
Multi-Scale Audio Spectrogram Transformer for Classroom Teaching Interaction Recognition



Abstract
:1. Introduction
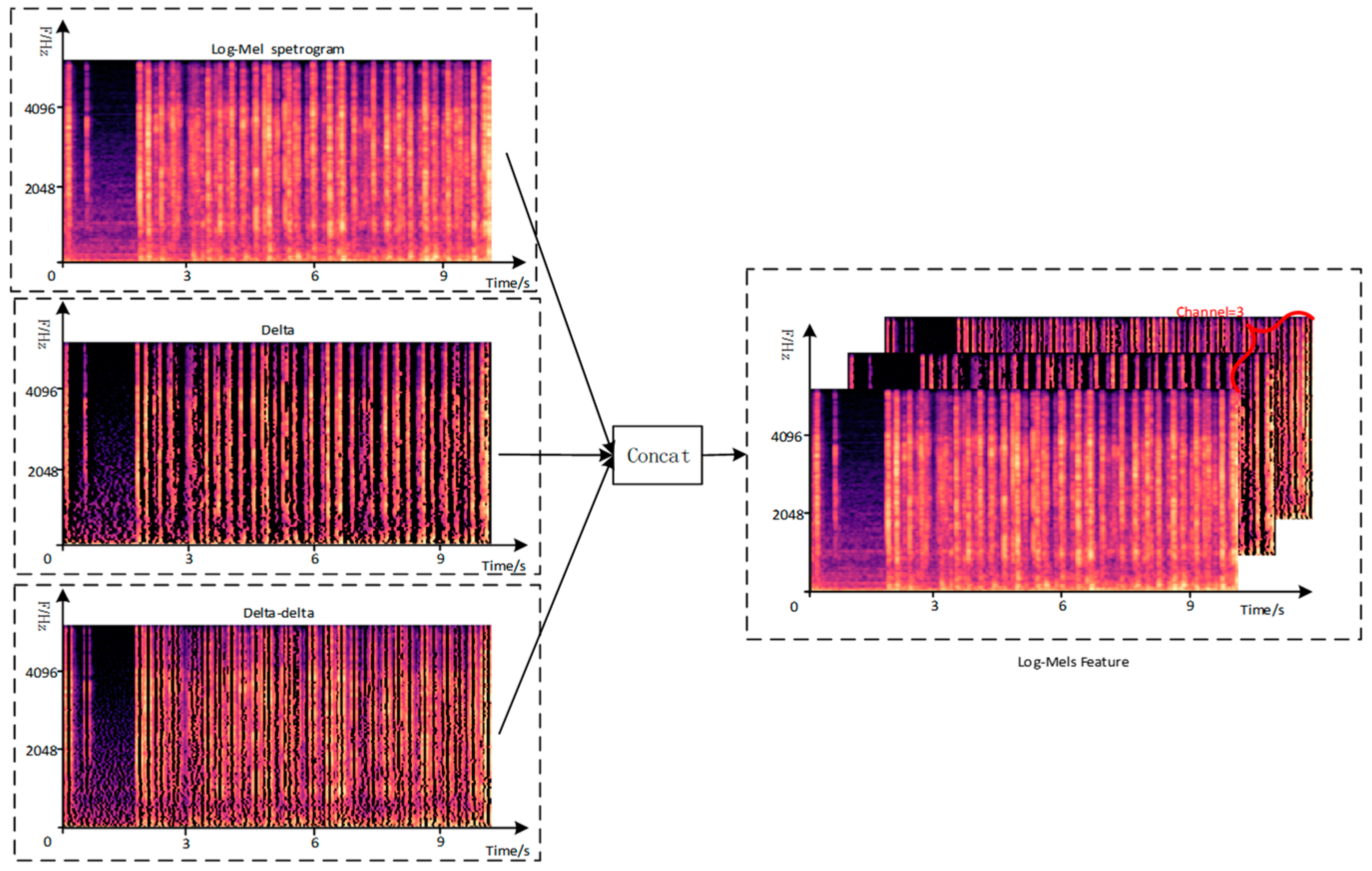
- The multi-channel features enhance the representation of the original signal by the audio spectrogram features while solving the problem of inconsistent input data dimensions during the transition from the visual model to the audio model.
- We propose the MAST model to achieve long-range global modeling of the audio spectrogram. The multi-scale self-attentive mechanism reduces the complexity of the model, as well as focuses on the vital information of the audio spectrogram and eliminates the interference of redundant information caused by multi-channel features.
- We constructed a classroom teacher–student interaction recognition dataset based on audio features and a real classroom audio database, providing basic data for the training of classroom interaction recognition models and classroom interactive evaluation. We also pioneered the application of audio classification models to smart education, which provides a certain reference for subsequent smart classroom research.
2. Related Work
2.1. Multi-Channel Audio Spectrogram Features
2.2. Audio Classification Based on Attention Mechanism
2.3. Classroom Audio Detection
3. Methods
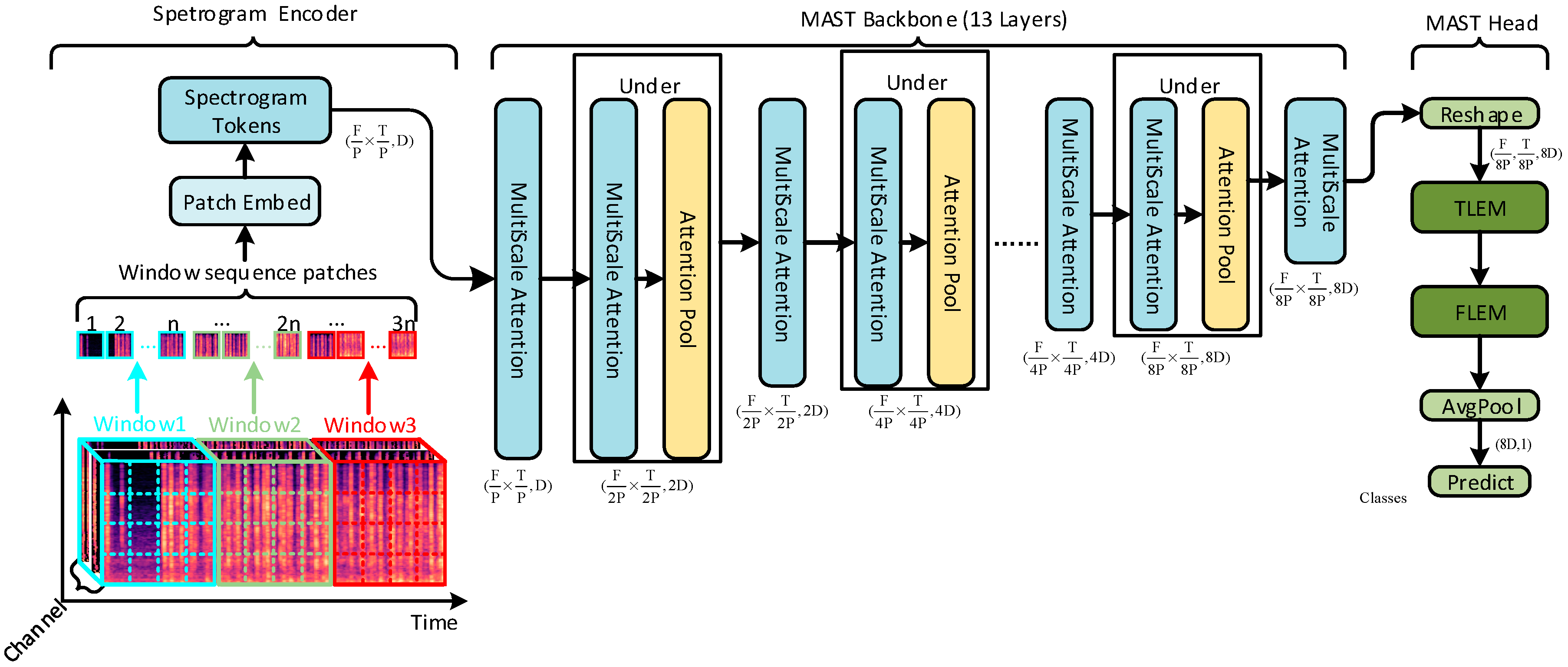
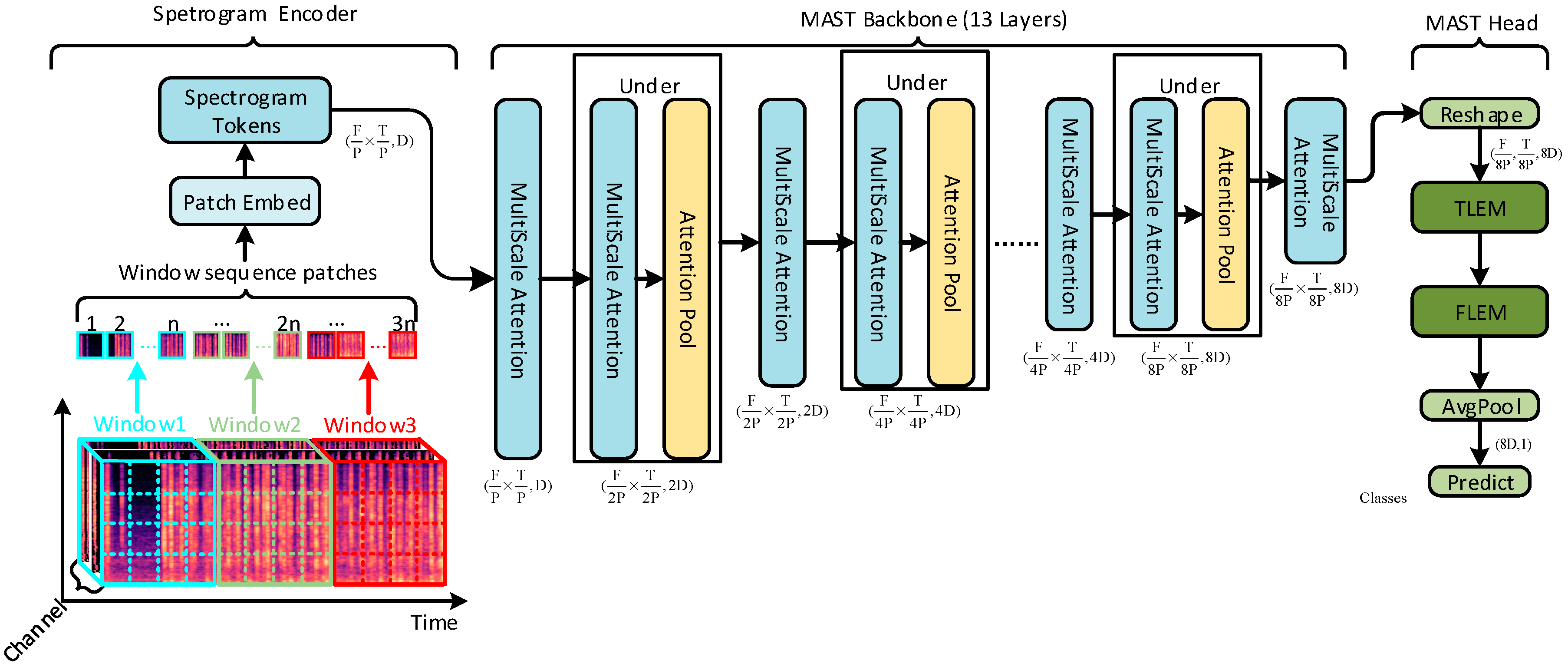
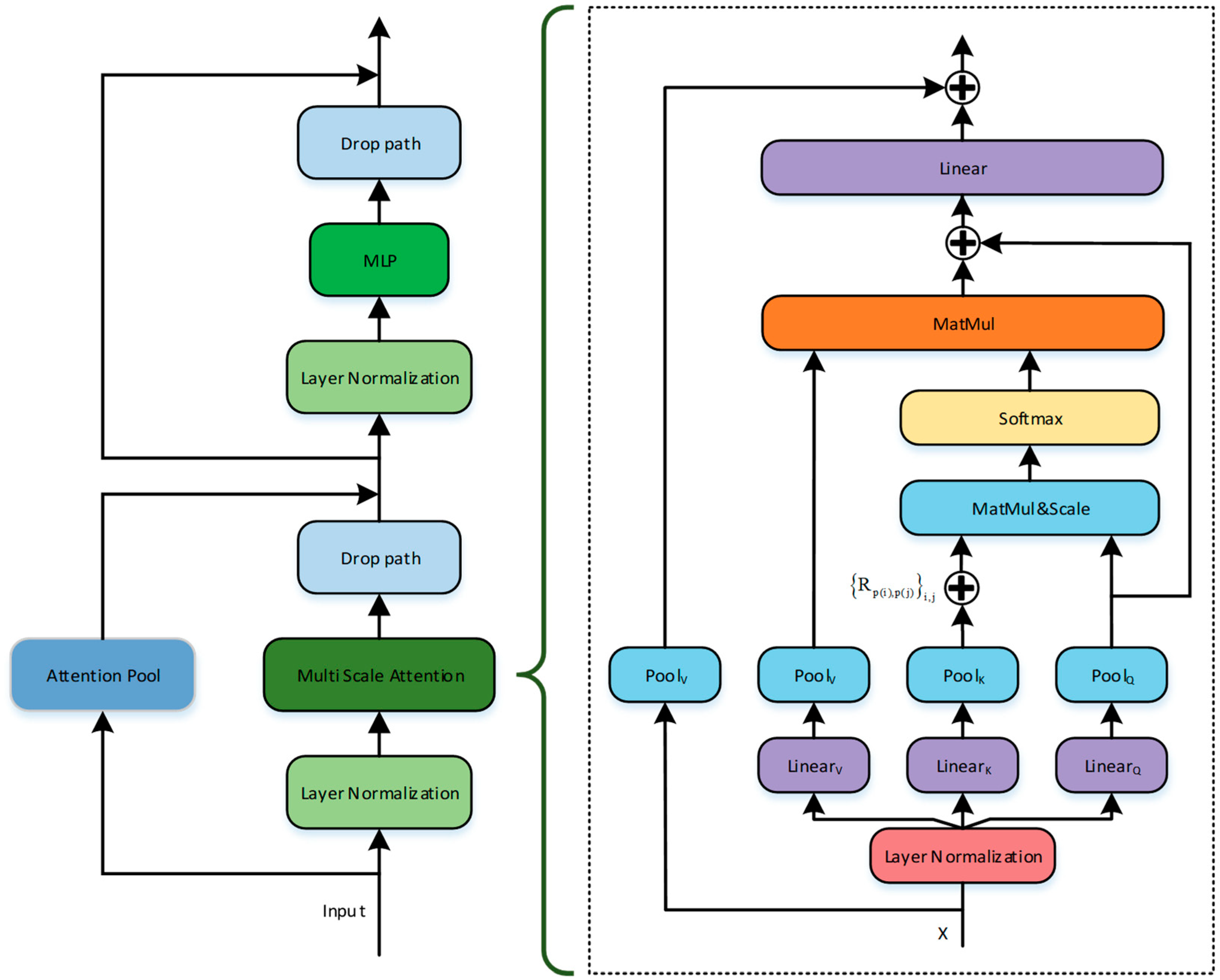
3.1. Model Overall Architecture
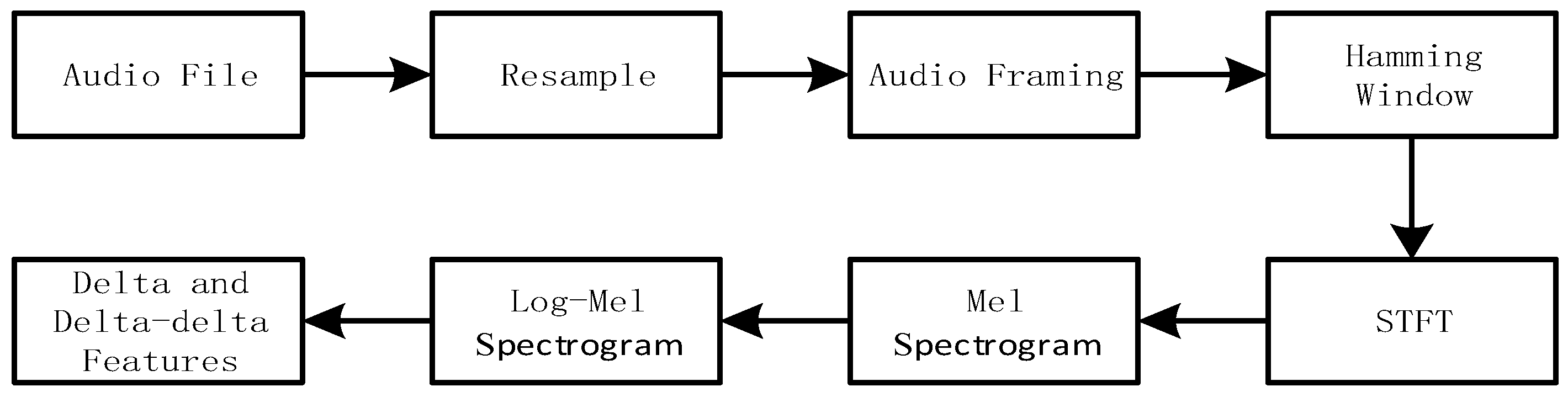
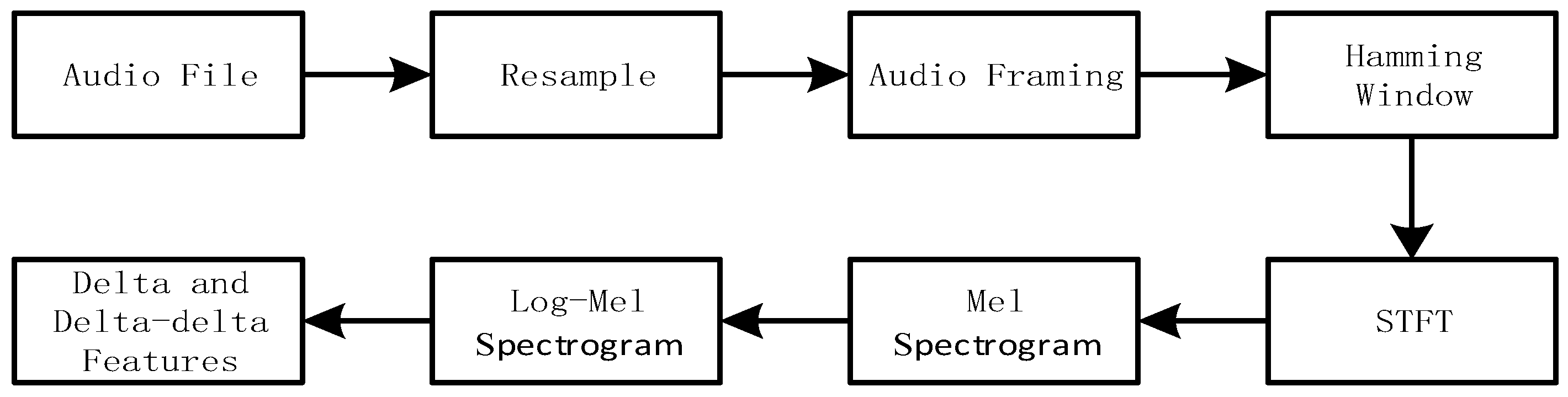
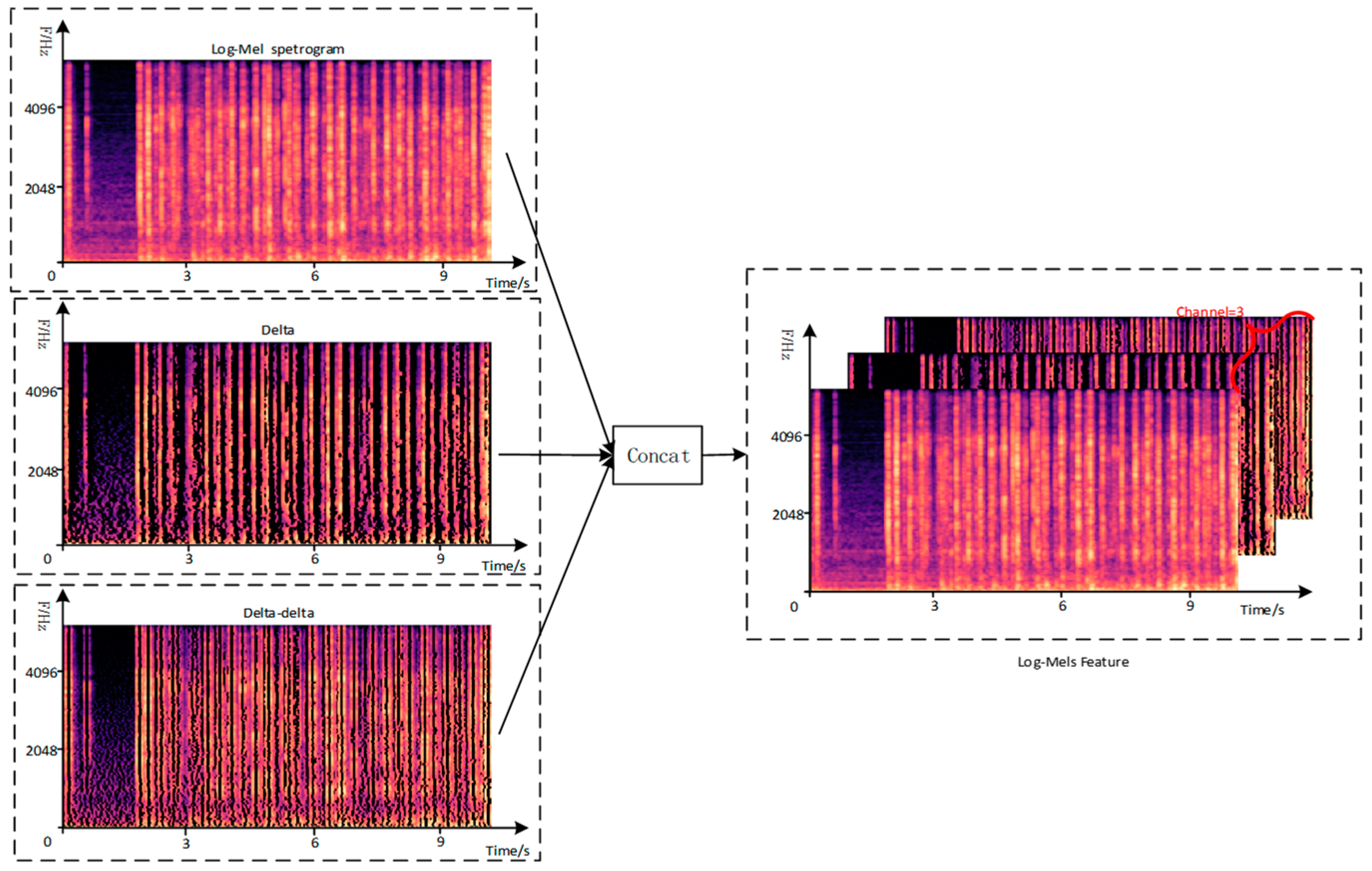
3.2. Multi-Channel Spectrogram Feature Construction
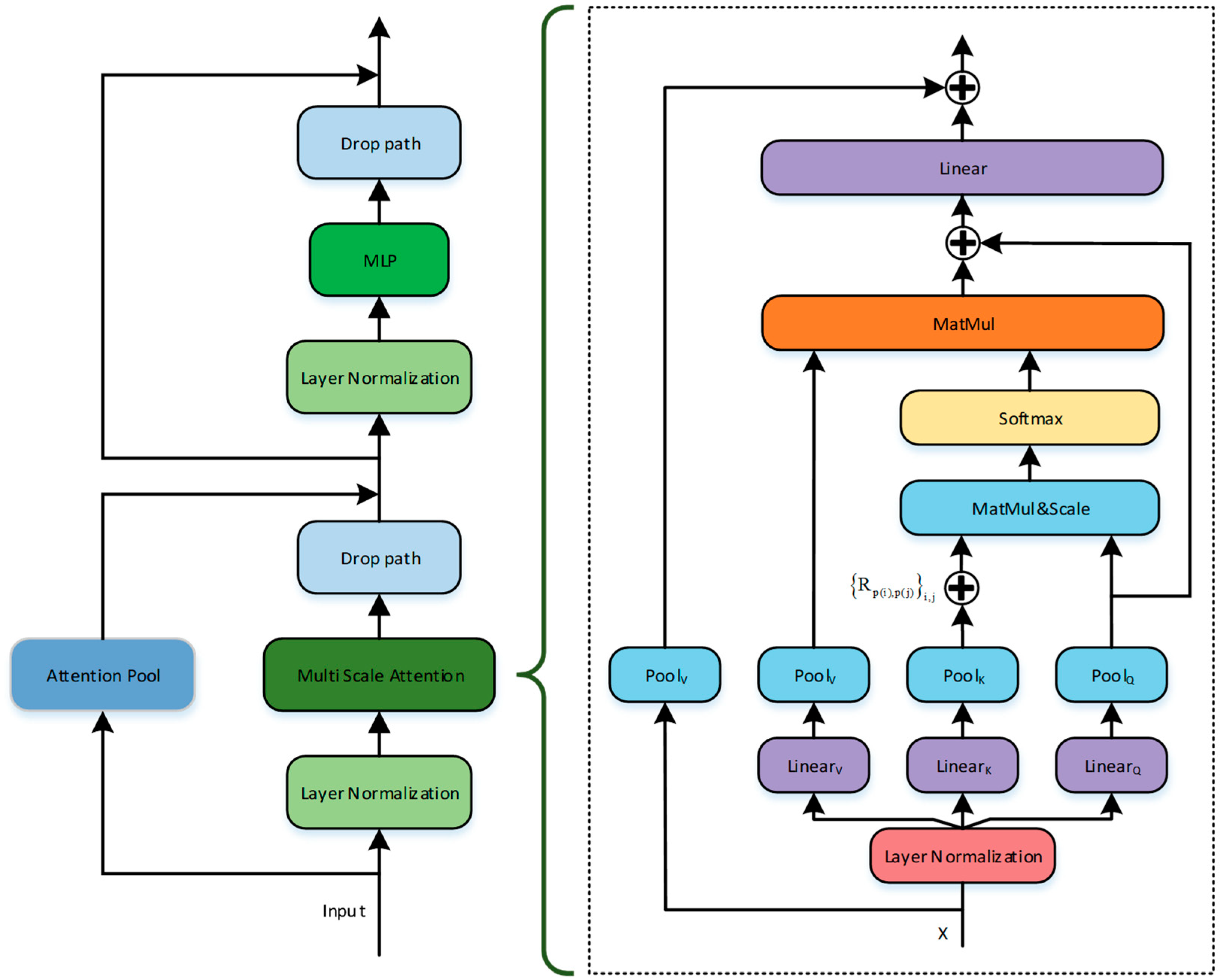
3.3. Multi-Scale Audio Spectrogram Transformer
3.3.1. Pooling Attention
3.3.2. Multi-Scale Audio Spectrogram Transformer Network
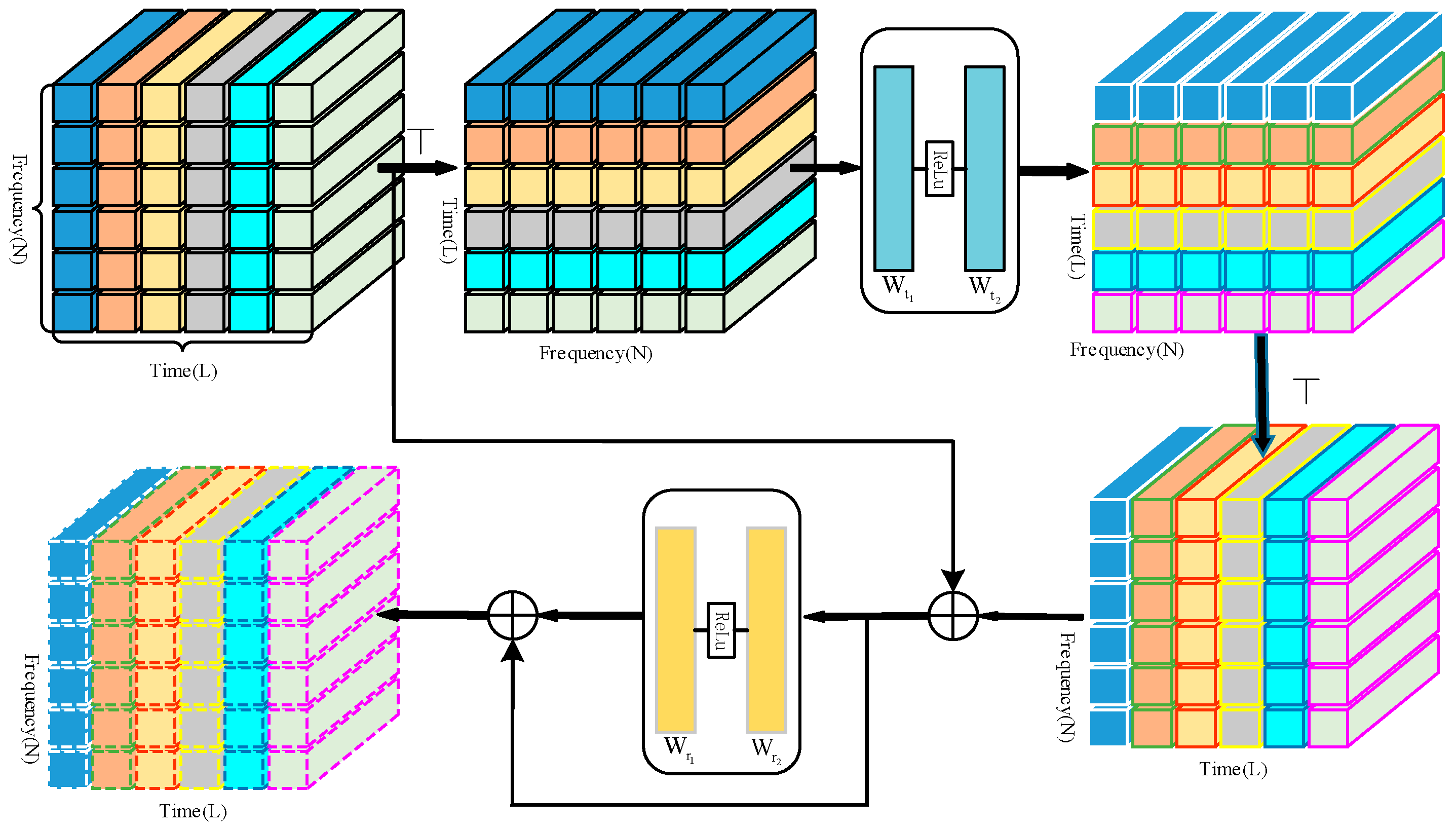
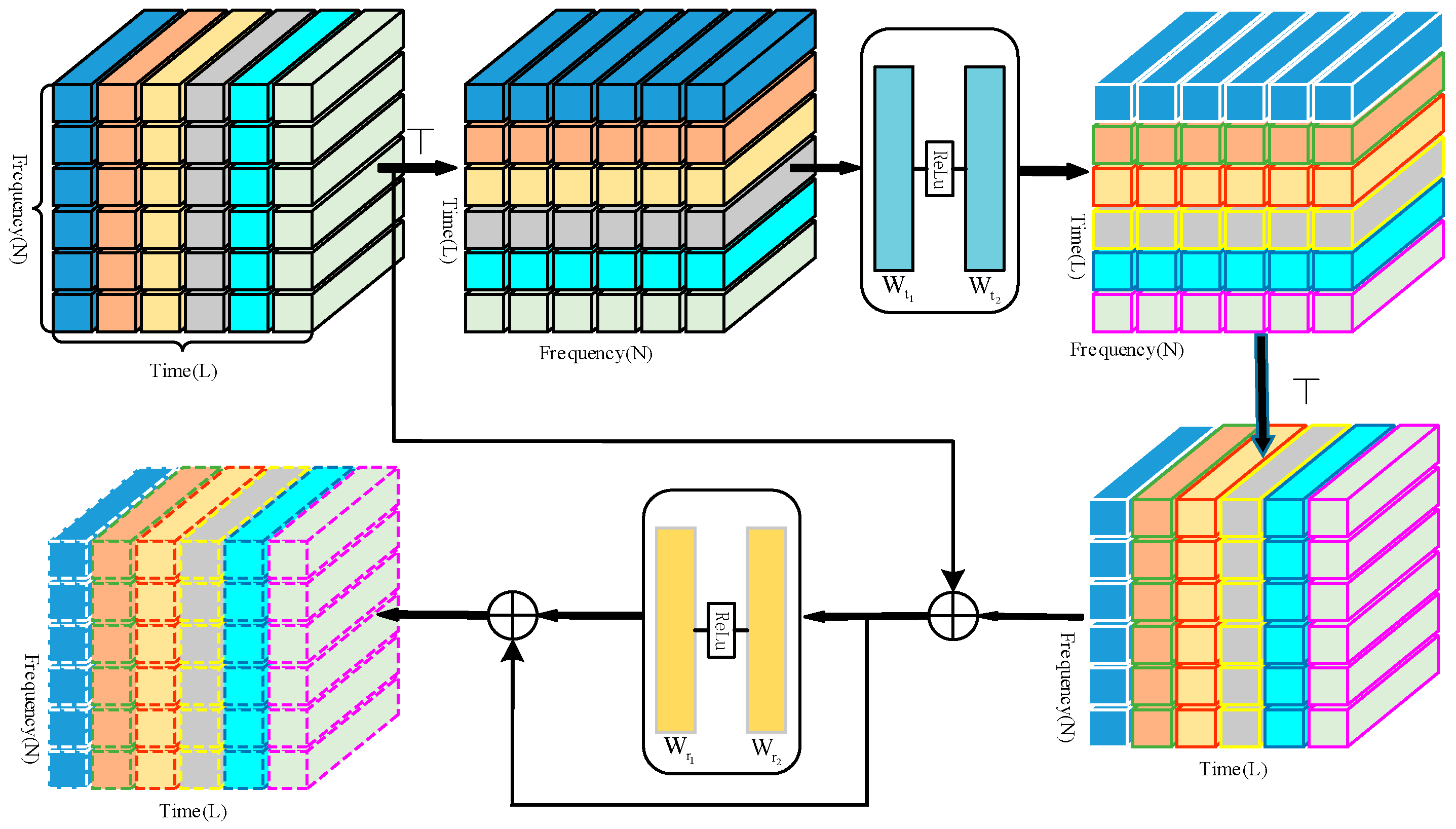
3.4. Time-Frequency Domain Local Enrichment Module
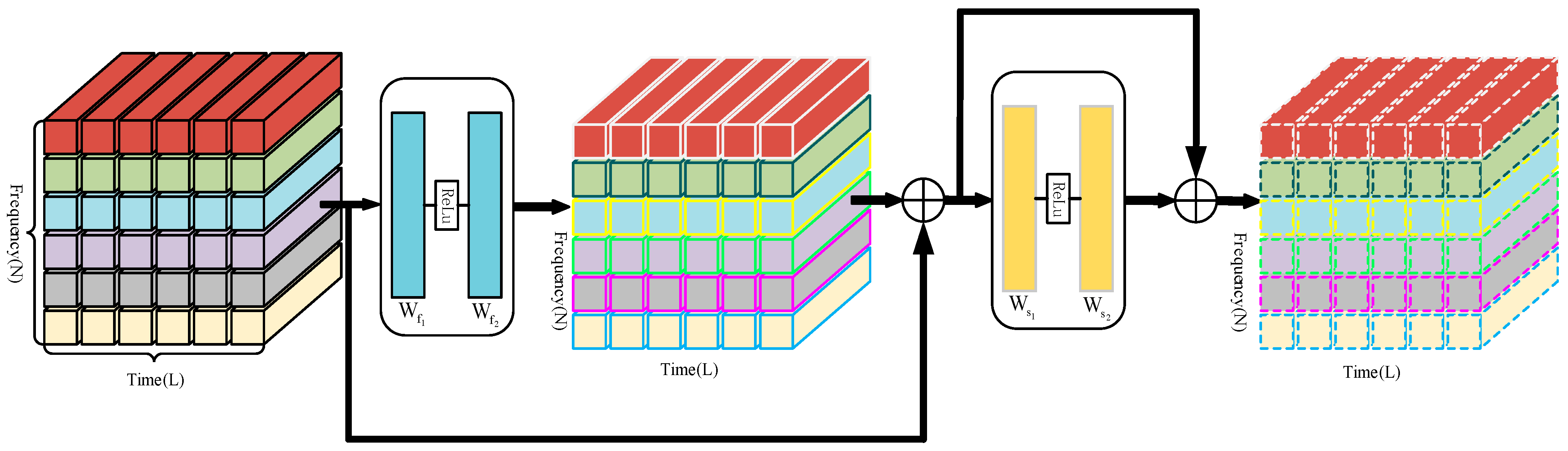
3.4.1. Time-Level Local Enrichment
3.4.2. Frequency-Level Local Enrichment
4. Experimental
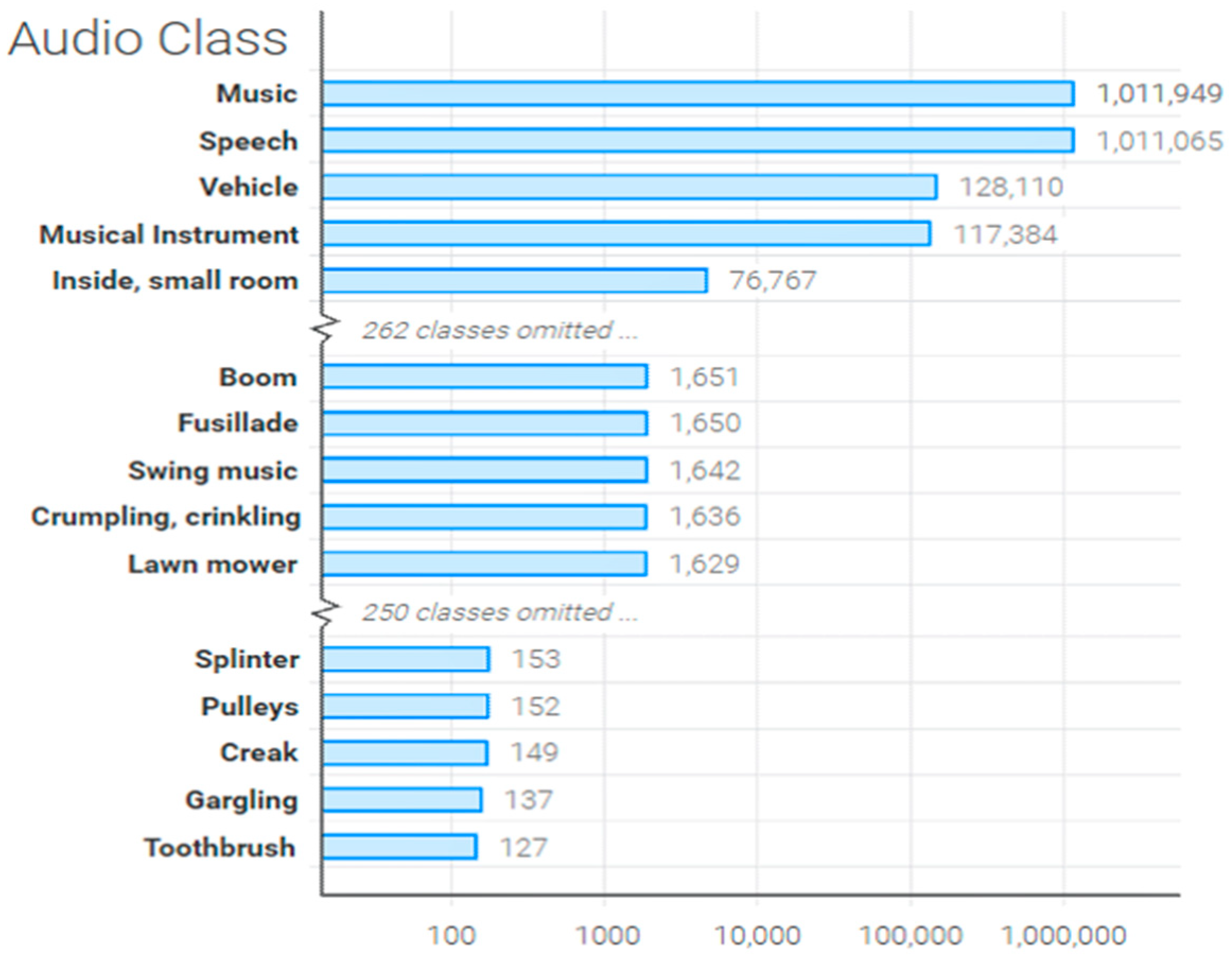
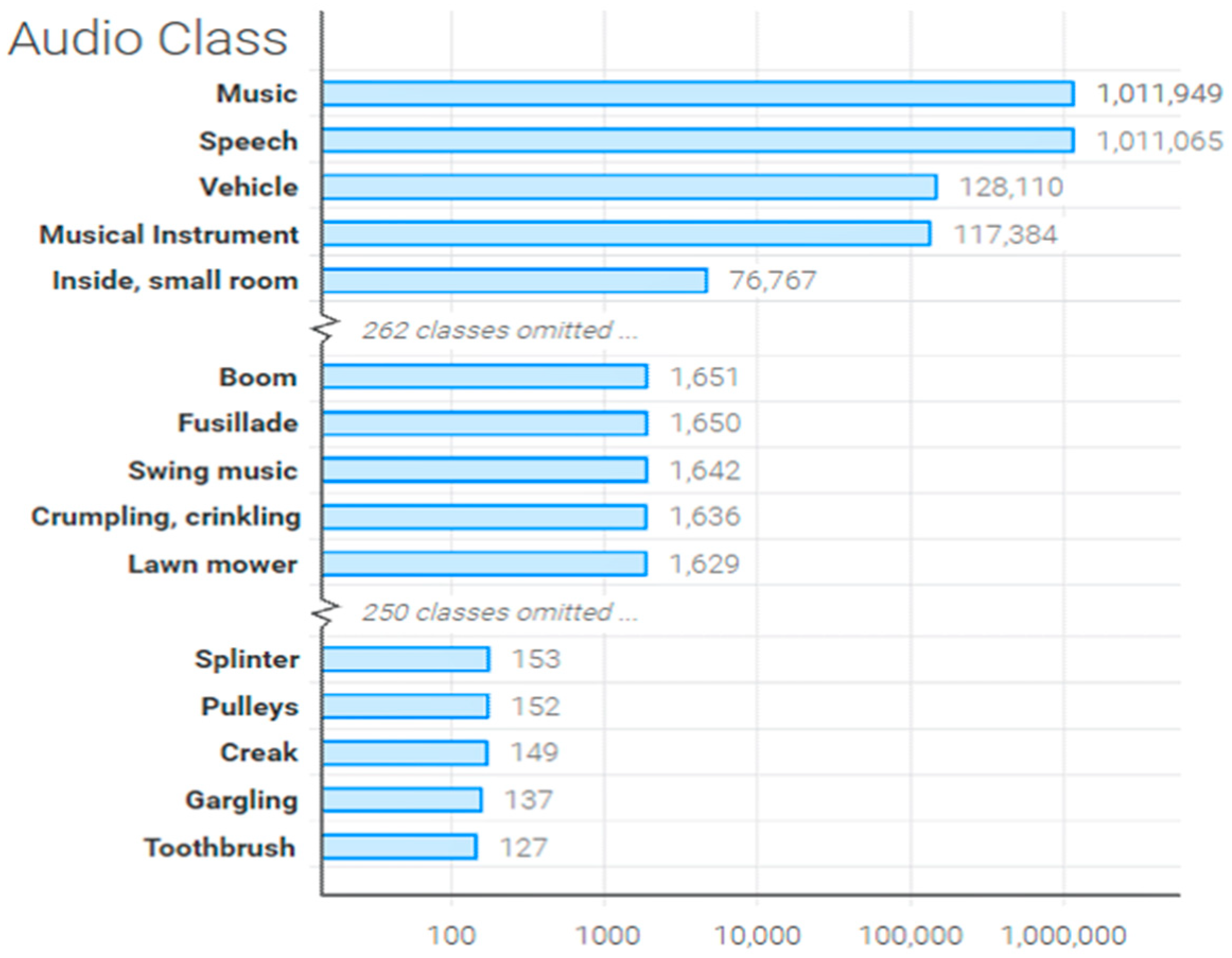
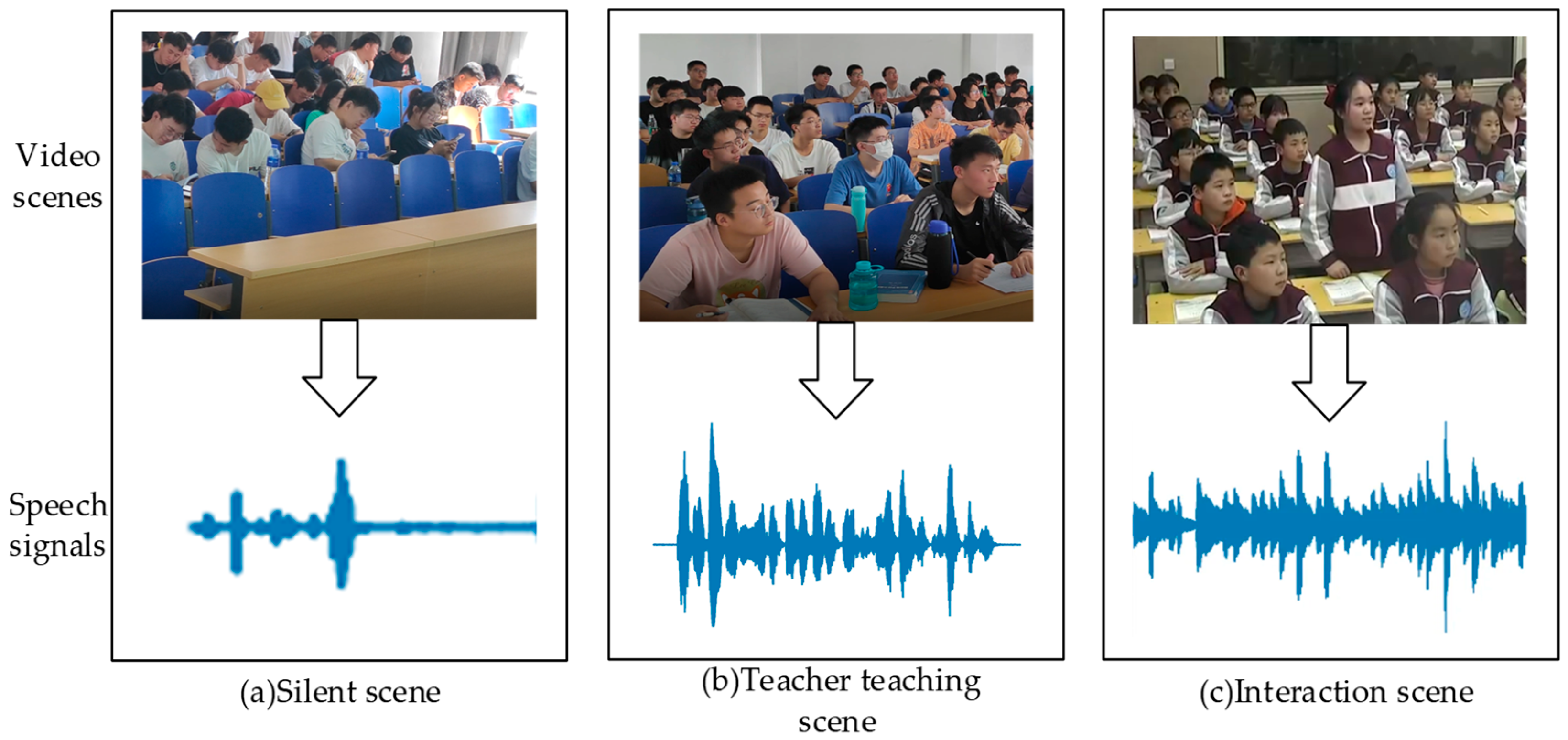
4.1. Datasets and Production
4.2. Experimental Equipment and Evaluation Metrics
4.3. Experimental Results and Analysis
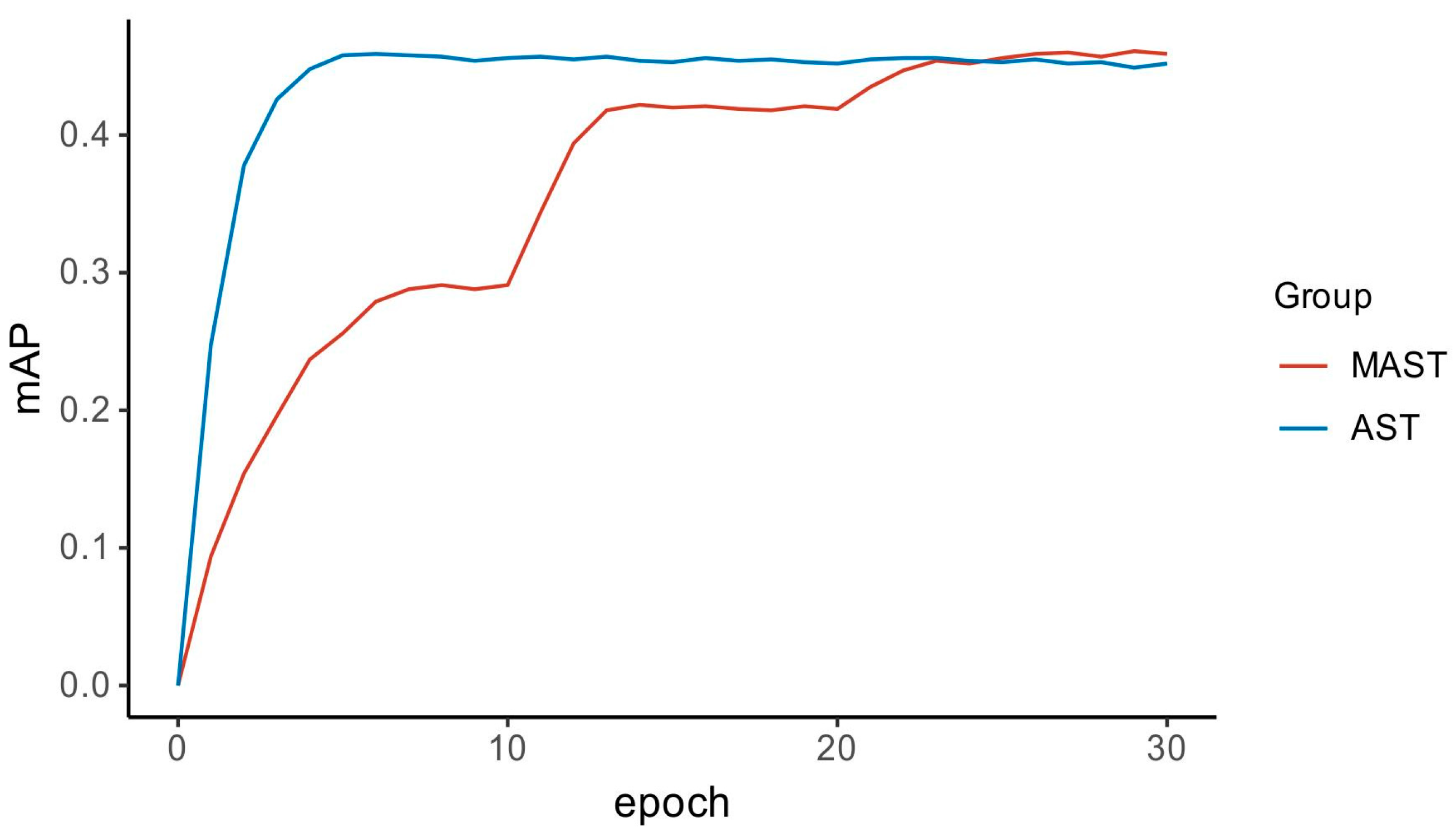
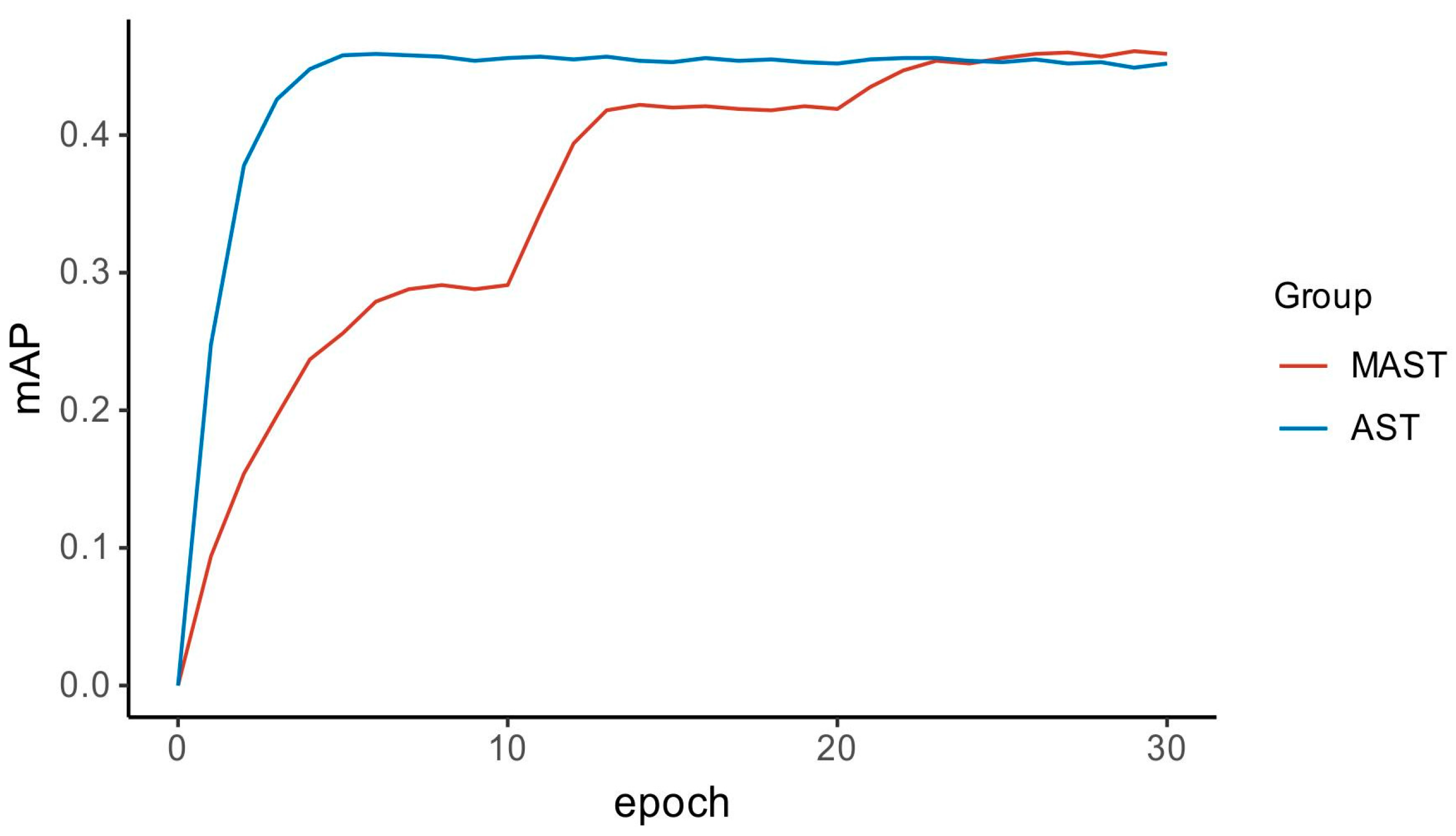
4.3.1. Experimental Results of Event Classification on AudioSet
4.3.2. Experimental Results of Event Classification on ESC-50
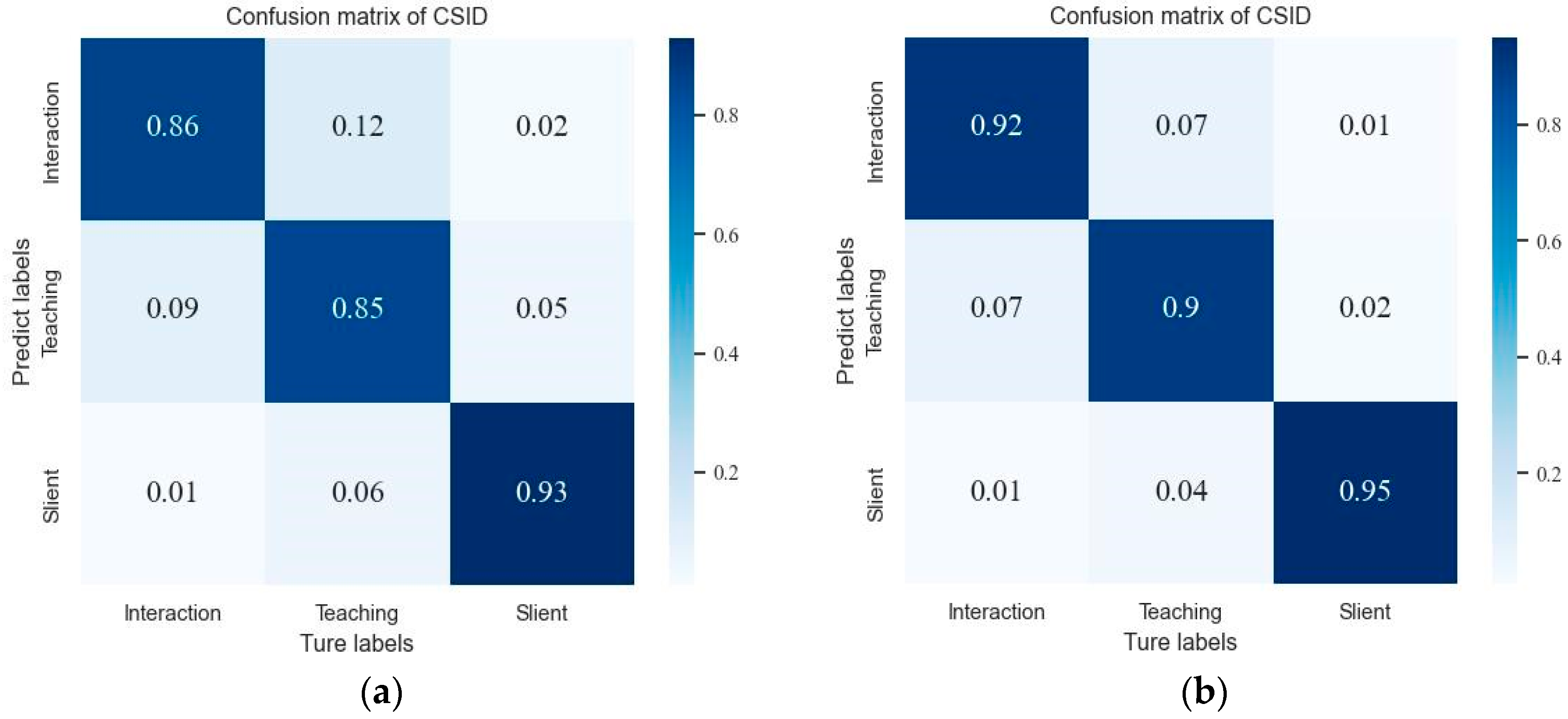
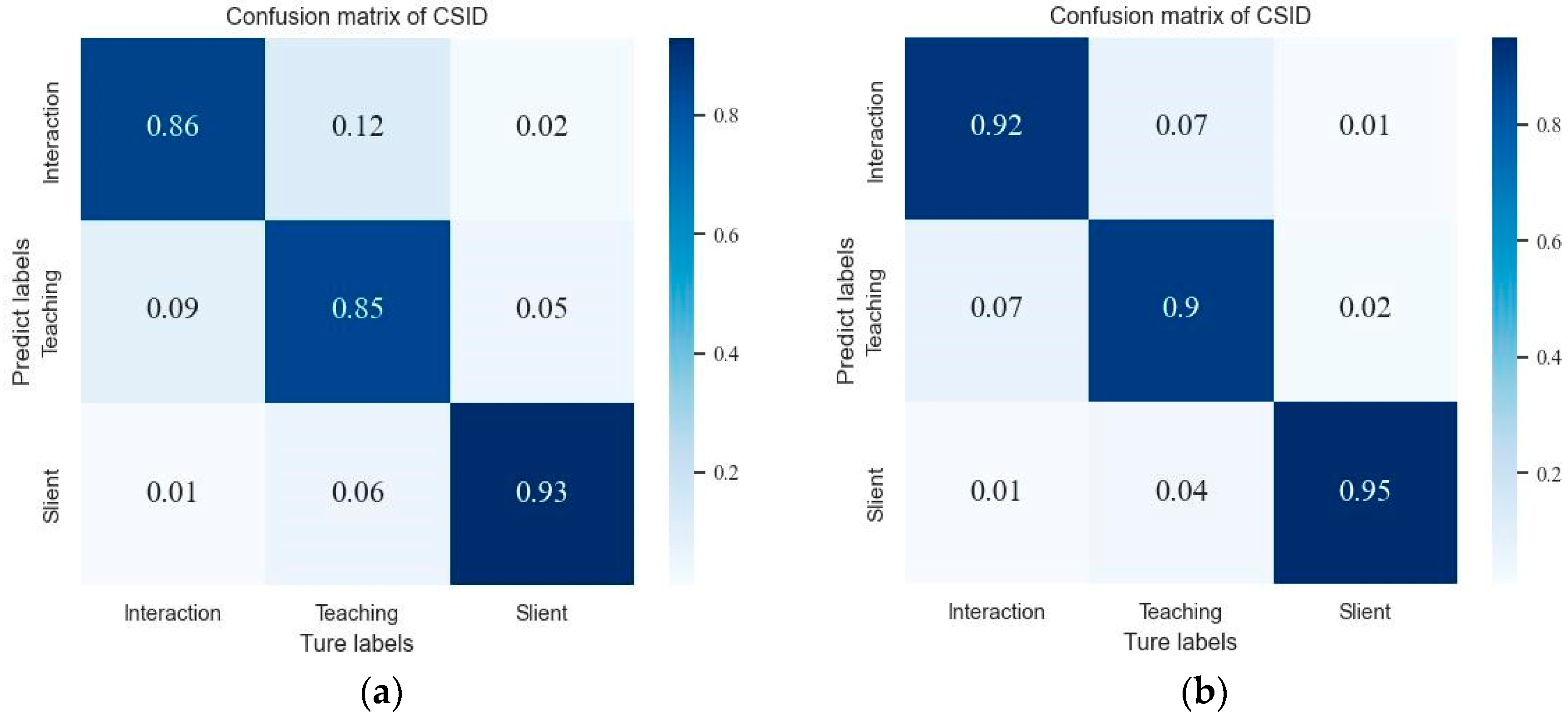
4.3.3. Experimental Results of Event Classification on CSID
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Solis, O.J.; Turner, W.D. Strategies for Building Positive Student-Instructor Interactions in Large Classes. J. Eff. Teach. 2016, 16, 36–51. [Google Scholar]
- Solis, O.J.; Turner, W.D. Building positive student-instructor interactions: Engaging students through caring leadership in the classroom. J. Empower. Teach. Excell. 2017, 1, 4. [Google Scholar]
- An, J.; Macaro, E.; Childs, A. Classroom interaction in EMI high schools: Do teachers who are native speakers of English make a difference? System 2021, 98, 102482. [Google Scholar] [CrossRef]
- Flanders, N.A. Intent, action and feedback: A preparation for teaching. J. Teach. Educ. 1963, 14, 251–260. [Google Scholar] [CrossRef]
- Khalil, R.A.; Jones, E.; Babar, M.I.; Jan, T.; Zafar, M.H.; Alhussain, T. Speech emotion recognition using deep learning techniques: A review. IEEE Access 2019, 7, 117327–117345. [Google Scholar] [CrossRef]
- Yoon, S.; Byun, S.; Jung, K. Multimodal speech emotion recognition using audio and text. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 112–118. [Google Scholar]
- Mushtaq, Z.; Su, S.-F. Environmental sound classification using a regularized deep convolutional neural network with data augmentation. Appl. Acoust. 2020, 167, 107389. [Google Scholar] [CrossRef]
- Tripathi, A.M.; Mishra, A. Environment sound classification using an attention-based residual neural network. Neurocomputing 2021, 460, 409–423. [Google Scholar] [CrossRef]
- Eyben, F.; Weninger, F.; Gross, F.; Schuller, B. Recent developments in opensmile, the munich open-source multimedia feature extractor. In Proceedings of the 21st ACM International Conference on Multimedia, Barcelona, Spain, 21–25 October 2013; pp. 835–838. [Google Scholar]
- Davis, S.; Mermelstein, P. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 357–366. [Google Scholar] [CrossRef]
- Wang, J.-C.; Wang, J.-F.; He, K.W.; Hsu, C.-S. Environmental sound classification using hybrid SVM/KNN classifier and MPEG-7 audio low-level descriptor. In Proceedings of the The 2006 IEEE International Joint Conference on Neural Network Proceedings, Vancouver, BC, Canada, 16–21 July 2006; pp. 1731–1735. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. Handb. Brain Theory Neural Netw. 1995, 3361, 1995. [Google Scholar]
- Salamon, J.; Bello, J.P. Deep convolutional neural networks and data augmentation for environmental sound classification. IEEE Signal Process. Lett. 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Issa, D.; Demirci, M.F.; Yazici, A. Speech emotion recognition with deep convolutional neural networks. Biomed. Signal Process. Control 2020, 59, 101894. [Google Scholar] [CrossRef]
- Kao, C.-C.; Wang, W.; Sun, M.; Wang, C. R-crnn: Region-based convolutional recurrent neural network for audio event detection. arXiv 2018, arXiv:1808.06627. [Google Scholar]
- Heyun, L.; Xinhong, P.; Zhihai, Z.; Xiaolin, G. A method for domestic audio event recognition based on attention-CRNN. In Proceedings of the 2020 IEEE 5th International Conference on Signal and Image Processing (ICSIP), Nanjing, China, 23–25 October 2020; pp. 552–556. [Google Scholar]
- Zhang, Z.; Xu, S.; Zhang, S.; Qiao, T.; Cao, S. Attention based convolutional recurrent neural network for environmental sound classification. Neurocomputing 2021, 453, 896–903. [Google Scholar] [CrossRef]
- Sang, J.; Park, S.; Lee, J. Convolutional recurrent neural networks for urban sound classification using raw waveforms. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 2444–2448. [Google Scholar]
- De Benito-Gorrón, D.; Ramos, D.; Toledano, D.T. A multi-resolution CRNN-based approach for semi-supervised sound event detection in DCASE 2020 challenge. IEEE Access 2021, 9, 89029–89042. [Google Scholar] [CrossRef]
- Kim, N.K.; Jeon, K.M.; Kim, H.K. Convolutional recurrent neural network-based event detection in tunnels using multiple microphones. Sensors 2019, 19, 2695. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Gong, Y.; Chung, Y.-A.; Glass, J. AST: Audio Spectrogram Transformer. arXiv 2021, arXiv:2104.01778. [Google Scholar]
- Mollahosseini, A.; Hasani, B.; Mahoor, M.H. Affectnet: A database for facial expression, valence, and arousal computing in the wild. IEEE Trans. Affect. Comput. 2017, 10, 18–31. [Google Scholar] [CrossRef]
- Antoniadis, P.; Filntisis, P.P.; Maragos, P. Exploiting emotional dependencies with graph convolutional networks for facial expression recognition. In Proceedings of the 2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021), Jodhpur, India, 15–18 December 2021; pp. 1–8. [Google Scholar]
- Ryumina, E.; Dresvyanskiy, D.; Karpov, A. In search of a robust facial expressions recognition model: A large-scale visual cross-corpus study. Neurocomputing 2022, 514, 435–450. [Google Scholar] [CrossRef]
- Tang, L.; Xie, T.; Yang, Y.; Wang, H. Classroom Behavior Detection Based on Improved YOLOv5 Algorithm Combining Multi-Scale Feature Fusion and Attention Mechanism. Appl. Sci. 2022, 12, 6790. [Google Scholar] [CrossRef]
- Dukić, D.; Sovic Krzic, A. Real-time facial expression recognition using deep learning with application in the active classroom environment. Electronics 2022, 11, 1240. [Google Scholar] [CrossRef]
- Lin, F.-C.; Ngo, H.-H.; Dow, C.-R.; Lam, K.-H.; Le, H.L. Student behavior recognition system for the classroom environment based on skeleton pose estimation and person detection. Sensors 2021, 21, 5314. [Google Scholar] [CrossRef]
- Hou, C.; Ai, J.; Lin, Y.; Guan, C.; Li, J.; Zhu, W. Evaluation of Online Teaching Quality Based on Facial Expression Recognition. Future Internet 2022, 14, 177. [Google Scholar] [CrossRef]
- Savchenko, A.V.; Savchenko, L.V.; Makarov, I. Classifying emotions and engagement in online learning based on a single facial expression recognition neural network. IEEE Trans. Affect. Comput. 2022, 13, 2132–2143. [Google Scholar] [CrossRef]
- Liu, S.; Gao, P.; Li, Y.; Fu, W.; Ding, W. Multi-modal fusion network with complementarity and importance for emotion recognition. Inf. Sci. 2023, 619, 679–694. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Piczak, K.J. Environmental sound classification with convolutional neural networks. In Proceedings of the 2015 IEEE 25th International Workshop on Machine Learning for Signal Processing (MLSP), Boston, MA, USA, 17–20 September 2015; pp. 1–6. [Google Scholar]
- Huang, C.-W.; Narayanan, S.S. Deep convolutional recurrent neural network with attention mechanism for robust speech emotion recognition. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 583–588. [Google Scholar]
- Atila, O.; Şengür, A. Attention guided 3D CNN-LSTM model for accurate speech based emotion recognition. Appl. Acoust. 2021, 182, 108260. [Google Scholar] [CrossRef]
- Chen, K.; Du, X.; Zhu, B.; Ma, Z.; Berg-Kirkpatrick, T.; Dubnov, S. HTS-AT: A hierarchical token-semantic audio transformer for sound classification and detection. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singpore, 23–27 May 2022; pp. 646–650. [Google Scholar]
- Ristea, N.-C.; Ionescu, R.T.; Khan, F.S. SepTr: Separable Transformer for Audio Spectrogram Processing. arXiv 2022, arXiv:2203.09581. [Google Scholar]
- Mirsamadi, S.; Barsoum, E.; Zhang, C. Automatic speech emotion recognition using recurrent neural networks with local attention. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2227–2231. [Google Scholar]
- Dangol, R.; Alsadoon, A.; Prasad, P.; Seher, I.; Alsadoon, O.H. Speech emotion recognition Using Convolutional neural network and long-short TermMemory. Multimed. Tools Appl. 2020, 79, 32917–32934. [Google Scholar] [CrossRef]
- Ford, L.; Tang, H.; Grondin, F.; Glass, J.R. A Deep residual network for large-scale acoustic scene analysis. In Proceedings of the InterSpeech, Graz, Austria, 15–19 September 2019; pp. 2568–2572. [Google Scholar]
- Wang, H.; Zou, Y.; Chong, D.; Wang, W. Environmental sound classification with parallel temporal-spectral Attention. In Proceedings of the InterSpeech 2020, Shanghai, China, 25–29 October 2020. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Gemmeke, J.F.; Ellis, D.P.; Freedman, D.; Jansen, A.; Lawrence, W.; Moore, R.C.; Plakal, M.; Ritter, M. Audio set: An ontology and human-labeled dataset for audio events. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 776–780. [Google Scholar]
- Piczak, K.J. ESC: Dataset for environmental sound classification. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1015–1018. [Google Scholar]
- Owens, M.T.; Seidel, S.B.; Wong, M.; Bejines, T.E.; Lietz, S.; Perez, J.R.; Sit, S.; Subedar, Z.-S.; Acker, G.N.; Akana, S.F. Classroom sound can be used to classify teaching practices in college science courses. Proc. Natl. Acad. Sci. 2017, 114, 3085–3090. [Google Scholar] [CrossRef] [PubMed]
- Cosbey, R.; Wusterbarth, A.; Hutchinson, B. Deep learning for classroom activity detection from audio. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3727–3731. [Google Scholar]
- Li, Y.; Wu, C.-Y.; Fan, H.; Mangalam, K.; Xiong, B.; Malik, J.; Feichtenhofer, C. MViTv2: Improved multiscale vision transformers for classification and detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4804–4814. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.-C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. Specaugment: A simple data augmentation method for automatic speech recognition. arXiv 2019, arXiv:1904.08779. [Google Scholar]
- Kong, Q.; Cao, Y.; Iqbal, T.; Wang, Y.; Wang, W.; Plumbley, M.D. Panns: Large-scale pretrained audio neural networks for audio pattern recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2880–2894. [Google Scholar] [CrossRef]
- Gong, Y.; Chung, Y.-A.; Glass, J. Psla: Improving audio tagging with pretraining, sampling, labeling, and aggregation. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3292–3306. [Google Scholar] [CrossRef]
- Kim, J. Urban sound tagging using multi-channel audio feature with convolutional neural networks. In Proceedings of the Detection and Classification of Acoustic Scenes and Events, Tokyo, Japan, 2–3 November 2020. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stages | Operators | Output Sizes | |
|---|---|---|---|
| data layer | stride 1 × 1 | ||
| cube 1 | CH × CW, D | ||
| stride 4 × 4 | |||
| scale 2 | MHPSA (D) | 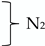 | |
| MLP (4D) | |||
| scale 3 | MHPSA (2D) | 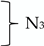 | |
| MLP (8D) | |||
| scale 4 | MHPSA (4D) | 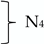 | |
| MLP (16D) | |||
| scale 5 | MHPSA (8D) | 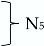 | |
| MLP (32D) | |||
| Title 1 | Training Set | Validation Set | Total |
|---|---|---|---|
| Silent scene | 1057 | 264 | 1321 |
| Teachers teaching scene | 1367 | 342 | 1709 |
| Interaction scene | 1899 | 475 | 2374 |
| Total | 4323 | 1081 | 5404 |
| Method | Year | Params. | mAP |
|---|---|---|---|
| Baseline [45] | 2017 | 2.6M | 0.314 |
| DeepRes [42] | 2019 | 26M | 0.392 |
| PANN [54] | 2020 | 81M | 0.434 |
| PSLA [55] | 2021 | 13.6M | 0.444 |
| AST [25] | 2021 | 87M | 0.459 |
| MAST | 2022 | 36M | 0.461 |
| Method | Multi-Channel Features | TLEM | FLEM | mAP |
|---|---|---|---|---|
| Multi-scale Transformer | × | × | × | 0.451 |
| +Multi-channel features | √ | × | × | 0.454 |
| +TLEM | √ | √ | × | 0.457 |
| +FLEM | √ | √ | √ | 0.461 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, F.; Fang, J. Multi-Scale Audio Spectrogram Transformer for Classroom Teaching Interaction Recognition. Future Internet 2023, 15, 65. https://doi.org/10.3390/fi15020065
Liu F, Fang J. Multi-Scale Audio Spectrogram Transformer for Classroom Teaching Interaction Recognition. Future Internet. 2023; 15(2):65. https://doi.org/10.3390/fi15020065
Chicago/Turabian StyleLiu, Fan, and Jiandong Fang. 2023. "Multi-Scale Audio Spectrogram Transformer for Classroom Teaching Interaction Recognition" Future Internet 15, no. 2: 65. https://doi.org/10.3390/fi15020065
APA StyleLiu, F., & Fang, J. (2023). Multi-Scale Audio Spectrogram Transformer for Classroom Teaching Interaction Recognition. Future Internet, 15(2), 65. https://doi.org/10.3390/fi15020065