
MeVer NetworkX: Network Analysis and Visualization for Tracing Disinformation

 , , , ,
, , , ,  and
and 
Abstract
:1. Introduction
2. Related Work
2.1. Data Collection and Analysis
2.2. Bot/Spammer Detection
2.3. Visualization Tools
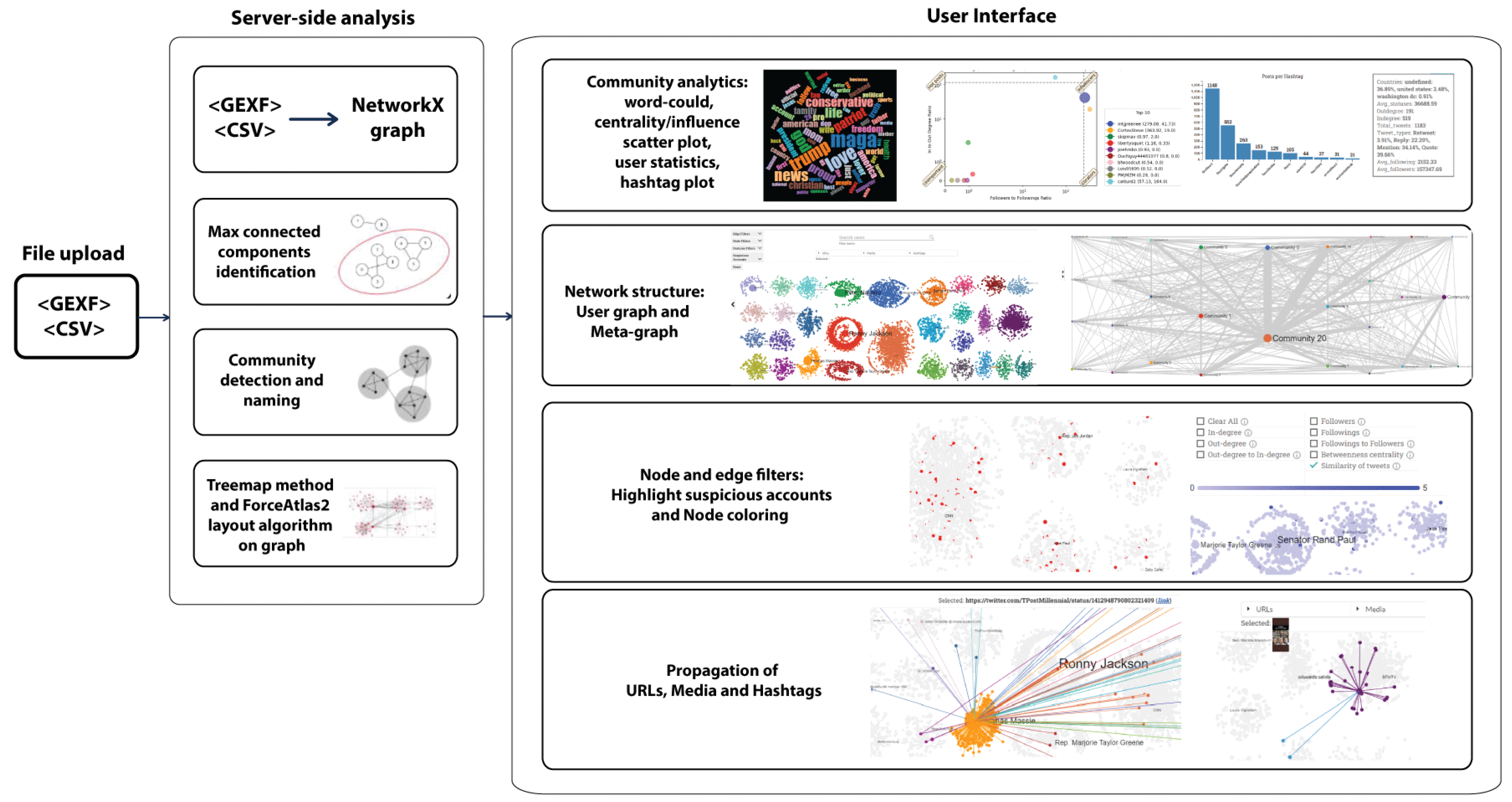
3. MeVer NetworkX Tool
3.1. Input Files
3.2. Features and Functionalities
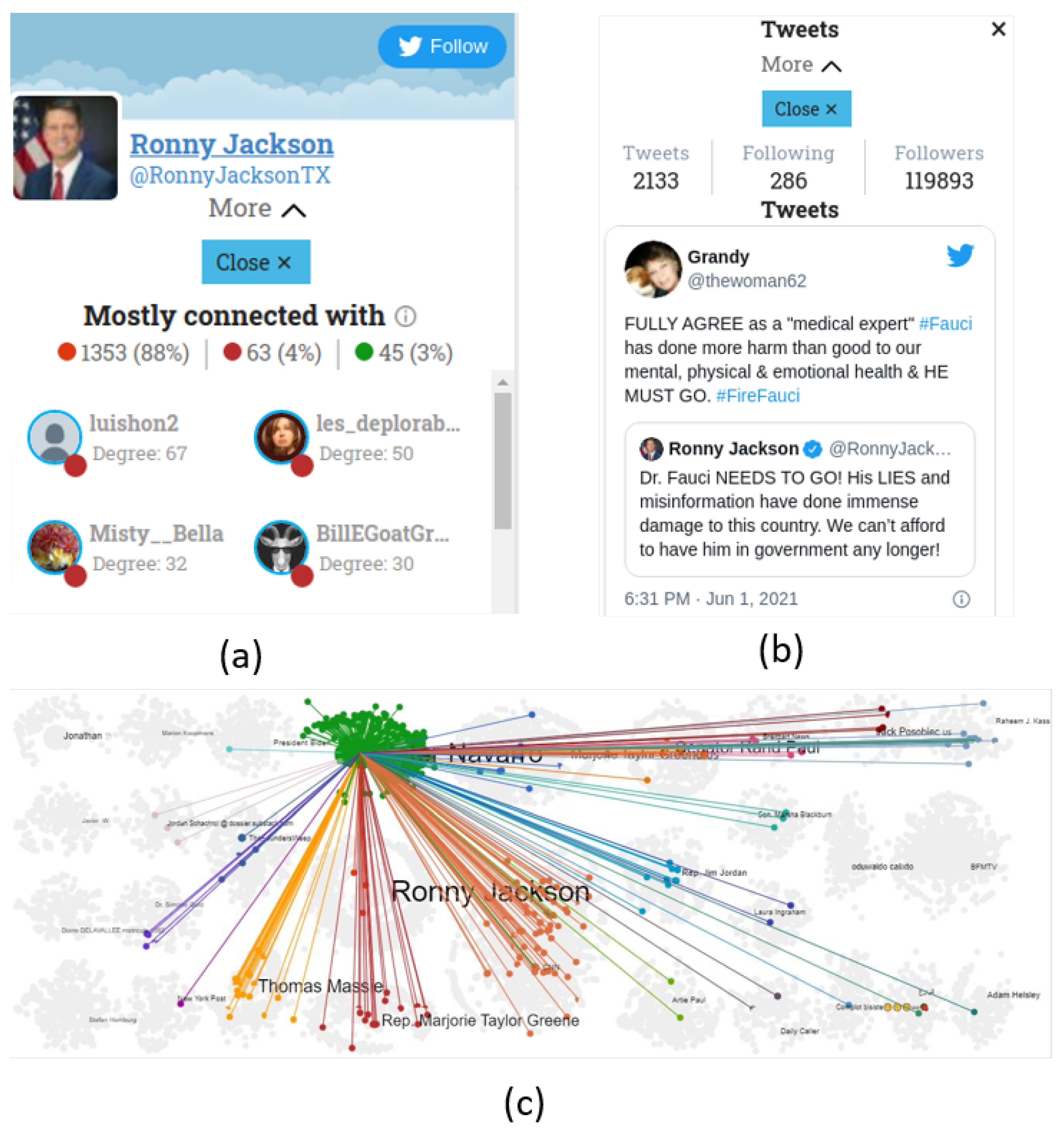
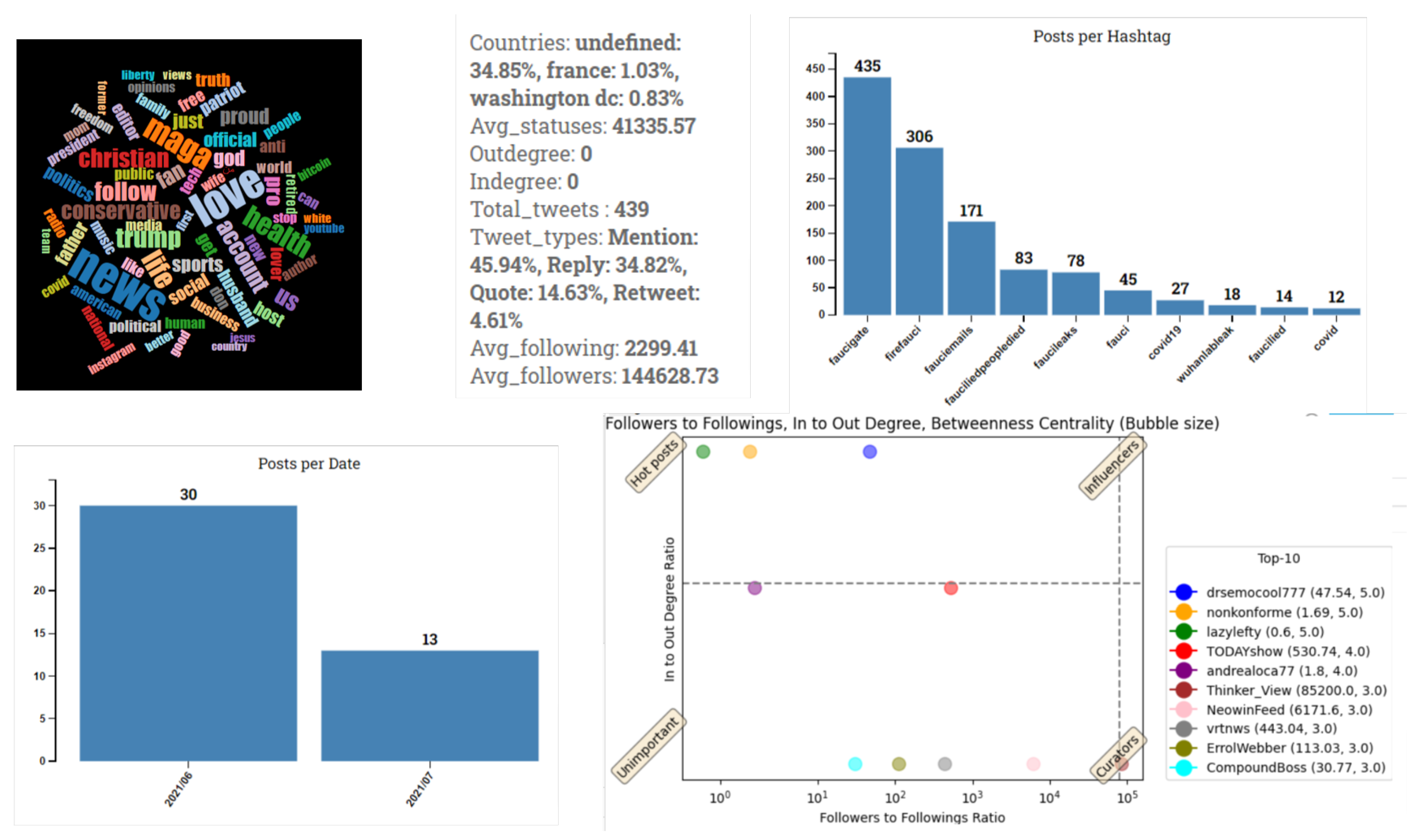
3.2.1. Individual Account and Post Inspections
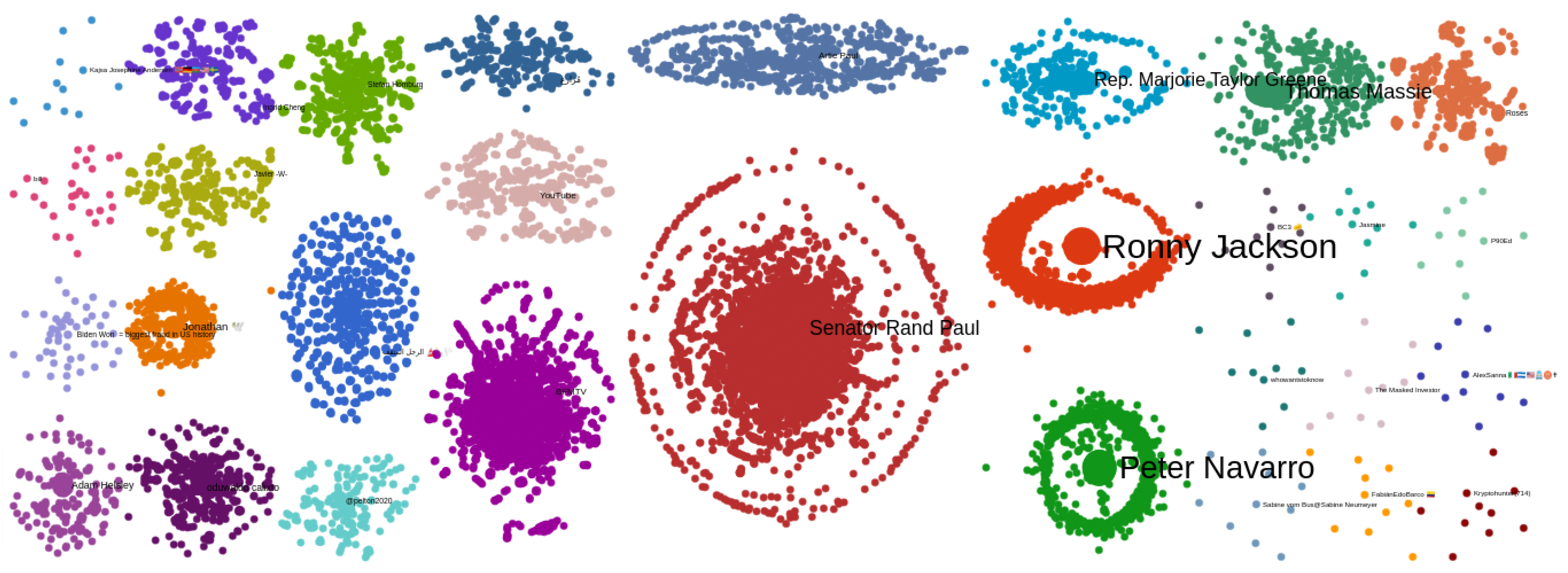
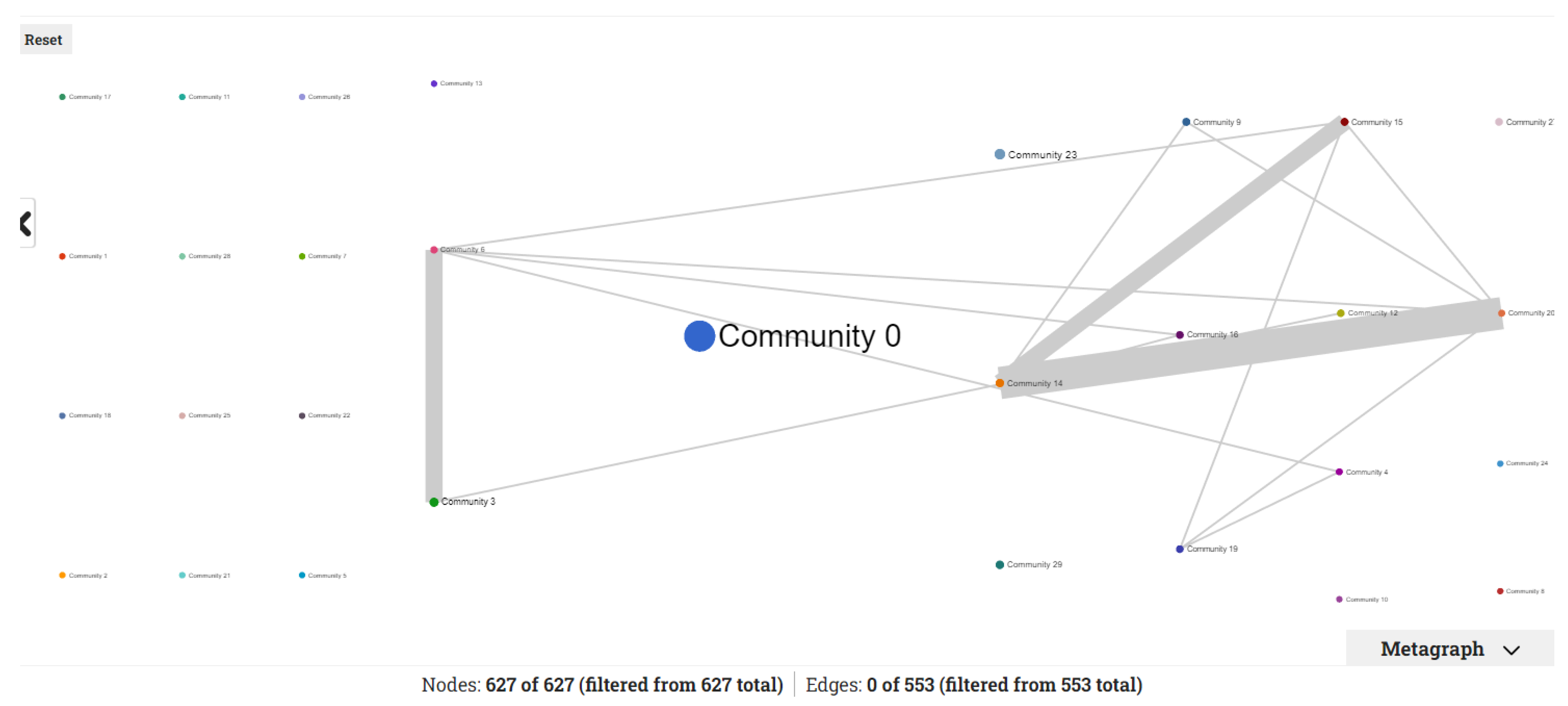
3.2.2. Community Detection
| Algorithm 1 Order communities. Largest community at the center of the graph. Communities with most interactions are closest. |
|
| Algorithm 2 Allocation of areas to communities based on the communities’ sizes. |
|
| Algorithm 3 Positioning of communities and nodes. |
|
3.2.3. Community Analytics
3.2.4. Propagation of URLs, Media, and Hashtags
3.2.5. Metagraph
3.2.6. Node and Edge Filters
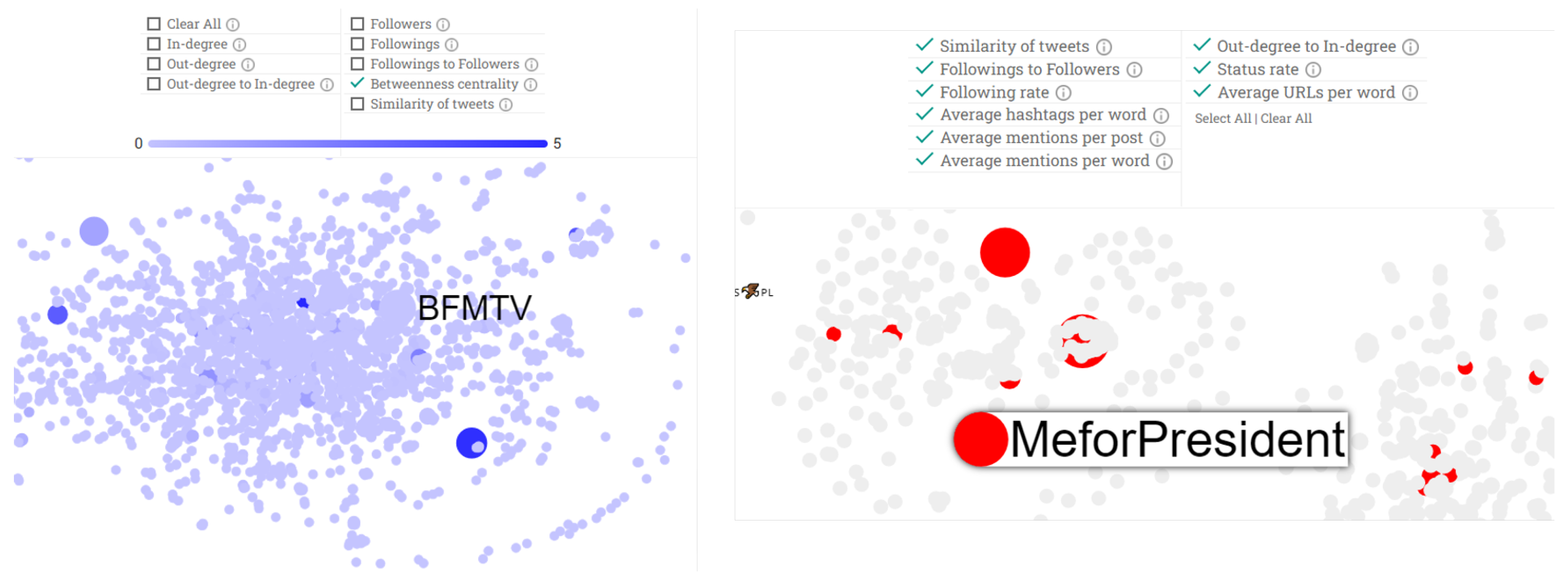
3.2.7. Node Coloring
- In-degree quantifies the popularities of nodes, i.e., how much a node is referenced/linked to by others.
- Out-degree shows the extroversion of nodes. A node that references many other nodes on its tweets has a high value in this feature.
- Out-degree to in-degree is the ratio of out- to in-degree. Accounts that regularly reference other nodes in their tweets and are rarely referenced by others have high values in this feature. Accounts that are both extroverted and popular have low values.
- Followers is the number of account followers.
- Followings is the number of accounts that the account follows.
- Followings to followers is the ratio of the number of followings to the number of followers. This feature quantifies how popular an account is (low value), how selective it is with its followings (low value), and how likely it is to follow back (high value).
- Betweenness centrality captures the role of a node in the spread of information across a network. Higher values indicate more important roles.
- Similarity of tweets shows how similar the posts of an account are. A node with a high value in this feature regularly posts similar content on its tweets.
3.2.8. Highlight Suspicious Accounts
- Following rate is the ratio of the number of followings to the number of days since an account was first created.
- Status rate is the ratio of the number of posts to the number of days since an account was created.
- Average mentions per post shows the average number of mentions in an account’s tweets. A common strategy for spreading disinformation is mentioning many accounts in tweets.
- Average mentions per word shows the average number of mentions in a tweet’s text. The tactic of posting tweets with many mentions and a single hashtag is often regarded as spam-like or suspicious. This feature is normalized to the total number of posts.
- Average hashtags per word calculates the average number of hashtags in a tweet’s text.
- Average URLs per word calculates the average number of URLs in a tweet’s text.
4. COVID-19-Related Use Cases
4.1. Twitter Data
4.2. Facebook Data
4.3. Telegram Data
4.4. Iterative Evaluation and Feedback
5. Analysis Using the MeVer NetworkX Analysis and Visualization Tool
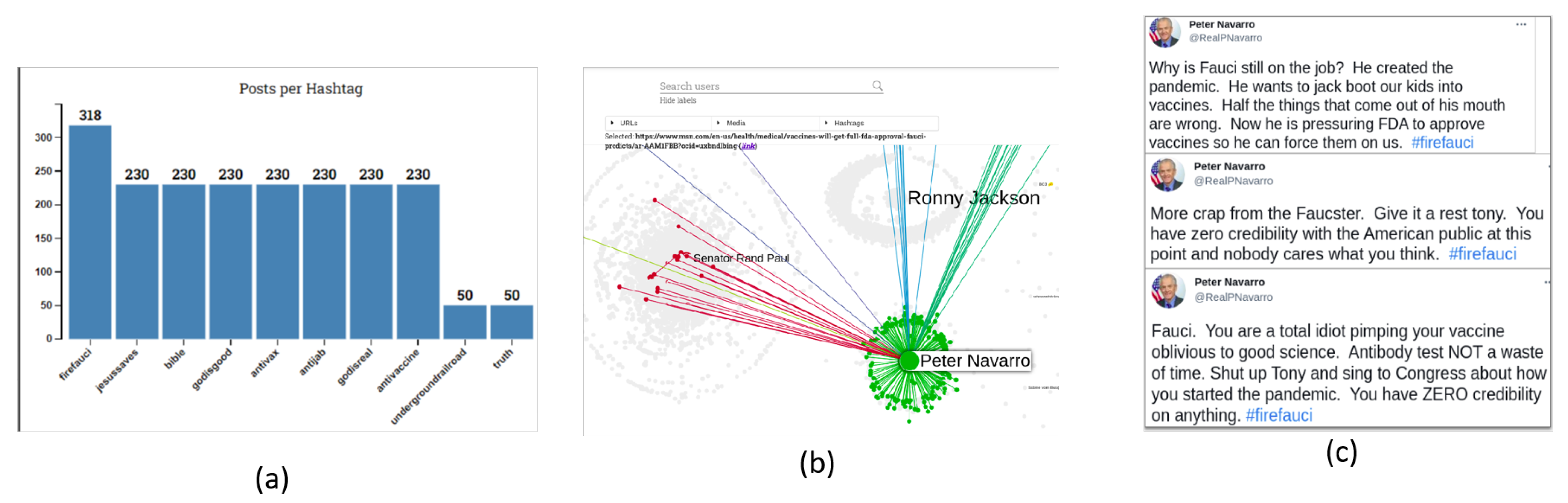
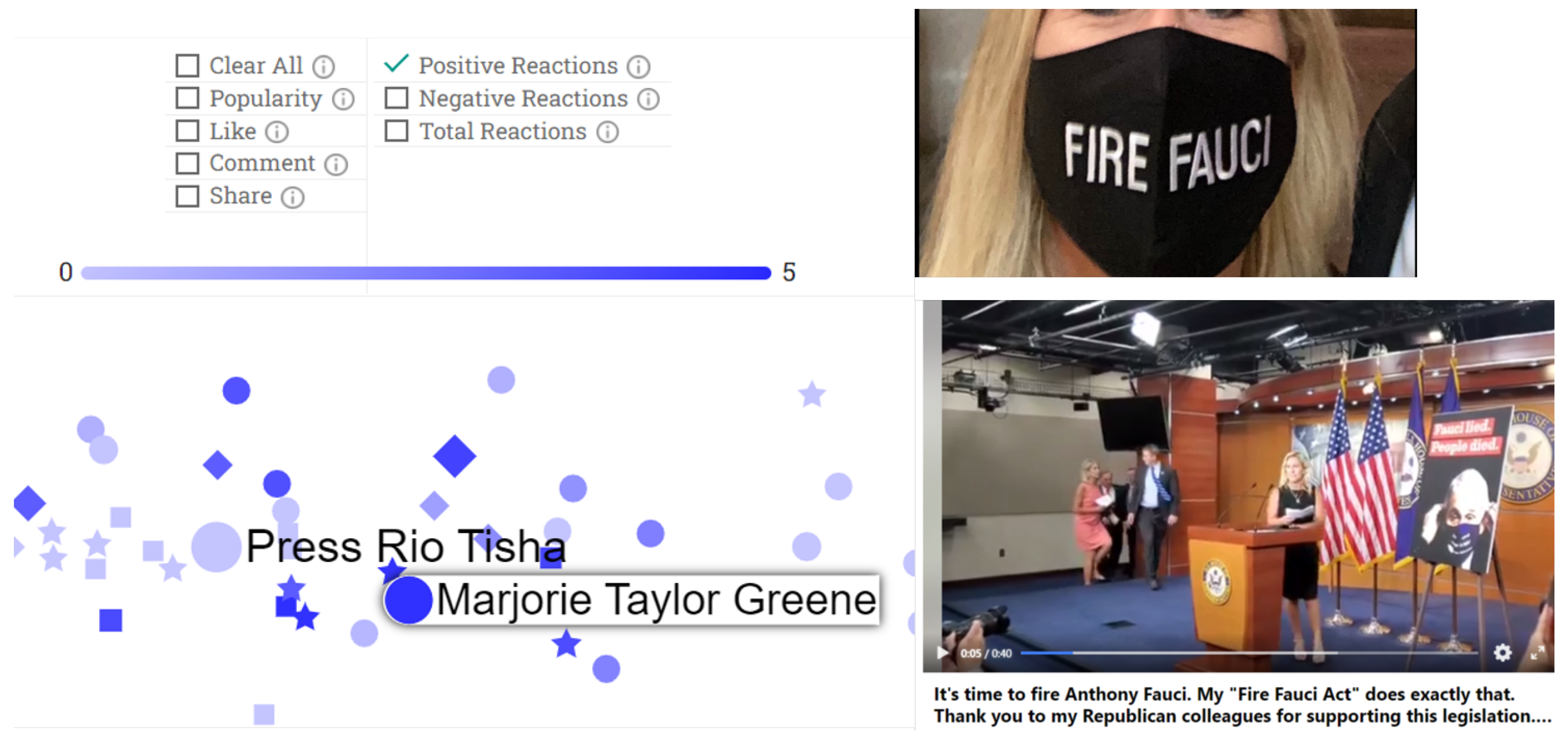
5.1. Fauci
5.1.1. Twitter Analysis
5.1.2. Facebook Analysis
5.1.3. Telegram Analysis
5.2. Hydroxychloroquine
5.3. Big Pharma Use Case
5.4. Great Reset Use Case
5.5. Quantitative Analysis of Suspicious Users
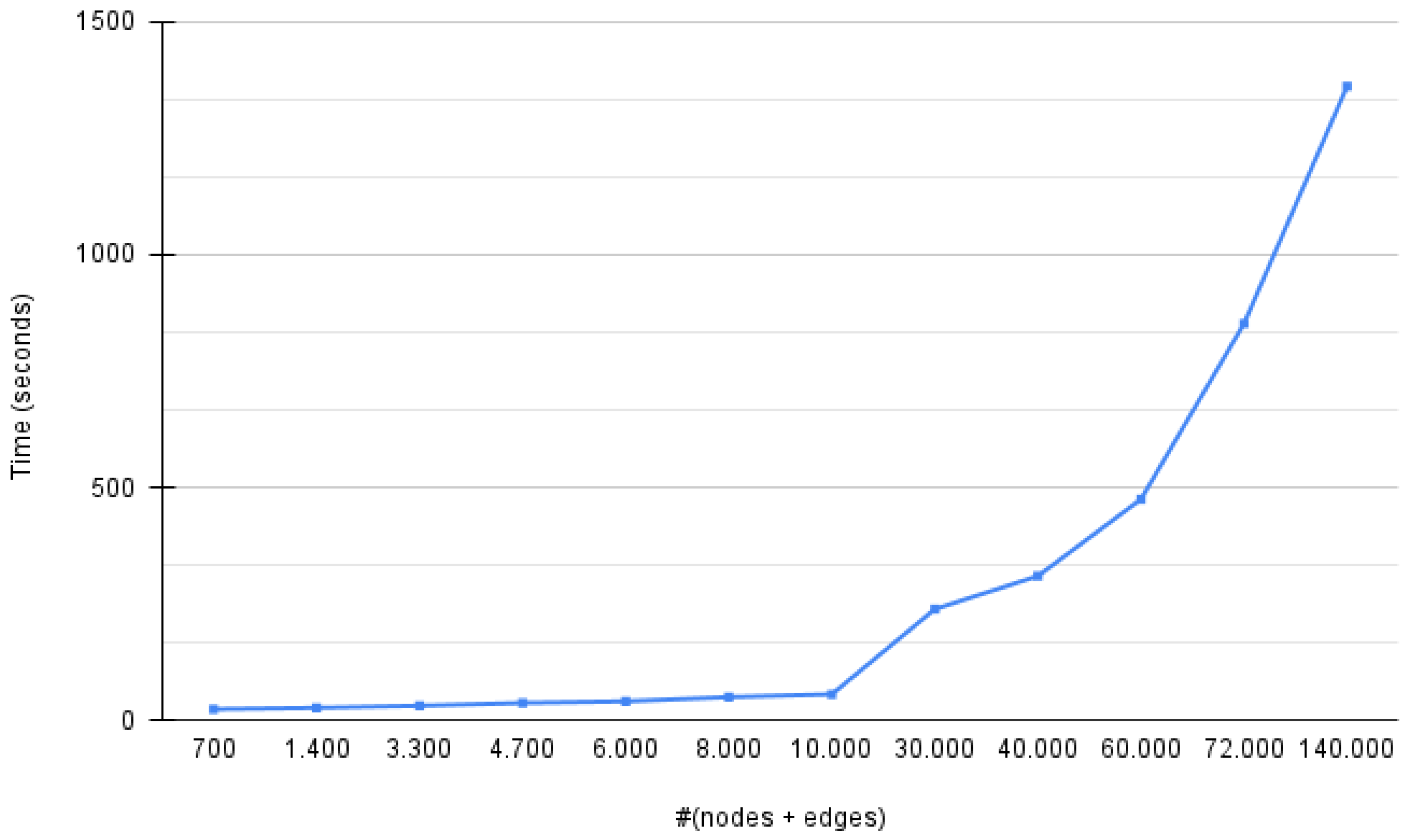
6. Execution Time
7. Comparison with Gephi and Hoaxy
8. Discussion and Future Steps
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Posetti, J. News industry transformation: Digital technology, social platforms and the spread of misinformation and disinformation. In Journalism,‘Fake News’ and Disinformation: A Handbook for Journalism Education and Training; UNESCO: Paris, France, 2018; Available online: https://bit.ly/2XLRRlA (accessed on 8 April 2022).
- Vosoughi, S.; Roy, D.; Aral, S. The spread of true and false news online. Science 2018, 359, 1146–1151. [Google Scholar] [CrossRef] [PubMed]
- Meserole, C. How Misinformation Spreads on Social Media—And What to Do about It; The Brookings Institution: Washington, DC, USA, 2018; Available online: https://www.brookings.edu/blog/order-from-chaos/2018/05/09/how-misinformation-spreads-on-social-media-and-what-to-do-about-it (accessed on 8 April 2022).
- Himelein-Wachowiak, M.; Giorgi, S.; Devoto, A.; Rahman, M.; Ungar, L.; Schwartz, H.A.; Epstein, D.H.; Leggio, L.; Curtis, B. Bots and Misinformation Spread on Social Media: Implications for COVID-19. J. Med. Internet Res. 2021, 23, e26933. [Google Scholar] [CrossRef] [PubMed]
- Shao, C.; Ciampaglia, G.L.; Varol, O.; Yang, K.C.; Flammini, A.; Menczer, F. The spread of low-credibility content by social bots. Nat. Commun. 2018, 9, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Erik Borra, B.R. Programmed method: Developing a toolset for capturing and analyzing tweets. Aslib J. Inf. Manag. 2014, 66, 262–278. [Google Scholar] [CrossRef]
- Marinova, Z.; Spangenberg, J.; Teyssou, D.; Papadopoulos, S.; Sarris, N.; Alaphilippe, A.; Bontcheva, K. Weverify: Wider and enhanced verification for you project overview and tools. In Proceedings of the 2020 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), London, UK, 6–10 July 2020; pp. 1–4. [Google Scholar]
- Teyssou, D.; Leung, J.M.; Apostolidis, E.; Apostolidis, K.; Papadopoulos, S.; Zampoglou, M.; Papadopoulou, O.; Mezaris, V. The InVID plug-in: Web video verification on the browser. In Proceedings of the First International Workshop on Multimedia Verification, Mountain View, CA, USA, 27 October 2017; pp. 23–30. [Google Scholar]
- Peeters, S.; Hagen, S. The 4CAT capture and analysis toolkit: A modular tool for transparent and traceable social media research. SSRN 2021, 3914892. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3914892 (accessed on 8 April 2022). [CrossRef]
- Wang, B.; Zubiaga, A.; Liakata, M.; Procter, R. Making the Most of Tweet-Inherent Features for Social Spam Detection on Twitter. arXiv 2015, arXiv:1503.07405. [Google Scholar]
- ElAzab, A. Fake Account Detection in Twitter Based on Minimum Weighted Feature set. World Acad. Sci. Eng. Technol. Int. J. Comput. Inf. Eng. 2016, 10, 13–18. [Google Scholar]
- Mateen, M.; Iqbal, M.A.; Aleem, M.; Islam, M.A. A hybrid approach for spam detection for Twitter. In Proceedings of the 2017 14th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 10–14 January 2017. [Google Scholar] [CrossRef]
- Yang, C.; Harkreader, R.; Gu, G. Empirical Evaluation and New Design for Fighting Evolving Twitter Spammers. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1280–1293. [Google Scholar] [CrossRef]
- Rodríguez-Ruiz, J.; Mata-Sánchez, J.I.; Monroy, R.; Loyola-González, O.; López-Cuevas, A. A one-class classification approach for bot detection on Twitter. Comput. Secur. 2020, 91, 101715. [Google Scholar] [CrossRef]
- Zhang, Z.; Hou, R.; Yang, J. Detection of Social Network Spam Based on Improved Extreme Learning Machine. IEEE Access 2020, 8, 112003–112014. [Google Scholar] [CrossRef]
- Alom, Z.; Carminati, B.; Ferrari, E. Detecting Spam Accounts on Twitter. In Proceedings of the 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Barcelona, Spain, 28–31 August 2018. [Google Scholar] [CrossRef]
- Keller, F.B.; Schoch, D.; Stier, S.; Yang, J. Political Astroturfing on Twitter: How to Coordinate a Disinformation Campaign. Political Commun. 2019, 37, 256–280. [Google Scholar] [CrossRef]
- El-Mawass, N.; Honeine, P.; Vercouter, L. SimilCatch: Enhanced social spammers detection on Twitter using Markov Random Fields. Inf. Process. Manag. 2020, 57, 102317. [Google Scholar] [CrossRef]
- Masood, F.; Almogren, A.; Abbas, A.; Khattak, H.A.; Din, I.U.; Guizani, M.; Zuair, M. Spammer Detection and Fake User Identification on Social Networks. IEEE Access 2019, 7, 68140–68152. [Google Scholar] [CrossRef]
- Hansen, D.; Shneiderman, B.; Smith, M.A. Analyzing Social Media Networks with NodeXL: Insights from a Connected World; Morgan Kaufmann: Burlington, MA, USA, 2010. [Google Scholar]
- Pournaki, A.; Gaisbauer, F.; Banisch, S.; Olbrich, E. The twitter explorer: A framework for observing Twitter through interactive networks. Digit. Soc. Res. 2021, 3, 106–118. [Google Scholar] [CrossRef]
- Karmakharm, T.; Aletras, N.; Bontcheva, K. Journalist-in-the-loop: Continuous learning as a service for rumour analysis. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP): System Demonstrations, Hong Kong, China, 3–7 November 2019; pp. 115–120. [Google Scholar]
- Bevensee, E.; Aliapoulios, M.; Dougherty, Q.; Baumgartner, J.; Mccoy, D.; Blackburn, J. SMAT: The social media analysis toolkit. In Proceedings of the 14th International AAAI Conference on Web and Social Media, Atlanta, GA, USA, 8–11 June 2020; Volume 14. [Google Scholar]
- Hui, P.M.; Yang, K.C.; Torres-Lugo, C.; Monroe, Z.; McCarty, M.; Serrette, B.D.; Pentchev, V.; Menczer, F. Botslayer: Real-time detection of bot amplification on twitter. J. Open Source Softw. 2019, 4, 1706. [Google Scholar] [CrossRef]
- Liu, X.; Li, Q.; Nourbakhsh, A.; Fang, R.; Thomas, M.; Anderson, K.; Kociuba, R.; Vedder, M.; Pomerville, S.; Wudali, R.; et al. Reuters tracer: A large scale system of detecting & verifying real-time news events from twitter. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 207–216. [Google Scholar]
- Ram, R.; Kong, Q.; Rizoiu, M.A. Birdspotter: A Tool for Analyzing and Labeling Twitter Users. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Virtual Event, 8–12 March 2021; pp. 918–921. [Google Scholar]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef] [Green Version]
- Bruls, M.; Huizing, K.; Van Wijk, J.J. Squarified treemaps. In Data visualization 2000; Springer: Berlin/Heidelberg, Germany, 2000; pp. 33–42. [Google Scholar]
- Jacomy, M.; Venturini, T.; Heymann, S.; Bastian, M. ForceAtlas2, a continuous graph layout algorithm for handy network visualization designed for the Gephi software. PLoS ONE 2014, 9, e98679. [Google Scholar] [CrossRef] [PubMed]
- Majeed, S.; Uzair, M.; Qamar, U.; Farooq, A. Social Network Analysis Visualization Tools: A Comparative Review. In Proceedings of the 2020 IEEE 23rd International Multitopic Conference (INMIC), Bahawalpur, Pakistan, 5–7 November 2020; pp. 1–6. [Google Scholar]
- Pavlopoulos, G.A.; Paez-Espino, D.; Kyrpides, N.C.; Iliopoulos, I. Empirical comparison of visualization tools for larger-scale network analysis. Adv. Bioinform. 2017, 2017, 1278932. [Google Scholar] [CrossRef] [PubMed] [Green Version]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | Description | Type |
|---|---|---|
| Node ID * | Unique ID | Node |
| Type of node | Set to true if the node is a user node | Node |
| Tweet ID | Unique tweet ID | Node |
| Screen name | Screen name, handle, or alias that a user identifies themselves as; screen_names are unique but subject to change. | Node |
| Created at | UTC time when this tweet was created. Example: | Node |
| User description | User-defined UTF-8 string describing their account. | Node |
| Names | Name of the user as they have defined it in Twitter. | Node |
| Number of followers | Number of followers this account currently has | Node |
| Location | User-defined location for this account’s profile. | Node |
| Number of accounts following | Number of users this account is following | Node |
| Verified | When true, indicates that the user has a verified account. | Node |
| Number of statuses | Number of tweets (including retweets) issued by the user. | Node |
| Profile image | HTTPS-based URL pointing to the user’s profile image. | Node |
| Background image | HTTPS-based URL pointing to the standard Web representation of the user’s uploaded profile banner. | Node |
| Edge ID | Unique ID | Edge |
| Source * | Node that the edge starts at | Edge |
| Target * | Node that the edge points to | Edge |
| Tweet ID | Unique tweet ID | Edge |
| Retweet | Whether the edge is a retweet | Edge |
| Reply | Whether the edge is a reply | Edge |
| Mention | Whether the edge is a mention | Edge |
| Quote | Whether the edge is a quote | Edge |
| Created at | UTC time when this tweet was created. | Edge |
| Number of retweets | Number of times this tweet has been retweeted. | Edge |
| Number of favorites | Approximately how many times this tweet has been liked by Twitter users. | Edge |
| Text | Actual UTF-8 text of the status update. | Edge |
| Hashtags | Hashtags that have been parsed out of the tweet text. | Edge |
| URLs | URLs included in the text of a tweet. | Edge |
| Media | Media elements uploaded with the tweet. | Edge |
| Attribute | Description | Type |
|---|---|---|
| Page/group name | Name of the page/group that posted | Node |
| User name | Username of the page/group | Node |
| Facebook ID * | ID of the page/group | Node |
| Likes at posting | Number of likes of the page/group at the time of posting | Node |
| Followers at posting | Number of page/group followers at the time of posting | Node |
| Type | Types of links (articles, photos, and videos) included in the post | Node |
| Resource * | Link included in the post | Node/edge |
| Total interactions | Total number of all reactions (likes, shares, etc.) | Edge |
| Message | Message written in the post | Edge |
| Created | Time the post was published | Edge |
| Likes | Number of likes on the post | Edge |
| Comments | Number of comments on the post | Edge |
| Shares | Number of shares of the post | Edge |
| Love | Number of love reactions on the post | Edge |
| Wow | Number of wow reactions on the post | Edge |
| Haha | Number of haha reactions on the post | Edge |
| Sad | Number of sad reactions on the post | Edge |
| Angry | Number of angry reactions on the post | Edge |
| Care | Number of care reactions on the post | Edge |
| Attribute | Description | Type |
|---|---|---|
| ID | Unique identifier of the message within the channel | Edge |
| Message link | URL to the message in the object | Edge |
| Hashtags | Hashtags included in the message | Node/edge |
| Links | Links included in the message | Node/edge |
| Timestamp | The time at which the message was sent | Edge |
| Message | Text of message | Edge |
| Author’s signature * | First and last name of the author of the message | Edge |
| Views | Number of times a message was viewed | Edge |
| Features/Functionalities | Telegram | ||
|---|---|---|---|
| Communities | ✓ | ✓ | ✓ |
| Individual account inspections | ✓ | ✓ | ✓ |
| Post text | ✓ | ✗ | ✗ |
| Statistics per community | ✓ | ✓ | ✗ |
| Word clouds per community | ✓ | ✓ | ✓ |
| Centrality plots per community | ✓ | ✗ | ✗ |
| Date plots per community | ✓ | ✓ | ✓ |
| Hashtag plots per community | ✓ | ✗ | ✓ |
| Heatmaps of reactions per community | ✗ | ✓ | ✗ |
| Propagation flow of top 10 URLs | ✓ | ✓ | ✓ |
| Propagation flow of top 10 media | ✓ | ✓ | ✓ |
| Propagation flow of top 10 hashtags | ✓ | ✗ | ✓ |
| Metagraphs | ✓ | ✓ | ✓ |
| Edge Filters | ✓ | ✗ | ✗ |
| Node Filters | ✓ | ✓ | ✓ |
| Node coloring | ✓ | ✓ | ✓ |
| Suspicious accounts | ✓ | ✗ | ✗ |
| Fauci | Hydroxychloroquine | Big Pharma | Great Reset | |
|---|---|---|---|---|
| Total tweets | 18,500 | 6239 | 16,568 | 13,380 |
| Retweets | 4790 | 3597 | 9667 | 6780 |
| Quotes | 7787 | 1114 | 2281 | 2615 |
| Tweets with replies | 4696 | 1046 | 3579 | 3037 |
| Tweets with mentions | 4926 | 2439 | 5609 | 4884 |
| User-posted tweets | 11,155 | 4310 | 10,474 | 8175 |
| Total users in tweets | 18,310 | 7078 | 18,175 | 14,716 |
| Fauci | Hydroxychloroquine | |
|---|---|---|
| FB posts | 553 | 1572 |
| FB groups/pages | 352 | 984 |
| Articles | 95 | 504 |
| Photos | 109 | 264 |
| Videos | 71 | 53 |
| FireFauci | FauciGate | Hydroxychloroquine | |
|---|---|---|---|
| Subscribers | 326,586 | 6488 | 186,236 |
| Messages | 14,762 | 181,700 | 13,422 |
| URLs | 6453 | 83,993 | 10,032 |
| Hashtags | 871 | 18,653 | 106 |
| “Jesus heals the sick when men had leprosy, the worst diseases back then and people were afraid to be around them. Don’t take Covid Vaccine because JESUS IS A HEALER. Repent and confess to Jesus. #AntiVax #AntiVaccine #AntiJab #GodIsReal #FireFauci #Bible #GodisGood #JesusSaves” | “Praise God! YES Jesus heals the sick and did so when men had leprosy and people were afraid to be around them. That’s why Christians shouldn’t take Covid Vaccine because our GOD IS A HEALER. #AntiVax #AntiVaccine #AntiJab #GodIsReal #FireFauci #Bible #GodisGood #JesusSaves #God” |
| Suspicious Account Features | Fauci | Hydro | Big Pharma | Great Reset |
|---|---|---|---|---|
| Out-degree to in-degree | 62 | 3 | 18 | 10 |
| Followings to followers | 28 | 7 | 18 | 13 |
| Following rate | 27 | 14 | 33 | 35 |
| Status rate | 19 | 6 | 16 | 16 |
| Average mentions per post | 143 | 0 | 61 | 110 |
| Average mentions per word | 8 | 0 | 50 | 0 |
| Average hashtags per word | 18 | 37 | 1 | 4 |
| Average URLs per word | 57 | 9 | 11 | 11 |
| Cosine similarity of tweets | 122 | 44 | 62 | 50 |
| Fauci | Hydro | Big Pharma | Great Reset | |
|---|---|---|---|---|
| All users | 18,310 | 7078 | 18,175 | 14,716 |
| Nonexistent | 1529 | 477 | 1261 | 1187 |
| Suspended | 868 | 257 | 653 | 610 |
| Suspicious | 425 | 110 | 220 | 231 |
| Percentage of suspicious users in relation to all users | 2.3% | 1.6% | 1.2% | 1.6% |
| Percentage of suspicious users not available on Twitter | 10.1% | 13.6% | 8.6% | 12.5% |
| Percentage of suspicious users not available on Twitter due to being suspended | 6.1% | 6.4% | 5.5% | 5.6% |
| Users with bot scores (not available for unavailable users) | 16,635 | 6548 | 16,755 | 13,396 |
| Percentage of users with bot scores ≥ 4 | 10.7% | 6.8% | 7.0% | 7.12% |
| Percentage of users with 4 >bot scores ≥ 3 | 13.9% | 21.2% | 19.3% | 16.1% |
| Fauci | Hydro | Big Pharma | Great Reset | |
|---|---|---|---|---|
| Hoaxy (time in s) | 240 | 105 | 230 | 185 |
| MeVer (time in s) | 355 | 139 | 349 | 261 |
| Feature | MeVer Tool | Hoaxy | Feature | MeVer Tool | Hoaxy |
|---|---|---|---|---|---|
| Community detection | + | − | Centrality/influence scatter plots | + | − |
| Individual user inspections | + | + | Propagation flows of URLs | + | + |
| Tweet texts | Embedded | External links | Propagation flows of media | + | − |
| Word clouds | + | − | Propagation flows of hashtags | + | − |
| Statistics for each community | + | − | Metagraphs | + | − |
| Hashtag plots | + | − | Tweet timelines | + | + |
| Date plots | + | − | Highlight of suspicious accounts | + | − |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Papadopoulou , O.; Makedas , T.; Apostolidis , L.; Poldi , F.; Papadopoulos, S.; Kompatsiaris , I. MeVer NetworkX: Network Analysis and Visualization for Tracing Disinformation. Future Internet 2022, 14, 147. https://doi.org/10.3390/fi14050147
Papadopoulou O, Makedas T, Apostolidis L, Poldi F, Papadopoulos S, Kompatsiaris I. MeVer NetworkX: Network Analysis and Visualization for Tracing Disinformation. Future Internet. 2022; 14(5):147. https://doi.org/10.3390/fi14050147
Chicago/Turabian StylePapadopoulou , Olga, Themistoklis Makedas , Lazaros Apostolidis , Francesco Poldi , Symeon Papadopoulos, and Ioannis Kompatsiaris . 2022. "MeVer NetworkX: Network Analysis and Visualization for Tracing Disinformation" Future Internet 14, no. 5: 147. https://doi.org/10.3390/fi14050147
APA StylePapadopoulou , O., Makedas , T., Apostolidis , L., Poldi , F., Papadopoulos, S., & Kompatsiaris , I. (2022). MeVer NetworkX: Network Analysis and Visualization for Tracing Disinformation. Future Internet, 14(5), 147. https://doi.org/10.3390/fi14050147