



View Synthesis with Scene Recognition for Cross-View Image Localization


Abstract
1. Introduction
- We proposed a deep generative network-based view synthesis framework to address the challenges in the existing cross-view matching tasks. It was accomplished by updating the reference images, which are usually updated in an infrequent manner, with a weather/time patch. The synthesized reference view contains features from reference views, current time, and weather conditions.
- We propose a novel evaluation metric to measure the quality of the view synthesis instead of a subjective judgment. With the assistance of an auxiliary attribute extraction network, we can effectively select the best synthesis results by comparing the attributes before and after the view synthesizing under various testing conditions.
2. Related Work
3. System Design
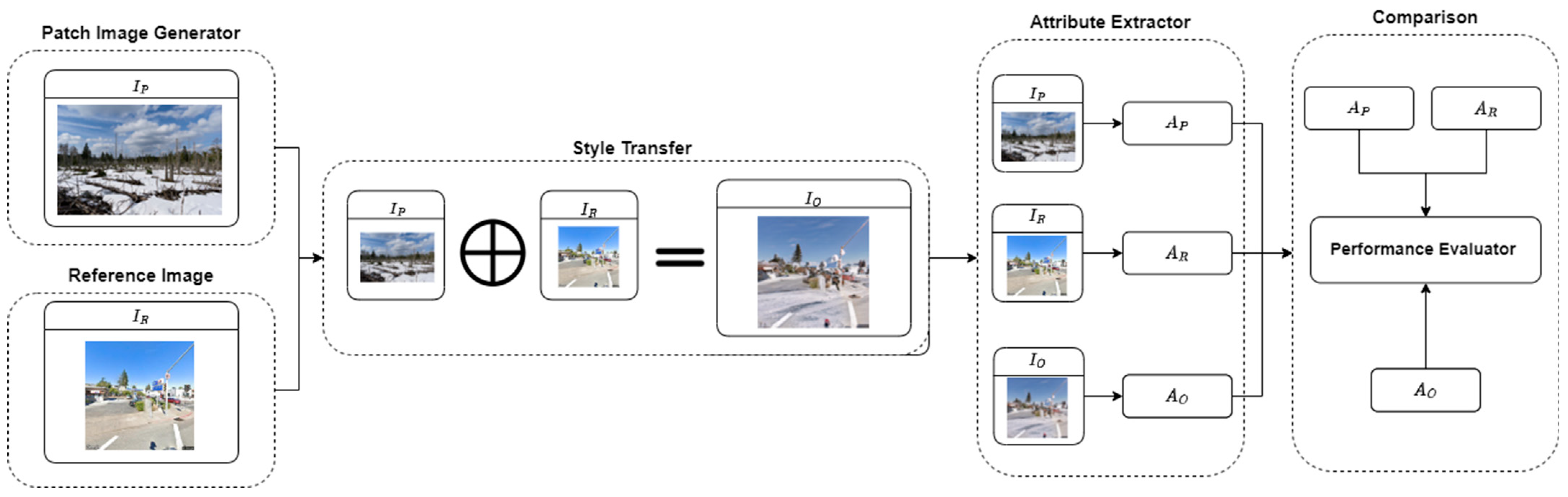
3.1. Framework Overview
3.2. Patch Image Generator
3.3. Attribute Extractor
3.4. Style Transfer
4. Performance Evaluation for View Synthesis
4.1. Dataset and Experimental Setup
4.2. Subjective Evaluation
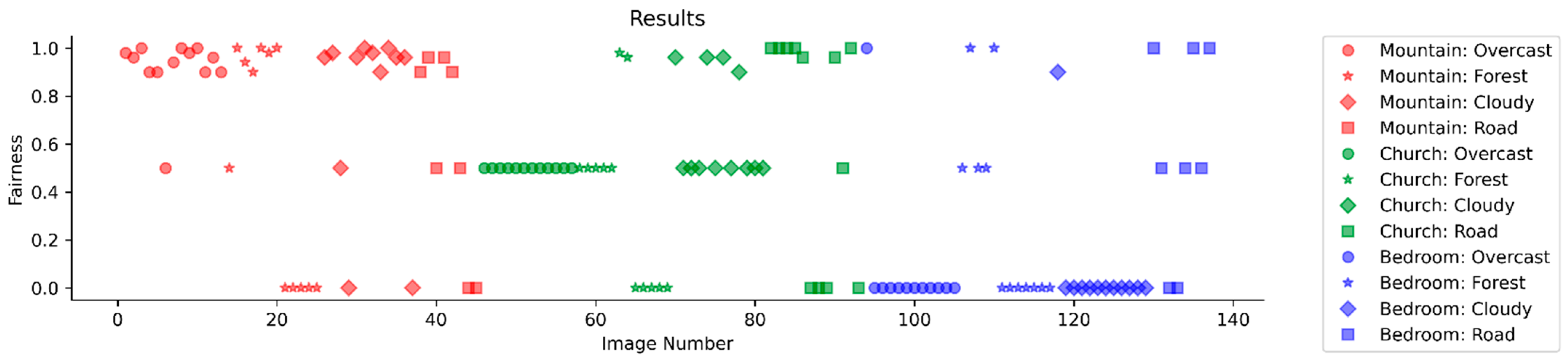
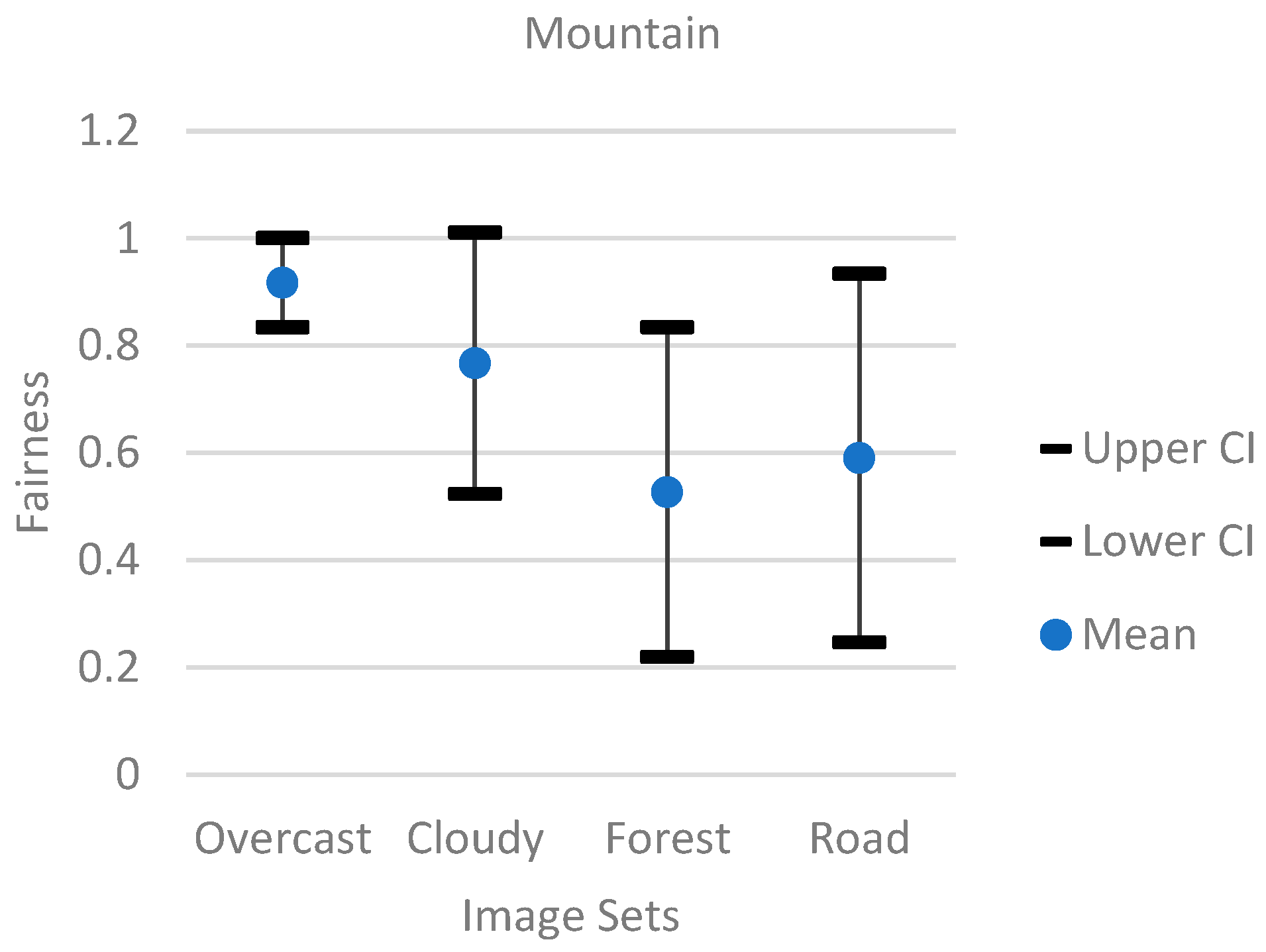
4.3. Evaluation Using Jain Index
- Mountain Model. The mountain model had the most trouble with the forest image group. The mountain model also performed very well with the overcast and cloudy image group. Overall, the mountain model with more training could achieve higher Jain index results. However, since the model was mostly trained on images consisting of different mountains, the model would struggle to adapt to images with many buildings.
- Church Model. The church model had trouble with the overcast image group. All the overcast images only had a Jain index of 0.5. With more training, the church model could achieve results similar to the mountain model. However, the church model was primarily trained on buildings, so any images that do not have many buildings would pose a problem for the church model.
- Bedroom Model. The bedroom model struggled with all the image groups. Only a few of the images had a Jain index of 1. Moreover, even fewer images had a Jain index of 0.5, and many images had a Jain index of 0. However, this was not too surprising since the model was trained on images based on indoor scenes and features. Therefore, it was not a good fit to transfer styles for reference images that were mostly outdoor images.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ding, L.; Zhou, J.; Meng, L.; Long, Z. A Practical Cross-View Image Matching Method Between UAV and Satellite for UAV-Based Geo-Localization. Remote Sens. 2020, 13, 47. [Google Scholar] [CrossRef]
- Zhuang, J.; Dai, M.; Chen, X.; Zheng, E. A Faster and More Effective Cross-View Matching Method of UAV and Satellite Images for UAV Geolocalization. Remote Sens. 2021, 13, 3979. [Google Scholar] [CrossRef]
- Shetty, A.; Gao, G.X. UAV Pose Estimation Using Cross-View Geolocalization with Satellite Imagery. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Hu, S.; Feng, M.; Nguyen, R.M.; Hee Lee, G. CVM-Net: Cross-View Matching Network for Image-Based Ground-to-Aerial Geo-Localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Lu, X.; Zhu, Y. Cross-View Geo-Localization with Layer-to-Layer Transformer. In Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems, Online, 7–10 December 2021. [Google Scholar]
- Tian, Y.; Chen, C.; Shah, M. Cross-View Image Matching for Geo-Localization in Urban Environments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Xia, Z.; Booij, O.; Manfredi, M.; Kooij, J.F. Cross-View Matching for Vehicle Localization by Learning Geographically Local Representations. IEEE Robot. Autom. Lett. 2021, 6, 5921–5928. [Google Scholar] [CrossRef]
- Zhu, S.; Shah, M.; Chen, C. TransGeo: Transformer Is All You Need for Cross-view Image Geo-localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Shi, Y.; Liu, L.; Yu, X.; Li, H. Spatial-Aware Feature Aggregation for Image Based Cross-View Geo-Localization. Adv. Neural Inf. Process. Syst. 2019, 32, 10090–10100. [Google Scholar]
- Tian, X.; Shao, J.; Ouyang, D.; Shen, H.T. UAV-Satellite View Synthesis for Cross-View Geo-Localization. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4804–4815. [Google Scholar] [CrossRef]
- Anguelov, D.; Dulong, C.; Filip, D.; Frueh, C.; Lafon, S.; Lyon, R.; Ogale, A.; Vincent, L.; Weaver, J. Google Street View: Capturing the World at Street Level. Computer 2010, 43, 32–38. [Google Scholar] [CrossRef]
- Jiang, P.; Wu, H.; Zhao, Y.; Zhao, D.; Xin, C. SEEK: Detecting GPS Spoofing via a Sequential Dashcam-Based Vehicle Localization Framework. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications, Atlanta, GA, USA, 13–17 March 2023. [Google Scholar]
- Park, T.; Zhu, J.-Y.; Wang, O.; Lu, J.; Shechtman, E.; Efros, A.; Zhang, R. Swapping Autoencoder for Deep Image Manipulation. Adv. Neural Inf. Process. Syst. 2020, 33, 7198–7211. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 Million Image Database for Scene Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1452–1464. [Google Scholar] [CrossRef] [PubMed]
- Abdal, R.; Qin, Y.; Wonka, P. Image2stylegan: How to Embed Images into the Stylegan Latent Space? In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 29 October 2019.
- Brock, A.; Lim, T.; Ritchie, J.M.; Weston, N. Neural Photo Editing with Introspective Adversarial Networks. arXiv 2016, arXiv:1609.07093. [Google Scholar]
- Yeh, R.A.; Chen, C.; Yian Lim, T.; Schwing, A.G.; Hasegawa-Johnson, M.; Do, M.N. Semantic Image Inpainting with Deep Generative Models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhu, S.; Yang, T.; Chen, C. Revisiting Street-to-Aerial View Image Geo-Localization and Orientation Estimation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Cai, S.; Guo, Y.; Khan, S.; Hu, J.; Wen, G. Ground-to-Aerial Image Geo-Localization with a Hard Exemplar Reweighting Triplet Loss. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 29 October 2019. [Google Scholar]
- Liu, L.; Li, H. Lending Orientation to Neural Networks for Cross-View Geo-Localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Xue, N.; Niu, L.; Hong, X.; Li, Z.; Hoffaeller, L.; Pöpper, C. DeepSIM: GPS Spoofing Detection on UAVs Using Satellite Imagery Matching. In Proceedings of the Annual Computer Security Applications Conference, Online, 7–11 December 2020. [Google Scholar]
- Regmi, K.; Shah, M. Video Geo-Localization Employing Geo-Temporal Feature Learning and Gps Trajectory Smoothing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Shi, Y.; Yu, X.; Campbell, D.; Li, H. Where am I Looking at? Joint Location and Orientation Estimation by Cross-View Matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Toker, A.; Zhou, Q.; Maximov, M.; Leal-Taixé, L. Coming Down to Earth: Satellite-to-Street View Synthesis for Geo-Localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Bi, J.; Huang, L.; Cao, H.; Yao, G.; Sang, W.; Zhen, J.; Liu, Y. Improved Indoor Fingerprinting Localization Method Using Clustering Algorithm and Dynamic Compensation. ISPRS Int. J. Geo-Inf. 2021, 10, 613. [Google Scholar] [CrossRef]
- Manzo, M. Graph-Based Image Matching for Indoor Localization. Mach. Learn Knowl. Extr. 2019, 1, 46. [Google Scholar] [CrossRef]
- Ding, J.; Yan, Z.; We, X. High-Accuracy Recognition and Localization of Moving Targets in an Indoor Environment Using Binocular Stereo Vision. ISPRS Int. J. Geo-Inf. 2021, 10, 234. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Viazovetskyi, Y.; Ivashkin, V.; Kashin, E. Stylegan2 Distillation for Feed-Forward Image Manipulation. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Flickr. Available online: https://www.flickr.com/photos/tags/flicker/ (accessed on 7 February 2023).
- Yu, F.; Seff, A.; Zhang, Y.; Song, S.; Funkhouser, T.; Xiao, J. Lsun: Construction of a Large-Scale Image Dataset Using Deep Learning with Humans in the Loop. arXiv 2015, arXiv:1506.03365. [Google Scholar]
- Yu, F.; Xian, W.; Chen, Y.; Liu, F.; Liao, M.; Madhavan, V.; Darrell, T. BDD100K: A Diverse Driving Video Database with Scalable Annotation Tooling. arXiv 2018, arXiv:1805.04687. [Google Scholar]
- Kolkin, N.; Salavon, J.; Shakhnarovich, G. Style Transfer by Relaxed Optimal Transport And Self-Similarity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Shaham, T.R.; Dekel, T.; Michaeli, T. Singan: Learning a Generative Model from a Single Natural Image. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 29 October 2019. [Google Scholar]
- Jain, R.K.; Chiu, D.-M.W.; Hawe, W.R. A Quantitative Measure of Fairness and Discrimination; Eastern Research Laboratory, Digital Equipment Corporation: Hudson, MA, USA, 1984; pp. 1–38. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute extractor | |
| Style transfer | |
| Patch image and the corresponding attributes | |
| Reference image and the corresponding attributes | |
| Output image and the corresponding attributes | |
| Pretrained model for style transfer |
| Figure 3a | Figure 3b | |
|---|---|---|
| Type of environment | Outdoor | Indoor |
| Scene categories | Beach, swamp, lagoon, coast | Alley |
| Scene attributes | Natural light, open area, natural, trees, foliage, sunny, leaves, faraway horizon, vegetation | Plaza, shopping mall/indoor, gym/indoor, atrium/public, construction site |
| Keywords for Filtering Patch Images | |||||
|---|---|---|---|---|---|
| Keyword | Cloudy | Forest | Overcast | Roads | |
| Mountain | O | O | X | O | |
| Church | O | O | X | X | |
| Bedroom | X | X | X | X | |
| Cloudy | Forest | Overcast | Roads | |||||
|---|---|---|---|---|---|---|---|---|
| Sub. | Sub. | Sub. | Sub. | Sub. | Sub. | Sub. | Sub. | |
| Bedroom | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% |
| Church | 15% | 15% | 5% | 0% | 10% | 10% | 8.33% | 8.33% |
| Mountain | 10% | 5% | 5% | 3.33% | 8.33% | 1.67% | 0% | 0% |
| Cloudy | Forest | Overcast | Roads | |||||
|---|---|---|---|---|---|---|---|---|
| Sub. | Sub. | Sub. | Sub. | Sub. | Sub. | Sub. | Sub. | |
| Bedroom | 5% | 5% | 28.33% | 11.67% | 1.67% | 5% | 5% | 28.33% |
| Church | 33.33% | 31.67% | 50% | 28.33% | 20% | 33.33% | 31.67% | 50% |
| Mountain | 41.67% | 41.67% | 40% | 40% | 46.67% | 41.67% | 41.67% | 40% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, U.; Jiang, P.; Wu, H.; Xin, C. View Synthesis with Scene Recognition for Cross-View Image Localization. Future Internet 2023, 15, 126. https://doi.org/10.3390/fi15040126
Lee U, Jiang P, Wu H, Xin C. View Synthesis with Scene Recognition for Cross-View Image Localization. Future Internet. 2023; 15(4):126. https://doi.org/10.3390/fi15040126
Chicago/Turabian StyleLee, Uddom, Peng Jiang, Hongyi Wu, and Chunsheng Xin. 2023. "View Synthesis with Scene Recognition for Cross-View Image Localization" Future Internet 15, no. 4: 126. https://doi.org/10.3390/fi15040126
APA StyleLee, U., Jiang, P., Wu, H., & Xin, C. (2023). View Synthesis with Scene Recognition for Cross-View Image Localization. Future Internet, 15(4), 126. https://doi.org/10.3390/fi15040126