1. Introduction
According to the World Health Organization (WHO), lung diseases are among the leading causes of mortality worldwide, resulting in the deaths of millions of people each year [
1]. Respiratory diseases are often detected late, making treatment less effective [
2].
Various clinical approaches have been developed to diagnose and assess lung health issues, including computed tomographic scans, chest X-rays, and pulmonary function tests. However, these techniques are restricted to specialized medical facilities due to their complexity, high cost, and time-consuming nature [
3]. Additionally, medical professionals in hospitals are often overworked, which increases the likelihood of errors and patient waiting times [
3]. Therefore, it becomes apparent that a different approach is needed to better assist practitioners in making an initial diagnosis.
In contrast, the stethoscope is used as a non-invasive and patient-friendly tool for diagnosing respiratory conditions through lung auscultation [
4]. This procedure involves listening to the sounds produced by air moving in and out of the lungs.
During lung auscultation, experts are able to identify various abnormal respiratory sounds, like wheezing and crackling [
4]. These sounds serve as indicators of possible respiratory conditions for the patient. However, traditional stethoscopes come with several associated challenges. Firstly, their effectiveness relies heavily on the physician’s expertise and judgment, introducing potential for diagnostic errors [
5]. Secondly, they lack a recording feature, preventing other medical personnel from analyzing the sounds heard during consultations [
6]. Thirdly, they are not equipped with noise-canceling capabilities, making it difficult to hear lung sounds in noisy environments such as emergency rooms or busy clinics [
7].
The digital stethoscope has introduced a new approach to auscultation, benefiting research, education, and clinical practice [
8]. It digitizes lung sounds, allowing for recording and playback, which reduces reliance on a single physician’s judgment and enables collaboration with other medical professionals [
8]. It incorporates digital filters to eliminate noise and isolate the relevant acoustic signals within specific frequency bands [
8]. This enhances diagnostic accuracy and improves clinical decision making. It also allows for the visualization and retrospective analysis of lung sounds. The integration of wireless transmission capabilities, such as Bluetooth or WiFi, with the digital stethoscope will facilitate remote diagnosis, greatly enhancing convenience and application in a variety of medical contexts [
8].
In recent years, there has been growing interest in the automated analysis of lung sounds. By using machine learning, particularly Deep Learning (DL) techniques, the experience, quality of diagnosis, and care for both patients and healthcare professionals have significantly improved [
3,
8]. The utilization of DL algorithms to examine lung sound patterns captured by digital stethoscopes represents a promising approach for the early and precise detection of disease [
9]. Moreover, these technologies aim not only to reduce dependency on specialist facilities but also to overcome the limitations of traditional stethoscopes, making diagnosis more accurate by removing human error [
3].
However, coupling digital stethoscopes with DL presents certain limitations. DL algorithms require significant computational resources, posing challenges in resource-constrained environments [
10,
11]. Latency in cloud-based solutions can impact real-time analysis, particularly in areas with insufficient internet bandwidth for large data transmission [
10,
11,
12], and privacy concerns arise when transmitting sensitive health data over the internet [
10,
11]. To address these limitations, Tiny Machine Learning (TinyML) [
13] offers a compelling solution by enabling efficient ML codes to run on small, energy-efficient devices.
TinyML is a fast-growing field of ML including hardware, algorithms, and software that aims to facilitate running ML models on ultra-low-power devices having very limited power (under 1 mW), less memory, and limited processor capabilities [
14]. TinyML offers tiny IoT devices the ability to analyze data collected by various sensors and act based on the decisions made by the embedded ML model without the need for the cloud. TinyML finds applications in diverse fields [
11], including agriculture [
11,
15], healthcare [
10,
11,
16], and environmental monitoring [
11,
17].
The hardware limitations of tiny IoT devices require the minimizing of the ML model in order to deploy it in extremely resource-limited devices. The minimization of the model can be performed by the following techniques: pruning and quantization [
14]. These techniques aim to reduce the size of the ML model while trying not to impact its accuracy. The pruning technique is the process of removing unused weights in the model to increase speed inference and minimize its size, while quantization reduces the precision of the model parameters from floating-point (e.g., 32-bit) to lower (e.g., 8-bit) precision [
11]; this decreases the model’s memory footprint as well as the amount of processing required.
TinyML holds immense potential in the healthcare sector [
10,
11,
16]. TinyML’s ability to run directly on devices at the edge offers numerous advantages. One of the most significant benefits is the ability to perform real-time data analysis without the need for continuous data transmission to centralized cloud systems [
11,
16,
18]. This reduces latency, enhances data privacy by minimizing the transfer of sensitive patient data, and lowers dependency on reliable internet connections [
10,
16], which is particularly beneficial for remote health monitoring in remote and undeserved areas [
12,
16].
Many studies have demonstrated the practical applications of TinyML in healthcare, showcasing its potential to optimize real-time health monitoring and diagnostic tools. The authors of [
19] optimized a Convolutional Neural Network (CNN) model through pruning and quantization, making it deployable on low-cost microcontrollers like the Raspberry Pi Pico and ESP32 for real-time blood pressure estimation using photoplethysmogram (PPG) signals. This approach enables efficient, low-power solutions for continuous blood pressure monitoring. The authors of [
20] proposed a TinyML-based solution for predicting and detecting falls among elderly individuals, utilizing a wearable device placed on the leg to capture movement data. The system employs a nonlinear support vector machine classifier for real-time fall detection and prediction. Similarly, the authors of [
21] used CNN models combined with audio data to detect falls. In [
22], researchers developed a system that predicts blood glucose levels in individuals with type 1 diabetes by deploying DL models on edge devices. This system, which relies on recurrent neural networks (RNNs), processes continuous glucose monitoring (CGM) data on low-power, resource-constrained devices, enabling real-time monitoring without the need for cloud infrastructure. Additionally, the authors of [
23] introduced a lightweight solution based on Temporal Convolutional Networks (TCNs) for heart rate estimation in wearable devices. By leveraging optimized TCN models, the system achieved accurate heart rate monitoring while maintaining low latency and energy consumption, making it suitable for use in resource-constrained environments like wearable health devices.
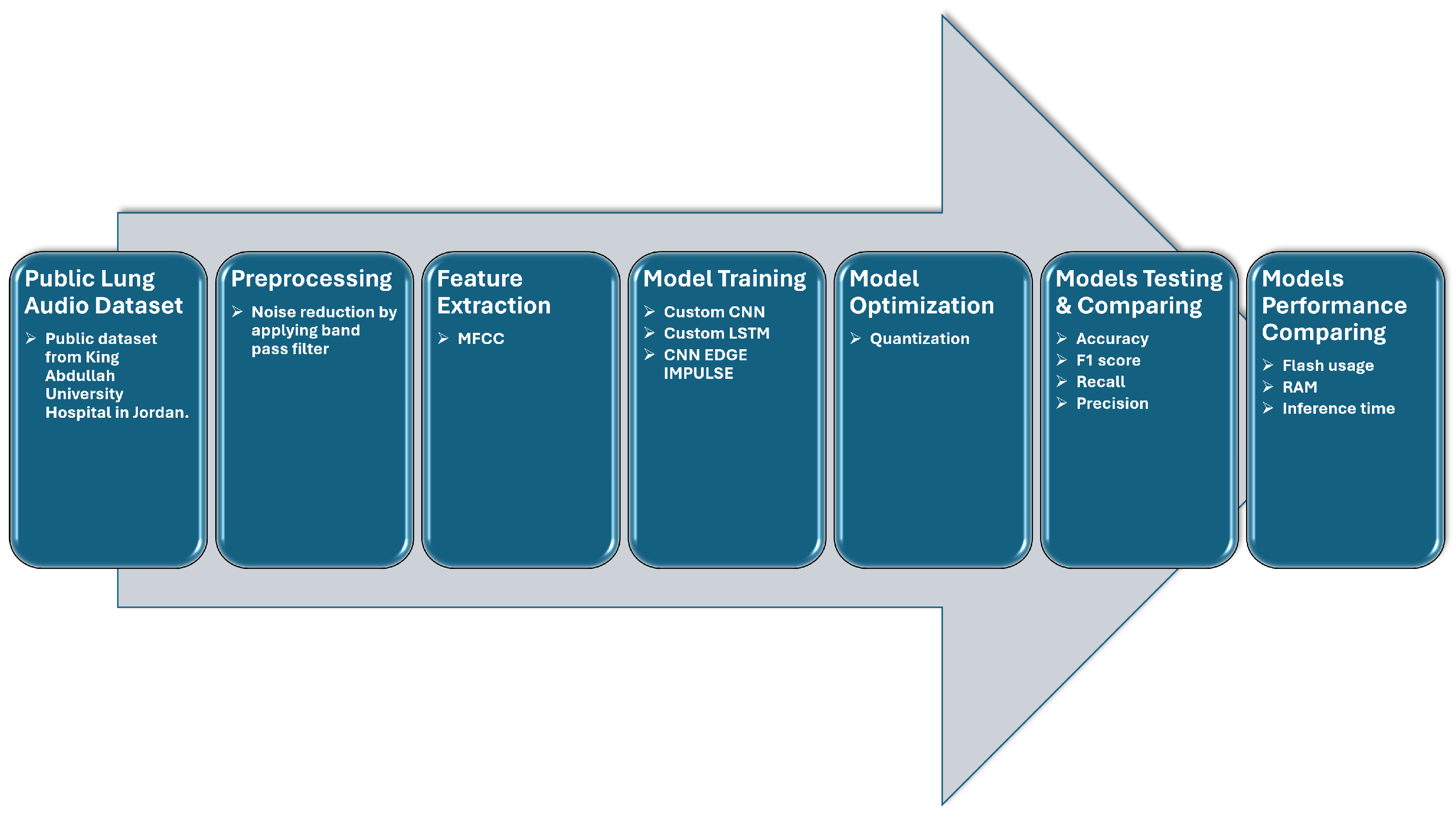
In this paper, we present a new approach focused on creating TinyML models to distinguish between asthma and non-asthma conditions by using lung sound recordings. We developed and compared various ML models based on different metrics. To ensure these models are suitable for cost-effective platforms such as the Arduino Nano 33 BLE, we employed quantization techniques.
The remainder of the paper is organized as follows:
Section 2 reviews existing studies that have addressed similar challenges.
Section 3 details the materials and methodologies used in our experiments.
Section 4 provides a comprehensive analysis of the empirical results and their implications. Finally,
Section 5 presents our conclusions and proposes directions for future research.
2. Related Works
Numerous research papers have examined the application of DL to identify patterns and distinguish among various lung conditions by using raw respiratory sound data.
The authors of [
24] developed a framework for classifying various respiratory diseases by using lung sound recordings. They employed a CNN with Mel-Frequency Cepstral Coefficients (MFCC) for feature extraction. The proposed model achieved a classification accuracy of 95.7%, effectively distinguishing among different respiratory diseases, such as asthma, COPD, URTI, LRTI, and bronchiectasis, and a class representing healthy people.
In [
25], the authors developed a framework for classifying lung sounds, addressing the challenge of noise interference from the heart and lung sounds. By utilizing two public datasets with 280 lung sounds of varying durations and sampling rates, the study preprocessed signals for uniformity and employed Mel-Frequency Cepstral Coefficients (MFCCs) [
26] and Short-Time Fourier Transform (STFT) [
27] for feature extraction. It tested several models, achieving the highest accuracy with an STFT+MFCC-ANN combination, demonstrating promising results for automatic respiratory diagnosis with high precision and recall rates.
In the paper [
5], the authors evaluated the efficacy of various deep learning models for diagnosing respiratory pathologies by using lung auscultation sounds. The study compared three deep learning models across both non-augmented and augmented datasets, revealing that the CNN–LSTM model outperformed others with high accuracy rates in all scenarios. Augmentation significantly enhances model performance, with the CNN–LSTM hybrid showing particular strength by combining the CNN’s feature extraction capabilities with LSTM’s [
28] classification efficiency.
In [
29], the authors explored the effectiveness of Mel Frequency Cepstral Coefficients (MFCCs) in classifying cough sounds for diagnosing five respiratory diseases, such as asthma and chronic obstructive pulmonary diseases (COPDs). The study employed a unique ensemble of recurrent neural network models with LSTM cells and tested various meta-classifiers, achieving over 87% accuracy. This approach underscores MFCCs’ potential as standalone features for cough signal classification and suggests future directions, including further disease characteristic diagnosis and COVID-19 cough classification.
In [
30], the authors tackled the challenge of detecting respiratory pathologies from sounds, using the ICBHI Benchmark dataset. Given the dataset’s imbalance, the study employed a Variational Convolutional Autoencoder for data augmentation, alongside traditional oversampling techniques. A CNN was employed for classification into healthy, chronic, and non-chronic categories, achieving an F-score of 0.993 in the three-label classification. For the six-class classification, which included RTI, COPD, Bronchiectasis, Pneumonia, and Bronchiolitis, the CNN achieved an F-score of 0.99.
In [
31], the authors developed a non-invasive method for classifying respiratory sounds by using an electronic stethoscope and audio recording software. By using MFCC with SVM and spectrogram images with CNN, they benchmarked the CNN’s performance against the SVM method across various sound classifications. The CNN and SVM both reached 86% in distinguishing healthy versus pathological sounds; for rale, rhonchus, and normal sounds, the CNN achieved 76% and SVM 75%; in singular-sound-type classification, both achieved 80%. These results underline the effectiveness of CNNs and SVM in respiratory sound analysis.
In [
32], the authors developed a system for diagnosing asthma using deep learning by analyzing respiratory sounds from asthmatic and non-asthmatic individuals. They developed a web interface and a mobile app for real-time prediction, aiding doctors in performing accurate diagnoses. Utilizing features such as chroma, RMS, Spectral centroid, Rolloff, and MFCCs, the ConvNet model demonstrated impressive performance metrics, including 99.8% accuracy, 100% sensitivity, 100% specificity, and a 99% F-score.
In [
33], the authors proposed RDsLINet, a novel lightweight inception network for classifying a broad spectrum of respiratory diseases through lung sound signals. The framework involves preprocessing, melspectrogram image conversion, and classification via RDsLINet. The proposed RDsLINet achieved impressive accuracy rates: 96% for seven-class, 99.5% for six-class, and 94% for healthy vs. asthma classifications.
In [
34], the authors proposed a novel approach to respiratory disease detection through a wearable auscultation device. They developed a Respiratory Sound Diagnosis Processor Unit (RSDPU) utilizing LSTM networks to analyze respiratory sounds in real time. The study highlights the implementation of Dynamic Normalization Mapping (DNM) to optimize quantization and reduce overfitting, crucial to maintaining model accuracy with limited computational resources. The hardware implementation of the RSDPU includes a noise corrector to enhance diagnostic reliability. The results show that the RSDPU achieved an 81.4% accuracy in abnormality diagnosis, with a minimal power consumption of 381.8 μW. The study demonstrates the potential of combining advanced machine learning techniques with efficient hardware design to create effective and practical healthcare solutions for continuous respiratory monitoring
A startup called Respira Labs [
35] has introduced an innovative, cost-effective wearable sensor that leverages TinyML to analyze cough sounds for signs of respiratory diseases like pneumonia. This compact device integrates a microphone and a microcontroller executing a neural network to discern specific cough characteristics such as wheezing and crackling. Designed for ease of use, it features a simple strap mechanism, operates without batteries, and communicates results via LED indicators and sound signals.
Table 1 summarizes existing research on lung disease detection and classification using audio data, covering diseases such as asthma, COPD, lung fibrosis, bronchitis, and pneumonia and various pathological lung sounds. Datasets vary from publicly available ICBHI 2017 to self-collected data, indicating diversity in data sources. The extracted audio features include STFT, MFCC, and spectrograms, with MFCC being the most common. The models used range from ANN, CNN, and LSTM, to hybrid CNN-LSTM, achieving high accuracy rates and mostly deploying solutions on cloud platforms. While some studies [
33,
34] have explored computation directly on edge devices, our work leverages TinyML to push the boundaries of what can be achieved on resource-limited hardware. This approach allows for efficient real-time analysis and model deployment on compact, low-power devices, making advanced diagnostics more accessible in a wide range of settings.
4. Results and Discussion
In this section, we compare the performance of the three models by using metrics such as accuracy, precision, recall, F1-score, and Area Under the Curve (AUC), as well as model size, inference time, and peak RAM usage, which are critical for deployment on TinyML devices. The dataset was split into 72% training, 10% validation, and 18% testing. Each model was trained and quantized by Edge Impulse for deployment suitability.
Table 8 shows the results of our experiments. the custom CNN model achieved the highest performance, with an accuracy of 96% on the test set and an AUC of 0.96. In contrast, the CNN Edge Impulse model, while faster and less resource-intensive, demonstrated lower accuracy, 85%, and an AUC of 0.85. This difference can be attributed to the simpler architecture of the Edge Impulse model. The custom LSTM model, however, achieved lower accuracy, 90%, compared with the CNN.
The confusion matrix in
Table 9 provides a detailed evaluation of the classification performance of the CNN, LSTM, and CNN-EDGE-IMPULSE models on the test set data. The custom CNN outperformed the other models, correctly classifying 94.1% of “Asthma” cases and 98.3% of “Normal” cases, while the LSTM achieved 82.4% and 98.3%, respectively. CNN Edge Impulse, while more resource-efficient, had the lowest performance, with accuracy of 76.5% for “Asthma” and 88.1% for “Normal”.
Table 10 compares the models based on resource consumption, as estimated by the Edge Impulse cloud platform on the Arduino Nano 33. The CNN Edge Impulse model demonstrates its clear advantage for low-power, resource-constrained environments, requiring only 4.5 KB of RAM. However, this comes at the cost of lower classification performance. The custom CNN, which uses more RAM (12 KB) and has a longer inference time, strikes a balance between resource usage and accuracy, making it a more suitable option when both high classification performance and moderate resource usage are required.
On the other hand, the LSTM model, while providing good accuracy (90%) and the ability to process sequential data, has the highest resource demands, consuming 23.2 KB of RAM. This makes it less practical for highly resource-constrained devices.
Table 11 presents a comparative analysis between our proposed CNN model and similar works that utilize Edge ML models. Our TinyML model demonstrates superior performance, achieving higher accuracy, 96%, while also excelling in resource efficiency, making it more suitable for deployment on low-power devices.
One of the key reasons our model outperforms that of [
33], which used the same dataset, lies in the application of pruning and quantization techniques. These methods allowed us to significantly reduce both model size and inference time, optimizing the model for resource-constrained environments. Pruning effectively removes less critical weights from the network, thus speeding up computation and reducing memory usage, while quantization lowers the precision of the model’s parameters without substantially affecting its accuracy, leading to more efficient deployment on embedded devices.
In contrast, in [
33], the authors applied depthwise separable convolutions and global average pooling (GAP) layers instead of fully connected layers to reduce the model size and execution time. This likely contributes to the differences in execution time and accuracy observed in our model compared with [
33].
5. Conclusions and Future Work
In this work, we have exploited TinyML models for detecting respiratory diseases, particularly asthma, using lung sound recordings. Our custom CNN model achieved an accuracy of 96% while maintaining efficient resource usage. This demonstrates the feasibility of deploying real-time, accurate diagnostic tools on resource-constrained devices, making them suitable for portable medical applications.
The potential impact of this approach on healthcare is significant. By offering a low-cost, portable solution for respiratory disease detection, our models can enhance access to reliable diagnostics in remote and underserved areas, reducing the reliance on traditional medical facilities and expensive equipment. This advancement is crucial to improving early disease detection and patient outcomes.
In future work, we will address the challenges encountered with dataset imbalance, which limited the diversity of the training data. To overcome this challenge, we will explore merging multiple publicly available lung sound datasets and applying data augmentation techniques, such as variational autoencoders [
30]. Additionally, real-world clinical validation and the inclusion of more respiratory conditions will be key steps toward refining and extending the applicability of our models.





{kind=link}