
Linked Open Government Data: Still a Viable Option for Sharing and Integrating Public Data?


Abstract
1. Introduction
2. Background
2.1. Open Government Data
2.2. Linked (Open) Data
- Use of URIs as Identifiers: Employ Uniform Resource Identifiers (URIs) as names for entities or things.
- HTTP URIs for Accessibility: Utilize HTTP URIs to ensure that others can easily look up and access the identified entities.
- Provide Useful Information on Lookup: When a URI is looked up, furnish relevant and valuable information utilizing standard technologies like RDF (Resource Description Framework) and SPARQL (SPARQL Protocol and RDF Query Language).
- Incorporate Links to Other URIs: Enhance discoverability by including links to additional URIs, thereby enabling users to explore related information.
3. Methodology
4. Related Works
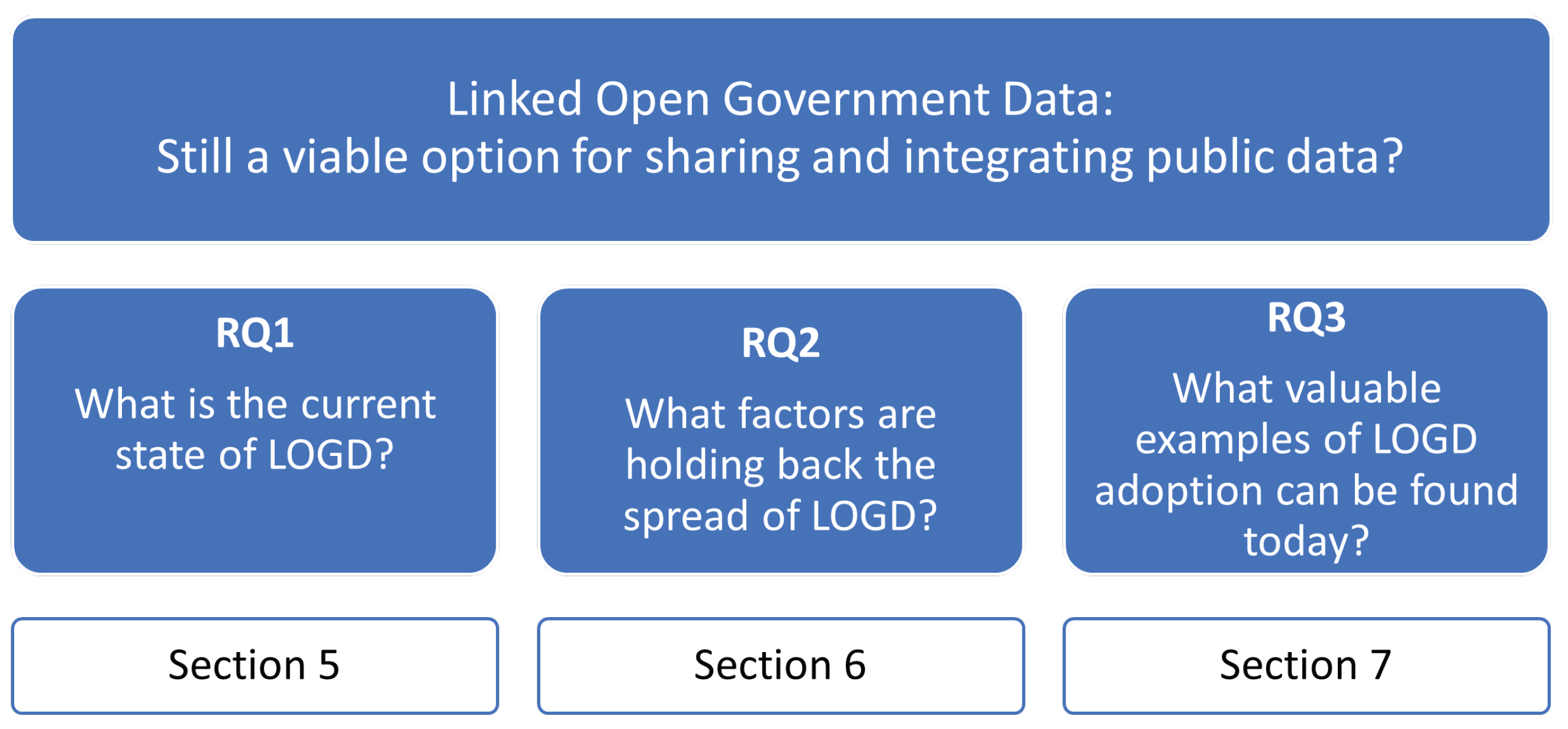
5. What Is the Current State of Linked Open Government Data?
5.1. What Is the Prevalence of RDF and SPARQL Endpoint Distributions in National OGD Portals?
5.2. What Are the Relations between OGD and LOGD Found in the Literature?
6. What Factors Are Holding back the Spread of LOGD?
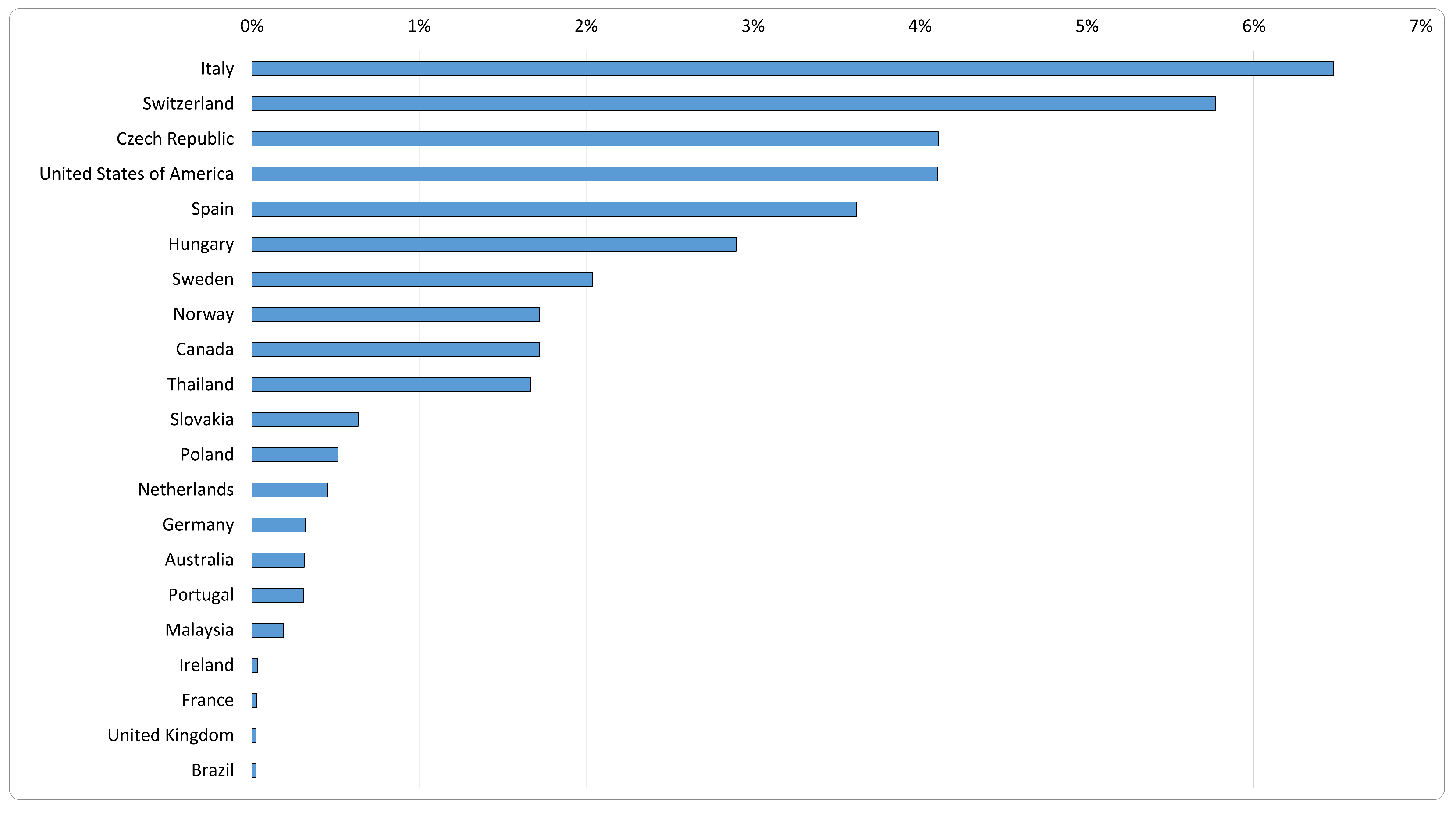
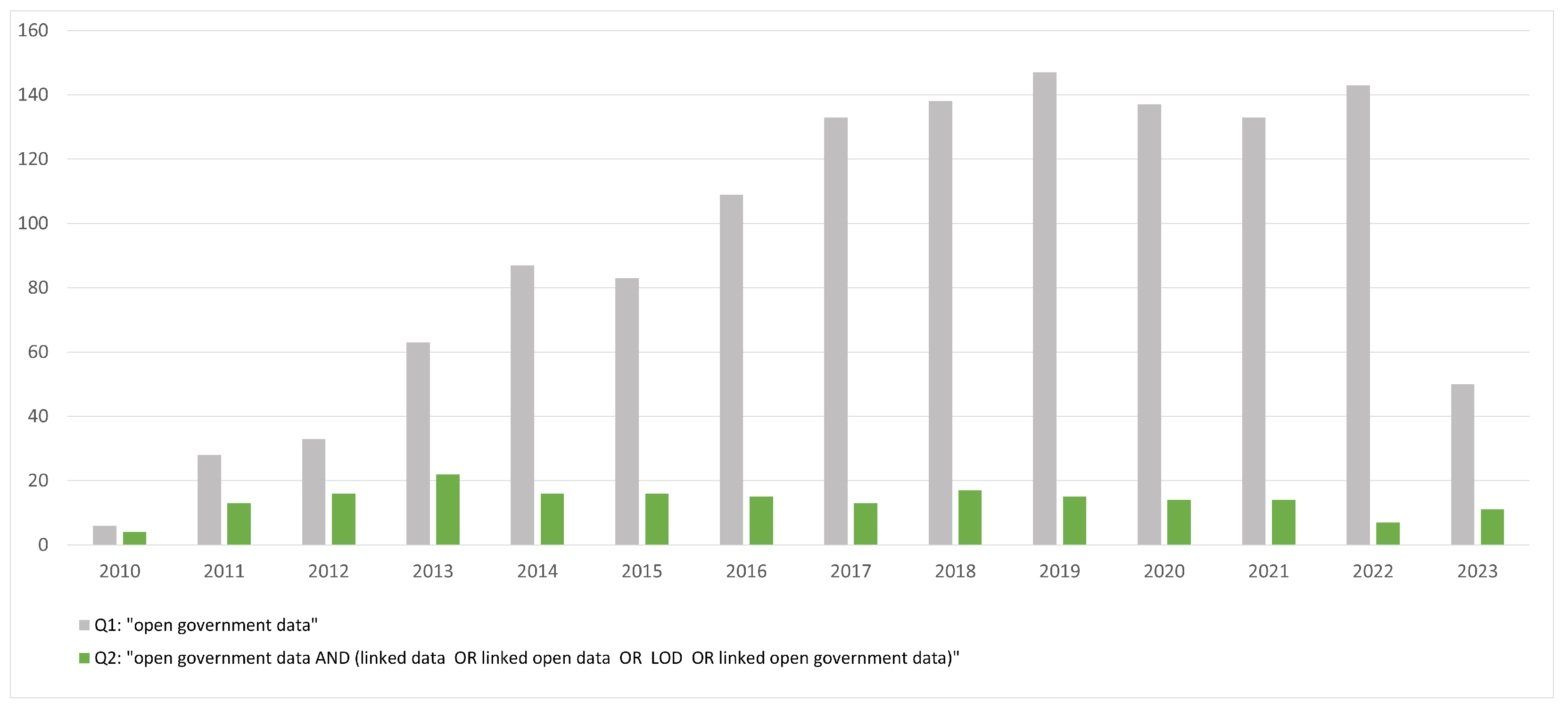
6.1. Bibliographic Analysis
6.2. LOGD Data Friction
6.2.1. Technical Dimension
Heterogeneity
Vocabularies
LD Lifecycle Complexity
Data Quality
6.2.2. Organizational Dimension
Cultural Change
Lack of Technical Expertise
6.2.3. Policy/Legal Dimension
Data Ownership and Licensing
Legal Regulation
Data Privacy and Security
6.2.4. Social Dimension
6.2.5. Economic/Financial Dimension
7. What Valuable Examples of LOGD Adoption Can Be Found Today?
7.1. DCAT and Open Data Catalog Interoperability
7.2. Vocabularies
7.3. European Data Portal
| Listing 1. Number of catalogs on data.europa.eu providing OWL, RDF, or SPARQL distributions. |
| PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX dct: <http://purl.org/dc/terms/> PREFIX dcat: <http://www.w3.org/ns/dcat#> SELECT (count(distinct ?catalog) as ?numberOfCatalogs) { { ?distribution dct:format ?format . filter(regex(str(?format), "RDF", "i")). } UNION { ?distribution dct:format ?format . filter(regex(str(?format), "SPARQL", "i")).} UNION { ?distribution dct:format ?format . filter(regex(str(?format), "OWL", "i")) } ?catalog dcat:dataset ?dataset . ?dataset dcat:distribution ?distribution . } |
7.4. National and International LOGD Take-Up
8. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Country | Region | OGDI | Portal URL (accessed on 1 February 2024) | #Datasets | #RDF | %RDF | SPARQL |
|---|---|---|---|---|---|---|---|
| Italy | Europe | Very High | https://www.dati.gov.it | 59,516 | 3854 | 6.5% | YES |
| Switzerland | Europe | High | https://opendata.swiss | 9910 | 572 | 5.8% | NO |
| Czech Republic | Europe | Very High | https://data.gov.cz | 5474 | 225 | 4.1% | YES |
| USA | Americas | Very High | https://catalog.data.gov | 250,717 | 10,297 | 4.1% | NO |
| Spain | Europe | High | https://datos.gob.es | 69,879 | 2530 | 3.6% | YES |
| Hungary | Europe | High | https://www.opendata.hu/dataset | 69 | 2 | 2.9% | NO |
| Sweden | Europe | Very High | https://www.dataportal.se | 8585 | 175 | 2.0% | NO |
| Norway | Europe | Very High | https://data.norge.no | 1683 | 29 | 1.7% | NO |
| Canada | Americas | Very High | https://search.open.canada.ca/opendata | 37,724 | 650 | 1.7% | NO |
| Thailand | Asia | Very High | https://data.go.th/en/dataset | 9172 | 153 | 1.7% | NO |
| Slovakia | Europe | High | https://data.gov.sk | 3306 | 21 | 0.6% | NO |
| Poland | Europe | High | https://dane.gov.pl | 2336 | 12 | 0.5% | NO |
| The Netherlands | Europe | Very High | https://data.overheid.nl | 15,326 | 69 | 0.5% | NO |
| Germany | Europe | Very High | https://www.govdata.de | 82,845 | 265 | 0.3% | YES |
| Australia | Oceania | Very High | https://data.gov.au | 105,647 | 331 | 0.3% | NO |
| Portugal | Europe | Very High | https://dados.gov.pt | 4205 | 13 | 0.3% | NO |
| Malaysia | Asia | Very High | https://data.gov.my | 12,227 | 23 | 0.2% | NO |
| Latvia | Europe | High | https://data.gov.lv | 793 | 1 | 0.1% | NO |
| Luxembourg | Europe | High | https://data.public.lu | 1796 | 1 | 0.1% | NO |
| Uruguay | Americas | Very High | https://catalogodatos.gub.uy | 2397 | 1 | 0.0% | NO |
| Ireland | Europe | Very High | https://data.gov.ie | 14,758 | 5 | 0.0% | NO |
| France | Europe | Very High | https://www.data.gouv.fr | 44,486 | 13 | 0.0% | NO |
| United Kingdom | Europe | Very High | https://www.data.gov.uk | 51,502 | 13 | 0.0% | NO |
| Brazil | Americas | Very High | https://dados.gov.br/dados/conjuntos-dados | 12,398 | 3 | 0.0% | NO |
| Slovenia | Europe | High | https://podatki.gov.si | 4549 | 1 | 0.0% | NO |
| Austria | Europe | Very High | https://www.data.gv.at | 44,418 | 1 | 0.0% | NO |
| Argentina | Americas | Very High | https://www.datos.gob.ar | 1175 | 0 | 0% | NO |
| Bulgaria | Europe | Very High | https://data.egov.bg/data | 11,216 | 0 | 0% | NO |
| China | Asia | Very High | n.a | - | - | - | NO |
| Colombia | Americas | Very High | https://www.datos.gov.co/en | 7373 | 0 | 0% | NO |
| Cyprus | Asia | Very High | https://www.data.gov.cy | 1278 | 0 | 0% | NO |
| Denmark | Europe | Very High | https://www.opendata.dk | 700 | 0 | 0% | NO |
| Estonia | Europe | Very High | https://avaandmed.eesti.ee | 1769 | 0 | 0% | NO |
| Finland | Europe | Very High | https://www.avoindata.fi | 2096 | 0 | 0% | NO |
| Greece | Europe | Very High | http://geodata.gov.gr | 248 | 0 | 0% | NO |
| India | Asia | Very High | https://data.gov.in | 601,498 | 0 | 0% | NO |
| Indonesia | Asia | Very High | https://www.satupemerintah.net | - | - | - | NO |
| Japan | Asia | Very High | https://data.e-gov.go.jp | 22,126 | 0 | 0% | NO |
| Kazakhstan | Asia | Very High | https://data.egov.kz | 3757 | 0 | 0% | NO |
| Mexico | Americas | Very High | https://datos.gob.mx | 10,014 | 0 | 0% | NO |
| New Zealand | Oceania | Very High | https://catalogue.data.govt.nz | 32,082 | 0 | 0% | NO |
| Philippines | Asia | Very High | https://data.gov.ph | 171 | 0 | 0% | NO |
| Republic of Korea | Asia | Very High | https://www.data.go.kr/en/index.do | 77,980 | 0 | 0% | NO |
| Republic of Moldova | Europe | Very High | https://date.gov.md | 1176 | 0 | 0% | NO |
| Russian Federation | Europe | Very High | n.a | - | - | - | NO |
| Saudi Arabia | Asia | Very High | https://od.data.gov.sa | 6860 | 0 | 0% | NO |
| Singapore | Asia | Very High | https://data.gov.sg | 1945 | 0 | 0% | NO |
| United Arab Emirates | Asia | Very High | n.a | - | - | - | NO |
| Uzbekistan | Asia | Very High | https://data.egov.uz | 8017 | 0 | 0% | NO |
| Belarus | Europe | High | n.a | - | - | - | NO |
| Peru | Americas | High | https://www.datosabiertos.gob.pe | 3270 | 0 | 0% | NO |
| Belgium | Europe | High | https://data.gov.be | >10,000 | 0 | 0% | NO |
| Ghana | Africa | High | https://data.gov.gh | 315 | 0 | 0% | NO |
| Mauritius | Africa | High | https://data.govmu.org/dkan | 464 | 0 | 0% | NO |
| Romania | Europe | High | https://data.gov.ro | 3604 | 0 | 0% | NO |
| Turkey | Asia | High | n.a | - | - | - | NO |
| Albania | Europe | High | n.a | - | - | - | NO |
| Panama | Americas | High | https://www.datosabiertos.gob.pa | 4191 | 0 | 0% | NO |
| South Africa | Africa | High | https://southafrica.opendataforafrica.org | - | - | - | NO |
| Ukraine | Europe | High | https://data.gov.ua | 29,552 | 0 | 0% | NO |
| Burkina Faso | Africa | High | https://burkinafaso.opendataforafrica.org | - | - | - | NO |
| Croatia | Europe | High | https://data.gov.hr/ckan/dataset | 2491 | 0 | 0% | YES |
| Georgia | Asia | High | n.a. | - | - | - | NO |
| Qatar | Asia | High | https://www.data.gov.qa | 173 | 0 | 0% | NO |
| Uganda | Africa | High | https://uganda.opendataforafrica.org | - | - | - | NO |
| Azerbaijan | Asia | High | https://www.opendata.az | 510 | 0 | 0% | NO |
| Kenya | Africa | High | https://kenya.opendataforafrica.org | - | - | - | NO |
| Kuwait | Asia | High | n.a | - | - | - | NO |
| North Macedonia | Europe | High | n.a | - | - | - | NO |
| Serbia | Europe | High | https://data.gov.rs/sr | 2198 | 0 | 0% | NO |
| Dominican Republic | Americas | High | n.a | - | - | - | NO |
| Bahrain | Asia | High | https://www.data.gov.bh | 373 | 0 | 0% | NO |
| Ecuador | Americas | High | https://www.datosabiertos.gob.ec | 1013 | 0 | 0% | NO |
| Mongolia | Asia | High | https://opendata.gov.mn/en/dataset | 839 | 0 | 0% | NO |
| Montenegro | Europe | High | https://data.gov.me/datasets | 197 | 0 | 0% | NO |
| Sri Lanka | Asia | High | https://data.gov.lk | 144 | 0 | 0% | NO |
| Costa Rica | Americas | High | n.a | - | - | - | NO |
| Guatemala | Americas | High | n.a | - | - | - | NO |
References
- Davies, T.; Walker, S.B.; Rubinstein, M.; Perini, F. The State of Open Data: Histories and Horizons; African Minds and IDRC: Cape Town, South Africa; Ottawa, ON, Canada, 2019. [Google Scholar] [CrossRef]
- Ding, L.; Peristeras, V.; Hausenblas, M. Linked open government data. IEEE Intell. Syst. 2012, 27, 11–15. [Google Scholar] [CrossRef]
- Kapoor, K.; Weerakkody, V.; Sivarajah, U. Open Data Platforms and Their Usability: Proposing a Framework for Evaluating Citizen Intentions. In Open and Big Data Management and Innovation; Janssen, M., Mäntymäki, M., Hidders, J., Klievink, B., Lamersdorf, W., Van Loenen, B., Zuiderwijk, A., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2015; Volume 9373, pp. 261–271. [Google Scholar] [CrossRef]
- Krishnamurthy, R.; Awazu, Y. Liberating data for public value: The case of Data.gov. Int. J. Inf. Manag. 2016, 36, 668–672. [Google Scholar] [CrossRef]
- Berends, J.; Carrara, W.; Radu, C. The Economic Benefits of Open Data; Analytical Report 9; European Union: Brussels, Belgium, 2017. [Google Scholar]
- Hendler, J.; Holm, J.; Musialek, C.; Thomas, G. US government linked open data: Semantic.data.gov. IEEE Intell. Syst. 2012, 27, 25–31. [Google Scholar] [CrossRef]
- Aquaro, V. Digital Government in the Decade of Action for Sustainable Development; Number 2020 in United Nations e-Government Survey; Department of Economic and Social Affairs, United Nations: New York, NY, USA, 2020. [Google Scholar]
- Barbero, M.; Bartz, K.; Linz, F.; Mauritz, S.; Wauters, P.; Chrzanowski, P.; Graux, H.; Hillebrand, A.; de Vries, M.; Innesti, A.; et al. Study to support the review of Directive 2003/98. Reuse Public Sect. Inf. 2018. [Google Scholar] [CrossRef]
- Kaschesky, M.; Selmi, L. 7R Data Value Framework for Open Data in Practice: Fusepool. Future Internet 2014, 6, 556–583. [Google Scholar] [CrossRef]
- Compton, S. Success Stories: Issue 2, Global Open Data for Agriculture and Nutrition (GODAN). 2017. Available online: https://www.godan.info/v2.pdf (accessed on 2 February 2024).
- Stagars, M. Promises, Barriers, and Success Stories of Open Data. In Open Data in Southeast Asia: Towards Economic Prosperity, Government Transparency, and Citizen Participation in the ASEAN; Springer International Publishing: Cham, Switzerland, 2016; pp. 13–28. [Google Scholar] [CrossRef]
- Eggers, W.D.; Datar, A. Connecting data to residents through data storytelling. In The Chief Data Officer in Government: A CDO Playbook; Shah, S., Eggers, W.D., Eds.; Deloitte: Seoul, Republic of Korea, 2018; pp. 1–4. [Google Scholar]
- Sadiq, S.; Indulska, M. Open data: Quality over quantity. Int. J. Inf. Manag. 2017, 37, 150–154. [Google Scholar] [CrossRef]
- Safarov, I.; Meijer, A.J.; Grimmelikhuijsen, S. Utilization of open government data: A systematic literature review of types, conditions, effects and users. Inf. Polity 2017, 22, 1–24. [Google Scholar] [CrossRef]
- Lassinantti, J.; Ståhlbröst, A.; Runardotter, M. Relevant social groups for open data use and engagement. Gov. Inf. Q. 2019, 36, 98–111. [Google Scholar] [CrossRef]
- Stone, A. Are Open Data Efforts Working? 2018. Available online: http://www.govtech.com/data/Are-Open-Data-Efforts-Working.html (accessed on 2 February 2024).
- Quarati, A.; De Martino, M. Open government data usage: A brief overview. In Proceedings of the 23rd International Database Applications & Engineering Symposium, IDEAS 2019, Athens, Greece, 10–12 June 2019; pp. 28:1–28:8. [Google Scholar] [CrossRef]
- Quarati, A. Open Government Data: Usage trends and metadata quality. J. Inf. Sci. 2023, 49, 887–910. [Google Scholar] [CrossRef]
- Edwards, P.N. A Vast Machine: Computer Models, Climate Data, and the Politics of Global Warming; The MIT Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Janssen, M.; Charalabidis, Y.; Zuiderwijk, A. Benefits, Adoption Barriers and Myths of Open Data and Open Government. Inf. Syst. Manag. 2012, 29, 258–268. [Google Scholar] [CrossRef]
- Science, D.; Hahnel, M.; Fane, B.; Treadway, J.; Baynes, G.; Wilkinson, R.; Mons, B.; Schultes, E.; Bonino da Silva Santos, L.O.; Arefiev, P.; et al. The State of Open Data Report 2018; Digital Science: London, UK, 2018. [Google Scholar] [CrossRef]
- Zuiderwijk, A.; Janssen, M.; Susha, I. Improving the speed and ease of open data use through metadata, interaction mechanisms, and quality indicators. J. Organ. Comput. Electron. Commer. 2016, 26, 116–146. [Google Scholar] [CrossRef]
- Reiche, K.; Hofig, E. Implementation of metadata quality metrics and application on public government data. In Proceedings of the 2013 IEEE 37th Annual Computer Software and Applications Conference Workshops, Kyoto, Japan, 22–26 July 2013; pp. 236–241. [Google Scholar] [CrossRef]
- Neumaier, S.; Umbrich, J.; Polleres, A. Automated Quality Assessment of Metadata Across Open Data Portals. J. Data Inf. Qual. 2016, 8, 2:1–2:29. [Google Scholar] [CrossRef]
- Santos-Hermosa, G.; Quarati, A.; Loría-Soriano, E.; Raffaghelli, J.E. Why Does Open Data Get Underused? A Focus on the Role of (Open) Data Literacy. In Data Cultures in Higher Education: Emergent Practices and the Challenge Ahead; Raffaghelli, J.E., Sangrà, A., Eds.; Springer International Publishing: Cham, Switzerland, 2023; pp. 145–177. [Google Scholar] [CrossRef]
- Jarke, J. Open government for all? Co-creating digital public services for older adults through data walks. Online Inf. Rev. 2019, 43, 1003–1020. [Google Scholar] [CrossRef]
- Zuiderwijk, A.; Janssen, M.; Dwivedi, Y.K. Acceptance and use predictors of open data technologies: Drawing upon the unified theory of acceptance and use of technology. Gov. Inf. Q. 2015, 32, 429–440. [Google Scholar] [CrossRef]
- Ruijer, E.; Grimmelikhuijsen, S.; van den Berg, J.; Meijer, A. Open data work: Understanding open data usage from a practice lens. Int. Rev. Adm. Sci. 2020, 86, 3–19. [Google Scholar] [CrossRef]
- Dadzie, A.S.; Rowe, M. Approaches to visualising linked data: A survey. Semant. Web 2011, 2, 89–124. [Google Scholar] [CrossRef]
- Lnenicka, M.; Komarkova, J. Big and open linked data analytics ecosystem: Theoretical background and essential elements. Gov. Inf. Q. 2019, 36, 129–144. [Google Scholar] [CrossRef]
- Archer, P.; Dekkers, M.; Hazard, N.; Loutas, N.; Karalopoulos, A.; Peristeras, V.; Wigard, S. Business Models for Linked Open Government Data: What Lies Beneath? 2013. Available online: https://www.w3.org/2013/share-psi/workshop/krems/papers/LinkedOpenGovernmentDataBusinessModel (accessed on 1 February 2024).
- Shadbolt, N.; O’Hara, K. Linked Data in Government. IEEE Internet Comput. 2013, 17, 72–77. [Google Scholar] [CrossRef]
- Penteado, B.E.; Maldonado, J.C.; Isotani, S. Methodologies for publishing linked open government data on the Web: A systematic mapping and a unified process model. Semant. Web 2022, 14, 585–610. [Google Scholar] [CrossRef]
- Attard, J.; Orlandi, F.; Auer, S. Value creation on open government data. In Proceedings of the 2016 49th Hawaii International Conference on System Sciences (HICSS), Koloa, HI, USA, 5–8 January 2016; pp. 2605–2614. [Google Scholar] [CrossRef]
- Klein, E.; Gschwend, A.; Neuroni, A. Towards a linked data publishing methodology. In Proceedings of the 6th International Conference for E-Democracy and Open Government, CeDEM 2016, Krems, Austria, 18–20 May 2016. [Google Scholar] [CrossRef]
- DiFranzo, D.; Graves, A.; Erickson, J.S.; Ding, L.; Michaelis, J.; Lebo, T.; Patton, E.; Williams, G.T.; Li, X.; Zheng, J.G.; et al. The Web is My Back-end: Creating Mashups with Linked Open Government Data. In Linking Government Data; Wood, D., Ed.; Springer: New York, NY, USA, 2011; pp. 205–219. [Google Scholar] [CrossRef]
- Kalampokis, E.; Karacapilidis, N.; Tsakalidis, D.; Tarabanis, K. Understanding the Use of Emerging Technologies in the Public Sector: A Review of Horizon 2020 Projects. Digit. Gov. Res. Pract. 2023, 4, 1–28. [Google Scholar] [CrossRef]
- Futia, G.; Melandri, A.; Vetrò, A.; Morando, F.; De Martin, J.C. Removing Barriers to Transparency: A Case Study on the Use of Semantic Technologies to Tackle Procurement Data Inconsistency. In The Semantic Web; Blomqvist, E., Maynard, D., Gangemi, A., Hoekstra, R., Hitzler, P., Hartig, O., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 623–637. [Google Scholar] [CrossRef]
- Sheridan, J.; Tennison, J. Linking UK Government data. In Proceedings of the CEUR Workshop Proceedings, Heraklion, Greece, 31 May 2010. [Google Scholar]
- Galiotou, E.; Fragkou, P. Applying Linked Data Technologies to Greek Open Government Data: A Case Study. Procedia Soc. Behav. Sci. 2013, 73, 479–486. [Google Scholar] [CrossRef]
- Breitman, K.; Viterbo, J.; Salas, P.; Saraiva, D.; Magalhães, R.; Gama, V.; Casanova, M.; Chaves, M.; Franzosi, E. Open government data in Brazil. IEEE Intell. Syst. 2012, 27, 45–49. [Google Scholar] [CrossRef]
- Ding, L.; Lebo, T.; Erickson, J.; Difranzo, D.; Williams, G.; Li, X.; Michaelis, J.; Graves, A.; Zheng, J.; Shangguan, Z.; et al. TWC LOGD: A portal for linked open government data ecosystems. J. Web Semant. 2011, 9, 325–333. [Google Scholar] [CrossRef]
- Cyganiak, R.; Maali, F.; Peristeras, V. Self-service linked government data with dcat and gridworks. In Proceedings of the 6th International Conference on Semantic Systems; ACM International Conference Proceeding Series; ACM: New York, NY, USA, 2010. [Google Scholar] [CrossRef]
- Janev, V.; Miloševic, U.; Spasić, M.; Milojković, J.; Vraneš, S. Linked open data infrastructure for public sector information: Example from Serbia. In I-SEMANTICS (Posters & Demos); CEUR Workshop Proceedings; ACM: New York, NY, USA, 2012. [Google Scholar]
- Kalampokis, E.; Tambouris, E.; Tarabanis, K. On publishing linked open government data. In Proceedings of the 17th Panhellenic Conference on Informatics; ACM International Conference Proceeding Series; ACM: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Quarati, A.; De Martino, M.; Rosim, S. Geospatial Open Data Usage and Metadata Quality. ISPRS Int. J. Geo-Inf. 2021, 10, 30. [Google Scholar] [CrossRef]
- Hogan, A. The Semantic Web: Two decades on. Semant. Web 2020, 11, 169–185. [Google Scholar] [CrossRef]
- Wirtz, B.W.; Weyerer, J.C.; Becker, M.; Müller, W.M. Open government data: A systematic literature review of empirical research. Electron. Mark. 2022, 32, 2381–2404. [Google Scholar] [CrossRef] [PubMed]
- Bulazel, A.; DiFranzo, D.; Erickson, J.; Hendler, J. The importance of authoritative uri design schemes for open government data. In Information Retrieval and Management: Concepts, Methodologies, Tools, and Applications; IGI Global: Hershey, PA, USA, 2018. [Google Scholar] [CrossRef]
- Lnenicka, M.; Luterek, M.; Nikiforova, A. Benchmarking open data efforts through indices and rankings: Assessing development and contexts of use. Telemat. Inform. 2022, 66, 101745. [Google Scholar] [CrossRef]
- Zheng, L.; Kwok, W.M.; Aquaro, V.; Qi, X.; Lyu, W. Evaluating Global Open Government Data: Methods and Status. In Proceedings of the 13th International Conference on Theory and Practice of Electronic Governance, ICEGOV ’20, Athens, Greece, 23–25 September 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 381–391. [Google Scholar] [CrossRef]
- Berners-Lee, T. Linked Data. 2006. Available online: https://www.w3.org/DesignIssues/LinkedData.html (accessed on 1 February 2024).
- Heath, T.; Bizer, C. Linked Data: Evolving the Web into a Global Data Space, 1st ed.; html version ed.; Synthesis Lectures on the Semantic Web: Theory and Technology; Morgan & Claypool: San Rafael, CA, USA, 2011; Volume 1, pp. 1–136. [Google Scholar] [CrossRef]
- Cyganiak, R.; Wood, D.; Lanthaler, M. RDF 1.1 Concepts and Abstract Syntax. W3C Recommendation, W3C. 2014. Available online: https://www.w3.org/TR/2014/REC-rdf11-concepts-20140225/ (accessed on 1 February 2024).
- OWL 2 Web Ontology Language Document Overview (Second Edition). W3C Recommendation, W3C. 2012. Available online: https://www.w3.org/TR/2012/REC-owl2-overview-20121211/ (accessed on 1 February 2024).
- SPARQL 1.1 Overview. W3C Recommendation, W3C. 2013. Available online: https://www.w3.org/TR/2013/REC-sparql11-overview-20130321/ (accessed on 1 February 2024).
- Mahmud, S.; Hossin, M.; Hasan, M.; Jahan, H.; Noori, S.; Ahmed, M. Publishing CSV Data as Linked Data on the Web. In Proceedings of ICETIT 2019; Springer: Cham, Switzerland, 2020; Volume 605, pp. 805–817. [Google Scholar] [CrossRef]
- Kumar, B.P. 9—Open Data for smart cities. In Solving Urban Infrastructure Problems Using Smart City Technologies; Vacca, J.R., Ed.; Elsevier: Amsterdam, The Netherlands, 2021; pp. 185–211. [Google Scholar] [CrossRef]
- Guha, R.V.; Brickley, D.; MacBeth, S. Schema.Org: Evolution of Structured Data on the Web: Big Data Makes Common Schemas Even More Necessary. Queue 2015, 13, 10–37. [Google Scholar] [CrossRef]
- Velitchkov, I.; Linked Data Uptake. 4 April 2021. Available online: https://www.strategicstructures.com/?p=2193 (accessed on 12 January 2024).
- Pawełoszek, I.; Wieczorkowski, J. Open government data and linked data in the practice of selected countries. In European Conference on e-Digital Government; Academic Conferences International Limited: Reading, UK, 2018. [Google Scholar]
- Ibanez, L.; Millard, I.; Glaser, H.; Simperl, E. An Assessment of Adoption and Quality of Linked Data in European Open Government Data. In The Semantic Web–ISWC 2019; Springer: Cham, Switzerland, 2019; Volume 11779, pp. 436–453. [Google Scholar] [CrossRef]
- Akatkin, Y.; Yasinovskaya, E. Data-Driven Government in Russia: Linked Open Data Challenges, Opportunities, Solutions. In Communications in Computer and Information Science; Springer: Cham, Switzerland, 2020. [Google Scholar] [CrossRef]
- Zuiderwijk, A.; Janssen, M.; Choenni, S.; Meijer, R.; Alibaks, R.S. Socio-technical Impediments of Open Data. Electron. J.-Gov. 2012, 10, 156–172. [Google Scholar]
- Attard, J.; Orlandi, F.; Scerri, S.; Auer, S. A systematic review of open government data initiatives. Gov. Inf. Q. 2015, 32, 399–418. [Google Scholar] [CrossRef]
- Verma, N.; Gupta, M. Challenges in publishing open government data: A study in Indian context. In Proceedings of the 2015 2nd International Conference on Electronic Governance and Open Society: Challenges in Eurasia; ACM International Conference Proceeding Series; ACM: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Roa, H.N.; Loza-Aguirre, E.; Flores, P. A Survey on the Problems Affecting the Development of Open Government Data Initiatives. In Proceedings of the 2019 Sixth International Conference on eDemocracy & eGovernment (ICEDEG), Quito, Ecuador, 24–26 April 2019; pp. 157–163. [Google Scholar] [CrossRef]
- Portisch, J.; Fallatah, O.; Neumaier, S.; Jaradeh, M.Y.; Polleres, A. Challenges of Linking Organizational Information in Open Government Data to Knowledge Graphs. In Knowledge Engineering and Knowledge Management; Keet, C.M., Dumontier, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2020; Volume 12387, pp. 271–286. [Google Scholar] [CrossRef]
- Geci, M.; Csáki, C. The Potential of BOLD in National Budget Planning: Opportunities and Challenges for Kosovo. In Electronic Government; Scholl, H.J., Gil-Garcia, J.R., Janssen, M., Kalampokis, E., Lindgren, I., Rodríguez Bolívar, M.P., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2021; Volume 12850, pp. 178–189. [Google Scholar] [CrossRef]
- Mouzakitis, S.; Papaspyros, D.; Petychakis, M.; Koussouris, S.; Zafeiropoulos, A.; Fotopoulou, E.; Farid, L.; Orlandi, F.; Attard, J.; Psarras, J. Challenges and opportunities in renovating public sector information by enabling linked data and analytics. Inf. Syst. Front. 2017, 19, 321–336. [Google Scholar] [CrossRef]
- Buil-Aranda, C.; Hogan, A.; Umbrich, J.; Vandenbussche, P.Y. SPARQL Web-Querying Infrastructure: Ready for Action? In The Semantic Web–ISWC 2013; Alani, H., Kagal, L., Fokoue, A., Groth, P., Biemann, C., Parreira, J.X., Aroyo, L., Noy, N., Welty, C., Janowicz, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 277–293. [Google Scholar]
- de Oliveira, E.F.; Silveira, M.S. Open Government Data in Brazil a Systematic Review of Its Uses and Issues. In Proceedings of the 19th Annual International Conference on Digital Government Research: Governance in the Data Age; dg.o ’18; Association for Computing Machinery: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Attard, J.; Orlandi, F.; Auer, S. Data driven governments: Creating value through open government data. In Transactions on Large-Scale Data- and Knowledge-Centered Systems XXVII; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar] [CrossRef]
- Kaoudi, Z.; Manolescu, I. Triples in the clouds. In Proceedings of the 2013 IEEE 29th International Conference on Data Engineering (ICDE), Brisbane, QLD, Australia, 8–12 April 2013. [Google Scholar] [CrossRef]
- Theocharis, S.; Tsihrintzis, G. Ontology development to support the Open Public data—The Greek case. In Proceedings of the IISA 2014—5th International Conference on Information, Intelligence, Systems and Applications, Chania, Greece, 7–9 July 2014. [Google Scholar] [CrossRef]
- Araújo, I.; Reis, A.; Mariano, A.; Oviedo, V. Design and Application of the AHP-TOPSIS-2N to Evaluate (Linked) Open Government Data from the Electricity Datasets. In Intelligent Sustainable Systems; Lecture Notes in Networks and Systems; Springer: Singapore, 2023. [Google Scholar] [CrossRef]
- Vert, S.; Vasiu, R. Relevant Aspects for the Integration of Linked Data in Mobile Augmented Reality Applications for Tourism. In Information and Software Technologies; Dregvaite, G., Damasevicius, R., Eds.; Communications in Computer and Information Science; Springer International Publishing: Cham, Switzerland, 2014; Volume 465, pp. 334–345. [Google Scholar] [CrossRef]
- Wieczorkowski, J. Barriers to Using Open Government Data; ACM International Conference Proceeding Series; ACM: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Narducci, F.; Palmonari, M.; Semeraro, G. Cross-Language Semantic Retrieval and Linking of E-Gov Services. In The Semantic Web–ISWC 2013; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8219, pp. 130–145. [Google Scholar]
- Akatkin, Y.; Laikam, K.; Yasinovskaya, E. The Concept and the Roadmap to Linked Open Statistical Data in the Russian Federation. In Electronic Governance and Open Society: Challenges in Eurasia. EGOSE 2021; Communications in Computer and Information Science; Springer: Cham, Switzerland, 2022. [Google Scholar] [CrossRef]
- Subramanian, A.; Garg, A.; Poddar, O.; Srinivasa, S. Towards semantically aggregating indian open government data from data.gov.in. In ISWC (Posters, Demos & Industry Tracks); CEUR Workshop Proceedings; ACM: New York, NY, USA, 2017. [Google Scholar]
- Espinoza-Arias, P.; Fernandez-Ruiz, M.; Morlan-Plo, V.; Notivol-Bezares, R.; Corcho, O. The Zaragoza’s Knowledge Graph: Open Data to Harness the City Knowledge. Information 2020, 11, 129. [Google Scholar] [CrossRef]
- Höchtl, J.; Reichstädter, P. Linked open data—A means for public sector information management. In Electronic Government and the Information Systems Perspective. EGOVIS 2011; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar] [CrossRef]
- Brys, C.; Aldana-Montes, J. A semantic model for electronic government and its enforcement in the Province of Misiones, Argentina. Electron. Gov. 2016, 12, 337–356. [Google Scholar] [CrossRef]
- Buranarach, M.; Ruengittinun, S.; Krataithong, P.; Supnithi, T.; Hinsheranan, S. A scalable framework for creating open government data services from open government data catalog. In Proceedings of the 9th International Conference on Management of Digital EcoSystems, MEDES 2017, Bangkok, Thailand, 7–10 November 2017. [Google Scholar] [CrossRef]
- Lebo, T.; Erickson, J.; Ding, L.; Graves, A.; Williams, G.; DiFranzo, D.; Li, X.; Michaelis, J.; Zheng, J.; Flores, J.; et al. Producing and Using Linked Open Government Data in the TWC LOGD Portal. In Linking Government Data; Springer: Berlin/Heidelberg, Germany, 2011; p. 72. [Google Scholar] [CrossRef]
- Shi, L.; Sukhobok, D.; Nikolov, N.; Roman, D. Norwegian State of estate report as linked open data. In On the Move to Meaningful Internet Systems. OTM 2017 Conferences. OTM 2017; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2017. [Google Scholar] [CrossRef]
- Deng, D.; Mai, G.; Shiau, S. Construction and Reuse of Linked Agriculture Data: An Experience of Taiwan Government Open Data. In Semantic Technology. JIST 2018; Springer: Cham, Switzerland, 2018; Volume 11341, pp. 367–382. [Google Scholar] [CrossRef]
- Publications Office of the European Union; European Commission, Directorate General for Informatics. Creating Public Sector Value through the Use of Open Data: Insights and Recommendations from the data.europa.eu Campaign: Summary Paper 2023; Publications Office of the European Union: Luxembourg, 2023.
- Tambouris, E. Multidimensional open government data. EJournal EDemocracy Open Gov. 2016, 8, 1–11. [Google Scholar] [CrossRef]
- Abida, R.; Belghith, E.; Cleve, A. An End-to-End Framework for Integrating and Publishing Linked Open Government Data. In Proceedings of the Workshop on Enabling Technologies: Infrastructure for Collaborative Enterprises, WETICE, Bayonne, France, 10–13 September 2020. [Google Scholar] [CrossRef]
- Sinif, L.; Bounabat, B. Approaching an Optimizing Open Linked Government Data Portal; ACM International Conference Proceeding Series; ACM: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Trinh, T.D.; Do, B.L.; Wetz, P.; Anjomshoaa, A.; Tjoa, A. Linked widgets: An approach to exploit open government data. In Proceedings of the 2nd International Conference on Smart Digital Environment; ACM International Conference Proceeding Series; ACM: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Zhu, X.; Thomas, C.; Moore, J.; Allen, S. Open Government Data Licensing: An Analysis of the U.S. State Open Government Data Portals. In Diversity, Divergence, Dialogue. iConference 2021; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2021. [Google Scholar] [CrossRef]
- Morando, F. Legal Interoperability: Making Open (Government) Data Compatible with Businesses and Communities. JLIS.IT 2013, 4, 441–452. [Google Scholar] [CrossRef]
- Matheus, R.; Ribeiro, M.; Vaz, J. Brazil towards government 2.0: Strategies for adopting open government data in national and subnational governments. In Case Studies in E-Government 2.0: Changing Citizen Relationships; Springer: Cham, Switzerland, 2015. [Google Scholar] [CrossRef]
- Alexopoulos, C.; Loukis, E.; Mouzakitis, S.; Petychakis, M.; Charalabidis, Y. Analysing the Characteristics of Open Government Data Sources in Greece. J. Knowl. Econ. 2018, 9, 721–753. [Google Scholar] [CrossRef]
- Lebo, T.; Wang, P.; Graves, A.; McGuinness, D. Towards Unified Provenance Granularities. In Provenance and Annotation of Data and Processes. IPAW 2012; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7525, pp. 39–51. [Google Scholar]
- Albertoni, R.; Martino, M.D.; Podestà, P. Quality measures for skos: ExactMatch linksets: An application to the thesaurus framework LusTRE. Data Technol. Appl. 2018, 52, 405–423. [Google Scholar] [CrossRef]
- Albertoni, R.; Gómez-Pérez, A. Assessing linkset quality for complementing third-party datasets. In Proceedings of the Joint EDBT/ICDT 2013 Workshops; ACM: New York, NY, USA, 2013; pp. 52–59. [Google Scholar]
- Quarati, A.; Albertoni, R.; Martino, M.D. Overall quality assessment of SKOS thesauri: An AHP-based approach. J. Inf. Sci. 2017, 43, 816–834. [Google Scholar] [CrossRef]
- Albertoni, R.; De Martino, M.; Quarati, A. Documenting Context-Based Quality Assessment of Controlled Vocabularies. IEEE Trans. Emerg. Top. Comput. 2021, 9, 144–160. [Google Scholar] [CrossRef]
- Ngomo, A.C.N.; Auer, S.; Lehmann, J.; Zaveri, A. Introduction to Linked Data and Its Lifecycle on the Web. In Reasoning Web. Reasoning on the Web in the Big Data Era: 10th International Summer School 2014, Athens, Greece, September 8–13, 2014. Proceedings; Koubarakis, M., Stamou, G., Stoilos, G., Horrocks, I., Kolaitis, P., Lausen, G., Weikum, G., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 1–99. [Google Scholar] [CrossRef]
- European Commission; Directorate-General for Communications Networks, Content and Technology. Identification of Data Themes for the Extensions of Public Sector High-Value Datasets–Final Study; Publications Office of the European Union: Luxembourg, 2023. [CrossRef]
- European Commission; Directorate-General for Communications Networks, Content and Technology. Directive (EU) 2019/1024 of the European Parliament and of the Council of 20 June 2019 on Open Data and the Re-Use of Public Sector Information (Recast); Publications Office of the European Union: Luxembourg, 2019.
- Nikiforova, A.; Rizun, N.; Ciesielska, M.; Alexopoulos, C.; Miletić, A. Towards High-Value Datasets Determination for Data-Driven Development: A Systematic Literature Review. In Electronic Government; Lindgren, I., Csáki, C., Kalampokis, E., Janssen, M., Viale Pereira, G., Virkar, S., Tambouris, E., Zuiderwijk, A., Eds.; Springer Nature: Cham, Switzerland, 2023; pp. 211–229. [Google Scholar]
- Gomes, J., Jr.; Bernardino, H.S.; de Souza, J.F.; Rajabi, E. Indexing, enriching, and understanding Brazilian missing person cases from data of distributed repositories on the web. AI Soc. 2023, 38, 565–579. [Google Scholar] [CrossRef]
- Karamanou, A.; Kalampokis, E.; Tarabanis, K.A. Linked Open Government Data to Predict and Explain House Prices: The Case of Scottish Statistics Portal. Big Data Res. 2022, 30, 100355. [Google Scholar] [CrossRef]
- Albertoni, R.; Browning, D.; Cox, S.; González Beltrán, A.; Perego, A.; Winstanley, P. Data Catalog Vocabulary (DCAT)-Version 2. W3C Recommendation, W3C. 2020. Available online: https://www.w3.org/TR/vocab-dcat-2/ (accessed on 1 February 2024).
- Albertoni, R.; Browning, D.; Cox, S.; Gonzalez-Beltran, A.N.; Perego, A.; Winstanley, P. The W3C Data Catalog Vocabulary, Version 2: Rationale, Design Principles, and Uptake. Data Intell. 2023, 1–37. [Google Scholar] [CrossRef]
- van Nuffelen, B. DCAT Application Profile for Data Portals in Europe, Version 2.1; Technical Specification; European Commission: Brussels, Belgium, 2020.
- Perego, A.; van Nuffelen, B. GeoDCAT-AP-Version 2.0.0: A Geospatial Extension for the DCAT Application Profile for Data Portals in Europe; Semic Recommendation; European Commission: Brussels, Belgium, 2020.
- Dragan, A.; Sofou, N. StatDCAT-AP–DCAT Application Profile for Description of Statistical Datasets, Version 1.0.1; Technical Specification; European Commission: Brussels, Belgium, 2019.
- Interian, R.; Mendoza, I.; Bernardini, F.; Viterbo, J. Unified vocabulary in Official Gazettes: An exploratory study on procurement data. In Proceedings of the 15th International Conference on Theory and Practice of Electronic Governance, ICEGOV ’22, Guimarães, Portugal, 4–7 October 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 195–202. [Google Scholar] [CrossRef]
- Alvarez-Rodríguez, J.M.; Labra-Gayo, J.E.; Rodríguez-González, A.; De Pablos, P.O. Empowering the access to public procurement opportunities by means of linking controlled vocabularies. A case study of Product Scheme Classifications in the European e-Procurement sector. Comput. Hum. Behav. 2014, 30, 674–688. [Google Scholar] [CrossRef]
- Baker, T.; Bechhofer, S.; Isaac, A.; Miles, A.; Schreiber, G.; Summers, E. Key choices in the design of Simple Knowledge Organization System (SKOS). J. Web Semant. 2013, 20, 35–49. [Google Scholar] [CrossRef]
- Bechhofer, S.; Miles, A. SKOS Simple Knowledge Organization System Reference. W3C Recommendation, W3C. 2009. Available online: https://www.w3.org/TR/2009/REC-skos-reference-20090818/ (accessed on 1 February 2024).
- Coll, I.S.; Kolshus, K.; Turbati, A.; Stellato, A.; Mietzsch, E.; Martini, D.; Zeng, M. AGROVOC: The linked data concept hub for food and agriculture. Comput. Electron. Agric. 2022, 196, 105965. [Google Scholar] [CrossRef]
- Albertoni, R.; Martino, M.D.; Podestà, P.; Abecker, A.; Wössner, R.; Schnitter, K. LusTRE: A framework of linked environmental thesauri for metadata management. Earth Sci. Inform. 2018, 11, 525–544. [Google Scholar] [CrossRef]


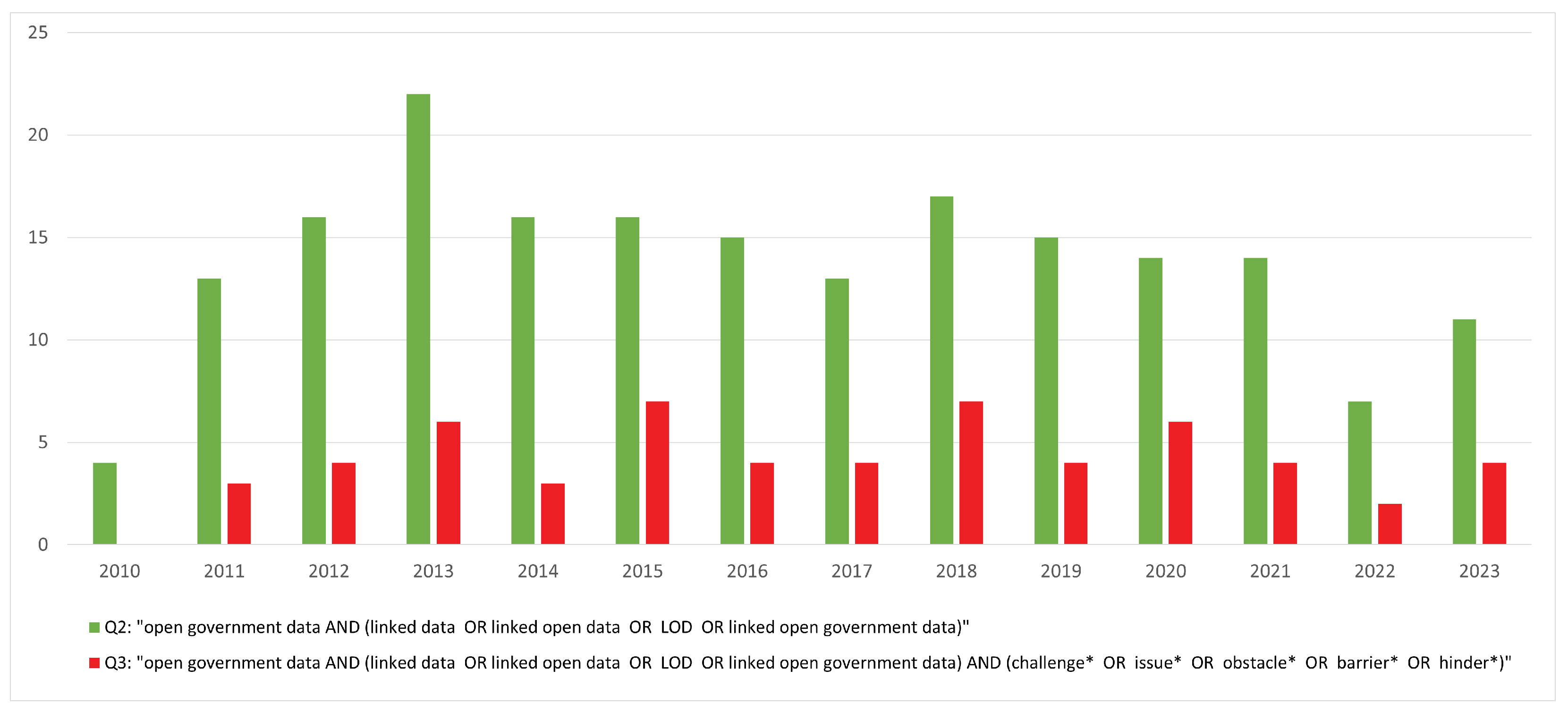
| Query | Sources | Search Text | All |
|---|---|---|---|
| Q1 | Scopus | TITLE-ABS-KEY (“open government data”) | 1236 |
| WoS | (TI = (“open government data”) OR AB = (“open government data”) OR AK = (“open government data”)) | 790 | |
| Scopus ∪ WoS | 1290 | ||
| Q2 | Scopus | TITLE-ABS-KEY ( “open government data”) AND TITLE-ABS-KEY ( “linked data” OR “linked open data” OR “LOD” OR “linked open government data”) | 180 |
| WoS | (TI = (“open government data”) OR AB = (“open government data”) OR AK = (“open government data”)) AND (TI = (“linked data” OR “linked open data” OR “LOD” OR “linked open government data”) OR AB = (“linked data” OR “linked open data” OR “LOD” OR “linked open government data”) OR AK = (“linked data” OR “linked open data” OR “LOD” OR “linked open government data”)) | 105 | |
| Scopus ∪ WoS | 193 | ||
| Q3 | Scopus | TITLE-ABS-KEY (“open government data”) AND TITLE-ABS-KEY (“linked data” OR “linked open data” OR “LOD” OR “linked open government data”) AND TITLE-ABS-KEY (challenge* OR issue* OR obstacle* OR barrier* OR hinder*) | 52 |
| WoS | (TI = (“open government data”) OR AB = (“open government data”) OR AK = (“open government data”)) AND (TI = (“linked data” OR “linked open data” OR “LOD” OR “linked open government data”) OR AB = (“linked data” OR “linked open data” OR “LOD” OR “linked open government data”) OR AK = (“linked data” OR “linked open data” OR “LOD” OR “linked open government data”)) AND (TI = (challenge* OR issue* OR obstacle* OR barrier* OR hinder*) OR AB = (challenge* OR issue* OR obstacle* OR barrier* OR hinder*) OR AK = (challenge* OR issue* OR obstacle* OR barrier* OR hinder*)) | 35 | |
| Scopus ∪ WoS | 58 |
| Dimension | Description | Issues |
|---|---|---|
| Technical | deals with challenges like diverse data sources, vocabulary alignment for semantic interoperability, managing LD complexity, and ensuring data quality for LOGD production | Heterogeneity [2,33,41,49,61,68,69,74,75,76,77,78,79] Vocabularies [2,33,35,41,61,62,76,80,81,82,83,84] LD lifecycle complexity [33,35,41,62,74,79,80,85,86] Data quality [33,62,68,69,77,78,79,87,88] |
| Organizational | emphasizes strategic data management in government structures, directing attention and enhancing the skills of public servants, fostering a culture that understands and effectively manages LOGD, aligning with broader public sector objectives | Cultural change [32,33,68,70,80,89,90] Lack of technical expertise [33,35,41,62,69,70,74,80,83,90,91,92,93] |
| Policy/Legal | deals with crucial aspects of data management and usage, requiring a thorough understanding of the legal and regulatory landscape | Data ownership and licensing [73,94,95] Legal regulation [69,78,89] Data privacy and security [73,78] |
| Social | discusses challenges related to stakeholder awareness and motivation, as well as public misconceptions about open data | User engagement [9,33,64,68,69,89,93,96,97,98] |
| Economic/Financial | underlines the importance of financial commitment for valuable data release | Sustainability [2,43,97] Maintenance [9,33,88] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Quarati, A.; Albertoni, R. Linked Open Government Data: Still a Viable Option for Sharing and Integrating Public Data? Future Internet 2024, 16, 99. https://doi.org/10.3390/fi16030099
Quarati A, Albertoni R. Linked Open Government Data: Still a Viable Option for Sharing and Integrating Public Data? Future Internet. 2024; 16(3):99. https://doi.org/10.3390/fi16030099
Chicago/Turabian StyleQuarati, Alfonso, and Riccardo Albertoni. 2024. "Linked Open Government Data: Still a Viable Option for Sharing and Integrating Public Data?" Future Internet 16, no. 3: 99. https://doi.org/10.3390/fi16030099
APA StyleQuarati, A., & Albertoni, R. (2024). Linked Open Government Data: Still a Viable Option for Sharing and Integrating Public Data? Future Internet, 16(3), 99. https://doi.org/10.3390/fi16030099