
Refined Semi-Supervised Modulation Classification: Integrating Consistency Regularization and Pseudo-Labeling Techniques


Abstract
1. Introduction
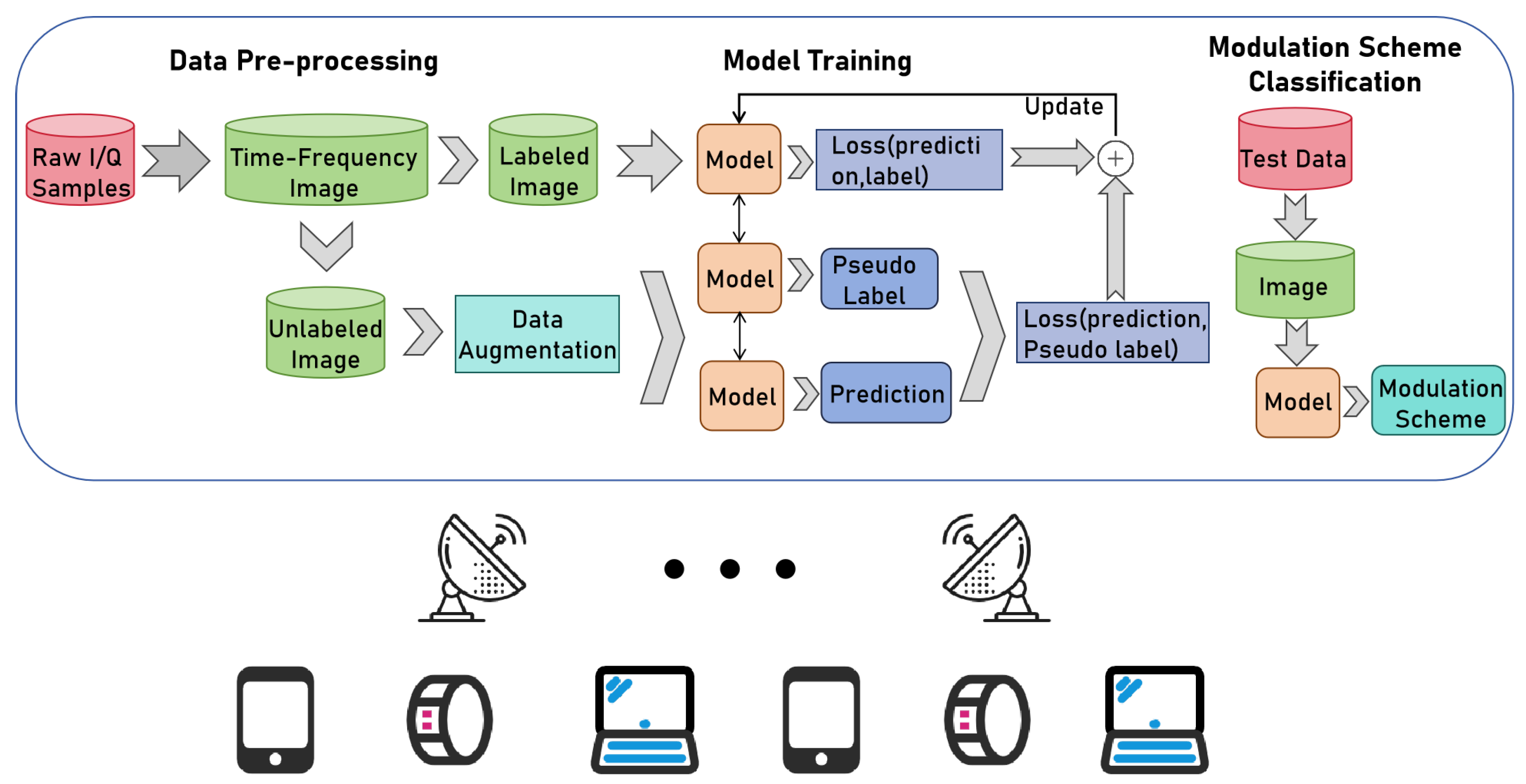
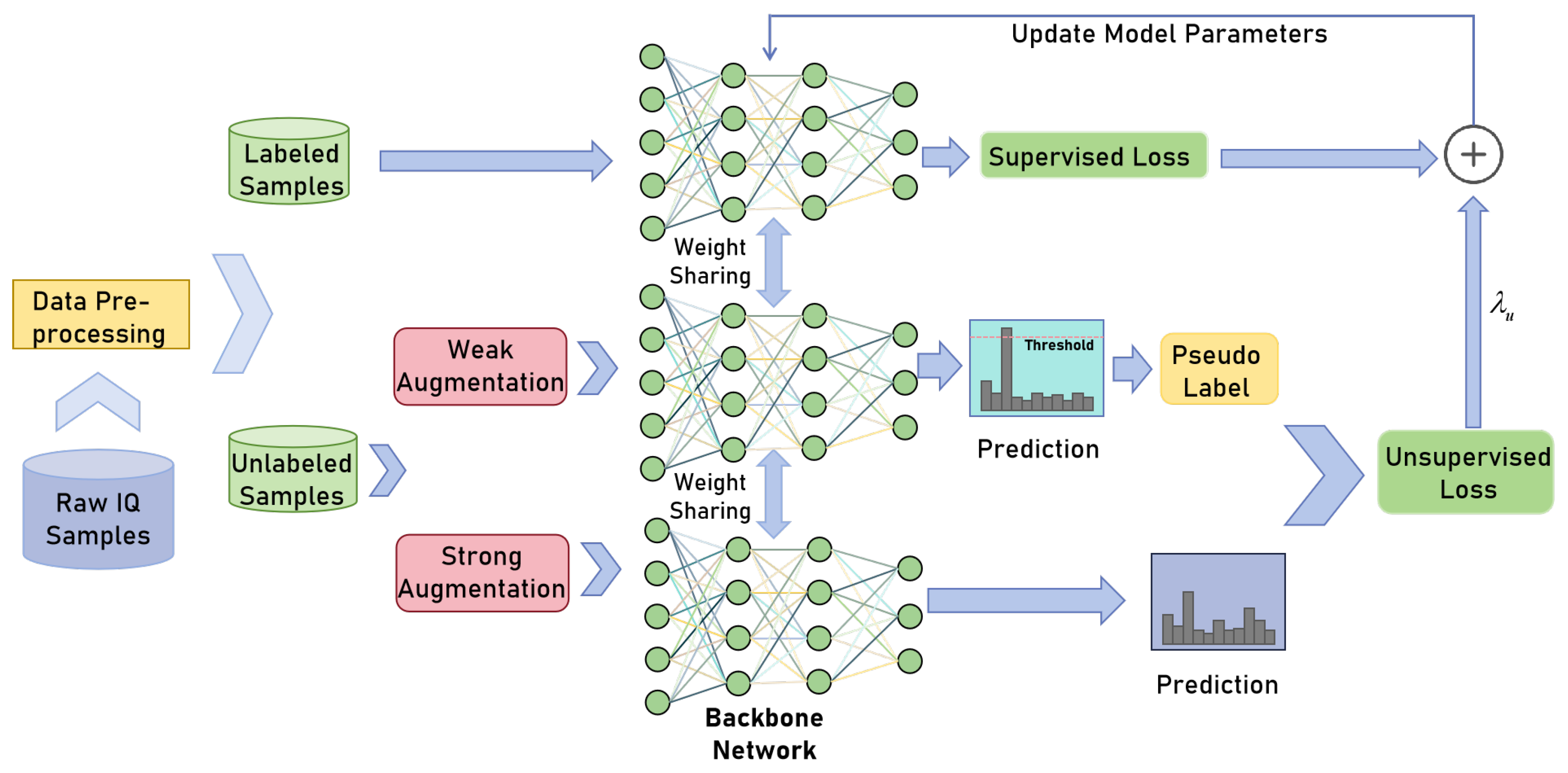
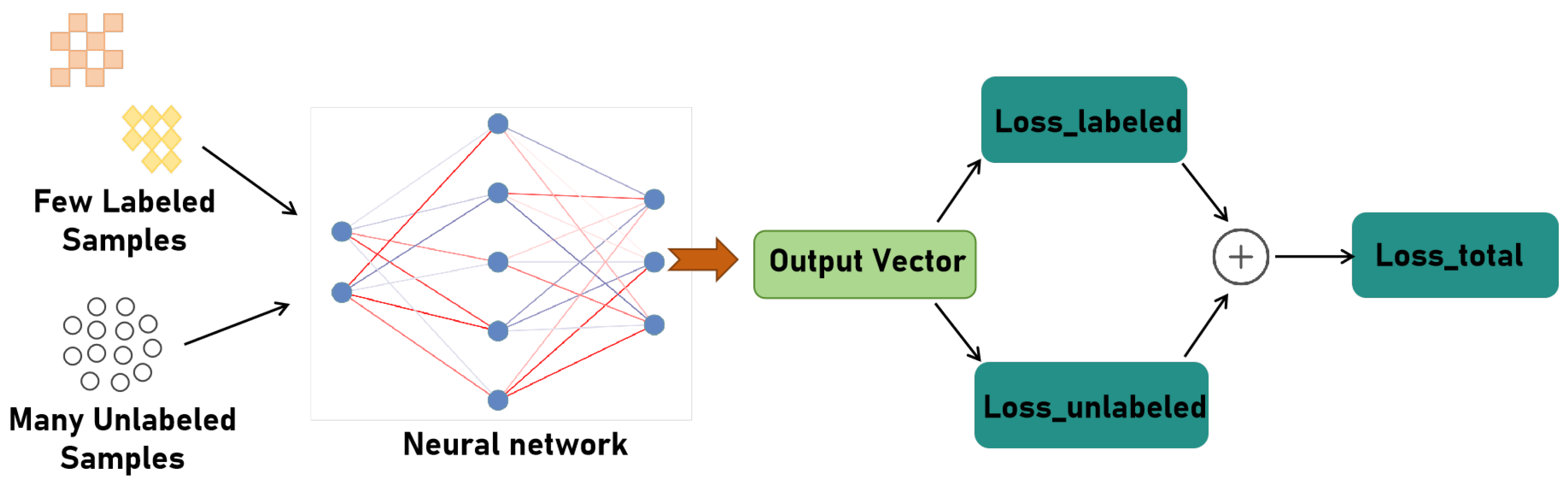
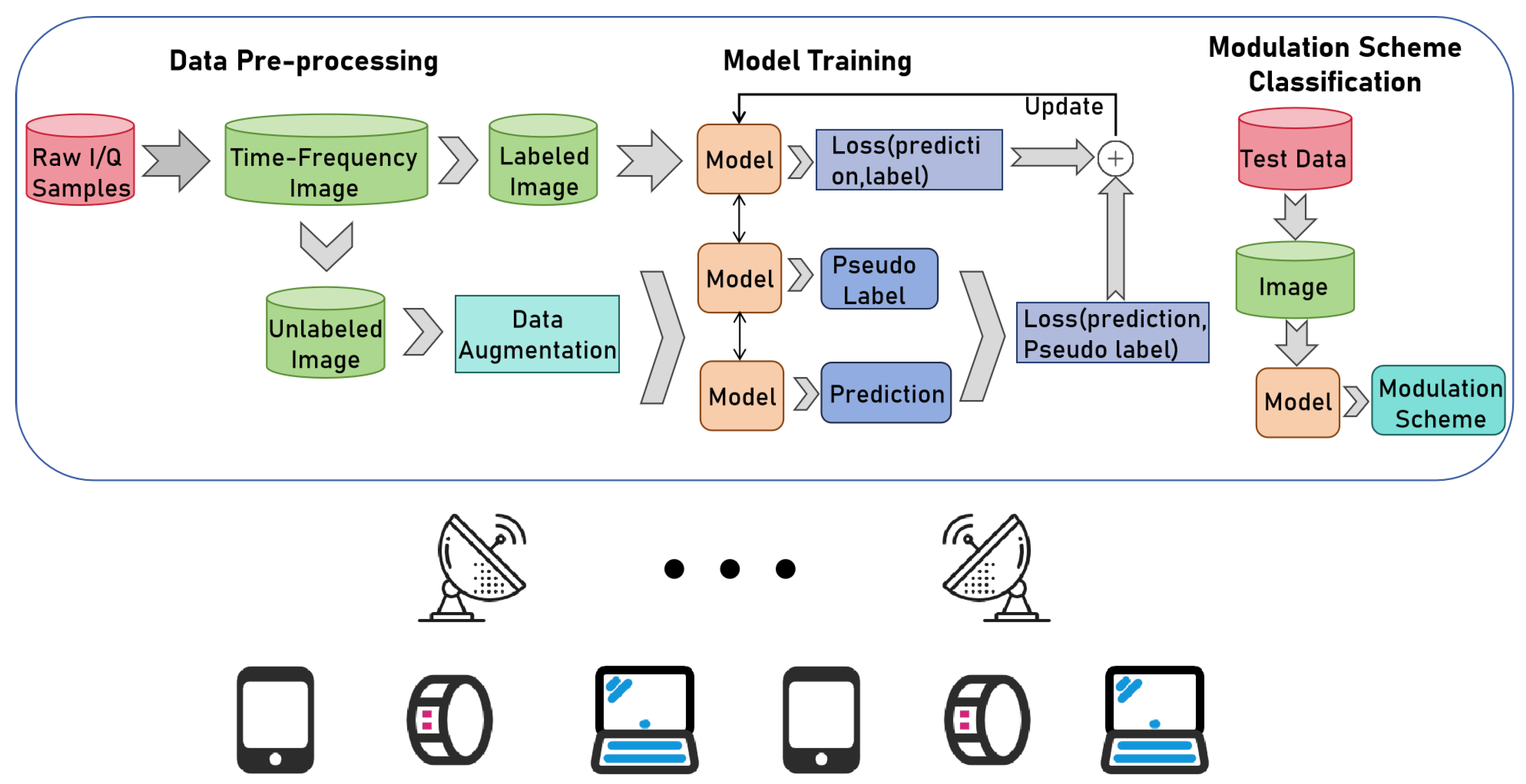
- We present a semi-supervised AMC method based on consistency regularization and pseudo-labeling. Consistency regularization is used to encourage the model to extract generalized features from the signal data. Pseudo-labeling is used to make manual predictions for unlabeled data. Both methods are alternatively used to improve the identification performance.
2. Related Works
2.1. Traditional AMC Methods
2.2. AMC Methods Based on Deep Learning
2.3. Semi-Supervised Learning and Its Applications
3. System Model and Data Preprocessing
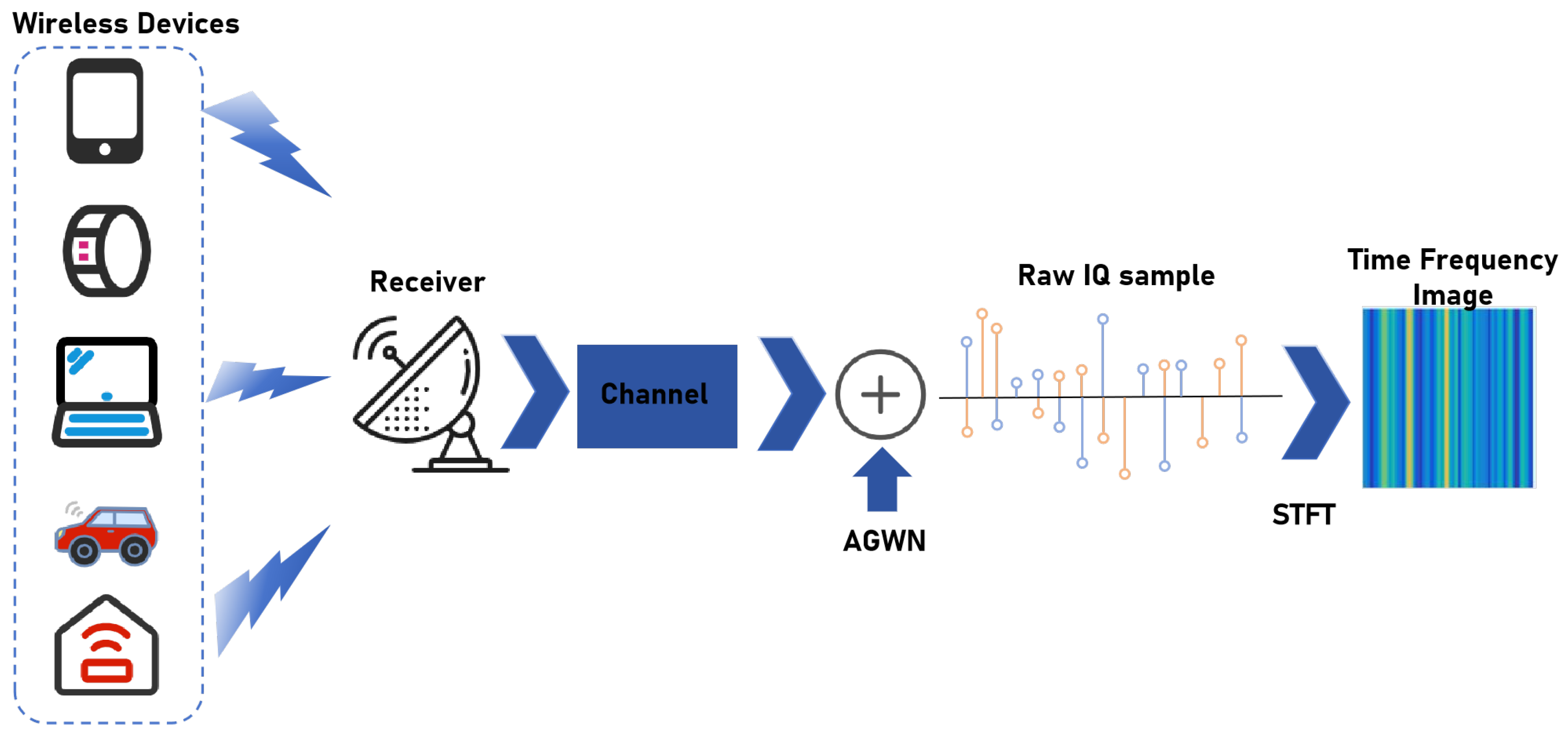
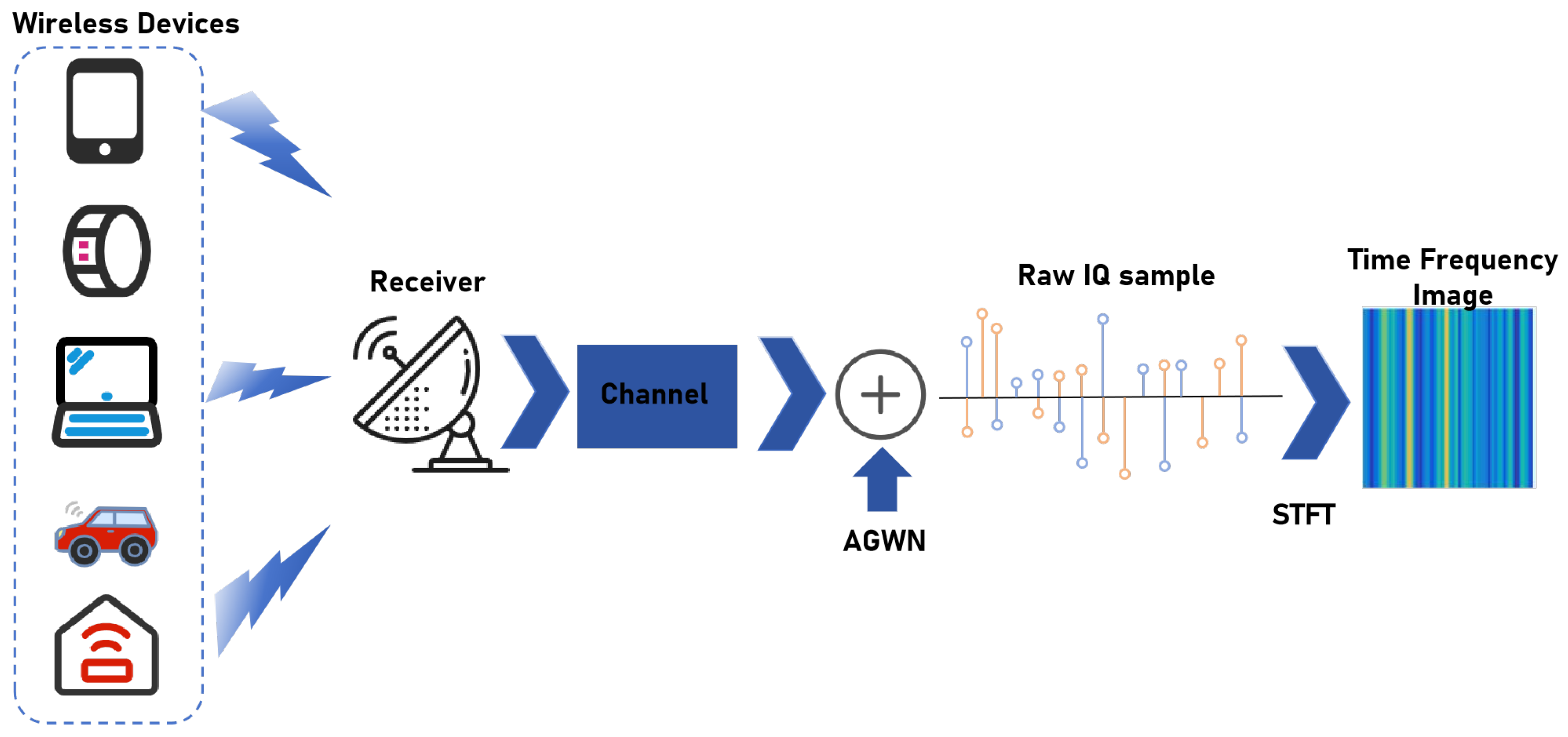
3.1. System Model
3.2. Data Preprocessing
3.3. Problem Description
3.3.1. AMC Problem
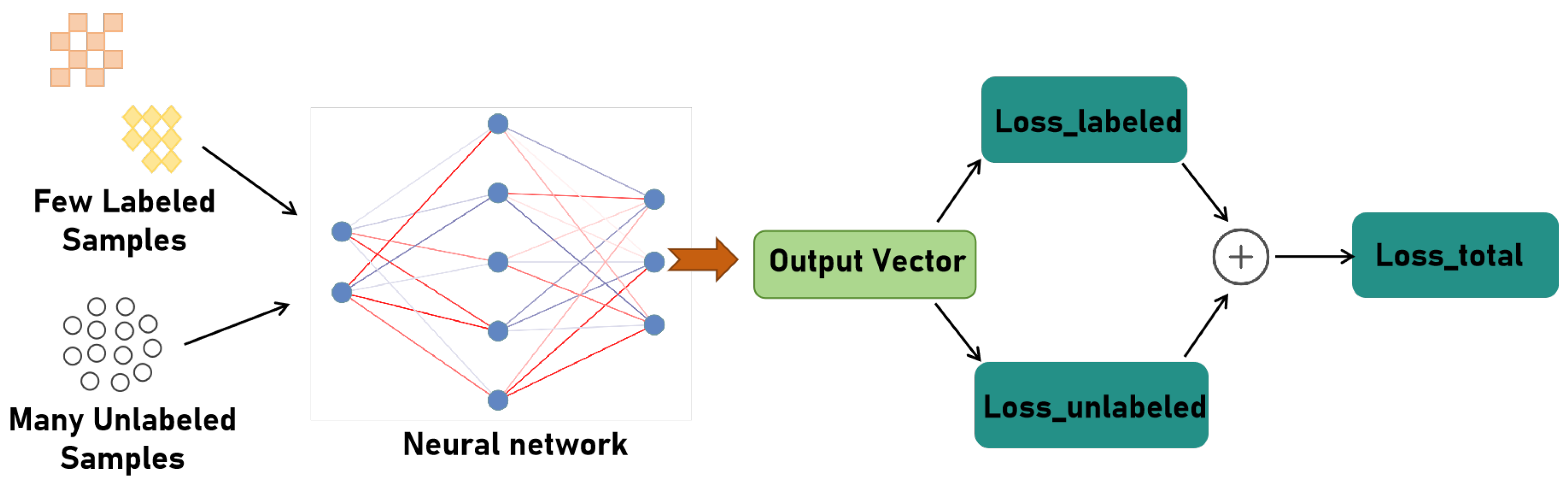
3.3.2. Semi-Supervised AMC Problem
4. Our Proposed Method
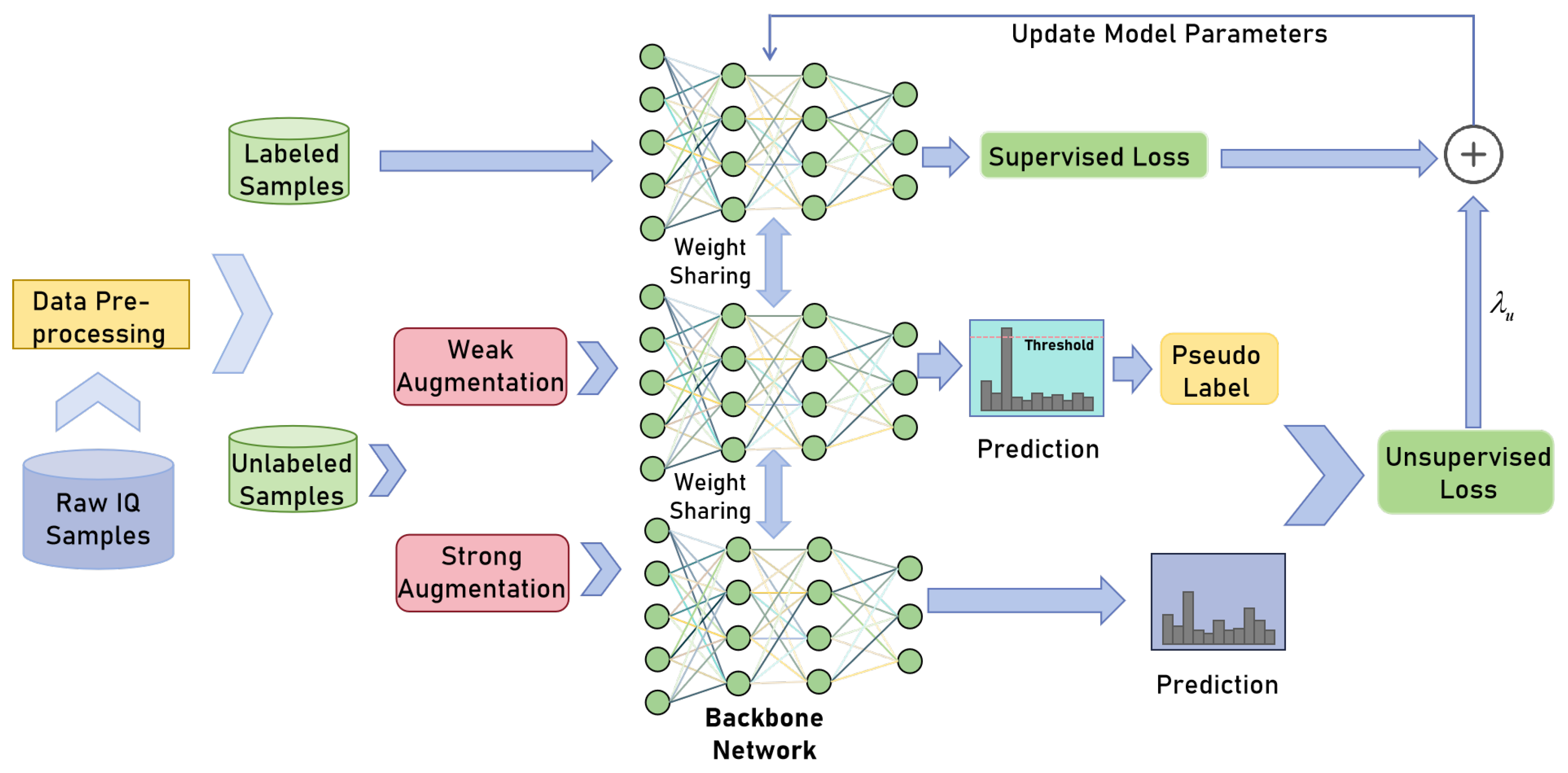
4.1. Proposed Semi-Supervised AMC Method Based on Consistency Regularization and Pseudo Labeling
4.2. Benchmark Methods
4.2.1. Decision-Tree-Based AMC Method
4.2.2. VAT-Based AMC Method
5. Simulation Results and Discussion
5.1. Experimental Setup
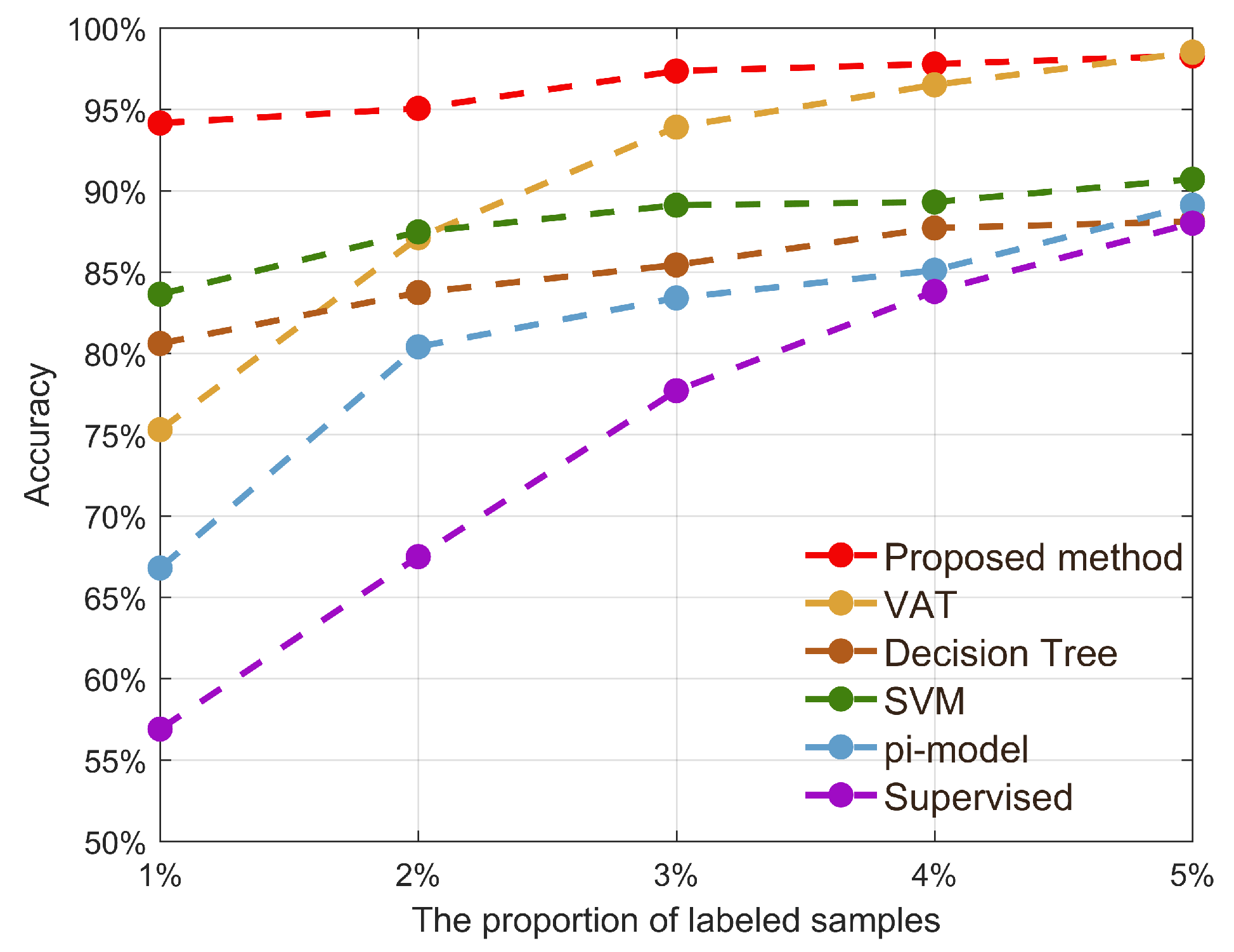
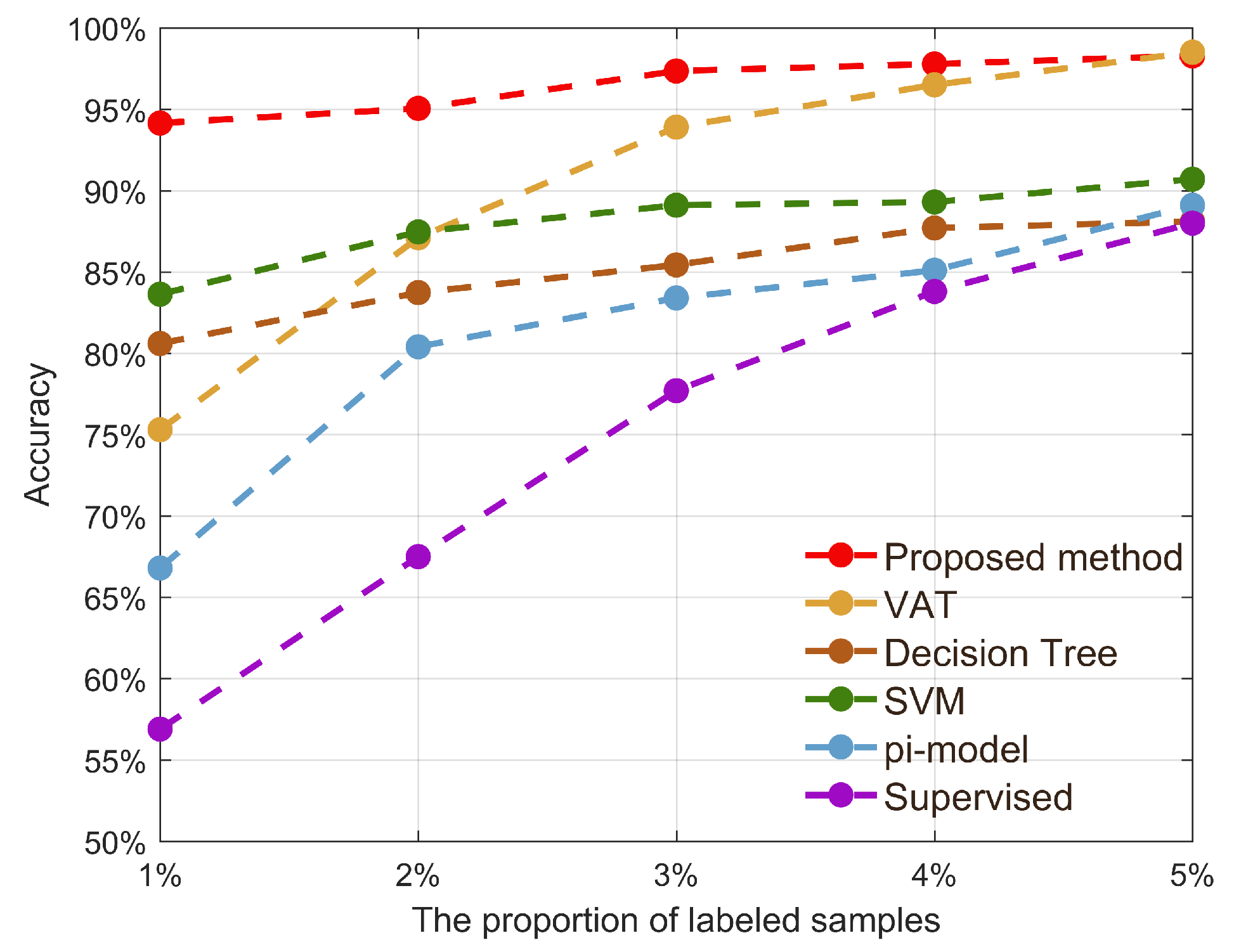
5.2. Experimental Results and Analysis
6. Limitations and Future Work
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zheng, S.; Zhou, X.; Zhang, L.; Qi, P.; Qiu, K.; Zhu, J.; Yang, X. Toward next-generation signal intelligence: A hybrid knowledge and data-driven deep learning framework for radio signal classification. IEEE Trans. Cogn. Commun. Netw. 2023, 9, 564–579. [Google Scholar] [CrossRef]
- Ohtsuki, T. Machine learning in 6G wireless communications. IEICE Trans. Commun. 2023, 106, 75–83. [Google Scholar] [CrossRef]
- Dobre, O.A.; Abdi, A.; Bar-Ness, Y.; Su, W. Survey of automatic modulation classification techniques: Classical approaches and new trends. IET Commun. 2007, 1, 137–156. [Google Scholar] [CrossRef]
- Lin, Y.; Tu, Y.; Dou, Z.; Chen, L.; Mao, S. Contour stella image and deep learning for signal recognition in the physical layer. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 34–46. [Google Scholar] [CrossRef]
- Meng, F.; Chen, P.; Wu, L.; Wang, X. Automatic modulation classification: A deep learning enabled approach. IEEE Trans. Veh. Technol. 2018, 67, 10760–10772. [Google Scholar] [CrossRef]
- Huan, C.; Polydoros, A. Likelihood methods for MPSK modulation classification. IEEE Trans. Commun. 1995, 43, 1493–1504. [Google Scholar] [CrossRef]
- Wei, W.; Mendel, J.M. Maximum-likelihood classification for digital amplitude-phase modulations. IEEE Trans. Commun. 2000, 48, 189–193. [Google Scholar] [CrossRef]
- Hong, L.; Ho, K.C. Antenna array likelihood modulation classifier for BPSK and QPSK signals. In Proceedings of the Military Communications Conference 2002, Anaheim, CA, USA, 7–10 October 2002; pp. 647–651. [Google Scholar]
- Dobre, O.A.; Abdi, A.; Bar-Ness, Y.; Su, W. Selection combining for modulation recognition in fading channels. In Proceedings of the MILCOM 2005–2005 IEEE Military Communications Conference, Atlantic City, NJ, USA, 17–20 October 2005; pp. 2499–2505. [Google Scholar]
- Swami, A.; Sadler, B.M. Hierarchical digital modulation classification using cumulants. IEEE Trans. Commun. 2000, 48, 416–429. [Google Scholar] [CrossRef]
- Ho, K.C.; Prokopiw, W.; Chan, Y.T. Modulation identification by the wavelet transform. In Proceedings of the Military Communications Conference 1995, San Diego, CA, USA, 5–8 November 1995; pp. 886–890. [Google Scholar]
- Chan, Y.T.; Gadbois, L.G. Identification of the modulation type of a signal. Signal Process. 1989, 16, 149–154. [Google Scholar] [CrossRef]
- Xie, L.; Wan, Q. Cyclic Feature-Based Modulation Recognition Using Compressive Sensing. IEEE Wirel. Commun. Lett. 2017, 6, 402–405. [Google Scholar] [CrossRef]
- Wu, H.-C.; Saquib, M.; Yun, Z. Novel Automatic Modulation Classification Using Cumulant Features for Communications via Multipath Channels. IEEE Trans. Wirel. Commun. 2008, 7, 3098–3105. [Google Scholar]
- Peng, S.; Jiang, H.; Wang, H.; Alwageed, H.; Zhou, Y.; Sebdani, M.M.; Yao, Y.D. Modulation Classification Based on Signal Constellation Diagrams and Deep Learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 718–727. [Google Scholar] [CrossRef] [PubMed]
- Park, C.-S.; Choi, J.-H.; Nah, S.-P.; Jang, W.; Kim, D.Y. Automatic Modulation Recognition of Digital Signals using Wavelet Features and SVM. In Proceedings of the 2008 10th International Conference on Advanced Communication Technology, Gangwon, Republic of Korea, 17–20 February 2008; pp. 387–390. [Google Scholar]
- Park, C.-S.; Jang, W.; Nah, S.-P.; Kim, D.Y. Automatic Modulation Recognition using Support Vector Machine in Software Radio Applications. In Proceedings of the 9th International Conference on Advanced Communication Technology, Gangwon, Republic of Korea, 12–14 February 2007; pp. 9–12. [Google Scholar]
- Liu, Y.; Liang, G.; Xu, X.; Li, X. The Methods of Recognition for Common Used M-ary Digital Modulations. In Proceedings of the 2008 4th International Conference on Wireless Communications, Networking and Mobile Computing, Dalian, China, 12–14 October 2008; pp. 1–4. [Google Scholar]
- Zhang, X.L.; Guo, L.; Ben, C.; Peng, Y.; Wang, Y.; Shi, S.; Lin, Y.; Gui, G. A-GCRNN: Attention graph convolution recurrent neural network for multi-band spectrum prediction. IEEE Trans. Veh. Technol. 2023; early access. [Google Scholar] [CrossRef]
- Gui, G.; Tao, M.; Wang, C.; Fu, X.; Wang, Y. Survey of few-shot learning methods for specific emitter identification. J. Nantong Univ. 2023, 22, 1–16. [Google Scholar]
- Yao, Z.; Fu, X.; Guo, L.; Wang, Y.; Lin, Y.; Shi, S.; Gui, G. Few-shot specific emitter identification using asymmetric masked auto-encoder. IEEE Commun. Lett. 2023, 27, 2657–2661. [Google Scholar] [CrossRef]
- Liu, C.; Fu, X.; Wang, Y.; Guo, L.; Liu, Y.; Lin, Y.; Zhao, H.; Gui, G. Overcoming data limitations: A few-shot specific emitter identification method using self-supervised learning and adversarial augmentation. IEEE Trans. Inf. Forensics Secur. 2023, 19, 500–513. [Google Scholar] [CrossRef]
- Zhang, Q.Y.; Wang, Z.D.; Wu, B.Y.; Gui, G. A robust and practical solution to ADS-B security against denial-of-service attacks. IEEE Internet Things J. 2023. [Google Scholar] [CrossRef]
- Peng, Y.; Hou, C.; Zhang, Y.; Lin, Y.; Gui, G.; Gacanin, H.; Mao, S.; Adachi, A. Supervised contrastive learning for RFF identification with limited samples. IEEE Internet Things J. 2023, 10, 17293–17306. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, X.; Wang, Y.; Gui, G.; Adebisi, B.; Sari, H.; Adachi, F. Lightweight automatic modulation classification via progressive differentiable architecture search. IEEE Trans. Cogn. Commun. Netw. 2023, 9, 1519–1530. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, J.; Liu, M.; Gui, G. LightAMC: Lightweight Automatic Modulation Classification via Deep Learning and Compressive Sensing. IEEE Trans. Veh. Technol. 2020, 69, 3491–3495. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, M.; Yang, J.; Gui, G. Data-Driven Deep Learning for Automatic Modulation Recognition in Cognitive Radios. IEEE Trans. Veh. Technol. 2019, 68, 4074–4077. [Google Scholar] [CrossRef]
- Hong, S.; Zhang, Y.; Wang, Y.; Gu, H.; Gui, G.; Sari, H. Deep Learning-Based Signal Modulation Identification in OFDM Systems. IEEE Access 2019, 7, 114631–114638. [Google Scholar] [CrossRef]
- Guo, Y.; Jiang, H.; Wu, J.; Zhou, J. Open set modulation recognition based on dual-channel LSTM model. arXiv 2020, arXiv:2002.12037. [Google Scholar]
- Zhou, Q.; Zhang, R.; Mu, J.; Zhang, H.; Zhang, F.; Jing, X. AMCRN: Few-Shot Learning for Automatic Modulation Classification. IEEE Commun. Lett. 2022, 26, 542–546. [Google Scholar] [CrossRef]
- Patel, M.; Wang, X.; Mao, S. Data augmentation with conditional GAN for automatic modulation classification. In Proceedings of the 2nd ACM Workshop on Wireless Security and Machine Learning, Virtual, 13 July 2020. [Google Scholar]
- Azzouz, E.; Nandi, A.K. Automatic modulation recognition of communication signals. IEEE Trans. Commun. 1998, 46, 431–436. [Google Scholar]
- Han, Y.; Wei, G.; Song, C.; Lai, L. Hierarchical digital modulation recognition based on higher-order cumulants. In Proceedings of the 2012 Second International Conference on Instrumentation, Measurement, Computer, Communication and Control, Harbin, China, 8–10 December 2012; pp. 1645–1648. [Google Scholar]
- Chou, Z.; Jiang, W.; Xiang, C.; Li, M. Modulation recognition based on constellation diagram for M-QAM signals. In Proceedings of the 2013 IEEE 11th International Conference on Electronic Measurement & Instruments, Harbin, China, 16–19 August 2013; pp. 70–74. [Google Scholar]
- Li, S.; Chen, F.; Wang, L. Modulation identification algorithm based on cyclic spectrum characteristics in multipath channel. J. Comput. Appl. 2012, 32, 2123–2127. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, M.; Li, Z.; Li, J.; Fu, M.; Cui, Y.; Chen, X. Modulation Format Recognition and OSNR Estimation Using CNN-Based Deep Learning. IEEE Photon. Technol. Lett. 2017, 29, 1667–1670. [Google Scholar] [CrossRef]
- O’Shea, T.J.; Corgan, J.; Clancy, T.C. Convolutional radio modulation recognition networks. In Engineering Applications of Neural Networks: 17th International Conference, EANN 2016, Aberdeen, UK, 2–5 September 2016; Proceedings 17; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 213–226. [Google Scholar]
- Rajendran, S.; Meert, W.; Giustiniano, D.; Lenders, V.; Pollin, S. Deep Learning Models for Wireless Signal Classification With Distributed Low-Cost Spectrum Sensors. IEEE Trans. Cogn. Commun. Netw. 2018, 4, 433–445. [Google Scholar] [CrossRef]
- Ali, A.; Yangyu, F.; Liu, S. Automatic modulation classification of digital modulation signals with stacked autoencoders. Digit. Signal Process. 2017, 71, 108–116. [Google Scholar] [CrossRef]
- Tu, Y.; Lin, Y. Deep Neural Network Compression Technique Towards Efficient Digital Signal Modulation Recognition in Edge Device. IEEE Access 2019, 7, 58113–58119. [Google Scholar] [CrossRef]
- Lee, D. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. Workshop Challenges Represent. Learn. ICML 2013, 3, 896. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/file/68053af2923e00204c3ca7c6a3150cf7-Paper.pdf (accessed on 18 January 2024).
- Berthelot, D.; Carlini, N.; Goodfellow, I.; Papernot, N.; Oliver, A.; Raffel, C.A. Mixmatch: A holistic approach to semi-supervised learning. Adv. Neural Inf. Process. Syst. 2019, 32, 1–11. [Google Scholar]
- Zhang, Q.; Xu, Z.; Zhang, P. Modulation scheme recognition using convolutional neural network. J. Eng. 2019, 2019, 9075–9078. [Google Scholar] [CrossRef]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. RandAugment: Practical automated data augmentation with a reduced search space. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 3008–3017. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. Autoaugment: Learning augmentation policies from data. arXiv 2018, arXiv:1805.09501. [Google Scholar]
- Sohn, K.; Berthelot, D.; Carlini, N.; Zhang, Z.; Zhang, H.; Raffel, C.A.; Cubuk, E.D.; Kurakin, A.; Li, C.L. FixMatch: Simplifying semi-supervised learning with consistency and confidence. Adv. Neural Inf. Process. Syst. 2020, 33, 596–608. [Google Scholar]
- Mohammed, A.; Tahir, A. A new optimizer for image classification using wide ResNet (WRN). Acad. J. Nawroz Univ. 2020, 9, 1–13. [Google Scholar] [CrossRef]
- Miyato, T.; Maeda, S.-I.; Koyama, M.; Ishii, S. Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1979–1993. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Dimension of the original signal | |
| Input data dimension | |
| The number of training samples | 16,000 |
| The number of testing samples | 4000 |
| The proportion of labeled samples | 1%, 2%, 3%, 4%, 5% |
| Arch | WideResnet |
| Optimizer | SGD |
| Initial learning rate | 0.3 |
| Threshold | 0.95 |
| Unlabeled loss weight | 1.0 |
| Methods | Accuracy | Recall | F1-Score |
|---|---|---|---|
| Supervised | 0.569 | 0.596 | 0.619 |
| Decision Tree | 0.806 | 0.822 | 0.816 |
| SVM | 0.836 | 0.864 | 0.863 |
| pi-model | 0.668 | 0.688 | 0.694 |
| VAT | 0.753 | 0.768 | 0.772 |
| Proposed method | 0.941 | 0.945 | 0.939 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, M.; Liu, S.; Wang, S.; Shi, S. Refined Semi-Supervised Modulation Classification: Integrating Consistency Regularization and Pseudo-Labeling Techniques. Future Internet 2024, 16, 38. https://doi.org/10.3390/fi16020038
Ma M, Liu S, Wang S, Shi S. Refined Semi-Supervised Modulation Classification: Integrating Consistency Regularization and Pseudo-Labeling Techniques. Future Internet. 2024; 16(2):38. https://doi.org/10.3390/fi16020038
Chicago/Turabian StyleMa, Min, Shanrong Liu, Shufei Wang, and Shengnan Shi. 2024. "Refined Semi-Supervised Modulation Classification: Integrating Consistency Regularization and Pseudo-Labeling Techniques" Future Internet 16, no. 2: 38. https://doi.org/10.3390/fi16020038
APA StyleMa, M., Liu, S., Wang, S., & Shi, S. (2024). Refined Semi-Supervised Modulation Classification: Integrating Consistency Regularization and Pseudo-Labeling Techniques. Future Internet, 16(2), 38. https://doi.org/10.3390/fi16020038