1. Introduction
The coronavirus pandemic has wreaked havoc on every aspect of our modern society. The world was challenged on an unprecedented scale. In response, most governments around the world authorized containment measures including social distancing and the temporary suspension of schools and educational institutions. Educational pedagogies were moved to online education. In some countries, distance education was adopted to maintain the educational activities [
1,
2,
3]. As a result of the vital need to replace face-to-face learning, educational institutions had to adopt a digital approach where teaching is delivered on digital platforms [
4,
5,
6,
7,
8].
Contrary to general belief, distance education is not a new phenomenon. The emergence of distance education dates back to the 18th century. Countries such as the USA, England, and Australia have provided distance education in the form of correspondence study to reach learners who are geographically dispersed [
9]. With the rapid development in technology, several models in distance education have developed such as online learning in which students use Internet and associated technologies to learn from their homes [
10] and blended learning that combines online and in-person learning [
11]. All these models use technology in learning but adapt different learning processes. While there has been an increase in the use of online distance learning in various countries, some challenges have been posed for students, parents, teachers, and institutions due to the abrupt transition.
As the use of online distance learning continues to increase, the need for quality data to detect underlying trends in order to optimize the efforts of improving the educational experience is essential. Currently, existing research largely relies on surveys through interviews or questionnaires [
8,
10,
12]. The collected data from these surveys are critical in identifying the themes regarding to the perspectives about distance learning experience. However, their reliability relied on the respondents. Furthermore, generating the result from these data commonly takes time; meanwhile, the observed trends might be changed by the time the result is reported. Hence, alternative methods are needed, including analyzing the data of social media platforms such as Twitter, Facebook, and YouTube. Such platforms offer open sources to students to share their experience and seek social support. This vast amount of data provides educational researchers with implicit knowledge and new perspectives to better understand the students’ experiences that inform of the improvement of education quality [
13].
Despite the challenges associated with analyzing this massive amount of data to obtain valuable insight, the research collaborations and improvement increased. In response, this study presents a new approach using Twitter data in order to gain insights of distance education issues. Our focus is on Arabic Twitter content posted by users related to distance education in Saudi Arabia at all educational levels. The aim of this study is to detect and classify the potential topics in social media content related to distance education to identify the major issues students face through their distance education experience. To attain this goal, the objectives of this study are as follows:
Collect Arabic tweets regarding distance education in Saudi Arabia and perform filtering and preprocessing process.
Apply and train biterm topic model (BTM), an unsupervised machine learning approach on the cleaned tweets to identify the underlying topics and cluster them into themes.
Annotate the resulting themes into major categories and sub-categories that represent the issues of the distance education.
Use multi-class SVM classifier model to classify the entire dataset into the generated categories from the previous step to identify the major issues.
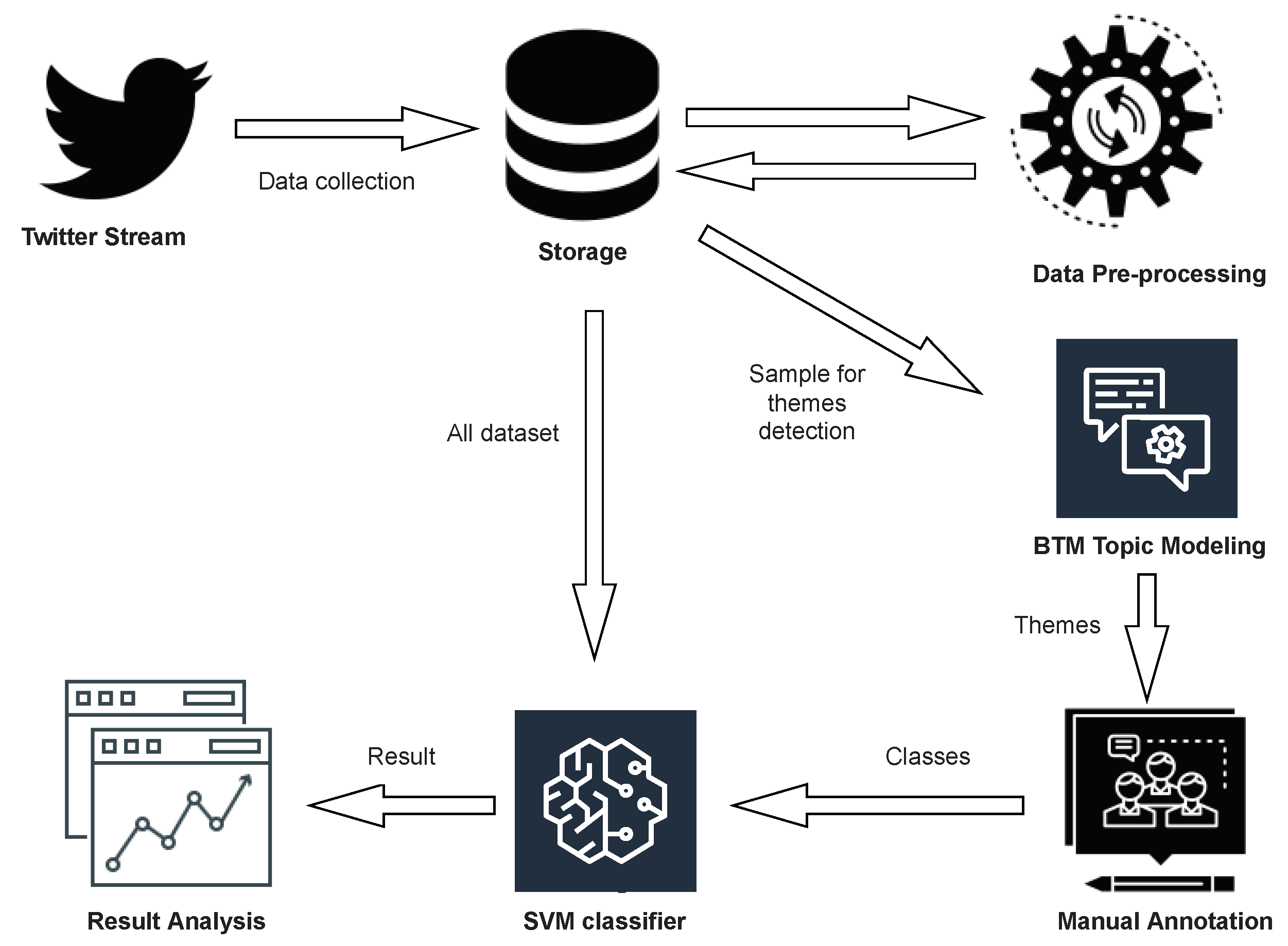
In this study, we proposed a new methodology that integrates clustering and classification machine learning techniques to explore the textual Twitter data shown in
Figure 1. Hence, the study differs from prior work in implementing the automatic filtering of a large dataset of tweets and detecting topics that are contained in the data in order to inform educational decision makers about the issues and problems that the students face in their learning experience.
The rest of the paper is organized as follows:
Section 2 introduces related work.
Section 3 contains the illustration and implementation of the proposed method.
Section 4 shows the results.
Section 5 presents the discussion and limitation followed by the conclusion in
Section 6.
2. Related Work
Extracting the topics that reflect students’ concerns according to their online conversations has become an important source to enhance distance education and develop a new learning styles. Consequently, many studies have been conducted extensively. In this section, we will focus on studies related to the topic detection methods and educational data analysis.
The widely used models to uncover the hidden topics in the text are the probabilistic semantic-based indexing model (PLSI) [
14] and latent dirichlet allocation (LDA) [
15]. PLSI underlines the topic based on the semantic indexing wherein low-dimensional representation has been utilized to evaluate the similarities. The LDA model is an unsupervised model that has been used to discover and document subject knowledge. For online communities, several models were proposed based on the LDA model to mine the online content and identify the topics. Nagori et al. developed a personalized recommendation system for e-learning based on the content of the text. They utilized the topic model by introducing the similarity measures [
16]. Zhong et al. [
17] designed a model for the quality of online students’ comments; they constructed a set of topic features that strongly related to the quality comments. Applying such models directly on short texts will yield to data sparsity problem [
18]. Yan et al. [
18] proposed a model to detect topics in short textual data called Biterm Topic Model (BTM); their model generates the term co-occurrence in the whole corpus to improve the topic learning.
Distance education is a system of learning and teaching. Analyzing and mining the data generated in an online education setting is an effective method to mine and understand students’ learning environments. Data-driven approaches have been used to analyze structured data including student performance, activity, or course discussion forums [
19]. In fact, the exchange of the information about online education has been increased using online platforms, and various studies have been put forward to enhance the quality of data mining in distance learning. Kagklis et al. [
20] utilized text mining techniques to improve the educational process; they used regression techniques to predict the performance of the students. Rooyen investigated students’ opinions in the accounting department at the University of South Africa about integrating social media apps in the learning process to improve their education. They found that students have positive opinions toward using social media for academic support [
21]. The authors in [
22] proposed an intellectual distance education system to exchange information of artificial immune systems. The system allows learners to experience a real-time training to gain necessary skills.
The opinion mining system has been widely used to measure public opinion about any topic or event. Many studies have been carried out to investigate the opinion regarding distance education. Kumar et al. [
23] developed a multi-aspect-based system to explore students’ opinion about distance education in India. They applied sentiment classification on online reviews using Naive Bayes classifier. A recent study by Aljabri et al. [
24] employed a sentiment analysis approach to investigate people’s opinions about distance learning in Saudi Arabia. They utilized different classification techniques including support vector machine, Naive Bayes, logistic regression, k-nearest neighbor, and XGBoost, and the best accuracy was achieved in logistic regression with a unigram feature. Their finding demonstrates that there was a general positive opinion at the school level and negative opinion at the higher education level. A more recently study by Alqurashi [
25] applied several classical machine-learning models to explore public’s opinion in KSA regarding distance education. The author classified the tweet into two classes (Infavor, Against), which represent negative and positive opinion. The result of the study showed positive opinion related to distance education.
Regarding the challenges, research has identified challenges concerning distance education. A study by Abuhammad [
26] applied the qualitative method to investigate the challenges of distance learning with regard to parents’ perceptions during the coronavirus outbreak in Jordan. The analysis was applied on Facebook groups with a total of 248 posts. The finding revealed four themes, naming personal barriers, technical barriers, logistical barriers, and financial barriers. A recent study by Almendingen et al. [
27] developed a methodology to assess the Norwegian faculty and students’ experiences for shifting to distance learning. They utilized a mixed methods approach that combined quantitative and qualitative analysis. They found that students adapted quickly to the new learning style but also experience difficulties such as lack of social interaction, limited participation, and stressful situations. A more recent study by Segbenya et al. [
28] examined students’ perspectives about distance education. They employed a descriptive statistics method using a survey to analyze students’ learning challenges. Their finding identified two main challenges, including unreliable internet and power and lack of collaboration and motivation.
3. Materials and Methods
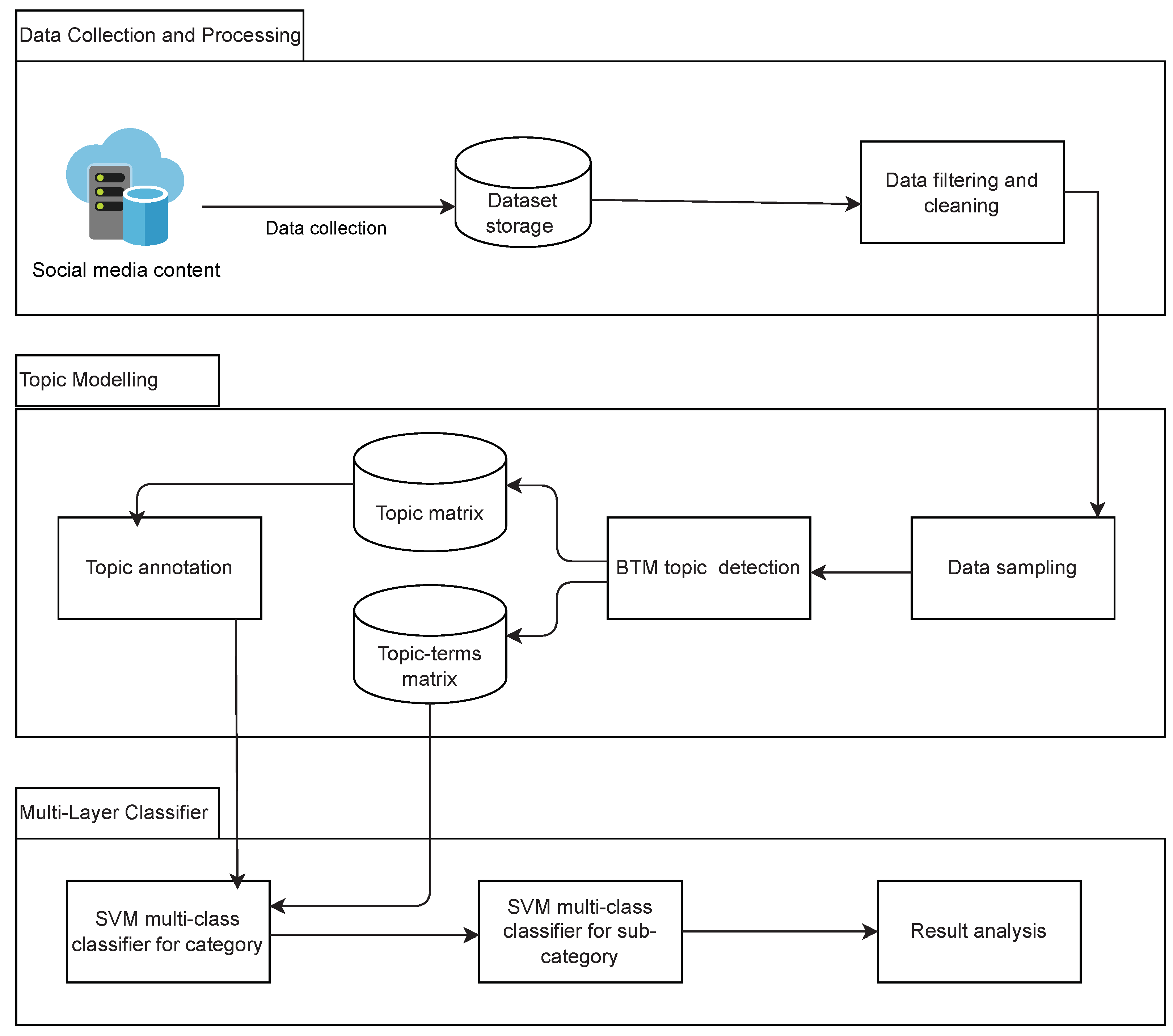
This study was conducted in three phases: (1) data collection using public Twitter API followed by subsequent preprocessing steps to filter and clean the tweets; (2) topic modeling using an unsupervised machine learning approach to identify the underlying themes; and (3) classification using a supervised machine learning approach to classify the whole dataset into categories and sub-categories. The structure of the method is shown in
Figure 2. Detailed descriptions of these phases are in the following subsections.
3.1. Data Collection and Preprocessing
The data were collected using Twitter API; we first collected Arabic tweets containing specific keywords including (”الدراسة عن بعد”), (”التعليم عن بعد”), (”الدراسة اون لاين”), and (”التعليم اون لاين”). The translation of these keywords is “distance education”, “distance learning”, “online education”, and “online learning”. We streamed tweets for about three months from 1 July 2020 to 29 September 2020. A total of 2,811,327 tweets were collected. We further filtered this corpus for tweets belonging to Saudi Arabia, resulting in 901,938. Additionally, repeated tweets and tweets not related to user content such as tweets contain news or commercial information were removed, resulting in 207,488, as shown in
Table 1.
Twitter posts include special symbols to convey certain meaning; also, the collected tweets may contain lots of noisy and uninformative data. Therefore, the tweets were cleaned by several standard data preprocessing steps.
Convert text files to UTF-8 encoding.
Remove punctuation marks, non-letters, and diacritics.
All tweet’s features include hashtags, mentions (@user), URLs, and retweet symbol (RT) were removed.
Replace the repeated letters such as (”تعباااان”) with two letters (”تعباان”) to identify the word.
All Arabic stop words such as (”عن”, ”اين”) were removed.
3.2. Topic Modeling
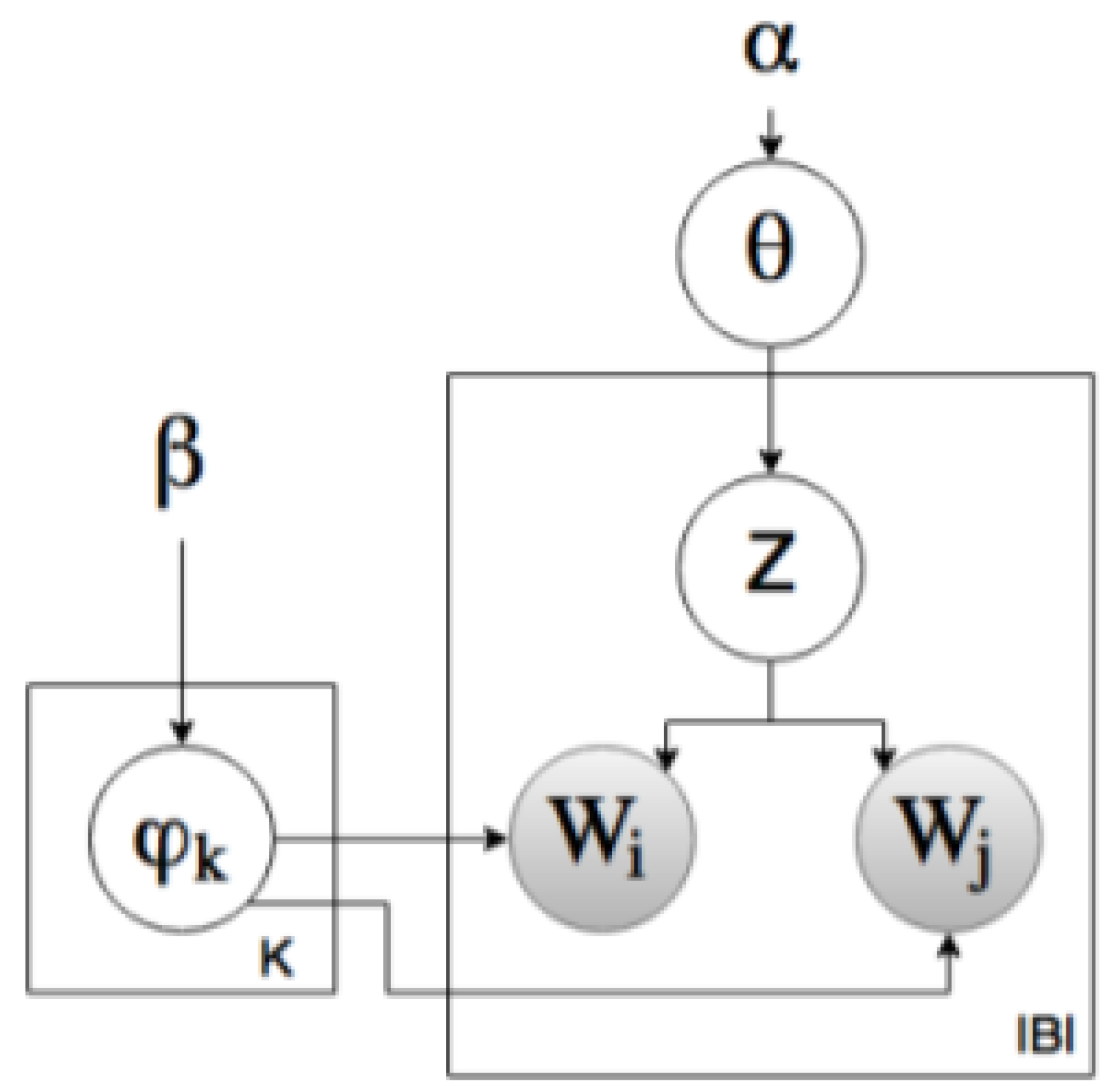
Topic modeling is a probability generation for text content to discover the hidden themes and their vocabulary. The focus of this study is to identify what were the major issues that students encounter through their distance education experience in Saudi Arabia. We used the biterm topic model (BTM), an unsupervised machine learning approach [
18] as a core for discovering the themes in our corpus, where each tweet is treated as a document. BTM is a mathematical method developed to work with a sort text. A graphical representation of this model is shown in
Figure 3 [
18]. BTM works by generating the co-occurrence of all word-pairs which are called biterms within each text across the corpus. The generative process of BTM is presented in Equation (
1).
An implementation of BTM was provided by bitermplus package [
29]. In the learning step, the tweets corpus and the number of topics (k) are fed to the BTM. Then, the model generates the topics themes as word groupings and their discrete probability distribution. The highest probabilities were assigned to the words that are the most representative of the theme. We implemented the algorithm by using bitermplus package [
29] in Python language version 3.7.10. We developed the themes in two stages; the first involved the implementation steps of the BTM approach, and the second involved the manual annotation to identify the themes that related to the issues of the distance education. In the following, we will explain these stages in detail.
3.2.1. BTM Implementation
The following steps are performed to train the BTM and extract the themes.
Selecting the training sample: In this step, random sample was extracted from the corpus to train and fit the BTM model. All empty tweets or with less than three words generated from the preprocessing step were filtered. Then, the resulted 5000 tweets were used for training.
Estimating the number of topics (k): Identifying k is very important step because it can affect the produced topis. A large k could lead to many clusters that can not be interpreted, while a small k could lead to a general cluster in term of semantic contexts. To define the optimal k, different qualitative or quantitative approaches have been used. We used a coherence score to measure the quality of learned topics; a higher score means high correlation of the topics in the cluster. The UMmass coherence score was used to calculate the scores as shown in Equation (
2) [
30].
represents the documents count in which words
and
co-occur, where 1 is added to this term to avoid calculating the logarithm of zero when the two words never appear together. This step was repeated with different values of k, (k = 5, 7, 10, 15) to ensure that the filtered topics are highly relevant to the issues of interest. We found the best value of k was 5.
Training the BTM model: In the traning phase, we trained and fitted BTM with k = 5 as estimated in the previous step. Then, we applied the inference phase; in this phase, the algorithm determines how each tweet correlates to the themes discovered in the learning phase. As a result, the themes were produced with five tweets in each.
A sample of the result of this stage is demonstrated in
Table 2. Notably, there is an overlap between the themes, which might be because the tweets represent very connected issues in distance education.
3.2.2. Topics Annotation
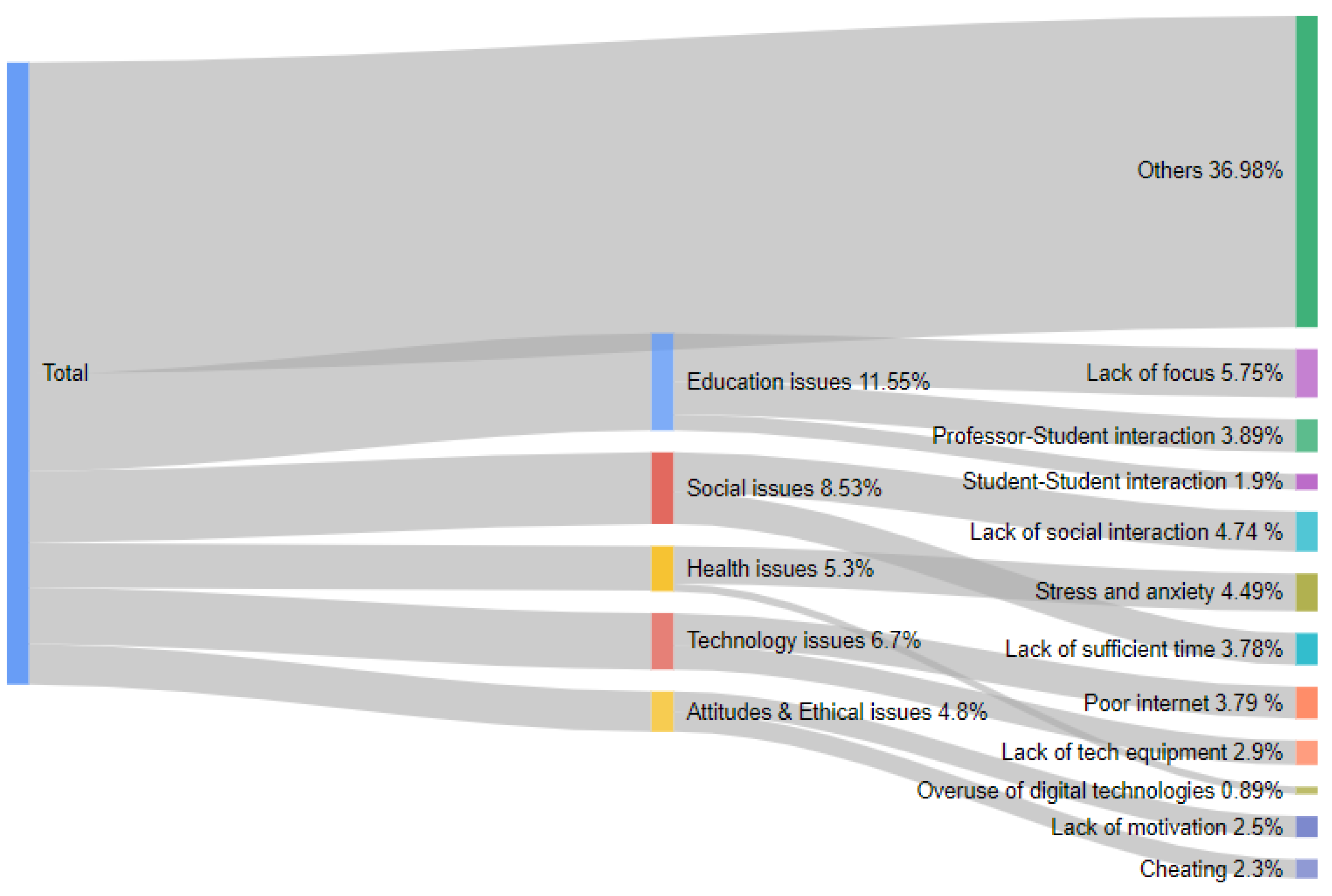
The resulted themes from the BTM model were annotated manually by two annotators: the author and one of the colleague as a native Arabic speker. Each annotator developed a set of categories independently. Then, these categories were narrowed down into 11 notable themes. In addition, these themes were considered as sub-categories and grouped in general categories. The agreement between the two annotators achieved a high inter-rate with kappa = 0.91. These sub-categories have been identified to cover the issues that students experienced through their educational process. Each sub-category belongs to one of the five general categories: education issues, social issues, health issues, technology issues, and attitude and ethical issues.
Table 3 lists the top 20 terms with highest probabilities in all selected topics.
3.3. Multi-Layer Classification Model
Many approaches in the literature have been developed to address a multi-class classification problem. However, the most common solution is to decompose the multi-class classification problem into a set of binary classification problems. One of these methods is called one-versus-all [
31]; the basic concept of this method is conducting a binary classifier for each label with assuming independence among the labels. Based on this mechanism, we performed a multi-class learning by using standard support vector machines (SVMs). If we have k classes, then SVM classifiers are constructed for each class. Every classifier is trained to distinguish the samples of one class from the samples of all the other classes. To predict a new sample, the sample is classified by all k classifiers, and then, the class with the maximum decision value is chosen.
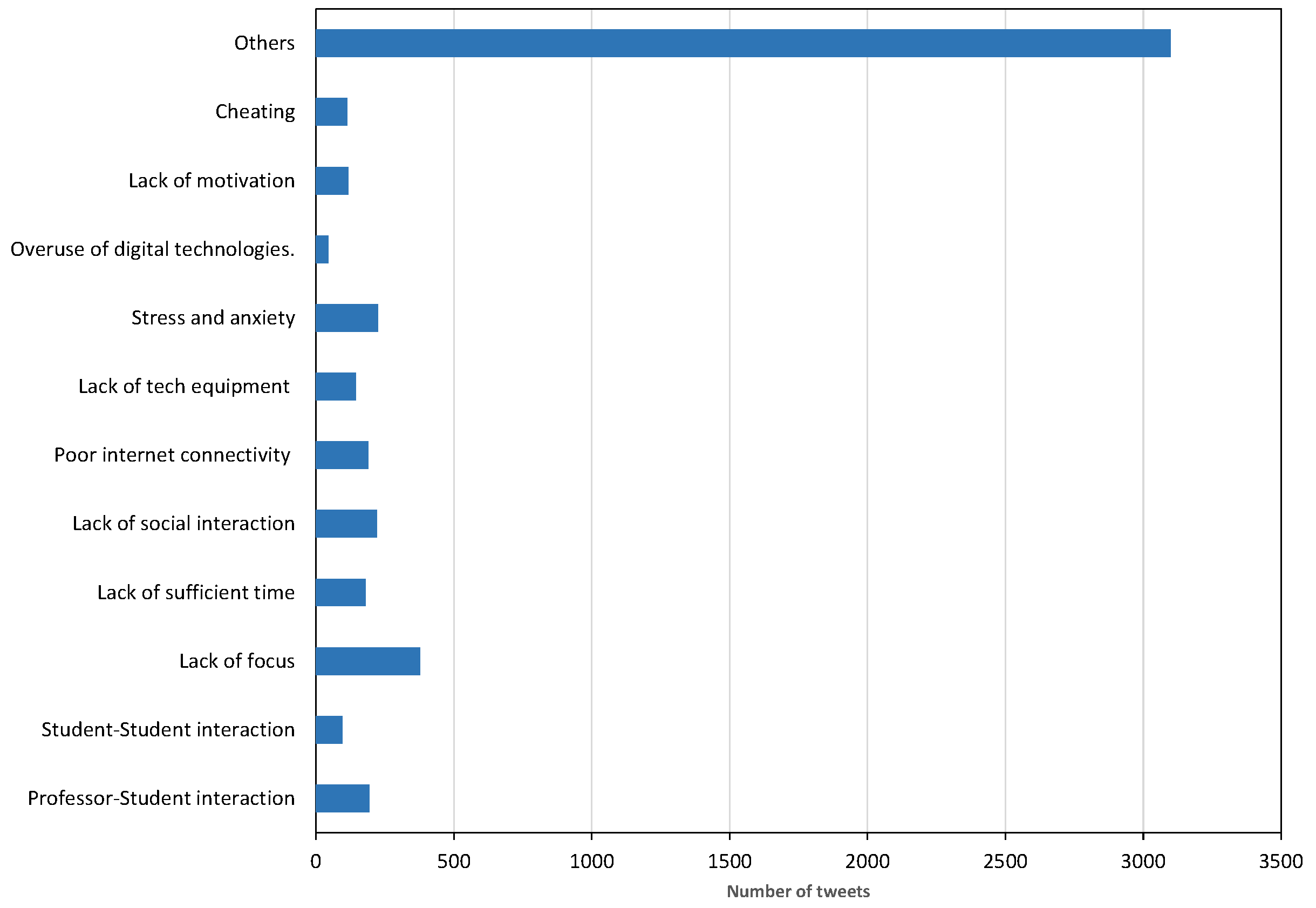
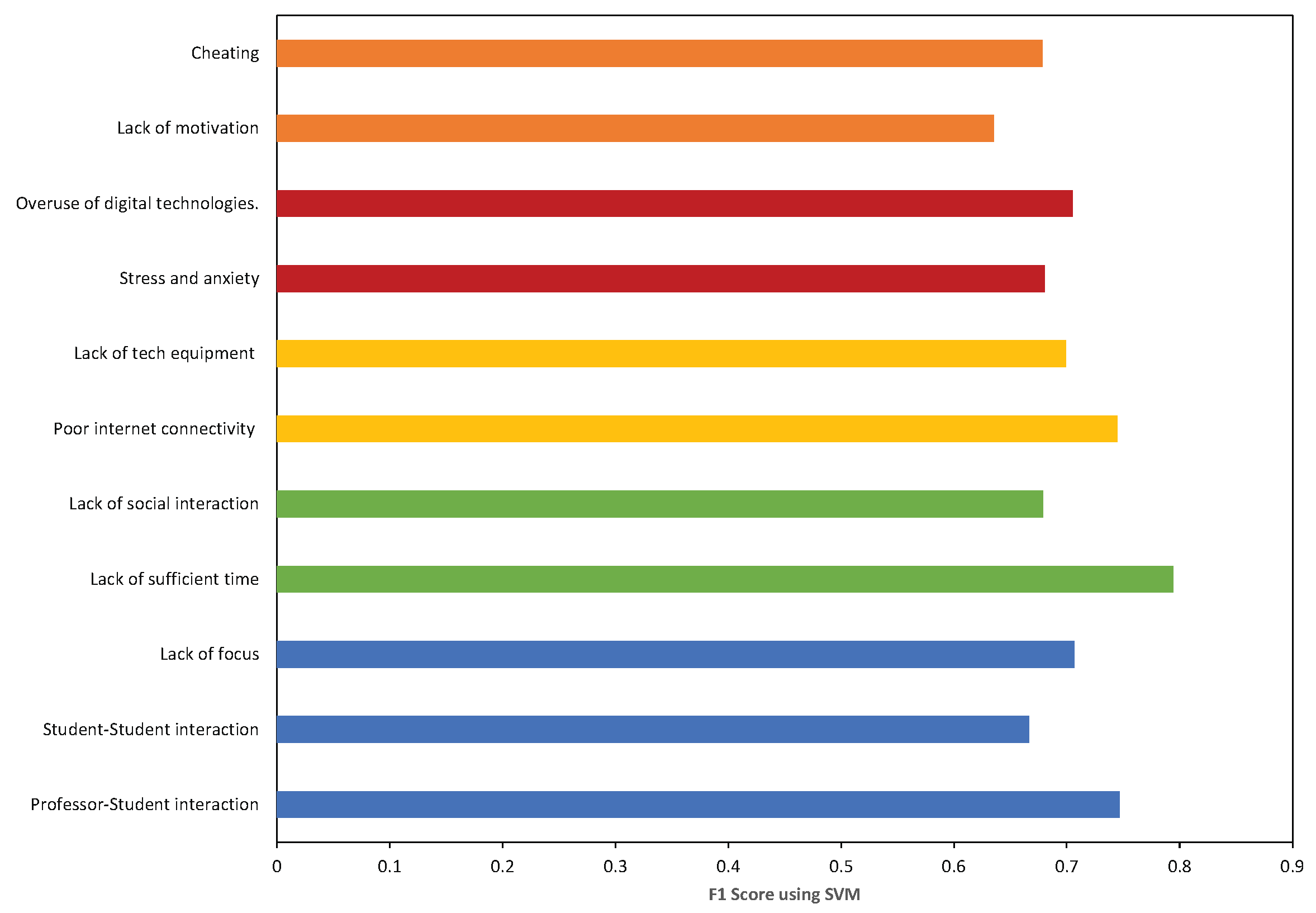
Our classification approach includes two layers of a multi-class SVM classifier. The topics that were produced from the annotation stage in the second phase are used as classes for classification of the tweets in the entire dataset. The general set of classes is (education issues, social issues, technology issues, health issues, and attitudes and ethical issues), which represents the general categories. The other set of classes is (professor–student interaction, lack of focus, student–student interaction, lack of time, lack of social interaction, poor internet connectivity, lack of tech equipment, overuse of digital technologies, stress and anxiety, lack of motivation, and cheating) that represents the sub-categories. The first classifier is trained to predict if the tweet belongs to one of the basic categories. The second classifier is used to predict if the tweet belongs to sub-categories. We implemented the two classification tasks in a multi-layer classification model. In the upper layer, the multi-class classifier for the categories is applied. Then, the predicted category will be passed as a feature to the lower layer to classify the tweet as a sub-category. To avoid the misclassification that could occur on the upper level, all sub-category classifiers are applied in the lower level.
Features extraction is an essential step in the classification process in order to represent the tweet text as numerical vectors. For features extraction, we extracted two features as follows:
The top 20 words with the highest probability of occurrence that are extracted from BTM for each category are used to build a set of features that is used for classification in the first layer.
N-gram is a set of consecutive order of words based on the value of N. We extracted the bigram where N = 2 is to be used for classification in the second layer.
The experiment is performed using Python language version 3.7.10; we used scikit-learn library [
32] to implement the multi-class SVM classifiers. The random sample of tweets that was used to train BTM algorithm was also used to train and fit the multi-class SVM classifier. We first partitioned the data into 70% training set and 30% test set to train and fit the classifers. Then, we applied the classifers on the rest of the data.
5. Discussion and Limitation
Considering the results presented in the previous section, a detailed description of the discovered issues that represent students’ experience in distance education will be presented in terms of analysis and comparison to the recent studies.
Education Issues: Our analysis reveals that students find difficulties in adapting to a distance learning environment. The result shows that the highest proportion of tweets, around 11.55%, reflects problems such as the lack of interactions between students themselves and between students and teachers. Students who have been studying in physical classroom are finding difficulties focusing in online platforms. These issues might be raised because of the sudden change from face-to-face learning to a new model of learning. There are some students who lack communication skills and who are unprepared to interact in the class with their teachers and friends; they feel separated. This finding echoes a study on challenges in distance education [
9], which indicates the lack of communication between teachers and students, and their finding shows that the teachers and students are not ready for distance education. In fact, with distance learning, the course plan and design should be aligned with the online learning style. Many studies [
9,
35,
36] recommended to train teachers to be open to alternative ways of teaching.
Social Issues: The analysis shows that 8.53% of tweets’ content implies that social issues significantly influence student social well-being. Students trade off their daily life and social engagement to perform their studying tasks; they face difficulty adapting the new learning style, and that requires intensive work to manage their daily time. Social engagement provides positive impact and sense of predictability and stability [
37]. Students might benefit from being involved in social activities because learning is a social process that is supported by many learning theories [
38].
Technology Issues: Technology is immensely useful in distance learning; several online platforms were available to support online education. Our analysis finds that technology problems such as internet shortage, technical problems, and shortage of digital equipment arise due to a deficiency of technology. Many students not equipped with high-speed internet services, which plays an important role in how quickly they attend their classes. In addition, students may encounter technical issues as they lack skills related to using computer applications. All students could experience access issues in terms of problems with technology or lack of access [
9,
39]. In addition, there are some homes where there are many people with limited numbers of digital devices.
Health Issues: Our analysis finds that students suffer from stress and anxiety problems. Moreover, online learning has increased the time students spend on digital devices, and that may impact on student’s health. This radical change in learning style affects the lifestyle and can lead to loneliness, anxiety, and depression. Some studies have revealed that students are suffering from stress and anxiety during this pandemic period [
40,
41].
Attitude and Ethical Issues: Another factor influencing students’ success is their motivation and discipline. A significant problem in distance education is the ability of student to devote to their learning. A percentage of 4.8% of tweets’ content is related to the motivation and discipline of students. Some students misunderstand the distance education; they deal with it as a vacation because they are at home through the learning process. This finding confirmed the results stated by [
9] that students did not absorb the importance of the lessons because of their perceptions and lack of face-to-face communication. A lack of control leads students not to take their tasks seriously [
42]. The issue of cheating is one of the most declared problems in online education during COVID-19. The most noted reason for cheating is the lack of proper monitoring systems. Teachers concerned about the risk of cheating feel that students might cheat to get better scores. Cheating in an online environment takes less effort compared to face-to-face [
43]. According to [
44], the perception of cheating of the majority of students is consistent with a sociologic perspective of deviance. Therefore, understanding students’ perception of cheating in online learning is important for institutions and developers to raise the level of honesty in the academic environments.
By comparing our finding with recent studies, we found that education issues were dominant among other issues. In particular, a lack of focus was noted as the most significant educational challenge. This result ties well with the finding by Hietanen et al. [
45] wherein the highest percentage of challenges for students was pedagogical challenges followed by technical challenges. In contrast, they found that the lack of personal contact was the highest pedagogical challenge which comes second in our finding. In addition, an agreement to our finding by [
27] reveals students found interactions through the class challenging, and it is easy to lose focus.
The most common technological issues found by our study are lack of tech equipment and poor internet connection, which are consistent with what has been found in [
9], in which the lack of infrastructure and unreliable internet connection are the largest challenges in technology. Furthermore, they showed that technological challenges are the main source of the problems that students meet in their distance education process. More interestingly, Ref. [
45] found that a lack of technological devices is not an issue because the technical infrastructure was already in place. However, using the technological tools was the most technical challenge, which disagrees with our finding. Another study by Abuhammad [
26] was broadly in line with our result that showed that the technical barriers was the most discussed theme in their data because of the insufficient maintenance and connectivity. In addition, we agree with Segbenya [
28], who suggested that students must acquire online devices to ensure the success of their learning experience. Such lack of tech devices could negatively impact on distance education.
A finding by Khalil et al. [
46] reveals that time organization was improved because online sessions save students’ time. In addition, the students found enough time to spend with their family and friends. Our finding is almost the opposite of that: a lack of time and social interaction with family and friends has a negative impact on students’ distance learning.
This study demonstrates that lack of motivation, stress, and anxiety are social issues that prevent students from pursuing their study effectively. Similar issues were obtained by Segbenya [
28]; they found that challenges for students during online lectures were motivation and fear of collaboration. Another study by Kari et al. [
27] supports our finding that students require more effort to stay motivated and have self-discipline.
Overall, most of the studies concluded that the most crucial issues among students were technological and education barriers. Additionally, a lack of face-to-face contact might cause more challenges such as lack of focus, lack of social interaction, and low motivation and well-being, which could also provoke a stressful situation.
The current findings offer a wide picture of the experience of students during their distance education. Students have increasingly become engaged in the improvement of their learning experience. Their feedback regarding the learning process has become an indicator of educational quality. The present materials in their social media content could provide insights in which educators can make improvements to the quality of the learning process. For example, conversations about lessons and material can give insight into how to interpret and develop the concepts of the lesson, which will impact on the quality of teaching and learning.
A large stream of Twitter posts that discuss sparsely events were annotated as ‘others’. In this category, some tweets do not have obvious meaning; also, some do not reflect students’ concerns. Since Twitter posts are considered as user-generated content, they follow the long-tail distribution [
47]. Therefore, a small number of tweets that exhibit major students’ problems have high occurrence, whereas the large numbers of tweets that exhibit insignificant problems have low occurrence. Investigation of this category can reveal insightful information.
Certain aspects of the work uncover some limitations in achieving the goal. Firstly, we found that most of tweets’ content include issues and problems; on the other hand, several tweets contain positive aspects. However, the focus of this study is on the problems because they could be the most revealing and insightful for improvement of the education process. Secondly, great numbers of tweets were classified as ‘Others’ due to their lack of sufficient description. There are a variety of other issues hidden in this category, but this study did not conduct further analysis into the content of it. Lastly, the study is an exploratory study to discover the main issues related to distance education. The classification was built based on label independency. In fact, we did not consider the correlation between the issues under classification. However, to gain a full understanding would be optimal to address the correlations among these problems.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
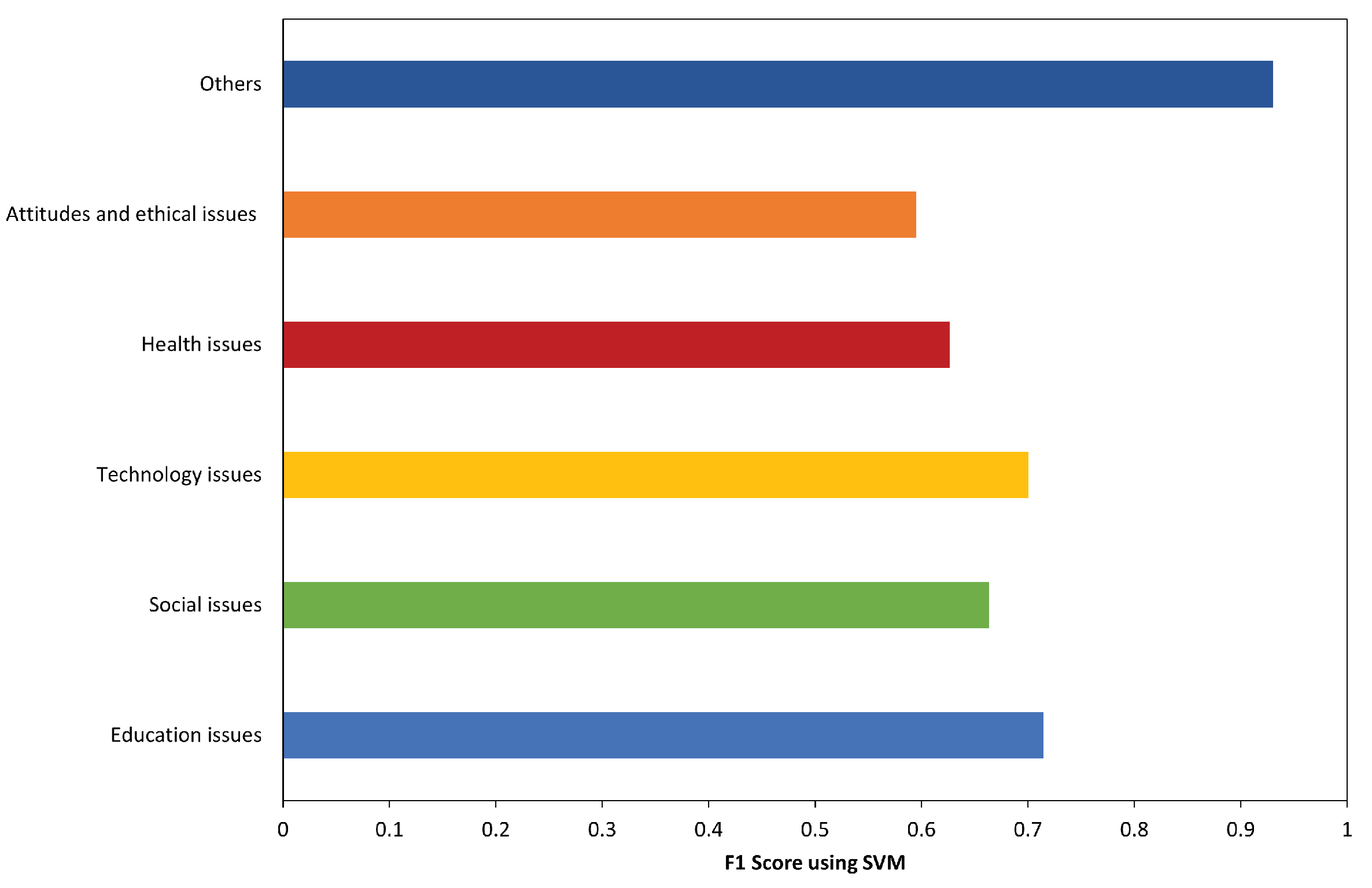{kind=link}
{kind=link}