
Countering Social Media Cybercrime Using Deep Learning: Instagram Fake Accounts Detection


Abstract
1. Introduction
- To build a strong and efficient fake account detection framework by leveraging the advantage of the power of LSTM networks. The major goal is to develop a system for detecting fake Instagram accounts, taking into account the particular characteristics and challenges presented by this social media environment.
- To conduct a thorough performance comparison of the proposed LSTM-based framework with existing machine learning and deep learning algorithms typically used for fraudulent account identification. This objective entails determining the effectiveness and superiority of the LSTM technique in discriminating between real and fake Instagram accounts.
- To validate the created LSTM-based framework’s reliability and effectiveness by applying it to two separate Instagram datasets and one X dataset. This goal allows us to compare the results from the Instagram datasets to those from the X dataset, thus confirming the LSTM approach’s usefulness in detecting fake accounts across several social media sites.
2. Backgrounds
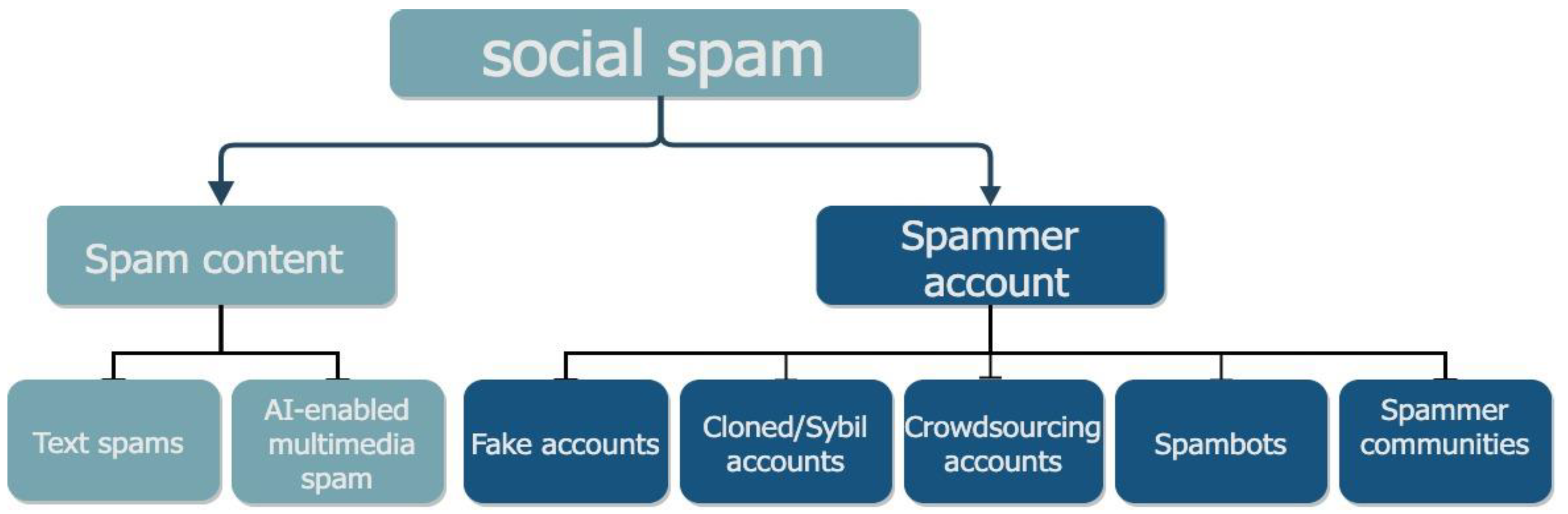
2.1. Social Spam
2.1.1. Social Spam Content
- Spam text is any text that is unwanted by a user’s but however transmitted to others without their consent. They include a malicious link to open website, a link to download files, and a link sent to a phone number [10].
- AI-enabled multimedia spam is a form of social spam that is AI-generated from a more extensive set of datasets to simulate and mimic human behavior, i.e., expression, voice, etc. [11].
2.1.2. Social Spam Content
- Fake accounts are legitimate user accounts controlled by cybercriminals to perform malicious activities on their social network sites. They are mainly used to send fake friend requests, spread fake information, and spread malicious content to target unaware victims. With the growth of technology, detecting fake accounts is increasingly tricky. Fake accounts have mastered the way of mimicking legitimate users in OSNs [8].
- Cloned/Sybil accounts refer to multiple fake user identities that mainly work by providing the OSN with fake and malicious data. The Sybil users may contain a list of accounts mainly made up of the same users or have similar intentions to many users [12].
- A crowdsourcing account is a form of marketing strategy where an organization works by outsourcing its online, operational services to an ambiguous group of people or another company. This may include freelancers for commercial services, spamming, swaying followers in social media accounts, etc. However, astroturfing is a marketing strategy used to create a false impression of widespread support of something. However, an organization behind this marketing strategy conceals sit identity [13].
- Spambots are controlled computer programs that mimic human activity to spread spam content across the internet. They automatically produce content on social media and operate at a significantly higher pace. Spambots are hard to detect since they keep their robotic identity and nature undisclosed. An example of the adoption of spambots was the US midterm election in 2010, where political communication was manipulated by spreading malicious posts to websites with fake news headlines [14].
- A spammer community refers to an organized crime syndicate where social spammers collaborate and form a collective anomaly to spread spam messages to legitimate users. The spammers collaborate with other spammers and working in tandem to influence and control their effectiveness online to form a social spammer community [8].
2.2. Fake Account Detection
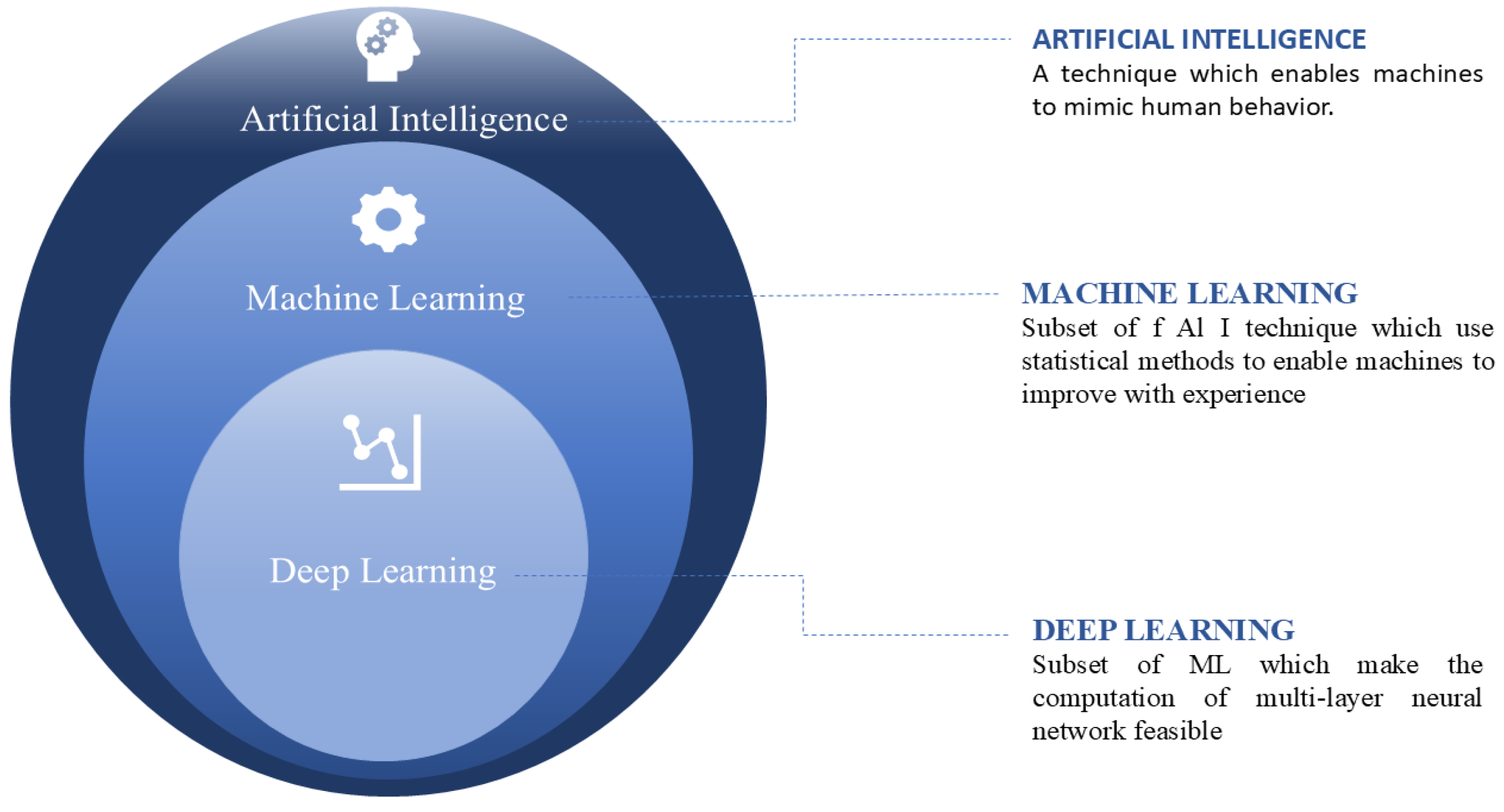
2.2.1. Machine Learning
- Unsupervised ML is a form of ML that deals with grouping unlabeled data into various clusters [21]. This form of ML is mainly applied in data mining to cluster data patterns into similar groups instead of giving the prediction directly. They are thus used as complementary tools to supervised ML [20].
2.2.2. Deep Learning
- It can take a sequence of information and uses the recurrent mechanisms and gate techniques.
- It uses the feedback gained to remember previous states.
3. Related Works
Discussion

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Year | OSN | ML/DL | Techniques Used | Accuracy (A) | Limitation |
|---|---|---|---|---|---|---|
| [45] | 2023 | Hybrid ML | Neural network | A = 93% | Low accuracy | |
| [28] | 2023 | DL | DNN | A = 99.4% | It focuses on a Facebook dataset | |
| [29] | 2022 | X | DL | LSTM | A = 99.6% | No combination multiple models used for more better performance |
| [30] | 2022 | ML | XGBoost and RF | A = 96.00% | One dataset | |
| [31] | 2021 | X | Hybrid ML | LR, DE, and RF | A = 99.9% | The datasets used did not have a relationship amongst the individual and thus made it impossible to draw a social graph |
| [32] | 2021 | X | ML | LR | A = 96.2% | LR is vulnerable to over-fitting and can handle only small volumes of data |
| [33] | 2021 | OSNs | Hybrid ML | RF Classifier, SVM, and Optimized NB | A = 97.6% | The research requires manual feature selection |
| [34] | 2020 | ML | RF, ANN, LR, NB, and J48 Decision Tree | Up to A = 91.76% | The computation time is enormous in supervised learning Unwanted data reduces efficiency | |
| [35] | 2020 | X | ML/DL | RF, SVM, and MLP | Up to A = 96.2% | SVM performance reduces with an increase in data size MLP is requires a large number of iterations and it only for linear data |
| [36] | 2020 | ML | SVM, PCA, and WA | A = 87.34% | Limited profile data | |
| [37] | 2020 | OSNs | DL | Dynamic CNN | A = 94% | Limitation of neuron number It enlarges computing resource |
| [38] | 2019 | X | ML | EGSLA | A = 90.3% | Iteration results are not stable It has low accuracy |
| [39] | 2019 | X | Hybrid ML | RF, Bagging, JRip, Random tree, PART, J48, and LR | A = 99.16% | The RF is that with an increase in tress it leads to a decrease in the algorithm performance and it has high computational cost and slow prediction generator |
| [6] | 2019 | ML/Dl | NB, LR, ANN, and SVM | Up to F-Measure = 94% | LR is prone to over-fitting SVM is not suitable for large and complex datasets | |
| [16] | 2019 | X | ML | LB | A = 97.7% | difficult or complex to work with a large amount of data |
| [40] | 2018 | X | Hybrid ML | K-means integrated levy flight algorithm | A = 97.98% | K-means algorithm cannot handle noisy data and outliers |
| [41] | 2018 | X | DL | LSTM | A = 99% | It focuses on an X dataset |
| [42] | 2017 | Sina Weibo | ML | Message tree | A = 95.3% | Data collection for the study of OSN was rendered very difficult due to personal private issues A small variation in data can lead to a greater change in the structure of the decision tress thus leading to instability |
| [5] | 2015 | X | ML | RF, Decorate, DT, AB, BN, KNN, LR, and SVM. | Up to A = 97.5%, | Lack of parallelism, slow computation, and ineffective memory utilization |
4. Proposed Framework
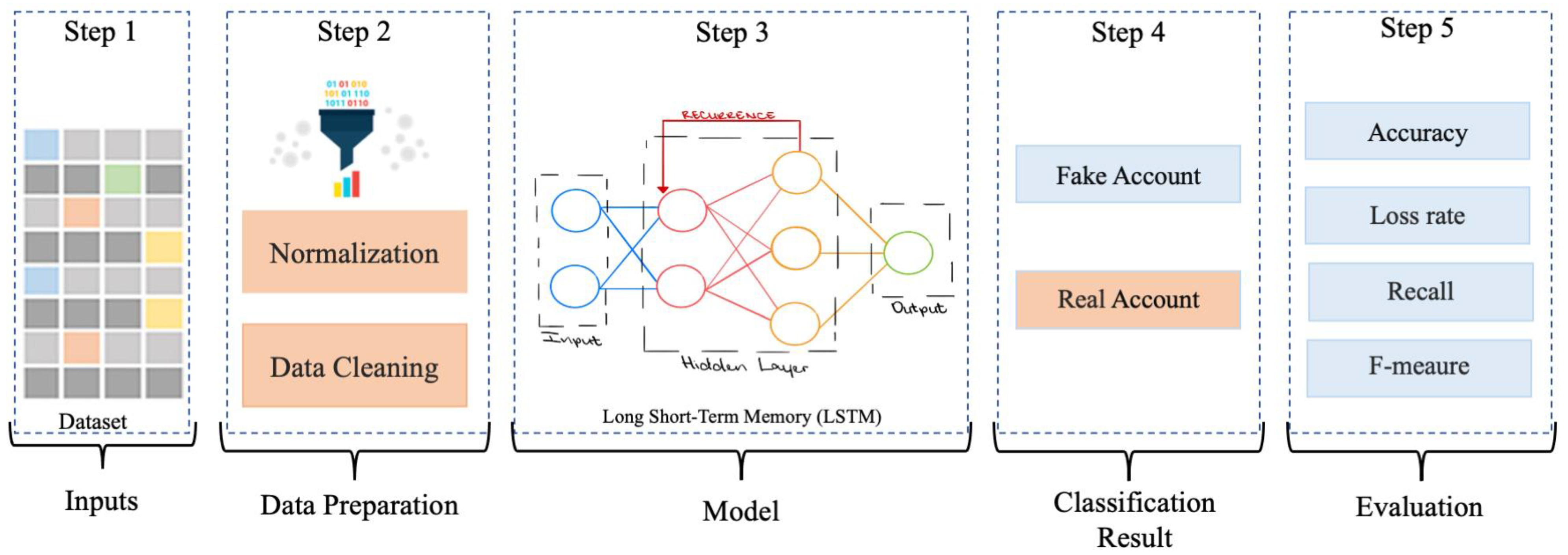
4.1. Stage1: Input (Dataset and Features)
4.1.1. Dataset 1
4.1.2. Dataset 2
4.1.3. Dataset 3
4.2. Stage2: Data Preparation
4.2.1. Normalization
4.2.2. Data Cleaning
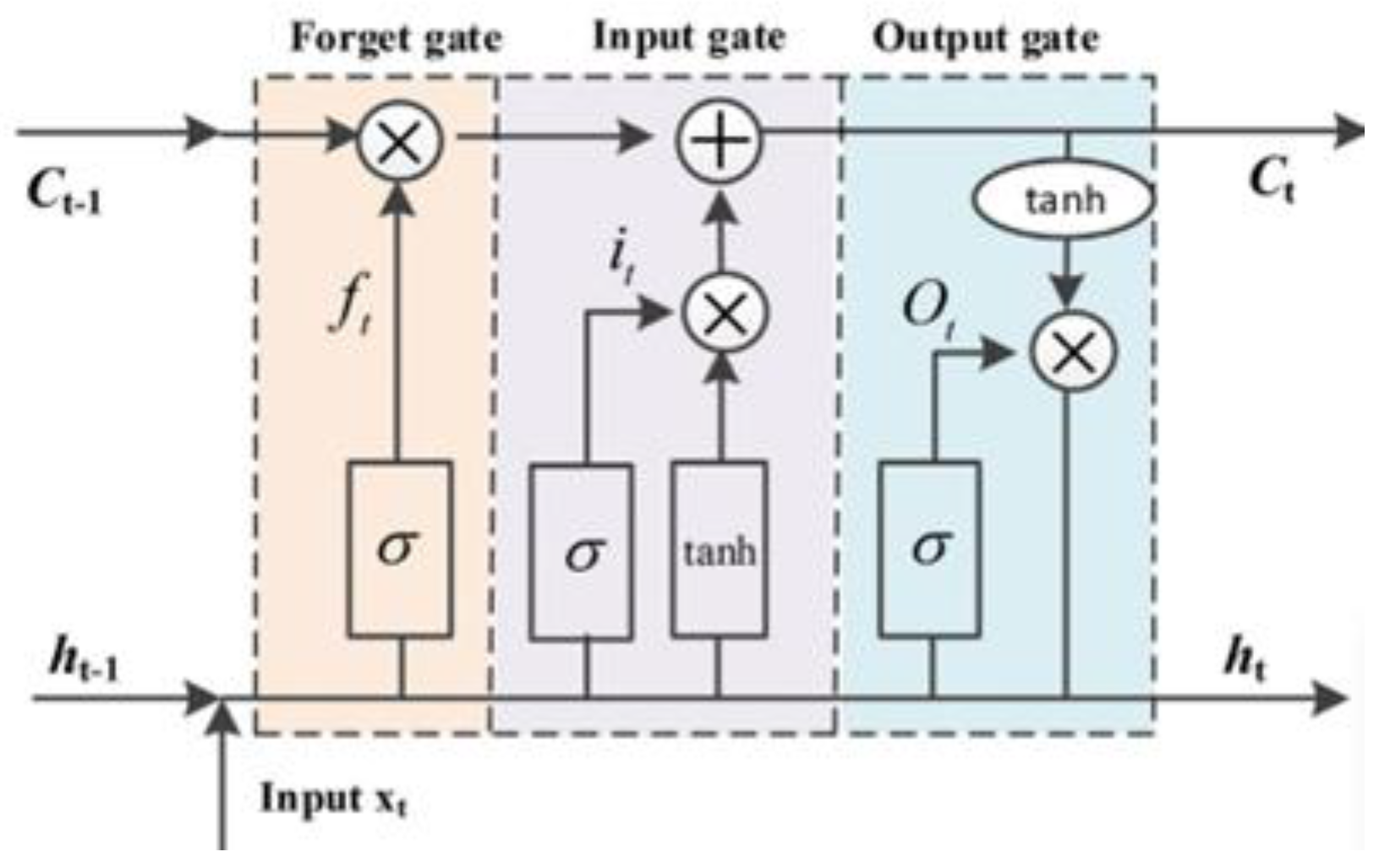
4.3. Stage3: Framework Structure
LSTM Parameters and Performance Measures
4.4. Stage 4: Classification Result
4.5. Stage 5: Evaluation
4.6. Framework Setup
5. Results and Analysis
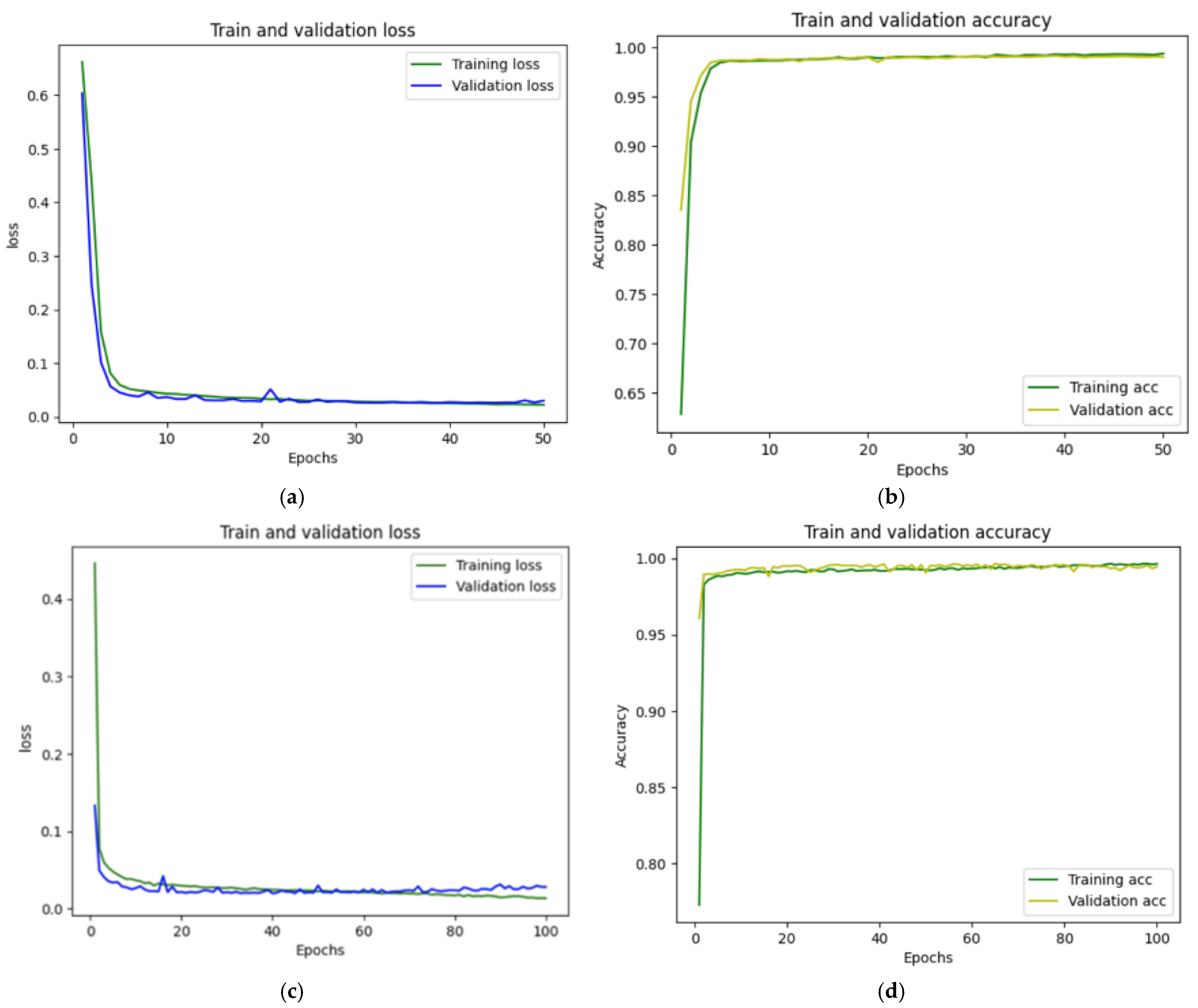
5.1. Experimental Results
5.2. Results Analysis
5.3. Comparison with Machine Learning- and Deep Learning-Based Techniques
5.4. Apply LSTM on X Dataset
5.5. Comparison with Other Machine Learning- and Deep Learning-Based Techniques
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Çıtlak, O.; Dörterler, M.; Doğru, İ.A. A survey on detecting spam accounts on Twitter network. Soc. Netw. Anal. Min. 2019, 9, 1–13. [Google Scholar] [CrossRef]
- Alom, Z.; Carminati, B.; Ferrari, E. A deep learning model for Twitter spam detection. Online Soc. Netw. Media 2020, 18, 100079. [Google Scholar] [CrossRef]
- Roberts, J.A.; David, M.E. Instagram and TikTok Flow States and Their Association with Psychological Well-Being. Cyberpsychology Behav. Soc. Netw. 2023, 26, 80–89. [Google Scholar] [CrossRef] [PubMed]
- Karayiğit, H.; İnan Acı, Ç.; Akdağlı, A. Detecting abusive Instagram comments in Turkish using convolutional Neural network and machine learning methods. Expert Syst. Appl. 2021, 174, 114802. [Google Scholar] [CrossRef]
- Cresci, S.; di Pietro, R.; Petrocchi, M.; Spognardi, A.; Tesconi, M. Fame for sale: Efficient detection of fake Twitter followers. Decis. Support Syst. 2015, 80, 56–71. [Google Scholar] [CrossRef]
- Akyon, F.C.; Kalfaoglu, M.E. Instagram Fake and Automated Account Detection. In Proceedings of the 2019 Innovations in Intelligent Systems and Applications Conference, ASYU 2019, Izmir, Turkey, 31 October–2 November 2019. [Google Scholar] [CrossRef]
- El-Mawass, N.; Honeine, P.; Vercouter, L. SimilCatch: Enhanced social spammers detection on Twitter using Markov Random Fields. Inf. Process. Manag. 2020, 57, 102317. [Google Scholar] [CrossRef]
- Rao, S.; Verma, A.K.; Bhatia, T. A review on social spam detection: Challenges, open issues, and future directions. Expert Syst. Appl. 2021, 186, 115742. [Google Scholar] [CrossRef]
- Ferrara, E. The history of digital spam. Commun. ACM 2019, 62, 82–91. [Google Scholar] [CrossRef]
- Yang, H.; Liu, Q.; Zhou, S.; Luo, Y. A spam filtering method based on multi-modal fusion. Appl. Sci. 2019, 9, 1152. [Google Scholar] [CrossRef]
- Fagni, T.; Falchi, F.; Gambini, M.; Martella, A.; Tesconi, M. TweepFake: About detecting deepfake tweets. PLoS ONE 2021, 16, e0251415. [Google Scholar] [CrossRef]
- Li, Y.; Chang, M.-C.; Lyu, S. In Ictu Oculi: Exposing AI Created Fake Videos by Detecting Eye Blinking. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, 11–13 December 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Cruickshank, I.J.; Carley, K.M. Characterizing communities of hashtag usage on Twitter during the 2020 COVID-19 pandemic by multi-view clustering. Appl. Netw. Sci. 2020, 5, 66. [Google Scholar] [CrossRef] [PubMed]
- Ferrara, E. Measuring social spam and the effect of bots on information diffusion in social media. In Complex Spreading Phenomena in Social Systems. Computational Social Sciences; Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Sahoo, S.R.; Gupta, B. Fake Profile Detection in Multimedia Big Data on Online Social Networks. 2020. Available online: https://scholar.google.com/scholar?q=Sahoo,%20S.R.;%20Gupta,%20B.%20Fake%20profile%20detection%20in%20multimedia%20big%20data%20on%20online%20social%20networks,%202020 (accessed on 7 October 2024).
- Adewole, K.S.; Anuar, N.B.; Kamsin, A.; Sangaiah, A.K. SMSAD: A framework for spam message and spam account detection. Multimedia Tools Appl. 2017, 78, 3925–3960. [Google Scholar] [CrossRef]
- Janiesch, C.; Zschech, P.; Heinrich, K. Machine learning and deep learning. Electron. Mark. 2021, 31, 685–695. [Google Scholar] [CrossRef]
- ODSC Team. Artificial Intelligence and Machine Learning in Practice: Anomaly Detection in Army ERP Data. 2019. Available online: https://opendatascience.com/artificial-intelligence-and-machine-learning-in-practice-anomaly-detection-in-army-erp-data/ (accessed on 9 October 2024).
- Sohail, A.; Arif, F. Supervised and unsupervised algorithms for bioinformatics and data science. Prog. Biophys. Mol. Biol. 2019, 151, 14–22. [Google Scholar] [CrossRef]
- Hood, S.B.; Cracknell, M.J.; Gazley, M.F. Linking protolith rocks to altered equivalents by combining unsupervised and supervised machine learning. J. Geochem. Explor. 2018, 186, 270–280. [Google Scholar] [CrossRef]
- Soheily-Khah, S.; Marteau, P.-F.; Bechet, N. Intrusion detection in network systems through hybrid supervised and unsupervised machine learning process: A case study on the iscx dataset. In Proceedings of the 2018 1st International Conference on Data Intelligence and Security, ICDIS 2018, South Padre Island, TX, USA, 8–10 April 2018; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2018; pp. 219–226. [Google Scholar] [CrossRef]
- Bao, W.; Lianju, N.; Yue, K. Integration of unsupervised and supervised machine learning algorithms for credit risk assessment. Expert Syst. Appl. 2019, 128, 301–315. [Google Scholar] [CrossRef]
- Jain, G.; Sharma, M.; Agarwal, B. Optimizing semantic LSTM for spam detection. Int. J. Inf. Technol. 2019, 11, 239–250. [Google Scholar] [CrossRef]
- Liu, H.; Lang, B. Machine learning and deep learning methods for intrusion detection systems: A survey. Appl. Sci. 2019, 9, 4396. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Imrana, Y.; Xiang, Y.; Ali, L.; Abdul-Rauf, Z. A bidirectional LSTM deep learning approach for intrusion detection. Expert Syst. Appl. 2021, 185, 115524. [Google Scholar] [CrossRef]
- Smagulova, K.; James, A.P. A survey on LSTM memristive neural network architectures and applications. Eur. Phys. J. Spéc. Topics 2019, 228, 2313–2324. [Google Scholar] [CrossRef]
- Amankeldin, D.; Kurmangaziyeva, L.; Mailybayeva, A.; Glazyrina, N.; Zhumadillayeva, A.; Karasheva, N. Deep Neural Network for Detecting Fake Profiles in Social Networks. Comput. Syst. Sci. Eng. 2023, 47, 1091–1108. [Google Scholar] [CrossRef]
- Chakraborty, P.; Shazan, M.M.; Nahid, M.; Ahmed, K.; Talukder, P.C. Fake Profile Detection Using Machine Learning Techniques. J. Comput. Commun. 2022, 10, 74–87. [Google Scholar] [CrossRef]
- Sallah, A.; Alaoui, A.A.E.; Agoujil, S.; Nayyar, A. Machine Learning Interpretability to Detect Fake Accounts in Instagram. Int. J. Inf. Secur. Priv. 2022, 16, 1–25. [Google Scholar] [CrossRef]
- Abkenar, S.B.; Mahdipour, E.; Jameii, S.M.; Kashani, M.H. A hybrid classification method for Twitter spam detection based on differential evolution and random forest. Concurr. Comput. 2021, 33, e6381. [Google Scholar] [CrossRef]
- Bharti, K.K.; Pandey, S. Fake account detection in Twitter using logistic regression with particle swarm optimization. Soft Comput. 2021, 25, 11333–11345. [Google Scholar] [CrossRef]
- Ajesh, F.; Aswathy, S.U.; Philip, F.M.; Jeyakrishnan, V. A Hybrid Method for Fake Profile Detection in Social Network Using Artificial Intelligence. In Security Issues and Privacy Concerns in Industry 4.0 Applications; John Wiley & Sons Inc.: Hoboken, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Purba, K.R.; Asirvatham, D.; Murugesan, R.K. Classification of instagram fake users using supervised machine learning algorithms. Int. J. Electr. Comput. Eng. 2020, 10, 2763–2772. [Google Scholar] [CrossRef]
- Adewole, K.S.; Han, T.; Wu, W.; Song, H.; Sangaiah, A.K. Twitter spam account detection based on clustering and classification methods. J. Supercomput. 2018, 76, 4802–4837. [Google Scholar] [CrossRef]
- Shalinda, A.; Kaushik, D. Identifying Fake Profiles in LinkedIn. arXiv 2022, arXiv:2006.01381. [Google Scholar]
- Wanda, P.; Jie, H.J. DeepProfile: Finding fake profile in online social network using dynamic CNN. J. Inf. Secur. Appl. 2020, 52, 102465. [Google Scholar] [CrossRef]
- BalaAnand, M.; Karthikeyan, N.; Karthik, S.; Varatharajan, R.; Manogaran, G.; Sivaparthipan, C.B. An enhanced graph-based semi-supervised learning algorithm to detect fake users on Twitter. J. Supercomput. 2019, 75, 6085–6105. [Google Scholar] [CrossRef]
- Sahoo, S.R.; Gupta, B.B. Hybrid approach for detection of malicious profiles in Twitter. Comput. Electr. Eng. 2019, 76, 65–81. [Google Scholar] [CrossRef]
- Aswani, R.; Kar, A.K.; Ilavarasan, P.V. Detection of Spammers in Twitter marketing: A Hybrid Approach Using Social Media Analytics and Bio Inspired Computing. Inf. Syst. Front. 2017, 20, 515–530. [Google Scholar] [CrossRef]
- Kudugunta, S.; Ferrara, E. Deep neural networks for bot detection. Inf. Sci. 2018, 467, 312–322. [Google Scholar] [CrossRef]
- Cao, J.; Fu, Q.; Li, Q.; Guo, D. Discovering hidden suspicious accounts in online social networks. Inf. Sci. 2017, 394–395, 123–140. [Google Scholar] [CrossRef]
- Khan, S.A.; Iqbal, K.; Mohammad, N.; Akbar, R.; Ali, S.S.A.; Siddiqui, A.A. A Novel Fuzzy-Logic-Based Multi-Criteria Metric for Performance Evaluation of Spam Email Detection Algorithms. Appl. Sci. 2022, 12, 7043. [Google Scholar] [CrossRef]
- Dewis, M.; Viana, T. Phish Responder: A Hybrid Machine Learning Approach to Detect Phishing and Spam Emails. Appl. Syst. Innov. 2022, 5, 73. [Google Scholar] [CrossRef]
- Kaushik, K.; Bhardwaj, A.; Kumar, M.; Gupta, S.K.; Gupta, A. A novel machine learning-based framework for detecting fake Instagram profiles. Concurr. Comput. 2022, 34, e7349. [Google Scholar] [CrossRef]
- Akyon, E.K.F.C. InstaFake Dataset. Available online: https://github.com/fcakyon/instafake-dataset (accessed on 25 February 2022).
- Bakhshandeh, B. Instagram-Fake-Spammer-Genuine-Accounts. Available online: https://www.kaggle.com/datasets/free4ever1/instagram-fake-spammer-genuine-accounts (accessed on 14 March 2022).
- Fan, D.; Sun, H.; Yao, J.; Zhang, K.; Yan, X.; Sun, Z. Well production forecasting based on ARIMA-LSTM model considering manual operations. Energy 2020, 220, 119708. [Google Scholar] [CrossRef]
- Shrestha, A.; Mahmood, A. Review of deep learning algorithms and architectures. IEEE Access 2019, 7, 53040–53065. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Ruder, S. An Overview of Gradient Descent Optimization Algorithms. 2016. Available online: http://arxiv.org/abs/1609.04747 (accessed on 9 October 2024).
- Behera, R.K.; Jena, M.; Rath, S.K.; Misra, S. Co-LSTM: Convolutional LSTM model for sentiment analysis in social big data. Inf. Process. Manag. 2020, 58, 102435. [Google Scholar] [CrossRef]
| Description | Feature Name |
|---|---|
| user_media_count | Total number of posts an account has. |
| userFollowerCount | The account’s follower count. |
| userFollowingCount | Following of account |
| user_has_profil_pic | Whether or not an account has a profile picture. |
| user_is_private | Whether an account is a private profile or not. |
| userBiographyLength | The total number of characters in the account biography. |
| username_length | The number of characters in the username of the account. |
| username_digit_count | The number of digits in the username of the account. |
| is_fake | True, if account is a spam/fake account, False otherwise |
| Description | Feature Name |
|---|---|
| profile Pic | Whether the account have profile pic or not. |
| nums/Length Username | The percentage of a username’s length to its number of numeric characters. |
| fullname Words | Whole name in word tokens. |
| nums/Length Fullname | The percentage of the number of numeric characters in whole name to its length. |
| name = =Username | Username and whole name are equals. |
| description Length | User bio length in characters. |
| external URL (Uniform Resource Locator) | Whether the account have an external c or not. |
| Private | Whether the account is private or public. |
| Posts | Total posts number. |
| Followers | Follower count of the account. |
| Fake | True, if account is a spam/fake account, False otherwise. |
| Parameters | Description |
|---|---|
| Optimizer | Refers to adjusting the framework parameters to minimize the framework error in the training step. |
| Loss function: | Used to optimize your framework. It is the function that is minimized by the optimizer. |
| Batch Size | The number of data samples that are sent via the network before the parameters are updated. |
| Epoch | Refers to an iterative process of the training framework that occurs at each iteration |
| Learning Rate | A hyperparameter that controls how much to change the model in response to the estimated error each time the model weights are updated |
| Optimizers | Description |
|---|---|
| RMSProp | RMSProd effectively eliminates the influence of historical gradient by substituting an exponentially decaying moving average for the summation of squared gradient in AdaGrad [49]. |
| Adaptive Moment Estimation (Adam) | Adam is a learning method created exclusively for deep neural network training. Adam has the advantages of being more memory efficient and using less compute resources [50]. |
| AdaGrad | With its more complex AdaGrad algorithm, learning rates are scaled inversely in relation to the square root of the cumulative squared gradient [50]. |
| Stochastic gradient descent (SGD) | Due to SGD’s frequent updates and large variation, the objective function highly fluctuates [51]. |
| Parameters | Value |
|---|---|
| Language | Python |
| Libraries | Pandas, Numpy, Matplotlib, and Keras |
| Train set | 70% |
| Test set | 30% |
| Activation functions | sigmoid activation |
| Optimizer | Adam |
| Epochs number | 50 and 100 |
| Batch size | 25 |
| Dataset 1 | |||
|---|---|---|---|
| Optimizer | Accuracy (%) | Loss Rate | Time (s) |
| Adam | 97.42% | 0.085 | 147 s |
| RMSprop | 96.81% | 0.075 | 200 s |
| Adagrad | 82.33% | 0.726 | 120 s |
| SGD | 82.33% | 0.700 | 100 s |
| Dataset 2 | |||
|---|---|---|---|
| Optimizer | Accuracy (%) | Loss Rate | Time (s) |
| Adam | 94.21% | 0.144 | 12 s |
| RMSprop | 92.59% | 0.1693 | 25 s |
| Adagrad | 79.93% | 0.6737 | 13 s |
| SGD | 86.44% | 0.376 | 12 s |
| Dataset 1 | ||||||
|---|---|---|---|---|---|---|
| Iterations | Accuracy (%) | Loss Rate | Recall (%) | Precision (%) | F-Measure (%) | Time (s) |
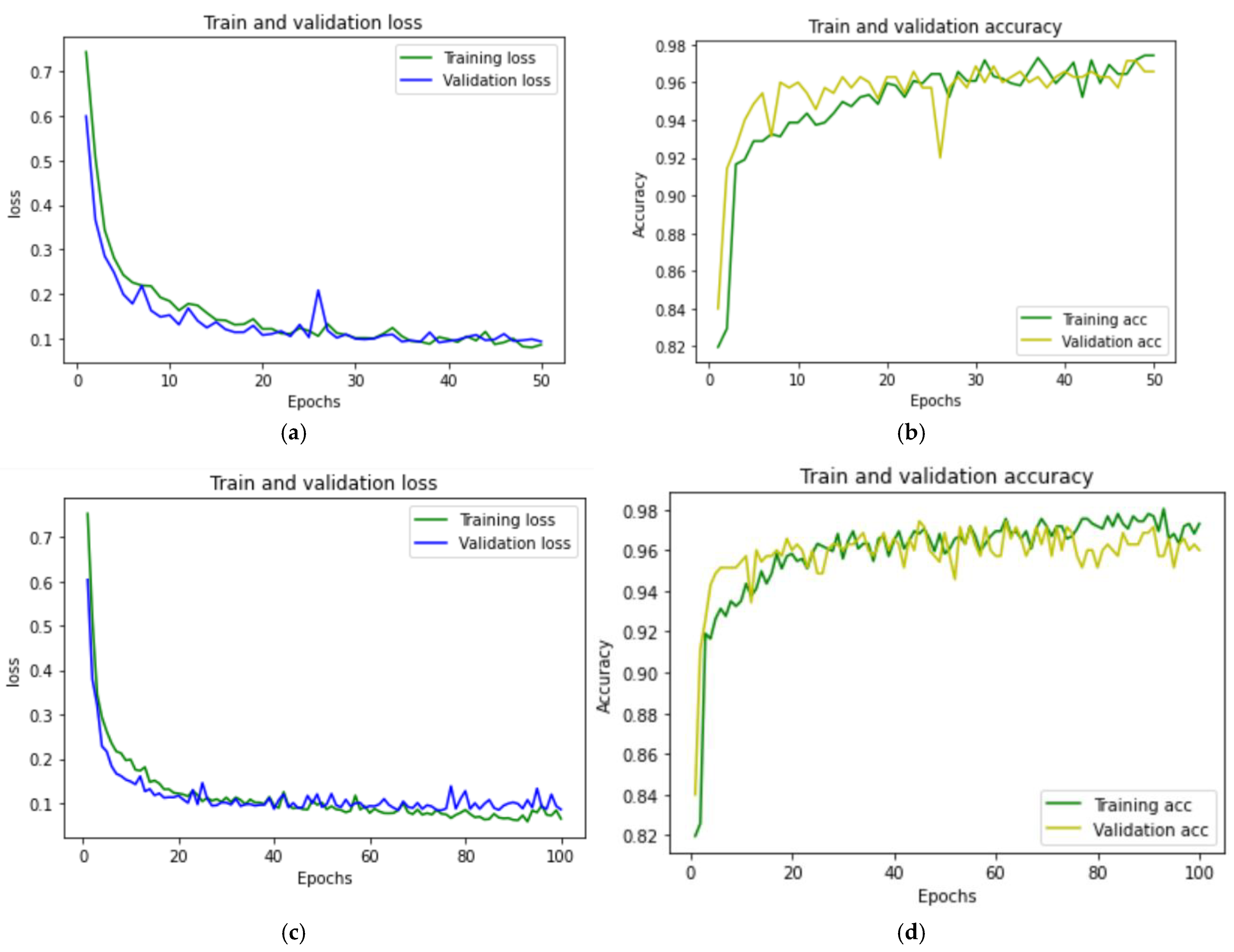
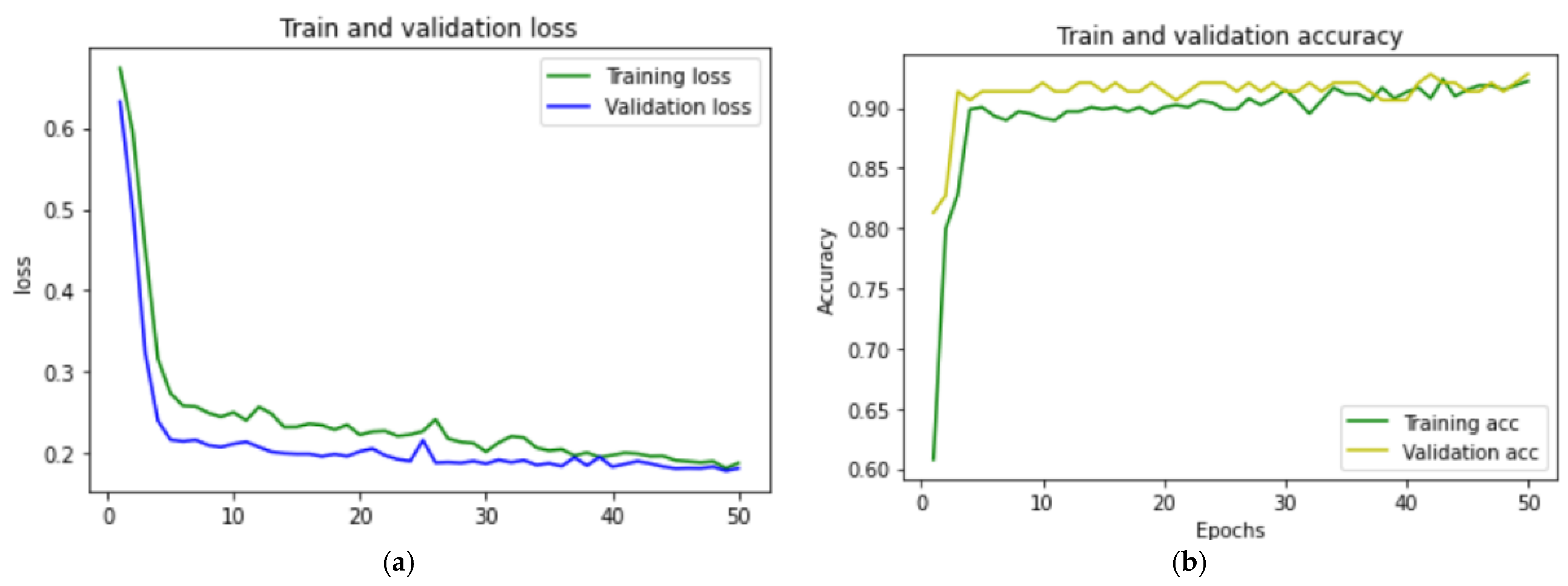
| 50 | 97.14% | 0.097 | 94.64% | 89.83% | 91.37% | 150 s |
| 100 | 97.42% | 0.085 | 94.64% | 89.65% | 92.17% | 228 s |
| Dataset 2 | ||||||
|---|---|---|---|---|---|---|
| Iterations | Accuracy (%) | Loss Rate | Recall (%) | Precision (%) | F-Measure (%) | Time (s) |
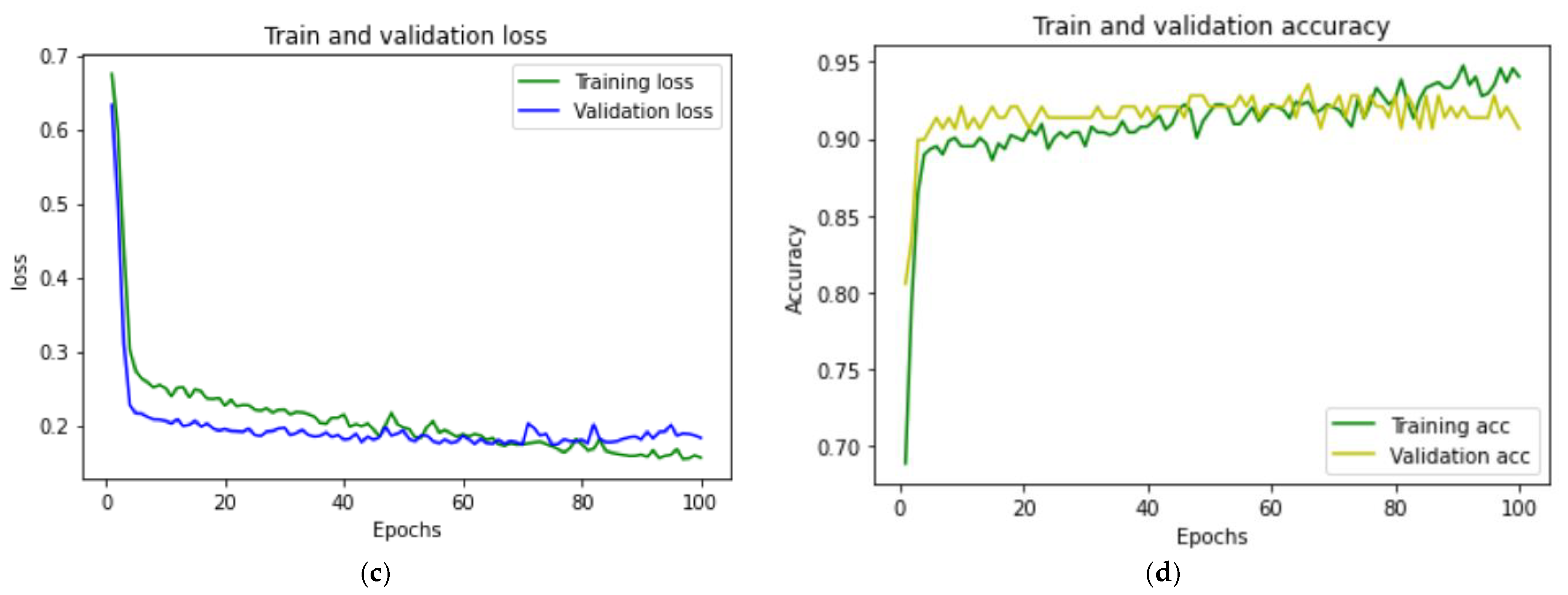
| 50 | 92.22% | 0.188 | 92.30% | 92.42% | 92.30% | 15 s |
| 100 | 94.21% | 0.144 | 92.30% | 96.72% | 89.55% | 12 s |
| Classifier | Accuracy | Recall | F-Measure | |
|---|---|---|---|---|
| ML | SVM | 93.31% | 72.2% | 76.5% |
| GNB | 91.92% | 66.7% | 71.3% | |
| LR | 94.75% | 74.1% | 80.8% | |
| RF | 97.77% | 87.0% | 92.2% | |
| KNC | 95.26% | 87.0% | 84.7% | |
| DT | 96.93% | 90.7% | 89.9% | |
| LDA | 92.75% | 59.3% | 71.1% | |
| DL | DNN | 97.21% | 87.03% | 90.38% |
| Dynamic CNN | 95.82% | 77.77% | 84.84% | |
| MLP | 96.10% | 81.48% | 86.27% | |
| Proposed framework | 97.42% | 94.64% | 92.17% | |
| Classifier | Accuracy | Recall | F-Measure | |
|---|---|---|---|---|
| ML | SVM | 50.71% | 100% | 65.6% |
| GNB | 67.46% | 98.0% | 73.8% | |
| LR | 88.99% | 91.8% | 88.7% | |
| RF | 93.30% | 90.8% | 91.3% | |
| KNC | 90.43% | 88.8% | 89.7% | |
| DT | 89.95% | 88.8% | 82.2% | |
| LDA | 88.51% | 81.6% | 87.0% | |
| DL | DNN | 91.42% | 89.47% | 91.89% |
| Dynamic CNN | 90.71% | 89.47% | 91.27% | |
| MLP | 90.71% | 88.15% | 91.15% | |
| Proposed framework | 94.21% | 92.30% | 89.55% | |
| Ref | Approach | Accuracy | Dataset Source |
|---|---|---|---|
| [45] | Neural Network | A = 91% | 576 Instagram accounts: 288 were fake and 288 were genuine. |
| [34] | RF, ANN, LR, NB, and J48 Decision Tree | A = 91.76% | 32,869 fake users and 32,460 authentic users, totaling 65,329 users on Instagram. |
| [6] | NB, LR, ANN, and SVM | A = 86% | 1203 Instagram accounts, 201 were fake, and 1002 were genuine. |
| Proposed Method | LSTM | A = 97.42% | Two datasets Dataset 1: 1203 Instagram accounts, 201 were fake and 1002 were genuine. Dataset 2: 696 Instagram users, 348 were real users and 348 were fake users. |
| Dataset 3 | ||||||
|---|---|---|---|---|---|---|
| Iterations | Accuracy (%) | Loss Rate | Recall (%) | Precision (%) | F-Measure (%) | Time (s) |
| 50 | 99.00% | 0.0300 | 98.54% | 99.51% | 99.13% | 19 s |
| 100 | 99.44% | 0.0279 | 99.10% | 99.73% | 99.52% | 43 s |
| Classifier | Accuracy | Recall | F-Measure | ||
|---|---|---|---|---|---|
| ML | SVM | 77.50% | 72.50% | 78.80% | |
| GNB | 92.88% | 99.50% | 94.10% | ||
| LR | 96.22% | 99.40% | 96.80% | ||
| RF | 99.16% | 99.00% | 99.30% | ||
| KNC | 93.08% | 93.80% | 94.00% | ||
| DT | 99.00% | 99.10% | 99.10% | ||
| LDA | 98.72% | 98.80% | 98.90% | ||
| DL | Proposed framework | 99.44% | 99.12% | 99.52% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alharbi, N.; Alkalifah, B.; Alqarawi, G.; Rassam, M.A. Countering Social Media Cybercrime Using Deep Learning: Instagram Fake Accounts Detection. Future Internet 2024, 16, 367. https://doi.org/10.3390/fi16100367
Alharbi N, Alkalifah B, Alqarawi G, Rassam MA. Countering Social Media Cybercrime Using Deep Learning: Instagram Fake Accounts Detection. Future Internet. 2024; 16(10):367. https://doi.org/10.3390/fi16100367
Chicago/Turabian StyleAlharbi, Najla, Bashayer Alkalifah, Ghaida Alqarawi, and Murad A. Rassam. 2024. "Countering Social Media Cybercrime Using Deep Learning: Instagram Fake Accounts Detection" Future Internet 16, no. 10: 367. https://doi.org/10.3390/fi16100367
APA StyleAlharbi, N., Alkalifah, B., Alqarawi, G., & Rassam, M. A. (2024). Countering Social Media Cybercrime Using Deep Learning: Instagram Fake Accounts Detection. Future Internet, 16(10), 367. https://doi.org/10.3390/fi16100367