Abstract
Digital deliberation has been steadily growing in recent years, enabling citizens from different geographical locations and diverse opinions and expertise to participate in policy-making processes. Software platforms aiming to support digital deliberation usually suffer from information overload, due to the large amount of feedback that is often provided. While Machine Learning and Natural Language Processing techniques can alleviate this drawback, their complex structure discourages users from trusting their results. This paper proposes two Explainable Artificial Intelligence models to enhance transparency and trust in the modus operandi of the above techniques, which concern the processes of clustering and summarization of citizens’ feedback that has been uploaded on a digital deliberation platform.
1. Introduction
Digital deliberation refers to the participation and engagement of people in policy and decision-making processes via digital online platforms [1]. This practice has been steadily adopted in recent years by both the public and private sectors, in order to enhance civil participation and augment transparency. For instance, the European Union has developed the “Have your say (https://ec.europa.eu/info/law/better-regulation/, accesssed on 5 March 2024)” platform, which enables citizens to provide feedback on upcoming initiatives and policies. Such platforms enable users from different countries or locations to cooperate in an asynchronous mode, thus promoting global collaboration [2]. Additionally, while traditional deliberation schemes are limited, as far as diversity is concerned, digital deliberation platforms connect citizens with different backgrounds, domains of expertise, and abilities, enabling the expression of a wide variety of different ideas and arguments.
The advantages of obtaining feedback from as many entities as possible is undeniable. However, information overload issues may arise, due to this inherent availability [3]. The stakeholders of each discussion may have to extract and dilate the underlying ideas and tendencies from each discussion, reach an understanding of the participants’ sentiment, and make a decision about the issue under consideration. The complexity of this task is proportional to the number of users involved and the feedback provided [4]. The necessity of automating the processing of a large corpus of documents has led to the employment of Natural Language Processing (NLP) and Machine Learning (ML) techniques. Functionalities that are significantly augmented by NLP technologies include information extraction, text classification, sentiment analysis, and semantic text matching. In the scope of this paper, we focus on two functionalities that are usually utilized in digital deliberation platforms, namely clustering and summarization. By utilizing such methods, stakeholders can extract clusters and summaries of similar positions and/or arguments, thus alleviating information overload issues. Specifically, Large Language Models (LLMs) can be employed for tasks such as generating summaries that are not based on ranking algorithms but on deep relational learning.
While ML models have proven to be precise and efficient, research has shown that the complexity and uncertainty associated with their inner logic can impact users’ behavior and interaction with them [5]. The necessity of enhancing users’ trust and gaining meaningful insights about the behavior of complex Deep Learning models has led to the advancement of Explainable Artificial Intelligence (XAI) methods. Explainability refers to the ability to interpret the results of a (Machine Learning) model, with respect to the identification of the importance of the input features to the output. For the purposes of this paper, we employed two different XAI technologies to generate explanations concerning the above-mentioned functionalities, namely LIME [6] and SHAP [7], whose aim is to create local-based explanations by perturbating the inputs of the ML models and measuring how the outputs are affected. The scope of the proposed approach is the exploitation of well-known and established techniques to assist digital deliberation. Moreover, by meaningfully facilitating clustering and summarization with explainability tools, we focus on alleviating users’ distrust of ML results.
2. Related Work
2.1. Clustering
Clustering is the process of dividing objects into groups. Specifically, the objects that belong in the same cluster exhibit greater similarity (based on a predefined similarity metric) to each other when compared to those belonging to other clusters. At present, there are different clustering approaches in accordance with the techniques employed. The main categories are partition-based, hierarchical, and density-based. Partition-based clustering approaches (such as K-Means [8] and K-Medoids [9]) use the method of extracting a center point for each cluster, which is used for distributing data points to clusters. K-Means is based on the calculation of the center of data points conducted by an iterative procedure until some convergence criteria are met. K-Medoids and K-Means share comparable philosophies, with the only difference between them being that K-Medoids has the ability to process discrete data. For each cluster, a medoid is extracted, which serves as a representative candidate. High computing efficiency and low time complexity are the main advantages of these approaches. However, there are also some disadvantages, such as their lack of efficiency in handling non-convex data, in the sense that outlier data points can affect the clustering procedure. Furthermore, a predefinition of the exact number of clusters is required.
Hierarchical clustering approaches are based on the extraction of the hierarchical relationships among data. The first step of this approach is to correspond each data point with an individual cluster. These models operate by combining two clusters into a new one iteratively, based on a predefined metric, until convergence is reached. Some of the most well-defined approaches include ROCK [10] and BIRCH [11]. Density-based approaches share a basic principle, which dictates that data points that belong to the same cluster should form a high-density region in the data space. DBSCAN [12], falls into this category of approaches. These approaches excel in the efficiency of the clustering process while handling arbitrarily-shaped data. On the other hand, there are some disadvantages, with the most concerning one being that they produce low-quality clustering results when the density of data space is not even.
Research has indicated recently that word/document embeddings (i.e., real-valued vector representations of words/documents) can be employed to facilitate clustering applications [13]. By employing embeddings, the task of clustering a corpus of documents is simplified by clustering data points with real-valued features that capture the semantical and structural semantics of the documents at hand. The majority of the approaches utilize a variation of the Word2Vec model [14].
2.2. Summarization
Summarization is an NLP task whose aim is to generate a descriptive summary either for a single text or for a corpus. Advancements in ML and Deep Learning have led to three categories of approaches, namely extractive, abstractive, and hybrid ones. Extractive summarization techniques employ ranking algorithms that divide the documents at a predefined level (i.e., usually in sentences) and measure the importance and relevance of the tokens to the overall document. The top-k tokens are then combined to produce a concise summary. Based on the ranking algorithm utilized, we can further divide extractive summarization techniques into three distinctive categories: (i) statistic-based approaches [15,16] that rank the tokens by word or sentence frequency; (ii) semantic-based approaches [17] that use similarity metrics to create a co-occurrence matrix for the tokens; additionally, they employ dimensionality reduction techniques (such as Latent Semantic Analysis, Principal Component Analysis, etc.) to extract the most significant tokens; (iii) graph-based approaches that create a graph of sentences (tokens); the produced graph is employed for extracting and ranking the most significant measures via a series of graph-based metrics. Some of the most prominent approaches falling into this category are TextRank [18] and LexRank [19].
On the other hand, abstractive summarization techniques operate by utilizing Deep Learning technologies to obtain vector representations (i.e., embeddings) of the sentences. The embeddings are utilized by a language model to generate an abstractive summary (i.e., summaries that may include different text compared to the original document). The recent appeal of Large Language Models, due to the impressive results they have demonstrated as far as the task of text generation is concerned, has led to the development of Transformer-based abstractive approaches (such as BERT [20], BART [21], T5 [22], etc.). Hybrid approaches employ a combination of extractive and abstractive summarization techniques for generating a representative summary.
2.3. Explainability
Explainability, as a concept, involves interpreting the outcome of a Machine Learning model via the detection of the importance of the input features to the output. Recently, as AI and ML tasks have been integrated into numerous industries and also into daily activities, Explainable Artificial Intelligence (XAI) has drawn major attention globally. However, ML models are treated by several approaches as “black boxes”, focusing exclusively on the input and output of these models for interpretation without considering the inner structure. One such method is LIME (Local Interpretable Model-Agnostic Explanation), which is able to generate explanations for any type of classifier by the method of forming local perturbations across every prediction. LIME creates a large number of data points by sampling locally around an instance. These data points are utilized to identify the changes concerning the classifier’s output. The produced explanations highlight the importance of the features in an understandable and interpretable fashion. On the other hand, SHAP (SHapley Additive exPlanation) uses game theory concepts to measure each feature’s contribution to the prediction. Specifically, it focuses on assigning a value to each feature, which portrays the change in the expected model prediction when conditioning that feature.
Depending on whether an XAI model generates explanations for each instance of the dataset individually or general patterns with high-level insights are produced, these methods can be distinguished into two main categories, namely, instance-level and model-level methods. Instance-level methods generate for each example individual explanations that are usually more understandable, as real input instances are provided. However, these approaches require more human oversight, due to the individuality of the explanation generated. On the other hand, model-level methods do not rely on specific inputs to provide interpretable explanations; instead, they utilize the total of the training instances to optimize a target prediction.
2.4. Digital Democracy and Machine Learning
Digital democracy aims to facilitate the engagement of wide masses of participants in policy-making processes. In recent years, a wide variety of platforms have been developed towards this aim, with “Have your say” and Consul [23] being two of the most prominent ones. Such platforms leverage recent technological advancements to collect and exploit collective knowledge and opinion sharing in order to facilitate governance and to render these processes more transparent, inclusive, and efficient [3]. However, mass digital participation presents new challenges to the stakeholders, as the increase, in terms of scalability and complexity, can be overwhelming for both institutions and participants. In addition, stakeholders must employ personnel with relevant expertise to extract meaningful ideas or opinions from citizen input, thus rendering these tasks too expensive and time-consuming.
The necessary automation of the extraction and synthetic processing of citizen input has led many research approaches to the employment of ML and NLP methods. The approach proposed in [24] introduces a conceptual framework for integrating AI tools into digital democracy. Specifically, by employing knowledge processing and data management services this approach aims to create a formalization scheme for argumentative deliberations, to augment sense-making, and to facilitate knowledge exchange and pioneer generation via a series of tools. DelibAnalysis [25], on the other hand, is a framework that aims to measure the discourse quality of political discussions online. The proposed framework uses supervised algorithms to predict a discourse quality index that exploits six indicators—namely, participation, level of justification, content of justification, respect, counterarguments, and constructive politics—for the corpus of the documents. This index is manually extracted for each discourse during the training phase and is used as a label for the ML model employed. Additionally, Polis [26] utilizes social input to automatically collect and synthesize feedback from deliberations, using dimensionality reduction techniques and clustering models to create groups of similar opinions. Then, for each group a series of comments are selected, with the choice influenced both by the users’ votes and by their expressivity concerning the rest of the comments.
3. The Proposed Approach
The proposed approach consists of three components: (i) the identification of clusters for the set of documents at hand; (ii) the generation of summaries for each cluster; (iii) the generation of interpretable explanations via appropriate XAI models.
The first step of the proposed pipeline is the construction of discrete clusters for the corpus of the documents at hand. Instead of handling sentences and words as categorical values, we employ an LLM to produce sentence embeddings. Specifically, we use a pre-trained MPNet [27] language model. MPNet (Masked and Permuted Network) is a language model designed to understand and generate text in the form of natural language. The main functionalities of MPNet are the following:
- Masked Language Modeling (MLM): Similar to BERT, MPNet masks some of the words in a sentence and tries to predict them (e.g., the sentence “The pesticides should be banned in EU”. is truncated to generate the masked version “The pesticides should be banned in [MASK]”.)
- Permuted Language Modeling (PLM): The second functionality shuffles the words of a sentence, in order to predict the original order. Such permutations allow MPNet to extract statistical dependencies between words.
- Generation of Sentence Embeddings: Each sentence is represented as a real-value vector that incorporates the insights and the information extracted by the above-mentioned functionalities. By default, MPNet produces a 768-dimensional embedding for each sentence. To obtain the overall document embeddings, a mean pooling operator is utilized that takes into account the embeddings of each sentence of the document.
MPNet was developed to overcome the negligence of BERT networks, as far as the dependency of the predicted tokens is concerned. For the implementation of our approach, we utilize the “all-mpnet-base-v2” variation, which is publicly available at the HuggingFace (https://huggingface.co/sentence-transformers/all-mpnet-base-v2, accesssed on 5 March 2024) platform.
For the assignment of documents to discrete clusters, a K-Medoids algorithm is employed. As stated in Section 2.1, K-Medoids create a representative data point for each cluster via an iterative process. The process commences with a random division of the documents into a predefined number of clusters. The data points are then utilized to generate a medoid for each cluster. In the next step, a data point changes label (i.e., is assigned to a different cluster) if and only if
with denoting the medoid of cluster , and with denoting the distance of data point from medoid . For our implementation, we utilize the cosine similarity metric. The process is terminated when equilibrium is reached (i.e., there is no change to the data points’s labels). The K-Medoids algorithm (Algorithm 1) is presented below:
| Algorithm 1 K-Medoids Clustering |
| Input: Dataset , number of clusters k |
| Output: Clusters and medoids |
|
Having created the clusters, we employ a BART network for summarization purposes. BART (Bidirectional and Auto-Regressive Transformers) is a model that can generate summaries by understanding and reconstructing text. The basic principle behind its functionality concerns the addition of noise to the original data (i.e, document embeddings), such as deletion, shuffle and masking of words, sentences, etc. Moreover, it uses an auto-encoder deep network whose purpose is to learn the original document embeddings. When the training of the auto-encoder is completed, the model generates an abstractive summary for each document, extracting and highlighting the most relevant information. A BART model is trained by inserting “noise” into text and employing an auto-encoder network whose aim is to reconstruct the original text. For the proposed approach, we employ a pre-trained BART language model that is publicly available at HuggingFace (https://huggingface.co/facebook/bart-large-cnn, accesssed on 5 March 2024), and which has been trained on a CNN Daily (https://huggingface.co/datasets/cnn_dailymail, accesssed on 5 March 2024) dataset.
Explaining the Model
As far as the generation of interpretable explanations is concerned, we have elected to employ three XAI models. For the clustering component, a SHAP and a LIME model are employed. The basic principle behind these models is that there exists a simpler approximation of the original model that can be utilized to calculate the importance of each feature (i.e., word). SHAP relies on additive feature attribution methods, which dictates that
LIME, on the other hand, operates as a local surrogate model considering the ML model as a black box. To find an explanation model, LIME generates variations of the input to test the behavior of the model output. The explanation model should approximately generate the same output as the original model locally, without any such restrictions applying globally. The aim of LIME is to extract the model that minimizes . A proximity score is denoted by , so that we can define the concept of locality around an instance x. The explanation produced by LIME is as follows:
However, both models require a supervised ML model, in order to produce explanations. Both models consider the ML model at hand as a black box, and they create perturbations to the input features, to induce changes in the model’s output. Nevertheless, current implementations assume that a label is provided for each instance. To overcome this barrier, we simulate the clustering process with a supervised Neural Network (NN) architecture, utilizing cluster_id generated via the clustering process as the label for each data point. The NN consists of three fully connected layers. For the output layer, a Softmax activation function is employed. Both XAI models utilize this supervised NN network to gain insights about the clustering process. Specifically, given a test instance, both models create importance scores for each word individually, which reflect the changes in the output probabilities in the absence of these words.
For the summarization component, we use a SHAP model that captures the importance of sentences to the produced summary. Similarly, in the clustering process SHAP perturbates the input text by utilizing a masking sequence, with the differentiating factor being that the maskers work on a sentence level rather than on a word level. By examining the induced alterations to the generated summary, SHAP calculates the importance of each feature (i.e., sentence) individually. However, current implementations of SHAP models are expensive as far as their execution time is concerned, especially when handling large texts, thus rendering the process prohibitive for online scenarios. To this end, we utilize a hybrid summarization technique, where the text of the documents is fed to a TextRank extractive summarization model. The output of this model is then used as input for the BART language model. Subsequently, the SHAP model considers as input only the generated extractive summary (i.e., the top-k sentences of the texts) rather than the original set of documents for the cluster.
4. Case Study
The dataset utilized for our experiments contained 2310 issues extracted from the “Have your say (https://ec.europa.eu/info/law/better-regulation/have-your-say/initiatives/13750-Hazardous-chemicals-prohibiting-production-for-export-of-chemicals-banned-in-the-European-Union_en, accesssed on 5 March 2024)” platform. The issues concerned a discussion initiated about hazardous chemicals and the potential prohibition of exporting chemicals banned in the European Union. Each instance contained the feedback provided by the users, as well as important metadata, such as the date of creation, the username, the country of origin, etc. We primarily focused on the ‘englishfeedback’ column that contained the textual data that we utilized for the proposed approach. In our experiments, we made the following assumptions: (i) we disregarded instances that contained 10 or less words, thus filtering out noisy data points; (ii) we removed duplicated comments, as they might lead to overfitting issues without adding more information; (iii) we removed highly similar texts, to ensure the robustness of our method.
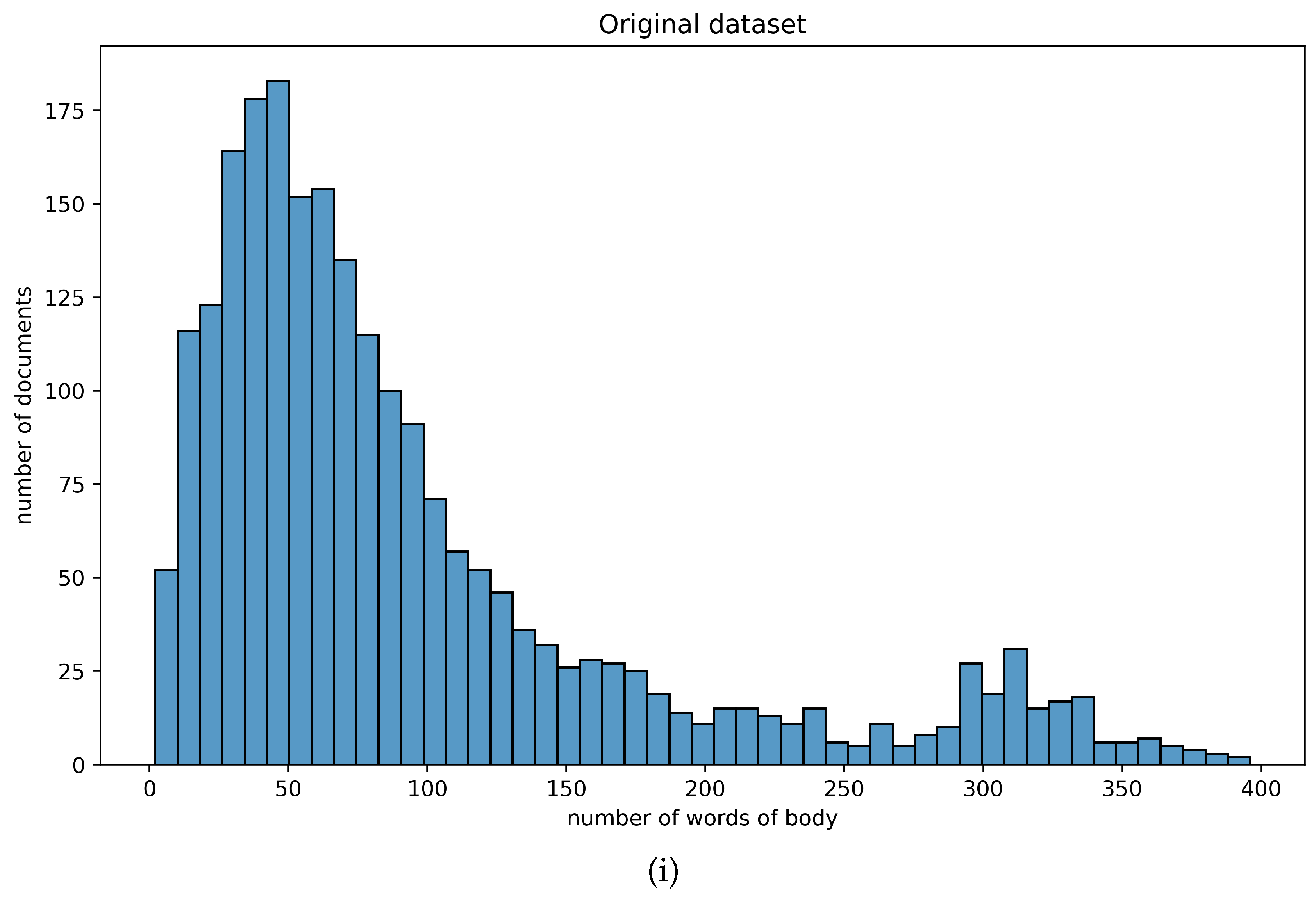
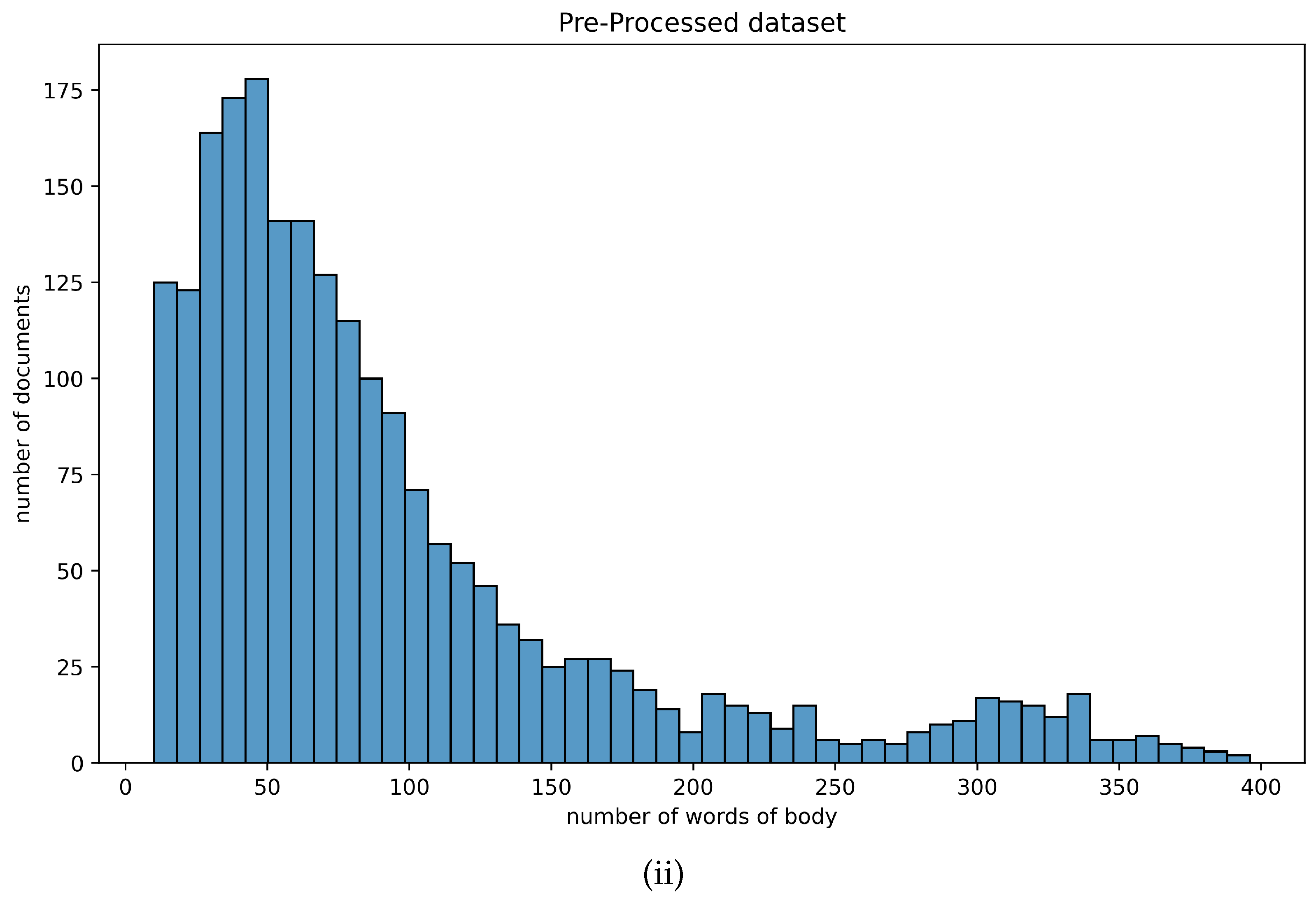
The statistical information concerning the textual attributes of the dataset at hand is summarized in Table 1. As illustrated in Figure 1, the vast majority of the corpus comprised short-text documents (i.e., ranging from 10 to 100 words), while 25% of the documents had a body of less than 41 words. These observations indicate that the dataset contained rather short-text samples. More important, however, was the fact that there existed a uniformity across the original and the pre-processed dataset, which enabled the employment of standard clustering algorithms. Figure 1 illustrates how the number of words was distributed across the totality of the corpus at hand.

Table 1.
Statistics of the documents of the datasets. The minimum and maximum number of words are reported for each dataset, as well as the average, standard deviation, and median. Moreover, the 25th and 75th percentiles are included (i.e., the number of words for 25% and 75% of the documents, respectively).
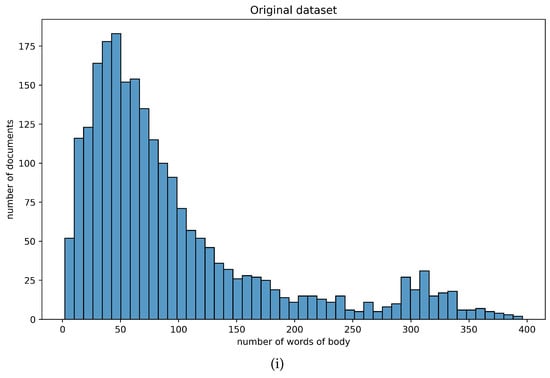
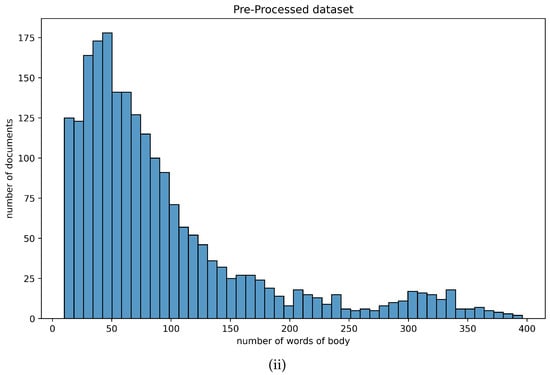
Figure 1.
Distribution of number of words, in terms of (i) the original corpus of documents and (ii) the pre-processed corpus of documents.
As far as clustering was concerned, we employed a Silhouette and Inertia plot to determine the most suitable algorithm as well as the number of clusters we should create. Silhouette quantifies the consistency within the cluster data. Specifically, the Silhouette value takes into account the similarity of an instance when compared with instances from the same cluster (i.e., cohesion) as well as the similarity to instances from other clusters (i.e., separation). The value obtains ranges from −1 to +1, with high values indicating better clustering quality. To calculate the Silhouette value for an instance i, the mean intra-cluster distance (Equation (8)) and the mean nearest-cluster distance (Equation (9)) must be calculated. Then, the Silhouette score for the instance at hand is calculated, using Equation (10), while the overall Silhouette score is calculated by Equation (11).
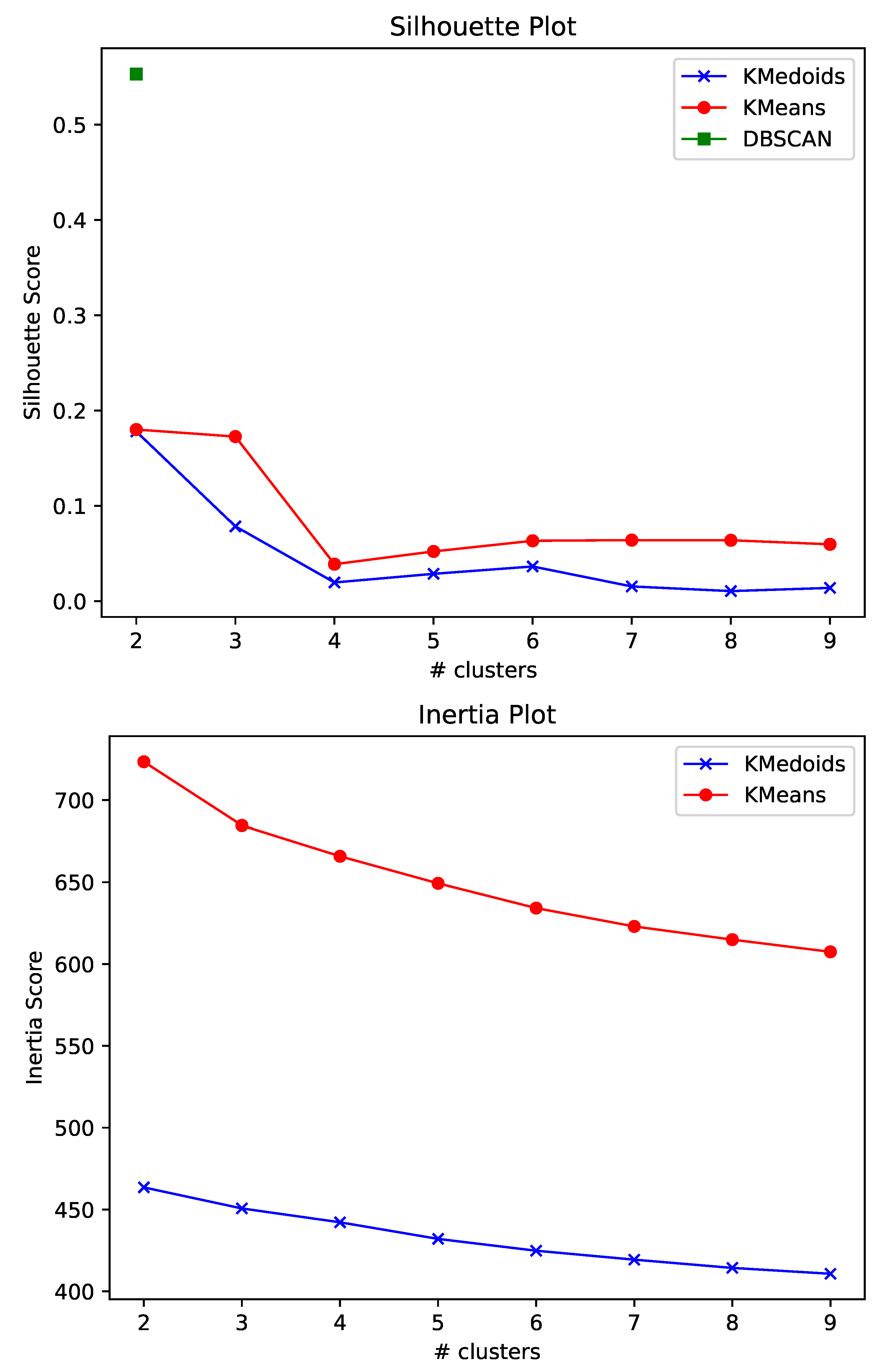
Figure 2 illustrates the results obtained for three distinct algorithms, namely, K-Medoids, K-Means, and DBSCAN. Based on the results reported in Figure 2, we elected to utilize the K-Medoids algorithm with two distinct clusters, maintaining a meaningful balance between computation cost and performance. While DBSCAN managed to obtain a substantially higher Silhouette value, it was disregarded, as the analysis of the results showed that the clusters formulated were highly imbalanced. Table 2 summarizes the statistical information concerning the textual attributes for the documents of each cluster. As observed, while the clusters formulated were rather balanced, the number of documents for each cluster remained large, hence rendering crucial the necessity of generating summaries for each cluster.
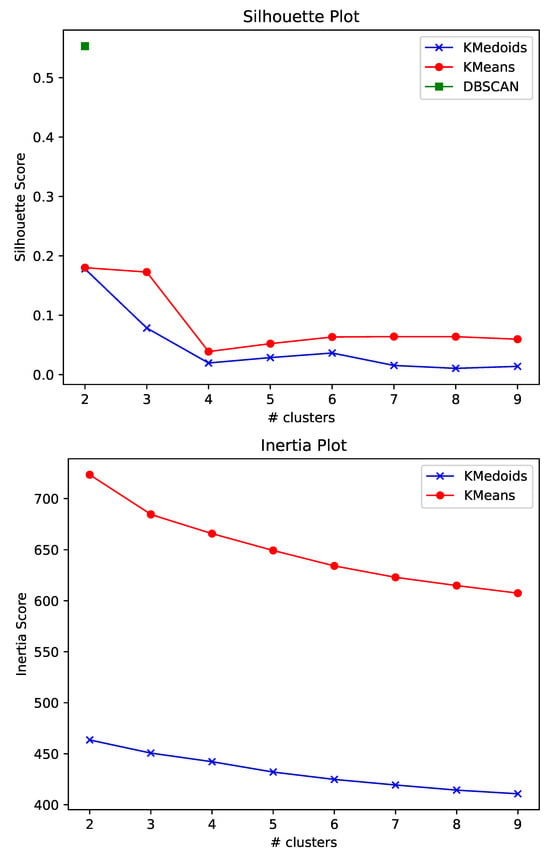
Figure 2.
The Silhouette and Inertia plots obtained by running each algorithm multiple times with varying numbers of clusters. Concerning DBSCAN, we do not report the Inertia results, as the concept of Inertia only applies to partition-based clustering algorithms. K-Medoids overall demonstrated better results across each experiment, while using the ELBOW method we can extract from the figures that the best option concerning the number of clusters is two.
Table 2.
Statistics of the documents for each cluster. The minimum and maximum number of words are reported for each dataset, as well as the average, standard deviation, and median. Moreover, the 25th and 75th percentiles are included (i.e., the number of words for 25% and 75% of the documents, respectively).
The XAI models utilized to gain insights and provide meaningful explanations about the clustering process were developed with the Python programming language; we particularly relied on the PyTorch, LIME, and SHAP libraries. For each document, we can create an interactive HTML file using the SHAP library, where users can click on individual words to examine their significance. Similarly, LIME generates either a list of words that are significant for the prediction or an HTML file containing the original text with the most important words highlighted. Figure 3 illustrates an example of a document analyzed with SHAP, while Figure 4 presents the LIME output for the same document.

Figure 3.
The output of SHAP for a document; users can interact with each word, to view its significance.

Figure 4.
The output of LIME for a document; users can examine either the generated list of important words or the text with highlighted words.
The summarization process was implemented using the transformers and spacy Python libraries, while the corresponding XAI model was implemented using the SHAP library. The outcomes of our SHAP model for each cluster are presented in Figure 5 and Figure 6.

Figure 5.
The output of SHAP for cluster 0.
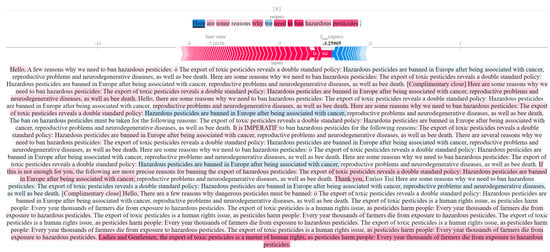
Figure 6.
The output of SHAP for cluster 1.
5. Ethical Considerations
The application of SHAP and LIME for achieving transparency and confidence in digital deliberations introduces several ethical considerations that must be addressed, to ensure responsible and fair use. This section explores potential ethical issues related to data privacy, bias in AI models, transparency, and the implications of automated decision making specific to our study.
5.1. Data Privacy
Our study involved analyzing feedback data from digital deliberation platforms, which might contain personal and sensitive information. To protect user privacy, we anonymized all personal data. Compliance with data protection regulations, such as the General Data Protection Regulation (GDPR), is essential, to safeguard users’ personal information and maintain their trust in digital deliberation systems.
5.2. Bias and Fairness
The AI models used in our study, including MPNet for sentence representation, K-Medoids for clustering, and BART for summarization, may enhance biases present in the training data. This can lead to unfair outcomes, particularly if certain groups are underrepresented or marginalized in the data. The dataset used throughout the case study was validated for bias detection and mitigation (e.g., regular audits of the training data, ensuring diverse representation, etc.). Continuous monitoring and updating of the models is necessary, to maintain fairness and equity in digital deliberations.
5.3. Transparency and Explainability
The complexity of AI models often makes their decision-making processes opaque, which may cause user disbelief concerning the validity of the results, thus reducing acceptance of AI-driven digital deliberation platforms. By employing SHAP and LIME, we provide insights into how the models make decisions, enhancing transparency and accountability. These explainability techniques allow users to understand the factors influencing the clustering and summarization of feedback, thereby increasing confidence in the system. This is particularly important in the context of digital deliberation, where the outcomes can influence public opinion and policy decisions.
5.4. Automated Decision Making
The reliance on AI for clustering and summarizing feedback data raises concerns about the loss of human oversight and the potential for errors. While our system automates these processes, to improve efficiency, it is crucial to maintain a balance between automated and human decision making. We advocate for a human-in-the-loop approach, where AI assists but does not replace human judgment. This ensures that critical decisions, especially those affecting policy and public sentiment, are reviewed and validated by humans, maintaining accountability and trust in the system.
6. Discussion and Conclusions
We have proposed the employment of two XAI models, namely, SHAP and LIME, to enhance digital deliberation. We consider two downstream NLP applications (i.e., clustering and summarization) that can heavily augment decision making in digital environments where the amount of feedback may be enormous. While these applications have proven very helpful in deliberation analysis and can save valuable labor hours, users seem to be suspicious about the quality of their outcomes. XAI models can augment users’ trust in ML models by extracting meaningful insights about the inner logic of these models and presenting them in a simplified and easily understandable form. To this end, we presented a case study, based on a dataset from the “Have your say” platform, to illustrate the outcomes of LIME and SHAP when utilized to explain document clustering and a summarization model.
Aiming to advance the performance of our approach, future work will focus on improving its clustering and summarization phases by employing more sophisticated techniques to evaluate the proposed framework. Another future work direction will be the exploitation of global-based XAI techniques that will be combined with local-based approaches as a means to extract more meaningful insights from each discussion.
The scalability of SHAP models also presents a significant challenge, due to their computational intensity, particularly in large-scale and real-time applications. This issue arises from the need to evaluate the contribution of each feature by considering all possible subsets, leading to exponential growth in computations as the number of features increases. To address this, future research could focus on developing approximate SHAP methods that use sampling techniques to estimate Shapley values, thereby significantly reducing computational overhead while maintaining accuracy. Additionally, leveraging dimensionality reduction techniques and parallel computing can help decrease computation time by reducing the number of features and distributing the workload across multiple processors.
Moreover, integrating SHAP with other less computationally intensive explainability methods or newer libraries (e.g., Captum) could offer a hybrid solution that balances accuracy and efficiency. Captum, for example, provides a range of model interpretability algorithms designed to be scalable and easy to use. By exploring these avenues, it is possible to develop more efficient SHAP models capable of scaling appropriately, making them suitable for online and real-time applications. This research direction promises to enhance the practical applicability of SHAP in dynamic environments where quick, reliable explanations are crucial.
Author Contributions
Conceptualization, I.S. and N.K.; methodology, I.S.; software, I.S.; validation, I.S.; formal analysis, I.S.; investigation, I.S. and N.K.; resources, N.K.; data curation, I.S. and N.K.; writing—original draft preparation, I.S. and N.K.; writing—review and editing, I.S. and N.K.; visualization, I.S.; supervision, N.K.; project administration, N.K.; funding acquisition, N.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The original data presented in the study are openly available in Github at https://github.com/HliasSiachos/XAI-Summarization-Clustering (accessed on 5 March 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wisniewski, C. Digital deliberation? Crit. Rev. 2013, 25, 245–259. [Google Scholar] [CrossRef]
- Chambers, S.; Gastil, J. Deliberation, democracy, and the digital landscape. Political Stud. 2021, 69, 3–6. [Google Scholar] [CrossRef]
- Arana-Catania, M.; Lier, F.A.V.; Procter, R.; Tkachenko, N.; He, Y.; Zubiaga, A.; Liakata, M. Citizen participation and machine learning for a better democracy. Digit. Gov. Res. Pract. 2021, 2, 1–22. [Google Scholar] [CrossRef]
- Cambria, E.; White, B. Jumping NLP curves: A review of natural language processing research. IEEE Comput. Intell. Mag. 2014, 9, 48–57. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4768–4777. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, 21 June–18 July 1967; Volume 1, pp. 281–297. [Google Scholar]
- Park, H.S.; Jun, C.H. A simple and fast algorithm for K-medoids clustering. Expert Syst. Appl. 2009, 36, 3336–3341. [Google Scholar] [CrossRef]
- Guha, S.; Rastogi, R.; Shim, K. ROCK: A robust clustering algorithm for categorical attributes. Inf. Syst. 2000, 25, 345–366. [Google Scholar] [CrossRef]
- Zhang, T.; Ramakrishnan, R.; Livny, M. BIRCH: An efficient data clustering method for very large databases. ACM Sigmod Rec. 1996, 25, 103–114. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In kdd; ACM: New York, NY, USA, 1996; Volume 96, pp. 226–231. [Google Scholar]
- Mehta, V.; Bawa, S.; Singh, J. WEClustering: Word embeddings based text clustering technique for large datasets. Complex Intell. Syst. 2021, 7, 3211–3224. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Luhn, H.P. The automatic creation of literature abstracts. IBM J. Res. Dev. 1958, 2, 159–165. [Google Scholar] [CrossRef]
- Ko, Y.; Seo, J. An effective sentence-extraction technique using contextual information and statistical approaches for text summarization. Pattern Recognit. Lett. 2008, 29, 1366–1371. [Google Scholar] [CrossRef]
- Steinberger, J.; Jezek, K. Using latent semantic analysis in text summarization and summary evaluation. Proc. ISIM 2004, 4, 8. [Google Scholar]
- Mihalcea, R.; Tarau, P. Textrank: Bringing order into text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; pp. 404–411. [Google Scholar]
- Erkan, G.; Radev, D.R. Lexrank: Graph-based lexical centrality as salience in text summarization. J. Artif. Intell. Res. 2004, 22, 457–479. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Royo, S.; Pina, V.; Garcia-Rayado, J. Decide Madrid: A critical analysis of an award-winning e-participation initiative. Sustainability 2020, 12, 1674. [Google Scholar] [CrossRef]
- Karacapilidis, N.; Tsakalidis, D.; Domalis, G. An AI-Enhanced Solution for Large-Scale Deliberation Mapping and Explainable Reasoning. In Proceedings of the European, Mediterranean, and Middle Eastern Conference on Information Systems; Springer: Berlin/Heidelberg, Germany, 2022; pp. 305–316. [Google Scholar]
- Fournier-Tombs, E.; Di Marzo Serugendo, G. DelibAnalysis: Understanding the quality of online political discourse with machine learning. J. Inf. Sci. 2020, 46, 810–822. [Google Scholar] [CrossRef]
- Small, C.; Bjorkegren, M.; Erkkilä, T.; Shaw, L.; Megill, C. Polis: Scaling deliberation by mapping high dimensional opinion spaces. Recer. Rev. De Pensam. I Anàlisi 2021, 26. [Google Scholar] [CrossRef]
- Song, K.; Tan, X.; Qin, T.; Lu, J.; Liu, T.Y. Mpnet: Masked and permuted pre-training for language understanding. Adv. Neural Inf. Process. Syst. 2020, 33, 16857–16867. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).