
1-D Convolutional Neural Network-Based Models for Cooperative Spectrum Sensing



Abstract
:1. Introduction
2. Related Works
3. Overview of Spectrum Sensing and Adopted Deep Learning Algorithms
3.1. Spectrum Sensing Principle
3.2. Deep Neural Networks
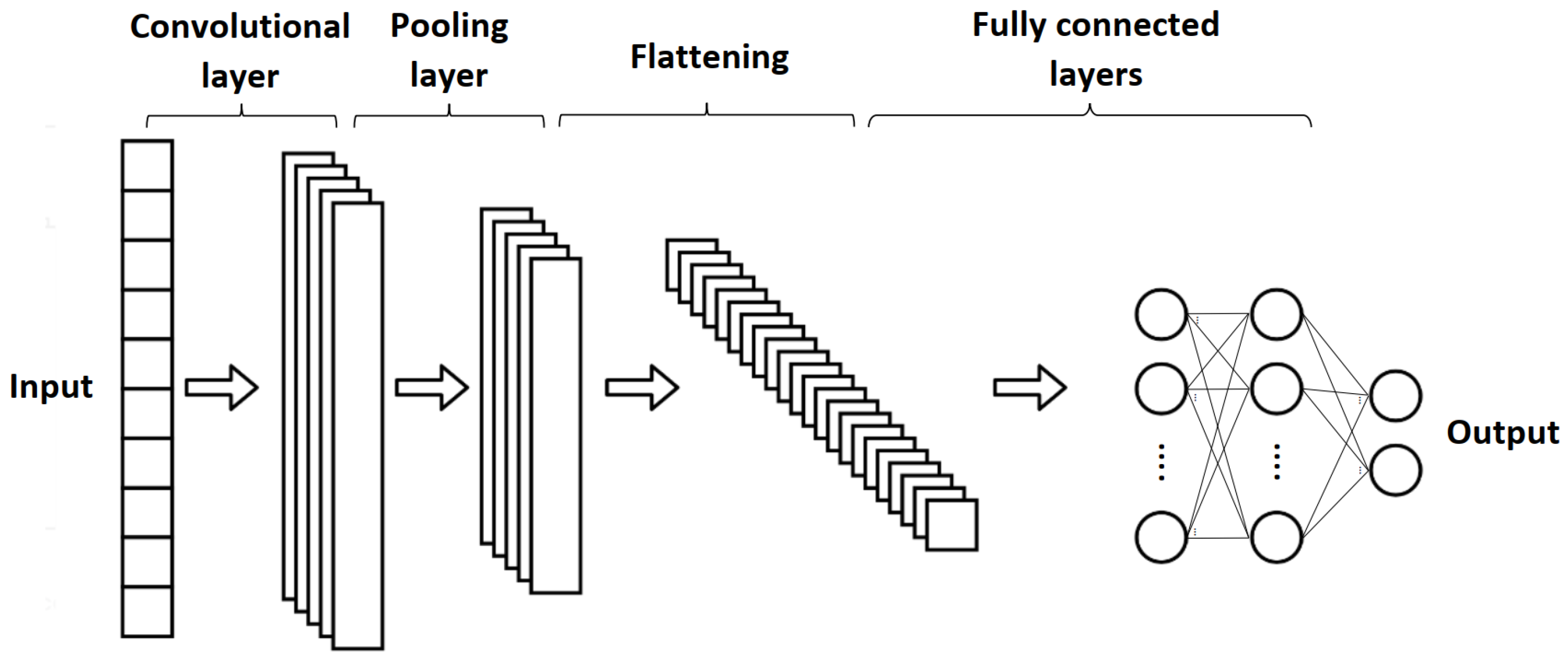
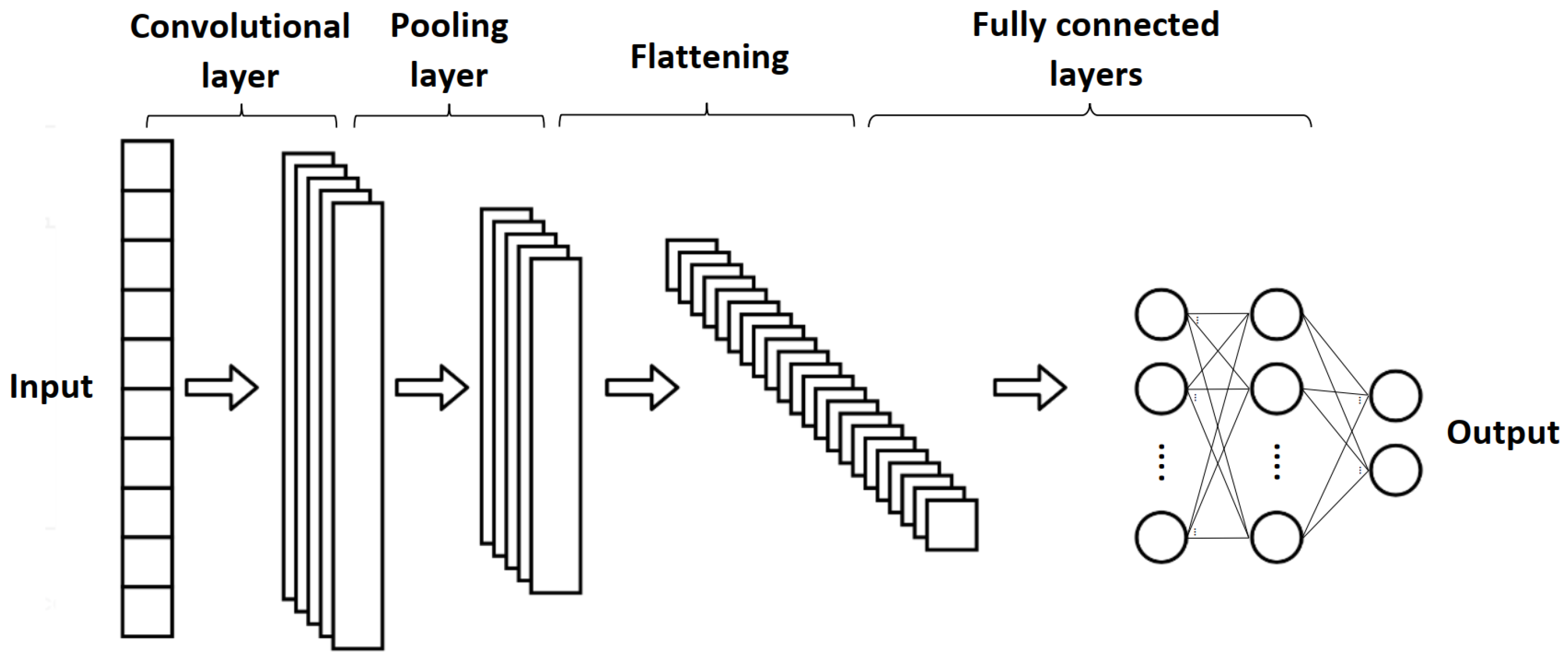
3.3. One-Dimensional Convolutional Neural Network
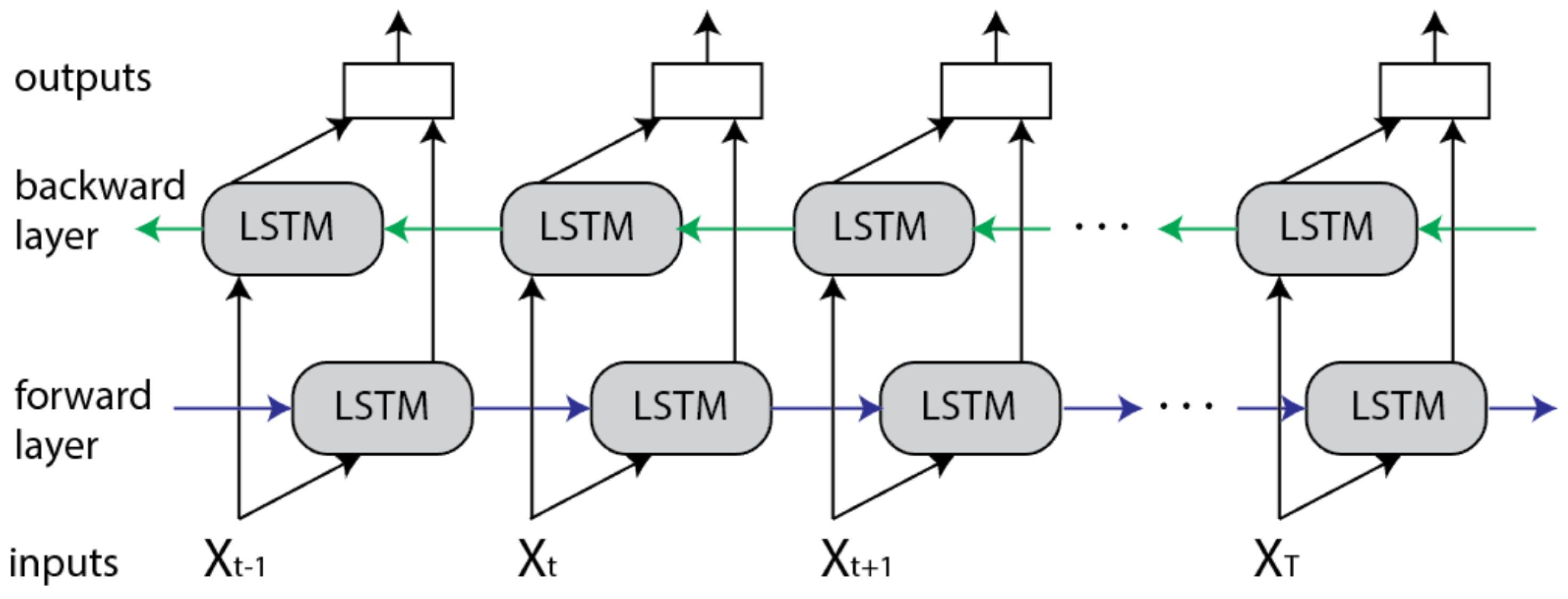
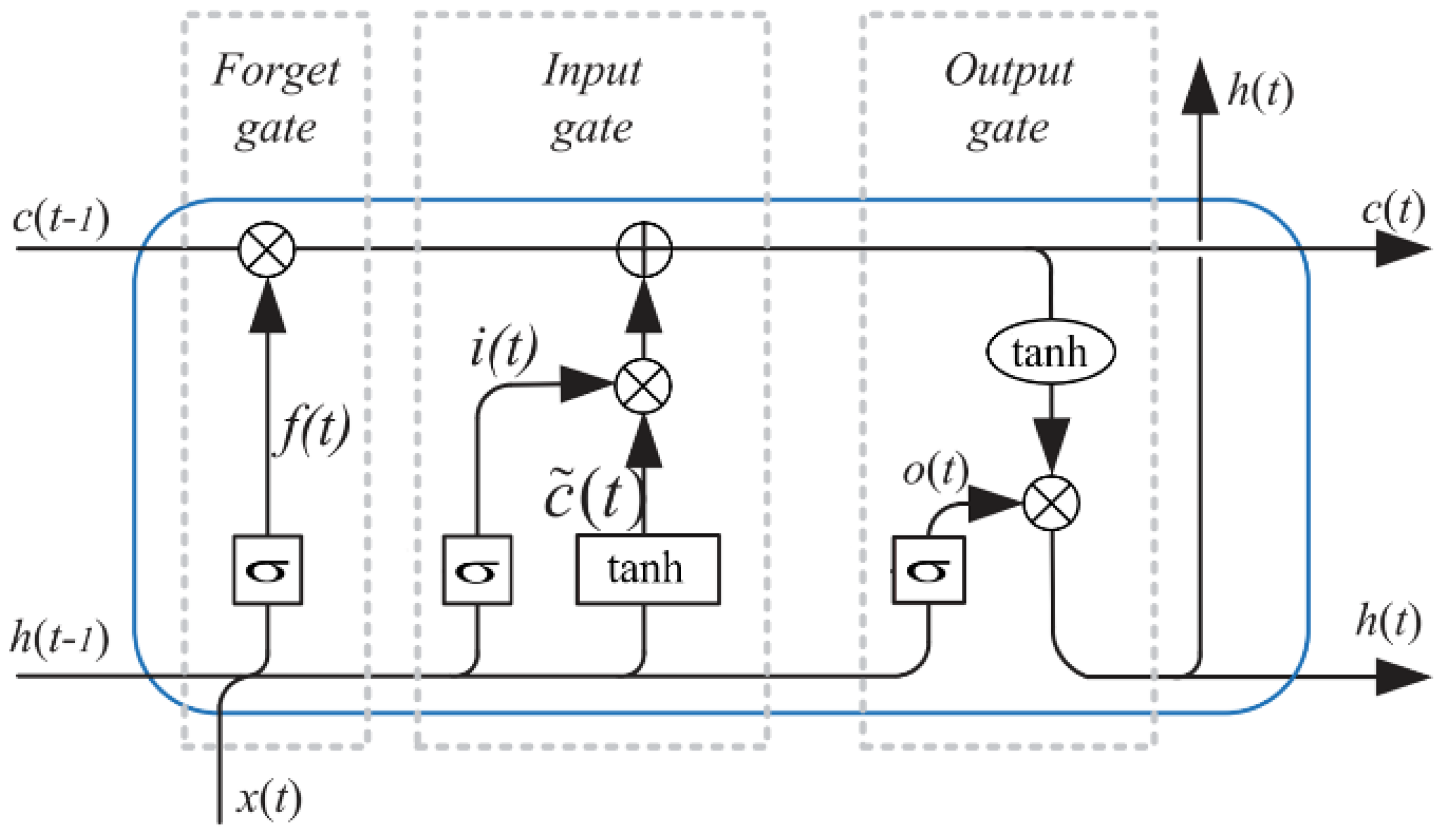
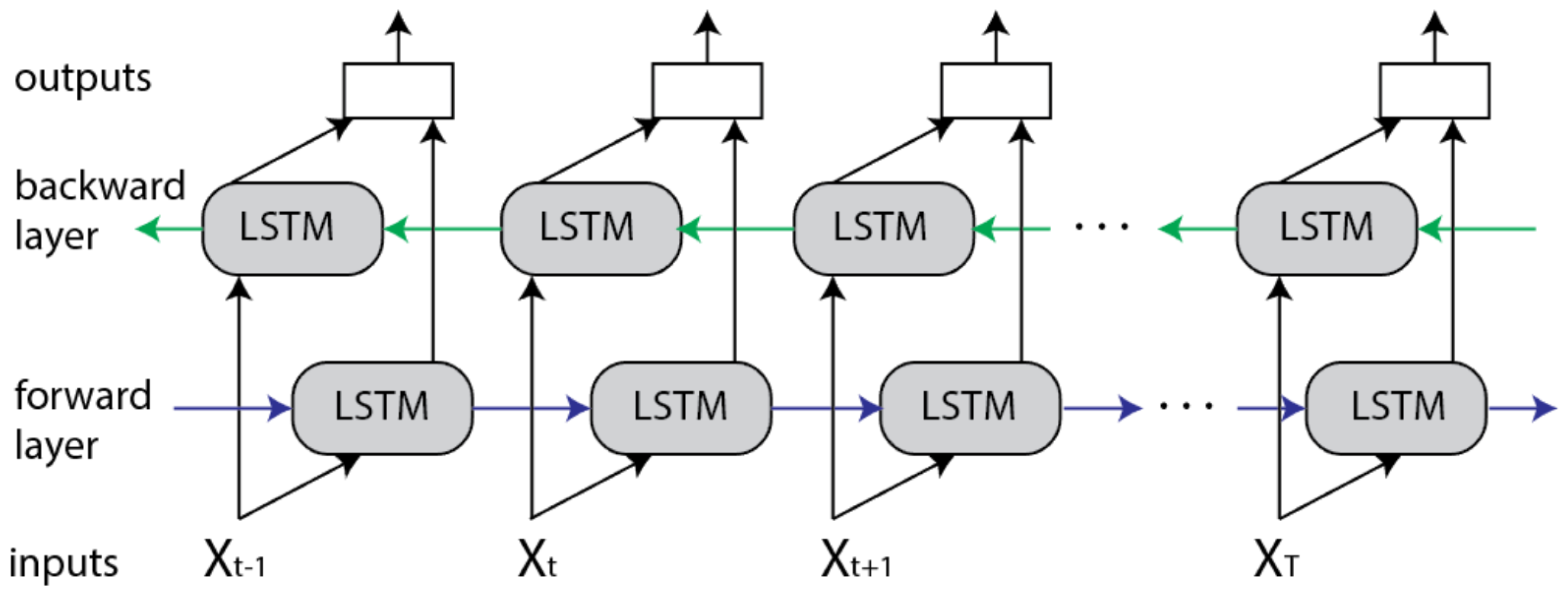
3.4. Bidirectional Long Short-Term Memory
4. Deep Learning-Based Detectors
4.1. Data Requirement and Generation
4.2. Network Architecture Design
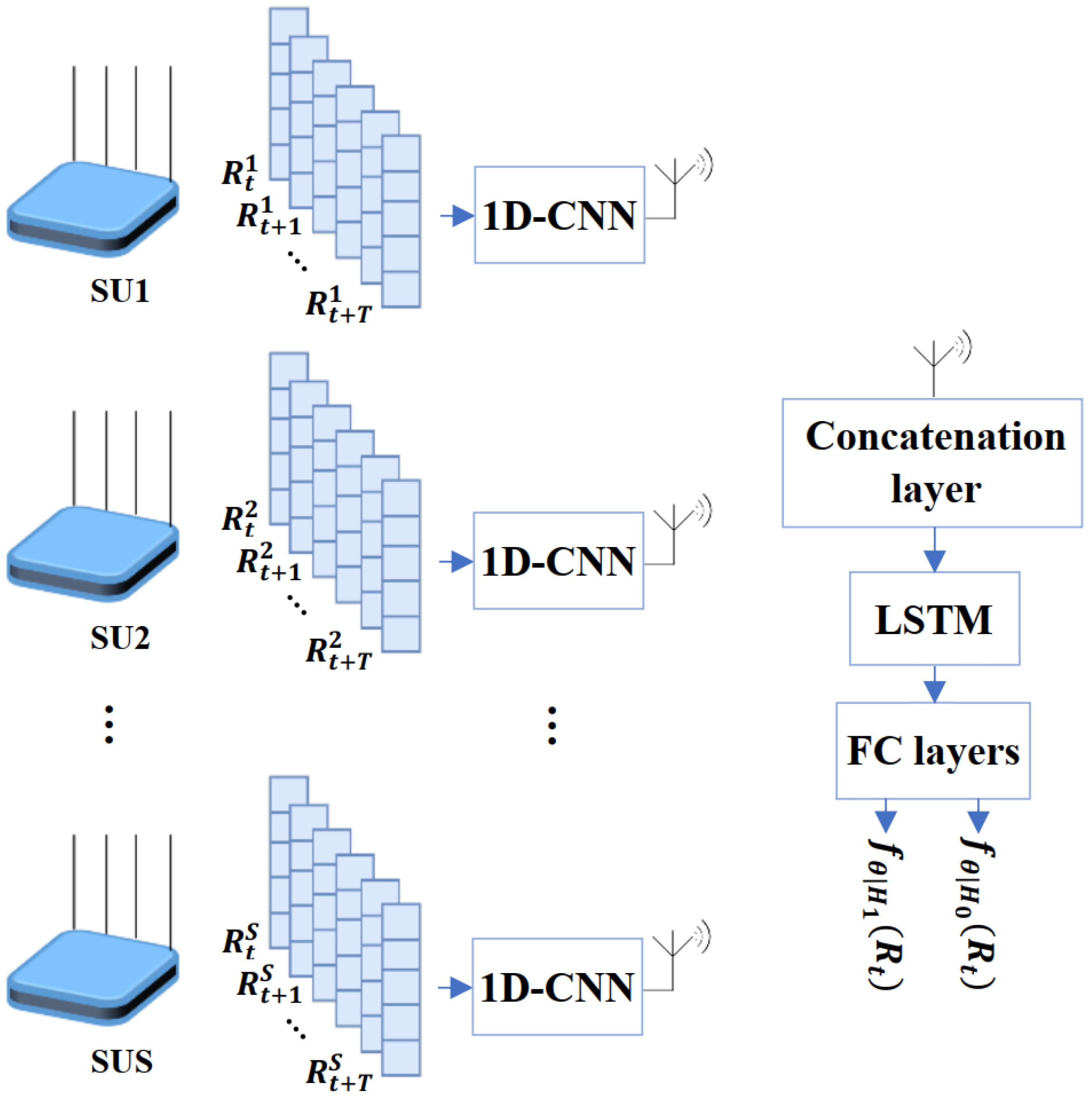
4.2.1. Hierarchical LSTM with 1DCNN
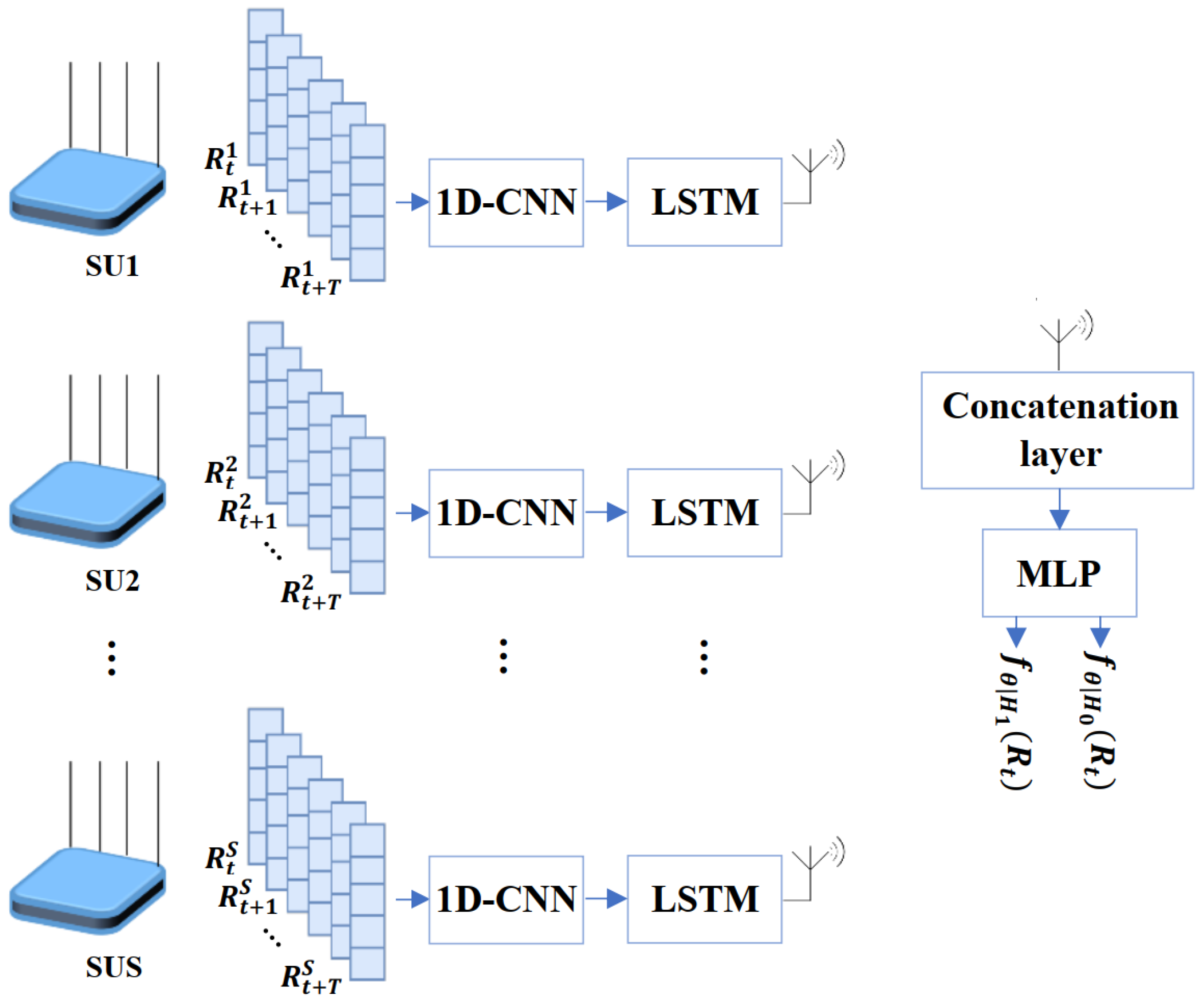
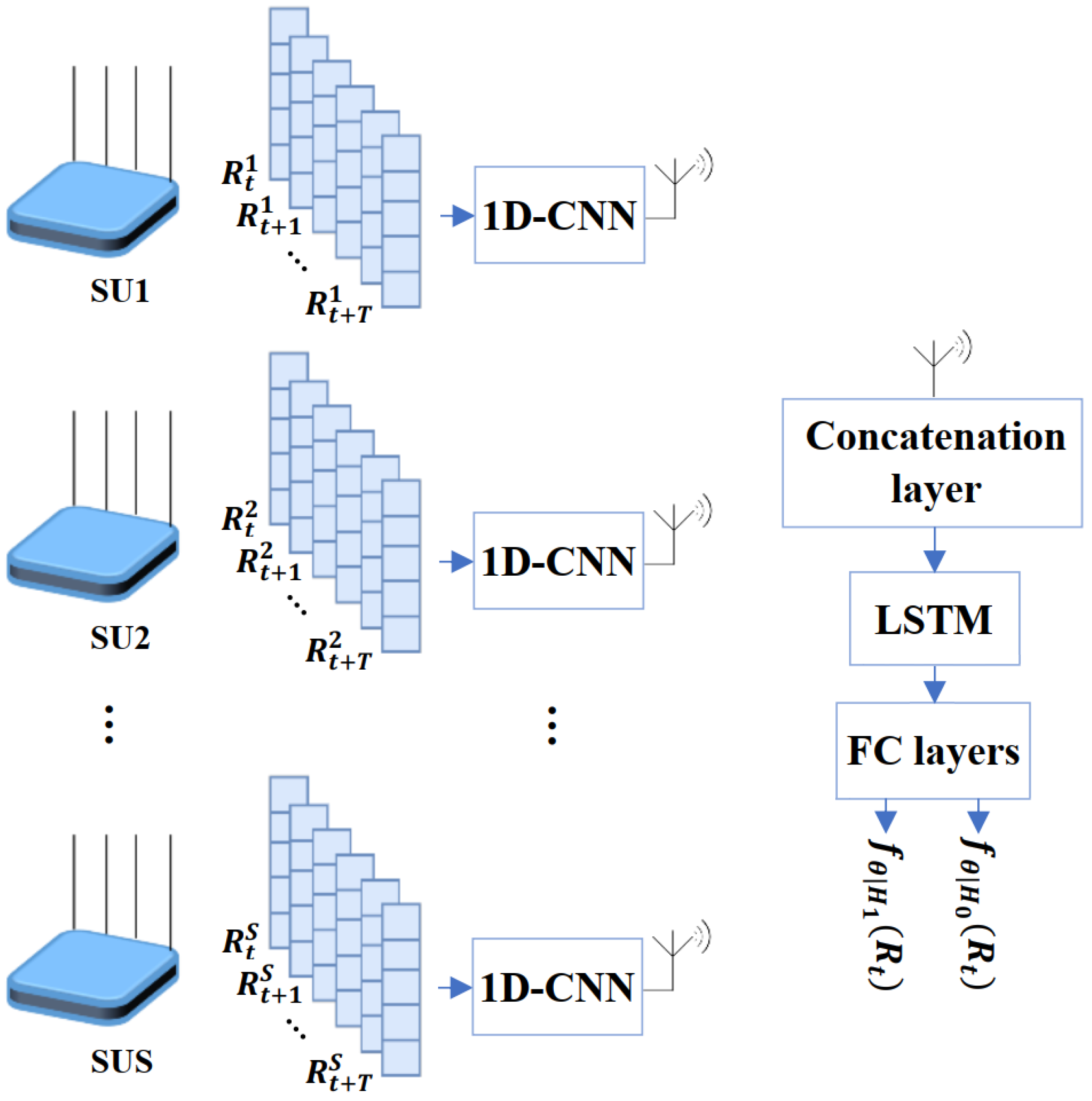
4.2.2. Hierarchical MLP with 1DCNN-LSTM
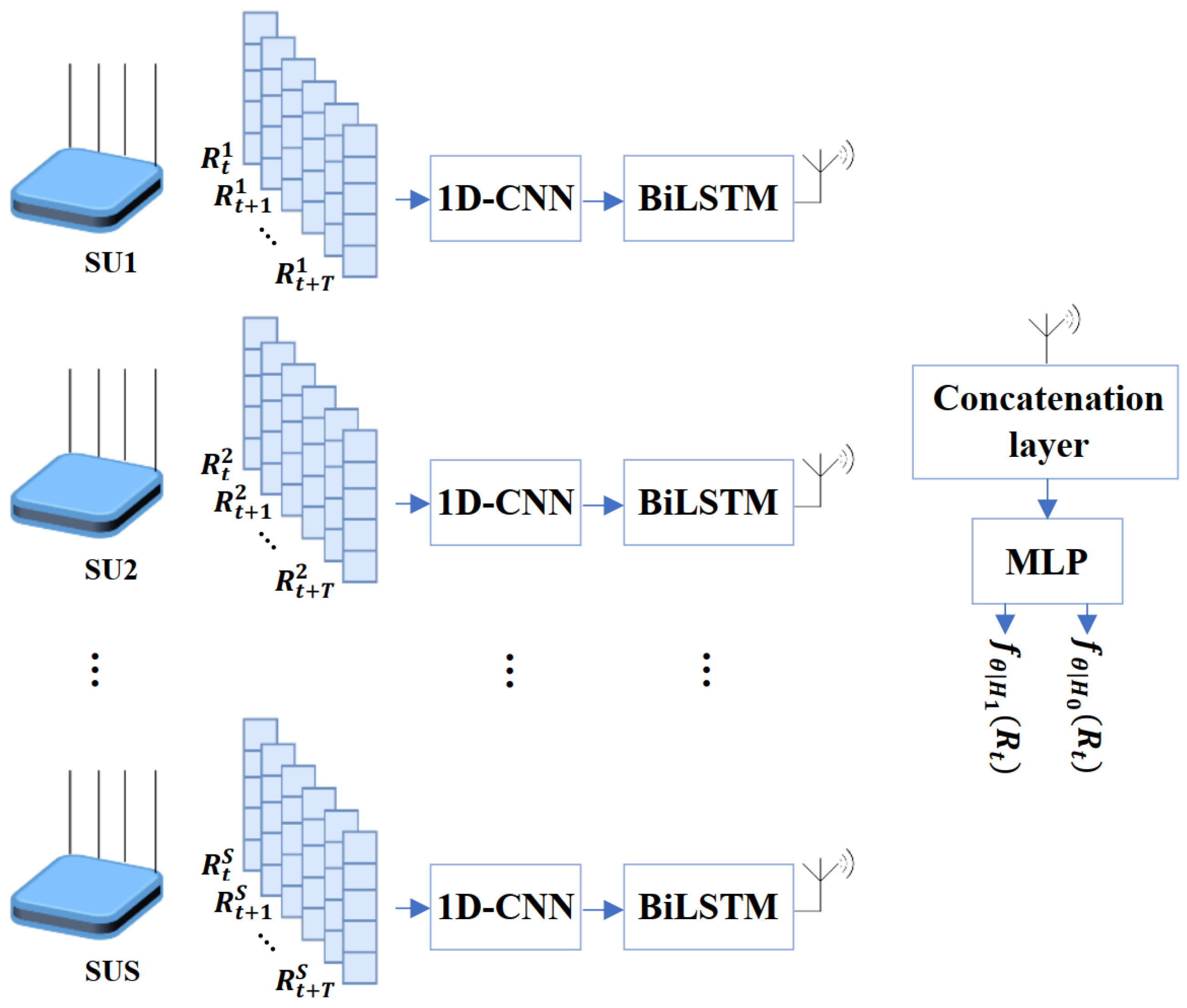
4.2.3. Hierarchical MLP with 1DCNN-BiLSTM
4.3. Training Model
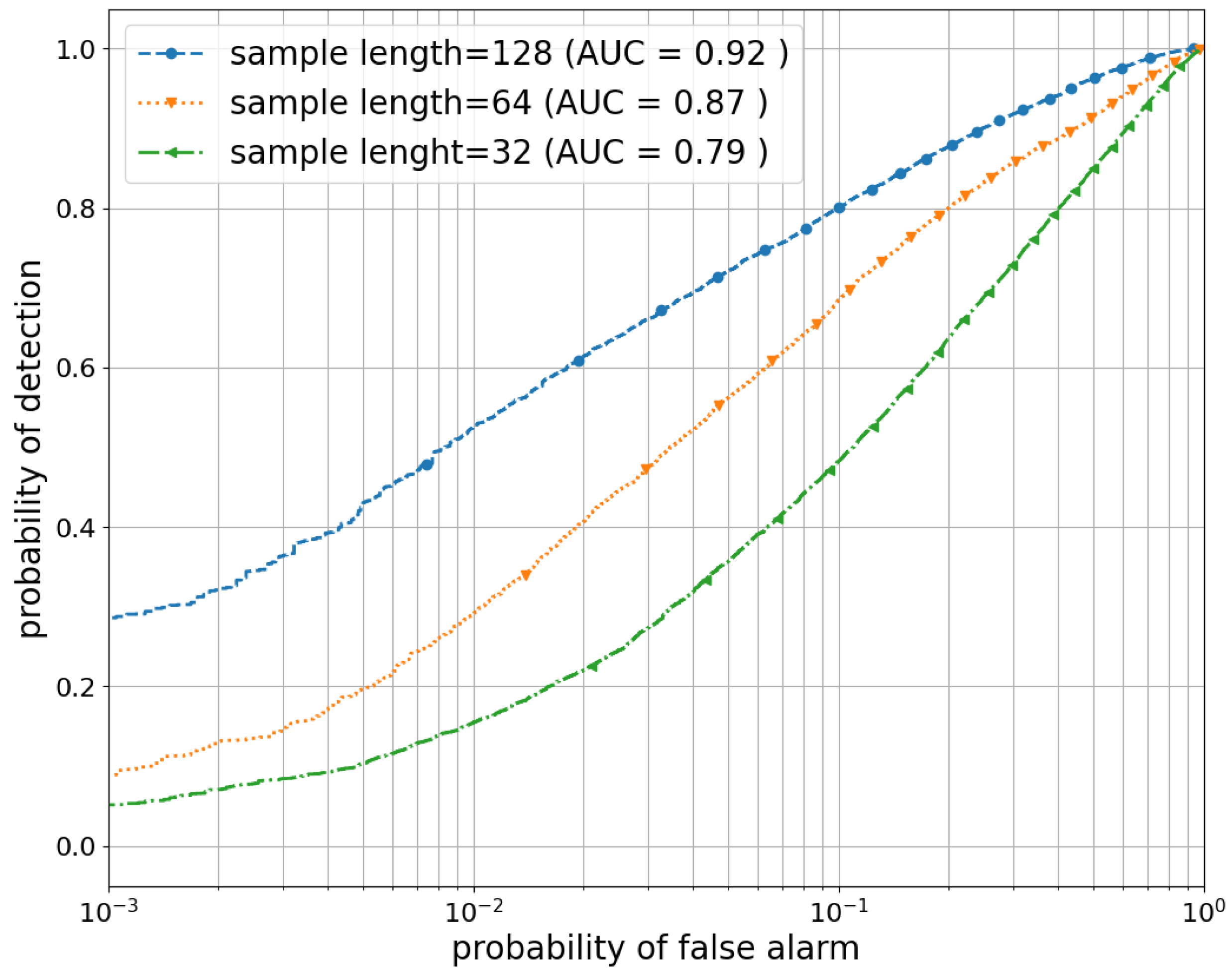
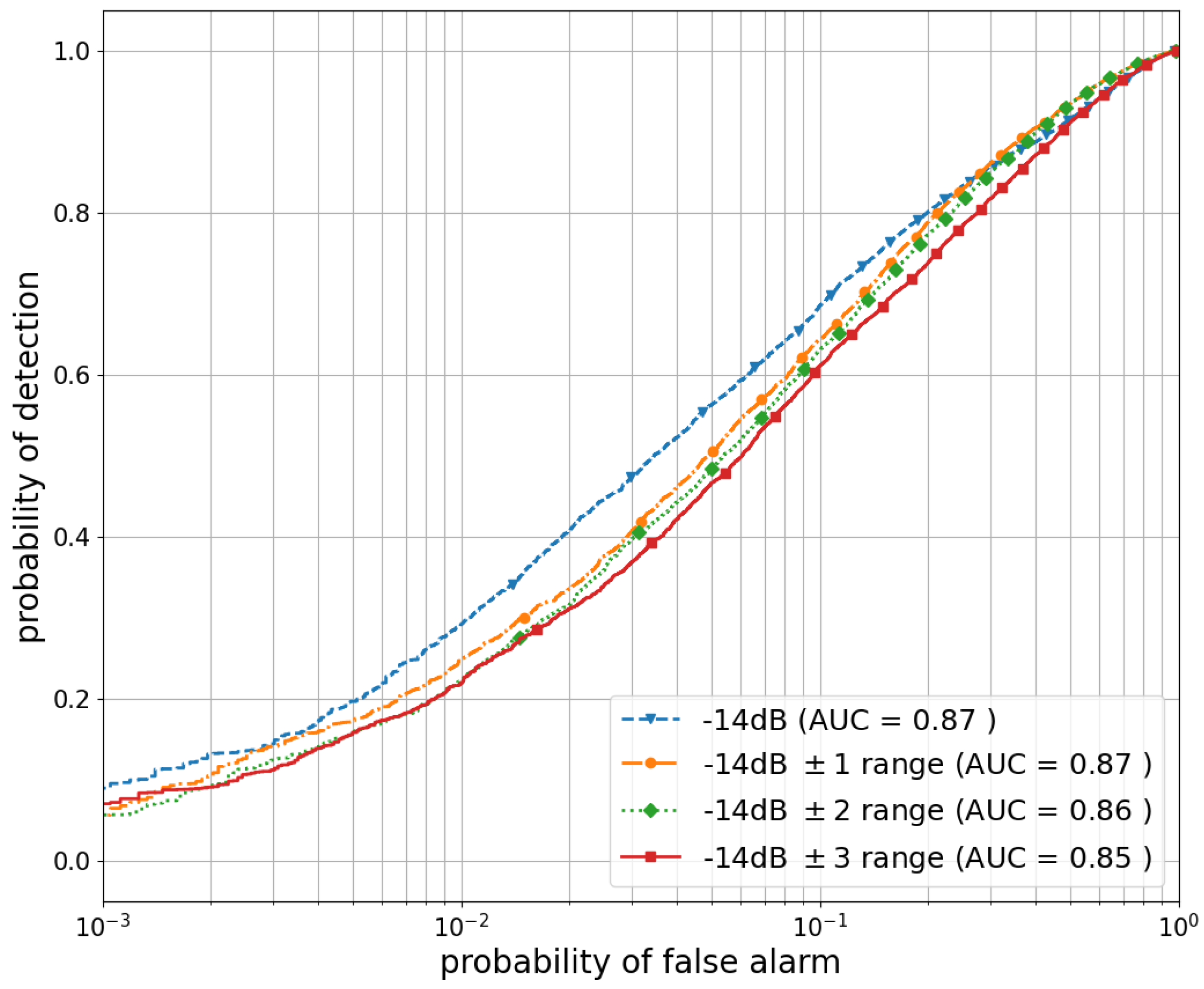
5. Simulation Results and Discussion
5.1. Simulation Environment
- For the PU-SU channel models, we assumed
- noise signals as i.i.d. Gaussian random vectors with zero mean and variance that add up the PU signal at the SU receivers;
- gains following a Rayleigh distribution with parameter .
5.2. Model Hyper-Parameters and Training Conditions
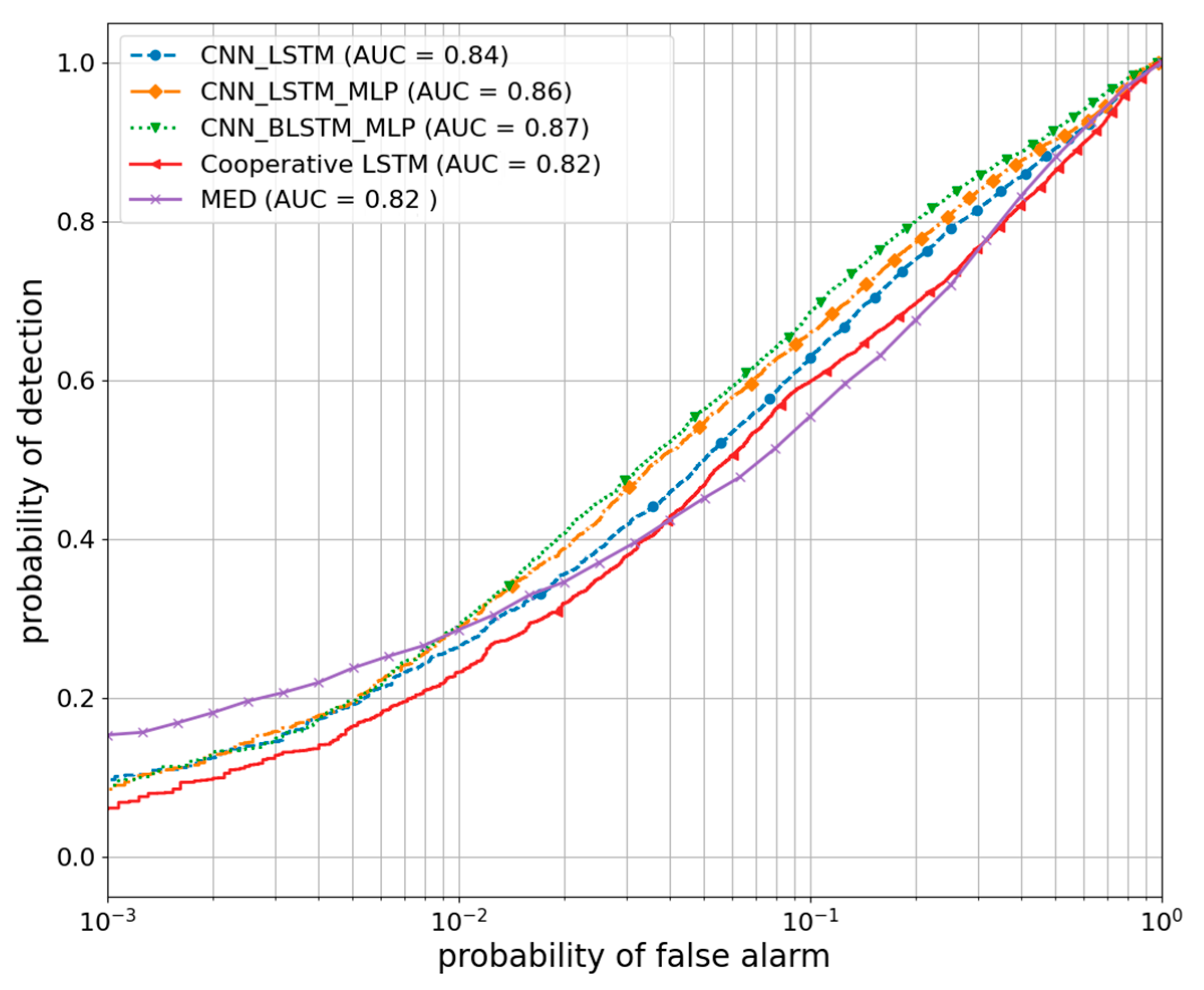
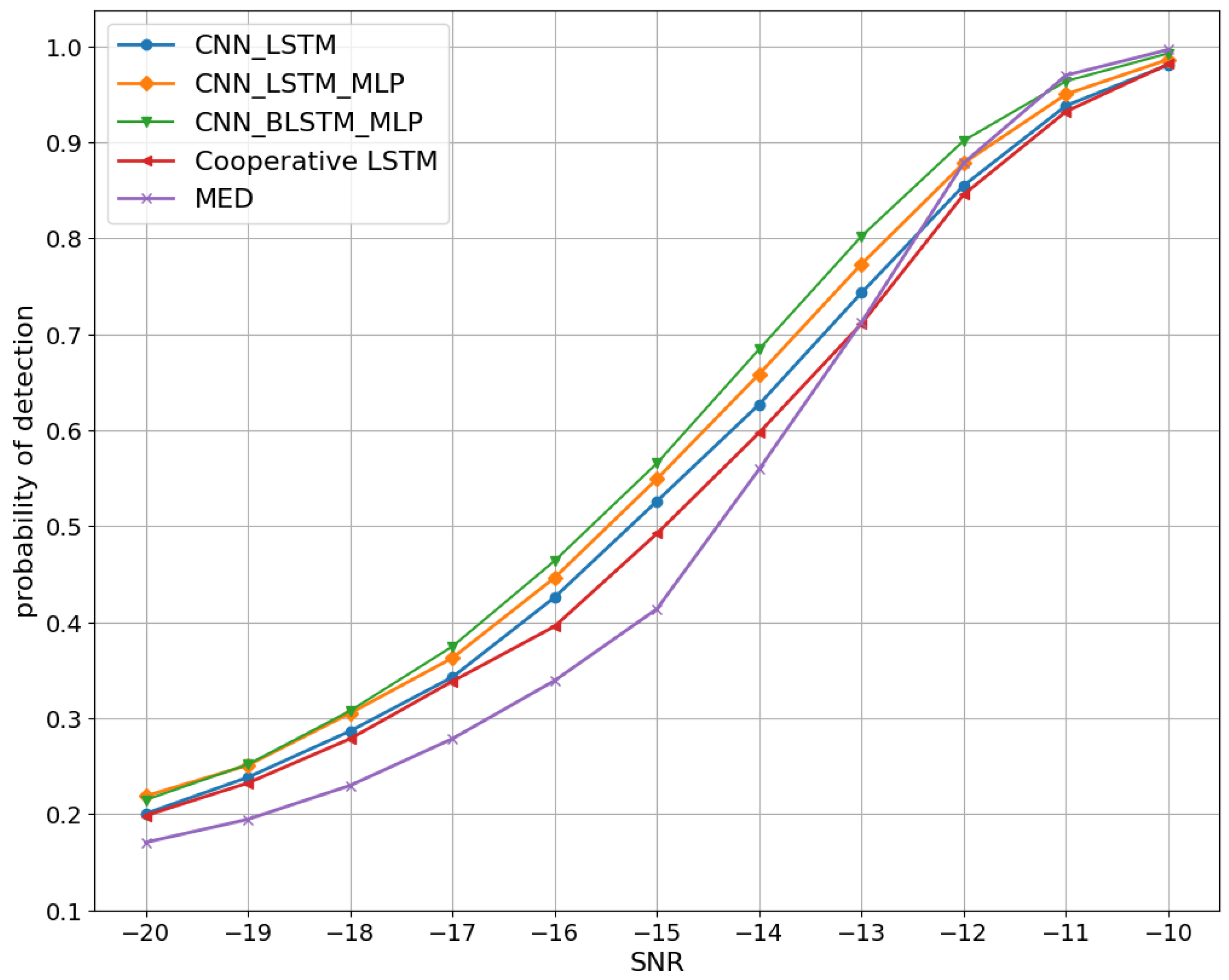
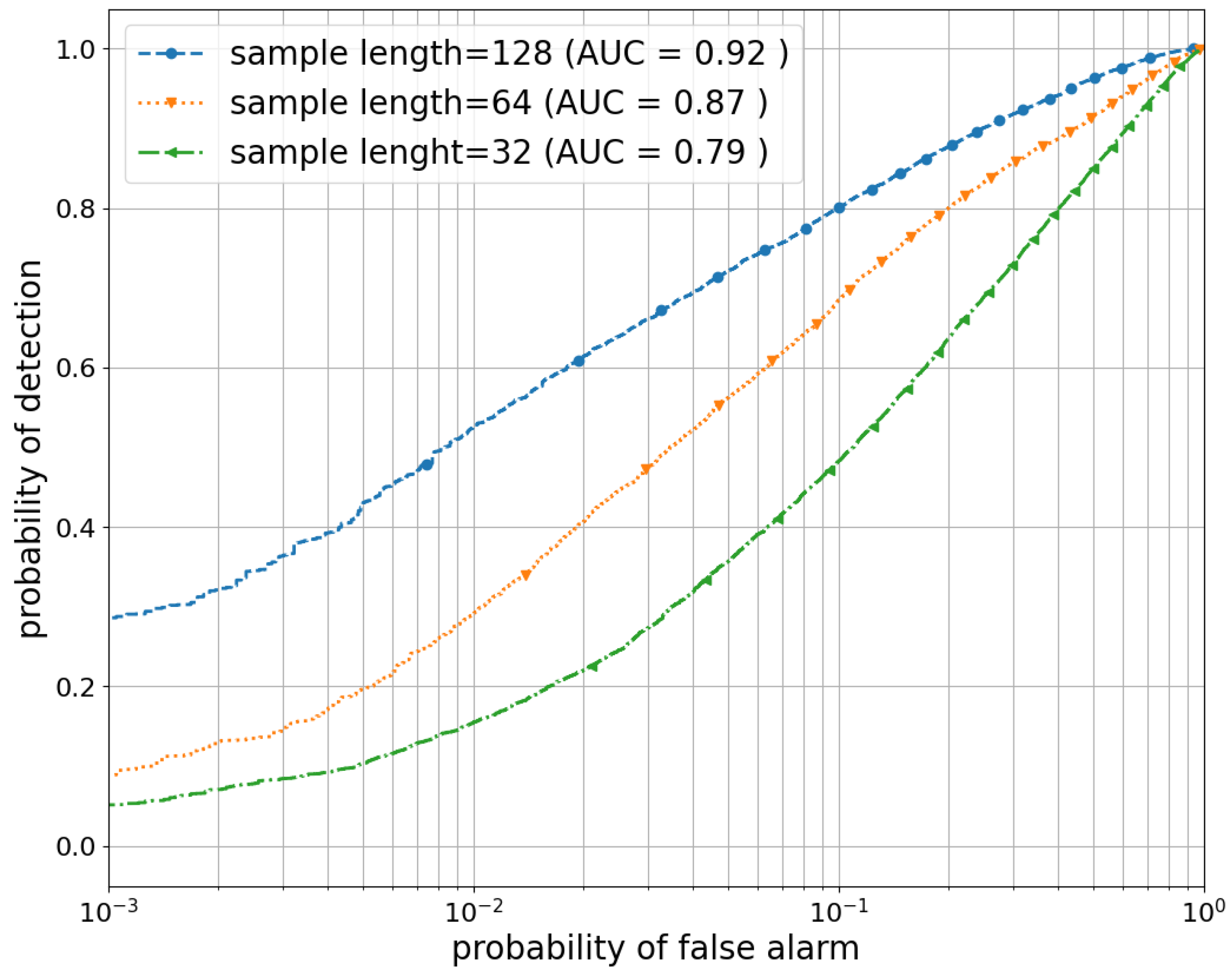
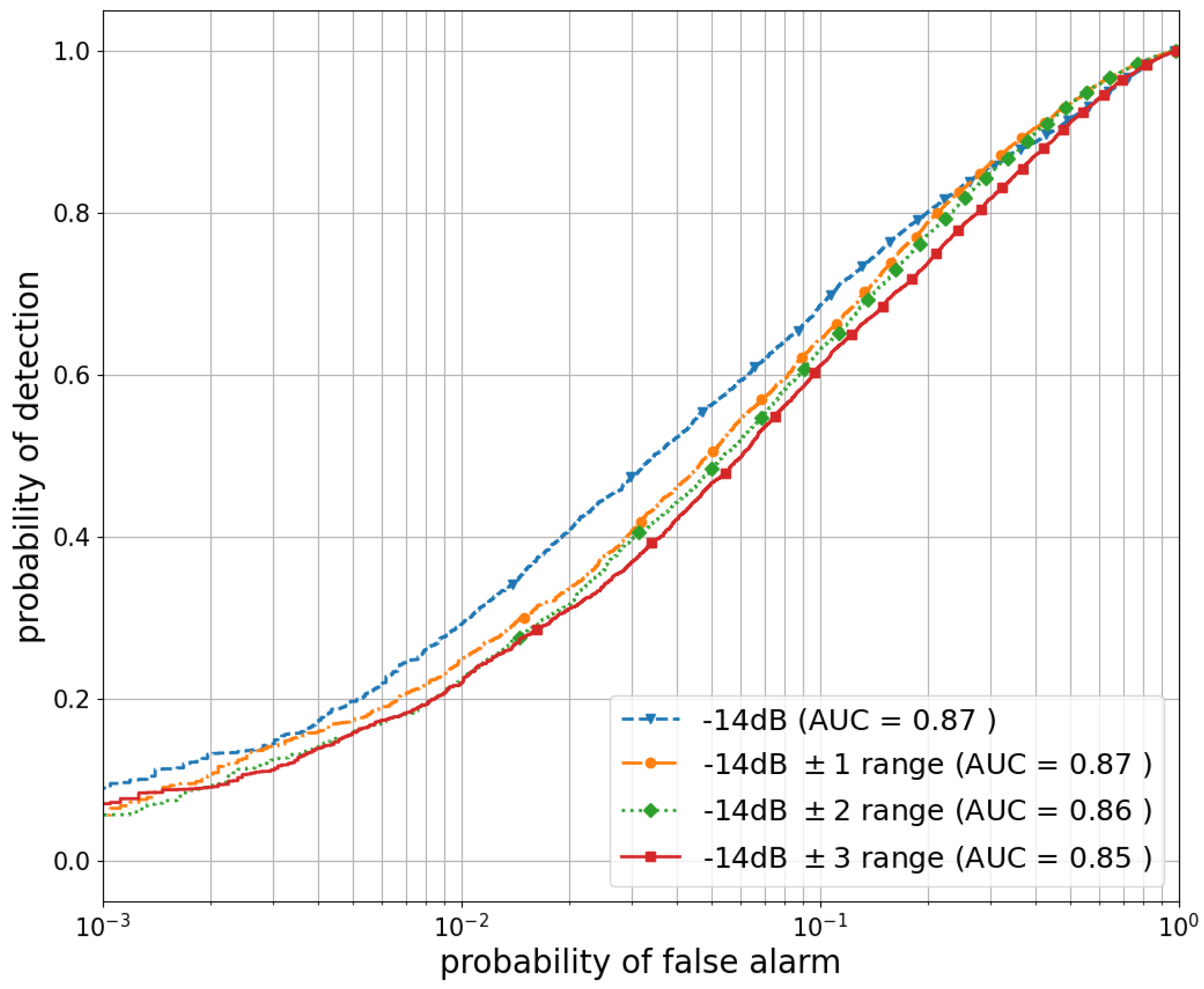
5.3. Performance Evaluation
6. Conclusions and Future Work
- The cooperative architecture is based only on centralized processing at the fusion center. In practical applications, this could lead to delays in decision making, particularly if there are difficulties in transmitting data quickly from the SUs to the fusion center. Other network topologies and/or distributed processing can be investigated.
- The current simulation involved only four secondary users and four antennas for the SU. A more complete dataset encompassing broader SU and antenna configurations would enable a more nuanced and comprehensive assessment.
- The study did not explicitly consider scenarios in which certain SUs might be sub-optimally positioned for data transmission. Factors such as SU mobility, obstacles on the communication path or SU malfunctions could be modeled in a future work. Effectively addressing these real-world challenges can lead to a more authentic evaluation of the cooperative spectrum sensing system.
- Finally, situations in which cooperation fails should be addressed. A thorough understanding and effective mitigation of these cases of cooperation failure can give information about the resilience and reliability of the proposed models in dynamic wireless environments.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Atzori, L.; Iera, A.; Morabito, G. The Internet of Things: A survey. Comput. Netw. 2010, 54, 2787–2805. [Google Scholar] [CrossRef]
- Raj, P.; Raman, A.C. Intelligent Cities: Enabling Tools and Technology; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
- Bin Sahbudin, M.A.; Chaouch, C.; Scarpa, M.; Serrano, S. IoT based Song Recognition for FM Radio Station Broadcasting. In Proceedings of the 2019 7th International Conference on Information and Communication Technology (ICoICT), Kuala Lumpur, Malaysia, 24–26 July 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Aswathy, G.P.; Gopakumar, K. Sub-Nyquist Wideband Spectrum Sensing Techniques for Cognitive Radio: A Review and Proposed Techniques. AEU-Int. J. Electron. Commun. 2019, 104, 44–57. [Google Scholar] [CrossRef]
- Mitola, J.; Maguire, G. Cognitive radio: Making software radios more personal. IEEE Pers. Commun. 1999, 6, 13–18. [Google Scholar] [CrossRef]
- Yucek, T.; Arslan, H. A survey of spectrum sensing algorithms for cognitive radio applications. IEEE Commun. Surv. Tutorials 2009, 11, 116–130. [Google Scholar] [CrossRef]
- Serrano, S.; Scarpa, M. A Petri Net Model for Cognitive Radio Internet of Things Networks Exploiting GSM Bands. Future Internet 2023, 15, 115. [Google Scholar] [CrossRef]
- Nasser, A.; Al Haj Hassan, H.; Abou Chaaya, J.; Mansour, A.; Yao, K.C. Spectrum Sensing for Cognitive Radio: Recent Advances and Future Challenge. Sensors 2021, 21, 2408. [Google Scholar] [CrossRef]
- Patil, A.; Iyer, S.; Lopez, O.L.; Pandya, R.J.; Pai, K.; Kalla, A.; Kallimani, R. A Comprehensive Survey on Spectrum Sharing Techniques for 5G/B5G Intelligent Wireless Networks: Opportunities, Challenges and Future Research Directions. arXiv 2022, arXiv:2211.08956. [Google Scholar] [CrossRef]
- Hu, X.L.; Ho, P.H.; Peng, L. Fundamental Limitations in Energy Detection for Spectrum Sensing. J. Sens. Actuator Netw. 2018, 7, 25. [Google Scholar] [CrossRef]
- Serrano, S.; Scarpa, M.; Maali, A.; Soulmani, A.; Boumaaz, N. Random sampling for effective spectrum sensing in cognitive radio time slotted environment. Phys. Commun. 2021, 49, 101482. [Google Scholar] [CrossRef]
- Barrak, S.E.; Lyhyaoui, A.; Gonnouni, A.E.; Puliafito, A.; Serrano, S. Application of MVDR and MUSIC Spectrum Sensing Techniques with Implementation of Node’s Prototype for Cognitive Radio Ad-Hoc Networks. In Proceedings of the 2017 International Conference on Smart Digital Environment, New York, NY, USA, 21–23 July 2017; pp. 101–106. [Google Scholar] [CrossRef]
- Coluccia, A.; Fascista, A.; Ricci, G. Spectrum sensing by higher-order SVM-based detection. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), A Coruna, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Saber, M.; El Rharras, A.; Saadane, R.; Kharraz, A.H.; Chehri, A. An Optimized Spectrum Sensing Implementation Based on SVM, KNN and TREE Algorithms. In Proceedings of the 2019 15th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Sorrento, Italy, 26–29 November 2019; pp. 383–389. [Google Scholar] [CrossRef]
- Chen, W.; Wu, H.; Ren, S. CM-LSTM Based Spectrum Sensing. Sensors 2022, 22, 2286. [Google Scholar] [CrossRef]
- Janu, D.; Singh, K.; Kumar, S. Machine learning for cooperative spectrum sensing and sharing: A survey. Trans. Emerg. Telecommun. Technol. 2022, 33, e4352. [Google Scholar] [CrossRef]
- Janu, D.; Singh, K.; Kumar, S.; Mandia, S. Hierarchical Cooperative LSTM-Based Spectrum Sensing. IEEE Commun. Lett. 2023, 27, 866–870. [Google Scholar] [CrossRef]
- Sarala, B.; Rukmani Devi, S.; Sheela, J.J.J. Spectrum energy detection in cognitive radio networks based on a novel adaptive threshold energy detection method. Comput. Commun. 2020, 152, 1–7. [Google Scholar] [CrossRef]
- Kumar, A.; NandhaKumar, P. OFDM system with cyclostationary feature detection spectrum sensing. ICT Express 2019, 5, 21–25. [Google Scholar] [CrossRef]
- Brito, A.; Sebastião, P.; Velez, F.J. Hybrid Matched Filter Detection Spectrum Sensing. IEEE Access 2021, 9, 165504–165516. [Google Scholar] [CrossRef]
- Awin, F.; Abdel-Raheem, E.; Tepe, K. Blind Spectrum Sensing Approaches for Interweaved Cognitive Radio System: A Tutorial and Short Course. IEEE Commun. Surv. Tutor. 2018, 21, 238–259. [Google Scholar] [CrossRef]
- Semlali, H.; Boumaaz, N.; Soulmani, A.; Ghammaz, A.; Diouris, J.F. Energy detection approach for spectrum sensing in cognitive radio systems with the use of random sampling. Wirel. Pers. Commun. 2014, 79, 1053–1061. [Google Scholar] [CrossRef]
- Gao, R.; Qi, P.; Zhang, Z. Performance analysis of spectrum sensing schemes based on energy detector in generalized Gaussian noise. Signal Process. 2021, 181, 107893. [Google Scholar] [CrossRef]
- Zeng, Y.; Koh, C.L.; Liang, Y.C. Maximum Eigenvalue Detection: Theory and Application. In Proceedings of the 2008 IEEE International Conference on Communications, Beijing, China, 19–23 May 2008; pp. 4160–4164. [Google Scholar] [CrossRef]
- Kumar, A.; Khan, A.S.; Modanwal, N.; Saha, S. Experimental studies on energy and eigenvalue based Spectrum sensing algorithms using USRP devices in OFDM systems. Radio Sci. 2020, 55, 1–11. [Google Scholar] [CrossRef]
- Tan, P.N.; Steinbach, M.; Kumar, V. Introduction to Data Mining; Pearson Education: Bangalore, India, 2016. [Google Scholar]
- Sahbudin, M.A.B.; Scarpa, M.; Serrano, S. MongoDB Clustering using K-means for Real-Time Song Recognition. In Proceedings of the 2019 International Conference on Computing, Networking and Communications (ICNC), Honolulu, HI, USA, 18–21 February 2019; pp. 350–354. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, Y.; Wan, P.; Zhang, S.; Yang, J. A spectrum sensing method based on empirical mode decomposition and k-means clustering algorithm. Wirel. Commun. Mob. Comput. 2018, 2018, 6104502. [Google Scholar] [CrossRef]
- Lei, K.j.; Tan, Y.h.; Yang, X.; Wang, H.r. A K-means clustering based blind multiband spectrum sensing algorithm for cognitive radio. J. Cent. South Univ. 2018, 25, 2451–2461. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Peng, Q.; Gilman, A.; Vasconcelos, N.; Cosman, P.C.; Milstein, L.B. Robust Deep Sensing Through Transfer Learning in Cognitive Radio. IEEE Wirel. Commun. Lett. 2020, 9, 38–41. [Google Scholar] [CrossRef]
- Zheng, S.; Chen, S.; Qi, P.; Zhou, H.; Yang, X. Spectrum sensing based on deep learning classification for cognitive radios. China Commun. 2020, 17, 138–148. [Google Scholar] [CrossRef]
- Gao, J.; Yi, X.; Zhong, C.; Chen, X.; Zhang, Z. Deep Learning for Spectrum Sensing. IEEE Wirel. Commun. Lett. 2019, 8, 1727–1730. [Google Scholar] [CrossRef]
- Yang, K.; Huang, Z.; Wang, X.; Li, X. A Blind Spectrum Sensing Method Based on Deep Learning. Sensors 2019, 19, 2270. [Google Scholar] [CrossRef]
- Wasilewska, M.; Bogucka, H.; Kliks, A. Federated Learning for 5G Radio Spectrum Sensing. Sensors 2021, 22, 198. [Google Scholar] [CrossRef]
- Tan, Y.; Jing, X. Cooperative Spectrum Sensing Based on Convolutional Neural Networks. Appl. Sci. 2021, 11, 4440. [Google Scholar] [CrossRef]
- Soni, B.; Patel, D.K.; López-Benítez, M. Long Short-Term Memory Based Spectrum Sensing Scheme for Cognitive Radio Using Primary Activity Statistics. IEEE Access 2020, 8, 97437–97451. [Google Scholar] [CrossRef]
- Xu, M.; Yin, Z.; Zhao, Y.; Wu, Z. Cooperative Spectrum Sensing Based on Multi-Features Combination Network in Cognitive Radio Network. Entropy 2022, 24, 129. [Google Scholar] [CrossRef] [PubMed]
- Xie, J.; Fang, J.; Liu, C.; Li, X. Deep Learning-Based Spectrum Sensing in Cognitive Radio: A CNN-LSTM Approach. IEEE Commun. Lett. 2020, 24, 2196–2200. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Xiao, Z.; Xu, X.; Xing, H.; Luo, S.; Dai, P.; Zhan, D. RTFN: A robust temporal feature network for time series classification. Inf. Sci. 2021, 571, 65–86. [Google Scholar] [CrossRef]
- Xing, H.; Qin, H.; Luo, S.; Dai, P.; Xu, L.; Cheng, X. Spectrum sensing in cognitive radio: A deep learning based model. Trans. Emerg. Telecommun. Technol. 2022, 33, e4388. [Google Scholar] [CrossRef]
- Grasso, C.; Raftopoulos, R.; Schembra, G.; Serrano, S. H-HOME: A learning framework of federated FANETs to provide edge computing to future delay-constrained IoT systems. Comput. Netw. 2022, 219, 109449. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated Machine Learning: Concept and Applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Chen, Z.; Xu, Y.Q.; Wang, H.; Guo, D. Federated Learning-Based Cooperative Spectrum Sensing in Cognitive Radio. IEEE Commun. Lett. 2022, 26, 330–334. [Google Scholar] [CrossRef]
- Zhu, R.; Li, M.; Liu, H.; Liu, L.; Ma, M. Federated Deep Reinforcement Learning-Based Spectrum Access Algorithm With Warranty Contract in Intelligent Transportation Systems. IEEE Trans. Intell. Transp. Syst. 2023, 24, 1178–1190. [Google Scholar] [CrossRef]
- Du, K.L.; Leung, C.S.; Mow, W.H.; Swamy, M.N.S. Perceptron: Learning, Generalization, Model Selection, Fault Tolerance, and Role in the Deep Learning Era. Mathematics 2022, 10, 4730. [Google Scholar] [CrossRef]
- Wang, Y.; Li, Y.; Song, Y.; Rong, X. The Influence of the Activation Function in a Convolution Neural Network Model of Facial Expression Recognition. Appl. Sci. 2020, 10, 1897. [Google Scholar] [CrossRef]
- Keskar, N.S.; Socher, R. Improving Generalization Performance by Switching from Adam to SGD. arXiv 2017, arXiv:1712.07628. [Google Scholar] [CrossRef]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Reddi, S.J.; Kale, S.; Kumar, S. On the Convergence of Adam and Beyond. arXiv 2019, arXiv:1904.09237. [Google Scholar]
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the Variance of the Adaptive Learning Rate and Beyond. arXiv 2021, arXiv:1908.03265. [Google Scholar]
- Tavares, C.H.A.; Marinello, J.C.; Proenca Jr, M.L.; Abrao, T. Machine learning-based models for spectrum sensing in cooperative radio networks. IET Commun. 2020, 14, 3102–3109. [Google Scholar] [CrossRef]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D convolutional neural networks and applications: A survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description | Value |
|---|---|---|
| N | Number of samples in a sensing period | 64 |
| S | Number of cooperating SUs | 4 |
| M | Number of antennas on each SU | 4 |
| PU samples | Gaussian random variables | |
| PU sample mean | 0 | |
| PU sample variance | 1 | |
| Path gain at antenna m of SU s | Rayleigh random variable | |
| Scale parameter of the Rayleigh distribution | ||
| Noise samples at antenna m of SU s | Gaussian random variables | |
| Noise sample mean | 0 | |
| Noise sample variance | Evaluated according to desired SNR and current | |
| SNR | default SNR at SU | dB |
| BER | Bit error rate for service messages |
| Parameter Settings | Parameter Description | Layer Name |
|---|---|---|
| CNN module | (Activation: ReLU) | |
| Input | (256 × 1) | |
| Kernel number and size | (40, 9) | Conv 1, 2 |
| Pool size | 2 | MaxPool |
| LSTM module | Unit number: 64 | LSTM layer 1 |
| BiLSTM module | Unit number: 64 | BiLSTM layer 1 |
| Cooperative LSTM | Unit number: 64 | CLSTM layer 1 |
| Cooperative MLP | Unit number: 128, 64, 2 | MLP layer 1, 2, 3 |
| Method | Online Detection (ms) |
|---|---|
| CNN_LSTM | 22 |
| CNN_LSTM_MLP | 22 |
| CNN_BLSTM_MLP | 23 |
| Cooperative LSTM | 25 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Serghini, O.; Semlali, H.; Maali, A.; Ghammaz, A.; Serrano, S. 1-D Convolutional Neural Network-Based Models for Cooperative Spectrum Sensing. Future Internet 2024, 16, 14. https://doi.org/10.3390/fi16010014
Serghini O, Semlali H, Maali A, Ghammaz A, Serrano S. 1-D Convolutional Neural Network-Based Models for Cooperative Spectrum Sensing. Future Internet. 2024; 16(1):14. https://doi.org/10.3390/fi16010014
Chicago/Turabian StyleSerghini, Omar, Hayat Semlali, Asmaa Maali, Abdelilah Ghammaz, and Salvatore Serrano. 2024. "1-D Convolutional Neural Network-Based Models for Cooperative Spectrum Sensing" Future Internet 16, no. 1: 14. https://doi.org/10.3390/fi16010014
APA StyleSerghini, O., Semlali, H., Maali, A., Ghammaz, A., & Serrano, S. (2024). 1-D Convolutional Neural Network-Based Models for Cooperative Spectrum Sensing. Future Internet, 16(1), 14. https://doi.org/10.3390/fi16010014