
Fast Library Recommendation in Software Dependency Graphs with Symmetric Partially Absorbing Random Walks



Abstract
:1. Introduction
2. Background and Related Work
2.1. Library Recommendation
2.2. Graph Signal Processing
2.3. Graph Neural Networks for Link Prediction
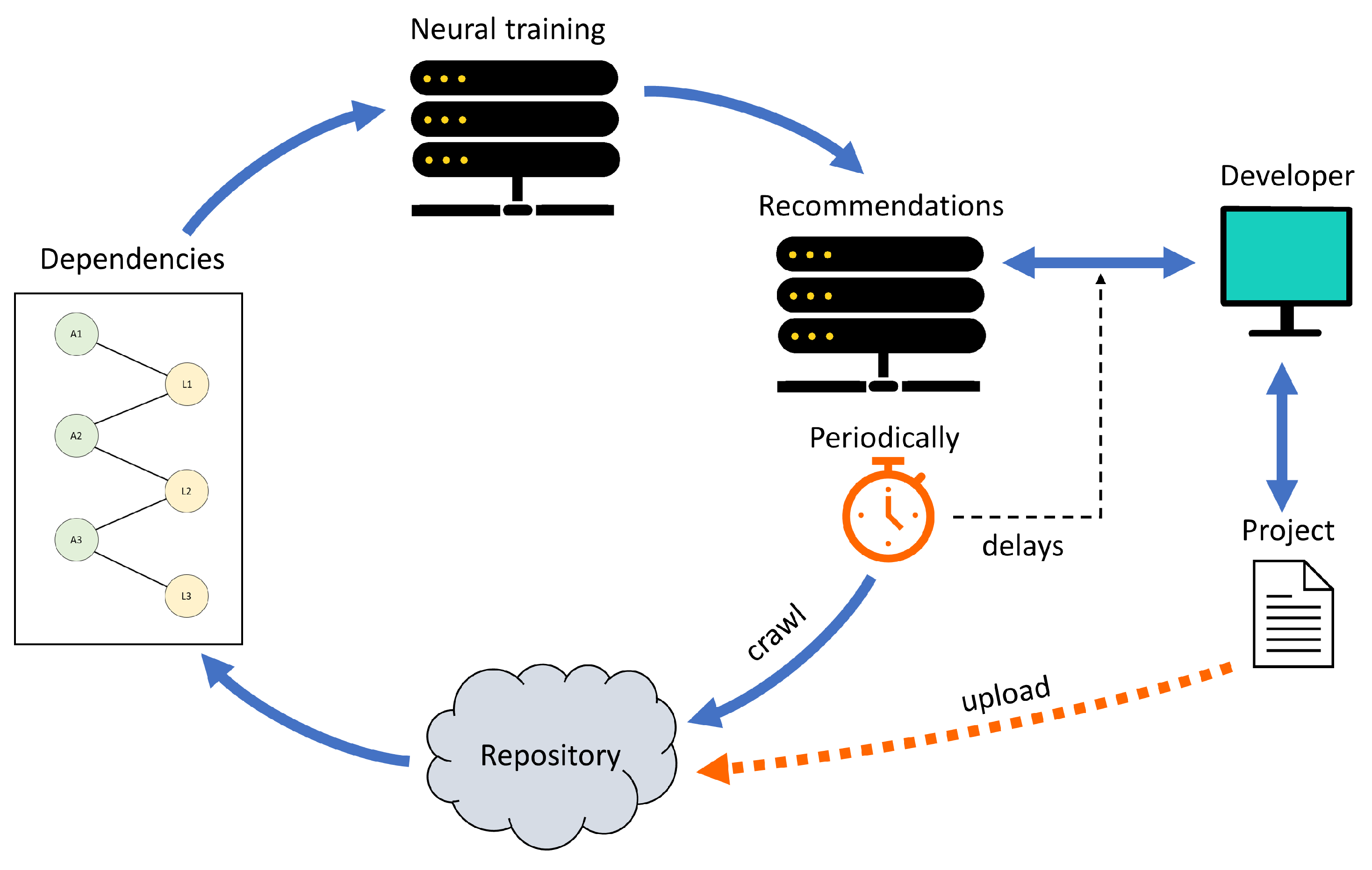
3. Deploying Library Recommendation Services
3.1. Deploying Representation Learning for Library Recommendations
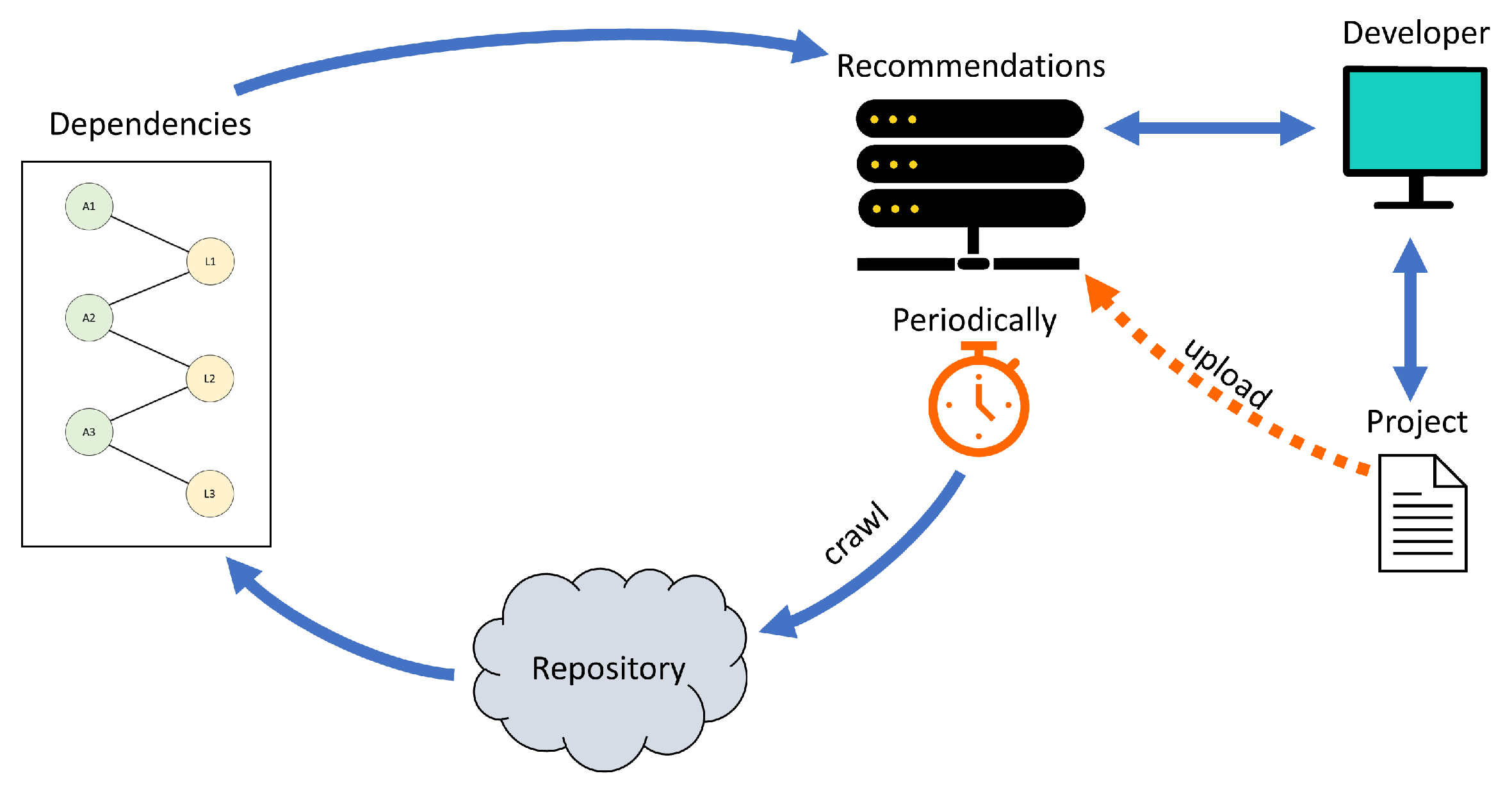
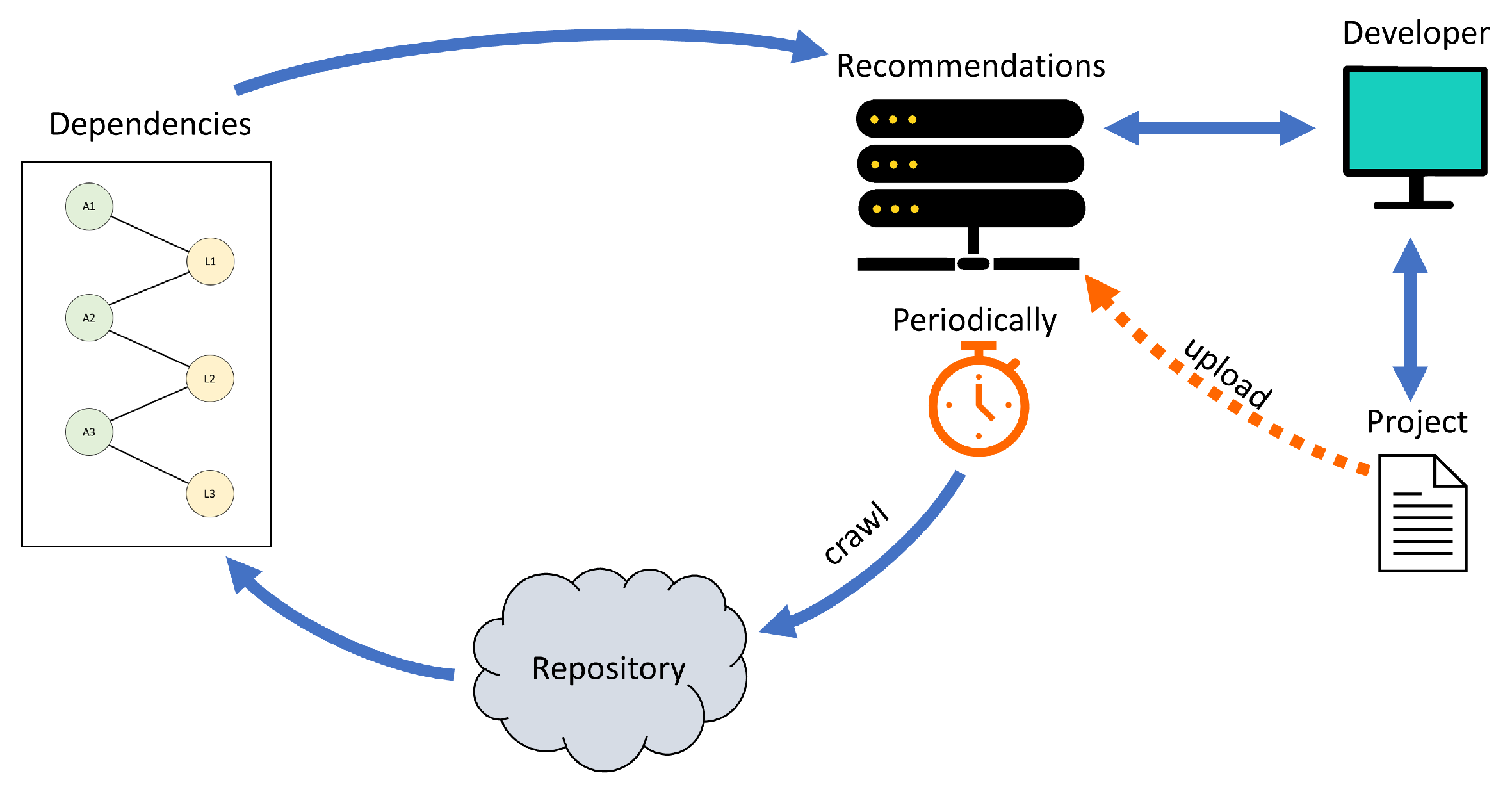
3.2. Deploying No-Learning Library Recommendations
4. Graph Filters for Library Recommendations
4.1. Revisiting Graph Filters for Collaborative Library Recommendations
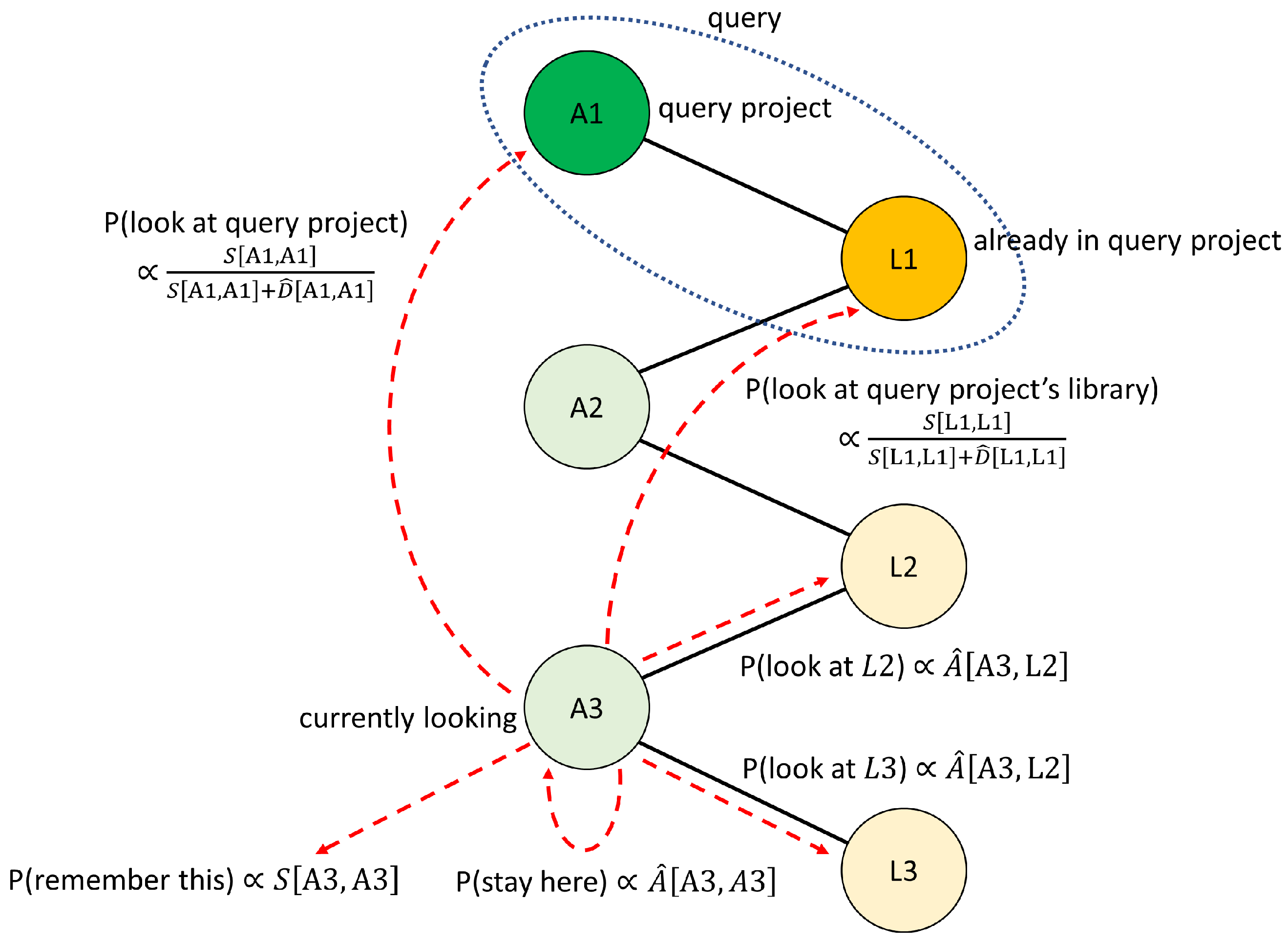
4.2. Low-Pass Filters with Memory to Emulate Human-Driven Library Search
4.3. Symmetric Absorbing Random Walks
5. Experiments
5.1. Experiment Setting
5.2. Compared Approaches
5.3. Results
6. Discussion
6.1. Qualitative Approach Comparison
6.2. Library Popularity and Memorability
6.3. Threats to Validity
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Cov | Coverage |
| MAP | Mean Average Precision |
| MF1 | Mean F1 Score |
| MP | Mean Precision |
| MR | Mean Recall |
| GNN | Graph Neural Network |
| GPU | Graphics Processing Unit |
References
- Nerur, S.; Balijepally, V. Theoretical reflections on agile development methodologies. Commun. ACM 2007, 50, 79–83. [Google Scholar] [CrossRef]
- Miller, F.P.; Vandome, A.F.; McBrewster, J. Apache Maven; Alpha Press: Indianapolis, IN, USA, 2010. [Google Scholar]
- Python Package Index—PyPI. Python Software Foundation. Available online: https://pypi.org (accessed on 2 March 2022).
- npm. npm, Inc. Available online: https://www.npmjs.com (accessed on 2 March 2022).
- Raemaekers, S.; Van Deursen, A.; Visser, J. The maven repository dataset of metrics, changes, and dependencies. In Proceedings of the 2013 10th Working Conference on Mining Software Repositories (MSR), San Francisco, CA, USA, 18–19 May 2013; IEEE Computer Society: Washington, DC, USA, 2013; pp. 221–224. [Google Scholar]
- Li, Z.; Avgeriou, P.; Liang, P. A systematic mapping study on technical debt and its management. J. Syst. Softw. 2015, 101, 193–220. [Google Scholar] [CrossRef]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 May 2017; pp. 173–182. [Google Scholar]
- Barbosa, E.A.; Garcia, A. Global-aware recommendations for repairing violations in exception handling. IEEE Trans. Softw. Eng. 2017, 44, 855–873. [Google Scholar] [CrossRef]
- Huang, Q.; Xia, X.; Xing, Z.; Lo, D.; Wang, X. API method recommendation without worrying about the task-API knowledge gap. In Proceedings of the 2018 33rd IEEE/ACM International Conference on Automated Software Engineering (ASE), Montpellier, France, 3–7 September 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 293–304. [Google Scholar]
- Ichii, M.; Hayase, Y.; Yokomori, R.; Yamamoto, T.; Inoue, K. Software component recommendation using collaborative filtering. In Proceedings of the 2009 ICSE Workshop on Search-Driven Development-Users, Infrastructure, Tools and Evaluation, Vancouver, BC, Canada, 16 May 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 17–20. [Google Scholar]
- Thung, F.; Lo, D.; Lawall, J. Automated library recommendation. In Proceedings of the 2013 20th Working conference on reverse engineering (WCRE), Koblenz, Germany, 14–17 October 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 182–191. [Google Scholar]
- Ouni, A.; Kula, R.G.; Kessentini, M.; Ishio, T.; German, D.M.; Inoue, K. Search-based Software Library Recommendation using multi-objective optimization. Inf. Softw. Technol. 2017, 83, 55–75. [Google Scholar] [CrossRef]
- Su, X.; Khoshgoftaar, T.M. A survey of collaborative filtering techniques. Adv. Artif. Intell. 2009, 2009, 421425. [Google Scholar] [CrossRef]
- He, Q.; Li, B.; Chen, F.; Grundy, J.; Xia, X.; Yang, Y. Diversified third-party library prediction for mobile app development. IEEE Trans. Softw. Eng. 2020, 48, 150–165. [Google Scholar] [CrossRef]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of the COMPSTAT’2010: 19th International Conference on Computational Statistics, Paris, France, 22–27 August 2010; Keynote, Invited and Contributed Papers. Springer: Berlin/Heidelberg, Germany, 2010; pp. 177–186. [Google Scholar]
- Li, B.; He, Q.; Chen, F.; Xia, X.; Li, L.; Grundy, J.; Yang, Y. Embedding app-library graph for neural third party library recommendation. In Proceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Athens, Greece, 23–28 August 2021; pp. 466–477. [Google Scholar]
- Yan, D.; Tang, T.; Xie, W.; Zhang, Y.; He, Q. Session-based Social and Dependency-aware Software Recommendation. arXiv 2021, arXiv:2103.06109. [Google Scholar] [CrossRef]
- Ortega, A.; Frossard, P.; Kovačević, J.; Moura, J.M.; Vandergheynst, P. Graph signal processing: Overview, challenges, and applications. Proc. IEEE 2018, 106, 808–828. [Google Scholar] [CrossRef] [Green Version]
- Krasanakis, E.; Papadopoulos, S.; Kompatsiaris, I.; Symeonidis, A. pygrank: A Python Package for Graph Node Ranking. arXiv 2021, arXiv:2110.09274. [Google Scholar]
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The PageRank Citation Ranking: Bringing Order to the Web; Technical Report; Stanford InfoLab: Stanford, CA, USA, 1999. [Google Scholar]
- Andersen, R.; Chung, F.; Lang, K. Local graph partitioning using pagerank vectors. In Proceedings of the 2006 47th Annual IEEE Symposium on Foundations of Computer Science (FOCS’06), Berkeley, CA, USA, 21–24 October 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 475–486. [Google Scholar]
- Bahmani, B.; Chowdhury, A.; Goel, A. Fast incremental and personalized pagerank. arXiv 2010, arXiv:1006.2880. [Google Scholar] [CrossRef] [Green Version]
- Chung, F. The heat kernel as the pagerank of a graph. Proc. Natl. Acad. Sci. USA 2007, 104, 19735–19740. [Google Scholar] [CrossRef] [Green Version]
- Kloster, K.; Gleich, D.F. Heat kernel based community detection. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 1386–1395. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S.Y. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Z.; Cui, P.; Zhu, W. Deep learning on graphs: A survey. IEEE Trans. Knowl. Data Eng. 2020, 34, 249–270. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; He, X.; Wang, M.; Feng, F.; Chua, T.S. Neural graph collaborative filtering. In Proceedings of the 42nd international ACM SIGIR conference on Research and development in Information Retrieval, Paris, French, 21–25 July 2019; pp. 165–174. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1025–1035. [Google Scholar]
- Klicpera, J.; Bojchevski, A.; Günnemann, S. Predict then propagate: Graph neural networks meet personalized pagerank. arXiv 2018, arXiv:1810.05997. [Google Scholar]
- Chen, M.; Wei, Z.; Huang, Z.; Ding, B.; Li, Y. Simple and deep graph convolutional networks. In Proceedings of the International Conference on Machine Learning. PMLR, Virtual Event, 13–18 July 2020; pp. 1725–1735. [Google Scholar]
- Adamczyk, P.; Smith, P.H.; Johnson, R.E.; Hafiz, M. Rest and web services: In theory and in practice. In REST: From Research to Practice; Springer: Berlin/Heidelberg, Germany, 2011; pp. 35–57. [Google Scholar]
- Gunasekaran, A. Agile manufacturing: A framework for research and development. Int. J. Prod. Econ. 1999, 62, 87–105. [Google Scholar] [CrossRef]
- Dong, H.; Chen, J.; Feng, F.; He, X.; Bi, S.; Ding, Z.; Cui, P. On the equivalence of decoupled graph convolution network and label propagation. In Proceedings of the Web Conference 2021, New York, NY, USA, 19–23 April 2021; pp. 3651–3662. [Google Scholar]
- Yang, F.; Zhang, H.; Tao, S.; Hao, S. Graph representation learning via simple jumping knowledge networks. Appl. Intell. 2022, 1–19. [Google Scholar] [CrossRef]
- Gleich, D.F.; Seshadhri, C. Vertex neighborhoods, low conductance cuts, and good seeds for local community methods. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 597–605. [Google Scholar]
- Tong, H.; Faloutsos, C.; Pan, J.Y. Fast random walk with restart and its applications. In Proceedings of the Sixth International Conference on Data Mining (ICDM’06), Hong Kong, China, 18–22 December 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 613–622. [Google Scholar]
- Wu, X.M.; Li, Z.; So, A.; Wright, J.; Chang, S.F. Learning with partially absorbing random walks. Adv. Neural Inf. Process. Syst. 2012, 25, 3077–3085. [Google Scholar]
- Krasanakis, E.; Papadopoulos, S.; Kompatsiaris, I. Stopping personalized PageRank without an error tolerance parameter. In Proceedings of the 2020 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Hague, The Netherlands, 7–10 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 242–249. [Google Scholar]
- Wang, J.; Song, G.; Wu, Y.; Wang, L. Streaming graph neural networks via continual learning. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual, 19–23 October 2020; pp. 1515–1524. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Approach | Citation | Type | Training Time | Inference Time |
|---|---|---|---|---|
| LibSeek | [14] | Repr. learning | ||
| GRec | [16] | Repr. learning | ||
| LibPPR | [22], this work | Graph filter | — | |
| LibARW | [39], this work | Graph filter | — | |
| LibFilter | [this work] | Graph filter | — |
| Top 5 Recommendations | Top 10 Recommendations | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Approach | MP | MR | MF1 | MAP | Cov | MP | MR | MF1 | MAP | Cov | No-Learn |
| Leave out 1 test library per project | |||||||||||
| GRec | 0.152 | 0.761 | 0.254 | 0.623 | 0.695 | 0.083 | 0.828 | 0.151 | 0.636 | 0.792 | ✕ |
| LibSeek | 0.135 | 0.674 | 0.225 | 0.524 | 0.335 | 0.076 | 0.755 | 0.137 | 0.535 | 0.396 | ✕ |
| LibPPR | 0.119 | 0.596 | 0.199 | 0.461 | 0.211 | 0.072 | 0.715 | 0.130 | 0.477 | 0.283 | ✔ |
| LibARW | 0.135 | 0.676 | 0.226 | 0.528 | 0.520 | 0.077 | 0.772 | 0.140 | 0.541 | 0.602 | ✔ |
| LibFilter | 0.140 | 0.700 | 0.234 | 0.552 | 0.544 | 0.079 | 0.789 | 0.143 | 0.564 | 0.620 | ✔ |
| Leave out 3 test libraries per project | |||||||||||
| GRec | 0.410 | 0.692 | 0.514 | 0.797 | 0.685 | 0.234 | 0.788 | 0.360 | 0.761 | 0.782 | ✕ |
| LibSeek | 0.371 | 0.618 | 0.464 | 0.728 | 0.325 | 0.216 | 0.719 | 0.332 | 0.697 | 0.391 | ✕ |
| LibPPR | 0.330 | 0.550 | 0.413 | 0.575 | 0.241 | 0.207 | 0.691 | 0.319 | 0.509 | 0.324 | ✔ |
| LibARW | 0.377 | 0.628 | 0.471 | 0.595 | 0.557 | 0.224 | 0.746 | 0.344 | 0.535 | 0.640 | ✔ |
| LibFilter | 0.391 | 0.652 | 0.489 | 0.597 | 0.579 | 0.228 | 0.760 | 0.351 | 0.542 | 0.655 | ✔ |
| Leave out 5 test libraries per project | |||||||||||
| GRec | 0.587 | 0.594 | 0.590 | 0.840 | 0.657 | 0.361 | 0.731 | 0.483 | 0.786 | 0.754 | ✕ |
| LibSeek | 0.529 | 0.529 | 0.529 | 0.790 | 0.314 | 0.329 | 0.658 | 0.439 | 0.740 | 0.380 | ✕ |
| LibPPR | 0.495 | 0.495 | 0.495 | 0.572 | 0.282 | 0.329 | 0.658 | 0.438 | 0.470 | 0.369 | ✔ |
| LibARW | 0.570 | 0.570 | 0.570 | 0.562 | 0.599 | 0.357 | 0.714 | 0.476 | 0.474 | 0.689 | ✔ |
| LibFilter | 0.588 | 0.588 | 0.588 | 0.558 | 0.602 | 0.363 | 0.725 | 0.484 | 0.476 | 0.688 | ✔ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krasanakis, E.; Symeonidis, A. Fast Library Recommendation in Software Dependency Graphs with Symmetric Partially Absorbing Random Walks. Future Internet 2022, 14, 124. https://doi.org/10.3390/fi14050124
Krasanakis E, Symeonidis A. Fast Library Recommendation in Software Dependency Graphs with Symmetric Partially Absorbing Random Walks. Future Internet. 2022; 14(5):124. https://doi.org/10.3390/fi14050124
Chicago/Turabian StyleKrasanakis, Emmanouil, and Andreas Symeonidis. 2022. "Fast Library Recommendation in Software Dependency Graphs with Symmetric Partially Absorbing Random Walks" Future Internet 14, no. 5: 124. https://doi.org/10.3390/fi14050124
APA StyleKrasanakis, E., & Symeonidis, A. (2022). Fast Library Recommendation in Software Dependency Graphs with Symmetric Partially Absorbing Random Walks. Future Internet, 14(5), 124. https://doi.org/10.3390/fi14050124