
Maximizing UAV Coverage in Maritime Wireless Networks: A Multiagent Reinforcement Learning Approach


Abstract
:1. Introduction
- (1)
- A path-planning method based on a multi-intelligence deep reinforcement learning framework is proposed to maximize the coverage of the target area.
- (2)
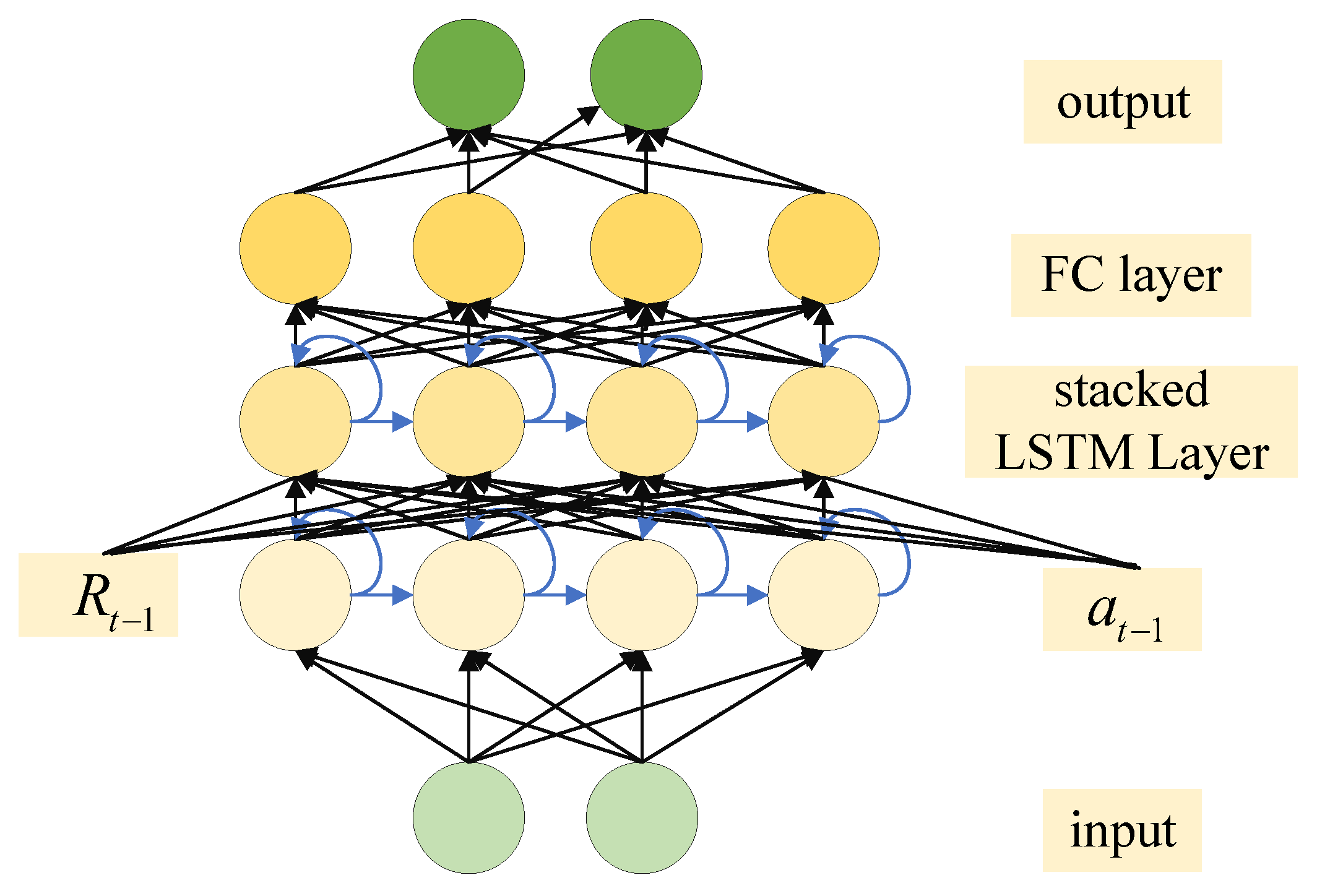
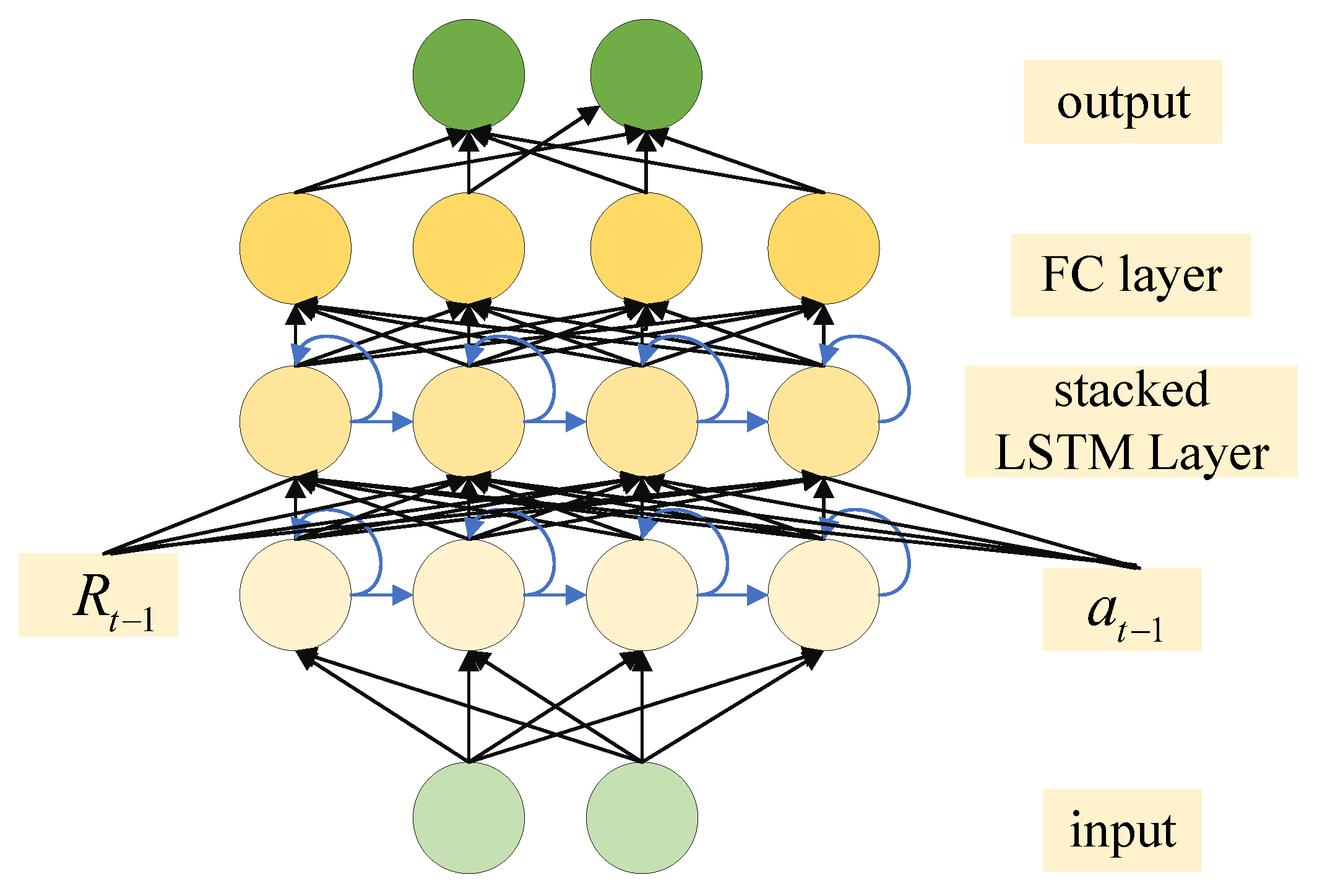
- To address the path-planning problem under the condition of partially incomplete information, we utilized an S-LSTM to store and utilize previous states. Furthermore, to address the non-convex problem in optimizing the objective function, we employed multiagent collaboration and experience sharing within the MATD3 algorithm.
- (3)
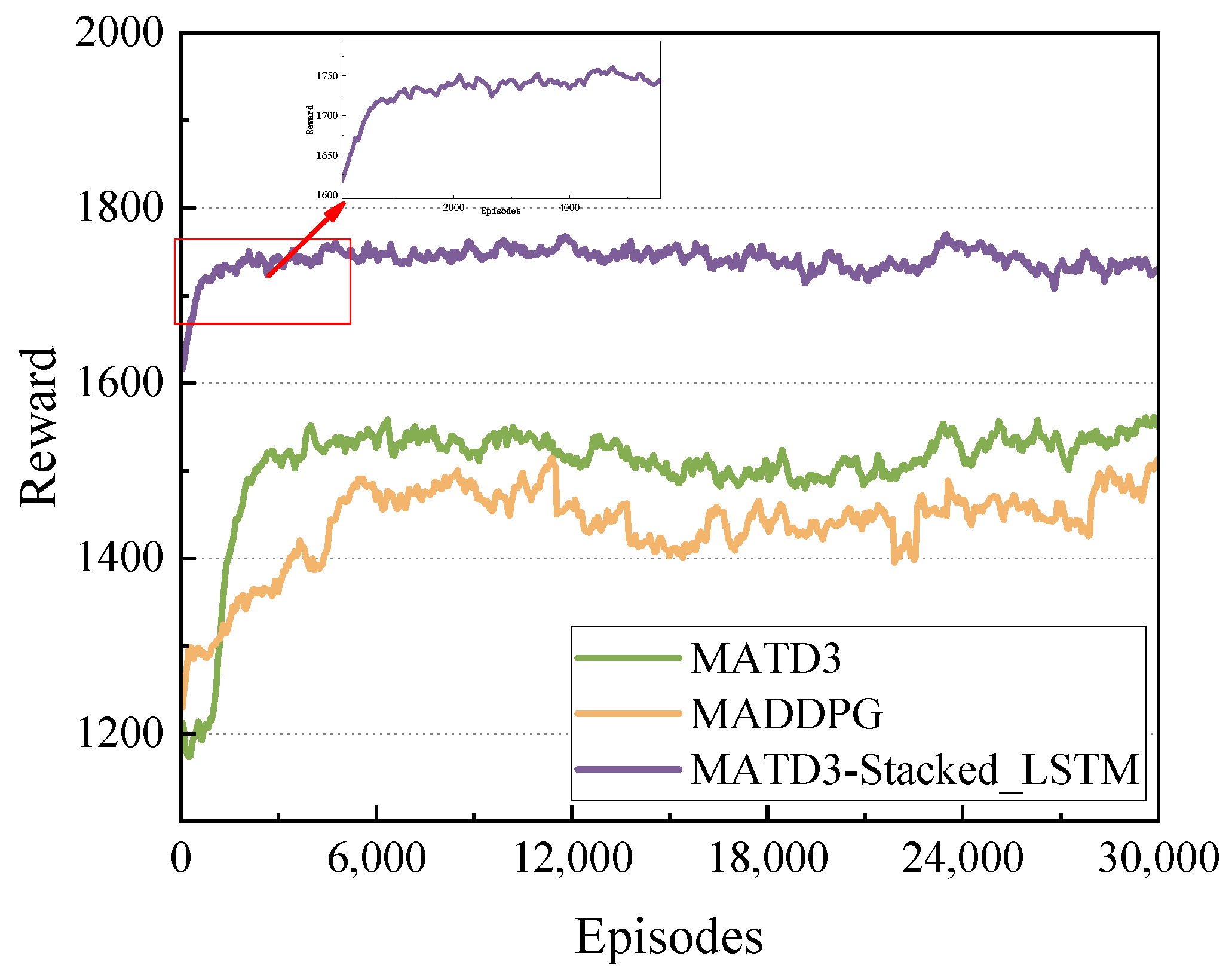
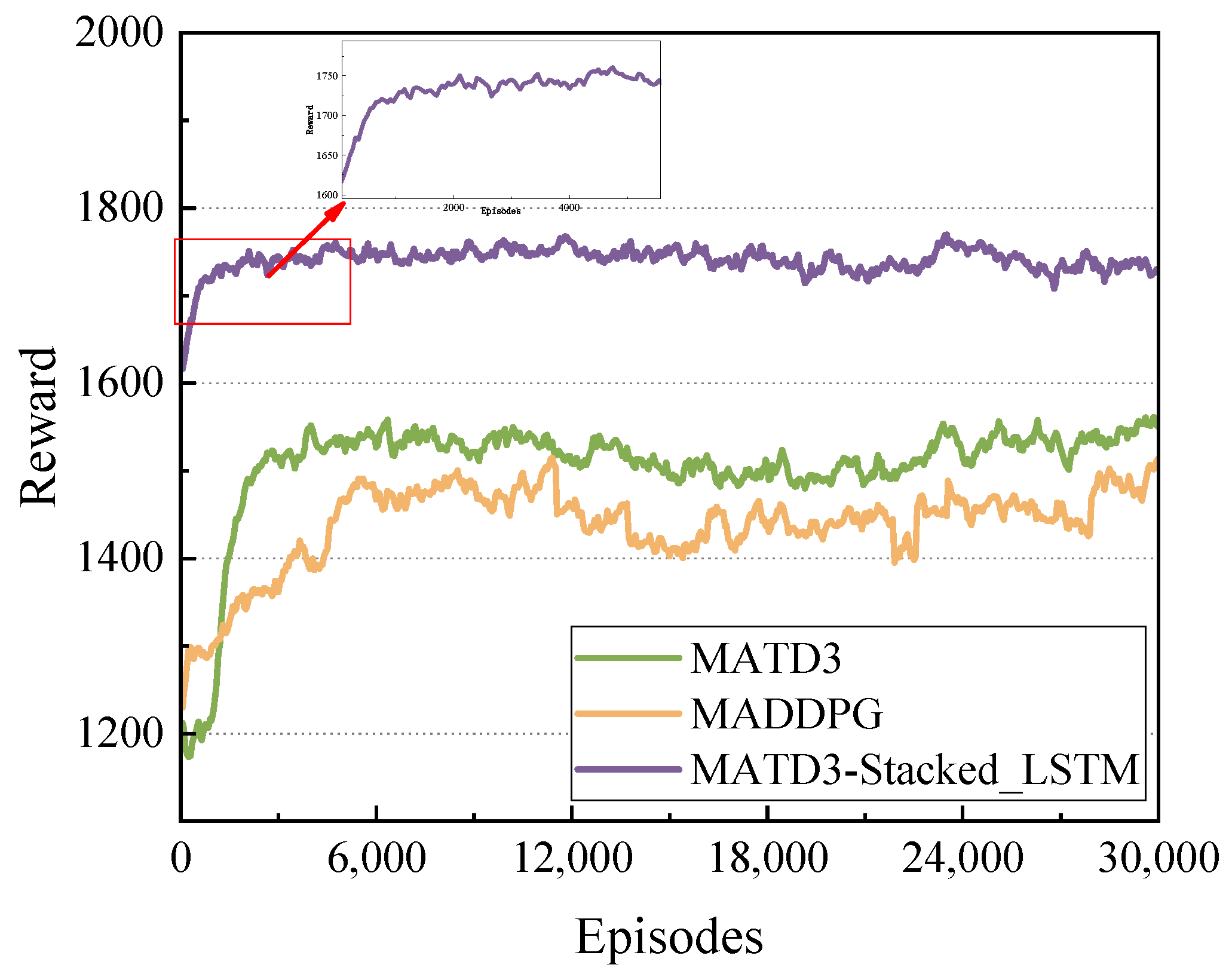
- The simulation results demonstrate that the proposed MATD3-Stacked_LSTM algorithm has better convergence and significantly improves the coverage of the target area compared to the other two algorithms.
2. Related Work
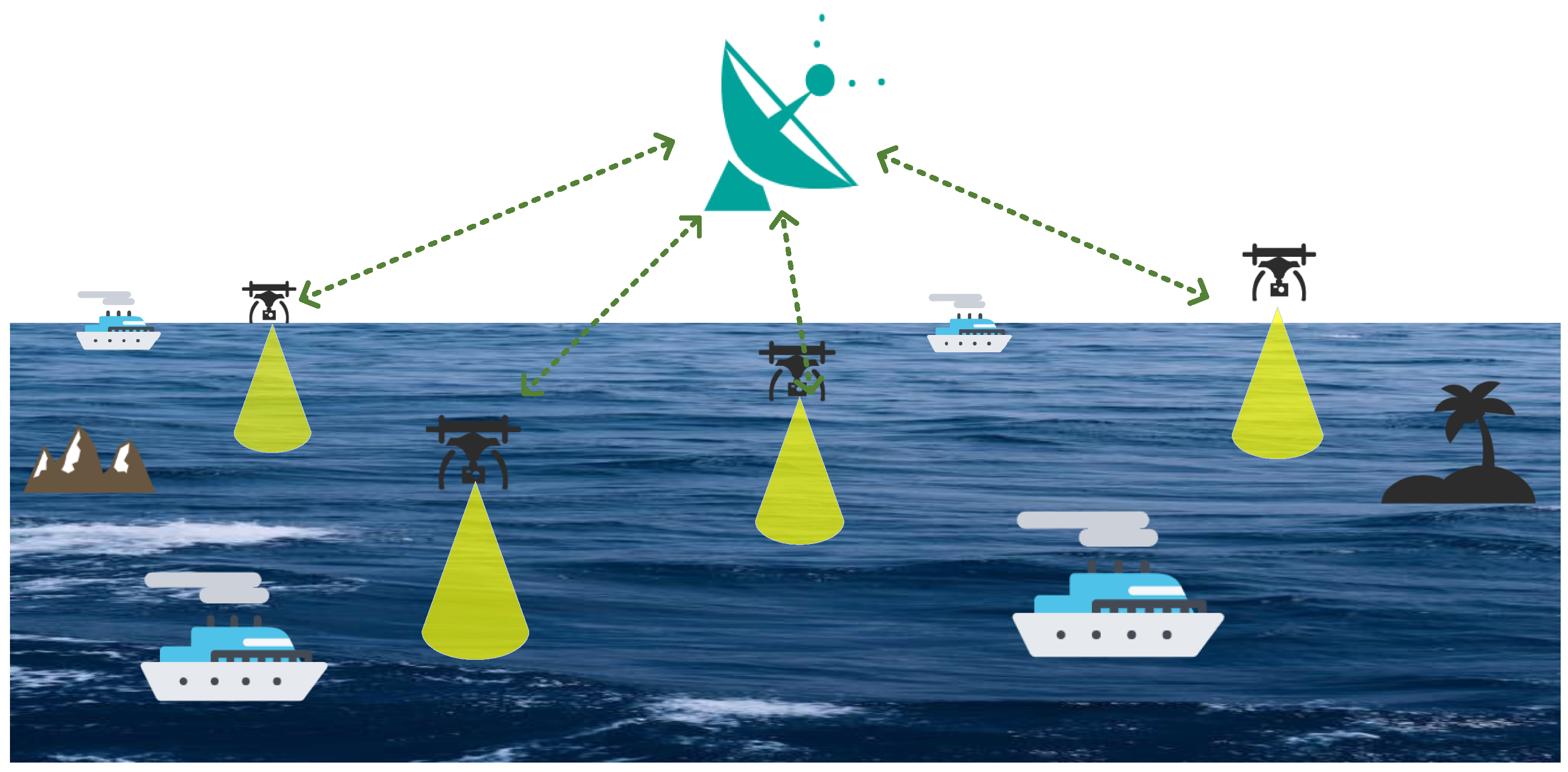
3. System Model and Problem Statement
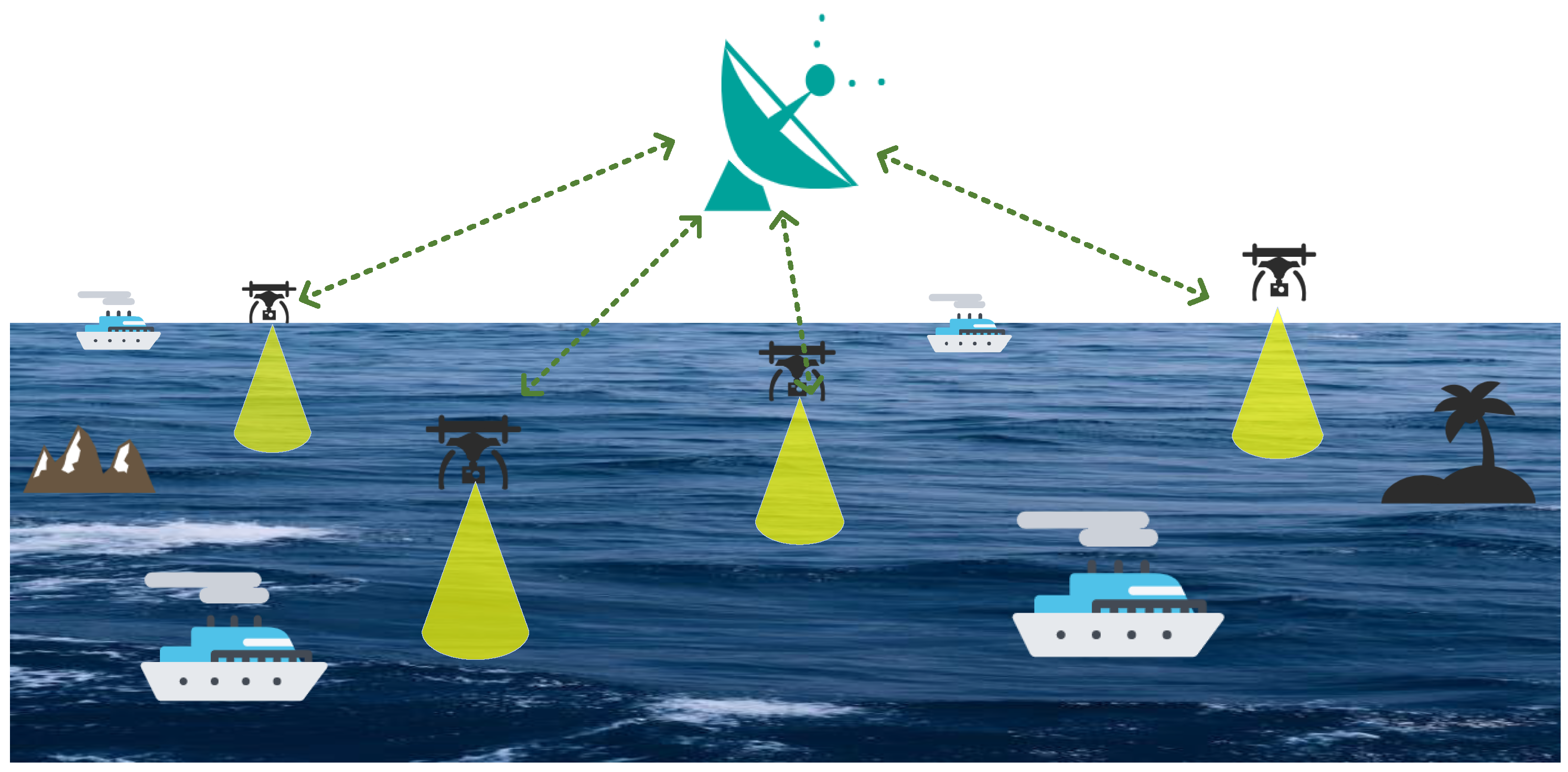
3.1. System Model
3.1.1. UAV Model
3.1.2. Energy Model
3.2. Problem Formulation
- (1)
- (2)
- (3)
- (4)
- (5)
- (6)
- (7)
- (8)
4. Design
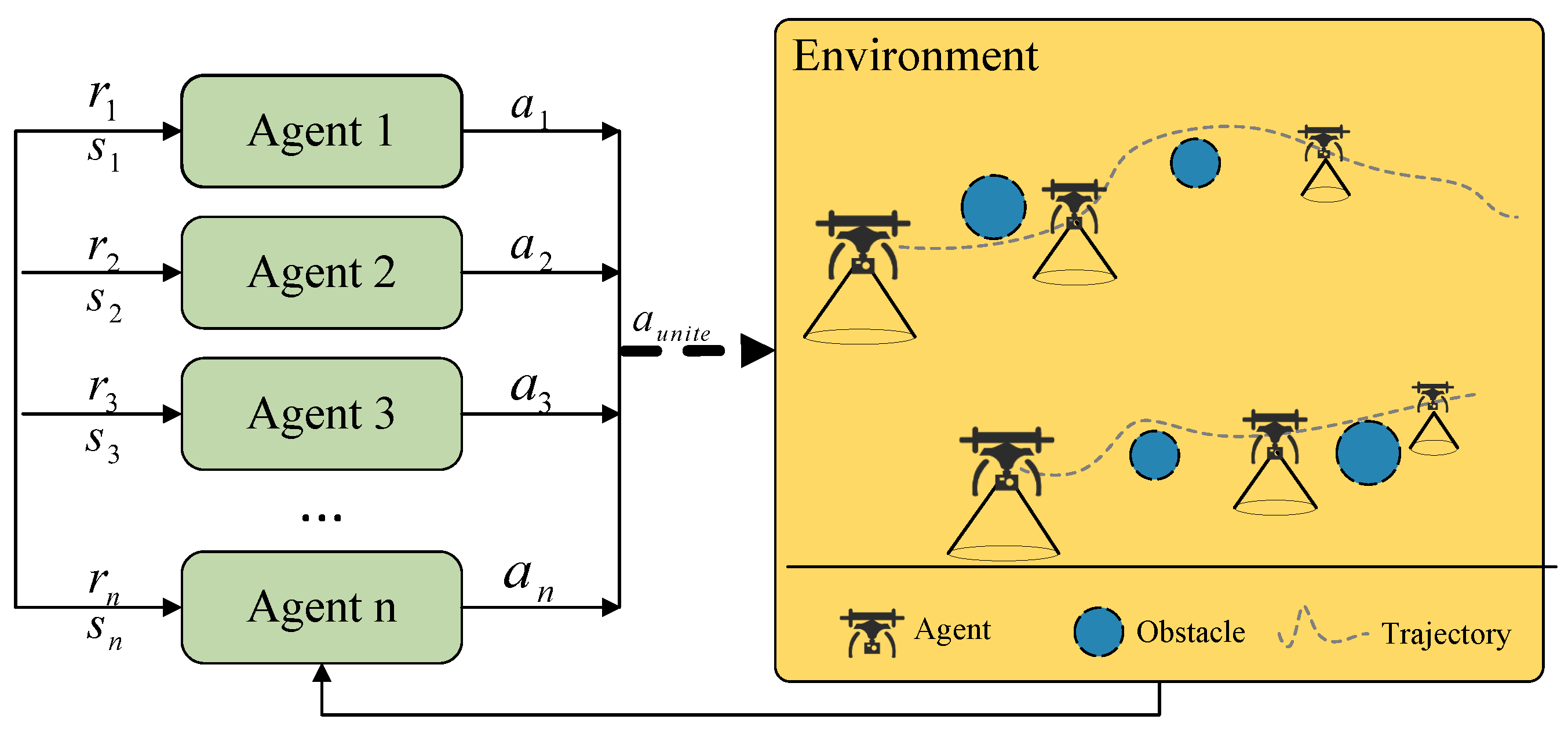
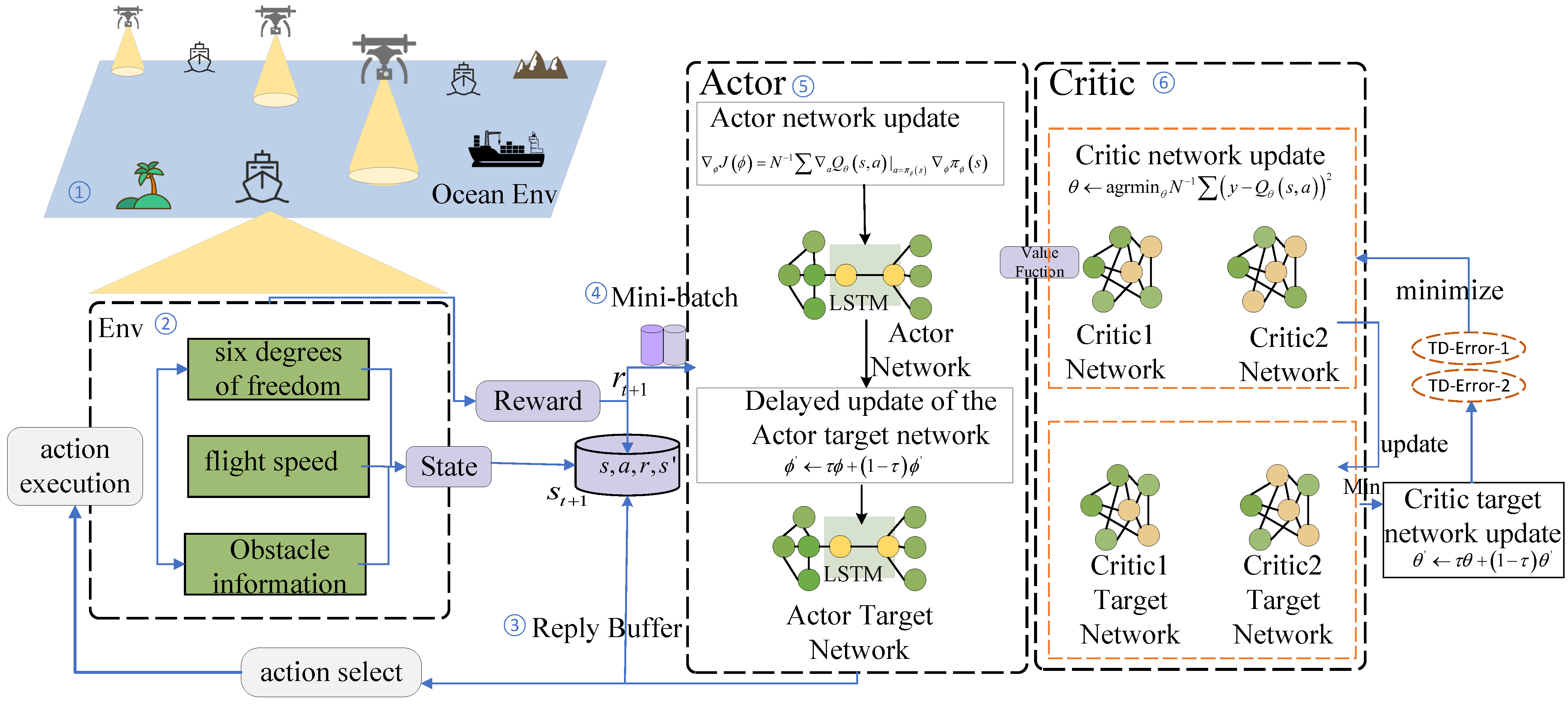
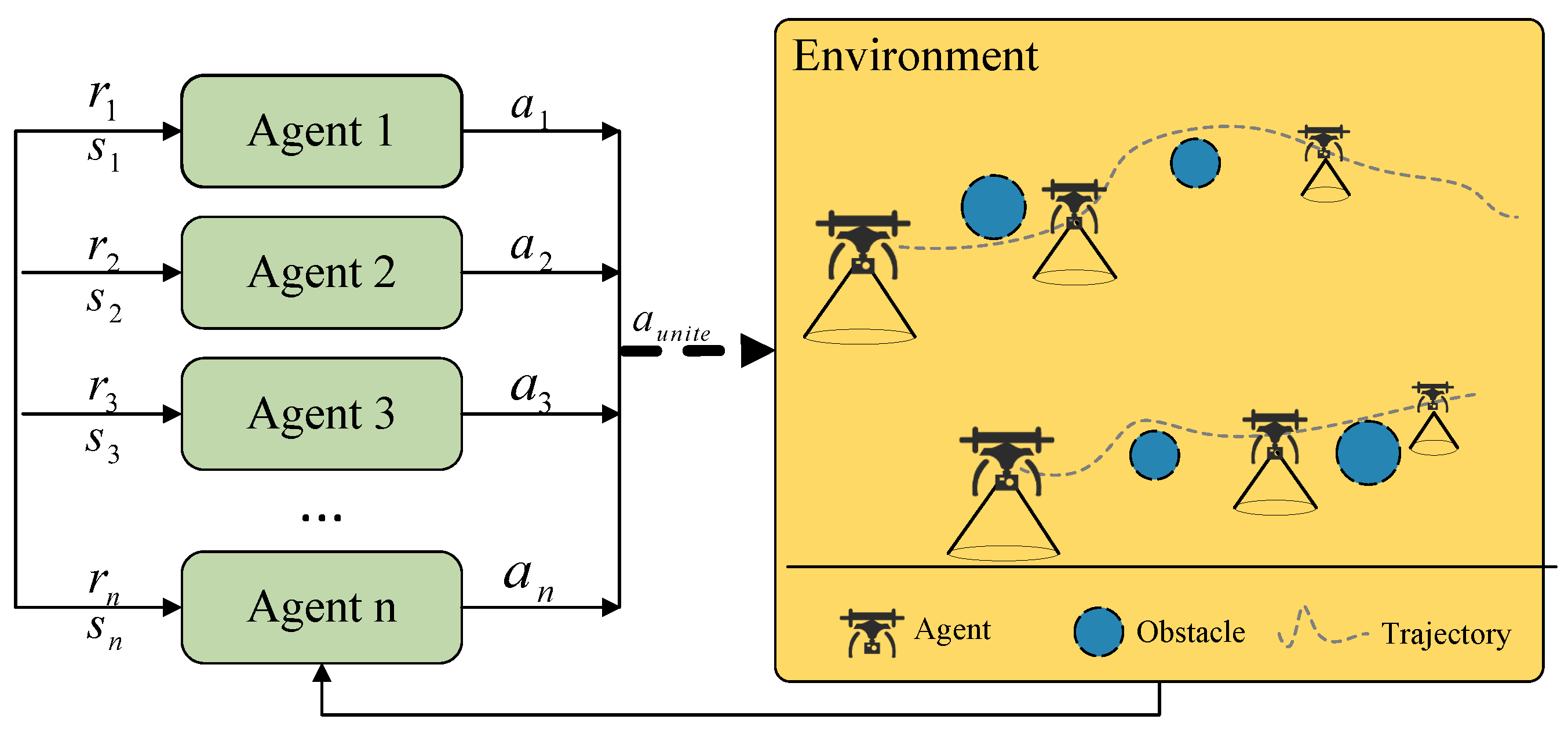
4.1. MATD3
| Algorithm 1 Multi-UAV coverage path planning based on MATD3-Stacked_LSTM algorithm |
|
4.2. Markov Decision Process
4.2.1. Environment
4.2.2. State
4.2.3. Action
4.2.4. Reward
5. Numerical Result
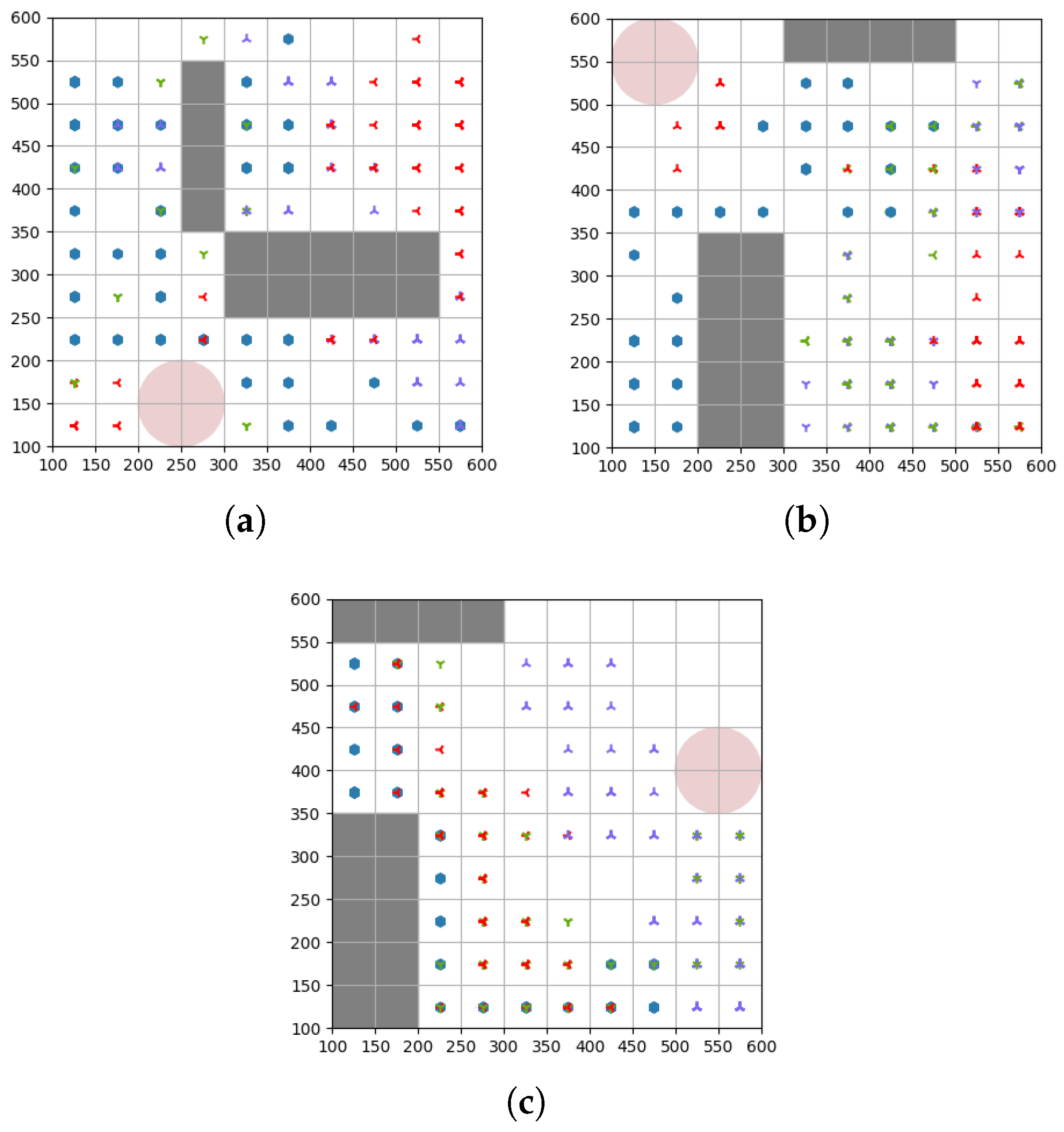
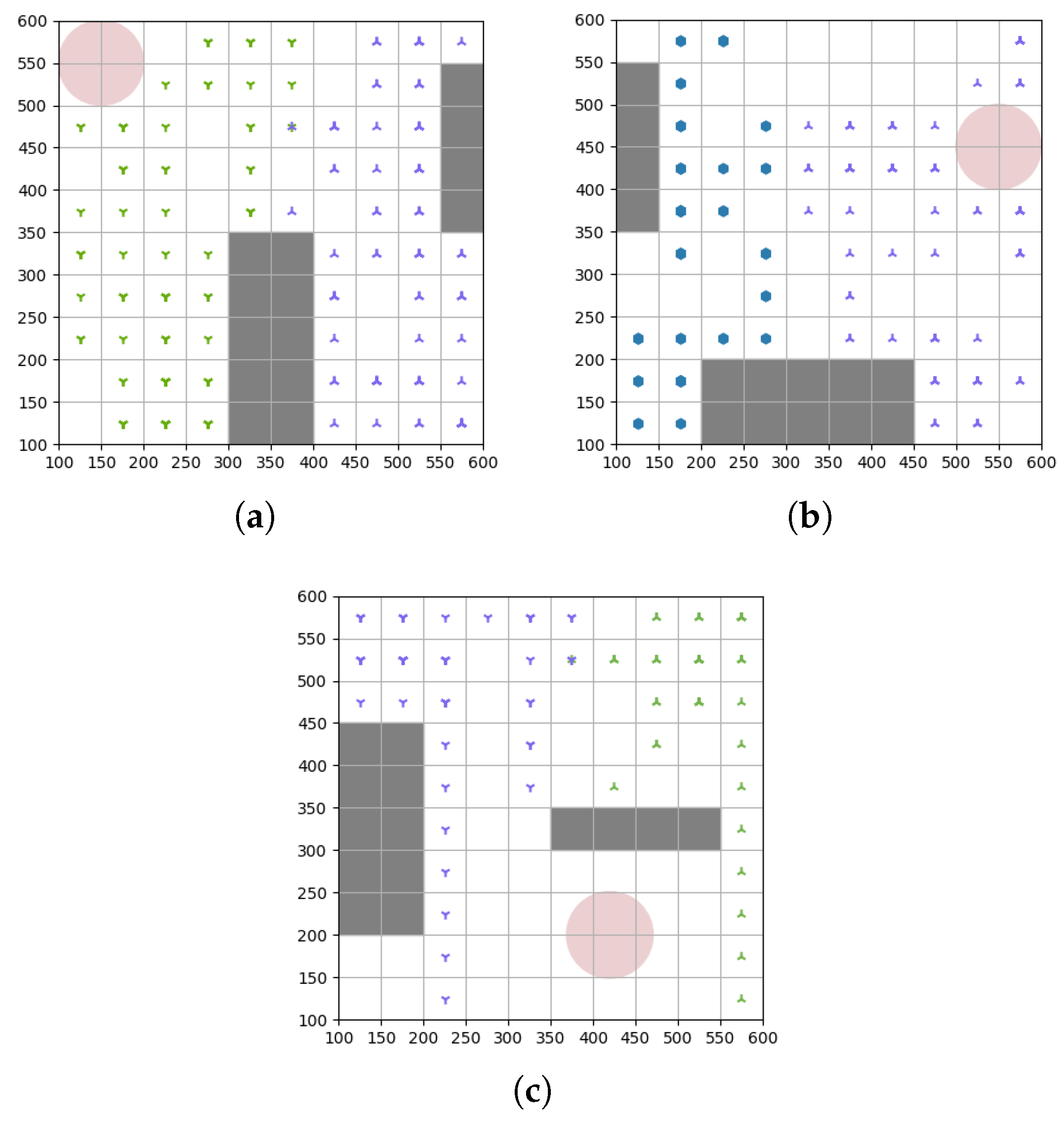
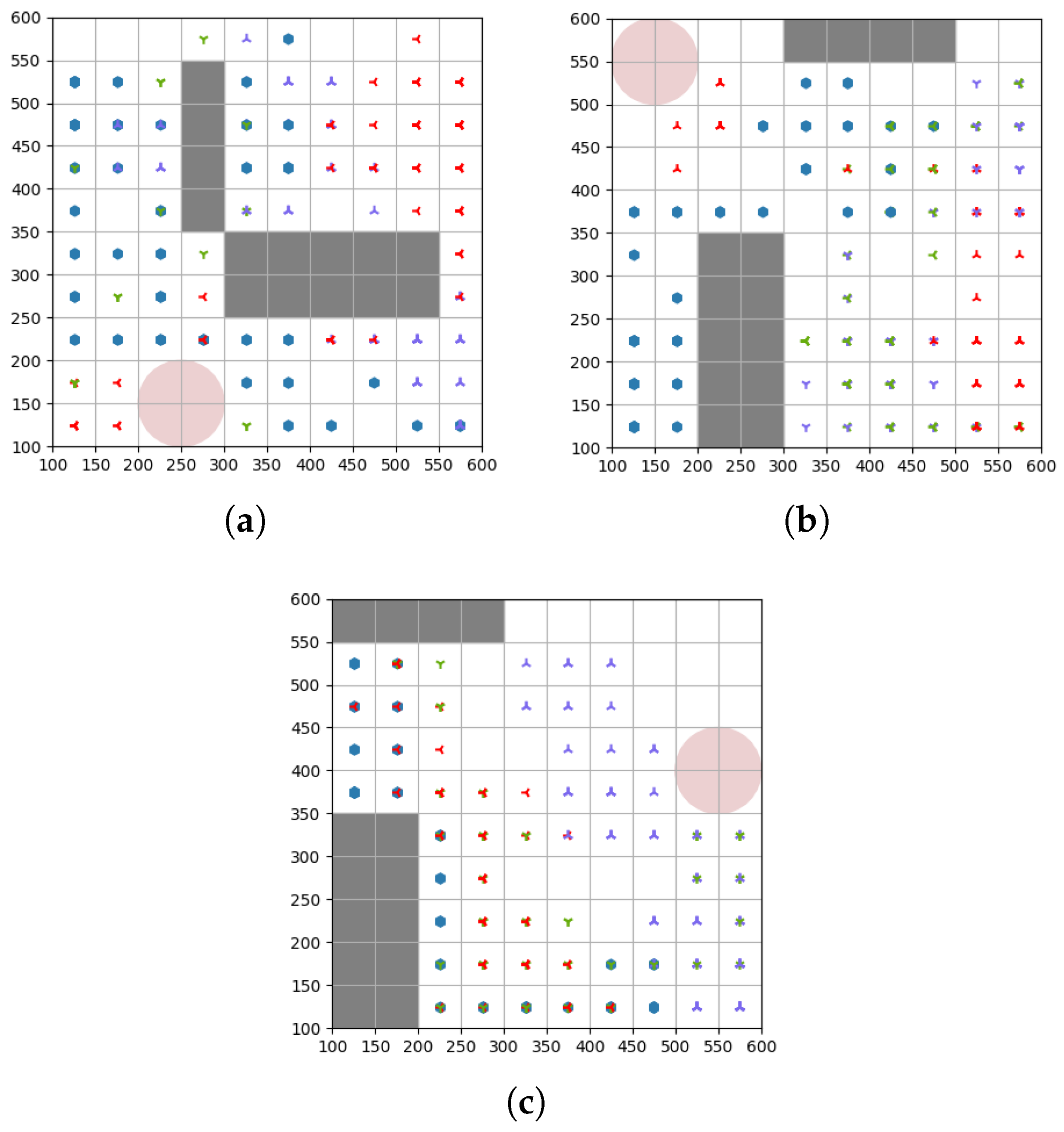
5.1. Simulation Settings
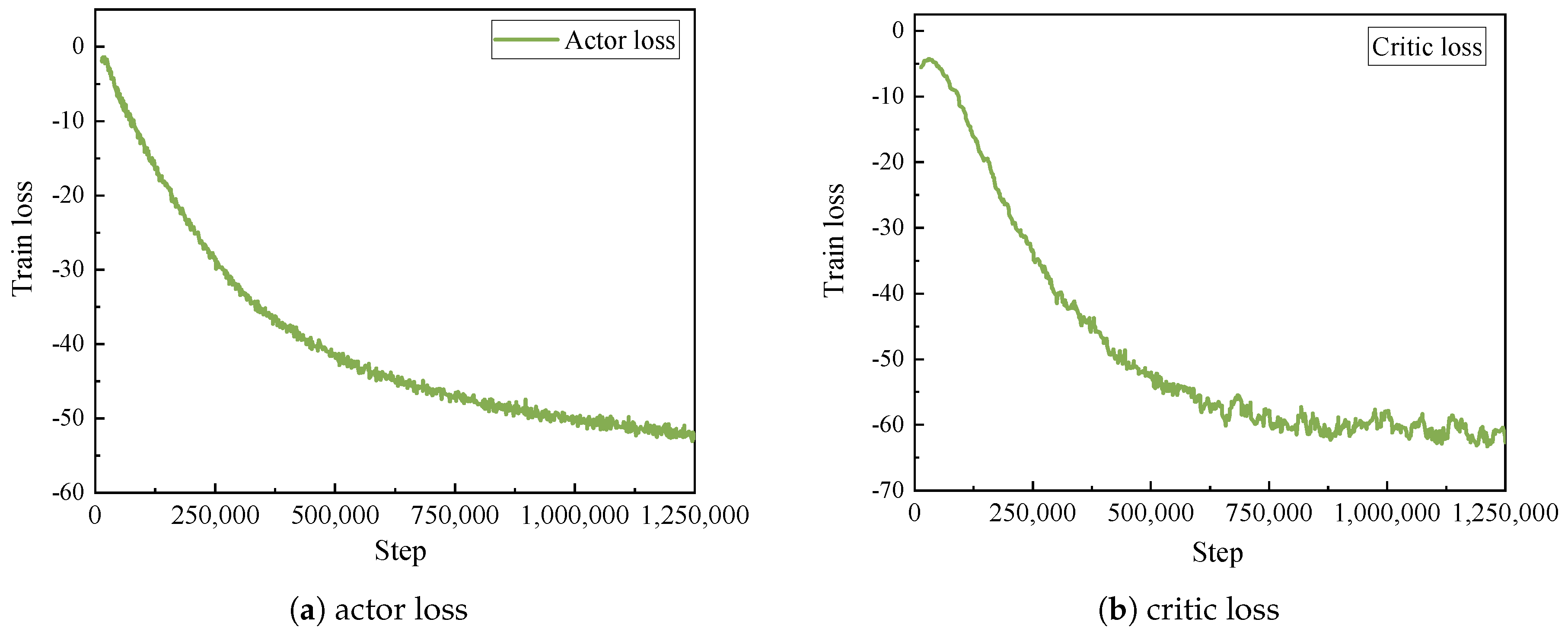
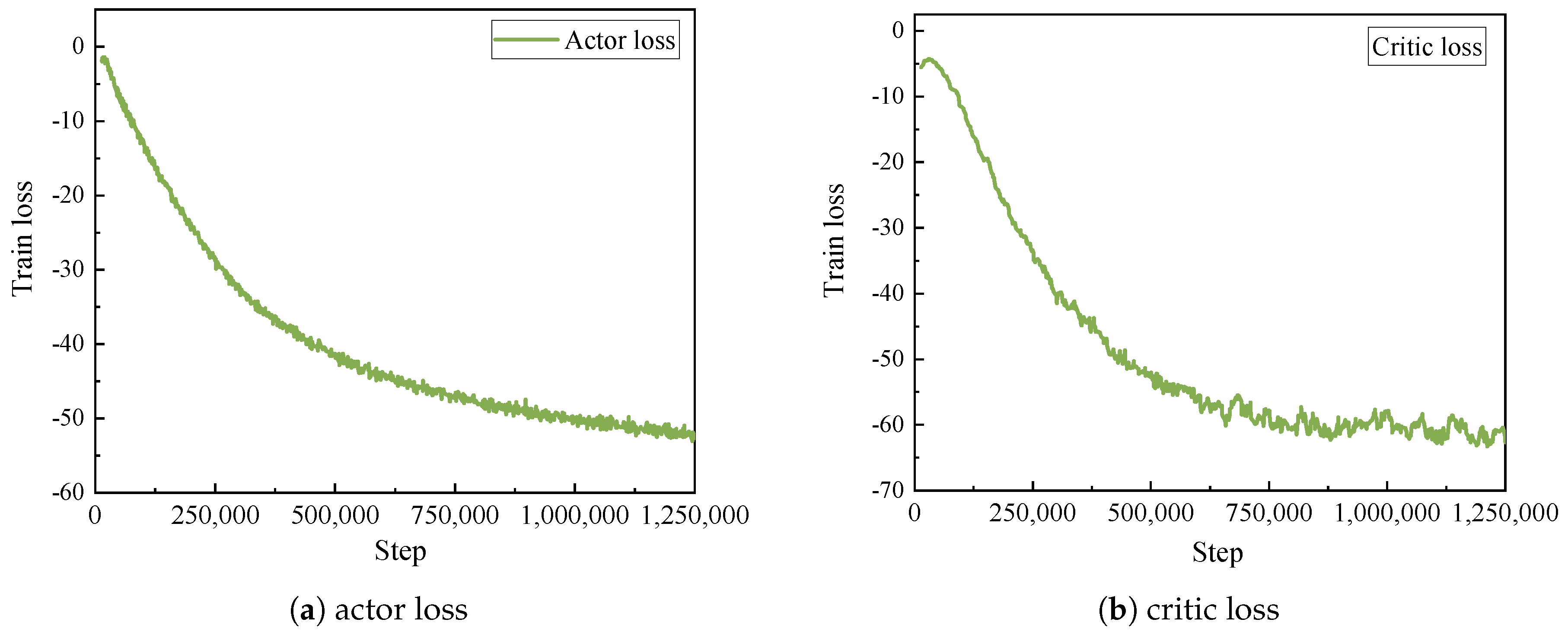
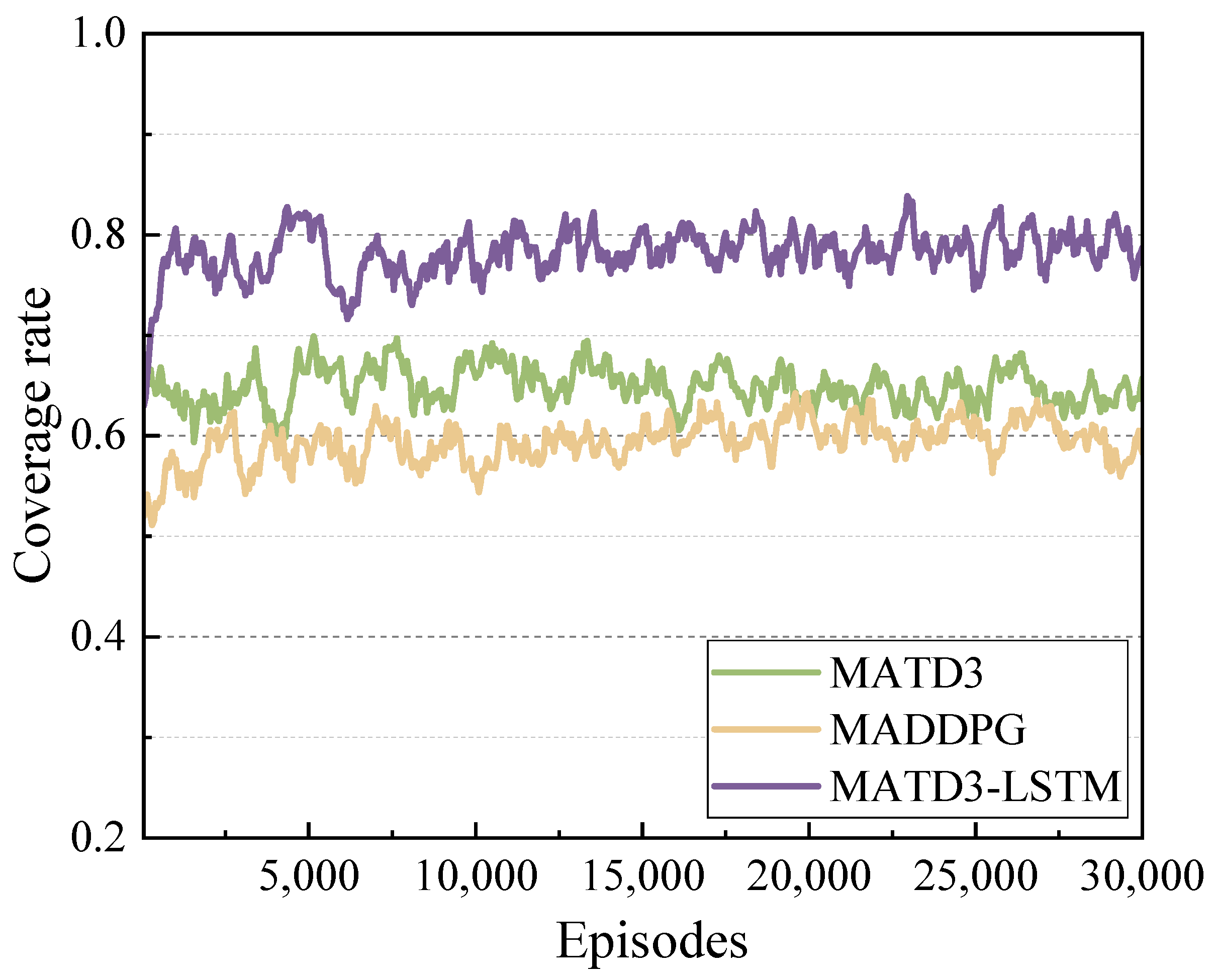
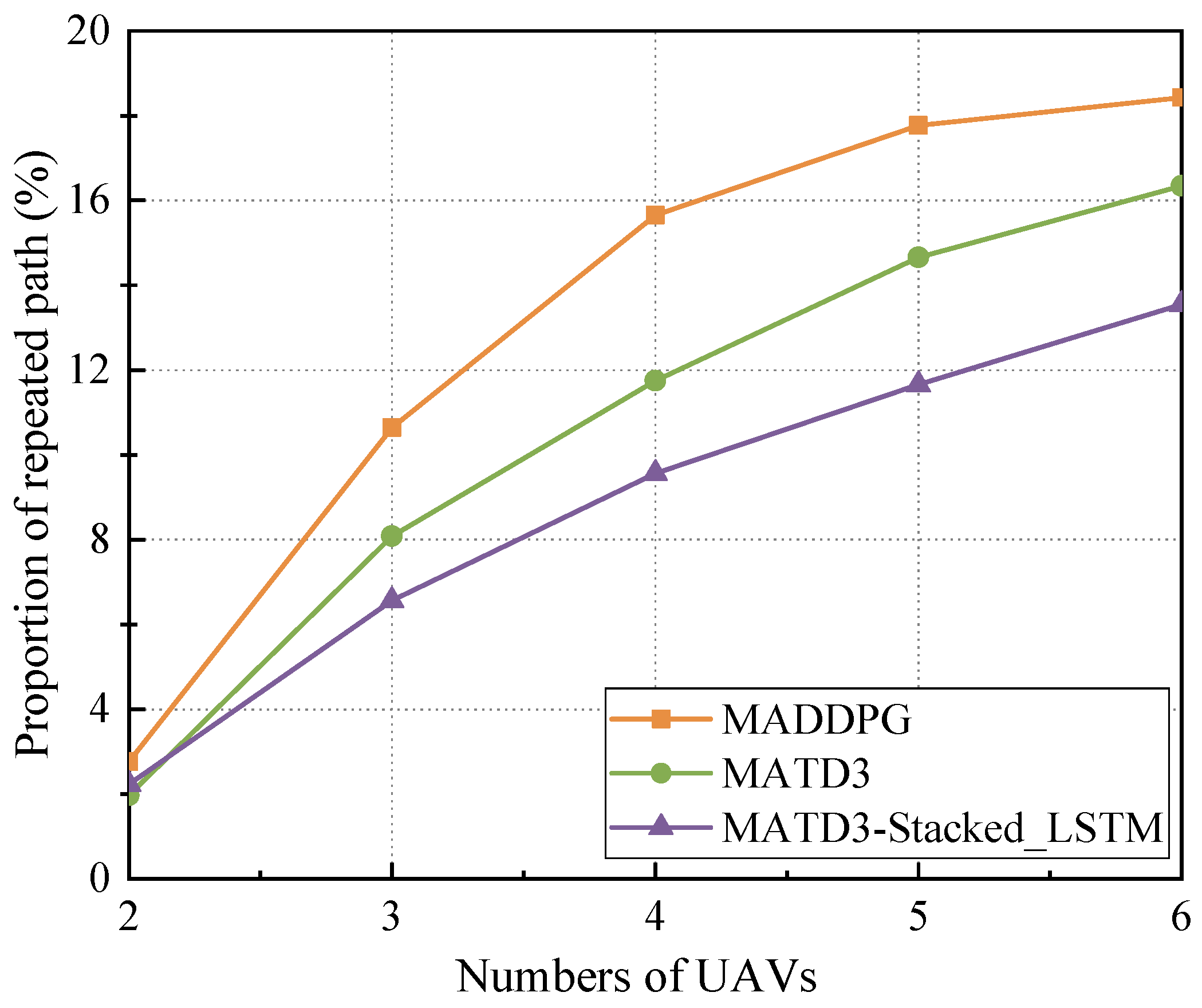
5.2. Convergence Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yang, F.; Wang, P.; Zhang, Y.; Zheng, L.; Lu, J. Survey of swarm intelligence optimization algorithms. In Proceedings of the 2017 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 27–29 October 2017; pp. 544–549. [Google Scholar] [CrossRef]
- Chang, S.Y.; Park, K.; Kim, J.; Kim, J. Securing UAV Flying Base Station for Mobile Networking: A Review. Future Internet 2023, 15, 176. [Google Scholar] [CrossRef]
- Li, H.; Wu, S.; Jiao, J.; Lin, X.H.; Zhang, N.; Zhang, Q. Energy-Efficient Task Offloading of Edge-Aided Maritime UAV Systems. IEEE Trans. Veh. Technol. 2022, 72, 1116–1126. [Google Scholar] [CrossRef]
- Ma, M.; Wang, Z. Distributed Offloading for Multi-UAV Swarms in MEC-Assisted 5G Heterogeneous Networks. Drones 2023, 7, 226. [Google Scholar] [CrossRef]
- Dai, Z.; Xu, G.; Liu, Z.; Ge, J.; Wang, W. Energy saving strategy of uav in mec based on deep reinforcement learning. Future Internet 2022, 14, 226. [Google Scholar] [CrossRef]
- Jiang, Y.; Ma, Y.; Liu, J.; Hu, L.; Chen, M.; Humar, I. MER-WearNet: Medical-Emergency Response Wearable Networking Powered by UAV-Assisted Computing Offloading and WPT. IEEE Trans. Netw. Sci. Eng. 2022, 9, 299–309. [Google Scholar] [CrossRef]
- Savkin, A.V.; Huang, C.; Ni, W. Joint multi-UAV path planning and LoS communication for mobile-edge computing in IoT networks with RISs. IEEE Internet Things J. 2022, 10, 2720–2727. [Google Scholar] [CrossRef]
- Aggarwal, S.; Kumar, N. Path planning techniques for unmanned aerial vehicles: A review, solutions, and challenges. Comput. Commun. 2020, 149, 270–299. [Google Scholar] [CrossRef]
- Xie, H.; Yang, D.; Xiao, L.; Lyu, J. Connectivity-Aware 3D UAV Path Design with Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2021, 70, 13022–13034. [Google Scholar] [CrossRef]
- Qiming, Z.; Husheng, W.; Zhaowang, F. A review of intelligent optimization algorithm applied to unmanned aerial vehicle swarm search task. In Proceedings of the 2021 11th International Conference on Information Science and Technology (ICIST), Chengdu, China, 21–23 May 2021; pp. 383–393. [Google Scholar] [CrossRef]
- Gao, S.; Wang, Y.; Feng, N.; Wei, Z.; Zhao, J. Deep Reinforcement Learning-Based Video Offloading and Resource Allocation in NOMA-Enabled Networks. Future Internet 2023, 15, 184. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Nguyen, N.D.; Nahavandi, S. Deep reinforcement learning for multiagent systems: A review of challenges, solutions, and applications. IEEE Trans. Cybern. 2020, 50, 3826–3839. [Google Scholar] [CrossRef] [PubMed]
- Ozdag, R. Multi-metric optimization with a new metaheuristic approach developed for 3D deployment of multiple drone-BSs. Peer-Peer Netw. Appl. 2022, 15, 1535–1561. [Google Scholar] [CrossRef]
- Bouhamed, O.; Ghazzai, H.; Besbes, H.; Massoud, Y. Autonomous UAV Navigation: A DDPG-Based Deep Reinforcement Learning Approach. In Proceedings of the 2020 IEEE International Symposium on Circuits and Systems (ISCAS), Sevilla, Spain, 10–21 October 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Li, J.; Liu, Y. Deep Reinforcement Learning based Adaptive Real-Time Path Planning for UAV. In Proceedings of the 2021 8th International Conference on Dependable Systems and Their Applications (DSA), Yinchuan, China, 11–12 September 2021; pp. 522–530. [Google Scholar]
- Wang, X.; Gursoy, M.C.; Erpek, T.; Sagduyu, Y.E. Learning-Based UAV Path Planning for Data Collection with Integrated Collision Avoidance. IEEE Internet Things J. 2022, 9, 16663–16676. [Google Scholar] [CrossRef]
- Liu, Q.; Shi, L.; Sun, L.; Li, J.; Ding, M.; Shu, F. Path planning for UAV-mounted mobile edge computing with deep reinforcement learning. IEEE Trans. Veh. Technol. 2020, 69, 5723–5728. [Google Scholar] [CrossRef]
- Chen, B.; Liu, D.; Hanzo, L. Decentralized Trajectory and Power Control Based on Multi-Agent Deep Reinforcement Learning in UAV Networks. In Proceedings of the ICC 2022—IEEE International Conference on Communications, Seoul, Republic of Korea, 16–20 May 2022; pp. 3983–3988. [Google Scholar] [CrossRef]
- Bayerlein, H.; Theile, M.; Caccamo, M.; Gesbert, D. UAV Path Planning for Wireless Data Harvesting: A Deep Reinforcement Learning Approach. In Proceedings of the GLOBECOM 2020—2020 IEEE Global Communications Conference, Taipei, China, 7–11 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Zhu, X.; Wang, L.; Li, Y.; Song, S.; Ma, S.; Yang, F.; Zhai, L. Path planning of multi-UAVs based on deep Q-network for energy-efficient data collection in UAVs-assisted IoT. Veh. Commun. 2022, 36, 100491. [Google Scholar] [CrossRef]
- Prédhumeau, M.; Mancheva, L.; Dugdale, J.; Spalanzani, A. Agent-based modeling for predicting pedestrian trajectories around an autonomous vehicle. J. Artif. Intell. Res. 2022, 73, 1385–1433. [Google Scholar] [CrossRef]
- Wen, G.; Qin, J.; Fu, X.; Yu, W. DLSTM: Distributed Long Short-Term Memory Neural Networks for the Internet of Things. IEEE Trans. Netw. Sci. Eng. 2022, 9, 111–120. [Google Scholar] [CrossRef]
- Ackermann, J.; Gabler, V.; Osa, T.; Sugiyama, M. Reducing Overestimation Bias in Multi-Agent Domains Using Double Centralized Critics. arXiv 2019, arXiv:1910.01465. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 3.1 System Model | |
| m, | Index, set of UAVs |
| Time slot | |
| Drone coordinates | |
| UAV path collection | |
| Indicator for UAV trajectory avoiding no-fly zones | |
| Indicator for UAV trajectory avoiding obstacles | |
| Flight steering angle | |
| Shadow area | |
| Specified airspace boundary | |
| H | Flying height |
| Spatial resolution | |
| Turning radius | |
| , | Distance between UAVs |
| V, | Speed and acceleration |
| E | Energy consumption of UAVs |
| C | Battery capacity |
| Battery consumption rate | |
| T | Total time |
| Set of non-obstacle and non-restricted areas | |
| 3.2 Problem Formulation | |
| N | The number of grid cells |
| The set of all non-obstacles (non-restricted) | |
| Notation | Definition |
|---|---|
| Actor learning rate | 1 × 10 |
| Critic learning rate | 1 × 10 |
| 0.95 | |
| 1 × 10 | |
| Memory capacity | 100,000 |
| Batch size | 512 |
| Policy noise | 0.6 |
| Noise clip | 0.5 |
| Policy delay | 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Q.; Liu, Q.; Wu, Z.; Zhang, J. Maximizing UAV Coverage in Maritime Wireless Networks: A Multiagent Reinforcement Learning Approach. Future Internet 2023, 15, 369. https://doi.org/10.3390/fi15110369
Wu Q, Liu Q, Wu Z, Zhang J. Maximizing UAV Coverage in Maritime Wireless Networks: A Multiagent Reinforcement Learning Approach. Future Internet. 2023; 15(11):369. https://doi.org/10.3390/fi15110369
Chicago/Turabian StyleWu, Qianqian, Qiang Liu, Zefan Wu, and Jiye Zhang. 2023. "Maximizing UAV Coverage in Maritime Wireless Networks: A Multiagent Reinforcement Learning Approach" Future Internet 15, no. 11: 369. https://doi.org/10.3390/fi15110369
APA StyleWu, Q., Liu, Q., Wu, Z., & Zhang, J. (2023). Maximizing UAV Coverage in Maritime Wireless Networks: A Multiagent Reinforcement Learning Approach. Future Internet, 15(11), 369. https://doi.org/10.3390/fi15110369