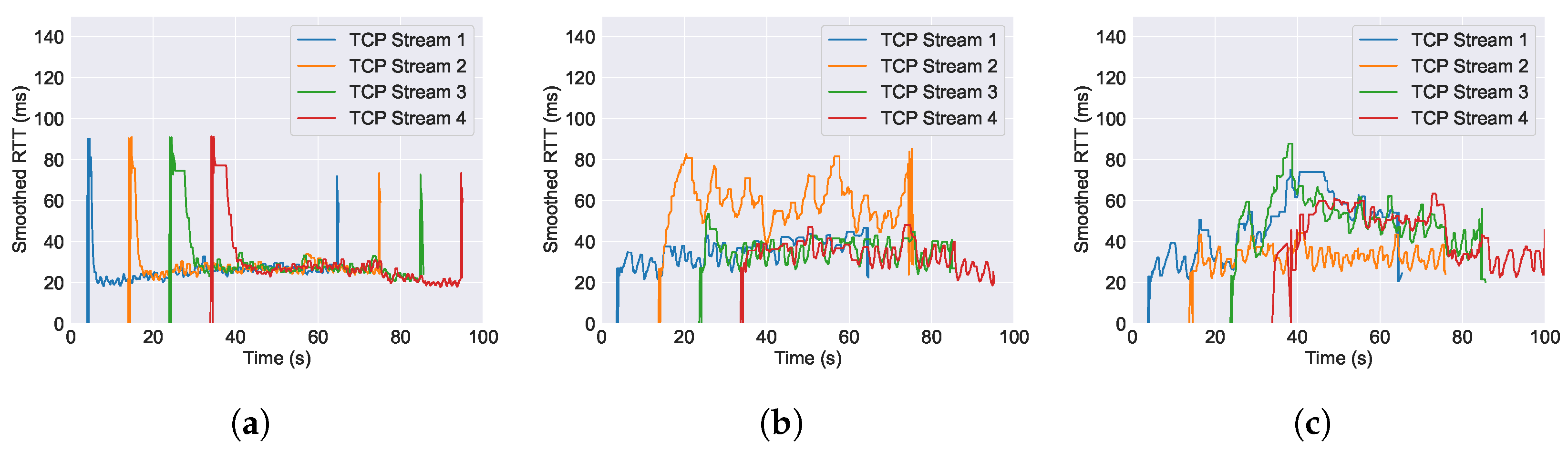
6.2. Performance of RTT across Varying AQM Algorithms
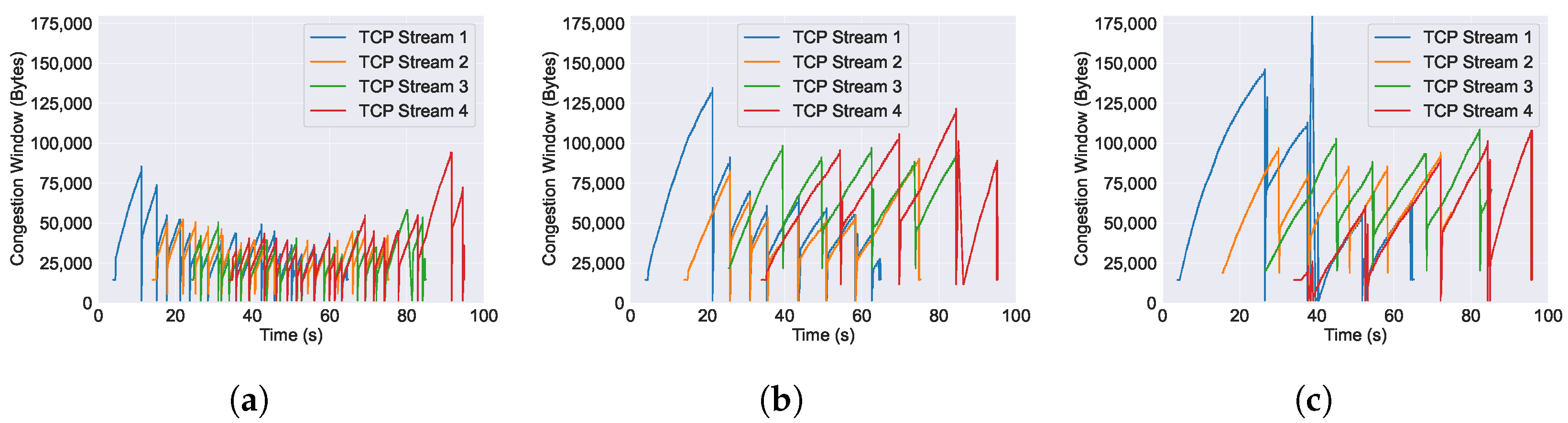
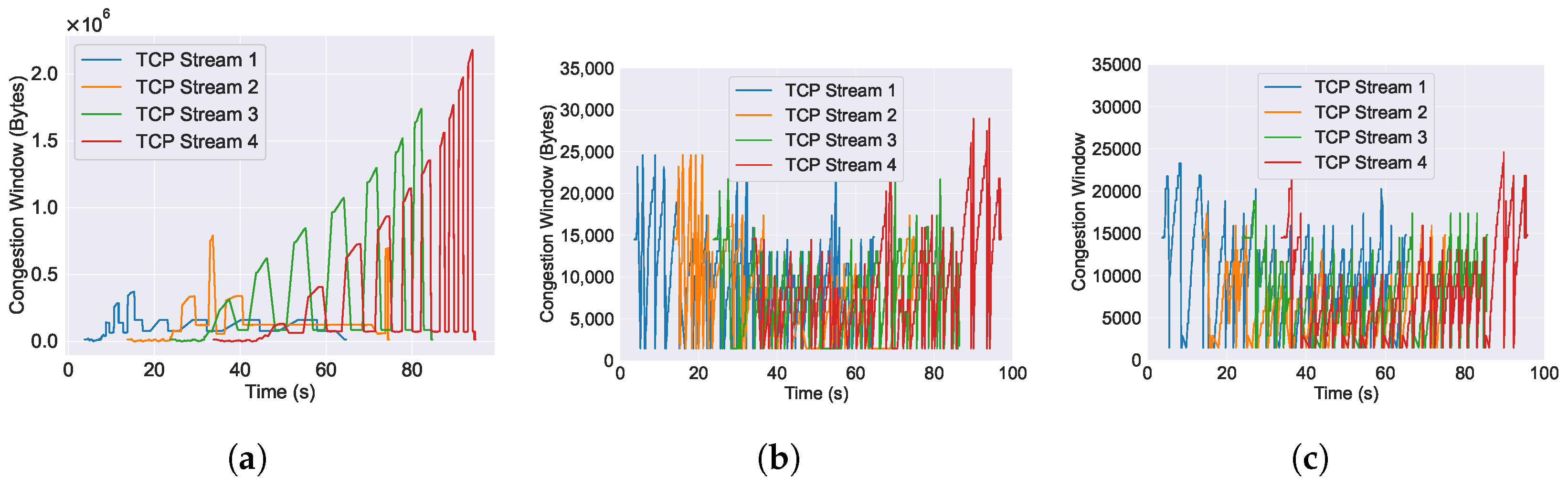
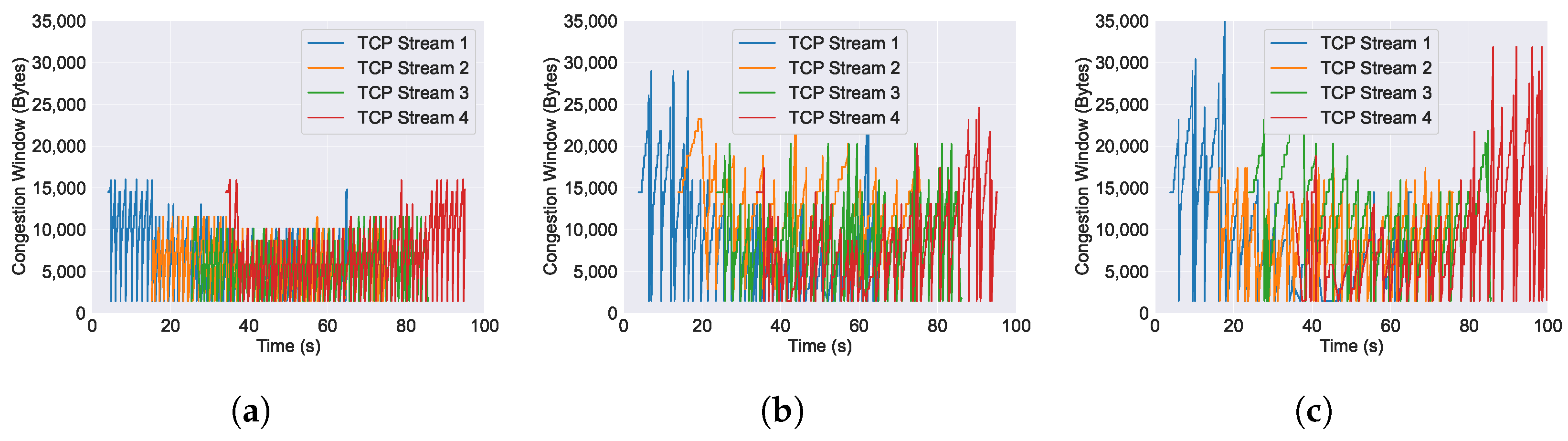
6.3. Performance of Congestion Window across Varying AQM Algorithms
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gettys, J.; Nichols, K. Bufferbloat: Dark Buffers in the Internet: Networks without effective AQM may again be vulnerable to congestion collapse. Queue 2011, 9, 40–54. [Google Scholar] [CrossRef]
- Floyd, S.; Jacobson, V. Random early detection gateways for congestion avoidance. IEEE/ACM Trans. Netw. 1993, 1, 397–413. [Google Scholar] [CrossRef]
- Kua, J.; Armitage, G.; Branch, P. A survey of rate adaptation techniques for dynamic adaptive streaming over HTTP. IEEE Commun. Surv. Tutorials 2017, 19, 1842–1866. [Google Scholar] [CrossRef]
- Kua, J.; Armitage, G.; Branch, P.; But, J. Adaptive Chunklets and AQM for higher-performance content streaming. Acm Trans. Multimed. Comput. Commun. Appl. (TOMM) 2019, 15, 1–24. [Google Scholar] [CrossRef]
- Hoeiland-Joergensen, T.; McKenney, P.; Taht, D.; Gettys, J.; Dumazet, E. The Flow Queue Codel Packet Scheduler and Active Queue Management Algorithm. Technical Report. 2018. Available online: https://www.rfc-editor.org/rfc/rfc8290.html (accessed on 18 July 2024).
- Pan, R.; Natarajan, P.; Baker, F.; White, G. Proportional Integral Controller Enhanced (PIE): A Lightweight Control Scheme to Address the Bufferbloat Problem. RFC 8033. 2017. Available online: https://www.rfc-editor.org/info/rfc8033 (accessed on 18 July 2024).
- White, G.; Pan, R. Active Queue Management (AQM) Based on Proportional Integral Controller Enhanced (PIE) for Data-Over-Cable Service Interface Specifications (DOCSIS) Cable Modems. RFC 8034. 2017. Available online: https://www.rfc-editor.org/info/rfc8034 (accessed on 18 July 2024).
- Cardozo, T.B.; da Silva, A.P.C.; Vieira, A.B.; Ziviani, A. Bufferbloat systematic analysis. In Proceedings of the 2014 International Telecommunications Symposium (ITS), Sao Paulo, Brazil, 17–20 August 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1–5. [Google Scholar]
- Ahammed, G.; Banu, R. Anakyzing the performance of active queue management algorithms. arXiv 2010, arXiv:1003.3909. [Google Scholar]
- Kua, J.; Nguyen, S.H.; Armitage, G.; Branch, P. Using active queue management to assist IoT application flows in home broadband networks. IEEE Internet Things J. 2017, 4, 1399–1407. [Google Scholar] [CrossRef]
- Kua, J.; Branch, P.; Armitage, G. Detecting bottleneck use of pie or fq-codel active queue management during dash-like content streaming. In Proceedings of the 2020 IEEE 45th Conference on Local Computer Networks (LCN), Sydney, Australia, 16–19 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 445–448. [Google Scholar]
- Amol, D.; Rajesh, P. A review on active queue management techniques of congestion control. In Proceedings of the 2014 International Conference on Electronic Systems, Signal Processing and Computing Technologies; IEEE: Piscataway, NJ, USA, 2014; pp. 166–169. [Google Scholar]
- Nichols, K.; Jacobson, V. Controlling queue delay. Commun. ACM 2012, 55, 42–50. [Google Scholar] [CrossRef]
- Hoeiland-Joergensen, T.; McKenney, P.; Taht, D.; Ghettys, J.; Dumazet, E. Flowqueue-Codel: Draft-Hoeiland-Joergensen-Aqm-fq-Codel-00. 2014. Available online: https://datatracker.ietf.org/doc/draft-ietf-aqm-fq-codel/00/ (accessed on 18 July 2024).
- Ramakrishnan, G.; Bhasi, M.; Saicharan, V.; Monis, L.; Patil, S.D.; Tahiliani, M.P. FQ-PIE queue discipline in the Linux kernel: Design, implementation and challenges. In Proceedings of the 2019 IEEE 44th LCN Symposium on Emerging Topics in Networking (LCN Symposium), Osnabrück, Germany, 14–17 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 117–124. [Google Scholar]
- Al-Saadi, R.; Armitage, G. Dummynet AQM v0. 2–CoDel, FQ-CoDel, PIE and FQ-PIE for FreeBSD’s ipfw/Dummynet Framework; Tech. Rep. A 160418; Centre for Advanced Internet Architectures, Swinburne University of Technology: Melbourne, Australia, 2016; p. 18. [Google Scholar]
- Ramakrishnan, K.; Floyd, S.; Black, D. The Addition of Explicit Congestion Notification (ECN) to IP. Technical Report. 2001. Available online: https://www.rfc-editor.org/rfc/rfc3168.html (accessed on 18 July 2024).
- De Schepper, K.; Albisser, O.; Tilmans, O.; Briscoe, B. Dual Queue Coupled AQM: Deployable Very Low Queuing Delay for All. arXiv 2022, arXiv:2209.01078. [Google Scholar]
- Schepper, K.D.; Briscoe, B.; White, G. Dual-Queue Coupled Active Queue Management (AQM) for Low Latency, Low Loss, and Scalable Throughput (L4S). RFC 9332. 2023. Available online: https://www.rfc-editor.org/info/rfc9332 (accessed on 18 July 2024).
- Hollot, C.V.; Misra, V.; Towsley, D.; Gong, W.B. On designing improved controllers for AQM routers supporting TCP flows. In Proceedings of the IEEE INFOCOM 2001 Conference on Computer Communications, Twentieth Annual Joint Conference of the IEEE 61 Computer and Communications Society (Cat. No.01CH37213), Anchorage, AK, USA, 22–26 April 2001; IEEE: Piscataway, NJ, USA, 2001; Volume 3, pp. 1726–1734. [Google Scholar] [CrossRef]
- Szyguła, J.; Domański, A.; Domańska, J.; Marek, D.; Filus, K.; Mendla, S. Supervised Learning of Neural Networks for Active Queue Management in the Internet. Sensors 2021, 21, 4979. [Google Scholar] [CrossRef] [PubMed]
- Su, Y.; Huang, L.; Feng, C. QRED: A Q-learning-based active queue management scheme. J. Internet Technol. 2018, 19, 1169–1178. [Google Scholar]
- Liu, J.; Wei, D. Active Queue Management Based on Q-Learning Traffic Predictor. In Proceedings of the 2022 International Conference on Cyber-Physical Social Intelligence (ICCSI), Nanjing, China, 18–21 November 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 399–404. [Google Scholar]
- Gomez, C.A.; Wang, X.; Shami, A. Intelligent active queue management using explicit congestion notification. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Ma, H.; Xu, D.; Dai, Y.; Dong, Q. An intelligent scheme for congestion control: When active queue management meets deep reinforcement learning. Comput. Netw. 2021, 200, 108515. [Google Scholar] [CrossRef]
- Kim, M.; Jaseemuddin, M.; Anpalagan, A. Deep reinforcement learning based active queue management for iot networks. J. Netw. Syst. Manag. 2021, 29, 34. [Google Scholar] [CrossRef]
- Fawaz, H.; Zeghlache, D.; Pham, Q.T.A.; Jérémie, L.; Medagliani, P. Deep Reinforcement Learning for Smart Queue Management. In Proceedings of the NETSYS 2021: Conference on Networked Systems 2021, Lübeck, Germany, 13–16 September 2021; pp. 1–14. Available online: https://hal.archives-ouvertes.fr/hal-03546621 (accessed on 18 July 2024).
- Albisser, O.; De Schepper, K.; Briscoe, B.; Tilmans, O.; Steen, H. DUALPI2—Low Latency, Low Loss and Scalable Throughput (L4S) AQM. In Proceedings of the Linux Netdev 0x13, Prague, Czech Republic, 20–22 March 2019; pp. 1–8. Available online: https://www.netdevconf.org/0x13/session.html?talk-DUALPI2-AQM (accessed on 18 July 2024).
- Briscoe, B.; Schepper, K.D.; Bagnulo, M.; White, G. Low Latency, Low Loss, and Scalable Throughput (L4S) Internet Service: Architecture. RFC 9330. 2023. Available online: https://www.rfc-editor.org/info/rfc9330 (accessed on 18 July 2024).
- De Schepper, K.; Bondarenko, O.; Tsang, I.J.; Briscoe, B. Pi2: A linearized aqm for both classic and scalable tcp. In Proceedings of the 12th International on Conference on emerging Networking EXperiments and Technologies, Irvine, CA, USA, 12–15 December 2016; pp. 105–119. [Google Scholar]
- Briscoe, B. PI2 Parameters. arXiv 2021, arXiv:2107.01003. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning. PMLR, New York, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Palamuttam, R.; Chen, W. Vision Enhanced Asynchronous Advantage Actor-Critic on Racing Games. Methods 2017, 4, A3C. [Google Scholar]
- Stewart, L.; Healy, J. Characterising the Behaviour and Performance of SIFTR v1. 1.0. Technical Report, CAIA, Tech. Rep. 2007. Available online: http://caia.swinburne.edu.au/reports/070824A/CAIA-TR-070824A.pdf (accessed on 18 July 2024).
- The Tcpdump Group. Tcpdump. Available online: https://www.tcpdump.org/ (accessed on 12 July 2024).
- Dpkt Contributors. Dpkt. Available online: https://pypi.org/project/dpkt/ (accessed on 12 July 2024).
- Wireshark Foundation. Wireshark. Available online: https://www.wireshark.org/ (accessed on 12 July 2024).
- Pokhrel, S.R.; Kua, J.; Satish, D.; Ozer, S.; Howe, J.; Walid, A. DDPG-MPCC: An Experience Driven Multipath Performance Oriented Congestion Control. Future Internet 2024, 16, 37. [Google Scholar] [CrossRef]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Definition |
|---|---|
| burst_allowance | Maximum allowed burst size of packets before congestion control measures are applied. |
| drop_prob | Probability of dropping a packet when the queue is congested. |
| current_qdelay | Current queue delay, which is the time a packet spends in the queue before being transmitted. |
| qdelay_old | Previous queue delay value used for comparison and calculation in the FQ-PIE algorithm. |
| accu_prob | Accumulated probability value used in FQ-PIE to determine the drop probability for incoming packets. |
| measurement_start | Start time of the measurement interval for collecting statistics. |
| tot_pkts | Total number of packets observed during the measurement interval. |
| tot_bytes | Total number of bytes observed during the measurement interval. |
| length | Average length (in packets) of the queue during the measurement interval. |
| len_bytes | Average length (in bytes) of the queue during the measurement interval. |
| drops | Number of packets dropped during the measurement interval. |
| ECN | is a packet flag marked with explicit congestion notification (ECN) during the measurement interval. |
| action | Action taken by the A3C algorithm |
| reward | Reward or penalty assigned to a specific action taken by the A3C algorithm. |
| AQM Algorithm | Data Transferred (Mbytes)—NoECN | Data Transferred (Mbytes)—ECN |
|---|---|---|
| CoDel Scenario 10 Mbps | 46.574638 | 41.101404 |
| CoDel Scenario 1 Mbps | 4.938126 | 4.523826 |
| PIE Scenario 10 Mbps | 50.339712 | 45.790667 |
| PIE Scenario 1 Mbps | 4.976113 | 6.371356 |
| FQ-CoDel Scenario 10 Mbps | 38.928913 | 53.030176 |
| FQ-CoDel Scenario 1 Mbps | 5.245358 | 5.571887 |
| FQ-PIE Scenario 10 Mbps | 47.984545 | 48.413749 |
| FQ-PIE Scenario 1 Mbps | 5.389362 | 5.438388 |
| L4S Scenario 10 Mbps | 48.196893 | 48.748529 |
| L4S Scenario 1 Mbps | 5.676679 | 5.159440 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Satish, D.; Kua, J.; Pokhrel, S.R. Active Queue Management in L4S with Asynchronous Advantage Actor-Critic: A FreeBSD Networking Stack Perspective. Future Internet 2024, 16, 265. https://doi.org/10.3390/fi16080265
Satish D, Kua J, Pokhrel SR. Active Queue Management in L4S with Asynchronous Advantage Actor-Critic: A FreeBSD Networking Stack Perspective. Future Internet. 2024; 16(8):265. https://doi.org/10.3390/fi16080265
Chicago/Turabian StyleSatish, Deol, Jonathan Kua, and Shiva Raj Pokhrel. 2024. "Active Queue Management in L4S with Asynchronous Advantage Actor-Critic: A FreeBSD Networking Stack Perspective" Future Internet 16, no. 8: 265. https://doi.org/10.3390/fi16080265
APA StyleSatish, D., Kua, J., & Pokhrel, S. R. (2024). Active Queue Management in L4S with Asynchronous Advantage Actor-Critic: A FreeBSD Networking Stack Perspective. Future Internet, 16(8), 265. https://doi.org/10.3390/fi16080265