1. Introduction
With the rapid development of multi-unmanned systems, these systems are increasingly being utilized to replace human involvement when performing tasks that are difficult and entail high degrees of risk. For example, multi-unmanned systems are deployed to specific areas for search [
1], rescue [
2], and reconnaissance tasks [
3]. To enhance the efficiency of task execution in multi-unmanned systems, researchers have developed various task allocation algorithms to address the task allocation challenges encountered by such systems. Task allocation algorithms require the integration of task information and the capabilities of multi-unmanned systems to effectively distribute tasks among unmanned systems. The fundamental objective of task allocation algorithms is to maximize benefits while minimizing costs [
4]. To further enhance the cost efficiency of tasks executed by multi-unmanned systems and augment the associated benefits, researchers have introduced numerous refinements for cooperative task allocation methods in multi-unmanned systems [
5]. Throughout the task allocation process, multiple unmanned systems engage in interaction and information sharing via a communication network, gathering task requirements and system status information. By utilizing this comprehensive information, they formulate precise task allocation decisions. Via this effective information exchange strategy, the multiple unmanned systems can collaborate effectively, mitigating conflicts and eliminating redundant task execution steps, thereby enhancing the overall efficiency of the task completion process. The research task discussed in this text is centered on collaborative coverage and search missions, which include a few relatively large task areas and a multitude of heterogeneous unmanned surface vessels (USVs). The focus is on how to allocate tasks to these USVs to achieve high mission execution efficiency. The specific details of the task background are introduced in
Section 3.
Currently, two main types of cooperative task allocation methods are used for multi-unmanned systems: centralized and distributed approaches. Centralized systems can be uniformly controlled, but their disadvantage is that they have poor scalability. On the other hand, distributed systems have strong scalability, but they require a higher standard for communication systems [
1,
6]. The mainstream cooperative task allocation methods for centralized multi-unmanned systems can be roughly divided into three categories: mathematical programming, market auction, and intelligent optimization algorithms. However, with the expansion of the scale of unmanned systems, mathematical programming and market auction methods face limitations when addressing large-scale unmanned systems. For cases with large-scale systems, a market auction method consumes considerable time and communication resources; mathematical programming makes it difficult to establish and solve complex cooperative work constraint models in a short period. In contrast, intelligent optimization algorithms are suitable for large-scale systems due to their high adjustability and flexibility levels. Therefore, using intelligent optimization algorithms to solve the cooperative task allocation problem encountered by large-scale unmanned systems has become a mainstream method. Currently, the classic intelligent algorithms include the genetic algorithm (GA), ant colony optimization (ACO), particle swarm optimization (PSO), the wolf pack algorithm (WPA), the black widow algorithm (BWO), and the sheep flock optimization algorithm (SFOA) [
7,
8,
9,
10,
11]. The GA has good global optimization capabilities, but the parameters selected for this algorithm have a significant impact on its performance. The WPA simulates the process of wolf predation, fully embodying the ideas of cooperation and division of labour in a wolf pack. A “survival of the fittest” elimination mechanism is also included in the wolf pack, which gives the algorithm good optimization performance. However, when the algorithm falls into a local optimum, if no better solution is found during the process of the wolf pack moving towards this local optimum, the algorithm eventually falls into this local optimum. The BWO simulates the reproductive mechanism in the black widow population. Each round of reproduction allows the information in the population to merge, and a “survival of the fittest” mechanism is utilized. The structure of this algorithm is simple and easy to implement. However, some steps in the algorithm are based on a greedy strategy, which makes the algorithm prone to falling into local optima. The SFOA simulates the process of sheep grazing. The flock continuously moves towards the position where the grass is most fertile. Moreover, various movement mechanisms are present among the individuals in the flock, which gives the algorithm a strong ability to escape from local optima. Compared to the aforementioned intelligent algorithms, the SFOA has better optimization effects under the premise of relatively simple population behaviours and smaller populations. Therefore, this paper builds on the SFOA, constructs a prior knowledge set using some individuals in the population, and uses this prior knowledge set to guide the regeneration of subsequent populations. This method can enable the developed algorithm to escape from local optima and find global optima more quickly.
Early research on task allocation for multi-unmanned system collaboration focused mainly on multiobjective optimization algorithms. Sheng [
12] established a dynamic multiobjective optimization model and used an improved adaptive particle swarm algorithm to solve it. Saeedvand [
13] proposed a multiobjective task allocation algorithm considering four optimization objectives, which achieved better results than those of other multiobjective evolutionary algorithms. These works laid the foundation for the application of multiobjective optimization methods to this problem.
In addition, researchers have begun to apply various classic intelligent algorithms to the problem of task allocation in multi-unmanned systems and have made improvements to these algorithms [
14,
15,
16,
17]. Chen [
4] proposed an improved double wolf pack search algorithm to address the task allocation problem. The algorithm models the task allocation issue as a one-dimensional array, reducing the required computational complexity. However, the experimental section of the associated paper only addressed a limited number of tasks and agents and failed to validate the performance of their algorithm in situations with more agents. Ye [
18] combined the task allocation problem with GAs and introduced a novel gene encoding method. However, this improvement did not overcome the propensity of the GA to become stuck in local optima, nor did it consider large-scale clusters. As research into intelligent algorithms has deepened, researchers have begun designing mixed strategies and focusing on diverse individual behaviours to attain enhanced global search capabilities. Abualigah [
19] integrated Levy flight into intelligent algorithms to boost their random search capabilities, but this approach lacked experimental support.
Moreover, the use of adaptive parameter adjustment has become a crucial method for enhancing algorithmic performance. Tripathi [
20] incorporated adaptive factors into the particle swarm algorithm to enhance its multiobjective optimization effect, but this strategy may not be suitable for single-objective optimization problems. Omran [
21] achieved parameter self-adjustment through an adaptive mutation operator, but their algorithm suffers from slow convergence.
Due to their excellent global search capabilities, novel optimization algorithms simulating natural predation behaviours have attracted widespread attention [
22]. For instance, WU Husheng [
10] simulated the cooperative strategy of a wolf pack surrounding prey, but this algorithm tends to become trapped in local optima and struggles to escape. Yao’s Harris-Hawk algorithm [
23], which simulates the entire hunting process of hawks, is complex and computationally demanding. Faramarzi [
24] proposed a marine predator algorithm that integrates multiple mechanisms to achieve improved global search capabilities, but a specific approach for addressing local optima is lacking. Dehkordi [
25] combined the marine predator algorithm with the hill climbing algorithm; when trapped in local optima for an extended period, the hill climbing algorithm, which is based on a greedy strategy, is used to attempt an escape, but the probability of escaping local optima with this method is relatively low.
The algorithms proposed in the aforementioned studies predominantly incorporate mechanisms to escape local optima. However, these mechanisms utilize only the current population information and neglect the data derived from individuals eliminated from the population, leading to wasted information. Individuals excluded from the population are typically those unable to escape local optima over extended periods. The subsequent generation of individuals within the population should be directed away from these eliminated individuals, thereby reducing the probability of the algorithm falling into local optima.
The main contributions of this paper are outlined as follows.
① A prior knowledge set is proposed, and the SFOA is integrated with this prior knowledge set to enhance the ability of the algorithm to escape local optima.
② Candidate prior knowledge sets are proposed and utilized to update the existing prior knowledge set. It is ensured that the a priori knowledge set can assimilate the latest knowledge, thereby enhancing the global optimization-seeking capability of the algorithm.
This paper incorporates prior knowledge and rules for updating prior knowledge in the SFOA, reducing the frequency at which the algorithm becomes trapped in local optima and enhancing its global optimization ability. Furthermore, the algorithm is integrated with the context of task allocation, resulting in superior allocation outcomes.
This paper is structured as follows.
Section 2 provides an exposition of the fundamental concepts of the SFOA and the notions behind its enhancement.
Section 3 delves into the background of task allocation, encompassing an experimental verification and an analysis.
Section 4 outlines the conclusions drawn in this paper.
2. Introduction to the Details of the Algorithm
This paper utilizes an advanced version of the SFOA to address the task allocation problem. In this section, the emphasis is placed on delineating the SFOA and the enhancements applied within the framework of this study. The first part details the core principles of the SFOA, including its group structure and movement factors. The second part explores the integration of a prior knowledge set and its amalgamation with the SFOA.
2.1. Sheep Flock Optimization Algorithm (SFOA)
The SFOA was designed to mimic the process through which a flock of sheep seeks out fertile pastures during grazing. Throughout the grazing period, the flock endeavours to locate areas with richer grasslands within a specified vicinity and proceeds to move. The flock comprises two varieties of animals, goats and sheep, along with a shepherd. The shepherd is responsible for documenting the richest grassland identified by the flock and attempting to lead the flock towards that location. During grazing, three elements influence sheep movement: the guidance of the shepherd, the previously identified rich grassland, and the proximity of other sheep. Goats typically constitute of the flock population. During grazing, the movement of goats is dictated by two factors: the guidance of the shepherd and the richest grassland previously identified by the goats. As grazing progresses, the movement of the flock persists. Whenever the flock discovers richer grasslands, the shepherd likewise documents the details of this location. Upon completion of the grazing process (when the algorithm reaches its maximum number of iterations), the location noted by the shepherd represents the richest grassland.
In the SFOA, the flock consists of
sheep, each symbolizing a feasible solution. Each sheep endeavours to locate areas with richer grasslands within its detection range [
9].
In the SFOA, is the grazing radius of the sheep, is the grazing radius of the goats, is the upper limit of the entire grazing area, and is the lower limit of the entire grazing area. is the current number of iterations, is the maximum number of iterations, and is a time influence factor. The value of is related to the movement behaviour of the flock.
The movements of a sheep can be divided into two stages. When
, the sheep exhibits the following three behaviours [
9]:
(1) The movement generated by the interest of the sheep in the globally optimal solution (where the shepherd is located).
(2) The movement generated by the interest of the sheep in the previous best experiences.
(3) The movement
caused by the interest of the sheep in approaching other sheep.
represents the current position of the sheep,
represents the position of the global optimal solution found by the entire flock thus far, and
represents the position of the optimal solution found by each sheep itself.
is a random sheep position,
is the dimensionality of the problem, and
is a
-dimensional array between 0 and 1.
enhances the randomness of population movements.
is a constant whose initial value is determined by
, and
is a random number ranging between 0 and 1.
is usually taken as 0.3 [
9].
When , the sheep exhibits the following two behaviours:
The movement generated by the interest of the sheep in the global optimal solution (where the shepherd is located).
The movement
generated by the interest of the sheep in the previous best experiences.
After determining the speed of the sheep and the current position of the sheep,
can be updated [
9].
where
represents the current position of the sheep,
denotes the position of the sheep at the next moment, and
is the comprehensive movement factor of the sheep.
Similarly, the movements of a goat can also be classified into two stages. When
, a goat exhibits the following two behaviours [
9]:
(1) The movement generated by the interest of the goat in the globally optimal solution (where the shepherd is located).
(2) The movement
generated by the interest of goat in the previous best experiences.
is usually set to 0.7 [
9]. When
, the goat exhibits the following behaviour:
The movement
generated by the interest of the goat in the global optimal solution (where the shepherd is located) [
9].
After determining the speed of the goat and the current position of the goat,
can be updated [
9].
represents the current position of the goat, denotes the position of the goat at the next moment, and represents the comprehensive movement factor of the goat.
After updating the position of the flock, the global optimal solution and the local optimal solution for each sheep are simultaneously updated.
Although the SFOA has advantages over other methods such as a smaller population size and a simpler algorithmic implementation process, it does not fully utilize the information of individuals eliminated from the population, thereby limiting the optimization effect of the algorithm.
2.2. Real-Time Prior Knowledge-Based Sheep Flock Optimization Algorithm (RTPK-SFOA)
2.2.1. Initialization of a 2D Sheep Flock
Since the SFOA in the literature is used to solve engineering problems, the feasible solution for each sheep is a one-dimensional space; however, the problem modelled in this paper is a two-dimensional space. Consequently, the position and movement factors of the flocking algorithm need to be modified from one dimension to two dimensions.
In response to the issue of potentially initializing a dense sheep flock in the SFOA, a threshold strategy is used for optimization: it is stipulated that the distance between two sheep cannot be less than a specified threshold
. This strategy can enhance the global optimization ability of the algorithm. The formula for calculating the distance between sheep is as follows.
In the above formula,
represents the position (two-dimensional feasible solution) of the
th sheep,
represents the position of the
th sheep,
represents the value in the
th row and
th column of the two-dimensional matrix
, and
represents the value in the
th row and
th column of the two-dimensional matrix
. The two-dimensional matrices
and
consist of 0 s and 1 s, respectively, and
represents the distance between the
th sheep and the
th sheep. The flock initialization pseudo-code is shown in Algorithm 1.
| Algorithm 1: Initialization of the Sheep Flock |
|
2.2.2. Two-Dimensional Sheep Flock Movement Factor
The physical meaning of the two-dimensional movement factor of the sheep flock is that sheep moves towards sheep , and is the moving step size of sheep . The movement process is as follows.
(1) Randomly select a certain row and column in , determine the value of , and compare this value to ; if the two values are equal, repeat step (1).
(2) If the value of is 1, change the value of to 0, and jump to step (4).
(3) If the value of is 0, change the value of to 1.
(4) Number of iterations + 1; if the number of iterations is less than , jump to step (1); otherwise, end the loop.
The pseudo-code for sheep movement is shown in Algorithm 2.
| Algorithm 2: Sheep Flock Movement |
|
2.2.3. Building, Using, and Updating the Prior Knowledge Set
This paper aims to utilize the population information of a flock of sheep to address the problem of algorithms becoming stuck in local optima. In this paper, we introduce a prior knowledge set, which is denoted as . When the historical best fitness level of a sheep remains unchanged for a long time, it is eliminated and stored in the prior knowledge set . During the reproduction process of the sheep flock, the newly generated sheep must be sufficiently far from all the sheep in the prior knowledge set to be allowed into the generation process. When the set is sufficiently large, the algorithm can prevent the sheep population generated through reproduction from becoming stuck in known local optima. However, the set requires a significant amount of memory resources, and the algorithm spends considerable time calculating distances during the reproduction phase. On the other hand, when the set is too small, it fails to capture the population information in the later stages, leading to the algorithm still becoming stuck in new local optima later on. To overcome the aforementioned issues, this study introduces a secondary prior knowledge set, which is denoted as . When the data stored in the prior knowledge set reach its maximum capacity, the eliminated sheep are stored in . The purpose of is to preserve the latest information from the current population and use it as the basis for updating the prior knowledge set . This allows to utilize a smaller space to store useful and cutting-edge population information.
As the algorithm runs, sheep are continuously eliminated. To maintain the stability of the sheep population, this study stipulates that when the total number of sheep in the population is less than the threshold value , the sheep population undergoes a reproductive operation. The steps used to generate a sheep through reproduction are as follows.
(1) Create a sheep denoted as , and randomly initialize its position .
(2) For each sheep in the candidate prior knowledge set , calculate the distance , where represents the newly generated sheep and represents a sheep in the prior knowledge set . is recorded as the attribute of sheep , representing the distance between the newly generated sheep and sheep .
(3) If , where is the size of the set , then the newly generated sheep is far from all the sheep in , and the generation of sheep is allowed. The eliminated sheep in the population are replaced with sheep , and the algorithm ends.
(4) If , where represents a threshold value, this indicates that the newly generated sheep is close to the sheep in the set . It is considered probable that sheep will fall into a local optimum. Therefore, the generation of sheep is not allowed, and the process returns to step (1).
The pseudo-code for the sheep reproduction operation is shown in Algorithm 3.
| Algorithm 3: Pseudocode for the Sheep Reproduction Operation |
|
The prior knowledge set ensures that newly generated sheep can explore more unknown areas, avoiding repeated explorations of the same regions and thereby preventing their entrapment in local optima. Since the prior knowledge set does not possess the most up-to-date population information, its role in the sheep breeding phase gradually diminishes during the algorithmic iteration process. Therefore, it becomes necessary to update the prior knowledge set . At this point, includes the most recently eliminated sheep, and is updated with , enabling to learn the latest information from the population. The process of updating the prior knowledge set is as follows.
(1) For the
-th sheep in
, calculate the sum of the distances between sheep
and all sheep in the prior knowledge set
; denote this distance as
. The formula for calculating this sum is as follows.
(2) Select the sheep in with the maximum value and record it.
(3) Add sheep to the prior knowledge set and clear . To prevent from becoming too large, it is necessary to remove one sheep from the prior knowledge set . The sheep in the set with the maximum value for the attribute is selected for removal. Additionally, reset (set to 0) the attributes for all sheep in the set .
The pseudo-code for updating the prior knowledge of the sheep flock is shown in Algorithm 4.
| Algorithm 4: Pseudocode for Updating the Prior Knowledge of the Sheep Flock |
|
This section modifies the initialization part and the movement factor of the SFOA, making it capable of solving two-dimensional problems. To address the insufficient utilization of population information and the tendency of the algorithm to become trapped in local optima, the concepts of prior knowledge sets and candidate prior knowledge sets are introduced. This prevents the algorithm from becoming stuck in local optima during the reproduction phase and enables better exploration of unknown areas.
Notably, the computational complexity of the SFOA is , where represents the number of iterations, is the size of the sheep flock, is the function evaluation cost, and is the dimensionality of the problem. The computational complexity of the RTPK-SFOA is . Here, denotes the number of sheep flock breeding iterations, is the number of updates for the prior knowledge set, is the number of sheep flocks required for breeding, is the size of the prior knowledge set, and is the size of the prospective prior knowledge set. In practice, with the introduction of prior knowledge and prospective prior knowledge sets, the RTPK-SFOA does not incur a significant time expenditure due to the relatively low frequencies of breeding and prior knowledge updates. Moreover, when a sheep is eliminated from the flock, it ceases all its activities, which is a strategy that further contributes to substantial time savings.
3. Simulation Experiments and Analysis
To facilitate the reader’s understanding, this section describes how to combine the proposed intelligent algorithm with the task allocation context. In the initial phase of the intelligent algorithm, a flock is initialized (as shown in Algorithm 1), and the position of each sheep can be denoted by
(
is described in
Section 2.2.1); each position represents a feasible solution in the context of task allocation. After completing the initialization process, based on the position of each sheep (feasible solution), its fitness is calculated (according to Equation (20)). The flock is sorted according to the fitness values, and the top 10% of the sheep with the optimal fitness values are selected as goats, while the remaining sheep are selected as sheep. The shepherd moves to the position of the sheep with the optimal fitness level.
In
Section 2.2.1 of this paper, the modelling approach of the proposed algorithm is described in detail, and it is adopted to better use the algorithm for solving the task assignment problem. All operations in the algorithm (
Section 2.2) are based on the modelling process described in
Section 2.2.1 and therefore can be directly combined with the task allocation problem.
3.1. Background Introduction
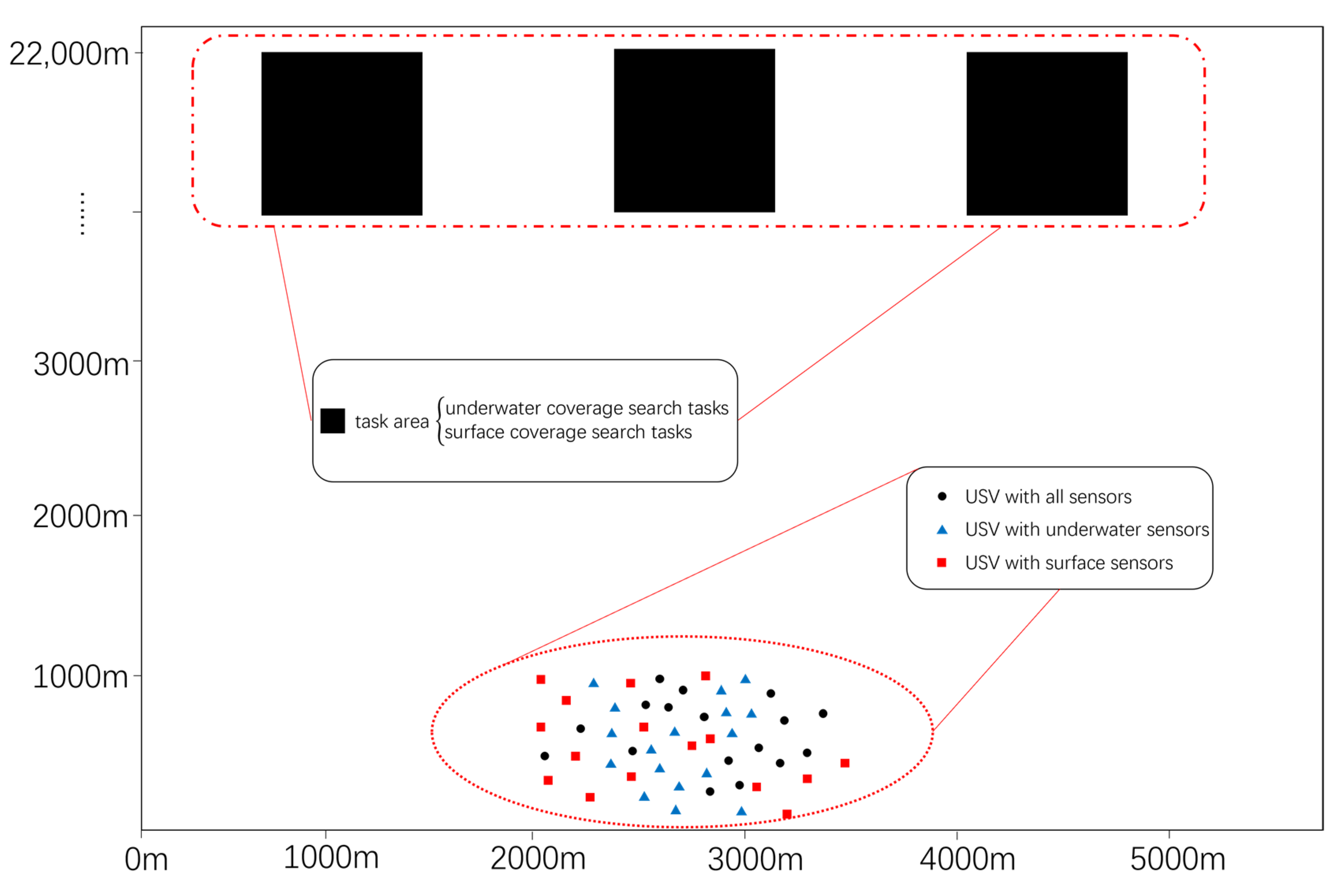
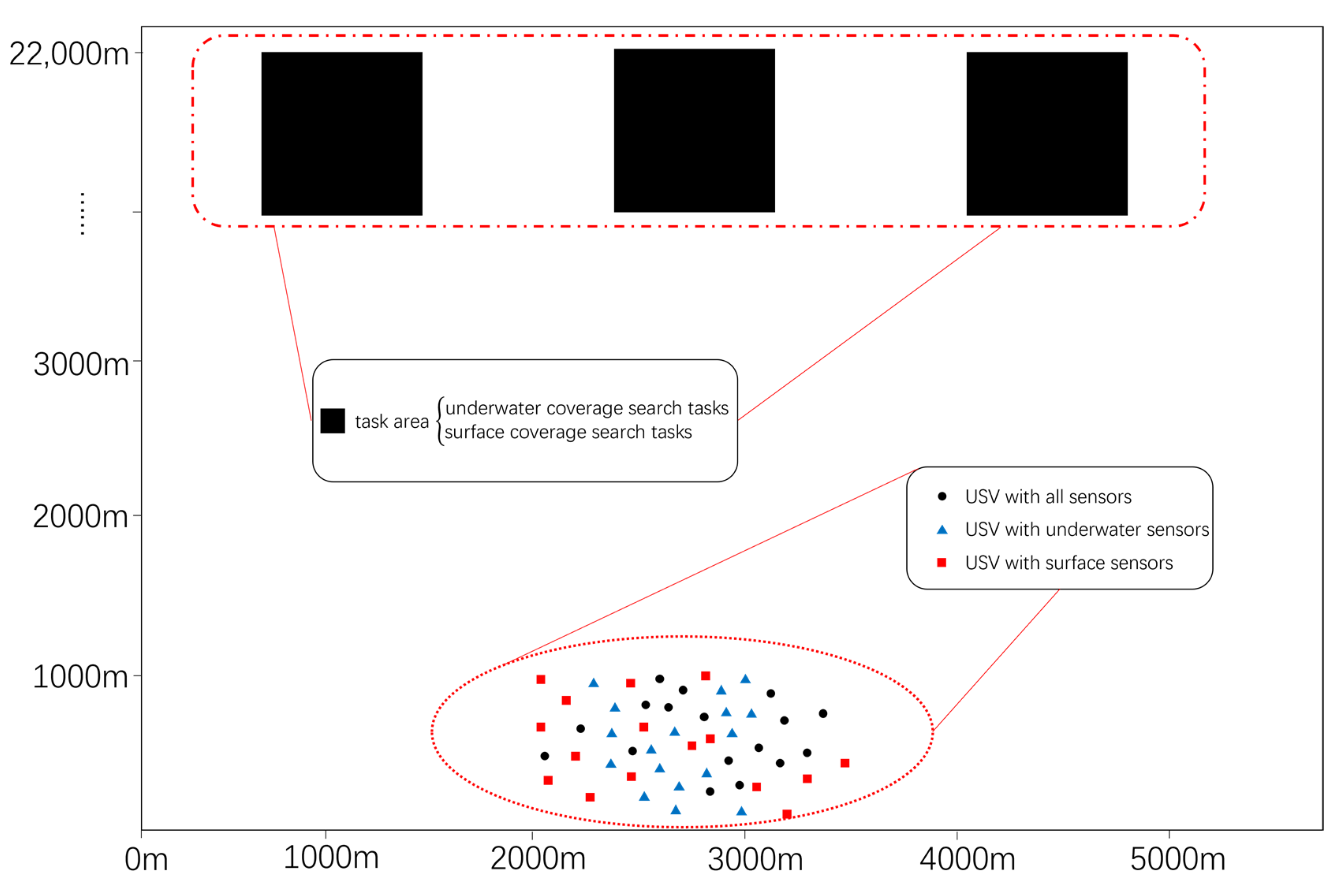
This paper establishes a framework for conducting autonomous search missions involving USVs in detection scenarios. Each autonomous search mission comprises underwater and surface coverage-based search tasks. Each USV is equipped with either a surface detection sensor (exclusively for surface detection), an underwater detection sensor (exclusively for underwater detection), or both sensors (for both surface and underwater detection) and initiates its journey from a starting point, carrying its respective sensors to the designated mission area for search coverage. The mission is considered complete once all USVs have fulfilled their individual search tasks. This detection scheme is described further in the document.
In
Figure 1, the operational area of the USVs is confined to a rectangular zone measuring 5000 m by 22,000 m. The red squares represent USVs equipped with surface detection sensors, the blue triangles indicate USVs with underwater detection sensors, and the black dots denote USVs carrying both types of sensors. The black rectangular area at the top represents the mission area, with each USV allocated to a maximum of one mission area for conducting detection tasks. The capabilities of the USVs within the scenario vary, specifically in terms of their maximum sailing speeds (5 m/s to 10 m/s), the types of sensors carried, and their maximum coverage detection speeds (1.4 m/s to 2 m/s). The sensors onboard the USVs are capable of detecting information within a 100 m radius of their location.
At this point, a set of USVs denoted as
is present, where
represents the number of USVs;
, where
denotes the number of target areas. Once the task allocation process for the USVs is completed, they commence their respective missions. While navigating to their task areas and initiating their sensors to conduct searches over the designated regions, the USVs experience energy losses. The ultimate objective of the USV task allocation process is to ensure minimal energy depletion for all USVs while efficiently completing the area search tasks. To assess the quality of the allocation results, this paper introduces a fitness function.
and
are terms used to the quantify energy loss and temporal expenditure, respectively, within the context of the allocation scheme. The weighting coefficients
and
represent the relative importance levels assigned to energy conservation and expedited completion during the task allocation process, respectively. It is stipulated that
. With the aim of minimizing the total time spent, this study sets
to 0.1 and
to 0.9. The subsequent sections detail the computational methodologies for determining
and
.
In this context, denotes the energy expended by all USVs as they navigate to and execute area search operations within the -th task region. The energy consumed during navigation increases with the number of sensors equipped on each USV. Moreover, the activation of sensors for area search tasks incurs additional energy consumption. The baseline energy consumption for the USVs is quantified as 1 unit per 100 m travelled. For each additional sensor carried or activated for detection purposes, an incremental energy expenditure of 0.03 units per 100 m is incurred.
and represent the energy loss induced by all USVs travelling to the -th mission area and the energy loss of each USV performing the search task, respectively. represents the number of USVs carrying the -th type of sensor in the -th mission area ( for the surface detection sensor, for the submerged detection sensor, and for both types of sensors). represents the distance between the -th USV carrying the -th sensor and the -th mission area. represents the energy loss induced by the USVs during navigation. denotes the path length required by the -th USV carrying the -th sensor for area detection. denotes the energy loss induced by the USVs during area detection (when their sensors are activated).
denotes the total time spent by all USVs travelling to the -th mission area and performing the coverage search task. denotes the time consumed by all USVs to travel to the -th target. denotes the maximum navigational speed of the -th USV carrying the -th sensor when travelling to the mission area. denotes the total length required for surface sounding in the -th mission area. denotes the total length to be covered for underwater detection in the -th mission area. denotes the maximum speed of the -th USV when travelling to the mission area.
In this paper, the quality of the allocation scheme is assessed using the level, which has a value between 0 and 1. A higher value of indicates a better allocation scheme.
To better relate the context of this paper to intelligent algorithms, an example of utilizing the RTPK-SFOA is illustrated. In the task scenario, each task assignment scheme is modelled as a two-dimensional array. In the RTPK-SFOA, the position of each sheep represents a task allocation scheme (a feasible solution), and the fitness of each sheep indicates the quality of the corresponding allocation scheme. The extent of the pasture represents the entire solution space. The goat may be a randomly selected sheep after the initialization of the flock. During the iterative process of the algorithm, the shepherd represents the global optimum solution (the feasible solution with the highest fitness value). For the flock, the speeds of the sheep and the goats are related to the dimensions of the feasible solutions. The specific speed values can be determined according to the specific problem, and an appropriate speed can accelerate the convergence of the algorithm.
To give the reader a better understanding of the variables used in this paper, the variables that appear in the theory section of the algorithm are described in
Table 1.
3.2. Experimental Setup
The CPU used in the experiments of this article is an AMD Ryzen 7 7840HS CPU at 3.80 GHz with 40 GB of memory.
To ensure that the algorithm has good real-time performance and can be applied to practical scenarios, it is specified in this article that the algorithm should run within 120 s and 100 iterations. Based on this, various algorithm parameter settings are determined, as shown in
Table 2 (for the SFOA, PK-SFOA, RTPK-SFOA, WPA, GA, and BWO).
Experimental Scenario 1: The task is an area search task containing three task areas. The specific attributes are shown in
Table 3.
represents the
-axis coordinate of the bottom centre point of the task area,
represents the
-axis coordinate of the bottom centre point of the task area, and
represents the size of the task area. All task areas require areas searches both on the surface of the water and underwater. The relevant attributes of the unmanned boats are shown in
Table A1 (located in
Appendix A).
represents the -coordinate of the starting point of the unmanned boat, represents the -coordinate of the starting point of the unmanned boat, represents the maximum cruising speed of the unmanned boat towards the task area, represents the maximum cruising speed of the unmanned boat during the area search process, represents the type of detection sensor carried by the unmanned boat, represents that the boat is carrying a surface detection sensor, represents that the boar is carrying an underwater detection sensor, and represents that the boat is carrying both types of detection sensors.
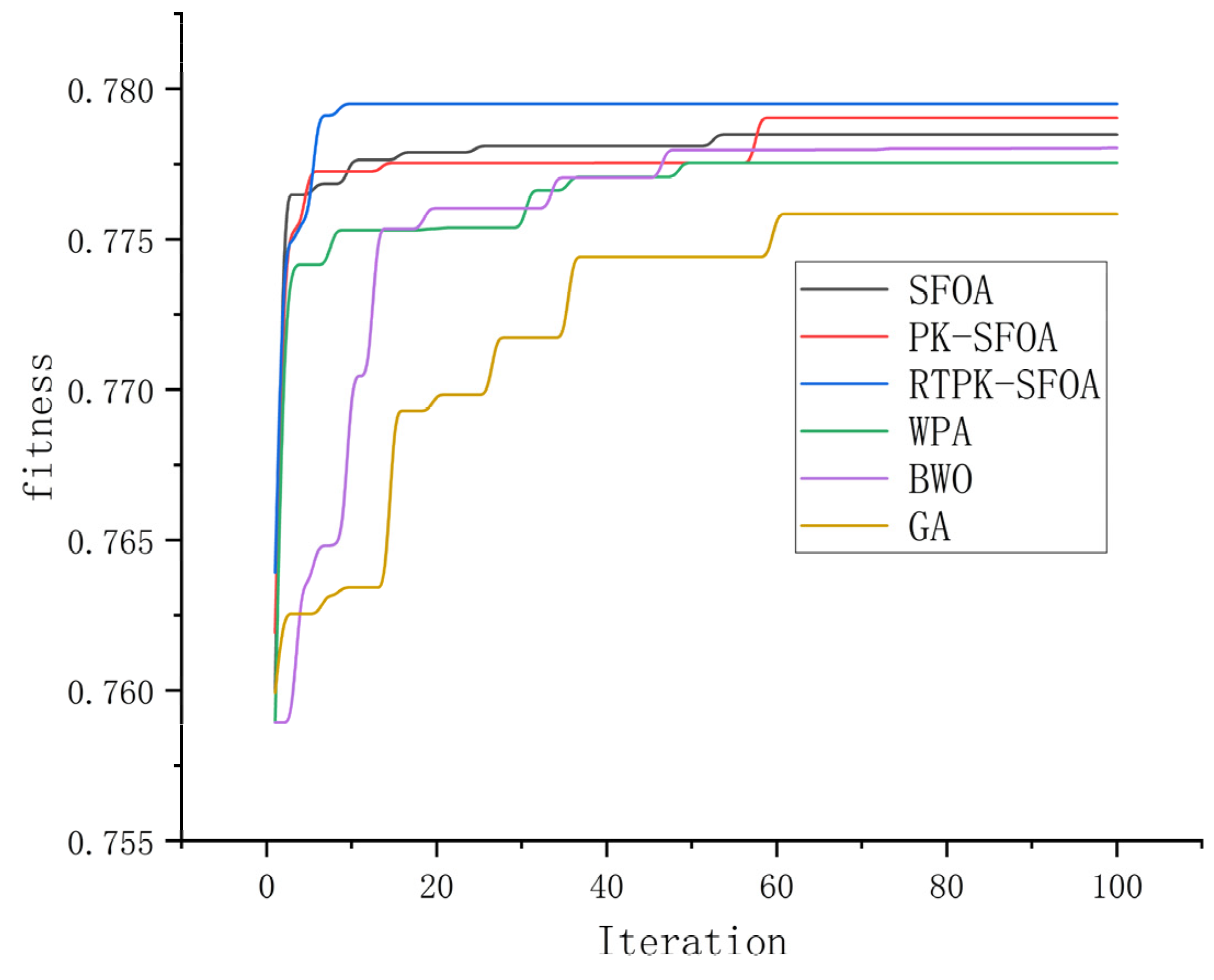
By running various algorithms, algorithm allocation results (
Table A2 (located in
Appendix A)) and a schematic diagram of the iteration process are obtained (
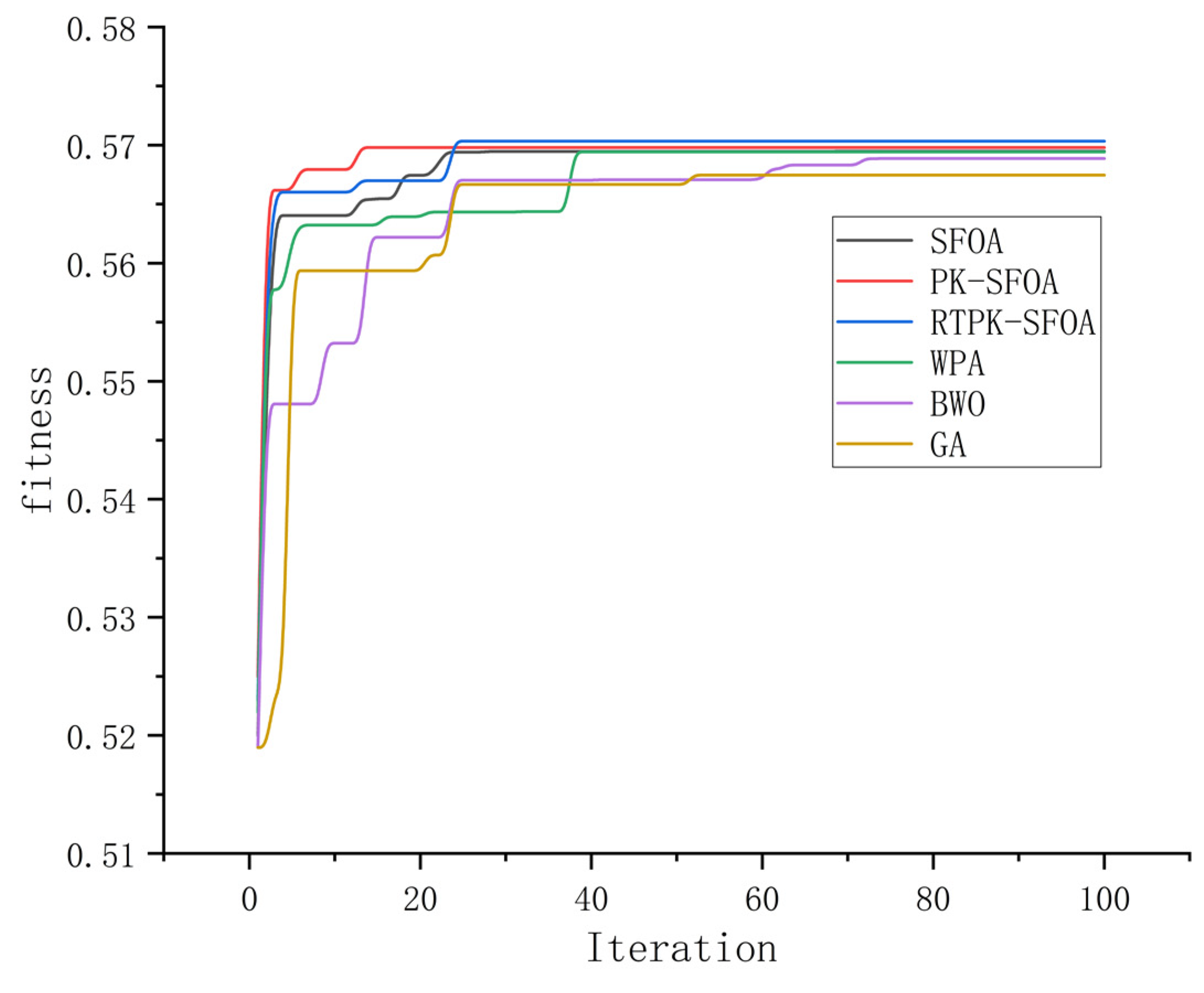
Figure 2). The fitness values in
Figure 2 are capable of assessing the quality of the tested allocation schemes. A higher fitness value indicates that the corresponding allocation scheme enables the USVs to complete tasks in a shorter period with less energy expenditure. In
Figure 2, the larger the fitness value at the convergence time of an algorithm, the better the allocation scheme obtained by that algorithm.
According to
Figure 2, compared to the SFOA [
9], due to the presence of prior knowledge, the PK-SFOA can better escape from local optima and achieve better convergence. Compared to the PK-SFOA, the RTPK-SFOA introduces an updating mechanism based on prior knowledge, which enhances its ability to escape local optima and guide the population towards the optimal solution. Moreover, the RTPK-SFOA outperforms other algorithms, such as the GA [
7], BWO [
11], and WPA [
10], in terms of the optimization effect.
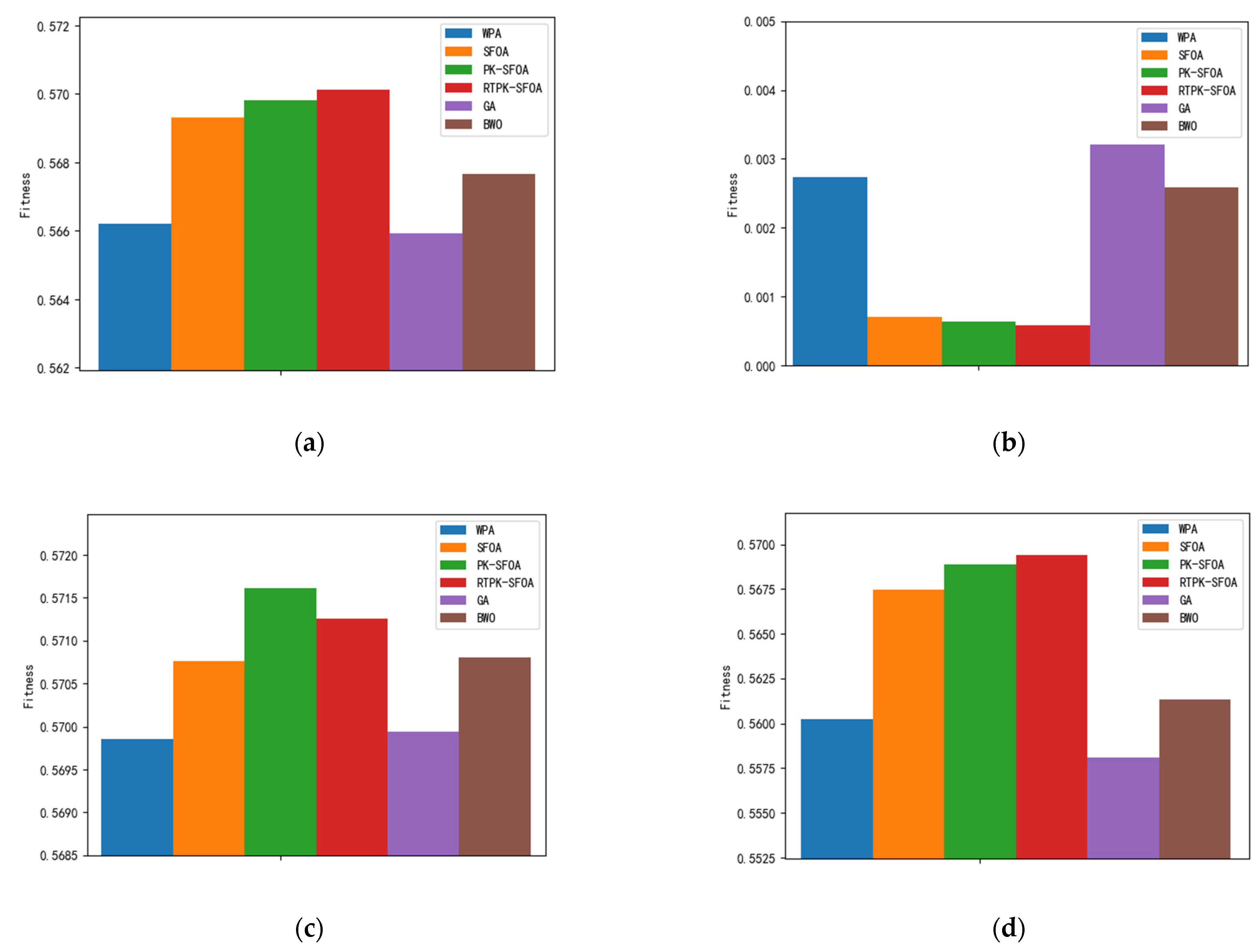
Due to the random nature of intelligent algorithms, this paper runs the various algorithms 30 times against the background of experimental scenario 1 and statistically analyses the final results, as shown in
Figure 3. In
Figure 3, the mean values represent the average fitness levels of the algorithms after 30 runs, which represent the average performance of the algorithms. The best and worst values are the best (upper limit) and worst (lower limit) fitness values produced by the algorithms after 30 runs, respectively, and the Std values are the standard deviations of the fitness levels of the algorithms after 30 repeated runs; the smaller a value is, the more stable the corresponding algorithm is.
As shown in
Figure 3, the PK-SFOA with a priori knowledge significantly improves the mean fitness, best fitness and worst fitness values over those of the SFOA [
9]. This is because the a priori knowledge helps to prevent the algorithm from falling into a local optimum. However, since the a priori knowledge is not updated, underexplored regions may be located near the a priori knowledge set, which may result in the algorithm failing to find the optimal solution if the optimal solution occurs in that region. Compared with the PK-SFOA, the RTPK-SFOA updates the a priori knowledge set to better explore the previously underexplored regions. As a result, the RTPK-SFOA obtains better mean fitness and worst fitness values than those of the PK-SFOA.
Figure 3a,b show that the RTPK-SFOA has a greater mean fitness and a lower standard deviation value than those of the SFOA, PK-SFOA, GA [
7], BWO [
11] and WPA [
10]. This indicates that the RTPK-SFOA is more stable and able to obtain better allocation schemes in a shorter period.
Due to the presence of both prior and candidate prior knowledge sets in the RTPK-SFOA, the algorithm effectively reduces the probability of falling into a local optimum. As a result, compared to all other algorithms, the RTPK-SFOA has a higher mean (indicating better performance) and a smaller standard deviation (indicating greater stability). However, the disadvantage of the RTPK-SFOA is that it requires more computational resources and has a longer computation time than the other algorithms.
To prove that the improved algorithm proposed in this paper performs well in different experimental scenarios, the location and size of the task area are modified, and a new task scenario 2 is constructed for testing (the relevant information concerning the USVs remains unchanged).
Experimental Scenario 2: The task area properties are reset (The specific attributes are shown in
Table 4).
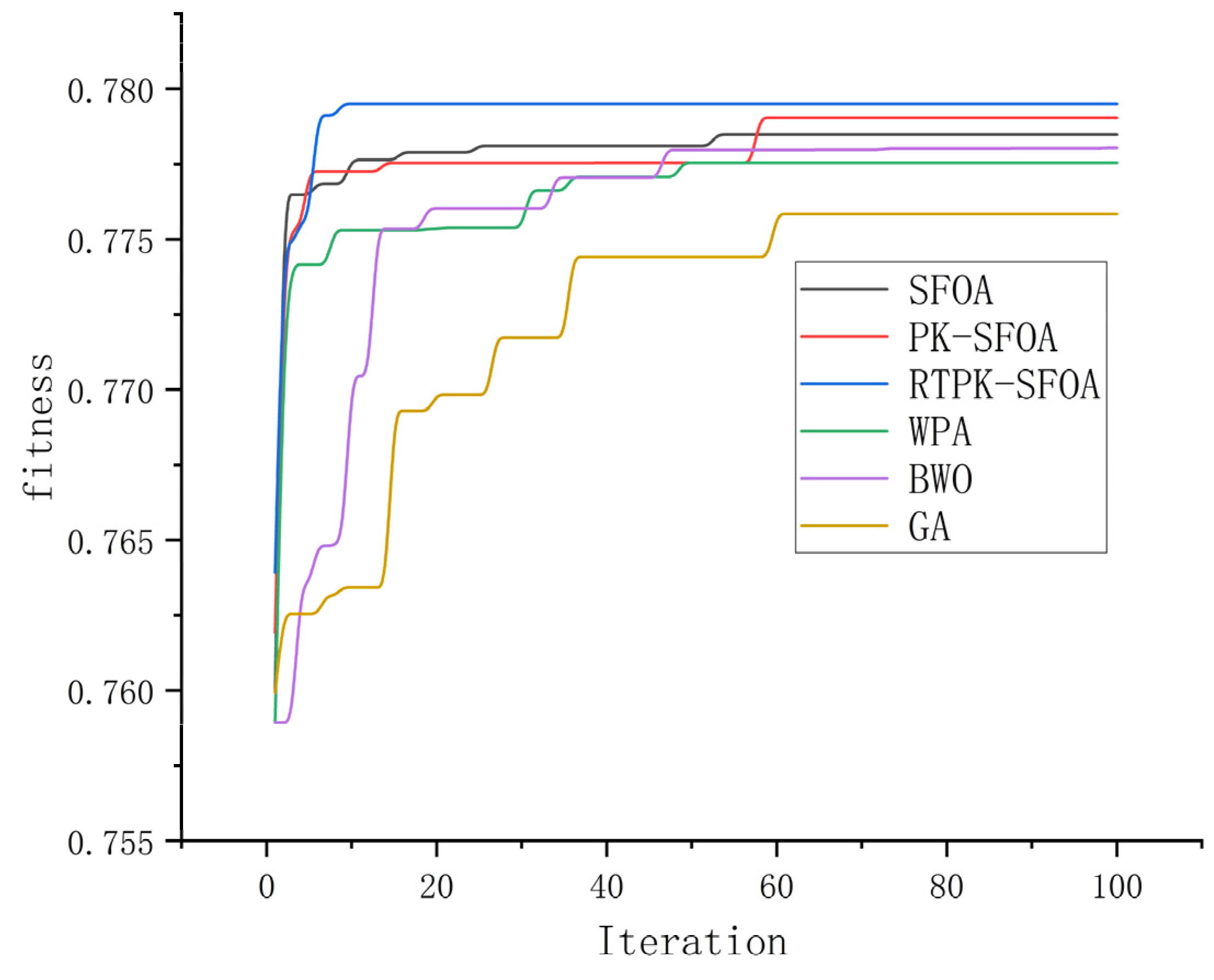
Various algorithms are run to obtain algorithmic assignment results (
Table A3 (located in
Appendix A)), and a schematic diagram of the iteration process is shown in
Figure 4.
According to
Figure 4, the PK-SFOA outperforms the SFOA, and the final fitness of the PK-SFOA is greater than that of the SFOA because the PK-SFOA introduces an a priori knowledge set. Since the RTPK-SFOA introduces a set of prior knowledge and a set of candidate prior knowledge, which reduces the probability of the algorithm falling into a local optimal solution, the RTPK-SFOA converges faster and has the highest adaptability.
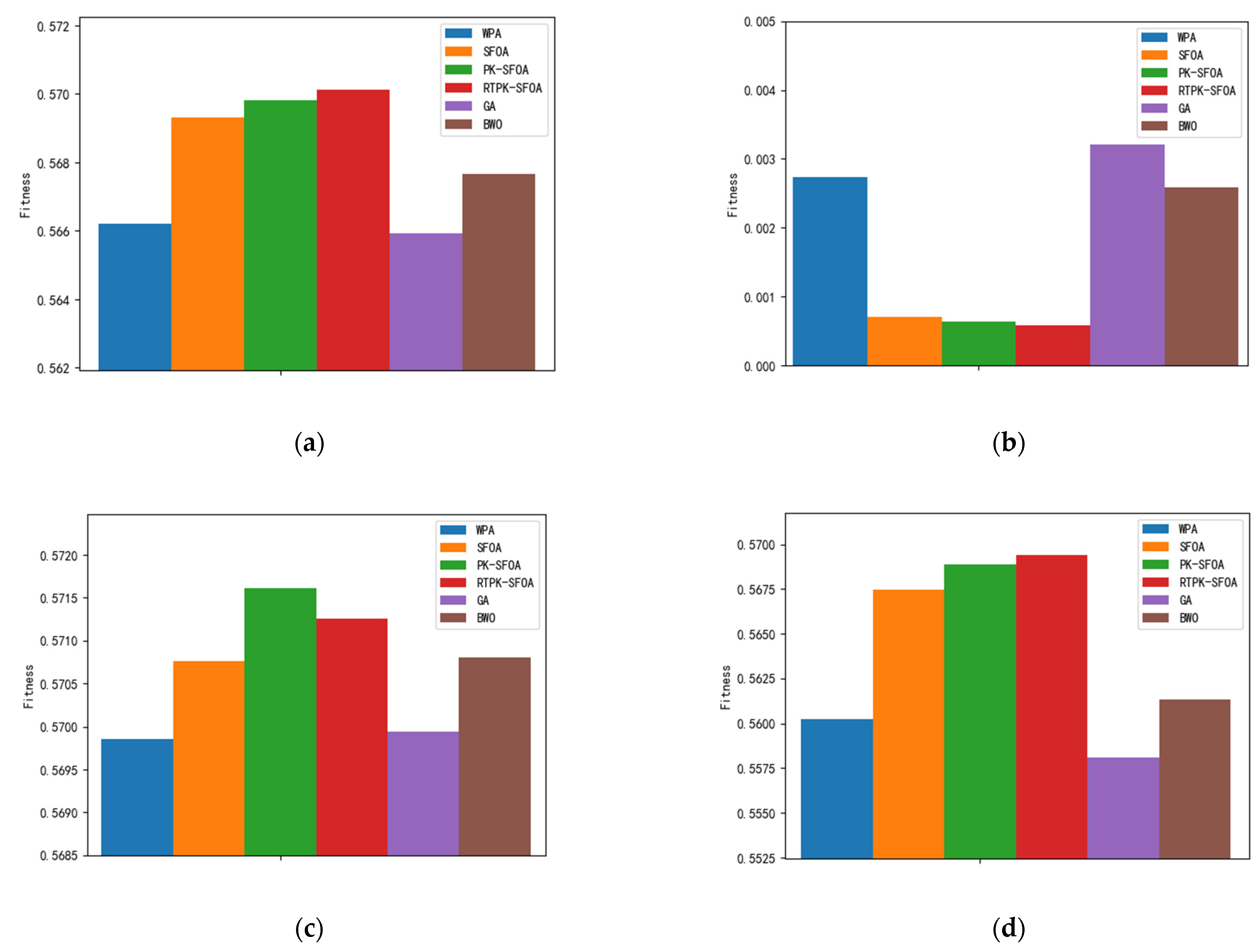
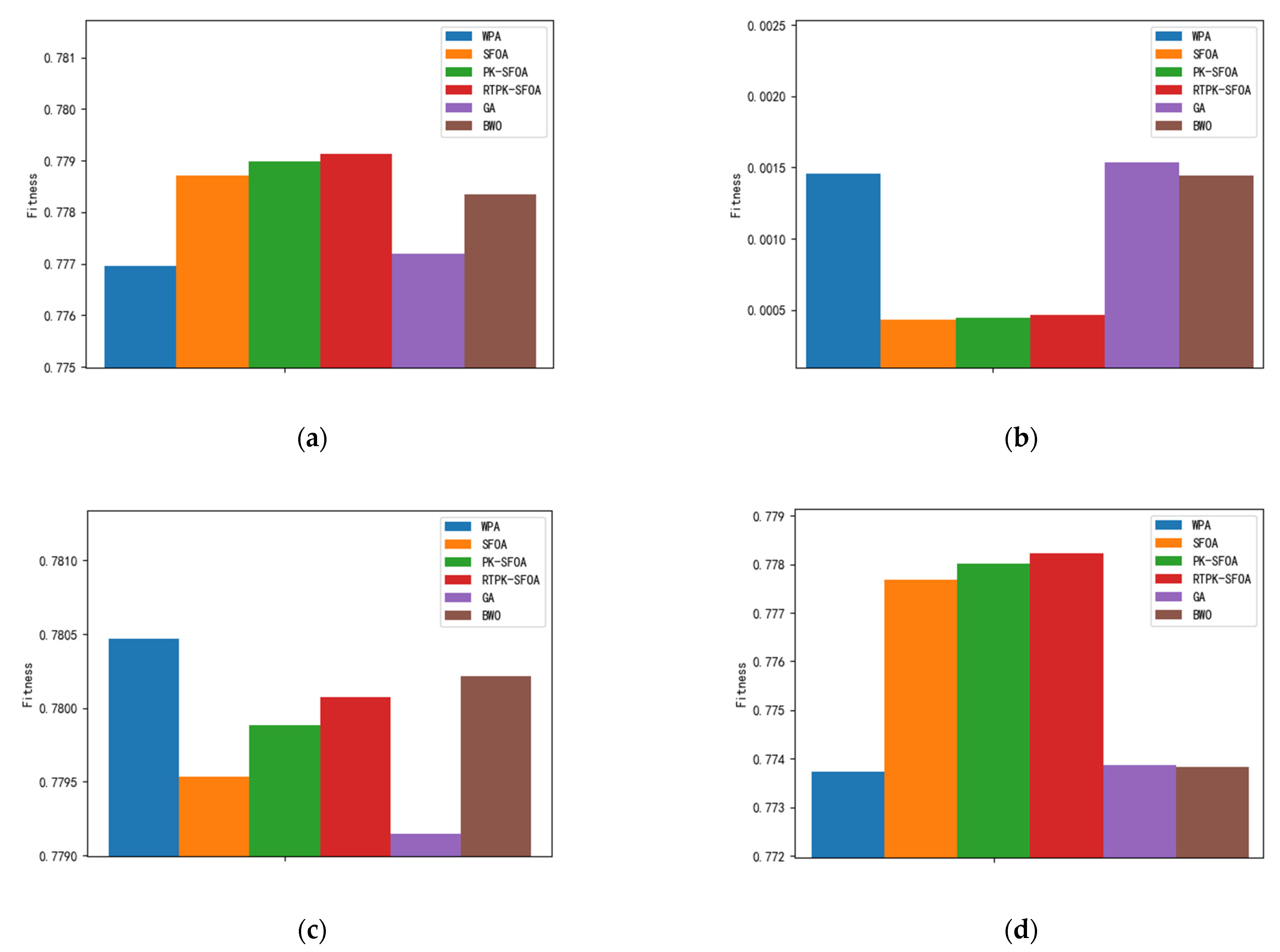
Due to the random nature of the intelligent algorithms, to verify the average performance of the algorithms, this paper runs each algorithm 30 times in Scenario 2 and statistically analyses their final results. The results are shown in
Figure 5.
After changing the task scenario, it can be seen from
Figure 5a,b that compared with other algorithms, the RTPK-SFOA has a smaller standard deviation, the highest average adaptation, and better performance.
Figure 5b–d show that although the best adaptations of the WPA [
10] and BWO [
11] are better than those of the RTPK-SFOA proposed in this paper, their worst adaptations are lower, and their standard deviations are larger, which indicates that these algorithms are less stable and cannot guarantee the acquisition of the optimal solution in a short period.
The experimental part of this paper simulates real task scenarios and proves that the RTPK-SFOA has good performance and stability. However, compared with other algorithms, the RTPK-SFOA needs more parameters to be defined and requires more computational resources. In real-world applications, if the CPU performance at the control centre is inferior, extended durations might be needed to obtain allocation results.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}