
2D Semantic Segmentation: Recent Developments and Future Directions


Abstract
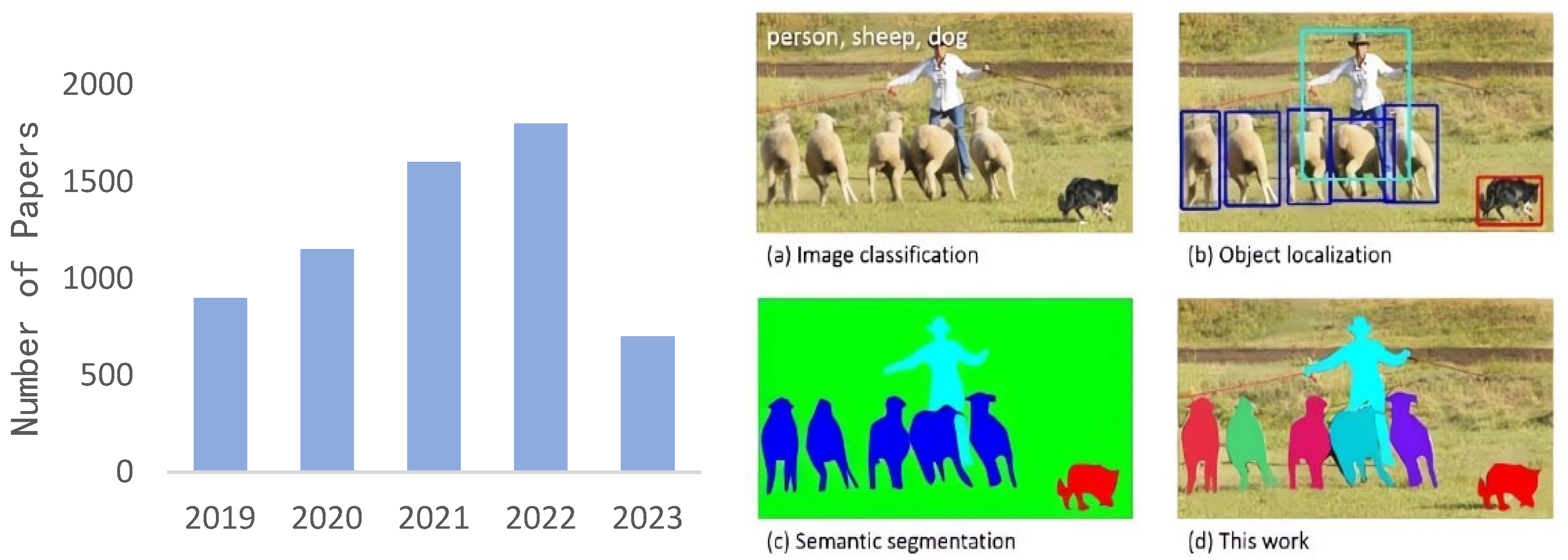
1. Introduction
2. Traditional Methods before Deep Learning
2.1. SVMs
2.2. Decision Trees
2.3. K-Means
2.4. CRFs
3. Classical Networks Based on Deep Learning
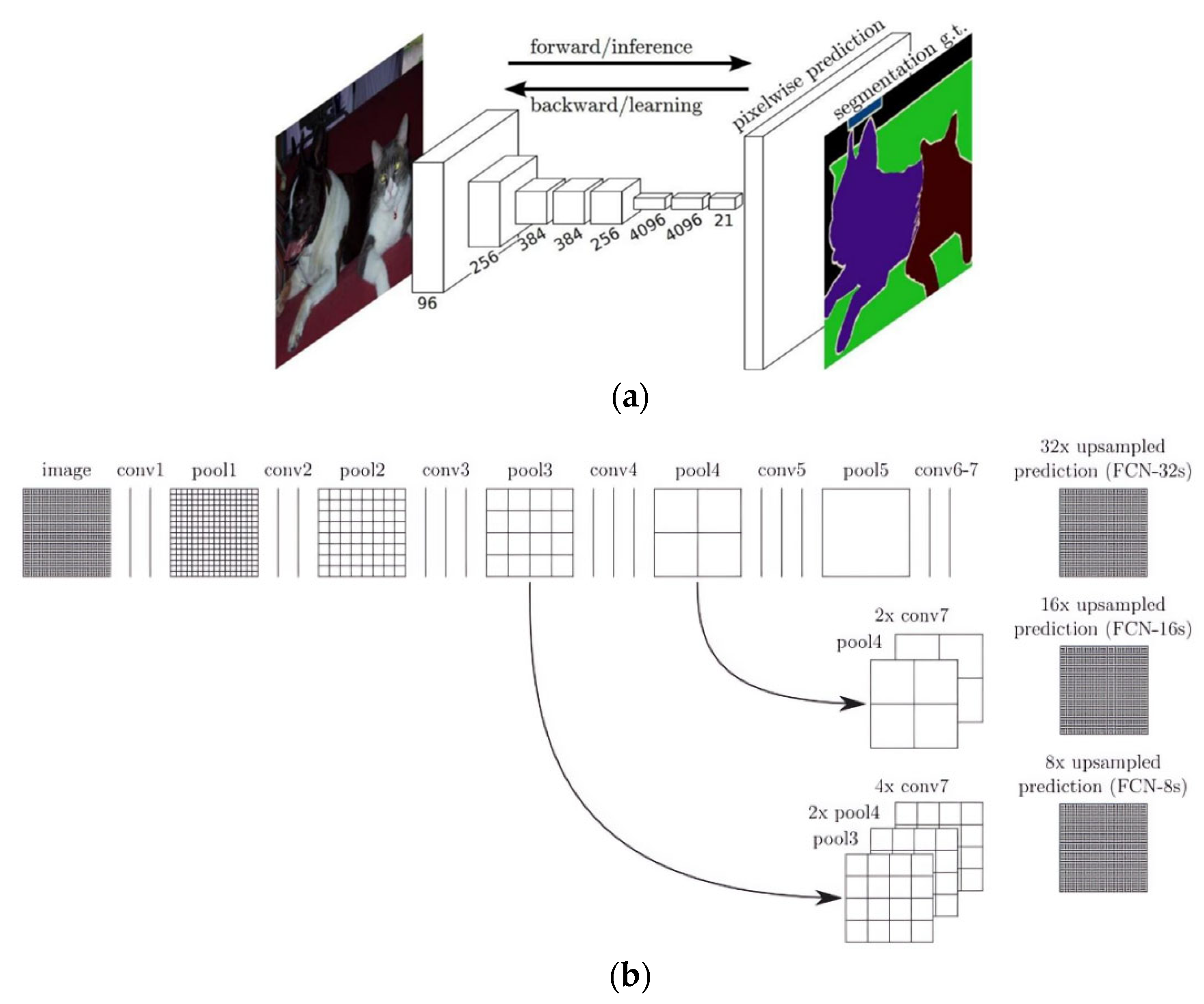
3.1. Fully Convolutional Networks
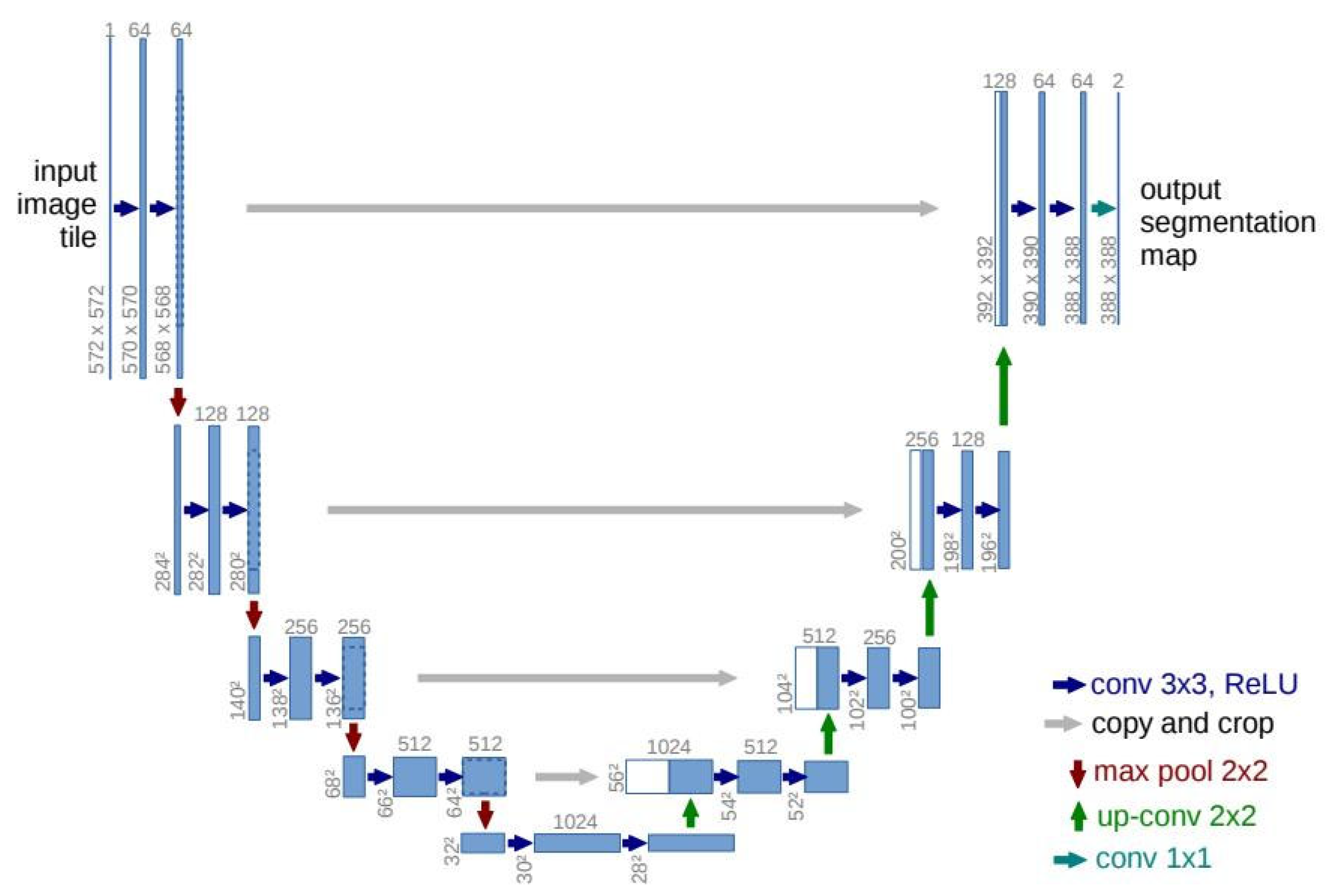
3.2. U-Net
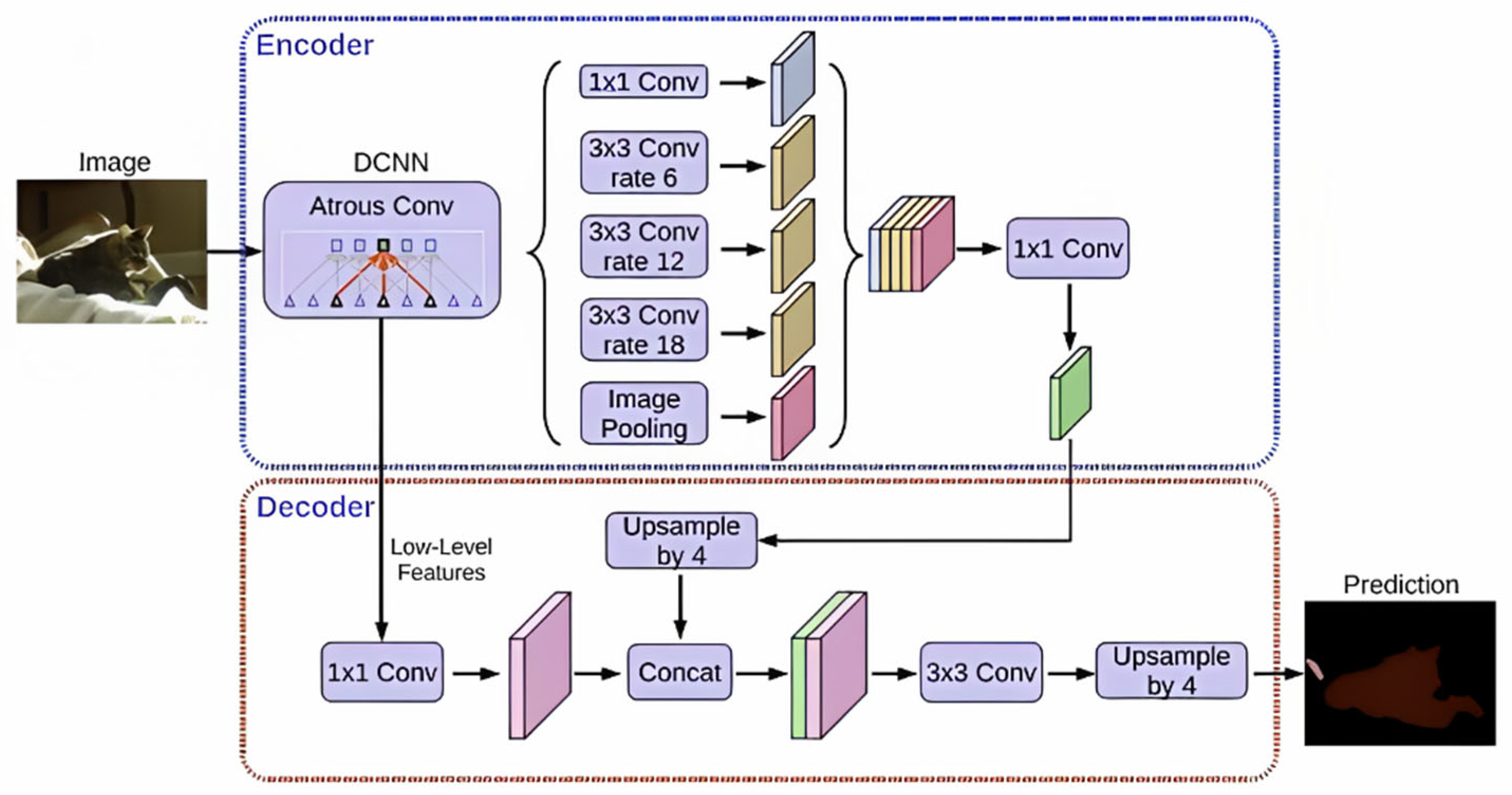
3.3. DeepLab Family
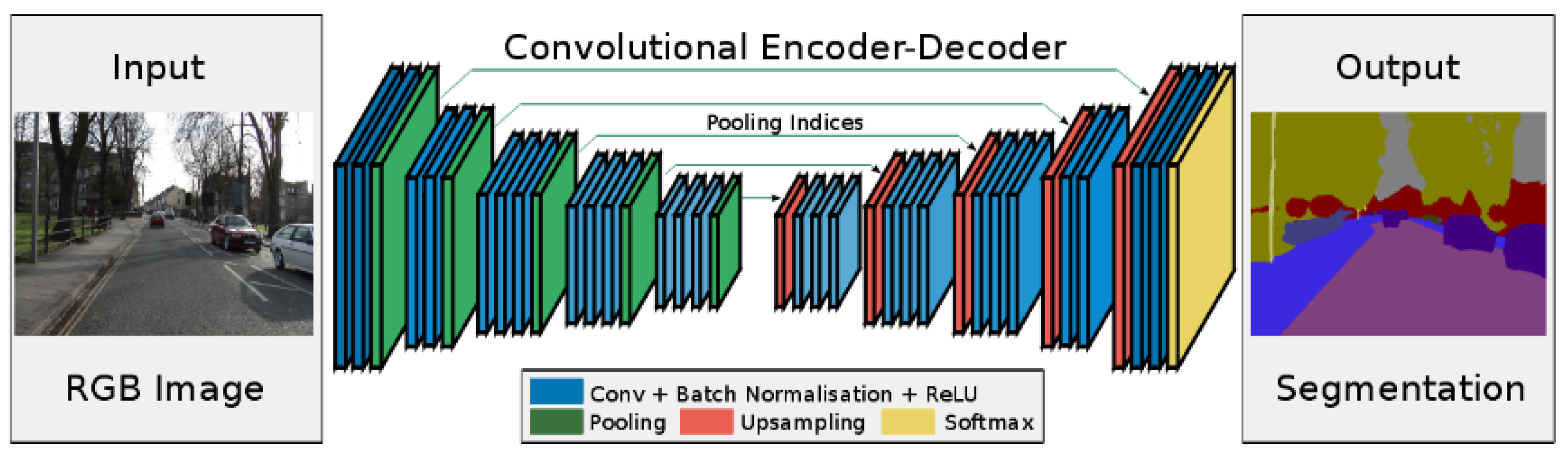
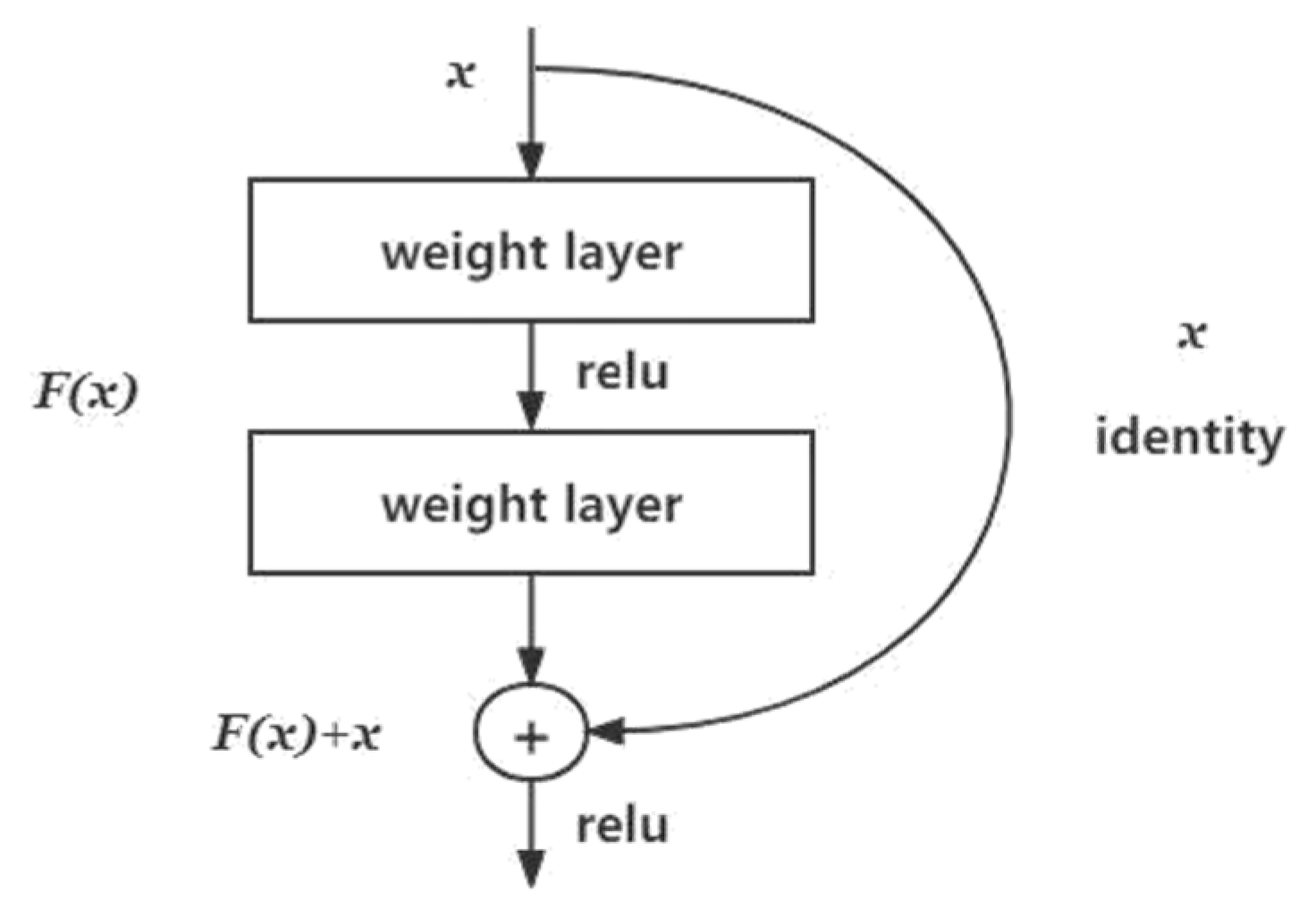
3.4. SegNet
- (1)
- Introducing multiscale information such as pyramid pooling and multiscale fusion can improve segmentation accuracy. SegNet’s model structure can be simplified using a lightweight network structure to reduce memory and computational resource consumption.
- (2)
- Other methods such as residual connections and attention mechanisms can be explored to address the problem of vanishing gradients. Although the SegNet algorithm has certain limitations, it is still a classic semantic segmentation algorithm that can perform well in specific scenarios.
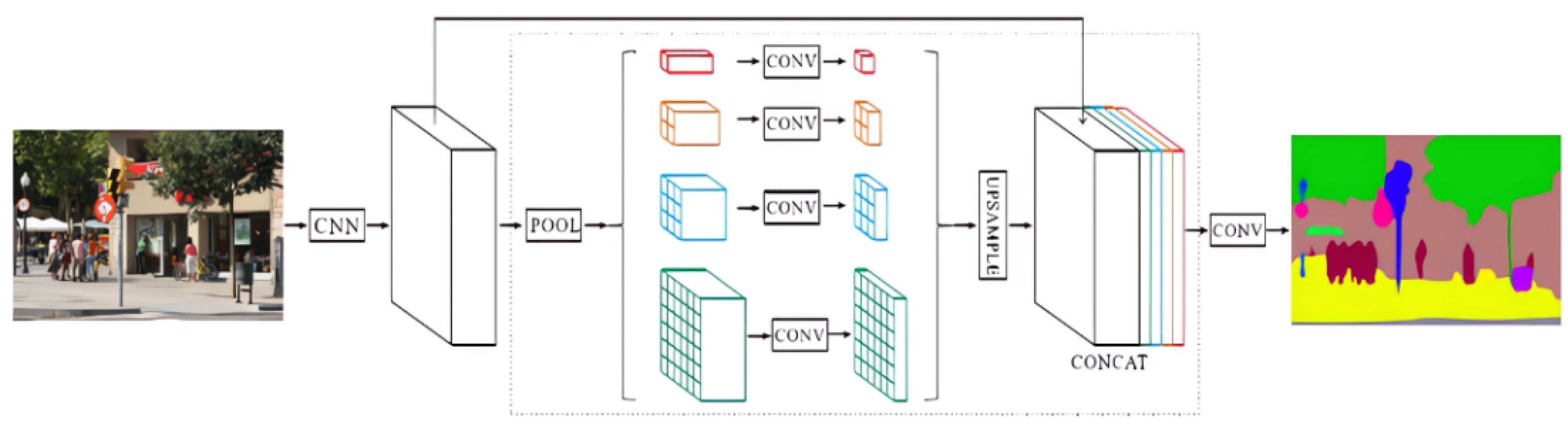
3.5. PSPNet
4. Key Technologies to Improve the Effect of Semantic Segmentation
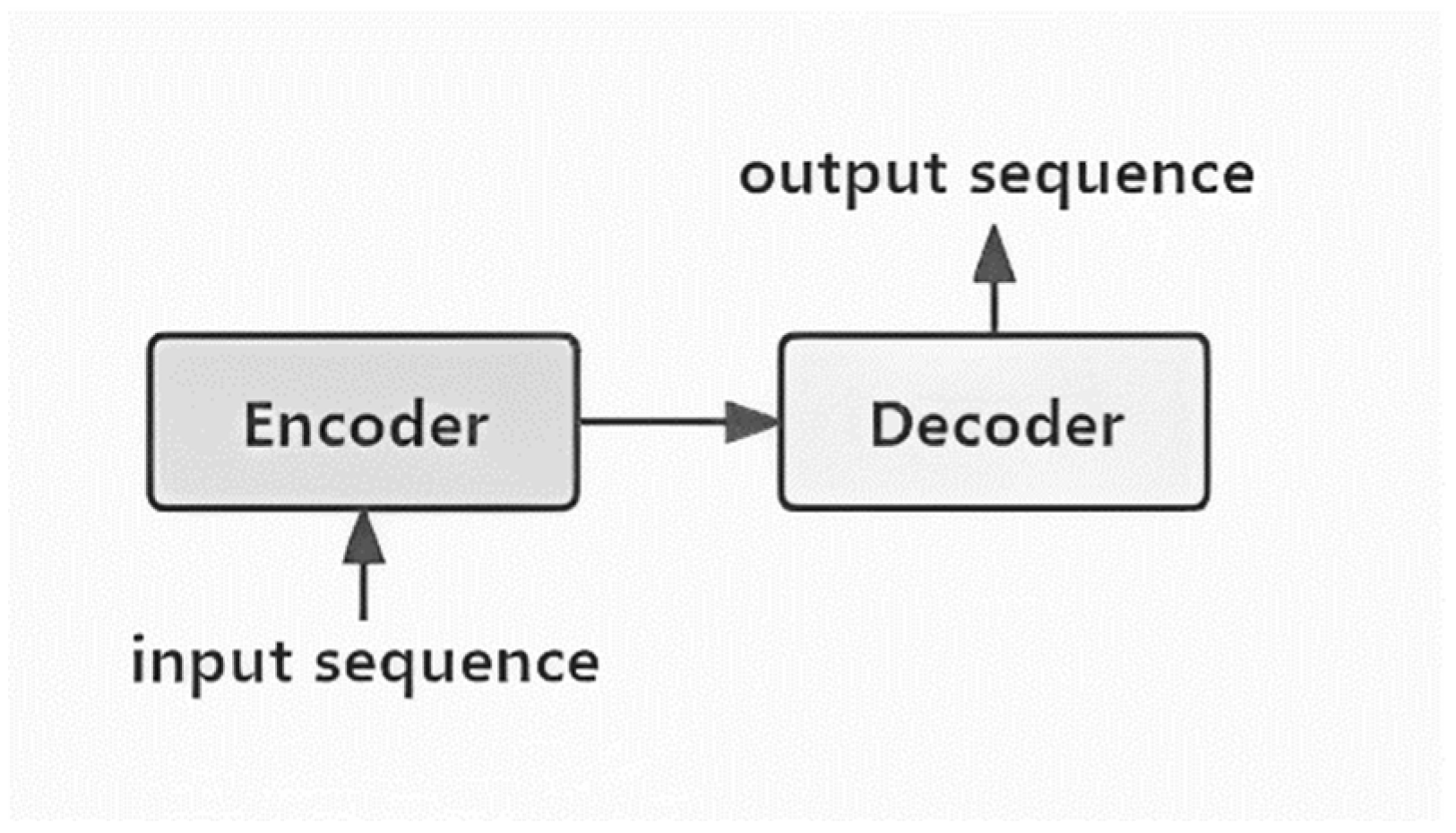
4.1. Development Trend of Encoder–Decoder Systems
- (1)
- Adaptive Feature Fusion: Traditional encoder–decoder architectures often rely on fixed feature fusion strategies. However, these strategies may not fully exploit the multiscale information in images. Therefore, we suggest continuing research on adaptive feature fusion methods that dynamically adjust the feature fusion weights based on the input image characteristics, thereby achieving more precise semantic segmentation.
- (2)
- Task-Oriented Encoder Design: Current encoder–decoder architectures often employ generic encoder structures such as ResNet and VGG. Although these generic encoders exhibit excellent feature extraction capabilities, they may not be optimized for specific semantic segmentation tasks. To address this issue, we propose designing a task-oriented encoder structure that incorporates modules specifically designed for semantic segmentation, thereby improving feature extraction effectiveness.
- (3)
- Dynamic Decoder Optimization: Traditional decoder structures usually adopt fixed upsampling and fusion strategies. However, these strategies may not fully recover the image’s detail information. To address this issue, we suggest further investigation of dynamic decoder optimization methods by introducing adaptive upsampling and fusion strategies to dynamically recover detail information based on input image characteristics.
- (4)
- Integration of Vision Transformers (ViTs): Vision Transformers (ViTs) have achieved significant success in the computer vision field. It is worth continuing in-depth research on better integrating ViTs with encoder–decoder architectures, leveraging ViTs’ powerful remote dependency modeling capabilities, and achieving more accurate semantic segmentation through end-to-end training.
- (5)
- Guiding Semantic Segmentation with Prior Knowledge: In many practical applications, images often exhibit specific structures and prior knowledge. For example, in medical image segmentation, we usually have some understanding of the target structure’s shape and location. Therefore, introducing this prior knowledge into encoder–decoder architectures can guide the model toward learning more reasonable semantic segmentation results. This can be achieved by adding prior knowledge constraints to the loss function or designing specific prior knowledge modules.
- (6)
- Adaptive Domain Adaptation: In practical applications, domain differences may cause performance fluctuations in the model across different data sets. To address this issue, we suggest researching an adaptive domain adaptation method based on encoder–decoder architectures to learn the mapping relationship between source and target domains to improve the model’s generalization capabilities in the target domain.
- (7)
- Integration of Multimodal Information: In many practical scenarios, besides RGB images, other modalities of data such as depth information and spectral information can be obtained. This multimodal information provides a richer context for semantic segmentation. Therefore, we propose incorporating multimodal information into encoder–decoder architectures to improve segmentation performance. Specific approaches may include designing multimodal fusion modules or using multitask learning to simultaneously learn feature representations of different modalities.
4.2. Skip Connections
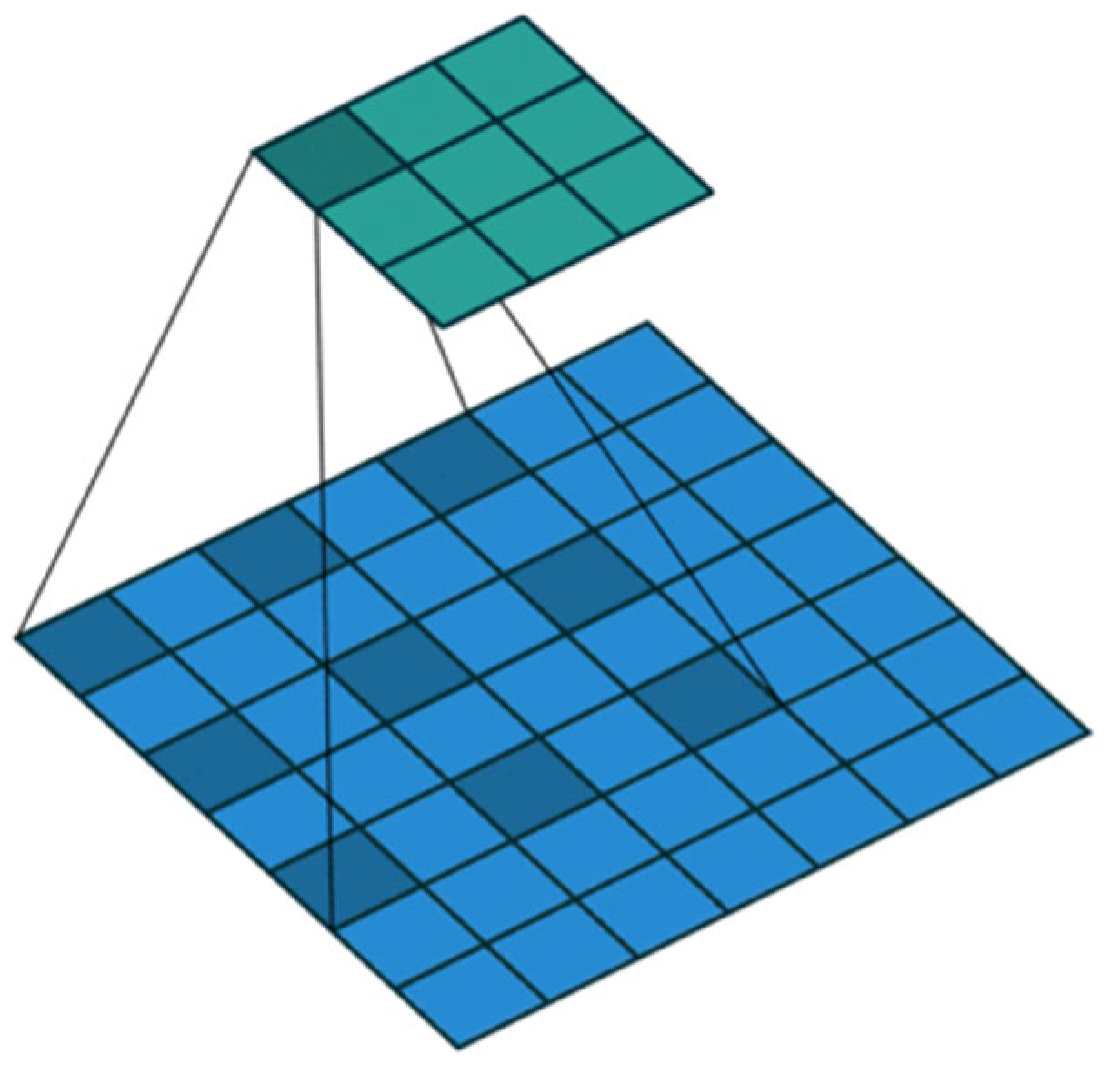
4.3. Spatial Pyramid Pooling
4.4. Dilated Convolutions
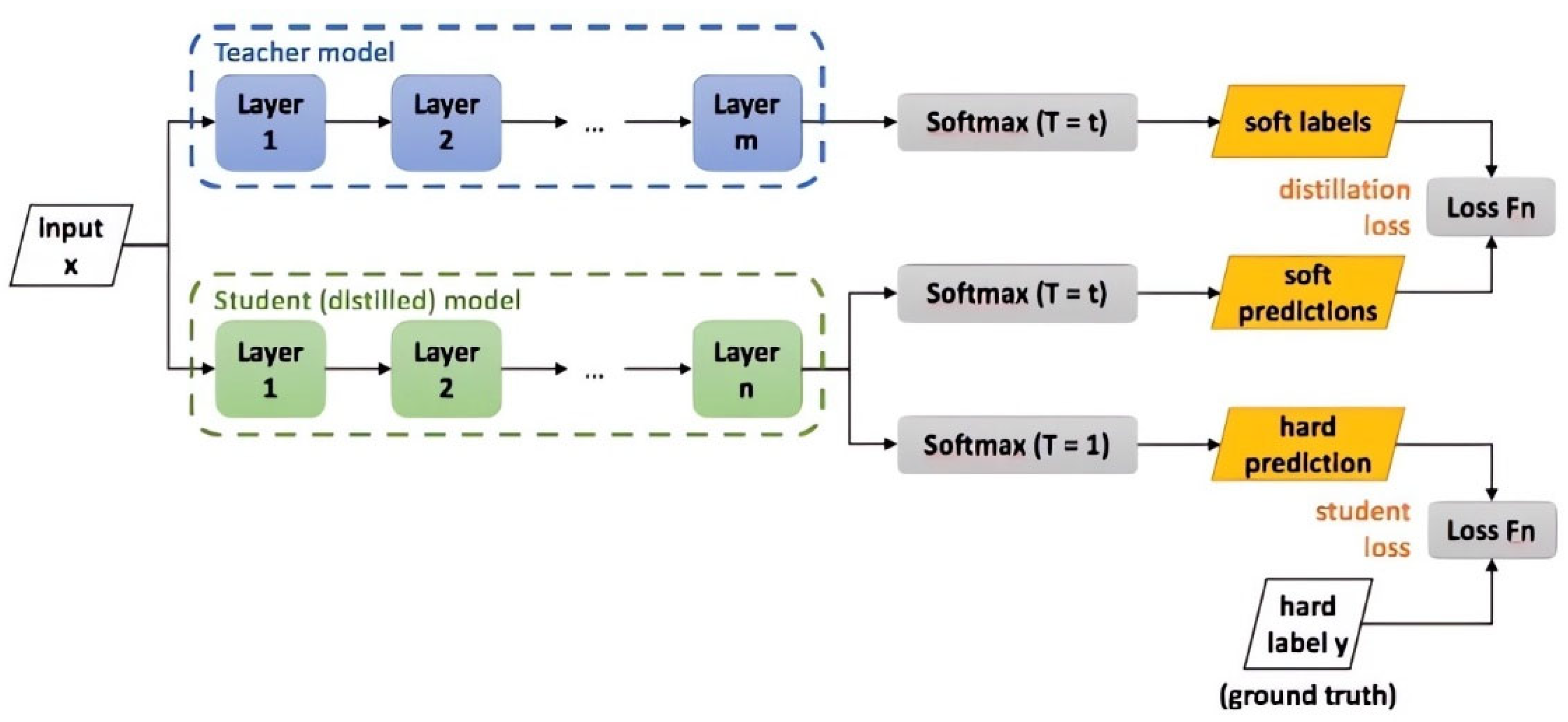
4.5. Knowledge Distillation
- (1)
- Adaptive Knowledge Distillation: Traditional knowledge distillation methods often require manually setting fixed loss weights. To reduce human intervention and improve distillation performance, it is worth exploring adaptive methods for adjusting loss weights. This can be achieved by introducing dynamic weight allocation strategies that automatically adjust loss weights based on the model’s performance during training.
- (2)
- Task-Driven Knowledge Distillation: To enhance the effectiveness of knowledge distillation in semantic segmentation tasks, prior knowledge of the target task can be incorporated into the distillation process. For instance, task-specific loss functions can be designed to guide the smaller model toward learning more effective feature representations for the target task.
- (3)
- Weakly Supervised Knowledge Distillation: High-quality annotation of semantic segmentation data is often time-consuming and expensive. To reduce annotation costs, it is worth investigating the application of knowledge distillation in weakly supervised semantic segmentation tasks. By utilizing weakly labeled data (e.g., image-level labels or edge labels), the performance of lightweight models can be effectively improved.
- (4)
- Integration of Model Architecture Search and Knowledge Distillation: To select a more suitable lightweight model, knowledge distillation can be combined with model architecture search (NAS). By automatically searching for the optimal lightweight model structure, the performance of the distilled model can be further enhanced.
- (5)
- Online Knowledge Distillation: To reduce the computational cost of the distillation process, online knowledge distillation methods can be explored. Online knowledge distillation performs knowledge distillation of smaller models simultaneously with the training of larger models, thus avoiding additional distillation computation overhead. By updating the smaller model’s parameters in real time, knowledge can be effectively transferred, thereby accelerating model convergence.
- (6)
- Cross-Model Knowledge Distillation: In practical applications, it may be necessary to transfer knowledge from multiple large-scale models into a single lightweight model. Investigating cross-model knowledge distillation methods can efficiently integrate the knowledge from multiple large-scale models, further improving the performance of the lightweight model.
- (7)
- Explainable Knowledge Distillation: Although knowledge distillation can enhance the performance of lightweight models, the distillation process may result in a reduction in model interpretability. To improve model interpretability, it is worth exploring the introduction of explainability constraints into the knowledge distillation process. By constraining the feature representations learned by the lightweight model to have similar explainability to those of the larger model, the model can maintain its performance while exhibiting better interpretability.
4.6. Domain Adaptation
- Instance-based domain adaptation: This method improves the classifier’s performance in the target domain by weighting the samples from the source and target domains. Typical methods include maximum mean discrepancy and kernel mean matching.
- Feature-based domain adaptation: This method improves the model’s performance in the target domain by finding a mapping in the feature space that minimizes the distribution difference between the source and target domains. Typical methods include domain-invariant feature extraction and deep adversarial domain adaptation networks.
- Adversarial domain adaptation: This method improves the model’s generalization ability in the target domain by making the feature distributions similar in the source and target domains through adversarial training. Typical methods include generative adversarial networks (GANs) and domain adversarial neural networks.
- (1)
- Domain-specific information transfer methods: Domain-specific information transfer methods should be investigated by analyzing structured information, local and global semantic relationships, and high-order features within the domain. This task can help enhance the model’s adaptability and generalization capabilities for domain differences.
- (2)
- Application of adversarial training in domain adaptation: Adversarial training strategies must be utilized to strengthen the model’s robustness against the distribution differences between the source and target domains. By introducing domain-adversarial loss functions, the distribution gap between source and target domain features can be reduced, thus improving domain adaptation performance.
- (3)
- Data augmentation and sample generation using generative models: Generative models such as GANs can be explored to generate samples with target-domain characteristics during the training process, thereby enhancing the model’s generalization ability in the target domain. Furthermore, generative models can be used for data augmentation to expand the training data for source and target domains and therefore increase the model’s robustness.
- (4)
- Incorporation of multitask learning and domain knowledge: Models’ generalization ability can be improved by learning multiple related tasks in a single model. Simultaneously, domain knowledge can be integrated to provide additional information about the source and target domains, which can guide the model in domain adaptation.
- (5)
- Enhancement of model interpretability: The interpretability of domain adaptation models can be increased to make the domain transfer process transparent. This task can be achieved through the introduction of interpretability metrics and visualization methods. It can also help researchers understand the model’s behavior and influential factors during the transfer process.
- (6)
- Online domain adaptation and incremental learning: Online domain adaptation methods and incremental learning algorithms can be designed to enable a model to adjust in real time as it continuously receives new data and adapt to the changes in the target domain. This task can improve the model’s adaptability and practicality in dynamic environments.
- (7)
- Incorporation of unsupervised or weakly supervised learning methods: Considering the scarcity of annotated data, domain adaptation techniques can be optimized by using unsupervised or weakly supervised learning methods. Doing so can effectively reduce annotation costs while enhancing the generalization ability of models in the target domain.
- (8)
- Multimodal data fusion: Multimodal data (such as images, point clouds, and depth information) can be utilized for domain adaptation to fully leverage information from different data sources. Fusing multiple data types can enhance the performance and robustness of domain adaptation models.
- (9)
- Knowledge-graph-based domain adaptation: Knowledge graphs can be employed to provide domain adaptation models with rich background knowledge and semantic information. Combining knowledge graphs with domain adaptation techniques can improve the model’s ability to understand and transfer complex scenarios.
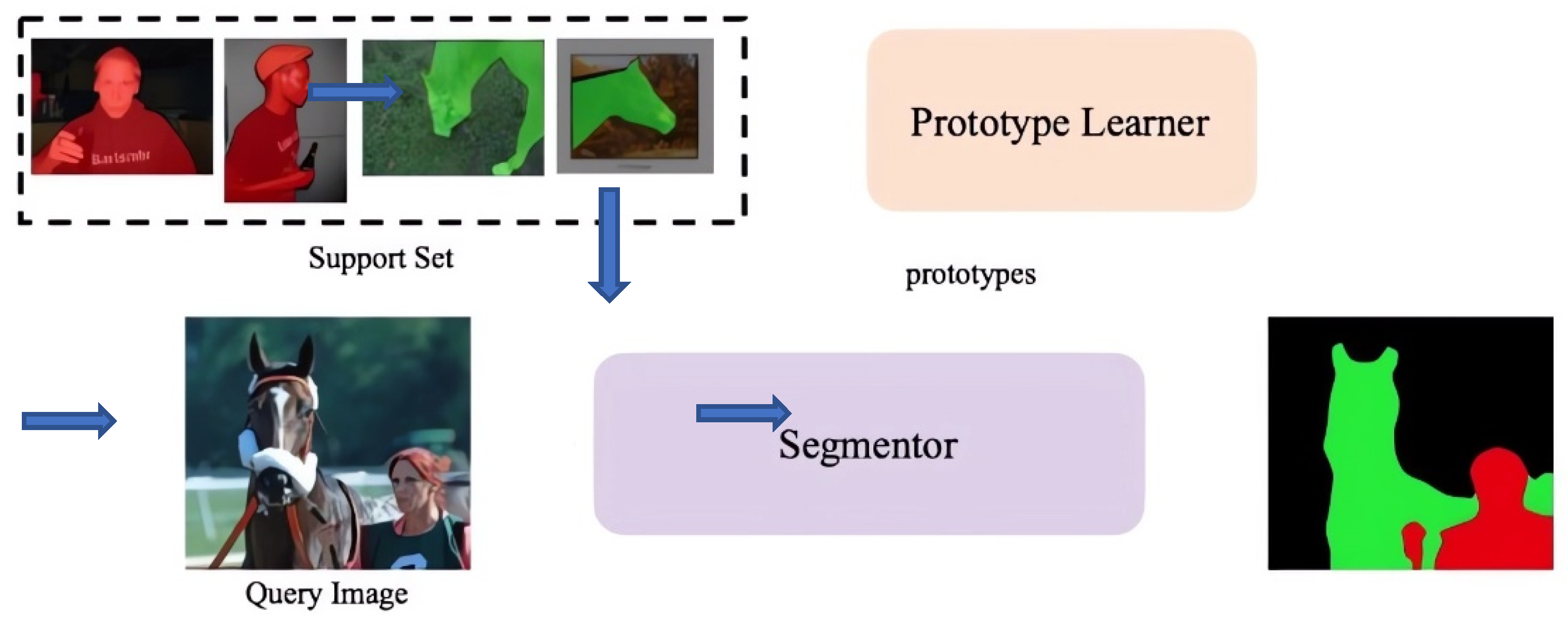
4.7. Few-Shot/Zero-Shot Semantic Segmentation
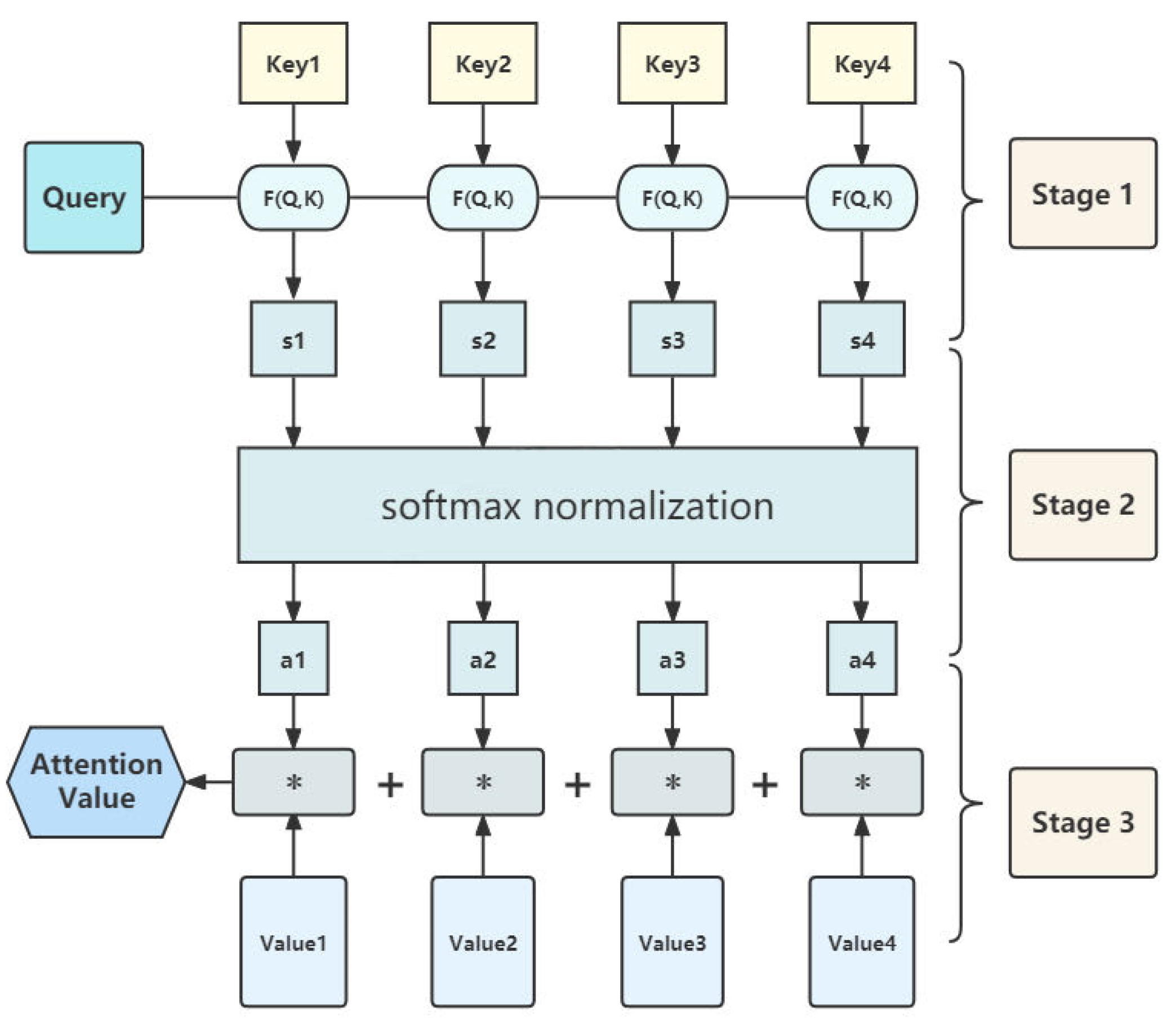
4.8. Attention Mechanism
4.9. Method Based on Multimodal Fusion
- (1)
- Introducing adaptive fusion strategies: Previous multimodal fusion methods mainly relied on fixed fusion strategies. However, in different scenarios and applications, the importance of information from different modalities may vary. Therefore, introducing adaptive fusion strategies that dynamically adjust the weights of different modalities in accordance with the scene context or application requirements can improve fusion results. This goal can be achieved using attention mechanisms, which allow the network to automatically determine the contributions of different modalities.
- (2)
- Utilizing GCNs: Given that GCNs can effectively process irregular structured data, they can be considered for multimodal fusion. By representing multimodal data as graph structures, GCNs can successfully capture the relationships between different modalities, further improving fusion performance.
- (3)
- Cross-modal self-supervised learning: A major challenge in multimodal fusion is effectively transferring information between different modalities. By introducing cross-modal self-supervised learning, models can automatically learn how to share information between modalities. This approach can be realized through alignment and generation tasks such as reconstructing one modality’s data by generating another modality’s data.
- (4)
- Adopting multiscale fusion strategies: Information from different modalities may be complementary on different scales. To fully exploit this feature, multiscale fusion strategies can be adopted. By fusing on different spatial scales, the local and global relationships between modalities can be captured, thus enhancing fusion performance.
- (5)
- Combining domain adaptation with multimodal fusion: To further improve the robustness of multimodal fusion, domain adaptation techniques can be combined with multimodal fusion. By adopting multimodal data from source and target domains, the distribution discrepancy between domains can be effectively reduced, thus enhancing the model’s generalization ability in new domains.
- (6)
- Incorporating knowledge distillation: In multimodal fusion, knowledge distillation can be considered to improve model efficiency and scalability. By allowing small models to learn the relationships between different modalities, computational and storage requirements can be reduced while maintaining high performance.
- (7)
- Applying end-to-end multimodal training methods: Traditional multimodal fusion methods typically require pretraining of single-modality models before fusion, which may lead to computational resource wastage and information loss. By developing end-to-end multimodal training methods, the optimal means to fuse different modalities can be directly learned, thereby improving overall performance.
- (8)
- Utilizing ensemble learning methods: In multimodal fusion, ensemble learning methods can be considered to enhance performance. By combining multiple models with different fusion strategies, the accuracy and robustness of semantic segmentation can be further improved. Ensemble methods may include voting, bagging, and boosting.
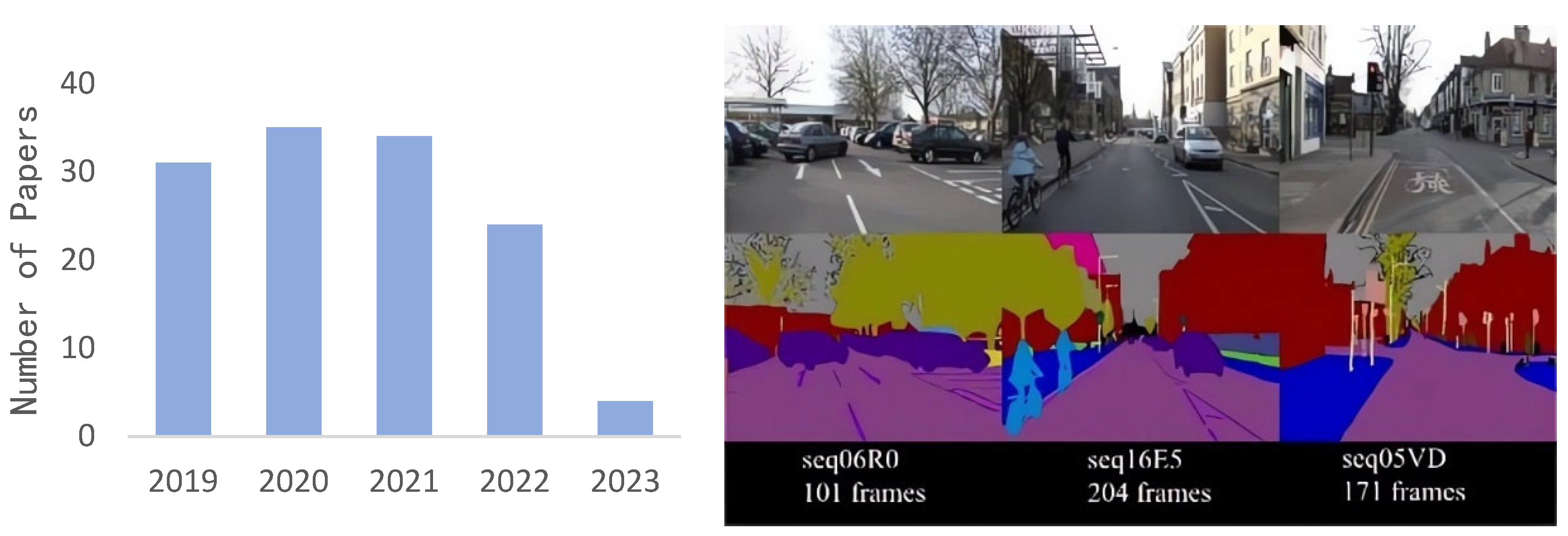
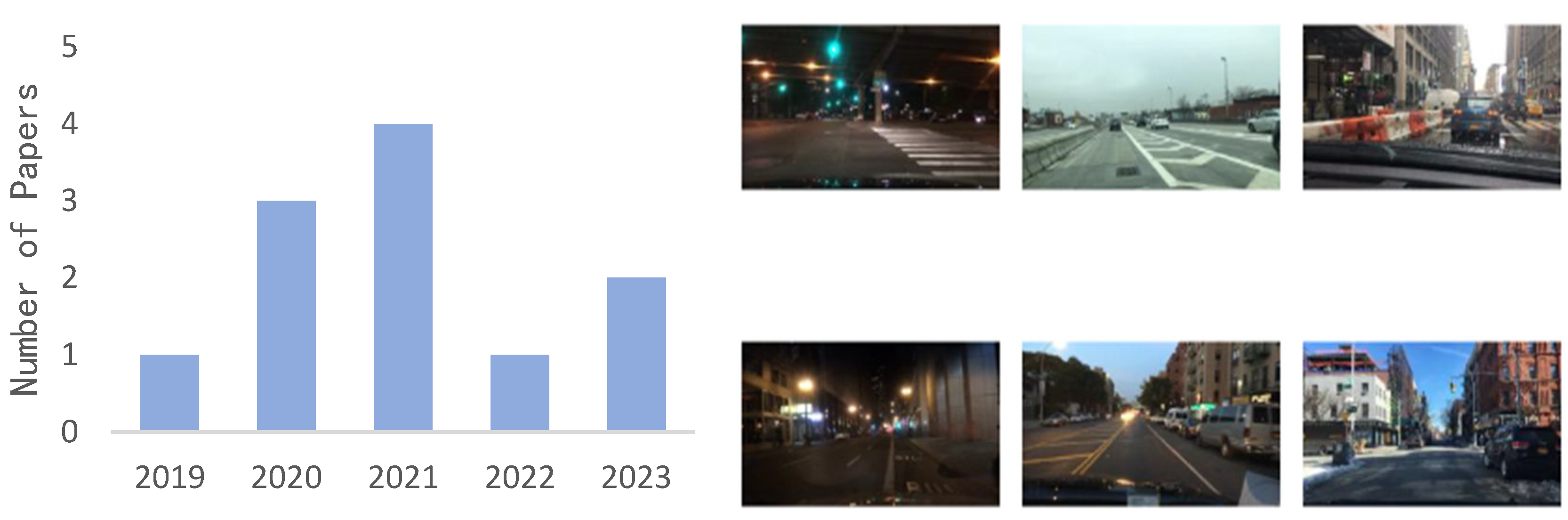
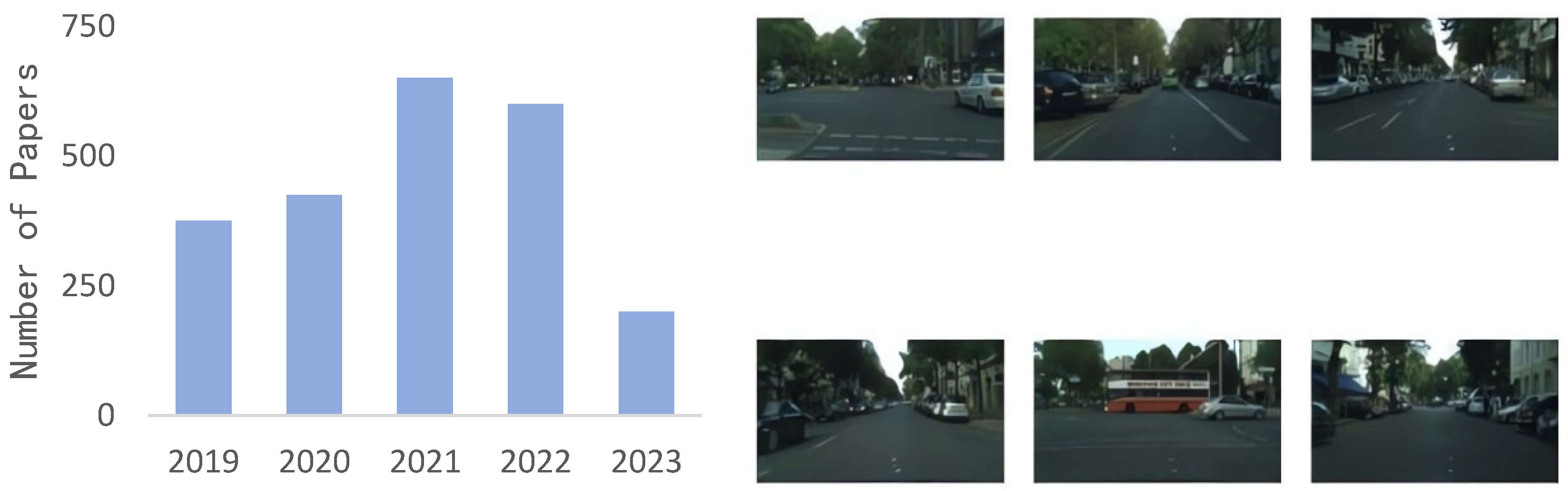
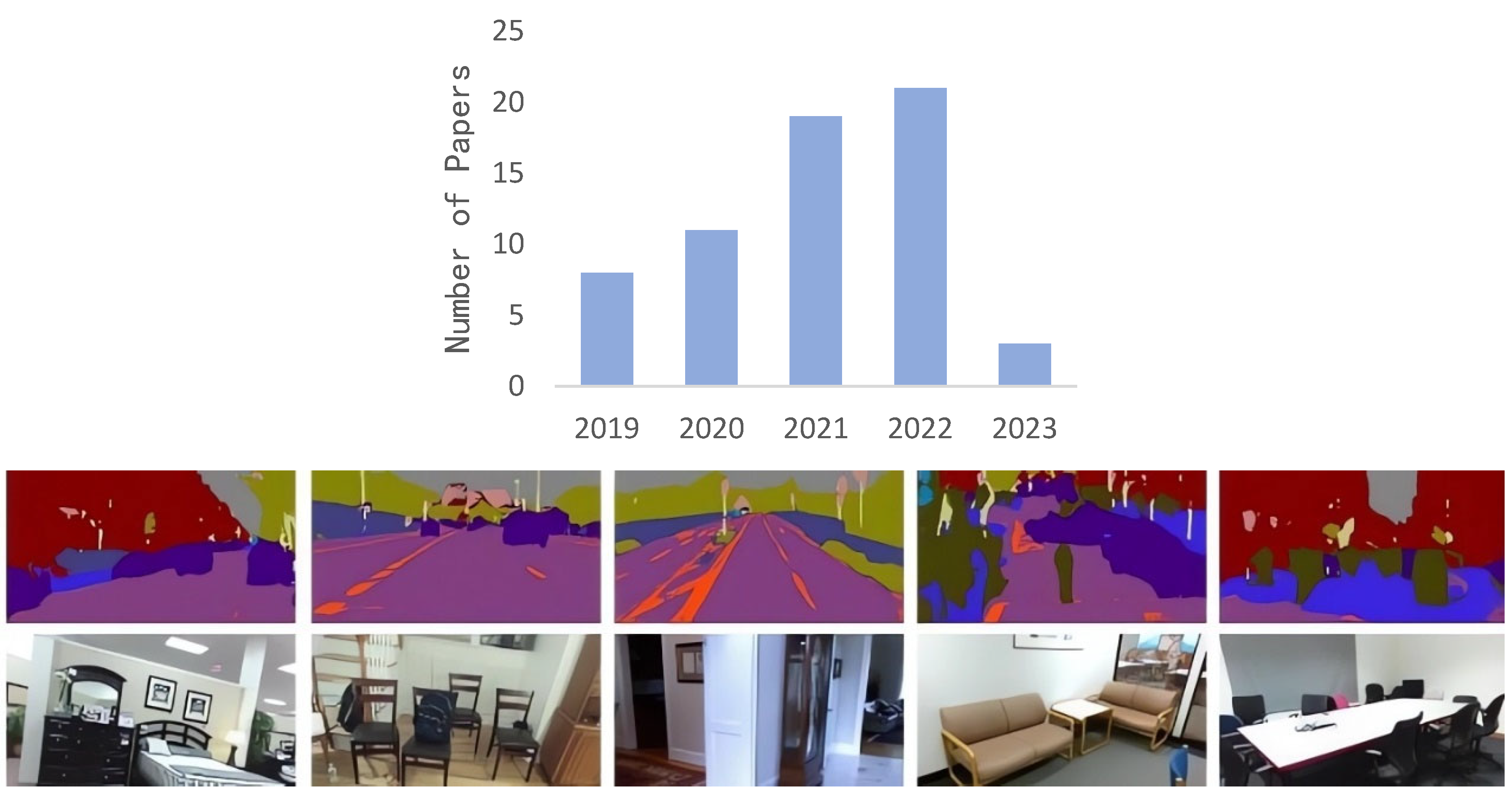
5. Common Data Sets and Evaluation Indicators
6. Prospects and Challenges
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Janai, J.; Güney, F.; Behl, A.; Geiger, A. Computer Vision for Autonomous Vehicles: Problems, Datasets and State of the Art. Found. Trends® Comput. Graph. Vis. 2020, 12, 1–308. [Google Scholar] [CrossRef]
- Lu, X.; Wang, W.; Ma, C.; Shen, J.; Shao, L.; Porikli, F. See More, Know More: Unsupervised Video Object Segmentation with Co-Attention Siamese Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3618–3627. [Google Scholar]
- Lu, X.; Wang, W.; Shen, J.; Crandall, D.; Luo, J. Zero-Shot Video Object Segmentation with Co-Attention Siamese Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2228–2242. [Google Scholar] [CrossRef] [PubMed]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5168–5177. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Santiago, Chile, 11–18 December 2015. [Google Scholar]
- Wei, Z.; Sun, Y.; Wang, J.; Lai, H.; Liu, S. Learning adaptive receptive fields for deep image parsing network. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Batra, A.; Singh, S.; Pang, G.; Basu, S.; Jawahar, C.V.; Paluri, M. Improved road connectivity by joint learning of orientation and segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Farha, Y.A.; Gall, J. Ms-tcn: Multi-stage temporal convolutional network for action segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Sun, J.; Li, Y. Multi-feature fusion network for road scene semantic segmentation. Comput. Electr. Eng. 2021, 92, 107155. [Google Scholar] [CrossRef]
- Yanc, M. Review on semantic segmentation of road scenes. Laser Optoelectron. Prog. 2021, 58, 36–58. [Google Scholar]
- Li, J.; Jiang, F.; Yang, J.; Kong, B.; Gogate, M.; Dashtipour, K.; Hussain, A. Lane-deeplab: Lane semantic segmentation in automatic driving scenarios for high-definition maps. Neurocomputing 2021, 465, 15–25. [Google Scholar] [CrossRef]
- Ghosh, S.; Pal, A.; Jaiswal, S.; Santosh, K.C.; Das, N.; Nasipuri, M. SegFast-V2: Semantic image segmentation with less parameters in deep learning for autonomous driving. Int. J. Mach. Learn. Cybern. 2019, 10, 3145–3154. [Google Scholar] [CrossRef]
- Mao, J.; Xiao, T.; Jiang, Y.; Cao, Z. What can help pedestrian detection? In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Guo, Z.; Liao, W.; Xiao, Y.; Veelaert, P.; Philips, W. Weak segmentation supervised deep neural networks for pedestrian detection. Pattern Recognit. 2021, 119, 108063. [Google Scholar] [CrossRef]
- Kampffmeyer, M.; Salberg, A.B.; Jenssen, R. Semantic segmentation of small objects and modeling of uncertainty in urban remote sensing images using deep convolutional neural networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, VA, USA, 26 June–1 July 2016. [Google Scholar]
- Ouyang, S.; Li, Y. Combining deep semantic segmentation network and graph convolutional neural network for semantic segmentation of remote sensing imagery. Remote Sens. 2020, 13, 119. [Google Scholar] [CrossRef]
- Peng, S.; Liu, Y.; Huang, Q.; Zhou, X.; Bao, H. Pvnet: Pixel-wise voting network for 6dof pose estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Gao, F.; Li, H.; Fei, J.; Huang, Y.; Liu, L. Segmentation-Based Background-Inference and Small-Person Pose Estimation. IEEE Signal Process. Lett. 2022, 29, 1584–1588. [Google Scholar] [CrossRef]
- Cheng, Z.; Qu, A.; He, X. Contour-aware semantic segmentation network with spatial attention mechanism for medical image. Vis. Comput. 2022, 38, 749–762. [Google Scholar] [CrossRef]
- Asgari Taghanaki, S.; Abhishek, K.; Cohen, J.P.; Cohen-Adad, J.; Hamarneh, G. Deep semantic segmentation of natural and medical images: A review. Artif. Intell. Rev. 2021, 54, 137–178. [Google Scholar] [CrossRef]
- Yang, R.; Yu, Y. Artificial convolutional neural network in object detection and semantic segmentation for medical imaging analysis. Front. Oncol. 2021, 11, 638182. [Google Scholar] [CrossRef]
- Xia, K.J.; Yin, H.S.; Zhang, Y.D. Deep semantic segmentation of kidney and space-occupying lesion area based on SCNN and ResNet models combined with SIFT-flow algorithm. J. Med. Syst. 2019, 43, 2. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016. [Google Scholar]
- Liu, F.; Shen, C.; Lin, G. Deep convolutional neural fields for depth estimation from a single image. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Xu, D.; Ricci, E.; Ouyang, W.; Wang, X.; Sebe, N. Multi-scale continuous crfs as sequential deep networks for monocular depth estimation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Santiago, Chile, 11–18 December 2015. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Li, Y.; Qi, H.; Dai, J.; Ji, X.; Wei, Y. Fully convolutional instance-aware semantic segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact: Real-time instance segmentation. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wang, X.; Kong, T.; Shen, C.; Jiang, Y.; Li, L. Solo: Segmenting objects by locations. In Proceedings of the 2020 European Conference, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Yuan, Y.; Huang, L.; Guo, J.; Zhang, C.; Chen, X.; Wang, J. OCNet: Object context for semantic segmentation. Int. J. Comput. Vis. 2021, 129, 2375–2398. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 12, 2481–2495. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 2015 International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Zhou, Q.; Wu, X.; Zhang, S.; Kang, B.; Ge, Z.; Latecki, L.J. Contextual ensemble network for semantic segmentation. Pattern Recognit. 2022, 122, 108290. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Fan, H.; Xiong, B.; Mangalam, K.; Li, Y.; Yan, Z.; Malik, J.; Feichtenhofer, C. Multiscale vision transformers. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 6804–6815. [Google Scholar]
- Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Jiang, Z.H.; Tay, F.E.; Feng, J.; Yan, S. Tokens-to-token vit: Training vision transformers from scratch on imagenet. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 538–547. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Yu, Q.; Xia, Y.; Bai, Y.; Lu, Y.; Yuille, A.L.; Shen, W. Glance-and-gaze vision transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 12992–13003. [Google Scholar]
- Tian, Z.; He, T.; Shen, C.; Yan, Y. Decoders matter for semantic segmentation: Data-dependent decoding enables flexible feature aggregation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3121–3130. [Google Scholar]
- Jiao, J.; Wei, Y.; Jie, Z.; Shi, H.; Lau, R.W.; Huang, T.S. Geometry-aware distillation for indoor semantic segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2864–2873. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Wu, H.; Liang, C.; Liu, M.; Wen, Z. Optimized HRNet for image semantic segmentation. Expert Syst. Appl. 2021, 174, 114532. [Google Scholar] [CrossRef]
- Kim, D.S.; Kim, Y.H.; Park, K.R. Semantic segmentation by multi-scale feature extraction based on grouped dilated convolution module. Mathematics 2021, 9, 947. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Liu, Y.; Chen, K.; Liu, C.; Qin, Z.; Luo, Z.; Wang, J. Structured knowledge distillation for semantic segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2599–2608. [Google Scholar]
- Wu, J.; Ji, R.; Liu, J.; Xu, M.; Zheng, J.; Shao, L.; Tian, Q. Real-time semantic segmentation via sequential knowledge distillation. Neurocomputing 2021, 439, 134–145. [Google Scholar] [CrossRef]
- Amirkhani, A.; Khosravian, A.; Masih-Tehrani, M.; Kashiani, H. Robust Semantic Segmentation with Multi-Teacher Knowledge Distillation. IEEE Access 2021, 9, 119049–119066. [Google Scholar] [CrossRef]
- Feng, Y.; Sun, X.; Diao, W.; Li, J.; Gao, X. Double similarity distillation for semantic image segmentation. IEEE Trans. Image Process. 2021, 30, 5363–5376. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Deng, W. Deep visual domain adaptation: A survey. Neurocomputing 2018, 312, 135–153. [Google Scholar] [CrossRef]
- Zhang, Y.; Ye, M.; Gan, Y.; Zhang, W. Knowledge based domain adaptation for semantic segmentation. Knowl.-Based Syst. 2020, 193, 105444. [Google Scholar] [CrossRef]
- Tian, Y.; Zhu, S. Partial domain adaptation on semantic segmentation. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 3798–3809. [Google Scholar] [CrossRef]
- Zhou, Z.H. A brief introduction to weakly supervised learning. Natl. Sci. Rev. 2018, 5, 44–53. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-supervised visual feature learning with deep neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4037–4058. [Google Scholar] [CrossRef]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Wang, J.; Wang, Y.; Jiang, M.; Yan, X.; Song, M. Moving cast shadow detection using online sub-scene shadow modeling and object inner-edges analysis. J. Vis. Commun. Image Represent. 2014, 25, 978–993. [Google Scholar] [CrossRef]
- Bao, Y.; Song, K.; Wang, J.; Huang, L.; Dong, H.; Yan, Y. Visible and thermal images fusion architecture for few-shot semantic segmentation. J. Vis. Commun. Image Represent. 2021, 80, 103306. [Google Scholar] [CrossRef]
- Bucher, M.; Vu, T.H.; Cord, M.; Pérez, P. Zero-shot semantic segmentation. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Gu, Z.; Zhou, S.; Niu, L.; Zhao, Z.; Zhang, L. Context-aware feature generation for zero-shot semantic segmentation. In Proceedings of the 2020 28th ACM International Conference on Multimedia (MM), Seattle, WA, USA, 12–16 October 2020; pp. 1921–1929. [Google Scholar]
- Li, B.; Weinberger, K.Q.; Belongie, S.; Koltun, V.; Ranftl, R. Language-driven semantic segmentation. arXiv 2022, arXiv:2201.03546. [Google Scholar]
- Zhang, H.; Ding, H. Prototypical matching and open set rejection for zero-shot semantic segmentation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 6954–6963. [Google Scholar]
- Xu, J.; De Mello, S.; Liu, S.; Byeon, W.; Breuel, T.; Kautz, J.; Wang, X. GroupViT: Semantic Segmentation Emerges from Text Supervision. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 18113–18123. [Google Scholar]
- Scheirer, W.J.; de Rezende Rocha, A.; Sapkota, A.; Boult, T.E. Toward open set recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1757–1772. [Google Scholar] [CrossRef] [PubMed]
- Pastore, G.; Cermelli, F.; Xian, Y.; Mancini, M.; Akata, Z.; Caputo, B. A closer look at self-training for zero-label semantic segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 2687–2696. [Google Scholar]
- Shen, F.; Lu, Z.M.; Lu, Z.; Wang, Z. Dual semantic-guided model for weakly-supervised zero-shot semantic segmentation. Multimed. Tools Appl. 2022, 81, 5443–5458. [Google Scholar] [CrossRef]
- Gu, Z.; Zhou, S.; Niu, L.; Zhao, Z.; Zhang, L. From pixel to patch: Synthesize context-aware features for zero-shot semantic segmentation. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–15. [Google Scholar] [CrossRef]
- Bian, C.; Yuan, C.; Ma, K.; Yu, S.; Wei, D.; Zheng, Y. Domain Adaptation Meets Zero-Shot Learning: An Annotation-Efficient Approach to Multi-Modality Medical Image Segmentation. IEEE Trans. Med. Imaging 2021, 41, 1043–1056. [Google Scholar] [CrossRef] [PubMed]
- Kosiorek, A. Attention Mechanism in Neural Networks. Robot. Ind. 2017, 6, 14. [Google Scholar]
- Lambert, J.; Liu, Z.; Sener, O.; Hays, J.; Koltun, V. MSeg: A composite dataset for multi-domain semantic segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 2876–2885. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Zhu, X.; Cheng, D.; Zhang, Z.; Lin, S.; Dai, J. An empirical study of spatial attention mechanisms in deep networks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, South Korea, 27 October–2 November 2019; pp. 6687–6696. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar]
- Kang, J.; Liu, L.; Zhang, F.; Shen, C.; Wang, N.; Shao, L. Semantic segmentation model of cotton roots in-situ image based on attention mechanism. Comput. Electron. Agric. 2021, 189, 106370. [Google Scholar] [CrossRef]
- Lv, N.; Zhang, Z.; Li, C.; Deng, J.; Su, T.; Chen, C.; Zhou, Y. A hybrid-attention semantic segmentation network for remote sensing interpretation in land-use surveillance. Int. J. Mach. Learn. Cybern. 2022, 14, 395–406. [Google Scholar] [CrossRef]
- Wang, K.; He, R.; Wang, L.; Wang, W.; Tan, T. Joint feature selection and subspace learning for cross-modal retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 2010–2023. [Google Scholar] [CrossRef]
- Yang, M.; Rosenhahn, B.; Murino, V. Multimodal Scene Understanding: Algorithms, Applications and Deep Learning; Academic Press: Cambridge, MA, USA, 2019. [Google Scholar]
- Zhang, Y.; Sidibé, D.; Morel, O.; Mériaudeau, F. Deep multimodal fusion for semantic image segmentation: A survey. Image Vis. Comput. 2021, 105, 104042. [Google Scholar] [CrossRef]
- Zhou, W.; Guo, Q.; Lei, J.; Yu, L.; Hwang, J.N. ECFFNet: Effective and consistent feature fusion network for RGB-T salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1224–1235. [Google Scholar] [CrossRef]
- Patel, N.; Choromanska, A.; Krishnamurthy, P.; Khorrami, F. Sensor modality fusion with CNNs for UGV autonomous driving in indoor environments. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1531–1536. [Google Scholar]
- Zou, Z.; Zhang, X.; Liu, H.; Li, Z.; Hussain, A.; Li, J. A novel multimodal fusion network based on a joint coding model for lane line segmentation. Inf. Fusion 2022, 80, 167–178. [Google Scholar] [CrossRef]
- Brostow, G.J.; Fauqueur, J.; Cipolla, R. Semantic object classes in video: A high-definition ground truth database. Pattern Recognit. Lett. 2009, 30, 88–97. [Google Scholar] [CrossRef]
- Larsson, M.; Stenborg, E.; Hammarstrand, L.; Pollefeys, M.; Sattler, T.; Kahl, F. A cross-season correspondence dataset for robust semantic segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9524–9534. [Google Scholar]
- Orsic, M.; Kreso, I.; Bevandic, P.; Segvic, S. In defense of pre-trained imagenet architectures for real-time semantic segmentation of road-driving images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12599–12608. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the 2014 European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Hu, Y.T.; Chen, H.S.; Hui, K.; Huang, J.B.; Schwing, A.G. Sail-vos: Semantic amodal instance level video object segmentation-a synthetic dataset and baselines. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3105–3115. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Everingham, M.; Eslami, S.M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Hariharan, B.; Arbeláez, P.; Bourdev, L.; Maji, S.; Malik, J. Semantic contours from inverse detectors. In Proceedings of the 2011 International Conference on Computer Vision (ICCV), Barcelona, Spain, 6-13 November 2011; pp. 991–998. [Google Scholar]
- Brostow, G.J.; Shotton, J.; Fauqueur, J.; Cipolla, R. Segmentation and recognition using structure from motion point clouds. In Proceedings of the 2008 European Conference on Computer Vision (ECCV), Berlin, Germany, 12–18 October 2008; pp. 44–57. [Google Scholar]
- Miao, J.; Wei, Y.; Wu, Y.; Liang, C.; Li, G.; Yang, Y. Vspw: A large-scale dataset for video scene parsing in the wild. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electr Network, Virtual, 19–25 June 2021; pp. 4131–4141. [Google Scholar]
- Staal, J.; Abràmoff, M.D.; Niemeijer, M.; Viergever, M.A.; Van Ginneken, B. Ridge-based vessel segmentation in color images of the retina. IEEE Trans. Med. Imaging 2004, 23, 501–509. [Google Scholar] [CrossRef]
- Menze, B.H.; Jakab, A.; Bauer, S.; Kalpathy-Cramer, J.; Farahani, K.; Kirby, J.; Burren, Y.; Porz, N.; Slotboom, J.; Wiest, R.; et al. The multimodal brain tumor image segmentation benchmark (BRATS). IEEE Trans. Med. Imaging 2014, 34, 1993–2024. [Google Scholar] [CrossRef]
- Paisitkriangkrai, S.; Sherrah, J.; Janney, P.; Van Den Hengel, A. Semantic labeling of aerial and satellite imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2868–2881. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can semantic labeling methods generalize to any city? The inria aerial image labeling benchmark. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar]
- Miao, L.; Zhang, Y. A hierarchical feature extraction network for fast scene segmentation. Sensors 2021, 21, 7730. [Google Scholar] [CrossRef]
- Huang, S.; Lu, Z.; Cheng, R.; He, C. Fapn: Feature-aligned pyramid network for dense image prediction. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 10–17 October 2021. [Google Scholar]
- Hong, Y.; Pan, H.; Sun, W.; Member, S.; Jia, Y. Deep dual-resolution networks for real-time and accurate semantic segmentation of road scenes. arXiv 2021, arXiv:2101.06085. [Google Scholar]
- Cheng, J.; Peng, X.; Tang, X.; Tu, W.; Xu, W. Mifnet: A lightweight multiscale information fusion network. Int. J. Intell. Syst. 2021, 37, 5617–5642. [Google Scholar] [CrossRef]
- Chen, Z.; Duan, Y.; Wang, W.; He, J.; Lu, T.; Dai, J.; Qiao, Y. Vision transformer adapter for dense predictions. arXiv 2022, arXiv:2205.08534. [Google Scholar]
- Fu, J.; Liu, J.; Jiang, J.; Li, Y.; Lu, H. Scene segmentation with dual relation-aware attention network. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 2547–2560. [Google Scholar] [CrossRef] [PubMed]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | Time | Application Scenario | Classification | Quantity | Number of Training Sets | Number of Validation Sets | Number of Test Sets |
|---|---|---|---|---|---|---|---|
| CamVid | 2008 | City street | 32 | 700+ | 367 | 100 | 233 |
| COCO | 2014 | Multiple scenarios | 81 | 308,000 | 82,783 | 40,504 | 81,434 |
| BDD | 2018 | City street | 19 | 100,000 | 70,000 | — | 30,000 |
| Cityscapes | 2016 | City street | 30 | 5000 | 2975 | 500 | 1525 |
| PASCAL-VOC 2012 | 2015 | Multiple scenarios | 21 | 9993 | 1464 | 1449 | 1452 |
| SBD | 2014 | Multiple scenarios | 21 | — | 8498 | 2857 | — |
| KITTI | 2015 | Multiple scenarios | 7 | 7000+ | 3712 | — | 3769 |
| Mapillary Vistas 3. 0 | 2021 | City scenarios | 66 | 250 K | 180 K | 20 K | 30 K |
| VSPW | 2021 | City scenarios | 124 | 3537 (video) | — | — | — |
| Method | Time | Backbone | VOC 2012 (MIoU/%) | Cityscapes (MIoU/%) | CamVid (MIoU/%) |
|---|---|---|---|---|---|
| FCN | 2015 | VGG16 | 62.2 | 65.3 | — |
| U-Net | 2015 | VGG16 | — | — | — |
| DeepLab v1 | 2016 | ResNet | 71.6 | — | — |
| DeepLab v2 | 2017 | ResNet | 79.7 | 70.4 | — |
| DeepLab v3 | 2017 | ResNet | 86.9 | 81.3 | — |
| DeepLab v3+ | 2018 | ResNet | 89 | 82.1 | |
| SegNet | 2017 | VGG16 | — | — | 60.1 |
| PSPNet | 2017 | ResNet | 85.4 | 80.2 | — |
| Method | Time | Backbone | Cityscapes (MIoU/%) | CamVid (MIoU/%) |
|---|---|---|---|---|
| HFEN [110] | 2021 | — | 69.5 | 66.1 |
| FaPN [111] | 2021 | ResNet-18 | 75.0 | — |
| DDRNet [112] | 2021 | DDRNet-39 | 80.4 | — |
| MIFNet [113] | 2021 | MobileNetV2 | 72.2 | — |
| ViT-Adaptor-L [114] | 2022 | UPerNet | 85.2 | — |
| DRANet [115] | 2020 | ResNet-101 | 82.9 | — |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Y.; Nie, G.; Gao, W.; Liao, M. 2D Semantic Segmentation: Recent Developments and Future Directions. Future Internet 2023, 15, 205. https://doi.org/10.3390/fi15060205
Guo Y, Nie G, Gao W, Liao M. 2D Semantic Segmentation: Recent Developments and Future Directions. Future Internet. 2023; 15(6):205. https://doi.org/10.3390/fi15060205
Chicago/Turabian StyleGuo, Yu, Guigen Nie, Wenliang Gao, and Mi Liao. 2023. "2D Semantic Segmentation: Recent Developments and Future Directions" Future Internet 15, no. 6: 205. https://doi.org/10.3390/fi15060205
APA StyleGuo, Y., Nie, G., Gao, W., & Liao, M. (2023). 2D Semantic Segmentation: Recent Developments and Future Directions. Future Internet, 15(6), 205. https://doi.org/10.3390/fi15060205