

Retrieving Adversarial Cliques in Cognitive Communities: A New Conceptual Framework for Scientific Knowledge Graphs





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction: Representing the Manifold of Cognitive Communities with Their Adversarial Cliques
1.1. Research Question
1.2. Main Findings
2. Background and Other Works
2.1. Background: Information Space of Cliques in Cognitive Communities
- Cognitive community detection
- Building cliques in a co-authorship or citation graph and in GRAPHYP: comparative features
- Manifold of the cognitive communities featured in subnetworks
- Consistent manifold of search history of cognitive communities
- Graph matchings of subnetworks of cognitive communities
- Meta learning experience in the analysis of documentary routes
2.2. Other Works on Information Space of Cognitive Communities: “Learning from Predecessors”
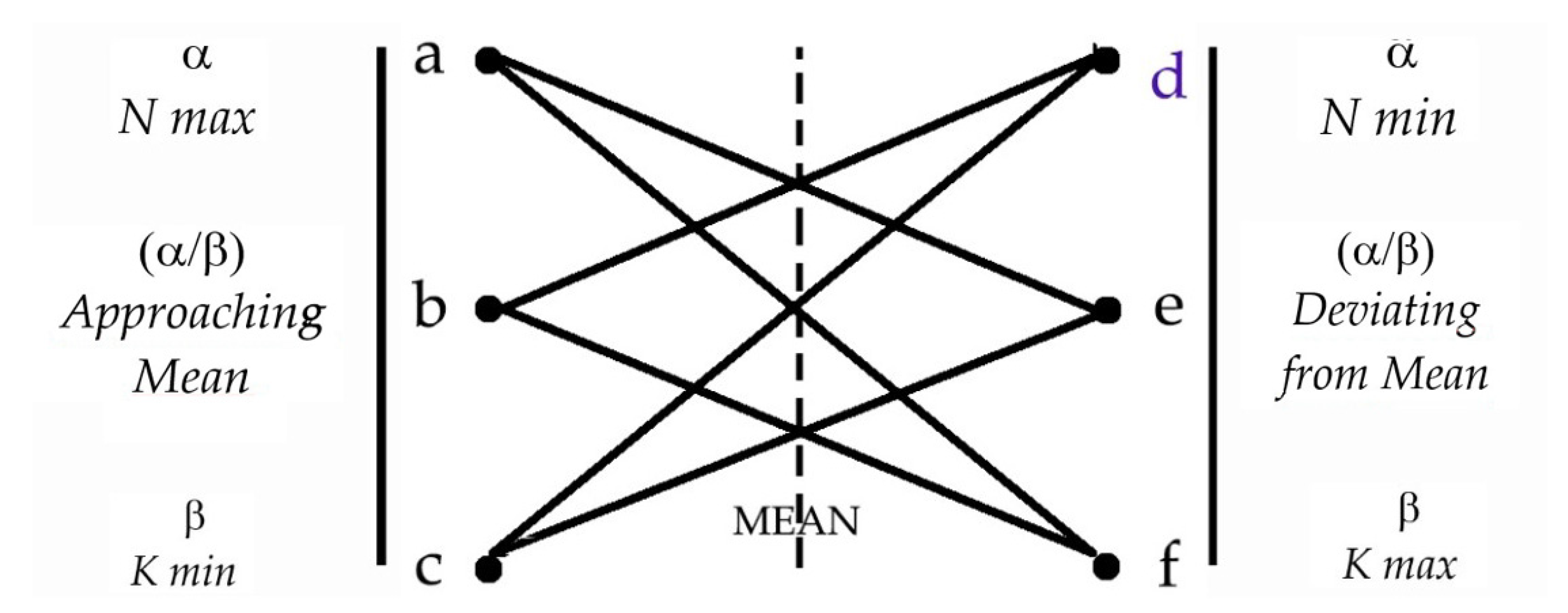
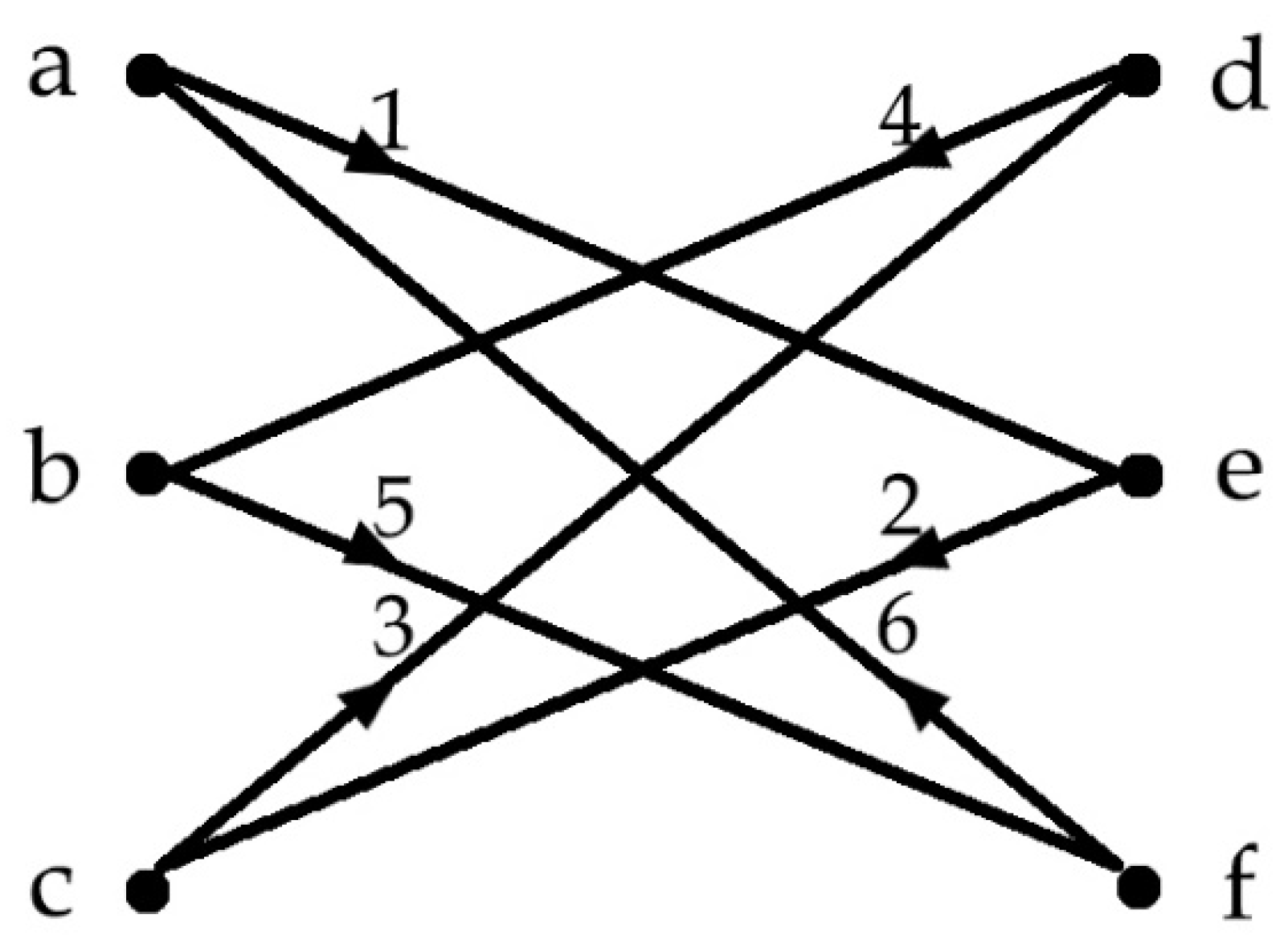
3. Approach. SRK GRAPHYP: Detection and Search of Cognitive Communities in Geometric Adversarial Information Routes
3.1. Design of the SKG GRAPHYP: Building the Information Space of a Cognitive System
- (i)
- General modeling and problem set-up
- (ii)
- Design of SKG GRAPHYP
- ○
- it allows each clique in its community to be positioned in the searchable space, according to the characteristics of its search history;
- ○
- it assists a clique inside a community in navigating on the graph, to reach the position of neighboring cliques in the same community, linked by the same characteristics of search goals («Search goals» as a generic term, encompasses similar queries, keywords, or groups of URLs).
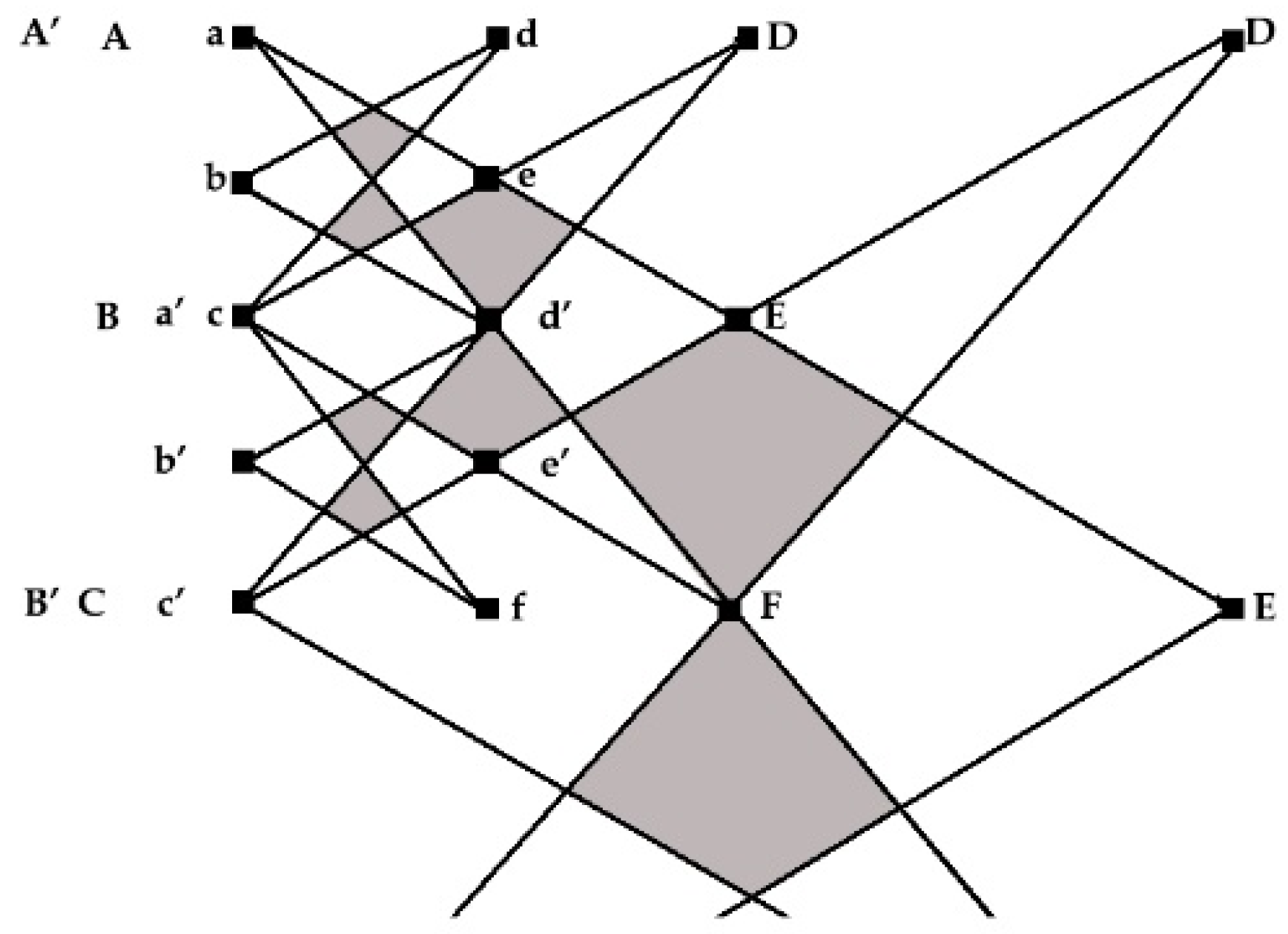
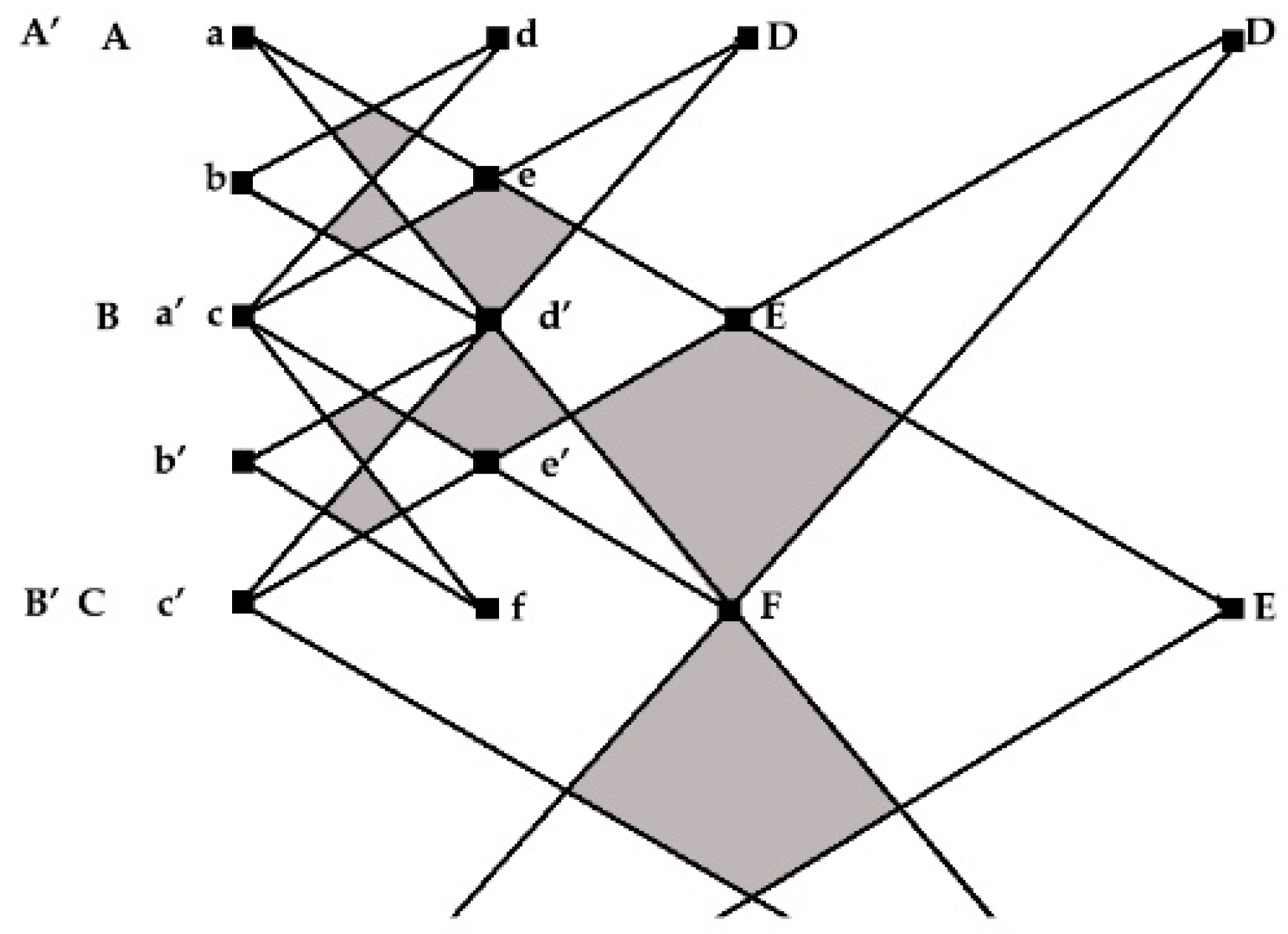
3.2. Subnetworks of Cognitive Communities: Detection and Integration in the SKG GRAPHYP
- (i)
- Cognitive community and its cliques: Definition and detection
- ○
- Positioning of cognitive communities in the SKG geometry of a bipartite crown hypergraph
- ○
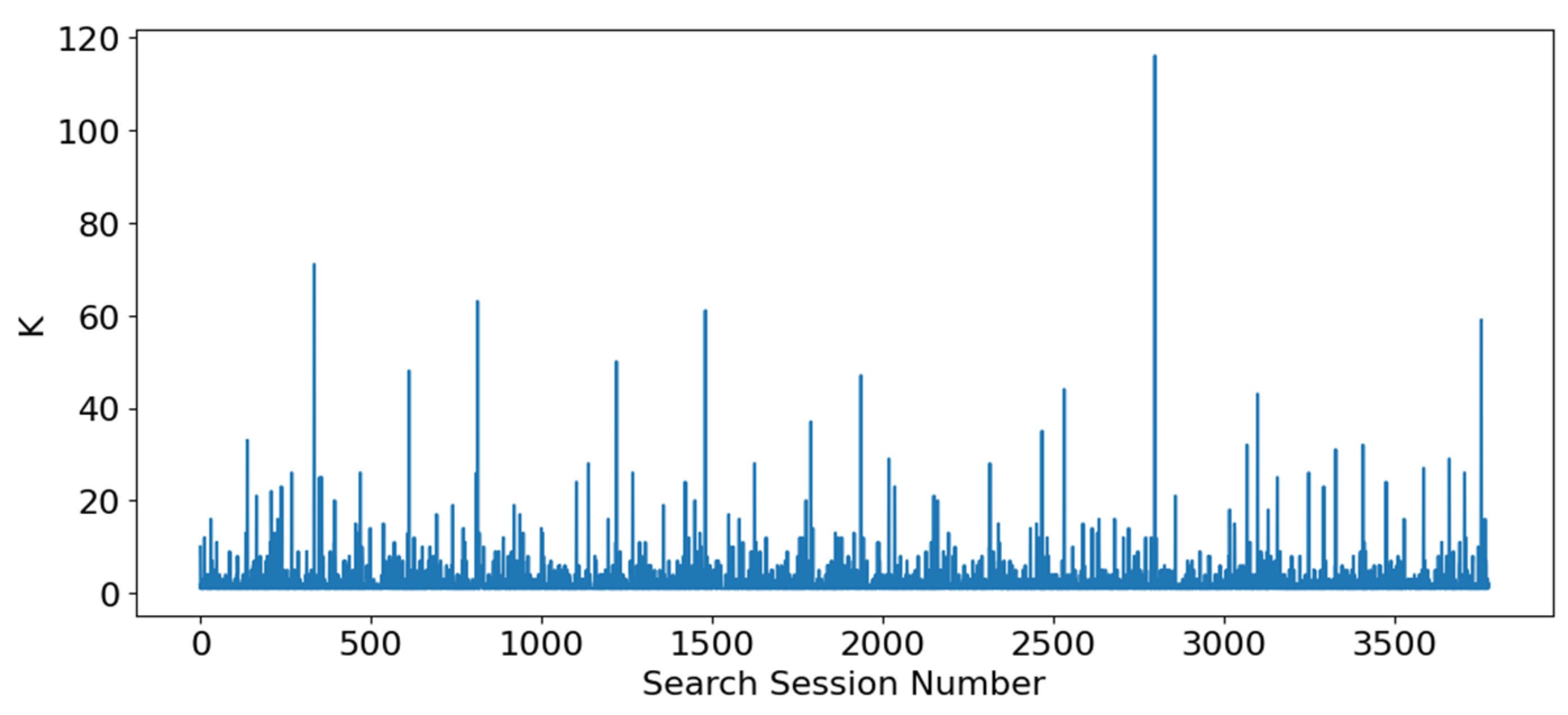
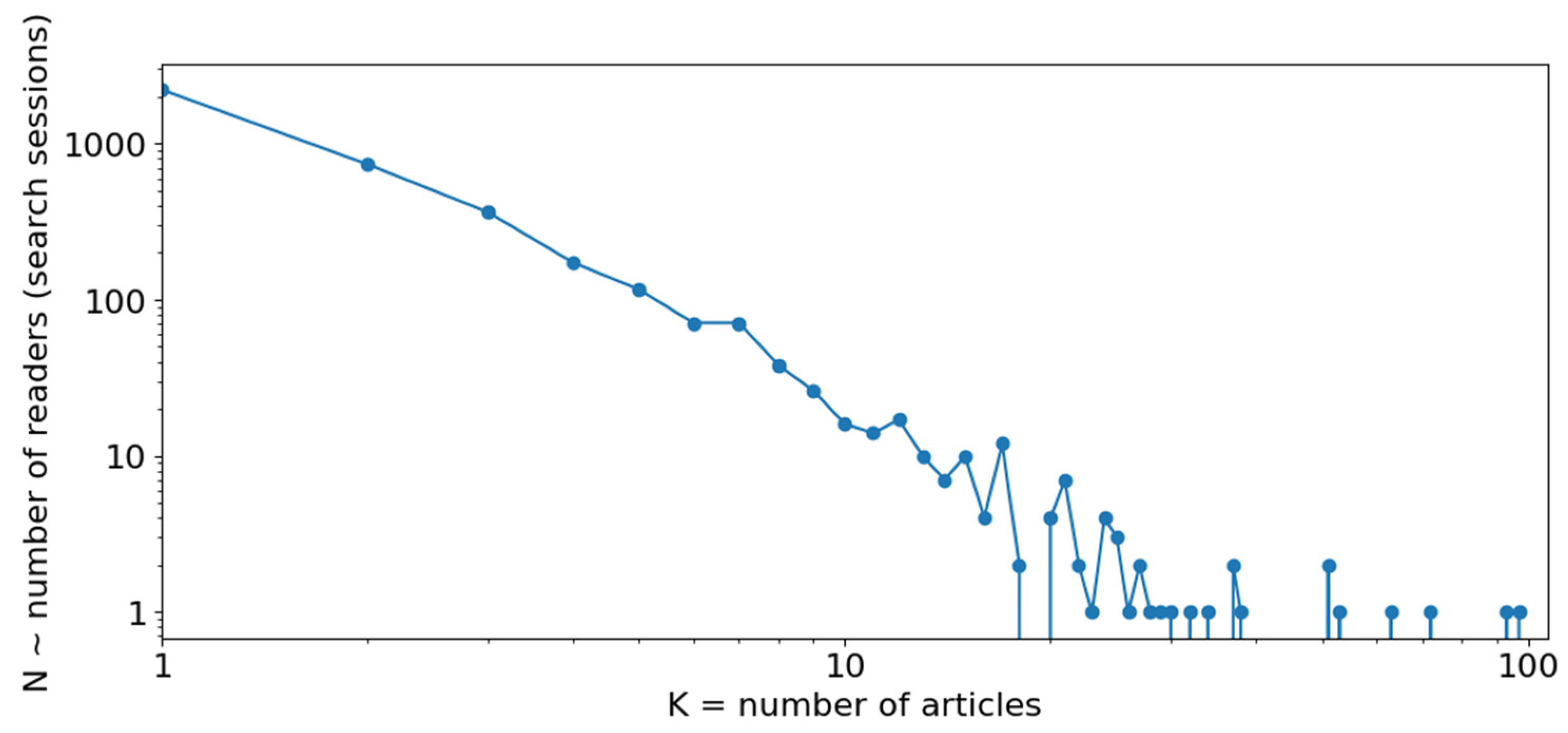
- Basic identification of the retrieval profile of a cognitive community on its search route: mass and intensity of nodes in search history
- ○
- Recording dynamics of search sessions: a third node measuring the value of a parameter of attention
- (ii)
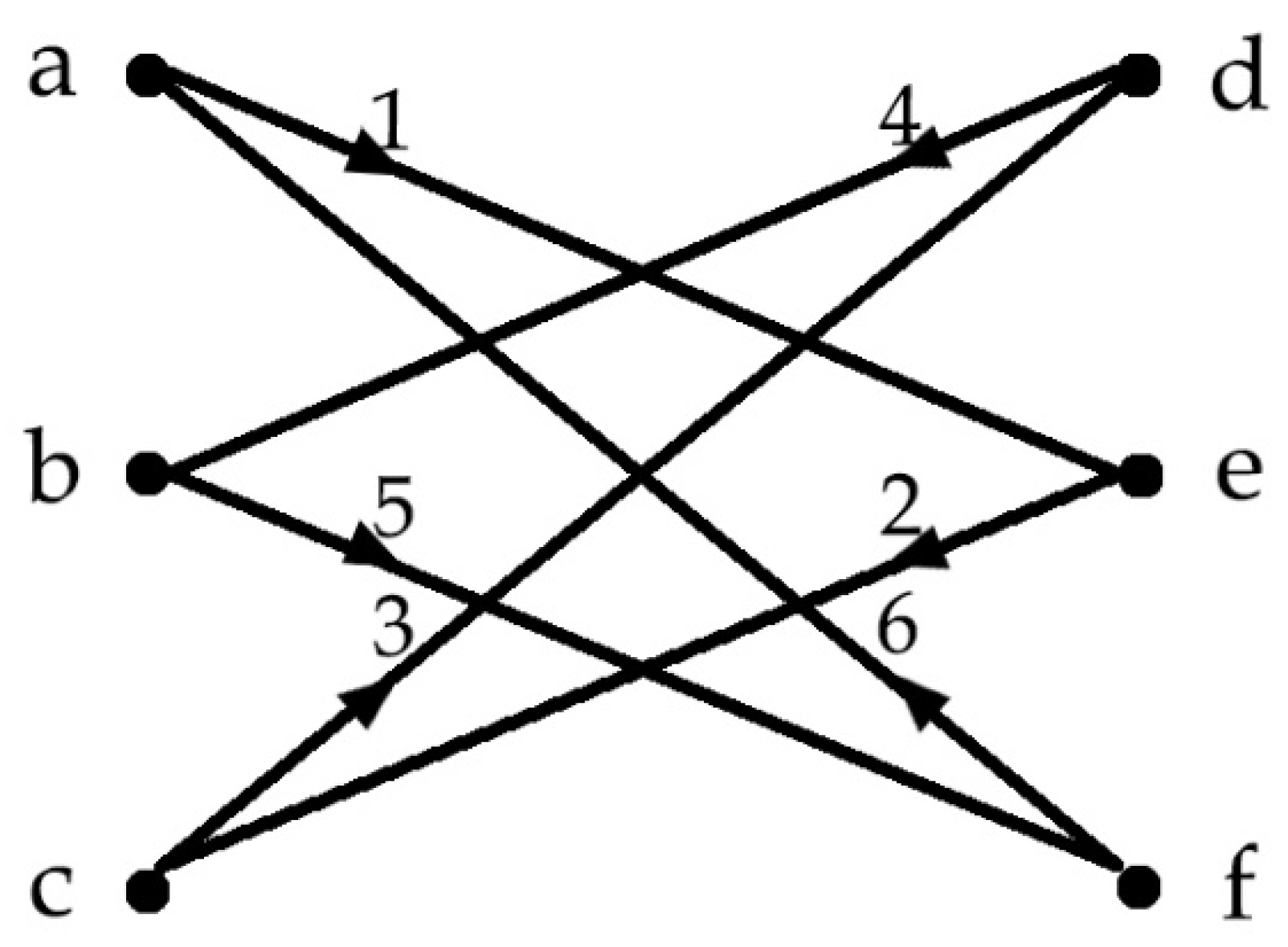
- Entity alignment of cognitive communities in GRAPHYP modeling
- ○
- Networking search sessions and detection of cliques in cognitive communities in the SKG
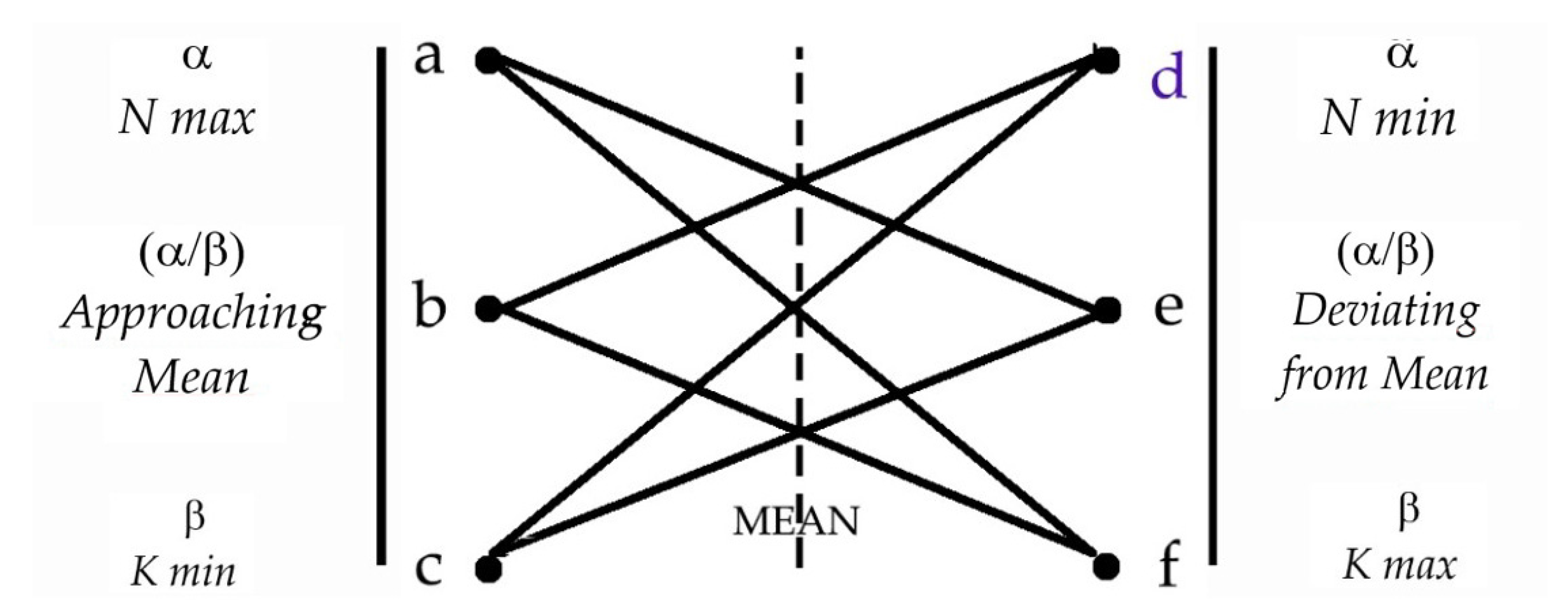
3.3. Tests of GRAPHYP’s Triplet Adjustment: Mapping of Retrieval Profile
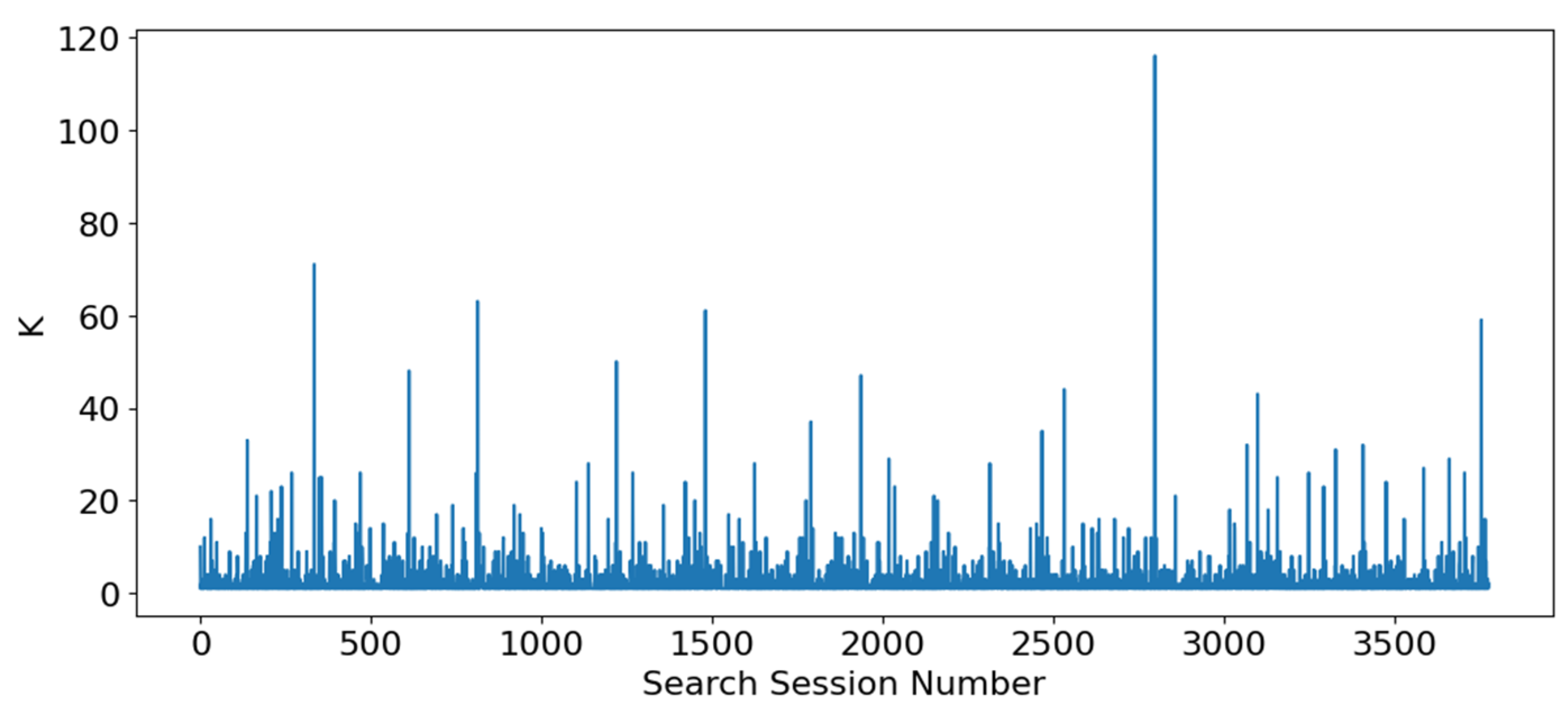
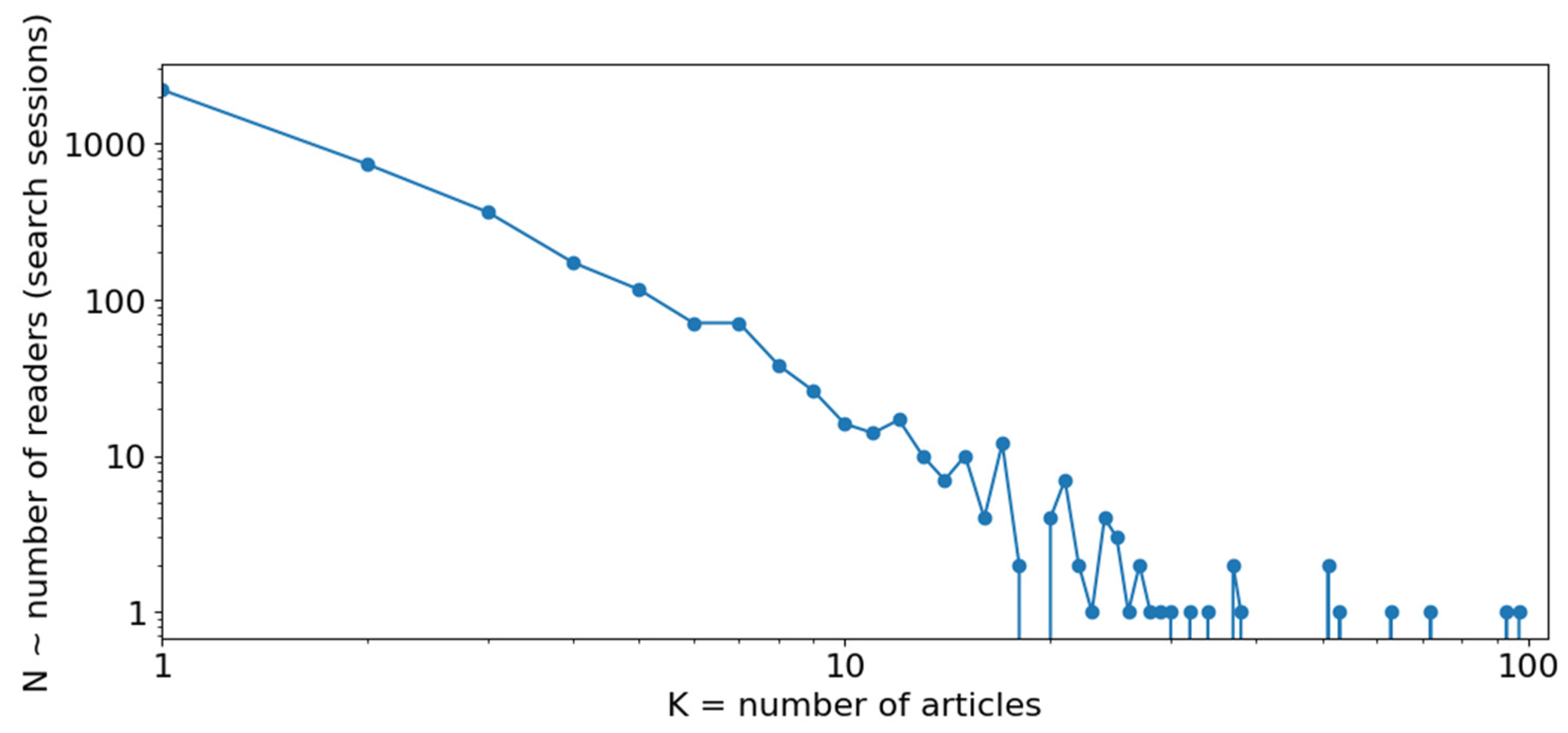
3.4. Subnetwork Analysis and Comparisons of Cliques in Cognitive Community
- (i)
- Comparing cliques inside a cognitive community on adversarial search route
- (ii)
- Representing cliques in cognitive communities at various scales
4. Discussion
5. Conclusions and Further Works
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Manghi, P.; Mannocci, M.; Osborne, F.; Sacharidis, D.; Salatino, A.; Vergoulis, T. New trends in scientific knowledge graphs and research impact assessment. Quant. Sci. Stud. 2021, 2, 1296–1300. [Google Scholar] [CrossRef]
- Lamers, W.S.; Boyack, K.; Larivière, V.; Sugimoto, C.R.; van Eck, N.J.; Waltman, L.; Murray, D. Meta-Research: Investigating disagreement in the scientific literature. eLife 2021, 10, e72737. [Google Scholar] [CrossRef]
- Tay, Y.; Luu, A.; Hui, S.C. Multi-Cast Attention Networks for Retrieval-based Question Answering and Response Prediction. arXiv 2018, arXiv:1806.00778v1. [Google Scholar] [CrossRef]
- Nedioui, M.A.; Moussaoui, A.; Saoud, B.; Babahenini, M.C. Detecting communities in social networks based on cliques. Phys. A Stat. Mech. Appl. 2020, 551, 124100. [Google Scholar] [CrossRef]
- Fried, Y.; Kessler, D.; Shnerb, N. Communities as cliques. Sci. Rep. 2016, 6, 35648. [Google Scholar] [CrossRef] [PubMed]
- Rossetti, G.; Cazabet, R. Community Discovery in Dynamic Networks: A Survey. ACM Comput. Surv. 2019, 51, 1–37. [Google Scholar] [CrossRef]
- Jaradeh, M.Y.; Singh, K.; Stocker, M.; Auer, S. Triple Classification for Scholarly Knowledge Graph Completion. In Proceedings of the 11th on Knowledge Capture Conference, Vitual Event, 2–3 December 2021; pp. 225–232. [Google Scholar] [CrossRef]
- Hund, A.; Wagner, H.-T.; Beimborn, D.; Weitzel, T. Digital innovation: Review and novel perspective. J. Strateg. Inf. Syst. 2021, 30, 101695. [Google Scholar] [CrossRef]
- Zitt, M.; Lelu, A.; Cadot, M.; Cabanac, G. Bibliometric Delineation of Scientific Fields. In Springer Handbook of Science and Technology Indicators; Glänzel, W., Moed, H.F., Schmoch, U., Thelwall, M., Eds.; Springer: Cham, Switzerland, 2019; pp. 25–68. [Google Scholar] [CrossRef]
- Jaradeh, M.Y.; Oelen, A.; Farfar, K.E.; Prinz, M.; D’Souza, J.; Kismihók, G.; Stocker, M.; Auer, S. Open Research Knowledge Graph: Next Generation Infrastructure for Semantic Scholarly Knowledge. In Proceedings of the 10th International Conference on Knowledge Capture, Marina Del Rey, CA, USA, 19–21 November 2019; pp. 243–246. [Google Scholar] [CrossRef]
- Lin, Y.; Evans, J.A.; Wu, L. New directions in science emerge from disconnection and discord. J. Informetr. 2022, 16, 101234. [Google Scholar] [CrossRef]
- Milojević, S. Quantifying the cognitive extent of science. J. Informetr. 2015, 9, 962–973. [Google Scholar] [CrossRef]
- Hogan, A.; Blomqvist, E.; Cochez, M.; d’Amato, C.; de Melo, G.; Gutierrez, C.; Kirrane, S.; Gayo, J.E.L.; Navigli, R.; Neumaier, S.; et al. Knowledge Graphs. Synth. Lect. Data Semant. Knowl. 2021, 22, 1–237. [Google Scholar] [CrossRef]
- Nayyeri, M.; Müge Çil, G.; Vahdati, S.; Osborne, F.; Rahman, M.; Angioni, S.; Salatino, A.; Recupero, D.R.; Vassilyeva, N.; Motta, E.; et al. Trans4E: Link Prediction on Scholarly Knowledge Graphs. arXiv 2021, arXiv:2107.03297v1. [Google Scholar] [CrossRef]
- Destandau, M.; Fekete, J.-D. The missing path: Analysing incompleteness in knowledge graphs. Inf. Vis. 2021, 20, 66–82. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, Y.; Zhao, B.; Cheng, J.; Zhao, X.; Duan, Z. Knowledge Graph Completion: A Review. IEEE Access 2020, 8, 192435–192456. [Google Scholar] [CrossRef]
- Glazebrook, J.F.; Wallace, R. Rate Distortion Manifolds as Model Spaces for Cognitive Information. Informatica 2009, 33, 309–345. [Google Scholar]
- Han, J.; Rong, Y.; Xu, T.; Huang, W. Geometrically Equivariant Graph Neural Networks: A Survey. arXiv 2022, arXiv:2202.07230. [Google Scholar] [CrossRef]
- Huvila, I.; Enwald, H.; Eriksson-Backa, K.; Liu, Y.-H.; Hirvonen, N. Information behavior and practices research informing information systems design. J. Assoc. Inf. Sci. Technol. 2021, 73, 1043–1057. [Google Scholar] [CrossRef]
- Easley, D.; Kleinberg, J. Networks, Crowds, and Markets: Reasoning about a Highly Connected World; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar] [CrossRef]
- Munne, R.F.; Ichise, R. Entity alignment via summary and attribute embeddings. Log. J. IGPL 2022, jzac021. [Google Scholar] [CrossRef]
- Bevilacqua, B.; Frasca, F.; Lim, D.; Srinivasan, B.; Cai, C.; Balamurugan, G.; Bronstein, M.M.; Maron, H. Equivariant Subgraph Aggregation Networks. arXiv 2022, arXiv:2110.02910. [Google Scholar] [CrossRef]
- Chakraborty, R.; Bouza, J.; Manton, J.H.; Vemuri, B.C. ManifoldNet: A Deep Neural Network for Manifold-Valued Data with Applications. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 799–810. [Google Scholar] [CrossRef]
- Yu, R.; Tang, R.; Rokicki, M.; Gadiraju, U.; Dietze, S. Topic-independent modeling of user knowledge in informational search sessions. Inf. Retr. J. 2021, 24, 240–268. [Google Scholar] [CrossRef]
- Bronstein, M.M.; Bruna, J.; Cohen, T.; Veličković, P. Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges. arXiv 2021, arXiv:2104.13478. [Google Scholar] [CrossRef]
- Dimitrova, T.; Petrovski, K.; Kocarev, L. Graphlets in Multiplex Networks. Sci. Rep. 2020, 10, 1928. [Google Scholar] [CrossRef] [PubMed]
- Agosti, M.; Crivellari, F.; Di Nunzio, G.M. Evaluation of Digital Library Services Using Complementary Logs. In Proceedings of the 32nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Boston, MA, USA, 19–23 July 2009. [Google Scholar]
- Xiong, C.; Power, R.; Callan, J. Explicit Semantic Ranking for Academic Search via Knowledge Graph Embedding. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 1271–1279. [Google Scholar] [CrossRef]
- Ghojogh, B.; Ghodsi, A.; Karray, F.; Crowley, M. Generative Adversarial Networks and Adversarial Autoencoders: Tutorial and Survey. arXiv 2021, arXiv:2111.13282. [Google Scholar] [CrossRef]
- Grilo Rosa, M.; Sousa Fadigas, I.; Tamanini Andrade, M.; Barros Pereira, H. Clique Approach for Networks: Applications for Coauthorship Networks. Soc. Netw. 2014, 3, 80–85. [Google Scholar] [CrossRef]
- Buscher, G.; Gwizdka, J.; Teevan, J.; Belkin, N.J.; Bierig, R.; van Elst, L.; Jose, J. SIGIR 2009 workshop on understanding the user: Logging and interpreting user interactions in information search and retrieval. ACM SIGIR Forum 2009, 43, 57–62. [Google Scholar] [CrossRef]
- Clarke, C.L.A.; Freund, L.; Smucker, M.D.; Yilmaz, E. SIGIR 2013 workshop on modeling user behavior for information retrieval evaluation. In Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 28 July–1 August 2013; p. 1134. [Google Scholar] [CrossRef] [Green Version]
- Heidari, M.; Zad, S.; Berlin, B.; Rafatirad, S. Ontology Creation Model based on Attention Mechanism for a Specific Business. In Proceedings of the 2021 IEEE International IOT, Electronics and Mechatronics Conference (IEMTRONICS), Toronto, ON, Canada, 21–24 April 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Lin, J.; Ma, X. A Few Brief Notes on DeepImpact, COIL, and a Conceptual Framework for Information Retrieval Techniques. arXiv 2021, arXiv:2106.14807. [Google Scholar] [CrossRef]
- Lin, J. A proposed conceptual framework for a representational approach to information retrieval. ACM SIGIR Forum 2022, 55, 1–29. [Google Scholar] [CrossRef]
- Roweis, S.T.; Saul, L.K. Nonlinear Dimensionality Reduction by Locally Linear Embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [PubMed]
- Shao, S.; Xu, R.; Wang, Z.; Liu, W.; Wang, Y.; Liu, B. DLDL: Dynamic label dictionary learning via hypergraph regularization. Neurocomputing 2022, 475, 80–88. [Google Scholar] [CrossRef]
- Chen, M.; Tian, Y.; Wang, Z.; Xu, H.; Jiang, B. A Comprehensive Survey of Cognitive Graphs: Techniques, Applications, Challenges. Preprints 2021, 2021080155. [Google Scholar] [CrossRef]
- Eickhoff, C. Contextual Multidimensional Relevance Models. Ph.D. Thesis, TU Delft, Delft, The Netherlands, 14 October 2014. [Google Scholar] [CrossRef]
- Bouritsas, G.; Frasca, F.; Zafeiriou, S.; Bronstein, M.M. Improving Graph Neural Network Expressivity via Subgraph Isomorphism Counting. arXiv 2006, arXiv:2006.09252. [Google Scholar] [CrossRef] [PubMed]
- Tripuraneni, N.; Jin, C.; Jordan, M.I. Provable Meta-Learning of Linear Representations. In Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual Event, 18–24 July 2022; Volume 139, pp. 10434–10443. [Google Scholar]
- Cheng, R.; Liu, C.; Meng, S. A Study of Cognitive Orbits Based on Man-machine Interactions. Open Cybern. Syst. J. 2015, 9, 2694–2702. [Google Scholar]
- Maggioni, M.; Miller, J.J.; Qiu, H.; Zhong, M. Learning Interaction Kernels for Agent Systems on Riemannian Manifolds. arXiv 2021, arXiv:2102.00327v3. [Google Scholar] [CrossRef]
- Rizzoglio, F.; Casadio, M.; De Santis, D.; Mussa-Ivaldi, F.A. Building an adaptive interface via unsupervised tracking of latent manifolds. Neural Netw. 2021, 137, 174–187. [Google Scholar] [CrossRef]
- Metzler, D.; Tay, Y.; Bahri, B.; Najork, M. Rethinking search: Making domain experts out of dilettantes. ACM SIGIR Forum 2021, 55, 1–27. [Google Scholar] [CrossRef]
- Fabre, R. A searchable space with routes for querying scientific information. In Proceedings of the 8th International Workshop on Bibliometric-Enhanced Information Retrieval (BIR 2019), Cologne, Germany, 14 April 2019; pp. 112–124. Available online: http://ceur-ws.org/Vol-2345/paper10.pdf (accessed on 2 August 2022).
- Weber, T. A Philological Perspective on Meta-scientific Knowledge Graphs. In ADBIS, TPDL and EDA 2020 Common Workshops and Doctoral Consortium; Springer: Cham, Switzerland, 2022. [Google Scholar] [CrossRef]
- Marsh, L.; Onof, C. Stigmergic epistemology, stigmergic cognition. Cogn. Syst. Res. 2008, 9, 136–149. [Google Scholar] [CrossRef]
- Logan, R.K.; Pruska-Oldenhof, I. A Topology of Mind: Spiral Thought Patterns, the Hyperlinking of Text, Ideas and More; Springer: Cham, Switzerland, 2022; 244p, Available online: https://link.springer.com/book/9783030964351 (accessed on 2 August 2022).
- Li, A.; Du, J.; Kou, F.; Xue, Z.; Xu, X.; Xu, M.; Jiang, Y. Scientific and Technological Information Oriented Semantics-adversarial and Media-adversarial Cross-media Retrieval. arXiv 2022, arXiv:2203.08615. [Google Scholar] [CrossRef]
- Liu, W.; Chen, P.; Yu, F.; Suzumaru, T.; Hu, G. Learning Graph Topological Features via GAN. IEEE Access 2019, 2019, 2898693. [Google Scholar] [CrossRef]
- Liu, L.; Zhang, Y.; Deng, J.; Soatto, S. Dynamically Grown Generative Adversarial Networks. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21), Virtual Event, 2–9 February 2021; pp. 8680–8687. Available online: https://ojs.aaai.org/index.php/AAAI/article/download/17052/16859 (accessed on 2 August 2022).
- Rosvall, M.; Bergstrom, C.T. Maps of random walks on complex networks reveal community structure. Proc. Natl. Acad. Sci. USA 2008, 105, 1118–1123. [Google Scholar] [CrossRef] [PubMed]
- Rosvall, M.; Axelsson, D.; Bergstrom, C.T. The map equation. Eur. Phys. J. Spec. Top. 2010, 178, 13–23. [Google Scholar] [CrossRef]
- Fang, Z.; Costas, R.; Tian, W.; Wang, X.; Wouters, P. How is science clicked on Twitter? Click metrics for Bitly short links to scientific publications. J. Assoc. Inf. Sci. Technol. 2021, 72, 918–932. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fabre, R.; Azeroual, O.; Bellot, P.; Schöpfel, J.; Egret, D. Retrieving Adversarial Cliques in Cognitive Communities: A New Conceptual Framework for Scientific Knowledge Graphs. Future Internet 2022, 14, 262. https://doi.org/10.3390/fi14090262
Fabre R, Azeroual O, Bellot P, Schöpfel J, Egret D. Retrieving Adversarial Cliques in Cognitive Communities: A New Conceptual Framework for Scientific Knowledge Graphs. Future Internet. 2022; 14(9):262. https://doi.org/10.3390/fi14090262
Chicago/Turabian StyleFabre, Renaud, Otmane Azeroual, Patrice Bellot, Joachim Schöpfel, and Daniel Egret. 2022. "Retrieving Adversarial Cliques in Cognitive Communities: A New Conceptual Framework for Scientific Knowledge Graphs" Future Internet 14, no. 9: 262. https://doi.org/10.3390/fi14090262
APA StyleFabre, R., Azeroual, O., Bellot, P., Schöpfel, J., & Egret, D. (2022). Retrieving Adversarial Cliques in Cognitive Communities: A New Conceptual Framework for Scientific Knowledge Graphs. Future Internet, 14(9), 262. https://doi.org/10.3390/fi14090262