
AI-Empowered Multimodal Hierarchical Graph-Based Learning for Situation Awareness on Enhancing Disaster Responses




Abstract
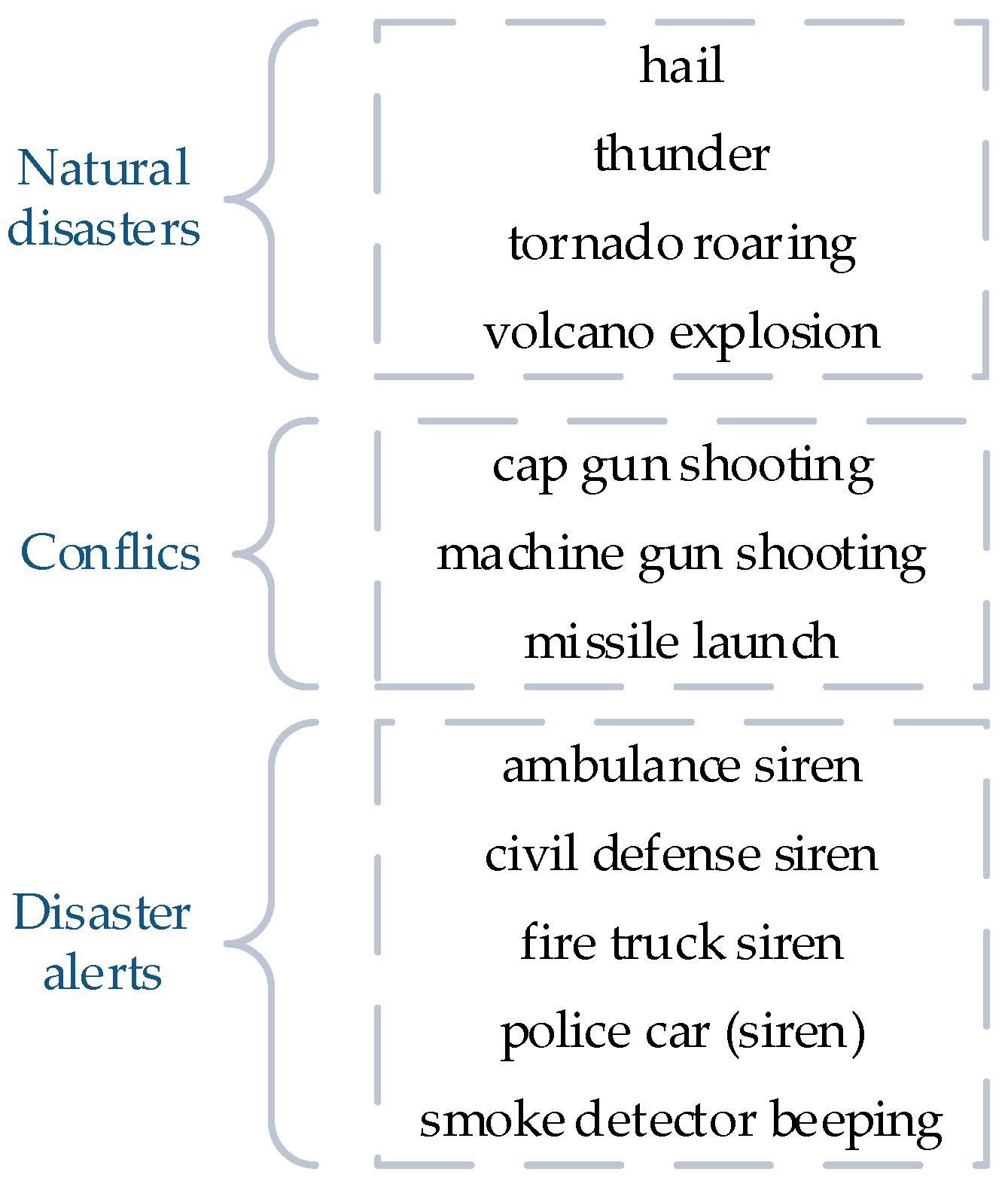
1. Introduction
- Providing an effective discriminative representation of multimodal data;
- Placing demands on the construction of the graph structure to ensure that the network can learn the relationships between the different modalities.
- We propose a multi-branching feature extraction framework that consists of shared convolutional layers and branching convolutional layers for events of specific granularity to provide independent trainable parameters for different granularities during end-to-end joint optimization;
- We construct an event-relational multimodal hierarchical graph to represent disaster events at different granularities to improve the performance of the system in advanced perception by multilayering the perception of the SA system;
- We propose a method for multimodal fusion using hierarchical graph representation learning, which enhances relational learning of multimodal data;
- The proposed MHGSA system is evaluated on datasets and consists of a significant improvement over the unimodal baseline approach.
2. Proposed Methodology
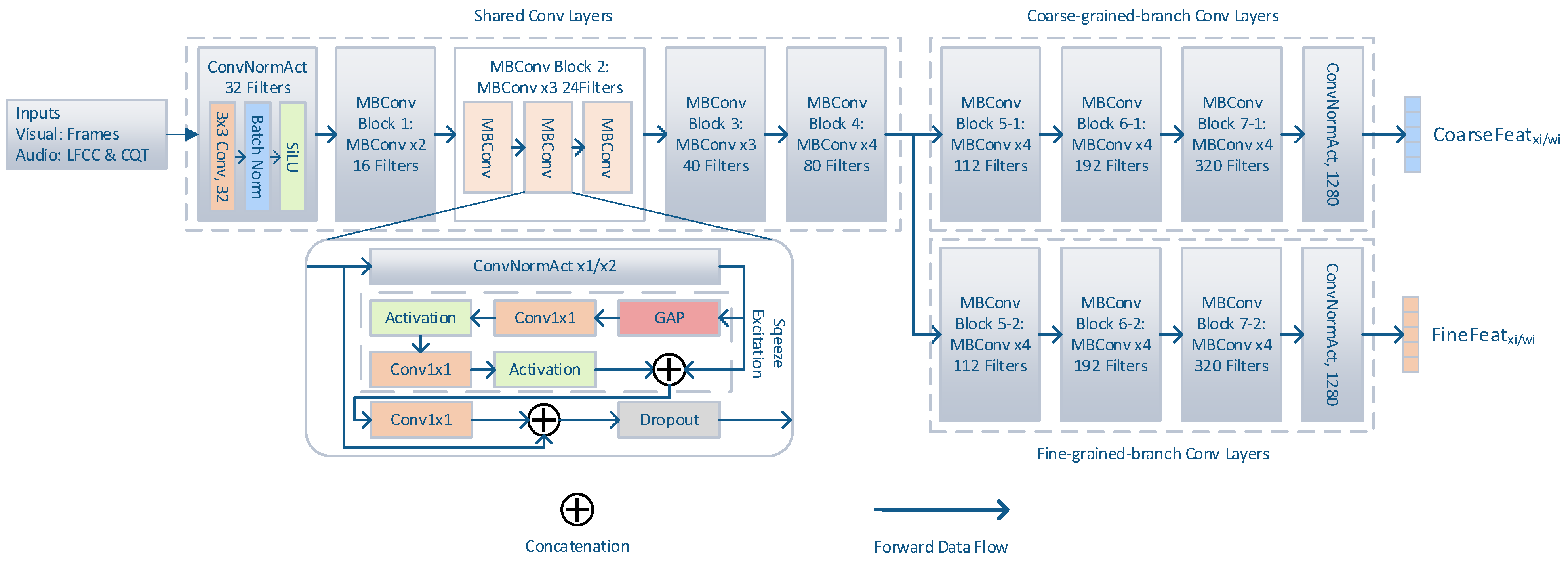
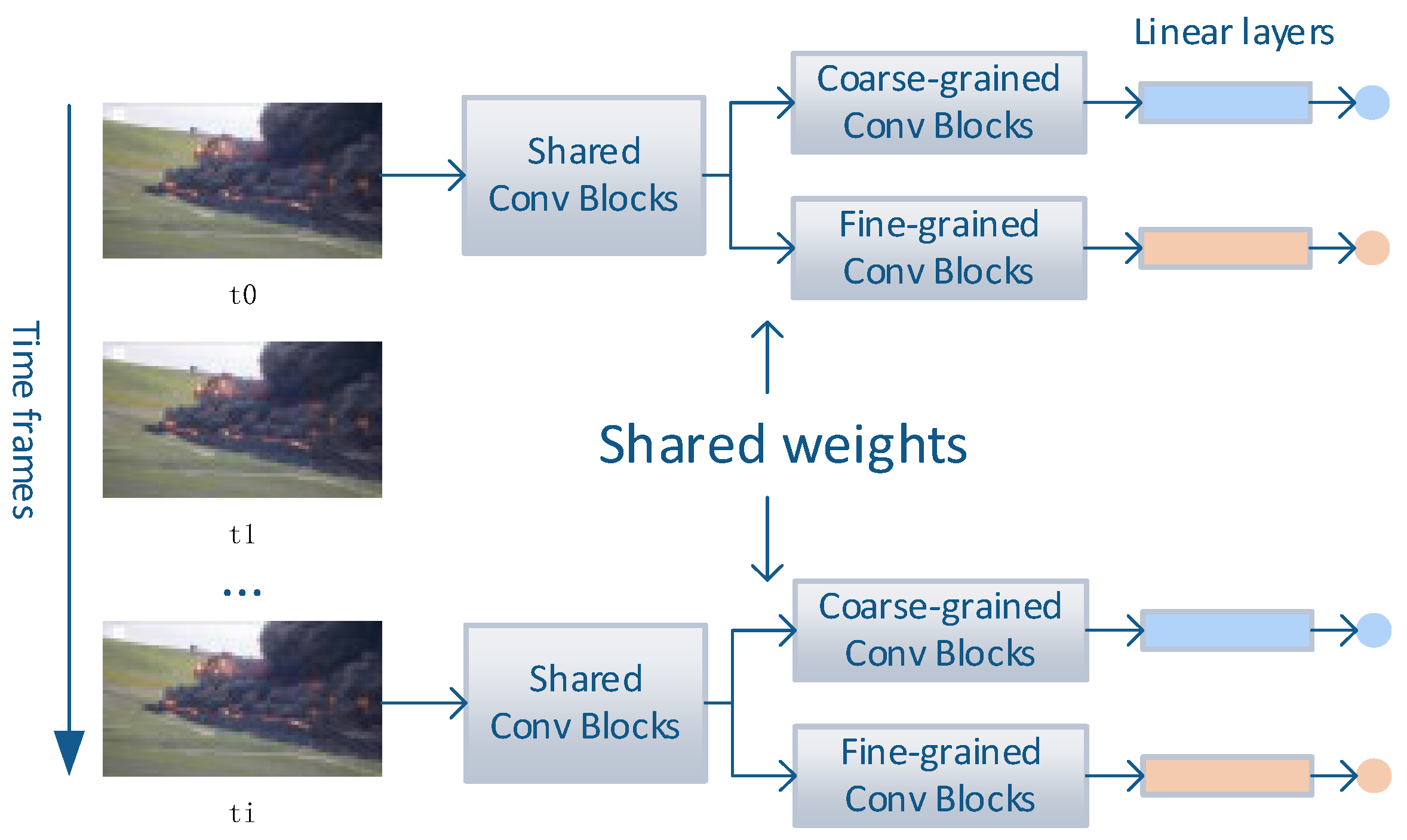
2.1. Multi-Branch Featrue Extraction Module
2.1.1. Visual Feature Extraction for Multigranularity
2.1.2. Audio Feature Extraction for Multigranularity
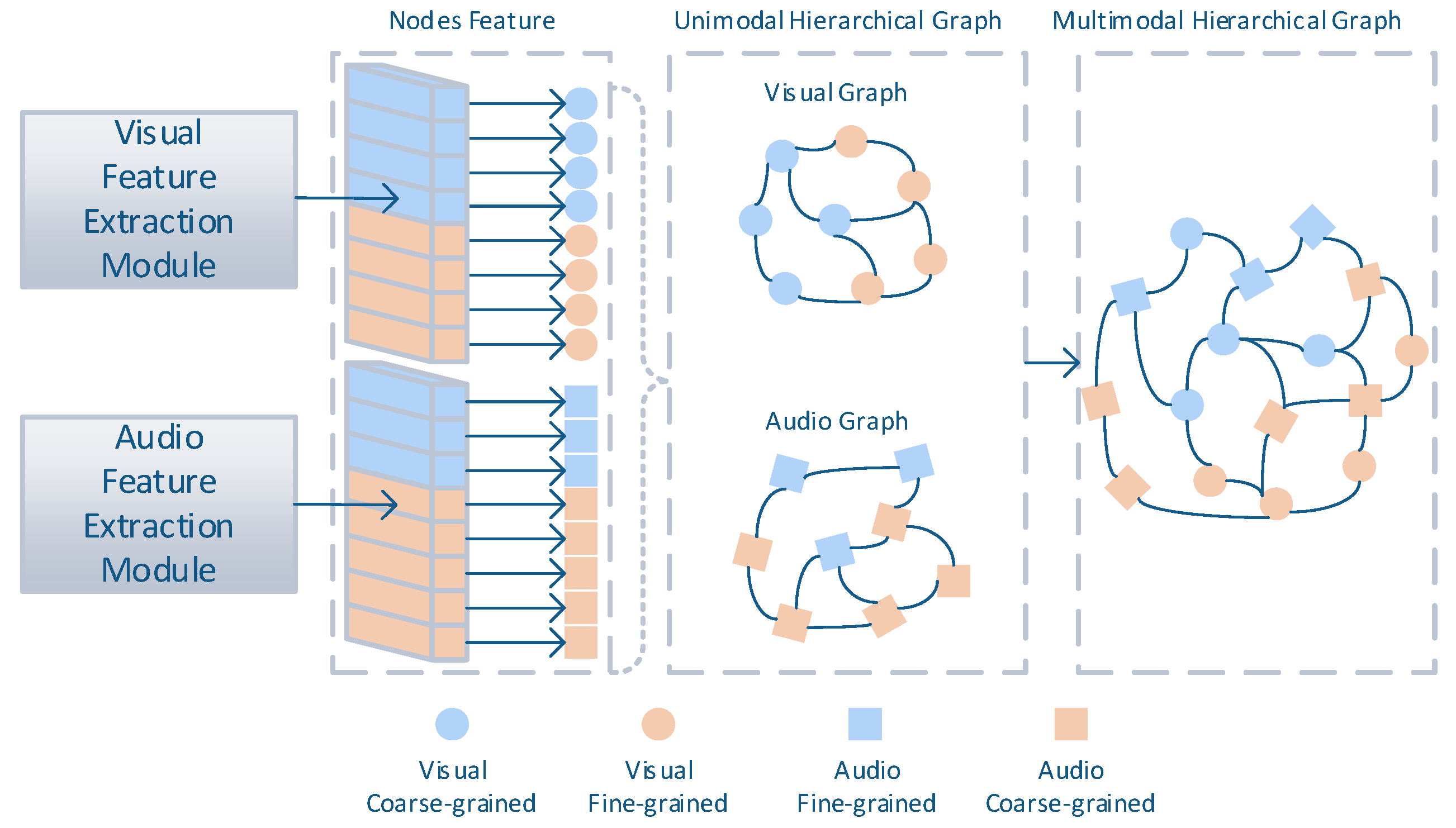
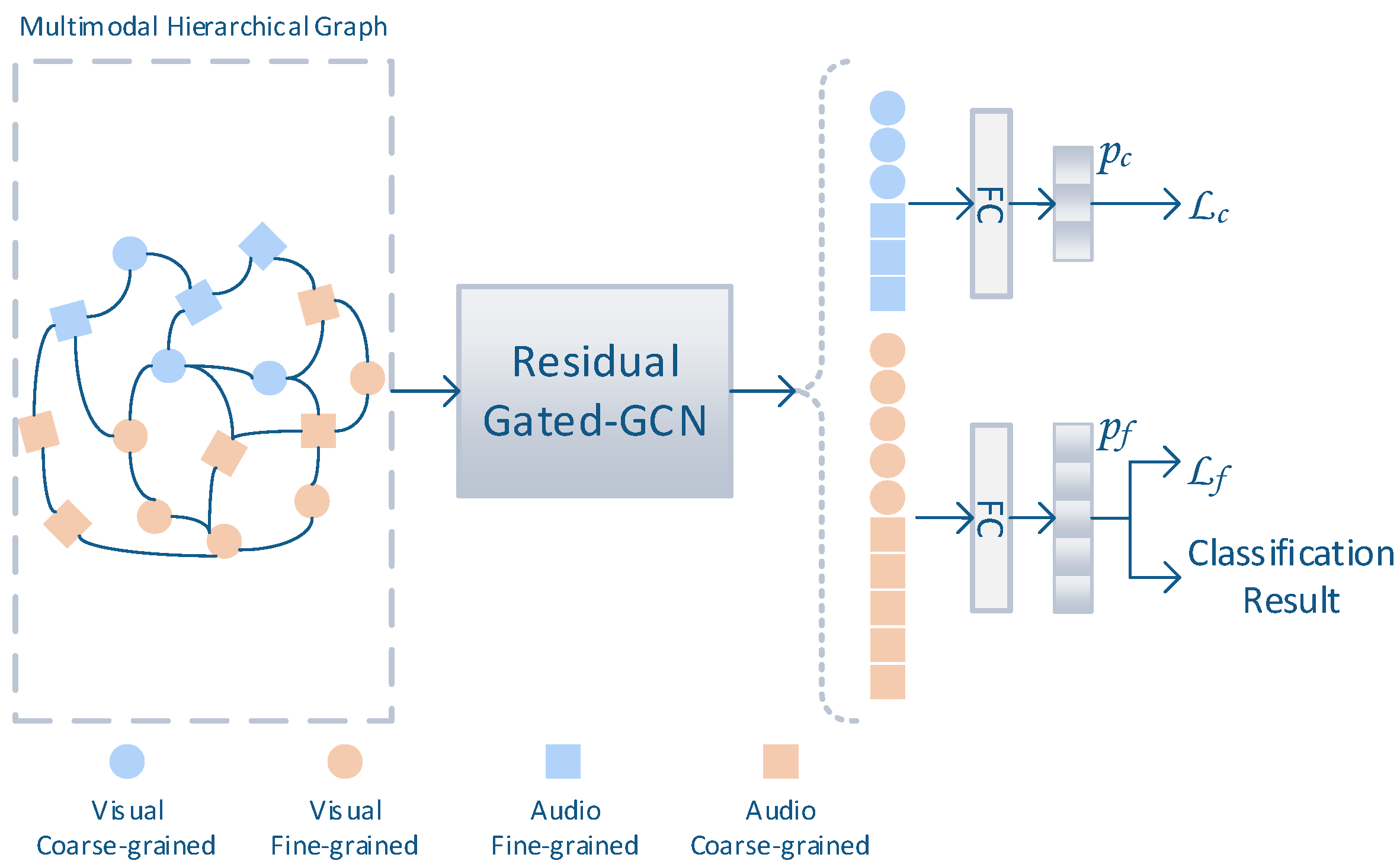
2.2. Hierarchical Graph for Disaster Event Classification
2.2.1. Hierarchical Graph Construction
2.2.2. Graph Convolutional Network for Classification
2.2.3. Loss Function
3. Experiments and Results
3.1. Experiment Datasets
3.2. Details of Implementation
3.3. Experiments on the MHGSA System
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Priya, S.; Bhanu, M.; Dandapat, S.K.; Ghosh, K.; Chandra, J. TAQE: Tweet Retrieval-Based Infrastructure Damage Assessment During Disasters. IEEE Trans. Comput. Soc. Syst. 2020, 7, 389–403. [Google Scholar] [CrossRef]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Earthquake Shakes Twitter Users: Real-Time Event Detection by Social Sensors. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 851–860. [Google Scholar]
- Chu, L.; Zhang, Y.; Li, G.; Wang, S.; Zhang, W.; Huang, Q. Effective Multimodality Fusion Framework for Cross-Media Topic Detection. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 556–569. [Google Scholar] [CrossRef]
- Blandfort, P.; Patton, D.; Frey, W.R.; Karaman, S.; Bhargava, S.; Lee, F.-T.; Varia, S.; Kedzie, C.; Gaskell, M.B.; Schifanella, R.; et al. Multimodal Social Media Analysis for Gang Violence Prevention. In Proceedings of the International AAAI Conference on Web and Social Media, Palo Alto, CA, USA, 25–28 June 2018. [Google Scholar]
- Zhou, H.; Yin, H.; Zheng, H.; Li, Y. A Survey on Multi-Modal Social Event Detection. Knowl. Based Syst. 2020, 195, 105695. [Google Scholar] [CrossRef]
- Muhammad, K.; Khan, S.; Elhoseny, M.; Hassan Ahmed, S.; Wook Baik, S. Efficient Fire Detection for Uncertain Surveillance Environment. IEEE Trans. Ind. Inform. 2019, 15, 3113–3122. [Google Scholar] [CrossRef]
- Muhammad, K.; Khan, S.; Palade, V.; Mehmood, I.; de Albuquerque, V.H.C. Edge Intelligence-Assisted Smoke Detection in Foggy Surveillance Environments. IEEE Trans. Ind. Inform. 2020, 16, 1067–1075. [Google Scholar] [CrossRef]
- Kyrkou, C.; Theocharides, T. EmergencyNet: Efficient Aerial Image Classification for Drone-Based Emergency Monitoring Using Atrous Convolutional Feature Fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1687–1699. [Google Scholar] [CrossRef]
- Ramachandran, U.; Hong, K.; Iftode, L.; Jain, R.; Kumar, R.; Rothermel, K.; Shin, J.; Sivakumar, R. Large-Scale Situation Awareness with Camera Networks and Multimodal Sensing. Proc. IEEE 2012, 100, 878–892. [Google Scholar] [CrossRef]
- Fan, C.; Wu, F.; Mostafavi, A. A Hybrid Machine Learning Pipeline for Automated Mapping of Events and Locations From Social Media in Disasters. IEEE Access 2020, 8, 10478–10490. [Google Scholar] [CrossRef]
- Ektefaie, Y.; Dasoulas, G.; Noori, A.; Farhat, M.; Zitnik, M. Multimodal Learning with Graphs. Nat. Mach Intell. 2023, 5, 340–350. [Google Scholar] [CrossRef]
- Alam, F.; Joty, S.; Imran, M. Graph Based Semi-Supervised Learning with Convolution Neural Networks to Classify Crisis Related Tweets. In Proceedings of the International AAAI Conference on Web and Social Media, Palo Alto, CA, USA, 25–28 June 2018. [Google Scholar]
- Luo, C.; Song, S.; Xie, W.; Shen, L.; Gunes, H. Learning Multi-Dimensional Edge Feature-Based AU Relation Graph for Facial Action Unit Recognition. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, Vienna, Austria, 23–29 July 2022; pp. 1239–1246. [Google Scholar]
- Liu, Q.; Xiao, L.; Yang, J.; Wei, Z. CNN-Enhanced Graph Convolutional Network with Pixel- and Superpixel-Level Feature Fusion for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 8657–8671. [Google Scholar] [CrossRef]
- Sui, L.; Guan, X.; Cui, C.; Jiang, H.; Pan, H.; Ohtsuki, T. Graph Learning Empowered Situation Awareness in Internet of Energy with Graph Digital Twin. IEEE Trans. Ind. Inform. 2023, 19, 7268–7277. [Google Scholar] [CrossRef]
- Zheng, S.; Zhu, Z.; Liu, Z.; Guo, Z.; Liu, Y.; Yang, Y.; Zhao, Y. Multi-Modal Graph Learning for Disease Prediction. IEEE Trans. Med. Imaging 2022, 41, 2207–2216. [Google Scholar] [CrossRef] [PubMed]
- Hou, Y.; Song, S.; Yu, C.; Wang, W.; Botteldooren, D. Audio Event-Relational Graph Representation Learning for Acoustic Scene Classification. IEEE Signal Process. Lett. 2023, 30, 1382–1386. [Google Scholar] [CrossRef]
- Endsley, M.R. Toward a Theory of Situation Awareness in Dynamic Systems. Hum Factors 1995, 37, 32–64. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, L.; Li, T.; Wang, D.; Wang, Z. Dual Attention Guided Multi-Scale CNN for Fine-Grained Image Classification. Inf. Sci. 2021, 573, 37–45. [Google Scholar] [CrossRef]
- Won, C.S. Multi-Scale CNN for Fine-Grained Image Recognition. IEEE Access 2020, 8, 116663–116674. [Google Scholar] [CrossRef]
- Qiu, Z.; Hu, M.; Zhao, H. Hierarchical Classification Based on Coarse- to Fine-Grained Knowledge Transfer. Int. J. Approx. Reason. 2022, 149, 61–69. [Google Scholar] [CrossRef]
- Zhu, X.; Bain, M. B-CNN: Branch Convolutional Neural Network for Hierarchical Classification. arXiv 2017, arXiv:1709.09890. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wei, J.; Zhang, Q.; Ning, W. Self-Supervised Learning Representation for Abnormal Acoustic Event Detection Based on Attentional Contrastive Learning. Digit. Signal Process. 2023, 142, 104199. [Google Scholar] [CrossRef]
- Bresson, X.; Laurent, T. Residual Gated Graph ConvNets. arXiv 2018, arXiv:1711.07553. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2017, arXiv:1609.02907. [Google Scholar]
- Marcheggiani, D.; Titov, I. Encoding Sentences with Graph Convolutional Networks for Semantic Role Labeling. arXiv 2017, arXiv:1703.04826. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Chen, H.; Xie, W.; Vedaldi, A.; Zisserman, A. Vggsound: A Large-Scale Audio-Visual Dataset. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 721–725. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A Closer Look at Spatiotemporal Convolutions for Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6450–6459. [Google Scholar]
- Kong, Q.; Cao, Y.; Iqbal, T.; Wang, Y.; Wang, W.; Plumbley, M.D. PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2880–2894. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mode | Model | Avg. Acc. (S.D.) | Best Acc. | Avg. Time (ms/Video) | Params |
|---|---|---|---|---|---|
| Visual-Only | ResNet-50 | 54.1 (±0.5)% | 54.8% | 13.1 | 26M |
| Eff.Net-b1 | 57.2 (±0.6)% | 58.0% | 18.2 | 8M | |
| R3D-18 * | 58.2 (±0.2)% | 58.5% | 10.4 | 33M | |
| MHSA-VO | 59.4 (±0.5)% | 60.0% | 18.8 | 15M | |
| MHSA-VO * | 64.9 (±0.4)% | 65.3% | 37.8 | 15M | |
| MHGSA-VO * | 66.2 (±0.4)% | 66.7% | 46.1 | 17M |
| Mode | Model | Avg. Acc. (S.D.) | Best Acc. | Avg. Time (ms/Video) | Params |
|---|---|---|---|---|---|
| Audio-Only | ResNet-50 | 64.8 (±0.2)% | 65.1% | 49.2 | 26M |
| Eff.Net-b1 | 65.3 (±0.3)% | 65.8% | 52.6 | 8M | |
| PANNs | 51.9 (±0.5)% | 52.6% | 42.6 | 75M | |
| MHSA-AO | 66.7 (±0.4)% | 67.2% | 52.8 | 15M | |
| MHGSA-AO | 67.3 (±0.4)% | 67.8% | 74.7 | 17M |
| Mode | Model | Avg. Acc. (S.D.) | Best Acc. | Avg. Time (ms/Video) | Params |
|---|---|---|---|---|---|
| Multi-Modal | ResNet-50-MM | 69.1 (±0.4)% | 69.7% | 61.4 | 52M |
| Eff.Net-b1-MM | 71.3 (±0.5)% | 71.9% | 74.3 | 17M | |
| MHSA * | 75.9 (±0.5)% | 76.5% | 91.1 | 30M | |
| MHGSA * | 77.3 (±0.3)% | 77.6% | 149.3 | 34M |
| Coarse-Grained | VO | AO | MM | Fine-Grained | VO | AO | MM |
|---|---|---|---|---|---|---|---|
| Natural Disasters | 94.4 | 86.1 | 97.4 | Hail | 91.7 | 84.2 | 92.3 |
| Thunder | 56.7 | 81.2 | 87.1 | ||||
| Tornado Roaring | 95.0 | 53.7 | 72.1 | ||||
| Volcano explosion | 71.2 | 57.4 | 80.4 | ||||
| Conflicts | 77.2 | 79.6 | 91.1 | Cap gun shooting | 50.7 | 74.1 | 75.4 |
| Machine gun shooting | 72.3 | 80.0 | 87.0 | ||||
| Missile launch | 73.4 | 65.1 | 92.5 | ||||
| Disaster Alerts | 90.3 | 96.2 | 98.8 | Ambulance siren | 33.3 | 48.7 | 44.2 |
| Civil defense siren | 55.7 | 89.6 | 91.7 | ||||
| Fire truck siren | 67.4 | 49.1 | 65.9 | ||||
| Police car (siren) | 49.2 | 44.0 | 51.0 | ||||
| Smoke detector beeping | 86.0 | 91.7 | 97.8 | ||||
| Overall | 88.4 | 88.7 | 96.4 | Overall | 67.0 | 68.3 | 78.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Seng, K.P.; Ang, L.M.; Smith, J.; Xu, H. AI-Empowered Multimodal Hierarchical Graph-Based Learning for Situation Awareness on Enhancing Disaster Responses. Future Internet 2024, 16, 161. https://doi.org/10.3390/fi16050161
Chen J, Seng KP, Ang LM, Smith J, Xu H. AI-Empowered Multimodal Hierarchical Graph-Based Learning for Situation Awareness on Enhancing Disaster Responses. Future Internet. 2024; 16(5):161. https://doi.org/10.3390/fi16050161
Chicago/Turabian StyleChen, Jieli, Kah Phooi Seng, Li Minn Ang, Jeremy Smith, and Hanyue Xu. 2024. "AI-Empowered Multimodal Hierarchical Graph-Based Learning for Situation Awareness on Enhancing Disaster Responses" Future Internet 16, no. 5: 161. https://doi.org/10.3390/fi16050161
APA StyleChen, J., Seng, K. P., Ang, L. M., Smith, J., & Xu, H. (2024). AI-Empowered Multimodal Hierarchical Graph-Based Learning for Situation Awareness on Enhancing Disaster Responses. Future Internet, 16(5), 161. https://doi.org/10.3390/fi16050161