


BART-IT: An Efficient Sequence-to-Sequence Model for Italian Text Summarization


Abstract
1. Introduction
- We present BART-IT, a sequence-to-sequence BART-based model specifically designed for the Italian language (see Section 3);
- We release the model pre-trained on a large Italian corpus. It can be used to solve various NLP tasks on Italian documents (see the Data Availability Statement);
- We fine-tune BART-IT for the abstractive text summarization task (see Section 4.3);
- We assess model performance on Italian benchmark data, showing that BART-IT achieves the best balancing between efficiency and effectiveness compared to various baselines (see Figure 1);
- We discuss the ethical aspects behind the practical use of the BART-IT model (see Section 5).
2. Related Works
Italian Language Modeling
3. BART-IT
3.1. Denoising Objectives
- Document rotation: the input document is first divided into sentences using full stops as separators. Then, one sentence is randomly selected as the first sentence and the remaining sentences follow the selected one using the original order of the input document.
- Sentence permutation: Similar to the previous case, the input document is first divided into sentences using full stops as separators. Then, the sentences are randomly shuffled and the resulting sequence is used as input for the model. In this case, no sentence of the corrupted sequence is forced to follow the order of the original document.
- Token infilling: a span length L is randomly selected using a Poisson distribution with lambda parameter . Then, each span of length L is replaced by a single [MASK] token with a probability of . The remaining spans are left unchanged.
- Token masking: similar to the original BERT [7] pretraining objective, each token is replaced by a [MASK] token with a probability of . In contrast to Token infilling, only one token at a time is replaced by a [MASK] token. Similar to Token infilling, the remaining tokens are not modified.
- Token deletion: each token is randomly deleted (with a probability of ) from the input sequence. The remaining tokens remain unchanged.
3.2. Model Architecture
3.3. Training Data Collection
4. Experiments
4.1. Fine-Tuning Datasets
- FanPage [30] is a dataset of Italian news articles from the online newspaper Fanpage.it (https://www.fanpage.it/, latest access: 19 December 2022). It includes 84,365 news articles as well as their corresponding summaries. The dataset is split into a training set of 67,492 documents, a validation set of 8436 documents, and a test set of 8437 documents. The average length of the documents is approximately 312 words and the average length of the summaries is approximately 43 words.
- IlPost [30], similar to FanPage, is a dataset of Italian news articles from the online newspaper IlPost.it (https://www.ilpost.it/, latest access: 19 December 2022). It contains a total of 44,001 article-summary pairs divided into a training set of 35,201 documents, a validation set of 4400 documents, and a test set of 4400 documents. The average length of the documents is shorter than FanPage, with an average length of approximately 174 words, while the average length of the summaries is approximately 26 words.
- WITS [31] is a dataset of Wikipedia articles and their corresponding summaries. The dataset is automatically generated by crawling the Italian Wikipedia (https://it.wikipedia.org/, latest access: 19 December 2022) and extracting the leading section of each Wikipedia article and using it as the summary. The dataset is the largest among the three, containing a total of 700,000 article-summary pairs. Analogously to the original authors, we randomly select 10,000 articles as the test set, 10,000 articles as the validation set, and the remaining articles are used for training. Given the different nature of the articles, the average length of the documents is 956.66 words, and the average length of the summaries is 70.93 words.
4.2. Evaluation Metrics
4.3. Experimental Setup
- CPU: Intel® CoreTM i9-10980XE CPU @ 3.00 GHz;
- GPU: 2 x NVIDIA® RTX A6000 GPU, with 48 GB of VRAM each
- RAM: 128 GB.
- Pre-Training Phase
- Fine-Tuning Phase
4.4. Baseline Models
- IT5 [9] is a state-of-the-art sequence-to-sequence model that relies on the same architecture proposed by T5 [22] but is trained on the Italian language. This model is trained on the same dataset used for the pre-training of BART-IT and is fine-tuned on the same summarization datasets used for its evaluation. The model is available in three different sizes: small, base, and large. We use the base version of the model since it is the most similar in terms of the number of parameters compared to the proposed model (i.e., 220 million parameters);
- mBART [10] is a multilingual sequence-to-sequence model that uses the same architecture of the original BART model. It is trained on a multilingual corpus of 25 languages. By construction, the model size for the base model is more than four times larger than the model size of BART-IT (i.e., 610 million parameters). Even in this case, the model is fine-tuned on the same summarization datasets used for the evaluation of BART-IT;
- mT5 [11] is a multilingual sequence-to-sequence model that uses the same architecture of T5 [22] and is trained on a multilingual corpus of 101 languages. The model is available in five different sizes: small, base, large, xlarge, and xxlarge. We use the base version of the model that has 390 million parameters (e.g., more than 2.5 times larger than the model size of BART-IT). Similar to the previous models, the model is fine-tuned on the same datasets used for the evaluation of BART-IT.
- Lead-K is a baseline method that extracts the first k sentences of the input document. In our experiments, we set k to 2;
- LexRank [38] is an established summarization method that extracts the most important sentences from the input document by first modeling the input document as a graph and then computing the PageRank score [39] of each sentence. The similarity between two sentences is computed using the IDF-weighted cosine similarity between the TF-IDF vectors of the sentences;
- TextRank [40] is a baseline method that, similar to LexRank, extracts the most important sentences of the input document by modeling the input document as a graph and computing the PageRank score [39] of each sentence. The pairwise sentence similarity is computed by exploiting the word-level overlap between each pair of sentences.
4.5. Experimental Results
- News summarization datasets
- Wikipedia summarization dataset
5. Discussions of Model Limitations and Ethical Issues
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- El-Kassas, W.S.; Salama, C.R.; Rafea, A.A.; Mohamed, H.K. Automatic text summarization: A comprehensive survey. Expert Syst. Appl. 2021, 165, 113679. [Google Scholar] [CrossRef]
- La Quatra, M.; Cagliero, L. Transformer-based highlights extraction from scientific papers. Knowl. Based Syst. 2022, 252, 109382. [Google Scholar] [CrossRef]
- Duan, Z.; Lu, L.; Yang, W.; Wang, J.; Wang, Y. An Abstract Summarization Method Combining Global Topics. Appl. Sci. 2022, 12, 10378. [Google Scholar] [CrossRef]
- Vaiani, L.; La Quatra, M.; Cagliero, L.; Garza, P. Leveraging multimodal content for podcast summarization. In Proceedings of the 37th ACM/SIGAPP Symposium on Applied Computing, Virtual, 25–29 April 2022; pp. 863–870. [Google Scholar]
- Inoue, N.; Trivedi, H.; Sinha, S.; Balasubramanian, N.; Inui, K. Summarize-then-Answer: Generating Concise Explanations for Multi-hop Reading Comprehension. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Virtual, 7–11 November 2021; Association for Computational Linguistics: Stratsbourg, PA, USA, 2021; pp. 6064–6080. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 7871–7880. [Google Scholar]
- Sarti, G.; Nissim, M. IT5: Large-scale Text-to-text Pretraining for Italian Language Understanding and Generation. arXiv 2022, arXiv:2203.03759. [Google Scholar]
- Liu, Y.; Gu, J.; Goyal, N.; Li, X.; Edunov, S.; Ghazvininejad, M.; Lewis, M.; Zettlemoyer, L. Multilingual Denoising Pre-training for Neural Machine Translation. Trans. Assoc. Comput. Linguist. 2020, 8, 726–742. [Google Scholar] [CrossRef]
- Xue, L.; Constant, N.; Roberts, A.; Kale, M.; Al-Rfou, R.; Siddhant, A.; Barua, A.; Raffel, C. mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 483–498. [Google Scholar]
- Li, Z.; Wang, Z.; Tan, M.; Nallapati, R.; Bhatia, P.; Arnold, A.; Xiang, B.; Roth, D. DQ-BART: Efficient Sequence-to-Sequence Model via Joint Distillation and Quantization. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022. [Google Scholar]
- Abdel-Salam, S.; Rafea, A. Performance Study on Extractive Text Summarization Using BERT Models. Information 2022, 13, 67. [Google Scholar] [CrossRef]
- Zhang, J.; Zhao, Y.; Saleh, M.; Liu, P. Pegasus: Pre-training with extracted gap-sentences for abstractive summarization. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 11328–11339. [Google Scholar]
- Xiao, W.; Beltagy, I.; Carenini, G.; Cohan, A. PRIMERA: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 5245–5263. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 27, 3104–3112. [Google Scholar]
- Rumelhart, D.; Hinton, G.; Williams, R. Learning internal representations by error propagation. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Volume 1: Foundations; MIT Press: Cambridge, MA, USA, 1986; pp. 318–362. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Nallapati, R.; Zhai, F.; Zhou, B. Summarunner: A recurrent neural network based sequence model for extractive summarization of documents. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- See, A.; Liu, P.J.; Manning, C.D. Get To The Point: Summarization with Pointer-Generator Networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 1073–1083. [Google Scholar]
- Hochreiter, S. The vanishing gradient problem during learning recurrent neural nets and problem solutions. Int. J. Uncertainty Fuzziness Knowl. Based Syst. 1998, 6, 107–116. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Kamal Eddine, M.; Tixier, A.; Vazirgiannis, M. BARThez: A Skilled Pretrained French Sequence-to-Sequence Model. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 9369–9390. [Google Scholar]
- Tran, N.L.; Le, D.M.; Nguyen, D.Q. BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese. In Proceedings of the 23rd Annual Conference of the International Speech Communication Association, Incheon, Republic of Korea, 18–22 September 2022. [Google Scholar]
- Shao, Y.; Geng, Z.; Liu, Y.; Dai, J.; Yang, F.; Zhe, L.; Bao, H.; Qiu, X. Cpt: A pre-trained unbalanced transformer for both chinese language understanding and generation. arXiv 2021, arXiv:2109.05729. [Google Scholar]
- Schweter, S. Italian BERT and ELECTRA Models. Zenodo 2020. Available online: https://zenodo.org/record/4263142#.Y741KhVBzIU (accessed on 29 November 2022). [CrossRef]
- Polignano, M.; Basile, P.; De Gemmis, M.; Semeraro, G.; Basile, V. Alberto: Italian BERT language understanding model for NLP challenging tasks based on tweets. In Proceedings of the 6th Italian Conference on Computational Linguistics, CLiC-it 2019, CEUR, Bari, Italy, 13–15 November 2019; Volume 2481, pp. 1–6. [Google Scholar]
- Guarasci, R.; Minutolo, A.; Damiano, E.; De Pietro, G.; Fujita, H.; Esposito, M. ELECTRA for neural coreference resolution in Italian. IEEE Access 2021, 9, 115643–115654. [Google Scholar] [CrossRef]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 1715–1725. [Google Scholar]
- Landro, N.; Gallo, I.; La Grassa, R.; Federici, E. Two New Datasets for Italian-Language Abstractive Text Summarization. Information 2022, 13, 228. [Google Scholar] [CrossRef]
- Casola, S.; Lavelli, A. WITS: Wikipedia for Italian Text Summarization. In Proceedings of the CLiC-it, Milan, Italy, 26–28 January 2022. [Google Scholar]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; Association for Computational Linguistics: Stroudsburg, PA, USA, 2004; pp. 74–81. [Google Scholar]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. BERTScore: Evaluating Text Generation with BERT. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 38–45. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Hernandez, D.; Brown, T.; Conerly, T.; DasSarma, N.; Drain, D.; El-Showk, S.; Elhage, N.; Hatfield-Dodds, Z.; Henighan, T.; Hume, T.; et al. Scaling Laws and Interpretability of Learning from Repeated Data. arXiv 2022, arXiv:2205.10487. [Google Scholar]
- Erkan, G.; Radev, D.R. LexRank: Graph-Based Lexical Centrality as Salience in Text Summarization. J. Artif. Int. Res. 2004, 22, 457–479. [Google Scholar] [CrossRef]
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The PageRank Citation Ranking: Bringing Order to the Web; Technical Report; Stanford InfoLab: Stanford, CA, USA, 1999. [Google Scholar]
- Mihalcea, R.; Tarau, P. TextRank: Bringing Order into Text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; Association for Computational Linguistics: Stroudsburg, PA, USA, 2004; pp. 404–411. [Google Scholar]
- Cao, M.; Dong, Y.; Cheung, J. Hallucinated but Factual! Inspecting the Factuality of Hallucinations in Abstractive Summarization. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 3340–3354. [Google Scholar]
- Zhou, C.; Neubig, G.; Gu, J.; Diab, M.; Guzmán, F.; Zettlemoyer, L.; Ghazvininejad, M. Detecting Hallucinated Content in Conditional Neural Sequence Generation. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online Event, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 1393–1404. [Google Scholar]


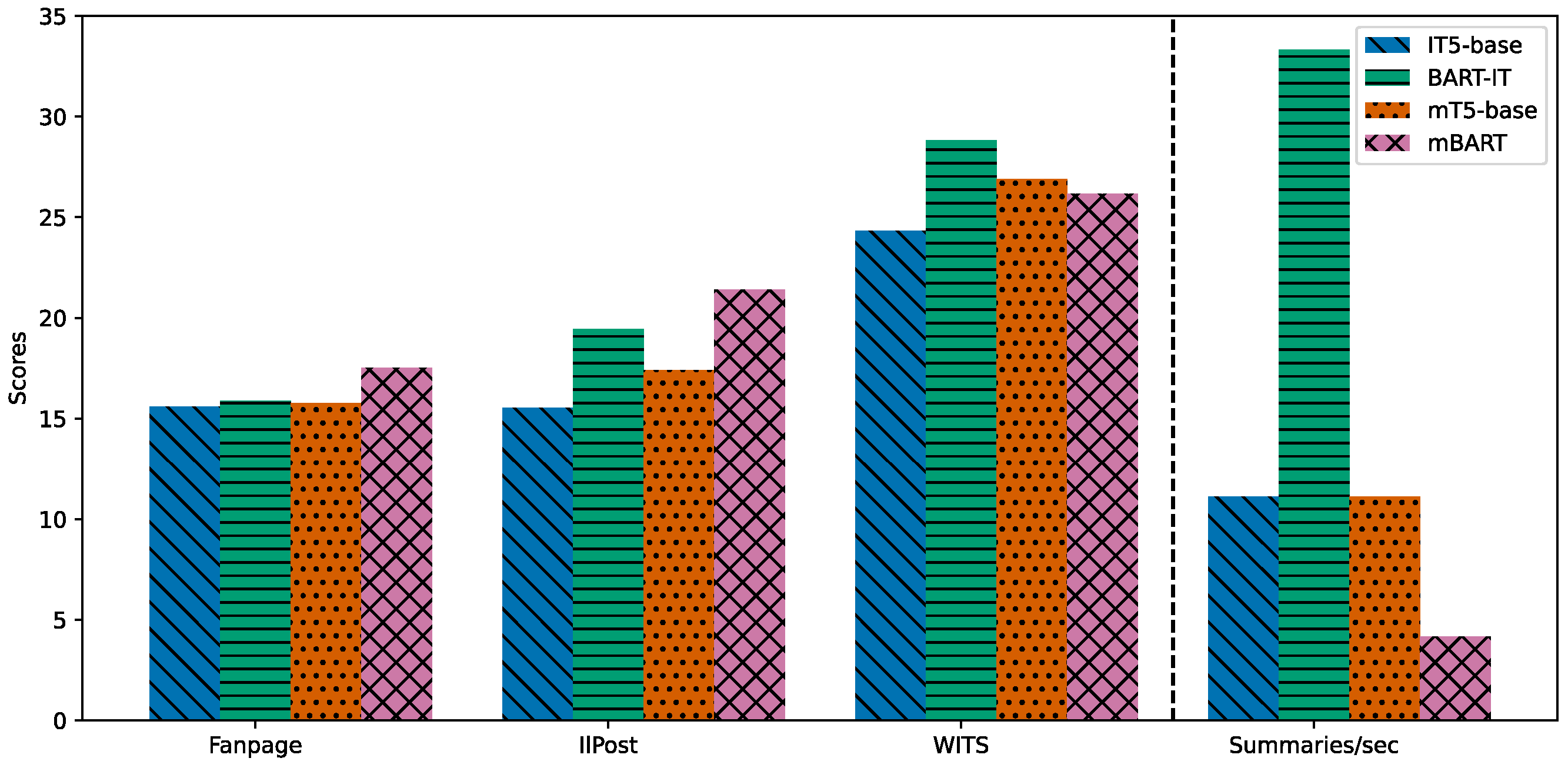{kind=link}
| Corruption | Original Sequence | Corrupted Sequence |
|---|---|---|
| Document Rotation | A. B. C. D. | C. D. A. B. |
| Sentence permutation | A. B. C. D. | C. A. D. B. |
| Token infilling | 1 2 3 4 5 6 7 | 1 [MASK] 5 6 7 |
| Token masking | 1 2 3 4 5 | 1 2 3 [MASK] 5 |
| Token deletion | 1 2 3 4 5 | 1 2 3 5 |
| Parameter | Value |
|---|---|
| Model parameters | |
| # encoder layers | 12 |
| # decoder layers | 12 |
| # attention heads | 12 |
| Hidden size | 768 |
| Feed-forward size | 3072 |
| Tokenizer parameters | |
| Vocab size | 52,000 |
| Min frequency | 10 |
| Special tokens | <s>, </s>, <pad>, <unk>, <mask> |
| Model | # Parameters | R1 | R2 | RL | BERTScore |
|---|---|---|---|---|---|
| LEAD-2 | × | 31.88 | 14.11 | 21.68 | 70.84 |
| TextRank | × | 26.39 | 9.06 | 16.81 | 68.63 |
| LexRank | × | 29.85 | 11.69 | 19.58 | 69.9 |
| IT5-base | 220 M | 33.99 | 15.59 | 24.91 | 70.3 |
| BART-IT | 140 M | 35.42 | 15.88 | 25.12 | 73.24 |
| mT5 | 390 M | 34.13 | 15.76 | 24.84 | 72.77 |
| mBART | 610 M | 36.52 | 17.52 | 26.14 | 73.4 |
| Model | # Parameters | R1 | R2 | RL | BERTScore |
|---|---|---|---|---|---|
| LEAD-2 | × | 27.72 | 11.66 | 19.62 | 70.25 |
| TextRank | × | 22.63 | 8.0 | 15.48 | 68.4 |
| LexRank | × | 26.96 | 10.94 | 18.94 | 69.94 |
| IT5-base | 220 M | 32.88 | 15.53 | 26.7 | 71.06 |
| BART-IT | 140 M | 37.31 | 19.44 | 30.41 | 75.36 |
| mT5 | 390 M | 35.04 | 17.41 | 28.68 | 74.69 |
| mBART | 610 M | 38.91 | 21.41 | 32.08 | 75.86 |
| Model | # Parameters | R1 | R2 | RL | BERTScore |
|---|---|---|---|---|---|
| LEAD-2 | × | 15.63 | 3.32 | 10.51 | 63.01 |
| TextRank | × | 15.35 | 3.04 | 9.84 | 62.12 |
| LexRank | × | 15.96 | 3.3 | 10.48 | 62.81 |
| IT5-base | 220 M | 37.98 | 24.32 | 34.94 | 77.14 |
| BART-IT | 140 M | 42.32 | 28.83 | 38.84 | 79.28 |
| mT5 | 390 M | 40.6 | 26.9 | 37.43 | 80.73 |
| mBART | 610 M | 39.32 | 26.18 | 35.9 | 78.65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
La Quatra, M.; Cagliero, L. BART-IT: An Efficient Sequence-to-Sequence Model for Italian Text Summarization. Future Internet 2023, 15, 15. https://doi.org/10.3390/fi15010015
La Quatra M, Cagliero L. BART-IT: An Efficient Sequence-to-Sequence Model for Italian Text Summarization. Future Internet. 2023; 15(1):15. https://doi.org/10.3390/fi15010015
Chicago/Turabian StyleLa Quatra, Moreno, and Luca Cagliero. 2023. "BART-IT: An Efficient Sequence-to-Sequence Model for Italian Text Summarization" Future Internet 15, no. 1: 15. https://doi.org/10.3390/fi15010015
APA StyleLa Quatra, M., & Cagliero, L. (2023). BART-IT: An Efficient Sequence-to-Sequence Model for Italian Text Summarization. Future Internet, 15(1), 15. https://doi.org/10.3390/fi15010015