
Learning Modality Consistency and Difference Information with Multitask Learning for Multimodal Sentiment Analysis


Abstract
1. Introduction
- A multimodal sentiment analysis model that operates on joint representations is introduced. This model employs an attention mechanism to effectively allocate attention weights to each modality, thereby enabling the features of each modality to be more effectively integrated.
- Adversarial training is used to ensure the consistency of the distribution between the source and translated modalities, which acquire consistent information between modalities.
- The generalization ability of the model is improved by a multitask learning framework. A single-modal label generation module is adopted to obtain single-modal sentiment labels and thus learn the differences among the modalities.
2. Related Work
2.1. Multimodal Sentiment Analysis
2.2. Multitask Learning
3. Proposed Method
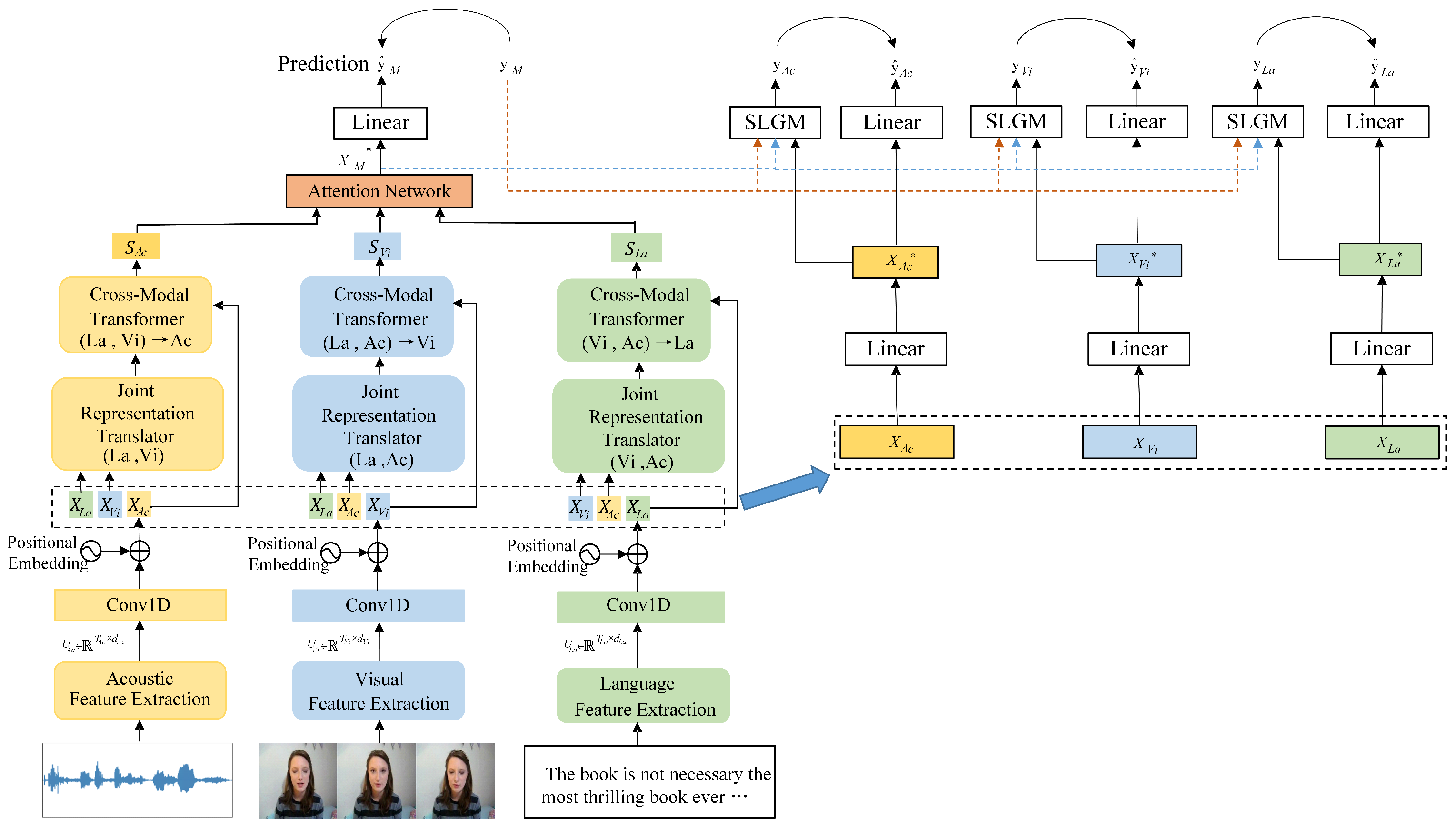
3.1. Overall Architecture
3.2. Data Processing
3.3. Modality Fusion
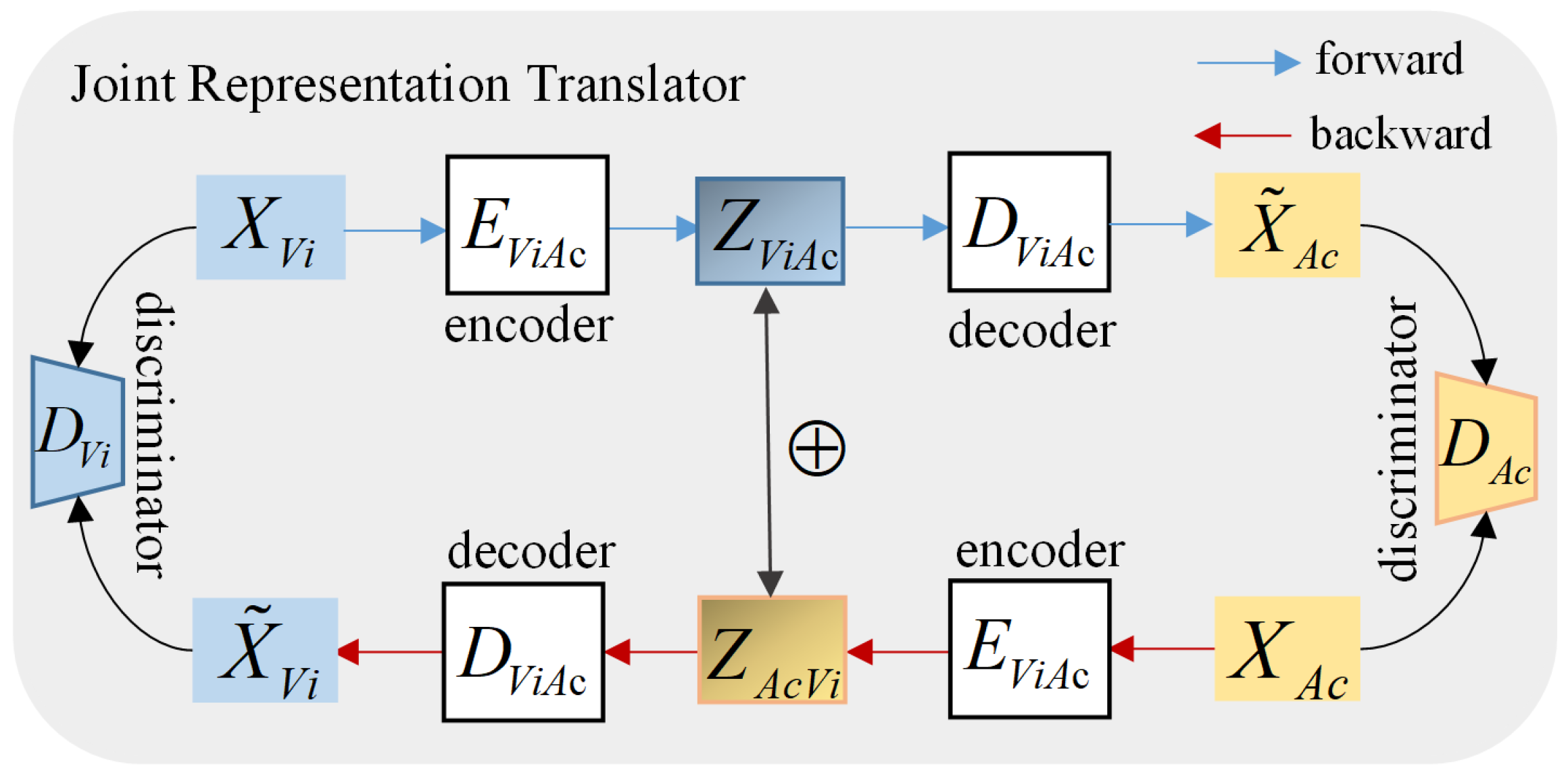
3.3.1. Joint Representation Translator
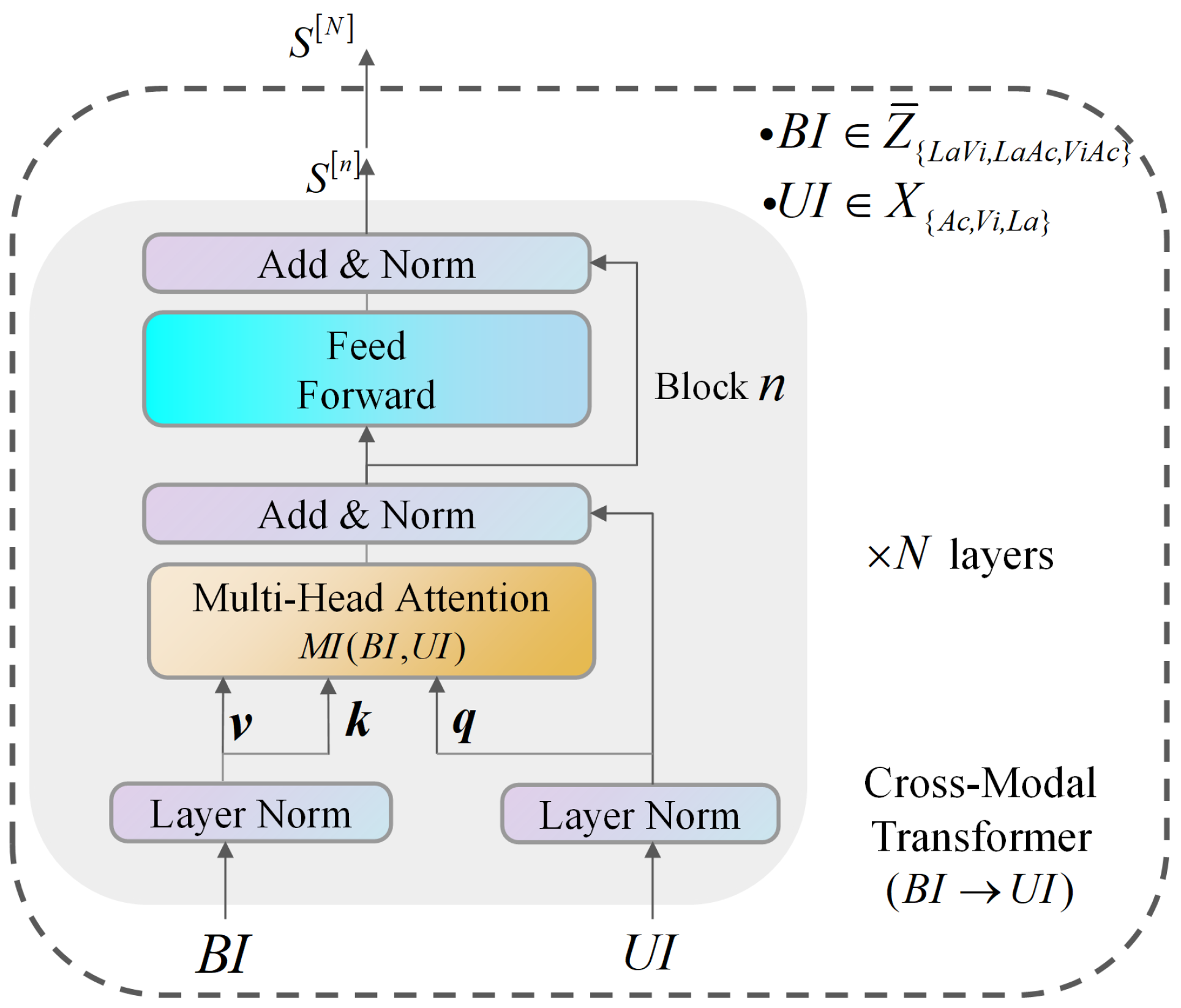
3.3.2. Cross-Modality Transformer
3.3.3. Attention Network
3.3.4. Multitask Learning
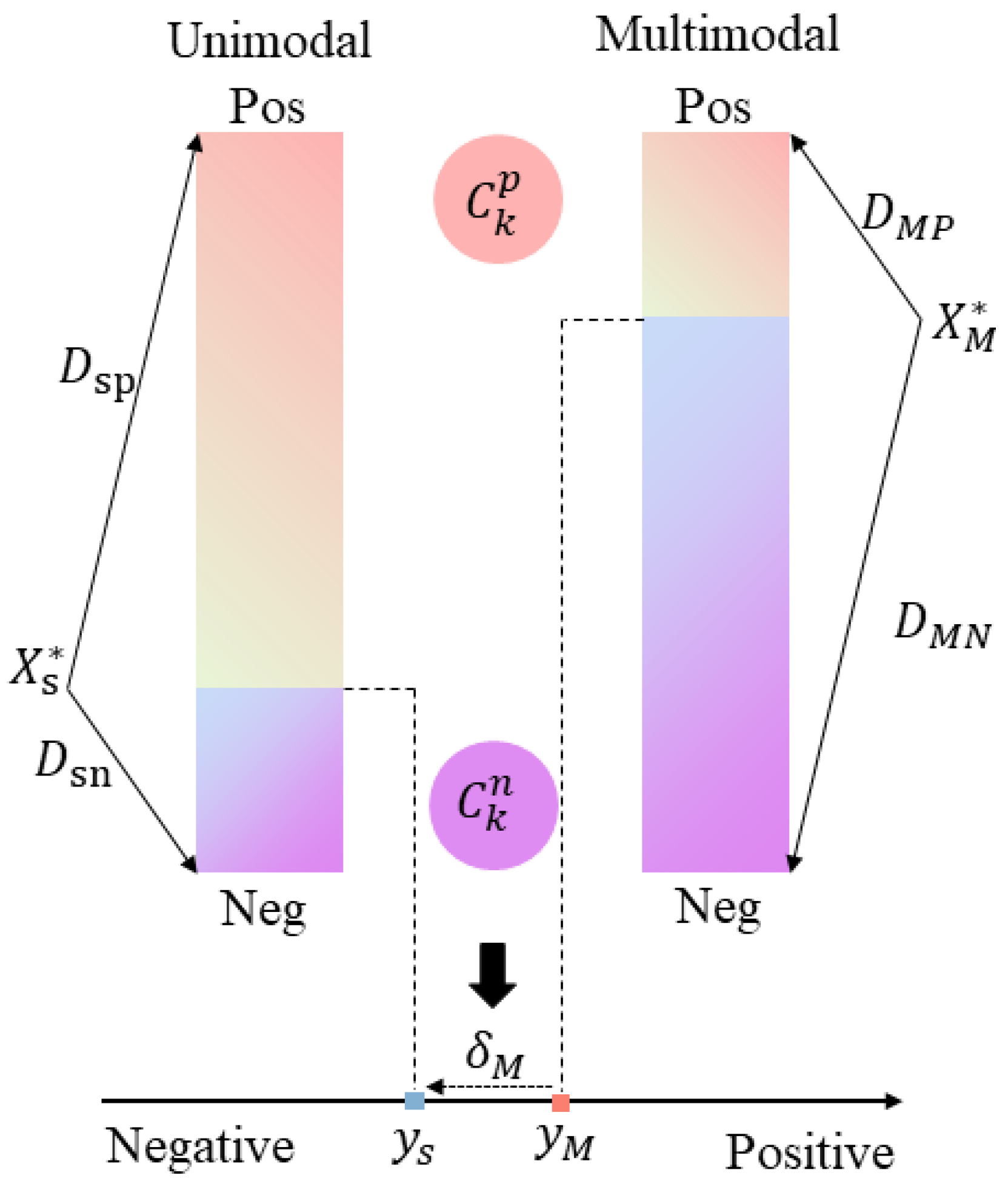
3.4. Loss Function
4. Experiment and Analysis
4.1. Dataset
4.2. Baselines
4.3. Basic Settings
4.4. Experimental Results
4.5. Ablation Study
4.5.1. Modality Ablation Experiment
4.5.2. Algorithm Ablation Experiment
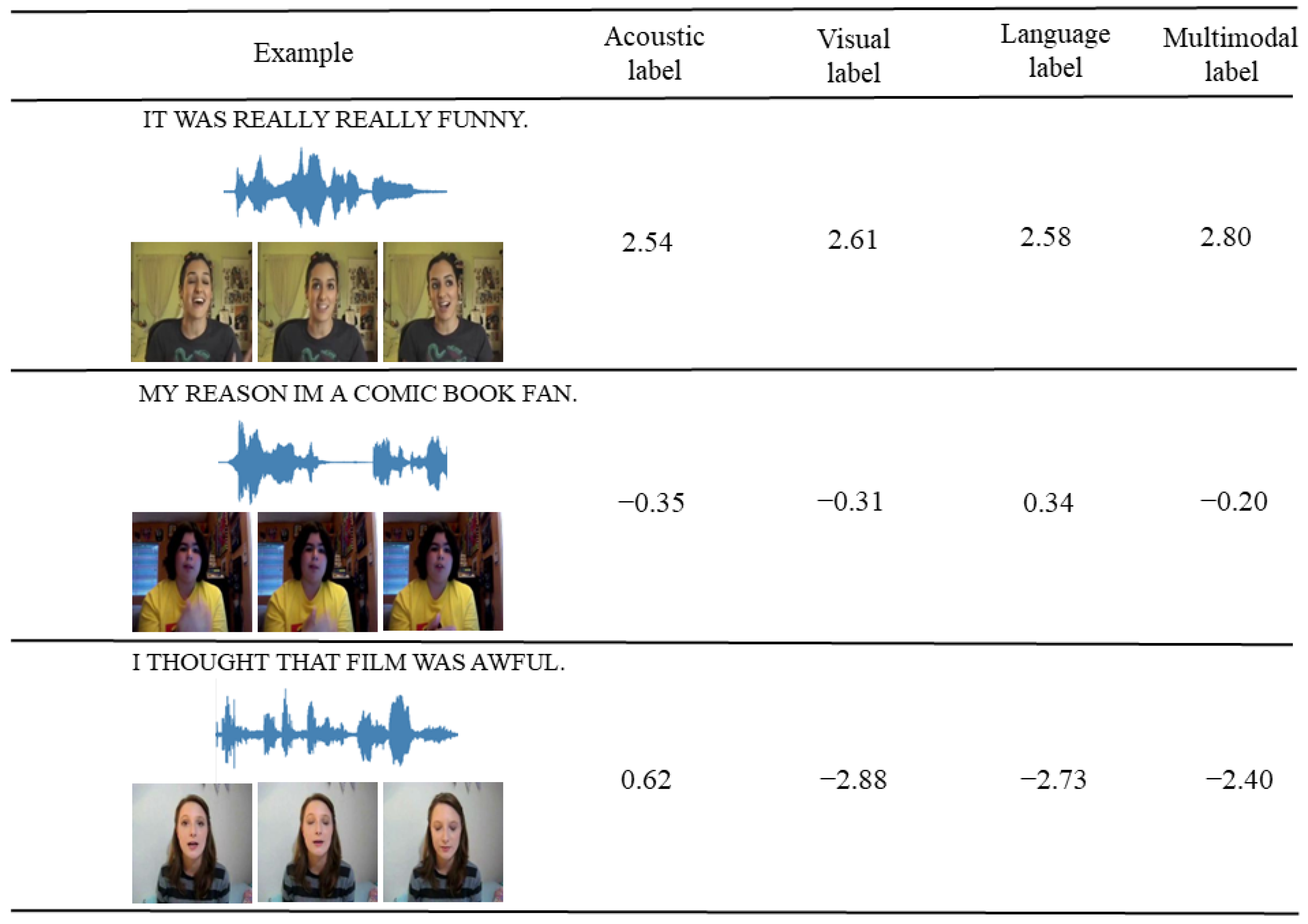
4.6. Case Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xu, P.; Zhu, X.; Clifton, D.A. Multimodal learning with transformers: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12113–12132. [Google Scholar] [CrossRef] [PubMed]
- Rahate, A.; Walambe, R.; Ramanna, S.; Kotecha, K. Multimodal co-learning: Challenges, applications with datasets, recent advances and future directions. Inf. Fusion 2022, 81, 203–239. [Google Scholar] [CrossRef]
- Al-Qablan, T.A.; Mohd Noor, M.H.; Al-Betar, M.A.; Khader, A.T. A survey on sentiment analysis and its applications. Neural Comput. Appl. 2023, 35, 21567–21601. [Google Scholar] [CrossRef]
- Gandhi, A.; Adhvaryu, K.; Poria, S.; Cambria, E.; Hussain, A. Multimodal sentiment analysis: A systematic review of history, datasets, multimodal fusion methods, applications, challenges and future directions. Inf. Fusion 2023, 91, 424–444. [Google Scholar] [CrossRef]
- Zhu, T.; Li, L.; Yang, J.; Zhao, S.; Liu, H.; Qian, J. Multimodal sentiment analysis with image-text interaction network. IEEE Trans. Multimed. 2022, 25, 3375–3385. [Google Scholar] [CrossRef]
- Kaur, R.; Kautish, S. Multimodal sentiment analysis: A survey and comparison. In Research Anthology on Implementing Sentiment Analysis Across Multiple Disciplines; IGI Global: Hershey, PA, USA, 2022; pp. 1846–1870. [Google Scholar]
- Poria, S.; Cambria, E.; Howard, N.; Huang, G.B.; Hussain, A. Fusing audio, visual and textual clues for sentiment analysis from multimodal content. Neurocomputing 2016, 174, 50–59. [Google Scholar] [CrossRef]
- Zadeh, A.; Liang, P.P.; Poria, S.; Vij, P.; Cambria, E.; Morency, L.P. Multi-attention recurrent network for human communication comprehension. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Zadeh, A.; Liang, P.P.; Mazumder, N.; Poria, S.; Cambria, E.; Morency, L.P. Memory fusion network for multi-view sequential learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Zadeh, A.; Chen, M.; Poria, S.; Cambria, E.; Morency, L.P. Tensor fusion network for multimodal sentiment analysis. arXiv 2017, arXiv:1707.07250. [Google Scholar]
- Tsai, Y.H.H.; Bai, S.; Liang, P.P.; Kolter, J.Z.; Morency, L.P.; Salakhutdinov, R. Multimodal transformer for unaligned multimodal language sequences. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Volume 2019, pp. 6558–6569. [Google Scholar]
- Lv, F.; Chen, X.; Huang, Y.; Duan, L.; Lin, G. Progressive modality reinforcement for human multimodal emotion recognition from unaligned multimodal sequences. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 2554–2562. [Google Scholar]
- Soleymani, M.; Garcia, D.; Jou, B.; Schuller, B.; Chang, S.F.; Pantic, M. A survey of multimodal sentiment analysis. Image Vis. Comput. 2017, 65, 3–14. [Google Scholar] [CrossRef]
- Chen, C.; Ling, Q. Adaptive convolution for object detection. IEEE Trans. Multimed. 2019, 21, 3205–3217. [Google Scholar] [CrossRef]
- Zhou, H.Y.; Gao, B.B.; Wu, J. Adaptive feeding: Achieving fast and accurate detections by adaptively combining object detectors. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3505–3513. [Google Scholar]
- Chen, X.; Lin, K.Y.; Wang, J.; Wu, W.; Qian, C.; Li, H.; Zeng, G. Bi-directional cross-modality feature propagation with separation-and-aggregation gate for RGB-D semantic segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 561–577. [Google Scholar]
- Seichter, D.; Köhler, M.; Lewandowski, B.; Wengefeld, T.; Gross, H.M. Efficient rgb-d semantic segmentation for indoor scene analysis. In Proceedings of the 2021 IEEE international conference on robotics and automation (ICRA), Xi’an, China, 30 May–5 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 13525–13531. [Google Scholar]
- Wang, Y.; Huang, W.; Sun, F.; Xu, T.; Rong, Y.; Huang, J. Deep multimodal fusion by channel exchanging. Adv. Neural Inf. Process. Syst. 2020, 33, 4835–4845. [Google Scholar]
- Ramachandram, D.; Taylor, G.W. Deep multimodal learning: A survey on recent advances and trends. IEEE Signal Process. Mag. 2017, 34, 96–108. [Google Scholar] [CrossRef]
- Liu, Z.; Shen, Y.; Lakshminarasimhan, V.B.; Liang, P.P.; Zadeh, A.; Morency, L.P. Efficient low-rank multimodal fusion with modality-specific factors. arXiv 2018, arXiv:1806.00064. [Google Scholar]
- Wang, Y.; Shen, Y.; Liu, Z.; Liang, P.P.; Zadeh, A.; Morency, L.P. Words can shift: Dynamically adjusting word representations using nonverbal behaviors. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 7216–7223. [Google Scholar]
- Sun, Z.; Sarma, P.; Sethares, W.; Liang, Y. Learning relationships between text, audio, and video via deep canonical correlation for multimodal language analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8992–8999. [Google Scholar]
- Zhang, Y.; Yang, Q. An overview of multi-task learning. Natl. Sci. Rev. 2018, 5, 30–43. [Google Scholar] [CrossRef]
- Zhou, Y.; Yuan, Y.; Shi, X. A multitask co-training framework for improving speech translation by leveraging speech recognition and machine translation tasks. Neural Comput. Appl. 2024, 36, 8641–8656. [Google Scholar] [CrossRef]
- Lee, T.; Seok, J. Multi Task Learning: A Survey and Future Directions. In Proceedings of the 2023 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Bali, Indonesia, 20–23 February 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 232–235. [Google Scholar]
- Jiang, D.; Wei, R.; Liu, H.; Wen, J.; Tu, G.; Zheng, L.; Cambria, E. A multitask learning framework for multimodal sentiment analysis. In Proceedings of the 2021 International Conference on Data Mining Workshops (ICDMW), Virtual, 7–10 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 151–157. [Google Scholar]
- Akhtar, M.S.; Chauhan, D.S.; Ghosal, D.; Poria, S.; Ekbal, A.; Bhattacharyya, P. Multi-task learning for multi-modal emotion recognition and sentiment analysis. arXiv 2019, arXiv:1905.05812. [Google Scholar]
- Zheng, Y.; Gong, J.; Wen, Y.; Zhang, P. DJMF: A discriminative joint multi-task framework for multimodal sentiment analysis based on intra-and inter-task dynamics. Expert Syst. Appl. 2024, 242, 122728. [Google Scholar] [CrossRef]
- Yu, W.; Xu, H.; Yuan, Z.; Wu, J. Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 10790–10797. [Google Scholar]
- Degottex, G.; Kane, J.; Drugman, T.; Raitio, T.; Scherer, S. COVAREP—A collaborative voice analysis repository for speech technologies. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 960–964. [Google Scholar]
- Baltrušaitis, T.; Robinson, P.; Morency, L.P. Openface: An open source facial behavior analysis toolkit. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–10. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 27, 3104–3112. [Google Scholar]
- Wu, L.; Wang, Y.; Shao, L. Cycle-consistent deep generative hashing for cross-modal retrieval. IEEE Trans. Image Process. 2018, 28, 1602–1612. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 139–144. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Zadeh, A.; Zellers, R.; Pincus, E.; Morency, L.P. Multimodal sentiment intensity analysis in videos: Facial gestures and verbal messages. IEEE Intell. Syst. 2016, 31, 82–88. [Google Scholar] [CrossRef]
- Zadeh, A.B.; Liang, P.P.; Poria, S.; Cambria, E.; Morency, L.P. Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Melbourne, Australia, 2018; pp. 2236–2246. [Google Scholar]
- Pham, H.; Liang, P.P.; Manzini, T.; Morency, L.P.; Póczos, B. Found in translation: Learning robust joint representations by cyclic translations between modalities. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 6892–6899. [Google Scholar]
- Hazarika, D.; Zimmermann, R.; Poria, S. Misa: Modality-invariant and-specific representations for multimodal sentiment analysis. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1122–1131. [Google Scholar]
- Ma, H.; Han, Z.; Zhang, C.; Fu, H.; Zhou, J.T.; Hu, Q. Trustworthy multimodal regression with mixture of normal-inverse gamma distributions. Adv. Neural Inf. Process. Syst. 2021, 34, 6881–6893. [Google Scholar]
- Xu, M.; Liang, F.; Su, X.; Fang, C. CMJRT: Cross-Modal Joint Representation Transformer for Multimodal Sentiment Analysis. IEEE Access 2022, 10, 131671–131679. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train | Valid | Test | All |
|---|---|---|---|---|
| CMU-MOSI | 1284 | 229 | 686 | 2199 |
| CMU-MOSEI | 16,326 | 1871 | 4659 | 22,856 |
| Setting | CMU-MOSEI | CMU-MOSI |
|---|---|---|
| Batch Size | 16 | 32 |
| Initial Learning Rate | 1 × | 1 × |
| Optimizer | Adam | Adam |
| Cross-modal Layers | 4 | 4 |
| Multihead Attention Heads | 8 | 8 |
| Dropout | 0.1 | 0.1 |
| Epochs | 50 | 100 |
| Model | Acc-7 (↑) | Acc-2 (↑) | F1 (↑) | Corr (↑) | MAE (↓) |
|---|---|---|---|---|---|
| RAVEN | 33.2 | 78.0 | 76.6 | 0.691 | 0.915 |
| MCTN | 35.6 | 79.3 | 79.1 | 0.676 | 0.909 |
| MulT | 35.1 | 80.2 | 80.1 | 0.679 | 0.972 |
| MISA | 35.6 | 80.4 | 79.8 | 0.689 | 0.969 |
| Self-MM | 35.8 | 80.7 | 80.6 | 0.693 | 0.954 |
| MoNIG | 34.1 | 80.6 | 80.6 | 0.680 | 0.951 |
| CMJRT | 37.9 | 82.4 | 82.8 | 0.704 | 0.887 |
| CDML | 39.1 | 83.7 | 84.3 | 0.725 | 0.864 |
| Model | Acc-7 (↑) | Acc-2 (↑) | F1 (↑) | Corr (↑) | MAE (↓) |
|---|---|---|---|---|---|
| RAVEN | 50.0 | 79.1 | 79.5 | 0.662 | 0.614 |
| MCTN | 49.6 | 79.8 | 80.6 | 0.670 | 0.609 |
| MulT | 51.1 | 80.1 | 80.3 | 0.628 | 0.610 |
| MISA | 51.2 | 80.5 | 80.8 | 0.662 | 0.629 |
| Self-MM | 51.0 | 80.8 | 81.2 | 0.674 | 0.609 |
| MoNIG | 50.0 | 81.0 | 81.5 | 0.600 | 0.688 |
| CMJRT | 51.6 | 82.9 | 82.6 | 0.742 | 0.581 |
| CDML | 52.9 | 84.3 | 84.3 | 0.761 | 0.553 |
| Acoustic Modality | Visual Modality | Textual Modality | Acc-7 (↑) | Acc-2 (↑) | F1 (↑) | Corr (↑) | MAE (↓) |
|---|---|---|---|---|---|---|---|
| ✓ | 47.6 | 79.9 | 80.2 | 0.598 | 0.704 | ||
| ✓ | 48.5 | 80.4 | 80.9 | 0.625 | 0.693 | ||
| ✓ | 48.9 | 80.4 | 80.6 | 0.614 | 0.698 | ||
| ✓ | ✓ | 50.7 | 81.2 | 81.6 | 0.648 | 0.659 | |
| ✓ | ✓ | 50.3 | 81.3 | 81.8 | 0.632 | 0.662 | |
| ✓ | ✓ | 51.2 | 81.7 | 82.0 | 0.702 | 0.624 | |
| ✓ | ✓ | ✓ | 52.9 | 84.3 | 84.3 | 0.761 | 0.553 |
| Model Design | Acc-7 (↑) | Acc-2 (↑) | F1 (↑) | Corr (↑) | MAE (↓) |
|---|---|---|---|---|---|
| CDML (full model) | 39.1 | 83.7 | 84.3 | 0.725 | 0.864 |
| (-) multitask learning | 38.7 | 83.0 | 83.7 | 0.717 | 0.871 |
| (-) adversarial training | 38.4 | 82.9 | 83.6 | 0.714 | 0.875 |
| (-) attention mechanism | 37.9 | 82.4 | 82.8 | 0.704 | 0.887 |
| Model Design | Acc-7 (↑) | Acc-2 (↑) | F1 (↑) | Corr (↑) | MAE (↓) |
|---|---|---|---|---|---|
| CDML (full model) | 52.9 | 84.3 | 84.3 | 0.761 | 0.553 |
| (-) multitask learning | 52.6 | 83.7 | 83.6 | 0.751 | 0.573 |
| (-) adversarial training | 52.2 | 83.5 | 83.4 | 0.747 | 0.578 |
| (-) attention mechanism | 51.6 | 82.9 | 82.6 | 0.742 | 0.581 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, C.; Liang, F.; Li, T.; Guan, F. Learning Modality Consistency and Difference Information with Multitask Learning for Multimodal Sentiment Analysis. Future Internet 2024, 16, 213. https://doi.org/10.3390/fi16060213
Fang C, Liang F, Li T, Guan F. Learning Modality Consistency and Difference Information with Multitask Learning for Multimodal Sentiment Analysis. Future Internet. 2024; 16(6):213. https://doi.org/10.3390/fi16060213
Chicago/Turabian StyleFang, Cheng, Feifei Liang, Tianchi Li, and Fangheng Guan. 2024. "Learning Modality Consistency and Difference Information with Multitask Learning for Multimodal Sentiment Analysis" Future Internet 16, no. 6: 213. https://doi.org/10.3390/fi16060213
APA StyleFang, C., Liang, F., Li, T., & Guan, F. (2024). Learning Modality Consistency and Difference Information with Multitask Learning for Multimodal Sentiment Analysis. Future Internet, 16(6), 213. https://doi.org/10.3390/fi16060213